
9 minute read
Rogelio Mamani Ramos


Rogelio Mamani Ramos*†
Advertisement
RESUMEN
Se diseña la red neuronal artificial Kohonen y Minería de Datos en el análisis de la canasta de mercado, para el mismo se utiliza datos de la Empresa de Apoyo a la Producción de Alimentos (EMAPA), en una primera instancia se cumple los métodos de la minería de datos y posteriormente se elige una muestra de registros de ventas de una base de datos para el análisis de la minería de datos por medio de la Red Neuronal Kohonen. Durante los resultados, se realiza cinco entrenamientos de red neuronal donde pueda asociar la canasta de mercado y en los entrenamientos la red neuronal Kohonen, logra asociar patrones de la canasta de mercado, posteriormente se hace una comparación con los algoritmos ECLAT y FP-Growth, presentando un comportamiento similar, por lo que Kohonen es aceptable para el análisis de la canasta de mercado al igual que otros modelos.
Palabras Clave: <Kohonen><Minería de datos><Reglas de asociación>
ABSTRACT
The Kohonen artificial neural network and Data Mining are designed in the analysis of the market basket, for which data from the EMAPA Super Market is used, in the first instance the data mining methods are fulfilled and later a sample is chosen. of sales records of a database for the analysis of data mining by means of the Kohonen Neural Network. During the results, five neural network trainings are carried out where the market basket can be associated and in the trainings the Kohonen neural network manages to associate patterns of the market basket, later a comparison is made with the ECLAT and FP-Growth algorithms, presenting a similar behavior, so Kohonen is acceptable for the analysis of the market basket as well as other models.
Keywords: <Kohonen><Data mining><Association rules>
1.- Introducción
La empresa a diario almacena grandes cantidades de datos en los procesos de negocio (Beltrán, 2018), estos datos son una fuente de información acerca del negocio, de los procesos de compraventa y de los clientes. Actualmente uno de los retos más importantes es lograr competitividad en un negocio, a partir de la información contenida en los datos, éstas pueden ser utilizadas como estrategia del negocio.
Entonces se observa empresas de comercialización que realizan registro de datos acerca de las ventas. Sin embargo, en la mayoría de las empresas tienen almacenados información (DB-ENGINES, 2022), más propiamente la empresa supermercado EMAPA, que desaprovecha los datos registrados que pueden ser de utilidad para definir criterios de adquisición y reventa de los productos adquiridos en el mercado.
Entonces, es importante trabajar en el volumen de información que tienen las empresas comerciales (MNRVA, 2017), por lo que se propone el diseño de un modelo de minería de datos y redes neuronales artificiales Kohonen en la canasta de mercado.
2.- Metodología
A continuación, se describe el proceso algorítmico de la red neuronal Kohonen, aplicable a diferentes comportamientos
*†
Informático con mención en Ingeniería de Sistemas Informáticos, maestría en Ciencias de la Computación y candidato a doctor en Ciencias de la Computación, profesor universitario y consultor informático. Correo electrónico: cienciaroy@gmail.com
predictivos y asociación (Krose y Smagt, 1996).
Gráfico 1: Topología de RNA Kohonen
Para el desarrollo de la topología Kohonen según Haykin (2001), se recurre a la secuencia siguiente:
a) Inicializando los parámetros con el número de Neuronas ( ) en la capa de entrada y en la capa de salida , identificando a como el número de filas y el número de columnas. La Entrada está definida por el vector de datos que parten de los registros que contempla la entidad detalle. b) A cada neurona se define con el vector de pesos sinápticos , inicializandosé de forma aleatoria en el rango de 0 , 1 , asimismo, se define con la dimensión de
, c) También se define los parámetros: - Rango de vecindad inicial ( ) - Rango de vecindad final ( ) - Rata de aprendizaje inicial ( ) - Rata de aprendizaje final ( ) - Número máximo de iteraciones ( ) - Se debe elegir el vector de entrada de forma aleatoria, orientando hacia el patrón de entrenamiento. d) Selección de neuronas ganadora ( ) arg ‖ ! ‖
e) Modificación de las neuronas " ! é $ , Δ & ' ()&*' (' ! &(
También:
,-.'&,*( 012/ /3 Δ &: Variación del vector de pesos para la neurona r-ésima : Rata de aprendizaje )&*' (: Función de vecindad : Índice de iteración : Vector de entrada &: Vector de pesos de la neurona " ! é $
f) Incrementar 5 1
Si 6 retornar al inciso c
En este sentido se utiliza datos del supermercado EMAPA, a la evaluación ingresa la cantidad de registros realizados considerando que es la población ( 25477) en la base de datos del sistema de ventas durante el mes de enero de 2020. De forma aleatoria se elige una muestra de 379 registros, que ingresarán a la evaluación del modelo de minería de datos y redes neuronales artificiales.
Por otro lado, se elige criterios para su análisis por las topologías RNA (Kohonen), estas son patrones de consumo de la canasta de mercado.
Después de la depuración de los campos y registros se tiene para la evaluación de la topología de red neuronal Kohonen en registros habilitados 363 datos (96 %).
Para el entrenamiento de la red neuronal, se realiza la variación en algunos campos y atributos de las neuronas, permitiendo de esta forma identificar las fallas u errores que pueden presentar hasta el ajuste en el modelo. Tabla 1: Ítems por neurona y consolidación de segmentos
Neurona D1 D2 Sop Conf.
N1 10 10 0,6 0,8
N2 15 15 0,6 0,9
N3 20 20 0,4 0,5
N4 25 20 0,41 0,5
N5 30 25 0,5 0,65
3.- Resultados Los resultados que se han obtenido después del entrenamiento de la topología Kohonen, son la asociación de los ítems siguientes:
Tabla 2: Resultados de Asociación bajo Topología Kohonen
N° Antecedente Consumo Sop. Conf. 1 Harina Princesa Manteca balde 16 kl, azúcar Guabirá 0,60 0,80 2 Harina Princesa Manteca balde 16 kl, azúcar Guabirá 0,60 0,90 3 Fideo Cortado la Suprema Aceite Sabrosa, leche chocolatada Ebba, 0,51 0,92 4 Fideo Cortado la Suprema Aceite Sabrosa, leche chocolatada Ebba, 0,41 0,93 5 Harina Princesa Fideo cortado la Suprema, aceite Sabrosa, leche chocolatada Ebba, 0,50 0,65
Para comprender el comportamiento de los antecedentes y consecuentes, se realiza las gráficas que apoyen en ver el comportamiento de las asociaciones.
Gráfico 2: Descripción del entrenamiento 1 Gráfico 3: Descripción del entrenamiento 2
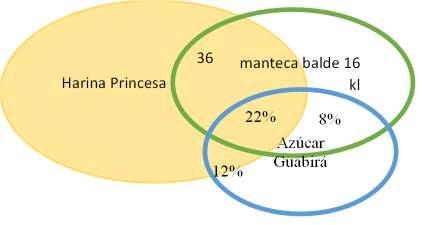
Nota: Se observa las compras más comunes son adquiridos asociados en 22%, lo que indica que el patrón de consuma referente a los demás es aceptable. Nota: El patrón de consumo de la canasta de mercado, se observa las compras más comunes que realizan, los tres productos son adquiridos asociados en 30 %

Gráfico 4: Descripción del entrenamiento 3 Gráfico 5: Descripción del entrenamiento 4
Fideo Cortado la Suprema 20 %
Aceite sabrosa, Leche
20 % 8% 12% chocolata % da Ebba,
Nota: El patrón de consumo de la canasta de mercado, se observa las compras más comunes los tres productos son adquiridos asociados en un 8 %.
20%
Aceite sabrosa, Leche
Fideo Cortado la Suprema
9% 12%% chocolatad20% a Ebba,
Nota: El patrón de consumo de la canasta de mercado, se observa las compras más comunes que realizan, los tres productos son adquiridos asociados en un 9 %.
Gráfico 6: Descripción del entrenamiento 5
Harina Princesa Fideo Cortado la Suprema,
8%
Nota: El patrón de Consumo de la canasta de mercado, se observa las compras más comunes que realizan, los cuatro productos son adquiridos asociados en un 8 %
4.- Discusión
Mediante la topología Kohonen de la Red Neuronal Artificial, se llega a trabajar los patrones de consumo de la canasta de mercado, por lo que también se evalúa y compara en la experimentación.
Se realiza una comparación a la topología Kohonen con los algoritmos que presentan mayor precisión en el análisis de patrones de Consumo de la canasta de mercado, para el mismo se llega a determinar los resultados con las métricas de evaluación Lift, Leverage y Conviction, las interpretaciones están dadas de la forma siguientes:
• Lift: se identifica la relación, si Lift es mayor a 1, describe que la correlación es positiva;
si Lift es menor a 1, se correlacionan negativamente; y si Lift es igual a 1 significa que son independientes. • Leverage: Mide el recuento de la coocurrencia del antecedente y el consecuente. • Conviction: también permitirá medir el grado de relación de los ítems.
Por tanto, en la tabla 3, se observa los resultados determinados por las métricas de evaluación aplicado a la topología Kohonen, también, en la tabla 4, se observa los resultados determinados por las métricas de evaluación aplicado al algoritmo de asociación ECLAT, donde se puede observar los diferentes resultados obtenidos.
Tabla 3: Métricas de evaluación a la topología Tabla 4: Métricas de evaluación al algoritmo Kohonen ECLAT
Regla Soporte Conf. Lift Leverage Conviction 1 0,6 0,97 1,06 0,2 1,53 2 0,6 0,95 1,05 0,08 1,54 3 0,4 0,95 1,04 0,04 1,54 4 0,41 0,96 1,03 0,05 1,53 5 0,5 0,94 1,01 0,09 1 Regla Soporte Conf. Lift Leverage Conviction 1 0,6 0,97 1,06 0,09 1,53 2 0,6 0,95 0,99 0,05 0,8 3 0,4 0,95 1,04 0,04 1,54 4 0,41 0,96 1,03 0,05 1,53 5 0,5 0,94 1,01 0,09 0,89
Y de la misma forma, en la tabla 5, se observa los resultados determinados por las métricas de evaluación aplicado al algoritmo FP-Growth, donde se puede observar los diferentes resultados obtenidos.
Tabla 6: Métricas de evaluación al algoritmo FP-Growth
Regla Soporte Conf. Lift Leverage Conviction 1 0,6 0,97 1,05 0,1 1,53 2 0,6 0,95 1,05 0,08 1,54 3 0,4 0,95 1,04 0,04 1,54 4 0,41 0,96 1,03 0,05 1,53 5 0,5 0,94 1 0,09 2 6 0,55 0,97 1 0,09 0,92 7 0,56 0,93 1,02 0,09 0,99 8 0,8 0,92 1,06 0,1 1,54 9 0,65 0,94 1,05 0,11 1,53 10 0,51 0,93 1,03 0,11 0,82
Por Tanto, si se aplica la red neuronal Kohonen en la minería de datos, tendrá un comportamiento similar a modelos similares, lo . que resalta su funcionamiento en el análisis de la canasta de mercado
Referencias bibliográficas
Beltrán, B. (2018). Minería de Datos. Puebla: Benemérita Universidad Autónoma de Puebla. DB-ENGINES. (5 de Junio de 2022). DB-Engines Ranking - Trend of Graph DBMS Popularity. Recuperado de https://db-engines.com/en/ranking_trend/graph+dbms Haykin, S. (2001). Kalman filtering and neural network. New York: A Wiley-Interscience Publication. MNRVA. (2017). Knowledge discovery in databases. Recuperado de https://mnrva.io/kdd-platform.html
Recepción: 25 de julio de 2022 Aprobación: 21 de agosto de 2022 Publicación: agosto 2022








