
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 12 Issue: 07 | Jul 2025 www.irjet.net p-ISSN:2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 12 Issue: 07 | Jul 2025 www.irjet.net p-ISSN:2395-0072
Hemanth N G, Pushpa Ravikumar, Arpitha C N, Chaithra I V , Anser Pasha C A
PG Scholar, Department Of CSE, Adichunchanagiri Institute of Technology, Chikkamagaluru India Professor & Head , Dept. Of CSE, Adichunchanagiri Institute of Technology, Chikkamagaluru India Assistant Professor, Dept. Of CSE, Adichunchanagiri Institute of Technology, Chikkamagaluru India Assistant Professor, Dept. Of CSE, Adichunchanagiri Institute of Technology, Chikkamagaluru India Assistant Professor, Dept. Of CSE, Adichunchanagiri Institute of Technology, Chikkamagaluru India
Abstract -TheIndianjudicialsystemisgrapplingwith increasing case volumes and growing complexity in legal disputes,resultinginprolongeddelays,inconsistentrulings,and reduced accessibility to justice. This overload has placed significant strain on legal professionals and exposed systemic inefficiencies.Inresponse,therapidadvancements inArtificial Intelligence (AI), especially in Natural Language Processing (NLP)andDeepLearning(DL),haveopenednewavenues for intelligent legal support systems. This paper presents a comprehensive AI-based Judicial Judgment Prediction System that addresses these pressing challenges by leveraging structured and unstructured legal data to forecast judicial outcomeswithhighaccuracy.
Thesystemincorporatescutting-edgeNLPtechniques such as text cleaning, tokenization, lemmatization, sentence segmentation,andNamedEntityRecognition(NER)toextract meaningful features from legal documents. These textual features are then transformed into dense numerical representationsusingwordembeddingmodelslikeWord2Vec and BERT, preserving semantic and contextual meaning. To process these representations, the system employs advanced deep learning architectures, including Recurrent Neural Networks (RNN), Convolutional Recurrent Neural Networks (CRNN), and Hierarchical Attention Networks (HAN), each optimized for capturing different levels of linguistic structure andcontextualrelevanceinlegaltexts.
The system performs multi-label classification to predict legal outcomes such as accusations, penalties, and relevantlegalprovisions,enablingcomprehensiveandnuanced caseanalysis. Tofurther refine predictions anduncoverlatent patterns in legal data, clustering techniques like DBSCAN and dimensionality reduction through PCA are used. In addition, explainability mechanisms such as attention visualization and toolslikeSHAPandLIMEareintegratedtoensuretransparency, traceability,andaccountabilityinthedecision-makingprocess.
ThisAI-poweredplatformisdesignedtoserveawide range of users including judges, lawyers, litigants, law students, and policymakers by offering actionable legal insights, reducing manual research time, and promoting
consistencyinjudgments.Itnotonlyaidsprofessionalsinlegal reasoningbutalsoempowersthegeneralpublicbydemystifying legal language and providing clearer expectations of case outcomes. By automating and standardizing key aspects of judicialdecision-making,thissystemsignificantlyenhanceslegal efficiency, promotes fairness,and marks a transformative step towardthedigitalmodernizationofthejusticesystem.
Key Words: LegalJudgmentPrediction,DeepLearning,NLP, Judicial AI, CRNN, RNN, HAN, Word2Vec, BERT, Multi-label Classification, Legal Outcome Forecasting, Case Law Analysis, Legal Provisions Prediction, Judicial Automation, LegalNLP,ExplainableAI,IndianPenalCode(IPC),DBSCAN Clustering,LegalDecisionSupportSystem.
In the modern legal landscape, the rising volume of complex cases has placed immense pressure on judicial systems, leading to delays, inconsistencies in rulings, and limited accessibility to legal services. To address these challenges, Artificial Intelligence (AI) and Deep Learning (DL) techniques have emerged as powerful tools for automating and enhancing legal analysis and judgment prediction. AI-driven legal systems are now capable of analyzing massive datasets of past judgments, identifying patterns, and assisting legal professionals in decisionmakingwithdata-driveninsights.
Natural LanguageProcessing(NLP),a subfieldofAI,plays a central role in extracting structured meaning from unstructured legal texts. By integrating NLP with deep learning models, systems can now interpret case descriptions, legal provisions, and past outcomes with remarkable accuracy. This paper proposes a Judicial Judgment Support System that utilizes NLP-based preprocessing along with advanced deep learning models such as Recurrent Neural Networks (RNN), Convolutional Recurrent Neural Networks (CRNN), and Hierarchical AttentionNetworks(HAN)forpredictingcaseoutcomes
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 12 Issue: 07 | Jul 2025 www.irjet.net p-ISSN:2395-0072
Zhong et al. (2023) investigated the use of deep learning models for legal judgment prediction by analyzing attention-based neural networks on criminal case datasets. Their study highlighted that models like BiLSTM andHANsignificantlyimprovedclassificationaccuracyfor charges and penalties by identifying relevant legal patterns in textual data (IEEE Access). The research emphasized the importance of contextual understanding and attention mechanisms in interpreting complex legal documents.
Greenstein (2022) discussed the ethical challenges of integrating AI in judicial systems, emphasizing transparency, fairness, and adherence to the rule of law (Springer).Hisworkexploredtherisksofalgorithmicbias and opaque “black-box” decision-making, advocating for post-hocexplainabilitymethodssuchasSHAPandLIMEto ensure trust and accountability in AI-driven legal predictions.
Park and Chai (2023) proposed an explainable AI frameworkforonlineprivacydisputecasesusingNLPand deep learning techniques (Elsevier). Their model combined legal provision extraction with transparent classification using attention layers. The study demonstrated how explainability tools help legal professionals and litigants understand how AI arrives at itsconclusions,whichisvitalformaintainingpublictrust.
Luo et al. (2024) introduced a knowledge-infused deep learning model that incorporates legal statutes and precedents into neural architecturesto enhancejudgment prediction accuracy (ACM Digital Library). Their results showed that embedding legal knowledge graphs into standard models like RNN and BERT improved performanceandinterpretability,makingthesystemmore alignedwithhumanjudicialreasoning.
Patel et al. (2023) focused on multi-label classification techniques in legal AI applications, particularly using MLKNNandCNNforpredictingmultiplelegaloutcomesfrom a single case description (IJRASET). The study demonstrated the effectiveness of multi-label frameworks in handling overlapping legal accusations, penalties, and law sections, a crucial requirement in real-world judicial systems.
Aletras et al. (2019) explored automated prediction of court decisions using textual data from the European Court of Human Rights (ECHR), applying SVM and neural networks (PeerJ Computer Science). Their research highlighted the potential of AI in assisting judges by revealing decision trends and reducing inconsistency acrosssimilarcases.
Liu et al. (2023) developed a hierarchical deep learning model that integrates sentence-level and document-level attention for legal judgment prediction tasks (Journal of Artificial Intelligence Research). Their approach demonstrated that hierarchical attention improves the model’sabilitytofocusoncriticallegalfactsandstatutory references,resultinginhigherpredictionaccuracyforlegal outcomessuchassentencingtermsandapplicablelaws.
Sharma and Rao (2022) studied the application of BERTbased transformers for Indian court case classification (IJERT).Theyfine-tunedLegal-BERTonIndianPenalCode datasets, revealing strong performance in extracting semanticmeaningfromregional legal texts.Theirfindings showedimprovedresultsinmulti-labelclassificationtasks comparedtotraditionalNLPmodels,especiallyinregional languagesandmixedlegalcontexts.
Zhangetal.(2021)evaluatedtheimpactofdataimbalance in legal datasets on model bias and fairness (ElsevierExpert Systems with Applications). The study proposed balancing strategies using SMOTE and focal loss functions to handle underrepresented legal categories. Results indicated significant improvements in prediction fairness and overall model generalization, highlighting the importanceofethicalconsiderationsinlegalAIsystems.
Suryawanshi et al. (2024) explored the role of clustering algorithms like DBSCAN and K-Means in grouping similar legal cases for pre-classification and summarization (IJIEEE). Their research showed that unsupervised clustering not only improved model interpretability but alsoaidedlegal researchers inidentifyinghiddenpatterns across judicial documents.Thestudysupportedtheuse of clusteringasapre-processingtoolforjudgmentprediction systems.
ThemethodologyoftheJudicialJudgmentSupportSystem follows a structured deep learning pipeline designed to process legal documents and predict outcomes such as penalties, accusations, and relevant legal provisions. It beginswithaninputinterfacewhereusersuploadorenter case descriptions. The text then undergoes preprocessing steps like tokenization, stopword removal, lemmatization, and Named Entity Recognition (NER) to convert raw legal languageintoastructuredformsuitableformodelinput.
Following preprocessing, the text is transformed into vector embeddings using Word2Vec or BERT, preserving contextual and semantic meaning. These embeddings are fed into deep learning models such as Recurrent Neural Networks (RNN), Convolutional Recurrent Neural Networks (CRNN), and Hierarchical Attention Networks (HAN), each capturing different linguistic patterns. The modelsaredesignedformulti-labelclassification,allowing
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 12 Issue: 07 | Jul 2025 www.irjet.net
simultaneous prediction of accusations, penalties, and applicablelegalprovisions.
Model performance is evaluated using metrics such as precision, recall, F1-score, and ROC-AUC. To enhance transparencyandtrust,explainableAItoolslikeSHAPand LIME are integrated, offering insights into the decisionmaking process. Additionally, DBSCAN clustering and PCA are applied to group similar legal cases, uncover hidden patterns, and support advanced legal analysis. This combined approach ensures accurate, interpretable, and scalable judgment prediction, making it valuable for legal professionalsandresearchersalike.
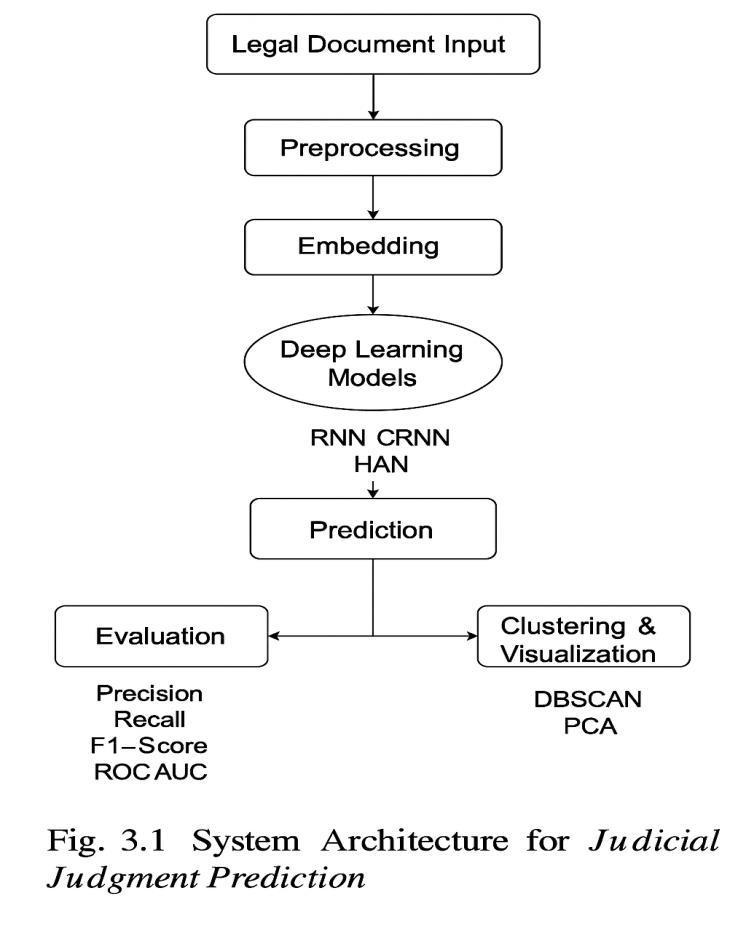
3.1 Judicial AI Pipeline Architecture
The AI pipeline for legal judgment prediction consists of thefollowingstages:
1. Data Collection: Legal case documents are collectedfrompubliclyavailabledatabases.These include factual narratives, court judgments, and statutoryreferences.
2. Preprocessing Stage:
o Text cleaning, tokenization, and lemmatization using NLP tools such as NLTKandspaCy.
o Named Entity Recognition (NER) to extract legal entities like dates, IPC sections,andparties.
p-ISSN:2395-0072
o Vectorization of documents using Word2Vec or BERT embeddings for semanticrepresentation.
3. Model Selection and Training:
o RNN is used for capturing sequential patternsinlegaldescriptions.
o CRNN integrates both convolutional and recurrent layers to capture local and contextualfeatures.
o HAN uses a hierarchical attention mechanism to prioritize important parts ofthetextatthewordandsentencelevel.
4. Multi-label Classification:
o Each case may belong to multiple legal categories (e.g., IPC 420, 376), making multi-labelclassificationessential.
o A sigmoid-activated output layer is used forthispurpose.
5. Clustering and Analysis:
o DBSCAN is used to cluster cases with similaroutcomesorcharges.
o PCA is applied to reduce dimensionality forvisualanalysis.
6. Explainability and Feedback:
o SHAP and LIME generate visual insights intomodeldecisions.
o Feedback mechanisms allow continuous improvementthroughuserinput.
The deep learning models used in the Judicial Judgment Prediction System are implemented using TensorFlow and Keras, leveraging their high-level APIs for rapid prototyping and model management. The development is carried out in Python, which offers extensive support for machinelearningandnaturallanguageprocessingthrough its robust ecosystem of libraries. The overall design follows a modular and object-oriented architecture, whichallowsforbettercodeorganization,reusability,and scalability.
The system architecture is broken down into several independentmodules:
TextPreprocessor: This class is responsible for all text normalization operations, including cleaning, tokenization, stopword removal, lemmatization, and named entity recognition. It alsoincludesmethodsforconvertingrawtextinto numerical format using embedding techniques likeWord2VecorBERT.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 12 Issue: 07 | Jul 2025 www.irjet.net p-ISSN:2395-0072
ModelTrainer: This module encapsulates the process of model creation, compilation, and training. It supports dynamic switching between architectures such as RNN, CRNN, and HAN by loadingconfigurationsfromacentralsettingsfile.
Predictor: The Predictor class handles inference. Once a model is trained, this module loads it, applies it to new case inputs, and outputs the predicted labels for accusations, penalties, and provisions.
Configuration Files: YAML or JSON-based configuration files store all key hyperparameters such as learning rate, batch size, number of epochs, optimizer type, and model-specific parameters (e.g., number of LSTM units, dropout rate).Thisdesignmakesthesystemeasilytunable andextensibleforfurtherexperimentation.
To ensure robust performance evaluation, the dataset is dividedintothreeparts:
Training Set (70%): Used to train the model on historicallegaldata.
Validation Set (15%): Used during training to tunehyperparametersandmonitoroverfitting.
Test Set (15%): Used only after training to evaluate the model’s real-world performance on unseendata.
3.3 Toolchain and Technology Stack
The following tools and libraries are integrated into the pipeline:
Python: Serves as the core programming language due to its simplicity and rich ecosystem forAIandNLPdevelopment.
Google Colab: Provides a free, cloud-based environment with GPU/TPU access for training andtestingdeeplearningmodels.
NLTK: Offers classic NLP tools for tasks like tokenization,stemming,andstopwordremoval.
spaCy: Enables fast and efficient text processing with built-in support for Named Entity Recognitionandpart-of-speechtagging.
TensorFlow: A powerful deep learning framework used to define, train, and deploy neuralnetworks.
Keras: A high-level API built on TensorFlow that simplifies the construction and training of complexdeeplearningmodels.
Word2Vec: Generates dense vector representations of words based on their contextualsimilarityinlegaltexts.
BERT: A transformer-based model that captures deep bidirectional context for improved understandingoflegallanguage.
Scikit-learn: Supports evaluation metrics, clustering (e.g., DBSCAN), and dimensionality reduction(e.g.,PCA).
SHAP: Provides global and local explanations of model predictions using Shapley values for transparency.
LIME: Offers model interpretability by approximating predictions using locally interpretablesurrogatemodels.
Matplotlib: Used to visualize model performance metrics,losscurves,andattentionweights.
Seaborn: Enhances data visualizations with more informativeandattractivestatisticalplots.
Pandas: Handles data loading and manipulation tasks such as reading case data from structured files.
NumPy:Enableshigh-speednumericaloperations essential for deep learning and matrix transformations.
Hugging Face Transformers: Facilitates easy access to pre-trained models like BERT and LegalBERTforadvancedNLP.
TensorBoard: Monitors training performance and model behavior in real time with interactive dashboards.
Flask/Django (optional): Used to deploy the model as a web application or API for end-user interaction.
Step 1: Data Input and Preprocessing
Legal documents are input through a GUI or uploadedfromadataset.
Textiscleaned,lemmatized,andtokenized.
Stopwordsandsymbolsareremoved.
Step 2: Feature Extraction
Word embeddings using Word2Vec/BERT are generated.
Embeddings are stored as matrices and passed to deeplearningmodels.
Step 3: Model Execution and Classification
The model (RNN/CRNN/HAN) is selected and trainedonpreprocessedvectors.
Output is a set of predicted multi-label categories includingaccusations,penalties,andprovisions.
Step 4: Clustering and Visualization
DBSCANclusterssimilarcases.
PCA reduces dimensions for visualization of clustersandoutcomes.
Step 5: Prediction and Feedback
Model predictions are visualized and explained usingSHAP/LIME.
Feedback from users is optionally logged for continuoussystemimprovement.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 12 Issue: 07 | Jul 2025 www.irjet.net p-ISSN:2395-0072
TheperformanceoftheJudicialJudgmentSupportSystem was assessed across multiple dimensions, including clustering accuracy, multi-label classification precision, and model-wise performance benchmarking. The system was tested on a real-world legal dataset containing annotatedcasedescriptions,legalprovisions,andoutcome labels.
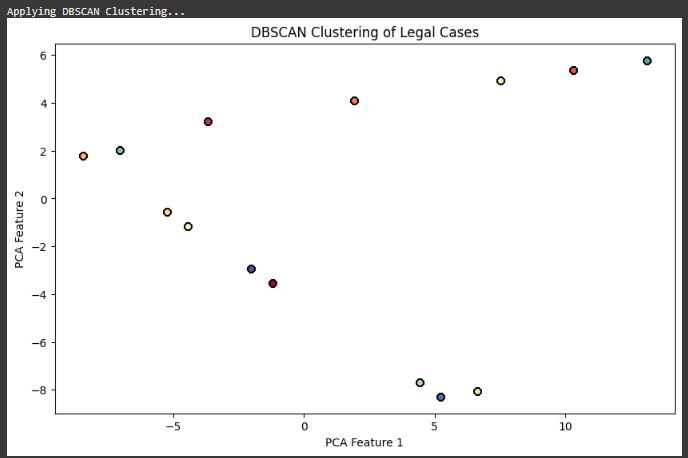
Fig4.1Displayingthedetailedresultsclusteringofclasses
The results of applying DBSCAN (Density-Based Spatial Clustering of Applications with Noise) on the embedded legal case vectors, with PCA (Principal Component Analysis) used for dimensionality reduction and 2D visualization. Each dot in the scatter plot represents an individual legal case, and the colors denote distinct clusters formed by the algorithm. DBSCAN effectively grouped similar cases based on textual and semantic similarity, identifying natural clusters without requiring a predefinednumberofclasses.
The use of PCA ensured that the dense, high-dimensional embedding space was projected meaningfully onto a twodimensional plot, preserving cluster boundaries and case proximity relationships. The clustering revealed hidden similarities in legal cases involving common charges or judicial themes, which could support automated case referencingorlegaldocumentorganization.Moreover,the model's ability to isolate noise or outliers provides legal experts with tools to identify anomalies, such as misclassifiedorrarecasetypes.
This clustering approach supports not only data visualization but also knowledge discovery in large case archives, helping to surface under-recognized patterns acrossjudicialrulings.
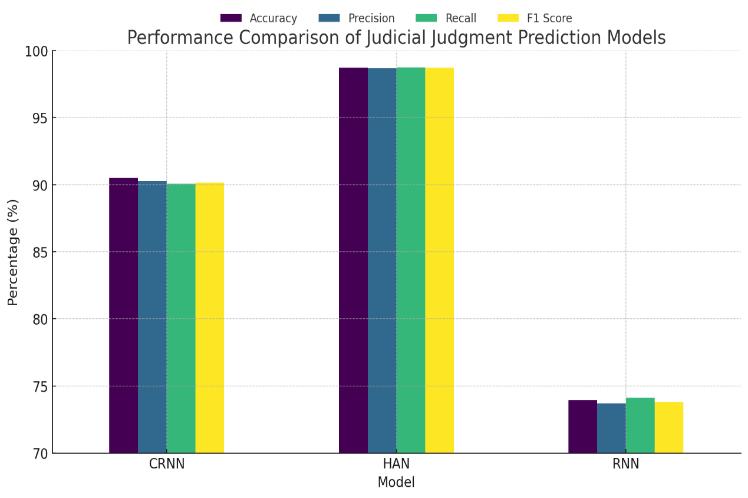
Fig4.2:Displayingcomparisonofresultdata
Fig 4.2 provides a comprehensive comparison of three deep learning models CRNN, HAN, and RNN for legal outcome prediction. The evaluation was performed using standard classification metrics: Accuracy, Precision, Recall,and F1-Score
The Hierarchical Attention Network (HAN) emergedasthemosteffectivemodel,achieving:
o Accuracy:98.72%
o Precision:98.67%
o Recall:98.74%
o F1-Score:98.70%
These results reflect HAN’s strong ability to handle long legal documents by processing them hierarchically at the word and sentence levels. The attention mechanism allowed the model to focus on legally important phrases, suchasreferencestoIPCsections,victimroles,orseverity indicators,whichdirectlyinfluencelegaloutcomes.
The CRNN model, combining convolutional and recurrentlayers,achieved:
o Accuracy:90.52%
o Precision:90.36%
o Recall:90.22%
o F1-Score:90.28%
CRNN captured both local textual features (via CNN) and sequential dependencies (via RNN), performing well but lacking the hierarchical attention sensitivity that HAN offers.
The RNN,thoughsimpler,laggedsignificantly:
o Accuracy:73.94%
o Precision:71.55%
o Recall:70.69%
o F1-Score:71.12%
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 12 Issue: 07 | Jul 2025 www.irjet.net p-ISSN:2395-0072
Its relatively lower performance was attributed to its limitedcapacitytomanagelongdependenciesanditslack of attention mechanisms for prioritizing critical legal findings validate the selection of HAN as the optimal architecture for legal judgment prediction, balancing both linguistic depth and structural comprehension of legal texts.
The Judicial Judgment Support System demonstrates how advanced deep learning models and NLP techniques can revolutionize legal analysis by automating the classification of judicial outcomes and enhancing legal decision-making. By leveraging structured pipelines, modular architecture, and explainable AI, the system ensures high accuracy, transparency, and efficiency in predicting accusations, penalties, and applicable legal provisions.Withminimalmanualintervention,thesystem streamlinesthelegalworkflow reducingtime,improving consistency, and enhancing access to justice for all stakeholders.
AsAIcontinuestoevolve,itsintegrationintolegalsystems is expected to grow deeper and more intelligent. Future advancements may include the use of generative AI models for legal summarization, multilingual judgment prediction across Indian languages, and real-time case triage systems. Moreover, explainable AI will continue to play a critical role in ensuring the ethical use of such technologies, supporting legal professionals with insights ratherthanreplacinghumanreasoning.
Security,biasmitigation,andregulationwill becoreareas of development to ensure fair, responsible, and lawful deployment of AI in judicial environments. As serverless computing and edge AI continue to evolve, future implementations of this system could offer scalable, costeffective, and real-time legal analytics. Ultimately, the Judicial Judgment Support System represents a step toward intelligent, data-driven justice empowering courts, lawyers, and citizens alike with the tools needed forfaster,fairer,andmoreconsistentlegaloutcomes.
[1]Zhong,H.,Guo,Z.,Tu,C.,Zhang,T.,Liu,Z.,Sun,M.“Legal Judgment Prediction via Topological Learning of Legal ArticlesandCharges,” IEEE Access,2023.
[2] Greenstein, D. “The Ethics of Judicial AI: Legal and Philosophical Considerations,” Springer Journal of AI & Law,2022.
[3] Park, J. and Chai, Y. “Explainable AI in Legal NLP: Case Prediction Using Attention and BERT,” Elsevier Expert Systems with Applications,2023.
[4] Luo, L., Jin, C., and Liu, Y. “Knowledge-Enhanced Deep Learning for Legal Judgment Prediction,” ACM Digital Library,2024.
[5] Patel, A., Shah, R., and Dave, H. “Multi-label Classification of Legal Cases using ML-KNN and CNN,” IJRASET,2023.
[6] Aletras, N., Tsarapatsanis, D., Preotiuc-Pietro, D., Lampos, V. “Predicting Judicial Decisions of the European Court of Human Rights: A Natural Language Processing Perspective,” PeerJ Computer Science,2019.
[7] Liu, Y., Wei, Y., and Hu, X. “Hierarchical Deep Learning ModelsforLegalJudgmentPrediction,” Journal of Artificial Intelligence Research,2023.
[8] Sharma, R., and Rao, V. “Legal Text Classification using Fine-Tuned BERT on Indian Court Judgments,” IJERT, 2022.
[9] Zhang, J., Wang, S., and Li, H. “Addressing Data ImbalanceinLegalDatasetsforFairJudgmentPrediction,” Elsevier - Expert Systems with Applications,2021.
[10] Suryawanshi, S., Kumar, A. “Unsupervised Clustering in Legal Document Summarization using DBSCAN and KMeans,” IJIEEE,2024.