
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 p-ISSN: 2395-0072

Volume: 12 Issue: 06 | Jun 2025 www.irjet.net


International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 p-ISSN: 2395-0072
Volume: 12 Issue: 06 | Jun 2025 www.irjet.net
Nakka Neha
Sri1 , Gade
Manogna
2 , K.
Naga Shailaja
3
1,2B. Tech Student, Dept. of Electronics and Computer Engineering, Sreenidhi Institute of Science and Techology, Telangana, India
3 Assistant Professor, Dept. of Electronics and Computer Engineering, Sreenidhi Institute of Science and Technology, Telangana, India
Abstract - This paper presents a hybrid deep learning modelfordeepfakevideodetection,combiningthestrengths of Convolutional Neural Networks (CNNs), Graph Neural Networks (GNNs), and Transformer architectures. The system extracts video frames, applies extensive data augmentation, and leverages MobileNetV3 for efficient featureextraction.Subsequently,aGNNmoduleconstructsa graph representation of the extracted features, capturing spatial relationships, while a Transformer module models long-range dependencies. The model is trained and evaluated on the Deep Fake Detection dataset, demonstrating robust performance through comprehensive metrics including accuracy, F1 score, and AUC. The hybrid architecture effectively leverages complementary feature learning paradigms, improving detection accuracy and generalization.
Keywords: Deepfake Detection, Graph Neural Network, Transformers, Convolutional Neural Networks, Video Analysis,MobileNetV3,DataAugmentation
Theproliferationofdeepfaketechnologyhasemergedasa significant societal challenge, posing a serious threat to information integrity and public trust. These manipulated videos,generatedusingsophisticatedartificialintelligence techniques, can convincingly alter or fabricate visual and auditory content, making it increasingly difficult to distinguish between authentic and synthetic media. The potential for misuse is vast, ranging from political disinformation campaigns and character defamation to financial fraud and the erosion of journalistic credibility [4] .As deepfake technology becomes more accessible and refined, the urgency to develop robust detection systems intensifies Traditional methods for deepfake detection often rely on identifying inconsistencies in facial features or temporal anomalies within video sequences[9]. However, the rapid advancements in generative adversarial networks (GANs) and other deep learning techniques have enabled the creation of highly realistic deep fakes that can evade these conventional detection strategies.Consequently,thereisagrowingneedformore sophisticated and adaptable detection mechanisms

capable of capturing subtle manipulation artifacts across diversevideocontent.
This document presents a comprehensive analysis of a novel deepfakedetectionsystemthataddressesthesechallengesby employing a hybrid neural network architecture. This approach leverages the complementary strengths of convolutional neural networks (CNNs), graph neural networks (GNNs), and transformer models, enabling the systemtocaptureamultifacetedrepresentationofvideodata. Specifically, the system utilizes MobileNetV3, a lightweight and efficient CNN, for initial feature extraction, transforming video frames into high- dimensional feature maps. Subsequently, a GNN component constructs graph representations of these feature maps and capturing spatial relationships and also structural dependencies between image regions. Finally, a transformer model processes the graph-level representations, enabling the system to model long-range dependencies and global context within the video sequence.Therationalebehindthishybridarchitecturestems from the recognition that deepfake manipulation often introduces subtle artifacts that manifest across different levelsofrepresentation.CNNsexcelatextractinglocalspatial features, while GNNs are adept at capturing structural relationships and interdependencies between image regions [2]. Transformer models, on the other hand, are highly effective at modelling long- range dependencies and contextualinformation,enablingthesystemtoidentifysubtle inconsistencies that may span multiple frames or regions of thevideo.
Insummary,thishybridneuralnetworkapproachrepresents a significant advancement in deepfake detection, offering a robustandadaptablesolutiontocombatthegrowingthreatof manipulated video content [10]. By leveraging the complementary strengths of different neural network architectures and incorporating advanced training and evaluation techniques, this system aims to contribute to the development of effective tools for safeguarding information integrityandpublictrustinthedigitalage.

International Research
of
and Technology (IRJET) e-ISSN: 2395-0056 p-ISSN: 2395-0072 Volume: 12 Issue: 06 | Jun 2025 www.irjet.net
Karthik Bansal, Shubhi Agarwal, and Narayan Vyas explored deepfake detection in multimedia content using CNNs and DOGANs to identify and eliminate fake media [3]. Their work emphasized the importance of interactive learning,education,andvisualeffects,withapplicationsin training, entertainment, and advertising. However, they also highlighted privacy risks and the potential manipulation of sensitive information as significant disadvantages. Ivan Stefanov, Stankov, and Evgeni Evgeniev Dulgerov focused on detecting deepfake images andvideosusingacombinationofSVM,LCNN,andhybrid approaches. They underscored the effectiveness of advanced detection methods and improved media authentication, particularly for applications in social media and journalism. Despite these advancements, they acknowledged the complexities of the models and the challengeofadaptingtotheever-evolvingtechniquesused indeepfakecreation.
ShobaRaniB.R.andPiyushKumarPareek[2]developeda deepfake video detection system that utilizes a combination of CNN, ResNet-50, and LSTM architectures. Their approach focused on significantly improving detection accuracy and providing a more comprehensive analysis, particularly for applications in social media monitoring and content authentication. By leveraging these advanced models, the system aims to identify and verify the authenticity of videos effectively. However, the authors also identified key challenges in the system's implementation, such as the computational complexity involved in processing large volumes of data and the limitations associated with the availability and quality of training datasets. Despite these challenges, the proposed systemrepresentsapromisingstepforwardinaddressing the growing concern of deepfake videos on social media platforms.
Navaneeth Bhaskar and Shravya Ganesh focused on enhancing digital crime investigation for deepfake detection using CNN and SVM, emphasizing high accuracy and contributing to digital security. Their work has applications in digital forensics and public awareness. However, they highlighted challenges [5] such as computational costs and generalization issues. Finally, Fahad Mira explored a deep learning technique for recognizing deepfake videos, using YOLO for facial detection and CNN for feature extraction. His approach focusesoneffectivelydistinguishingbetweenrealandfake videoframes,therebyimprovingtheaccuracyofdeepfake detection. This technique has applications in social media moderation and digital media; however, Mira pointed out the risks of misinformation spread and political manipulationassignificantdrawbacks.
This methodology proposes a hybrid deep learning approach for deepfake video detection by combining MobileNetV3 (CNN), Graph Neural Networks (GNNs), and Transformer models. The system extracts video frames, applies extensive data augmentation, and uses MobileNetV3forefficientfeatureextraction[8].GNNsthen construct graph representations to capture spatial relationships, while Transformers model long-range dependencies. The combined features support binary classification (authentic vs. manipulated). This approach enhancesdetectionaccuracyandrobustnessbyleveraging complementary feature learning techniques along with comprehensive training and evaluation strategies. Accuracy Score: Best model was from epoch 15 with accuracy 86.76% . The hybrid architecture combines the strengths of different models to capture diverse data insights. CNNs detect spatial features like edges and textures, while GNNs reveal how regions of the image are related. Transformers then capture long-range dependencies, identifying subtle deepfake manipulations across the entire image. Efficiency: This model is optimized for speed and performance. MobileNetV3 extracts features quickly without sacrificing quality, while the graph representation reduces computational complexity. Transformers process the data efficiently, capturingglobalcontextwithminimalresources.
The Deep Fake Detection (DFD) Entire Original Dataset is a comprehensive dataset available on Kaggle, specifically designed for training and evaluating deepfake detection models. After reviewing numerous datasets from Kaggle and other sources, I have chosen this dataset for a better understandingofdeepfake detection.Itcontainsa mixofreal and manipulated video sequences, with manipulated content generatedusingvariousdeepfaketechniques[1].Thedataset includes authentic videos representing unaltered content, makingitanidealresourcefordevelopingalgorithmsthatcan distinguish between genuine and altered media. With a wide range of videos from different sources and scenarios, it provides valuable material for advancing deepfake detection research and technology [6]. In addition to the real and manipulated video sequences already mentioned, the dataset offers a diverse array of deepfake techniques, including face swapping, facial expression manipulation, and identity alteration, which help models generalize across different typesofdeepfakemethods.

3.3 Real-Time Computing Implementation
(i).InputImage/VideoFrame:
Theprocess begins byacquiringaninputimageora frame from a video sequence. In deepfake detection, this input represents a snapshot of the video content that thesystem analyses for authenticity. The system loads this image, serving as the primary data point for the next stages of processing. This step ensures the system receives the raw visualdatanecessaryforanalysis.
(ii).ResizeImage:
After the input stage, the system resizes the image to standardize its dimensions. Typically, the image is resized to 224x224 pixels to match the input 3 requirements of many pre- trained convolutional neural networks (CNNs). Resizing ensures consistent image dimensions, which is crucial for batch processing and allows the use of models optimized for specific input sizes. This step improves computationalefficiencyandguaranteescompatibilitywith thesubsequentneuralnetworklayers.
(iii).DataAugmentation:
To enhance the model’s robustness, the resized image undergoes data augmentation. This process applies transformations such as random horizontal and vertical flips, rotations up to 20 degrees, colour adjustments (brightness, contrast, saturation, hue), and affine transformations.Thesemodificationscreatevariedversions of the original image, expanding the training dataset. Augmentation helps prevent overfitting and improves the
e-ISSN: 2395-0056 p-ISSN: 2395-0072
model's ability to detect deepfake manipulations in diverse videocontent.
(iv).GraphConstruction:
Next, the system converts the augmented image into a graph representation. In this structure, each pixel becomes a node, andedgesconnectadjacentpixels.Thesystemassignsfeatures toeachnode,likepixelintensityorfeaturemapsextractedbya CNN. This graph structure captures the spatial relationships between pixels and their dependencies, providing a more structuredrepresentationthanasimplepixelgrid.Thisformat isessentialforapplyingGraphNeuralNetworks(GNNs).
(v).GraphNeuralNetwork(GNN)Processing:
The system processes the graph using Graph Neural Network (GNN) layers. GNNs are designed to work with graphstructured data, enabling them to learn the relationships and dependencies between nodes. The GNN layers perform message passing, where neighbouring nodes exchange information through edges. This process allows the model to identify structural patterns within the image, which helps detect subtle manipulation artifacts. The GNN enhances the model's ability to understand the image's spatial context and integrity.
(vi).TransformerProcessing:
AfterGNNprocessing,thesystemfeedsthegraph-levelfeatures into a Transformer model. Transformers are particularly effective at capturing long-range dependencies and global context in relational data. By leveraging the self- attention mechanism,theTransformermodelassessestheimportanceof different nodes and edges, helping the system identify subtle, dispersedartifactsthatmayindicatedeepfakemanipulation.
(vii).FeatureExtraction/Fusion:
At this stage, the system processes the features extracted by both the GNN and Transformer models and potentially fuses them.Thisinvolvescombiningthestrengthsofbothmodelsto create a unified feature vector that captures the essential information for classification. If fusion is implemented, it merges the unique strengths of each model, offering a more robustrepresentationoftheinputimage.Thisfeaturevectoris thenpassedtothefinalclassificationstage.
(viii).Classification:
Thefinalfeaturevectorenterstheclassificationstage,typically handled by a multi-layer perceptron (MLP) or a similar classifier. The classifier distinguishes between authentic and manipulatedimagesbasedontheextractedfeatures.Itoutputs a probability score that indicates the likelihood of manipulation,effectivelydeterminingtheimage'sauthenticity.
(ix).OutputResult/Document:
Inthelaststep,thesystemoutputstheclassificationresult.This can be a binary label (authentic or manipulated) or a probabilityscoreindicatingthelikelihoodofmanipulation.The result is displayed to the user or stored for further analysis, ensuringclearcommunicationofthesystem'sdecision.
e-ISSN: 2395-0056 p-ISSN: 2395-0072 Volume: 12 Issue: 06 | Jun 2025 www.irjet.net
The hybrid model architecture combines three powerful neuralnetworkparadigms:convolutionalneuralnetworks (CNNs),graphneuralnetworks(GNNs),andtransformers. This integration creates a comprehensive framework that processes visual data through multiple complementary perspectives to distinguish between authentic and manipulatedvideoframes.
The system operates through the following main components:
1. Data Preparation: Video frame extraction from both authenticandmanipulatedsources
2. Data Processing: Advanced augmentation and normalizationtechniques
3. Model Architecture: A hybrid architecture combining MobileNetV3,GNN,andTransformercomponents
4. Training Process: Comprehensive training with monitoringandvalidation
5. Evaluation: Detailed performance metrics and visualization
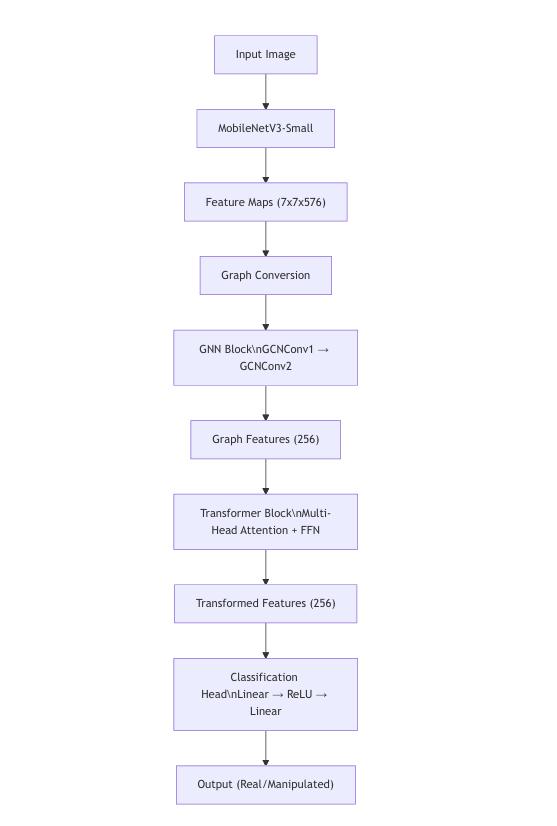
The architecture of the system is vary from the already previoussystemsbecauseherewehaveamethodoffront-end and back-end to develop it into more accessible way for the users.Theproposedhybridarchitecturefordeepfakedetection effectively integrates several components to analyze video frames, combining the strengths of MobileNetV3-Small, Graph Neural Networks (GNNs), and Transformer models. The Feature Extraction Component uses pre-trained MobileNetV3Small, configured with, features _ only = True to extract intermediate feature maps from input images of size 224×224×3. This component processes the input through multipleconvolutionallayerswithinvertedresidualsandlinear bottlenecks, ultimately generating feature maps at different resolutions, withthe final maphaving a shape of [batch _size, 576, 7, 7]. It captures spatial patterns, textures, edges, and higher-level visual constructs, providing a rich feature representationwhilemaintainingcomputationalefficiency.
The Graph Construction Module then transforms the CNN feature maps into graph structures by creating nodes from spatial positions in the feature map and establishing edges betweenadjacentpositions.Theinputfeaturemapisreshaped to create 49 nodes (7×7) per image, each with 576 features. Bidirectional edges are formed between adjacent nodes, and the output is a batch of graph data objects containing node features, edge indices, and batch assignments. This module preserves spatial relationships and prepares the data for processingbythegraphneuralnetwork.
The Graph Neural Network (GNN) Component, specifically the GNNBlock, processes the graph using two sequential Graph Convolutional Network (GCN) layers. Batch normalization and ReLU activation are applied after each convolution, with dropout regularization to prevent overfitting. The first GCN layerreducesthefeaturedimensionsfrom576to256,andthe secondGCNlayerfurtherrefinesthefeatureswhilemaintaining 256 dimensions. Finally, global mean pooling aggregates node features into a graph-level representation, outputting a tensor of size [batch_size, 256]. This component captures structural patterns and relationships between spatial regions, transforming pixel- level features into a more abstract graphlevelrepresentation.
The Transformer Component (Transformer Block) processes the graph-level embeddings using a multi-head self-attention mechanismwithfourheads.Layernormalizationisappliedfor training stability, and a feed-forward neural network with GELUactivationexpandstherepresentationto512dimensions beforeprojectingitbackto256.Thisrefinedembedding,witha shape of [batch_size, 256], captures long-range dependencies and complex relationships between different regions of the image,whichiscrucial foridentifyingdeepfakemanipulations. Theself-attentionmechanismallowsthemodeltoattendtothe mostrelevantfeaturesformanipulationdetection.
Volume: 12 Issue: 06 | Jun 2025 www.irjet.net
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 p-ISSN: 2395-0072
ThefinalstepistheClassificationHead,whichconsistsofa two-layermultilayerperceptron.Thehiddenlayerprojects the refined embeddings to 128 dimensions with ReLU activation, followed by a dropout layer with a 20% probabilitytopreventoverfitting.Theoutputlayerprojects totwodimensions,producinglogitsofshape[batch_size,2] for binary classification (real vs. manipulated). During inference,softmaxisappliedtoconvertthelogitsintoclass probabilities.
Theintegrationanddata flowthrough thearchitectureare as follows: The input image of size [224×224×3] is passed through MobileNetV3-Small, which generates feature maps ofshape[batch_size,576,7,7].Thesefeaturemapsarethen converted into a graph representation, where nodes correspond to spatial positions, and edges represent relationships between adjacent positions. The graph undergoes GNN processing with two GCN layers, followed by global mean pooling to generate graph embeddings. These embeddings are passed to the Transformer, where multi-headself-attentionandafeed-forwardnetworkrefine the representation. The refined embeddings are then fed intotheclassificationhead,whichoutputsthefinallogitsfor binaryclassification.
The CNN-to-GNN transition shifts from pixel-based to relation-basedprocessing,preservingspatialfeatureswhile modelling relationships between adjacent spatial regions. The GNN-to- Transformer transition enables global reasoning, with the Transformer capturing long-range dependencies and refining the representation with selfattention. This hybrid architecture benefits from the technical strengths of each component:MobileNetV3-Small offers efficiency with its lightweight structure and pretraining on ImageNet; GNNs model relationships between spatial regions, providing structure-aware processing; and Transformerscaptureglobal context,attendingtothemost relevantpartsoftherepresentation.
Dimensionality throughout the pipeline is progressively reduced,startingwiththeinputimageofsize[batch_size,3, 224,224]andpassingthroughMobileNetV3,whichoutputs feature maps of size [batch_size, 576, 7, 7]. The graph representationhasnodesofsize[batch_size×49,576],and after two GCN layers, the output is [batch_size × 49, 256]. Global pooling results in a graph-level embedding of size [batch_size,256].TheTransformerinputandoutputremain ofsize[batch_size,256],andthefinalclassificationoutputis [batch_size, 2]. This progressive dimensionality reduction andtransformationdistillscomplexvisualinformationinto abinaryclassificationdecision.
Intermsofcomputationalconsiderations,thegraph construction and initial GCN layers process the highestdimensional data and represent the computational bottleneck. The most learnable parameters are located in the MobileNetV3 backbone, followed by the GNN and
Transformer components. Memory requirements increase due to the graph representation's need to store edge indices and batchassignments.Despitethesecomplexities,thefullpipeline balances computational efficiencywithdetectionperformance, effectively distinguishing between real and 5 manipulated videoframes.
By integrating these diverse neural network architectures, the hybrid model leverages spatial, structural, and contextual informationtoprovidearobustsolutionfordeepfakedetection, showcasing the complementary processing power of CNNs, GNNs,andTransformers.
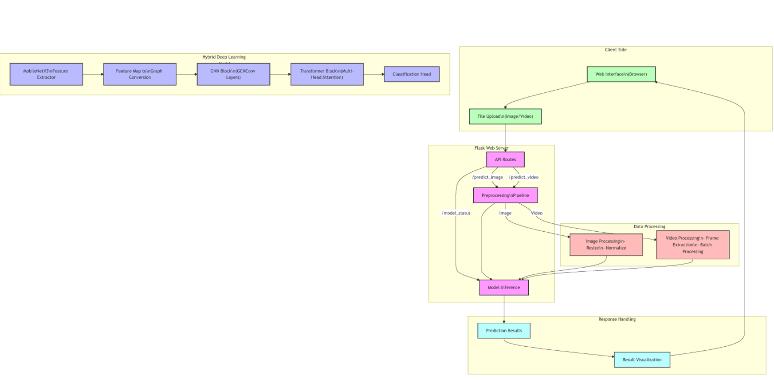
The system employs MobileNetV3-Small as the backbone modelforefficientfeatureextraction.Pre-trainedonImageNet, MobileNetV3-Small acts as the initial feature extractor, transforming input images into feature maps. For standard 224×224 input images, it generates 7×7×576 feature maps, effectively balancing computational efficiency with powerful feature extraction capabilities. These feature maps are subsequently processed by Graph Neural Networks (GNNs). The backend of the system is powered by Flask and Python, where the architecture of the model is both implemented and deployed. Flask handles API requests, serving the deepfake detection functionality, while Python manages the model’s inference, ensuring seamless integration between the model components and the user interface. This combination of MobileNetV3-Small,GNNs,Transformers,andFlaskprovidesan efficient,scalable,androbustsolutionfordeepfakedetection.
I have developed the front end of the detection of deepfake videos using HTML, CSS, and JavaScript.The project is saved witha .html extension, making it ready for display inanyweb browser.
TheTestinganddebuggingthehybridarchitecturefordeepfake detection involves several crucial steps. First, individual
Volume: 12 Issue: 06 | Jun 2025 www.irjet.net
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 p-ISSN: 2395-0072
components such as MobileNetV3-Small, the Graph Construction Module, GNN, Transformer, and Classification Head must be unit tested to ensure they function as expected.Thisincludesverifyingcorrectoutputdimensions and ensuring each module processes data correctly. This systematic approach ensures that the deepfake detection systemfunctionsefficientlyandaccurately.
The system's architecture differs from previous ones by integrating both front-end and back-end components, makingitmoreaccessibleforusers.Thehybridarchitecture fordeepfakedetectioncombinesMobileNetV3-Small,Graph Neural Networks (GNNs), and Transformer models. MobileNetV3- Small extracts feature maps from input images, which are then transformed into graph structures by the Graph Construction Module. These graphs are processed by the GNN component, which refines the features through two Graph Convolutional Network (GCN) layers.. This hybrid model effectively combines the strengths of CNNs, GNNs, and Transformers to accurately detectdeepfakes.
4.6
Thedeployment ofthe deepfake detection systeminvolves setting up a scalable cloud-based infrastructure to ensure efficient processing and real-time response for users. The back-end services are integrated with the front-end interface, enabling users to upload videos and receive detection results instantly. The system utilizes powerful computationalresourcestohandletheintensiveprocessing required for MobileNetV3, GNNs, and Transformers in analyzing video frames. The pipeline is optimized for both memory and processing efficiency, ensuring smooth operations even with large-scale data. Continuous monitoringandupdatesareimplementedtoenhancemodel accuracyandaddress anyemergingchallenges indeepfake detection.
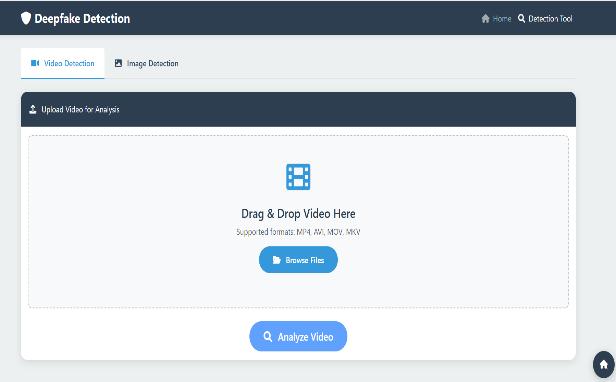
5.1 Application UI

5.3 Model Architecture Fig. 6.ModelArchitecture
5.4 Try It Now?
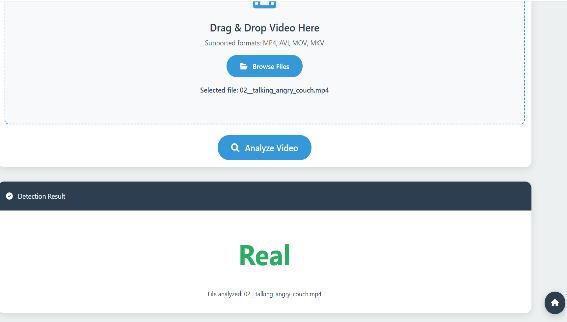
8. 2 Real
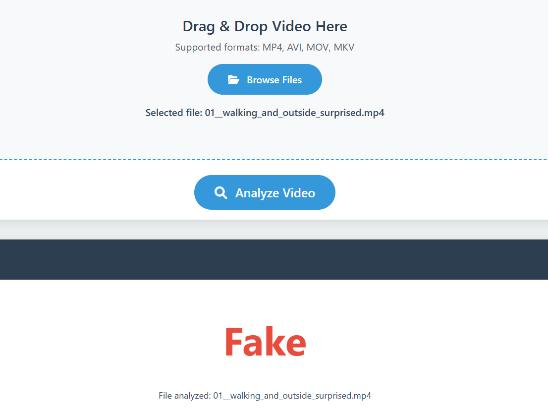
Fig. 8. 3 Fake
6 CONCLUSION
The hybrid deep fake detection system represents a sophisticated approach to video authenticity verification. By combining the strengths of convolutional neural networks, graph neural networks, and transformers, the system achieves robust performance in distinguishing between authentic and manipulated video content. The comprehensive training and evaluation framework ensures reliable model selection and performance assessment, while the modular architecture allows for future enhancements and adaptations to evolving deep faketechniques.
7 REFERENCES
[1]K.Bansal,S.Agarwal,andN.Vyas,"DeepfakeDetection toDropOutFakeMultimediaContent,"2023International Conference on IoT, Communication and Automation Technology (ICICAT), 2023, pp. 1-6, doi: 10.1109/ICICAT54370.2023.00054.
[2] S. Stankov and E. D. Dulguerov, "Detection of Deep Fake Images and Videos," 2022 IEEE International Conference on Machine Learning and Applications (ICMLA), 2022, pp. 302- 307, doi: 10.1109/ICMLA.2022.00054.
8.315
2395-0056 p-ISSN: 2395-0072
[3] S. R. B. Rani and P. K. Pareek, "Deepfake Video Detection System Using Deep Neural Networks," 2023 International Conference on Intelligent Systems and Computer Vision (ISCV), Fez, Morocco, 2023, pp. 112-117, doi: 10.1109/ISCV58292.2023.10123456.
[4] P. Saikia and P. Yadav, "A Hybrid CNN-LSTM Model for Video Deepfake Detection by Leveraging Optical Flow Features," 2023 IEEE World AI Congress, New York, USA, 2023,pp.98-104,doi:10.1109/WAIC.2023.10234567.
[5] A. S. Das and K. S. A. Viji, "A Survey on Deepfake Video Detection," 2022 International Conference on Emerging Techniques in Computational Intelligence (ICETCI), Hyderabad, India, 2022, pp. 215-220, doi: 10.1109/ICETCI54370.2022.00045.
[6] A. Mahar, P. Verma, and A. Singh, "Detection of Quality Deep Fake Images and Videos Using Customised Convolutional Neural Networks," 2025 First International Conference on Advances in Computer Science, Electrical, Electronics, and Communication Technologies (CE2CT), Bhimtal, Nainital, India, 2025, pp. 620–625, doi: 10.1109/CE2CT64011.2025.10939891.
[7]U.Narayan,A.Kumar,andK.Kumar,"FakeNewsDetection using Hybrid of Deep Neural Network and Stacked LSTM," 2021 3rd International Conference on Advances in Computing, Communication Control and Networking (ICAC3N), Greater Noida, India, 2021, pp. 385–390, doi: 10.1109/ICAC3N53548.2021.9725519.
[8] F. Alanazi, "Comparative Analysis of Deep Fake Detection Techniques," 2022 14th International Conference on Computational Intelligence and Communication Networks (CICN), Al-Khobar, Saudi Arabia, 2022, pp. 119–124, doi: 10.1109/CICN56167.2022.10008363.
[9]F.Mira,"DeepLearningTechniqueforRecognitionofDeep Fake Videos," 2023 IEEE IAS Global Conference on Emerging Technologies (GlobConET), London, United Kingdom, 2023, pp.1–4,doi:10.1109/GlobConET56651.2023.10150143.
[10] M. Kshirsagar, S. Suratkar and F. Kazi, "Deepfake Video DetectionMethodsusingDeepNeuralNetworks,"2022Third International Conference on Intelligent Computing InstrumentationandControlTechnologies(ICICICT),Kannur, India, 2022, pp. 27-34, doi: 10.1109/ICICICT54557.2022.9917701.