19 minute read
Segmenting Lungs Under Adverse Conditions Using MultiStage Transfer Learning: Preliminary Evidence of the Increased Generalisability when Retraining on Flipped Datasets

Segmenting Lungs Under Adverse Conditions Using MultiStage Transfer Learning: Preliminary Evidence of the Increased Generalisability when Retraining on Flipped Datasets
Minalu de Graaf – Lambton High School
Abstract
This investigation is a pilot study of performance of multi-stage transfer learning (MSTL) on a lung segmentation task within adverse conditions. Copies of a segmentation model were re-trained on different datasets of lung X-rays (rotated, flipped, 12.5% and 5% noise) and cross-evaluated on every dataset. It was concluded that most of the retrained models likely experienced covariate shifts with the exception of models trained on flipped datasets which show promising accuracy improvements that may indicate a route towards a retraining regime to increase generalisability. Additionally, noise as an adverse condition challenged the models the most due to the inconsistent scattering present on the object masks generated from the 12.5% noise test. Thus, this investigation gives insight into the thresholds of models trained on small datasets to perform under adverse conditions, adding to the knowledge base required to successfully integrate deep learning (DL) into the medical workflow.
Literature Review
The issue being addressed in this research is the occurrence of covariate shifts between the training and testing stages and live environment of DL models in radiology; MSTL will be utilised to minimise this issue. A model which detects lung areas for real world medical diagnostic applications must produce highly accurate results, which require significantly sized datasets. This is an issue in DL models’ development for medical image analysis as it requires expertise to create correct masks, greatly reducing the availability of accurate and sizable X-ray datasets (Quan et al., 2021). The rising importance of these issues resulted in studies on MSTL, which allows for the use of smaller datasets to develop models of similar accuracy (Ausawalaithong et al., 2018), aiming to minimise the occurrence and effect of covariate shifts (Wang & Schneider, 2014). MSTL has a limited number of studies which analyse the application of this approach and its accuracy as a result of only recently being applied to medical imaging. However, transfer learning (TL) has ample research surrounding it within this field, which will be evaluated alongside studies focused on MSTL due to their similar methodologies.
Raghu and coworkers (2019) claim that knowledge surrounding the effect and application of TL is vital for the changing nature of the clinical workflow as the computational strain of complex models is too strong. When studying the literature, clashing results and conclusions were drawn between journals regarding the performance of TL models in clinical settings, for instance Alzubaidi and coworkers (2020) confidently note that TL significantly increases the performance of models by 2.8-11% (depending on the methodology employed), whereas Raghu and coworkers (2019) claim that there was no substantial improvement in performance due to TL, as the difference was under 1% for most of their results. The specified nature of DL models is likely the cause of this disparity between these published performances.
Investigations on Transfer Learning:
An investigation published in 2019 by Raghu and coworkers studied the effect of TL on a multitude of models and found that model training set size is a large factor in the effectiveness of TL. The initial methodology tested large ImageNet models against smaller custom-made CNN models, however, it branched out to explore the hidden representation unveiled by TL in the smaller models, depicting a change while training, similar in nature to a covariate shift.

Figure 1: the visualisation of filters at initialisation and after training
(Raghu et al., 2019)
In Figure 1, a distinct shift can be observed between (e) and (f) which correspond to the models with the smaller training set; Raghu and coworkers (2019) claim that this may be due to overparameterisation. Hence, the performance of these models were slightly improved as this phenomenon increased accuracy along with the time taken to train the given models (Godasu et al., 2020). As suggested by Godasu and coworkers (2020), MSTL is a possible solution for this issue, claiming that it allows models to shorten the traditionally long training time, extended epochs and expensive computations. Ultimately, the study found that models trained on >200 000 images were largely unaffected by TL, whereas models trained on <5000 images depicted an accuracy increase of a few percent due to the occurrence of overparameterization as a result of changes similar to covariate shifts, highlighting a potential opportunity to investigate the impact of this effect on model training methodology.
Investigations on Multi-Stage Transfer Learning:
Ausawalaithong and coworkers (2018) tested the performance of MSTL models against a TL base model. Within their methodology, three different datasets were utilised to re-train four models in varied ways. One of these datasets was the JSRT Dataset, which will be used in this investigation as well. To increase the reliability of each model’s performance, Ausawalaithong and coworkers (2018) performed a 10-fold cross-validation, which splits up the dataset to testing and training sets to estimate the classification ability of learning models. This procedure will be incorporated into the methodology of this investigation as it is an effective measure taken to minimise the difference between larger and smaller datasets.
Within Ausawalaithong and coworkers' (2018) methodology, it states that the training images were randomly flipped horizontally for Model A, randomly rotated by 30 degrees for Model B and randomly flipped horizontally and rotated 30 degrees for Model C. This method of data augmentation is performed to increase the size of the datasets and simulate the adverse conditions of a live environment. However, this randomness may skew the performance of the models in unpredictable ways, hence, this investigation will control these variables by investigating the effect of individual adverse conditions. Ausawalaithong and coworkers (2018) claim that re-training a model to fit around specific conditions results in better performance. However, a notable issue encountered was overfitting in Model C, which resulted in the model’s lower accuracy in detecting the exact position of the cancer.
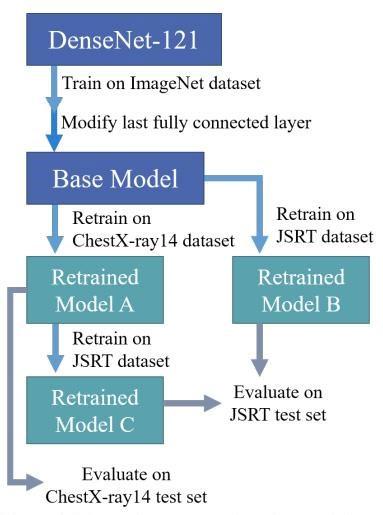
Figure 2 Schematic representation of methodology
(Ausawalaithong et al., 2018)
A similar investigation conducted by Samala and coworkers (2018) used MSTL to successfully train an algorithm using datasets in a similar auxiliary domain to the target of breast cancer detection. This yielded complementary results to Ausawalaithong and coworkers’ investigation (2018). In their two-stage approach, the model was trained using non-target data, followed by fine-tuning using the target dataset. The performance of this MSTL model was compared to a TL model. The TL model’s performance had 0.85±0.05 accuracy and the MSTL model outperformed this with 0.91±0.03 accuracy, alongside reducing the standard deviation of the results. Supporting the results from Ausawalaithong and coworkers (2018) by depicting the ability of MSTLs to generalise more effectively than standard DLs and TLs.
Ultimately, the literature demonstrates that MSTL has the potential to be used as a source of computationally smaller CADx in the clinical environment. However, the results of some studies are inconsistent due to covariate shifts and the subsequent poor generalisation; hence, this investigation will aim to develop four models which are retrained and tested on small datasets to examine the effect of covariate shifts on model performance
Scientific Research Question
To what extent can multi-stage transfer learning increase the performance of lung area-detecting models under adverse conditions (i.e., rotated, noisy and flipped images) when analysing X-ray images of chests?
Scientific Hypotheses
H0: The ability of the base and restrained models to generalise will not be significantly different.
HA: The retrained models will be able to generalise better than the base model.
Variables

Table 1: Investigation variables examined during model training, testing and evaluation.
Methodology
Dataset Creation and Processing:
The set of 60 lung X-rays and corresponding segmentation masks used in this study were sourced from JSRT (Japanese Society of Radiological Technology & Japanese Radiology Society, 1998), which has a collection of open source datasets of lung X-rays. A small dataset was required to be able to test the effect of MSTL on model performance, therefore, the “Segmentation01” dataset was used from the miniJSRT set. Manual augmentation was performed using Adobe Photoshop’s filter tool and Free Transform tool to create additional rotated(90, 180 and 270 degrees), noisy (12.5% and 5%) and flipped datasets. All images were randomly partitioned into train (80%), test (10%) and validation (10%) sets across all 5 datasets.
CNN Architecture:
To create an efficient, small model, the Unet architecture and its number of fully connected layers and kernel size (Shallue & vanderburg, 2018) was most appropriate for this task. The primary alteration made to this architecture is the addition of padding on both the contracting and expansive paths to ensure that no border pixels are lost when passing through convolutions. The images were down-sampled, with maximum pooling between each convolutional layer, followed by upsampling paired with up-convolutions between each of these layers. ReLU (rectified linear unit) activation was used for all input and output layers, in addition, the output layer utilised sigmoid activation. The predicted mask and performance metrics were output by the models.
Implementation, Training & Testing:
The models were programmed in the Jupyter Notebook integrated development environment (IDE), and the models were trained on a school-provided device with an i7 CPU and a NVIDIA GPU to train the models in a feasible time frame. The environment installed onto the IDE was sourced from Portilla and coworkers (2021) which included the following libraries:
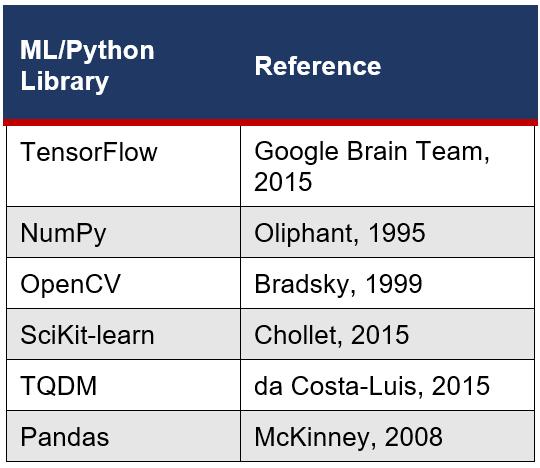
Table 2: Machine Learning and Python Libraries used to build each model.
The Base model was trained on the untouched dataset; this was used as the starting point to retrain each of the other 4 models. The Rotated, Flipped, 12.5% and 5% Noise models were retrained on their respective datasets from copies of the Base model. As shown in Figure 3 all models were evaluated against every test set to measure their performances on each under each condition using a methodology inspired by Ausawalaithong and coworkers (2018); model performance was assessed by performing a right-tailed T-test with the performance of the Base model as the global control.

Figure 3: Schematic representation of the training, testing and evaluating process
Results
The four most effective measures of model performance are Accuracy, F1score, Recall and Precision; the mean and standard deviation was recorded to summarise the results. F1-score and Accuracy are the most representative metrics due to the F1-Score punishing large differences in Precision and Recall, thus, they were the only two metrics used in the statistical tests to evaluate model performance. These metrics of all models examined are shown in Table 3 and the trends apparent are summarised in Table 4.
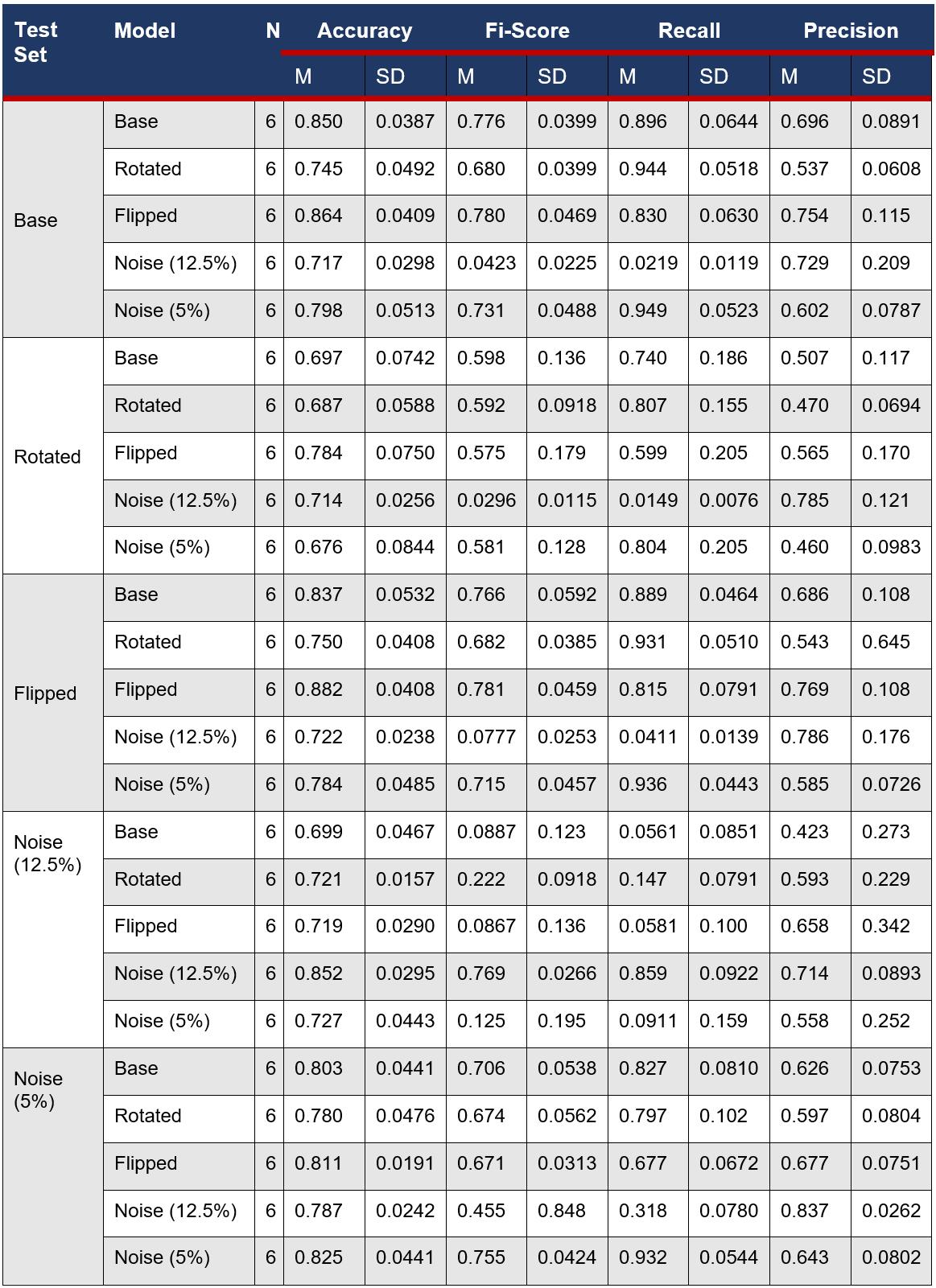
Table 3: The mean and standard deviation of the Accuracy, F1-Score, Recall and Precision of all model performances.

Table 4: Trends found from the Accuracy, F1-Score, Recall and Precision of all model performances data reported in Table 4.
Hypothesis Testing:
Right tailed t-tests assuming equal variances with an alpha value of 0.05 were performed between the Base model performance and all others individually for each test set. These compared the F1Scores (Table 5) and the Accuracy (Table 6).
The Flipped model performed statistically significantly better than the Base model on the base (Flipped: M = 0.864, SD = 0.0409, Base: M = 0.850, SD = 0.0387) and rotated (Flipped: M = 0.784, SD = 0.0750, Base: M = 0.697, SD = 0.0742) test sets (Flipped on base test set: t(6) = 2.26, p = .0238 and Flipped on rotated test set: t(6) = 1.85, p = .0467) when evaluated for Accuracy. However, when evaluated for the F1-score, the Base model outperformed most of the other models. For F1-Score, the Rotated model (t(6) = 1.95, p = .0402) and 12.5% Noise model (t(6) = 0.353, p = 1.39E-07) had a statistically significant improvement in the 12.5% noise test set (Base: M = 0.0887, SD = 0.123, Rotated: M = 0.222, SD = 0.0918, 12.5% Noise: M = 0.769, SD =0.0266). The mean F1-score and the mean Accuracy of the retrained models in 14 out of 16 cases were found to not be significantly improved over the Base model’s performance. This suggests that the retrained models as a whole had poor ability to generalise, leading to the null hypothesis being accepted. However, there are some notable anomalies which defy this trend that will be further discussed in the discussion.

Table 5: The results of the statistical right-tailed T-test, evaluating the F1-Score for each model on each test set. Alpha = 0.05.
*Underlined values indicate the p-values which were under the alpha value.
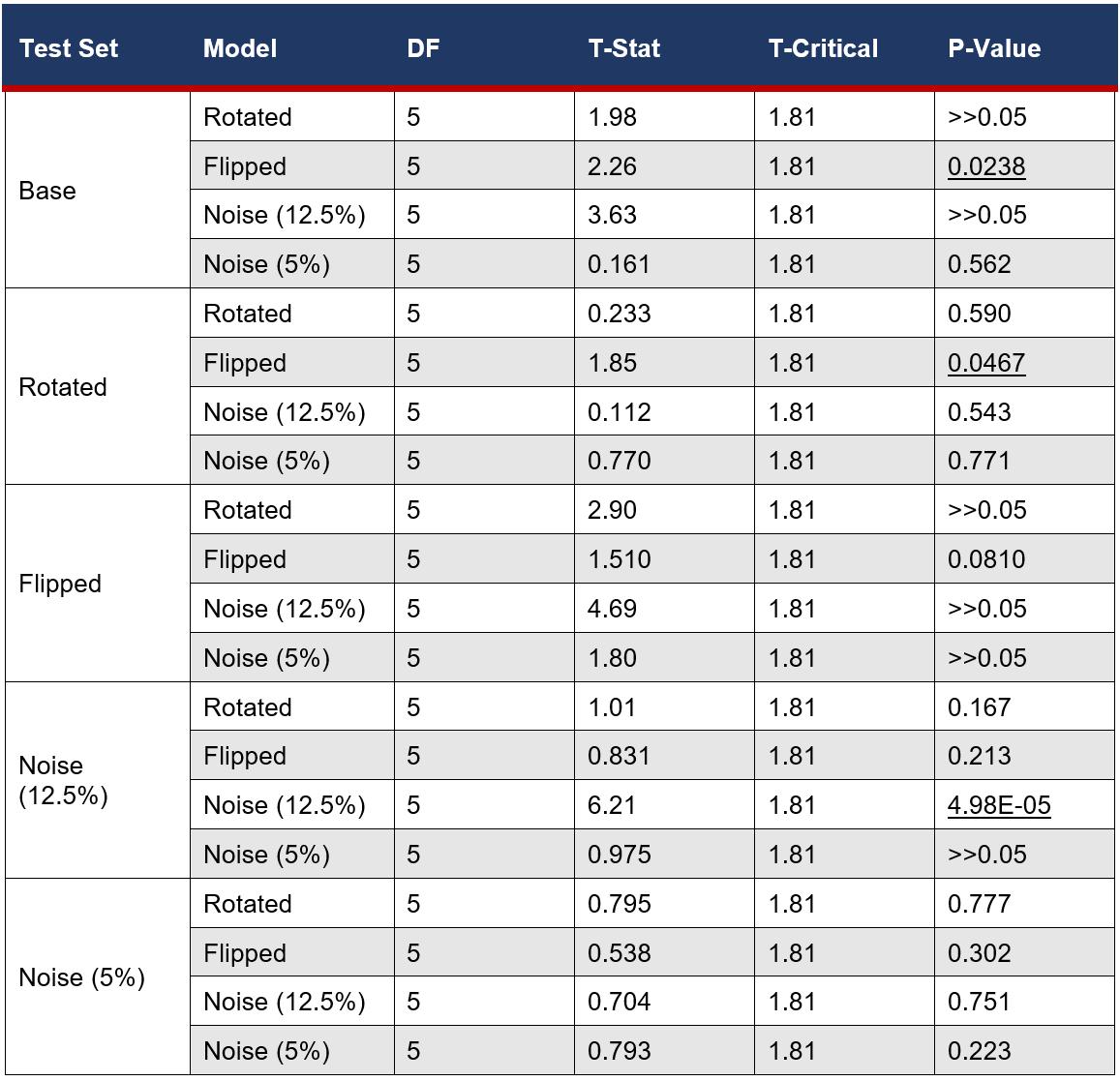
Table 6: The results of the statistical right-tailed T-test, evaluating the Accuracy for each model on each test set. Alpha = 0.05.
*Underlined values indicate the p-values which were under the alpha value.
Visualisations:
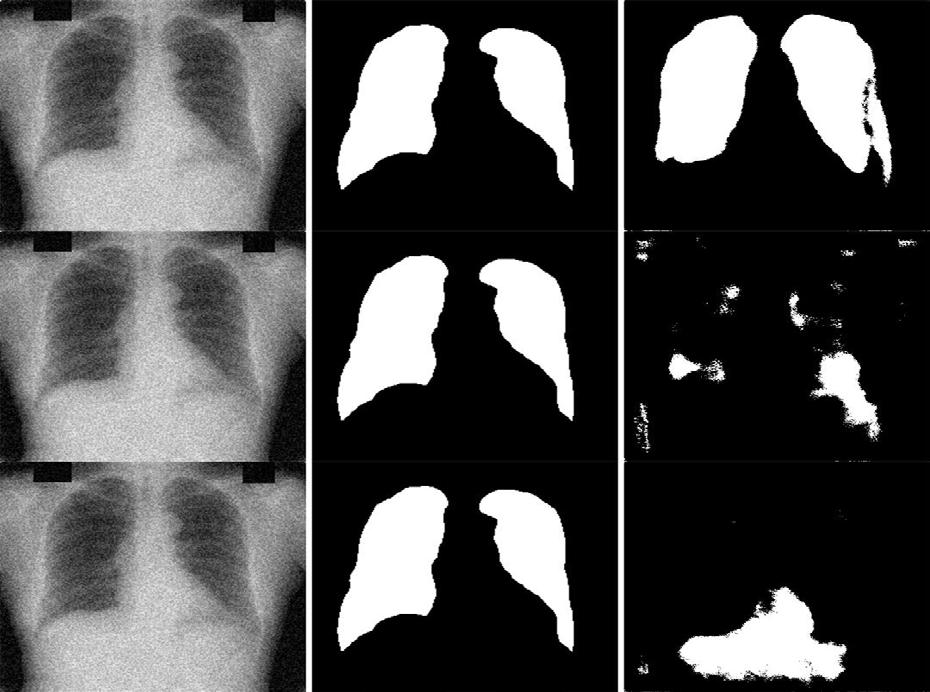
In total, 150 images were produced by the models, therefore the most appropriate images from each test were randomly selected. These include the primary statistically significant evaluations and the overall best performing evaluation, providing a clear view of the visual correlations to the data. Each image contains the original X-ray (left), the correct mask (middle) and the predicted mask (right).

Figure 4: Flipped model on base test set (top) vs Base model on base test set (bottom)

Figure 5: Flipped model on rotated test set (top) vs Base model on rotated test set (bottom)

Figure 6: 12.5% Noise model on 12.5% noise test set (top) vs Rotated model on 12.5% noise test set (middle) vs Base model on 12.5% noise test set (bottom)

Figure 7: Flipped model on flipped test set (overall best performance in F1-Score and Accuracy)
In Figures 4 and 5, the Flipped model outperformed the Base model in a statistically significant manner. Rather than exact precision and coverage, the Flipped model contains a significantly smaller amount of false positives (identification of lung tissue where there is none) compared to the Base model, thus creating a more accurate overlap with the correct mask. Additionally, there is less “random” scattering around the primary lung mask.
The overall best performance in both F1score (M = 0.781, SD = 0.0459) and Accuracy (M = 0.882, SD = 0.0408) is depicted in Figure 7 which shows the Flipped model evaluated on the flipped test set. Compared to the other models, Figure 7, depicts minimal false positives, however, it does contain one separate formation beside the left lung. From Figures 4, 5 and 7, it can be suggested that higher performing evaluations present minimised false positives and the object masks are more representative of the true shape of the lungs.
Discussion
The use of DL in medical environments provides an important addition to the toolset physicians use to analyse X-rays by introducing unbiased analysis. However, the inability for most models to effectively generalise is a major barrier for its implementation into the medical workflow (Lundervold & Lundervold, 2019). Therefore, understanding the interactions between models and adverse conditions (modelling real life) is important to increase their generalisability for its use in the clinical environment.
The retrained models did not perform better than the Base model on their respective sets aside from the 12.5% Noise model. This is a likely example of covariate shifts resulting in poor generalisation in a testing environment akin to a live environment. A vast majority of the models did not exceed the Base model’s performance in a statistically significant manner, however, the Flipped model had a statistically significantly better Accuracy than the Base model when tested against the base and rotated sets, additionally, it performed similarly to the Base model on all of the other tests. This may indicate that retraining a model on a flipped dataset can improve its generalisability. While promising, this must be investigated further to confirm this claim confidently.
With the chosen dataset, the “fine-tuning” of the models was performed by retraining on images with simulated adverse conditions instead of another task (e.g., classifying nodules). This can model MSTL to a certain extent, however, there are numerous limitations with this approach, evident in the varied data which does not entirely align with Godasu and coworker’s (2020) claims and Ausawalaithong and coworker’s (2018) findings. However, this data gives insight into the thresholds of models trained on small datasets to perform under adverse conditions. In future investigations, expanding the size of the training and test sets may allow for better generalisation by the retrained models. Despite this study’s altered scale of the MSTL, the methodology was valid and reliable because the widely cited and trusted Unet architecture was used to structure the models (Ronneberger et al., 2015). When each model generates object masks, the images are sampled over 512 times as the filters strides over each individual pixel to extract its features (transforming raw data into a numerical scale). This process is repeated at every convolutional layer where the image is down-sampled by systematically evolving filters, increasing its accuracy as no sampling errors are carried through the entire process. This process reduces the amount of parameters, and dropout layers randomly turn off neurons to regulate overfitting. Every convolutional layer extracts more information to compare against the model’s knowledge base, thus, ensuring a reliable object mask is created. The metrics represent the extent to which the model succeeded at a correct segmentation. The standard deviation across all metrics averaged from 6 images is below 0.3, indicating that the generation of the object masks was consistent across each image.
The visualisations and the metrics give a unique insight into the relationship between these two mediums of evaluation, leading to the formation of numerous research questions about the obscure reaction of the models to a large amount of noise. The 12.5% noise dataset challenged all but the 12.5% Noise model the most, which is reflected in Figure 6 and the corresponding metrics. Some of the masks generated by these models did not have a single pixel of overlap with the true mask, whereas the other object masks consisted of random scattering, hardly ever representing the typical shape of lungs. It would be valuable to investigate if a threshold is evident in the ability of DL models to tolerate noise in a future study which focuses solely on retraining against increasingly noisy datasets. Expanding upon this, models could be retrained to classify nodules to determine if this effect translates into a model more akin to true MSTL models.
Ongoing investigation into numeric visualisation (weights) of the filters for each layer of the models has given preliminary indications that overparametisation is unlikely due to the similar weight values in each model. Therefore, to determine whether a covariate shift occurred, the models should be trained on larger datasets and tested on randomly augmented data. This process was beyond the timeframe and scope of this investigation, however, adding this process would allow for greater understanding of the commonly non-transparent internal mechanisms of DL models.
Conclusion
This investigation has revealed the potential for retraining models on a flipped dataset to improve their ability to generalise. A Base model and 4 other retrained models (on flipped, rotated, 12.5% or 5% noise datasets) were cross evaluated on base, flipped, rotated, 12.5% and 5% noise test sets to compare their performances. Statistical evaluations found that the 12.5% Noise model outperformed the Base model’s accuracy and F1-Score on the 12.5% noise test set. Further, the Flipped model outperformed the Base model’s accuracy on the base and rotated test sets. As only the 12.5% Noise model outperformed the Base model on its respective test set, the null hypothesis was accepted, however, there is evidence supporting the claim that retraining models on purposefully flipped datasets can be advantageous by increasing generalisation. This finding provides strong evidence for further research into MSTL model retraining and testing involving larger datasets. Future investigation into the effect of noisy datasets on a true MSTL model which classifies lung nodules would unpack the abnormally large influence which noise had on this investigation’s models.
Acknowledgements
Thank you Mr. Nicholson for your continued support and advice in the creation of this investigation and solving programming problems, and Mr. Redding for providing the device to train the models and for the devoted help with programming problems.
Source Code Access
The repository containing the source code is accessed through the QR code below:

Reference List
Alzubaidi, L., Fadhel, M. A., Al-Shamma, O., Zhang, J., Santamaría, J., Duan, Y., & R Oleiwi, S. (2020). Towards a better understanding of transfer learning for medical imaging: A case study. Applied Sciences, 10(13), 4523.
Ausawalaithong, W., Thirach, A., Marukatat, S., & Wilaiprasitporn, T. (2018). Automatic lung cancer prediction from chest X-ray images using the deep learning approach. 2018 11th Biomedical Engineering International Conference (BMEICON), 1–5.
Cohen, J. P., Viviano, J. D., Bertin, P., Morrison, P., Torabian, P., Guarrera, M., Lungren, M. P., Chaudhari, A., Brooks, R., Hashir, M., & others. (2021). TorchXRayVision: A library of chest X-ray datasets and models. ArXiv Preprint ArXiv:2111.00595.
Godasu, R., Zeng, D., & Sutrave, K. (2020). Transfer learning in medical image classification: Challenges and opportunities. Transfer, 5, 28–2020.
Hosny, A., Parmar, C., Quackenbush, J., Schwartz, L. H., & Aerts, H. J. (2018). Artificial intelligence in radiology. Nature Reviews Cancer, 18(8), 500–510.
Lundervold, A. S., & Lundervold, A. (2019). An overview of deep learning in medical imaging focusing on MRI. Zeitschrift Für Medizinische Physik, 29(2), 102–127.
Prevedello, L. M., Halabi, S. S., Shih, G., Wu, C. C., Kohli, M. D., Chokshi, F. H., Erickson, B. J., Kalpathy-Cramer, J., Andriole, K. P., & Flanders, A. E. (2019). Challenges related to artificial intelligence research in medical imaging and the importance of image analysis competitions. Radiology: Artificial Intelligence, 1(1), e180031.
Quan, H., Xu, X., Zheng, T., Li, Z., Zhao, M., & Cui, X. (2021). DenseCapsNet: Detection of COVID-19 from X-ray images using a capsule neural network. Computers in Biology and Medicine, 133, 104399.
Raghu, M., Zhang, C., Kleinberg, J., & Bengio, S. (2019). Transfusion: Understanding transfer learning for medical imaging. ArXiv Preprint ArXiv:1902.07208.
Ronneberger, O., Fischer, P., & Brox, T. (2015). U-net: Convolutional networks for biomedical image segmentation. International Conference on Medical Image Computing and ComputerAssisted Intervention, 234–241.
Samala, R. K., Chan, H.-P., Hadjiiski, L., Helvie, M. A., Richter, C. D., & Cha, K. H. (2018). Breast cancer diagnosis in digital breast tomosynthesis: Effects of training sample size on multi-stage transfer learning using deep neural nets. IEEE Transactions on Medical Imaging, 38(3), 686–696.
Schneider, S., Rusak, E., Eck, L., Bringmann, O., Brendel, W., & Bethge, M. (2020). Improving robustness against common corruptions by covariate shift adaptation. Advances in Neural Information Processing Systems, 33.
Shallue, C. J., & Vanderburg, A. (2018). Identifying exoplanets with deep learning: A five-planet resonant chain around kepler-80 and an eighth planet around kepler-90. The Astronomical Journal, 155(2), 94.
Wang, X., & Schneider, J. (2014) Flexible transfer learning under support and model shift. Advances in Neural Information Processing Systems, 1898–1906.
Appendix 1 - Ethical Report
A large array of chest X-rays will be analysed by a CNN within this investigation to test the previously established hypothesis. The initial X-ray images contain confidential information regarding the patients (full name, age, condition etc.), thus, they are protected under the Privacy Act 1988. However, as all of the confidential information has been removed by JSRT (Japanese Society of Radiological Technology & Japanese Radiology Society, 1998) prior to its use in this investigation, thus, all of the patients’ confidential information was protected as it was never accessible at any stage of this investigation.








