Konrad Cop, Morteza Haghbeigi, Marcin Gajewski, Tomasz Trzciński
Perception Systems for Autonomous Mobile Robots: Selecting and Mitigating Limits 17
Krzysztof Mianowski, Filip Gruca, Jakub Grzonkowski, Jan Makulec Roboty równoległe do precyzyjnej manipulacji w operacjach chirurgicznych
Sebastian Dudzik, Piotr Szeląg
31
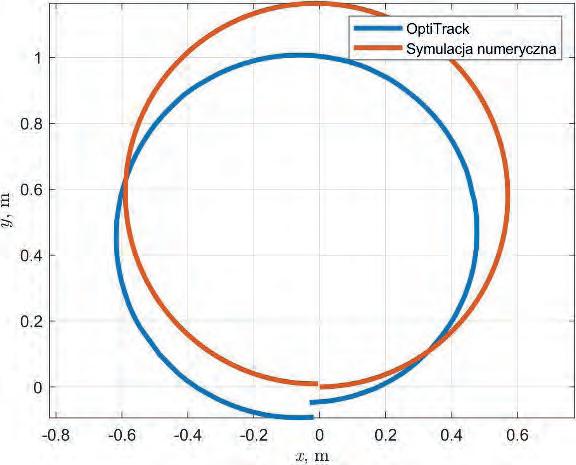
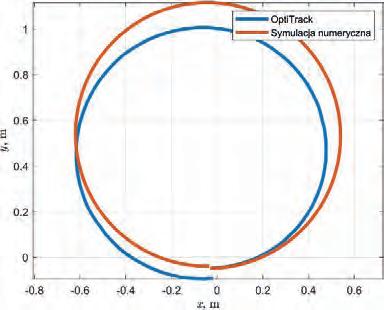
Analiza niepewności lokalizacji odometrycznej z wykorzystaniem systemu przechwytywania ruchu i symulacji Monte Carlo 41
Krzysztof Pieńkosz Optymalizacja kolejności pakowania towarów na paletach 47
Andrzej Bożek Szybki dyskretny regulator PID dla serwomechanizmu prądowego
Kamil Borawski Simple Stability Conditions of Linear Switched Systems with Time-Dependent Switching
Ponadto:
Informacje dla Autorów – 115 | XVII Konkurs Młodzi Innowacyjni – 119 | Awans naukowy – dr hab. inż. Ewa Chodakowska, prof. PB – 120 | Wspomnienia –Profesor Ryszard Rojek – 122 | Nasze Wydawnictwa – III okładka
Rok 29 (2025) Nr 1 (255)
ISSN 1427-9126, Indeks 339512
Redaktor naczelny
prof. Cezary Zieliński
Zastępca redaktora naczelnego dr inż. Małgorzata Kaliczyńska
Zespół redakcyjny dr inż. Jerzy Borzymiński
prof. Wojciech Grega – automatyka prof. Krzysztof Janiszowski dr inż. Małgorzata Kaliczyńska – redaktor merytoryczny/statystyczny dr inż. Michał Nowicki – mechatronika prof. Mateusz Turkowski – metrologia prof. Cezary Zieliński – robotyka
Korekta
dr inż. Janusz Madejski
Skład i redakcja techniczna
Ewa Markowska
Druk
Drukarnia „PAPER & TINTA” Barbara Tokłowska Sp. K. Nakład 400 egz.
Wydawca
Sieć Badawcza Łukasiewicz –Przemysłowy Instytut Automatyki i Pomiarów PIAP Al. Jerozolimskie 202, 02-486 Warszawa
Pomiary Automatyka Robotyka jest czasopismem naukowo-technicznym obecnym na rynku od 1997 r. Przez 18 lat ukazywało się jako miesięcznik. Aktualnie wydawany kwartalnik zawiera artykuły recenzowane, prezentujące wyniki teoretyczne i praktyczne prowadzonych prac naukowo-badawczych w zakresie szeroko rozumianej automatyki, robotyki i metrologii. Kwartalnik naukowo-techniczny Pomiary Automatyka Robotyka jest indeksowany w bazach BAZTECH, Google Scholar oraz ICI Journals Master List (ICV 2023: 98,13), a także w bazie naukowych i branżowych polskich czasopism elektronicznych ARIANTA. Przyłączając się do realizacji idei Otwartej Nauki, udostępniamy bezpłatnie wszystkie artykuły naukowe publikowane w kwartalniku naukowo-technicznym Pomiary Automatyka Robotyka. Wersją pierwotną (referencyjną) jest wersja papierowa.
Punktacja Ministerstwa Edukacji i Nauki za publikacje naukowe w kwartalniku Pomiary Automatyka Robotyka wynosi obecnie 70 pkt. (wykaz czasopism naukowych i recenzowanych materiałów z konferencji międzynarodowych z dnia 5 stycznia 2024 r., poz. 29984). Przypisane dyscypliny naukowe – automatyka, elektronika, elektrotechnika i technologie kosmiczne.
Kwartalnik jest organem wydawniczym Polskiego Stowarzyszenia Pomiarów, Automatyki i Robotyki POLSPAR – organizacji prowadzącej działalność naukowo-techniczną w obszarze metrologii, automatyki, robotyki i pomiarów, reprezentującej Polskę w międzynarodowych organizacjach IFAC, IFR, IMEKO.
Rada Naukowa
prof. Jan Awrejcewicz
Katedra Automatyki, Biomechaniki i Mechatroniki, Politechnika Łódzka
prof. Milan Dado University of Žilina (Słowacja)
prof. Ignacy Dulęba Wydział Elektroniki, Fotoniki i Mikrosystemów, Politechnika Wrocławska
prof. Tadeusz Glinka Instytut Elektrotechniki i Informatyki, Politechnika Śląska
prof. Evangelos V. Hristoforou National Technical University of Athens (Grecja)
dr Oleg Ivlev University of Bremen (Niemcy)
prof. Larysa A. Koshevaja Narodowy Uniwersytet Lotnictwa, Kiev (Ukraina)
prof. Igor P. Kurytnik
Małopolska Uczelnia Państwowa im. rot. W. Pileckiego
prof. J. Tenreiro Machado Polytechnic Institute of Porto (Portugalia)
prof. Jacek Malec
Lund University (Szwecja)
prof. Andrzej Masłowski Sieć Badawcza Łukasiewicz –Przemysłowy Instytut Automatyki i Pomiarów PIAP, Warszawa
prof. Maciej Michałek
Wydział Automatyki, Robotyki i Elektrotechniki, Politechnika Poznańska
dr Vassilis C. Moulianitis University of Patras (Grecja)
prof. Joanicjusz Nazarko
Wydział Inżynierii Zarządzania, Politechnika Białostocka
prof. Serhiy Prokhorenko
„Lviv Polytechnic” National University (Ukraina)
prof. Eugeniusz Ratajczyk
Wydział Inżynierii i Zarządzania, Wyższa Szkoła Ekologii i Zarządzania w Warszawie
prof. Jerzy Sąsiadek Carleton University (Kanada)
prof. Rossi Setchi
Cardiff University (Wielka Brytania)
prof. Waldemar Skomudek
Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej, Akademia Górniczo-Hutnicza
dr Dragan Stokic
ATB – Institute for Applied Systems Technology Bremen GmbH (Niemcy)
prof. Eugeniusz Świtoński
Wydział Mechaniczny Technologiczny, Politechnika Śląska
prof. Peter Švec Slovak Academy of Sciences (Słowacja)
prof. Wojciech Włodarski
RMIT University, Melbourne (Australia)
prof. Eugenij T. Volodarsky
„Kyiv Polytechnic” National University (Ukraina)
Wydawanie kwartalnika Pomiary Automatyka Robotyka – zadanie finansowane w ramach umowy 907/P-DUN/2019 ze środków Ministra Nauki i Szkolnictwa Wyższego przeznaczonych na działalność upowszechniającą naukę.
Spis treści
3 Od Redakcji
5 Konrad Cop, Morteza Haghbeigi, Marcin Gajewski, Tomasz Trzciński
Perception Systems for Autonomous Mobile Robots: Selecting and Mitigating Limits Systemy percepcji dla autonomicznych robotów mobilnych: wybór i redukcja ograniczeń
17 Krzysztof Mianowski, Filip Gruca, Jakub Grzonkowski, Jan Makulec Roboty równoległe do precyzyjnej manipulacji w operacjach chirurgicznych
Parallel Robots for Precise Manipulation in Surgical Operations
31 Sebastian Dudzik, Piotr Szeląg
Analiza niepewności lokalizacji odometrycznej z wykorzystaniem systemu przechwytywania ruchu i symulacji Monte Carlo
Analysis of Odometric Localization Uncertainty Using a Motion Capture System and Monte Carlo Simulation
41 Krzysztof Pieńkosz
Optymalizacja kolejności pakowania towarów na paletach
Optimization of the Loading Sequence of Goods on Pallets
47 Andrzej Bożek
Szybki dyskretny regulator PID dla serwomechanizmu prądowego Fast Discrete-Time PID Controller for Current Servo
55 Kamil Borawski
Simple Stability Conditions of Linear Switched Systems with Time-Dependent Switching
Proste warunki stabilności liniowych układów przełączalnych z przełączaniem zależnym od czasu
61 Marcin Hubacz, Andrzej Paszkiewicz, Bartosz Pawłowicz, Mateusz Salach, Bartosz Trybus, Konrad Żak
System testowania i walidacji modeli do sterowania ruchem pojazdów
A System for Testing and Verifying Prototypes of Models for Vehicle Traffic Control
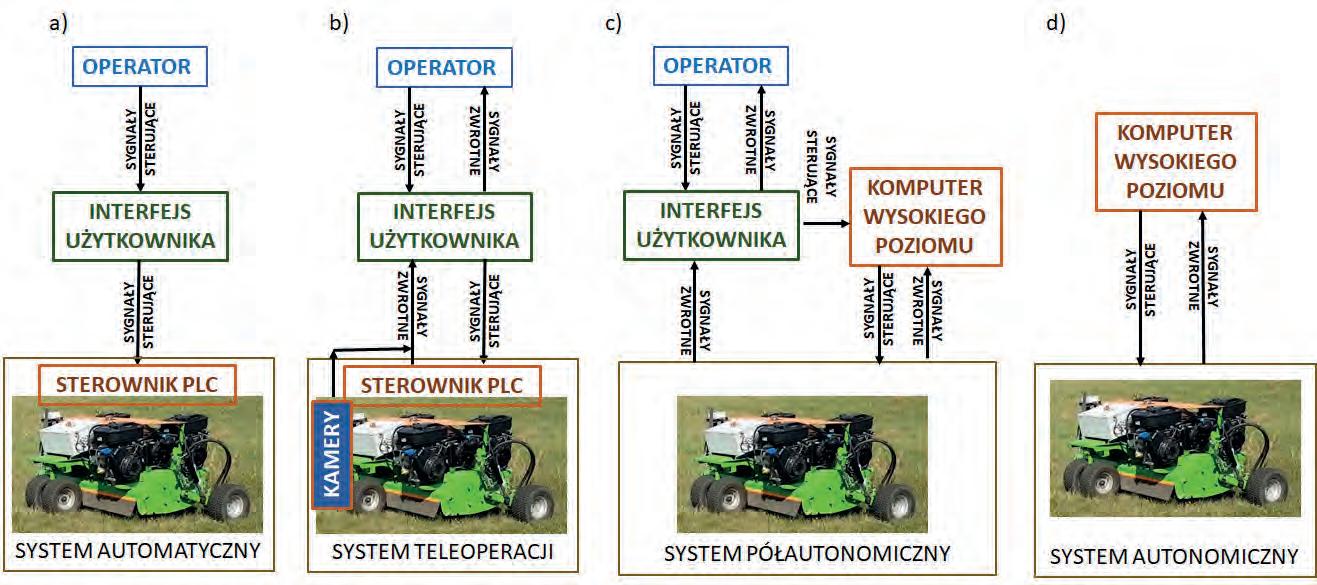
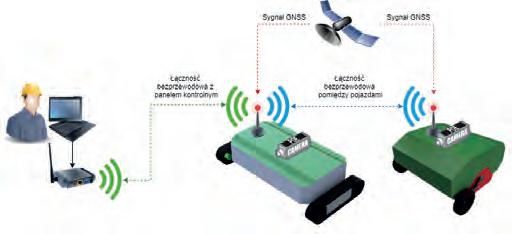
69 Andrzej Typiak, Rafał Typiak, Zbigniew Zienowicz, Mateusz Nowakowski, Patrycja Matejek
System półautonomicznego sterowania tandemem kosiarek do koszenia terenów przydrożnych
A System of Semi-Autonomous Tandem Mowers for Mowing Roadside Area
75 Janusz Kobaka, Jacek Katzer, Machi Zawidzki
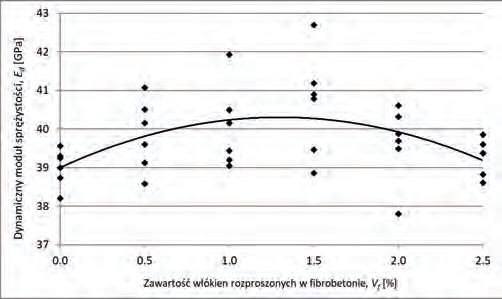
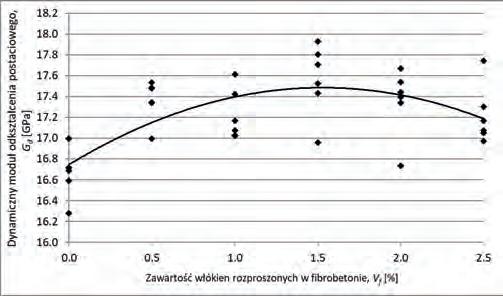
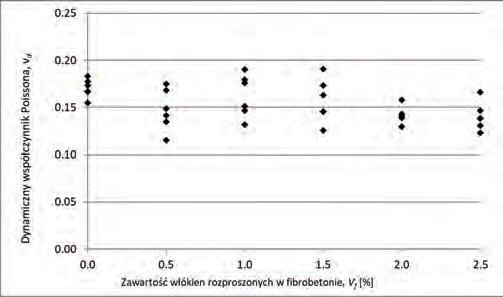
Dynamiczne właściwości fibrobetonu wytworzonego na baize piasków odpadowych Dynamic Properties of SFRC Made on the Basis of Waste Sand
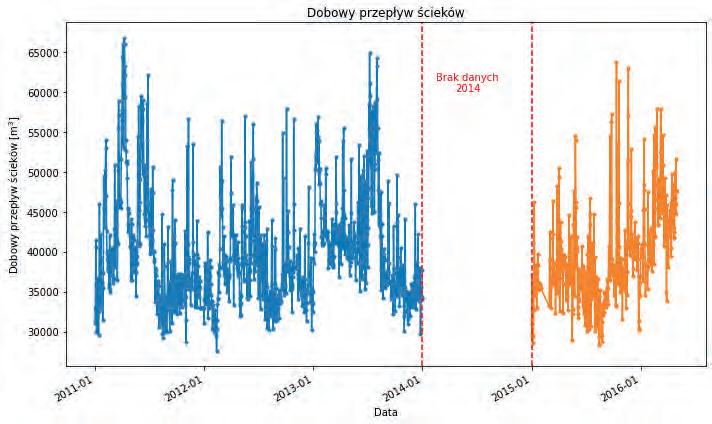
81 Bartosz Kowal, Patryk Organiściak, Paweł Kuraś, Adam Masłoń, Bartosz Wadiak Uczenie maszynowe w prognozowaniu ilości ścieków dla oczyszczalni ścieków miasta Rzeszowa na podstawie warunków pogodowych Machine Learning in Forecasting the Amount of Sewage for the Wastewater Treatment Plant of the City of Rzeszów Based on Weather Conditions
91 Władysław Iwaniec Macierzowy cyfrowy cień sieci czujników IoT
Matrix Digital Shadow of IoT Sensors Network
99 Rafał Wojszczyk
Architektura oprogramowania systemu kontrolno-pomiarowego z interfejsem USB
Software Architecture of the Control and Measurement System Using the USB Interface
107 Robert Tomasiewicz
CTS i EPICS – moduły automatyzujące montaż i kontrolę jakości w produkcji amortyzatorów samochodowych
CTS and EPICS – Modules for Automating the Assembly and Quality Control in the Production of Automotive Dampers
115 Informacje dla Autorów
119 XVII Konkurs Młodzi Innowacyjni
120 Awans naukowy | Habilitacja Opracowanie hybrydowego modelu priorytetyzacji technologii opartego na metodzie analizy obwiedni danych oraz koncepcji zbiorów przybliżonych – dr hab. inż. Ewa Chodakowska, prof. PB
122 Wspomnienia
Profesor Ryszard Rojek
Drodzy Czytelnicy,
oddajemy w Państwa ręce kolejny numer kwartalnika. W tym wydaniu zostały zgromadzone artykuły dotyczące wszystkich trzech dziedzin występujących w nazwie naszego czasopisma. Cieszy nas stale wzrastająca popularność i zwiększająca się liczba autorów. Do grupy artykułów poświęconych automatyce należy zaliczyć pracę poświęconą stabilności układów przełączających opisywanych zarówno w dziedzinie czasu ciągłego, jak i dyskretnego. Przykłady numeryczne wskazują na efektywność opracowanej metody. Kolejna praca dotyczy doboru nastaw dyskretnych regulatorów PID dla serwomechanizmów prądowych. Metodę strojenia zweryfikowano symulacyjnie. Artykuł poświęcony automatyzacji linii montażowej pokazuje, jak przy jej projektowaniu wzięto pod uwagę parametry technologiczne oraz ekonomiczne. Kolejny artykuł dotyczy sposobu testowania różnych scenariuszy monitorowania i zarządzania ruchem pojazdów w środowisku miejskim bądź przemysłowym z wykorzystaniem Internetu Rzeczy oraz urządzeń RFID.
Grupa artykułów dotyczących robotyki jest równie liczna. Obejmuje ona pracę na temat systemów percepcji przeznaczonych dla robotów mobilnych. Wybór czujników bierze pod uwagę ograniczenia budżetowe. Kolejna praca zajmuje się oszacowaniem niepewności lokalizacji robota mobilnego wykorzystującego napęd oparty na dwóch niezależnych silnikach. W tej samej grupie znajduje się praca poświęcona zastosowaniu robotów o równoległej strukturze kinematycznej do wykonywania zabiegów chirurgicznych. Problem paletyzacji obiektów o jednakowych wymiarach i regularnych kształtach został rozwiązany przez roboty przemysłowe. Jeżeli jednak paletyzowane obiekty mają nieregularne kształty, to problem ich układania na palecie staje się dużo bardziej skomplikowany. By go rozwiązać, przedstawiono grafowy model pakowania palety. Kolejny artykuł przedstawia system składający się z dwóch samobieżnych kosiarek ścinających trawę na poboczach dróg. Jedna z kosiarek sterowana jest zdalnie, a druga jest z nią sprzężona.
Jeden z artykułów opisujących techniki pomiarowe poświęcony jest badaniu właściwości fibrobetonu. Przedmiotem zainteresowania był wpływ włókien stalowych na właściwości dynamiczne tego materiału budowlanego. Belki były poddawane drganiom, a dzięki analizie Fouriera określano poszukiwane współczynniki. Kolejny artykuł zajmuje się przewidywaniem wpływu warunków pogodowych na skład ścieków dopływających do oczyszczalni. Znajomość stężenia zanieczyszczeń umożliwia optymalizację pracy oczyszczalni. Do prognozowania wykorzystano modele uczenia maszynowego. Następny artykuł z grupy pomiarowej dotyczy architektury systemu kontrolno-pomiarowego wykorzystującego komunikację z urządzeniami przez USB. Dzięki temu możliwa jest rejestracja sygnałów analogowych bądź cyfrowych oraz sterowanie za pomocą sygnałów cyfrowych bądź wytwarzanie przebiegu PWM. Kolejny artykuł przedstawia sposób symulacji sieci IoT za pomocą tzw. cienia cyfrowego, koncepcji podobnej do bliźniaka cyfrowego. Mamy nadzieję, że wśród poruszanych tematów znajdą Państwo coś interesującego dla siebie. Życzymy miłej lektury.
Redaktor naczelny kwartalnika Pomiary Automatyka Robotyka prof. dr hab. inż. Cezary Zieliński
Perception Systems for Autonomous Mobile Robots: Selecting and Mitigating Limits
Konrad Cop 1, 2, Morteza Haghbeigi 1, 2, Marcin Gajewski 2, Tomasz Trzciński 1
1 Warsaw University of Technology, Pl. Politechniki 1, 00-661 Warsaw, Poland
2 United Robots Sp. z o.o., ul. Świeradowska 47, 02-622 Warszawa
Abstract: A well-designed perception system is crucial for the proper operation of an autonomous mobile robot however it is not trivial to engineer. For a comprehensive system not only the sensors’ features must be considered but also the way their data are utilised for robotic operation. In this paper, we present a set of tightly coupled strategies that allow the creation of an end-to-end perception system utilising 3D representation in the form of point clouds. Our proposal is generic enough to be applied to various mobile robots as it is aware of the context of robotic operation and accounts for hardware constraints. As the first strategy, we introduce a formalised sensors selection process formulated as a multi-objective optimization problem with metrics relaxation which allows to choose an optimal set of sensors within budgetary limitations. Secondly, we validate various data filtration strategies and their combination in the context of the navigation system to find a trade-off between accuracy and computational effort. Finally, to mitigate the suboptimal field of view of combined sensors and augment the perception system we introduce a new concept for the occupancy grid layer which utilises motion information in the occupancy calculation. For these strategies, we conduct experimental verification and apply the results in an autonomous cleaning robot.
One of the key enablers of robotic autonomy is the robot’s ability to perceive its surroundings. Observation of the environment is realised by means of a multitude of onboard sensors combined into a perception system. In the context of mobile robots, what the robot perceives is directly propagated to the navigation system. Sensors inputs are utilised to estimate achievable space in the environment to plan actions (trajectories) of the robot in short- and long-time perspectives. Therefore, the ability to navigate efficiently highly depends on the sensors’ choice and how they are deployed. In this paper, we formulate three key aspects that allow the creation of a successful end-to-end perception solution. Our proposal focuses solely on the 3D data in the format of point clouds which are
Autor korespondujący:
Konrad Cop, konrad.cop@unitedrobots.co
Artykuł recenzowany nadesłany 08.10.2024 r., przyjęty do druku 16.01.2025 r.
commonly used in robotic perception systems due to their effectiveness in representing complex environments.
The first aspect which must be considered is that the choice of the sensors that would satisfy multiple, often contradicting requirements is not trivial. Depending on the mechanical design of the robot, characteristics of the robotic process, features of the environment, and budgetary limitations, various combinations of sensors can be selected. So far the selection process has usually been considered case-specific, for example, Shi et al. designed a perception system for a humanoid robot [1] while Deshpande et al. tackled a designated mobile platform [2] but no generic approach was proposed. Others proposed to compare sensors solely such as different LiDAR solutions [3] or RGBD cameras [4, 5] without deeply considering the application. Instead of going this path, we propose to formulate the selection process as an iterative procedure that takes into account multiple “nice-to-have” requirements of the application and optimizes the costs of the solution. The process is formally defined and was used already for selecting a sensor rig for an autonomous cleaning robot.
Secondly, each sensor is a piece of hardware that has some production irregularities and detection inaccuracies, which lead to more or less noisy data. Using such data would cause the robot to experience unstable operation. Therefore, proper filtration mechanisms are required to improve the behaviour of the robot. Additionally, depending on the sensor, the incoming data might be very dense or contain redundant information,
which potentially leads to unnecessary utilisation of computational resources when using such information for navigation. Multiple works were conducted in this regard to propose filtration strategies for purposes of object reconstruction [6, 7] or 3D video streaming [8] and this is a well-explored field. However, in the context of mobile robots with limited onboard resources, it is not only important how well the filtration procedure performs but also how efficient it is. Therefore in this paper, we evaluate the influence of various filtration methods and their combination on the process efficiency.
Finally, as most robotic projects usually face budgetary limitations, purchasing enough sensors to satisfy all requirements might not be feasible. As a result, some criteria must be sacrificed. Based on practical experience, a common consequence of this limitation is the incomplete spatial coverage provided by the selected sensors, which fails to fully capture the robot’s entire surroundings. This, in turn, makes navigation particularly challenging, as the reduced sensor coverage compromises the safety and reliability of the robot’s movement through its environment. With inadequate hardware, one could utilise the software to fill in the gap. Few approaches have been proposed to address similar challenges, but they primarily focus on developing local planners or controllers that calculate collision-free trajectories based on limited sensing capabilities, such as maximum sensor range [9, 10]. These methods often assume a 2D field of view, where obstacles within this plane are guaranteed to be detected. However, this assumption does not hold in 3D environments, where detecting blind spots is far more complex. For instance, Phan et al. introduced a decision-making module for robots with limited sensing capabilities, which enables collision avoidance based on partial detections in 2D [11]. Despite these advancements, none of these approaches have fully explored the use of spatio-temporal information for generating navigation occupancy maps, which could significantly enhance the reliability of autonomous navigation. We therefore, propose to utilise the information from both the sensor’s returns and the robot’s motion to accumulate the relevant information by means of a Hit Layer.
The three aforementioned strategies are interrelated and essential when creating a perception system for a mobile robot in an end-to-end manner. The combined analysis constitutes the contribution of this paper which includes three aspects:
− We propose an iterative, generic process for selecting sensors for any mobile robot.
− We evaluate combinations of various filtration algorithms in terms of their computational efficiency.
− We introduce an approach for utilising perception and motion information into occupancy estimation by means of a newly proposed Hit Layer.
The following sections describe the contributions in details.
2. Selection of sensors
Selecting an appropriate sensor rig for mobile navigation is not a trivial task and it depends on multiple factors related to both robot’s mechanical features (e.g. dimensions and inertia) and application specifics, which may lead to contradicting requirements. For example, one might require high resolution of data and simultaneously low hardware costs. Better-quality sensors are typically more expensive. In such a situation, a question arises of which parameters should be sacrificed. To facilitate the decision, we introduce a selection process that takes into account multiple aspects and formulate it as a multi-objective optimization problem with metrics relaxation. The overview of the process is depicted in Fig. 1. The base of our proposal is the definition of eight Application Requirements and six Sensor Features which are the starting point for the selection
process. Careful analysis of these two groups of parameters allows us to formulate Rig Selection Metrics which are quantitative expressions of the system requirements. The metrics are split into Satisficing Metrics which aim to define boundary selection conditions for the sensors and the Optimizing Metric which allows finding the best constrained solution.
The selection process should be conducted as follows. At the start, one should define the set of most desirable parameters of the complete rig i.e. the most strict Satisficing Metrics for which the knowledge about the Application Requirements and the Sensor Features should be used. At this stage, multiple sensors can be considered. Details are described in Sections 2.1 and 2.2. Very likely, at the first step, multiple high-quality devices will be picked, but the choice implies the costs of both the sensors and the hardware to process the data arriving from them. This leads to the initial value of the solution costs, which we define as the Optimizing metric. If, after the first iteration, the result is within the budgetary limit of the project, the selection can be directly used for the robot’s sensor rig. If not, one must repeat the process, by iteratively relaxing the Satisficing Metrics until the reasonable cost level is reached.
2.1. Application requirements definition
To be able to specify the needs of the application, we propose to characterise the intended system according to the following requirements (for the extended names and process scheme refer to Fig. 1):
R1 The physical dimensions of the robot and the required area that should be perceived constantly around it need to be defined.
R2 Kinematics and the intended direction of the robot motion should be considered. E.g. if the robot travels forward only, a sensor on the back is redundant.
R3 It is also important to match how quickly and how far the robot can see with the application it is intended to. For example, if the robot is supposed to detect dead-ends on the fly, while travelling across a complex combination of corridors, both the range and the frequency should allow correct decisions. This metric is coupled heavily to the environment characteristics and path planning algorithm used by the robot.
R4 Various objects in the environment can appear in the robot’s surroundings rapidly or slowly. It is important to ensure that the frequency of observation (the frame rate) is fast enough to notice object dynamics, i.e. that the robot can notice the motion of the object quickly enough to react [12].
R5 Similarly, the frame rate should be adjusted to the robot’s velocity. Distance travelled between consecutive observations should be small enough to allow the robot to replan the path and avoid obstacles on the way.
R6 The resolution of the sensor should be high enough to notice the tiniest objects that can endanger the robot. For example, if the environment is full of hanging, thin cables the sensor must be able to reflect them in the perceived point cloud [13].
R7 This requirement expresses how accurately the objects should be perceived by the robot to safely conduct its operation. Low-quality sensors might experience distortion that influences reconstruction accuracy, which, depending on the application, might become harmful. As an example, a sensor might not be considered flat the surfaces that actually are flat [14].
R8 The lighting in the environment has a direct impact on a sensor’s performance. If the robot is supposed to work with limited light or in darkness, the sensors’ visible light spectrum must be selected accordingly, potentially with active projection [15].
APPLICATION REQUIREMENTS RIG SELECTION METRICS
R1: Robot's exterior and footprint
R2: Type of possible motion
R3: Spatio-temporal characteristics
R4: Dynamics of objects in the environment
R5: Robot's speed
R6: Size and character of obstacles
R7: Accuracy of objects reconstruction
R8: Light conditions in the environment
n Possible to improve using "Hit Layer"
Spatial coverage (overall) SC ≥ SCmin
Resultant frequency (slowest sensor) F ≥ Fmin
Resultant resolution (least accurate sensor) R ≤ Rmin
Possible to improve using Filtering
Resultant noise (most noisy sensor) N ≤ Nmin
Light fluctuations immunity (least immune sensor) L ≥ Lmin
required for data transfer
/
Processor power required for data filtering Uf n sensors selected Overall cost of sensors
Processor power required for sensors processing Up
of CPU
Sensors' placement adjustment
Fig. 1. Overview of the selection process in the form of Multi-Objective Optimization with Metrics Relaxation
Rys. 1. Schemat procesu selekcji w postaci optymalizacji wielokryterialnej z relaksacją metryk
2.2. Sensors features
Comparison of different sensors exceeds the scope of this paper, as the variety of available solutions is massive. There exists multiple publications on sensor types and technologies. Specifically detailed description and comparison can be found in [16, 17]. A comprehensive explanation of various characteristics of sensors in [18], Chapter 4. To be able to conduct the analysis process, the following features of potential sensors should be considered:
− Range: what is the distance at which the sensor can effectively notice an object
− FOV: Field Of View, defines the shape of the perception space. Usually a pyramid or cone.
− Frequency: (alternatively Frame Rate), a notion of how often the sensor can receive views of the environment.
− Resolution: how many discrete points are available per single scan and FOV cross-section. Usually, drops with the range.
− Noise and accuracy: expresses the noise level and ability to precisely reconstruct object shapes.
− Perception Technology: how is the point cloud generated e.g. Stereo Camera (passive), Structured Light (active), Time Of Flight (active) etc.
Cost of the system C
2.3. Satisficing metrics
Having analysed Application Requirements and Sensor
Features one can conclude five metrics that are intended to define the “No-go” limits of the selection. In other words, Satisficing metrics are the system’s minimum requirements at the given selection process iteration. The list includes (brackets explain the corresponding units):
− Spatial Coverage SC [% of coverage], described in details in the following section.
− Resultant Frequency F [Hz], encompasses the publication frequency of all sensors (i.e. how often new data is observed) and expresses the combined metric as the frequency of the slowest sensor.
− Resultant Resolution R [mm], expressed as the resolution of the lowest-resolution sensor at the distance of interest.
− Resultant Noise N [mm], expressed as the noise level of least accurate sensor.
− Light Fluctuations Immunity L [binary], we propose as binary metric whether the sensor can handle given lighting conditions.
Konrad Cop, Morteza Haghbeigi, Marcin Gajewski, Tomasz Trzciński
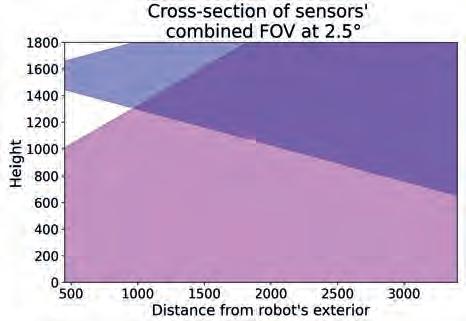
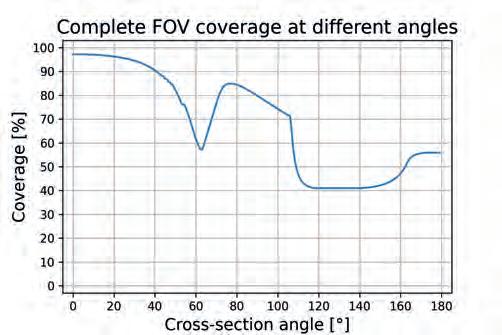
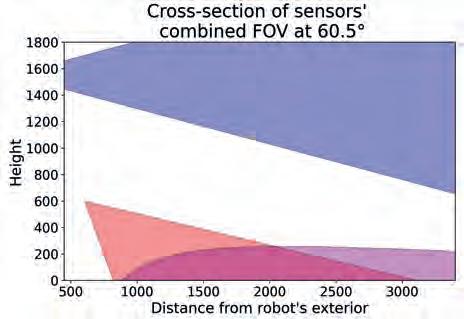
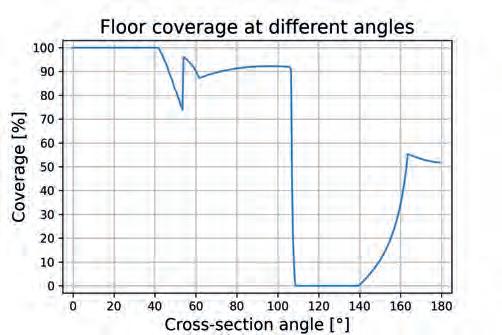
It is important that Satisficing metrics are not modified directly. Instead, Application Requirements and Sensor Features should be adjusted (relaxed) to alter Satisficing metrics. Spatial Coverage SC For the purpose of this paper, we introduce a new metric that encapsulates the notion of how well the space around the robot is covered. Where and how the sensors are mounted on the robot results in a complex shape of the combined FOV, as shown in the example from Fig. 2a). To qualitatively express the coverage, we propose to compute intersections of the combined Field of View at various angles around the vertical axis of the robot and calculate areas covered by sensors in each intersection from ground to the robot’s height h. As the robot has a non-zero diameter, we propose to take into account only the area from the robot’s exterior r to the given range d. Examples of such intersections for r = 450 mm and d = 3500 mm can be seen in Fig. 2b, c). As it is visible, depending on the angle, different ratio of space is covered by the combination of the sensors. We propose to combine the coverage ratios into the Spatial Coverage metric expressed as two graphs of coverage plotted against rotation angle, as depicted in Fig. 2 d, e). The first one shows the complete coverages h × [r, d]. We also introduce the second metric which corresponds to floor coverage within the range [r, d]. To justify the purpose of the second metric, one must remember that most obstacles “stand on the ground” therefore even if an object is not completely visible, noticing just the bottom part might be sufficient for efficient navigation. As this is very application-specific, it is a designer who needs to decide to which part of the complete space (as defined by the first graph) the system can be limited. If there are hanging or “sticking-out-of-wall” objects in the environment, they may impose danger to the robot as depicted in Fig. 7. This however can also be mitigated software-wise as described in section 4.
2.4. Optimizing metric and iterative relaxation
The final optimization parameter of the process is the purchase cost of the complete system. It consists of multiple elements mentioned in the following section:
Overall cost of sensors This cost component is expressed as the sum of prices Psi of all sensors:
12 . sss sn CPPP =+++ (1)
Overall cost of data transfer hardware This cost component incorporates the purchase price of devices like routers, cables, and network cards. To select appropriate components the amount of data per second generated by each sensor must be computed. More specifically, each sensor occupies a specific bandwidth Bi, which is a product of the weight of single data shot wi and i-th sensor’s frequency fi, expressed in Bps (bits per second):
Where wi results from the Field of View of the sensor, resolution, precision of data representation etc., and is a characteristic of each device usually expressed in bytes. The bandwidth occupied by all sensors is the sum of each sensor’s bandwidth:
12 n BBBB =+++ (3)
Each component in the transfer system (cables switches, routers etc.) should be selected to have a bandwidth capacity higher than all sensors’ bandwidth B tj > B. The cost of transfer components is the sum of prices P tj of all m devices and components in the system that fulfill the aforementioned criterion: 1122 ()()().ttttt CPBPBPBtmtm =+++ (4)
Cost of CPU This cost component describes the cost of a processing unit used for performing operations on the data arriving from sensors. To define processing power requirements of such a CPU, two factors need to be taken into accout:
− Processing power for sensor operation. Each sensor is operated by means of a software driver which performs data reception, conversion into the appropriate format, and communication with higher-level software. The exact processing power requirement for i-th sensor Upi is difficult to analytically compute and requires experimental measurement for each sensor.
− Processing power for data filtering. If a sensor needs specific preprocessing e.g. filtering, additional CPU power is needed Ufi. Further analysis of this topic is described in Section 3.
The CPU should be selected in a way that fulfills the following condition:
And the cost of the CPU is the purchase price of a device:
Finally, the overall cost of the system is expressed simply as the sum of all costs mentioned above:
If the resultant cost exceeds the intended budget, one should return to the initial step and relax the Application Requirements and desired Sensor Features. At this step, if it is mechanically possible, one might consider modifying the mounting position of the sensors. When wisely considered, this can even reduce the number of sensors. Finally, the process of relaxation should be repeated until a satisfactory cost is achieved.
2.5. Applicability
UR Cleaner use case The described process was used for the selection of sensors for the autonomous cleaning robot The resultant sensor rig consists of five depth sensors. Kinect Azure [26] as the front sensor, three PMD pico flexx [27] for side and back and the Velodyne VLP-16 Puck [28] for the top. The Satisficing metrics for which the acceptable cost level (which cannot be disclosed due to business sensitivity) was reached are described in Table 1. The SC metric for this robot is depicted in Fig. 2 d, e).
Tab. 1. Satisficing metrics for industrial use case
Tab. 1. Metryki satysfakcjonujące w przypadku przemysłowego robota sprzątającego F [Hz] R [mm] N [mm] L [binary] 15 122 30 True
Potential of generalization The proposed approach for the selection of sensors was designed to generalize for various robot types. Specifically one can consider a situation when the robot does not move on a flat surface but instead moves on uneven terrain, in the air, or under water. In such scenarios, the robot’s orientation varies in a 3D space. Importantly, all Application Requirements remain valid but require careful
analysis and potentially experimental verification. E.g. the same sensor working in an outdoor environment might experience different noise characteristics than in the indoor case. Similarly, the dynamics of the objects in the environment and the size of obstacles heavily depend on the application use case. Nevertheless, most of the Satisficing Metrics, namely F, R, N, L remain fully valid regardless of the working conditions of the robot whether it is an outdoor, indoor, structured environment, air or underwater robot. The remaining metric i.e. SC is defined within the space limited by the flat ground in the bottom and specific height at the top. Such a definition is especially useful for robots operating in structured environments and does not apply to robots whose orientation varies in 3D space. It can however be easily generalized by not reducing the lower and upper limits but using the complete sphere around the robot instead.
3. Data preprocessing
When the sensors are selected one has to consider whether using raw data outputs for multi-sensor systems is feasible. Sensors produce high-frequency data that can strain the robot’s computational resources. Filtering serves to reduce the data
Fig. 2. Explanation of the SC metric. a) 3D view of sensors’ FOV; b, c) examples of cross-sections at specific angles; d, e) plots of metric evaluation for complete coverage and floor coverage. The angles of cross-section are evaluated from 0° to 180° as the sensors are symmetrically positioned on both sides of the robot Rys. 2. Opis metryki SC. a) widok 3D przedstawiający pole widzenia czujników; b, c) przykładowe przekroje w wybranych kątach; d, e) wykresy oceny metryki dla całkowitego pokrycia oraz pokrycia powierzchni podłogi. Kąty przekrojów analizowane są od 0° do 180°, ponieważ czujniki są symetrycznie rozmieszczone po obu stronach robota
volume, thereby facilitating more efficient real-time processing. Furthermore, it diminishes noise and filters out irrelevant information, enhancing the accuracy of environment mapping, object detection, and navigation. This specifically allows to use cost-effective sensors while ensuring data quality through effective filtering techniques. Additionally, filtering ensures that data processing is consistent with sensor data rates, preventing delays and enabling timely responses to dynamic environmental conditions.
Multiple filtration methods have been developed so far and can be used together but the overall performance is highly dependent on the combination of parameters and sequence of processing. This section introduces some wellknown filtration methods and evaluates the influence of the order of execution on computational efficiency. A comparative evaluation is presented based on experimental results.
3.1. Preprocessing methods
Out of multiple algorithms which have been developed so far, we selected four well-established methods that, in our assessment, are sufficient to construct effective filtering pipelines: − Statistical Outlier Removal — a method that removes noise by analysing the distribution of distances between neighbouring points. Points with distances significantly deviat-
Konrad Cop, Morteza Haghbeigi, Marcin Gajewski, Tomasz Trzciński
Perception Systems for Autonomous Mobile Robots:
ing from the mean are classified as outliers and excluded, resulting in a cleaner and more reliable point cloud [7, 19]. The filter is parameterized by the number of neighbouring points N and the standard deviation multiplier M, which defines the threshold as a multiple of the standard deviation from the mean distance. Points falling outside this range are classified as outliers and subsequently removed.
− Voxel Grid Filtering — A method for downsampling point clouds by approximating points within a cubic region (voxel) with their centroid [7, 19]. The process is parameterized by a voxel grid size V
− Pass-Through Filters — a method that selects points within a specified range along a given axis (e.g., x, y, or z). Points outside this defined interval are excluded, allowing for targeted segmentation of a region of interest [19]. Parametrized by coordinates of interval <A, B> along given axis.
− RANSAC (Random Sample Consensus) algorithm for plane segmentation — an algorithm used to identify and segment planes in point clouds by fitting models to random subsets of points and selecting the model with the highest number of inliers [19, 20]. Parametrized by max iterations I that specifies the maximum number of iterations to run, determining how many random samples are tested and distance threshold T that defines the maximum allowable distance from a point to the plane for it to be considered an inlier. Despite their simplicity, these techniques can be combined to create efficient filtration pipelines that address the constraints of time and resources. We will present example pipelines that integrate these filters to achieve both resource efficiency and effective operation.
3.2. Proposed filtration pipelines
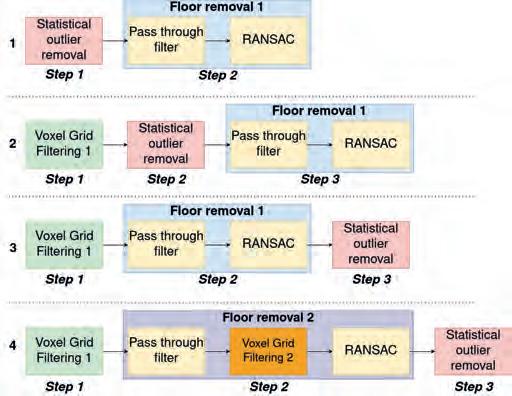
In this study, we propose four distinct data filtration pipelines for point cloud processing, which essentially consist of various combinations of the four basic filtration algorithms described before. We aimed to develop a filtration pipeline that allows getting rid of information that is irrelevant for the navigation and would cause unnecessary load when other algorithms of a robot, such as navigation, utilise the data. This can be achieved not only by reducing the noise level and downsampling the point clouds but also by making additional assumptions. More specifically, in our case, the sensors are firmly located in the robot’s reference frame and the robot is always traveling on the ground, therefore the surface of contact (floor) can be removed. This further reduces the weight of the point cloud. With this in mind, we propose four pipelines consisting of noise
removal, size reduction, and floor removal in various combinations as depicted in Fig. 3.
For the first three pipelines, a two-step process for floor removal, referred to as “Floor Removal 1”, is implemented in the following manner:
1. The region of interest, where the floor plane is assumed to be located, is identified using a pass-through filter. The point cloud is divided parallel to the estimated floor plane, creating a slice within which the plane is searched.
2. The floor plane is then segmented using the RANSAC algorithm and corresponding points are removed.
In the fourth pipeline, the floor removal process, referred to as “Floor removal 2”, is enhanced by introducing an additional voxelization step, applied to a copy of the original point cloud before running the RANSAC algorithm. By using a voxel filter with larger voxel dimensions, the floor plane equation can be determined more efficiently, allowing points to be segmented based on their distance from the plane (same value as RANSAC threshold).
3.3. Empirical Experiment Results
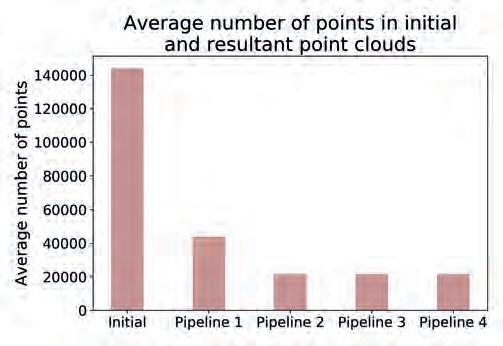
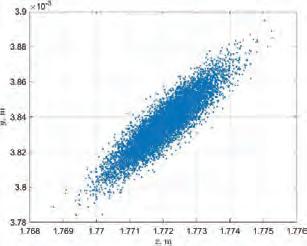
Experiments on proposed pipelines were conducted using 100 example point clouds gathered from an interior of UR offices employing Microsoft Azure Kinect ToF camera. They consist of vast open spaces (typical for industrial cleaning robots), as well as office objects like tables, chairs, etc. An example point cloud that consists of 144 545 points, is presented in Fig. 4, top. We assume that the point cloud is already in the robot’s navigational coordination frame that is placed on the floor plane.
Fig. 3. Proposed filtration pipelines
Rys. 3. Proponowane sposoby filtracji
Fig. 4. Top: Example initial point cloud, Bottom: Corresponding result point cloud for Pipeline 4
Rys. 4. Góra: Przykładowa wejściowa chmura punktów; Dół: ta sama chmura odfiltrowana zgodnie z procesem Pipeline 4
Tab. 2. Filters parameters for analyzed pipelines. V1 is voxel grid size for “Voxel Grid Filtering 1” and V2 for “Voxel Grid Filtering 2”
Tab. 2. Wartości parametrów filtrów dla analizowanych sposobów filtracji; V1 – wielkość siatki woksela dla „Voxel Grid Filtering 1”, V2 – dla „Voxel Grid Filtering 2”
Fig. 5. Comparison of the four filtering pipelines by their average processing time total and in each stage
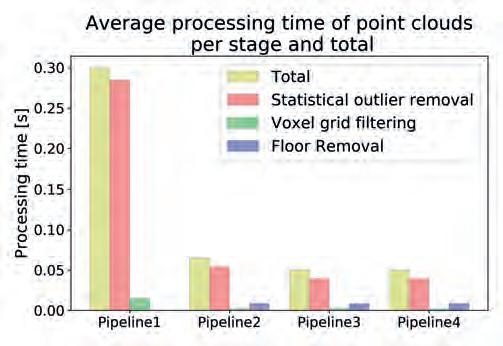
Rys. 5. Porównanie czterech proponowanych sposobów filtracji pod względem całkowitego średniego czasu przetwarzania oraz czasu przetwarzania na każdym z etapów
Thanks to that, the time required for transformation is ignored and the operation of floor plane removal is more intuitive. To get a comparable result, the same filters used in different pipelines have the same parameters, as presented in Tab. 2. To select filtration parameters, prior to the experiments, an extensive review of scientific literature on point cloud filtering techniques was conducted. The review identified only a single study that implemented precise versions of both statistical outlier filtering and voxel grid filtering, along with a thorough parameter analysis [6]. To the best of our knowledge, no existing studies offer a comprehensive evaluation of filter parameters. Due to that, the parameter values for this research were established based on the authors’ industrial experience, ensuring an optimal balance between detailed scene reconstruction and processing efficiency, while preserving crucial data necessary for navigation. The initial voxel grid filtering was configured with a grid size large enough to reduce the number of points, yet small enough to maintain an appropriate resolution for accurate object representation. Parameters for statistical outlier removal were selected to eliminate outliers without omitting small objects. The parameters for floor removal (using RANSAC and Pass-through filters) were optimized to ensure computational efficiency while retaining small floor-level objects. For the secondary voxel grid filtering, a larger grid size was chosen to accelerate processing without compromising critical data. Pipelines were compared in terms of processing time (total and per stage) as depicted in Fig. 5, and the number of points in the resultant point cloud, shown in Fig. 6.
An examination of Fig. 5 reveals that reducing data complexity through basic voxel grid filtering significantly decreases processing time. With each subsequent optimization, the processing time can be further reduced to below 0.05 seconds, corresponding to a frequency exceeding 20 Hz, which is higher than the operating frequency of any sensor listed in Table 1 for before mentioned UR case. Furthermore, as illustrated in Fig. 4, the example output point cloud produced by Pipeline 4 (the most
Fig. 6. Comparison of the four filtering pipelines by their average number of points in resultant point clouds and average number of points in corresponding initial point clouds
Rys. 6. Porównanie czterech proponowanych sposobów filtracji pod względem średniej liczby punktów w uzyskanych chmurach punktów oraz średniej liczby punktów w odpowiadających im początkowych chmurach punktów
timeefficient option) demonstrates the successful elimination of the floor plane and a reduction in the number of small outliers, thereby providing accurate yet efficient environmental reconstruction. The differences in memory consumption across the pipelines are negligible, amounting to around 200 MB of RAM memory on average for each pipeline. This indicates that the proposed methods can be effectively applied in mobile robotics, enhancing autonomous navigation capabilities.
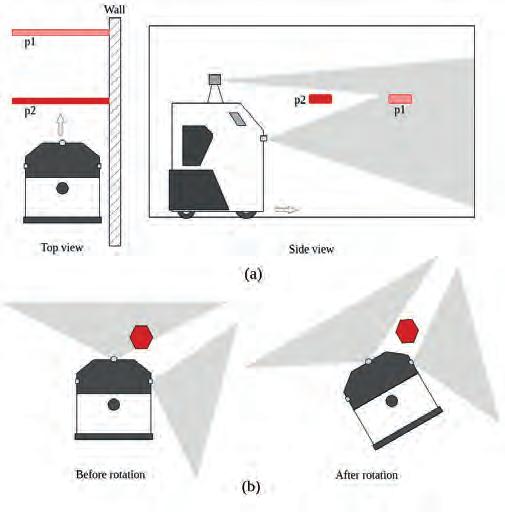
Fig. 7. Examples illustrating navigation challenges caused by partial sensor coverage. (a) The obstacle protruding from the wall is detectable in pose p1 relative to the robot, but after the robot’s linear displacement, it becomes undetectable in the new relative pose p2. (b) An obstacle below the Lidar’s detection range is identified by the front sensor, but after the robot’s rotation, it is no longer detectable
Rys. 7. Przykłady ilustrujące wyzwania nawigacyjne spowodowane częściowym pokryciem przestrzeni przez czujniki. (a) Przeszkoda wystająca ze ściany jest wykrywalna w położeniu p1 względem robota, ale po liniowym przemieszczeniu robota staje się niewykrywalna w nowym położeniu p2. (b) Przeszkoda znajdująca się poniżej zasięgu detekcji LIDARa jest identyfikowana przez czujnik przedni, jednak po obrocie robota przestaje być wykrywana
Konrad Cop, Morteza Haghbeigi, Marcin Gajewski, Tomasz Trzciński
Perception Systems for Autonomous Mobile Robots: Selecting and Mitigating Limits
4. Mitigation of limited field of view
Once the detailed analysis is conducted and the optimal arrangement of sensors is not achievable due to the system costs, one can resort to the algorithmic solution to eliminate the threats caused by the blind spots of the sensory rig during the navigation. More specifically, with the limited FOV of sensors, achieving full coverage of the surroundings at all times is not possible. An obstacle may be detected in one position, but as the robot moves, the same obstacle could fall into the sensors’ blind spot (Fig. 7). This makes navigation challenging, especially when moving close to the walls and obstacles. To address this issue, we propose an approach that utilises spatio-temporal sensor’s information.
The core concept of our proposal is to update the navigation map by integrating both current sensor data and previous detections, along with the robot’s movements. This approach is implemented within the framework of the costmap [21], a crucial component of the navigation stack in the Robot Operating System (ROS) [22]. Nevertheless, it is adaptable and can be applied to other navigation systems as well. In the following section, we provide a brief overview of the navigation costmaps. This is followed by an explanation of the proposed approach, called Hit Map, and the presentation of empirical experiment results.
4.1. Costmap-Based Navigation
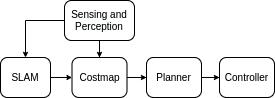
Navigation systems require a well-defined configuration space. Costmaps provide an efficient way to represent the robot’s operational environment, facilitating safe and optimal path planning. As illustrated in Fig. 8, the Costmap module receives
the map and the robot’s pose from the SLAM (Simultaneous Localization and Mapping), along with processed sensor data from the Perception system [23]. It processes this information into a 2-D grid of cells, known as an occupancy grid, which serves as the primary input for the planning system. Each cell in the occupancy grid has a value representing the cost of traversing through that grid cell [24].
To enhance flexibility and accommodate various navigational constraints, a layered approach is proposed that separates the processing of costmap data into semantically distinct layers [21, 25]. In this approach, each layer handles data from a specific source using designated functionalities. The Costmap features a primary occupancy grid, known as the master grid, while each layer maintains its own layer grid. Three basic layers are commonly used in navigation systems:
− Static Layer: Represents data from the Mapping component, providing a representation of the environment.
− Obstacle Layer: Aggregates data from sensors to represent obstacles as a unified obstacle grid. Each grid cell is either free or occupied.
− Inflation Layer: Accounts for the robot’s dimensions, specifically its footprint, by inflating the obstacles in the final grid.
The obstacle grid is the main input for the proposed Hit Layer.
4.2. Hit Map
In this section, we propose a new Costmap layer, referred to as the Hit Layer. The occupancy grid associated with this layer, termed the Hit Map, contains cell values (hit) that are proportional to the duration of time each cell has been detected either as an obstacle or free.
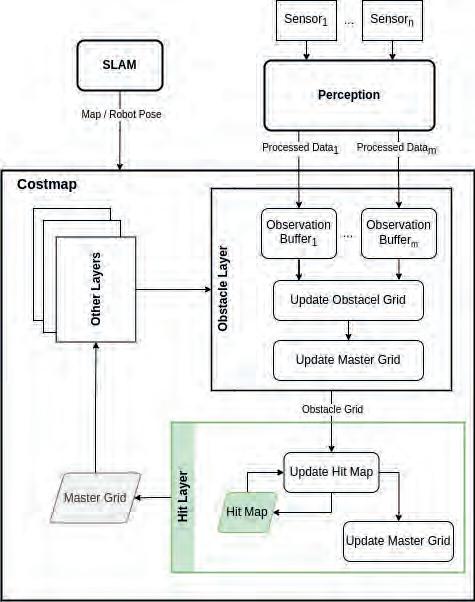
Figure 9 depicts the structure of the Costmap module, incorporating the Hit Layer. The Costmap module is responsible for updating the master grid, a fundamental element for all autonomous planning functions, at a predefined frequency. Throughout this process, each layer refreshes its respective occupancy grid, which in turn contributes to the update of the master grid. Although the Costmap module may consist of several layers, the Obstacle Layer plays a critical role in the creation and continuous updating of the Hit Layer.
Obstacle Layer Update The Perception module receives data from sensors and applies preprocessing operations (e.g. the actions described in Section 3). Processed data is then published into specific channels. The Obstacle layer maintains an Observation Buffer for each specified data channel. During the update process, it modifies the obstacle grid based on the most recent data in the Observation Buffers. Each cell in the obstacle grid will have one of two values, indicating whether it is free or occupied. Then, the master grid is modified based on the updated obstacle grid.
Fig. 9. Update process overview of the costmap module which includes the proposed Hit Layer: Sensor data is processed and published into designated channels, where observation buffers temporarily store it. During each update cycle, the Obstacle Layer refreshes the Obstacle Grid using the data from the observation buffers and updates the Master Grid. The Hit Layer then revises the Hit Map based on the current Obstacle Grid and finalizes the Master Grid update
Rys. 9. Przegląd procesu aktualizacji mapy kosztów, który obejmuje proponowaną warstwę Hit Layer: Dane z czujników są przetwarzane i publikowane w wyznaczonych kanałach, gdzie tymczasowo przechowywane są w buforach obserwacji. Podczas każdego cyklu aktualizacji, warstwa przeszkód odświeża siatkę przeszkód, korzystając z danych z buforów obserwacji, i aktualizuje mapę główną. Następnie warstwa Hit Layer dokonuje rewizji mapy trafień na podstawie aktualnej mapy przeszkód i finalizuje aktualizację mapy głównej
Fig. 8. Main components of the navigation system
Rys. 8. Główne komponenty systemu nawigacji
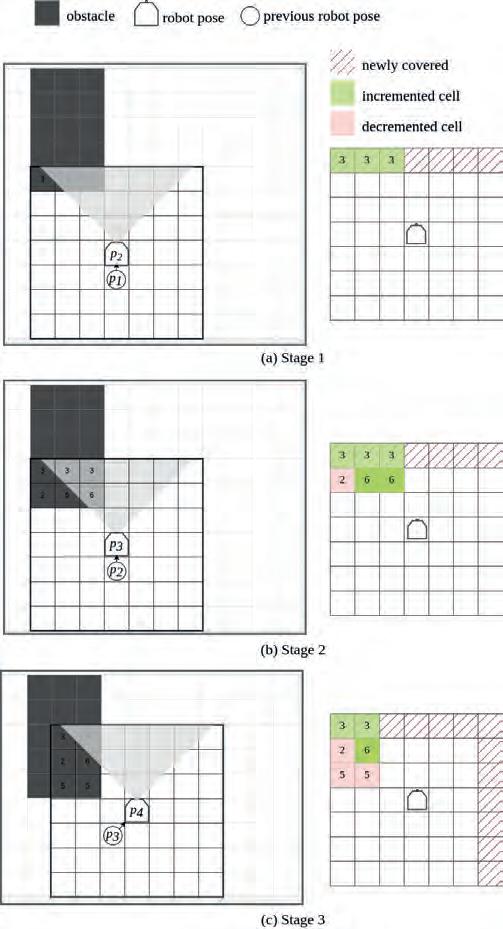
Hit Layer Update Each Hit Map cell is an integer within the range [0, hitmax]. Initially, all cell values are set to zero. The Hit Layer updates the Hit Map based on the latest obstacle grid received from the Obstacle Layer, as well as the robot’s movements in three main steps. Figure 10 illustrates the Hit Map update process using a simplified example.
First, the Hit Map is relocated using a Sliding Window approach, which accounts for the robot’s displacement. Subsequently, the portion of the Hit Map corresponding to newly covered areas
Fig. 10. An illustrative example of the Hit Map update process. In this example, the Hit Map is updated when the robot moves to a new cell, though in practice, costmaps typically have a higher update frequency. On the left, the positions of the obstacle and costmap are shown, while the Hit Map is displayed on the right. Cells where an obstacle is detected and the hit value is increased are shown as incremented cells. Additionally, cells that are free in the obstacle grid but have a hit value greater than zero (still considered occupied in the final master grid) are displayed as decremented cells
Rys. 10. Przykład ilustrujący proces aktualizacji mapy trafień. W tym przykładzie mapa trafień jest aktualizowana, gdy robot przemieszcza się do nowej komórki, chociaż w praktyce mapy kosztów zazwyczaj mają wyższą częstotliwość aktualizacji. Po lewej stronie przedstawiono pozycje przeszkody i mapa kosztów, natomiast po prawej stronie widoczna jest mapa trafień. Komórki, w których wykryto przeszkodę i wartość trafienia została zwiększona, są oznaczone jako komórki inkrementowane. Dodatkowo komórki, które są wolne w mapie przeszkód, ale mają wartość trafienia większą niż zero (wciąż uznawane za zajęte w finalnej mapie głównej), są wyświetlane jako komórki dekrementowane
is reset to 0, while the cells that remain in the common area before and after the update are left unchanged.
In the next stage, the Hit Map is updated. During this process, the value of each cell in the Hit Map is recalculated according to the corresponding cell in the obstacle grid, as shown in equation 8. Let hi represent the i-th cell in the Hit Map, and oi represent the i-th cell in the obstacle grid. If oi is occupied, hi is increased according to the hit and hit max parameters. Conversely, if oi is free, hi is decreased by one.
Finally, the master grid is updated based on the Hit Map. Let mi denote the i-th cell in the master grid, and let coccupied represent the cost value of an occupied cell. The value of mi is then updated according to equation 9:
By adding the Hit Layer to the set of layers in the costmap, obstacles that have been detected for a longer duration are more likely to be retained in the Hit Map, even if they are no longer detected. The parameters hit and hit max control the cautiousness of the Hit Layer. Higher values for these parameters result in safer navigation, as obstacles are more likely to be retained. However, this can also lead to more cells being marked as occupied in the costmap. Choosing appropriate values depends on the specific environment in which the robot is operating and the coverage provided by the sensors.
4.3. Motion Condition
The Hit Map update process involves two main operations: incrementing and decrementing. By decrementing, occupied cells that are no longer detected by the Obstacle Layer will eventually be freed. This helps to prevent costmap from becoming cluttered. However, this approach also introduces a potential issue. If the robot remains stationary for an extended period, the Hit Map continues to decrement and free the cells. If some of these cells correspond to obstacles that have moved into a blind spot, they might not be considered when the robot starts moving again.
Rys. 11. Stanowisko eksperymentalne do testów systemu nawigacji z warstwą Hit Layer oraz bez niej
Fig. 11. Experiment setup for navigation test with and without the Hit Layer
Konrad Cop, Morteza Haghbeigi, Marcin Gajewski, Tomasz Trzciński
To address this issue, the motion condition is evaluated during the decrement step using two data sources: (1) velocity commands from the controller and (2) the robot’s displacement over a predefined time interval. Specifically, if the robot’s displacement within the specified time period, denoted as dduration, falls below a defined threshold dthreshold, the robot is considered stationary, and the decrement operation is skipped.
4.4. Empirical Experiment Results
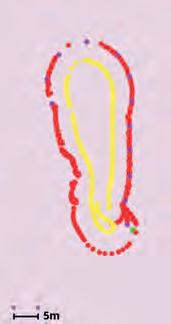
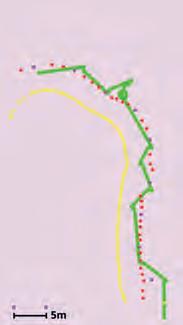
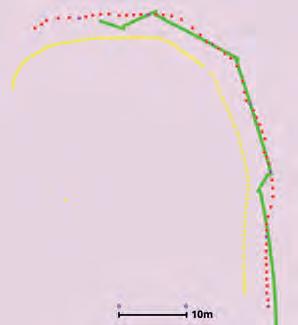
A test scenario was designed to evaluate the efficiency of the proposed Hit Layer. This scenario involves a wallfollowing operation, where the navigation system must guide the robot to maintain a close distance to the wall. This is particularly challenging in industrial environments, where various objects of differing heights may be present near the walls and could fall into the sensors’ blind spots. Due to the proximity to the wall, such scenarios increase the risk of collisions. Specifically risky are the situations where the objects do not stretch vertically from the ground but “stick out of the wall”.
Figure 11 illustrates the test setup, which includes a table with a foam layer on top. The foam extends beyond the edges of the table and is only detectable by the robot’s front depth camera. We conducted tests both with and without the Hit Layer. Table 3 summarizes the parameters chosen for the test scenario.
Tab. 3. Hit layer parameters selected for the wall-following navigation test
Tab. 3. Parametry warstwy Hit Layer wybrane do testów nawigacji w trybie śledzenia ściany hit hit max dthresh [mm] dduration [s]
3 1500 0.1 10
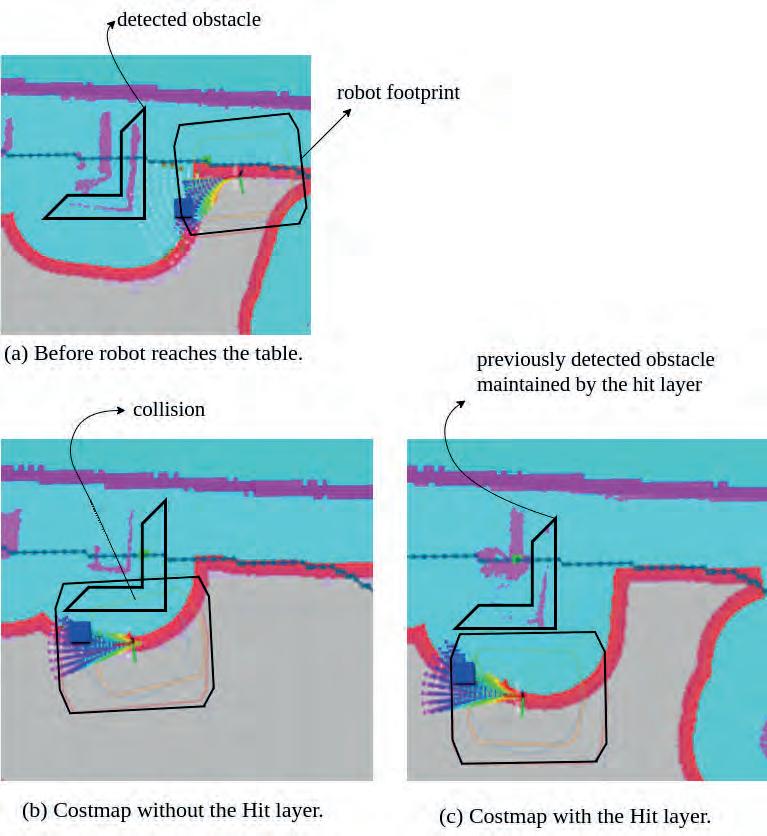
Figure 12 (a) shows the costmap shortly after the wallfollowing behaviour begins, but before the robot reaches the table. At this stage, the front sensor detects the foam. As the robot approaches the foam, it starts navigating around it. Figure 12 (b) and (c) represent the costmap in this pose, with and without the Hit Layer, respectively. When using the Hit Layer, the foam that was previously detected by the camera remains in the costmap for an extended period, allowing the robot to navigate around it successfully. In contrast, without the Hit Layer, the foam disappears from the costmap, causing the robot to move to close to the table and hit the foam.
5. Conclusions
In this paper, we have presented three strategies that allow to engineer an end-to-end perception system of a robot. The presented selection process can be used to any autonomous robot in a generic way. We also evaluated the applicability of various filtration pipelines and experimentally evaluated their performance. Finally, we introduced a method to mitigate limited sensors FOV thus allowing to fill perception system gaps and potentially limit the number of sensors. All strategies were successfully applied in the autonomous floor scrubber UR\Cleaner and can be reused in other autonomous robots.
Acknowledgments
Project co-financed by the European Union through the European Regional Development Fund under Action 1.1 of the Smart Growth Operational Programme 2014-2020. The project is implemented within the competition organized by the National Centre for Research and Development: Call number: 1/1.1.1/2017 – Industrial research and development work conducted by enterprises. Project Number POIR.01.01.01-000206/17: „Designing a prototype of an autonomous platform moving in a production environment”.
Fig. 12. Costmaps from the navigation test during wallfollowing, with and without the Hit Layer. The graphics are generated using rviz tool. (a) Before the robot reaches the table, which is within the observation range of the front camera. A few seconds later, the robot attempts to navigate around the table and the foam placed on it. Due to the robot’s rotation, the foam falls into the camera’s blind spot. (b) Without further detection, the robot moves too close to the table and collides with the foam. (c) Using prior detections, the Hit Layer preserves the foam as an obstacle in the costmap, allowing the robot to successfully navigate around the table
Rys. 12. Mapy kosztów z testu nawigacji w trybie śledzenia ścian, z warstwą Hit Layer oraz bez niej. Grafiki zostały wygenerowane za pomocą narzędzia rviz. (a) Przed dotarciem robota do stołu znajdującego się w zasięgu kamery przedniej. Kilka sekund później robot podejmuje próbę ominięcia stołu oraz pianki umieszczonej na jego powierzchni. Ze względu na obrót robota, pianka znika z pola widzenia kamery. (b) W wyniku braku dalszej detekcji robot przemieszcza się zbyt blisko stołu i uderza w piankę. (c) Dzięki wcześniejszym detekcjom warstwa Hit Layer zachowuje piankę jako przeszkodę na mapie kosztów, umożliwiając robotowi skuteczne ominięcie stołu
References
1. Shi Q., Li C., Wang C., Luo H., Huang Q., Fukuda T., Design and implementation of an omnidirectional vision system for robot perception, “Mechatronics”, Vol. 41, 2017, 58–66, DOI: 10.1016/j.mechatronics.2016.11.005.
2. Deshpande P., Reddy V.R., Saha A., Vaiapury K., Dewangan K., Dasgupta R., A next generation mobile robot with multi-mode sense of 3D perception, [In:] 2015 International Conference on Advanced Robotics (ICAR). IEEE. 2015, 382–387, DOI: 10.1109/ICAR.2015.7251484.
3. Lambert J., Carballo A., Cano A.M., Narksri P., Wong D., Takeuchi E., Performance analysis of 10 models of 3D LiDARs for automated driving. “IEEE Access”, Vol. 8, 2020, 131699–131722, DOI: 10.1109/ACCESS.2020.3009680.
4. Stoyanov T., Louloudi A., Andreasson H., Lilienthal A.J., Comparative evaluation of range sensor accuracy in indoor environments, [In:] 5th European Conference on Mobile Robots, ECMR 2011, Orebro, Sweden, 2011, 19–24.
5. Diaz M.G., Tombari F., Rodriguez-Gonzalvez P., Gonzalez-Aguilera D., Analysis and evaluation between the first and the second generation of RGBD sensors, “IEEE Sensors journal”, Vol. 15, No. 11, 2015, 6507–6516, DOI: 10.1109/JSEN.2015.2459139.
6. Jin Y., Yuan X., Wang Z., Zhai B., Filtering Processing of LIDAR Point Cloud Data, [In:] IOP Conference Series: Earth and Environmental Science, Vol. 783, May 2021, DOI: 10.1088/1755-1315/783/1/012125.
7. Han X.-F., Jin J.S., Wang M.-J., Jiang W., Gao L., Xiao L., A review of algorithms for filtering the 3D point cloud, “Signal Processing: Image Communication”, Vol. 57, 2017, 103–112, DOI: 10.1016/j.image.2017.05.009.
8. Moreno C., A Comparative Study of Filtering Methods for Point Clouds in Real-Time Video Streaming, [https://api.semanticscholar.org/CorpusID:162172879].
9. Ro elofsen S., Gillet D., Martinoli A., Collision avoidance with limited field of view sensing: A velocity obstacle approach. [In:] 2017 IEEE International Conference on Robotics and Automation (ICRA), 2017, 1922–1927. DOI: 10.1109/ICRA.2017.7989223.
10. Bouraine S., Fraichard T., Salhi H., Provably safe navigation for mobile robots with limited field-of-views in unknown dynamic environments, [In:] 2012 IEEE International Conference on Robotics and Automation, 2012, 174–179, DOI: 10.1109/ICRA.2012.6224932.
11. Phan D., Yang J., Grosu R., Smolka S.A., Stoller S.D., Collision avoidance for mobile robots with limited sensing and limited information about moving obstacles. “Formal Methods in System Design”, Vol. 51, 2017, 62–86, DOI: 10.1007/s10703-016-0265-4.
12. He B., Wu S., Wang D., Zhang Z., Dong Q., Fast-dynamic-vision: Detection and tracking dynamic objects with event and depth sensing, [In:] 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, 2021, 3071–3078, DOI: 10.1109/IROS51168.2021.9636448.
13. Cop K.P., Peters A., Žagar B.L., Hettegger D., Knoll A.C., New metrics for industrial depth sensors evaluation for precise robotic applications, [In:] 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, 2021, 5350–5356, DOI: 10.1109/IROS51168.2021.9636322. Peter
14. Hausamann P., Sinnott C.B., Daumer M., MacNeilage P.R., Evaluation of the Intel RealSense T265 for tracking natural human head motion, “Scientific Reports”, Vol. 11, 2021, DOI: 10.1038/s41598-021-91861-5.
15. Tadic T. at al. Perspectives of RealSense and ZED depth sensors for robotic vision applications, “Machines”, Vol. 10, No. 3, 2022, DOI: 10.3390/machines10030183.
16. Pinto A.M. et al. Evaluation of depth sensors for robotic applications, [In:] 2015 IEEE International Conference on Autonomous Robot Systems and Competitions, IEEE, 2015, 139–143, DOI: 10.1109/ICARSC.2015.24.
17. Haenel R., Semler Q., Semin E., Grussenmeyer P., Tabbone S., Evaluation of low-cost depth sensors for outdoor applications, “The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences”, Vol. 48, 2022, 101–108, DOI: 10.5194/isprs-archives-XLVIII-2-W1-2022-101-2022.
18. Siegwart R., Nourbakhsh I.R., Scaramuzza D., Introduction to autonomous mobile robots. MIT press, 2011.
19. Rusu R.B., Cousins S., 3D is here: Point Cloud Library (PCL), [In:] 2011 IEEE International Conference on Robotics and Automation, 2011, DOI: 10.1109/ICRA.2011.5980567.
20. Fischler M.A., Robert C., Bolles A., Random Sample Consensus: a Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography, “Communications of the ACM”, Vol. 24, No. 6, 1981, 381–395, DOI: 10.1145/358669.358692.
21. Lu D.V., Hershberger D., Smart W.D., Layered costmaps for context-sensitive navigation, [In:] 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, 2014, 709–715, DOI: 10.1109/IROS.2014.6942636.
22. Quigley M., Conley K., Gerkey B., Faust J., Foote T., Leibs J., Wheeler R., Ng A.Y., ROS: an open-source Robot Operating System, ICRA workshop on open source software, 2009, Vol. 3, No. 3.2.
23. Ra ja P., Pugazhenthi S., Optimal path planning of mobile robots: A review, “International Journal of the Physical Sciences”, Vol. 7, No. 9, 2012, 1314–1320, DOI: 10.5897/IJPS11.1745.
24. Carlos Andre Seara da Silva. Robot Navigation in Highly-Dynamic Environments. PhD thesis. University of Coimbra, 2022.
25. Lu D.V., Smart W.D., Towards more efficient navigation for robots and humans, [In:] 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, IEEE, 2013, 1707–1713, DOI: 10.1109/IROS.2013.6696579.
Konrad Cop, Morteza Haghbeigi, Marcin Gajewski, Tomasz Trzciński
Systemy percepcji dla autonomicznych robotów mobilnych: wybór i redukcja ograniczeń
Streszczenie: Dobrze zaprojektowany system percepcji jest kluczowy dla prawidłowego działania autonomicznego robota mobilnego, jednak jego stworzenie nie jest trywialnym zadaniem. Aby stworzyć kompleksowy system, należy brać pod uwagę nie tylko cechy samych czujników, ale także sposób, w jaki dane z nich są używane do działania robota. W artykule przedstawiono zestaw ścisłe powiązanych strategii, które umożliwiają stworzenie kompleksowego systemu percepcji, wykorzystującego reprezentację 3D w postaci chmur punktów. Nasza propozycja jest na tyle uniwersalna, że może być stosowana w różnych robotach mobilnych, ponieważ uwzględnia kontekst działania robota oraz ograniczenia sprzętowe. Pierwszą strategią jest wprowadzenie sformalizowanego procesu wyboru czujników, ujętego jako problem optymalizacji wielokryterialnej z relaksacją metryk, co pozwala na wybór optymalnego zestawu czujników w ramach ograniczeń budżetowych. W drugiej strategii weryfikujemy różne metody filtrowania danych i ich kombinację w kontekście systemu nawigacji, aby znaleźć kompromis między dokładnością a nakładem obliczeniowym. Wreszcie, aby zniwelować suboptymalne pole widzenia połączonych czujników i ulepszyć system percepcji, proponujemy nową koncepcję warstwy siatki zajętości, która wykorzystuje informacje o ruchu w obliczeniach dostępności obszaru nawigacyjnego. W ramach badań, przeprowadziliśmy eksperymentalną weryfikację tych strategii i zastosowaliśmy wyniki w autonomicznym robocie sprzątającym.
Słowa kluczowe: percepcja robotyczna, roboty autonomiczne, sensory robotyczne, robotyka, nawigacja, filtracja danych
Konrad Cop, MSc Eng. konrad.cop@unitedrobots.co
ORCID: 0000-0001-8159-9307
He is a Technology Lead United Robots and a PhD student at Warsaw University of Technology. He received Bachelor of Control Engineering and Robotics from Wrocław University of Science and Technology and Master of Robotics, Systems and Control from ETH Zurich. He was a researcher in Autonomous Robots at CSIRO in Brisbane, Australia and in robotic manipulation at TUM in Munich, Germany. His experience combines a mixture of scientific research and applied development activities. His research interests include Autonomous Robotics, Application of Deep Learning to Robotics Perception and general AI topics in Mobile Robots.
Marcin Gajewski, MSc Eng. marcin.gajewski@unitedrobots.co
ORCID: 0009-0005-2593-4808
He is a Team Leader of the Architecture and Stability Team at United Robots. He received Bachelor of Control Engineering and Robotics and Master of Computer Science from Warsaw University of Technology. Additionally received Master of E-Business from Warsaw School of Economics. His experience combines applied development activities and project management. His research interest include Autonomous Robotics, Robotics Perception and Robotics for Space Exploration.
He is an Autonomous Navigation Engineer at United Robots and a Ph.D. student at Warsaw University of Technology. He holds a Master’s degree in Mechanical Engineering from the Iran University of Science and Technology. His research focuses on cooperative guidance methods, motion and path planning for both single and multi-robot systems, as well as optimization techniques using co-evolutionary methods. He also has practical experience as a robotics developer in industrial applications, where he has designed and implemented autonomous planning and navigation systems.
Prof. Tomasz Trzciński, DSc PhD Eng. tomasz.trzcinski@pw.edu.pl ORCID: 0000-0002-1486-8906
He is a Professor at Warsaw University of Technology, where he leads a Computer Vision Lab. He was an Associate Professor at Jagiellonian University of Krakow in years 2020-2023, a Visiting Scholar at Stanford University in 2017 and at Nanyang Technological University in 2019 and 2023. He worked at Google (2013), Qualcomm (2012) and Telefonica (2010). He is a Senior Member of IEEE, member of ELLIS Society and director of ELLIS Unit Warsaw, member of the ALICE Collaboration at CERN and an expert of National Science Centre and Foundation for Polish Science. He is a Chief Scientist at Tooploox.
Roboty równoległe do precyzyjnej manipulacji
w operacjach chirurgicznych
Krzysztof Mianowski, Filip Gruca, Jakub Grzonkowski, Jan Makulec Politechnika Warszawska, Wydział Mechaniczny Energetyki i Lotnictwa, ul. Nowowiejska 24, 00-665 Warszawa
Streszczenie: W artykule przedstawiono wybrane zagadnienia poruszające problematykę robotów równoległych w zastosowaniu do precyzyjnej manipulacji w zabiegach operacji chirurgicznych. Zreferowano krótko stan nowych, opracowywanych współcześnie technik operacyjnych wymagających dużej dokładności i efektywności prowadzonych zabiegów zapewniających bardzo małą inwazyjność operacji. Na podstawie dostępnej literatury i materiałów internetowych przedstawiono szereg nowatorskich rozwiązań konstrukcji manipulatorów równoległych spełniających kryteria kwalifikujące do prowadzenia operacji chirurgicznych. Szczególną uwagę zwrócono na interdyscyplinarność tej dziedziny badań.
Słowa kluczowe: robot równoległy, chirurgiczny robot operacyjny, precyzyjna manipulacja zdalna
1. Wprowadzenie
Na przestrzeni wieków ludzkość była świadkiem wielu przełomowych odkryć i zmian w dziedzinie medycyny. Co chwila wymyślano nowe remedia na trapiące nas choroby i dolegliwości. Również wiele zabiegów oraz procedur medycznych zostało znacznie usprawnionych. To wszystko za sprawą możliwości, jakie daje nieustanny rozwój nowych dziedzin technologii, takich jak fotonika1 lub robotyka. Dzięki nim mamy do dyspozycji wiele narzędzi ułatwiających pracę lekarzy, diagnostów a nawet fizjoterapeutów. W ostatnich latach można zaobserwować znaczną zmianę w podejściu do procedur chirurgicznych, związaną z ogólnym rozwojem techniki i technologii. Dotyczy to bardzo dynamicznego postępu w zakresie automatyzacji wybranych procedur chirurgicznych oraz robotyzacji całych zabiegów chirurgicznych wykonywanych metodami operacyjnymi.
Czytelnikowi należy wyjaśnić, że w artykule będziemy korzystać z pojęcia „robot chirurgiczny”, podczas gdy większość tego typu urządzeń stosowanych w praktyce medycznej nie jest robotami (które z definicji mają określony poziom autonomii działania i sztucznej inteligencji) lecz tzw. telemanipulatorami. Z punktu widzenia prawa aktualnie nie jest możliwe, aby sztuczne urządzenie techniczne – robot – mogło odpowiadać za 1 Dziedzina nauki zajmująca się manipulacją cząstkami światła (fotonami). Obszary zastosowań to technologie laserowe, światłowodowe, diagnostykę medyczną i wiele innych.
Autor korespondujący: Krzysztof Mianowski, krzysztof.mianowski@pw.edu.pl
Artykuł recenzowany nadesłany 13.12.2024 r., przyjęty do druku 05.02.2025 r.
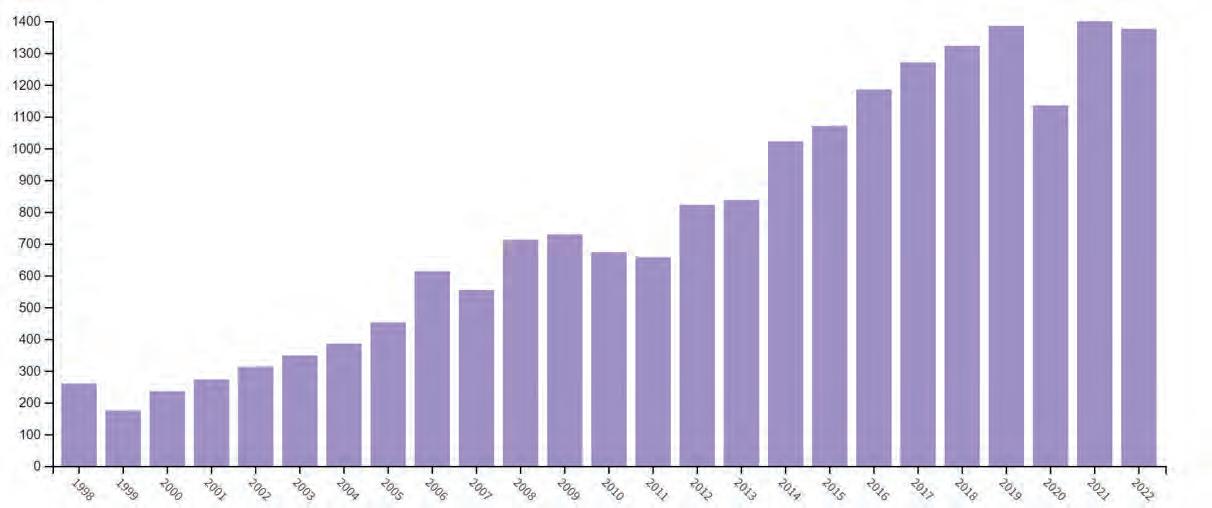
zdrowie lub życie pacjenta. Za leczenie pacjenta, w tym metodami operacyjnymi musi odpowiadać człowiek-lekarz. Robot chirurgiczny jest tylko narzędziem w dyspozycji lekarza, który dzięki tej technice może wykonać operację w sposób bardziej komfortowy dla pacjenta i dla lekarza. Lekarz wspomagając się robotem podczas operacji, dysponuje bardziej precyzyjnym i znacznie bezpieczniejszym narzędziem, niż stosowane dotychczas skalpel, szczypce, nożyczki chirurgiczne, czy igłotrzymak. W tym procesie od pewnego czasu pojawił się nowy trend stosowania w konstrukcjach mechanizmów robotów chirurgicznych, tzw. manipulatorów równoległych2. Okazało się to „strzałem w dziesiątkę” i obecnie to ten trend zaczyna wieść prym w rozwoju robotów chirurgicznych. Rozwiązania z manipulatorami równoległymi cieszą się coraz większym zainteresowaniem ze strony środowisk naukowych i akademickich. Dobitnie świadczy o tym statystyka obrazująca liczbę opublikowanych artykułów ze słowem kluczowym „parallel robot” na przestrzeni lat (rys. 1). Nic więc dziwnego, że z roku na rok wzrasta liczba potencjalnych zastosowań tych konstrukcji. Na przestrzeni lat starano się wykorzystać unikalne cechy manipulatorów równoległych w medycynie – dysponują one bowiem bardzo dużym poziomem precyzji, co jest niezwykle pożądaną cechą w tej dziedzinie. W artykule przeglądowym pochylimy się bliżej nad problematyką zastosowania manipulatorów równoległych w medycynie. Przeanalizujemy najnowsze rozwiązania, koncepty i ich możliwe kierunki rozwoju.
W literaturze przedmiotu przyjęły się dwa podstawowe pojęcia dotyczące zagadnienia takich konstrukcji: parallel robot – robot równoległy oraz parallel manipulator – manipulator równoległy. Według normy ISO 8383 Robotics – Vocabulary, definicji 4.14.7 – parallel robot, pod pojęciem robota równoległego rozumie się robota z układem manipulacyjnym zawierającym w swojej struk-
2 Są to roboty charakteryzujące się tym, że w swojej konstrukcji zawierają kilka tzw kończyn mechanicznych połączonych jednocześnie („równolegle”) z podstawą manipulatora i jego końcowym elementem ruchomym tworząc w ten sposób między sobą kilka zamkniętych pętli kinematycznych.
Rys. 1. Liczba powstałych artykułów ze słowem kluczowym „parallel robot” w latach 1998–2022 [30] Fig. 1. Number of articles with the keyword „parallel robot” in the years 1998–2022 [30]
turze kinematycznej zamknięte pętle kinematyczne. Oznacza to m.in., że obciążenie zewnętrzne działające na chwytak manipulatora jest równoważone jednocześnie przez kilka jego tzw. kończyn, co z jednej strony znacznie zmniejsza ich naprężenia wewnętrzne a z drugiej strony znacznie poprawia dokładność realizacji trajektorii zadanej.
2. Przegląd technologii i konceptów dostępnych na rynku
Na przestrzeni ostatnich lat byliśmy świadkami nieustannej robotyzacji chirurgii. Tendencja ta wciąż nabiera rozpędu i co chwila na rynku pojawiają się nowe rozwiązania. Dlatego na wstępie warto dokonać przeglądu gotowych rozwiązań robotów chirurgicznych zawierających zastosowane rozwiązania manipulatorów równoległych. Wiedza ta pomoże nam lepiej zrozumieć istniejące trendy, którymi kieruje się postępujący rozwój tej technologii. Dodatkowo ułatwi nam możliwość przewidzenia, czego należy się spodziewać w przyszłości.
W czasie ostatnich 30–40 lat w medycynie postępuje systematyczny rozwój i upowszechnienie operacji chirurgicznych, tzw. małoinwazyjnych. Przyczynia się do tego ogólny postęp techniki, opracowywanie nowych materiałów, w tym kompozytowych i nowych technologii, np. cięcia promieniem lasera, cięcia strugą cieczy, również z dodatkiem ścierniwa, wydruku 3D z tworzyw sztucznych i materiałów metalicznych, plazmowego natryskowego pokrywania powierzchni protez wszczepialnych hydroksyapatytem. Jednocześnie są opracowywane i rozwijane nowoczesne narzędzia projektowe typu CAD (ang. Computer Aided Design), narzędzia wspomagania technologii CAM (ang. Computer Aided Manufacturing) oraz narzędzia wspomagania prac inżynierskich CAE (ang. Computer Aided Engineering) pozwalające na komputerowe, w pełni zintegrowane projektowanie narzędzi chirurgicznych, urządzeń medycznych, m.in. robotów–telemanipulatorów do wspomagania operacji chirurgicznych typu małoinwazyjnego. Takie narzędzia projektowe pozwalają na powstawanie nowych koncepcji i wzorów projektowych oraz umożliwiają zupełnie nowe, innowacyjne podejście do całego procesu wdrażania nowych technik i technologii operacyjnych, umożliwiając przeprowadzanie operacji chirurgicznych według zupełnie nowych reguł z korzyścią dla pacjenta i personelu medycznego. Systematycznie wprowadza się do sal operacyjnych nowe rozwiązania techniczne, jak obrazowody w układach wizyjnych zawierające włókna światłowodowe, miniaturowe
wysokorozdzielcze kamery cyfrowe, żarówki ksenonowe, co przyczynia się do poprawy jakości wewnętrznego obrazu zamkniętego (nieotwartego) pola operacyjnego.
Stosowanie w medycynie różnego rodzaju tzw. inteligentnych urządzeń, w tym manipulatorów i robotów (np. sterowanych głosem) systematycznie rośnie. Zwiększa to wygodę i pozwala na znaczne usprawnienie pracy lekarza oraz pozwala na zmniejszenie kosztów procedur medycznych. Roboty w medycynie są głównie używane do: −asystowania w przebiegu zabiegów chirurgicznych, −p omocniczej obsługi szpitalnej, w rehabilitacji prowadzonej według powtarzalnych programów, −wsp omagania różnych procedur medycznych.
Stosowanie opracowywanych współcześnie nowoczesnych technik operacyjnych gwarantuje dużą dokładność i efektywność prowadzonych zabiegów oraz bardzo niską inwazyjność operacji. Wymaga to przeprowadzenia odpowiedniej ukierunkowanej diagnostyki, zaplanowania przebiegu operacji z zastosowaniem nowoczesnego sprzętu, sprawnego przeprowadzenia zabiegu i odpowiednio dobranej terapii rehabilitacyjnej. Początkiem takich zmian w sposobie podejścia do operacji chirurgicznych było wprowadzenie komputerowo wspomaganych technik uzyskiwania i przetwarzania obrazów, korzystania z komputerowych baz wiedzy na bieżąco i w sposób interaktywny oraz korzystanie z komputerowo wspomaganych technik operacyjnych z udziałem sterowania narzędziami za pomocą mikroprocesorowych układów sterowania. Oczywiście wymaga to nowoczesnego podejścia do kształcenia personelu medycznego w tym w zakresie korzystania z technik komputerowych. Potrzebna jest znajomość technik komputerowych, sposobu obsługi urządzeń peryferyjnych komputera, zasad korzystania z komputera w zastosowaniu do obsługi technik medycznych, oraz umiejętność czytania wyników analiz opracowywanych przez algorytmy komputerowe.
Od blisko czterdziestu lat do prowadzenia operacji chirurgicznych metodami małoinwazyjnymi (tj. z zastosowaniem narzędzi laparoskopowych) stosuje się mechaniczne manipulatory wspomagające proces manipulowania tymi narzędziami. Dla zwiększenia ich funkcjonalności, szczególnie przy prowadzeniu zabiegów, które wymagają wysokiej precyzji i odpowiedniego poziomu ruchliwości końcówki narzędzia operującego wewnątrz ciała pacjenta, zostały opracowane nowe narzędzia typu laparoskopowego, o znacznie większym poziomie skomplikowania układów mechanicznych i często znacznie bardziej rozbudowanych,
Krzysztof Mianowski, Filip Gruca, Jakub Grzonkowski, Jan Makulec
w celu łatwiejszego operowania z użyciem napędu elektrycznego. Wymagają one jednak odpowiedniego sterowania. Pozwala to na odejście lekarza-operatora od stołu operacyjnego i prowadzenie przez niego operacji nawet ze znacznej odległości. Można sobie wyobrazić prowadzenie operacji chirurgicznej w trakcie działań kryzysowych, gdy operowany pacjent po urazie znajduje się na stole operacyjnym w strefie stanowiącej zagrożenie dla lekarza, podczas gdy operujący go lekarz zajmuje miejsce w strefie bezpiecznej siedząc wygodnie przy konsoli operatorskiej pozwalającej na zdalne prowadzenie zabiegu ratującego życie pacjenta. W Politechnice Warszawskiej pierwsze próby opracowania wysoko dokładnych mechanizmów układów manipulacyjnych do zastosowania w chirurgii laparoskopowej narządów wewnętrznych (m.in. operacji mózgu) podjęto z końcem lat 90. XX w. [13–23]. Opracowane konstrukcje charakteryzują się dużą sztywnością, wysokim poziomem powtarzalności i dokładności pozycjonowania, a w szczególności prostotą rozwiązań konstrukcyjnych. Dalszy rozwój tych konstrukcji był realizowany w ramach współpracy z Fundacją Rozwoju Kardiochirurgii [14, 15, 17–19].
Prowadzenie operacji chirurgicznej na organach ciała pacjenta polega na jego ulokowaniu w miejscu odpowiednio przygotowanym i zabezpieczonym przed działaniami szkodliwych drobnoustrojów w pozycji pozwalającej na prowadzenie zabiegu, tj. w szpitalnej sali operacyjnej, na stole lub siedzisku operacyjnym. Typowa operacja chirurgiczna polega na odpowiednim rozcięciu zewnętrznej powłoki ciała pacjenta, dotarciu w sposób niezagrażający zdrowiu i życiu pacjenta do miejsca operowanego schorzenia, przeprowadzeniu bezpiecznego zabiegu wycięcia fragmentu narządu objętego zmianą chorobową, zabezpieczeniu miejsca ingerencji przed zakażeniem i wyciekiem płynów ustrojowych przez tzw. zespolenie lub zszycie, co może wymagać jednoczesnego zewnętrznego podtrzymywania tkanki miękkiej, a następnie wyprowadzeniu użytych narzędzi na zewnątrz. Typowa operacja chirurgiczna polega na zszyciu powłok zewnętrznych ciała. Można powiedzieć, że operacja chirurgiczna składa się z kilku czynności elementarnych: −cięcie, −trzymanie, p odtrzymywanie, −szycie, przy czym wykonujący te czynności lekarz-operator musi na bieżąco mieć możliwość obserwacji całego pola operacyjnego, konieczne jest więc widzenie lub tzw. sztuczne widzenie.
W przypadku zastosowania robota operacyjnego – telemanipulatora – konieczne jest stosowanie komputerowych metod tworzenia obrazów (ang. imaging methods) oraz przesyłanie obrazów na odległość. Są one stosowane zarówno w procesach diagnostycznych, jak i w procedurach operacyjnych. Służą do tego endoskopy i laparoskopy, umożliwiające lekarzowi odpowiednio dokładny bezpośredni lub pośredni ogląd zewnętrznych powierzchni organów wewnętrznych w sposób pozwalający na postawienie diagnozy bieżącej, a także śledzenie postępujących efektów prowadzenia operacji. Aktualnie w czasie operacji lekarz może korzystać z innych metod obrazowania, jak tomografia komputerowa i rezonans magnetyczny. Wymaga to jednak odrębnego podejścia.
Aktualnie medycyna operacyjna coraz szerzej korzysta z osiągnięć współczesnej techniki – z wykorzystaniem Internetu możliwe jest przesyłanie obrazów na duże odległości, również w czasie rzeczywistym, co pozwala na rozszerzenie konsylium lekarskiego o specjalistów w celu skorzystania z wiedzy większego gremium medycznego o szerszym spektrum zainteresowań, co może mieć też duże znaczenie dydaktyczne.
Możliwość wykorzystania algorytmów sztucznej inteligencji AI (ang. Artificial Inteligence) do analizy trójwymiarowych obrazów wnętrza ciała uzyskanych metodami tomograficznymi, przez ich porównywanie z obrazami standardowymi stworzonymi w opracowanych tymi samymi metodami nowoczesnych atlasach ana-
tomicznych, stanowi cenne narzędzie diagnostyczne. Diagnoza przed operacją okazuje się znacznie szybsza, co pozwala na lepsze planowanie z zastosowaniem skuteczniejszych metod leczenia, co pozwala na skrócenie procedur i w efekcie daje lepsze rokowania szybszego powrotu do zdrowia.
Roboty medyczne do wspomagania operacji chirurgicznych stosowane podczas teleoperacji, mogą być sterowane bez użycia rąk, np. głosem albo w sposób automatyczny, szczególnie w zakresie precyzyjnych czynności powtarzalnych. Niezależnie od tego mogą być używane jako tzw. lokalizatory zarówno pasywne, jak i częściowo lub całkowicie aktywne.
Każda operacja chirurgiczna z zastosowaniem robota, jak i operacja wykonywana zdalnie przez chirurga z jednoczesną obserwacją pola pracy za pomocą kamery laparoskopowej lub endoskopowej przebiega w trzech fazach: planowanie przedoperacyjne, w trakcie którego chirurg planuje operację z wykorzystaniem trójwymiarowych obrazów uzyskanych za pomocą kamery stereowizyjnej, porównując uzyskane obrazy z odpowiednim trójwymiarowym modelem komputerowym. W tej fazie ustala się optymalną strategię planowanej operacji i rejestruje się ją w pamięci komputera centralnego oraz przygotowuje się programy sterujące pracą robota, planowanie operacji z użyciem robota (telemanipulatora), pierwszą czynnością prowadzonej operacji jest synchronizacja i kalibracja układów pomiarowych i wykonawczych robota względem pacjenta, tj. charakterystycznych anatomicznych punktów operacyjnych, ustalenie pola pracy robota i ustalenie właściwych układów odniesienia, zasadniczy zabieg op eracyjny, robot realizuje zaplanowane zadania pod nadzorem chirurga, w trakcie zabiegu procedury operacyjne są interaktywnie kontrolowane za pomocą odpowiednich układów sensorycznych. Przebieg operacji jest bez udziału chirurga prowadzącego, obserwowany i korygowany w sposób automatyczny przez odpowiednie procedury komputera głównego, nad bezpieczeństwem pacjenta czuwa komputerowy system bezpieczeństwa oraz zespół operacyjny.
Należy podkreślić, że operacja jest prowadzona przez lekarza-operatora, który w zależności od jej przebiegu podejmuje decyzje co do dalszej kontynuacji z zastosowaniem robota, a w razie potrzeby przerywa ją i kontynuuje pracę metodami klasycznymi.
2.1. Nowa generacja robotów chirurgicznych z manipulatorami równoległymi
Ostatnie dziesięciolecie było niezwykle owocne w dokonania z zakresu rozwoju medycyny i robotyki medycznej. Jednym z najnowszych dokonań, łączących te dwie gałęzie jest opracowanie tzw. robotów równoległych o strukturze ciągłej (ang. Parallel Continuum Robot). Roboty takie składają się z segmentów oraz odpowiadających im aktuatorów, wprawiających segmenty w ruch. W grupie ciągłych robotów równoległych wyróżnia się [1]:
−Rob oty elastyczne ciągłe (ang. Tendon-actuated PCR), −Rob oty szkieletowe (ang. Multibackbone PCR), Roboty z rurą koncentryczną (ang. Concentric Tube PCR), Rob oty napędzane sterowane magnetycznie w sposób bezpośredni, Rob oty miękkie (gładkie o łagodnych ciągłych przejściach geometrycznych kształtu struktury) (ang. Soft robot)3.
Na rys. 2 przedstawiono przykład rozwiązania robota szkieletowego napędzanego z podstawy za pomocą systemu linek
3 Działające dzięki wykorzystaniu mięśni pneumatycznych. W takiej konstrukcji aktuator jest jednocześnie segmentem robota. Charakterem swoich ruchów, oraz sposobem wysterowania mogą przypominać trąbę słonia.
Rys. 2. Przykład rozwiązania robota szkieletowego typu Multibackbone PCR – rozwiązanie własne
Fig. 2. Example of a Multibackbone PCR skeleton robot solution – the own solution
Rys. 3. Przykład robota o konstrukcji elastycznej ciągłej – prezentacja właściwości co do zakresu ruchów [2]
Fig. 3. An example of a robot with a flexible continuous structure –presentation of properties regarding the range of movements [2]
prowadzonych w osłonach i mocowanych do wybranych segmentów struktury.
Wszystkie odznaczają się nieosiąganym dotąd tzw. poziomem zręczności (ang. dexterity) co do zakresu obsługiwanych czynności operacyjnych, korzystnym dla prowadzenia zabiegów chirurgicznych, również robotów równoległych. Co ciekawe, wszystkie wymienione manipulatory można w pewnym zakresie rozpatrywać jako połączone ze sobą, tj. zwielokrotnione platformy Stewarta4. Takie podejście do modelowania ich kinematyki zostało opisane w [2].
Nie jest to rozwiązanie idealne. Do budowy robota (rys. 3) trzeba zastosować cienkie, odkształcalne pręty lub struny, natomiast w trakcie wykonywania ruchów wszystkie części manipulatora narażone są na występowanie dużych, nieliniowych odkształceń. Wobec tego zjawisko to nie może zostać pominięte w procesie modelowania jego właściwości, jak i w procesie sterowania pracą manipulatora. Należy również zadbać, aby poszczególne segmenty składowe robota pozostawały względem siebie w kontrolowanych stanach lub konfiguracjach, np. by pewne charakterystyczne punkty platform nie zmieniały odległości od siebie podczas ruchu. Zapewnia się to m.in. przez implementację centralnie umieszczonej sprężyny rozprężnej, której zadaniem jest odpowiednie rozstawienie zamocowanych na pręcie centralnym (lince) kolejnych segmentów konstrukcji. Warto zaznaczyć, że sprężyna z reguły nie bierze aktywnego udziału we wspomaganiu ruchów czynnych (sterowanych) manipulatora.
Zastosowanie w konstrukcji manipulatora wielu segmentów, stanowiących swoiste prowadnice dla prętów odpowiedzialnych za ruch ogólny robota, znacząco zwiększa jego obszar roboczy, przy czym zachowane są wszystkie niezbędne do obsługi czynności operacyjnych zewnętrzne stopnie swobody (jest ich tu sześć, a ruch ogólny może być wykonywany w sposób redundantny, tj. na różne sposoby tak, jakby robot miał więcej stopni swobody). Ponadto konstrukcja całego manipulatora umożliwia jego odkształcalność – takie cechy są szczególnie pożądane podczas wykonywania zabiegów chirurgicznych, w których wymagana
4 Platforma Stewarta – manipulator równoległy składający się z sześciu liniowych siłowników napędowych (hydraulicznych lub elektrycznych), które są w odpowiedni sposób zamocowane przegubowo zarówno do platformy podstawy manipulatora, jak i do jego platformy ruchomej [29] tworząc między sobą zamknięte pętle kinematyczne.
jest wysoka precyzja i minimalna inwazyjność ze strony układu mechanicznego robota.
Konstrukcja robota z centralnie umieszczoną sprężyną zapewnia dodatkowo odpowiedni poziom naprężenia „ścięgien” (linek) robota, co pozwala na unikanie kłopotliwego w eksploatacji i trudnego do modelowania zjawiska wyboczenia. Zjawisko to mogłoby powodować problemy z zadawaniem pozycji. Jednak przez wprowadzanie zadawanych sił naprężenia wewnętrznego linek sterujących, możliwe jest kontrolowanie sztywności zewnętrznej konstrukcji mechanicznej manipulatora, co znacznie polepsza jego właściwości użytkowe. Podczas wprowadzania manipulatora do obszaru pracy przez odpowiedni dukt rurowy, można luzując linki sterujące wprowadzić manipulator w stan „zwiotczenia”, co usprawnia ten proces. Natomiast po wprowadzeniu końcówki manipulatora w obszar pracy można go odpowiednio usztywnić napinając linki, co pozwala na precyzyjniejszą manipulację i zwiększa dokładność procesów operacyjnych oraz polepsza kontrolę operatora nad prowadzonym zabiegiem.
2.2. Przesuwanie granic precyzji
Pierwsze wzmianki o operacjach gałki ocznej pochodzą już sprzed szóstego stulecia przed naszą erą. W hinduskim Sanskrycie znajdują się zapiski o wykonywaniu operacji usunięcia zaćmy przez nakłuwanie soczewki oka igłą. Ówczesne realia nie pozwalały jednak na całkowite naprawienie wzroku pacjenta, z uwagi na wymiary używanego narzędzia oraz obiektywnie niski poziom higieny przy wykonywaniu operacji. Na przestrzeni wieków wiele się w tej materii zmieniło [11].
Jedną z najbardziej wymagających dziedzin chirurgii jest chirurgia siatkówki oka. Konieczna tutaj jest bardzo duża precyzja ruchu – roboty potrafiące wykonywać operacje oka są niemalże wyłącznie robotami równoległymi.
Obecnie przedmiotem najnowszych badań w dziedzinie okulistyki jest udoskonalanie konstrukcji robota opracowanego na uniwersytecie Vanderbilta w Nashville (USA). Robot ten przeznaczony jest do operowania zakrzepów gałązek żyły środkowej siatkówki. Jest to przypadek, w którym w wyniku miażdżycy lub zapalenia naczyń dochodzi do powstania zakrzepów w żyłach siatkówkowych. Objawami są: niewyraźne widzenie lub utrata widzenia w pewnym obszarze oka. Do dwóch znanych obecnie metod operacji takiego schorzenia należy witrektomia oraz kaniulacja mikronaczynkowa [5–7]. Celem naukowców z Nashville było
Krzysztof
4.
w
opracowanie metody minimalizującej ryzyko powikłań, polegającej na precyzyjnym umieszczeniu stentów w żyłkach siatkówki oka pacjenta. Zabieg ten został przedstawiony na rys. 4. Nietrudno zauważyć, że wszystkie trzy dostępne rozwiązania należą do zabiegów niezwykle trudnych (witrektomia bywa nazywana „operacją ostatniej szansy”) – aby operować żyły siatkówki należy dostać się do nich, nie uszkadzając rogówki, tęczówki oraz soczewki.
Zrobotyzowane stanowisko opracowane na Uniwersytecie Vanderbilta składa się z dwóch manipulatorów typu platforma Stewarta, zamontowanych naprzeciwko siebie na wspólnej okrągłej podstawie. Napędem tych platform są siłowniki elektryczne liniowe z przekładniami śrubowymi. Na platformach ruchomych manipulatorów podstawowych zamocowane są dodatkowe mechanizmy pozycjonujące o dwóch stopniach swobody, wstępnie ustalające pozycje robotów stentujących. Te z kolei mają po trzy stopnie swobody – dwa obroty względem przecinających się w jednym punkcie osi prostopadłych, oraz przesuw wzdłuż linii przechodzącej przez ten punkt. Jest to zatem rozwiązanie umożliwiające ruch we współrzędnych kulistych. Roboty stentujące odpowiedzialne są za wprowadzanie stentów w gałkę oczną oraz wykonywanie delikatnych ruchów końcówek operacyjnych robotów pozycjonujących stenty. Konstrukcja całego robota została pokazana w postaci wizualizacji 3D (rys. 5).
Opisana konfiguracja ma zapewnić możliwość jednoczesnego wprowadzenia do oka pacjenta dwóch narzędzi lub wzierników. Operację wykonuje dwóch lekarzy jednocześnie, kontrolując przypisane im zestawy manipulatorów [4].
Wstępne badania opisywanego robota wykazały, że dokładność pozycjonowania stentu w gałce ocznej może wynosić nawet poniżej 5 µm, co stanowi poziom precyzji odpowiedni do obsługi założonych i wymaganych zadań [3]. Warto zaznaczyć, że wynikowa efektywna i całkowita dokładność operowania narzędziem chirurgicznym utrzymuje się na poziomie ≈ 10 µm. Obecnie trwają prace nad inteligentnymi algorytmami sterowania robotem z wykorzystaniem sztucznej inteligencji (AI), które mają wspomagać pracę chirurgów i ułatwiać im obsługę robotów i wykonywanie operacji za pomocą tego systemu [5].
2.3. Robot chirurgiczny da Vinci
Robot chirurgiczny da Vinci jest robotem typu master-slave (robotem-teleoperatorem), w którym część sterowniczą
Mianowski, Filip Gruca, Jakub Grzonkowski, Jan Makulec
Rys. 5. Konstrukcja robota zaproponowana przez Uniwersytet Vanderbilta: 1 – platforma Stewarta o sześciu stopniach swobody, 2 – mechanizm pozycjonujący o dwóch stopniach swobody, 3 – robot stentujący o trzech stopniach swobody, koncepcja własna inspirowana przez [5]
Fig. 5. Robot design proposed by Vanderbilt University: 1 – Stewart platform with six degrees of freedom, 2 – positioning mechanism with two degrees of freedom, 3 – stent robot with three degrees of freedom, according to [5]
Rys. 6. Robot chirurgiczny da Vinci w układzie 4-ramiennym [25]
Fig. 6. da Vinci surgical robot in a 4-arm system [25]
(master) stanowi konsola z interfejsem użytkownika, natomiast częścią wykonawczą (slave) jest robot o czterech ramionach interaktywnych – każdy o siedmiu stopniach swobody. Każde z czterech ramion robota wygląda z zewnątrz jak manipulator szeregowy, jednak budowa wewnętrzna tego ramienia ma strukturę manipulatora równoległego. Oprócz podstawowych komponentów (konsoli i robota) system da Vinci wyposażony jest w najbardziej zaawansowaną technikę obrazowania 3D w kolorze oraz specjalistyczne robotyczne narzędzia chirurgiczne EndoWrist. Dzięki układowi wizyjnemu złożonemu z dwóch kamer, chirurg ma wrażenie trójwymiarowości. Możliwe są też zmiany parametrów obrazu (powiększenie, kontrast).
Stosowane narzędzia EndoWrist zostały skonstruowane tak, aby imitowały umiejętności ludzkiej dłoni wraz z nadgarstkiem. Mają do pięciu stopni swobody każde i ich końcówka może zginać się pod kątem 90°, a w przypadku operacji tylnej części serca wprowadza się je z przodu pacjenta a następnie można ją obrócić
Rys.
Stent umieszczany
jednej z żył siatkówki oka [3]
Fig. 4. Stent placed in one of the retinal veins [3]
nawet o około 180°. Dzięki układom redukcji drżenia rąk oraz kompensacji gwałtownych ruchów chirurga system robota niweluje możliwość wystąpienia błędów ludzkich. Za pomocą robota można wykonywać operacje z zastosowaniem precyzyjnych minimalnych cięć, co znacznie zmniejsza czas rekonwalescencji, utratę krwi i prawdopodobieństwo komplikacji pooperacyjnych. Warto dodać, że aby operacja była udana, należy stosować szybkie i niezawodne połączenie sieciowe (minimum 10 Mb/s) o małym czasie opóźnienia transmisji (poniżej 200 ms).
2.4. Chirurgia teleoperacyjna
Dla pacjenta, który dowiedział się, że jest poważnie chory i konieczna jest interwencja chirurgiczna, ważnymi aspektami w szukaniu pomocy jest możliwość szybkiego jej otrzymania, spodziewana dobra skuteczność leczenia i oczekiwana wysoka niezawodność zabiegu. W przypadku konieczności wykonania trudnych i skomplikowanych operacji ważnych narządów, takich jak serce czy mózg ograniczona jest liczba specjalistów, których doświadczenie pozwala na podjęcie się takiego zadania. Przedstawiciele ochrony zdrowia narzekają na przeciągający się czas oczekiwania pacjentów w kolejkach. W momencie, gdy pacjent potrzebuje wykonania natychmiastowego zabiegu, a stan jego zdrowia nie pozwala na przewiezienie go na większą odległość, z pomocą może przyjść zabieg wykonywany metodą teleoperacji.
Zabieg na odległość wykonuje się z zastosowaniem robota chirurgicznego – teleoperatora. Do najbardziej znanych systemów należą ZEUS (którym wykonano operację przez Ocean Atlantycki Robot ZEUS niestety został już wycofany z rynku) i da Vinci. Wystarczy, aby pacjenta przewieźć do ośrodka leczniczego posiadającego ambulatorium lub salę operacyjną wyposażoną w system z odpowiednim robotem chirurgicznym, odpowiednio przygotowaną i utrzymaną w gotowości przez personel medyczny. Co więcej, nie jest tu wymagana obecność fizyczna chirurga specjalizującego się w danym typie operacji. Lekarz-operator może się znajdować w innym ośrodku (w dowolnym miejscu na świecie), wyposażonym w system zdalnego zadawania ruchu robota (master) i połączenie internetowe z odpowiednio szybkim łączem. Wystarczy, że lekarz zostanie odpowiednio wcześniej powiadomiony i połączy się w zadanym czasie z robotem operacyjnym (slave) w celu zdalnego instruowania personelu pomocniczego pracującego w sali z pacjentem i przeprowadzenia samej operacji przez zdalne sterowanie robotem za pomocą manetek systemu master. Takie rozwiązanie może umożliwić najlepszym specjalistom przeprowadzanie skomplikowanych operacji nawet z własnego domu, praktycznie bez konieczności jego opuszczania, np. w trakcie groźnej epidemii. Aby polepszyć komunikację między chirurgiem a asystującymi
mu lekarzami przebywającymi na miejscu wykonywania zabiegu, wykorzystuje się audio oraz wideo komunikację.
Pojawiają się informacje o możliwym wykorzystywaniu technologii 5G do usprawnienia tego procesu. Ma ona znacznie przyspieszyć przesyłanie danych na duże odległości, a tym samym znacznie zniwelować opóźnienia czasu reakcji robota oraz zwiększyć jego dokładność, a tym samym precyzję wykonywanych zabiegów.
Pierwszy tego typu międzykontynentalny zabieg odbył się w 2001 r. Został ochrzczony nazwą „Operacja Lindbergh”. Polegała ona na usunięciu pęcherzyka żółciowego 68-letniej pacjentce znajdującej się w Strasburgu. Odległość stanowiska operacyjnego typu (master) obsługiwanego przez doktora Jacques’a Marescaux (rys. 8), a chirurga wykonującego ten zabieg, znajdującego się w tym samym czasie w Nowym Jorku, wynosiła 6230 km. Do tego pionierskiego zabiegu chirurgicznego wykorzystano system ZEUS, zbudowany z trzech ramion kontrolowanych (sterowanych zadajnikami) przez lekarza z konsoli głównej i systemu czujników/sensorów przesyłających informacje zwrotne do pulpitu użytkownika. Z powodu fuzji dwóch firm Computer Motion produkującą robota ZEUS z konkurencyjnym producentem Intuitive Surgical produkującym robota da Vinci, zaprzestano produkcję robota ZEUS a od 2003 r. rozpoczęto sukcesywne ulepszanie systemu z robotem da Vinci.
3. Kierunki rozwoju manipulatorów równoległych w medycynie
Przytoczone wcześniej przykłady wyraźnie dowodzą, że automatyzacja medycyny stwarza chirurgom nowe możliwości w zakresie precyzji, dostępności wysokospecjalistycznych procedur oraz sposobów dostarczania opieki zdrowotnej. Wprowadzone technologie pozwalają sukcesywnie podnosić jakość usług medycznych i wynosić je na nowe wyższe poziomy. Nadal jest wiele obszarów, w których możliwy jest dalszy rozwój i poprawa działania urządzeń. Mimo dynamicznej automatyzacji i robotyzacji, znaczna część zabiegów chirurgicznych nadal wykonywana jest metodami tradycyjnymi. Teraz przyjrzymy się możliwym kierunkom rozwoju tych zaawansowanych systemów w kontekście medycyny, analizując zarówno ich obecne zastosowania, jak i perspektywy przyszłych innowacji.
3.1. Autonomiczność systemów
Jak powszechnie wiadomo „lenistwo” w jego nieco innym znaczeniu określane jest jako jeden z motorów postępu. Coraz częściej dąży się do tego, aby systemy automatyki coraz wydatniej wspierały nasze działania lub całkowicie nas w nich wyręczały. Nie dziwi więc fakt, iż na przestrzeni ostatnich lat wyraźnie widać rosnącą tendencję do nadawania systemom automatyki coraz większej autonomii w działaniu. Nie inaczej ma się sprawa w chirurgii. Tutaj jednak, przez wzgląd na uwarunkowania prawne i niechęć ludzi do powierzania swojego zdrowia lub życia w ręce maszyny, zmiany zwykle następowały znacznie wolniej, niż w innych dziedzinach.
Rys. 7. Testy aparatury do wykonywania teleoperacji da Vinci na sali operacyjnej [26]
Fig. 7. Tests of da Vinci teleoperation equipment in the operating room [26]
Rys. 8. Robot ZEUS w układzie wykorzystywanym w Operacji Lindbergh [27]
Fig. 8. ZEUS robot in the system used in Operation Lindbergh [27]
Krzysztof Mianowski, Filip Gruca, Jakub Grzonkowski, Jan Makulec
Do zdefiniowania stopnia autonomiczności w automatyce, powszechnie stosuje się 10-stopniową skalę Sheridana (ang. Sheridan’s Levels of Autonomous Behavior) [12]. Jej twórcą był Thomas B. Sheridan, pionier badań nad interakcją człowieka i maszyny. Systemy charakteryzujące się poziomem najniższym nie mają żadnej autonomii i mogą wykonywać jedynie wcześniej zaprogramowane czynności (sterowanie ręczne). Do niedawna były to najbardziej powszechne rozwiązania. W ostatnim czasie są powoli zastępowane przez systemy będące na najwyższym poziomie autonomiczności – tutaj robot na podstawie oceny sytuacji sam wybiera cel oraz środki dążenia do niego. W chirurgii robotycznej mimo wielu przeszkód, przeprowadza się coraz więcej eksperymentów mających na celu wdrażanie takich technologii. Sztandarowym przykładem są udane zabiegi chirurgiczne wykonane metodą teleoperacji. Zyskały one dużą popularność mimo wykorzystania robota będącego zaledwie na trzecim poziomie autonomiczności. Inżynierowie pracują obecnie nad przeprowadzaniem całkowicie autonomicznych operacji tego typu.
Opracowany przez zespół z Johns Hopkins University inteligentny autonomiczny robot tkankowy STAR (ang. Smart Tissue Autonomous Robot) w 2022 r. przeprowadził całkowicie autonomiczną operację laparoskopową na tkance zwierzęcej [9]. Testując laparoskopię manualną i wspomaganą robotem operację zespolenia jelit świńskich, naukowcy odkryli, że autonomiczna operacja oferowana przez system STAR była dokładniejsza, a zatem lepsza. Cechą wyróżniającą jest to, że jest to pierwszy system robotyczny, który planuje, dostosowuje i wykonuje operacje na tkankach miękkich przy minimalnej ingerencji człowieka.
Rys. 9. Robot STAR przeprowadzający całkowicie autonomiczną operację laparoskopową [9]
Jest kwestią czasu, kiedy zabiegi wymagające dużej precyzji, np. operacje siatkówki oka będą wykonywane przez autonomiczne roboty-manipulatory, w tym roboty równoległe. W tym przypadku bardzo pomocne mogą okazać się równolegle rozwijające się technologie, takie jak widzenie maszynowe oraz sztuczna inteligencja (AI). Zabiegi te mogłyby być wykonywane z niespotykaną dotąd dokładnością. Uprzednio zbadana, za pomocą widzenia maszynowego, siatkówka oka mogłaby być operowana przez bardzo precyzyjne manipulatory równoległe. Dodatkowo zapewniając dużą bazę danych z już wykonanych zabiegów można by nieustannie poprawiać ich skuteczność przy użyciu AI. Precyzyjnie wykonane w ten sposób scenariusze operacji, w połączeniu z dużą dokładnością i stabilnością manipulatorów równoległych mogą odznaczać się bardzo wysoką skutecznością i niskim ryzykiem powikłań.
Dodatkowym atutem autonomicznych robotów równoległych jest 100-procentowa powtarzalność wykonywanych zabiegów. Przez wzgląd na tę cechę, pewnym jest, że technologie te zdo-
minują w przyszłości te gałęzie chirurgii, gdzie przeprowadza się szereg prostych zabiegów, takich jak np. usuwanie kamieni nerkowych czy enukleacja prostaty, czyli minimalnie-inwazyjne zmniejszenie objętości gruczołu z użyciem lasera. Rocznie przeprowadza się wiele takich operacji i dziedziny te, przez wzgląd na wciąż rosnące kolejki wymagają automatyzacji. Autonomiczne roboty równoległe, z łatwością wykonają szereg takich zabiegów, nie tracąc przy tym precyzji. Pomoże to znacznie zmniejszyć ryzyko powikłań poważnych i niepotrzebnych urazów, które w tym obszarze zdarzają się niestety dość często. Dodatkowo każdy przypadek może zostać zarejestrowany i w odpowiednim czasie odtworzony do celów szkoleniowych, w celu poprawy jakości wykonywanych zabiegów.
Widać więc szereg niewątpliwych zalet, jakie oferują nam manipulatory równoległe w połączeniu z innymi technologiami, co sprawi, że prędzej czy później bezpieczniejszym rozwiązaniem będzie poddanie się zabiegom z ich udziałem niż tradycyjna operacja chirurgiczna, nawet jeśli skalpel będzie trzymał najbardziej wykwalifikowany specjalista. Bo przecież nic nie stoi na przeszkodzie, aby jego doświadczenie i wypracowane techniki zostały wkomponowane w precyzyjne modele AI, a jego ręce zostały zastąpione przez manipulatory równoległe wykonujące cięcia z dokładnością na poziomie nanometrów. Taka przyszłość jest bliższa niż nam się wydaje.
3.2.
Duża precyzja
Oprócz doskonalenia algorytmów sterowania, wart uwagi jest również rozwój rozwiązań konstrukcyjnych. W tym obszarze należy rozważyć wykorzystanie materiałów inteligentnych, minimalizację stref niejednoznaczności geometrycznej (mechanicznej, tzw. luzów), zastosowanie hybrydowych układów napędowych oraz implementację systemów pomiarowych nowej generacji.
3.2.1. Materiały inteligentne
W konstrukcji robotów równoległych można z powodzeniem stosować różne materiały inteligentne, które mają zdolność do reakcji na zmienne warunki otoczenia lub na odpowiednie sterowanie zewnętrzne. Materiały te oferują nowe możliwości, pozwalając na tworzenie bardziej elastycznych, tj. adaptacyjnych i bardziej efektywnych konstrukcji nowej generacji.
Jedną z grup materiałów inteligentnych stanowią polimery elektroaktywne. Są to elastyczne materiały, które ulegają deformacji pod wpływem zmian pola elektrycznego. Użycie odpowiednich impulsów elektrycznych może powodować skurcze, wydłużenia lub skręty tych materiałów. Cecha ta może zostać wykorzystana, gdy użycie standardowych aktuatorów jest utrudnione lub niemożliwe, np. w razie konieczności sterowania końcówką robota w ograniczonej przestrzeni gałki ocznej pacjenta. Inną grupę materiałów inteligentnych stanowią materiały piezoelektryczne. Ich cechą szczególną jest zdolność elektrostrykcji czyli możliwość zastosowania do pracy jako aktuator (siłownik zmiany położenia) i jednocześnie czujnik/sensor do pomiaru jego stanu. Sterowanie aktuatorami elektrostrykcyjnymi należy do zadań relatywnie nieskomplikowanych, natomiast generowane ruchy są powtarzalne i odznaczają się bardzo dużą precyzją. W zależności od użytej konfiguracji zmiana sterowania o 1 V może powodować odkształcenie rzędu 0,29 nm. Dodatkową zaletę stanowi również możliwość osiągania znaczących prędkości i przyspieszeń ruchu elementu wykonawczego takiego aktuatora.
3.2.2. Struktury podatne
Jednym z kluczowych aspektów wykorzystania struktur podatnych w budowie manipulatorów równoległych jest ich znaczący wpływ na zwiększenie precyzji adaptacji mechanicznej tych urządzeń. Elastyczność, charakterystyczna dla struktur podatnych, pozwala na skuteczne tłumienie drgań oraz absorpcję energii impulsów sił zewnętrznych, co w rezultacie prowadzi
Fig. 9. STAR robot performing a completely autonomous laparoscopic surgery [9]
do wyższej precyzji w wykonywaniu obsługiwanych zadań. Elastyczność elementów konstrukcyjnych sprawia, że manipulatory są bardziej odporne na niewielkie błędy operatora, oraz niejednorodności w strukturze, co jest szczególnie istotne w przypadku długotrwałych operacji wymagających stałej, wysokiej precyzji. W zastosowaniach medycznych czy przemyśle precyzyjnym, gdzie nawet niewielkie odchylenia mogą mieć istotne znaczenie, struktury podatne przyczyniają się do eliminacji błędów wynikających z niedoskonałości konstrukcyjnych czy nieuniknionych wibracji środowiska pracy.
3.2.3. Hybrydowe układy napędowe
Hybrydowe systemy napędowe, łączące różne technologie, oferują unikalne możliwości adaptacji do różnorodnych zadań, jednocześnie utrzymując wysoką precyzję ruchów. Integracja silników elektrycznych, pneumatycznych i hydraulicznych pozwala na optymalne wykorzystanie ich zalet w zależności od wymagań konkretnego zadania. Silniki elektryczne zapewniają szybkie i precyzyjne ruchy, silniki pneumatyczne oferują elastyczność, natomiast silniki hydrauliczne zapewniają wysoki poziom sił napędowych. Połączenie tych trzech typów napędu ułatwi manipulatorowi równoległemu adaptację w warunkach dynamicznych w celu odpowiednio szybkiego dostosowywania swoich właściwości do zmieniających się warunków pracy, co znacznie rozszerzy zakres jego potencjalnych zastosowań.
3.2.4. Systemy pomiarowe
Sensory o wysokiej rozdzielczości, takie jak enkodery optyczne czy technologie LiDAR, umożliwiają precyzyjne śledzenie ruchów manipulatora w czasie rzeczywistym. Integracja pozyskanych w ten sposób danych z zaawansowanymi algorytmami sterowania pozwala na skuteczniejsze kompensowanie wszelkich zakłóceń.
Równocześnie rozwój sztucznej inteligencji we wspomaganiu systemów pomiarowych/sterujących i kontrolnych pozwala na przystosowawcze (adaptacyjne), samoczynne uczenie się systemu robota-manipulatora, co przekłada się m.in. na dynamiczną optymalizację trajektorii ruchów. Wykorzystanie technologii sztucznej wizji otwiera nowe możliwości, umożliwiając manipulatorowi równoległemu interakcję ze środowiskiem w sposób bardziej intuicyjny, dokładny i adekwatny do stawianych wymagań.
3.3. Aspekty edukacyjne
Edukacja przez zastosowanie manipulatorów równoległych w medycynie stanowi istotny element szkolenia przyszłych specjalistów, w tym chirurgów, technologów medycznych i innych pracowników związanych z obszarem opieki zdrowotnej. Zastosowanie układów wizyjnych i komunikacji werbalnej w operacyjnych systemach zrobotyzowanych pozwala na rejestrację i/lub strumieniowy przesył sygnałów do sal, w których odbywają się konsylia specjalistów lub sal konferencyjnych i/lub dydaktycznych, w tym nawet na duże odległości. Sygnały te mogą być wykorzystane podczas konsultacji medycznych operatora w czasie operacji, prezentacji przebiegu i wyników operacji na konferencjach, jak też do wykorzystania w dydaktyce do kształcenia nowej kadry oraz w ocenie okresowej lekarza-operatora i ocenie jakości wykonywanych zabiegów w danej jednostce opieki zdrowotnej.
3.3.1. Chirurgia minimalnie inwazyjna
Manipulatory równoległe są często wykorzystywane do prowadzenia procedur chirurgii minimalnie inwazyjnej, takich jak laparoskopia czy torakoskopia. Studenci medycyny uczą się obsługi i sterowania takimi systemami, co umożliwia precyzyjne wykonywanie zabiegów przy minimalnych nacięciach skórnych.
3.3.2. Symulacje medyczne
Manipulatory równoległe są integralną częścią symulacji medycznych, które pozwalają na realistyczne odtwarzanie warunków chirurgicznych. Studenci praktykują na modelach anatomicznych, symulatorach cielesnych lub w tzw. środowisku wirtualnym, co pomaga im rozwijać umiejętności praktyczne bez konieczności bezpośredniego kontaktu z pacjentem, szczególnie na etapie początkowym przygotowania do zawodu.
3.3.3. Telechirurgia
Edukacja w zakresie telechirurgii przy użyciu manipulatorów równoległych pozwala na zdalne wykonywanie procedur chirurgicznych. Studenci uczą się obsługi zdalnych systemów chirurgicznych, co może być przydatne w przypadku prowadzenia operacji na odległość.
3.3.4. Zastosowanie Wirtualnej Rzeczywistości
Integracja manipulatorów równoległych z technologią wirtualnej rzeczywistości umożliwia tworzenie realistycznych scenariuszy edukacyjnych. Studenci mogą trenować na wirtualnych pacjentach, co pozwala na bezpieczne i wielokrotne powtarzanie różnych procedur.
3.3.5. Badania nad poprawą procedur medycznych
Edukacja przy wykorzystaniu manipulatorów równoległych stwarza studentom możliwość uczestniczenia w badaniach nad innowacyjnymi rozwiązaniami medycznymi. Studenci mogą angażować się w rozwijanie nowych technologii, które mają potencjał poprawy skuteczności i bezpieczeństwa procedur medycznych.
3.3.6. Współpraca z przemysłem medycznym
Dzięki współpracy z firmami produkującymi manipulatory równoległe, studenci mają dostęp do najnowocześniejszych rozwiązań stosowanych w medycynie. To pozwala na lepsze zrozumienie aktualnych trendów i standardów w branży. Warto tu zaznaczyć, że zastosowanie robotów w medycynie przyczyni się do szybszego i efektywniejszego wdrażania nowych technik i technologii oraz opracowania zupełnie nowych metod leczenia, np. nieznanych dotychczas chorób.
Niezależnie od tego komputeryzacja systemów organizacji pracy w medycynie pozwoli na bardziej efektywne prowadzenie statystyk wykonywanych zabiegów, co może się przyczynić do racjonalizacji planowania pracy jednostek medycznych oraz do predykcji możliwych zachorowań i przebiegu chorób w wytypowanej populacji objętej prowadzeniem takich statystyk.
4. Chirurgia 4.0 w Polsce i na świecie
W dzisiejszych czasach technologia robotów chirurgicznych stanowi istotny element postępu w dziedzinie medycyny. Firmy, takie jak Synektik, będące dystrybutorem systemów da Vinci w Polsce, dostarczają cenne dane dotyczące rozprzestrzenienia tych zaawansowanych technologii. Analiza danych wskazuje, że Polska pozostaje w tyle w zakresie nasycenia robotami chirurgicznymi, w porównaniu do niektórych krajów Europy Zachodniej.
Według danych Synektika, Polska charakteryzuje się relatywnie niższym nasyceniem robotami chirurgicznymi na tle liczby mieszkańców w porównaniu do dużych krajów Zachodniej Europy. Kraje te wykazują 4–6-krotnie wyższe nasycenie systemami automatyki chirurgicznej, co stanowi istotny wskaźnik rozwoju technologicznego w dziedzinie medycyny.
Wyniki analizy ilustrują, że choć Polska uczestniczy aktywnie w adaptacji nowoczesnych technologii medycznych, to nadal istnieje znacząca przepaść w dostępie do robotów chirurgicznych w porównaniu z krajami Zachodniej Europy. Wpływ na to
stanowić mogą różnice w budżetach zdrowotnych, dostępności finansowania na innowacje medyczne oraz specyficzne wybory strategiczne w planowaniu inwestycji w służbie zdrowia. Robotyczne systemy chirurgiczne należą bowiem do kosztownych rozwiązań. Robot da Vinci kosztuje obecnie 2,5 mln dolarów. Poza wysoką ceną zakupu, należy pamiętać również o zapewnieniu właściwego serwisowania jednostek.
Liczba robotów da Vinci w wybranych krajach Europy na dzień 1 czerwca 2023 r. wynosi: −Francja – 340, −Niemcy – 330, −Wło chy – 180, −Wielka Brytania – 160, −Hiszpania + Portugalia – 110, −Szwecja – 60, −Czechy – 17, −Słowacja – 4.
Systemy da Vinci są jednymi z najbardziej popularnych i powszechnie używanych na całym świecie. Kluczową rolę w tej dominacji odgrywa firma Intuitive Surgical Inc., której innowacyjne podejście do robotów chirurgicznych zrewolucjonizowało sposób, w jaki lekarze przeprowadzają operacje. Jednak wraz z wygasaniem patentów od 2017 r., rynek ten stał się bardziej otwarty na konkurencję i nowe technologie. Obecnie na świecie działa ponad 8 tysięcy systemów automatyki chirurgicznej, z czego około 570 zlokalizowanych jest w Japonii. Tam dominuje nie tylko obecność systemów da Vinci,
Tab. 1. Liczba operacji robotowych w 2020 r. w poszczególnych województwach [8]
Tab. 1. Number of robotic operations in 2020 in individual voivodeships [8]
Województwo
Liczba operacji robotowych
Liczba zabiegów na 100 000 mieszkańców
Liczba mieszkańców (tys.)
mazowieckie 871 15,85513
kujawsko-pomorskie206 10,22018
podlaskie 109 9,5 1149
małopolskie 220 6,4 3430
wielkopolskie152 4,3 3500
zachodniopomorskie66 4,0 1650
łódzkie 51 2,1 2395
dolnośląskie 51 1,8 2898 pomorskie 18 0,8 2359
lubuskie 0 0,0 985
lubelskie 0 0,0 2038
podkarpackie 0 0,0 2086
śląskie 0 0,0 4376
świętokrzyskie 0 0,0 1188 opolskie 0 0,0 949
warmińsko-mazurskie 0 0,0 1375
Polska 1744 4,6 37 909
ale także ponad 35 systemów Hinotori oraz pionierskie systemy Hugo, tworząc w ten sposób zróżnicowane środowisko technologiczne. W Korei Południowej 69 systemów da Vinci obsługuje 51 szpitali, podczas gdy w Indiach przeszło 50 robotów chirurgicznych rewolucjonizuje podejście do medycyny.
4.1. Rozwój w podziale na regiony
Rozwój automatyzacji chirurgii w Polsce nie jest jednolity i wykazuje zróżnicowanie między poszczególnymi regionami kraju. Szczególnie różnice w rozwoju pokazują tabele 1 i 2. Pierwsze ośrodki wyposażone w roboty chirurgiczne pojawiły się we Wrocławiu i Toruniu, stanowiąc pionierskie inwestycje w tej dziedzinie. Kolejne etapy rozwoju związane były z warszawskimi placówkami medycznymi, w tym szpitalami prywatnymi.
Bydgoszcz, Poznań, Kraków, Białystok i Łódź dołączyły do grona miast, które wzbogaciły swoją ofertę medyczną o roboty chirurgiczne. Od końca 2019 r. nastąpił dynamiczny rozwój Mazowsza jako centralnego obszaru skupiającego wysoką liczbę ośrodków korzystających z technologii automatyki chirurgicznej. Robotyzacja chirurgii nie ogranicza się już jedynie do głównych miast, wzbogacając swoją dostępność także w mniejszych miejscowościach, takich jak Wieliszew, Siedlce, Otwock, Międzylesie czy Piaseczno. Dodatkowo, od 2020 r. większe warszawskie szpitale, takie jak Wojskowy Instytut Medyczny, Centralny Szpital Kliniczny MSWiA czy Uniwersyteckie Centrum Kliniczne WUM, włączyły możliwość przeprowadzenia pewnych zabiegów przez roboty do swoich ofert. Mimo wcześniejszego dynamicz-
Tab. 2. Liczba operacji robotowych w 2022 r. w poszczególnych województwach [8]
Tab. 2. Number of robotic operations in 2022 in individual voivodeships [8]
Rys. 10. Systemy automatyki medycznej stosowane przez szpitale w Polsce (2022 r.) [8]
Fig. 10. Types of medical automation systems used by hospitals in Poland (2022) [8]
Rys. 11. Koncept polskiego medycznego teleoperatora stacjonarnego [28]
Fig. 11. The concept of a Polish medical stationary teleoperator [28]
nego rozwoju, od 2021 r. żadna nowa placówka na Mazowszu nie zrobotyzowała uruchamianej sali chirurgicznej. Choć warszawski Szpital św. Elżbiety, będący własnością LUXMED, otworzył pracownię z nowym systemem da Vinci w kwietniu 2023 r., to należy podkreślić, że jest to kontynuacja wcześniej przejętego ośrodka, który działał od 2018 r. jako Carolina Medical Center/Hifu Clinic.
Mimo nie najlepszych statystyk robotyzacji polskiego sektora chirurgii, na naszym podwórku powstają liczne koncepty oraz prototypy takich urządzeń. Jednym z nich był projekt teleoperatora stacjonarnego NeuroGuide (rys. 11). Jego zadaniem było wykonywanie precyzyjnych otworów w kręgosłupie pacjenta przystosowanych do montażu implantów usztywniających. Wiadomo, że urazy dwóch pierwszych kręgów (dźwigacza i obrotnika), na skutek wypadków samochodowych lub zmian chorobowych, są bardzo powszechne. Zabiegi leczące tę dolegliwość charakteryzują się dość długim czasem oczekiwania na wolne terminy oraz wysokim ryzykiem dla pacjenta. Urządzania mogące znacznie przyspieszyć oraz usprawnić ten proces są bardzo pożądane. Polski koncept został nawet skutecznie przetestowany na odpowiednio spreparowanych tkankach ludzkich. Dodatkowo był przystosowany do wykonywania operacji zdalnych. Z powodu braku zainteresowania tematem polskiej ochrony zdrowia oraz braku funduszy, badania nad projektem były kontynuowane za granicą. Aktualnie los tego konceptu nie jest nam znany. Jego los podzieliło wiele podobnych innowacyjnych projektów. Dlatego obecnie Polska nie jest gotowa na przyjęcie innowacyjnych robotów w medycynie
4.2. Robin Heart
W kontekście dynamicznego rozwoju, pojawia się też projekt polskiego robota chirurgicznego o nazwie RobIn Heart. Nazwa ta odnosi się do słów „rob in heart”, co tłumaczy się jako
Fig. 12. Construction diagram of the tool platform [10]
13. RobIn Heart mc2 – widok ogólny [10]
„robot w sercu”. Projekt jest opracowywany głównie jako urządzenie robotowe do wykonywania zabiegów w trakcie operacji na sercu i stanowi innowacyjne podejście do rozwiązań robotów chirurgicznych, które będą wykorzystywane również w innych dziedzinach medycyny.
Dr Zbigniew Nawrat, lider projektu, wyjaśnia, że nazwa RobIn Heart nie tylko odnosi się do „robota w sercu”, ale również ma skojarzenia z postacią Robin Hooda. Projekt ten zakładał stworzenie robota, który byłby nie tylko zaawansowany technologicznie, ale również dostępny finansowo dla szerokiego grona użytkowników, w przeciwieństwie do kosztownego systemu da Vinci.
Dr Nawrat podkreśla, że zespół rozpoczął pracę od jednego z najtrudniejszych obszarów – chirurgii serca. Pierwsza teleoperacja, czyli operacja na odległość miała miejsce w 2010 r. w Fundacji Rozwoju Kardiochirurgii w Zabrzu. Wykorzystano prototyp robota RobIn Heart, za którego konsolą zajęła miejsce kardiochirurg pani doktor medycyny Joanna Śliwka. Operacja na sztucznym szkielecie z umieszczonym w klatce piersiowej świńskim sercem odbyła się na odległości około 30 km. Opóźnienie wyniosło niecałe 280 ms, przy czym do transmisji sygnałów sterujących wykorzystano łącze radiowe. Robot chirurgiczny RobIn Heart (RiH) mc2 stanowi innowacyjną próbę rozwiązania współczesnych problemów w dziedzinie chirurgii. Jest to pierwszy modułowy i wielonarzędziowy system chirurgiczny, wyposażony w układ ramion 2 + 1. Oznacza to, że ma dwa zewnętrzne ramiona pełniące funkcję narzędzi chirurgicznych, a także środkowe ramię, które jest wyposażone w platformę umożliwiającą jednoczesną pracę dwóch narzędzi roboczych typu RiH Uni System oraz toru wizyjnego.
Nowy model RiH mc2 powstał w odpowiedzi na wnioski dotyczące funkcjonalności wcześniejszych modeli RiH 1, 2, 3 oraz Vision, które zostały zweryfikowane podczas eksperymen-
Rys.
Fig. 13. RobIn Heart mc2 – general view [10]
Rys.
tów na zwierzętach. Problemy związane z kolizyjnością ramion robota, zwłaszcza w warunkach blisko siebie osadzonych narzędzi, takich jak podczas pobierania tętnicy piersiowej, zainspirowały do zmiany koncepcji przestrzennej, funkcjonalnej i konstrukcyjnej robota.
Tradycyjne telemanipulatory używane w chirurgii miały ramiona wyposażone jedynie w jedno narzędzie. Celem opracowania RiH mc2 było stworzenie rozwiązania eliminującego kolizyjność ramion telemanipulatora i umożliwiającego operowanie wieloma narzędziami jednocześnie. Przyrząd do wykonywania zabiegów medycznych zawiera trzy narzędzia (rys. 12, 13), z których dwa są wyposażone w chirurgiczne końcówki robocze, a trzecie, umieszczone między narzędziami, jest wyposażone w kamerę endoskopową. Narzędzia są osadzone na wspólnej konstrukcji wsporczej, poruszają się po indywidualnych prowadnicach z listwami zębatymi, a napęd realizowany jest za pomocą kół zębatych i silników bezszczotkowych firmy Maxon.
Platforma narzędziowa może być zamocowana na wózku jezdnym, który przemieszcza się po szynie zamocowanej na końcu ramienia telemanipulatora chirurgicznego (rys. 13) [10].
Należy podkreślić, że manipulatory równoległe pozwalają w sposób bezpośredni realizować funkcje kinematyczne bardzo trudne lub niemożliwe do uzyskania innymi metodami a bardzo korzystne w konstrukcji manipulatorów medycznych, w tym chirurgicznych. Na przykład możliwa jest realizacja czystego obrotu narzędzia chirurgicznego będącego przedmiotem manipulacji, względem nieistniejącej fizycznie osi. Mechanizmy równoległowodowe pozwalają przesuwać (offsetować) osie obrotu wybranych członów i ustalać je w przestrzeni względem innych wskazanych członów składowych, np. względem członu podstawy albo członu wyjściowego. Zasada ta jest podstawą dla projektowania mechanizmów manipulatorów tzw. stało-osiowych o osi obrotu ulokowanej na zewnętrz obszaru zajmowanego przez elementy mechanizmu. Konsolidacja takiego mechanizmu z szeregowo połączonym obrotem względem osi leżącej w płaszczyźnie jego ruchu pozwala na uzyskanie mechanizmu sferycznego, w którym punkty członu wyjściowego poruszają się po współśrodkowych powierzchniach sferycznych. Mówimy wtedy o mechanizmach stało-punktowych (sferycznych, kulistych). Ruch wypadkowy mechanizmu stało-osiowego jest efektem złożenia ruchów składowych połączonych ze sobą w odpowiedni sposób mechanizmów równoległowodowych. Mechanizm sprzężonego płaskiego równoległowodu podwójnego o czystym obrocie względnym członów skrajnych pokazano na rys. 14.
Ważnym zastosowaniem manipulatora równoległego typu Delta jest zrobotyzowany mikroskop operacyjny SurgiScope [24] (rys. 15). Jest on stosowany podczas operacji oczu.
W konstrukcji tego urządzenia medycznego jako układ nośny zastosowano manipulator robotyczny typu Delta, który jest równoległowodem przestrzennym o trzech stopniach swobody. Zadaniem układu jest jak najprostsza obsługa precyzyjnego mikroskopu wraz z układem optycznym końcówki lasera operacyjnego. Jest to możliwe, gdyż tak skonstruowany układ manipulacyjny został w pełni odciążony od sił grawitacji i dodatkowo zmechanizowany oraz zautomatyzowany (zrobotyzowany). Zaletą urządzenia jest łatwa i bardzo intuicyjna obsługa, co jest ważnym czynnikiem w rozwiązaniach sprzętu do zastosowań w chirurgii małoinwazyjnej.
5. Podsumowanie
Robotyzacja w medycynie postępuje niezwykle dynamicznie i roboty-telemanipulatory stają się normalnym wyposażeniem szpitali do codziennego użytku. Maszyny te pełnią coraz bardziej odpowiedzialne funkcje, znacznie ułatwiając lekarzom pracę. Dodatkowo wiele innowacyjnych pomysłów, takich jak operacje wykonywane zdalnie lub automatyczne narzędzia chirurgiczne, skutecznie przeszły ze sfery science fiction i stały się realną alternatywą dla tradycyjnych metod operacyjnych. Jest więc kwestią czasu, kiedy rozwiązania te staną się powszechne w zastosowaniach medycznych. Zanim jednak do tego dojdzie, potencjalni pacjenci muszą nabyć zaufania do takich rozwiązań w rękach lekarzy, co pozwoli zapewnić odpowiednie fundusze na dalszy rozwój oraz badania w tej dziedzinie. Mimo że urodziliśmy się zbyt późno, aby być świadkami wynalezienia antybiotyków lub szczepionek, niewykluczone jest, że znaleźliśmy się na progu znacznie większej rewolucji medycznej – stopniowego zastępowania klasycznych metod chirurgii operacyjnej przez zrobotyzowane sale operacyjne obsługiwane przez lekarzy-operatorów pracujących pod nadzorem „wielkiego brata” –obserwacyjnych systemów nadzorczych z udziałem algorytmów sztucznej inteligencji.
Nota od autorów
Artykuł jest wynikiem opracowania zbiorczego dotyczącego zastosowania robotów równoległych w medycynie w ramach przedmiotu „Manipulatory równoległe” prowadzonego na Wydziale Mechanicznym Energetyki i Lotnictwa Politechniki Warszawskiej.
Rys. 14. Model techniczny manipulatora do chirurgii laparoskopowej z odsuniętą osią obrotu (rozwiązanie własne)
Fig. 14. Technical model of a manipulator for laparoscopic surgery with an offset axis of rotation (the own solution)
Krzysztof Mianowski, Filip Gruca, Jakub Grzonkowski, Jan Makulec
Bibliografia
1. Dupont P.E., Simaan N., Choset H., Rucker C., Continuum Robots for Medical Interventions, Proceedings of the IEEE, Vol. 110, No. 7, 2022, 847–870, DOI: 10.1109/JPROC.2022.3141338.
2. Orekhov A.L., Aloi V.A., Rucker D.C., Modeling parallel continuum robots with general intermediate constraints, 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 2017, 6142–6149, DOI: 10.1109/ICRA.2017.7989728.
3. Fine H.F., Wei W., Goldman R.E., Simaan N., Robot-assisted ophthalmic surgery, “Canadian Journal of Ophthalmology”, Vol. 45, No. 6, 2010, 581–584, DOI: 10.3129/i10-106.
4. Wei W., Goldman R.E., Fine H.F., Chang S., Simaan N., Performance Evaluation for Multi-arm Manipulation of Hollow Suspended Organs, “IEEE Transactions on Robotics”, Vol. 25, No. 1, 2009, 147–157, DOI: 10.1109/TRO.2008.2006865.
5. Yu H., Shen J.-H., Joos K.M., Simaan N., Design, calibration and preliminary testing of a robotic telemanipulator for OCT guided retinal surgery, 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 2013, 225–231, DOI: 10.1109/ICRA.2013.6630580.
6. Myers K.J., Arteriovenous Sheathotomy, “Optometry –Journal of the American Optometric Association”, Vol. 75, No. 1, 2004, DOI: 10.1016/S1529-1839(04)70005-6.
7. Laatikainen, L., Tarkkanen, A. & Koivuniemi, A. Vitrectomy, “International Ophthalmology”, Vol. 7, 1985, 215–222, DOI: 10.1007/BF00128368.
8. Cepolina F., Diyon A., Jakubiak K., Matyja A., Matyja M., Ostrowski A., Razzoli R.P., Wilson T., Chirurgia robotowa, Raport 2023, Modern Healthcare Institute, ISBN: 978-83968652-2-9.
9. Saeidi H., Opferman J.D., Wei S., Leonard S., Hsieh M.H., Kang J.U., Krieger A., Autonomous robotic laparoscopic surgery for intestinal anastomosis, “Science Robotics”, Vol. 7, No. 62, 2022, DOI: 10.1126/scirob otics.abj2908.
10. Nawrat Z., Mucha Ł., Lis K., Lehrich K., Rohr K., Kostka P., Robot chirurgiczny Robin Heart Tele – następca Robin Heart mc2, “Medical Robotics Reports”, Vol. 5, 2016, 27–33.
11. Sangeeta S., Ophthalmology in ancient time – the Sushruta Samhita, “Journal of Clinical Ophthalmology and Research”, Vol. 6, No. 3, 2018, 117–120, DOI: 10.4103/jcor.jcor_15_17.
12. Parasuraman R.R., Sheridan T.B., Wickens C.D., A model for types and levels of human interaction with automation, “IEEE Transactions on Systems, Man, and Cybernetics – Part A: Systems and Humans”, Vol. 30, No. 3, 2000, 286–297, DOI: 10.1109/3468.844354.
13. Mianowski K., Manipulatory i roboty rehabilitacyjne oraz medyczne, rozdział w „Biocybernetyka i Inżynieria Biomedyczna 2000”, t. 5 Biomechanika i Inżynieria Rehabilitacyjna pod red. M. Nałęcza, AOW EXIT, Warszawa 2004, 823–846.
14. Nawrat Z., Podsędkowski L., Mianowski K., Kostka P., Wróblewski P., Pruski R., Małota Z., Religa Z., RobIn Heart – polski robot kardiochirurgiczny – opis konstrukcji i sterowania, „Pomiary Automatyka Robotyka”, Nr 3, 2004.
15. Nawrat Z., Podsędkowski L., Mianowski K., Religa Z., RobIn Heart 2003 – present state of the Polish telemanipulator project for cardiac surgery assistance, “International Journal of Artificial Organs”, Vol. 26, No 7, 2003, 1115–1119, DOI: 10.1177/039139880302601209.
16. Mianowski K., On Some Aspects of Kinematic Properties of Parallel Manipulators Destined for Some New Applications, Proceedings of the Third International Conference RoMoCo ’02, 2002, 343–350, DOI: 10.1109/ROMOCO.2002.1177130.
17. Nawrat Z., Podsędkowski L., Mianowski K., Wróblewski P., Kostka P., Baczyński M., Małota Z., Granosik G., Jezierski E., Wróblewska A., Religa Z., RobIn Heart in 2002 –Actual State of Polish Cardio-Robot, Proceedings of the Third International Conference RoMoCo ’02, 2002, 33–38, DOI: 10.1109/ROMOCO.2002.1177080.
18. Mianowski K., Nawrat Z., Perspectives of medical robotics evolution in Poland in the beginning of twenty first century, Proceedings of International Conference MMAR ’02, Szczecin 2002, 933–940.
19. Podsędkowski L., Mianowski K., Wróblewski P., Nawrat Z., Kinematic aspects of selected manipulators for cardiac surgery, Proceedings of International Conference MMAR ’02, Szczecin 2002, 923–928.
20. Witkowski M., Mianowski K., Mechanical design of a new type of surgical manipulator, Proceedings of 5th International PhD Conference on Mechanical Engineering, 2007.
21. Barczak T., Mianowski K., Projekt zadajnika i manipulatora sferycznego przeznaczonego do chirurgii laparoskopowej, „Problemy Robotyki”, red. K. Tchoń i C. Zieliński, Oficyna Wydawnicza Politechniki Warszawskiej, 2012, t. 1, 25–34.
22. Mianowski K., Nowe rozwiązanie manipulatora równoległego typu POLMAN do wspomagania operacji chirurgicznych metodą laparoskopową, „Nowoczesne Narzędzia Informatyczne w Praktyce Chirurgicznej”, Wydawnictwo CEMED, Warszawa 2007, 97–104.
23. Witkowski M., Mianowski K., Projekt manipulatora nowego typu o wysokich właściwościach funkcjonalnych, Materiały Konferencji Doktorantów Politechniki Warszawskiej młodzi naukowcy wobec wyzwań współczesnej techniki, Warszawa 2007.
24. Bonev I., Delta Parallel Robot — the Story of Success, [www.parallemic.org/Reviews/Review002.html].
Inne źródła
25. Synektik, Chirurgia robotyczna da Vinci, [https://synektik.com.pl/produkty/chirurgia-robotyczna-da-vinci].
26. WP Tech, Operacje na odległość to dopiero początek. 5G zmieni ochronę zdrowia, [https://tech.wp.pl/operacje-na-odleglosc-to-dopieropoczatek-5g-zmieni-ochrone-zdrowia,6453058679244929a].
27. IRCAD, Obraz przedstawiający zabieg chirurgiczny na odległość, [www.ircad.fr/le-geste-chirurgical-a-traverse-latlantique].
28. Olszewski M., Robotyka studia inżynierskie V – PW Mechatronika, Robotyka_03_inż 2022.
29. Wikip edia contributors. Stewart platform, [https://en.wikipedia.org/w/index.php?title=Stewart_ platform&oldid=1230138190].
30. https://www.webofscience.com/wos/woscc/analyzeresults/30664974-8319-48b6-b33a-cc8fd6e01b07-b9d20b93) (dostęp na dzień 02.12.2023).
Parallel Robots for Precise Manipulation in Surgical Operations
Abstract: The article presents the state of the art solutions, regarding parallel robots used for precise manipulation in surgical procedures. The status of new, modern surgical techniques currently being developed, requiring high accuracy and efficiency of procedures ensuring very low invasiveness of the surgery, was briefly reported. Based on the available literature and Internet materials, a number of new, innovative solutions for the design of parallel manipulators that meet the criteria for conducting surgical operations were presented. Particular attention was paid to the interdisciplinarity of this field of research.
inż. Jakub Grzonkowski jakub.grzonkowski.stud@pw.edu.pl
ORCID: 0009-0007-8978-3847
Student Wydziału Mechanicznego Energetyki i Lotnictwa Politechniki Warszawskiej. Absolwent Wydziału Mechatroniki na specjalności „Inżynieria Fotoniczna” oraz Technikum Mechatronicznego nr 1 przy ul. Wiśniowej. Zainteresowany robotyką, szeroko pojętą automatyką oraz budową maszyn.
inż. Jan Makulec
jan.makulec.stud@pw.edu.pl
ORCID: 0009-0000-7278-9088
Student Wydziału Mechanicznego Energetyki i Lotnictwa. Absolwent Wydziału Inżynierii Produkcji (nowa nazwa Mechaniczny Technologiczny) na kierunku Automatyzacja i Robotyzacja Procesów Produkcyjnych. Zainteresowany automatyką, konstruowaniem i tworzeniem animacji.
inż. Filip Gruca
filip.gruca.stud@pw.edu.pl
ORCID: 0009-0006-0409-6064
Student Wydziału Mechanicznego Energetyki i Lotnictwa Politechniki Warszawskiej. Absolwent Wydziału Samochodów i Maszyn Roboczych. Zainteresowany elektroniką, programowaniem systemów wbudowanych, robotyką medyczną i systemami wizji maszynowej.
dr inż. Krzysztof Mianowski
krzysztof.mianowski@pw.edu.pl
ORCID: 0000-0002-0721-1172
Adiunkt w Zakładzie Teorii Maszyn i Robotów w Instytucie Techniki Lotniczej i Mechaniki Stosowanej na Wydziale Mechanicznym Energetyki i Lotnictwa w Politechnice Warszawskiej, którego jest absolwentem. Jego zainteresowania naukowe skupione są wokół tematyki konstrukcji mechanicznych robotów, w szczególności robotów medycznych i manipulatorów równoległych, jest także współtwórcą koncepcji robota chirurgicznego RobIn Heart opracowanego w latach 2001–2004 w Fundacji Rozwoju Kardiochirurgii w Zabrzu oraz głównym konstruktorem manipulatora robota chirurgicznego RobIn Heart v. 2.0.
Krzysztof Mianowski, Filip Gruca, Jakub Grzonkowski, Jan Makulec
Analiza niepewności lokalizacji odometrycznej
z
wykorzystaniem systemu przechwytywania ruchu i symulacji Monte Carlo
Sebastian Dudzik, Piotr Szeląg
Politechnika Częstochowska, Wydział Elektryczny, Al. Armii Krajowej 17, 42-200 Częstochowa
Streszczenie: W ostatnich latach obserwuje się bardzo dynamiczny rozwój technologii związanych z robotami mobilnymi, zwłaszcza robotami autonomicznymi. Jedną z podstawowych kompetencji robotów mobilnych jest nawigacja i związana z nią lokalizacja. W artykule przedstawiono wyniki badań mających na celu oszacowanie niepewności lokalizacji z wykorzystaniem modelu kinematyki napędu różnicowego. Wykonano badania eksperymentalne i symulacyjne robota mobilnego QBot 2e. W ramach badań eksperymentalnych przeprowadzono symulacje sprzętowe ruchu robota wzdłuż zadanych tras z jednoczesnym pomiarem prędkości. Wyniki pomiarów posłużyły do przeprowadzania symulacji Monte Carlo mającej na celu oszacowanie niepewności wyznaczania położenia robota. Na podstawie wyników badań stwierdzono, że niepewność lokalizacji rośnie wraz z czasem a gęstości prawdopodobieństwa zmiennych losowych reprezentujących położenie robota, mogą być z dużą dokładnością aproksymowane rozkładem normalnym.
Słowa kluczowe: lokalizacja robota mobilnego, metoda Monte Carlo, model kinematyki
1. Wprowadzenie
1.1. Autonomiczne roboty mobilne
Robotyka mobilna jest dziedziną, która rozwija się bardzo dynamicznie. Dzięki zastosowaniu złożonych systemów nawigacji i lokalizacji wspomaganych zaawansowanymi technologiami pozyskiwania informacji z otoczenia, roboty mobilne mogą wykonywać coraz bardziej złożone zadania. Na proces autonomicznego poruszania się robota składa się kilka czynników wzajemnie przenikających się. Podstawą jest sposób postrzegania otoczenia przez robota. Realizowany jest za pomocą czujników. Często stosowane są równocześnie różne rodzaje sensorów, przez co robot może dokładniej określić swoje położenie. Najczęściej stosowane są różnego rodzaju kamery (RGB, RGBD), lidary, czujniki ultradźwiękowe, GPS, żyroskopy, akcelerometry, enkodery i inne. Pozyskiwane dane zasilają algorytmy lokalizacji. Lokalizacja jest fundamentalnym elementem, umożliwiającym nawigację. Lokalizacja polega na ustaleniu pozy robota względem układu odniesienia, bazując
Autor korespondujący:
Sebastian Dudzik, sebastian.dudzik@pcz.pl
Artykuł recenzowany nadesłany 30.10.2024 r., przyjęty do druku 20.02.2025 r.
się na korzystanie z artykułu na warunkach
na dostępnych czujnikach i innych istotnych, dostępnych informacjach umożliwiających oszacowanie pozy [1–5]. Lokalizację można określić również jako wyznaczenie położenia robota w środowisku na podstawie znanej wcześniej mapy. Problem ten sprowadza się do określenia pozy robota, na którą składają się współrzędne oraz orientacja. Istnieje wiele sposobów lokalizacji, uzależnionych od dostępnego zestawu czujników czy warunków środowiskowych, w których znajduje się autonomiczny robot mobilny. Lokalizację robota autonomicznego można określić jako stan przekonania o tym, że znajduje się w określonym miejscu w konkretnej chwili czasu na podstawie znanej mapy [6].
Współczesne systemy przechwytywania ruchu (ang. motion capture) znajdują szerokie zastosowanie w przemyśle rozrywkowym, medycynie, sporcie i robotyce. Wykorzystują zaawansowane technologie, jak kamery optyczne, systemy inercyjne (IMU) oraz techniki hybrydowe, które integrują różne źródła danych w celu uzyskania precyzyjnych informacji o ruchu. Optyczne systemy motion capture, zapewniają najwyższą dokładność dzięki zastosowaniu markerów refleksyjnych i kamer o wysokiej rozdzielczości, ale są kosztowne i wymagają specjalistycznych warunków pracy [7]. Z kolei systemy inercyjne oferują mobilność i łatwość użycia w środowiskach dynamicznych (tj. położenie obiektów jest zmienne, zmieniają się warunki oświetleniowe). Nie mniej jednak należy zwrócić uwagę na fakt akumulacji błędów związanych z niepewnością czujników [8]. Szczególnie istotne, w przypadku robotyki mobilnej, wydają się rozwiązania hybrydowe, które łączą technologie optyczne i inercyjne [9]. W niniejszej pracy zastosowano system przechwytywania ruchu OptiTrack i oprogramowanie Motive.
Niepewność wyznaczania lokalizacji robota mobilnego za pomocą odometrii jest określana na podstawie analizy błędów systematycznych i losowych. W celu oszacowania błędów systematycznych, takich jak różnice średnic kół lub błędy enkoderów, przeprowadza się kalibracje eksperymentalne na trasach testowych. W trakcie kalibracji porównywane są rzeczywiste przemieszczenia z wynikami pomiarów odometrycznych. Dodatkowo oblicza się odpowiednie poprawki korekcyjne [10, 11].
Do oceny błędów losowych występujących w pomiarach odometrycznych zazwyczaj stosuje się metody statystyczne. Najczęściej polegają one na estymacji odchylenia standardowego przemieszczenia w różnych kierunkach (przód-tył i obrót). Stosowane są też bardziej zaawansowane podejścia, takie jak analiza kowariancji odometrii. Są to kluczowe narzędzia stosowane w algorytmach probabilistycznych, takich jak np. filtr Kalmana [12, 13]. Należy podkreślić, że analiza niepewności jest często prowadzona w zmiennych warunkach środowiskowych, w tym na nierównym podłożu lub przy zmiennym tarciu [14]. W niniejszym artykule zastosowano odmienne podejście. Do określenia niepewności lokalizacji zastosowano metodę propagacji rozkładów i symulację Monte Carlo. Analizę niepewności lokalizacji przeprowadzono zgodne z zaleceniami BIPM [25, 26], przy czym w celu redukcji błędów systematycznych wykonano kalibrację za pomocą systemu przechwytywania ruchu OptiTrack.
1.2. Lokalizacja robota mobilnego za pomocą modelu kinematyki napędu różnicowego Podstawowym wyzwaniem współczesnej robotyki, w szczególności w przypadku mobilnych robotów autonomicznych, jest projektowanie algorytmów sterowania i ich implementacja w postaci oprogramowania sterującego współpracującego z wybraną architekturą sprzętową [4, 15]. W tym celu, w pierwszej kolejności niezbędne jest uzyskanie spójnego opisu ruchu robota w przestrzeni roboczej. Opis ten stanowią równania kinematyki prostej i odwrotnej oparte na parametrach geometrycznych, bezpośrednio związanych z konstrukcją robota. W przypadku robotów mobilnych, model kinematyki nakłada ograniczenia (więzy), które wpływają na możliwe trajektorie. Istnieje wiele modeli kinematyki robotów mobilnych, w tym modele dla pojazdów czterokołowych i trójkołowych, a także dwukołowego napędu różnicowego [16]. W odniesieniu do równań kinematycznych wyróżniamy modele kinematyki prostej pozwalające na lokalizację robota oraz modele kinematyki odwrotnej stosowane do sterowania. W pracy zaprezentowano wyniki badań niepewności metody lokalizacji dwukołowego robota mobilnego Quanser QBot 2e (rys. 1) z wykorzystaniem
modelu kinematyki. Z tego powodu dalej opisano model kinematyki prostej napędu różnicowego.
Na rys. 1 przyjęto następujące oznaczenia: d [m] – odległość między kołami platformy jezdnej; vL, vR [m/s] – prędkości liniowe odpowiednio lewego i prawego koła; vC [m/s] – prędkość liniowa platformy jezdnej (robota); OxGyG – globalny układ odniesienia; OxLyL – lokalny układ odniesienia związany z robotem; θ [rad] – kąt między globalnym a lokalnym układem odniesienia; P c – chwilowy środek krzywizny toru jazdy robota; RC – chwilowy promień krzywizny toru jazdy robota.
Na podstawie modelu kinematyki prostej możliwe jest wyznaczenie prędkości liniowej vC i kątowej C ωθ = platformy dla zadanych prędkości liniowych vL i vR, odpowiednio lewego i prawego koła z wykorzystaniem zależności:
Równania (1) obowiązują przy założeniu wykorzystania lokalnego układu odniesienia związanego z robotem. W praktyce dla celów nawigacji i mapowania, niezbędne jest określenie położenia i prędkości robota w odniesieniu do globalnego układu odniesienia OxGyG. W tym celu wprowadza się macierz rotacji o postaci:
Niech wektor stanu ma postać:
Zmianę stanu S względem globalnego układu odniesienia można opisać jako:
Równanie (4) stanowi model kinematyki prostej napędu różnicowego [4].
Jedną z podstawowych metod lokalizacji robotów mobilnych jest metoda odometryczna [19]. Polega ona na wykorzystaniu pomiarów z enkoderów i żyroskopu w celu określenia położenia robota [4, 16, 17]. Procedura lokalizacji przebiega w następujących krokach:
1. Estymacja prędkości liniowej kół vR(x), vL(x) z wykorzystaniem enkoderów i/lub żyroskopu.
2. Zastosowanie równania kinematyki (4) w celu estymacji prędkości liniowej vC i kątowej ωC platformy jezdnej.
3. Estymacja bieżącej pozy robota ()[(),(),()]T txtytt ξθ = przez całkowanie w czasie równania (4) od pozy początkowej T 0 ()[(0),(0),(0)] txy ξθ = zgodnie z zależnością:
W wyniku zastosowania opisanej procedury uzyskuje się estymatę bieżącej pozycji w globalnym układzie odniesienia. W celu oszacowania niepewności lokalizacji przyjęto opisany dalej model lokalizacji oparty na dyskretyzacji równania (5), sprowadzający się do sumowania kolejnych przemieszczeń wzdłuż trajektorii przebytej przez robota [4, 18, 19]. Zakładając że poza jest uaktualniana w dyskretnych chwilach czasu z okresem próbkowania Δt, przemieszczenia i zmiana orientacji w czasie Δt mogą być określone jako następujące przyrosty:
Ostatecznie zależność (7), stanowiąca podstawowe równanie aktualizacji pozycji stosowane w metodzie odometrii, umożliwia wyznaczenie pozy robota w każdej dyskretnej chwili czasowej, a co za tym idzie pozwala na jego lokalizację w przestrzeni roboczej. Jednym z celów badań prezentowanych w pracy było określenie niepewności lokalizacji z wykorzystaniem estymatora (7). Do oszacowania niepewności estymatora zastosowano metodę propagacji rozkładów i symulację Monte Carlo opisaną w dalszej części artykułu [25, 26].
2. Metodyka badań
2.1. Badania eksperymentalne
gdzie Δs r, Δsl to odpowiednio odległość pokonana przez prawe i lewe koło w czasie Δt
Stąd estymator pozy () tt ξ +∆ w chwili t + Δt może być wyznaczony za pomocą równania [18, 19]:
Celem pracy było oszacowanie niepewności lokalizacji z wykorzystaniem modelu kinematyki prostej napędu różnicowego robota mobilnego. Aby określić niepewność wyznaczania położenia robota zastosowano metodę propagacji rozkładów i symulację Monte Carlo. Jako wielkości wejściowe modelu przyjęto prędkości liniowe prawego i lewego koła, zgodnie z równaniem (4). Z uwagi na konieczność oszacowania niepewności standardowej pomiaru tych wielkości, niezbędne było przeprowadzenie eksperymentów z użyciem rzeczywistego robota poruszającego się po zadanych z góry trajektoriach, a w szczególności rejestracja wartości prędkości liniowych kół i aktualnej pozy robota. Badania zostały przeprowadzone w Laboratorium Inteligentnych Robotów Mobilnych, które wchodzi w skład struktury Wydziału Elektrycznego Politechniki Częstochowskiej [20]. Eksperymentom poddano mobilny robot kołowy QBot 2e, w którym zastosowano napęd różnicowy opisany modelem (4). Robot poruszał się w zabezpieczonej przestrzeni, która monitorowana jest za pomocą ośmiu kamer przez optyczny system przechwytywania ruchu OptiTrack, nadzorowany przez aplikację Motive 2.0 [21, 22]. Zastosowanie systemu OptiTrack pozwoliło na ciągłe pozyskiwanie danych o lokalizacji robota, którą następnie porównywano z lokalizacją wyznaczoną na podstawie pomiarów odometrycznych [23]. Sterowanie ruchem robota oraz pozyskiwanie danych pomiarowych z czujników robota realizowano za pomocą aplikacji stworzonej w środowisku obliczeniowym MATLAB/Simulink 2019b. Aplikacje te wchodzą w skład naziemnej stacji kontroli. Całość zastosowanego w badaniach sprzętu i oprogramowania jest elementem profesjonalnego rozwiązania Autonomous Vehicles Research Studio [24].
Wykorzystując aplikację Motive 2.0 utworzono wirtualny model ciała sztywnego. Zastosowano w tym celu specjalne markery zamontowane na robocie mobilnym. Dzięki zamodelowaniu ciała sztywnego możliwe było śledzenie ruchu robota z niepewnością 0,5 mm.
Aplikacja Motive 2.0 pozwala na przekazywanie w czasie rzeczywistym danych o pozie ciała sztywnego do środowiska MATLAB/Simulink. Wartości te mogą być następnie wykorzystane do wyznaczenia rzeczywistej trajektorii robota. W badaniach opisywanych w pracy niezbędne było wyznaczanie bieżącej pozy z użyciem systemu OptiTrack. W tym celu zasto-
Rys. 3. Diagramu programu do sterowania ruchem robota i lokalizacji z wykorzystaniem czujników i modelu kinematyki prostej Fig. 3. Simulink diagram used for robot motion control and localization using sensors and a simple kinematics model
sowano schemat symulacyjny aplikacji stworzonej w środowisku MATLAB/Simulink przedstawiony na rys. 2. Oprócz pozyskiwania danych o lokalizacji niezbędna była również kontrola ruchu robota, tak aby poruszał się po zadanej trajektorii. W tym celu, w programie Simulink, stworzono aplikację, której zadaniem było sterowanie robotem dla zadanych parametrów ruchu, tj. prędkości liniowej prawego i lewego koła. Jednocześnie rejestrowano w czasie rzeczywistym dane z enkoderów i żyroskopu. Poza rejestracją danych, w aplikacja przeliczano wartości z enkoderów na prędkości liniowe kół. Ostatecznie wartości prędkości i odczyty z żyroskopu stanowiły dane wejściowe dla modelu kinematyki prostej opisanej zależnością (4). Położenie robota uzyskano przez całkowanie prędkości liniowych zgodnie z zależnością (5). Na rys. 3 przedstawiono schemat diagramu opisanej aplikacji.
Badania eksperymentalne przeprowadzono w następujących etapach:
1. Kalibracja systemu OptiTrack.
2. Ustalenie zadanych trajektorii.
3. Symulacja sprzętowa (ang. hardware-in-the-loop) ruchu robota dla zadanych trajektorii w przestrzeni roboczej. 4. Zapis danych z systemu OptiTrack i czujników robota.
Podstawowym warunkiem prawidłowego przeprowadzenia pomiarów z wykorzystaniem systemu OptiTrack jest wykonanie ściśle określonych czynności kalibracyjnych. W związku z tym każdorazowo, przed przystąpieniem do badań przeprowadzana była kalibracja systemu mająca na celu uzyskanie jak najwyższej dokładności określania położenia robota w przestrzeni roboczej. Przygotowane wcześniej schematy posłużyły do zaprogramowania trajektorii. W trakcie badań zbiór możliwych trajektorii został ograniczony do poruszania się robota po linii prostej (w przypadku jednakowych zadanych prędkości liniowych) lub po okręgu o różnym promieniu, zależnym od różnicy między zadanymi wartościami prędkości. W ramach eksperymentów
Tab. 1. Zadane wartości prędkości liniowych prawego i lewego koła oraz całkowite czasy przejazdu dla poszczególnych tras
Tab. 1. Set values of linear speeds of the right and left wheels and values of travel times for individual path
Trasa 1Trasa 2Trasa 3
vR [m/s] 0,3 0,3 0,2
vL [m/s] 0,2 0,6 0,2
ttot [s] 13,00 5,00 14,00
wykonano serię przejazdów o różnych wartościach zadanych prędkości kół. Wartości prędkości liniowych dla każdej z tras zestawiono w tabeli 1. Dodatkowo przedstawiono całkowite czasy przejazdów każdą z tras.
Kolejnym etapem była symulacja sprzętowa ruchu robota dla ustalonych z góry trajektorii. W trakcie symulacji pozyskiwano dane pomiarowe z systemu OptiTrack z wykorzystaniem schematu przedstawionego na rys. 2 oraz dane niezbędne do lokalizacji robota przy użyciu diagramu z rys. 3. Ostatecznie w ramach symulacji zostały zgromadzone dane pomiarowe z rzeczywistych przejazdów robota kołowego. Dane pozyskiwano z dwóch źródeł, tj. systemu OptiTrack oraz czujników robota.
W przypadku danych pochodzących z systemu OptiTrack, pomiary rejestrowane były z okresem próbkowania równym 0,001 s, natomiast dla pomiarów z czujników przyjęto okres próbkowania równy 0,01 s. W celu synchronizacji pomiarów ustalono jeden okres próbkowania wynoszący 0,01 s, wybierając co dziesiątą próbkę z systemu OptiTrack.
2.2. Badania symulacyjne
Badania symulacyjne przeprowadzono w następujących krokach:
1. Wykonanie symulacji Monte Carlo w celu wyznaczenia rozkładów zmiennych losowych reprezentujących wielkości wejściowe modelu (4), tj. prędkości liniowych prawego i lewego koła.
2. Symulacja numeryczna ruchu robota dla zadanych trajektorii – równanie (7).
3. Kalibracja wyników symulacji z wykorzystaniem systemu OptiTrack, w celu skorygowania oddziaływań systematycznych.
4. Wyznaczenie rozkładów prawdopodobieństwa położeń robota dla każdej chwili czasowej z wykorzystaniem modelu (4) i metody propagacji rozkładów.
5. Oszacowanie parametrów wynikowego rozkładu prawdopodobieństwa – wartości oczekiwanej i złożonej niepewności standardowej.
W celu wygenerowania rozkładów zmiennych losowych reprezentujących wielkości wejściowe modelu (4) niezbędne było wyznaczenie wartości oczekiwanej i odchylenia standardowego prędkości liniowej prawego i lewego koła zarejestrowanych podczas przejazdu robota, w trakcie badań eksperymentalnych. W dalszej kolejności wyznaczono parametry rozkładu jednostajnego odpowiadające wartościom odchylenia standardowego i wartości oczekiwanej wyznaczonych dla prędkości liniowych prawego i lewego koła zgodnie z zależnością:
(8)
gdzie: a, b – parametry rozkładu jednostajnego natomiast Vµ i Vσ stanowią odpowiednio wartość oczekiwaną i odchylenie standardowe prędkości liniowej, opisane następującymi wzorami:
tych prędkości. Jeżeli do wyznaczania orientacji robota zostaną użyte czujniki inercyjne, takie jak żyroskop, niezbędne będzie uzupełnienie budżetu niepewności o niepewność standardową związaną z pomiarem żyroskopowym.
Dane lokalizacyjne z systemu OptiTrack umożliwiły kalibrację niezbędną do skorygowania wpływu oddziaływań systematycznych. Kalibrację przeprowadzono w następujących krokach: 1. Odczyt współrzędnych (x0, y0) punktu startowego z systemu OptiTrack dla każdej z tras.
2. Korekta współrzędnych punktów każdej z tras wygenerowanych na podstawie zależności (7) z uwzględnieniem przesunięcia wprowadzanego przez współrzędne (x0, y0).
gdzie: vi(t) [m/s] – wartość prędkości liniowej koła w i-tej chwili, N – całkowita liczba zmierzonych wartości prędkości liniowej koła.
Na podstawie parametrów obliczonych z równań (8, 9) wygenerowano po 10 000 próbek wartości reprezentujących zmienne losowe o rozkładzie jednostajnym, reprezentujące prędkości linowe prawego i lewego koła. W kolejnym kroku przeprowadzono symulację ruchu robota na podstawie zależności (5–7). W trakcie symulacji obliczano wartości prędkości liniowej i obrotowej platformy jezdnej robota. Celem symulacji było wyznaczenie zestawu wyjściowych zmiennych losowych modelu kinematyki (4), reprezentujących współrzędne x i y położenia oraz orientację robota. Należy podkreślić, że w badaniach symulacyjnych zastosowano uproszczony model kinematyki bazujący jedynie na prędkościach liniowych prawego i lewego koła. W takim modelu bieżąca orientacja robota jest wyznaczana jedynie na podstawie
Rys. 4. Przebieg trasy 1 robota zarejestrowany przez system OptiTrack Fig. 4. Path No. 1 recorded by the OptiTrack system
Rys. 7. Przebiegi prędkości liniowych prawego i lewego koła robota dla trasy 1
Fig. 7. Linear velocity curves of the right and left robot wheel for path No. 1
Ostatnim etapem badań symulacyjnych było wyznaczenie parametrów wynikowego rozkładu prawdopodobieństwa, tj. wartości oczekiwanej i odchylenia standardowego. W tym celu przeprowadzono aproksymację rozkładów zmiennych losowych reprezentujących współrzędne x i y położenia, aproksymacji uzyskanych w trakcie symulacji modelu kinematyki. Do aproksymacji zastosowano rozkład normalny.
3. Wyniki badań
3.1. Wyniki badań eksperymentalnych
Wyniki badań eksperymentalnych przedstawiono na rys. 4–9. Na rys. 4–6 zaprezentowano przebiegi trajektorii robota zarejestrowane przez system OptiTrack, odpowiednio dla tras 1, 2 i 3. Dodatkowo na rys. 7–9 przedstawiono przebiegi czasowe wartości prędkości liniowych prawego i lewego koła robota w trakcie pokonywania tras 1, 2 i 3. Na wykresach 7–9 są przebiegi prędkości zarejestrowane w stanie ustalonym, tj. po zakończeniu procesu przyspieszania.
Rys. 5. Przebieg trasy 2 robota zarejestrowany przez system OptiTrack
Fig. 5. Path No. 2 recorded by the OptiTrack system
Rys. 8. Przebiegi prędkości liniowych prawego i lewego koła robota dla trasy 2
Fig. 8. Linear velocity curves of the right and left robot wheel for path No. 2
Rys. 6. Przebieg trasy 3 robota zarejestrowany przez system OptiTrack
Fig. 6. Path No. 3 recorded by the OptiTrack system
Rys. 9. Przebiegi prędkości liniowych prawego i lewego koła robota dla trasy 3
Fig. 9. Linear velocity curves of the right and left robot wheel for path No. 3
3.2. Wyniki badań symulacyjnych
W dalszej części pracy przedstawiono wyniki badań symulacyjnych. Przykładowe wyniki kalibracji uzyskane dla trasy 1 zaprezentowano na rys. 10 (trajektoria przed kalibracją) oraz 11 (trajektoria po kalibracji). Dodatkowo wartości położenia robota pozyskiwane z systemu OptiTrack w trakcie pokonywania każdej z tras, oznaczone jako POSR, zestawiono w tab. 2–4. Jak widać z rys. 10 i 11, położenie początkowe robota przed kalibracją różni się od położenia wskazywanego przez system OptiTrack. Dzięki kalibracji wartość położenia początkowego ustalono jako równą położeniu odczytanemu z systemu OptiTrack. Dodatkowo z rysunków widać znaczące różnice
Rys. 10. Przebieg trasy 1 robota przed przeprowadzeniem kalibracji
Fig. 10. Path no. 1 before calibration
Rys. 11. Przebieg trasy 1 robota po wykonaniu kalibracji
Fig. 11. Path no. 1 after calibration
Tab. 2. Parametry rozkładu prawdopodobieństwa zmiennych losowych wyjściowych oraz położenie wyznaczone przez system OptiTrack w wybranych chwilach (Trasa 1)
Tab. 2. The parameters of the probability distribution of output random variables and position measured by OptiTrack at selected time instants (Path No. 1)
Tab. 3. Parametry rozkładu prawdopodobieństwa zmiennych losowych wyjściowych oraz położenie wyznaczone przez system OptiTrack w wybranych chwilach (Trasa 2)
Tab. 3. The parameters of the probability distribution
(Path No. 2)
Tab. 4. Parametry rozkładu prawdopodobieństwa zmiennych losowych wyjściowych oraz położenie wyznaczone przez system OptiTrack w wybranych chwilach (Trasa 3)
Tab. 4. The parameters of the probability distribution of output random variables and position measured by OptiTrack at
w przebiegach zadanych trajektorii odczytanych z systemu OptiTrack i wyznaczonych za pomocą równania (7).
Estymowane parametry wartości oczekiwanej µ i odchylenia standardowego σ rozkładu zmiennych losowych wyjściowych, reprezentujących współrzędne x i y robota w wybranych chwilach oraz położenie wyznaczone z wykorzystaniem systemu OptiTrack przedstawiono w tabelach 2–4. Na wykresach 12–20 zaprezentowano też odpowiednio: rozrzuty wartości położenia robota (rys. 12, 15, 18) oraz dopasowanie funkcji gęstości prawdopodobieństwa do
Rys. 12. Rozrzut wartości położenia robota w chwili t = 9,5 s dla trasy 1
Fig. 12. The dispersion of the robot position values at time t = 9.5 s for Path No. 1
Rys. 15. Rozrzut wartości położenia robota w chwili czasowej t = 3,5 s dla trasy 2
Fig. 15. The dispersion of the robot position values at time t = 3.5 s for Path No. 2
Rys. 18. Rozrzut wartości położenia robota w chwili czasowej t = 9,5 s dla trasy 3
Fig. 18. The dispersion of the robot position values at time t = 9.5 s for Path No. 3
rozkładu położenia robota wzdłuż osi x (rys. 13, 15, 19) i y (rys. 14, 17, 20) dla tras 1, 2, 3 w wybranych chwilach czasowych. Analizując wyniki zebrane w tab. 2–4, oraz przedstawione na rys. 12–20, stwierdzono, że występują różnice między wartościami oczekiwanymi POSR odczytanymi z systemu OptiTrack a wartościami uzyskanymi z równania (7). Dodatkowo zaobserwowano, że wartość odchyleń standardowych rozkładów zmiennych losowych reprezentujących współrzędne x i y rośnie wraz z czasem.
Rys. 13. Dopasowanie funkcji gęstości prawdopodobieństwa rozkładu położenia robota wzdłuż osi x, w chwili t = 9,5 s dla trasy 1
Fig. 13. Fitting the probability density function of the robot position distribution along the x-axis at time t = 9.5 s for Path No. 1
Rys. 16. Dopasowanie funkcji gęstości prawdopodobieństwa rozkładu położenia robota wzdłuż osi x, w chwili t = 3,5 s dla trasy 2
Fig. 16. Fitting the probability density function of the robot position distribution along the x-axis at time t = 3.5 s for Path No. 2
Rys. 19. Dopasowanie funkcji gęstości prawdopodobieństwa do rozkładu położenia robota wzdłuż osi x, w chwili t = 9,5 s dla trasy 3
Fig. 19. Fitting the probability density function of the robot position distribution along the x-axis at time t = 9.5 s for Path No. 2
Rys. 14. Dopasowanie funkcji gęstości prawdopodobieństwa rozkładu położenia robota wzdłuż osi y, w chwili t = 9,5 s dla trasy 1
Fig. 14. Fitting the probability density function of the robot position distribution along the y-axis at time t = 9.5 s for Path No. 1
Rys. 17. Dopasowanie funkcji gęstości prawdopodobieństwa rozkładu położenia robota wzdłuż osi y, w chwili t = 3,5 s dla trasy 2
Fig. 17. Fitting the probability density function of the robot position distribution along the y-axis at time t = 3.5 s for Path No. 2
Rys. 20. Dopasowanie funkcji gęstości prawdopodobieństwa do rozkładu położenia robota wzdłuż osi y, w chwili t = 9,5 s dla trasy 3
Fig. 20. Fitting the probability density function of the robot position distribution along the 8-axis at time t = 9.5 s for Path No. 2
4. Wnioski
W pracy przeprowadzono ocenę niepewności lokalizacji robota mobilnego z wykorzystaniem modelu kinematyki i symulacji Monte Carlo. Badania przeprowadzono dla trzech trajektorii robota. Niepewności standardowe zmiennych wejściowych modelu (tj. prędkości liniowych prawego i lewego koła) wyznaczono z wykorzystaniem enkoderów zainstalowanych w kołach. Wyznaczono rozkłady zmiennych losowych wyjściowych reprezentujących współrzędne x i y położenia robota w przestrzeni roboczej.
W wyniku przeprowadzonych badań sformułowano następujące wnioski:
System OptiTrack wraz z oprogramowaniem Motive stanowi doskonałe narzędzie do lokalizacji robotów mobilnych. Dzięki zastosowaniu systemu OptiTrack w badaniach eksperymentalnych możliwa była redukcja wpływu oddziaływań systematycznych. W przypadku badań prowadzonych w niniejszej pracy system OptiTrack pozwolił na skorygowanie początkowego położenia robota w przestrzeni roboczej.
W toku badań zaobserwowano znaczące różnice między przebiegami trajektorii, zarejestrowanymi przez system OptiTrack (rys. 10, 11) a przebiegami wartości oczekiwanej położeń uzyskanymi w trakcie symulacji. Stwierdzono, że różnice mogły być wynikiem m.in. uproszczonej struktury modelu kinematyki, nieuwzględniającej pomiarów żyroskopowych (orientacja robota obliczana tylko na podstawie pomiarów odometrycznych). W przyszłych badaniach niezbędne jest przeprowadzenie analizy z uwzględnieniem niepewności pomiarów żyroskopowych.
Do datkowo stwierdzono, że przesunięcie między trajektoriami może również wynikać z nieuwzględnienia dynamiki robota w początkowej fazie ruchu, tj. na etapie przyspieszania. Równania modelu kinematyki robota wyznaczają kolejne położenia przy założeniu, że wartości początkowe prędkości liniowych kół są równe wartościom zadanym.
W rzeczywistości, z uwagi na bezwładność, wartości te są równe zadanym dopiero po pewnym czasie. Z tego względu celowe jest przeprowadzenie symulacji uwzględniających uzupełnienie modelu kinematyki o równania dynamiki. W symulacjach rozkład zmiennych losowych wyjściowych, tj. rozkład zmiennych reprezentujących współrzędne x i y położenia robota w przestrzeni roboczej aproksymowano za pomocą funkcji gęstości prawdopodobieństwa rozkładu normalnego. Uzyskana duża dokładność aproksymacji była wynikiem agregowania zmiennych losowych o rozkładzie jednostajnym, reprezentujących odcinki drogi pokonane przez robota w kolejnych chwilach. Ostatecznie rozkład zmiennych losowych reprezentujących zmienne wyjściowe wraz z upływem czasu dążył do rozkładu normalnego. Tak sformułowany wniosek jest zgodny z centralnym twierdzeniem granicznym.
Bibliografia
1. Klancar G., Zdesar A., Blazic S., Skrjanc I., Eds., Wheeled Mobile Robotics, „Butterworth-Heinemann”, 2017.
2. Rostkowska M., Topolski M., Skrzypczyński P., A modular mobile robot for multi-robot applications, „Pomiary Automatyka Robotyka”, Vol. 17, No. 2, 2013, 288–293.
3. Maciel G.M., Pinto M.F., Júnior I.C.D.S., Marcato A.L.M., Methodology for autonomous crossing narrow passages applied on assistive mobile robots, „Journal of Control, Automation and Electrical Systems”, Vol. 30, No. 6, 2019, 943–953, DOI: 10.1007/s40313-019-00499-2.
4. Siegwart R., Nourbakhsh Illah R., Scaramuzza D., Introduction to Autonomous Mobile Robots, 2nd ed., The MIT Press Cambridge, Massachusetts, 2011.
5. Kleinberg J., The localization problem for mobile robots, Proceedings 35th Annual Symposium on Foundations of Computer Science, 1994, 521–531, DOI: 10.1109/SFCS.1994.365739.
6. Wiech J., Podążanie za zadaną trajektorią grupy robotów kołowych z użyciem wirtualnych połączeń sprężysto-tłumiących, „Pomiary Automatyka Robotyka”, Vol. 27, Nr 3, 2023, 107–117, DOI: 10.14313/PAR_249/107.
7. Menolotto M., Komaris D.-S., Tedesco S., O’Flynn B., Walsh M., Motion Capture Technology in Industrial Applications: A Systematic Review, „Sensors”, Vol. 20, No. 19, 2020, DOI: 10.3390/s20195687.
8. Palacin J., Rubies E., Clotet E., Systematic Odometry Error Evaluation and Correction in a Human-Sized Three-Wheeled Omnidirectional Mobile Robot Using Flower-Shaped Calibration Trajectories, „Applied Sciences”, Vol. 12, No. 5, 2022, DOI: 10.3390/app12052606.
9. Almassri A.M.M., Shirasawa N., Purev A., Uehara K., Oshiumi W., Mishima S., Wagatsuma H., Artificial Neural Network Approach to Guarantee the Positioning Accuracy of Moving Robots by Using the Integration of IMU/ UWB with Motion Capture System Data Fusion, „Sensors”, Vol. 22, No. 15, 2022, DOI: 10.3390/s22155737.
10. Borenstein J., Everett H.R., Feng L., Navigating mobile robots: Systems and techniques, A K Peters Ltd, 1996.
11. Thrun S., Burgard W., Fox D. Probabilistic Robotics, MIT Press, 2005.
12. Scaramuzza D., Siegwart R., Appearance-guided monocular omnidirectional visual odometry for outdoor ground vehicles, „IEEE Transactions on Robotics”, Vol. 24, No. 5, 2008, 1015–1026, DOI: 10.1109/TRO.2008.2004490.
13. Censi A., An accurate closed-form estimate of ICP’s covariance, Proceedings 2007 IEEE International Conference on Robotics and Automation, 2007, 3167–3172, DOI: 10.1109/ROBOT.2007.363961.
14. Fox D., Burgard W., Thrun S., Markov localization for mobile robots in dynamic environments, „Journal of Artificial Intelligence Research”, Vol. 11, 1999, 391–427, DOI: 10.1613/jair.616.
15. Pająk G., Pająk I., Trajectory Planning for Mobile Manipulators with Control Constraints, „Pomiary Automatyka Robotyka”, R. 27, Nr 2, 2023, 21–30, DOI: 10.14313/PAR_248/21.
16. Sp ong M., Hutchinson S., Vidyasagar M., Robot Modeling and Control, John Wiley & Sons, 2005.
17. Nemec D., Šimák V., Janota A., Hruboš M., Bubeníková E., Precise localization of the mobile wheeled robot using sensor fusion of odometry, visual artificial landmarks and inertial sensors, „Robotics and Autonomous Systems”, Vol. 112, 2019, 168–177, DOI: 10.1016/j.robot.2018.11.019.
18. Chenavier F., Crowley J.L., Position estimation for a mobile robot using vision and odometry, Proceedings of the IEEE International Conference on Robotics and Automation, 1992, DOI: 10.1109/ROBOT.1992.220052.
19. Chong K.S., Kleeman L., Accurate odometry and error modelling for a mobile robot, Proceedings of the IEEE International Conference on Robotics and Automation, 1997, DOI: 10.1109/ROBOT.1997.606708.
20. Dudzik S., Szeląg P., Baran J., Research Studio for Testing Control Algorithms of Mobile Robots, „International Journal of Electronics and Telecommunications”, Vol. 66, No 4, 2020, 759–768, DOI: 10.24425-ijet.2020.134038.
21. Žla jpah L., Petrič T., Kinematic calibration for collaborative robots on a mobile platform using motion capture sys-
tem, „Robotics and Computer-Integrated Manufacturing”, Vol. 79, 2023, DOI: 10.1016/j.rcim.2022.102446.
22. Al-Kamil S., Szabolcsi R., Optimizing path planning in mobile robot systems using motion capture technology, „Results in Engineering”, Vol. 22, 102043, ISSN 2590-1230, 2024, DOI: 10.1016/j.rineng.2024.102043.
23. De Giorgi C., De Palma D., Parlangeli G., Online Odometry Calibration for Differential Drive Mobile Robots in Low Traction Conditions with Slippage, „Robotics”, Vol. 13, No. 1, 2024, DOI: 10.3390/robotics13010007.
24. Rapalski A., Dudzik S., Energy Consumption Analysis of the Selected Navigation Algorithms for Wheeled Mobile Robots, „Energies”, Vol. 16, No. 3, 2023, DOI: 10.3390/en16031532.
Inne źródła
25. BIPM, IEC, IFCC, ILAC, ISO, IUPAC, IUPAP, and OIML. Evaluation of measurement data — Guide to the expression of uncertainty in measurement. Joint Committee for Guides in Metrology, JCGM 100:2008.
26. BIPM, IEC, IFCC, ILAC, ISO, IUPAC, IUPAP, and OIML. Evaluation of measurement data — Supplement 1 to the “Guide to the expression of uncertainty in measurement” — Propagation of distributions using a Monte Carlo method. Joint Committee for Guides in Metrology, JCGM 101:2008.
Analysis of Odometric Localization Uncertainty
Using a Motion Capture System and Monte Carlo Simulation
Abstract: In recent years, there has been a very dynamic development of technologies related to mobile robots, especially autonomous robots. One of the basic competences of mobile robots is navigation and related localization. The article presents the results of research aimed at estimating the accuracy of localization using the differential drive kinematics model. Experimental and simulation studies of the QBot 2e mobile robot were performed. As part of the experimental studies, hardware-in-the-loop simulations of the robot’s movement along the given paths were carried out with simultaneous speed measurements. The measurement results were used to conduct Monte Carlo simulations aimed at estimating the uncertainty of determining the robot’s position. Based on the research results, it was found that the uncertainty of localization increases with time and the probability densities of random variables representing the robot’s position can be approximated with high accuracy by the Gaussian distribution.
Keywords: mobile robot localization, Monte Carlo method, kinematic model
dr hab. inż. Sebastian Dudzik, prof. PCz
sebastian.dudzik@pcz.pl
ORCID: 0000-0002-9559-7115
Specjalizuje się w tematyce termografii w podczerwieni ze szczególnym uwzględnieniem termografii ilościowej oraz badań nieniszczących z wykorzystaniem aktywnej termografii dynamicznej. Jest autorem i współautorem monografii w języku polskim i angielskim oraz rozdziałów w monografiach, a także kilkudziesięciu prac z zakresu dokładności pomiarów w termografii w podczerwieni oraz algorytmów sterowania i przetwarzania danych pomiarowych w systemach robotyki mobilnej. Jest też twórcą oprogramowania do analizy wrażliwości modeli pomiarowych stosowanych w nowoczesnych kamerach termowizyjnych oraz oprogramowania do przetwarzania danych radiometrycznych w paśmie podczerwieni. Jest współautorem czterech patentów zarejestrowanych w Urzędzie Patentowym RP.
dr inż. Piotr Szeląg
piotr.szelag@pcz.pl
ORCID: 0000-0002-9528-3263
Zajmuje się prognozowaniem mocy i energii elektrycznej generowanej przez odnawialne źródła energii oraz integracją tych źródeł w ramach elektrowni wirtualnych. Prowadzi badania naukowe związane z algorytmami lokalizacji robotów mobilnych. W swoich badaniach wykorzystuje narzędzia umożliwiające fuzję sygnałów i zastosowanie jej w algorytmach sterowania robotami mobilnymi.
Sebastian Dudzik, Piotr Szeląg
Optymalizacja kolejności pakowania towarów
na
paletach
Krzysztof Pieńkosz
Politechnika Warszawska, Instytut Automatyki i Informatyki Stosowanej, ul. Nowowiejska 15/19, 00-665 Warszawa
Streszczenie: W artykule analizowane są możliwości wykorzystania robota do pakowania towarów na paletach. Jeżeli towary mają zróżnicowane wymiary, to istotna jest kolejność ich ładowania. Po pierwsze, żeby robot mógł umieścić towar na częściowo załadowanej palecie, musi mieć swobodny dostęp do miejsca jego ułożenia, tzn. miejsce to nie może być zasłonięte. Po drugie, sposób wyboru kolejnych towarów do pakowania może mieć wpływ na czas zapakowania palety, gdyż dostarczenie poszczególnych towarów z magazynu może być mniej lub bardziej czasochłonne. W artykule przedstawiona jest metoda wyznaczania kolejności umieszczania towarów na palecie przez robota, biorąca pod uwagę oba te względy. W zaproponowanym algorytmie wykorzystuje się grafowy model reprezentujący sposób zapakowania palety.
1. Wprowadzenie
Słowa kluczowe: załadunek palet, kolejność pakowania, pakowanie robotowe, zagregowane grafy poprzedzania, multisortowanie topologiczne towaru, wynikające z wzoru upakowania, nie było zasłonięte przez inne wcześniej załadowane produkty. Kolejność pakowania spełniająca taki warunek będzie nazywana dopuszczalną kolejnością pakowania
Do transportu i składowania produktów często wykorzystuje się palety. W magazynach na paletach przechowywane są towary jednego typu. Zamówienia ze sklepów detalicznych zwykle dotyczą jednak zróżnicowanego asortymentu. W związku z tym, pojawia konieczność załadowania do wysyłki wymaganych towarów na palety i chcąc zautomatyzować ten proces, wykorzystuje się do tego roboty. Gdy różnorodność zamawianych towarów jest duża, określenie sposobu ich układania na palecie może sprawiać sporo trudności. Po pierwsze, należy wyznaczyć wzór upakowania towarów, czyli miejsca umieszczenia poszczególnych towarów na palecie. Dąży się przy tym do tego, aby przestrzeń nad paletą była w jak największym stopniu wykorzystana. Po drugie trzeba określić kolejność pakowania towarów przez robota. W literaturze dość szeroko są opisane różnorodne metody i algorytmy wyznaczenia wzorów upakowania. Obszerny przegląd tych metod można znaleźć m.in. w [1, 5, 7, 8].
Artykuł dotyczy tej drugiej kwestii, tzn. określenia właściwej kolejności pakowania towarów. Mając bowiem wyznaczony wzór upakowania, nie jest oczywiste w jakiej kolejności poszczególne towary powinny być umieszczane na palecie przez robota. Musi to być taka kolejność, żeby miejsce ustawienia
Autor korespondujący:
Krzysztof Pieńkosz, Krzysztof.Pienkosz@pw.edu.pl
Artykuł recenzowany nadesłany 14.11.2024 r., przyjęty do druku 24.01.2025 r..
Zwykle istnieje więcej niż jedna dopuszczalna kolejność pakowania palety. Można się wtedy zastanawiać, która z nich jest bardziej korzystna. Bierze tu się pod uwagę to, że nie wszystkie towary, które mają być zapakowane na palecie są jednakowo dostępne. Niektóre z nich znajdują się przy stanowisku pakowania, a inne trzeba dostarczyć z magazynu, co wymaga dodatkowego czasu. Chodzi więc o to, aby tak skoordynować kolejność pakowania towarów, aby operacji dostarczania ich z magazynu było jak najmniej.
W rozdziale 2 przedstawiona jest metoda, która pozwala sprawdzić, czy dla danego wzoru upakowania istnieje dopuszczalna kolejność pakowania towarów na palecie, uwzględniająca uwarunkowania pracy robota. Metoda ta wykorzystuje koncepcję zagregowanych grafów poprzedzania oraz algorytm multisortowania topologicznego zbioru grafów. Rozdział 3 dotyczy optymalizacji kolejności pakowania. Przestawiona jest tam propozycja algorytmu, który można zastosować w celu wyboru jak najkorzystniejszej kolejności pakowania towarów na palecie. W rozdziale 4 zawarto końcowe wnioski i podsumowanie.
2. Dopuszczalne kolejności pakowania
Towary umieszczane na paletach są zwykle przewożone w opakowaniach zbiorczych, np. kartonach, zgrzewkach opakowanych folią, tackach, itp. W dalszej części artykułu takie opakowania będą nazywane paczkami. Mają one przeważnie kształty zbliżone do prostopadłościanów i w związku z tym są układane na paletach równolegle do jej boków.
Żeby umieścić paczkę na palecie, robot musi mieć swobodny dostęp do miejsca jej położenia. W zależności od konstrukcji robota i jego zdolności manipulacyjnych, te wymagania mogą mieć różny charakter. W pracy [2] wprowadzono pojęcie upakowania robotowego (ang. robot packing). Jest to upakowanie, które da się ułożyć startując z dolnego, tylnego, lewego rogu palety i wstawiając kolejne paczki tak, żeby były one zawsze nad, przed i z prawej strony poprzednio ułożonych paczek. Odpowiada to sytuacji, gdy ramię robota pakującego znajduje się przed przednią stroną palety i do wstawienia paczki w określone miejsce, musi być wolny dostęp od góry, od przodu i z prawej strony. W niniejszym artykule taki sposób pakowania będzie nazywany pakowaniem jednostronnym palety, zaś kolejność pakowania towarów spełniającą powyższe warunki –dopuszczalną kolejnością dla pakowania jednostronnego.
Istnieją też stanowiska pakujące o większej funkcjonalności, umożliwiające pakowanie paczek z każdej strony palety, np. przez robota z ramieniem umieszczonym nad paletą lub poprzez obrót palety. Wystarczy wtedy, żeby robot miał pustą przestrzeń od jednej ze stron palety, a także od góry i od co najmniej jednego z boków paczki. Taki sposób pakowania palety będzie nazywany pakowaniem wielostronnym. Oczywiście dopuszczalna kolejność pakowania jednostronnego jest też kolejnością dopuszczalną dla pakowania wielostronnego, ale odwrotna zależność nie zawsze zachodzi.
Dla danego wzoru upakowania, niech N będzie zbiorem paczek zapakowanych na palecie. Położenie tych paczek i ∈ N jest określane przez współrzędne (xi, yi, zi) ich dolnego, tylnego, lewego rogu w układzie współrzędnych X, Y, Z, gdzie oś X jest skierowana w prawo, oś Y do przodu, a oś Z do góry (jak na rys. 1). Punkt (0, 0, 0) to dolny, tylny, lewy róg palety. Wymiary poszczególnych paczek wzdłuż osi X, Y oraz Z będą oznaczane odpowiednio jako li, wi oraz hi Okazuje się, że nie dla każdego wzoru upakowania istnieje dopuszczalna kolejność dla pakowania jednostronnego, czy nawet wielostronnego. Na rys. 1 jest przedstawiony przykład upakowania palety, które nie da się ułożyć stosując pakowanie jednostronne. Paczka 4 musi być bowiem załadowana po paczce 2, bo na niej leży, a jednocześnie przed paczką 3, która ją zasłania od przodu. Z tego wynika, że paczka 3 musiałby
Fig. 1. An example packing pattern (items 1 and 2 are identical)
być ułożona po paczce 2. Jest to jednak niemożliwe, bo paczka 2 zasłania paczkę 3 z prawej strony.
W przypadku przykładu z rys. 1 istnieje natomiast kilka dopuszczalnych kolejności dla pakowania wielostronnego, np. 2-3-1-4 z lewej lub od tylnej strony palety. Gdyby jednak trzeba było ułożyć jeszcze jedną dodatkową paczkę identyczną jak 3 w miejscu o współrzędnych (1, 0, 0), czyli tuż za paczką 4, to wówczas nie istniałaby żadna dopuszczalna kolejność nawet dla pakowania wielostronnego.
W pracy [4] zaproponowano metodę wyznaczania dopuszczalnych kolejności dla pakowania jednostronnego oraz wielostronnego, o ile takie dopuszczalne kolejności istnieją. Metoda ta bazuje na grafowej reprezentacji upakowania palety [9]. Dla danego upakowania, graf poprzedzania GX = (VX, EX) dla osi X to graf skierowany, w którym: −każdej paczce i ∈ N odpowiada jeden wierzchołek vi ∈ VX, istnieje łuk od wierzchołka vi do vj wtedy i tylko wtedy, gdy xi + li ⩽ xj, gdzie li jest wymiarem paczki i wzdłuż osi X
Graf GX określa wzajemne położenie zapakowanych paczek wzdłuż osi X. Łuk od wierzchołka vi do vj w tym grafie oznacza, że paczka j znajduje się całkowicie po prawej stronie paczki i. Analogicznie zdefiniowane są grafy poprzedzania GY oraz GZ dla osi Y oraz Z. Każdy z tych grafów jest zawsze grafem acyklicznym, tzn. nie zawiera skierowanych cykli. Na rys. 2 są przedstawione grafy poprzedzania dla upakowania z rys. 1. Dopuszczalną kolejność pakowania paczek można wyznaczyć na podstawie zagregowanych grafów poprzedzania [4]. Dla grafów poprzedzania GX, GY, GZ odpowiadających danemu upakowaniu palety, zagregowany graf poprzedzania to graf skierowany, w którym: −zbiór wierzchołków jest taki sam jak w GX, GY oraz GZ, istnieje łuk od wierzchołka vi do vj wtedy i tylko wtedy, gdy w jednym z grafów GX, GY bądź GZ istnieje łuk od vi do vj i w żadnym z tych grafów nie ma łuku przeciwnie skierowanego, tzn. od vj do vi
Taki zagregowany graf poprzedzania będzie oznaczany symbolem GX + GY + GZ. Określa on dopuszczalną kolejność pakowania przez robota poszczególnych par paczek. Jeżeli w grafie GX + GY + GZ występuje łuk od wierzchołka vi do vj to paczka j jest powyżej, bądź z przodu, albo z prawej strony paczki i, a zatem przy pakowaniu jednostronnym musi być później od niej wstawiona. Z drugiej strony, jeżeli w grafie GX + GY + GZ wierzchołki vi i vj nie są połączone łukiem, to paczki i oraz j nie zasłaniają się nawzajem i mogą być pakowane w dowolnej kolejności.
W przypadku pakowania wielostronnego można ustawiać paczki z dowolnej strony palety. Aby to uwzględnić, niech GX będzie grafem, który różni się od grafu poprzedzania GX tym, że wszystkie łuki są przeciwnie skierowane. Graf ten jest więc też grafem poprzedzania, ale w kierunku przeciwnym do osi X i opisuje dopuszczalną kolejność pakowania elementów od tej strony. W analogiczny sposób zdefiniowany jest graf poprzedzania GY Grafy GX + GY + GZ, GX + GY + GZ, GX + GY +GZ, GX + GY + GZ będą więc opisywać ograniczenia dotyczące kolejności pakowania paczek z poszczególnych czterech
Rys. 2. Grafy poprzedzania dla przykładu z rys. 1
Fig. 2. The comparability graphs for the example presented in Fig. 1
Rys. 1. Przykładowe upakowanie palety (paczki 1 i 2 są identyczne)
Na podstawie zagregowanych grafów poprzedzania można określić dopuszczalną kolejność pakowania, stosując algorytm multisortowania topologicznego zaproponowany w pracy [4] o złożoności obliczeniowej O(|N|2).
Rys. 3. Zagregowane grafy poprzedzania dla przykładu z rys. 1 Fig. 3. The aggregated precedence graphs for the example from Fig. 1 stron palety. Grafy te nie zawsze będą grafami acyklicznymi. Na rys. 3 są przedstawione zagregowane grafy poprzedzania dla upakowania z rys. 1.
W przypadku, gdy zostaną ponumerowane wszystkie wierzchołki, czyli zmienna n osiągnie wartość 1, to numery przypisane wierzchołkom będą określały dopuszczalną kolejność pakowania paczek na palecie. Jeżeli na wejściu algorytmu zbiór składa się tylko z jednego grafu GX + GY + GZ, to będzie to dopuszczalna kolejność dla pakowania jednostronnego. Wtedy algorytm multisortowania topologicznego sprowadza się do dobrze znanego w teorii grafów klasycznego sortowania topologicznego [3]. Jeżeli zbiór będzie się składał z czerech grafów: GX + GY + GZ, GX + GY + GZ, GX + GY +GZ, GX + GY + GZ, to algorytm multisortowania topologicznego będzie wyznaczać dopuszczalną kolejność dla pakowania wielostronnego. Gdy zmienna n nie osiągnie wartości 1, gdyż w każdym z grafów ze zbioru występuje cykl, to nie istnieje dopuszczalna kolejność pakownia, czyli robot nie jest w stanie bezkolizyjnie zapakować wszystkich paczek zgodnie z zadanym wzorem upakowania palety.
W algorytmie multisortowania topologicznego dokonujemy w istocie tak jakby rozpakowywania palety, zdejmując w każdym kroku jedną paczkę, która nie jest zasłonięta dla robota. Odwrotna kolejność odpowiada więc dopuszczalnej kolejności pakowania i dlatego w kolejnych iteracjach wierzchołkom są przypisywane malejące numery. Zapamiętując typ grafu zagregowanego, w którym znaleziono wierzchołek bez wychodzących łuków, mamy też informację, od której strony palety należy wstawić paczkę reprezentowaną przez ten wierzchołek.
Analizując dopuszczalność pakowania przykładu z rys. 1 w przypadku pakowania jednostronnego, należy zastosować algorytm multisortowania topologicznego tylko dla grafu GX + GY + GZ (rys. 3). Okaże się wówczas, że już w pierwszej iteracji zostanie wykryty cykl, gdyż w tym grafie nie ma wierzchołka bez wychodzących łuków. Ten cykl tworzą wierzchołki 2, 4, 3. Oznacza to, że nie istnieje dopuszczalna kolejność dla pakowania jednostronnego.
W przypadku pakowania wielostronnego, algorytm multisortowania topologicznego należy zastosować dla wszystkich czterech zagregowanych grafów poprzedzania z rys. 3. W pierwszej iteracji algorytmu zostanie wybrany wierzchołek 4, bo jest to jedyny wierzchołek, który nie ma wychodzących łuków ani w grafie GX + GY + GZ, ani w GX + GY + GZ. Paczka 4 musi więc być umieszczana jako ostatnia albo z tyłu palety (z kierunku przeciwnego do osi Y ), albo z lewej strony (kierunek osi X), bądź prawej strony (kierunek przeciwny do osi X). W drugiej iteracji będzie wybrany wierzchołek 1 lub 2, a potem pozostałe wierzchołki w dowolnej kolejności. W związku z tym istnieją cztery dopuszczalne kolejności dla pakowania wielostronnego: 2-3-1-4, 3-2-1-4, 1-3-2-4 oraz 3-1-2-4.
3. Optymalizacja kolejności pakowania
Niezależnie od tego, czy mamy do czynienia z pakowaniem jednostronnym czy wielostronnym, często istnieje kilka dopuszczalnych kolejności pakowania dla zadanego wzoru upakowania. Biorąc pod uwagę dostępność poszczególnych typów paczek, nie wszystkie kolejności są jednakowo korzystne. Dotyczy to zwłaszcza sytuacji, gdy trzeba zapakować nie pojedyncze paczki, ale większą liczbę paczek tego samego typu, np. 10 zgrzewek wody mineralnej, 5 kartonów masła, 6 tacek tego samego jogurtu, itp. We wzorze upakowania jednakowe paczki mogą być rozmieszczone w różnych miejscach na palecie, niekoniecznie obok siebie.
Do stanowiska pakowania dostarcza się z magazynu palety magazynowe załadowane jednakowymi paczkami. Po pobraniu i zapakowaniu stosownej liczby takich paczek, żeby umieścić paczki innego typu na pakowanej dla odbiorcy palecie, trzeba dostarczyć z magazynu paletę z tymi paczkami i zastąpić poprzednią paletę magazynową. Operacja ta będzie nazywana przestawianiem palet magazynowych. Przestawianie palet magazynowych jest czasochłonne, gdyż wiąże się z odstawieniem poprzedniej palety magazynowej i dostarczeniem nowej. Dlatego w procesie optymalizacji, mając do wyboru kilka dopuszczalnych kolejności pakowania palety, warto wybrać taką kolejność, która wymaga najmniejszej liczby operacji przestawiania palet magazynowych. Poniżej zostanie przedstawiona propozycja algorytmu, który dokonuje takiej optymalizacji. Proponowany algorytm optymalizacji kolejności pakowania paczek na palecie bazuje na grafowej reprezentacji upakowania w postaci zagregowanych grafów poprzedzania i jest rozwinięciem koncepcji multisortowania topologicznego. Wyznaczając dopuszczalną kolejność pakowania paczek na palecie, w każdej iteracji algorytmu multisortowania topologicznego, spośród wierzchołków, z których nie wychodzi żaden łuk, jest wybierany wierzchołek dowolny. Aby określić najkorzystniejszą kolejność
pod względem liczby przestawień palet magazynowych, należałoby wziąć pod uwagę wszystkie możliwości wyboru takich wierzchołków. W rezultacie rozpatrzenia różnych możliwości jest tworzone drzewo przeglądu. Każda ścieżka od liścia do korzenia takiego drzewa reprezentuje wtedy jedną z dopuszczalnych kolejności pakowania, spośród których należy wybrać wariant z najmniejszą liczbą przestawień. Poszczególne wierzchołki drzewa mają tyle gałęzi, ile w zagregowanych grafach poprzedzania odpowiadających paczkom, które jeszcze nie były rozpatrywane, jest wierzchołków bez wychodzących łuków. Aby ograniczyć wielkość drzewa i proces przeglądu takiego drzewa, można, podobnie jak w metodzie podziału i oszacowań [6], wykorzystać oszacowania. Niech w trakcie budowania drzewa przeglądu, N v oznacza zbiór paczek, które jeszcze nie były rozpatrywane w danej gałęzi, a K(N v) zbiór różnych typów paczek w zbiorze N v. Gdy nie ma żadnych identycznych paczek w zbiorze N v, to oczywiście K(N v) = N v, ale w ogólnym przypadku |K(N v)| |N v|. Niech LB(N v, u) oznacza dolne oszacowanie na liczbę przestawień, które trzeba będzie dokonać dla załadowania paczek ze zbioru N v, zakładając, że bezpośrednio przed paczką reprezentowaną przez wierzchołek v będzie pakowana paczka u. Możemy przyjąć, że LB(N v, u) = |K(N v)|, gdy paczka u jest innego typu niż v i LB(N v, u) = |K(N v)| − 1, gdy paczka u jest taka sama jak v. To oszacowanie będzie stosowane po pierwsze, żeby określić, które gałęzie drzewa należy w pierwszej kolejności rozpatrywać. Drzewo przeglądu będzie rozbudowywane w głąb z wyborem w pierwszej kolejności tego wierzchołka, dla którego oszacowanie jest najmniejsze. Po drugie, oszacowanie będzie wykorzystywane do pomijania w przeglądzie gałęzi, dla których na podstawie tego oszacowania można stwierdzić, że na pewno nie prowadzą do lepszych rozwiązań od już znalezionych. Schemat algorytmu optymalizacji kolejności pakowania paczek na palecie jest przedstawiony poniżej w postaci rekurencyjnej procedury OPTSEQ. Parametry v, N v, n, p mają charakter lokalny i oznaczają kolejno: v – wierzchołek odpowiadający paczce, która została rozpatrzona jako dotychczas ostatnia, N v – zbiór paczek do rozpatrzenia, które pozostały po ponumerowaniu wierzchołka v, n – numer określający kolejność pakowania, p – liczba koniecznych przestawień dla dostarczenia już rozpatrzonych paczek.
Zmienna pmin jest globalna i określa liczbę przestawień dla najlepszej znalezionej kolejności pakowania. Symbol (N v) oznacza zaś zbiór zagregowanych grafów poprzedzania z , zredukowanych do wierzchołków odpowiadających tylko paczkom ze zbioru N v, czyli zawierających tylko te wierzchołki i łuki między nimi.
Rys. 4. Drzewo przeglądu dla przykładu z rys. 1
Fig. 4. The search tree for the example presented in Fig. 1
Wartości początkowe przy pierwszym wywołaniu procedury OPTSEQ są następujące: v = 0, N v = N, n = |N|, p = 0, pmin = |N| + 1. Dla formalności, dostarczenie pierwszej palety magazynowej na stanowisko pakowania też jest traktowane jako operacja przestawienia. Dlatego v = 0 jest sztuczną wartością początkową, aby na początku to przestawienie było również zliczane w zmiennej p. Podobnie sztuczną – zawyżoną wartością początkową jest pmin = |N| + 1. Wszystkich przestawień może być co najwyżej |N|, więc jeżeli w trakcie wykonywania algorytmu wartość zmiennej pmin się nie zmniejszy i taka pozostanie po zakończeniu algorytmu, to oznacza, że nie istnieje dla robota żadna dopuszczalna kolejność jej pakowania.
Powyższy algorytm wyznacza optymalną kolejność pakowania paczek na palecie lub stwierdza, że nie ma żadnej dopuszczalnej kolejności pakowania. Algorytm można nieco usprawnić kończąc go w momencie, gdy pmin osiągnie wartość |K(N)|, będącą dolnym oszacowaniem liczby przestawień dla zbioru wszystkich paczek N. Lepszego rozwiązania już się bowiem nie uzyska, dalej kontynuując obliczenia. Jeżeli w liście T jest kilka wierzchołków o takim samym oszacowaniu LB(N v, u), to warto w pierwszej kolejności rozpatrywać te, które odpowiadają najliczniej występującym paczkom w zbiorze N v Prześledźmy działanie powyższego algorytmu dla przykładu upakowania z rys. 1 i pakowania wielostronnego. Paczki 1 i 2 są jednakowe, natomiast pozostałe są innych typów. Drzewo przeglądu tworzone podczas poszukiwania optymalnej kolejności pakowania dla tego przykładu jest przedstawione na rys. 4. Na początku, przy pierwszym wywołaniu procedury rekurencyjnej OPTSEQ mamy v = 0, N0 = N = {1, 2, 3, 4}, n = 4, p = 0 oraz pmin = 5. Zbiór (N0) składa się z zagregowanych grafów poprzedzania przedstawionych na rys. 3. Jedynym wierzchołkiem, z którego nie wychodzi żaden łuk w przynajmniej w jednym z tych grafów jest wierzchołek 4, a zatem zostanie mu przypisany numer n = 4. Oznacza to, że paczka 4 będzie pakowana jako ostatnia. Na stanowisko pakowania musi więc być dostarczona paleta magazynowa z paczką 4, a zatem p przyjmuje wartość 1.
Przy drugim (rekurencyjnym) wywołaniu procedury OPTSEQ jest v = 4, N 4 = {1 , 2 , 3}, n = 3 oraz p = 1. W zredukowanych zagregowanych grafach poprzedzania nie będzie już wierzchołka 4 i wówczas wierzchołek 1 nie będzie miał wychodzących łuków np. w grafie GX + GY + GZ, a wierzchołek 2 w grafie GX + GY + GZ. Lista T będzie składała się z tych dwóch wierzchołków i w drzewie przeglądu pojawią się dwie gałęzie. Paczki 1 i 2 są jednakowe, ale inne niż paczka 3 i rozpatrywana wcześniej paczka 4. Zatem dla obu tych wierzchołków mamy takie samo oszacowanie LB({1, 2, 3}, 1) = LB({1, 2, 3}, 2) = |K({1, 2, 3})| = 2. Zostanie więc wybrany dowolny z nich np. wierzchołek 1 i zwiększy się wtedy liczba przestawień do p = 2. Przy trzecim wywołaniu procedury OPTSEQ będzie v = 1, N1 = {2, 3}, n = 2 oraz p = 2. W zredukowanych zagregowanych grafach poprzedzania zbioru (N1) wystąpią więc tylko wierzchołki: 2 i 3. W grafie GX + GY + GZ wierzchołek 2 nie b ędzie miał wychodzącego łuku, a w grafie GX + GY + GZ – wierzchołek 3. Pojawią się więc znowu dwie gałęzie w drzewie przeglądu. Ze względu na to, że gałęzie te wychodzą z wierzchołka 1, który reprezentuje taką samą paczkę jak wierzchołek 2, to wierzchołek 2 będzie rozpatrywany i ponumerowany jako następny. Ma on bowiem mniejsze dolne oszacowanie niż wierzchołek 3. Nie zwiększy się przy tym liczba przestawień i pozostanie p = 2. Przy czwartym wywołaniu procedury OPTSEQ , zagregowane grafy poprzedzania zredukują się do tylko jednego wierzchołka – wierzchołka 3. Zostanie mu przypisany numer n = 1 i liczba przestawień się zwiększy do p = 3. W tym momencie uzyskujemy pierwsze pełne rozwiązanie dopuszczalne odpowiadające kolejności pakowania 3-2-1-4 z p = 3 przestawieniami. Zmienna p min przyjmie wartość 3. Po wyznaczeniu tego rozwiązania, nastąpi rekurencyjny powrót w drzewie przeglądu i będą rozpatrywane dwie pozostałe boczne gałęzie. Ponieważ jednak z oszacowań wynika, że w obu tych gałęziach nie uzyskamy mniejszej liczby przestawień niż 3 (linia 4 procedury OPTSEQ), więc gałęzie te nie będą dalej rekurencyjnie rozbudowywane i algorytm się zakończy. Wynika z tego, że kolejność pakowania 3-2-1-4 z trzema przestawieniami, jest rozwiązaniem optymalnym. Nie ma innej dopuszczalnej kolejności pakowania z mniejszą liczbą przestawień.
Algorytm można było też zakończyć wcześniej bez konieczności rozpatrywania bocznych gałęzi, bo w momencie wyznaczenia pierwszego dopuszczalnego rozwiązania, zmienna pmin przyjęła wartość 3 równą |K(N)|, czyli dolnemu oszacowaniu na liczbę wszystkich możliwych przestawień. Zatem takie rozwiązanie musi być optymalne, bo na podstawie wartości oszacowania |K(N)| mamy pewność, że lepszego rozwiązania już nie ma.
4. Podsumowanie
W artykule zaproponowano metodę wyznaczania kolejności pakowania towarów na palecie, która bierze po uwagę zarówno możliwość, jak i efektywność realizacji tego procesu przez robota. Pokazano jak można zastosować tę metodę w przypadku, gdy robot jest w stanie pakować towary tylko z jednej strony palety oraz bardziej uniwersalnego stanowiska pakującego, gdy można umieszczać towary z różnych jej stron. Przy wyznaczaniu najkorzystniejszej kolejności pakowania towarów istotne znaczenie ma wykorzystanie grafowej reprezentacji upakowania palety oraz zastosowanie oszacowań, które pozwalają znacząco ograniczyć wielkość drzewa przeglądu i czas obliczeń.
Bibliografia
1. Ali S., Ramos A.G., Carravilla M.A., Oliveira J.F., On-line three-dimensional packing problems: A review of off-line and on-line solution approaches, “Computers & Industrial Engineering”, Vol. 168, 2022, DOI: 10.1016/j.cie.2022.108122.
2. den Bo ef E., Korst J., Martello S., Pisinger D., Vigo D., Erratum to “The three-dimensional bin packing problem”: Robot-packable and orthogonal variants of packing problems, “Operations Research”, Vol. 53, No. 4, 2005, 735–736, DOI: 10.1287/opre.1050.0210.
3. Cormen T., Leiserson C., Rivest R., Wprowadzenie do algorytmów, WNT, Warszawa, 1997.
4. Pieńkosz K., Wyznaczanie sposobu pakowania palet dla robota, “Pomiary Automatyka Robotyka”, R. 25, Nr 2, 2021, 11–16, DOI: 10.14313/PAR_240/11.
5. Silva E.F., Toffolo T.A.M., Wauters T., Exact methods for three-dimensional cutting and packing: A comparative study concerning single container problems, “Computers & Operations Research”, Vol. 109, 2019, 12–27, DOI: 10.1016/j.cor.2019.04.020.
7. Zhao X., Bennell J.A., Bektas T., Dowsland K., A comparative review of 3D container loading algorithms, “International Transactions in Operational Research”, Vol. 23, No 1–2, 2016, 287–320, DOI: 10.1111/itor.12094.
8. Zhu W., Oon W., Lim A., Weng Y., The six elements to block-building approaches for the single container loading problem, “Applied Intelligence”, Vol. 37, 2012, 431–445, DOI: 10.1007/s10489-012-0337-0.
9. Zhu W., Zhang Z., Oon W.-C., Lim A., Space defragmentation for packing problems, “European Journal of Operational Research”, Vol. 222, No. 3, 2012, 452–463, DOI: 10.1016/j.ejor.2012.05.031.
Optimization of the Loading Sequence of Goods on Pallets
Abstract: In the paper the capability of using a robot to pack goods on pallets is analyzed. If the goods have different dimensions, the sequence in which they are loaded is important. First, in order to place the goods on a partially loaded pallet, the robot must have free access to their location, i.e. the location must not be covered. Second, the way in which the next goods to be packed are selected can affect the time it takes to load a pallet, since it can take more or less time to deliver individual goods from the warehouse. This paper presents a method for determining the order in which goods should be placed on a pallet by a robot, taking into account both of these considerations. The proposed algorithm uses the graph model representing a pallet packing.
Absolwent Wydziału Elektroniki i Technik Informacyjnych Politechniki Warszawskiej (1984). W latach 1984–1986 pracował w Instytucie Górnictwa Naftowego i Gazownictwa, a od 1986 r. jest zatrudniony w Instytucie Automatyki i Informatyki Stosowanej Politechniki Warszawskiej. Uzyskał stopień doktora nauk technicznych w 1992 r. i w 2011 r. doktora habilitowanego. Jego zainteresowania naukowe dotyczą badań operacyjnych, w szczególności metod optymalizacji dyskretnej, algorytmów rozwiązywania problemów kombinatorycznych oraz zagadnień planowania i harmonogramowania.
Szybki dyskretny regulator PID dla serwomechanizmu prądowego
Andrzej Bożek
Politechnika Rzeszowska, Katedra Informatyki i Automatyki, ul. W. Pola 2, 35-959 Rzeszów
Streszczenie: Przedstawiono opracowaną metodę doboru nastaw dyskretnego regulatora PID dla serwomechanizmu prądowego modelowanego przez podwójny integrator. Metoda pozwala uzyskać dowolnie szybką dynamikę odpowiedzi, aż do regulacji typu dead-beat. Jej zastosowanie wymaga czteroparametrowego wariantu regulatora z filtracją w członie różniczkującym. Wyprowadzono analityczne zależności pozwalające na obliczenie nastaw w oparciu o podstawowe proste parametry projektowe: wzmocnienie obiektu, czas cyklu regulatora oraz zadany czas regulacji. Zweryfikowano metodę strojenia symulacyjnie i przeanalizowano zależność między szybkością regulacji, a wrażliwością na odchyłki wzmocnienia obiektu od wartości projektowej. W eksperymencie z obiektem rzeczywistym potwierdzono prawidłowe działanie układu regulacji dla nastaw ustalających czas regulacji na 5-krotność oraz 10-krotność czasu cyklu regulatora. Nastawy proponowane w poprzednich pracach pozwalały uzyskać czas regulacji co najmniej 25-krotnie dłuższy od czasu cyklu.
1. Wpowadzenie
Słowa kluczowe: serwomechanizm prądowy, podwójny integrator, regulacja dyskretna, regulator PID, regulacja dead-beat, lokalizacja biegunów, biegun wielokrotny inżynierom. Jeśli zatem wstępnie obliczone nastawy będą nieodpowiednie, np. ze względu na niedokładną identyfikację obiektu, łatwo dokonać ich ręcznej korekty. Dodatkowo, pakiety oprogramowania inżynierskiego i narzędziowego dla automatyki, jak również biblioteki algorytmów dla urządzeń sterujących zawierają szerokie wsparcie dla regulatorów PID. W związku z tym, przyjęto ograniczenie, aby zaprojektowany algorytm regulacji miał strukturę PID.
Współczesne układy regulacji oparte są na sterownikach cyfrowych, które realizują algorytmy dyskretne. Zwykle jednak cykl pracy sterowników jest na tyle krótki w relacji do dynamiki sterowanego obiektu lub procesu, że do strojenia regulatorów można stosować nastawy wynikające z teorii regulacji ciągłej. Niekiedy warunki takie mogą być jednak niespełnione i wtedy wymagane są metody strojenia uwzględniające dyskretne działanie układu. W artykule przedstawiono sposób strojenia dyskretnego regulatora PID dla obiektu o transmitancji podwójnie całkującej. Transmitancja taka została skojarzona z serwomechanizmem prądowym, ale uzyskane wyniki można zastosować do dowolnych obiektów o tej dynamice. Ze względu na prosty sposób programowej implementacji dowolnych transmitancji dyskretnych, liniowe regulatory dyskretne nie muszą mieć struktury PID. Pozwala to na ich bardziej elastyczne projektowanie, np. metodą syntezy bezpośredniej. Z drugiej strony, zachowanie struktury PID ma wiele korzyści. Przede wszystkim, regulator PID ma tylko kilka nastaw, których typowy wpływ na działanie układu regulacji jest dobrze znany
Autor korespondujący:
Andrzej Bożek, abozek@kia.prz.edu.pl
Artykuł recenzowany nadesłany 22.02.2024 r., przyjęty do druku 15.12.2024 r.
Wybrana konfiguracja regulatora PID i wyprowadzone nastawy zostały określone jako szybkie w sensie relacji czasu regulacji t r do czasu cyklu sterownika Δ. Istniejące prace prezentują sposoby strojenia minimalizujące t r /Δ do wartości około 25, przy czym limit ten wynika z ograniczenia w lokalizacji bieguna dominującego transmitancji układu zamkniętego. W niniejszej pracy ustalono, że to ograniczenie można pokonać przez zastosowanie w dyskretnym regulatorze PID członu różniczkującego z filtracją. W takim przypadku możliwe staje się dowolne zlokalizowanie bieguna wielokrotnego i dowolne zmniejszenie stosunku t r /Δ, aż do biegunów w położeniu 0, tj. regulacji typu dead-beat.
W kolejnym rozdziale przedstawiono przegląd literatury związanej z tematyką pracy. W rozdziale trzecim wprowadzono transmitancje dyskretne elementów rozważanej struktury regulacyjnej. Zasadniczy tok projektowy prowadzący do uzyskania nastaw dyskretnego regulatora PID został omówiony w rozdziale czwartym. W rozdziale piątym zostały przeanalizowane wybrane właściwości układu z zaprojektowanym regulatorem. W rozdziale szóstym przedstawiono weryfikację zaproponowanej metody strojenia opartą na eksperymentach z rzeczywistym układem serwomechanizmu prądowego. Ostatni rozdział zawiera podsumowanie pracy.
2. Przegląd literatury
Istnieje wiele metod sterowania podwójnym integratorem. Przegląd popularnych rozwiązań został przedstawiony w pracy [1]. Podwójny integrator jest podstawowym, ale wystarczającym w większości zastosowań, modelem silników sterowanych prądowo, tzn. generujących moment obrotowy lub siłę proporcjonalną do sygnału sterującego [2]. W bardziej szczegółowych symulacjach i sposobach identyfikacji silników stosuje się czasami modele uwzględniające więcej parametrów, przede wszystkim związanych z tarciem [3, 4].
W praktyce, zwłaszcza w zastosowaniach przemysłowych, preferowane są dla serwomechanizmów regulatory proste w strojeniu i odporne na niedokładności nastaw oraz zmienność parametrów. Są to zwykle regulatory typu PID pracujące w strukturze jednoobwodowej lub kaskadowej (położenie-prędkość) [2], strojone metodami częstotliwościowymi [5] lub metodą lokalizacji biegunów.
Lokalizacja biegunów systemu liniowego nie nastręcza problemów w przypadku zastosowania regulatora stanu [6], bywa natomiast trudniejsza z wykorzystaniem regulatora PID, zwłaszcza gdy liczba jego parametrów nie odpowiada liczbie lokowanych biegunów. W dopasowaniu regulatora PID do obiektu mogą być stosowane założenia upraszczające, takie jak eliminacja biegun-zero [6, 7] lub podwójne zero regulatora [8]. Używane są również zmodyfikowane postacie algorytmów PID ułatwiające lokalizację [9]. Dla przypadków, w których nie można dokładnie zlokalizować wszystkich biegunów, zaproponowano metody gwarantujące wymagane położenia biegunów dominujących w układach ciągłych [10] oraz dyskretnych [11]. W zagadnieniu lokalizacji biegunów pomocna jest metoda linii pierwiastkowych [6, 12, 8], łącząca cechy graficzne, numeryczne i analityczne.
Szczególnym przypadkiem lokalizacji bieguna wielokrotnego w układzie dyskretnym jest jego umiejscowienie w położeniu 0. Prowadzi to do szybkich przebiegów regulacyjnych ustalających się w skończonej liczbie cykli (dead-beat) [6]. Metoda ta stosowana jest dosyć często w regulacji układów energoelektronicznych, a w przypadku napędów głownie w regulatorach prądu [13].
Niniejsza praca nawiązuje najbliżej do badań przedstawionych w [8, 14], których celem było uzyskanie analitycznych zależności na nastawy regulatorów PID dla serwomechanizmów w oparciu o lokalizację biegunów wspieraną metodą linii pierwiastkowych. Jednym z celów szczegółowych było otrzymanie szybkiego dyskretnego regulatora PID dla serwomechanizmu prądowego. Stosując regulator z podwójnym zerem uzyskano minimalny stosunek czasu regulacji do czasu cyklu /45 r t ∆≅ [8], następnie zwiększono szybkość uzyskując /25 r t ∆≅ w oparciu o nastawy z biegunem wielokrotnym [14]. Biegun wielokrotny ma jednak stałą lokalizację, której nie da się modyfikować nastawami, i dalsze przyspieszanie regulacji dla przyjętej struktury PID jest niemożliwe. W niniejszej pracy rozszerzono model regulatora o filtrację w członie różniczkującym, co pozwoliło pokonać wcześniejsze ograniczenie i opracować nastawy zapewniające dowolną szybkość regulacji osiągalną w układzie dyskretnym, tzn. aż do przebiegów typu dead-beat.
3. Modele transmitancyjne obiektu i regulatora
Jako referencyjną postać dyskretnego algorytmu PID przyjęto implementację zastosowaną w bloku PID oprogramowania Simulink. Transmitancja regulatora
PIDpi d ()()() GzkkIzkDz =++ (2)
zawiera człony dyskretnego całkowania I(z) oraz różniczkowania D(z). Możliwy jest wybór kilku wariantów implementacji tych członów. Całkowanie może być realizowane metodą prostokątów wprzód i wstecz oraz metodą trapezów, co odpowiada transmitancjom członu I(z) równym kolejno
FBT 1 (),(),(). 1121 IzIzIzzz zzz
= = = (3)
Człon D(z) realizuje albo aproksymację różnicową, albo różniczkowanie z filtracją, mając transmitancję odpowiednio AF 1 ()lub(), 1() zN Dz Dz z NIz = = ∆+
przy czym integrator I(z) użyty w DF(z) może mieć również dowolną realizację spośród podanych w (3). Konfiguracja PID pozwala więc na trzy warianty bloku całkującego i niezależnie cztery warianty bloku różniczkującego, łącznie dwanaście wariantów. Nastawami regulatora są wzmocnienia: proporcjonalne (kp), całkujące (ki) i różniczkujące (kd), a także parametr
N w konfiguracjach z członem DF(z). Respektowany będzie klasyczny warunek stosowania nastaw o wartościach nieujemnych. Niezależnie od wariantu regulatora, jego zastępczą transmitancję zawsze można zapisać w postaci
2 PIDr () , (1)() zbzc Gzk zzd −+ = −+ (4)
ponieważ człon całkujący wnosi do mianownika czynnik z − 1, a człon różniczkujący czynnik z + d, w szczególności d = 0 dla DA(z). Konkretny wariant decyduje o relacji między parametrami kr, b, c, d i nastawami kp, ki, kd, N.
4. Nastawy dla wielokrotnego bieguna układu zamkniętego
Na podstawie (1) i (4) transmitancja układu otwartego 22 opr o 2 2 3 1 () (1)()2 (1) ()(1) , ()(1)
Gzkkzbzcz zzd z Kzbzcz zdz −+∆+ = −+ −++ = +−
gdzie 2 ro 2 Kkk ∆ = (5)
Stąd, przy jednostkowym sprzężeniu zwrotnym stosowanym w strukturze serwomechanizmu, transmitancja układu zamkniętego
Obiektem sterowania jest silnik o transmitancji ciągłej podwójnie całkującej k o /s2. W typowej implementacji cyfrowego sterowania serwomechanizmem sygnał sterujący jest generowany przez przetwornik cyfrowo-analogowy, który ekstrapoluje jego wartość na przedziały czasu równe cyklowi próbkowania Δ. W efekcie modelem dyskretnym obiektu jest ZOH – odpowiednik jego transmitancji ciągłej 2 2 1 () 2 (1) oo z Gzk z ∆+ = (1)
Lokalizację wielokrotnego (tutaj poczwórnego) bieguna układu zamkniętego w położeniu r uzyska się przyrównując mianownik transmitancji (6) do wielomianu
4432234 (4)464. zzrzrzrzr −=−+−+
Prowadzi to do układu równań
który ma rozwiązanie
22 (1)(617) , 8 rrr K −++ = (7a)
2 4(1)(5) , 617 rr b rr ++ = ++ (7b)
2 2 7107 , 617 rr c rr ++ = ++ (7c) (7d)
zatem parametry K, b, c, d wyrażają się przez funkcje wymierne bieguna r określone dla każdej jego wartości. Możliwa jest więc dowolna lokalizacja rzeczywistego bieguna poczwórnego, przynajmniej w sensie realizowalności algorytmu regulacji reprezentowanego przez transmitancję (4). Pozostaje do zweryfikowania, czy uzyskane parametry pociągają za sobą dozwolone nastawy kp, ki, kd, N Podstawienie d = 0 w (7d), odpowiadające zastosowaniu różniczkowania DA(z) w regulatorze, prowadzi do równania, którego jedynym rozwiązaniem reprezentującym biegun stabilny jest r ∗ = 23 /4−1. Wynik ten jest spójny z rezultatem pracy [14], w której ustalono, że regulator z różniczkowaniem w formie aproksymacji różnicowej może zlokalizować biegun poczwórny tylko w położeniu r∗. Wynikają stąd założenia dla dalszego toku projektowania: Rozważane będą wartości r ∈ [0, r∗), ponieważ przypadek z lokalizacją biegunów dominujących w przedziale [r ∗, 1) został uwzględniony w [14]. Niniejszy projekt obejmuje zatem najszybsze możliwe nastawy regulatora w sensie minimalizacji ilorazu t r /Δ.
Aby zlokalizować biegun poczwórny w przedziale [0, r∗) niezbędne jest d ≠ 0, zatem musi zostać użyty człon różniczkujący z filtracją DF(z).
Zakres i charakter zmienności parametrów transmitancji regulatora w funkcji r ∈ [0, r∗) przedstawiono na wykresach (Rys. 1). Wykresy mogą służyć również jako nomogramy do przybliżonego określenia wartości parametrów, zamiast ich dokładnego obliczania na podstawie zależności (7a)−(7d). Projektowy czas regulacji wynika z zależności z = eΔs łączącej lokalizację bieguna dyskretnego i jego odpowiednika ciągłego oraz z obserwacji, że
biegunowi ciągłemu poczwórnemu s odpowiada czas ustalania odpowiedzi skokowej równy około 9,1/|s|. W efekcie uzyskuje się oszacowanie czasu regulacji r 9,1 ln t r =∆ (8)
Na wykresie czasu regulacji skonfrontowano również wartość projektową (8) z wynikiem opartym na symulacji odpowiedzi skokowej. Porównywane wartości wykazują dobrą zgodność, różnica bezwzględna nie przekracza czasu jednego cyklu. Zależnie od wyboru wariantu integratora (3) w bloku filtrowanego różniczkowania, parametr d w mianowniku transmitancji (4) uzyskuje wartość
12 1, lub, 12 N N NN ∆− ∆− ∆+ ∆+
odpowiednio dla IF(z), IB(z) i IT(z). Trzeba zatem odrzucić wariant z całkowaniem metodą prostokątów wstecz, ponieważ nie zapewni on właściwej wartości d dla N ≥ 0. Możliwe do użycia pozostają warianty z dowolną realizacją członu całkującego oraz z integratorami IF(z) lub IT(z) w członie DF(z). Szczegółowe wyprowadzenie nastaw zostanie przedstawione dla przypadku wykorzystania IF(z) w obu członach, dla pozostałych wariantów przebieg obliczeń jest analogiczny. Ukonkretniony wariant regulatora ma transmitancję
PID_FFpi d () 1 1 1 N Gzkkk z N z ∆ =++ ∆ + (9)
Porównanie (4) z (9) z uwzględnieniem (5) prowadzi do układu równań, z którego można uzyskać nastawy ( ) p 22 o 2(2)1 , (1) Kdbc k kd −−+ = ∆+ (10a) i 3 o 2(1) , (1) Kcb k kd −+ = ∆+ (10b) () d 3 o 2() , (1) Kdbdc k kd ++ = ∆+ (10c)
1 d N + = ∆ (10d)
Podstawienie (7a)−(7d) do (10a)−(10d) pozwala otrzymać zależności
2432 p 222 2 o 4(1)(12469289) , (3)(25) rrrrr k krrr −++++ = ∆+++ (11a)
3 i 32 o 8(1) , (3)(25) r k krrr = ∆+++ (11b) (11c)
Rys. 1. Czas regulacji i parametry transmitancji regulatora w funkcji bieguna r
Fig. 1. Settling time and controller transfer function parameters as a function of r pole
Rys. 2. Linie pierwiastkowe i odpowiedzi skokowe dla r = 0; 0,16; 0,4 Fig. 2. Root locus and step responses for r = 0, 0.16, 0.4
02468101214161820
2 (1)(3)(25) , 8 rrrr N −+++ = ∆ (11d)
które wyrażają nastawy regulatora w funkcji podstawowych danych projektowych ko, Δ i r. Postać uzyskanych wyrażeń wskazuje, że wszystkie nastawy będą nieujemne dla użytecznych wartości r
Procedura strojenia sprowadza się do określenia wartości r ∈ [0, r∗) odpowiadającej wymaganemu stosunkowi t r /Δ, zgodnie z (8), a następnie obliczenia nastaw na podstawie zależności (11a)−(11d).
5. Właściwości układu regulacji
Dla zbadania właściwości układu przeanalizowano przebieg linii pierwiastkowych parametryzowanych wzmocnieniem toru otwartego oraz kształt odpowiedzi skokowych. Odpowiedzi skokowe wygenerowano dla pętli regulacyjnej poprzedzonej filtrem wielkości zadanej, który redukuje zera transmitancji wnoszone przez regulator (4) i w efekcie eliminuje przeregulowanie. Transmitancja filtra
Graniczna wartość r = 0 odpowiada regulacji typu dead-beat. Transmitancja układu z uwzględnieniem filtra (12) upraszcza się dla nastaw dead-beat do postaci
DB 2 11 (), 2 z Gz z + =
zatem wyjście osiąga połowę amplitudy wielkości zadanej w czasie Δ i ustala się dokładnie na tej wartości po czasie 2Δ. Takie działanie układu potwierdza wykres z Rys. 2.
6. Weryfikacja eksperymentalna
Zaproponowaną metodę strojenia regulatora dyskretnego przetestowano na rzeczywistym układzie serwomechanizmu. Eksperymenty zrealizowano na stanowisku z serwonapędem przemysłowym firmy Estun i modułem ruchu liniowego. Na Rys. 3 przedstawiono jego konstrukcję i wskazano główne elementy:
Wyniki weryfikacji przedstawiono na Rys. 2. Uwzględniono trzy położenia bieguna wielokrotnego, r = 0; 0,16; 0,4, dla których t r /Δ wynosi odpowiednio 2, 5 i 10. Współczynnik / KK κ = jest miarą odstrojenia rzeczywistego wzmocnienia układu otwartego K od wartości projektowej K. Na liniach pierwiastkowych wyróżniono fragmenty odpowiadające odstrojeniu w zakresach κ ∈ [0,7; 1] oraz κ ∈ [1; 1,3]. Odpowiedzi skokowe zasymulowano dla κ = 0,7; 1; 1,3. Graniczna dolna wartość r = 0 charakteryzuje się największą wrażliwością układu na odchyłki wzmocnienia. Przypadek κ = 1,3 odpowiada wzmocnieniu krytycznemu, zgodnie z wykresem linii pierwiastkowych, co potwierdza również wykres odpowiedzi skokowej wykazujący oscylacje na granicy stabilności. Odstrojenie w dół do κ = 0,7 również zbliża układ do granicy stabilności, a odpowiedź skokowa jest mocno oscylacyjna. Zwiększanie wartości r zmniejsza podatność układu na odstrojenie. To samo odstrojenie ±30 % powoduje wyraźnie mniejsze zaburzenia odpowiedzi dla r = 0,16 oraz już niewielkie dla r = 0,4. W przypadku idealnego nastrojenia, tj. dla κ = 1, wszystkie odpowiedzi skokowe mają założone właściwości. Ustalają się bez przeregulowania z oczekiwanym projektowym czasem regulacji.
(A) silnik AC trójfazowy, model EMJ-04AFD22, parametry znamionowe: moc 400 W, moment obrotowy 1,27 Nm, prędkość 3000 RPM, zintegrowany enkoder inkrementalny 20-bitowy, (B) serwokontroler kompatybilny z silnikiem, model PRONET-04AEG-EC, zarządzany przez protokół EtherCAT, (C) połączenie uzwojeń silnika z falownikiem wbudowanym w serwokontroler, (D) połączenie enkodera z serwokontrolerem, (E) moduł ruchu liniowego ze śrubą kulową, (F) wózek napędzany przez serwomechanizm, (G) komputer przemysłowy Beckhoff C6920 wykonujący program PLC z badanym algorytmem regulacji położenia, (H) komputer programujący ze środowiskiem inżynierskim TwinCAT 3, (I) połączenie Ethernet między komputerem przemysłowym i komputerem programującym, (J) połączenie EtherCAT między komputerem przemysłowym i serwokontrolerem.
Serwonapęd pracował w trybie kontroli momentu obrotowego, dzięki czemu miał dynamikę obiektu podwójnie całkującego. Wartość sygnału sterowania była mierzona jako bezwymiarowy stosunek zadanego momentu obrotowego do momentu nominalnego u = M/MN. Jako sygnał wyjścia obiektu y przyjęto położenie wózka (F) wyrażone w metrach. Cykl pracy programu PLC i komunikacji z serwonapędem przez połączenie EtherCAT wynosił δ = 1 ms, co pozwoliło na rejestrację zmian położenia z dużą rozdzielczością cza-
Rys. 3. Stanowisko eksperymentalne Fig. 3. Experimental system
Rys. 4. Wyniki identyfikacji obiektu dla różnych amplitud sterowania Fig. 4. Results of object identification for various control amplitudes
0.20.250.30.350.40.450.50.550.60.650.70.750.80.850.90.951 u
sową. Algorytm regulacji był jednak wywoływany z dłuższym konfigurowalnym czasem cyklu Δ = n δ W związku ze spodziewaną wrażliwością układu na zmiany i niedokładność oszacowania wzmocnienia k o, przeprowadzono szczegółową identyfikację tego parametru. Dla każdej wartości sterowania równej kolejno 20 %, 25 %, ..., 100 % sterowania nominalnego zarejestrowano 100-krotnie odpowiedź skokową i wyznaczono k o najlepiej dopasowujące model k o /s 2 do danych eksperymentalnych przez minimalizację błędu średniokwadratowego. Zestawienie wyników przedstawiono w formie wykresu pudełkowego (Rys. 4). Rozrzut przypadkowy wyników przy jednakowym sterowaniu nie jest duży, wyraźnie przeważa systematyczna tendencja wzrostu wartości k o wraz z amplitudą skoku sterowania. Jest to efekt tarcia, którego relatywny wpływ na pracę układu maleje ze wzrostem amplitudy sterowania. Obiektu nie można zatem uznać za w pełni liniowy i należy się liczyć z odstępstwami w działaniu serwomechanizmu w stosunku do wyników symulacyjnych. Do wyznaczenia nastaw przyjęto k o = 30 m/s2, ponieważ jest to wartość uzyskana dla 50 % nominalnego sterowania, a zatem oczekiwana w przypadku uproszczonej identyfikacji opartej na pojedynczym eksperymencie.
W programie PLC zaimplementowano regulator i filtr wielkości zadanej w formie równań rekurencyjnych wynikających z transmitancji (9) i (12). Po przekształceniu transmitancji członu różniczkującego 1 1 (1) , 1(1) 1 1 NNz Nz N z = ∆ +∆− + uzyskuje się dyskretny algorytm regulatora w postaci
11 DD 11 ID pid :, :(1)(), :, iii i iii iiii eee eNeNee ukekeke =+∆ =−∆+− =++ w którym zmienne ei, I , ei D , ei ui reprezentują odpowiednio uchyb regulacji, całkę uchybu, pochodną uchybu i sygnał wyjściowy regulatora w i-tym cyklu sterowania.
Przeprowadzono testy dla r = 0; 0,16; 0,4, analogicznie jak w przypadku symulacji z poprzedniego rozdziału. Dla r = 0 układ nie działał prawidłowo, po wymuszeniu skokowym występowały niegasnące oscylacje. Napotkane trudności są spójne z ustaloną symulacyjnie dużą wrażliwością układu na parametry obiektu i zaobserwowaną w wyniku identyfikacji nieliniowością. Dla wyższych wartości r = 0,16; 0,4 serwomechanizm pracował poprawnie. Wybrano (i) Δ = 60 ms dla r = 0,16 (t r /Δ = 5)
oraz (ii) Δ = 30 ms dla r = 0,4 (t r /Δ = 10), co daje jednakową wartość (i)(ii) 0,3s rr tt== w obu przypadkach, a w konsekwencji zbliżone wartości sygnału sterowania przy tej samej trajektorii zadanej.
Dla porównania przetestowano również pracę serwomechanizmu z dyskretnym regulatorem PID nastrojonym innymi metodami: (iii) z poczwórnym biegunem r ∗ = 23/4 1 układu zamkniętego [14], (iv) z podwójnym zerem regulatora [8]. W tych przypadkach zastosowano czas cyklu Δ = 30 ms, który skutkuje szacowanymi czasami regulacji odpowiednio (iii) 250,75s r t =∆= oraz (iv) 451,35s. r t =∆=
Uzyskane nastawy regulatora dla czterech testowanych przypadków zostały zestawione w Tab. 1. W przypadku testów (i) oraz (ii) nastawy dotyczą regulatora o transmitancji (9), metody z testów (iii) oraz (iv) wykorzystują regulator o transmitancji
Przebiegi regulacyjne dla skokowej i liniowej trajektorii zadanej zostały przedstawione na Rys. 5. We wszystkich testowanych przypadkach rzeczywiste czasy regulacji wykazują dobrą zgodność z wartościami projektowymi. Uchyb w śledzeniu liniowym jest wynikiem zastosowania filtra wielkości zadanej. Praca serwomechanizmu z nastawami opartymi na nowo proponowanej metodzie jest podobna dla obu wartości r w przypadkach (i) oraz (ii), przy czym jakość regulacji jest lepsza dla r = 0,4 i Δ = 30 ms, czego należało oczekiwać na podstawie wyników z poprzedniego rozdziału. W przypadku r = 0,16 i Δ = 60 ms w sygnale sterowania pojawiają się większe oscylacje i w konsekwencji ruch serwomechanizmu jest mniej płynny. Niezależnie od wartości r, odpowiedzi skokowe wykazują małe kilkuprocentowe przeregulowanie. Zestawienie wyników z wariantów (ii)–(iv) pokazuje, że dla takiego samego czasu cyklu Δ = 30 ms różne metody strojenia skutkują znacznie różniącymi się czasami regulacji, przy czym układ nastrojony nowo proponowaną metodą działa zdecydowanie najszybciej uzyskując (iii)(ii)/2,5 rr tt ≅ i (iv)(ii)/4. rr tt ≅ Wyniki potwierdzają spełnienie celu, jakim było-
pozycja zadana
(i) r = 0.16, = 60 ms
(ii) r = 0.40, = 30 ms
(iii) metoda [14], = 30 ms (iv) metoda [8], = 30 ms
(i) r = 0.16, = 60 ms
(ii) r = 0.40, = 30 ms
(iii) metoda [14], = 30 ms (iv) metoda [8], = 30 ms
opracowanie sposobu doboru nastaw minimalizujących czas regulacji dla ustalonego czasu cyklu sterowania lepiej, niż pozwalają na to wcześniej zaprojektowane metody.
7. Podsumowanie
W pracy przedstawiono metodę doboru nastaw dyskretnego regulatora PID dla serwomechanizmu prądowego pozwalającą zlokalizować poczwórny biegun układu zamkniętego w położeniu r ∈ [0, r∗), gdzie 3/4 210,6818. r ∗ =−≅ Daje to możliwość uzyskania dowolnie szybkiej regulacji w sensie minimalizacji ilorazu t r /Δ, aż do regulacji typu dead-beat odtwarzającej dokładnie zmienioną skokowo wielkość zadaną w dwóch cyklach regulacji. Zaproponowana metoda strojenia stanowi dopełnienie wcześniejszych prac, które omawiają nastawy pozwalające uzyskać lokalizację bieguna dominującego r ≥ r ∗ i czas regulacji t r ≥ 25Δ.
Ważnym atutem zaproponowanej procedury doboru nastaw jest to, że opiera się ona na relatywnie prostych wzorach analitycznych wymagających tylko trzech parametrów liczbowych: wzmocnienia obiektu ko, czasu cyklu regulatora Δ i lokalizacji bieguna wielokrotnego r. Czas Δ będzie zwykle wynikać z warunków technicznych sterownika, zatem jedyną decyzją projektową pozostaje dobór wartości r, wyznaczającej kompromis między szybkością regulacji, a jej odpornością na zakłócenia i niedoskonałość dynamiki obiektu.
pozycja zadana
(i) r = 0.16, = 60 ms
(ii) r = 0.40, = 30 ms
(iii) metoda [14], = 30 ms (iv) metoda [8], = 30 ms
(i) r = 0.16, = 60 ms (ii) r = 0.40, = 30 ms (iii) metoda [14], = 30 ms (iv) metoda [8], = 30 ms
Wymogiem zastosowania opracowanej metody strojenia jest użycie algorytmu PID o odpowiedniej konfiguracji, w której występuje człon różniczkujący z filtracją oparty na całkowaniu numerycznym metodą inną, niż algorytm prostokątów wstecz. Może to się wydawać ograniczeniem, np. gdy do dyspozycji jest regulator sprzętowy o zamkniętej architekturze. Trzeba jednak zauważyć, że w każdym przypadku strojenia PID w dziedzinie dyskretnej realizacja członów dynamicznych regulatora musi być dokładnie znana, ponieważ od niej zależy transmitancja. Jeśli jest znana, to zwykle istnieje też możliwość jej konfiguracji, jak np. w bloku PID w Simulink. Dodatkowo, praktycznie wszystkie współczesne sterowniki umożliwiają bezpośrednie kodowanie algorytmu, co pozwala zaimplementować wprost wymagany prosty kod regulatora PID, gdyby odpowiedni gotowy blok nie był dostępny.
W eksperymencie praktycznym regulator nastrojony dla r = 0 (dead-b eat) okazał się zbyt wrażliwy na niezgodność obiektu z modelem idealnym, aby uzyskać jego zadowalające działanie. Mała wartość t r /Δ oznacza niską jakością sprzężenia zwrotnego, które traci możliwość odpowiedniego korygowania niedoskonałości dynamiki obiektu. Dla innych obiektów o transmitancji podwójnie całkującej granica użyteczności przedstawionych nastaw może być odmienna. Uzyskano jednak zadowalające działanie serwomechanizmu dla t r = 5Δ i bardzo dobre dla t r = 10Δ, co byłoby niemożliwe z wykorzystaniem wcześniej proponowanych metod strojenia.
Bibliografia
1. Rao V.G., Bernstein D.S., Naive control of the double integrator, „IEEE Control Systems Magazine”, Vol. 21, No. 5, 2001, 86–97, DOI: 10.1109/37.954521.
3. Kim S., Moment of inertia and friction torque coefficient identification in a servo drive system, „IEEE Transactions on Industrial Electronics”, Vol. 66, No. 1, 2019, 60–70, DOI: 10.1109/TIE.2018.2826456.
4. Bożek A., Discovering stick-slip-resistant servo control algorithm using genetic programming, „Sensors”, Vol. 22, No. 1, 2022, DOI: 10.3390/s22010383.
5. Mikhalevich S.S., Baydali S.A., Manenti F., Development of a tunable method for PID controllers to achieve the desired phase margin, „Journal of Process Control”, Vol. 25, 2015, 28–34, DOI: 10.1016/j.jprocont.2014.10.009.
6. Aström K.J., Wittenmark B., Computer Controlled Systems: Theory and Design. Courier Corporation, 3rd ed., 2011.
7. Bożek A., Trybus L., Krok dyskretyzacji i nastawy PID w dyskretnym serwomechanizmie napięciowym, „Pomiary Automatyka Robotyka”, Vol. 26, No. 1, 2022, 5–10, DOI: 10.14313/PAR_243/5.
8. Żabiński T., Trybus L., Tuning P-PI and PI-PI controllers for electrical servos, „Bulletin of the Polish Academy of
9. Du H., Hu X., Ma C., Dominant pole placement with modified PID controllers, „International Journal of Control, Automation and Systems”, Vol. 17, No. 11, 2019, 2833–2838, DOI: 10.1007/s12555-018-0642-4.
10. Wang Q.-G., Zhang Z., Aström K.J., Chek L.S., Guaranteed dominant pole placement with PID controllers, „Journal of Process Control”, Vol. 19, No. 2, 2009, 349–352, DOI: 10.1016/j.jprocont.2008.04.012.
11. Dincel E., Söylemez M.T., Guaranteed Dominant Pole Placement with Discrete-PID Controllers: A Modified Nyquist Plot Approach, „IFAC Proceedings Volumes”, Vol. 47, No. 3, 2014, 3122–3127, DOI: 10.3182/20140824-6-ZA-1003.02442.
12. Šekara T.B., Rapaić M.R., A revision of root locus method with applications, „Journal of Process Control”, Vol. 34, 2015, 26–34, DOI: 10.1016/j.jprocont.2015.07.007.
13. Dhale S., Nahid-Mobarakeh B., Emadi A., A review of fixed switching frequency current control techniques for switched reluctance machines, „IEEE Access”, Vol. 9, 2021, 39375–39391, DOI: 10.1109/ACCESS.2021.3064660.
14. Bożek A., Trybus L., Tuning PID and PI-PI servo controllers by multiple pole placement, „Bulletin of the Polish Academy of Sciences Technical Sciences”, Vol. 70, No. 1, 2022, 1–12, DOI: 10.24425/bpasts.2021.139957.
Fast Discrete-Time PID Controller for Current Servo
Abstract: A tuning method for a discrete-time PID controller in a current sevro system was developed. The object is modelled by a double integrator. The method allows to obtain arbitrarily fast dynamics of the system, up to dead-beat control. Its use requires a four-parameter variant of the controller with a filtered derivative block. Analytical formulas were derived allowing the calculation of the controller settings based on simple basic design parameters: object gain, controller cycle time and settling time. The tuning method was verified by simulation and the relationship between the response dynamics and the sensitivity to deviation of the object gain from its design value was analyzed. In an experiment with a real object, the correct operation of the control system was confirmed for the settling time 5 and 10 times longer than the controller cycle time. The settings proposed in previous work allowed to obtain a settling time at least 25 times longer than the cycle time.
Keywords: current servo, double integrator, discrete-time control, PID controller, dead-beat control, pole placement, multiple pole
dr inż. Andrzej Bożek abozek@prz.edu.pl
ORCID: 0000-0003-3015-7474
Absolwent Wydziału Elektrotechniki i Informatyki Politechniki Rzeszowskiej (2008). Stopień doktora nauk technicznych w dyscyplinie informatyka uzyskał w 2015 r. Pracuje jako adiunkt w Katedrze Informatyki i Automatyki Politechniki Rzeszowskiej. Jego zainteresowania naukowe dotyczą optymalizacji dyskretnej, harmonogramowania zadań oraz projektowania układów sterowania.
Simple Stability Conditions of Linear Switched Systems with Time-Dependent Switching
Kamil Borawski Białystok University of Technology, Faculty of Electrical Engineering, Wiejska 45D, 15-351 Białystok
Abstract: In this paper, the stability of continuous-time and discrete-time linear switched systems with time-dependent switching is investigated. Solutions to the state equations are provided and sufficient conditions for the stability of such systems are established. The stability conditions presented for continuous-time systems are valid in the following cases: 1) there are no specific restrictions on the switching function if each switching interval is equal to or greater than 1 second; 2) the switching function has to be a periodic function (or a function describing permutations of identical sequences of subsystems) if at least one of the switching intervals is less than 1 second. In the case of discrete-time systems the switching function is arbitrary. The effectiveness of the presented approach is demonstrated by numerical examples.
Keywords: continuous-time, discrete-time, linear switched system, stability, time-dependent switching
1. Introduction
The dynamics of many real physical phenomena can be described by a set of subsystems and a logical rule that controls the switching between them [12]. Mathematical models of such systems are called switched systems. This class of dynamical systems has been considered since the end of the 20th century [4, 13].
The theory of switched systems is widely used in many engineering problems related to mechanical systems, power electronic converters, electric power systems, multi-agent systems, the automotive industry, aircraft and air traffic control, and many other fields, see, e.g., [1, 5, 8, 16, 20].
Stability is one of the most important concepts in dynamical systems theory. The stability of the considered class of systems has been studied in many papers and books for: standard switched systems [4, 12–14, 17, 19, 22], positive switched systems [7, 25], singular switched systems [2, 26], as well as hybrid systems [4, 15, 17]. Moreover, in recent years, fractional-order switched systems have attracted much attention from researchers and problems concerning the stability of such systems have also been studied [6, 9, 21, 23].
The literature also includes many works devoted to the control and stabilization of switched systems [12, 18, 24].
In this paper, the stability of continuous-time and discrete-time linear switched systems with time-dependent switching
Autor korespondujący:
Kamil Borawski, k.borawski@pb.edu.pl
Artykuł recenzowany nadesłany 27.08.2024 r., przyjęty do druku 04.03.2025 r.
will be investigated and some simple stability conditions for this class of dynamical systems will be established. It is assumed that it is possible to determine the relationship between the total switch-on time of individual subsystems. Moreover, the conditions presented for continuous-time systems are valid in the following cases: 1) there are no specific restrictions on the switching function if each switching interval is equal to or greater than 1 second; 2) the switching function has to be a periodic function (or a function describing permutations of identical sequences of subsystems) if at least one of the switching intervals is less than 1 second. In the case of discrete-time systems the switching function is arbitrary.
The paper is organized as follows. In Section 2 considered state-space models of switched linear systems are introduced and solutions to the state equations of such systems are provided. Section 3 is devoted to the stability analysis of switched systems. In this section, sufficient conditions for the stability are established. Numerical examples are presented in Section 4. Concluding remarks are given in Section 5.
The following notation will be used: – the set of real numbers, nm × – the set of n × m real matrices and 1 , nn × = 0 ≥ – the set of nonnegative integers.
2. Preliminaries
In this section considered state-space models will be presented and solutions to the state equations will be provided.
2.1. Continuous-time linear switched systems
Consider the continuous-time linear switched state-space model in the form () ()(), t xtAxt σ = (1) where () n xt ∈ is the state vector, () , nn t A σ × ∈ () t σ is the piecewise constant switching function which takes values in
the finite set {1, 2, . . . , N} and N is the number of subsystems. It is assumed that there are no jumps of the state variables at the switching instants ti, 0 i ≥ ∈ and the () ti σ -th system is active in the interval 1 [,).tttii + ∈
It is well-known [10] that the solution to the equation (1) in the interval 1 [,)tttii + ∈ is given by
() () (), ti i Att i xtex σ = (2)
where () n ii xxt=∈ is the initial condition at the switching instant ti, 0 i ≥ ∈
From (2) it follows that the initial conditions at the switching instants ti, 0 i ≥ ∈ can be computed using the following recursive formula () 11(), ti i At iii xxtex σ ∆ ++ == (3) where 1 iii ttt + ∆=− (4)
Using the equation (3) for i = 0 we obtain
0 10 t At xex σ ∆ = (5)
From the formula (3) for i = 1 and (5) we have ()0 ()1 ()1 0 11 210 t tt At AtAt xexeex
We can continue this procedure for 2. i ≥
Therefore, the initial condition n i x ∈ at i-th switching instant ti, 0 i ≥ ∈ for known initial condition 0 n x ∈ and previous switching instants t0, . . . , ti–1 is given by the formula
()1()2()0 120 0 , titit ii AtAtAt i xeeex σσσ ∆∆∆ = (7)
where ti∆ is defined by (4).
Thus, from equations (2) and (7) we obtain the following solution to the state equation (1).
Lemma 1. The solution to the equation (1) for known initial condition 0 n x ∈ and switching instants ti, 0 i ≥ ∈ is given by the formula () ()110()0 ()()() 0 () , titit ii AttAtAt xteeex σσσ −∆∆ = (8)
where ti∆ is defined by (4).
2.2.
Discrete-time linear switched systems
Consider the discrete-time linear switched state-space model in the form
10 ,, k kk xAxk σ +≥ = ∈ (9)
where n k x ∈ is the state vector, , k nn A σ × ∈ kσ is the switching function which takes values in the finite set {1, 2, . . . , N} and N is the number of subsystems. It is assumed that the kiσ -th system is active in the interval 1 [,)kkkii + ∈ and the initial condition of that system is the final value of the state vector in the previous switching interval 1 [,). ii kkk ∈
It is well-known [10] that the solution to the equation (9) in the interval 1 [,)kkkii + ∈ is given by
where () n ii xxk=∈ is the initial condition at the switching instant ki, 0 i ≥ ∈
For discrete-time systems, one can present considerations analogous to those introduced in Section 2.1. Therefore, the initial conditions n i x ∈ at the switching instants ki, 0 i ≥ ∈ can be computed either from the recursive formula
11()
or the equation
Thus, from (10) and (12) we obtain the following solution to the state equation (9).
Lemma 2. The solution to the equation (9) for known initial condition 0 n x ∈ and switching instants ki, 0 i ≥ ∈ is given by the formula
where ki∆ is defined by (13).
3. Stability of linear switched systems
In this section sufficient conditions for stability of continuous-time and discrete-time switched linear systems will be established.
To obtain the stability conditions the following norms will be used:
1) ∞-norm of a vector [] n i xx=∈ 1 max, i in xx ≤≤ = (15)
2) ∞-norm of a matrix [] nn ij Aa
In the following considerations we will use well-known operations on norms of vectors and matrices [11].
We also assume that it is possible to determine the relationship between the total switch-on time of individual subsystems of the switched systems (1) and (9). Moreover, the conditions presented for continuous-time systems are valid in the following cases:
1) there are no sp ecific restrictions on the switching function () t σ if each switching interval 1, ti ∆≥ 0 ; i ≥ ∈
2) the switching function has to be a periodic function (or a function describing permutations of identical sequences of subsystems) if at least one of the switching intervals 1. ti ∆<
In the case of discrete-time systems the switching function is arbitrary.
If the number of switching instants is finite, testing the stability of the switched system is reduced to testing the stability of the last active subsystem using methods known in the literature for standard linear systems [3, 10].
3.1. Stability of continuous-time switched systems
Definition 1. The continuous-time switched system (1) is called asymptotically stable if
for all initial conditions 0 n
From (8) we have
Let us introduce 0, j T ≥ T j > 0, j = 1, ..., N, which denotes the total switch-on time of the j-th subsystem and observe that
Theorem 1. The continuous-time switched system (1) is asymptotically stable if the switching function (): t σ 1) is any function satisfying the condition (24) for 1, ti ∆≥ 0 ; i ≥ ∈ 2) is a periodic function (or a function describing permutations of identical sequences of subsystems) satisfying the condition (24) for at least one 1, ti ∆<
3.2. Stability of discrete-time switched systems
Definition 2. The discrete-time switched system (9) is called asymptotically stable if
where 0, j c ≥ j = 1, . . . , N is the relative total switch-on time of the j-th subsystem. Therefore, the inequality (18) can be rewritten as
for all initial conditions 0 n x ∈
The analysis can be performed in a similar way as for continuous-time systems. From (14) we have
Introducing 0, j K ≥ j = 1, . . . , N as the total switch-on time of the j-th subsystem and noticing that 111 , 1, NNN jjj jjj kKdkd == =
where 0, j d ≥ j = 1, . . . , N is the relative total switch-on time of the j-th subsystem, the inequality (26) can be rewritten as
The ab ove considerations are valid in the following two cases: 1) for the switching intervals satisfying 1, ti ∆≥ 0 i ≥ ∈ we have () () i ti t ii t AtA ee
and the inequality (20) holds for an arbitrary switching function ();
2) for any switching interval satisfying 1 ti ∆< we have
() () i ti t ii t AtA ee σσ ∆ ∆ ≥ (22)
and the inequality (20) holds only for a periodic switching function () t σ (or a switching function describing permutations of identical sequences of subsystems).
Therefore, we obtain lim()0 t xt →∞ = if
The switching intervals always satisfy the condition 1, ki ∆≥
i
∈ since 0 k
∈ Therefore, the inequality (28) always holds for an arbitrary switching function kσ since
Thus, we obtain lim0
and this implies
and this implies
Thus, the following theorem has been proved.
Therefore, the following theorem has been proved.
Theorem 2. The discrete-time switched system (9) is asymptotically stable if the switching function kσ is any function satisfying the condition (31).
3.3. Discussion
The conditions given in Theorems 1 and 2 take advantage of the fact that the stability of switched systems depends mainly on the form of the switching function. The topic of stable switched systems composed of stable and unstable subsystems is well-known and widely discussed in the literature [14]. Therefore, an adequate ratio of the switch-on times of the individual subsystems must be ensured.
Due to the above, methods based on analyzing the position of the system poles on the complex plane do not apply to switched systems. Thus, the conditions proposed in the article are based on bounding the norm of the state vector. The undoubted advantage of this approach is its simplicity allowing the investigation of switched systems with various configurations, consisting of both stable and unstable subsystems, as long as the condition of the switch-on times ratio for individual subsystems is met.
However, the actual stability region boundaries of the switched system may be located further than the calculations result, as the conditions are obtained through the use of matrix norms inequalities. Therefore, it is an open problem to provide the necessary conditions for the stability of switched systems using the presented method. Furthermore, extending the analysis to a wider group of switching functions for the case of continuous-time systems with faster switching (with time intervals less than 1 second) is also an open issue.
4. Numerical examples
Example 1. Consider the continuous-time linear switched system (1) consisting of N = 3 subsystems with the state matrices given by
From (19), (24) and (33) we obtain 3 12
c cc
(34)
Therefore, the switched system (1) with (32) will be asymptotically stable if the switching function () t σ satisfies the condition (34), i.e., the ratio of the switch-on times of subsystems will be c1 : c2 : c3 such that (34) holds.
For further analysis we assume c1 = 0.5, c2 = 0.2, c3 = 0.3 satisfying (34) and we define the switching function as
(35)
It is easy to check that only the first subsystem is stable, while the other two are unstable. We compute the norms
3 120.045,18.1813,9.0262. A AA eee = = = (33)
In Figure 1 we present time plots of the state variables of the continuous-time linear switched system (1) with (32) for x0 = [ 4 2 5 ]T and the time plot of the switching function () t σ given by (35). We can see that the state variables tend to zero. Similar results can be obtained for any other initial condition x 0 and for any switching function () t σ satisfying the condition (34).
Example 2. Consider the discrete-time linear switched system (9) consisting of N = 2 subsystems with the state matrices given by
It is easy to check that the first subsystem is unstable and the second one is stable. We compute the norms
Fig.
Fig. 2. State variables (up) and the switching function (down) of the discrete-time linear switched system (9) with (36) for
]T Rys. 2. Zmienne stanu (u góry) i funkcja przełączająca (u dołu) liniowego dyskretnego układu przełączalnego (9) o macierzach (36) dla
1. State
Therefore, the switched system (9) with (36) will be asymptotically stable if the switching function kσ satisfies the condition (38), i.e., the ratio of the switch-on times of subsystems will be d1 : d2 such that (38) holds.
For further analysis we assume d1 = 0.3, d2 = 0.7 satisfying (38) and we define the switching function as
3,mod103,4,,9,
where mo d denotes the modulo operation.
In Figure 2 we present time plots of the state variables of the discrete-time linear switched system (9) with (36) for 0 x = [ 1 2 3 ]T and the time plot of the switching function kσ given by (39). We can see that the state variables tend to zero. Similar results can be obtained for any other initial condition 0 x and for any switching function kσ satisfying the condition (38).
5. Concluding remarks
In this paper, the stability of continuous-time and discrete-time linear switched systems with time-dependent switching has been investigated. Solutions to the state equations of such systems have been provided (Lemmas 1 and 2). The main result of the paper is the establishment of sufficient conditions for the stability of the continuous-time (Theorem 1) and discrete-time (Theorem 2) linear switched systems. The effectiveness of the presented approach has been demonstrated by numerical examples.
The conditions proposed in the article are based on the matrix and vector norms calculus since the methods using the analysis of the position of the system poles on the complex plane do not apply to switched systems. The undoubted advantage of this approach is its simplicity allowing the investigation of switched systems with various configurations, consisting of both stable and unstable subsystems, as long as the condition of the switch-on times ratio for individual subsystems is met.
The considerations can be further extended to fractional-order linear switched systems. Establishing the necessary conditions for the stability of this class of dynamical systems based on the presented methodology also remains an open problem. Furthermore, extending the analysis to a wider group of switching functions for the case of continuous-time systems with faster switching (with time intervals less than 1 second) is also an open issue.
Acknowledgments
This work was supported by National Science Centre in Poland under work No. 2022/45/B/ST7/03076.
References
1. Morse A.S. (editor), Control Using Logic-Based Switching, “Lecture Notes in Control and Information Sciences”, Vol. 222, DOI: 10.1007/BFb0036078.
2. Anh P.K., Linh P.T., Thuan D.D., Trenn S., Stability analysis for switched discrete-time linear singular systems, “Automatica”, Vol. 119, 2020, DOI: 10.1016/j.automatica.2020.109100.
3. Antsaklis P.J., Michel A.N., Linear Systems, Birkhäuser, Boston, 2006.
4. Branicky M.S., Stability of switched and hybrid systems, [In:] Proceedings of 33rd IEEE Conference on Decision and Control, 1994, 3498–3503, DOI: 10.1109/CDC.1994.411688.
5. Chen S., Jiang L., Yao W., Wu Q.H., Application of switched system theory in power system stability, [In:] Proceedings of 49th International Universities Power Engineering Conference (UPEC), 2014, DOI: 10.1109/UPEC.2014.6934651.
7. Fornasini E., Valcher M.E., Stability and stabilizability criteria for discrete-time positive switched systems, “IEEE Transactions on Automatic Control”, Vol. 57, No. 5, 2012, 1208–1221, DOI: 10.1109/TAC.2011.2173416.
8. Girejko E., Malinowska A.B., On stability of multi-agent systems on time scales under denial-of-service attacks, [In:] Proceedings of 16th International Conference on Control, Automation, Robotics and Vision (ICARCV), 2020, 489–496, DOI: 10.1109/ICARCV50220.2020.9305492.
9. HosseinNia S.H., Tejado I., Vinagre B.M., Stability of fractional-order switching systems, “Computers & Mathematics with Applications”, Vol. 66, No. 5, 2013, 585–596, DOI: 10.1016/j.camwa.2013.05.005.
10. Kaczorek T., Linear Control Systems, Vol. 1. Research Studies Press, J. Wiley, New York, USA, 1992.
11. Kaczorek T., Vectors and Matrices in Automation and Electrotechnics, WNT, Warsaw, 1998 (in Polish).
12. Lib erzon D., Switching in Systems and Control., Birkhäuser, Boston, 2003.
13. Lib erzon D., Morse A.S., Basic problems in stability and design of switched systems, “IEEE Control Systems Magazine”, Vol. 19, No. 5, 1999, 59–70, DOI: 10.1109/37.793443.
14. Lin H., Antsaklis P.J., Stability and stabilizability of switched linear systems: A survey of recent results, “IEEE Transactions on Automatic Control”, Vol. 54, No. 2, 2009, 308–322, DOI: 10.1109/TAC.2008.2012009.
15. Lin H., Antsaklis P.J., Hybrid dynamical systems: Stability and stabilization, [In:] W.S. Levine (editor), The Control Handbook: Control System Advanced Methods. CRC Press, 2010.
16. Ndoye A., Delpoux R., Trégouët J.F., Lin-Shi X., Switching control design for LTI system with uncertain equilibrium: Application to parallel interconnection of DC/DC converters, “Automatica”, Vol. 145, 2022, DOI: 10.1016/j.automatica.2022.110522.
17. Shorten R., Wirth F., Mason O., Wulff K., King C., Stability criteria for switched and hybrid systems, “SIAM Review”, Vol. 49, No. 4, 2007, 545–592, DOI: 10.1137/05063516X.
18. Sun Z., Ge S.S., Switched Linear Systems: Control and Design, Springer, London, 2005.
19. Sun Z., Ge S.S., Stability Theory of Switched Dynamical Systems, Springer-Verlag, London, 2011.
20. Tomaszuk A., Borawski K., A new approach to examine the dynamics of switched-mode step-up DC–DC converters—a switched state-space model, “Energies”, Vol. 17, No. 17, 2024, DOI: 10.3390/en17174413.
21. Wu C., Liu X.Z., Lyapunov and external stability of Caputo fractional-order switching systems, “Nonlinear Analysis: Hybrid Systems”, Vol. 34, 2019, 131–146, DOI: 10.1016/j.nahs.2019.06.002.
Kamil Borawski
22. Yin Y., Zhao X., Zheng X., New stability and stabilization conditions of switched systems with mode-dependent average dwell time, “Circuits, Systems and Signal Processing”, Vol. 36, 2017, 82–98, DOI: 10.1007/s00034-016-0306-7.
23. Zhang X.F., Wang Z., Stability and robust stabilization of uncertain switched fractional-order systems, “ISA Transactions”, Vol. 103, 2020, DOI: 10.1016/j.isatra.2020.03.019.
24. Zhao X., Kao Y., Niu B., Wu T., Control Synthesis of Switched Systems, Springer, Cham, 2017.
Proste warunki stabilności
25. Zhao X., Zhang L., Shi P., Liu M., Stability of switched positive linear systems with average dwell time switching, “Automatica”, Vol. 48, No. 6, 2012, 1132–1137, DOI: 10.1016/j.automatica.2012.03.008.
26. Zhou L., Ho D.W.C., Zhai G., Stability analysis of switched linear singular systems, “Automatica”, Vol. 49, No. 5, 2013, 1481–1487, DOI: 10.1016/j.automatica.2013.02.002.
liniowych układów przełączalnych z przełączaniem zależnym od czasu
Streszczenie: W artykule zbadano stabilność ciągłych i dyskretnych liniowych układów przełączalnych z przełączaniem zależnym od czasu. Podano rozwiązania równań stanu i wyznaczono warunki wystarczające stabilności takich układów. Warunki przedstawione dla układów ciągłych są słuszne w następujących przypadkach: 1) nie ma szczególnych ograniczeń na funkcję przełączania, jeżeli każdy przedział czasu w kolejnych przełączeniach jest nie krótszy niż 1 sekunda; 2) funkcja przełączająca musi być funkcją okresową (lub funkcją opisującą permutacje identycznych sekwencji załączanych podukładów), jeżeli co najmniej jeden z przedziałów czasu w kolejnych przełączeniach jest krótszy od 1 sekundy. W przypadku układów dyskretnych funkcja przełączająca jest dowolna. Skuteczność zaprezentowanego podejścia pokazano na przykładach numerycznych.
Słowa kluczowe: ciągły, dyskretny, liniowy, układ przełączalny, stabilność, przełączanie zależne od czasu
Kamil Borawski, PhD Eng. k.borawski@pb.edu.pl
ORCID: 0000-0001-7325-1159
He received the MSc degree (with honours) in electrical engineering from the Bialystok University of Technology in 2015 and then started his Ph.D. studies. In 2019 he received the PhD degree (with honours) in automatic control, electronics and electrical engineering from the Bialystok University of Technology. Currently, he is an assistant professor in the Department of Automatic Control and Robotics at the Faculty of Electrical Engineering. He has published over 20 scientific papers and a book. His research interests cover modern control theory, especially descriptor, fractional-order and switched systems.
System testowania i walidacji modeli do sterowania ruchem pojazdów
Marcin Hubacz, Andrzej Paszkiewicz, Bartosz Pawłowicz, Mateusz Salach, Bartosz Trybus, Konrad Żak
Politechnika Rzeszowska, Wydział Elektrotechniki i Informatyki, ul. W. Pola 2, 35-959 Rzeszów
Streszczenie: W artykule przedstawiono prototypowy model do testowania różnych koncepcji i scenariuszy monitorowania i zarządzania ruchem pojazdów z wykorzystaniem koncepcji RFID oraz Internetu Rzeczy. Wskazano na wyzwania związane z identyfikacją ruchomych obiektów oraz potrzebę stosowania wydajnych protokołów komunikacyjnych w środowiskach wielodostępowych. Przedstawiono badania związane z zastosowaniem automatycznej identyfikacji pojazdów (AVI) do zarządzania ruchem i kontrolą dostępu w czasie rzeczywistym, podkreślając korzyści płynące ze stosowania technologii RFID w tworzeniu w pełni zautomatyzowanych systemów zarządzania dostępem. Rozproszony system testowy pozwala na walidację prototypów i algorytmów związanych z procesami i strukturami do zarządzania ruchem. Model uwzględnia wykorzystanie rozwiązań chmurowych, w szczególności Azure IoT Hub do zbierania i monitorowania danych o ruchu pojazdów. Elastyczność proponowanej architektury testowej pozwala na sprawdzanie różnych konfiguracji sprzętu i oprogramowania w zróżnicowanych scenariuszach użytkowania, co prowadzi do szybszego rozwoju i wdrażania proponowanych rozwiązań.
Słowa kluczowe: zarządzanie ruchem, identyfikacja pojazdów, RFID, IoE
1. Wpowadzenie
Zarządzanie ruchem w mieście jest dużym wyzwaniem zarówno z perspektywy technologicznej, jak i logistycznej. Polega na kształtowaniu przepływu pojazdów w taki sposób, aby ruch przebiegał płynnie w ramach określonych parametrów i ograniczeń. Sterowanie ruchem w czasie rzeczywistym powinno być dynamicznie kształtowane w oparciu o zmieniające się warunki otoczenia, takie jak nieoczekiwane zdarzenia i planowane roboty drogowe. System sterowania ruchem powinien kompleksowo uwzględniać specyfikę całego miasta, w tym strefy ograniczonego ruchu zarezerwowane dla konkretnych pojazdów, zajętość miejsc parkingowych oraz zdarzenia społeczno-gospodarcze. Nowoczesne systemy sterowania ruchem powinny nie tylko uwzględniać wzorce ruchu, ale także aktywnie nimi zarządzać, aby ograniczać emisję gazów cieplarnianych, promować korzystanie z transportu publicznego, ograniczać dostęp niektórych pojazdów
Autor korespondujący:
Marcin Hubacz, m.hubacz@prz.edu.pl
Artykuł recenzowany nadesłany 24.09.2024 r., przyjęty do druku 13.01.2025 r.
Zezwala się na korzystanie z artykułu na warunkach licencji Creative Commons Uznanie autorstwa 4.0 Int.
do wybranych obszarów miejskich oraz ułatwiać przejazd pojazdów uprzywilejowanych.
Kluczowe dla takich systemów jest zapewnienie mechanizmów identyfikacji pojazdów w procesach zarządzania ruchem. W tym celu można wykorzystać systemy identyfikacji wizyjnej, jednak ich skuteczność jest silnie uzależniona od warunków atmosferycznych (deszcz, śnieg, mgła itp.). Jedną z technik, którą można zastosować są systemy identyfikacji oparte na identyfikatorach RFID (ang. Radio Frequency IDentification). Ich działanie polega na użyciu fal radiowych, które umożliwiają przesyłanie danych. Systemy te są wykorzystywane w różnych aplikacjach, jak Internet Rzeczy (IoT) [2], Fast Moving Consumer Goods (FMGC) [3], systemy bezpieczeństwa, a nawet w muzeach poprawiając wrażenia ze zwiedzania wystaw [4].
Technika RFID, jako system identyfikacji zbliżeniowej, może być użyta do zarządzania ruchem pojazdów. Przykładem są systemy zarządzania transportem publicznym [5], transportem towarowym i zarządzania ruchem [6, 7], monitorowanie ruchu [8] oraz pobór opłat drogowych [9, 10].
Wykorzystanie znaczników RFID w procesie dynamicznego zarządzania ruchem miejskim wiąże się z koniecznością identyfikacji dużej liczby poruszających się pojazdów. Intensywne badania prowadzą do ciągłej ewolucji istniejących standardów komunikacji. Pojawiają się nowe technologie, szczególnie w przypadku systemów RFID, które pracują na częstotliwościach HF i UHF [9]. Wyniki badań i nowe standardy pozwalają na skuteczną identyfikację pojedynczych pojazdów, nawet w dużych skupiskach.
Ważnym elementem systemu zarządzania ruchem są algorytmy sterowania. Podczas ich opracowywania konieczne jest testowanie w warunkach zbliżonych do rzeczywistych scenariuszy. W tym celu skonstruowano system do testowania i weryfikacji prototypów modeli i algorytmów dedykowanych do nadzoru nad procesami i strukturami IoE (ang. Internet of Everything ), w tym rozwiązań do zarządzania ruchem. System ten umożliwi efektywne testowanie nowych algorytmów i rozwiązań z zakresu dynamicznej identyfikacji pojazdów i zarządzania ruchem na terenach miejskich i przemysłowych.
2. Dynamiczn y system lokalizacji pojazdów wykorzystujący RFID
Rosnąca liczba dróg lokalnych, połączeń międzymiastowych i autostrad, wraz ze wzrostem natężenia ruchu, wymusza kompleksowe podejście do zarządzania ruchem samochodowym przez administratorów obszarów miejskich. Podejmując decyzje dotyczące kontroli przejazdu pojazdów na danej trasie, należy wziąć pod uwagę kilka czynników, takich jak typy pojazdów, strefy ograniczonego ruchu, pora dnia oraz prognoza natężenia ruchu skorelowana z potrzebami grup społecznych. Coraz częściej w centrach miast wyznaczane są specjalne strefy wyłącznie dla pojazdów elektrycznych i hybrydowych. Takie warunki wymagają wdrożenia mechanizmów automatycznej identyfikacji pojazdów, monitorujących i kontrolujących dostępu do tych stref. Rozwiązania tego typu należą do kategorii systemów automatycznej identyfikacji pojazdów (AVI) [1], które zajmują się monitorowaniem ich lokalizacji w czasie rzeczywistym.
W prowadzonych badaniach systemy RFID zostały wskazane jako rozwiązanie umożliwiające zarządzanie i monitorowanie ruchu, szczególnie w środowisku miejskim oraz identyfikację pojazdów i przekazywanie informacji do systemów automatyki w pojazdach. W tym celu pojazdy powinny
być wyposażone w identyfikatory RFID. Znaczniki te mogą być montowane np. na przedniej szybie pojazdu zarówno na etapie produkcji, jak i w pojazdach już eksploatowanych. Systemy instalowane na etapie produkcji mogą dostarczyć szeregu dodatkowych informacji serwisowych, pozwalających na właściwy dobór części zamiennych, identyfikację poziomów emisji do atmosfery czy zaplanowanie przeglądów serwisowych. Znakowanie pojazdów może być użyte w ograniczaniu stref ruchu, planowaniu przepływu i systemach parkingowych.
Na rys. 1 przedstawiono wybrane sposoby instalacji anten odczytująco-zapisujących RFID (RWD) w zależności od ograniczeń i wymagań. Anteny mogą być montowane na belkach montażowych nad drogą (rys. 1a), na masztach wzdłuż drogi (rys. 1b) lub bezpośrednio w nawierzchni drogi (rys. 1c). Należy zauważyć, że zagęszczenie instalacji antenowych zależy od przepustowości transmisji danych poszczególnych odcinków dróg. W lokalizacji (rys. 1d) każda antena RWD obsługuje jeden pas ruchu i identyfikuje pojazdy w obrębie swojej wiązki drogowej, dlatego w takich systemach często stosuje się anteny kierunkowe. Możliwe jest również zmniejszenie liczby anten przez wprowadzenie wielu procesów AVI, gdzie zasięg anten obejmuje wiele pasów ruchu (rys. 1e). Komercyjne systemy identyfikacji RFID działają zgodnie z przepisami prawnymi i standardami branżowymi. Przykładami takich wymagań są ISO 14443 [16], ISO 15693 [17], ISO 18000 [18]. Szczególnie interesująca z punktu widzenia identyfikacji pojazdów, jest norma ISO 18000 część 63.
3. Architektura modelu badawczego
W trakcie prac nad algorytmami sterowania ruchem pojazdów przyjęto dwa założenia. Do przeprowadzenia badań niezbędne jest stworzenie modelu badawczego, który pozwoli na symulację różnych układów ulic, systemów sterowania (np. sygnalizacji świetlnej) oraz przepływu ruchu. Model powinien uwzględniać różne możliwości wdrażania systemów RFID. Takie podejście ułatwi testowanie różnych algorytmów sterowania i weryfikację działania systemu w warunkach laboratoryjnych, ale zbliżonych do realistycznych. Drugie założenie dotyczy lokalizacji algorytmów przetwarzania i sterowania danymi. Zdecydowano, że zostaną one wdrożone w chmurze obliczeniowej. Projektowany model musi umożliwiać dwukierunkową komunikację z komponentami oprogramowania znajdującymi się w środowisku chmurowym.
Rys. 1. Przykłady lokalizacji anten RFID do pomiaru ruchu pojazdów na infrastrukturze drogowej
Fig. 1. Examples of RFID antenna locations for measuring vehicle traffic in road infrastructure
Opracowano model symulacji ruchu w obszarach zurbanizowanych z możliwością realizacji zmiennych scenariuszy drogowych z użyciem RFID. Model laboratoryjny składa się z modułów o wymiarach 60 cm × 60 cm, które można ze sobą łączyć (rys. 2). Model pozwala na testowanie i aktywację w dwóch trybach. Pierwszym jest scenariusz, w którym czytniki RFID działają na poziomie infrastruktury miejskiej, kontrolowanej przez mikrokomputer jednopłytkowy SBC. Platforma obliczeniowa komunikuje się z czytnikami RFID przez multiplekser 16:1 za pomocą protokołu SPI (rys. 3). Po wykryciu znacznika RFID w obszarze roboczym czytnika wysyła sygnał przerwania do multipleksera (rys. 3a). Po prawidłowym skonfigurowaniu multipleksera następuje komunikacja między czytnikiem RFID a SBC (rys. 3b). Czytnik RFID przesyła UID identyfikatora oraz informacje o pojeździe zapisane w jego pamięci (rys. 3c). Dane są przesyłane do chmury obliczeniowej, gdzie są przetwarzane w czasie rzeczywistym. Na podstawie informacji otrzymanych z chmury, jednostka SBC steruje infrastrukturą techniczną, np. oświetleniem ulicznym.
Powierzchnia pojedynczego stanowiska o wymiarach 60x60 cm
Otwór montażowy identyfikatora/czytnika w zależności od zdefiniowanej funkcji stacji
W obrębie każdego obszaru wydzielono obszary o wymiarach 10x10 cm
Otwory montażowe pod elementy infrastruktury ulicznej
Rys. 2. Schemat budowy modułowej platformy testowej Fig. 2. Construction diagram of a modular test platform
Drugi tryb polega na zbieraniu danych za pomocą czytników RFID zintegrowanych z pojazdem mobilnym, odczytujących dane z identyfikatorów umieszczonych w infrastrukturze drogowej. Pasywne znaczniki mogą dostarczać systemom pokładowym pojazdu informacje o warunkach drogowych, temperaturze powietrza i nawierzchni drogi, lokalizacji i nie tylko. Informacje o lokalizacji pojazdu są też dostępne w miejscach ograniczonego zasięgu GPS, takich jak tunele, parkingi podziemne czy obiekty przemysłowe.
4. Architektura systemu zarządzania ruchem
Zdecydowano, że architektura systemu sterowania i zarządzania ruchem będzie oparta na chmurze obliczeniowej komunikującej się z urządzeniami sterującymi ruchem, pojazdami i infrastrukturą drogową. Chmura obliczeniowa zapewnia usługi obliczeniowe, np. serwery, sieci, bazy danych i oprogramowanie. Rozwiązanie to umożliwia szybką rekonfigurację, dzięki dużej elastyczności i skali dostępnych zasobów. Istotnym elementem architektury omawianego prototypu są usługi platformy chmurowej Microsoft Azure, które obejmują:
Azure Cosmos DB – system nierelacyjnej bazy danych NoSQL, Azure Function – mechanizm uruchamiania funkcji niestandardowych, Azure IoT Hub – integrator rozwiązań Internetu Rzeczy, AppService – śro dowisko uruchomieniowe aplikacji.
Rozważane są dwa rozwiązania dotyczące architektury systemu zarządzania ruchem. W pierwszym przypadku (rys. 4a) zakłada się, że w pojazdach zainstalowany jest komputer pokładowy z czytnikiem RFID. Identyfikatory RFID są rozmieszczone w nawierzchni drogi, a pojazdy odczytują ich zawartość podczas ruchu. W drugim podejściu (rys. 4b), identyfikatory RFID umieszczane są w pojazdach i skanowane przez urządzenia znajdujące się w infrastrukturze drogowej. Chmura obliczeniowa komunikuje się z komputerami pokładowymi w pojazdach i systemami sterowania sygnalizacją świetlną.
Do przetwarzania danych służy usługa Azure IoT Hub, stanowiąca centrum całego systemu (rys. 4c). Przesyła komunikaty między aplikacją IoT a podłączonymi urządzeniami. Komunikacja z IoT Hub jest dwukierunkowa. Komunikaty umożliwiają sterowanie sygnalizacją świetlną.
Dane odebrane za pośrednictwem IoT Hub są przekazywane do usługi Azure Cosmos DB z wykorzystaniem Azure Functions. W proponowanej infrastrukturze usługa
Rys. 3. Etapy pobierania informacji z identyfikatorów RFID do systemu z wykorzystaniem SBC Fig. 3. Steps of downloading information from RFID identifiers to the system using SBC
Rys. 4. Architektura systemu; a) czytniki w jezdni, identyfikatory w pojazdach, b) czytniki w pojazdach, identyfikatory w jezdni, c) komunikacja z usługami chmurowymi
Fig. 4. System architecture a) readers in the road, identifiers in vehicles, b) readers in vehicles, identifiers in the road, c) communication with cloud services
Marcin Hubacz, Andrzej Paszkiewicz, Bartosz Pawłowicz, Mateusz Salach, Bartosz Trybus, Konrad Żak
ta służy do przechowywania danych telemetrycznych związanych z pozycjami pojazdów, ich liczbą, stanem sygnalizacji świetlnej itp.
Usługa Azure AppService jest pomostem między IoT Hub a interfejsem użytkownika, umożliwiając odbieranie i wyświetlanie danych w czasie rzeczywistym na ekranie przeglądarki. Aplikacja składa się z modułów środowiska Node.js, z których każdy służy określonemu celowi, tj.: generowanie tokenów sygnatury dostępu współdzielonego (SAS) w celu zapewnienia bezpiecznego dostępu do zasobów IoT Hub, interakcja z IoT Hub za pośrednictwem funkcji asynchronicznych do odczytywania komunikatów z IoT Hub (np. identyfikatora pojazdu), utrzymywanie połączenia WebSocket między aplikacją serwera a przeglądarką klienta.
Moduły te stanowią szkielet aplikacji, umożliwiając pobieranie, przetwarzanie i wyświetlanie danych o położeniu pojazdu.
5. Zastosowania opracowanego modelu
Prototyp laboratoryjny może być wykorzystany do symulacji różnych scenariuszy związanych z monitorowaniem i zarządzaniem ruchem w mieście.
W najprostszym przypadku (rys. 5a), w obszarze identyfikacji znajduje się tylko jeden pojazd. Ten scenariusz jest najmniej złożony, ponieważ projektanci systemu nie muszą implementować mechanizmów obsługi kolizji sygnałów ani algorytmów różnicowania pojazdów. Ponadto pojedyncza metoda identyfikacji charakteryzuje się najniższym zużyciem energii. Zastosowanie tego scenariusza w rzeczywistych warunkach drogowych jest mało prawdopodobne.
Rzeczywiste warunki na drodze wymagają identyfikowania wielu pojazdów jednocześnie (rys. 5b). W tym trybie wymagane są wyspecjalizowane algorytmy obsługujące potencjalne kolizje komunikacyjne wielu identyfikatorów RFID znajdujących się w obszarze poprawnej pracy IZ (ang. Interrogation Zone).
Dodatkowym warunkiem utrudniającym identyfikację jest ruch pojazdów podczas komunikacji (rys. 5c). Identyfikacja dynamiczna wydaje się być najbardziej odpowiednia dla aplikacji AVI. Jej skuteczność zależy od prędkości i liczby jednocześnie znajdujących się pojazdów w IZ. Cały czas system musi rozpoznawać nowe pojazdy wjeżdżające do strefy identyfikacji.
Jednym ze scenariuszy, w którym można wykorzystać system AVI, jest kontrola dostępu do wyznaczonych stref lub ulic (rys. 6). System nadzoru umożliwia pojazdom elektrycznym dostęp do obszarów, w których ruch samochodów z silnikami spalinowymi jest ograniczony. Dotyczy to również miejsc parkingowych, na których znajdują się ładowarki elektryczne. Pojazdy wyposażone w zasilanie LPG mogą nie zostać wpuszczone do stref wysokiego zagrożenia pożarowego lub parkingów podziemnych. Zastosowanie systemów AVI może obejmować również zastosowania przemysłowe, gdzie logistyka dostaw towarów w obrębie określonej strefy może być nadzorowana i kontrolowana przez system RFID. Wjazd nieupoważnionych pojazdów na wyznaczony obszar będzie ograniczony.
Wykorzystanie systemów RFID pozwala na budowanie w pełni zautomatyzowanych systemów zarządzania dostępem. Gdy pojazd zbliża się do bramki (rys. 6b, strona prawa), czytnik RFID wykrywa identyfikator w samochodzie i analizuje otrzymane informacje (numer rejestracyjny, nazwa firmy, typ pojazdu i inne). Zebrane informacje są następnie przekazywane do systemu zarządzania [14]. Po zweryfikowaniu uprawnień dostępu dla konkretnej strefy, system automatycznie decyduje, czy otworzyć bramę, czy wyświetlić komunikat informujący o braku autoryzacji do wejścia.
Alternatywnym podejściem jest instalacja identyfikatorów w infrastrukturze drogowej (rys. 6a, strona lewa). Tutaj poruszający się pojazd jest wyposażony w czytnik RFID. Pojazd poruszający się po drodze odczytuje kolejne identyfikatory RFID umieszczone na elementach infrastruktury drogowej. Następnie komputer pokładowy pojazdu przesyła zebrane dane do systemu zarządzania ruchem. Na podstawie tych informacji można obliczyć średnie obciążenie ruchem
Rys. 5. Tryby identyfikacji RFID: a) pojedyncza identyfikacja; b) wielokrotna identyfikacja; c) identyfikacja dynamiczna
Fig. 5. RFID identification modes: a) single identification; b) multiple identification; c) dynamic identification
Rys. 6. Miejska infrastruktura drogowa; a) z transponderami RFID umieszczonymi w nawierzchni drogi; b) z transponderami w pojazdach
Fig. 6. Urban road infrastructure; a) with RFID transponders placed in the road surface; b) with transponders in vehicles
na określonych odcinkach dróg i prędkości pojazdów. Uzyskane dane mogą być wykorzystane do zarządzania ruchem w czasie rzeczywistym. W czasie zwiększonego ruchu na danym odcinku drogi, pojazdy mogą zostać przekierowane na alternatywne trasy. Podobne działania można podjąć w przypadku zdarzeń losowych, takich jak wypadki drogowe.
6. Bad ania efektywności algorytmów sterowania ruchem
Korzystając ze zbudowanej makiety (rys. 7) przeprowadzono eksperymenty, których celem była ocena wpływu zastosowania techniki RFID na poprawę efektywności algorytmu sterowania sygnalizacją świetlną na skrzyżowaniu. Wykorzystano tu dane pochodzące z identyfikatorów RFID pojazdów. Przeprowadzono pomiary czasu oczekiwania pojazdów na skrzyżowaniu przyjmując cztery scenariusze natężania ruchu tj.: niskie natężenie ruchu, średnie natężenie ruchu, wysokie natężenie ruchu, zator drogowy.
Rys. 7. Makieta inteligentnego stanowiska pomiarowego Fig. 7. Mock-up of a smart measurement station
Wyniki badań podano w tabeli 1. Stosując przytoczone cztery scenariusze przeprowadzono serię badań oceny efektywności dwóch algorytmów: algorytm sekwencyjny, algorytm wykorzystujący informacje o liczbie pojazdów z wbudowanych identyfikatorów RFID.
Tab. 1. Wyniki porównania efektywności zastosowanych algorytmów w zależności od natężenia ruchu drogowego
Tab. 1. Results of the comparison of the efficiency of the algorithms used depending on the traffic intensity
Scenariusz Algorytm sekwencyjny [s] Algorytm RFID [s] Różnica [s]
Niskie natężenie
Zator drogowy 3,14 2,97 0,17
Pierwsza seria dotyczyła sterowania ruchem za pomocą algorytmu sekwencyjnego, który polega na przełączaniu świateł na poszczególnych skrzyżowaniach w zadeklarowanej, stałej jednostce czasu. Liczba pojazdów nie wpływa na działanie algorytmu, który będzie wykonywany nawet w przypadku, gdy pojazdów nie będzie na danej części skrzyżowania.
Druga seria uwzględniała zastosowanie techniki RFID do zliczania liczby pojazdów. W tym przypadku zastosowano zmodyfikowany algorytm Alana J. Millera [15]. Algorytm umożliwia podejmowanie decyzji o przełączeniu sygnalizacji świetlnej do kolejnej fazy w regularnych odstępach czasu T, np. co 1 s. Wynikiem działania algorytmu jest decyzja, czy przełączenie powinno nastąpić natychmiast, czy można je odroczyć o czas T. W tym celu obliczane są zyski i straty czasowe wynikające z różnych chwil podjęcia decyzji, przesuwając przełączanie o k × T sekund. Decyzja zależy od liczby pojazdów czekających na skrzyżowaniu. Celem jest neutralizacja obciążenia skrzyżowania przez: przepuszczenie większej liczby pojazdów (jeśli są) na danym odcinku, przełączenie algorytmu na kolejne światła w przypadku braków pojazdów.
Zastosowanie techniki RFID do identyfikacji pojazdów i ustalania ich liczby na skrzyżowaniu pozwala znacząco skrócić czas oczekiwania we wszystkich scenariuszach, poza przypadkiem wysokiego natężenia ruchu. Ten ostatni wynik można wytłumaczyć narzutem czasowym koniecznym do identyfikacji dużej liczby pojazdów w jednostce czasu. Jednocześnie wskazuje to kierunki przyszłych badań dotyczących modelowania i implementacji tego typu systemów. Kolejne badania będą nastawione nie tylko na doskonalenie algorytmów sterowania, ale również skrócenie czasu identyfikacji puli obiektów o dużej liczebności.
7. Podsumowanie
W ramach prowadzonych prac badawczych wdrożony został system do testowania i weryfikacji prototypów, modeli i algorytmów dedykowanych do nadzoru procesów i struktur reprezentatywnych dla zarządzania ruchem pojazdów. System ten pozwala na szybkie i łatwe testowanie nowych algorytmów i rozwiązań z zakresu dynamicznej identyfikacji pojazdów i zarządzania ruchem w systemach miejskich i przemysłowych. Zaprezentowana wysoka elastyczność funkcjonalna opracowanej i wykonanej architektury umożliwia testowanie różnych konfiguracji sprzętu i oprogramowania w różnych scenariuszach użytkowania.
Bibliografia
1. Ustundag The Value of RFID. Benefits vs. Costs, 1st ed., Springer, London, UK, 2013.
2. Greengard S., The Internet of Things, MIT Press, 2021.
3. Tseng C. W., Huang C. H., Toward a consistent expression of things on EPCglobal architecture framework, 2014 International Conference on Information Science, Electronics and Electrical Engineering, Sapporo, Japan, 2014, 1619–1623, DOI: 10.1109/InfoSEEE.2014.6946195.
4. Alrafaei M.N., Bushager A., Smart city mobility: Investigation of RFID adoption within transportation management, Smart Cities Symposium 2018, Bahrain, 2018, DOI: 10.1049/cp.2018.1403.
5. Yatao Z., Jiangfeng W., Sijie C., Zhijun G., Haitao H., Multi-tag Information Interactive Communication Model based on Precise Position Detection in Vehicle-Infra-
Marcin Hubacz, Andrzej Paszkiewicz, Bartosz Pawłowicz, Mateusz Salach, Bartosz Trybus, Konrad Żak
structure Collaboration Environment, 2020 IEEE 5th International Conference on Intelligent Transportation Engineering (ICITE), Beijing, China, 2020, 326–330, DOI: 10.1109/ICITE50838.2020.9231342.
6. Zhang X., Li H. X., Chung H. S. H., Setup-Independent Sensing Architecture With Multiple UHF RFID Sensor Tags, “IEEE Internet of Things Journal”, Vol. 9, No. 2, 2022, 1243–1251,DOI: 10.1109/JIOT.2021.3079448.
7. Hidalgo E., Muñoz F., Guerrero de Mier A., Carvajal R.G., Martín-Clemente R., Wireless inventory of traffic signs based on passive RFID technology, IECON 2013 – 39th Annual Conference of the IEEE Industrial Electronics Society, Vienna, Austria, 2013, 5467–5471, DOI: 10.1109/IECON.2013.6700026.
8. Adarsh A., Arjun C., Koushik S., Krishnan M., Purushothaman V S., Nair A.K., Integrated Real-time Vehicle Speed Control System using RFID and GPS, 2020 Second International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 2020, 194–200, DOI: 10.1109/ICIRCA48905.2020.9182925.
9. Dobkin D.M., The RF in RFID: UHF RFID in Practice, 2nd ed., Newnes, Oxford, UK, 2012.
10. Pawłowicz B., Salach M., Trybus B., Infrastructure of RFID-Based Smart City Traffic Control System: Progress in Automation , “Robotics and Measurement Techniques”, Springer International Publishing, Cham, Switzerland, Vol. 920, 2019, DOI: 10.1007/978-3-030-13273-6_19.
11. Wong S.F., Mak H.C., Ku C.H., Ho W.I., Developing advanced traffic violation detection system with RFID technology for smart city, 2017 IEEE International Conference on Industrial Engineering and Engineering Management (IEEM), Singapore, 2017, 334–338, DOI: 10.1109/IEEM.2017.8289907.
12. Chowdhury P., Bala P., Add D., Giri, S. Chaudhuri A. R., RFID and Android based smart ticketing and destination announcement system, 2016 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Jaipur, India, 2016, 2587–2591, DOI: 10.1109/ICACCI.2016.7732447.
13. Hassan M.A., Javed R., Farhatulla, Granelli F., Gen X., Rizwan M., Ali S. H., Junaid H., Ullah S., Intelligent Transportation Systems in Smart City: A Systematic Survey, 2023 International Conference on Robotics and Automation in Industry (ICRAI), Peshawar, Pakistan, 2023, DOI: 10.1109/ICRAI57502.2023.10089543.
15. Vincent R.A., Peirce J.R., ‘MOVA’: Traffic Responsive, Self-Optimising Signal Control for Isolated Intersections, TRRL Research Report RR 1. Transport and Road Research Laboratory, Wokingham, Berkshire, United Kingdom, 1988.
18. ISO 18000-6 – RFID for item management; Air interface; Part 6: Parameters for Air Interface Communications at 860 to 960 MHz, 2006.
A System for Testing and Verifying Prototypes of Models for Vehicle Traffic Control
Abstract: The paper presents an overview of a prototype model for testing various concepts and scenarios related to monitoring and managing traffic in urban and industrial environments using RFID and the Internet of Things (IoT) concepts. The challenges posed by identification of moving objects and the need for efficient communication protocols in multi-access environments are indicated. The use of Automatic vehicle identification (AVI) for access control and real-time traffic management is also explored, emphasizing the benefits of RFID technology in creating fully automated access management systems. The presented distributed testing system allows for validating prototypes and algorithms related to processes and structures for traffic management. The model considers the use of cloud solutions, in particular the Azure IoT Hub to collect and control vehicle traffic data. The flexibility of the proposed architecture allows for testing different hardware and software configurations in various usage scenarios, leading to faster development and deployment.
Keywords: traffic management, vehicle identification, RFID
mgr inż. Marcin Hubacz
m.hubacz@prz.edu.pl
ORCID: 0000-0002-2748-11454
W 2019 r. ukończył studia na Wydziale Elektrotechniki i Informatyki Politechniki Rzeszowskiej – kierunek Automatyka i Robotyka oraz Informatyka. Obecnie Asystent w Katedrze Informatyki i Automatyki Politechniki Rzeszowskiej. Jego główne zainteresowania dotyczą robotyki, elektroniki, systemów wbudowanych oraz druku 3D.
dr inż. Bartosz Trybus btrybus@kia.prz.edu.pl
ORCID: 0000-0002-4588-3973
Adiunkt w Katedrze Informatyki i Automatyki Politechniki Rzeszowskiej. Ukończył studia na Wydziale Elektrycznym, Automatyki, Informatyki i Elektroniki AGH w Krakowie. Doktorat z informatyki uzyskał w 2004 r. Jego główne badania dotyczą systemów czasu rzeczywistego i środowisk wykonawczych oprogramowania sterującego.
mgr inż. Mateusz Salach
m.salach@prz.edu.pl
ORCID: 0000-0002-9199-3460
Asystent w Zakładzie Systemów Złożonych Wydziału Elektrotechniki i Informatyki Politechniki Rzeszowskiej. Zajmuje się rozwiązaniami i badaniami z zakresu Internetu Rzeczy, VR oraz Smart City.
dr inż. Bartosz Pawłowicz barpaw@prz.edu.pl
ORCID: 0000-0001-9469-2754
Adiunkt w Katedrze Systemów Elektronicznych i Telekomunikacyjnych Wydziału Elektrotechniki i Informatyki Politechniki Rzeszowskiej. Doktorat w dyscyplinie telekomunikacja u zyskał na Wydziale Elektrotechniki, Automatyki, Informatyki i Elektroniki AGH w Krakowie w 2012 r. Jego główne badania dotyczą systemów identyfikacji bezstykowej RFID i ich zastosowań.
dr inż. Andrzej Paszkiewicz andrzejp@prz.edu.pl
ORCID: 0000-0001-7573-3856
Adiunkt w Zakładzie Systemów Złożonych Politechniki Rzeszowskiej. Stopień doktora nauk technicznych w zakresie informatyki uzyskał w 2009 r. na Politechnice Łódzkiej. Autor około 100 publikacji w krajowych i międzynarodowych czasopismach naukowych i materiałach konferencyjnych. Organizował warsztaty i konferencje z zakresu sieci komputerowych, inżynierii oprogramowania oraz Przemysłu 4.0. Jego zainteresowania badawcze skupiają się na procesach zachodzących w strukturach sieciowych, VR/AR, a także na rozwoju technologii dla przemysłu.
Konrad Żak
160818@stud.prz.edu.pl
ORCID: 0000-0002-8131-5789
Student kierunku Informatyka na Politechnice Rzeszowskiej. Interesuje się cyberbezpieczeństwem, rozwiązaniami z zakresu IoT oraz rozwiązaniami chmurowymi.
Marcin Hubacz, Andrzej Paszkiewicz, Bartosz Pawłowicz, Mateusz Salach, Bartosz Trybus, Konrad Żak
System półautonomicznego sterowania tandemem kosiarek do koszenia terenów przydrożnych
Andrzej Typiak, Rafał Typiak
Wojskowa Akademia Techniczna im. Jarosława Dąbrowskiego, ul. gen. Sylwestra Kaliskiego 2, 00-908 Warszawa
Zbigniew Zienowicz, Mateusz Nowakowski
HYDROMEGA sp. z o.o., ul. Konstruktorów 1, 81-336 Gdynia
Patrycja Matejek
Stowarzyszenie Robotyków SKALP, Gdański Park Naukowo-Technologiczny, ul. Trzy Lipy 3, 80-172 Gdańsk
Streszczenie: Dbanie o pas drogowy wymaga regularnego koszenia rowów i terenów przydrożnych. Jest to realizowane głównie za pomocą kosiarek montowanych na ciągnikach rolniczych. Tendencją jest wprowadzanie autonomicznych systemów koszących, jednak do tej pory pojawiło się szereg rozwiązań autonomicznych robotów koszących krótką trawę (przydomowe trawniki, pola golfowe), mało jest rozwiązań autonomicznych kosiarek do koszenia trawy wysokiej. W artykule opisano uwarunkowania determinujące prowadzenie prac nad rozwojem kosiarek do koszenia trawy. Przedstawiono propozycję półautonomicznego systemu sterowania tandemem kosiarek do koszenia terenów przydrożnych. Zaprojektowano i zbudowano w pełni funkcjonalny zestaw składający się z kosiarek: kołowej i gąsienicowej, układu zdalnego sterowania pierwszą kosiarką oraz komputera wysokiego poziomu z oprogramowaniem, zapewniającym wyznaczenie trasy przejazdu dla drugiej kosiarki. Seria testów poligonowych pozwoliła ocenić skuteczność i praktyczność proponowanego rozwiązania. Wydajność koszenia oceniano na podstawie spójności kolejnych ścieżek koszenia. Wyniki wskazują, że rozwój opracowanego systemu znacząco poprawi efektywność pracy i bezpieczeństwo pracowników.
Słowa kluczowe: koszenie, kosiarka autonomiczna, planowanie trasy, nawigacja
1. Wprowadzenie
Koszenie rowów i terenów przydrożnych jest ważnym elementem utrzymania pasa drogowego. Koszenie przydrożnej roślinności zmniejsza ryzyko pożaru, poprawia estetykę, widoczność oraz ogranicza wzrost i rozprzestrzenianie się chwastów. Firmy koszące bazują głównie na kosiarkach montowanych na ciągnikach rolniczych. Kosiarka z wysięgnikiem montowana na ciągniku (rys. 1), jest standardową konfiguracją koszenia stosowaną przez firmy koszące.
Koszenie mechaniczne, w odróżnieniu od stosowania pestycydów, jest korzystne z wielu powodów. Jest wyborem ekonomicznym do kontroli roślinności. To metoda o niewielkim wpływie na środowisko i niewielu ograniczeniach związanych z pogodą [19].
Autor korespondujący:
Andrzej Typiak, andrzej.typiak@wat.edu.pl
Artykuł recenzowany nadesłany 08.10.2024 r., przyjęty do druku 16.01.2025 r.
Zezwala się na korzystanie z artykułu na warunkach licencji Creative Commons Uznanie autorstwa 4.0 Int.
Aby zwiększyć wydajność oraz zmniejszyć obciążenie i liczbę pracowników zaangażowanych w koszenie trawy, prowadzone są prace nad automatyzacją kosiarek. Ukierunkowane są zarówno na rozwój elementów koszących, układów napędowych, jak i układów sterowania [1]. W kontekście zrobotyzowanych kosiarek szeroko przebadane są algorytmy planowania ścieżki i lokalizowania przeszkód dla kosiarek automatycznych. Jednak dotyczy to przede wszystkim kosiarek przeznaczonych do pracy w przydomowych ogródkach lub na polach golfowych [2].
Rys. 1. Kosiarka z wysięgnikiem montowana na ciągniku [19]
Fig. 1. Mower with a boom mounted on a tractor [19]
Fot. Konrad Stach
2. Rozwój automatycznych systemów koszenia
W ostatnich latach wzrasta liczba rozwiązań zarówno kosiarek zrobotyzowanych, jak i wyposażonych w elementy autonomii [3, 4]. Istnieje jednak wiele wyzwań technicznych i systemowych związanych z opracowywaniem autonomicznych kosiarek do trawy. Jest to złożone zagadnienie, gdyż: warunki brzegowe i środowiskowe podczas użytkowania kosiarek są zdefiniowane w bardzo ograniczonym zakresie; w przypadku awarii kosiarka może spowodować znaczne szkody i obrażenia zarówno ludzi i zwierząt oraz sprzętu; wymagany jest złożony zestaw czujników i dedykowany system sterowania; −jest to system bardzo drogi.
Zastosowanie autonomicznych i półautonomicznych kosiarek do trawy było tematem badań koncentrujących się na skutecznym planowaniu ścieżek i kontroli działania systemu [5]. Kosiarki autonomiczne i półautonomiczne różnią się od prostych kosiarek automatycznych. W przypadku systemu półautonomicznego mamy do czynienia z pewnym stopniem autonomii, ale nadal istnieje interfejs operatora z systemem, a operator zapewnia co najmniej część kontroli i kierowania systemem (system może czasami działać autonomicznie). Półautonomię można zdefiniować jako to wszystko, co wiąże się z podejmowaniem decyzji przez maszynę (w odpowiedzi na zewnętrzne, nieoczekiwane zdarzenia) podczas pracy, w co zaangażowany jest człowiek w niektórych z tych procesów i zapewnia pewną bezpośrednią kontrolę. Mamy tutaj współdzielenie kontroli systemu między komputerem a operatorem. System autonomiczny to taki, który może działać niezależnie, gdy zadanie zostanie zainicjowane przez użytkownika. Może to przybrać formę definiowania przez operatora warunków brzegowych, w których maszyna może operować i planowania operacji lub bezpośredniego inicjowania zadań jeśli to niezbędne. Obecnie konieczne jest zastosowanie pewnego rodzaju monitorowania na wypadek utraty kontroli nad systemem.
Logiczne zrozumienie teoretycznej zależności między systemami autonomicznymi, półautonomicznymi i zautomatyzowanymi/zdalnie sterowanymi przedstawiono na rys. 2. Zautomatyzowany system wykonuje zaprogramowany zestaw operacji [6, 7]; decyzje nie są podejmowane podczas pracy, a wszystkie operacje są zaprojektowane tak, aby wykonać z góry ustaloną serię zadań w znanym (lub założonym) układzie odniesienia.
Systemy sterowania w układzie teleoperacji działają podobnie, ale operator bezpośrednio steruje systemem i odbierając sygnały zwrotne może reagować na nieoczekiwane zdarzenia [7]. Zazwyczaj operator nie jest zaangażowany w system autonomiczny. Jednak należy podkreślić, że autonomiczne systemy koszące muszą być wyposażone w pewien rodzaj kontroli przez operatora w przypadku zaistnienia sytuacji awaryjnej [8, 9].
3. Koncepcja systemu koszenia tandemem robotów koszących
Na rys. 3 przedstawiono schemat koncepcyjny opracowanego półautonomicznego systemu koszenia. Istotną częścią projektu było opracowanie układu zdalnego sterowania, umożliwiającego sterowanie każdą z kosiarek w układzie teleoperacji, oraz układu autonomii umożliwiającego pracę kosiarek w tandemie, przy założeniu zdalnego sterowania przez operatora jedną kosiarką i autonomiczną pracą drugiej kosiarki, podążającej za kosiarką wiodącą. Przyjęto założenie, że system będzie pracował w terenie i pas przydrożny z przewidywalnymi i nieprzewidywalnymi przeszkodami jest przestrzenią operacyjną dla systemu. Podstawowymi elementami tej przestrzeni operacyjnej są użytkownik i interfejs użytkownika, kosiarki, teren do koszenia (tj. mapa terenu), baza operacyjna, granice pasa przydrożnego i przeszkody. Przeszkody można podzielić na trzy kategorie:
a) przewidywalne przeszkody oznaczone w przestrzeni roboczej (niezakłócające);
b) przewidywalne przeszkody zakłócające (np. znaki drogowe); c) nieprzewidywalne przeszkody (np. zwierzęta).
Jednym z głównych układów systemu autonomicznego sterowania jest układ lokalizacji wyznaczający pozycję każdej kosiarki i pozwalający określić postęp w realizacji zadania koszenia. Mapa terenu może być definiowana przez użytkownika. W zależności od lokalnych warunków i geometrii koszonego obszaru, może być konieczne mapowanie terenu na początku każdego koszenia lub może być wykonane tylko raz, gdy koszony teren nie uległ zmianie. Mapa powinna zostać przekształcona w siatkę zajętości (statystyczną lub binarną) lub inne dane nadające się do odczytu maszynowego, które system może wykorzystać do planowania trasy i omijania przeszkód. Założono, że tego rodzaju system będzie zaimplementowany na komputerze pokładowym, który będzie przetwarzał potrzebne dane, uruchamiał autonomiczną część systemu, komunikował się z użytkownikiem i uruchamiał podstawowe funkcje kosiarki.
System sterowania powinien uwzględniać przeszkody, niezależnie od tego, czy są to przeszkody przewidywane (tj. zazna-
Rys. 2. Koncepcje systemów zautomatyzowanych/zdalnie sterowanych, półautonomicznych i autonomicznych Fig. 2. Concepts of automated/remotely controlled, semi-autonomous and autonomous systems
Rys. 3. Koncepcja działania zintegrowanego z użytkownikiem półautonomicznego systemu koszenia
Fig. 3. Concept of the semi-autonomous mowing system integrated with the user
czone na mapie), czy nieprzewidziane. Nieprzewidziane przeszkody będą śledzone, przy użyciu kamery lub LiDAR. Użytkownik może być bezpośrednio zaangażowany w sterowanie kosiarką podczas omijania przeszkody. Przewidywane przeszkody są znane jeszcze przed rozpoczęciem koszenia (w postaci siatki zajętości), ponieważ zostały zlokalizowane przez system mapowania lub oznaczone przez użytkownika. Należy pamętać, że samochody, drzewa oraz budynki mogą zakłócać działanie i komunikację systemu, blokując sygnały sterujące lub sygnały GPS. Należy tak wyznaczać obszary koszenia, aby w miarę możliwości unikać tego rodzaju przeszkód.
4. Budowa i testy systemu
sterowania
jazdą tandemem robotów koszących
W ramach projektu opracowano, wykonano i przetestowano dwa typy kosiarek: kosiarkę nożową zabudowaną na podwoziu gąsienicowym, kosiarkę bijakową na podwoziu kołowym z aktywnym zawieszeniem.
Celem opracowanego systemu sterowania było zrealizowanie koncepcji półautonomicznej pracy tandemu składającego się z dwóch kosiarek: prowadzącej, bijakowo-kołowej (B-K) oraz nadążnej, nożycowo-gąsienicowej (N-G). Zastosowanie systemu umożliwi jednoczesną pracę dwóch kosiarek w celu redukcji pracy operatora. Kosiarka główna (B-K) jest zdalnie sterowana przez operatora, a kosiarka nadążna (N-G) podąża za nią w pełni autonomicznie w założonej odległości. Obie kosiarki zostały wyposażone w system monitorowania i przetwarzania danych oraz systemy bezpieczeństwa pozwalające na uniknięcie kolizji między pojazdami (rys. 4). W celu zapewnienia bezpieczeństwa całego systemu zastosowano czujniki typu LiDAR precyzyjnie wykrywające przeszkody w zakresie 270° i dystansie do 3 m [10, 11].
Algorytm rejestracji i przetwarzania danych oraz sterowania kosiarką nadążną został opracowany na podstawie analizy istniejących rozwiązań i dostosowaniu ich do indywidualnych potrzeb projektu, z uwzględnieniem zachowania najwyższej dokładności, bezpieczeństwa i niezawodności [12–16]. W celu wyznaczania trasy, którą podąża kosiarka główna wykorzystano fuzję danych z odbiornika GNSS, czujnika IMU oraz dane odometryczne otrzymane z przetworzenia sygnałów enkoderów zamontowanych przy kołach. Ponieważ bardzo istotnym elementem systemu z punktu widzenia autonomii jest odbiornik nawigacji satelitarnej, w projekcie wykorzystano system pozycjonowania satelitarnego w technologii RTK (ang. Real Time Kinematic), składający się ze stacji bazowej umieszczanej na terenie koszonym oraz odbiorników na pojazdach [17, 18]. Wyznaczony w czasie badań błąd określenia położenia kosiarki z użyciem tego systemu wynosi nie więcej niż 10 cm w każdym kierunku. Jego dokładność jest zapewniona przy braku zakłóceń sygnału GNSS.
Rys. 4. Widok kosiarek podczas testów, po lewej kosiarka bijakowo kołowa (B-K), po prawej nożycowo-gąsienicowa (N-G)
Fig. 4. View of mowers during tests, on the left a wheeled flail mower (B-K), on the right a scissor-track mower (N-G)
Do określenia kierunku, w którym poruszać się ma kosiarka nadążna, zastosowano mechanizm „cukierków”. Są to współrzędne, które system wyznacza jako cel, do którego kosiarka będzie starała się jechać. „Cukierki” wyznaczane są przez algorytm działający na kosiarce N-G, jednak dane do wyznaczenia współrzędnych cukierka pochodzą z odbiornika GNSS kosiarki B-K. Dlatego konieczne było zbudowanie mechanizmu komunikacji między kosiarkami. Przed dodaniem wyznaczonego “cukierka” jako następnego celu algorytm przeprowadza szereg testów aby zweryfikować poprawność wyznaczonych współrzędnych (rys. 5). Na podstawie analizy trasy kosiarki głównej i wyznaczenia odpowiednio przesuniętej od niej ścieżki dla kosiarki nadążnej zostają wyznaczone „cukierki” cele ruchu dla kosiarki nadążnej. Algorytmy analizy danych, komunikacji oraz wyznaczania trasy zostały zaimplementowane w systemie Robot Operating System (ROS). Testy systemów zostały przeprowadzone zarówno w środowisku symulacyjnym Gazebo, jak i w warunkach rzeczywistych. W pierwszym etapie badań w celu przygotowania testów jazdy autonomicznej tandemu kosiarek został przeprowadzony szereg prób mających na celu zweryfikowanie poprawności rejestracji i analizy danych przez każdy z pojazdów. W tym celu przeprowadzono próbne jazdy każdej z kosiarek i zweryfikowano zarejestrowane podczas przejazdów dane. Analizowane były zarówno dane rejestrowane przez komputer zainstalowany na kosiarce autonomicznej, jak i dane otrzymywane w czasie rzeczywistym z kosiarki zdalnie sterowanej. Przetestowano również długotrwałe przesyłanie danych do sterownika PLC oraz pilota operatora. Przeprowadzono też testy układu odometrii. Umożliwia on wyznaczanie położenia i kierunku jazdy kosiarki kołowej na podstawie pomiaru obrotów kół. Dane te pozwoliły na śledzenie położenia i rotacji pojazdu w lokalnej ramce odniesienia, w której pojazd się poruszał.
Po weryfikacji systemu rejestracji danych każdej z kosiarek oraz testów komunikacji przeprowadzono testy weryfikujące poprawność działania modułu wyznaczania „cukierków”, czyli punktów-celów do tworzenia trasy kosiarki nadążnej. Na rys. 6 przedstawiono wyniki testów wyznaczania „cukierków” dla kosiarki nadążnej. Kolorem żółtym zaznaczono trasę przejazdu kosiarki kołowej, kolorem zielonym pozycję kosiarki gąsienicowej (nieruchoma podczas testu), kolorem czerwonym zaznaczono położenie wszystkich wyznaczonych „cukierków”, kolorem fioletowym zaznaczono „cukierki”, które zostały zakwalifikowane przez algorytm jako cele dla nawigacji kosiarki gąsienicowej.
Przeprowadzone testy terenowe pozwoliły na dobranie parametrów układu sterowania, aby trasa kosiarki nadążnej była wyznaczona z jak największym odwzorowaniem trasy kosiarki prowadzącej przy jednoczesnym odpowiednim pokryciu terenu koszonego przez przejazdy kosiarek. Wyzwaniem było dobranie tak parametrów, aby kosiarki jak najlepiej radziły sobie pod-
Andrzej Typiak, Rafał Typiak, Zbigniew Zienowicz, Mateusz Nowakowski, Patrycja Matejek
Rys. 5. Schemat blokowy wyznaczania „cukierków”
Fig. 5. Block diagram for determining “candies”
czas manewrów zawracania, nie wjeżdżały w swoje wzajemne trasy i aby nie dochodziło do kolizji między pojazdami podczas manewrowania.
Na rys. 7 przedstawiono wyniki testów jazdy kosiarek w tandemie. Kolor żółty – punkty GPS kosiarki prowadzącej, sterowanej przez operatora, kolor czerwony – punkty trasy dla jazdy autonomicznej wyznaczone w systemie kosiarki nadążnej, kolor fioletowy – wyselekcjonowane punkty trasy dla autonomicznej jazdy kosiarki nadążnej, kolor zielony – dane GPS przejazdu autonomicznej kosiarki nadążnej, bez ingerencji operatora.
5. Podsumowanie
Koszenie terenów przydrożnych to złożone zadanie wykonywane na słabo rozpoznanym terenie. W artykule zaprezentowano nowatorskie rozwiązanie tandemu kosiarek sterowanych zdalnie przez jednego operatora. Opracowany zestaw kosiarek umożliwia zespołowe koszenie trawy w rzeczywistym środowisku.
a) b)
Rys. 6. Wyznaczanie „cukierków” dla kosiarki nadążnej
Fig. 6. Determining “candies” for a following mower
W przypadku półautonomicznego systemu koszenia zintegrowanego z użytkownikiem jego operatorzy powinni mieć na uwadze, że przestrzeganie zasad bezpiecznego użytkowania będzie miało kluczowe znaczenie zarówno dla rozwoju systemu koszenia, jak i jego wdrożenia. Należy pamiętać, że wiele technologii, które będą niezbędne do pomyślnego wdrożenia półautonomicznego systemu koszenia, jest niedojrzałych, a ich niezawodność we wszystkich przypadkach jest nieznana. Dalsze wykorzystanie robotyki w agroinżynierii ma ogromny potencjał na przyszłość, ale częściowo będzie on zależał od uniknięcia negatywnych doświadczeń lub zagrożeń dla użytkowników. Ponieważ system ten jest półautonomiczny, użytkownik nadal będzie zaangażowany w podejmowanie niektórych kluczowych decyzji operacyjnych, co może być dobrym przykładem interakcji człowiek–robot, który może służyć zwiększeniu lub zmniejszeniu zaufania użytkowników do systemów robotycznych. Staranne modelowanie i dokumentowanie problemu i rozwiązania może pomóc we wczesnym wykryciu problemów i zmniejszeniu ryzyka związanego z systemem/zawodności, co może skłaniać użytkownika do współpracy człowieka z robotem w przyszłości. Podczas dalszych prac nad systemem konieczne będzie wyznaczenie wydajności kosiarek dla różnych rodzajów układów napędowych. W przeciwieństwie do wielu systemów zrobotyzowanych, możliwe, a być może nawet pożądane, jest użycie małego silnika spalinowego jako źródła zasilania dla tego rodzaju systemu. Porównanie z systemem zasilanym bateryjnie ma zasadnicze znaczenie w przyszłych badaniach.
Bibliografia
1. Daniyan I., Balogunb V., Adeoduc A., Oladapod B., Peter J.K., Mpofu K., Development and performance evaluation of a robot for lawn mowing, “Procedia Manufacturing”, Vol. 49, 2020, 42–48, DOI: 10.1016/j.promfg.2020.06.009.
2. Nishimura Y., Yamaguchi T., Grass Cutting Robot for Inclined Surfaces in Hilly and Mountainous Areas, “Sensors”, Vol. 23, No. 1, 2023, DOI: 10.3390/s23010528.
3. Tribelhorn B., Dodds Z., Evaluating the Roomba: A low-cost, ubiquitous platform for robotics research and education, [In:] Proceedings of the 2007 IEEE International Conference on Robotics and Automation, Roma, Italy, 10–14 April 2007, 1393–1399, DOI: 10.1109/ROBOT.2007.363179.
4. Aponte-Roa D.A., Collazo X., Goenaga M., Espinoza A., Vazquez K., Development and Evaluation of a Remote Controlled Electric Lawn Mower, [In:] Proceedings of the 2019 IEEE 9th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 7–9 January 2019, DOI: 10.1109/CCWC.2019.8666455.
Rys. 7. Testy jazdy kosiarek w tandemie (opis w tekście)
Fig. 7. Tandem mowers driving tests (description in text)
5. Hicks R.W., Hall E.L., A Survey of robot lawn mowers. Intelligent Robots and Computer Vision XIX: Algorithms, Techniques, and Active Vision; Casasent, D.P., Ed.; SPIE: Bellingham, WA, USA, 2000, DOI: 10.1117/12.403770.
6. Sahin H., Givenc L., Household robotics: Autonomous devices for vacuuming and lawn mowing [Applications of control], “IEEE Control System Magazine”, Vol. 27, No. 2, 2007, 20–96, DOI: 10.1109/MCS.2007.338262.
7. Patterson A., Yuan Y., Norris W., Development of User-Integrated Semi-Autonomous Lawn Mowing Systems: A Systems Engineering Perspective and Proposed Architecture, “AgriEngineering”, Vol. 1, No. 3, 2019, 453–474, DOI: 10.3390/agriengineering1030033.
8. Norris W.R., Patterson A.E., Short Discussion Essay Automation Autonomy and Semi-Autonomy A Brief Definition Relative to Robotics and Machine Systems, 2019, [www.researchgate.net/publication/334414845].
9. Höffmann M., Patel S., Büskens Ch., Optimal Coverage Path Planning for Agricultural Vehicles with Curvature Constraints, “Agriculture”, Vol. 13, No. 11, 2023, DOI: 10.3390/agriculture13112112.
10. Peng Y., Qu D., Zhong Y., Xie S., Luo J., Gu J., The obstacle detection and obstacle avoidance algorithm based on 2-D lidar, 2015 IEEE International Conference on Information and Automation, Lijiang, China, 2015, 1648–1653, DOI: 10.1109/ICInfA.2015.7279550.
11. Ghorpade D., Thakare A.D., Doiphode S., Obstacle Detection and Avoidance Algorithm for Autonomous Mobile Robot using 2D LiDAR, 2017 International Conference on Computing, Communication, Control and Automation (ICCUBEA), Pune, India, 2017, DOI: 10.1109/ICCUBEA.2017.8463846.
12. Hague T., Marchant J.A., Tillett N.D., Ground based sensing systems for autonomous agricultural vehicles, “Computers and Electronics in Agriculture”, Vol. 25, No. 1–2, 2000, 11–28, DOI: 10.1016/S0168-1699(99)00053-8.
13. Kaczmarek A., Rohm W., Klingbeil L., Tchórzewski J., Experimental 2D extended Kalman filter sensor fusion for low-cost GNSS/IMU/Odometers precise positioning system, “Measurement”, Vol. 193, 2022, DOI: 10.1016/j.measurement.2022.110963.
14. Susnea I., Mînzu V., Vasiliu G., Simple, real-time obstacle avoidance algorithm for mobile robots, Proceedings of the 8th WSEAS International Conference on Computational Intelligence Man-Machine Systems and Cybernetics (CIMMACS ‘09), 2009, 24–29, DOI: 10.5555/1736097.1736102.
15. Larsen T.D., Hansen K.L., Andersen N.A., Ravn O., Design of Kalman filters for mobile robots; evaluation of the kinematic and odometric approach, Proceedings of the 1999 IEEE International Conference on Control Applications (Cat. No. 99CH36328), Kohala Coast, HI, USA, Vol. 2, 1999, 1021–1026, DOI: 10.1109/CCA.1999.801027.
16. Ben-Ari M., Mondada F., Robotic Motion and Odometry, [In:] “Elements of Robotics”, Springer, Cham, 2018, DOI: 10.1007/978-3-319-62533-1_5.
17. Rovira-Más F., Chatterjee I., Sáiz-Rubio V., The role of GNSS in the navigation strategies of cost-effective agricultural robots, “Computers and Electronics in Agriculture”, Vol. 112, 2015, 172–183, DOI: 10.1016/j.compag.2014.12.017.
18. Ferreira A., Matias B., Almeida J., Silva E., Real-time GNSS precise positioning: RTKLIB for ROS, “International Journal of Advanced Robotic Systems”, Vol. 17, No. 3, 2020, DOI: 10.1177/1729881420904526.
A System of Semi-Autonomous Tandem Mowers for Mowing Roadside Area
Abstract: Maintaining the road requires regular mowing of ditches and roadside areas. This is mainly done using mowers mounted on agricultural tractors. The trend is to introduce autonomous mowing systems, but so far a number of autonomous solutions for mowing short grass (home lawns, golf courses), and there are few autonomous mower solutions for mowing tall grass on the market. The first part of the article describes the conditions determining work on the development of lawn mowers. Then, a proposal for a semi-autonomous control system for tandem mowers for mowing roadside areas was presented. As part of its construction, a fully functional set was designed and built, consisting of two mowers: wheeled and tracked, a remote control system for the first mower, and a high-level computer with implemented software ensuring autonomous mowing with the second mower under active operator supervision. A series of field tests conducted allowed us to assess the effectiveness and practicality of the proposed solution. Mowing efficiency was assessed by the consistency of subsequent mowing paths. The obtained results indicate that the development of the developed system will significantly improve mowing efficiency and increase employee safety.
Andrzej Typiak, Rafał Typiak, Zbigniew Zienowicz, Mateusz Nowakowski, Patrycja Matejek
dr hab. inż. Andrzej Typiak andrzej.typiak@wat.edu.pl
ORCID: 0000-0003-1992-015X
Profesor na Wydziale Inżynierii Mechanicznej Wojskowej Akademii Technicznej. Wykładowca na kierunkach studiów: Energetyka, Maszyny inżynieryjno-budowlane i drogowe, Maszyny inżynieryjne, oraz Inżynieria systemów bezzałogowych. Autor wielu publikacji z obszaru zdalnego i autonomicznego sterowania maszynami inżynieryjnymi i pojazdami. Kierował czterema projektami badawczymi z tego obszaru. Prowadzi badania w obszarze sterowania maszyn inżynieryjnych i pojazdów w układzie teleoperacji, rozpoznania otoczenia na podstawie obrazów wizyjnych, lokalizowania obiektów i budowy mapy na podstawie pomiarów skanerami laserowymi oraz interfejsów do współpracy operator-maszyna.
dr inż. Rafał Typiak rafal.typiak@wat.edu.pl
ORCID: 0000-0003-1380-9979
Absolwent Wydziału Elektrycznego Politechniki Warszawskiej na kierunku Automatyka i Robotyka w 2008 r. Od końca 2008 r. pracownik Wojskowej Akademii Technicznej. W 2017 r. otrzymał stopień doktora za pracę „Wpływ konfiguracji układu akwizycji na sterowanie bezzałogową maszyną roboczą”. Aktualnie naukowo działa w obszarze automatyzacji i autonomizacji bezzałogowych platform lądowych. Specjalizuje się w opracowywaniu, wdrażaniu i testowaniu rozwiązań elektronicznych i programistycznych dla manipulatorów zrobotyzowanych i bezzałogowych pojazdów naziemnych (UGV). Ma doświadczenie w zakresie projektowania konstrukcji mechanicznych oraz opracowywania hydrostatycznych układów napędowych.
dr inż. Zbigniew Zienowicz zienowicz@hydromega.com.pl
ORCID: 0009-0007-6200-0654
Absolwent Wydziału Budowy Maszyn Politechniki Gdańskiej, stopień naukowy doktora w dyscyplinie budowy i eksploatacji maszyn w specjalności napęd i sterowanie hydrauliczne. Od 1988 r. był prezesem Zarządu firmy Hydromega Sp. z o.o. w Gdyni, zajmującej się projektowaniem i produkcją układów hydrauliki siłowej. Od października 2023 r. przewodniczący Rady Nadzorczej firmy Hydromega, członek Rady Konsultacyjnej przy Dziekanie Wydziału Mechanicznego Politechniki Gdańskiej, członek Rady Programowej Inteligentnych Specjalizacji Pomorza 1 „Technologie offshore i portowo-logistyczne” oraz Rady Rozwoju Obszaru Gospodarczego Pomorskiej Specjalnej Strefy Ekonomicznej i Rady Naukowej Pomorskiego Parku Naukowo-Technologicznego w Gdyni. Jest zwolennikiem i propagatorem budowania konkurencyjności polskiej gospodarki w oparciu o komercjalizację i wdrożenia krajowego dorobku w obszarze prowadzonych prac B+R. Od lat angażuje się w akcje charytatywne na rzecz lokalnej społeczności.
Absolwent Politechniki Lubelskiej na kierunkach Mechaniki i Budowy Maszyn spec. Technologia maszyn oraz Zarządzanie i Inżynieria Produkcji. Od 2023 r. zatrudniony na stanowisku starszego konstruktor B+R w spółce Hydromega. Obszar badawczy obejmuje innowacyjne projekty B+R w konstrukcji maszyn w różnych gałęziach przemysłu elektromaszynowego. Prowadzi prace konstrukcyjne, analityczne i badawcze maszyn samobieżnych pojazdów o różnej charakterystyce podwozia. Rezultaty prac prezentuje na konferencjach naukowych. W przeszłości brał udział w badaniach przemysłowych i pracach rozwojowych w jednostkach naukowych Sieci Badawczej Łukasiewicz.
Absolwentka Wydziału Elektroniki, Telekomunikacji i Informatyki Politechniki Gdańskiej, gdzie uzyskała tytuł magistra inżyniera na kierunku Inżynierii Biomedycznej w 2017 r. Członkini zarządu Stowarzyszenia Robotyków SKALP. Doświadczenie zawodowe zdobywała w zespołach badawczo-rozwojowych zajmujących się autonomicznymi pojazdami oraz urządzeniami medycznymi. W swojej pracy koncentruje się na promocji nowoczesnych technologii, edukacji w tym zakresie oraz zarządzaniu zespołami badawczymi. Specjalizuje się w projektowaniu systemów analizy i przetwarzania danych oraz algorytmami sterowania, w tym z wykorzystaniem ROS.
Dynamiczne właściwości fibrobetonu wytworzonego na bazie piasków odpadowych
Janusz Kobaka1,2, Jacek Katzer1, Machi Zawidzki3
1 AGH Akademia Górniczo-Hutnicza im. Stanisława Staszica w Krakowie, Wydział Inżynierii Mechanicznej i Robotyki, al. Adama Mickiewicza 30, 30-059 Kraków
2 Uniwersytet Warmińsko-Mazurski w Olsztynie, Wydział Geoinżynierii, ul. Michała Oczapowskiego 2, 10-719 Olsztyn
3 Sieć Badawcza Łukasiewicz – Przemysłowy Instytut Automatyki i Pomiarów PIAP, Al. Jerozolimskie 202, 02-486 Warszawa
Streszczenie: W artykule przedstawiono wyniki badań nieniszczących fibrobetonu z dodatkiem włókien stalowych wytworzonego na bazie piasków odpadowych. Belki fibrobetonowe o różnej zawartości włókien stalowych poddane były dwóm rodzajom drgań własnych: drganiom skrętnym i giętnym. Na podstawie przeprowadzonych testów i analizy Fouriera, wyznaczono częstotliwości tych drgań. Posłużyły one do określania dynamicznego modułu sprężystości, dynamicznego modułu odkształcenia postaciowego oraz dynamicznego współczynnika Poissona. Następnie określono wpływ włókien stalowych na te parametry. Badania wykazały, że dodatek włókien stalowych wpływa na zwiększenie dynamicznego modułu sprężystości oraz dynamicznego modułu odkształcenia postaciowego do pewnej krytycznej zawartości włókien, po przekroczeniu której, następuje zmniejszenie wartości tych modułów, ponadto włókna stalowe nie wpływają na wartości dynamicznego współczynnika Poissona.
Słowa kluczowe: badania nieniszczące, fibrobeton, właściwości dynamiczne, moduł sprężystości, odkształcenie postaciowe, współczynnik Poissona
1. Wpowadzenie
Fibrobetony stają się coraz bardziej popularne w budownictwie, stanowiąc często alternatywę dla betonu zwykłego przy wykonywaniu takich elementów jak: posadzki przemysłowe, nawierzchnie drogowe lub lotniskowe, elementy cienkościenne, elementy narażone na oddziaływania dynamiczne, obudowy tuneli, szybów górniczych, warstwy naprawcze konstrukcji żelbetowych wykonywane metodą natryskiwania (torkretowania) i in. [1–3]. Fibrobetony charakteryzują się większą wytrzymałością na rozciąganie [4, 5], większą wytrzymałością na rozciąganie przy zginaniu [6], większą wytrzymałością na siły ścinające [7, 8], odpornością na obciążenia cykliczne [9] oraz trwałością [4, 10] niż beton zwykły. Wśród wielu rodzajów materiałów, z których wykonuje się włókna przeznaczone do fibrobetonu, stalowe zbrojenie rozproszone znalazło najszersze zastosowanie [11] i wykorzystuje się je do wykonywania najbardziej odpowiedzialnych elementów konstrukcyjnych. W celu uzyskania właściwości mechanicznych fibrobetonów o wysokich parametrach, zawartość zbrojenia rozproszonego powinna być
Autor korespondujący:
Janusz Kobaka, Janusz.Kobaka@agh.edu.pl; Janusz.Kobaka@uwm.edu.pl
Artykuł recenzowany nadesłany 18.02.2024 r., przyjęty do druku 18.11.2024 r.
Zezwala się na korzystanie z artykułu na warunkach licencjiCreative Commons Uznanie autorstwa 4.0 Int.
stosunkowo duża. W takim wypadku stosowane jest kruszywo o mniejszym uziarnieniu niż w betonie zwykłym, często poniżej 2 mm, aby uzyskać równomierny rozkład zbrojenia rozproszonego w objętości kompozytu [12]. Zapotrzebowanie na takie kruszywo daje możliwość zastosowania zalegającego na hałdach piasku kwarcowego, będącym produktem odpadowym procesu hydroklasyfikacji pospółek regionu Pomorza. Hydroklasyfikacja polega na wypłukiwaniu frakcji piaskowych z pospółki w celu uzyskania frakcji żwirowych. Wykorzystanie piasków odpadowych do produkcji fibrobetonów jest alternatywą dla kosztownej rekultywacji terenów dawnych i obecnych kopalń kruszyw naturalnych.
Skuteczne stosowanie fibrobetonów do konstrukcji narażonych na obciążenia dynamiczne wymaga kompleksowego rozpoznania ich podstawowych cech dynamicznych, takich jak na przykład częstotliwość drgań własnych czy dynamiczny moduł sprężystości [13]. Właściwości współczynników dynamicznych, takich jak: dynamiczny moduł sprężystości, dynamiczny moduł odkształcenia postaciowego lub dynamiczny współczynnik Poissona różnią się od ich statycznych odpowiedników wyznaczanych na próbkach poddanych obciążeniom mając wartości około 10 % większe [14]. Biorąc pod uwagę powyższe fakty przeprowadzono program badań mający na celu określenie wybranych właściwości dynamicznych fibrobetonów.
2. Metodyka badań
Badania dynamicznego modułu sprężystości oraz dynamicznego modułu odkształcenia postaciowego oznaczano na podstawie pomiarów drgań własnych belek pryzmatycznych
o wymiarach 10 cm × 10 cm × 40 cm wykonanych z fibrobetonu. Wykonano belki o różnej zawartości włókien stalowych (mierzonej jako procent objętości): 0 %, 0,5 %, 1,0 %, 1,5 %, 2,0 % oraz 2,5 %. Zastosowano włókna stalowe o haczykowatym kształcie, średnicy 0,8 mm i długości 50 mm. Wykonano sześć belek z każdego rodzaju, łącznie otrzymując 36 belek. Jako składniki fibrobetonu podane na 1 m3 użyto: superplastyfikator 16,8 kg, woda 160 dm3, cement 420 kg, piasek płukany 1570 kg, pyły krzemionkowe 21 kg.
Badania drgań własnych wykonano układając belki na podstawie z gumy. Po wymuszeniu drgań przez uderzenie stalową kulką, sygnał z czujnika przekazywany jest do urządzenia monitorującego SVAN 910A (Rys. 1). W urządzeniu monitorującym, w oparciu o analizę Fouriera, wyznaczona jest częstotliwość drgań własnych badanych elementów. Drgania giętne posłużyły do wyznaczenia dynamicznego modułu sprężystości, natomiast drgania skrętne do wyznaczenia dynamicznego modułu odkształcenia postaciowego.
Rys. 1. Stanowisko do badań drgań własnych: a) drgania skrętne, b) drgania giętne, c) urządzenie monitorujące SVAN 910A użyte do badań drgań własnych
Fig. 1. Stand for testing natural vibrations: a) torsional vibrations, b) bending vibrations, c) SVAN 910A monitoring device used for natural vibration tests
Dynamiczny moduł sprężystości fibrobetonu wyznaczono według następującej zależności [14]:
2 3 22 64 , (21) flex d f ml ET I k π =⋅⋅⋅ + (1)
w której wsp ółczynnik korekcyjny T jest wyznaczany z następującej zależności:
gdzie: A – pole przekroju, I – moment bezwładności przekroju, k – składowa harmoniczna drgań, tutaj k = 1, l – długość belki, n – współczynnik korygujący, tutaj n = 1, – współczynnik Poissona.
Dynamiczny moduł odkształcenia postaciowego fibrobetonu wyznaczono według następującej zależności [14]:
(4)
w której R jest współczynnikiem zależnym od wymiarów przekroju poprzecznego belki b i h: 26 , 42,520,21 bh hb R bbb hhh + =
ki – składową harmoniczną drgań (dla pierwszej składowej k1 = 1) [-], ftors – częstotliwością drgań własnych [Hz], A – polem przekroju poprzecznego belki [mm2], b – szerokością przekroju belki [mm], h – wysokością przekroju belki [mm], m – masą belki [kg], l – długością belki [mm].
Dynamiczny współczynnik Poissona fibrobetonu wyznaczono według następującej zależności [15]:
1. 2 d d d E G υ =− (5)
3. Wyniki badań
Wyniki badań dynamicznego modułu sprężystości Ed wykazały nieznaczną tendencję wzrostową tej właściwości wraz ze wzrostem zawartości włókien (Rys. 2). Przy braku włókien w betonie (tzw. matrycy fibrobetonowej) wartość Ed wyniosła około 39 GPa wzrastając stopniowo do wartości powyżej 40 GPa przy zawartościach włókien 1,0 % i 1,5 %. Powyżej zawartości włókien 1,0 % i 1,5 % nastąpił spadek wartości dynamicznego modułu sprężystości do wartości 39,9 GPa dla 2,0 % włókien i 39,2 GPa dla zawartości włókien 2,5 %.
Podobny do dynamicznego modułu sprężystości Ed jest przebieg krzywej dynamicznego modułu odkształcenia postaciowego Gd. Najmniejszą wartością Gd, około 16,7 GPa, wykazała się
Rys. 2. Zależność dynamicznego modułu sprężystości Ed od zawartości włókien stalowych Vf
Fig. 2. Dependence of the dynamic modulus of elasticity Ed on the content of steel fibers Vf
Rys. 3. Wartości dynamicznego modułu odkształcenia postaciowego Gd w zależności od zawartości włókien stalowych Vf
Fig. 3. Values of the dynamic modulus of shear deformation Gd depending on the steel fiber content Vf
Rys. 4. Dynamiczny współczynnik Poissona νd dla różnych zawartości włókien stalowych Vf
Fig. 4. Dynamic Poisson’s ratio νd for different steel fiber contents Vf
matryca betonowa, po czym wraz ze wzrostem zawartości włókien stalowych w fibrobetonie, następował stopniowy wzrost wartości Gd do wartości maksymalnej. Wartość ta wyniosła ok. 17,5 GPa przy zawartości włókien 1,5 %. Po przekroczeniu zawartości włókien 1,5 % nastąpił spadek wartości Gd. Przy zawartości włókien 2,0 % było to około 17,4 GPa, natomiast przy zawartości włókien 2,5 % 17,2 GPa. Wartości wyznaczonego dynamicznego współczynnika Poissona νd nie wykazują wyraźnej tendencji wzrostowej lub spadkowej w zależności od zawartości włókien w fibrobetonie, jednak przeprowadzona jednoczynnikowa analiza wariancji, pozwalająca na porównanie średnich wartości dla grup wyników wykazała, że wartość prawdopodobieństwa p wyniosła 0,039 i była mniejsza od poziomu istotności wynoszącego 0,05. Oznacza to, że analizowane wartości średnich dla sześciu grup wyników różnią się od siebie w sposób statystycznie istotny. Średnia wartość dynamicznego współczynnika Poissona d wyniosła dla wszystkich sześciu grup pomiarów 0,15.
4. Podsumowanie i wnioski
Na podstawie przeprowadzonych badań można sformułować następujące wnioski:
− Dodatek włókien stalowych wpływa na zwiększenie dynamicznego modułu sprężystości oraz dynamicznego modułu odkształcenia postaciowego, jednak powyżej 1,5 % następuje jego zmniejszenie, co spowodowane jest napowietrzeniem mieszanki betonowej podczas mieszania przez zbyt dużą zawartość włókien.
− Włókna stalowe nie wpływają na wartości dynamicznego współczynnika Poissona.
Przeprowadzone badania nieniszczące betonu zbrojonego włóknami stalowymi przy użyciu piasku odpadowego dostarczyły cennych informacji na temat jego właściwości dynamicznych. Analiza drgań skrętnych i zginających w połączeniu z analizą Fouriera pozwoliła na wyznaczenie kluczowych parametrów, takich jak dynamiczny moduł sprężystości (moduł Younga), dynamiczny moduł ścinania (moduł sztywności) i dynamiczny współczynnik Poissona. Badanie wpływu zróżnicowanej zawartości włókien stalowych na te parametry pogłębia naszą wiedzę na temat zachowania fibrobetonu i stwarza możliwości optymalizacji jego charakterystyk mechanicznych w rzeczywistych zastosowaniach konstrukcyjnych. Wyniki rzucają światło na skuteczność włókien stalowych w kształtowaniu tych właściwości dynamicznych, oferując implikacje dla optymalizacji fibrobetonu w zastosowaniach budowlanych. Zaobserwowany wpływ włókien stalowych na te właściwości dostarcza cennych informacji dla inżynierów i badaczy dążących do poprawy właściwości mechanicznych SFRC, szczególnie przy wykorzystaniu materiałów odpadowych do jego produkcji. Uzyskane wyniki podkreślają znaczenie badań nieniszczących w ocenie właściwości użytkowych fibrobetonu wykonanego z piasku odpadowego.
Podsumowując, badania nieniszczące fibrobetonu opartego o piasek odpadowy pozwoliły uzyskać istotne informacje na temat dynamicznego zachowania materiału. Analiza drgań skrętnych i zginających, uzupełniona analizą Fouriera, ułatwiła wyznaczenie kluczowych parametrów dynamicznych. W badaniu zbadano także wpływ włókien stalowych na te właściwości, co umożliwiło kompleksowe zrozumienie, w jaki sposób różna zawartość włókien wpływa na dynamiczny moduł sprężystości, dynamiczny moduł ścinania i dynamiczny współczynnik Poissona. Odkrycia te wnoszą wkład w poszerzenie wiedzy na temat kompozytów cementowych i stanowią podstawę do dalszych prac uzupełniających luki w wiedzy. Badanie wpływu włókien stalowych na te właściwości dynamiczne dostarcza praktycznych spostrzeżeń umożliwiających optymalizację receptur fibrobetonów, szczególnie w przypadku wykorzystania materiałów odpadowych w praktyce budowlanej.
Dalsze kierunki badań powinny powinny być rozszerzone o wpływ składu matrycy fibrobetonowej oraz różnych rodzajów i typów włókien (włókna o innym kształcie i wykonane z innych materiałów) na właściwości dynamiczne fibrobetonów. Również różnice między właściwościami dynamicznymi i statycznymi powinny zostać wyraźnie określone, jak również ich korelacja z innymi właściwościami mechanicznymi fibrobetonów.
Bibliografia
1. Zych T., Współczesny fibrobeton – możliwość kształtowania elementów konstrukcyjnych i form architektonicznych, „Czasopismo Techniczne, Architektura”, Vol. 107, No. 18, 2010, 371–386.
2. Mu R., Mei S., Wang X., Chen X., Zhao Q., Qing L., Chen J., Fan C., Mechanical properties of a 3D-printed SFRC beam with steel fiber distribution adaptive to tensile stress, “Material Letters”, Vol. 349, 2023, DOI: 10.1016/J.MATLET.2023.134776.
3. Wang S., Madan A., Zhao C., Seong Huang E., Su T., Chiew B.J., Yang Y., Experimental study on strain of SFRC tunnel lining segments using a comprehensive embedded optical fiber sensing system, “Measurement”, Vol. 223, 2023, DOI: 10.1016/J.MEASUREMENT.2023.113791.
4. Li B., Chi Y., Xu L., Li C., Shi Y., Cyclic tensile behavior of SFRC: Experimental research and analytical model, “Construction and Building Materials”, Vol. 190, 2018, 1236–1250, DOI: 10.1016/J.CONBUILDMAT.2018.09.140.
Janusz Kobaka, Jacek Katzer, Machi Zawidzki
5. Kobaka J., Katzer J., Ponikiewski T., A combined electromagnetic induction and radar-based test for quality control of steel fibre reinforced concrete, “Materials”, Vol. 12, No. 21, 2019, DOI: 10.3390/ma12213507.
6. Safdar Raza S., Ali B., Noman M., Fahad M., Mohamed Elhadi K., Mechanical properties, flexural behavior, and chloride permeability of high-performance steel fiber-reinforced concrete (SFRC) modified with rice husk ash and micro-silica, “Construction and Building Materials”, Vol. 359, 2022, DOI: 10.1016/J.CONBUILDMAT.2022.129520.
7. Alshboul O., Almasabha G., Al-Shboul K.F., Shehadeh A., A comparative study of shear strength prediction models for SFRC deep beams without stirrups using Machine learning algorithms, “Structures”, Vol. 55, 2023, 97–111, DOI: 10.1016/J.ISTRUC.2023.06.026.
8. Chen C., Akiyama M., Lim S., Kondo S., Hosono Y., Lai Y., Aoki K., Shear performance of centrifugal forming hollow circular SFRC piles: Feasibility study of replacing stirrups with steel fibers, “Construction and Building Materials”, Vol. 409, 2023, DOI: 10.1016/J.CONBUILDMAT.2023.134140.
9. Xiang D., Liu S., Li Y., Liu Y., Improvement of flexural and cyclic performance of bridge deck slabs by utilizing
steel fiber reinforced concrete (SFRC), “Construction and Building Materials”, Vol. 329, 2022, DOI: 10.1016/J.CONBUILDMAT.2022.127184.
10. Marcos-Meson V., Fischer G., Edvardsen C., Skovhus T.L., Michel A., Durability of Steel Fibre Reinforced Concrete (SFRC) exposed to acid attack – A literature review, “Construction and Building Materials”, Vol. 200, 2019, 490–501, DOI: 10.1016/J.CONBUILDMAT.2018.12.051.
11. Zheng Y., Lv X., Hu S., Zhuo J., Wan C., Liu J., Mechanical properties and durability of steel fiber reinforced concrete: A review, “Journal of Building Engineering”, Vol. 82, 2023, DOI: 10.1016/J.JOBE.2023.108025.
13. Katzer J., Chosen Dynamic Features of Fiber Reinforced Concrete Beams, [In:] Life Cycle Assessment Behaviour and Properties of Concrete and Concrete Structures International Conference, Brno University of Technology, Brno, Czech Republic, 2004.
14. Weiler B., Grosse C., Elastic constants – their dynamic measurement and calculation. Elastische Parameter – ihre dynamische Messung und Berechnung., Otto Graf Journal, 1995.
15. Neville A.M., Właściwości betonu, 2010.
Dynamic Properties of SFRC Made on the Basis of Waste Sand
Abstract: The article presents the results of non-destructive testing of steel fiber reinforced concrete (SFRC) based on waste sand. Fiber concrete beams with different steel fiber content were subjected to two types of free vibrations: torsional and flexural vibrations. Based on the tests and Fourier analysis, the frequencies of these vibrations were determined. They were used to determine the dynamic modulus of elasticity (Young’s modulus), the dynamic shear modulus (modulus of rigidity) and the dynamic Poisson’s ratio. In the next stage, the influence of steel fibers on these parameters was determined. The tests have shown that the addition of steel fibers increases the value of dynamic modulus of elasticity and the dynamic shear modulus up to a certain critical fiber content, beyond which the values of these moduli decrease; moreover, steel fibers do not affect the value of the dynamic Poisson’s ratio.
Keywords: NDT, FRC, dynamic properties, modulus of elasticity, shear modulus, Poisson’s ratio
dr inż. Janusz Kobaka janusz.kobaka@uwm.edu.pl
ORCID: 0000-0002-3596-3187
Od 07/2021 post-doc w projekcie NCN „Wydobycie regolitu na powierzchni Księżyca w warunkach obniżonej grawitacji”. 03 .2021–05.2021 adiunkt na Uniwersytecie Warmińsko-Mazurskim w Olsztynie. 10 .2018–02.2021 adiunkt na Politechnice Koszalińskiej. 10.2007–09.2018 kierownik Laboratorium Techniki Budowlanej Politechniki Koszalińskiej. 03.2004–09.2007 specjalista inżynieryjno-techniczny w Laboratorium Techniki Budowlanej PK..
dr hab. inż. Jacek Katzer, prof. UWM
jacek.katzer@uwm.edu.pl
ORCID: 0000-0002-4049-5330
W swoich badaniach specjalizuje się w technologii betonu i fibrobetonu. Od 2017 r. zajmuje się również gruntami księżycowymi i symulantami gruntów księżycowych. Posiada doświadczenie jako badacz betonu, projektant mieszanek, kontroler jakości produkcji betonów (zarówno towarowych, jak i prefabrykatów) oraz wykładowca technologii betonu. Obecnie pracuje na Uniwersytecie Warmińsko-Mazurskim w Olsztynie kierując Centrum Inżynierii Lądowej. W trakcie swojej kariery naukowej związany był także z Politechniką Koszalińską (Polska), Uniwersytetem w Sheffield (Wielka Brytania), Politechniką w Brnie (Czechy) oraz VSB – Politechniką Ostrawską (Czechy).
dr hab. inż. Machi Zawidzki zawidzki@piap.lukasiewicz.gov.pl
ORCID: 0000-0001-8695-4400
Od 10/2022 kierownik ZBI – Dział Wsparcia Badań Aplikacyjnych w Sieci Badawczej Łukasiewicz – Przemysłowym Instytucie Automatyki i Pomiarów PIAP. Od 2/2017 adiunkt w Zakładzie Technologii Inteligentnych w Instytucie Podstawowych Problemów Techniki Polskiej Akademii Nauk. 7/2020 habilitacja w dziedzinie Nauk Technicznych, w dyscyplinie – Informatyka. Tytuł autoreferatu: Zastosowania metod inteligencji obliczeniowej do optymalizacji architektonicznych Systemów Ekstremalnie Modularnych. W latach 10/2007 – 09/2010 studia doktoranckie na Uniwersytecie Ritsumeikan w Japonii. Temat rozprawy: Application of Computational Intelligence to engineering design problems in Architecture – firmitatis, utilitatis, venustatis.
Janusz Kobaka, Jacek Katzer, Machi Zawidzki
Uczenie maszynowe w prognozowaniu ilości
ścieków
dla oczyszczalni ścieków miasta Rzeszowa na podstawie warunków pogodowych
Bartosz Kowal, Patryk Organiściak, Paweł Kuraś
Politechnika Rzeszowska im. Ignacego Łukasiewicza, Wydział Elektrotechniki i Informatyki, ul. Marii Skłodowskiej-Curie 8/2, 35-037 Rzeszów
Adam Masłoń
Politechnika Rzeszowska im. Ignacego Łukasiewicza, Wydział Budownictwa, Inżynierii Środowiska i Architektury, ul. Powstańców Warszawy 6, 35-959 Rzeszów
Bartosz Wadiak
Miejskie Przedsiębiorstwo Wodociągów i Kanalizacji Sp. z o.o. w Rzeszowie, ul. Naruszewicza 18, 35-055 Rzeszów
Streszczenie: Parametry oczyszczalni ścieków w Polsce muszą spełniać określone normy, które regulują jakość odpływu po procesie oczyszczania. Ilość oraz jakość dopływających ścieków zależy od wielu czynników, między innymi od warunków pogodowych. Prognozowanie tych parametrów pozwala zapewnić optymalną pracę oczyszczalni, co przyczynia się do redukcji kosztów ich pracy. W tym celu, korzystając z danych pogodowych, przeprowadzono próbę oszacowania ilości ścieków dopływających do oczyszczalni w Rzeszowie. Wykorzystano ponad 1000 modeli uczenia maszynowego (ML), w tym także modele statystyczne, takie jak ARIMA i SARIMAX, oraz algorytmy ML, takie jak KNN i sieci neuronowe, w różnych konfiguracjach i przedziałach czasowych. Uzyskano najmniejszy średni błąd bezwzględny (MAE) na poziomie 3598 m3 oraz błąd średniokwadratowy (RMSE) równe 4808 m3. Badanie pokazało, jak wybór parametrów oraz różnych typów modeli predykcyjnych (statycznych, dynamicznych, uczenia maszynowego) wpływa na dokładność prognoz, co bazując wyłącznie na podstawowych danych czasowych, okazuje się być wymagającym procesem.
1. Wpowadzenie
Słowa kluczowe: oczyszczalnie ścieków, sieci neuronowe, systemy sterowania, uczenie maszynowe a podażą wody, będą miały znaczący wpływ na jej obieg. Skutkiem tego może okazać się spadek dostępności słodkiej wody na mieszkańca i zagrożenie ekosystemów wodnych [3]. Sprawna gospodarka wodno-ściekowa może mieć duże znaczenie dla środowiska, a ponadto sam proces oczyszczania ścieków stanowi kluczowy krok w kierunku poprawy jakości środowiska wodnego [4]. Skład i ilość ścieków ma również istotny wpływ na inne czynniki środowiskowe, m.in. na produkcję biogazu w celu samowystarczalności energetycznej oczyszczalni [5].
Woda jest jednym z najważniejszych zasobów naturalnych, a jej jakość i dostępność są kluczowe dla zachowania zdrowia ludzi i równowagi ekosystemów [1, 2]. Ochrona i utrzymanie jakości wód, w tym proces oczyszczania ścieków, staja się coraz większym wyzwaniem, zwłaszcza w kontekście zmieniających się warunków klimatycznych i rosnącego nacisku na zrównoważony rozwój. Odnawialna słodka woda, choć stanowi niewielką część światowego zaopatrzenia w wodę, jest niezbędna dla ekosystemów, wspierając działalność człowieka (m.in. woda pitna, nawadnianie i zastosowania przemysłowe). Zmiany klimatu i rosnąca nierównowaga między zużyciem,
Autor korespondujący:
Paweł Organiściak, org@prz.edu.pl
Artykuł recenzowany nadesłany 18.02.2024 r., przyjęty do druku 10.01.2025 r.
Zezwala się na korzystanie z artykułu na warunkach licencji Creative Commons Uznanie autorstwa 4.0 Int.
Prędkość i kierunek przemieszczania się deszczu wpływają na ilość powstających ścieków w sieci kanalizacyjnej [6], co ma istotne znaczenie dla formowania się ilości i jakości ścieków dopływających do oczyszczalni. Opady deszczu, temperatura oraz zmiany sezonowe oddziałują na rodzaj i ilość substancji chemicznych i zanieczyszczeń biologicznych, jak również na fizyczne właściwości ścieków. Zrozumienie tych zależności jest możliwe [7] i ma duże znaczenie dla zapewnienia efektywnej pracy oczyszczalni ścieków, a zatem również redukcji kosztów związanych z ich funkcjonowaniem.
Celem tej pracy jest zrozumienie zależności między warunkami pogodowymi a parametrami ścieków, potwierdzenie korelacji między tymi danymi, oraz opracowanie modeli pro-
gnozujących na ich podstawie. Efekty badania mogą pomóc w zbilansowanym, nowoczesnym i efektywnym zarządzaniu oczyszczalniami ścieków, jak i również wskazać kierunek dla dalszych badań.
1.1. Kontekst i znaczenie badań
Rozwiniecie znaczenia ochrony środowiska jest istotnym tematem, który znajduje odzwierciedlenie w licznych źródłach. Takie zagadnienia, jak koncepcja zerowej ilości odpadów (ang. The Concept of Zero Waste [8]) czy też ograniczanie produkcji plastiku ciągle zyskują na popularności. Skuteczne gospodarowanie odpadami i niezawodna praca oczyszczalni ścieków mają znaczny wpływ na przyrodę biorąc pod uwagę, że oczyszczalnie ścieków zostały zidentyfikowane jako ważne źródła uwalniania tworzyw sztucznych do środowiska wodnego i lądowego, co w konsekwencji może prowadzić do dalszego zanieczyszczenia [9].
Nierównomierność dopływających ścieków, jak również towarzyszące im często zmiany jakościowe stanowią zasadniczy czynnik powodujący zakłócenia w prawidłowym przebiegu procesów oczyszczania ścieków. Bilans ilościowo-jakościowy ścieków dopływających do oczyszczalni jest źródłem cennych informacji zarówno dla projektanta, jak i dla eksploatatora obiektu – rzetelna wiedza na temat dynamiki dopływającego ładunku zanieczyszczeń do oczyszczalni wpływa na poprawną eksploatację zastosowanej technologii oczyszczania ścieków [10].
Niniejsze badanie może przyczynić się zarówno do poprawy efektywności procesów oczyszczania ścieków oraz zmniejszenia negatywnego wpływu na środowisko naturalne. Innym istotnym aspektem badań są wymagania prawne stawiane oczyszczalniom i idące za tym ryzyko kar. Państwo przewiduje kary pieniężne za przekraczanie norm [32]. Aby temu przeciwdziałać opracowano metody do wspierania podejmowanych decyzji [11] oraz modelowania ryzyka w eksploatacji oczyszczalni ścieków [12, 13].
2. Oczyszczalnia ścieków w Rzeszowie
Cykliczne modernizacje oraz rozbudowa oczyszczalni ścieków w Rzeszowie, zrealizowane w różnych okresach (1992–1998, 2001, 2003–2004, 2013–2014), przyczyniły się do ewolucji jej charakterystyki technologicznej. Zmiany wprowadzone podczas tych procesów mogą wymagać regularnych aktualizacji badań, aby monitorować aktualny stan oczyszczalni. Oczyszczalnia jest zlokalizowana przy ul. Ciepłowniczej 2, w północnej części miasta, na prawym brzegu rzeki Wisłok [14].
2.1. Parametry jakości wody w oczyszczalniach ścieków
Dane dotyczące jakości i ilości ścieków, który wykorzystano w analizie, pochodzą z oczyszczalni ścieków zlokalizowanej w mieście Rzeszów, zaś dane meteorologiczne zostały pozyskane z publicznie dostępnych danych ze stacji pogodowej działającej w obszarze Rzeszowa i Jasionki [33]. Zbiór danych w charakterze dobowym jest dostępny od 1 stycznia 2011 r. do 30 kwietnia 2016 r. z wyłączeniem okresu, w którym oczyszczalnia był modernizowana (rys. 1). Dane, które zawierają ładunek ścieków można opisać za pomocą kryteriów ilościowych, jak i jakościowych (tab. 1), a ich charakterystykę opisano w tab. 2.
Rys. 1. Dobowy przepływ danych w oczyszczalni ścieków Rzeszów Fig. 1. Daily data flow at Rzeszow wastewater treatment plant
Tab. 1. Badane parametry ścieków surowych
Tab. 1. Raw wastewater parameters analyzed
Parametr Opis
Z og Zawiesina ogólna (g/m3)
BZT5 Biochemiczne zapotrzebowanie na tlen (gO2/m3)
ChZTChemiczne zapotrzebowanie na tlen (g/m3) [15]
N og Azot ogólny (g/m3)
NH4-N Azot amonowy (g/m3)
Qdśr Przepływ średniodobowy (m3/d) [16]
Tab. 2. Charakterystyka danych dotyczących przepływu ścieków surowych w Rzeszowie od 1 stycznia 2011 r. do 30 kwietnia 2016 r. z wyłączeniem okresu modernizacji (rok 2014)
Tab. 2. Characteristics of raw wastewater data in Rzeszow from 1st January 2011 to 30 April 2016 excluding the modernization period (2014 year)
ParametrDni
Z og 1554416,63102,8180,00362,00418,00470,001200,00
Bartosz Kowal, Patryk Organiściak, Paweł Kuraś, Adam Masłoń, Bartosz Wadiak
2.2. Korelacja między opadami a ilością ścieków
Badania dotyczące ścieków jednoznacznie sugerują, że zachodzi korelacja między warunkami pogodowymi a jakością i ilością dopływających do oczyszczalni ścieków oraz, że jest ona zależna od przesunięcia sygnałów w czasie [17, 18]. Ilość ścieków dopływających do oczyszczalni w Rzeszowie w ciągu jednej doby może być przewidywana za pomocą sztucznych sieci neuronowych. W procesie prognozowania ilości ścieków, najważniejszymi czynnikami okazują się: wysokość opadów, ilość ścieków zmierzona z opóźnieniem jednego i dwóch dni oraz stan wody w odbiorniku, dostarczony z opóźnieniem wynoszącym jeden dzień [19]. Bartkiewicz i autorzy ustalili, że możliwe jest zbliżone prognozowanie wartości parametrów ilościowych ścieków z użyciem sieci neuronowych, bazując na parametrach, takich jak dopływ ścieków zmierzony z dwóch poprzednich dób oraz dopływ ścieków z trzech poprzednich dób. Jest to jedno z podejść do predykcji ilościowej, natomiast w tej pracy skupiono się na predykcji za pomocą wyłącznie danych czasowych, aby ocenić ich skuteczność w predykcji dobowej ilości ścieków [19].
3. Metodyka badań
Jednym z wyzwań w prognozowaniu danych metodami uczenia maszynowego ML (ang. Machine learning) [20] jest wybór odpowiednich parametrów konfiguracyjnych. W niniejszym rozdziale analizowano możliwości predykcji dobowego przepływu ścieków do oczyszczalni w Rzeszowie, wykorzystując metody ML w różnych konfiguracjach. Analizowane w badaniu dane składają się z informacji pogodowych, takich jak opady i temperatury oraz dobowy dopływ ścieków. Zbiór danych uzupełniono o dni tygodnia oraz miesiące, aby uwydatnić zależności między poszczególnymi dniami. Zbiór badano w konfiguracji danych stosując dni tygodnia z miesiącami. Dodatkowo badania te uwzględniają trzy różne metody opadów w ujęciu czasowym.
W analizie wykorzystano dwie główne kategorie metod: modele statystyczne (ARIMA, SARIMAX) oraz algorytmy uczenia maszynowego (drzewa decyzyjne, KNN, MLP, las losowy). Warto zaznaczyć, że nie wszystkie z tych metod są algorytmami uczenia maszynowego, jednak wszystkie służą do predykcji danych, których precyzję zbadano w trakcie analizy.
Dane pogodowe zaczerpnięte ze stacji meteorologicznej znajdującej się w Jasionce mają szereg parametrów, takich jak temperatura powietrza, wielkość opadów i ich czas trwania. Biorąc pod uwagę, że wody opadowe mogą dopływać do oczyszczalni z pewnym opóźnieniem czasowym o charakterze falowym [21, 22], rozważono je w trzech wariantach:
1. t1 – dobowy sumaryczny opad deszczu zarejestrowany w dniu pomiaru przepływu w oczyszczalni,
2. t2 – dobowy sumaryczny opad rejestrowany od 12:00 dnia poprzedniego do 12:00 dnia pomiarowego w oczyszczalni, 3. t3 – dobowy sumaryczny opad rejestrowany dnia poprzedzającego dzień pomiaru w oczyszczalni.
Proponowany podział umożliwił sprawdzenie wpływu opadów na precyzję budowanych modeli. W ocenie skuteczności modeli wzięto pod uwagę trzy wskaźniki:
1. – tzw. średni błąd bezwzględny [23].
Jest to średnia wartość bezwzględnych różnic między pro gnozowanymi a rzeczywistymi wartościami. MAE dostarcza informacji, jak daleko od rzeczywistych wartości są prognozy.
2. () ˆ max ii MaxErroryy =− – to największa różnica między prognozowaną a rzeczywistą wartością w badanych danych.
Ta statystyka pokazuje, jak duży może być najgorszy przypadek błędu w prognozach.
gdzie: yi = rzeczywista wartość i-tej obserwacji, ˆ yi = przewidywana wartość i-tej obserwacji, Tolerancja = ustalony próg tolerancji błędu, np. 10 %, n = liczba obserwacji.
Ostatni z modeli poprawności prognoz został zdefiniowany w kontekście niniejszych badań. Dokładność obliczana jest jako procent prognoz, które są wystarczająco blisko rzeczywistych wartości. Błędy rzędu 10 % do danych rzeczywistych były traktowane jako poprawne, pozostałe jako dane błędne.
4. Prognozowanie parametrów oczyszczalni na podstawie warunków pogodowych
Pierwszą ze stosowanych w badaniu metod do analizy szeregu czasowego jest analiza wykładnika Hursta [24] do analizy zależności długoterminowej. Hurst w swojej analizie podczas projektu budowy tamy na rzece Nil odkrył, że poziom rzeki Nil nie jest procesem losowym. Wykładnik ten jest narzędziem statystycznym służącym do klasyfikacji szeregów czasowych na trzy grupy: losowe, gdy H = 0,5; antypersystentne, gdy 0 < H < 0,5 oraz persystentne, gdy 0,5 < H < 1. Szacowanie wykładnika Hursta w swojej podstawowej wersji związane jest z analizą R\S czyli tzw. analizy przeskalowanego zakresu. Obliczony wykładnik Hursta dla danych przepływu ścieku wynosi 0,736, co wskazuje na zależności długoterminowe, czyli wzorce przepływu ścieków utrzymują się przez dłuższy czas. Gdyby zależności były krótkoterminowe lub losowe, oznaczałoby to, że przepływy szybko się zmieniają i byłyby trudniejsze do późniejszego przewidywania i analiz statystycznych.
4.1. Analiza stacjonarności
Stacjonarność jest właściwością szeregów czasowych, w której ich statystyczne charakterystyki, takie jak średnia, wariancja i autokorelacja, nie zmieniają się w czasie. Metoda badania szeregów czasowych pod względem stacjonarności jest jednym z podstawowych metod do analizy danych ekonomicznych [25]. Badanie stacjonarności w przypadku dobowego przepływu ścieków jest istotną kwestią, ponieważ pozwala z matematycznego punktu widzenia ocenić, czy te właściwości statystyczne szeregu czasowego pozostają stałe, co może rzutować na wiarygodności modeli ponieważ wiele metod statystycznych i ekonometrycznych zakłada stacjonarność danych. Zrozumienie, czy dane przepływu są stacjonarne, jest również ważne do identyfikacji trendów i sezonowości, co ma istotne implikacje dla planowania, projektowania i zarządzania infrastrukturą kanalizacyjną.
Na podstawie podanych wyników przedstawionych w tab. 3 można zauważyć, że testy ADF (ang. Augmented Dickey-Fuller) i PP (Phillips-Perron) sugerują stacjonarność badanego szeregu czasowego, ponieważ ich wartości p (P-value) są bardzo niskie – 0,01, co wskazuje na odrzucenie hipotezy o niestacjonarności. Test KPSS (Kwiatkowski-Phillips-Schmidt-Shin) daje wyższą wartość p = 0,079, co może sugerować stacjonarność, ale z mniejszą pewnością. Wartości ERS (Elliott-Rothenberg-Stock) wydają się mieć mieszane wyniki z jedną wysoką wartością P-test na poziomie 0,97 i innymi wartościami krytycznymi, co może wska-
Tab. 3. Wyniki stacjonarności dla dobowego przepływu ścieków
Tab. 3. Stationarity results for daily wastewater flow
zywać niepewności w stacjonarności szeregu. Użycie tych metod może pozwolić na określenie założenia, że wartości dobowego przepływu ścieków wskazują na potencjalną stacjonarność szeregu czasowego. Zapewnia to, że tworzone modele będą pracować na danych o stabilnych właściwościach statystycznych, co potencjalnie zwiększa ich zdolność do generowania dokładniejszych, a także bardziej wiarygodnych prognoz dobowego przepływu ścieków za pomocą modeli uczenia maszynowego oraz modeli statystycznych.
4.2. Analiza i porównanie metod predykcji
Pierwszą użytą metodą do predykcji była ARIMA [26], która opiera się na statystycznej koncepcji korelacji szeregowej, w której przeszłe punkty danych wpływają na przyszłe punkty danych. Jest to model, który przybiera tylko jedno wejście, tj. szereg czasowy i jedno wyjście, którym jest dobowy przepływ ścieków. Podczas badań stworzono 75 różnych konfiguracji modelu ARIMA, gdzie zmieniane były trzy parametry:
Tab. 4. Wyniki dla modeli ARIMA
Tab. 4. Results for ARIMA models
autoregresji, różnicowania i średniej ruchomej, które mogą odgrywać kluczową rolę w prognozowaniu szeregów czasowych. Analizując przedstawione w tab. 4 wyniki modelu ARIMA, zaobserwowano, że wartości MAE wahały się od 3800,88 do 162 433,32, RSME od 5306,39 do 187 392,46, zaś stopień poprawności modelu nie przekroczył 64 %, co wskazuje, że aż 36 % prognoz było niepoprawnych. Warto też zwrócić uwagę na znaczącą różnicę w maksymalnych wartościach między danymi rzeczywistymi a realnymi.
4.3. Drzewo decyzyjne
W tworzeniu i ocenie poprawności predykcji w tych testowano różne konfiguracje drzew decyzyjnych [27], zmieniając parametry, takie jak głębokość drzewa (od 10 do 100), liczbę próbek branych pod uwagę przy podziale w węźle (od 2 do 30) oraz kryteria podziału uwzględniając trzy różne czasy opadów. Łącznie dla każdego z czasu opadów t przebadano po 378 modeli. W tab. 5 przedstawiono wyniki z ponad 1000 modeli
MAE 3800,88 162 433,32 9764,63 4619,38
RMSE
Tab. 5. Wyniki dla modeli drzewa decyzyjnego z różnymi czasami opadów
Tab. 5. Results for Decision Tree models with different rainfall times
Bartosz Kowal, Patryk Organiściak, Paweł Kuraś, Adam Masłoń, Bartosz Wadiak
drzewa decyzyjnego. W tej metodzie uzyskano najniższy błąd MAE rzędu 4400 m3, RMSE 6100 m3, przy współczynniku poprawności na poziomie 56,95 % dla t2.
4.4. KNN
W badaniach rozważono również zastosowanie modelu K najbliższych sąsiadów [28]. W testach przebadano różne konfiguracje modelu, zmieniając parametry, takie jak liczba sąsiadów (K : 16, 32, 64, 128, 256, 512, 1024), metrykę odległości (euklidesowa, manhattan) oraz algorytmy wyboru sąsiadów. Łącznie dla każdego z czasu opadów t przebadano po 14 modeli KNN. W ponad 1000 stworzonych modeli KNN można zaobserwować poziom wyników zbliżony do wyników drzewa decyzyjnego. Wyniki zaprezentowano w tab. 6. W tej metodzie uzyskano
Tab. 6. Wyniki dla modeli KNN z różnymi czasami opadów
Tab. 6. Results for KNN models with different rainfall times
t2
t3
najmniejsze błędy MAE rzędu 4200 m3 oraz RMSE 5800 m3, przy współczynniku poprawności na poziomie 56,31 % dla t1
4.5 MLP
W analizie predykcji zastosowano również model perceptronu wielowarstwowego (MLP) [29]. Test obejmował różne konfiguracje modelu, takie jak liczba neuronów w warstwach ukrytych (16, 32, 64, 128, 256, 512, 1024, 2048), liczba epok treningowych (100, 200), a także dodawanie ukrytej warstwy drugiej (64, 128, 256, 512, 1024) i ukrytej warstwy trzeciej, której liczba neuronów zależała od warstwy drugiej. Łącznie dla każdego z czasu opadów przebadano po 100 modeli MLP. Wyniki tych modeli przedstawiono w tab. 7. Ta metoda zwróciła najwyższy, jak dotąd wskaźnik poprawności wynoszący
MAE 4212,59 4819,78 4388,69 4322,88
RMSE 5769,45 6293,71 5930,28 5855,44
Max Error 25 747,8427 553,2126 483,7426 307,56
Accuracy 47,53 %56,31 %53,48 %54,60 %
MAE 4280,39 4821,04 4438,07 4364,09
Max Error 25 697,2327 514,5126 406,2926 097,86
Accuracy 47,96 %55,46 %52,90 %53,96 %
MAE 4363,75 4866,41 4494,09 4405,66
RMSE 5971,32 6320,69 6064,36 6026,84
Max Error 25 075,3227 222,4826 222,0625 925,29
Accuracy 47,10 %56,31 %52,53 %53,10 %
Tab. 7. Wyniki dla modeli MLP z różnymi czasami opadów
Tab. 7. Results for MLP models with different rainfall times
MAE 4055,965402,654392,934349,71
RMSE 5736,096507,79 5939,9 5920,22
1
Max Error 23 638,7329 147,4526 193,8626 152,49
MAE 4106,884983,034427,064377,84
RMSE 5847,586380,896028,126002,11
Accuracy 37,9 % 62,95 % 54,8 % 55,24 % t2
Max Error 24 298,8328 601,7926 022,1425 935,07
Accuracy 43,68 %64,66 %54,37 %54,60 %
MAE 4096,145709,144514,204467,99
RMSE 5902,297043,866121,346097,94
Max Error 23 300,2129 177,925 688,9925 607,96
Accuracy 39,4 % 64,66 %53,44 %53,42 %
Min Max Średnia Mediana
Tab. 8. Wyniki dla modeli lasu losowego z różnymi czasami opadów
Tab. 8. Results for random forest models with different rainfall times
Min Max ŚredniaMediana t1
MAE 4569,324732,984620,284589,40
RMSE 6231,966433,566288,736243,57
Max Error 29 068,4030 227,6829 529,0729 410,11
MAE 4603,124665,704622,974611,53
RMSE 6439,29 6458 6449,286449,91
Accuracy 53,31 %55,24 %54,33 %54,38 % t2
Max Error 29 563,2030 440,0230 023,9230 046,22
MAE 4927,915042,704967,384949,45
RMSE 6588,11 6811,1 6665,16 6629,6
Accuracy 52,03 %55,03 %54,06 %54,60 % t3
Max Error 29 014,5530 123,7629 437,0429 304,92
Accuracy 48,39 %49,89 %49,19 %49,25 %
64,66 % poprawności z błędem MAE rzędu 4100 m3 oraz RMSE 5800 m3 dla t2 oraz t3. Niestety model też zwraca maksymalną różnicę błędu na poziomie 23 000 m3, co stanowi aż około 58 % realnego przepływu ścieków.
4.6. Random Forest (las losowy)
Las losowy jest jedną z bardziej popularnych metod ML, szeroko stosowaną w analizie danych [30]. W przeprowadzonym teście istotnym parametrem była liczba drzew decyzyjnych (estymatorów) w lesie. Analiza polegała na zmianie liczby drzew (10, 50, 100, 200) dla każdego z modeli. Łącznie, dla każdego okresu opadów, przebadano po cztery modele Random Forest. Algorytm Random Forest charakteryzował się niewielkimi zmianami w samej strukturze modelu. Jak przedstawiono w tab. 8, wyniki dla MAE, podobnie jak w przy-
Tab. 9. Wyniki dla modeli SARIMAX z różnymi czasami opadów Tab. 9. Results for SARIMAX models with different rainfall times
padku wcześniejszych modeli ML, wynosiły około 4600 m3, a RMSE około 6200 m3. Najskuteczniejsze modele Random Forest charakteryzowały się dokładnością na poziomie 55,24 % dla t1
4.7. SARIMAX
W rozdziale 4.2 stosowano modele ARIMA, które nie pozwalały na uwzględnienie zmiennych zewnętrznych, m.in. opadów, dlatego w kolejnych seriach obliczeń użyto modelu SARIMAX. SARIMAX to zaawansowany model statystyczny służący do analizy i prognozowania szeregów czasowych, który uwzględnia zarówno sezonowość, jak i wpływ zewnętrznych zmiennych regresorów [31]. Eksperymenty te obejmowały testowanie różnych konfiguracji modelu SARIMAX, zmieniając parametry autoregresji (od 0 do 4), stopień różnicowania (od 0 do 2)
MAE 3598,02157492,5316069,434805,26
RMSE 4908,4181754,7533045,226549,72
Max Error 17 337,93319 820,9041 363,5025 612,39
Accuracy 0 % 65,31 %39,76 %54,17 %
MAE 3757,9420 629 330 000275 072 8004907,21
RMSE 5124,7721 047 340 3972430 337 5296779,28
t2
Max Error 19841,8428 258 790 000376 830 40027,546
MAE 3857,05200 200,6217 651,745085,47
RMSE 5283,33200 408,0840 448,47036,39
Accuracy 0 % 63,38 %40,39 %52,46 % t3
Max Error 20 296,57331 182,5150 567,7627 974,81
Accuracy 0 % 62,95 %40,10 %51,82 %
Tab. 10. Podsumowanie dla skuteczności modeli ML
Tab. 10. Summary for effectiveness of ML models
Model MAE RMSEMax ErrorPrecyzjaCzas opadów
ARIMA 3800,885306,3920 298,2563,38 %brak
Decision tree 4389,766069,427 967,2856,95 %
2 KNN 4212,595769,4525 075,3256,31 %
4055,965736,0923 300,2164,66 %
Random forest 4569,326231,9629 014,5555,24 % t1
SARIMAX 3598,024908,427 974,5565,31 % t1
oraz stopień średniej ruchomej (od 0 do 4). Jako zmienną zewnętrzną ustawiono opady t. Łącznie dla każdego z czasu opadów przebadano po 72 modeli SARIMAX. W tab. 9 zaprezentowano wyniki ze wszystkich stworzonych modeli SARIMAX. Można zaobserwować, że metoda osiągnęła najwyższe wyniki równe 65,31 % z błędem MAE rzędu 3600 m3, RMSE 4900 m3 dla t1
4.8. Analiza wyników i osiągnięty błąd prognoz W ramach badań przeanalizowano skuteczność sześciu różnych modeli uczenia maszynowego (ARIMA, drzewa decyzyjne, KNN, MLP, las losowy, SARIMAX). Zbiorcze zestawienie wyników uzyskanych z tych metod przedstawiono w tab. 10, która zawiera najbardziej optymalne wyniki dla każdego modelu, w tym wartości MAE, RMSE, maksymalnego błędu oraz dokładność dopasowania danych predykcyjnych do rzeczywistych.
Model SARIMAX osiągnął najniższą wartość błędów MAE wynoszącą 3598,02 m3 oraz RMSE 4908,40 m3 dla wariantu czasu opadów t1. Jednocześnie różnica między RMSE a MAE w przypadku tego modelu była najmniejsza spośród wszystkich badanych metod, co potwierdza jego najwyższą jakość dopasowania oraz niewielką wrażliwość na duże odchylenia w prognozach.
Algorytm SARIMAX również uzyskał najwyższy poziom dokładności dopasowania, wynoszący 65,31 % (t1). Na podstawie uzyskanych wyników można stwierdzić, że SARIMAX jest najbardziej odpowiednim modelem do przyszłych analiz. Jego niski poziom błędu średniego oraz maksymalnego znacząco przewyższa inne modele, które w niektórych przypadkach generowały błędy maksymalne wynoszące nawet 100 % dobowego przepływu ścieków.
Istotnym czynnikiem wpływającym na skuteczność modeli okazał się dobór odpowiedniego zakresu czasowego dla danych opadów, co wskazuje na konieczność uwzględnienia tej zmiennej w przyszłych badaniach.
5. Podsumowanie
Artykuł prezentuje innowacyjną analizę wpływu warunków pogodowych na funkcjonowanie oczyszczalni ścieków, wykorzystując zaawansowane modele predykcyjne oparte na danych meteorologicznych. Ciekawym i innowacyjnym aspektem badań jest uwzględnienie analizy wykładnika Hursta i analizy stacjonarności do analizy zależności długoterminowych oraz wykorzystanie metody Tolerance-Bounded Accuracy w predykcji ścieków, co jest nowatorskim podejściem w porównaniu do tradycyjnej statystyki R2. To pozwala na lepsze zrozumienie potencjału modeli w realnych warunkach i ich
praktyczne zastosowanie w prognozowaniu dobowego przepływu ścieków.
Warto podkreślić, że przeprowadzone badania miały bardzo szeroki zakres i obejmowały 12 różnych metod, jednak ze względu na ograniczenia objętości publikacji, przedstawiono tylko najbardziej efektywne z nich. Zastosowane zostały m.in. algorytm najbliższego sąsiada (KNN), ARIMA, drzewa decyzyjne, lasy losowe oraz sieci neuronowe (MLP) dla różnych konfiguracji danych. Mimo że żaden z badanych modeli nie osiągnął optymalnej dokładności, nawet przy założeniu 10 % błędu pomiarowego, ich analiza otwiera drogę do dalszego rozwoju i udoskonalenia metod prognozowania. Badanie wykazało również znaczący wpływ czasu trwania opadów na dokładność modeli, szczególnie w algorytmach Random Forest czy MLP. To odkrycie wskazuje na potrzebę dalszych badań w tym kierunku, z potencjalnym rozszerzeniem bazy danych i dodatkowymi parametrami czasowymi oraz meteorologicznymi, aby jeszcze bardziej poprawić dokładność modeli predykcyjnych.
W długoterminowej perspektywie, uzyskane wyniki stanowią mocne fundamenty do kontynuacji badań nad prognozowaniem dobowego przepływu ścieków. Przyszłe etapy będą włączać nowe dane z kolejnych lat oraz rozważać nie tylko ilościowe, ale i jakościowe aspekty prognozowania przepływu ścieków, co stanowi ogromny potencjał dla rozwoju tej dziedziny.
Bibliografia
1. Kılıç Z., The importance of water and conscious use of water, “International Journal of Hydrology”, Vol. 4, No. 5, 2020, 239–241, DOI: 10.15406/ijh.2020.04.00250.
2. Małecki Z.J., Gołębiak P., Zasoby wodne polski i świata, „Zeszyty Naukowe. Inżynieria Lądowa I Wodna w Kształtowaniu Środowiska”, Nr 7, 2012, 50–56.
3. Jackson R.B., Carpenter S.R., Dahm C.N., et al., Water in a changing world, “Ecological applications”, Vol. 11, No. 4, 2001, 1027–1045, DOI: 10.1890/1051-0761(2001)011[1027:WIACW]2.0.CO;2.
4. Masłoń A., Tomaszek J.A., Ocena efektywności oczyszczalni ścieków w Lubaczowie, „Czasopismo Inżynierii Lądowej, Środowiska i Architektury”, Z. 60, Nr 3, 2013, 209–222.
5. Organiściak P., Masłoń A.A., Kowal B., et al., Machine learning-based prediction of biogas production from sludge characteristics in four anaerobic digesters-development of the AD2biogas prediction tool, “Advances in Science and Technology Research Journal”, Vol. 18, No. 8, 2024, 1–15, DOI: 10.12913/22998624/192936.
6. Dziopak J., Starzec M., Wpływ kierunku i prędkości przemieszczania się opadu deszczu na maksymalne szczytowe przepływy ścieków w sieci kanalizacyjnej, „Czasopismo
Inżynierii Lądowej, Środowiska i Architektury”, Z. 61, Nr 3, 2014, 63–81.
7. Skoczko I., Ofman P., Szatyłowicz E., Zastosowanie sztucznych sieci neuronowych do modelowania procesu oczyszczania ścieków w małej oczyszczalni ścieków, „Rocznik Ochrona Środowiska”, tom 18, cz. 1, 2016, 493–506.
8. Bogusz M., Matysik-Pejas R., Krasnodębski A., et al., The concept of zero waste in the context of supporting environmental protection by consumers, “Energies”, Vol. 14, No. 18, 2021, DOI: 10.3390/en14185964.
9. Okoffo E.D., O’Brien S., O’Brien J.W., et al., Wastewater treatment plants as a source of plastics in the environment: a review of occurrence, methods for identification, quantification and fate, “Environmental Science: Water Research & Technology”, Vol. 5, No. 11, 2019, 1908–1931, DOI: 10.1039/C9EW00428A.
10. Masłoń A., Dynamika dopływu ścieków do oczyszczalni w aspekcie funkcjonowania sekwencyjnych reaktorów porcjowych, „Instal”, Nr 10, 2017, 57–62.
11. Kuraś P., Strzalka D., Kowal B., et al., REDUCE –a python module for reducing inconsistency in pairwise comparison matrices, “Advances in Science and Technology. Research Journal”, Vol. 17, No. 4, 2023, 227–234, DOI: 10.12913/22998624/170187.
12. Andraka D., Dzienis L., Modelowanie ryzyka w eksploatacji oczyszczalni ścieków, „Rocznik Ochrona Środowiska”, t. 15, cz. 2, 2013, 1111–1125.
13. Deublein D., Steinhauser A., Biogas from waste and renewable resources: an introduction, John Wiley & Sons, 2011.
14. Maj K., Masłoń A., Wieloparametryczna ocena efektywności oczyszczalni ścieków w Rzeszowie przed modernizacją, „Czasopismo Inżynierii Lądowej, Środowiska i Architektury”, Z. 62, Nr 1, 2015, 299–315, DOI: 10.7862/rb.2015.20.
15. Sadecka Z., Płuciennik-Koropczuk E., Frakcje ChZT ścieków w mechaniczno-biologicznej oczyszczalni, „Rocznik Ochrona Środowiska”, tom 13, 2011, 1157–1172.
16. Szpindor A. Łomotowski J., Nowoczesne systemy oczyszczania ścieków, Wydawnictwo Arkady, Warszawa 2002.
17. Szelą g B., Studziński J., Chmielowski K., Leśniańska A., Rojek I., Prognozowanie ilości ścieków dopływających do oczyszczalni za pomocą sztucznych sieci neuronowych z wykorzystaniem liniowej analizy dyskryminacyjnej, „Ochrona Środowiska”, Vol. 40, No. 4, 2018, 9–14.
18. Bugajski P., Chmielowski K., Kaczor G., Wpływ wielkości dopływu wód opadowych na skład ścieków surowych w małym systemie kanalizacyjnym, „Acta Scientiarum Polonorum. Formatio Circumiectus”,Vol. 15, No. 2, 2016, 3–11, DOI: 10.15576/ASP.FC/2016.15.2.3.
19. Bartkiewicz L., Szeląg B., Studziński J., Ocena wpływu zmiennych wejściowych i struktury modelu sztucznej sieci neuronowej na prognozowanie dopływu ścieków komunalnych do oczyszczalni, „Ochrona Środowiska”, Vol. 38, No. 2, 2016, 29–36.
21. Bąk Ł., Górski J., Górska K., Szelą g B., Zawartość zawiesin i metali ciężkich w wybranych falach ścieków deszczowych w zlewni miejskiej, „Ochrona Środowiska”, Vol. 34, No. 2, 2012, 49–52.
22. Ociepa E., Ocena zanieczyszczenia ścieków deszczowych trafiających do systemów kanalizacyjnych, „Inżynieria i Ochrona Środowiska”, Vol. 14, No. 4, 2011, 357–364.
23. Chai T., Draxler R.R., Root mean square error (RMSE) or mean absolute error (MAE), “Geoscientific model development discussions”, Vol. 7, 2014, 1525–1534, DOI: 10.5194/gmdd-7-1525-2014.
24. Hurst H.E., Long-term storage capacity of reservoirs, “Transactions of the American Society of Civil Engineers”, Vol. 116, No. 1, 1951, 770–799, DOI: 10.1061/TACEAT.0006518.
25. Musbah H., Aly H., Little T., A proposed novel adaptive dc technique for non-stationary data removal, “Heliyon”, Vol. 9, No. 3, 2023, DOI: 10.1016/j.heliyon.2023.e13903.
26. Ghysels E., Osborn D.R., Rodrigues P.M., Chapter 13 Forecasting seasonal time series, “Handbook of Economic Forecasting”, Vol. 1, 2006, 659–711, DOI: 10.1016/S1574-0706(05)01013-X.
28. Fix E., Hodges J.L., Discriminatory Analysis. Nonparametric Discrimination: Consistency Properties, “International Statistical Review/Revue Internationale de Statistique”, Vol. 57, No. 3, 1989, 238–247, DOI: 10.2307/1403797.
29. Taud H., Mas J., Multilayer perceptron (MLP), “Geomatic approaches for modeling land change scenarios”, 2018, 451–455.
30. Ho T.K., Random decision forests, [In:] Proceedings of 3rd International Conference on Document Analysis and Recognition, 1995, 278–282, DOI: 10.1109/ICDAR.1995.598994.
31. Dub ey A.K., Kumar A., García-Díaz V., et al., Study and analysis of SARIMA and LSTM in forecasting time series data, “Sustainable Energy Technologies and Assessments”, Vol. 47, 2021, DOI: 10.1016/j.seta.2021.101474.
Inne źródła
32. Rozporządzenie Ministra Gospodarki Morskiej i Żeglugi Śródlądowej z dnia 12 lipca 2019 r. w sprawie substancji szczególnie szkodliwych oraz warunków, jakie należy spełnić przy wprowadzaniu do wód lub do ziemi ścieków, a także przy odprowadzaniu wód opadowych lub roztopowych do wód lub do urządzeń wodnych. (Dz.U. 2019, poz. 1311).
33. Instytut Meteorologii i Gospodarki Wodnej, https://danepubliczne.imgw.pl
Machine Learning in Forecasting the Amount of Sewage for the Wastewater Treatment Plant of the City of Rzeszów Based on Weather Conditions
Abstract: The parameters of wastewater treatment plants in Poland must meet certain standards that regulate the quality of wastewater after the treatment process. The quantity and quality of incoming sewage depend on many factors, including weather conditions. Forecasting these parameters can ensure optimal operation of the treatment plant, which will reduce operating costs. For this purpose, using weather data, an attempt was made to estimate the amount of sewage flowing into the sewage treatment plant in Rzeszow. Over 1000 machine learning (ML) models were used, including statistical models such as ARIMA and SARIMAX, and ML algorithms such as KNN and neural networks, in various configurations and time frames. The lowest mean absolute error (MAE) of 3598 m3 and the root mean square error (RMSE) of 4808 m³ were obtained. The study showed how the selection of parameters and different types of predictive models (static, dynamic, machine learning) affects forecast accuracy. It also highlighted that forecasting based solely on basic time-series data is a challenging process.
Keywords: wastewater treatment plants, neural networks, control systems, machine learning
mgr inż. Bartosz Kowal
b.kowal@prz.edu.pl
ORCID: 0000-0002-7909-6484
Asystent w Zakładzie Systemów Złożonych Wydziału Elektrotechniki i Informatyki Politechniki Rzeszowskiej. Jego badania skupiają się na analizie systemów złożonych, bezpieczeństwie komputerowym i sieciowym oraz inżynierii komputerowej.
mgr inż. Patryk Organiściak
org@prz.edu.pl
ORCID: 0000-0002-5277-4038
Jest pracownikiem naukowo-dydaktycznym na Politechnice Rzeszowskiej, gdzie prowadzi zajęcia z technologii informacyjnych, programowania, przetwarzania danych oraz cyberbezpieczeństwa. Jednocześnie realizuje projekty komercyjne w ramach własnego software house, specjalizując się w tworzeniu oprogramowania dla biznesu.
dr inż. Paweł Kuraś
p.kuras@prz.edu.pl
ORCID: 0000-0002-8658-0821
Adiunkt badawczo-dydaktyczny na Politechnice Rzeszowskiej oraz Akademii Górniczo-Hutniczej, a także wykładowcą Wyższej Szkoły Informatyki i Zarzadzania w Rzeszowie, Uniwersytetu WSB Merito w Poznaniu, Wyższej Szkoły Biznesu – National Louis University w Nowym Sączu. Realizował wiele projektów łączących naukę z biznesem, a także jest prezesem pierwszej spółki spin-off Politechniki Rzeszowskiej, Suntrail sp. z o.o.
dr hab. inż. Adam Masłoń, prof. PRz
amaslon@prz.edu.pl
ORCID: 0000-0002-3676-0031
Profesor uczelni w Katedrze Inżynierii i Chemii Środowiska Politechniki Rzeszowskiej. Autor i współautor ponad 270 prac naukowych i doniesień konferencyjnych, w tym 45 publikacji indeksowanych w WoS/Scopus. Twórca 15 patentów i pięciu wzorów użytkowych. Recenzent w Narodowym Centrum Badań i Rozwoju oraz Ekspert Regionalnego Programu Operacyjnego Województwa Podkarpackiego. Biegły sądowy z zakresu ochrony środowiska. Członek Regionalnej Komisji ds. Ocen Oddziaływania na Środowisko w Rzeszowie. Wykonawca i kierownik kilkunastu projektów badawczych z technologii ścieków i utylizacji odpadów. Autor ponad 60 opracowań technicznych i ekspertyz dla firm projektowych i przedsiębiorstw komunalnych. Obszar zainteresowań naukowych obejmuje technologie ścieków i utylizację odpadów, efektywność energetyczna w przedsiębiorstwach wodociągowo-kanalizacyjnych, technologie GOZ i bioenergetyczne, w tym technologie biogazowe.
mgr inż. Bartosz Wadiak bwadiak@mpwik.rzeszow.pl
ORCID: 0009-0004-8894-1952
Absolwent Wydziału Chemicznego Politechniki Rzeszowskiej na kierunku biotechnologia oraz Wydziału Chemii Uniwersytetu Wrocławskiego. Od 2015 r. pracownik Miejskiego Przedsiębiorstwa Wodociągów i Kanalizacji, gdzie początkowo pracował jako analityk w Laboratorium Centralnym, a obecnie zajmuje stanowisko technologa na oczyszczalni ścieków. Odpowiada za realizację i nadzór procesu oczyszczania ścieków komunalnych oraz zagospodarowanie osadów.
Macierzowy cyfrowy cień sieci czujników IoT
Władysław Iwaniec
Akademia Tarnowska w Tarnowie, Wydział Politechniczny, Katedra Automatyki i Robotyki, ul. Mickiewicza 8, 33-100 Tarnów
Streszczenie: W artykule przedstawiono koncepcję macierzowego cyfrowego cienia sieci czujników IoT. Omówiono różnice między cyfrowym bliźniakiem a cyfrowym cieniem i uzasadniono wybór koncepcji cienia sieci czujników. Przedstawiono macierzowy opis takiej sieci i wprowadzono koncepcję εk − sąsiedztwa czujnika. Zamieszczono wzory dla modeli liniowych εk − sąsiedztw typu plus i typu gwiazdka. Na wybranych przykładach pokazano możliwość wykrywania i eliminacji niektórych zagrożeń bezpieczeństwa takiej sieci.
Słowa kluczowe: cienie cyfrowe, bezpieczeństwo, Internet Rzeczy, zagrożenia bezpieczeństwa, urządzenia IoT, sieci czujników, modele macierzowe
1. Wprowadzenie
Sieci czujników, zwłaszcza bezprzewodowych WSN (ang. Wireless Sensor Network), są stosowane w wielu obszarach, w tym w rolnictwie, inteligentnych budynkach, medycynie czy monitorowaniu środowiska. Zestawy czujników, które mierzą wartość tej samej wielkości fizycznej lub chemicznej, np. temperatury, ciśnienia, wilgotności, zakwaszenia gleby są narażone na ataki lub awarie, w szczególności wskutek zużycia energii, podstawienia fałszywego czujnika czy przejęcia nad nim lub jego kanałem komunikacyjnym kontroli przez intruza. Sieci WSN dla czujników są podatne na rozmaite ataki, zwłaszcza w obszarze transmisji danych [1]. Przeprowadzona analiza i przegląd literatury [2] wskazują na znaczenie incydentu polegającego na przejęciu jednego z węzłów, który naśladuje pracę rzetelnego (prawowitego) węzła i zakłóca pracę układu. Pokazano, że istnieją różne metody, zgodne z zasadą CIA, ochrony sieci WSN przed naruszeniem bezpieczeństwa, w szczególności związane z ochroną kryptograficzną, jednakże nie dają one możliwości oceny danych generowanych przez czujniki. W przeglądowym artykule [3] zamieszczono m.in. analizę metod maszynowego uczenia się stosowanych do poprawy bezpieczeństwa bezprzewodowych sieci czujników, w szczególności opartą na algorytmie k-nn. Wykorzystanie idei najbliższych sąsiadów do budowy cyfrowego cienia DS (ang. Digital Shadow) siatki czujników pozwala na podniesienie poziomu jej bezpieczeństwa, w szczególności przez eliminację, względnie minimalizację wpływu fałszywych lub zakłóconych danych na zachowanie układu, a zwłaszcza na sterowanie. W kolejnym przeglądowym artykule [4] przedstawiającym rozmaite zagadnienia bezpieczeństwa Internetu Rzeczy przedyskutowane zostały m.in. różne architektury IoT. Jedno z podejść, wybrane przez autorów ze
Autor korespondujący: Władysław Iwaniec, wiw@atar.edu.pl
Artykuł recenzowany nadesłany 13.12.2024 r., przyjęty do druku 05.02.2025 r.
Zezwala się na korzystanie z artykułu na warunkach licencji Creative Commons Uznanie autorstwa 4.0 Int.
względu na „intuicyjny charakter architektury”, wyróżnia trzy warstwy: warstwę wykrywania lub percepcji, warstwę sieciową i warstwę aplikacji. Przedstawiony cień cyfrowy sieci czujników jest usytuowany w warstwie aplikacji, ale jego zadaniem jest poprawa bezpieczeństwa tej sieci przez wykrywanie i eliminację anomalii i błędów zarówno w warstwie percepcji, jak też w warstwie sieciowej.
2. Cyfrowe bliźniaki i cyfrowe cienie
David Gelernter przedstawił ideę cyfrowego bliźniaka [5], wskazując na możliwości odwzorowania świata rzeczywistego za pomocą metod symulacyjnych. Formalnie pierwszy raz ten termin został użyty w raporcie NASA z 2010 r., chociaż już w 2002 r. Michael Grieves przedstawił jego koncepcję na konferencji związanej z inteligentnymi systemami wytwórczymi w branży lotniczej. Agencja NASA zaproponowała w 2012 r. następującą definicję [6, 7]: “Bliźniak cyfrowy to zintegrowana, wielofizyczna, wieloskalowa, probabilistyczna symulacja złożonego produktu, która stosuje najlepszy z dostępnych modeli fizycznych, dane z sensorów w czasie rzeczywistym, dane historyczne itp., aby odzwierciedlić funkcjonowanie odpowiadającego mu bliźniaka”. W oryginalnej koncepcji bliźniaka cyfrowego M. Grieves zwrócił uwagę na fundamentalne znaczenie wzajemnego przepływu informacji między bliźniakami i oddziaływania cyfrowej repliki na układ fizyczny w czasie rzeczywistym.
W późniejszych przeglądowych pracach [8, 9] autorzy przedstawili rozmaite podejścia do tej definicji i możliwość wyróżnienia wśród analizowanych rozmaitych odmian cyfrowych odwzorowań tzw. cyfrowego cienia. Różnice między cyfrowym cieniem a cyfrowym bliźniakiem zostały przedstawione m.in. w [10]. W opracowaniu [21] przyjęto, że „cyfrowy cień” jako pole działania w Przemyśle 4.0 to „wystarczająco dokładny” obraz procesów „w obszarach produkcji, rozwoju i pokrewnych, w celu stworzenia podstawy oceny wszystkich istotnych danych w czasie rzeczywistym”. W celu utworzenia takiego cienia należy najpierw określić i utworzyć bazę danych z różnych źródeł danych, na przykład z produkcji lub rozwoju, następnie je przefiltrować, dokonać ich agregacji i dopiero wtedy poddać dalszemu przetwarzaniu. Takie podejście, w którym na podstawie zmierzonych wartości tworzy się model układu, pozwalający na „ocenę
wszystkich istotnych danych w czasie rzeczywistym” może być zastosowane również do zestawu urządzeń IoT, które są źródłem danych pomiarowych.
W przywołanym artykule [8] podkreślono, że w publikacjach spotyka się określenia „cyfrowy model”, „cyfrowy cień” i „cyfrowy bliźniak” dla rozróżnienia stopnia odwzorowania i wzajemnego oddziaływania świata rzeczywistego i wirtualnego. Taki podział spotkał się z krytyką [11], gdzie zwrócono uwagę na niedostatki zaproponowanego nazewnictwa i wskazano na potrzebę jednoznacznego posługiwania się pojęciem cyfrowego bliźniaka.
Mimo krytycznego stanowiska dotyczącego stosowanego nazewnictwa, dla analizowanego dalej rozwiązania, które jedynie odwzorowuje stan rzeczywisty, a następnie służy do przetwarzania uzyskanych danych w celu oceny ich wiarygodności, nie oddziałując bezpośrednio na siatkę czujników, zastosowanie określenia „cyfrowego cienia” jest zdecydowanie bardziej trafne, niż pojęcia „cyfrowego bliźniaka”.
Warto zauważyć, że trwają i postępują prace mające na celu ustalenie standardów dla cyfrowych replik świata rzeczywistego, w szczególności takie jak projekt NIST „Digital Twins for Advanced Manufacturing” [22] i norma ISO 23247, definiująca ramy wspierające tworzenie cyfrowych bliźniaków jako obserwowalnych elementów produkcyjnych, w tym personelu, sprzętu, materiałów, procesów produkcyjnych, obiektów, środowiska, produktów i dokumentów pomocniczych [12, 23].
3. Macierzowy cyfrowy cień wybranej klasy zestawu czujników
Zestawy czujników, obecnie najczęściej bezprzewodowych, ze względu na łatwość implementacji i względnie niskie koszty są stosowane do pomiarów rozmaitych wielkości fizykochemicznych w wielu układach automatyki. Takie zestawy są zazwyczaj połączone za pośrednictwem sieci z punktem odbioru pomiarów, a otrzymany strumień danych pomiarowych jest przetwarzany w celu uzyskania odpowiednich nastaw aktuatorów. Typowymi problemami bezpieczeństwa takich układów są ataki na pojedyncze sensory (węzły) sieci, awarie, utrata łączności z czujnikiem czy ograniczenia urządzenia związane ze zbyt małą pamięcią czy mocą obliczeniową [13]. Wskutek takich zagrożeń celowa jest ocena, czy wyniki pomiarów uzyskane i przesyłane przez każdy z czujników są rzetelne czy też fałszywe i czy należy je wtedy zastąpić danymi historycznymi z ostatniego poprawnego odczytu lub wartościami obliczonymi przez cień.
W pracy [14] przedstawiono koncepcję rozszerzenie modelu ochrony urządzeń IoT na brzegu sieci o macierze oddziaływań i powiązań. Zgodnie z zaproponowanym rozwiązaniem zakłada się, że ochronie podlega zbiór czujników tej samej wielkości fizykochemicznej, który przesyła dane do układu sterowania wyznaczającego sygnały dla urządzeń wykonawczych. Zakłada się, że czujniki mogą przesyłać dane niezależnie do urządzenia brzegowego BS (ang. Border Station), lecz nie mogą komunikować się bezpośrednio ze sobą. Do realizacji koncepcji ochrony takiego układu czujników przed atakami, polegającymi na podstawieniu czujnika czy falsyfikacji danych, może być zastosowany cyfrowy cień takiego zestawu. Założenie o jednorodności sensorów oznacza, że proponowany cień nie może być stosowany dla kolekcji czujników różnych wielkości fizycznych i oczywiście dla pojedynczych sensorów. W takich przypadkach dobre rezultaty można uzyskać stosując fuzję danych (rozumianą jako „Wielopoziomowy proces dotyczący powiazania, korelacji, połączenia danych i informacji z pojedynczego i większej liczby czujników, mający na celu osiągniecie dokładniejszej estymacji, kompletnej i terminowej oceny sytuacji, zagrożeń i ich znaczenia” [15, 24]) scha-
rakteryzowaną m.in. w [16] i wykorzystującą filtr Kalmana [17]. Szeroki przegląd zastosowań w robotyce zarówno klasycznego filtru, jak i jego modyfikacji jest przedstawiony w [18].
Trzeba zaznaczyć, że proponowany cyfrowy cień różni się istotnie od dobrze znanych zastosowań filtru Kalmana. Podstawowe różnice wynikają z faktu wyznaczania macierzy współczynników cienia na podstawie wielu poprzednich wyników pomiarów (a więc „głębszej” historii ) oraz na porównaniu wartości pomiaru w chwili t z wartością obliczoną przez cień dla tej chwili (na podstawie pomiarów uzyskanych przez sąsiednie czujniki także w tej chwili), a celem takiego porównania jest wykrycie anomalii w pracy sensora, a nie filtracja szumów.
W celu utworzenia „cyfrowego cienia” takiego układu rozważmy zestaw czujników tej samej wielkości fizykochemicznej, który może być rozpatrywany w układzie topologicznie równoważnym z siatką (kratą) sensorów usytuowanych w m rzędach po n czujników w każdym rzędzie; wtedy zbiór wartości zmierzonych w pewnej chwili t przez zbiór tych czujników można opisać macierzą:
gdzie cij oznacza wartość zmierzoną przez czujnik i,j w pewnej chwili t
Jak stwierdzono wcześniej, porównanie wartości przesłanych przez czujnik z wartościami obliczonymi przez cień pozwala na stwierdzenie nieprawidłowości. W takim przypadku układ sterowania (w trybie awaryjnym) w miejsce wartości błędnych przyjmie wartości obliczone przez cień i jednocześnie powiadomi operatora o konieczności podjęcia właściwych procedur naprawczych. Warto zauważyć, że ze względu na utrzymywanie w pamięci cienia historii (w praktyce kilku) poprzednich pomiarów, cień mógłby także wystawić jako wynik do obliczenia sygnału sterującego jeden z poprzednio zapamiętanych pomiarów, np. ostatni poprawny, jednakże dla zmieniających się wartości mierzonej wielkości, lepsze rezultaty zapewni wystawienie wartości obliczonej przez cień, gdyż ta wartość uwzględnia zachodzące zmiany.
W pracy przyjęto, że cieniem wartości mierzonej przez każdy z rozważanych czujników będzie wartość funkcji określonej dla argumentów, którymi są wartości zmierzone przez sąsiednie czujniki, przy czym rozważany jest model liniowy i dwa typy sąsiedztw – sąsiedztwo typu „plus” i sąsiedztwo typu „gwiazdka”. Przez „εk − sąsiedztwo typu plus” dla czujnika mierzącego wartość cij należy rozumieć układ czujników, które mierzą wartości c uv, przy czym wartości indeksu u albo indeksu v różnią się od wartości indeksów i albo j co najwyżej o wartość k
Przykład
Dla ε1 − sąsiedztwa typu plus wartości cij ∗ dla cienia rzeczywistej wartości, cij wyznaczane są z zależności: 11111111 , ijijijijijijijijij ccccc
(2)
gdzie: {} 1,2,,,im ∈ {} 1,2,,,jn ∈ przy czym dla indeksów niedodatnich lub odpowiednio większych od m albo n (dla czujników usytuowanych w narożach lub na brzegu siatki) wartości α uv przyjmuje się równe 0.
Dla ε2 − sąsiedztwa typu plus wartości cij ∗ dla cienia rzeczywistej wartości, cij wyznaczane są z zależności: 22112211 11221122
ijijijijijijijijij ijijijijijijijij
Ogólnie, dla εk − sąsiedztwa typu plus wartości cij ∗ cienia rzeczywistej wartości cij wyznaczane są z zależności (w postaci wektorowej): T , ijuvuv cc α ∗ =⋅ (4) gdzie: (1) 1 (1) 1 1 (1) 1 (1) [,,,,,,,, ,,,,,,,]
Przez „εk − sąsiedztwo typu gwiazdka” dla czujnika mierzącego wartość cij należy rozumieć układ czujników, które mierzą wartości c uv, przy czym wartości indeksu u lub indeksu v nie różnią się od i lub j o więcej niż k
Przykład
Dla ε1 − sąsiedztwa typu gwiazdka wartości cij ∗ dla cienia rzeczywistej wartości, cij wyznaczane są z zależności:
Problem analitycznych podstaw wyboru typu sąsiedztwa i wartości k wymaga dalszych badań, mających na celu w szczególności klasyfikację cieni w zależności od środowiska, mierzonej wielkości i usytuowania czujników.
4. Wyznaczanie wartości współczynników macierzowego liniowego cienia zestawu czujników
W celu wyznaczenia wartości współczynników [α uv] lub [α uv] i [βwz] każdego elementu cienia, konieczne jest rozwiązanie odpowiedniego układu równań liniowych: −dla εk − sąsiedztwa typu plus: układu 4k równań, dla εk − sąsiedztwa typu gwiazdka: układu 8k równań, uzyskiwanych w wyniku podstawienia w równaniach (4) lub (6) za cij ∗ wartości cij zmierzonych w kolejnych chwilach 1, 2, …, p i zapisywanych w macierzy trójwymiarowej B m×n×p, gdzie, odpowiednio, p ⩾ 4k lub p ⩾ 8k.
Dla cieni czujników εk − sąsiedztwa typu plus, które są usytuowane w narożach siatki czujników, układ równań (4) upraszcza się do układu 2k równań, a sąsiedztwo można nazwać sąsiedztwem typu gamma, a dla cieni czujników, które są na brzegu siatki, układ równań (4) upraszcza się do układu 3k równań, a sąsiedztwo można nazwać sąsiedztwem typu T.
Analogicznie, dla cieni czujników εk − sąsiedztwa typu gwiazdka, które są usytuowane w narożach siatki czujników, układ równań (6) upraszcza się do układu 3k równań, a sąsiedztwo można nazwać sąsiedztwem typu kwadrat, a dla cieni czujników, które są na brzegu siatki układ, równań (6) upraszcza się do układu 5k równań, a sąsiedztwa można nazwać sąsiedztwem typu prostokąt.
Na podstawie wyznaczonych wartości wektorów [α uv] w kolejnych chwilach możliwe jest obliczenie wartości cienia, porównanie jej z wartością zmierzoną, obliczenie błędu względnego
gdzie: {} 1,2,,,im ∈ {} 1,2,,,jn ∈ przy czym dla indeksów niedodatnich lub odpowiednio większych od m albo n (dla czujników usytuowanych w narożach lub na brzegu siatki) wartości α uv i βuv przyjmuje się równe 0.
Ogólnie, dla εk − sąsiedztwa typu gwiazdka wartości cij ∗ cienia rzeczywistej wartości cij wyznaczane są z zależności (w p ostaci wektorowej): TT , ijuvuv wzwz ccc αβ ∗
i wypracowanie rekomendacji o konieczności odrzucenia wartości zmierzonej jako wartości błędnej względnie ostrzeżenia, że zmierzona wartość może być błędna, w zależności od dopuszczalnej wartości błędu przyjętej polityki bezpieczeństwa. Dla arbitralnego określenia dopuszczalnych wartości błędu istotne znaczenie ma dokładność czujników.
Jak pokazano dalej na wybranych przykładach, zaprezentowany cyfrowy cień zestawu czujników pozwala na wykrycie i eliminację skutków utraty danych z czujnika, sfałszowania wartości przesyłanych danych oraz ataku podstawienia czujnika.
5. Przykład eliminacji zagrożeń
5.1. Obliczanie wartości współczynników cyfrowego cienia zestawu czujników
()()(1)(1)(1)(1)()()(1)(1)(1)(1) ()()(1)(1)(1)(1)(1)(1)()() [,,,,,,,, ,,,,,,] wzikjkikjk ijikjkikjk ij ikjkijij ikjkikjk
Dana jest siatka czujników o wymiarach 3 × 4, mierzących pewną wielkość. Czujniki wysyłają zmierzone wartości w chwilach tk do brzegowej stacji bazowej (rys. 1). W symulacji wykonanej w środowisku obliczeniowym MATLAB przyjęto, że w wyniku kolejnych pięciu pomiarów w chwilach t1, t2, …, t5 otrzymano zbiór wartości danych [cij], uzyskanych przez sumowanie wartości deterministycznych i losowych, generowanych funkcją randn()
Rys. 1. Sieć czujników i graniczna stacja bazowa
Fig. 1. Sensor network and border base station
5.1.1. W yznaczanie wartości współczynników cyfrowego cienia zestawu czujników mierzących wartości stabilne
Dane pomiarowe są zapisywane w macierzy trójwymiarowej, w której pierwsze dwa wymiary odpowiadają wymiarom siatki, a trzeci wymiar odzwierciedla liczbę chwil, w których wykonano te pomiary. Przykładowe dane są zestawione w tabeli 1.
Tab. 1. Zbiór danych
Tab. 1. Data set
tk
t1
t2
t3
t4
t5
Wartości cij
10,0179,0517,8816,935
9,0358,0057,0795,845
8,0177,0066,1204,920
9,8958,9258,0946,873
9,0507,7217,0736,077
7,9166,8876,1425,072
9,9228,9688,1416,960
8,9077,8396,9346,214
8,0547,1545,9805,050
9,9629,0417,9596,964
8,9408,0597,0856,185
8,0217,0276,0655,048
9,9939,0948,0167,027
9,0417,9296,9945,815
7,9607,0545,9094,935
W wyniku rozwiązania odpowiednich układów równań (4) otrzymuje się cyfrowy cień zestawu czujników, w którym wektory [α uv] wynoszą odpowiednio: −dla czujników narożnych:
Tab. 2. Błędy procentowe wartości c* i j
Tab. 2. Percentage errors of values c* i j
0,22 %−0,73 %−1,63 %6,60 %
0,48 %2,47 %−2,64 %3,15 %
−1,26 %−0,08 %3,11 %−1,53 %
−dla p ozostałych czujników na brzegu siatki:
−dla czujników wewnętrznych siatki:
1,0740 2,9626 , 0,4493
Błędy procentowe wyznaczonych dla cieni czujników wartości , cij ∗ obliczone z zależności () /100%ijijij ccc ∗ −⋅ są zestawione w tabeli 2, a ich wartości bezwzględne wahają się od 0,08 % do 6,60 %.
Biorąc pod uwagę dokładność pomiarów, która jest zwykle rzędu kilku procent, można przyjąć, że próg 10 % różnicy między wartością cienia a wartością zmierzoną jest podstawą do wygenerowania alarmu o możliwej awarii lub przejęciu czujnika; alarm ten może być również skutkiem nietypowego zdarzenia, np. punktowego zakwaszenia gleby.
5.1.2. W yznaczanie wartości współczynników cyfrowego cienia zestawu czujników mierzących wartości narastające mierzonej wielkości
Dla zbioru danych z tabeli 3, po obliczeniu wektorów [α uv] wartości błędów procentowych wyznaczonych dla cieni czujników , cij ∗ obliczone z zależności () /100%ijijij ccc ∗ są zestawione w tabeli 4, a ich wartości bezwzględne wahają się od 0,19 % do 3,82 %.
Tab. 3. Zbiór danych
Tab. 3. Data set
tk
t1
t2
t3
t4
t5
Wartości cij
11,00810,0959,0417,932
10,9149,9318,9558,010
11,0839,9469,0908,013
12,01511,10110,2128,950
11,87311,03810,0658,917
12,10110,9539,9868,971
13,03011,96010,90710,018
13,21312,11511,0639,880
12,97512,14310,99810,056
13,78213,11412,25011,044
13,86013,02612,01610,925
14,02713,15812,04811,033
15,06613,99113,08811,968
15,07813,81912,81411,940
15,01013,94413,01112,090
Tab. 4. Błędy procentowe wartości c* i j
Tab. 4. Percentage errors of values c*
−1,60 %0,19 %−2,79 %−3,82 %
1,36 %1,40 %0,37 %−2,28 %
2,46 %3,37 %−2,76 %0,46 %
W obu przeanalizowanych przykładach wartości błędów deltae są mniejsze od przyjętego progu 10 % jako wartości, której przekroczenie generuje alarm.
W celu zilustrowania eliminacji wybranych ataków zaprezentowano dalej przykład obliczeniowy na podstawie danych z pkt. 5.1.1.
5.2. Eliminacja utraty danych z czujnika
Niezależnie od przyczyny (losowej awarii czy też ataku intruza), jeżeli w BS zostanie wykryta utrata danych z czujnika cij, tj. cij = 0, cyfrowy cień w pierwszym kroku wylicza wartość , cij ∗ a w kolejnych krokach oblicza pozostałe wartości dla cieni poszczególnych czujników z uwzględnieniem wartości cienia i odpowiednie błędy procentowe.
Dla przykładu, jeżeli nastąpiła utrata danych dla c22, tj. c22 = 0, cyfrowy cień wyznaczył wartość 22 8,1245 c ∗ = i odpowiednie wartości błędów, zestawione w tabeli 5:
Tab. 5. Błędy procentowe wartości c* i j
Tab. 5. Percentage errors of values c* i
0,22 %−0,35 %−1,63 %6,60 %
−0,95 %0,00 %−2,29 %3,15 %
1,26 %−0,42 %3,11 %−1,53 %
Porównując dane w tabelach 2 i 5 można zauważyć, że dla czujnika c22 wyliczona wartość jest wartością cienia, gdyż błąd wynosi 0,00 %, wartości błędów dla tych czujników, dla których wartość cienia nie była zależna od wartości c22 nie uległy zmianie, natomiast uległy zmianie wartości obliczone dla cieni czujników sąsiadujących bezpośrednio z czujnikiem c22. Jeżeli, jak w analizowanym przykładzie, błędy te nie przekroczyły wartości przyjętej za graniczną, to zastosowane rozwiązanie umożliwia prawidłową pracę układu oraz podjęcie działań mających na celu ustalenie i usunięcie przyczyn, które wywołały utratę danych z czujnika.
5.3. Wykrywanie sfałszowanych danych z czujnika lub wykrywanie anomalii Jeżeli wartość bezwzględna obliczonego błędu procentowego dla czujnika cij przekracza wartość graniczną, BS zgłasza alarm i –w zależności od przyjętej polityki – wyznacza wartość sterowań dla aktuatorów na podstawie wartości obliczonej dla cienia cij ∗ albo na podstawie zmierzonej wartości lub wartości historycznych. Polityka może oczywiście przewidywać różne ścieżki zachowania się układu po wykryciu takiego stanu, w zależności od sterowanego układu, w szczególności na podstawie znajomości jego dynamiki, wartości stwierdzonej odchyłki, krotności wystąpienia odchyłki itp.
Przykład
Niech c11 = 12, co oznacza odchyłkę od wartości wyznaczonej przez cień o około 20 %, a zatem przekracza ustalony w przykładzie próg 10 %.
Obliczone błędy procentowe obliczonych wartości cienia w porównaniu do wartości zmierzonych są zestawione w tabeli 6 i wskazują, że zaatakowanym węzłem jest czujnik c11, który przesłał wartość przekraczającą przyjęty próg błędów i „zatruwa” wartości c12 i c22. Zarówno c13, jak i c21 nie są węzłami toksycznymi, gdyż błędy procentowe dla ich sąsiadów nie przekraczają ustalonego progu.
Tab. 7. Błędy procentowe wartości c* i j Tab. 7. Percentage errors of values c* i
0,22 %−0,73 %−1,63 %6,60 %
0,48 %2,47 %−2,64 %3,15 %
1,26 %−0,08 %3,11 %−1,53 %
Jeżeli zamiast przesłanej wartości zmierzonej przez czujnik c11 (lub wartości sfalsyfikowanej w transmisji) zostanie przyjęta wartość cienia 11 10,0146, c ∗ = to wówczas wartości błędów procentowych, jak pokazano w tab. 7, mieszczą się w granicach tolerancji i układ pracuje poprawnie.
5.4. Eliminacja podstawienia fałszywego czujnika
Eliminacja podstawienia fałszywego czujnika jest możliwa zarówno wtedy, gdy intruz zastępuje autentyczny czujnik czujnikiem fałszywym (przypadek a), jak i na skutek dodania do sieci czujników czujnika fałszywego (przypadek b). W przypadku (a) wykrycie ataku zamiany czujnika jest tożsame z wykryciem opisanych w pkt. 5.3. danych sfałszowa-
nych. W przypadku (b) wykrycie następuje przez porównanie danych otrzymanych przez BS ze zbiorem stanów dopuszczalnych urządzeń IoT opisanym w pracy [19]. Wskazany tam zbiór stanów pożądanych Z* może zawierać tylko takie elementy, w których ocena stanu bezpieczeństwa jest ustalona jako prawidłowa lub też takie elementy, dla których stany pracy przyjmują wyznaczone wartości, a zatem w szczególności znaną a priori listę czujników, dla których wartości zmierzone muszą zawierać się w określonym przedziale wartości.
6. Podsumowanie
Jak wynika z przeprowadzonej analizy, zaprezentowana propozycja wykorzystania macierzowego cyfrowego cienia sieci czujników IoT pozwala na ocenę prawidłowości pracy takiej sieci w czasie rzeczywistym od momentu zakończenia procesu tworzenia pierwszej wersji cienia, a zatem pierwszego cyklu „uczenia się” układu BS. Czas trwania procesu „uczenia się” zależy od przyjętego typu εk − sąsiedztwa, wymaga zapamiętania macierzy B m×n×p zawierającej co najmniej 4k albo 8k kolejnych wartości zmierzonych przez czujniki oraz wyznaczenia wartości wektorów [α uv] albo [α uv] i [βwz]. Proces wyznaczania wektorów współczynnika cienia powinien być ponawiany po każdym kolejnym odczycie wartości zmierzonych przez czujniki, jeśli ten odczyt zostanie uznany za prawidłowy. Proces uczenia się obejmuje również wprowadzenie do układu BS macierzy opisującej stany pożądane monitorowanej sieci czujników.
Jeżeli w macierzy deltae wartości błędów procentowych przekraczałyby arbitralnie przyjęty próg akceptowalnych wartości błędów deltae, wówczas układ BS może podjąć decyzję, czy przyczyną jest utrata danych z czujnika albo falsyfikacja tych danych, a na podstawie porównania z macierzą stanów pożądanych – wykrycie podstawienia fałszywego, dodatkowego czujnika.
Ze względu na obliczanie wartości wektorów [ α uv] i [ βwz] metodą rozwiązywania układów równań liniowych, proponowany proces może być stosowany wtedy, gdy odpowiednie macierze są nieosobliwe i na dokładność obliczeń nie ma istotnego wpływu ich ewentualne złe uwarunkowanie [20].
Wymagane dla zastosowania proponowanego cyfrowego cienia niewielkie zasoby pamięci i mocy obliczeniowej układu BS są niewątpliwą zaletą takiego rozwiązania, podnoszącego bezpieczeństwo pracy sieci czujników i układu BS wyznaczającego wartości sygnałów sterujących dla urządzeń wykonawczych.
Bibliografia
1. Faris M., Mahmud M.N., Salleh M.F.M., Alnoor A., Wireless sensor network security: A recent review based on state-of-the-art works, “International Journal of Engineering Business Management”, 2023, DOI: 10.1177/18479790231157220.
2. Jab een T., Jabeen I., Ashraf H., Jhanjhi N.Z., Yassine A., Hossain M.S., An Intelligent Healthcare System Using IoT in Wireless Sensor Network, “Sensors”, Vol. 23, No. 11, 2023, DOI: 10.3390/s23115055.
3. Ahmad R., Wazirali R., Abu-Ain T., Machine Learning for Wireless Sensor Networks Security: An Overview of Challenges and Issues, “Sensors”, Vol. 22, No. 13, 2022, DOI: 10.3390/s22134730.
4. Schiller E., Aidoo A., Fuhrer J., Stahl J., Ziörjen M., Stiller B., Landscape of IoT security, “Computer Science Review”, Vol. 44, 2022, DOI: 10.1016/j.cosrev.2022.100467.
5. Gelernter D., Mirror Worlds, Oxford University Press, 1993.
6. Glaessgen E., Stargel D., The Digital Twin Paradigm for Future NASA and U.S. Air Force Vehicles, DOI: 10.2514/6.2012-1818.
7. Singh S., Weeber M., Birke K.-P., Advancing digital twin implementation: a toolbox for modelling and simulation, “Procedia CIRP”, Vol. 99, 2021, 567−572, DOI: 10.1016/j.procir.2021.03.078.
8. Kritzinger W., Karner M., Traar G., Henjes J., Sihn W., Digital Twin in manufacturing: A categorical literature review and classification, “IFAC-PapersOnLine”, Vol. 51, No. 11, 2018, 1016−1022, DOI: 10.1016/j.ifacol.2018.08.474.
9. Singh M., Fuenmayor E., Hinchy E.P., Qiao Y., Murray N., Devine D., Digital Twin: Origin to Future, “Applied System Innovation”, Vol. 4, No. 2, 2021, DOI: 10.3390/asi4020036.
10. Grzesik W., Cyfrowy bliźniak w procesach wytwórczych Część I. Stan zagadnienia, architektura i zastosowania, “Mechanik”, No. 1, 2023, 8−13, DOI: 10.17814/mechanik.2023.1.1.
11. Grieves M., Digital Model, Digital Shadow, Digital Twin Preprint, 2023.
12. Shao G., Frechette S., Srinivasan V., An Analysis of the New ISO 23247 Series of Standards on Digital Twin Framework for Manufacturing, MSEC Manufacturing Science & Engineering Conference 2023, New Brunswick, New Jersey, USA, [https://tsapps.nist.gov/publication/get_pdf. cfm?pub_ id=935765].
13. Fragkiadakis A., Angelakis V., Tragos E.Z., Securing Cognitive Wireless Sensor Networks: A Survey, “International Journal of Distributed Sensor Networks”, Vol. 10, No. 3, 2014, DOI: 10.1155/2014/393248.
14. Iwaniec W., Ochrona urządzeń Internetu Rzeczy (IoT) na brzegu sieci lokalnej, [W:] Krzyńska-Nawrocka E. (red.): „Innowacje i inspiracje. 150-lecie urodzin Jana Szczepanika”, 2022, Tarnów, Wydawnictwa PWSZ w Tarnowie, 81−93, ISBN 978-83-963518-5-2 2022-12.
15. Jaroś K., Sterowanie predykcyjne i fuzja danych w systemie dynamicznego pozycjonowania statku, rozprawa doktorska, Politechnika Gdańska 2023.
16. Chen G., Liu Z., Yu G., Liang J., A new view of multisensor data fusion: Research on generalized fusion. “Mathematical Problems in Engineering”, 2021, DOI: 10.1155/2021/5471242.
17. Veysi P., Adeli M., Naziri N.P., Adeli E., A Gentle Approach to Multi-Sensor Fusion Data Using Linear Kalman Filter, “Computers and Society”, 2024, DOI: 10.48550/arXiv.2407.13062.
18. Urrea C., Agramonte R. Kalman Filter: Historical Overview and Review of Its Use in Robotics 60 Years after Its Creation, “Journal of Sensors”, 2021, DOI: 10.1155/2021/9674015.
19. Iwaniec W., Identyfikacja zagrożeń w macierzowym modelu stanu pracy i bezpieczeństwa urządzeń IoT, „Pomiary Automatyka Robotyka”, R. 24, Nr 1, 2020, 67−74, DOI: 10.14313/PAR_235/67.
20. Mitkowski W., Równania macierzowe i ich zastosowania. Wyd. drugie poprawione, Wydawnictwa AGH, Kraków 2007.
22. Digital Twins for Advanced Manufacturing, [www.nist.gov/ programs-projects/digital-twins-advanced-manufacturing].
23. ISO 23247-1:2021(en) Automation systems and integration — Digital twin framework for manufacturing — Part 1: Overview and general principles, https://www.iso.org/obp/ui/#iso:std:iso:23247:-1:ed-1:v1:en.
24. White F.E., Data Fusion Lexicon, Defense Technical Information Center, 1991.
Matrix Digital Shadow of IoT Sensors Network
Abstract: This paper presents the concept of a matrix digital shadow of an IoT sensor network. The differences between digital twin and digital shadow are discussed and the choice of the sensor network shadow concept is justified. A matrix description of such a network is presented and the concept of εk − neighborhood of sensor is introduced. Formulas for linear models of plus and star εk − neighborhoods are provided. Selected examples show the possibility of detecting and eliminating some security threats to sensor networks.
Keywords: digital shadows, Internet of Things security, IoT device security threats, sensors networks, matrix models
dr inż. Władysław Iwaniec wiw@atar.edu.pl
ORCID: 0000-0002-5253-7710
Adiunkt w Katedrze Automatyki i Robotyki Akademii Tarnowskiej w Tarnowie, w której był prorektorem w latach 1998−2007. Ma bogate doświadczenie w zakresie wdrażania i eksploatacji systemów informatycznych. Pracował m.in. jako dyrektor Ośrodka Informatyki Urzędu Wojewódzkiego w Tarnowie, brał udział w wielu przedsięwzięciach z zakresu zastosowań informatyki w służbie zdrowia, uczestniczył w organizacji obsługi informatycznej wyborów na szczeblu krajowym i okręgowym. Odznaczony m.in. Złotym Krzyżem Zasługi i Srebrnym Medalem za „Zasługi dla obronności kraju”. Zainteresowania naukowe obejmują zagadnienia kryptografii i bezpieczeństwa sieci i systemów komputerowych oraz identyfikacji układów sterowania.
Architektura oprogramowania systemu kontrolno-pomiarowego z interfejsem USB
Rafał Wojszczyk
Politechnika Koszalińska, ul. Śniadeckich 2, 75-453 Koszalin
Streszczenie: W pracy zaproponowano implementację wysokopoziomowej architektury oprogramowania, która pozwala na komunikację z urządzeniem zewnętrznym w sposób obiektowy. Opracowane rozwiązanie wraz z autorskim urządzeniem podłączanym do portu USB stanowią gotowy system kontrolno-pomiarowy. Wykorzystanie wielowarstwowej architektury oraz wybranych wzorców projektowych pozwoliło na opracowanie rozwiązania programowego, które zapewnia niski koszt rozbudowy, pozwala na łatwe wykorzystanie w sposób obiektowy oraz zapewnia możliwość wymiany modułów. Dodatkowo uniwersalność opracowanego narzędzia pozwala na wprowadzanie wybranych modyfikacji systemu bez konieczności ponownej kompilacji kodu źródłowego.
1. Wpowadzenie
Słowa kluczowe: USB, .NET, MVP, architektura oprogramowania, wzorce projektowe, LibUSB, AVR, ATmega układ kontrolno-pomiarowy. W implementacji wykorzystano łatwo dostępne komponenty elektroniczne (mikrokontroler z rodziny AVR) oraz darmowe i powszechnie dostępne narzędzia programistyczne (Visual Studio, .NET Framework, WinForms, SQL Server). Opracowany system kontrolno-pomiarowy pozwala na rejestrowanie wyników pomiarów wejściowych sygnałów analogowych, odczyt cyfrowych stanów logicznych, sterowanie sygnałami cyfrowymi oraz generowanie sygnału PWM. Funkcje realizowane przez system wykonywane są zgodnie z zaplanowanym harmonogramem, natomiast planowanie harmonogramu odbywa się przez graficzny interfejs użytkownika, co nie wymaga umiejętności programowania. Oferowane możliwości są uniwersalne, co pozwoli na użycie tego rozwiązania przez techników w przemyśle, informatyków, pasjonatów DIY (ang. Do It Yourself) oraz na zastosowanie w badaniach naukowych.
Komunikacja między komputerem a urządzeniem zewnętrznym jest możliwa na wiele sposobów. Większość urządzeń konsumenckich jest podłączanych za pomocą portu USB (ang. Universal Serial Bus), który jest stale rozwijany od 1996 r. Wydawać by się mogło, że bardzo duża popularność tego portu przyczyni się do używania również przez hobbystów i naukowców w budowie własnych urządzeń [6]. Praktyka pokazuje jednak, że dużo częściej w amatorskich oraz naukowych projektach stosowany jest port RS-232/UART, który już na etapie pierwotnych założeń oferował gorsze parametry niż USB. Wynika to z faktu, że środowisko hobbystów często nie ma odpowiedniej wiedzy, umiejętności lub zasobów finansowych, aby realizować komunikację przez interfejs USB. Celem niniejszego rozdziału jest wprowadzenie wysokopoziomowej architektury oprogramowania, która dzięki dekompozycji na wiele warstw i użycie wzorców projektowych, umożliwia stosowanie urządzeń zewnętrznych podłączanych do portu USB. Proponowane rozwiązanie współdzieli wybrane korzyści oferowane przez port RS-232 (tj. łatwość i koszt implementacji) i jednocześnie umożliwia wykorzystanie możliwości oferowanych przez USB (np. komunikacja współbieżna, możliwość enumeracji wielu urządzeń, automatyczne ustawienie parametrów połączenia). Proponowaną architekturę oprogramowania zaimplementowano w programie użytkowym, co w połączeniu z dedykowanym urządzeniem zewnętrznym stanowi gotowy
Autor korespondujący:
Rafał Wojszczyk, rafal.wojszczyk@tu.koszalin.pl
Artykuł recenzowany nadesłany 10.03.2024 r., przyjęty do druku 20.12.2024 r.
Artykuł zawiera cztery rozdziały. W drugim rozdziale artykułu przedstawiono wymagania jakich oczekuje się od proponowanego systemu. Trzeci rozdział przedstawia opis implementacji. Piąty rozdział stanowi podsumowanie artykułu.
2. Wymagania
W celu zebrania wymagań przeprowadzono analizę literatury, gdzie wykorzystano autorskie rozwiązania kontrolno-pomiarowe pełniące rolę narzędzi wspomagających badania naukowe oraz rolę głównej komunikacji w projektach hobbystycznych. Informacje otrzymane z przeprowadzonej analizy można zgrupować do omówionych dalej spostrzeżeń.
Nader często stosowana jest komunikacja przez port RS-232 (w tym emulacja USB za pomocą FT232R, CH340, CP2102) [4, 10, 11, 14]. Użycie RS-232 prowadzi do wielu trudności wynikających z założeń projektowych [15]: do jednego portu może być podłączone tylko jedno urządzenie, co dodatkowo wymaga wiedzy o parametrach połączenia,
aplikacja obsługująca takie urządzenie musi cyklicznie odczytywać dane z portu RS-232, aby otrzymać powiadomienie (brak asynchroniczności), brak możliwości obsługi wielowątkowej, ponieważ urządzenie podłączone do portu RS-232 jest zasobem niepodzielnym, naruszenie tej zasady doprowadzi do występowania błędów klasy zakleszczenia oraz naruszenia niepodzielności [2].
Wśród stosowanych rozwiązań dominuje implementacja metodą strukturalną (nawet w językach obiektowych) [9, 7]. Potocznie nazywane jest to płaską implementacją, gdzie nie są stosowane filary paradygmatu programowania obiektowego. Ocena jakości takiego kodu źródłowego za pomocą popularnych metryk oprogramowania obiektowego (np. Chidamber-Kemerer, MOOD, metryki R.C. Martina [12]) przypuszczalnie będzie bardzo niska, a to oznacza wysokie koszty rozbudowy i naprawy błędów. Ponadto mała liczba instancji wzorców projektowych powoduje, że kod źródłowy będzie trudniejszy w zrozumieniu dla doświadczonych programistów, natomiast implementacja bez stosowania wzorców architektury znacznie utrudnia decentralizację aplikacji oraz wymianę komponentów. Trzecie spostrzeżenie dotyczy dedykowania opracowanych rozwiązań wyłącznie do wybranych zastosowań (np. odczyt tylko wybranych wartości, komunikacji wyłącznie tekstowej) czy też wybranego standardu komunikacji (np. urządzenie w klasie Human Interface Device, co również może ograniczyć komunikację do trybu tekstowego) [3, 8]. W przypadku dedykowanych rozwiązań, ponowne wykorzystanie takiego narzędzia wymaga ponownej implementacji (zmiany kodu) i kompilacji programu, co nie jest trywialne. Na podstawie przedstawionych spostrzeżeń zaproponowano następujące wymagania, których spełnienie zapewni, że nowoopracowane rozwiązanie spełni współczesne standardy techniczne i programistyczne:
1. Stosowanie interfejsu USB – koresponduje z wymienionymi spostrzeżeniami w stosunku do portu RS-232. USB u podstaw rozwiązuje większość problemów RS-232. Współczesny komputer typu laptop wyposażony jest w przynajmniej kilka takich portów, a liczbę portów można bez problemu zwiększyć. Każde urządzenie USB jest unikatowe dzięki numerom PID i VID, które są znane od razu po podłączeniu. W każdym urządzeniu może występować wiele punktów końcowych, z którymi wymiana danych może odbywać się asynchronicznie [16, 5]. Urządzenie USB jest gotowe do działania od razu po podłączeniu, nie wymaga podawania parametrów takich jak
szybkość transmisji. Natomiast od strony elektrycznej linie zasilania oddzielone są od linii sygnałowych, a dodatkowo linie sygnałowe to sygnał symetryczny, co zwiększa odporność na zakłócenia.
2. Zastosowanie wielowarstwowej architektury oprogramowania oraz współczesnych standardów programistycznych koresponduje z wymienionymi spostrzeżeniami dotyczącymi sposobu implementacji programowej. Opracowanie odpowiedniej architektury oprogramowania ma na celu zapewnienia modularnej budowy aplikacji, co pozwoli na wymianę modułów (np. implementacja interfejsu użytkownika jako strony internetowej) oraz użycie modułów jako autonomicznych bibliotek. Wymagane jest stosowanie tzw. dobrych praktyk programistycznych (w tym wzorców projektowych oraz wzorców architektury), aby zapewnić niski koszt rozbudowy oraz naprawy błędów.
3. Uniwersalność aplikacji – koresponduje z wymienionymi spostrzeżeniami w zakresie dedykowania podobnych rozwiązań do wyłącznie jednego celu. Opracowane rozwiązanie powinno być konfigurowalne z poziomu interfejsu użytkownika, natomiast komunikacja z urządzeniem zewnętrznym powinna być realizowana z użyciem powszechnie dostępnych standardów USB, np. klasę urządzeń USB-CDC (ang. Communications Device Class).
3. Implementacja i testy
3.1. Implementacja sprzętowa
Testowe urządzenie zewnętrze zbudowano na bazie mikrokontrolera ATmega8, z wykorzystaniem biblioteki VUSB [17]. Biblioteka ta umożliwia emulację interfejsu USB w wersji 1.1 o szybkości FS [1]. Należy odróżnić realizację interfejsu USB w klasie CDC za pomocą emulacji przez mikrokontroler, od emulacji interfejsu RS-232 za pomocą gotowych układów scalonych (np. wspominany wcześniej FT232R), który jest podłączany do portu USB. W przypadku pierwszego komunikacja odbywa się zgodnie z protokołem USB (urządzenie będzie rozpoznawane przez system operacyjny jako USB), tj. przez odpowiednie punkty końcowe, w przypadku drugiego komunikacja odbywa się zgodnie z protokołem RS-232 (urządzenie będzie rozpoznawane przez system operacyjny jako port COM). Zaimplementowano klasę urządzenia USB-CDC, które przeznaczone jest do obsługi urządzeń zewnętrznych. Zdefiniowano również jeden punkt końcowy. Zgodnie z kodem deskryptora z listingu 1 został zdefiniowany zbiór rozkazów wraz z parametrami, które
Rys. 1. Schemat połączeń elektrycznych opracowanego urządzenia
Fig. 1. Wiring diagram of the developed device
Tab. 1. Specyfikacja rozkazów
Tab. 1. Command specification
Rozkaz (pole usbRequest)
100
102
103
104
Argument (pole wValue) Wyliczenie (pole wIndex)
Bez znaczenia
Bez znaczenia
Bez znaczenia
Bez znaczenia
105
Bez znaczenia
106
Dwubajtowa tablica, w której młodszy bajt zawiera osiem młodszych bitów argumentu, a starszy bajt zawiera dwa starsze bity argumentu
Bez znaczenia
Młodszy bajt określa logiczny adres portu.
Młodszy bajt określa logiczny adres portu.
Młodszy bajt określa logiczny adres portu.
Młodszy bajt określa logiczny adres portu.
Bez znaczenia
umożliwiają obsługę portów wejścia/wyjścia mikrokontrolera, tab. 1 przedstawia specyfikację rozkazów. Zestawienie adresacji odpowiada wykonanym połączeniom elektrycznym, co przedstawia rys. 1. Użycie urządzenia polega na wysłaniu uzupełnionej struktury danych z listingu 1 danymi z tab. 1 oraz rys. 1, przykładowo: 102, 0, 01 – oznacza ustawienie stanu wysokiego na porcie PB2 mikrokontrolera.
Listing 1. Struktura deskryptora rozkazu zaimplementowanego w urządzeniu zewnętrznym
Listing 1. Structure of the command descriptor implemented in an external device
Alternatywna realizacja urządzenia może zostać wykonana za pomocą innych mikrokontrolerów, które wspierają komunikację za pomocą interfejsu USB, np. AT90USB82, ATmega16U4, STM32F103C8T6. W celu wykonania takiego urządzenia, należy zdefiniować w urządzeniu zerowy punkt końcowy i zaimplementować obsługę deskryptora z listingu 1 zgodnie z tabelą rozkazów z tab. 1. Zestawienie adresacji będzie unikatowe dla każdego z mikrokontrolerów.
Implementacja oprogramowania obsługującego opracowane urządzenie zewnętrze, została wykonana w technologii Microsoft .NET Framework oraz z wykorzystaniem silnika baz danych Microsoft SQL Server. Implementacja została zdekomponowana na sześć osobnych warstw, które mogą być zastępowane innymi. Podział na warstwy oraz zależności między konkretnymi warstwami przedstawia rys. 2. Warstwa o największej odpowiedzialności w hierarchii zależności to CommonModel. Najważniejszym celem tej warstwy
Wartość zwracana Opis
Dwubajtowa tablica o wartościach [100] [101]
Brak
Brak
Dwubajtowa tablica, w której młodszy bajt ma wartość 0 lub 1, starszy zawsze 0
Dwubajtowa tablica, w której młodszy bajt zawiera osiem młodszych bitów z wyniku, a starszy bajt zawiera dwa starsze bity z wyniku
Rozkaz testowy, sprawdzający jedynie czy urządzenie odbiera żądania i wysyła dane
Rozkaz ustawia stan wysoki wybranego cyfrowego wyjścia
Rozkaz ustawia stan niski wybranego cyfrowego wyjścia
Rozkaz odczytuje i zwraca stan wybranego wejścia cyfrowego
Rozkaz odczytuje i zwraca wartość napięcia z wybranego wejścia analogowego
Rozkaz ustawia szerokość wypełnienia impulsu na wyjściu analogowym
Rys. 2. Diagram komponentów w notacji UML reprezentujący zaimplementowane warstwy oraz relacje użycia pomiędzy warstwami Fig. 2. Component diagram in UML notation representing the implemented layers and the use relationships between the layers
jest dostarczanie wspólnego modelu danych dziedziny problemowej, który jest stosowany w pozostałych warstwach. Model danych został opracowany zgodnie z celem aplikacji, tj. sterowania i rejestrowania, zgodnie z harmonogramem. Na rys. 3 przedstawiono diagram związek-encja, który odwzorowuje model danych. W warstwie CommonModel model ten odwzorowany jest w strukturę obiektową. Dodatkowo w CommonModel znajdują się wspólne dane, wykorzystywane w całej aplikacji, jest to m.in. informacja o bieżąco zalogowanym użytkowniku. Dane tego typu udostępniane są za pomocą wzorca projektowego Singleton, co zwiększa spójność danych.
Dane z modelu dziedziny zapisywane i odczytywane są za pomocą warstwy DataManager. Warstwa odpowiada za komunikację z bazą danych, stąd w celu skorzystania z innego silnika baz danych, należy zamienić tą warstwę na inną, obsługującą inny silnik baz danych. Wymagane jest, aby dostęp do danych był realizowany z wykorzystaniem wzorców Repozytorium oraz Jednostka pracy (ang. UnitOfWork), wówczas połączenie z nowym silnikiem bazy danych będzie kompatybilne z istniejącym kodem.
Brak
Rys. 3. Diagram związek-encja w notacji Barkera, który odwzorowuje konceptualny model dziedziny problemowej
Fig. 3. Entity-relationship diagram in Barker notation that maps the conceptual model of the problem domain
Warstwa Hardware odpowiedzialna jest za komunikację z urządzeniem zewnętrznym, za pomocą biblioteki programistycznej LibUsbDotNet, do której została utworzona fasada (dzięki temu wzorcowi uproszczono użycie tej biblioteki). Obsługa opracowanego urządzenia z mikrokontrolerem Atmega8 jest zrealizowane w sposób generyczny. Odpowiada za to wzorzec Strategia, tj. zdefiniowany jest interfejs IDeviceStrategy, którego implementacja konkretyzowana jest na dane urządzenie. Dodanie nowego urządzenia, niezgodnego z deskryptorem z listingu 1 (w tym wykorzystującego inne porty komunikacyjne) polega na zaimplementowaniu tego interfejsu i odpowiedniego uzupełnienia kodu, przedstawia to diagram klas z rys. 4. Natomiast dodanie nowego urządzenia zgodnego z wspomnianym deskryptorem nie wymaga wprowadzania modyfikacji w kodzie programu, wystarczy uzupełnienie danych z poziomu interfejsu użytkownika. Opracowane w ten sposób rozwiązanie jest otwarte na rozbudowę i zamknięte na modyfikacje (jedna z zasad S.O.L.I.D). Przekazywanie parametrów poprzez metodę Execute realizowane jest przez implementację wzorca Kompozyt (przekazywany jest obiekt kompozytu, zamiast wielu drobnych parametrów).
Warstwą, która łączy wszystkie omówione dotąd warstwy, jest BusinessLogic, co odpowiada logice biznesowej. Jest to implementacja zbioru reguł sterujących całym systemem, inicjalizuje
Rys. 4. Diagram klas przedstawiający koncepcję wykorzystania wzorca strategia do implementacji obsługi kolejnych urządzeń
Fig. 4. Class diagram showing the concept of using the strategy pattern to implement support for more devices
połączenie z warstwą Hardware, wykonuje schemat działania odczytany z bazy danych za pomocą DataManager. W tej warstwie zaimplementowano wzorzec stanu, który jest odpowiedzialny za bieżące monitorowanie stanu urządzenia. Natomiast powiadomienia o zmianach w urządzeniu USB (np. odłączenie, wystąpienie błędu, wystąpienie przerwania) realizowane jest za pomocą wzorca Obserwator, którzy przekazuje komunikaty za pomocą wzorca Łańcuch odpowiedzialności (ang. Chain of Responsibility). Połączenie trzech wzorców pozwoliło na realizację skutecznego mechanizmu nadzorującego prawidłową pracę urządzenia, reagowanie na zmiany w urządzeniu oraz uruchamianie odpowiednich działań w zależności od stanu.
Implementacja wzorca MVP
Ostatnie dwie warstwy odpowiedzialne są za implementację aplikacji w technologii WindowsForms, tj. klienta uruchamianego jako aplikacja stacjonarna. Aplikacja została zrealizowana zgodnie z wzorcem architektury oprogramowania MVP (ang. Model-Vidok-Presenter), w wariacji Supervising Controller. Strukturę wzorca przedstawia rys. 5. Model to warstwa CommomModel, widok to warstwa WinClient, natomiast prezenter to warstwa ApplicationLogic. Ze względu na wariant wzorca możliwe jest wykorzystanie struktury modelu przez widok, nie możliwe jest bezpośrednie manipulowanie danymi.
Rys. 5. Diagram komponentów przedstawiający koncepcję podziału warstw w wzorcu architektury MVP
Fig. 5. Component diagram showing the concept of layering in the MVP architecture pattern
Interfejs IInformer (rys. 6) należący do warstwy ApplicationLogic (oraz implementacja Informer należąca do warstwy WinClient) służą jedynie do pokazywania krótkich informacji dialogowych. Interfejs IBaseView należy do warstwy ApplicationLogic i zawiera prototypy metod odpowiedzialnych za wyświetlanie i ukrywanie widoków. Każdy interfejs widoku musi po nim dziedziczyć. Interfejsy IDeviceListView oraz IDeviceEditView opisują prototypy metod i właściwości, jakie musi implementować widok, czyli konkretne okno w aplikacji, należą do warstwy ApplicationLogic. Klasa abstrakcyjna BasePresenter jest typowana na interfejs IBaseView lub interfejs po nim dziedziczący. Typowany interfejs jest podstawowym widokiem dla danego prezentera, klasa należy do warstwy ApplicationLogic. Klasy DeviceListPresenter oraz DeviceEditPresenter dziedziczą po BasePresenter i są typowane na odpowiadający im interfejs widoku. Zawierają opis możliwych funkcji prezentera, należą do warstwy ApplicationLogic Klasa CommonContext jest wspólnym kontekstem dla warstwy ApplicationLogic, przechowuje informacje, które prezentery muszą między sobą wymieniać i nie mogą tego zrobić bezpośrednio. Klasa Device to zmapowana tabela bazy danych, przedstawia pojedynczy rekord. Lista obiektów jest przekazywana do interfejsu widoku, w tym przypadku IDeviceListView Pojedynczy obiekt Device jest przekazywany do interfejsu widoku pozwalającego na edycję, w tym przypadku IDeviceEditView. Dodatkowo z tą klasą powiązany jest typ wyliczeniowy InterfacesType wskazujący na typ interfejsu, przez jaki jest podłączone urządzenie. Klasa DataContext
Rys. 6. Diagram klas przedstawiający aplikację WindowsForms zaimplementowaną w architekturze MVP oraz wybrane klasy z pozostałych warstw. Diagram wygenerowany na podstawie istniejącego kodu
Fig. 6. Class diagram showing a WindowsForms application implemented in MVP architecture and selected classes from other layers. Diagram generated from existing code
należy do warstwy DataManager i odpowiada za wykonywanie operacji związanych z bazą danych. Interfejs IDataRepository jest typowany na obiekt modelu danych, zawiera prototypy podstawowych metod związanych z odczytem, zapisem, edycją oraz usuwaniem danych z bazy danych. Interfejs należy do warstwy DataManager. Klasa DeviceRepository implementuje interfejs IDataRepository z typowaniem na Device i odpowiada za odczytanie, zapisanie, edycję i usuwanie obiektów typu Device. Klasa należy do warstwy dostępu do danych. Każda operacja wpływająca na dane wykonywana jest przy użyciu klasy DataContext. Klasa BaseViewForm implementuje interfejs IBaseView oraz w swojej implementacji interfejsu IInformer opisuje jego zachowania, aby klasy dziedziczące po BaseViewForm nie musiały tego robić ponownie. Klasa należy do warstwy widoku, dziedziczy po systemowej klasie Form. Klasy DeviceListForm oraz DeviceEditForm dziedziczą po BaseViewForm oraz implementują odpowiadający im interfejs widoku, odpowiednio IDeviceListView oraz IDeviceEditView Każda klasa typu „Form” zawiera obiekt odpowiadającego jej prezentera i przy tworzeniu tego obiektu przekazuje do niego referencję do siebie samej. Prezenter dzięki tej referencji może wykonywać metody i korzystać z właściwości opisanych przez interfejs, który implementuje klasa typu „Form”.
Możliwości rozwoju i rozbudowy Implementacja wielowarstwowej architektury oraz wybranych wzorców projektowych dostarcza wiele korzyści, dostrzegalnych przede wszystkim z punktu widzenia programistów. Implementacja innego rodzaju widoku, np. aplikacji internetowej, wymaga zaimplementowania nowych warstw widoku i kontrolera (zamiast prezentera, co jest zgodne z wzorcem architektury oprogramowania MVC – ang. Model-ViewController). Nowe warstwy będą korzystały z pozostałych, opisanych wcześniej warstw. Podobnie możliwe jest wykorzystanie wyłącznie wybranych warstw (HardwareLayer, BusinessLayer)
w celu implementacji np. aplikacji konsolowych. Możliwe jest również rozproszenie systemu i uruchomienie wymienionych warstw jako usługi internetowe lub innych rozwiązań umożliwiających dostęp zdalny.
Inne korzyści wynikające ze stosowanej architektury to możliwość wymiany wybranych komponentów (warstw), a w związku z współdzieleniem znacznej części kodu, oznacza to niższe koszty budowy nowych aplikacji, bazujących na opracowanych komponentach.
3.3. Użytkowanie systemu
Do prawidłowego funkcjonowania systemu wymagane jest podłączenie urządzenia do portu USB oraz zainstalowanie w systemie Windows 5.1 lub nowszym, generycznego sterownika LibUSB lub LibUsbDotNet.
Użytkowanie aplikacji możliwe jest w kilku trybach: konfiguracyjnym, administracyjnym, wykonywania rozkazów, testowym. W trybie konfiguracyjnym możliwe jest zdefiniowanie rozbudowanej struktury użytkowników, komputerów (stacji pomiarowych) oraz urządzeń. Dany użytkownik może mieć dozwolony lub zabroniony dostęp do danego komputera i urządzenia, podobnie na danym komputerze może być dopuszczone lub zabronione dane urządzenie. Ustawieniem globalnym są jednostki miary, tj. przypisania odpowiednim wartością mierzonym wartości liczbowych lub słownych. Harmonogram wykonywania rozkazów sterujących i odczytujących to zagnieżdżona struktura, która na górze hierarchii rozpoczyna się od konfiguracji, w której zagregowane są listy rozkazów. Lista rozkazów zawiera zbiór rozkazów, które są egzemplarzami z pierwowzoru rozkazu (predefiniowanego słownika, zawierającego odpowiednio dobrane parametry do ustawiania lub odczytu wybranej własności). Dodanie nowych rozkazów wymaga modyfikacji programu danego urządzenia, natomiast nie wymaga modyfikacji kodu tego systemu, wystarczy aktualizacja danych słownikowych. Harmonogram wykonywany jest zgodnie z listą rozkazów.
Rafał Wojszczyk
Dostępność rozkazów warunkowana jest przypisaniem urządzenia do danej konfiguracji.
W trybie wykonywania rozkazów, użytkownik wybiera odpowiednie urządzenie i konfigurację, ma możliwość wprowadzenia opisu do całego działania, jak również do każdego rozkazu z osobna. Po uruchomieniu harmonogramu system działa autonomicznie, a użytkownik ma możliwość przerwania i wznowienia harmonogramu. Gdy harmonogram nie jest uruchomiony, użytkownik może wymusić wykonanie pojedynczego rozkazu. Rysunek 7 przedstawia fragment programu w trybie wykonywania rozkazów. W przypadku przerwania harmonogramu, np. przez odłączenie urządzenia, harmonogram jest zatrzymywany i wznawiany po ponownym podłączeniu. W przypadku nieprawidłowego zamknięcia aplikacji (np. w trakcie resetu komputera), zapamiętywany jest ostatni stan, a użytkownik otrzymuje odpowiedni komunikat.
Rys. 7. Widok program w trybie wykonywania rozkazów
Fig. 7. View of the programme in command execution mode
Rys. 8. Widok program w trybie testowym Fig. 8. View of the programme in test mode
Warty omówienia jest tryb testowy, w którym można ręcznie (tj. poprzez wpisanie odpowiednich wartości w polach tekstowych) nawiązać komunikację z urządzeniem zewnętrznym i wykonać rozkaz zgodnie z tab. 1. Wynik rozkazu (jeśli występuje) prezentowany jest w zapisie binarnym, dziesiętnym, szesnastkowym oraz ASCII. Widok trybu testowego przedstawia rys. 8.
3.4. Weryfikacja systemu
Proponowane rozwiązanie zostało uruchomione i użytkowane przez studentów Koła Naukowego AnyCode Politechniki Koszalińskiej (dawniej Grupa .NET) oraz wybranych pracowników Wydziału Elektroniki i Informatyki Politechniki Koszalińskiej. Wykorzystanie całego systemu polegało na sterowaniu diodami LED zgodnie z zaplanowanym harmonogramem oraz sterowanie i odczyt wartości w przygotowywanym torze testowym dla dronów. Poza tym, została zaimplementowana aplikacja konsolowa, która wykorzystywała bezpośrednio warstwę Hardware w celu prototypowania automatyki w projektach realizowanych przez Koło Naukowe. W opinii członków Koła Naukowego AnyCode, opracowane rozwiązanie jest szczególnie użyteczne w budowie prototypowych urządzeń, ponieważ pod względem kompilacji i debugowania przewyższa np. Arduino. W proponowanym rozwiązaniu nie ma potrzeby wgrywania kodu maszynowego do mikrokontrolera po kompilacji, ponieważ jednostką sterującą jest komputer PC. W związku z tym
debugowanie odbywa się również na poziomie komputera PC. Wykorzystane urządzenia USB bazowały m.in. na schemacie
PCB opublikowanym przez AVT-Korporacja Sp. z o.o. oraz na układach budowanych z wykorzystaniem uniwersalnych płytek
PCB. Zastosowane urządzenia przedstawia rys. 9.
Rys. 9. Wykonanie urządzenia USB z użyciem schematu płytki
PCB dostarczonej przez AVT-Korporacja Sp. z o.o. Do urządzenia podłączona jest płytka testowa
Fig. 9. Realisation of the USB device using the PCB schematic provided by AVT Corporation. A test board is connected to the device
Przeprowadzono również analizę porównawczą opracowanego rozwiązania względem analogicznego urządzenia podłączanego do portu RS-232. Urządzenie z interfejsem RS-232 zostało zrealizowane również z wykorzystaniem mikrokontrolera ATmega8, gdzie wykorzystano interfejs UART oraz konwerter napięć MAX232. Dodanie urządzenia do systemu zostało zrealizowane zgodnie z wzorcem Strategia. W przypadku USB dane wysyłane są w pakietach danych, które składają się z rozkazu i dwóch szesnastobitowych parametrów. W komunikacji RS-232 nie występuje podział na pakiety danych [18]. Przesyłane są kolejne bajty danych. Stąd konieczne było utworzenie mechanizmu, który zinterpretuje odbierane dane w podobny sposób jak przy interfejsie USB. Ponadto w przypadku USB zwracany wynik jest częścią jednej transakcji i programista ma 100 % pewności, że otrzymane dane są odpowiedzią na wysłane żądanie. W przypadku RS-232 programista jest zmuszony do odczytywania danych z portu. Dodatkowo nie można tego wykonać zaraz po wysłaniu rozkazu, należy jeszcze odczekać pewien czas na gotowość portu do transmisji. W tym przypadku bezpieczny czas oczekiwania to 20 milisekund. Kolejną różnicą zauważoną w trakcie implementacji jest brak możliwości sprawdzenia czy urządzenie jest podłączone. Jest możliwość jedynie sprawdzenia logicznego stanu, czy połączenie z wybranym portem zostało otwarte. Jednak w przypadku odłączenia urządzenia nie zostanie to wykryte i zasygnalizowane. Jedyny skutek to brak zwracanych danych z rozkazów, które powinny zwracać wyniki pomiarów. Utrudniło to w znaczący sposób monitorowanie stanu urządzenia, co ma związek z przerywaniem i wznawianiem pracy harmonogramu. Wykonano również testy weryfikujące wydajność i stabilność w działaniu systemu, wykorzystującego zarówno urządzenie z interfejsem USB oraz z RS-232. Test wydajności polegał na jak najczęstszym wykonywaniu rozkazów. Zostały wykonane dwa rodzaje testów: pierwszy rodzaj to ustawianie wartości logicznych przez jedną minutę, test powtórzony 10 razy, drugi rodzaj to odczyt wartości analogowej przez jedną minutę, test powtórzony 10 razy. Podział na dwa rodzaje był konieczny ze względu na zastosowany dodatkowy czas opóźnienia, przy odczytywaniu wartości z portu RS-232, co z góry stawia port RS-232 na gorszej pozycji. Wyniki zostały zweryfikowane na podstawie czasu zapisanego w bazie danych systemu, po wykonaniu każdego z rozkazów. Czas został zapisany jako typ
Tabela 2. Wyniki weryfikacji wydajności
Tab. 2. Performance verification results
Heading level Minimalna szybkość [rozkaz/sekundę]
Średnia szybkość [rozkaz/sekundę]
danych DateTime z dokładnością do 0,00333 sekund. Czas ten uwzględnia wykonanie kodu wszystkich warstw architektury programu. Wyniki testu dla obu rodzajów z podziałem na interfejsy przedstawia tab. 2.
Wyniki eksperymentu potwierdziły wstępne założenie, że urządzenie z RS-232 będzie mniej wydaje przy odczycie danych. Wyniki testu, w których ustawiana była wartość są zbliżone, co wynika z wykorzystania tej samej jednostki obliczeniowej obu urządzeń, w obu przypadkach jest to mikrokontroler ATmega8. Jednakże wyniki eksperymentu wskazują większą wydajność w przypadku interfejsu USB. Warto dodać, że mikrokontroler wyposażony jest w sprzętowy port UART, natomiast nie jest wyposażony w sprzętowy interfejs USB (co oznacza, że w przypadku USB wymagana jest dodatkowa moc obliczeniowa).
Realizację weryfikacji stabilności działania, poprzedzono kalibracją szybkości obu urządzeń, tj. dodano dodatkowe opóźnienie w przypadku interfejsu USB, aby uzyskać taką samą liczbę rozkazów wykonywanych w trakcie jednej godziny, ile wykonuje urządzenie z RS-232. Eksperyment polegał na wykonywaniu listy rozkazów, które były zapętlone w nieskończoność. Każdy z testów trwał równo 24 godziny. W przypadku urządzenia z USB wykonano 147 580 rozkazów. W przypadku RS-232 wykonano 146 282 rozkazów, z czego 2,5 % (3657 rozkazów) zostało zaklasyfikowanych jako błąd przez zaimplementowany mechanizm kontroli błędów. Uzyskany błąd wskazuje jednoznacznie niższą stabilność komunikacji za pomocą RS-232, dodatkowo o 1298 mniejsza liczba wykonanych rozkazów wskazuje, że wystąpiły kolejne problemy w tym sposobie komunikacji.
4. Podsumowanie
W pracy przedstawiono propozycję architektury oprogramowania, którą zastosowano do budowy systemu kontrolno-pomiarowego wykorzystującego interfejs USB. Opracowane rozwiązanie stanowi gotowe narzędzie do sterowania stanami logicznymi cyfrowych wyjść urządzenia zewnętrznego, sterowanie wyjściem analogowym, odczyt wejść cyfrowych i odczyt wejść analogowych w urządzeniu zewnętrznym, zgodnie z zaplanowanym harmonogramem.
Opracowane rozwiązania spełnia wszystkie wymagania postawione w drugim rozdziale niniejszej pracy. Oznacza to, że wady wykorzystania portu RS-232 zostały poprawione poprzez wykorzystanie portu USB. Dodatkowo opracowana architektura oprogramowania zapewnia niskie koszty rozbudowy, ponownego użycia kodu i łatwego wykorzystania przez programistów języków wysokopoziomowych. Uniwersalność rozwiązania pozwala na wprowadzanie modyfikacji w działaniu urządzenia, dodawanie nowych urządzeń, bez potrzeby modyfikacji kodu źródłowego.
Opracowane rozwiązanie poddano weryfikacji poprzez wykorzystanie w autorskich projektach studentów z Koła Naukowego oraz przez bezpośrednie porównanie z portem RS-232. Przepro-
Maksymalna szybkość [rozkaz/sekundę]
wadzone badania potwierdziły, że interfejs USB gwarantuje nie gorsze parametry niż RS-232. Porównywalna wydajność komunikacji wynika z wykorzystania takiej samej jednostki sterującej w każdym z urządzeń, tj. mikrokontrolera ATmega8. Różnice wystąpiły natomiast w stabilności działania, co jak potwierdziły eksperymenty, jest korzystniejsze w przypadku USB. Dalsze prace będą skupiać się na wykorzystaniu zaawansowanych mikrokontrolerów, które wyposażone są w sprzętowy interfejs USB (np. ESP32-S3, STM32F411CEU6) oraz inne interfejsy, aby rozbudować system o obsługę dodatkowych urządzeń. Równolegle mogą być prowadzone prace implementacyjne zwiększające użyteczność oprogramowania, np. umożliwiające dynamiczne sterowanie urządzeniem zewnętrznym. Wersja rozwojowa oprogramowania jest dostępna w repozytorium: https://github.com/anycode-pk/usb_cdc.
Bibliografia
1. Daniluk A., USB Praktyczne programowanie z Windows API w C++, Helion 2009.
2. Giebas D., Wojszczyk R., Atomicity Violation in Multithreaded Applications and Its Detection in Static Code Analysis Process, “Applied Sciences”, Vol. 10, No. 22, 2020, DOI: 10.3390/app10228005.
3. Kavaliauskas Ž., Šajev I., Blažiūnas G., Gecevičius G., Čapas V., Adomaitis D., Electronic System for the Remote Monitoring of Solar Power Plant Parameters and Environmental Conditions, “Electronics”, Vol. 11, No. 9, 2022, DOI: 10.3390/electronics11091431.
4. Kowol A., Internet Rzeczy – przykład implementacji protokołu LoRaWAN, „Pomiary Automatyka Robotyka”, R. 23, Nr 2, 2019, 61–68, DOI: 10.14313/PAR_232/61.
5. Mielczarek W., USB uniwersalny interfejs szeregowy, Helion 2005.
6. Nasution A.S., Adhitama B.S., Rasyidi F.H., Adi Aufarachman Putra Bambang Dwi, Imdad M.T., Jatmiko N.W., Development of the NOAA-19 Satellite Data Receiver Ingest System based on FPGA, 2022 International Conference on Radar, Antenna, Microwave, Electronics, and Telecommunications (ICRAMET), Bandung, Indonesia, 2022, 132–137, DOI: 10.1109/ICRAMET56917.2022.9991236.
7. Nithya M.R., Lakshmi P., Roshmi J., Sabana R., Swetha R.U., Machine Learning and IoT based Seed Suggestion: To Increase Agriculture Harvesting and Development, 2023 International Conference on Sustainable Computing and Data Communication Systems (ICSCDS), Erode, India, 2023, DOI: 10.1109/ICSCDS56580.2023.10104981.
8. Ladino K.S., Sama M.P., Stanton V.L., Development and Calibration of Pressure-Temperature-Humidity (PTH) Probes for Distributed Atmospheric Monitoring Using Unmanned Aircraft Systems, “Sensors”, Vol. 22, No. 9, 2022, DOI: 10.3390/s22093261.
9. Tambaro M., Bisio M., Maschietto M., Leparulo A., Vassanelli S., FPGA Design Integration of a 32-Microelectrodes
Low-Latency Spike Detector in a Commercial System for Intracortical Recordings, “Digital”, Vol. 1, No. 1, 2021, 34–53, DOI: 10.3390/digital1010003.
10. Tiboni M., Remino C., Condition Monitoring of Pneumatic Drive Systems Based on the AI Method Feed-Forward Backpropagation Neural Network, “Sensors”, Vol. 24, No. 6, 2024, DOI: 10.3390/s24061783.
11. Thalman R., Development and Testing of a Rocket-Based Sensor for Atmospheric Sensing Using an Unmanned Aerial System. “Sensors”, Vol. 24, No. 6, 2024, DOI: 10.3390/s24061768.
12. Wojszczyk R., Zestawienie metryk oprogramowania obiektowego opartych na statycznej analizie kodu źródłowego, „Zarządzanie projektami i modelowanie procesów”, Zeszyty Rady Naukowej Polskiego Towarzystwa Informatycznego, 2013, 95–107, Warszawa 2013.
13. Wojszczyk R., Giebas D., Multithreading Errors in Data Reading Automation, [In:] Szewczyk, R., Zieliński C., Kaliczyńska M. (eds) Automation 2022: New Solutions and
Technologies for Automation, Robotics and Measurement Techniques. AUTOMATION 2022. Advances in Intelligent Systems and Computing, Vol. 1427, DOI: 10.1007/978-3-031-03502-9_10.
14. Wójcicki S., Rutkowski T., Projekt i budowa uniwersalnego sterownika programowalnego, „Pomiary Automatyka Robotyka”, Nr 2, 2013, 436–442.
16. Jamrógiewicz T., Magistrala USB, Instytut Radioelektroniki Politechniki Warszawskiej
17. V-USB, www.obdev.at/vusb.
18. Szymczyk N., Jak działa interfejs RS232, https://ntronic.pl/rs232/.
Software Architecture of the Control and Measurement System Using the
USB Interface
Abstract: The paper proposes the implementation of a high-level software architecture that allows communication with an external device in an object-oriented manner. The developed solution, together with a proprietary device connected to a USB port, constitutes a ready-made control and measurement system. The use of a multilayered architecture and selected design patterns allowed for the development of a software solution that ensures low development costs, allows easy use in an object-oriented manner and ensures the possibility of module replacement. In addition, the versatility of the developed tool allows selected modifications to be made to the system without recompiling the source code.
dr inż. Rafał Wojszczyk rafal.wojszczyk@tu.koszalin.pl
ORCID: 0000-0003-4305-7253
Adiunkt na Wydziale Elektroniki i Informatyki Politechniki Koszalińskiej, gdzie uzyskał tytuł magistra inżyniera Informatyki, magistra Pedagogiki oraz stopień doktora w dyscyplinie Informatyka. Dydaktycznie i naukowo zajmuje się inżynierią oprogramowania, w szczególności statyczną analizą kodu źródłowego oraz tzw. dobrymi praktykami w programowaniu zorientowanym obiektowo. Jest autorem i współautorem ponad 40 publikacji, w tym artykułów w międzynarodowych czasopismach (JCR), rozdziałów w książkach i materiałów konferencyjnych. Jest recenzentem wielu międzynarodowych czasopism i konferencji.
CTS i EPICS – moduły automatyzujące montaż
i
kontrolę jakości w produkcji amortyzatorów samochodowych
Robert Tomasiewicz ELPLC S.A., ul. Rozwojowa 28, 33-100 Tarnów
Streszczenie: Rozwiązania proponowane przez kompetentnego producenta maszyn i linii, powinny być nie tylko ekonomicznie i technicznie uzasadnione ale również uniwersalne (łatwe przezbrojenie), modułowe (możliwość rozbudowy) oraz skalowalne (szybkie dostosowanie do dynamicznych potrzeb fabryki). Powstają w ten sposób innowacje odpowiadające na potrzeby klienta – redukcja przestrzeni potrzebnej na produkcję, skrócenie czasu cyklu, zwiększenie dokładności pomiaru itp. Publikacja zawiera rezultaty prac ELPLC S.A. nad projektem badawczo-rozwojowym nr POIR.01.01.01-00-1029/17-00 „Opracowanie i demonstracja modułowej linii technologicznej do montażu i testowania amortyzatorów samochodowych”. Podano kilka ogólnych informacji na temat prowadzenia projektów automatyzacji produkcji i niektórych kierunków innowacji. Opisano przykłady konkretnych modułów, jakie powstały w ramach projektu na czele z EPICS i CTS, dostosowanych do potrzeb branży samochodowej.
Słowa kluczowe: amortyzatory samochodowe, automatyzacja produkcji, linie montażowe, testowanie amortyzatorów, automatyczna kontrola jakości
1. Wprowadzenie
Inwestycja w automatyzację procesów produkcyjnych powinna być dobrze przemyślana. Konieczne jest zatem uwzględnienie szeregu czynników i kryteriów, dotyczących zarówno parametrów technicznych, jak i założeń o charakterze ekonomicznym. W aspekcie technologicznym trzeba mieć na uwadze m.in. odpowiednio wyspecyfikowany przebieg procesu, zdefiniowanie funkcjonalności systemu oraz obliczenie zakładanych parametrów technicznych dla poszczególnych operacji. Nie mniej ważne są standardy względem urządzeń techniki napędowej i sterowania, sposób pracy (automatyczny lub półautomatyczny), sposób zasilania maszyn w komponenty i odbiór wyrobów gotowych lub półproduktów, a także czasy cyklów, sposób przezbrajania, integracja z otoczeniem, zasilanie w media, itd. Z kolei w odniesieniu do otoczenia biznesowego analizuje się m.in. czas zwrotu inwestycji, sposób finansowania, czas realizacji, możliwość dostosowania maszyny do zmieniających się potrzeb rynkowych [9].
Autor korespondujący:
Robert Tomasiewicz, robert.tomasiewicz@elplc.pl
Artykuł recenzowany nadesłany 19.08.2024 r., przyjęty do druku 17.01.2025 r..
Zezwala się na korzystanie z artykułu na warunkach licencji Creative Commons Uznanie autorstwa 4.0 Int.
Osobne zagadnienie stanowi wybór dostawcy systemu automatyki. Jego kompetencje powinny przełożyć się na właściwie dobraną koncepcję automatyzacji, oraz jej przekonwertowanie na szczegółowy projekt wielobranżowy. Wybierając kompetentnego dostawcę zyskuje się ponadto gwarancję sprawnego przebiegu realizacji projektu, jego wdrożenia, oraz wprowadzania ewentualnych zmian, wynikających ze zmieniającego się przebiegu technologicznego, który musi być dostosowany do potrzeb rynkowych [9].
Producenci na poziomie OEM (producenci samochodów) oraz Tier1 (dostawcy podzespołów) poszukują nie tylko innowacji w budowie samych amortyzatorów ale również w modernizacji ich produkcji. Dotyczy to szczególnie optymalizacji zużycia energii i materiałów oraz testowania jakości z odpowiednią precyzją.
1.1.
Modernizacja techniki napędowej
Automatyzacja i robotyzacja produkcji nie byłaby możliwa bez techniki napędowej. Urządzenia napędowe są istotnym elementem linii i maszyn. Można je spotkać w szeregu procesów przemysłowych, takich jak transportowanie komponentów na linii produkcyjnej, różne rodzaje montażu, obróbka mechaniczna, mechaniczne testowanie funkcjonalne a także w różnego rodzaju urządzeniach pompujących, odciągających zanieczyszczenia czy wentylatorach. W czasie gdy ceny energii elektrycznej nie maleją a istotną kwestią w przemyśle jest ograniczanie szkodliwego wpływu produkcji na środowisko – znaczenia nabiera kwestia energooszczędności napędów i modernizacji procesów [5]. Według niektórych źródeł napędy elektryczne mogą odpowiadać nawet za 60–70 % zużycia energii elektrycznej w przemy-
śle [1]. Jest więc o co walczyć jeśli chodzi o energooszczędność i innowacyjność. Przeprowadza się oceny znamionowych sprawności poszczególnych komponentów układów napędowych, takich jak np. przemienniki częstotliwości [2] i szacunki możliwych do osiągnięcia poziomów oszczędności [3]. W przemyśle stosowane są głównie urządzenia napędowe elektryczne, pneumatyczne lub hydrauliczne. Ostatecznie urządzenia pneumatyczne czy hydrauliczne zasilane są kompresorami czy zasilaczami hydraulicznymi, których istotnym elementem jest silnik elektryczny. Same silniki elektryczne również są zróżnicowane w zależności od przeznaczenia. Silniki z magnesami trwałymi (PM) mogą zapewnić bardziej oszczędną pracę w aplikacjach ze zmianą prędkości niż typowe silniki asynchroniczne przez to, że sprawność silnika z magnesami trwałymi jest wyższa. Wśród zalet silników PM wymienia się również dużą przeciążalność momentem, szeroki zakres prędkości, dobre właściwości regulacyjne, mniejsze gabaryty (jeśli porównać z silnikami indukcyjnymi czy prądu stałego) czy zwiększoną niezawodność przez brak węzła szczotkowego. Współcześnie silniki z magnesami trwałymi dzieli się zasadniczo na dwie grupy – bezszczotkowe silniki prądu stałego (BLDC) oraz silniki synchroniczne (PMSM).
1.2. Automatyzacja kontroli jakości z zastosowaniem systemów wizyjnych
Automatyczna kontrola jakości, szczególnie oparta na systemach wizyjnych to częsty element linii montażowych i stacji. Automatyzacja tego procesu pozwala na powtarzalną kontrolę jakości bez potrzeby zatrzymywania linii produkcyjnej oraz wyeliminowanie błędów, które mogą wystąpić w procesie manualnym.
Rys. 1. Przykład działania automatycznego systemu wizyjnego ze wskazaniem defektu. Przykład pochodzi ze stanowiska inspekcji wizyjnej w produkcji skraplaczy klimatyzacji – pokazuje wykryte odkształcenie rurki po teście ciśnieniowym
Fig. 1. Example of the operation of an automatic vision system with defect indication. The example comes from a vision inspection station in the production of cooling systems condensers – it shows detected deformation of a tube after a pressure test
Nowoczesne systemy kontroli wizyjnej znajdują zastosowanie w aplikacjach wymagających sprawdzania poprawności takich cech jak: wymiary, poprawność montażu, właściwości powierzchni, kształt, kolor, etc. Systemy wizyjne są również wykorzystywane do weryfikacji elementów graficznych i tekstu, a także do kontrolowania obecności i położenia obiektów. Odpowiednio zaprojektowana aplikacja komputerowa, współpracująca z systemem, pozwala generować statystyki jakości z możliwością porównywania parametrów rzeczywistych ze zdefiniowanymi. System może informować o przekroczeniu założonych progów parametrów i sygnalizować konieczność wdrożenia działań zapobiegawczych lub korygujących dla procesu produkcji.
W wielu aplikacjach systemy wizyjnej kontroli jakości są sprzężone z maszynami produkcyjnymi - co pozwala na bieżące korygowanie parametrów ich pracy. Jest możliwe generowanie odpowiedniej dokumentacji na potrzeby kontroli jakości z uwzględnieniem np. wymagań norm systemowych i branżowych.
Spektrum zastosowania systemów Vision Control jest bardzo szerokie. W przemyśle motoryzacyjnym używa się ich chociażby na potrzeby dokładnego pozycjonowania części z weryfikacją swobodnego położenia we wnętrzu komponentów, z uwzględnieniem odpowiedniej tolerancji kształtów. W przemyśle maszynowym i metalowym poddaje się weryfikacji gwinty (zewnętrzne i wewnętrzne), wymiary i kształty (np. po obróbce), kolor, a także stan i strukturę powierzchni. Możliwe jest również wykrywanie defektów, np. korozji na elementach czy nieprawidłowości spoin [8].
Na linii zbudowanej w opisywanym tu projekcie, występują bramki kontroli wizyjnej weryfikujące np. gabaryty cylindra zewnętrznego amortyzatora czy też kontrolujące gwint tłoczyska.
1.3. O produkcji amortyzatorów
Zawieszenia współczesnych samochodów są złożonymi układami mechanicznymi z elementami tłumiącymi i sprężystymi. Amortyzatory występujące w zawieszeniach pojazdów można podzielić zasadniczo na dwie grupy z kilkoma odmianami: mono-tube oraz twin-tube.
Na rys. 2 zaznaczono główne komponenty składowe amortyzatorów dwóch podstawowych typów.
Rys. 2. Schematyczny rysunek amortyzatorów mono-tube (A) oraz twin-tube (B)
Fig. 2. Main damper types schematic drawing: mono-tube (A) and twin-tube (B)
Pierwszym etapem produkcji amortyzatora jest formowanie rur z arkusza stali. Pasma rozciętej stali przechodzą proces for-
mowania za pomocą wałków obrotowych i po nadaniu kształtu są automatycznie spawane.
Gotowe rury są cięte na odpowiednią długość w zależności od typu amortyzatora. Długość cięcia rury jest precyzyjnie określona w projekcie amortyzatora i zróżnicowana w zależności od tego, czy jest to rura ciśnieniowa czy zewnętrzna. Rura zewnętrzna zazwyczaj jest poddawana procesom dodatkowym związanym z zapewnieniem odpowiedniego interfejsu między amortyzatorem a zwrotnicą samochodu.
Przy produkcji amortyzatorów twin-tube, w rurze ciśnieniowej montowane są zawory kontrolujące wewnętrzny przepływ oleju oraz dodatkowe elementy w postaci ringów czy sprężyn w zależności od konstrukcji zaworu. Walcarka zagniata końcówkę zaworu zamykając dno rury ciśnieniowej. Rura zewnętrzna, zamykana jest pokrywą ze spawanym uchem montażowym, co stanowi tzw. układ podstawowy. Tak zmontowany podzespół można załadować otwartą częścią do góry na linię montażu finalnego, gdzie dopasowuje się i wkłada podzespół rury ciśnieniowej z tłoczyskiem. Następuje też napełnienie olejem. Ostatecznie amortyzator zostaje zamknięty przez montaż stalowego tłoka, zaworu tłocznego i prowadnicy tłoczyska z uszczelnieniem. Komponent gazowy w postaci azotu wprowadza się przed zamknięciem sztuki. Finalnie montuje się różnego rodzaju łączniki, tuleje czy kołnierze ochronne stalowe lub gumowe.
W produkcji amortyzatorów mono-tube rurę wytwarza się podobnie, jak w przypadku rury zewnętrznej twin-tube. Po zamknięciu z jednej strony i zgrzewaniu końcówki rury trafiają do myjki i następnie na linie montażu. Tam kontrolowana jest geometria, następuje napełnienie olejem, montaż tłoka pływającego i zespołu tłoczyska, testy funkcjonalne, napełnienie gazem i zamknięcie drugiej strony cylindra.
1.4. Główny cel projektu i rynek docelowy Wyniki projektu są bezpośrednio zgodne z zidentyfikowanymi potrzebami firm OEM oraz dostawców poziomu Tier 1. Główny nacisk położono na opracowanie i demonstrację hybrydowej, modułowej linii technologicznej do montażu i testowania amortyzatorów samochodowych (rys. 9), uwzględniającej różne usprawnienia procesów. Celem było zminimalizowanie całkowitego kosztu linii przez jednoczesne uwzględnienie czynników projektowych (np. modułowość, przestrzeń stacji, koszty), operacyjnych (np. czas cyklu, ograniczenia związane z kolejnością operacji, dostępność zasobów) oraz preferencji projektantów (np. złożoność zadań) [10, 11].
Dodatkowo oczekuje się, że nowe linie technologiczne zapewnią kilka ulepszeń jakościowych, takich jak zwiększona dokładność pomiaru siły tłumienia, optymalizacja procesu napełniania gazem oraz możliwość dostosowywania funkcji do zmieniających się trendów rynkowych.
2. CTS – tester charakterystyki amortyzatora z liniowym
napędem elektrycznym
W procesie produkcji amortyzatorów istotną kwestią jest ich testowanie funkcjonalne, czyli mówiąc prosto: zasymulowanie nierówności na drodze i zaobserwowanie reakcji amortyzatorów przedstawionej w postaci odpowiedniej charakterystyki siły tłumienia. Przy próbach automatyzowania procesu testowania konieczne jest zastosowanie odpowiednich napędów, wymuszających ruch na potrzeby pomiaru zależności między amplitudą drgań a ich częstotliwością, przy uwzględnieniu różnych współczynników tłumienia. Jak pokazała praktyka Spółki większość stosowanych testerów na liniach nie może zasymulować ruchów będących odzwierciedleniem pracy amortyzatora w warun-
Robert Tomasiewicz
kach rzeczywistych. Oprócz tego przy teście charakterystyki wymaga się możliwie najmniejszego błędu pomiarowego, który w standardowych aplikacjach może wynosić aż 10 %. Ponadto koniecznością jest krótki czas cyklu oraz precyzyjny pomiar przemieszczenia w dużym zakresie. Dla właściwego wykonania testu charakterystyki amortyzatora konieczne jest wykonanie pomiaru siły z określoną precyzją.
Typowe napotkane w praktyce branżowej rozwiązania rynkowe oparte są na napędzie serwo-hydraulicznym, który porusza tłoczysko amortyzatora z odpowiednią siłą. Konstrukcja napędów hydraulicznych ma swoje wady, a główną z nich jest zależność prędkości od temperatury oleju i działających obciążeń oraz duża bezwładność układu. Olej jako główny czynnik roboczy jest też bardzo wrażliwy na zanieczyszczenia, które są szkodliwe dla napędu. W zasadzie jedynym środkiem zapobiegawczym jest odpowiednio częsta wymiana oleju, co wiąże się z bardziej czaso- i zasobochłonną obsługą serwisową. Wielokrotne przekształcenia energii w napędzie hydraulicznym skutkują jego mniejszą sprawnością w stosunku do rozwiązań elektrycznych. Duże znaczenie ma też wzrastający z ciśnieniem poziom hałasu, wycieki czynnika roboczego oraz trudności w uzyskaniu dokładnej synchronizacji silników lub siłowników obciążanych w zróżnicowany sposób [7, 8].
Tab. 1. Porównanie CTS z typowymi testerami hydraulicznymi
Tab. 1. Comparison of CTS with typical hydraulic testers
Zakres mierzonej siły nawet ±10 kN (typowo: ±6,5 kN) ±5 kN
Możliwość testu w wysokiej częstotliwości
TAK (16 Hz) NIE
(*) podane parametry odnoszą się do grupy różnych rzeczywistych pracujących maszyn napotkanych typowo u klientów w praktyce biznesowej firmy
Rys. 3. Model 3D stanowiska CTS
Fig. 3. CTS station 3D model
W module CTS, który może być integralnym elementem linii automatycznej (inline) lub występować jako autonomiczne stanowisko testujące, zdecydowano się na elektryczne silniki liniowe jako napęd wymuszający. Tym sposobem uzyskano siłę kompresji (Fmax) wynoszącą 6,5 kN. O wyborze silnika zadecydowała również jego prędkość maksymalna (Vmax) osiągająca 1,5 m/s. Parametr ten pozwolił skrócić czas cyklu testowania i osiągnąć pożądane parametry testu. Pomiar siły jest uzupełniony kontrolą przebytej drogi w jednostce czasu. Wykorzystano do tego zintegrowany indukcyjny system pomiarowy. Efektem całości jest błąd pomiarowy rzędu 1,5 %. W porównywanych rozwiązaniach typowych, bazujących na napędzie hydraulicznym błąd ten może wynosić nawet 10 %. Uzyskano również nieznaczne skrócenie czasu cyklu – 6,8 s wobec 7,2 s. Zastąpienie klasycznego napędu hydraulicznego przyniosło
o stanie wybranego urządzeniu stacji
Rys. 5. CTS – narzędzie testujące
Fig. 5. CTS tooling
Rys. 6. Cyfrowy bliźniak CTS w okularach rozszerzonej rzeczywistości z w yświetlonymi informacjami
Fig. 6. Digital twin of CTS in augmented reality glasses with displayed information about the status of the selected device on station
Rys. 4. Zdjęcie CTS jako modułu 2 demonstracyjnej linii do montażu i testowania amortyzatorów Fig. 4. CTS as module 2 of demonstration line for dampers assembling and testing
wiele korzyści: brak dodatkowego układu zasilania olejem, brak konieczności kontrolowania temperatury, ciśnienia i zużycia oleju, duża dynamika sterowania przy dużej obciążalności. Testy częstotliwościowe przeprowadzane za pomocą CTS nie są możliwe do wykonania w systemach z napędem hydraulicznym. Zmiana techniki napędowej przyniosła w tym przypadku nie
Tab. 2. Podstawowe parametry CTS
Tab. 2. CTS main characteristics
Parametr Wartość
Tester charakterystyki (CTS) – siła testu od –6500 N do 6500 N
CTS – pomiar skoku amortyzatora 0–400 mm
CTS – prędkość testu 0,5–1000 mm/s
CTS – przyspieszenie maksymalne 10 g
CTS – krzywe przyspieszeniasinus, trójkąt, trapez
CTS – częstotliwość testu 16 Hz
Rys. 7. EPICS, główne podzespoły stacji Fig. 7. EPICS main elements
Tab. 3. Najważniejsze cechy EPICS w zestawieniu z rozwiązaniami typowymi
Tab. 3. Key features of EPICS compared to typical solutions
Podstawowe cechy ELPLC Typowo (*)
Napełnianie i zamykanie jedna maszyna jeden ruch
dwie osobne maszyny:
1 – napełnianie i wstępne zamknięcie
2 – zamknięcie końcowe
Całkowity czas operacji 6,8 s > 14 s (2 kroki)
Analiza danych (wykres siły zamykania) pojedynczy ciągły dwa oddzielne zbiory danych
System sterowania National Instruments (real-time) karta PC
(*) podane parametry odnoszą się do grupy różnych rzeczywistych pracujących maszyn napotkanych typowo u klientów Tier1 w praktyce biznesowej Spółki
Robert Tomasiewicz
tylko energooszczędność, ale również konkretne korzyści operacyjne i jakościowe w postaci krótszego cyklu i dokładniejszego pomiaru. W demonstracyjnej modułowej linii technologicznej do montażu i testowania amortyzatorów samochodowych zrealizowanej w ramach projektu, CTS stanowi moduł 2. Na linii testowano także aplikację rozszerzonej rzeczywistości w zakresie tworzenia cyfrowych bliźniaków modułów linii. Aplikacja umożliwiała wyświetlanie parametrów i kierowanie czynnościami operatora wyposażonego w okulary typu AR/ MR w czasie rzeczywistym.
3. EPICS – napełnianie azotem i zamykanie w jednym module
Amortyzator jest napełniany azotem oraz zamykany przez zaoblenie górnego fragmentu cylindra. Typowo ciśnienie gazu w amortyzatorze mieści się w przedziale do 25 bar. Praktyka produkcyjna zastana przez Spółkę u klientów Tier1 pokazała, że często ta operacja rozdzielona jest na dwie maszyny. Pierwsza z nich wykonuje napełnienie gazem i tylko wstępne uszczelnienie i zamknięcie amortyzatora. Finalne zamknięcie amortyzatora dokonywane jest dopiero na kolejnej stacji. W toku realizacji projektu, Spółka zaproponowała zintegrowanie całości procesu w jednej stacji – EPICS, będącym modułem 3 linii. Tym samym ostateczne zamknięcie amortyzatora odbywa się jednocześnie z wypełnieniem gazem. Na stacji EPICS osiągane jest ciśnienie azotu w amortyzatorze do 25 bar. Zaprojektowano do tego dedykowany układ pneumatyczny utrzymujący ciśnienie gazu oraz zespół uszczelnień głowicy i cylindra. Podanie azotu pod ciśnieniem do amortyzatora dokonuje się w głowicy zamykającej. Najazd układu zamykania jest realizowany za pomocą serwonapędu. Następnie przez przekładnię napędzana jest śruba planetarna sprzężona z głowicą gazująco-walcującą. Układ dojeżdża do momentu wystąpienia określonej wartości siły. Droga jest więc uzależniona od punktu wystąpienia zadanej siły, a ta zależy od rodzaju (referencji) amortyzatora i jego gabarytów.
Pomiar siły walcowania jest realizowany za pomocą tensometru oporowego o zakresie 250 kN. Umożliwia pomiar sił w założonym przedziale od 45 kN do 150 kN. Przewymiarowanie przetwornika pozwala zwiększyć trwałość układu dzięki znacznemu zapasowi zakresu i odporności na znaczne nawet przekroczenia założonego przedziału.
Rys. 8. Model 3D stanowiska EPICS
Fig. 8. EPICS 3D model
4. Wnioski końcowe
Opisywane w publikacji moduły stanowiły kamienie milowe projektu POIR 01.01.01.01-00-1029/17-00 „Opracowanie i demonstracja modułowej linii technologicznej do montażu i testowania amortyzatorów samochodowych”. Prace nad projektem były realizowane w ramach Działania: 1.1. Projekty B+R Przedsiębiorstw – Programu Operacyjnego Inteligentny Rozwój. W wyniku tych prac powstała szczegółowa koncepcja, projekt oraz została zbudowana i przetestowana linia montażowa amortyzatorów.
Zestawienie wszystkich modułów linii (rys. 9) w kolejności postępu prac:
moduł 2 – moduł wciskania prowadnicy tłoczyska amortyzatora zintegrowany z modułem kontroli charakterystyki tłumienia amortyzatora (CTS), moduł 3 – moduł napełniania azotem i zamykania amortyzatora przez walcowanie (EPICS), moduł 4 – moduł pomiaru siły generowanej przez azot w amortyzatorze oraz kontroli długości, moduł 5 – moduł wciskania nakładki ślizgowej oraz kontroli jakości gwintu, mo duł 1 – moduł początkowy składający się ze stacji załadunkowej i napełniania amortyzatora olejem, −mo duł 6 – moduł drukowania i naklejania etykiety, moduł 7 – stacja kontroli wybranych wymiarów amortyzatora.
Zaprojektowana i zbudowana linia technologiczna posiada założone parametry obejmujące szeroką grupę produkowanych na świecie typowych amortyzatorów. Po ukończeniu prac projektowych, montażowych i programistycznych przystąpiono do uruchomienia linii. Został przeprowadzony testowy przejazd komponentów na każdy z modułów i ich weryfikacja po procesie oraz ustawienie wartości referencyjnych. W wyniku walidacji wszystkich stacji i znajdujących się na nich komponentów w trakcie testu wykazano ponownie, że linia technologiczna spełnia założone cele. Do pełnej obsługi linii wymaganych jest tylko dwóch operatorów – na stacji załadunku (moduł 1) oraz rozładunku (moduł 7).
Warto zaznaczyć, że tak jak większość linii produkowanych w firmie, również ta jest w pełni przystosowana do pracy z TOMAI Factory System. Jest to system typu smart factory,
opracowany przez zespół inżynierski Spółki. Zapewnia pełne traceability, serializację produkcji oraz służy jako skalowalne narzędzie do monitorowania i kontrolowania procesów produkcyjnych w fabryce. Zbiera, przechowuje i analizuje dane pochodzące z procesów produkcyjnych w celu dostarczenia użytecznych informacji o wąskich gardłach, najczęstszych awariach, możliwych optymalizacjach OEE czy zużyciu zasobów produkcyjnych. Podstawowe funkcjonalności systemu zebrano w czterech modułach: zbierania danych, podglądu stanu linii, diagnostyki i analizy danych historycznych, analizy efektywności i awarii.
Podziękowania
Prace nad projektem były realizowane przez ELPLC S.A. zgodnie z planem, w okresie od 1 lipca 2018 r. do 29 stycznia 2021 r. W wyniku prac powstała szczegółowa koncepcja, projekt oraz została zbudowana i przetestowana linia montażowa amortyzatorów, składająca się m.in. z modułów opisanych w publikacji. Projekt otrzymał dofinansowanie w ramach Programu Innowacyjny Rozwój 2014–2020.
Bibliografia
1. Brenning G., Weber R., Skuteczne zwiększanie efektywności energetycznej w technice napędowej, WP040007PL, Eaton, Marzec 2021.
2. Szymczyk J., Podręcznik do samooceny zużycia energii dla małych i średnich przedsiębiorstw, KAPE. 2020, ISBN: 97883-932908-1-9.
6. Lipski J., Napędy i sterowania hydrauliczne, WKŁ 1981.
7. Garbacik A., Studium projektowania układów hydraulicznych, Ossolineum 1997.
8. Żabicki D., Dlaczego warto zautomatyzować proces kontroli jakości?, elplc.com.
Rys. 9. Panoramiczne zdjęcie gotowej linii modułowej z oznaczeniem modułów
Fig. 9. Damper assembly panoramic photo with module description
9. Żabicki D., Jak wybrać dostawcę automatyki, elplc.com.
10. Rihar L., Žužek T., Kušar J., How to successfully introduce concurrent engineering into new product development?, “Concurrent Engineering”, Vol. 29, No. 2, 2020, 87–101, DOI: 10.1177/1063293X20967929.
Robert Tomasiewicz
11. Nag Kumar M., Significance of concurrent engineering methods used in automotive industries, “International Journal of Scientific Research in Engineering and Management”, Vol. 7, No. 3, 2023, DOI: 10.55041/IJSREM18461.
CTS and EPICS – Modules for Automating the Assembly and Quality Control in the Production of Automotive Dampers
Abstract: Solutions proposed by a competent manufacturer of machines and lines should not only be economically and technically reasonable but also universal (easy retooling), modular (expandable) and scalable (quick adaptation to the dynamic needs of the factory). This creates innovations that respond to the customer’s needs – reducing the space needed for production, shortening the cycle time, increasing measurement accuracy, etc. The publication is based on the results of ELPLC S.A.’s work on R&D project no. POIR.01.01.01-00-1029/17-00 “Development and demonstration of a modular technological line for the assembly and testing of automotive dampers”. Some general information on the implementation of production automation projects and some directions of innovation are provided. Examples of specific modules developed within the project, led by EPICS and CTS, adapted to the needs of the automotive industry, are described. The work on the project was carried out by ELPLC S.A. according to plan, in the period from July 1, 2018 to January 29, 2021. As a result of these work, a detailed concept, design, and assembly line for dampers was created and tested, consisting the modules described in this article. The project received funding under the Innovative Development Program 2014–2020.
Keywords: automotive dampers, production automation, assembly lines, dampers testing, automatic quality control
mgr Robert Tomasiewicz, MBA
Robert Tomasiewicz, robert.tomasiewicz@elplc.pl ORCID: 0009-0000-0379-9127
Przedsiębiorca, ekspert w dziedzinie automatyzacji, robotyzacji i cyfryzacji przemysłu, absolwent MWSE w Tarnowie oraz MBA in General Management, Corporate Management – Krakowskiej Szkoły Biznesu UEK. Pracuje i angażuje się na rzecz nowoczesnego przemysłu i edukacji technicznej w Polsce. Członek grupy roboczej ds. automatyzacji i robotyki procesów technologicznych w Departamencie Innowacji i Polityki Przemysłowej Ministerstwa Rozwoju i Technologii, ekspert ds. opracowania Koncepcji Rozwoju Kraju do 2050 r. w Ministerstwie Funduszy i Polityki Regionalnej, Wiceprzewodniczący Małopolskiej Regionalnej Rady Przemysłu Przyszłości, członek Instytutu Rozwoju Miast i Regionów oraz grupy roboczej ds. małopolskich inteligentnych specjalizacji. Swoją obecnością i aktywnością w wielu gremiach branżowych i eksperckich pokazuje, że innowacje i podążanie w kierunku Przemysłu 4.0 to nieodzowny element stabilnej przyszłości. Fundator Inkubatora Przemysłu Przyszłości. Założyciel i Prezes Zarządu ELPLC S.A.
Informacje dla Autorów
Za artykuł naukowy – zgodnie z Komunikatem Ministra Nauki i Szkolnictwa Wyższego z dnia 29 maja 2013 r. w sprawie kryteriów i trybu oceny czasopism naukowych – należy rozumieć artykuł prezentujący wyniki oryginalnych badań o charakterze empirycznym, teoretycznym, technicznym lub analitycznym zawierający tytuł publikacji, nazwiska i imiona autorów wraz z ich afiliacją i przedstawiający obecny stan wiedzy, metodykę badań, przebieg procesu badawczego, jego wyniki oraz wnioski, z przytoczeniem cytowanej literatury (bibliografię). Do artykułów naukowych zalicza się także opublikowane w czasopismach naukowych opracowania o charakterze monograficznym, polemicznym lub przeglądowym, jak również glosy lub komentarze prawnicze.
Wskazówki dla Autorów przygotowujących artykuły naukowe do publikacji
Artykuły naukowe zgłoszone do publikacji w kwartalniku naukowotechnicznym Pomiary Automatyka Robotyka powinny spełniać następujące kryteria formalne: – t ytuł artykułu (nieprzekraczający 80 znaków) w języku polskim oraz angielskim,
– imię i nazwisko Autora/Autorów, adres e-mail, afiliacja (instytucja publiczna, uczelnia, zakład pracy, adres), – s treszczenie artykułu (o objętości 150–200 słów) w języku polskim oraz angielskim, – s łowa kluczowe (5–8 haseł) w języku polskim oraz w języku angielskim angielskim,
– z asadnicza część artykułu – w języku polskim (lub w j. angielskim), – podpisy pod rysunkami w języku polskim oraz w języku angielskim, – t ytuły tabel w języku polski oraz w języku angielskim, – ilustracje/grafika/zdjęcia jako osobne pliki w formacie .eps, .cdr, .jpg lub .tiff, w rozdzielczości min. 300 dpi, min. 1000 pikseli szerokości, opisane zgodnie z numeracją grafiki w tekście.
Artykuł powinien mieć objętość równą co najmniej 0,6 arkusza wydawniczego, nie powinien przekraczać objętości 1 arkusza wydawniczego (40 000 znaków ze spacjami lub 3000 cm2 ilustracji, wzorów), co daje ok. 8 stron złożonego tekstu. W przypadku artykułów przekraczających tę objętość sugerowany jest podział na części. Nie drukujemy komunikatów!
Do artykułu muszą być dołączone notki biograficzne wszystkich Autorów (w języku artykułu) o objętości
500–750 znaków oraz ich aktualne fotografie.
Redakcja zastrzega sobie prawo dokonywania skrótów, korekty językowej i stylistycznej oraz zmian terminologicznych.
Przed publikacją autorzy akceptują końcową postać artykułu.
System recenzencki PAR
Redakcja przyjmuje wyłącznie artykuły oryginalne, wcześniej niepublikowane w innych czasopismach, które przeszły etap weryfikacji redakcyjnej
Autorzy ponoszą całkowitą odpowiedzialność za treść artykułu. Autorzy materiałów nadesłanych do publikacji są odpowiedzialni za przestrzeganie prawa autorskiego. Zarówno treść pracy, jak i zawarte w niej ilustracje, zdjęcia i tabele muszą stanowić dorobek własny Autora, w przeciwnym razie muszą być opisane zgodnie z zasadami cytowania, z powołaniem się na źródło.
Oddaliśmy do dyspozycji Autorów i Recenzentów System Recenzencki, który gwarantuje realizację tzw. podwójnie ślepej recenzji. Przesyłając artykuł do recenzji należy usunąć wszelkie elementy wskazujące na pochodzenie artykułu – dane Autorów, ich afiliację, notki biograficzne.
Dopiero po recenzji i poprawkach sugerowanych przez Recenzentów artykuł jest formatowany zgodnie z przyjętymi zasadami. W przypadku zauważonych problemów, prosimy o kontakt z Redakcją.
Kwartalnik naukowotechniczny Pomiary Automatyka Robotyka jest indeksowany w bazach BAZTECH, Google Scholar oraz ICI Journals Master List (ICV 2023: 98,13), a także w bazie naukowych i branżowych polskich czasopism elektronicznych ARIANTA. Przyłączając się do realizacji idei Otwartej Nauki, udostępniamy bezpłatnie wszystkie artykuły naukowe publikowane w kwartalniku naukowo-technicznym Pomiary Automatyka Robotyka. Punktacja Ministerstwa Edukacji i Nauki za publikacje naukowe w kwartalniku Pomiary Automatyka Robotyka wynosi obecnie 70 pkt. (wykaz czasopism naukowych i recenzowanych materiałów z konferencji międzynarodowych z dnia 5 stycznia 2024 r., poz. 29984, Unikatowy Identyfikator Czasopisma 200205). Przypisane dyscypliny naukowe – automatyka, elektronika, elektrotechnika i technologie kosmiczne.
Oświadczenie dotyczące jawności informacji o podmiotach przyczyniających się do powstania publikacji
Redakcja kwartalnika naukowotechnicznego Pomiary Automatyka Robotyka , wdrażając politykę Ministra Nauki i Szkolnictwa Wyższego odnoszącą się do dokumentowania etycznego działania Autorów, wymaga od Autora/Autorów artykułów podpisania przed przyjęciem artykułu do druku druku w kwartalniku oświadczenia zawierającego:
1. i nformację o udziale merytorycznym każdego wymieniowego Autora w przygotowaniu publikacji –celem jest wykluczenie przypadków tzw. „guest authorship”, tj. dopisywania do listy Autorów publikacji nazwisk osób, których udział w powstaniu publikacji był znikomy albo w ogóle nie miał miejsca.
2. i nformację o uwzględnieniu w publikacji wszystkich osób, które miały istotny wpływ na jej powstanie – celem jest: – p otwierdzenie, że wszystkie osoby mające udział w powstaniu pracy zostały uwzględnione albo jako współautorzy albo jako osoby, którym autor/autorzy dziękują za pomoc przy opracowaniu publikacji, – p otwierdzenie, że nie występuje przypadek „ghostwriting”, tzn. nie występuje sytuacja, w której osoba wnosząca znaczny wkład w powstanie artykułu nie została wymieniona jako współautor ani nie wymieniono jej roli w podziękowaniach, natomiast przypisano autorstwo osobie, która nie wniosła istotnego wkładu w opracowanie publikacji;
3. informację o źródłach finansowania badań, których wyniki są przedmiotem publikacji – w przypadku finansowania publikacji przez instytucje naukowo-badawcze, stowarzyszenia lub inne podmioty, wymagane jest podanie informacji o źródle środków pieniężnych, tzw. „financial disclosure” – jest to informacja obligatoryjna, nie koliduje ze zwyczajowym zamieszczaniem na końcu publikacji informacji lub podziękowania za finansowanie badań.
Umowa o nieodpłatne przeniesienie praw majątkowych do utworów z zobowiązaniem do udzielania licencji CC-BY
Z chwilą przyjęcia artykułu do publikacji następuje przeniesienie majątkowych praw autorskich na wydawcę. Umowa jest podpisywana przed przekazaniem artykułu do recenzji. W przypadku negatywnych recenzji i odrzucenia artykułu umowa ulega rozwiązaniu.
Redakcja na mocy udzielonej licencji ma prawo do korzystania z utworu, rozporządzania nim i udostępniania dowolną techniką, w tym też elektroniczną oraz ma prawo do rozpowszechniania go dowolnymi kanałami dystrybucyjnymi.
Zapraszamy do współpracy
Poza artykułami naukowymi publikujemy również materiały informujące o aktualnych wydarzeniach, jak konferencje, obronione doktoraty, habilitacje, uzyskane profesury, a także o realizowanych projektach, konkursach – słowem, o wszystkim, co może interesować i integrować środowisko naukowe. Zapraszamy do recenzowania/ polecania ciekawych i wartościowych książek naukowych.
Podczas cytowania artykułów publikowanych w kwartalniku naukowo-technicznym
Pomiary Automatyka Robotyka prosimy o podawanie nazwisk wszystkich autorów, pełną nazwę czasopisma oraz numer DOI, np.:
Konrad Cop, Morteza Haghbeigi, Marcin Gajewski, Tomasz Trzciński, Perception Systems for Autonomous Mobile Robots: Selecting and Mitigating Limits, „Pomiary Automatyka Robotyka”, ISSN 1427-9126, R. 29, Nr 1/2025, 5–16, DOI: 10.14313/PAR_255/5.
młodziinnowacyjni
Sieć Badawcza Łukasiewicz –Przemysłowy Instytut Automatyki i Pomiarów PIAP ogłasza
XVII Ogólnopolski Konkurs na
w dziedzinach Automatyka Robotyka Pomiary
Zgłoszenie należy przesłać na adres konkurs@piap.lukasiewicz.gov.pl do dnia 28 marca 2025 r.
Regulamin konkursu i formularz zgłoszeniowy są dostępne na stronie piap.lukasiewicz.gov.pl
Autorzy najlepszych prac otrzymają nagrody pieniężne lub wyróżnienia
w kategorii prac doktorskich:
I nagroda 3500 zł II nagroda 2500 zł
w kategorii prac magisterskich:
I nagroda 3000 zł II nagroda 2000 zł
w kategorii prac inżynierskich: I nagroda 2500 zł II nagroda 1500 zł
Wyniki konkursu zostaną ogłoszone podczas XXIX Konferencji Naukowo-Technicznej AUTOMATION 2025 w Warszawie, w dniu 7 maja 2025 r.
Patronat
Komitet Automatyki i Robotyki Polskiej Akademii Nauk
Komitet Metrologii i Aparatury Naukowej Polskiej Akademii Nauk
Polska Izba Gospodarcza Zaawansowanych Technologii
Polskie Stowarzyszenie Pomiarów Automatyki i Robotyki POLSPAR
hybrydowego modelu priorytetyzacji technologii opartego na metodzie analizy obwiedni danych oraz
koncepcji zbiorów przybliżonych
Recenzenci – prof. dr hab. inż. Adam Mazurkiewicz, prof. dr hab. inż. Antoni Świć, dr hab. inż. Janusz Mikuła, prof. PK – ocenili dorobek naukowy zatytułowany Opracowanie hybrydowego modelu priorytetyzacji technologii opartego na metodzie analizy obwiedni danych oraz koncepcji zbiorów przybliżonych. Opinię wydali też prof. dr hab. inż. Andrzej Ambroziak oraz dr hab. inż. Jan Andrzej Duda, prof. PK. Osiągnięcie naukowe przedstawione zostało w formie jednotematycznego cyklu czterech publikacji.
Ewa Chodakowska, Hybrydowy model priorytetyzacji technologii, Oficyna Wydawnicza Politechniki Białostockiej, 2019, ISBN 978-83-6559690-1, str. 220.
Prace naukowe i wiążące się z tym osiągnięcia dr hab. inż. Ewy Chodakowskiej, profesor Politechniki Białostockiej koncentrowały się na zagadnieniach oceny i priorytetyzacji rozwoju technologii, prowadzonych w warunkach niepewności i ograniczonej informacji. Podjęty problem badawczy dotyczył możliwości wykorzystania w procesie priorytetyzacji technologii hybrydowego modelu, łączącego metody zbiorów przybliżonych (ang. Rough Sets) oraz metodę DEA (ang. Data Envelopment Analysis) w celu zwiększenia obiektywizmu oceny.
Technologie zawsze pełniły rolę napędową i transformacyjną. Ich analiza i ocena są szczególnie istotne z perspektywy rozwoju społeczno-gospodarczego, zwłaszcza w kontekście wyzwań i przemian związanych z wdrażaniem koncepcji przemysłu przyszłości (Przemysłu 4.0/5.0). W gospodarce opartej na wiedzy, w której innowacje technologiczne odgrywają zasadniczą rolę w budowaniu potencjału ekonomicznego na poziomie krajowym i regionalnym, a także w zwiększaniu konkurencyjności przedsię-
biorstw, badania nad technologiami stają się nieodzownym komponentem długoterminowego sukcesu. Potwierdzeniem znaczenia tego rodzaju prac są liczne strategiczne programy foresightowe, mające na celu określenie kierunków rozwoju gospodarczego na poziomie narodowym, regionalnym i sektorowym. Realizacja takich projektów opiera się przede wszystkim na danych ankietowych gromadzonych podczas panelów eksperckich oraz na jakościowych opiniach, które następnie są systematyzowane za pomocą wybranych metod statystycznych.
Hybrydowy model oceny technologii jest autorską próbą zobiektywizowania oceny i zastosowania podejścia ilościowego do priorytetyzacji technologii z użyciem rozwiązań z zakresu teorii zbiorów przybliżonych. Podstawą oryginalności i innowacyjności zaproponowanego podejścia jest sposób konstrukcji modelu. W hybrydowym modelu zastosowano: – koncepcję reduktów z teorii zbiorów przybliżonych, czyli minimalnych podzbiorów atrybutów zachowujących charaktery-
Hybrydowy model oceny technologii jest autorską próbą zobiektywizowania oceny i zastosowania podejścia ilościowego do priorytetyzacji technologii z użyciem rozwiązań z zakresu teorii zbiorów przybliżonych. Podstawą oryginalności i innowacyjności zaproponowanego podejścia jest sposób konstrukcji modelu.
stykę całego zbioru, do ograniczenia liczby kryteriów; – przybliżenia zbiorów do modelowania niepewności; – algorytmy optymalizacji liniowej stosowanych w metodzie DEA do obiektywnego określenia wag kryteriów; – relację efektywności metody DEA do wyznaczenia syntetycznej oceny.
Hybrydowy model dedykowany jest przyszłościowej, priorytetyzującej ocenie technologii zorientowanej na makrozarządzanie, przeprowadzanej w sytuacji braku możliwości jednoznacznego określenia parametrów i potencjału technologii oraz wynikającej z tego niepewności. Model zweryfikowano na podstawie danych projektu foresightu technologicznego „NT FOR Podlaskie 2020” porównując otrzymane wyniki z rezultatami zastosowanej w projekcie popularnej metody kluczowych technologii.
Joanicjusz Nazarko, Joanna Ejdys (red.), Metodologia i procedury badawcze w projekcie Foresight technologiczny <<NT FOR Podlaskie 2020>> Regionalna strategia rozwoju nanotechnologii, Oficyna Wydawnicza Politechniki Białostockiej, 2011, ISSN 0867-096X, str. 74.
Prezentowane osiągnięcia naukowe wzbogaciły wiedzę z zakresu łączenia metod badawczych w obszarze oceny technologii, przyczyniły się do rozwoju metodologii prowadzenia badań oraz jest wkładem w rozwój metodyk badawczych poprzez dostarczenie dostosowanego, spójnego narzędzia do wykorzystania w systemach wspomagania decyzji i zarządzania wiedzą produkcyjną w inżynierii produkcji. Hybrydowy model może
być traktowany jako referencyjny w złożonych problemach wielokryterialnej porównawczej oceny licznego zbioru technologii, które można scharakteryzować, korzystając ze zunifikowanego, określonego a priori zbioru atrybutów opisujących właściwości technologii lub wynikających z jej otoczenia bez ograniczeń co do specyfiki technologii. Zaproponowany model może ułatwić priorytetyzację technologii w warunkach niepewności, a w rezultacie zwiększyć efektywność wykorzystania prywatnych i publicznych środków na prace badawczo-rozwojowe związane z wdrażaniem w Polsce rozwiązań w zakresie przemysłu przyszłości.
Obecne prace naukowe i badawczo-rozwojowe realizowane przez dr hab. inż. Ewę Chodakowską, prof. PB są kontynuacją zagadnienia modelowania i analizy danych z wykorzystaniem zaawansowanych metod matematycznych i algorytmicznych (modeli sztucznej inteligencji, badań operacyjnych do poszukiwania rozwiązań zadań optymalizacyjnych przy zadanych ograniczeniach, modelowania niepewności) w praktycznych zastosowaniach odpowiadających potrzebom zrównoważonego rozwoju czy oceny technologii i innowacji, ale także w obszarze automatyzacji i robotyzacji procesów przemysłowych.
Aktualny dorobek publikacyjny liczy ponad 50 publikacji, indeks Hirscha w bazie Scopus osiągnął wartość 9, w bazie Web of Science jest równy 8, liczony dla 14 publikacji. Dr hab. inż. Ewa Chodakowska jest członkiem Komitetu Inżynierii Produkcji Polskiej Akademii Nauk, członkiem zarządu polskiego oddziału IEEE Technology and Engineering Management Society, ekspertem Narodowego Centrum Badań i Rozwoju (NCBiR) oraz Polskiej Agencji Rozwoju Przedsiębiorczości (PARP) (w obszarach: metodyka i technologie sztucznej inteligencji, projektowanie i optymalizacja procesów, zarządzanie informacją w inteligentnych sieciach, automatyzacja i robotyzacja), członkiem EPPM (ang. Association of Engineering, Project and Production Management) oraz Polskiego Towarzystwa Zarządzania Produkcją.
Małgorzata Kaliczyńska
dr hab. inż. Ewa Chodakowska, prof. PB
Absolwentka Instytutu Informatyki (2001 r.) a także Wydziału Zarzadzania (2003 r.) Politechniki Białostockiej. Pracę doktorską w naukach ekonomicznych w dyscyplinie nauki o zarządzaniu Ocena efektywności działania szkół gimnazjalnych metodą Data Envelopment Analysis na przykładzie powiatu grodzkiego Białystok obroniła na Wydziale Zarządzania Uniwersytetu Warszawskiego (2012 r.), jej promotorem był prof. dr hab. inż. Joanicjusz Nazarko. 27 maja 2020 r. uzyskała stopień doktora habilitowanego nauk inżynieryjno-technicznych w dyscyplinie naukowej inżynieria mechaniczna, nadany przez Radę Naukową Wydziału Mechanicznego Politechniki Krakowskiej. Interdyscyplinarne, z zakresu nauk inżynieryjno-technicznych i społecznych, zainteresowania naukowe wyrażają się w łączeniu w pracy naukowej zagadnień z wielowymiarowej analizy danych, badań operacyjnych, modelowania niepewności w obszarach dotyczących efektywności i produktywności, systemów wspomagania decyzji oraz prognozowania.
archiwum Politechniki Opolskiej
Profesor Ryszard Rojek
Z ogromnym smutkiem żegnamy profesora Ryszard Rojek, szanowanego i lubianego pracownika Politechniki Opolskiej, cenionego pedagoga, ogromnego pasjonata nauki, wspaniałego mentora i kolegę. Odszedł 6 grudnia 2024 r. w wieku 81 lat.
Prof. dr hab. inż. Ryszard Rojek urodził się 27 marca 1943 r. w Sokalu k. Lwowa w rodzinie inteligenckiej. Studia wyższe techniczne odbył w latach 1961–1966 w Politechnice Wrocławskiej na Wydziale Elektroniki, uzyskując tytuł magistra inżyniera elektronika. Tam również rozpoczął pracę jako asystent w Katedrze Automatyki i Telemechaniki. W 1977 r. uzyskał stopień doktora nauk technicznych w dyscyplinie automatyka na Wydziale Elektroniki w Politechnice Wrocławskiej, a już dziesięć lat później – w 1987 r – stopień doktora habilitowanego nauk technicznych na Wydziale Automatyki i Techniki Obliczeniowej w Państwowym Uniwersytecie Elektrotechnicznym w Sankt Petersburgu. Jego praca naukowa i dydaktyczna została doceniona i w 2007 r. z rąk profesora Lecha Kaczyńskiego, Prezydenta RP odebrał tytuł profesora.
Z opolską uczelnią był związany od 1 lutego 1966 r., kiedy to rozpoczął pracę w Wyższej Szkole Inżynierskiej w Opolu, początkowo na ówczesnym Wydziale Elektrycznym, następnie w Instytucie Elektrotechniki, ostatecznie na Wydziale Elektrotechniki, Automatyki i Informatyki już Politechniki Opolskiej. Specjalnością naukową prof. Ryszarda Rojka była automatyka i robotyka, przy czym tematyka badań obejmowała głównie teorię sterowania i modelowania układów z czasoprzestrzenną dynamiką, metody komputerowe w automatyce oraz zastosowania sztucznej inteligencji w automatyce. Dorobek naukowy Profesora obejmuje ponad 90 prac, w tym trzy monografie oraz udział w wielu pracach naukowo-badawczych. Recenzował i opiniował prace habilitacyjne i doktorskie oraz książki i podręczniki dla różnych wydawnictw. Był współautorem 12 skryptów i pomocy dydaktycznych. Wypromował sze-
ściu doktorów oraz ponad 200 magistrów i inżynierów.
Realizując zadania naukowe i dydaktyczne pełnił jednocześnie wiele funkcji organizacyjnych, w tym kierownika Zakładu Podstaw Elektrotechniki, Automatyki i Elektroniki, kierownika Katedry Automatyki, Elektroniki i Informatyki, której był organizatorem, prodziekana ds. studenckich, prodziekana ds. nauki, dziekana Wydziału Elektrotechniki i Automatyki. Wydział ten doprowadził w 2006 r. do przekształcenia w Wydział Elektrotechniki, Automatyki i Informatyki. Opracował założenia programowe i kierował uruchomieniem specjalności: automatyka i metrologia elektryczna oraz automatyzacja procesów przemysłowych. Był współorganizatorem uruchomienia kierunku studiów informatyka oraz automatyka i robotyka. Jako prodziekan ds. nauki oraz dziekan aktywnie uczestniczył w procesie uzyskania uprawnień nadawania stopnia doktora nauk technicznych i doktora habilitowanego w dyscyplinie elektrotechnika, a później automatyka i robotyka.
Za swoją pracę naukową, dydaktyczną i organizacyjną otrzymał szereg odznaczeń i wyróżnień. Ważniejsze z nich to: Srebrny i Złoty Krzyż Zasługi (1982, 1986), Złota Odznaka AZS (1978), Medal Komisji Edukacji Narodowej (2002), nagroda Marszałka Województwa Opolskiego za szczególne osiągnięcia w dziedzinie upowszechniania i rozwoju edukacji na Śląsku Opolskim (2000 r., nagroda zespołowa).
Opracowane na podstawie materiałów „Wiadomości Uczelnianych” Politechniki Opolskiej
Przeszedłem przez wszystkie etapy rozwoju uczelni, od punktu konsultacyjnego do stanu obecnego, do politechniki, która się w kraju liczy, ma liczne uprawnienia i bardzo atrakcyjne kierunki. Podczas 56 lat pracy na rzecz uczelni udało mi się nawiązać szereg bezcennych kontaktów, tu wspomnę prof. Tadeusza Kaczorka, wielkiego przyjaciela naszej uczelni, cieszę się, że mogłem być promotorem i autorem laudacji w przewodzie nadania profesora honoris causa Politechniki Opolskiej – tak profesor Ryszard Rojek podsumował swoją drogę zawodową odchodząc na emeryturę 28 września 2022 r.
Wiadomość o śmierci Ryszarda przekazała mi Jego żona Maria 6 grudnia 2024 r. rano o 8.30 w kościele św. Jacka w Opolu. To była nagła wiadomość, chociaż widząc rosnące cierpienie, z jakim Ryszard się zmagał od kilku miesięcy, poczułem, jednocześnie ze smutkiem, ulgę.
Był mi przyjacielem od 1973 r., a przez 46 lat współpracowałem z Nim na Politechnice Opolskiej. Współuczestniczyłem w wielu dokonaniach prof. Rojka, ale zawsze On był ich inicjatorem! W niektórych nieudanych przedsięwzięciach też brałem udział. Od 1997 r. jesteśmy sąsiadami – dzieli nas 200 m uliczki dzielnicowej.
To pomogło w bliższym poznaniu również trudnych doświadczeń życiowych Ryszarda. Odwiedzając Go częściej w ostatnich miesiącach słuchałem Jego opowieści z dawnych lat. Ojciec Ryszarda – Stanisław Rojek był wykształconym muzykiem, ukończył Akademię Muzyczną w Krakowie. Z Sokala nad Bugiem, 20 km od dzisiejszej granicy, rodzina uciekła w ostatniej chwili przez bieszczadzkie Zagórze, Czerną do Przeworska. (To bliżej Sokala – „a mama miała nadzieję, że do Sokala wrócimy”). Ucieczka się udała, bo w porę zostali ostrzeżeni przez przyjaznego Ukraińca. W Przeworsku mama Ryszarda – pani Józefa Rojek – była gospodynią w parafii pod wezwaniem Ducha Świętego w Przeworsku, gdzie proboszczem był ksiądz prałat Roman Penc, Honorowy Kanonik Przemyskiej Kapituły Kolegiackiej, prywatnie wuj Ryszarda. Z lat dziecięcych Ryszard wspominał śnieg i psoty urządzane z kolegami w wielu osadach bieszczadzkich.
Do Opola rodzina Ryszarda przyjechała około 1954 r. Wcześniej tułała się w Krakowie, Zielonej Górze, Gliwicach. Do pozostania w Opolu rodzinę Rojków namówił ówczesny dyrektor Filharmonii Opolskiej – przyjaciel ojca z lat studiów.
Ojciec, jako nauczyciel muzyki, pracował w kilku miejscowych szkołach. Przez krótki okres grał na organach w Opolskiej Katedrze. Zamieszkali przy ulicy Bończyka w Opolu, w domu nauczyciela. Ryszard wielokrotnie wspominał – z kolegami z sąsiedztwa kopaliśmy „Fussball”. Często słyszałem od nich „Einz, zwei, drei, gramy w Fussball. Mieszkali w Opolu już wcześniej. Wśród nich nieżyjący już Wacek. Niektórzy mówili po niemiecku, a ja trochę po rusku. Zostaliśmy przyjaciółmi do końca.”
Szkoła podstawowa na ulicy Bończyka, pierwsze liceum ogólnokształcące i studia na Politechnice Wrocławskiej. Za podpowiedzią prof. Zygmunta Szparkowskiego Ryszard wrócił do Opola w 1966 r. na ówczesną Wyższą Szkołę Inżynierską. Pomimo początkowych trudności z matematyką (skutki
przeprowadzek i zmian szkoły podstawowej) pierwsze prace naukowe Ryszarda dotyczyły zagadnień technicznych opisywanych równaniami różniczkowymi cząstkowymi. Przeszedł wszystkie szczeble naukowej pracy zawodowej. Był tytanem pracy. Pracował pod wszystkimi dotychczasowymi rektorami Politechniki Opolskiej.
W trudnej swojej chorobie interesował się do końca ludźmi, z którymi pracował. Pytał czy jeszcze pracują?
W 1997 r. (w czasie „powodzi Tysiąclecia”) Ryszard z całą rodziną przeprowadził się do parafii świętego Jacka w Opolu. Wcześniej od 1972 r. z żoną Marią mieszkali na ul. Łąkowej w parafii katedralnej. Ze wszystkimi sąsiadami utrzymywali przyjacielskie relacje. W trybie 24/7 służyli pomocą i radą edukacyjną (Ryszard) oraz medyczną (Maria).
Ostatni raz odwiedziłem Ryszarda w listopadzie. Tym razem rozmawiał o chorobie i nadziei, że po kolejnej operacji będzie lepiej. Mimo trudności z poruszaniem się, jak zawsze, wstał i odprowadził mnie do drzwi swojego domu. Dziękuję Ryszardzie, że obdarowałeś mnie zaufaniem i przyjaźnią. Odpoczywaj w pokoju.
dr inż. Karol Grandek przyjaciel i wieloletni współpracownik
Prof. dr hab. inż. Ryszard Rojek w 1966 r. był absolwentem ówczesnego Wydziału Łączności (potem od 1968 r. Wydział Elektroniki) Politechniki Wrocławskiej. Utrzymywał regularne kontakty z naszym środowiskiem naukowym, czego znakomitym finałem było uzyskanie doktoratu w 1977 r. w ówczesnym Instytucie Cybernetyki Technicznej (ICT) na Wydziale Elektroniki Politechniki Wrocławskiej. Czynnie uczestniczył w seminariach naszego Zakładu Automatyki i Modelowania w Instytucie Cybernetyki Technicznej, współtworząc ciekawe koncepcje naukowe i wychowując młode kadry automatyków. Zawsze można było liczyć na Jego obiektywne i kreatywne spojrzenie na stawiane i rozwiązywane zagadnienia naukowe. Miał zawsze czas i chęci na współpracę. Był Osobą o szczególnej empatii. Jakże szkoda, że odszedł na zawsze. Pamiętamy Go i dziękujemy. Był naszym Przyjacielem.
doc. dr inż. Ludwik Żebrowski kierownik Zakładu Automatyki i Modelowania w ICT dr inż. Andrzej Jabłoński Politechnika Wrocławska
Profesora Ryszarda Rojka znamy głównie ze spotkań na konferencjach naukowych i krótkich spotkań, gdy gościł na Politechnice Wrocławskiej. Zapamiętaliśmy Go jako człowieka bardzo pracowitego i niezwykle skromnego, otwartego, zawsze chętnego do rozmowy na każdy temat a także konsultacji i pomocy, gdy pojawiał się jakiś problem. Jego pomocy doświadczyliśmy osobiście wielokrotnie, gdyż był autorem recenzji sześciu naszych książek, a jak powszechnie wiadomo wydawnictwa bardzo oszczędzają na wynagrodzeniu za przygotowane recenzje i dalece nie odzwierciedla ono znacznego nakładu pracy koniecznej do opracowania recenzji. Mimo to nigdy nam nie odmówił, chociaż był wówczas bardzo zapracowany. Odszedł od nas Dobry Człowiek, pozostawiając nas w smutku i pozostając w naszej pamięci.
dr inż. Włodzimierz Solnik dr inż. Zbigniew Zajda Politechnika Wrocławska
Profesor Ryszard Rojek był moim szefem blisko trzydzieści lat. Pilnował rozwoju naukowego młodych pracowników, motywował. Do tej grupy należałam również ja, a Profesor akceptował niemal wszystkie moje szalone pomysły. Pod koniec lat 90. naszemu wydziałowi powierzono organizację XIII Krajowej Konferencji Automatyki. Profesor ufał mi i dał wolną rękę w przygotowaniu wielu działań. Konferencja odbyła się we wrześniu 1999 r. Miałam już doświadczenie, bo w 1994 r. prof. Danuta Turzeniecka i prof. Zdzisław Kabza zlecili mi podobne prace przy organizacji 26. Międzyuczelnianej Konferencji Metrologów. Równolegle włożyliśmy wiele serca w odrodzenie Polskiego Stowarzyszenia Pomiarów Automatyki i Automatyki POLSPAR. Dziś bardzo cenię sobie zdobyte doświadczenie i znajomość polskiego środowiska akademickiego. Ostatni raz spotkałam Profesora we wrześniu 2014 r. podczas XVIII KKA zorganizowanej przez Politechnikę Wrocławską. Wspominaliśmy dawne czasy, a Profesor wypytywał o moje funkcjonowanie w Warszawie. Podczas pogrzebu 13 grudnia 2024 r. wróciły wspomnienia i zrozumiałam, jak wiele zawdzięczam mojemu opolskiemu okresowi. Panie Profesorze, dziękuję za zaufanie. Odpoczywaj w spokoju.
dr inż. Małgorzata Kaliczyńska przewodnicząca Komitetu Robotyki POLSPAR; Łukasiewicz – PIAP
www.jamris.org
www.par.pl
www.automatykaonline.pl/automatyka
61
69
75
81
91
99
107
Marcin Hubacz, Andrzej Paszkiewicz, Bartosz Pawłowicz, Mateusz Salach, Bartosz Trybus, Konrad Żak
System testowania i walidacji modeli do sterowania ruchem pojazdów
Andrzej Typiak, Rafał Typiak, Zbigniew Zienowicz, Mateusz Nowakowski, Patrycja Matejek System półautonomicznego sterowania tandemem kosiarek do koszenia terenów przydrożnych
Janusz Kobaka, Jacek Katzer, Machi Zawidzki Dynamiczne właściwości fibrobetonu wytworzonego na baize piasków odpadowych
Bartosz Kowal, Patryk Organiściak, Paweł Kuraś, Adam Masłoń, Bartosz Wadiak Uczenie maszynowe w prognozowaniu ilości ścieków dla oczyszczalni ścieków miasta Rzeszowa na podstawie warunków pogodowych
Władysław Iwaniec Macierzowy cyfrowy cień sieci czujników IoT
Rafał Wojszczyk
Architektura oprogramowania systemu kontrolno-pomiarowego z interfejsem USB
Robert Tomasiewicz
CTS i EPICS – moduły automatyzujące montaż i kontrolę jakości w produkcji amortyzatorów samochodowych