The Swansea Applied Linguistics Journal







Issue 6, Autumn 2023

1

Issue 6, Autumn 2023
Welcome to the 6th issue of The Swansea Applied Linguistics Journal. For any new readers joining us, this is a student-run journal that allows our best and brightest students from Swansea University’s Applied Linguistics department to show off their first-class work from their first to final year. All the work you are about to read has each achieved a mark of 70 and above – a most impressive achievement. Once again, the 2023 issue offers a wide selection of work from all corners of the Applied Linguistics discipline, from Language Teaching Methodology, Psycholinguistics, Language in the Media, Forensic Linguistics, and many more!
As with all things, there come challenges. With the continuation of industrial action and implementation of marking boycotts, we students had to once again adapt to a new academic environment. So, to see such an output of first-class work despite these difficulties fills my heart with pride as this year’s editor. This journal strives to celebrate outstanding work, and this year is certainly no different.
Should you have any queries about any of the work featured in this issue, please feel free to email us at lingjournalswansea@gmail.com or DM us on our Twitter account @SwanseaApplied.
Chloe Williams Editor



Editor






































Chloe Williams
Assistant Editor
Martin Lee-Paterson
Proofreaders
Ellie Dickinson
Hannah Roddy
Martin Lee-Paterson
Photography
Swansea University
Staff Advisor
Dr Alexia Bowler
If

If you would like to join the editorial team for our next issue, don’t hesitate to contact us via our email.
Should you have any feedback, ideas, queries, or concerns about this issue or the journal in general, pleas contact us using the details below.
To
To students and staff alike, we thank you all for your continued support year after year.












1 Year
Language Teaching Methodology
Sida evaluates language teaching strategies in textbook grammar lessons
Mythbusters
Juwerya discusses the myths and perceptions surrounding the use of non-standard dialects
Language in Mind
Cerys identifies the types of aphasia two patients present with
2nd Year
Language Teaching in Context
Sida evaluates how a learner’s language proficiency is measured in a case study
Child Language and Literacy
Angharad highlights how children view differences in dialects
Angharad critically evaluates a set of publications where applied linguists and practitioners have worked in partnership
Madison explores the effects and differences between working memory and long-term memory
3rd Year
99 Second Language Acquisition











Rachel reviews recent studies in L1 attrition
11 Second Language Acquisition
Hannah reviews studies of working memory in bilingualism
134 Language in the Media
Rebecca uses corpus analysis to investigate Brexit discourse in editorials
18 Forensic Linguistics
Celyn analyses linguistic tools for attributing authorship





Sida Cong, 1 year
Evaluation and analysis of textbook pages for a grammar lesson focusing on “can, have to, must” and the negative forms
According to Scrivener (2011, p. 129), teachers can apply “present-practice” pattern to English grammar teaching. Specifically, presenting grammar requires teachers to show rules and give accurate explanations to learners. Practice focuses on restricted output and authentic output, and “authentic output is also known as production or simply as speaking or writing skills work” (Scrivener, 2011). The pattern of English grammar teaching is known as Present, Practice, Production (PPP). In this essay, I will evaluate and analyse the textbook pages given in the order of PPP, discuss the strengths and weaknesses in the grammar focus, and find ways to improve upon them. A brief discussion of how the materials relate to the concept of Global Englishes will also be included.
Starting with a direct explanation of the grammar without any context clues is not recommended in English teaching. Learners need some examples to get lexical information about the grammatical items. The article “Are Traditional Ways Of Learning The Best?” (Scrivener, 2011, p. 40) shows example sentences including the target grammatical items. Besides, on Page 41, Exercise 4 shows six example sentences that use these items to express necessity and possibility. Teaching with examples can help learners distinguish between items and prepare to learn the relevant grammar formally.
Correct examples of grammar in use should be shown during the presenting process. There exists a brief and clear statement of grammar rules with positive examples on Page 134. In addition, it is recommended that the presenting stage show the learners highly relevant grammar rules only. For example, the modal verb “can” has two meanings one expresses the possibility of doing something, and the other expresses the ability to do something. The
focus on grammar within these textbook pages allows learners to revise and distinguish the use of “can”, “have to,” and “must” as modal verbs expressing present obligation. The meaning of “be able to do something” does not belong to the grammar focus in this lesson. Practice and production
Production is also a type of practice that is more creative and gives learners more flexible ways to use grammar as opposed to other activities such as drills, which are easier to control by teachers and get predictable answers from learners. Practice for English grammar learning is encouraged to contain both meaningful and structured exercises. Exercise 5A on Page 40 shows a sentence completion task, which requires learners to use the target grammatical items. This task focuses on the form of the grammar.
6A on the same page is a writing activity including grammar practice. Learners are asked to use “can “, “have to,” and “must” as well as their negative forms to write sentences according to the context given in 5A. It is also a structured task. As mentioned
above, writing skills work is a kind of production. The instructions for 6A contain “work in pairs”, which according to Nation (2008) belongs to Shared Tasks. The benefit of such instruction makes it possible for partners to help each other complete the task. According to Ur (2012), Free discourse requires learners to complete speaking or writing tasks about a certain topic, but there is no instruction to use the target grammar. Thus, as a free discourse task, 6B is more flexible than a controlled practice and can focus more on the meaning of the grammar. The task requests the learner to give explanations and reasons for their opinions and gives them the opportunity to use the target grammar naturally. For example, if one of the learners says home-schooling is a good idea, he might give the reason that the students “don’t have to” wait for the school bus.
Since “students might need to use the grammar in both speech and writing” (Ur, 2012), grammar presentation should include International Phonetic Alphabet (IPA) transcriptions of the grammatical items. The textbook pages only demonstrate how to
pronounce “have to”, which is inadequate for the learners. Negative examples are as essential as positive examples in the explanation as they stress how the grammar is allowed to be used within the rules. On Page 134, there are no negative examples such as “can(‘t)” and “must(n’t)” when the subject in the third person singular is missed in the statement. In addition, there are some subtle differences and overlaps between “can” and “must”, “can’t” and “mustn’t”, which have not been explained at all.
Weaknesses to do with the subject in the third person singular are not limited to the presenting stage, and there is no practice for this usage in the whole grammar lesson. A learner should know that a modal verb will not change form with a change of subject or number. Furthermore, the production tasks are too restricted by the topic of home-schooling, which results in limited space for learner output and makes the task boring.
The following text will focus on one of the weaknesses mentioned above and state some of the author’s own ideas. To improve the weakness of the missing third-person singular subject and make its usage clear to the learners, teachers can give some accurate examples and set a gap-fill drill. An example such as “Monica must get home before 8 pm” or, “Monica get home before 8 pm” might be used. After receiving the responses from the learners, the teacher should then ensure all of the learners clearly understand this.
The concept of Global Englishes (GE) builds on World Englishes and English as a Lingua Franca (ELF), and states that all speakers of English own English. To evaluate the relations between English teaching materials and GE, the Global English Language Teaching (GELT) framework was created. In GELT, the target conversation partners should be NESs (Native English Speakers) and NNESs (Non-native English Speakers), which is demonstrated in the picture shown on Page 41 featuring non-native Englishspeaking children. The target culture in GELT is a mixture of
different cultures, and on Page 41, about Exercise 7A and 7B, the examples and discussion topics given contain cross-cultural communication elements. These two exercises also include materials from various countries in which English is spoken, rather than just those that speak it monolingually, therefore further aligning with GELT principles.
References:
Nation, I. S. P., & Newton, J. (2009). Teaching ESL/EFL Listening and Speaking. New York: Routledge
Scrivener, J. (2011). Learning teaching: the essential guide to English language teaching (3rd ed.). Macmillan Education.
Ur, P. (2012). A course in English language teaching (2nd ed.). Cambridge University Press.
Non-standard dialects have been derided as imprecise and incorrect, and hence not equal in value to the standard language, which is regarded as more prestigious (Gordon, 2012). In this essay, I will argue against the myth that non-standard dialects are deficient. Firstly, I will discuss the preconceptions and attitudes that influence our views on dialect, and people's perceptions as to what speaking a non-standard dialect entails. As a result, perceptual dialectology, which aims to discuss public perceptions of dialects, will be a focal point in the first section. Secondly, I will draw on evidence that shows how non-standard dialects are perceived as linguistic diversion in education, and how nonstandard dialects are frequently connected to negativity and speech-correction. This section will argue that non-standard dialect variations do not reflect a lack of educational understanding, but rather the failure of educational intuitions to put resources in place to promote diversity in language varieties. Finally, I will discuss how non-standard dialects are perceived on



a global scale, their significance in conversations about linguistics compared to standard dialects, and how they reflect certain cultures, as well as their importance to different social groups.
The study of how non-linguists evaluate dialect diversity is known as perceptual dialectology. As a result, this section will concentrate on these dialect perception issues and how they present the distinguishing of standard and non-standard dialects as problematic and subjective. In many societies, this distinction has been reinforced by prejudices and ideological biases. For example, Boughton’s (2006) study assessed how people from a variety of French dialects perceive one another and discovered social prejudices between regions. There were particularly noticeable prejudices for and against dialects from the West and Centre, as well as the capital Paris, which hosts the country’s standard dialect, and common social attitudes were supplied when applying the correct dialect to location. For example, when applying dialects to north and east regions, social prejudices were equated. Similarly, Iannàccaro and Dell’Aquila’s (2001) research on European dialect
perception focused on geographical location and discovered that people perceived dialects differently depending on which part of the country they originated from. The perception of language played a minimal role, but depending on where an individual came from and their language community, those who shared a language variety were less prejudiced than those who spoke different dialects. These findings support the idea that social views influence how we perceive dialect variations, and that “non-standard” dialects are considered to be entirely acceptable in particular social contexts. With these social biases in mind, one cannot reasonably describe dialect variations as deficient. For example, Bucholtz et al. (2007) highlighted perceptual dialectology variations within California. Their results revealed that Californian dialect distinctions were characterised by linguistic and stylistic traits connected with a particular area rather than just regional location. These considerations demonstrate that dialects can be more culturally and regionally proclaimed and are not synonymous with deficiency.

Regarding the varieties of dialect that exist in our society, Fridland and Bartlett (2006) highlights that our perception of dialects can be personal matters through assessments of correctness and pleasantness. Their findings demonstrated that those from southern American states evaluated their own correctness of speech lower than those from other American states, but they did not perceive their own accents as less pleasant or those from other states as more pleasant. This shows how dialects can be understood depending on characteristics. Labelling what we perceive to be a non-standard dialect as wholly insufficient may thus be inaccurate. On the contrary, we should recognise that it is difficult to maintain a standard dialect given the many different variations thereof within a language’s larger speaking community, a community which is already in itself subject to change. For example, Robinson’s (2007) research shows just how grammatically diverse usage of the verb ‘to be’ is in English dialects spoken across the UK. There are numerous cities especially in the north that use the form ‘were’ for both singular and plural, whereas those in the south use the distinction ‘was’ and ‘were’ for singular and plural subjects. This highlights dialectal variation across the United Kingdom and shows
how unwieldy the concept of a standard dialect has become. Conversely, respecting and identifying that these linguistic variants are part of a homogenous group and hold significant social value is crucial in dealing with negative perceptions of non-standard dialects.
Furthermore, it is important to understand the historical evolution of dialect variations has seen several become the ‘standard’ and some fall out of favour. Maxwell’s (2006) study highlights that dialect variation within the Slovak speech community has been exacerbated by political and ideological factors. These influences have been observed to spread throughout the region and have had an impact on the development of their language. As a result, a range of dialects have emerged from historical factors, and speakers’ dialogue preferences have been linked with the same political issues. The perceptions of nonstandard dialects can extend beyond the goal of being defective, and countries have developed to recognize the standard dialect. However, according to Preston (1999) regional dialect diversity has become influential prior to historic and structural influences on 17
language development. This corresponds to the Clopper and Pisoni (2006) study, which found that regional location and geographic mobility had an impact on determining where a person sounded like they were from as well as adding perceptions to dialects. These findings show how dialects, whether regional or historical, are objects of cultural significance, and that, discarding those we consider to be non-standard makes it more. Non-standard dialects in Education:
Within the educational field, the perception of a non-standard dialect has become increasingly negative. The belief is that students who speak a widely prevalent and approved language variation are often in a better position in the classroom than those who speak a different variety (Hart Blundon, 2016). For instance, Cushing’s (2021) study highlighted that Standard English in classrooms is ingrained as part of school policies. Teachers are compelled to utilise Standard English in the classroom, and students are expected to follow this standard in their education. This perspective highlights how children observe from a young age that their dialect is less prestigious, and this unjust judgement can have an impact on
how children understand what it means to have a dialect. Similarly, Messier’s (2012) research conducted on Ebonics English varieties found that efforts to employ these dialects in the classroom have seen difficulty and resistance due to institutional and cultural biases towards Standard English. This emphasises how the narrative of non-standard dialects being inferior is deeply recognised and embedded in the educational field. However, moving towards inclusivity and promoting nonstandard dialects in areas such as education can help shape people's understanding of what it means to have a non-standard dialect. Tan and Tan (2008) examined sentiments towards non-standard English in Singapore and discovered that they were linked with substantial social affiliations. Their findings indicated that non-standard English should be integrated into schooling to promote a better awareness of language issues. This could foster a better understanding of what a non-standard dialect entails and can raise the standing. of non-standard dialect usage from a deficiency to an alternative means of linguistic communication. Labov’s (1972) study found that BEV’s (Black English Vernacular) syntax involved complex structures such as deletion of the final vowel
structures which require significant grammatical skill. Likewise, Green (2002) discovered that AAVE (African American Vernacular English, formally BEV) used concepts such as be form and bin verbs to emphasise varied meanings, and that adverbs are unnecessary in this situation. This highlights an interesting case on how grammar is marked in different dialects. This further demonstrates how non-standard dialects, abundant as they are in grammaticality, cannot simply be presented as defective or simplified versions of English in the realm of education. As a result, by broadening dialect comprehension in education from standard to different varieties, students can better understand dialects, allowing them to be less prejudiced and recognise the linguistic differences seen in diverse cultures. Therefore, modifying the perspective of a non-standard dialect in schools can have a lasting effect on generations to come.
Non-standard dialects on a global scale:
Non-standard dialects have a global impact by providing a shared language to communities and social groups. A study by Jaffe (2000) demonstrated how AAVE orthography indicates the
genuineness and originality of the language, as well the importance it holds in the social context of a community, in comparison to standard language variations, which may not represent intimate personal engagement with language use. This underlines the belief that non-standard dialects and language variations have important cultural significance. Similarly, Mufwene’s (2015) research on creole language showed that numerous varieties of the language existed in the community, demonstrating the unstable character of languages in changing, multicultural environments. Mufwene (2015) also commented on how shifts in language variation may be directly or indirectly caused by colonisation. These findings show the significance of linguistic variations across many cultures, and that the dialects people choose to speak can be the result of either distancing themselves from or collectively acknowledging as a community the discrimination they have faced.
The view that non-standard dialects cannot become globally significant can be refuted by research demonstrating the importance of non-standard dialects in running parts of society. Zhu and Grigoriadis’s (2022) research discovered the importance of Chinese
dialect varieties and how they affect economic development and government spending. This shows how having an array of dialects inside a country can foster progression. This finding also shows that non-standard dialects can help rather than hinder the societies we live in.
Conclusion:
In conclusion, there are numerous possible arguments against the myth that a non-standard dialect must necessarily be deficient. For example, one can better understand how people judge non-standard dialects through linguistic frameworks such as perceptual dialectology. Furthermore, non-standard dialects within a country have significant regional or historical importance, which is sometimes overlooked when applying perception to dialects. As a result, viewing a non-standard dialect as deficient can be reductive. Additionally, investigating the role of education in defining standard and non-standard dialects might help to debunk the idea of more and less acceptable language varieties. Changing how nonstandard dialects are discussed in an educational context may also help combat the aforementioned myths and improve their standing
amongst students. Lastly, realising that non-standard dialects have an innate connection with the individuals who speak them is crucial, and being mindful of how their language variants are evolving allows for a deeper understanding of the non-standard dialect's community.
Reference list
Boughton, Z. (2006). When perception isn’t reality: Accent identification and perceptual dialectology in French. Journal of French Language Studies, 16(3), pp.277–304. doi:
https://doi.org/10.1017/s0959269506002535
Bucholtz, M., Bermudez, N., Fung, V., Edwards, L. and Vargas, R. (2007). Hella Nor Cal or Totally So Cal? Journal of English Linguistics, 35(4), pp.325–352. doi:
https://doi.org/10.1177/0075424207307780
Clopper, C.G. and Pisoni, D.B. (2006). Effects of region of origin and geographic mobility on perceptual dialect categorization. Language Variation and Change, 18(02). doi:
https://doi.org/10.1017/s0954394506060091
Cushing, I. (2021). Policy Mechanisms of the Standard Language
Ideology in England’s Education System. Journal of Language, Identity & Education, 22(3), pp.1–15. doi:
https://doi.org/10.1080/15348458.2021.1877542
Fridland, V. and Bartlett, K. (2006). Correctness, Pleasantness, and Degree of Difference Ratings Across Regions. American Speech, 81(4), pp.358–386. doi:
https://doi.org/10.1215/00031283-2006-025
Gordon, T. (2012). Relevant linguistics: A Textbook for Language Teachers. Charlotte, Nc: Information Age Pub. Green, L.J. (2002). African American English: A Linguistic Introduction. Cambridge: Cambridge University Press. Hart Blundon, P. (2016). Nonstandard Dialect and Educational Achievement: Potential Implications for First Nations Students. Canadian Journal of Speech-Language Pathology & Audiology, 40(3).
Iannàccaro, G. and Dell’Aquila, V. (2001). Mapping languages from inside: Notes on perceptual dialectology. Social & Cultural Geography, 2(3), pp.265–280. doi:
https://doi.org/10.1080/14649360120073851
Jaffe, A. (2000). Introduction: Non-standard orthography and nonstandard speech. Journal of Sociolinguistics, 4(4), pp.497–
513. doi https://doi.org/10.1111/1467-9481.00127
Labov, W. (1972). Language in the inner city: Studies in the Black English vernacular. Philadelphia: University Of Pennsylvania Press.
Maxwell, A. (2006). Why the Slovak Language Has Three Dialects: A Case Study in Historical Perceptual Dialectology. Austrian History Yearbook, 37, pp.141–162. doi: https://doi.org/10.1017/s0067237800016817
Messier, J. (2012). Ebonics, the Oakland resolution, and using nonstandard dialects in the classroom. The English Languages: History, Diaspora, Culture, 3.
Mufwene, S.S. (2015). The emergence of creoles and language change. In: N. Bonvillain, ed., The Routledge handbook of linguistic anthropology. New York; London: Routledge, p.pp. 362-379.
Preston, D.R. (1999). Handbook of perceptual dialectology: Volume 1. Amsterdam: J. Benjamins.
Robinson, J. (2007). Regional voices: Non-standard grammar.
[online] The British Library. Available at: https://www.bl.uk/british-accents-anddialects/articles/regional-voices-non-standard-grammar.
Tan, P.K.W. and Tan, D.K.H. (2008). Attitudes towards nonstandard English in Singapore1. World Englishes, 27(3-4), pp.465–479. doi: https://doi.org/10.1111/j.1467971x.2008.00578.x
Zhu, J. and Grigoriadis, T.N. (2022). Chinese dialects, culture & economic performance. China Economic Review, 73, p.101783. doi: https://doi.org/10.1016/j.chieco.2022.101783

Aphasia is a language disorder characterised by difficulties in speech production and communication. This can affect many aspects of language including phonology, morphology, syntax, and semantics (Code, 1989: 2). Aphasia is caused by damage to the brain, particularly in the left hemisphere as this is where speech and language production and processing is located (Sedivy, 2019: 69). A typical way in which the brain can be damaged resulting in language difficulties and more specifically aphasia is due to strokes. Damage to specific areas of the brain can result in different types of aphasia presenting varying severities and symptoms. The differences in symptoms for differing aphasia categories can be observed and used in diagnosing aphasia patients. This essay will define and characterise three types of aphasia, Broca’s, Wernicke’s, and Anomic aphasia. This information will then be applied to data

from two aphasia patients, aiming to diagnose them with a specific type of aphasia.
One type of aphasia affecting speech and language production is Broca’s aphasia. Broca’s aphasia, also known as expressive aphasia, motor aphasia, syntactic aphasia or agrammatic aphasia (Berndt and Caramazza, 2008: 3) is a type of non-fluent aphasia and is caused by damage to the Broca’s area, located in the left frontal lobe of the brain (Code, 1989: 4). This type of aphasia is characterised by slow speech with frequent pausing and difficulty in choosing which words to use (Sedivy, 2019: 69). Broca’s aphasia can also be identified through shorter sentences/phrases, simplified syntax and a reduction in function words and functional morphemes (Cutler, 2005: 57).
Another type of aphasia impacting language in patients is Wernicke’s aphasia. This is a fluent type of aphasia and is caused by damage to the Wernicke’s area, located in the left temporal lobe
of the brain (Sedivy, 2019: 71). Similar to Broca’s, and most types of aphasia, patients with Wernicke’s aphasia have difficulties in finding the right words to use. Unlike Broca’s aphasia patients, they are able to speak fluently. This results in speech that is fluid and continuous but lacks substance and relevant meaning often resulting in nonsensical speech or what Pallickal and Hema (2020) refer to as “neologistic jargon” (p1140).
The final type of aphasia to be discussed is Anomic aphasia. This is another type of fluent aphasia and can be cause by damage to the left hemisphere of the brain. Anomic aphasia is characterised by the patient’s inability to retrieve lexical items from their lexicon (Andreetta et al, 2012). Despite difficulties in retrieving words and some instances of pausing throughout speech, anomic aphasia is still considered a fluent type of aphasia due to frequent production of full, coherent sentences without error (Bar-On et al., 2018: 884).
Unlike other types of aphasia, anomic patients often produce wellformed, grammatically correct, and relevant speech however there is a significant difficulty in finding the words to use which causes
speech to be produced slower and less fluidly (Andreetta et al, 2012).
In order to identify what type of aphasia a patient has a Mean Length of Utterance (MLU) must be calculated. This is the average number of words or morphemes that are uttered by patients at a given time (Sedivy, 2019: 207). To find the Mean Length of Utterance, the number of words or morphemes uttered are counted and divided by the total number of utterances. In this analysis, nonlexical utterances, fillers, and unintelligible utterances will not be counted and will not contribute to the Mean Length of Utterance. This includes utterances such as ‘mhm,’ ‘oh,’ ‘xxx,’ and ‘Au’.
These utterances do not carry significant meaning in what the patients are trying to articulate therefore omitting them from the analysis will clarify the data making the MLU calculation more reflective of the type of aphasia present in each patient. Utterance such as ‘yeah,’ ‘okay’ and ‘alright’ however, have been counted towards the MLU as these reflect more meaning in the patients’ speech. Repetition of the same words multiple times consecutively have also been discarded from the data and will be counted just
once. For example, “Queen Queen Queen Queen” will be counted as “Queen” i.e., one utterance instead of four. It can be useful to investigate both patients’ data comparatively before analysing each of them individually. Below is a graph and table presenting the number of words and utterances spoken by each patient, followed by a graph presenting their respective MLU’s.
It is expected that patients with a lower Mean Length of Utterance will have non fluent aphasia i.e., Broca’s aphasia while patients with a higher MLU are expected to have a fluent type of aphasia i.e., Wernicke’s or Anomic aphasia.
 Figure 2: Table displaying both patients’ number of words and utterances spoken and their MLUs.
Figure 2: Table displaying both patients’ number of words and utterances spoken and their MLUs.
Another useful tool when diagnosing aphasia patients is to look at the relevance of the patients’ responses to the prompts given by the investigator. It is likely that patients with Wernicke’s aphasia will have fewer relevant responses while responses from those with Broca’s or Anomic aphasia will be mostly relevant.
It is likely that patient A has anomic aphasia as they have an MLU of 7.54. This is evidence that they have a type of fluent aphasia e.g., Anomic or Wernicke’s as Broca’s aphasia patients tend to have lower MLUs. It is unlikely that they have Wernicke’s aphasia
due to their score of 100% of relevant responses to the investigator’s prompts. This shows a level of comprehension that is only observed in patients with Broca’s and Anomic aphasia. Wernicke’s patients tend to experience disruptions in comprehension (Berndt and Caramazza, 2008: 249) meaning it would be unlikely for a Wernicke’s patient to produce 100% relevant responses. This can be found in the following example from the transcript when the investigator asks the patient to describe making a cheese and pickle sandwich.
It is evident from this example that the patient is able to comprehend and understand the task given and produce a relevant response with accurate grammar which is common for patients with anomic aphasia (Andreetta et al, 2012: 1788).

Further evidence supporting the diagnosis of Patient A with anomic aphasia can be found in the analysis of the frequency of different word classes in their speech. Many functional word classes such as determiners, conjunctions, pronouns, and prepositions are retained in this patient’s speech. Bird et al (2002) note that anomic patients have a very high frequency of function words whereas a deficit in function words tends to be found in other types of aphasia. Below is a table and pie chart illustrating the frequency of content and function words in Patient A’s speech.
As illustrated by the pie chart, there is a roughly even split between the number of content and function words spoken with function words making up 44% of the patient’s speech. The use of function words can be observed in example 1 when the patient uses conjunctions, determiners, and prepositions. Deficits in function words tend to be found in agrammatical types of aphasia (Broca’s).
This patient clearly does not lack function words in their speech therefore the deduction can be made that they have anomic aphasia
Patient B is likely a Broca’s patient. This can be deduced from the
low MLU score of 1.85. A mean length of utterance this low indicates that the patient has a non-fluent type of aphasia i.e., Broca’s. The patient’s percentage of relevant responses also supports their diagnosis of Broca’s aphasia. 63% of Patient B’s responses to the investigator’s prompts were relevant. This level of comprehension is fairly common in Broca’s patients, auditory comprehension skills tend to be somewhat retained (Nielsen et al, 2019: 3) hence the lower percentage than that of the anomic patient but a higher one than that which would be observed in a Wernicke’s patient. An example of a relevant response from Patient B can be seen below.
While this response is not very in-depth and consists of one-word utterances, it should be noted that it is relevant to the question

asked therefore displaying comprehension skills in the patient. However, there are also examples of the patient giving answers that are not relevant to the prompt. Such as:

The patient has once again given very short answers, which is common in Broca’s aphasia (Cutler, 2005: 57) and their answer is not necessarily relevant to the prompt given by the investigator. This shows a lack in their comprehension and understanding skills however, over half of their responses can be classed as relevant confirming that they have Broca’s aphasia as opposed to Wernicke’s. Patient B’s use of content and function words also support the diagnosis of Broca’s aphasia. Some function words are retained in their speech such as determiners, conjunctions and pronouns,
however there are very few in comparison to Patient A and there is a noticeable lack of prepositions. Bird et al (2002) note that Broca’s patients tend to have difficulty retrieving function words while content words such as verbs, nouns, adjectives and adverbs can be retrieved more easily. The figures below show Patient B’s use of content and function words.
Patient B
Number of Function Words
21%
Number of Content Words
Number of Content Words
79%
Number of Function Words

The pie chart illustrates Patient B’s heavy favouring of content words over function words with function words making up just 21% of Patient B’s speech. No function words are found in the previously provided examples however they can be observed in lines such as “well everything anything yeah” and “them and them”. This patient’s lack of function words in their speech supports the diagnosis of Broca’s aphasia.
To conclude, out of the three types of aphasia discussed in this essay, distinct symptoms of each can be identified and applied to patients. It is clear that Patient A has anomic aphasia due to their high MLU score, high percentage of relevant responses and frequency of function words in their speech. It has also been deduced that Patient B has Broca’s aphasia highlighted by their very low MLU score, significant number of relevant responses to prompts and severe lack in function words.
Andreetta, S., Cantagallo, A., & Marini, A. (2012). Narrative discourse in anomic aphasia. Neuropsychologia, 50(8), 1787–1793.
https://doi.org/10.1016/j.neuropsychologia.2012.04.003
Bar-On, A., Ravid, D., & Dattner, E. (Eds.). (2018). Handbook of Communication Disorders: Theoretical Empirical, and Applied Linguistics Perspectives. De Gruyter, Inc.
Berndt, R. S., & Caramazza, A. (2008). A redefinition of the syndrome of Broca's aphasia: Implications for a neuropsychological model of language. Applied Psycholinguistics. 1(3). 225-278.
DOI: https://doi.org/10.1017/S0142716400000552
Bird, H., Franklin, S., & Howard, D. (2002). ‘Little Words’ – Not really: function and content words in normal speech and aphasic speech. Journal of Neurolinguistics. 15(3), 209237.
Code, C. (1989). The Characteristics of Aphasia. Taylor & Francis Group.
Culter, A. (2005). Twenty-First Century Psycholinguistics: Four Cornerstones. Taylor & Francis Group.
Nielsen, S, R., Boye, K., Bastiaanse, R., Lange, V, M. (2019). The production of grammatical and lexical determiners in Broca’s aphasia. Language, Cognition and Neuroscience. 34(8). University of Copenhagen.
https://doi.org/10.1080/23273798.2019.1616104
Pallickal, M. & Hema, N. (2020). Discourse in Wernicke’s aphasia. Aphasiology. 34(9). 1138-1163.
https://doi.org/10.1080/02687038.2020.1739616
Sedivy, J. (2019). Language in Mind (2nd Ed.). Oxford University Press.
Sida Cong, 2nd year
According to Housen and Kuiken (2009), complexity, accuracy and fluency (CAF) have been generally used in linguistic research to evaluate oral and written productions, which can reflect learners’ language proficiency. Based on Daniel’s oral production video, which is excerpted from his IELTS speaking test (Ross IELTS Academy, 2022), this essay will evaluate how the author measured Daniel’s CAF and why she chose the activities (displayed in Appendix B) from the textbook (Liz & Soars, 2000) to develop Daniel’s CAF specifically. Besides, some discussion about elements in the test prompt which related to Global Englishes ideals will be included.


Housen and Kuiken (2009) argued that there exist plenty of definitions of CAF and summarized a definition which is believed by most linguistic researchers. Complexity is the hardest one to comprehend among the three concepts. It contains cognitive complexity and linguistic complexity. Cognitive complexity is mainly determined by learners’ subjective feelings, while linguistic complexity focuses on the system and features of L2 itself. The definition of accuracy has the least controversy, which can be described as the evaluation on the amount of errors. Fluency can represent overall language proficiency, which especially measures “smoothness” of oral and written production (Housen & Kuiken, 2009).
Considering the definition of CAF and calculations of the measurement applied by Ogawa (2022), the author calculated each index of CAF. The statistics helped the author to evaluate Daniel’s CAF comprehensively. Table 1 shows the factors the author considered in the evaluation and the statistics. There are two terms needing explanations in the table.As-unit refers to TheAnalysis of
Speech, which can be defined as “a single speaker’s utterance” (Foster et al., 2000). According to McCarthy and Jarvis (2010), MTLD is known as the measure of textual lexical diversity, which can be calculated automatically by a web tool called TEXTINSPECTOR (http://textinspector.com/workflow).
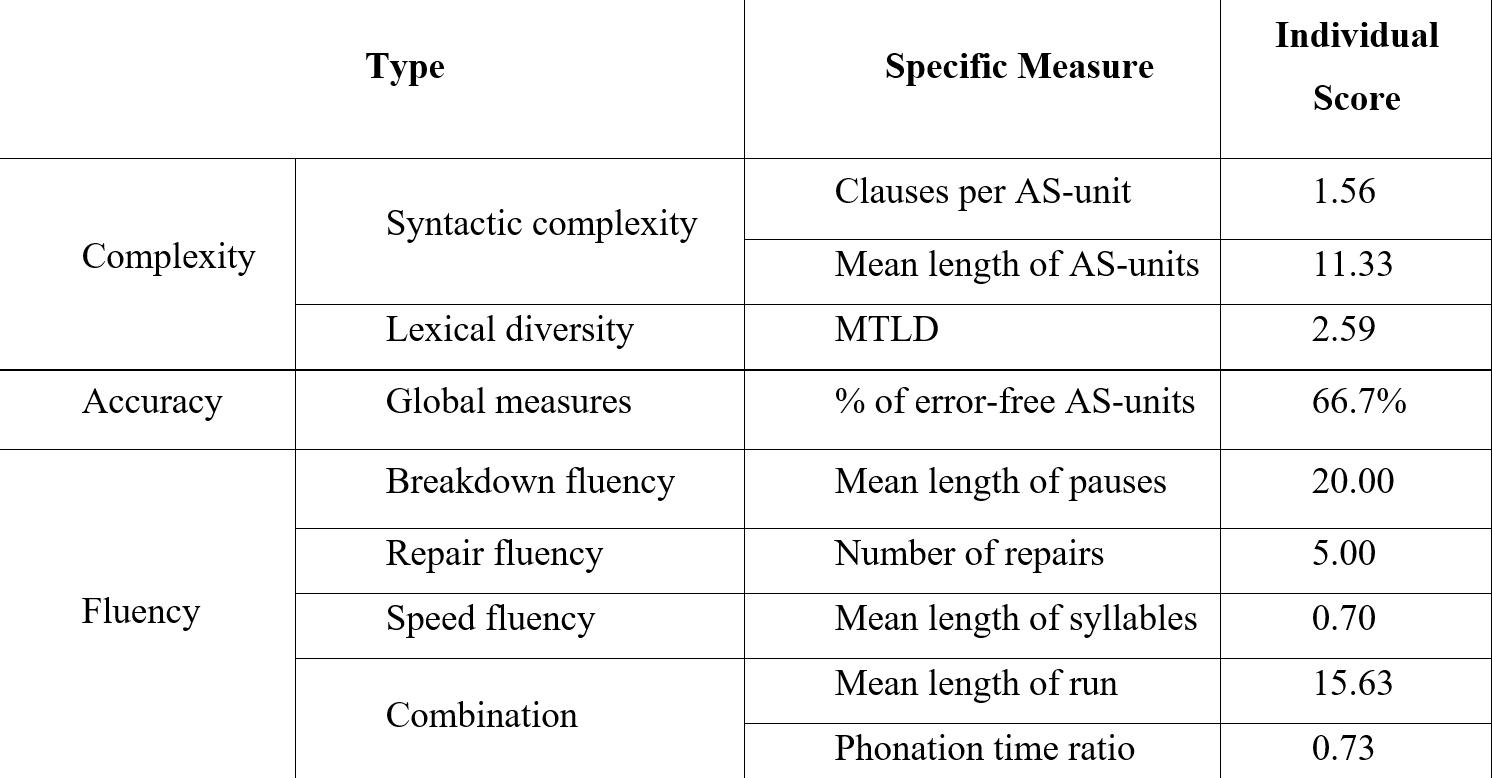
Note. Adapted from Ogawa (2022, p. 7).
In the study done by Ogawa (2022), the score of CAF can be relatively accurate after using the same calculations on a large amount of data. The author didn’t rely on the statistics in Table 1 completely because she had to evaluate Daniel’s CAF only through
Table 1. Statistics of CAF measuresone cut of his oral production. However, the statistics provided different aspects of Daniel’s linguistic performance in some ways.
The first problem the author met in the evaluation process is it is difficult to measure cognitive complexity. There is little linguistic background information of Daniel. Besides, external factors of complexity like the topic of the test question can also influence his oral production. The statistics cannot be reliable because there exist fortuities in one set of data. Especially, accuracy was just confirmed by percent of error-free AS-units. There were selfrepairs, pauses and repetitions which can influence the judgement on accuracy. Another problem worthwhile to be mentioned is the author could not ensure the degree of Daniel’s confidence on the speaking test. If he felt nervous, he probably could not perform as naturally as he practiced by himself. It’s another tough issue for the author to consider. Finally, Daniel was given one minute to take notes for his monologue task in the test. What if he could just answer that question immediately?
Global Englishes include Word Englishes and English as a lingua franca (ELF) (Galloway & Rose, 2015). Galloway and Rose (2019) also created Global English Language Teaching (GELT) to analyse the relations between English teaching materials and GE. Considering the whole speaking test, the questions mainly focus on topics in common daily life, which are understandable for the candidate without any obstacle of cross-cultural communication. As such, this provides evidence for the presence of the ELF in the test. In addition, Daniel was asked some questions about his country. In this case, it provided Daniel sources and information which he can recall from his experiences in L1. GELT encourages to regard L1 as a resource for language learning. The author proposed to add some questions related to different cultures, which will increase the degree of difficulty but can help candidates enlarge their view to the world and express their opinions towards different cultures in L2.
As Scrivener (2011) argued, teachers should know the definition of the achievement aim clearly and set up possible and appropriate achievement aims. Daniel will take another similar speaking test in three months, which means his English learning should focus on oral production. Based on the evaluation of Daniel’s CAF, there come out three achievement aims. First, about complexity, Daniel will be able to master more vocabulary about daily life and be more familiar with more grammatical items. Second, Daniel will produce a higher portion of error-free utterances. Third, Daniel is expected to be more confident to speak English, with less hesitations.
This paragraph will evaluate Activity Directions 1.4 on page 43 of the textbook. According to Hunter (2012), there are a lot of limitations of language teaching at present. On one hand, teachercentred classrooms commonly appear, which means there are less opportunities for learners to output target languages. In this case, learners can hardly develop their fluency. On the other hand, to
focus on natural conversation practices alone leaves no space to improve learners’ complexity or accuracy. Based on the materials given, the author did some adjustments by adapting the communitive methodology of “Small Talk” (Hunter, 2012). The basic intention of creating “Small Talk” is to make learners practice conversations by themselves and make the teacher an observer, who will give feedback and corrections after speaking activities (Hunter, 2012). With no interruption of the flow, learners can develop their fluency. In Activity Directions 1.4, there is a restricted topic- “Directions”. It can be classified as Meaningfocused Output according to Nation (2007). During the preparation for the speaking task, Daniel can get familiar with some new vocabulary related to daily life. By describing different positions on the map, Daniel can get opportunities to practice different grammatical items. Nation and Newton (2009) stated that activities focusing on fluency should be meaning-focused, familiar to learners and support learners to improve their language proficiency. Daniel can choose any position on the map to give descriptions in English orally, and his partner won’t know “where Daniel is” until they finish the conversation. Thus, the activity is meaningful. The
topic “Directions” was under the tag of “Everyday English”, which means to be familiar to learners. Time pressure can help Daniel to improve his speed fluency and produce less pauses. The colourful map makes the activity more engaging, which can motivate Daniel to learn English.
Practice 3 on page 39 is based on Grammar Point 3 on the same page. It follows the strand of “Language-focused Learning”. The learning focus is a grammatical item - Demonstrative Pronoun “this, that, these and those”. The achievement aim of this activity is that learners can use the four grammatical items to compose sentences accurately. Analysing Daniel’s oral production transcription in Appendix A, the author found that Daniel made more errors in using functional vocabulary than other types of vocabulary in the test. Therefore, this activity is helpful for Daniel to develop his accuracy. Scrivener (2011) pointed out that learners should take a series of steps to master each new grammar item. The whole process can be briefly described as exposure, noticing, understanding, practicing, using and memorizing new grammar items, which can be achieved by using the “Present-Practice-
Product” (PPP) grammar teaching framework (Scrivener, 2011).
Before Practice 3, there are listening materials which contain the new grammar items. The materials and the examples the teacher show with flash cards can be regarded as opportunities of exposure. The exercise in Grammar Point 3 can make Daniel notice the grammar items specifically. By stating and explaining the grammar rules given in the textbook, the teacher provides opportunities for learners to understand them. The practice in this activity makes learners ask and answer questions about the facts of their classroom by using new grammar items, which belongs to a drill (Scrivener, 2011). The drill can help Daniel to get familiar with new grammar items orally. The teacher should listen to learners carefully while they are speaking and then “use error awareness and correction techniques” to make the activity focus on accuracy (Scrivener, 2011).
Practice 1 on page 37 shows a communicative activity as Scrivener (2011) defined. It is a Meaning-focused Output activity. The pair work contains an exchange of information because Student A and Student B are required to use different pictures to make up conversations. There exist information gaps between two
students in a pair. Therefore, the activity is meaningful, which meets the first condition of fluency- focused activities. Before Practice 1, learners are required to do tasks based on new relevant vocabulary and new grammatical items- prepositions used to describe the positions of stuff. In this case, learners’ familiarity with new linguistic items can be improved. Time pressure is a direct way to focus on fluency in language learning activities. Considering the possible length of conversations learners can create, learners should be given 40/30/20 seconds by practicing the same conversations as Scrivener (2011) encouraged. No interruption of flow caused by the teacher is needed. The scores of Daniel’s CAF show that Daniel has obvious weakness with fluency. The teacher can make some tailored learning plans for him like asking him to do more time-limited speaking tasks after class. Besides, the teacher should give more positive feedback to help Daniel develop his confidence to speak English.
CAF is not an ideal measurement to evaluate learner’s language proficiency, although it has been generally used. The author has
addressed several problems which caused difficulties to give scores on Daniel’s CAF. Both subjective factors and objective factors influence CAF, which makes it not totally reliable to evaluate language proficiency. The evaluation of Daniel’s CAF directly influences the learning activities designed for him to improve his spoken English. Technically, the author should get more background information about Daniel himself and his English learning experiences. Language acquisition cannot avoid considering subjective factors. In addition, standard indices of CAF for different levels of language proficiency have limited authentic data to reference. Linguistic researchers should work on improving CAF either by adjustment or creating a new framework to collect data and do calculations, which can make this measurement more authentic to be widely used.
GELT should master both language teaching theories and language learning theories. The definition of CAF has variety of versions stated by linguistic researchers, but there is one which can provide a basic notion (Housen & Kuiken, 2009). The definition can connect CAF with language learning as three aspects of achievement aims. How to develop CAF is still an obstacle facing
language teaching. There are few activities which can develop complexity, accuracy, and fluency simultaneously. Teachers need to run activities with different focuses to make the three aims balanced. Different materials have different advantages, and it is important that teachers choose suitable materials and design activities to make effective use of them. There is one goal that by the end of a period time English learning (for Daniel, it refers to three months), learners should achieve the original achievement aims, which needs teachers to plan how to help learners to make progress gradually and monitor them regularly. For example, teachers can provide quizzes in class to check learners’ English skills. Finally, teachers should encourage learners by giving positive feedback because motivation is a powerful resource in language learning.
Boggs, J. (2020). ALE200: Language Teaching in Context: Week 6 notes [Google file]. Google File.
https://docs.google.com/document/d/1ClealSrzDiyBPdP25M4IYexwwvESO04QOTeyOqc2uk/edit
Foster, P., Tonkyn, A., & Wigglesworth, G. (2000). Measuring spoken language: a unit for all reasons. Applied Linguistics, 21(3), 354–375. https://doi.org/10.1093/applin/21.3.354
Galloway, N., & Rose, H. (2015). Introducing global Englishes.
Housen, A., & Kuiken, F. (2009). Complexity, Accuracy, and Fluency in Second Language Acquisition. Applied Linguistics, 30(4), 461–473. https://doi.org/10.1093/applin/amp048
Hunter, J. (2012). “Small Talk”: developing fluency, accuracy, and complexity in speaking. ELT Journal, 66(1), 30–41.
https://doi.org/10.1093/elt/ccq093
Liz., & Soars, J. (2000). New Headway English Course. Elementary Student’s Book. Oxford University Press.
McCarthy, P. M., & Jarvis, S. (2010). MTLD, vocd-D, and HD-D: A validation study of sophisticated approaches to lexical diversity assessment. Behavior Research Methods, 42(2), 381–
392. https://doi.org/10.3758/BRM.42.2.381
Nation, I. S. P., & Newton, J. (2009). Teaching ESL/EFL listening and speaking. Routledge.
Nation, P. (2007). The four strands. Innovation in Language
Learning and Teaching, 1(1), 2-13.
https://doi.org/10.2167/illt039.0
Ogawa, C. (2022). CAF indices and human ratings of oral performances in an opinion-based monologue task. Language
Testing in Asia, 12(1), 1–18. https://doi.org/10.1186/s40468-
022-00154-9
Rose, H., & Galloway, N. (2019). Global Englishes for language teaching. Cambridge University Press.
Ross IELTS Academy. (2022, August 13). IELTS Speaking test band score 2.5, 2022 [Video]. YouTube.
https://www.youtube.com/watch?v=7vzC-qMb0jQ&t=292s
Scrivener, J. (2011). Learning teaching: the essential guide to English language teaching. (3rd ed.). Macmillan Education.


How children view differences in dialects
Many child development researchers wonder whether young children notice differences between dialects – that is, how a person speaks a particular language based on where they are from - and if so, whether that affects the child’s opinion of that person. Two studies examined a group of 5–6-year-old children and how they viewed dialects. The children were asked to sort dialects of English into categories. They were given their own home dialect –the type of English they heard at home, a regional variation –spoken by a first language English speaker, but from a different area, and a second language variation – English spoken by a first language speaker of another language. Results showed that the children were able to tell the difference between their own dialect and the second language variation, but not between the second language and regional variation or the home and regional
variation.
What the researchers did
• The researchers carried out two experiments on separate groups of 5–6-year-old children from Ohio. One asked the children to consciously sort dialects into categories, while the other asked them to link each dialect to cultural items, such as houses or clothing.
• The three dialects used in the experiments were a home dialect; in this case Midland American English, a regional variant (meaning different dialect); Northern British English, and a second language variant; Maharashtran Indian English.
• In Experiment 1, 36 children were split into three groups. Each group was tested on two of the three dialects, for example: Group 1 was tested on the home versus regional dialect, Group 2 on the regional versus second language dialect and Group 3 on the home versus second language dialect.
• The experiment started with a training phase, where each group heard recorded sentences in their two dialects and were simultaneously shown green and purple puppets, which would move when they were supposedly speaking. A sentence would play, and the child would be told, for example, green puppets sound like this.
• The next step was a test phase, in which new sentences were played, and the children were asked to match them to the puppet.
• In Experiment 2, 36 children who had not taken part in Experiment 1 were split into three groups by the same categories as Experiment 1, and each group was played the same training sentences as in the previous experiment.
• This time, the children were asked to link the dialects to cultural items, such as houses.
• The children would be shown two pictures, one showing something that was familiar to them, for example, a house that was common where they lived, and one that was unfamiliar, for example, a mud hut. The children were then played a sentence in a dialect and asked which picture the dialect belonged to. What the researchers found
• Experiment 1 showed that most of the children matched the puppet to the correct dialect in the home versus second language dialect contrast, but in the other two conditions (home versus regional dialect and regional versus second language dialect), the number of children who answered correctly was no higher than would be expected by chance.
• This suggests that, overall, the children were not able to pick out anything specific in the home versus regional and regional versus second language dialects that helped to differentiate between them, and may just have been choosing an answer at random.
• It is important to remember that each experiment was done on a completely different set of children, meaning that the results would not have been affected by the children having picked up information from a previous experiment.
• The overall findings of this study show that, at this age, while the children are not always able to knowingly sort dialects into categories, they can make judgments on how similar or familiar someone is to them based on their speech.
• The results imply that as children start school, they are still in the process of learning what makes accents and dialects similar or different to their own. This could be useful for teachers who want to understand more about how young children interact with new peers and how they communicate as a result of information they pick up from each other’s accents. More research is needed to determine at which point children start to acknowledge these differences in peoples’ speech.
Reference Wagner, L., Clopper, C.G., & Pate, J.K. (2013). Children’s perception of dialect variation. Journal of child language, 41(5), 1062-1084.
https://doi:10.1017/S0305000913000330
Angharad John, 2nd year
Report on and critically evaluate a set of research outputs/publications from projects where applied linguists and practitioners have worked in partnership
This essay will examine the research outputs from a Research Excellence Framework (REF) Impact case study in the health domain. Undertaken by the University of Nottingham’s School of English, the study is titled: Raising Awareness of Adolescent Health Communication (University of Nottingham, 2014). The aim of this research was to “enhance practitioner-patient communication” (University of Nottingham, 2014, particularly when it came to adolescents and young people, and to better understand the ways that teenagers express worries they have about their health.
The Health Language Research Group was set up in 2002, which was an “interdisciplinary sub-group” (University of Nottingham, 2014) of the Centre for Research in Applied

Linguistics (CRAL). The research team in this group consisted of Ronald Carter, Professor of Modern English Language, Svenja Adolphs, Professor of English Language and Linguistics and Dr Louise Mullany, Associate Professor in Sociolinguistics (UoN, 2014). The researchers developed working relationships with Dr Aidan MacFarlane and Dr Ann McPherson, who were paediatricians working in the NHS at the time, and the co-creators of the Teenage Health Freak website (Teenage Health Freak, n.d.). This website allowed teenagers to submit health-related questions which were then answered by GPs (UoN, 2014). These questions were converted into data for one output of this research, which was a 2-million-word corpus created from the roughly 113,000 healthrelated questions that were submitted via the ‘Ask Doctor Ann’ (THF, n.d.) function (UoN, n.d.). When submitting the questions, adolescents were also able to specify their gender and age by using a drop-down list, however this was not essential. The corpus used this data to break down the words most commonly used, as well as the median number of words in questions sent by each age and gender.
The contents of the corpus were then judged against “CRAL’s multi-million word general English holdings” (UoN, 2014). This allowed researchers to identify terms that had a proportionally high usage (Harvey et al., 2007). From this, it was found that the most common topics queried were: sex, pregnancy and relationships; body parts; body changes; weight and eating; smoking, drugs and alcohol (UoN, 2014). An encyclopaedia containing 100 words on these topics was then created to aid health practitioners. The aim was for it to bring to light any trends in “adolescent sociolinguistic style and register” (UoN, n.d.). It showed the frequency of use of each word across different genders and age groups, as well as some examples of how the words were used in context. Some challenges faced while creating the encyclopaedia included converting the data from spreadsheet into XML (that is: Extensible Markup Language (FileInfo, 2022)) format, as well as finding and deleting duplicate messages that were sent on the same date (UoN, n.d.). Correction of spelling as often as possible was also necessary (UoN, n.d.). Obviously, in some cases this would have been difficult or even impossible, depending on whether the word was intelligible or distinguishable from another similar word which would have made
sense in the same context.
The third output of this project was a booklet designed to be accessible for a practitioner audience, and to provide health practitioners with more information on how adolescents express health worries, titled “Am I Normal?” (Harvey et al., 2007). It explains the background of the Teenage Health Freak (Teenage Health Freak, n.d.) website and the corpus, and points out that previously, sexual health research has found that young people will often use “vague terms and euphemisms” (Harvey et al., 2007) when talking about their body, however, while using the website they explained their concerns in “meticulous detail” (Harvey et al., 2007). It also advises that practitioners could learn useful communication lessons by analysing this bank of health language (Harvey et al., 2007). It was hoped that this publication would contribute to the “continuous professional development” (UoN, n.d.) of groups of practitioners within the NHS, while also being useful to adolescents, parents and teachers.
Until this point, not much linguistic research into adolescent health had been carried out. It was also noted that GPs generally wanted to better understand how young people viewed health and illness (UoN, 2014). The researchers’ decision to analyse the online communication was therefore an effective one for several reasons. Firstly, typing out questions anonymously online is a far less daunting prospect for a self-conscious teen than trying to articulate concerns to a doctor or parent face-to-face, especially if they are worried about the adult asking them uncomfortable questions in return. Being able to submit questions anonymously makes it more likely that the adolescents would share what is genuinely bothering them, meaning that the data would show a much wider picture of adolescents’ real concerns, not just what they would normally be willing to share with an adult. This also applies to the type of words they might use. When talking to adults, words considered rude or taboo might be avoided, but as mentioned in Harvey et al. (2007), more direct anatomical language is included in the questions. This shows that a corpus made up of online submissions more accurately reflects natural adolescent language and perspectives, as opposed to, for example, one made up of words used by adolescents in a
doctor’s surgery. Furthermore, the reach of this project was fairly wide. As the data was gathered online, there were no geographical barriers that stopped teenagers from providing questions. The 113,000 responses resulting in a 2-million word corpus indicates the moderately large scale of the project.
The main problem being addressed in this study was health practitioners'’ lack of knowledge of adolescent communication, and how best to respond to this style. As a result of the research, GPs stated that they felt more informed, and were able to engage “more effectively and confidently” (UoN, 2014) with teenage patients. Several GPs who read the ‘Am I Normal?’ (Harvey et al., 2007) booklet commented that it gave them more “knowledge and insight” (UoN, 2014) into adolescent communication. They also explained that the booklet helps to highlight the fact that teens often have “hidden agendas” (UoN, 2014) and concerns when consulting with GPs, and it details the best ways to make young patients comfortable enough to have conversations about said agendas. Ideally, the most successful outcomes for young people from this study would have been more effective treatment, or feeling less
intimidated and instead better understood by their health practitioner. This could then result in more positive attitudes towards talking to a GP, and improve overall confidence in the NHS. These comments exhibit that, according to the practitioners at least, the real-world challenges that were being addressed in this research were done so successfully.
In terms of ethical aspects, there is a question over whether teenagers were aware their questions would be collected and used for research purposes. As the Teenage Health Freak Website is no longer live, it is difficult to determine whether anything was displayed on the ‘Ask Doctor Ann’ (THF, n.d.) function explaining this. As the questions are anonymous, this would not be such a serious problem, but it is a particularly sensitive area given that these are the questions of minors.
It is mentioned that this research was carried out as a result of “demands” (UoN, 2014) from GPs, so it could be inferred that relationships between practitioners and researchers were initially strained. It is arguable that the main priorities of each group would
be different from each other. This would have not been a significant issue for earlier research as the Teenage Health Freak website was designed by GPs, who obviously understood the values of GPs’, for example, strict protocol and patient confidentiality; hence the anonymity of the questions submitted. It would therefore be more interesting to know where they stood on the ethics of research, and whether it was explained on the THF website that these questions would be recorded and analysed. The NHS is a huge stakeholder in this research, not necessarily in financial terms, but the outcomes of this research would make significant differences. Good results from the research would lead to better relationships with young patients and parents, and even a more positive overall image. There is even the potential for better funding, although this is a bold, oversimplified statement to make given the complexity of the NHS structure. The project also worked in collaboration with Medikidz (Medikidz, n.d.), a company which makes accessible health materials for children and young people, who managed to secure £42 000 worth of funding from the Horizon Digital Economy Research Institute (UoN, 2014). This is another
example of differing values and priorities working in partnership, as Medikidz is an “enterprise” (UoN, 2014) which has to consider making profit, while the NHS and researchers would have had the service they were providing as their main focus.
In terms of dynamics, researchers are likely to have faced pressure, as they were the ones providing the - arguably overdueservice to GPs. The GPs also had vested interest in this research; many might have felt on a personal level that they want to learn to communicate better with adolescents. Particularly if they work with them often, their job could have become easier and more rewarding with the better knowledge on how to communicate with them effectively.
In conclusion, the research for this REF Impact case study did succeed in identifying common linguistic patterns of adolescents when discussing their health and anatomy, and as a result was able to give guidance to practitioners on how best to communicate with young patients.
FileInfo. (2022, March 13). .XML File Extension. FileInfo.com.
XML File Extension - What is an .xml file and how do I open it? (fileinfo.com)
Harvey, K.J., Brown, B., Crawford, P., Macfarlane, A., McPherson, A. (2007). Am I normal?’ Teenagers, sexual health and the internet. Social Science & Medicine (65), 771–781.
https://doi.org/10.1016/j.socscimed.2007.04.005
Medikidz. (n.d.). Medikidz. Medikidz. http://www.medikidz.com/
Teenage Health Freak. (n.d.). Teenage Health Freak. Teenage Health Freak. http://www.teenagehealthfreak.org/
University of Nottingham. (2014). Raising Awareness of Adolescent Health Communication. Research Excellence Framework 2014, Impact Case Studies.
https://ref2014impact.azurewebsites.net/casestudies2/refservic e.svc/GetCaseStudyPDF/31746
University of Nottingham. (n.d.). Teenage Health Freak Corpus: Overview. Centre for Research in Applied Linguistics.
Teenage Health Freak Corpus: Overview - The University of Nottingham
University of Nottingham. (n.d.). Health Communication and the Internet: An Analysis of Adolescent Language Use on the Teenage Health Freak Website. Centre for Research in Applied Linguistics. Health Communication and the Internet: An Analysis of Adolescent Language Use on the Teenage Health Freak Website - The University of Nottingham
University of Nottingham. (n.d.). Teenage Health Freak Corpus: The data Transformation Process. Centre for Research in Applied Linguistics. THFdataPreparation - The University of Nottingham
University of Nottingham. (n.d.). Teenage Health Freak: The data Transformation Process. Centre for Research in Applied Linguistics. THF Encyclopedia - The University of Nottingham

 Madison Allardyce, 2nd year
Madison Allardyce, 2nd year
In this study I explore the effects and differences between memory systems. Simply, memory consists of the remembrance and recollection of information (Klein, 2015). However, from a more academic approach, the concept of memory involves three major steps:
(1) learning – new information is gathered and encoded into our memory,
(2) storage – the encoded information is then stored to maintain continuity,
(3) retrieval – when we decide to remember the piece of information, we retrieve it from our memory (Klein, 2015). For my research, I specifically investigate the use and comparisons between working memory and long-term memory.
Baddeley (2010, 2012) describes working memory as the temporary storage of small amounts of information over brief periods of time. Working memory is located in the pre-frontal cortex of the brain (Conway et al., 2005). This is where complex goal-directed human behaviour is studied (Conway et al., 2005). Within this system there are two main components: domain specific skills, and domain general capability (Conway et al., 2005). Domain specific skills include practices such as grouping and rehearsal (Conway et al., 2005). These practices are also found when using short term memory (Baddeley, 2010). Short term memory describes the temporary storage of information; however, the role of working memory goes beyond this simple storage (Baddeley, 2010, 2012). The role of working memory includes general cognitive control and executive attention, which provides techniques that can be applied practically to activities (Conway et al., 2005; Baddeley, 2010). This means that working memory is domain general (Conway et al., 2005). Baddeley and Hitch’s model (1974) explains that working memory is controlled by the central executive, which is where information is stored (Baddeley, 2010, 2012). This element is important during complex activities as it
allows the individual to switch attention and concentrate on different stimuli (Conway et al, 2005). Within the central executive, there are three structural components where information is stored (Baddeley, 2010, 2012). This element is important during complex activities as it allows the individual to switch attention and concentrate on different stimuli (Conway et al, 2005). Within the central executive, there are three structural components where information is processed (Turner & Engle, 1989). First, there is the phonological loop (Baddeley, 2010, 2012). This is where speechlike information is stored and where (sub)verbal rehearsal processing is achieved (Baddeley, 2010). It is suggested that it is more challenging to recall a sequence of words when the words contain similar sounds (Baddeley, 2010). Then there is the visuospatial sketchpad, which processes visual and spatial semantics in real life and reading (Baddeley, 2010, 2012). Finally, there is the episodic buffer, which was added later in Baddeley and Hitch’s (1974) model (Baddeley, 2010). This component temporarily stores visual and auditory information and is linked to long term memory (Baddeley, 2010, 2012).
I chose to use an operation span task (OSPAN) to measure
working memory capacity. OSPAN tasks are used to predict the level of complex cognition of individuals and their memory performance (Conway et al., 2005). An OSPAN task consists of two tasks: a word or digit span activity (in this study a word span) in accompaniment with a secondary task (in this study a maths task) (Turner & Engle 1989). These tasks were originally designed from Baddeley and Hitch’s (1974) theory of working memory, whereby they identify the importance of a memory system that can temporarily store information whilst other mental activities are taking place (Conway et al., 2005). Participants are shown sequences of maths equations, which are answered with a true/false answer, followed by a word, usually a concrete noun with 4-6 letters, to remember (Turner & Engle, 1989). Once the sequence is complete the participant records the words they can remember in order that they appeared. The combination of the ‘to-beremembered’ target stimuli (word span) and a demanding processing task (maths equations) stops participants using memory strategies, including rehearsal and grouping, allowing researchers to grasp a full picture of their participants working memory capacity (Conway et al., 2005). The results of these studies
highlight that there is no significant difference in performance between the sexes, working memory decreases as age increases, and working memory is lower when a participants’ second language (L2) is used in the experiment (Conway et al., 2005; Baddeley 2012).
The other task included in my study is a continuous visual memory task (CVMT) which measures long term memory (Paolo, 1998). Within long term memory there are two main systems: declarative memory and procedural memory (VanPatten et al., 2020). The declarative memory system is located in the hippocampus and other medial temporal lobe (MTL) (Ullman, 2016). This area of the brain is where: language is learned, knowledge and experiences and linked together, and where information and events are remembered (Ullman, 2016; VanPatten et al., 2020). More specifically within the MTL, the perirhinal cortex contributes to object recognition, the para-hippocampal cortex contributes to spatial recognition, and the hippocampus contributes to higher-level concept recognition (Ullman, 2016). The procedural memory system is based in the frontal, basal-ganglia circuits (Ullman, 2016). Processes including learning motor and
cognitive skills and learning to predict probabilistic outcomes are done in this area of the brain. Declarative memory acquires knowledge quicker, therefore explicit instructions and attention on stimuli increases learning in this system (Ullman, 2016). However, procedural memory processes knowledge quicker, therefore implicit, complex instructions increase learning in this system (Ullman, 2016). Research has proven that both memory systems decline through age as memory plateaus after adolescence and procedural memory decreases in adulthood (VanPatten et al., 2020). Ullman (2016) discovered that women rely more on declarative memory because higher levels of oestrogen result in better declarative memory. Due to this, men tend to use more procedural memory (Ullman, 2016). Research also shows that early language learners (L2) rely more on procedural memory, whereas later language learners rely on declarative memory (Ullman, 2016).
CVMT measures visual learning and declarative memory (Paolo, 1998). It removes the motor component linked with drawing tasks and decreases verbal labelling that may appear on tests involving simple geometric shapes (Paolo, 1998). In a continuous visual memory task, a series of shapes appear on a
screen (in this study 112 pictures were shown). Participants are required to state whether the picture is new or old; this promotes the use of their long-term memory (Paolo, 1998). Unlike Ullman’s(2016) discoveries CVMT are not influenced by gender or education, which is supported by Trahan and Larrabee’s (1988) test model (Paolo, 1998). However, Paolo’s study (1998) showed the CVMT results were largely influenced by age. Furthermore, PiliMoss et al. (2019) identified that declarative learning is the main predictor of accuracy in comprehension tasks.
The first task, to conduct my study, was to develop a research question: How do the effects of working and long-term memory differ, in relation to various demographic factors?
After this, I began to create my experiment. I used gorilla software to clone the OSPAN and CVMT tasks into my experiment (Gorilla Experiment Builder, 2016). Furthermore, I provided an information sheet, consent form, and background questionnaire at the beginning of the experiment to provide the participants with information about the experiment, choice to participate, and give information about themselves - which would later be compared.
Due to the cloning, I made alterations to each section in order for them to correspond with what specifically I was investigating. For example, in the questionnaire I included questions about the participants’ age, sex, education, first language (L1), and potential second language (L2). Moreover, I changed the OSPAN task to consist of 42 sequences, three sets of 2-5 sequences sorted randomly, and ensured that 50% of the maths equations were correct (Turner & Engle, 1989).
Once my experiment was complete, I sent the experiment to multiple friends and family members via various social media platforms and email. Overall, 30 anonymous participants were collected and categorised accordingly:
Figure 3.1
12
18
Male Female
60% of participants were female and 40% were male.
The age of the participants ranged between 19-75. I separated the participants’ ages into 4 groups to later compare.
Undergraduate degree Postgraduate degree Other
School until age 16 School until age 18
FigureMost of the participants have an undergraduate degree (30.3%).
The other forms of education by the participants include: RMN and specialist practitioner diploma level, Registered Nurse qualified 1991 pre-degree, and City and Guilds C&G 015 in agricultural engineering.
Majority of the participants’ first language is English (93.3%).
Figure 3.430% of the participants have reported that they can speak another language.
4.1 OSPAN Task
Table 4.1.1
Table 4.1.1 shows the results from the target stimuli in the OSPAN task. The y-axis represents the words in the task (42) and the x-axis shows the results from the participants. The highest participants scored 41 (97%) and the lowest scored 4 (10%). The average score of the participants was 31 out 42 (74%).
Table 4.1.2 highlights the results from the secondary processing task in the OSPAN task. The y-axis shows the number of equations in the task and the x-axis represents the results from the participants. The highest score was 42 (100%) and the lowest score was 22 (52%). The average score of the participants was 37 out of 42 (89%).
Table 4.2.1 displays the results from the continuous visual memory task. The y-axis shows the number of pictures that appeared in the task (the total number was 112 therefore the axis was rounded to 120). The x-axis represents the results from the participants. The highest score was 98 (87%) and the lowest score was 49 (43%). The average score of the participants was 74 out of 112 (66%).
Table 4.3.1 demonstrates the relationship between the memory tasks and the sex of the participants. The y-axis represents the accuracy of the tasks, and the x-axis shows the sex’s results of each task. It is clear that the female participants outperformed the males in both tasks. However, the difference between the sexes is not significant – 2.98% (OSPAN) and 4.27% (CVMT).
Table 4.3.2
Table 4.3.2 displays the relationship between the memory tasks and the age of the participants. 35-50 group performed best in the OSPAN task and 19-34 group performed best in the CVMT.
Table 4.3.3 highlights the relationship between the memory tasks and the participants’ L2 ability. On both tests participants who could speak an L2 performed better – significantly in the OSPAN task and slightly in the CVMT (note that the results from the OSPAN task only include the data from the word span).
From the results of the task, it is clear that there are differences between the memory systems in regard to the demographic factors that I compared. Table 4.3.1 shows that female participants outperformed males in both tasks. My results from the OSPAN task contradict Baddeley’s ideology (2010) that the task is not
influenced by gender. However, the CVMT results support the claims proposed by Ullman (2016). Females usually rely on their declarative memory during long-term memory tasks due to their level of oestrogen (Ullman, 2016). Due to this, female participants are able to acquire knowledge at a faster rate, even after little exposure to the stimuli, therefore are more likely to perform better on the CVMT (Ullman, 2016). This idea opposes Paolo’s study (1998) whereby sex does not have an influence on the results. To resolve this, another CVMT test can be conducted, with different participants, to identify whether sex has an influence on long-term memory.
Evidence from the scholars, in the literature review, agree that the largest influence on memory is age. Conway et al. (2005) explained that working memory declines with age, and Ullman (2016) found that declarative memory plateaus during adolescence and begins to decline in adulthood. Therefore, it can be predicted that younger participants have a greater memory capacity than older participants. However, from the results of Table 4.3.2, this is not the case. Whilst the 67+ group had the lowest score on the OSPAN task (53.96%), which supports the claim made by Conway
et al. (2005), on average the oldest group performed the second best on the CVMT test (67.26%). Paolo’s study (1998) included 177 participants with the age range of 60-94 and found that as the age increased the results of that task, and declarative memory capacity decreased. In order to make my test results more reliable, next time I will target more participants of an older generation. One way this can be achieved is to publish my experiment on different platforms, as older participants may not use social media.
Table 4.3.3 highlights the influence of knowing a second language on the memory tasks. In both tasks, participants who stated they knew a second language performed better than those who did not. It has been discovered that there are links between working memory and declarative memory, due to the same frontal brain structures used when the systems are activated (Ullman, 2016). As Pili-Moss et al. (2019) stated, declarative memory promotes accuracy in comprehension tasks. This could answer why participants with an L2 performed better on the OSPAN and CVMT tasks. This study did not explore how the memory systems were affected when participants were using their L2 to complete the tasks, therefore it would be interesting to see if Baddeley’s
(2012) claims that working memory is lower in participants’ L2 are accurate.
Whilst the main purpose of the study was to compare working memory task and the long-term memory task, it is also worth comparing the two activities in the OSPAN task. Table 4.1.3 displays that the participants performed better on the secondary task compared to the word span task. One limitation of the OSPAN task is that participants could guess the true/false questions in order to remember the target stimuli (Conway et al., 2005). However, this is not the case from this experiment. Therefore, the results from the word span task accurately represent the use of the participants working memory over their short-term memory. As well as this, the results from table 4.1.1 and 4.1.2 show that participants who recall the most target words perform better on the processing task (Conway et al., 2005). One way to test the reliability of the OSPAN results is to compare them to other span tasks (digit span tasks and reading tasks) (Conway et al., 2005). Even though I have chosen to use a mathematical secondary task, reliability can still be achieved between word and maths scores (Conway et al., 2005).
Overall, in this study it has been identified how various demographic factors affect our memory systems. The factor that has the most impact on memory is age (Conway et al., 2005; Paolo, 1998). However, it is interesting to discover how aspects of predetermined human anatomy (i.e. hormones) can cause significant differences between participants’ results. For future research, it would be compelling to explore how additional learning needs (dyslexia) affect the performance of the memory systems (Ullman, 2016).
If I were to perform this study again, I would collect the reaction times of the participants whilst they were performing the tasks. This would further prove if the results were reliable.
References
Baddeley, A. (2010). Working memory. Current Biology, 20(4), R136–R140. https://doi.org/10.1016/j.cub.2009.12.014
Baddeley, A. (2012). Working Memory: Theories, Models, and Controversies. Annual Review of Psychology, 63(1), 1–29.
https://doi.org/10.1146/annurev-psych-120710- 100422
Baddeley, A. D., & Hitch, G. (1974). Working Memory. Psychology of Learning and Motivation, 8(1), 47–89. https://doi.org/10.1016/s0079-7421(08)60452-1
Conway, A. R. A., Kane, M. J., Bunting, M. F., Hambrick, D. Z., Wilhelm, O., & Engle, R. W. (2005). Working memory span tasks: A methodological review and user’s guide. Psychonomic Bulletin & Review, 12(5), 769–786.
https://doi.org/10.3758/bf03196772
Gorilla Experiment Builder. (2016). Gorilla.
https://app.gorilla.sc/admin/home
Klein, S. B. (2015). What memory is. Wiley Interdisciplinary Reviews: Cognitive Science, 6(1), 1–38.
https://doi.org/10.1002/wcs.1333
Paolo, A. (1998). Continuous Visual Memory Test Performance in Healthy Persons 60 to 94 Years of Age. Archives of Clinical Neuropsychology, 13(4), 333–337.
https://doi.org/10.1016/s0887-6177(97)00018-8
Pili-Moss, D., Brill-Schuetz, K. A., Faretta-Stutenberg, M., & Morgan-Short, K. (2019). Contributions of declarative and procedural memory to accuracy and automatization during second language practice (*). Bilingualism: Language and Cognition, 1-13.
https://doi.org/10.1017/s1366728919000543
Trahan, D.E. and Larrabee, G.J. (1988) Continuous Visual Memory Test. Psychological Assessment Resources, Odessa, FL.
https://www.scirp.org/(S(351jmbntvnsjt1aadkposzje))/ref
erence/ReferencesPapers.aspx?ReferenceID=1281327
Turner, M. L., & Engle, R. W. (1989). Is working memory capacity task dependent? Journal of Memory and Language, 28(2), 127–154. https://doi.org/10.1016/0749596x(89)90040-5
Ullman, M. T. (2016). The Declarative/Procedural Model. Neurobiology of Language, 953–968.
https://doi.org/10.1016/b978-0-12-407794-2.00076-6
VanPatten, B., Keating, G. D., & Wulff, S. (Eds.). (2020). Theories in second language acquisition: An introduction. Taylor & Francis Group.
https://ebookcentral.proquest.com/lib/swanseaebooks/detail.action?pqorigsite=primo&docID=6120993#
Recent research in studies of L1 attrition: a mini systematic review
Introduction


The topic of language attrition is a relatively new and underexplored field which has led to a range of investigative approaches (Gallo et al., 2021). Schmid (2008, p. 10) defines attrition as “[a] loss of proficiency not caused by a deterioration of the brain due to age, illness or injury, but by a change in linguistic behaviour due to a severance of the contact with the community in which the language is spoken.”
The following review considers recent research in this field through a collection of studies from the Bilingualism: Language and Cognition journal (Cambridge) between the years 2012 and
2022. The resulting ten articles will now be examined. First, I discuss the theories used in the current research, then the methods employed, and finally, I discuss what we can conclude from the past decade of research and where to the field might go in the future.
Two studies drew on the Interface Hypothesis (Sorace & Filiaci, 2006) which posits that structures which meet at the interface with syntax such as semantics or pragmatics are more open to first language (L1) attrition, as they are harder to acquire. Chamorro et al. (2016, p. 520) used the updated hypothesis that attrition does not affect knowledge representations themselves but the “ability to process interface structures” to attempt to find the source of attrition through re-exposure. Flores (2012) applied this hypothesis to determine whether object-expression, occurring at the syntaxdiscourse interface, is more vulnerable to attrition than the narrow syntactic feature verb placement. Chamorro et al. (2016) also considered Paradis’ (1993) Activation Threshold Hypothesis (ATH) which demonstrates that less frequent items in the L1
become harder to access, especially if the corresponding second language (L2) item is used more regularly, suggesting re-exposure could reduce attrition effects. Schmid & Jarvis (2014) also applied the ATH to assess lexical accessibility in the L1 when it has been compromised by emigration and therefore the activation of an L2 environment.
The Speech Learning Model (SLM), developed by Flege (1995) posits that “L1 and L2 phonetic categories [exist] in a common phonological space” (Flege, 1995, p. 239) allowing the L1 to influence the L2 and vice versa (de Leeuw et al., 2018). This can lead to cross-linguistic assimilation (CLA) whereby the sounds of two languages become more similar (Mayr et al., 2012). Typically, this hypothesis is used for studies where bilinguals “have spoken their L2 for many years” (Flege, 1995, p. 238) which applies to Mayr et al.’s (2012) study investigating the change in L1 accent in Dutch twins, one of whom had moved to the UK, and lived there for 30 years. De Leeuw et al. (2018) also used the SLM to assess phonological attrition in native Albanians who had immigrated to England.
Similar to CLA, Cross Linguistic Influence (CLI) is a wellestablished hypothesis which James (2012, p. 858) defined as “the influence that knowledge of one language has on an individual’s learning or use of another language”, which “can involve various aspects of language”. A question that remains in the literature is to what extent attrition originates from CLI (Gallo et al., 2021), and this concept is mentioned in eight of the studies, with two of them developing previous research in CLI. Anderssen et al. (2018) built on Kupisch’s (2014) proposal for crosslinguistic overcorrection (CLO) which is when bilinguals “show a tendency to overstress what is different rather than what is common in their two languages” leading to an overuse of non-dominant language structures (Kupisch, 2014, p. 223). Anderssen et al. (2018) employed this proposal to address pre- and post-nominal structures in Norwegian heritage language speakers (HS). Hulk and Müller (2000) proposed that language dominance is not one of the causes of CLI. Contrasting this, Kang (2013) provided a revised model for CLI whereby language dominance can play a role, through assessing the attrition of a Korean-English boy’s dominant language changing and therefore affecting his L2.
Levy et al. (2007) proposed the Retrieval-Induced Forgetting (RIF) mechanism which posits that repeatedly retrieving words from the L2 inhibits the representation in the L1, therefore the decrease in availability of L1 representations “would be the basis for L1 attrition” (Runnqvist & Costa, 2012, p. 365). Runnqvist & Costa (2012) replicated this model to assess the reliability and theoretical implications of this.
Both Miller and Rothman (2020) and Kim and Kim (2022) used different theories to attempt to find causes of attrition. Miller and Rothman (2020) applied the Equilibrium Hypothesis (Iverson & Miller, 2017), which argues that language attrition and maintenance may be very closely related, using online and offline methods in an attempt to isolate the causes of attrition. Similarly, Kim and Kim (2022) investigated this following the Weaker Links Hypothesis (Gollan, et al., 2008). This claims that as bilinguals speak less of their languages than monolinguals do, the infrequent contact “[weakens
between forms and meanings, ultimately leading to language loss” (Kim & Kim, 2022, p. 539).
the links]
As demonstrated, many theories have been applied to the research of attrition, and this trend seems to apply to the types of methods employed as well. The majority of discussed articles used controlled tasks to elicit targeted speech from participants, such as eliciting minimal pairs with flashcards, as used by de Leeuw et al. (2018). This was used to investigate the phonological attrition of light /l/ and dark /l/ in late bilinguals.
Mayr et al. (2012) used a similar task to compare a set of twins by recording them producing isolated plosives and vowels in order to compare voice onset times (VOT). Other controlled tasks included picture naming tasks to measure lexical retrieval ability in Chinese and Russian children (M = 12 years) who emigrated to Korea (Kim & Kim, 2022), and to compare learners who ranged in proficiencies, replicating a previous study (Levy et al., 2007) to assess its reliability (Runnqvist & Costa, 2022). Another form of controlled task was used by Schmid and Jarvis (2014) who used two semantic verbal fluency tasks to assess lexical attrition of German in two adult groups who had emigrated to The Netherlands
and Anglophone Canada. Finally, Kang (2013), in the only longitudinal data collection study of the collection, used two production tasks. These tasks were repeated 15 times over a oneyear period to elicit irregular past tense and passives, focussing on one particular participant (aged 11;10) who spent two years in the US before returning to Korea. However, there are limits as to how useful controlled tasks are at eliciting attrition. Schmid and Jarvis (2014) and de Leeuw et al. (2018) both acknowledge that free speech tasks may be more beneficial for eliciting attrition as they allow for spontaneous speech. That being said, only three of the studies used this method. In order to compare object expression and verb placement attrition, Flores (2012) employed story re-telling and picture-description tasks to two groups of Portuguese second-generation migrants who had returned to Portugal at different ages (M = 8;4 and 12;6) subsequently losing contact with their other L1. Schmid and Jarvis (2014) also used a story-retelling task to assess lexical attrition in two groups of German attriters, who had emigrated to The Netherlands and Anglophone Canada. Spontaneous speech was also elicited through interviews in Anderssen et al.’s (2018) study
investigating possessives and definite determiners in NorwegianEnglish heritage speakers (ages 70-100 years) who had lost almost all contact with Norwegian. However, Anderssen et al. (2018) failed to disclose the content or length of these interviews.
With regard to hybrid online and offline methods, Miller and Rothman (2020) argue for the use of these methods to assess realtime processes, as well as subsequent outcomes. That being said only two studies made use of this combination. Miller and Rothman (2020) used Event Related potential (ERP) analyses for a picturesentence verification task among two groups of Spanish-English attriters, varying in length of residence to investigate scalar implicatures. This was followed by an offline acceptability task and a non-binary free interpretation task. The only other study to use online and offline tasks employed an eye-tracking-whilst-reading task to measure sensitivity when processing subject pronouns, and a naturalness judgement task to assess interpretations (Chamorro et al., 2016). This was administered to Spanish-English attriters and re-exposed attriters.
It should be noted that three of the studies compared bilingual performance to that of monolinguals (Chamorro et al., 2016; Schmid & Jarvis, 2014; de Leeuw et al., 2018). Crucially, Miller and Rothman (2020) raise the concept of the ‘bi/multilingual turn’ (Ortega, 2013). This notion calls to question the accuracy of comparing multilinguals to monolinguals, considering that multilingualism is not an accumulation of monolingual acquisition (Rothman and Iverson, 2010). They therefore advocate for “a more precise and accurate measure of multilingual competence” (Rothman and Iverson, 2010, p. 33), eliminating the influence of monolingual bias.
All of these studies carried out quantitative analyses of the results, and all used inferential statistics, apart from Kang (2013) and Mayr et al. (2012), presumably as these studies focussed on comparing very small samples of siblings. Despite this, both studies discussed relevant findings, though these are difficult to generalise due to sample size.
Three of the studies revealed language input as a likely factor of L1 attrition. Higher L2-L1 input ratio negatively affected word naming accuracy in Kim & Kim’s (2022) study; Miller and Rothman (2020) found bilinguals who relied on more types of L2 input were less sensitive to incorrect scalar implicatures. Finally, Flores (2012) discovered that a lack of L1 input caused German attriters to transfer their Portuguese null object onto their German. This also meant that CLI may have occurred. Crosslinguistic influence also seemed to occur in Anderssen et al.’s (2018) study whereby some Norwegian-English heritage speakers overused English-like structures (CLI) but the majority overused Norwegianlike structures (CLO) in their interviews. Anderssen et al. (2018) also attempted to link these findings to proficiency, however, a proficiency test was never carried out on the participants, so this conclusion should perhaps be made cautiously. Another crosslinguistic process was reported by Mayr et al. (2012) where the twin who immigrated to the UK pronounced her Dutch vowels with high F1 values, which has been reported as evidence of CLA.
Interestingly, a discrepancy has emerged within the findings:
Kim and Kim (2022) concluded that length of residence in the L2 country was a predictor for attrition, although Schmid and Jarvis (2014) concluded that it was not. Perhaps this is a variable that needs further research to determine its involvement in attrition. Age of L2 acquisition was also not found to be a predictor (Kim & Kim, 2022), and reflecting on the range of participant ages in the studies, this seems reasonable. Furthermore, Miller and Rothman (2020) claim that L2 social networks and a younger age of arrival affect L1 attrition.
Both Schmid and Jarvis (2014) and Mayr et al. (2012) conclude that it is still unknown why some individuals and areas of pronunciation are more prone to attrition than others. De Leeuw et al. (2018) made an interesting contribution to this, considering the finding that, for phonological attrition, three of the ten bilinguals in the study did not show any signs of attrition. On the one hand, this could inspire further research into comparing the same participants in different areas of language that may have been interrupted by attrition. However, as acknowledged by the authors, this study consisted only of a controlled task, and that the use of free speech
tasks may have provided some more insightful occurrences of attrition.
Meanwhile, Runnqvist and Costa (2012, p. 347) highlight the importance of replication studies as the results showed that “repeated production of words in a non-dominant language [enhanced] the memory for the translation words in the dominant language”, which did not reflect Levy et al.’s (2007) original study. This further highlights the complexity of attrition, in that findings cannot always be replicated across studies.
Kang (2013) proposed a revised model of CLI that has two potential directions, following the finding that their subject’s dominant language shifted after returning to Korea, transferring the Korean null-subject onto his English. Miller and Rothman (2020, p. 869) also make the brief remark that crosslinguistic effects “are not unidirectional” which further calls to question Hulk and Müller’s (2000) original CLI proposal. Perhaps a development of Kang’s (2013) revised proposal, using different language pairings, would further strengthen this model.
In Chamorro et al.’s (2016) investigation of whether re-exposure can diminish attrition effects, it appeared that monolinguals and reexposed attriters were sensitive to incorrect pronominal subjects but other attriters were not. Findings from this study supported both the Interface Hypothesis and the ATH which should be explored more in order to gain a further understanding of if/how attrition can be completely reversed.
Considering all the findings obtained from this collection of studies, we can draw together some final remarks. Firstly, it seems that factors affecting attrition are likely to include language input (Flores, 2012; Kim & Kim, 2022), L2 social network and age of arrival (Miller & Rothman, 2020). Secondly, it still seems unclear in what part of language attrition may occur, with no clear patterns appearing in multiple studies, in this review at least. In terms of methods, it seems clear that free speech tasks (de Leeuw et al., 2018; Schmid & Jarvis, 2014) and combined online and offline methods (Miller and Rothman, 2020) should be used in future research. Finally, future research in SLA might consider the concept of the bi/multilingual turn (Ortega, 2013) and its
applications to the wider applied linguistic field.
Anderssen, M., Lundquist, B., & Westergaard, M. (2018). Crosslinguistic similarities and differences in bilingual acquisition and attrition: Possessives and double definiteness in Norwegian heritage language. Bilingualism: Language and Cognition, 21(4), 748-764. doi:10.1017/S1366728918000330
Chamorro, G., Sorace, A., & Sturt, P. (2016). What is the source of L1 attrition? The effect of recent L1 re-exposure on Spanish speakers under L1 attrition. Bilingualism: Language and Cognition, 19(3), 520-532. doi:10.1017/S1366728915000152
De Leeuw, E., Tusha, A., & Schmid, M. (2018). Individual phonological attrition in Albanian–English late bilinguals. Bilingualism: Language and Cognition, 21(2), 278-295. doi:10.1017/S1366728917000025
Flege, J. E. (1995). Second Language Speech Learning: Theory, Findings, and Problems. In W. Strange (Ed.), Speech Perception and Linguistic Experience: Issues in CrossLanguage Research (pp. 233-277). York Press.
Flores, C. (2012). Differential effects of language attrition in the domains of verb placement and object expression. Bilingualism: Language and Cognition, 15(3), 550-567.
doi:10.1017/Sl1366728911000666
Gallo, F., Bermudez-Margaretto, B., Shtyrov, Y., Abutalebi, J., Kreiner, H., Chitaya, T., Petrova, A., & Myachykov, A. (2021). First Language Attrition: What It Is, What It Isn’t, and What It Can Be. Frontiers in Human Neuroscience, 15, 1-20.
Gollan, T. H., Montoya, R, I., Cera, C. & Scandoval, T. C. (2008). More use almost always means a smaller frequency effect: Aging, bilingualism, and the weaker links hypothesis. Journal of Memory and Language 58(3), 787-814.
https://doi.org/10.1016/j.jml.2007.07.001
Hulk, A., & Müller, N. (2000). Bilingual first language acquisition at the interface between syntax and pragmatics. Bilingualism: Language and Cognition, 3(3), 227–244.
James, M. A. (2012). Cross-Linguistic Influence and Transfer of Learning. In N. M. Seel (Ed.), Encyclopedia of the Sciences of Learning (pp. 858-861). Springer. 114
Kang, S. (2013). The role of language dominance in crosslinguistic syntactic influence: A Korean child's use of null subjects in attriting English. Bilingualism: Language and Cognition, 16(1), 219-230. doi:10.1017/S1366728912000545
Kim, K., & Kim, H. (2022). Sequential bilingual heritage children's L1 attrition in lexical retrieval: Age of acquisition versus language experience. Bilingualism: Language and Cognition, 25(4), 537-547. doi:10.1017/S1366728921001139
Kupisch, T. (2014). Adjective placement in simultaneous bilinguals (German-Italian) and the concept of cross-linguistic overcorrection. Bilingualism: Language and Cognition, 17(1), 222-233. doi:10.1017/S1366728913000382
Levy, B. J., Mc Veigh, N., Marful, A., & Anderson, M. C. (2007). Inhibiting your native language: The role of retrieval-induced forgetting during second-language acquisition. Psychological Science, 18(1), 29–34.
Mayr, R., Price, S., & Mennen, I. (2012). First language attrition in the speech of Dutch–English bilinguals: The case of monozygotic twin sisters. Bilingualism: Language and Cognition, 15(4), 687-700. doi:10.1017/S136672891100071X
Miller, D., & Rothman, J. (2020). You win some, you lose some: Comprehension and event-related potential evidence for L1 attrition. Bilingualism: Language and Cognition, 23(4), 869883. doi:10.1017/S1366728919000737
Ortega, L. (2013) SLA for the 21st Century: Disciplinary Progress, Transdisciplinary Relevance, and the Bi/multilingual Turn. Language learning: A journal of research in language studies, 63
Rothman, J. & Iverson, M. (2010). Independent multilingualism and normative assessments, where art thou? In M. CruzFerreira (Ed.), Multilingual Norms (pp. 33-50). Peter Lang.
Runnqvist, E., & Costa, A. (2012). Is retrieval-induced forgetting behind the bilingual disadvantage in word production?
Bilingualism: Language and Cognition, 15(2), 365-377. doi:10.1017/S1366728911000034
Schmid, M. (2008). Defining language attrition. Babylonia 2, 9–12.
Schmid, M., & Jarvis, S. (2014). Lexical access and lexical diversity in first language attrition. Bilingualism: Language and Cognition, 17(4), 729-748.
doi:10.1017/S136672891300077
Hannah Roddy 3 year
Mini-systematic review of Working Memory in Bilingualism/ L2 learners
Introduction:
Working memory has been described as a “temporary storage system” and a type of interactive processing aiding in the retrieval and processing of information within our short-term memory (Wen, 2016), (Martin, Jaime, Ramos, & Robles, 2021). It is composed of four subsections. Those being the central executive which oversees attentional control, the phonological loop which handles auditory processing, the visuospatial sketchpad to store both visual and spatial information, and lastly the episodic buffer, which was later proposed to store visual and verbal coding as well as material quantities (Baddeley, 2003).
Working memory’s relationship with language learning and language use has been a topic of extensive research specifically in regard to bilingualism. Barker & Bialystok (2019) suggested that bilingualism can enhance certain executive controls, but do these
enhancements transcend into working memory capacities? The aim of this mini-systematic review is to explore the research conducted within working memory and bilingualism/L2 learners from the journal Bilingualism: Language and Cognition between 2017 and 2022. This will be done by analysing what theories and hypotheses were constructed throughout research as well as the method used, and general findings discussed throughout.
Theories:
When investigating earlier research in this field, a range of theories and models were discussed. A common theme was the discussion of the working memory model. Baddeley’s (2003) working memory model was discussed to form a foundation of research by Morrison, Kamal, Le & Taler (2020) to assist in gaining an initial understanding of how working memory operates and which subsets oversee certain cognitive functions. This model later informed the decision of which task should be administered to target working memory. Similarly, relationships between the phonological loop and language acquisition were discussed regarding working memory and second language acquisition
(Atkins & Baddeley, 1998) by Morrison & Taler (2022) when referencing its controls over attention and problem-solving. Blom, Kuntay, Messer, Varhagen & Leseman (2014) was referenced by Cockcroft, Wigdorowitz, & Liversage (2017) to explore how bilinguals typically outperformed monolinguals when working memory demands were expanded for both verbal and visuospatial processing. This was further research addressing the working memory model (Baddeley, 2003). A second common area of literature covered was cognitive variables. Wamington, Kandru-Pothineni & Hitch (2018) discussed the concept of learning being concerned with the acquisition of skills and knowledge. Learning is shown to be enabled by cognitive controls such as executive processes (Abrahamse, Braem, Notebaert, & Verguts, 2016). This was similarly discussed in Yu & Dong’s (2021) research on the Dynamic System theory which bases the role of interaction around variables becoming a crucial part of motivation for development. Other cognitive variables explored within their topic include monolingual readers’ ability to subcategorize features (Van Gompel & Pickering, 2001). This was
noted by Brothers, Hoversten, & Traxler (2021) as they aimed to test if this differs for bilinguals and how it affects working memory performance. Continuous research has been performed throughout this field on whether bilinguals have underlying advantages compared to monolinguals. Following this, there are also texts which explore whether or not interpreting students have preexisting enhancements prior to training in comparison to translation students (Babcock, Capizzi, Arbula, & Vallesi, 2017). In Nour, Struys & Stengers (2020) research exploring this showed none. Kuperberg & Jaegar (2016) were referenced by both Coulter et al (2020) and Ito, Corley, & Pickering (2017), who explore different aspects of working memory’s effects on bilingualism. Ito focused on how constructs are made by participants which can aid in the prediction of what may be to come. Coulter et al (2020) was mainly focused on how N400 amplitudes reflect working memory functions. It was discussed that N400 can make identifying semantic access within language comprehension easier. Other ways of measuring neural activity were also important within this topic. Kok (2001) was cited by Morrison, Kamal, & Taler (2019)
regarding P300 latency scores. These scores measure the processing speed of information which is believed to be increased within bilinguals. This was suggested to be because of a higher number of cognitive resources.
Methods:
Electroencephalography (EEG) was a common practice within the research of working memory and bilingualism (Coulter, et al., 2020), (Morrison & Taler, 2022), (Morrison, Kamal, & Taler, 2019), & (Morrison, Kamal, Le, & Taler, 2020). It was used to track brain activity when completing certain working memory tasks such as the following: both forwards and backwards digit span tasks, letter and number sequencing tasks, Stroop tasks, Wisconsin card sorting tasks, Boston naming tasks and the written and verbal digit substitution subset of the Wechsler adult intelligence scale-III. However, Coulter et al (2020) administered fewer of these tasks. EEG was used to help examine how bilingualism directly affects working memory (Morrison, Kamal, & Taler, 2019) as well as the differences in neural activity between monolinguals and bilinguals (Morrison, Kamal, Le, & Taler, 2020). The effects of other features
such as linguistic distance (Morrison & Taler, 2022) and semantic context (Coulter, et al., 2020) on enhancements to working memory for bilinguals were also analysed through this process. Throughout the EEG testing, most participants were in the 18 to 30-year-old age group and all were university students.
Eye tracking was also an important part of data collection for research carried out on this topic. Both Brothers, Hoversten, & Traxler (2021) and Ito, Corley, & Pickering (2017) used the Eyelink 1000 software within their research to explore whether working memory had an effect on sentence processing for bilinguals (Brothers, Hoversten, & Traxler, 2021) as well as whether proficiency and cognitive load affect predictive eye movement (Ito, Corley, & Pickering, 2017). Both studies recruited university students who were either native English-speaking monolinguals or late bilinguals. While both were tracking eye movement, the tasks used to measure working memory were completely different for both studies. Brothers, Hoversten & Traxler (2021) had participants complete an individual differences test battery including the forward digit span task and an operation
task-specific to working memory. Ito, Corley & Pickering (2017) focused more on eye movement when faced with auditory and visual stimuli.
The effects of interpreting on working memory were explored by both Nour, Struys, & Stengers (2020) and Yu & Dong (2021). In these research papers, forwards, backwards and sequencing digit span tasks were administered as well as reading span tasks. Experiment procedures differed according to the slight differences in research topics. The research focused on interpreting training’s effects on working memory administered an additional LEAP-Q to measure the proficiency of participants (Nour, Struys, & Stengers, 2020). Research on the relationship between interpreting competence and training administered the listening span task, TEM 4, TEM 8 and a CI performance task (Yu & Dong, 2021). There was a vast difference in participants within these studies. Yu & Dong (2021) focused on Chinese undergraduate students pre- and post-interpreting masters courses while Nour, Struys & Stengers (2020) compared interpreting students with translation students prior to and after training, as well as later comparing them to
interpreting professionals.
Bilingualism’s effects on working memory were also studied by Wamington, Kandru-Pothineni, & Hitch (2018) and Cockcroft, Wigdorowitz, & Liversage (2017). Both had participants consisting of monolinguals and bilinguals which complete digit recall, nonword recall, listening recall, dot matrix task, block recall, odd one out task and special recall. Cockcroft, Wigdorowitz & Liversage (2017) did, however, carry out further testing consisting of automated working memory assessments, word recall, counting recall, backwards digit recall, mazes memory task and the Mister X task. Their research differed method-wise due to slight variance in topics, as Cockcroft, Wigdorowitz and Liversage’s study concerns multilinguals as well as bilinguals. While Wamington, KandruPothnineni & Hitch (2018) were also focused on whether bilingualism creates advantages within working memory capacities, they were also exploring if these advantages translated into novel word learning.
In half of the studies discussed in this mini systematic review, results suggest that working memory and bilingualism are indeed related somehow. When exploring different neural activities between monolinguals and bilinguals, it was shown that bilinguals do demonstrate enhanced working memory capacities and other cognitive processes such as inhibition control (Morrison, Kamal, Le, & Taler, 2020), (Wamington, Kandru-Pothineni, & Hitch, 2018). Bilinguals have different processes by which they retrieve information to monolinguals (Morrison, Kamal, Le, & Taler, 2020). This could be due to working memory’s role within language competence. Results also showed that language experience is directly related to working memory capacities as larger amounts of experience correlated with larger capacities (Yu & Dong, 2021). Similarly, when putting this research in the context of interpreting training, it was shown that working memory was also related to improvement within this setting (Nour, Struys, & Stengers, 2020). Monolinguals did show a larger N2 score when completing working memory tasks, showing a greater amount of effort needed to complete certain cognitive functions (Morrison & Taler, 2022).
This was suggested to be a difference within processing taking place within the phonological loop subsection of working memory.
On the other hand, the other half of this research typically showed a lack of contrast between working memory within bilinguals compared to monolinguals. It was commonly demonstrated that the monolinguals and bilinguals had no significant differences in working memory use (Brothers, Hoversten, & Traxler, 2021), (Morrison, Kamal, & Taler, 2019), (Cockcroft, Wigdorowitz, & Liversage, 2017). In more specific areas of research conducted there was a greater relationship between executive functions in regard to subcategorization, novel word learning and multilinguals than there were relationships for working memory (Brothers, Hoversten, & Traxler, 2021), (Cockcroft, Wigdorowitz, & Liversage, 2017), (Wamington, Kandru-Pothineni, & Hitch, 2018). This could suggest that working memory plays a larger role in generalised research while more specific areas are overseen by differing cognitive functions.
More specific research conducted around semantic context and
eye tracking related to cognitive load also showed limited differences between monolinguals and bilinguals (Coulter, et al., 2020) (Ito, Corley, & Pickering, 2017).
Working memory was shown to delay certain predictive eye movements as more cognitive resources were needed to complete certain tasks within the experiment. However, this was common throughout both bilinguals and monolinguals showing no significant difference related to bilingualism (Ito, Corley, & Pickering, 2017). While it was found bilinguals do benefit from certain semantic contexts, there was no significant N400 effect portrayed with working memory (Coulter, et al., 2020). When testing semantic context’s relationships with bilingualism and working memory, it was suggested it may differ for an older participant pool or experimenting with participants who have hearing disabilities, and research should be carried out specifically catered to this.
Overall, there is an extensive amount of research surrounding working memory in bilingualism and L2 learners. From recent research, we can assume that there are differences between monolinguals and bilinguals in regard to working memory capacities. However, it is unclear which specific subset of these capacities is expanded due to language learning. I would suggest that going forward, research should be conducted with older participant pools in order to see if age is a variable affecting working memory within a bilingual setting. If another minisystematic review were to be completed, I would draw from multiple journals as sources to further compare methodologies and findings across a larger scale.
References:
Abrahamse, E., Braem, S., Notebaert, W., & Verguts, T. (2016). Grounding cognitive control in associative learning. Psychological Bulletin , 693-728.
Atkins, P. W., & Baddeley, A. D. (1998). working memory and distributed vocabulary learning. Applied Psycholinguistics, 537-552.
Babcock, I., Capizzi, M., Arbula, S., & Vallesi, A. (2017). Shortterm memory imporovment after simultaneous interpretation training. Journal of Cognitive enhancement , 254-267.
Baddeley, A. (2003). Working memory and langauge: an overview. Journal of communication disorders, 198-208.
Barker, R., & Bialystok, E. (2019). Processing differences between monolingual and bilingual young adults on an emoticon nback task. Brain and cognition, 29-43.
Blom, E., Kuntay, A. C., Messer, M., Verhagen, J., & Leseman, P. (2014). The benefits of being bilingual: Working memory in bilingual Turkish-Dutch children. Journal of Experimental Child Psychology , 105-119.
Brothers, T., Hoversten, L. J., & Traxler, M. J. (2021). Bilinguals on the garden path: Individual differences in syntactic ambiguity resolution . Bilingualism: Language and Cognition, 612-627.
Cockcroft, K., Wigdorowitz, M., & Liversage, L. (2017). A multilingual advantage in the components of working memory . Bilingualism: Langauge and cognition, 15-29.
Coulter, K., Gilbert, A. C., Kousaie, S., Baum, S., Gracco, V. L., Klein, D., . . . Phillips, N. A. (2020). Bilinguals benefit from semantic context while perceiving speech in noise in both of their langauges: Electrophisiological evidence from the N400 ERP. Bilingualism: Language and Cognition, 344-357.
Ito, A., Corley, M., & Pickering, M. J. (2017). A cognitive load delays predictive eye movements similarly during L1 and L2. Bilingualism: Language and cognition, 251-264.
Kok, A. (2001). On the utility of P3 amplitude as a measure of processing capacity. Psychophysiology, 557-577.
Kuperberg, G. R., & Jaeger, T. F. (2016). What do we mean by prediction in langauge comprehension. Language & Neuroscience , 32-59.
Martin, L., Jaime, K., Ramos, F., & Robles, F. (2021). declarative working memory: A bio-inspired cognitive architecture proposal. Cognitive system research, 30.
Morrison, C., & Taler, V. (2022). ERP differences between monolinguals and bilinguals: the role of linguistic distance . Bilingualism: Langauge and Cognition , 1-14.
Morrison, C., Kamal, F., & Taler, V. (2019). The influence of bilingualism on working memory event-related potentials. Bilingualism: Language and Cognition, 191-199.
Morrison, C., Kamal, F., Le, K., & Taler, V. (2020). Monolinguals and bilinguals respond differently to a delayed matching-tosample task: An ERP study. Bilingualism: Language and Cognition, 858-868.
Nour, S., Struys, E., & Stengers, H. (2020). Adaptive control in interpreters: Assessing the impact of training and experience on working memory. Bilinguals: language and Cognition, 772-779.
Van Gompel, R. P., & Pickering, M. J. (2001). Lexical guidance in sentence processing: A note on Adams, Clifton and Mitchell (1998). Psychonomic Bulletin & Review 8, 851-857.
Wamington, M. A., Kandru-Pothineni, S., & Hitch, G. J. (2018). Novel-word learning, executive control and working memory: A bilingual advantage. Bilingualism: Langauge and cognition, 763-782.
Wen, E. (2016). Phonological and executive working memory in L2 based speech planning and performance . Langugae learning journal, 418-435.
Yu, Z., & Dong, Y. (2021). The emergence of a complex language skill: Evidence from the self-organization of interpreting competence in interpreting students. Bilingualism: Language and cognition , 269-282.



Introduction:
Today's editorials are more argumentative than ever. This is at least what Westin and Geisler (2002) discovered for British newspaper editorials from the late 20th century by analysing the Corpus of English Newspaper Editorials. They note that editorials became more argumentative because of a shift in the language from narrative styles, such as "reporting verbs" (e.g., comment), to more persuasive styles, such as "suasive verbs" (e.g., demand) (p. 141/146). This is noteworthy, given that newspaper editorials sway public opinion (Greenberg, 2000; Masroor & Ahmad, 2017). According to Greenberg (2000), this role is even more apparent in the advent of political or social instability. Thus, a topic such as Brexit would be highly reported
as it exacerbated polarisation between voters resulting in the Leave and Remain political divisions (Woollen, 2022).
Essentially, editorials consist of opinions that express the political views of the newspapers for which they are written (Kahn & Kenny, 2002) and are crafted to ensure familiarity with their audience (Greenberg, 2000; Fowler, 1991), catering to the readers' expectations. Thus, editorials can demonstrate the political views on Brexit of the newspapers and their readership. These views on Brexit indicate people's ideology, which constitutes "images, concepts and premises" facilitating the interpretation of "social existence" (Hall, 2006, p. 396). Ideology is intrinsic to the Brexit issue because, as Bennett (2019) suggests, discourse throughout the Brexit campaign conveyed opposing ideologies through common themes such as "control vs freedom" (p. 17). Therefore, the political views expressed in editorials may also reveal the ideologies of newspapers.
An investigation into editorials on Brexit is also insightful for Critical Discourse Analysis (CDA), considering that CDA is
interested in how "socio[-]political dominance" is challenged by discourse (Garrett & Bell, 1998, p. 6) and that, as suggested previously, editorials are increasingly persuasive during political or social uncertainty. Current research demonstrates this in Brexit discourse by exploiting the divisive nature of the topic. For example, while investigating a corpus of 88 public addresses of the UK Independence Party, Cap (2019) notes the presence of a conceptual boundary between an 'Us' and 'Them' at the heart of Nigel Farage's speech. This is a rhetorical tactic used to depict insiders (i.e., Us) in a good light and outsiders (i.e., Them) in a bad light. The tactic, alternatively known as a "strategy of polari(s)ation", may be observed through the word choices that negatively or positively evaluate each group or by the groups of words or clauses that make up propositions about each group (van Dijk, 1998, p. 33). This is yet to be explored in editorials on Brexit. Therefore, it is worth investigating the strategy of polarisation in the text (i.e., the "linguistic forms" for analysis, Cook, 2005, p. 1) of editorials because political discourse usually involves references to 'Us' and 'Them' (Wenzl, 2019).
Editorials may also challenge the public's opinions through interpersonal metadiscourse, which constitutes linguistic devices enabling writers to convey their stance. Du Bois and Kärkkäinen (2012) propose that when individuals evaluate something, they take a stance that positions themselves with that subject matter and others during interactions. Considering that editorials adjust their language to meet the readers’ expectations, stance may be expressed with metadiscourse markers, such as hedges (e.g., could), emphatics (e.g., definitely), attitude markers (e.g., surprisingly), relational markers (e.g., you see) and person markers (e.g., we) (Hyland, 2004a; Hyland, 2004b). Currently, there is no research investigating the metadiscourse of Brexit. Research mainly focuses on the ideological themes that emerge in Brexit discourse (see Rone, 2021 on the topic of 'sovereignty' in British newspaper articles & editorials). However, metadiscourse would be a valuable source of inquiry in editorials to see how the newspaper's stance is expressed because microstructures can express ideology (Garrett & Bell, 1998). Therefore, an investigation into these features may indicate the ideologies of newspapers.
Given the increased polarisation that has occurred in possibly the most "divisive" and "hostile" political campaign the UK has seen this century (Moore & Ramsay, 2017, p. 164), the current paper investigates Brexit in editorials. It aims to explore the strategy of polarisation and the metadiscourse markers in the editorials of two opposing newspapers, the Daily Mail (hereon as DML with L denoting Leave) and the Daily Mirror (hereon as DMR with R denoting Remain). DML supports the Leave position as this statement makes clear: "If you believe in Britain, vote Leave" (Daily Mail, 2016, para. 1). Conversely, DMR supports the Remain position as indicated by the statement: "why the Mirror is backing Remain for the sake of our great nations" (Daily Mirror, 2016, para. 1). Considering that the newspapers represent the two sides of Brexit, the researcher is concerned with comparing the language that demonstrates the position of Leave or Remain; thus, the researcher explores the following questions: RQ1: As the Daily Mail and the Daily Mirror represent different positions on Brexit, how do they represent the opposing side?
RQ2: How do the Daily Mail and Daily Mirror newspapers use metadiscourse markers to convey their stance on Brexit?
The current paper takes insight from corpus-assisted discourse analysis, which sheds light on the differential portrayal of sociopolitical topics under investigation in specific societal mediums (Partington & Marchi, 2015). To facilitate this approach, the study adopts the framework of CDA and Du Bois’ (2007) model of stance. Firstly, by marking a relationship between discourse in the media, opinion and ideology, the critical discourse researcher van Dijk (1998) argues that the structure of editorials is affected by the opinions of writers (or newspapers) that are ultimately affected by their ideologies. Because of this, “language use may be ideological” (Richardson, 2007, p. 27). Therefore, CDA reveals the ideological orientation of the newspapers, which assists in answering RQ1. The issue of stance is also relevant because, according to Du Bois’ (2007) stance triangle, taking a stance involves the processes of “evaluation”, “positioning”, and “alignment” (p. 143/144). When a specific referent is evaluated, a
position is made of the individual who made the evaluation. This evaluation is inevitably “compared and contrasted” with the evaluations of others in an alignment process (Du Bois & Kärkkäinen, 2012, p. 440). Although there is no overt ‘other’ in editorials, these processes also occur with editorials as their language aligns with the public’s, making editorials inherently interactive. Thus, to answer RQ2, analysing the metadiscourse in the editorials could reveal the language used to connect the newspapers to their readers.
The analysis is based on 9933 words of what constitutes corpora of 12 DML editorials and 20 DMR editorials (see Appendix A & B for corpora details). These editorials were selected from a specific period, spanning 2016 to 2017, which was motivated by the fact that this period marks an event that triggered a massive shift in British politics, the EU referendum on June 23rd, 2016. The UK has been a member of the EU since 1973 (Koller et al., 2019). Thus, the decision to leave the EU could impact Britain’s relations with the union and the daily lives of those in Britain and other countries of the EU (Woollen, 2022). Therefore, it was likely that
editorial material on Brexit would be abundant to source an empirical investigation. However, several steps had to be fulfilled to conduct the investigation, such as “building a corpus, cleaning and tagging the corpus” (Jones, 2012, p. 78). Because there was no database from which editorials could be retrieved, building the corpora was tedious because the editorials had to be copied and pasted into Microsoft Word directly from the newspapers. Further, the text analysis software Text Inspector (Weblingua Ltd, n.d.) was used (see Appendix C) to assist with the tagging because it automatically codes metadiscourse markers. However, this website merely guided the coding process because it is inconsistent (Bax et al., 2019), as the example in Appendix C shows with must marked as an attitude marker instead of a booster (see Table 3 in Zarza, 2018). Therefore, the tagging mostly involved reading each editorial and individually noting the linguistic features to ensure consistency in the results. The subsequent step adopted the corpus software AntConc (Anthony, 2022) for generating word frequencies using the Word tool and for investigating specific linguistic items in their sentential
Thus far, it has been argued that Brexit increased the polarisation of the British public. With divisive sentiments being demonstrated from the Brexit campaign (see Wenzl, 2019), it was inevitable that the media outlets would convey their position, thereby taking on a partisan role (Moore & Ramsay, 2017, p. 164). One way the editorials of the DML and DMR adopt this role is through their ideological representation of the 'other', which here are those who voted Leave or Remain. Thus, Table 1 demonstrates how the newspapers use labels to refer to 'Them'. DML refers to the supporters of Remain through the labels Bremoaners, Doommongers, Europhiles, Remain campaigners, Remain camp, Remain supporters, and Whingers. Conversely, DMR refers to the supporters of Leave through the labels Leave liars, Brexiteers, Leavers, Leave camp, and The quitters. Fundamentally, these examples are what Molek-Kozakowska and Chovanec (2017) consider as an act of "othering" whereby the differences of others are discursively expressed (p. 3). Therefore, the editorials can distinguish the newspapers they represent from others by engaging in an othering act (i.e., a polarisation strategy). In accomplishing
this, the newspapers can be seen as a reliable source for the readership that aligns with their view on Brexit, be it Leave or Remain.
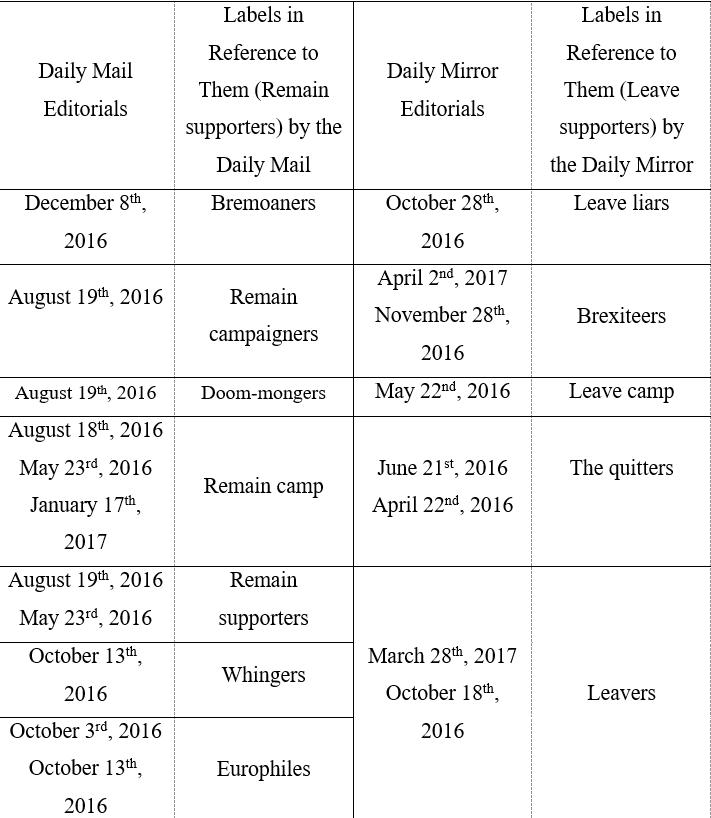 Table 1.
Table 1.
Note. The left-hand column of each newspaper contains the dates of the editorials that contain the labels. These labels are displayed in the right-hand column of each newspaper.
These word choices are important because they express “value judgement(s)” that constitute opinions (van Dijk, 1998, p. 31) and these opinions themselves constitute ideology provided that they integrate “groups and conflicting groups interests” (p. 29). The DML, for example, flouts the interests of the Remain group by using labels such as Bremoaners. According to Macmillan Dictionary (n.d.), the label refers to those who want the UK to remain in the EU. However, it has a more negative connotation than this because moaner denotes someone who complains about something not considered important by others (Cambridge Dictionary, n.d.-c). Accordingly, the DML dismisses the Remain position, as evident in the sarcastic proposition in Example 1. Conversely, the DMR flouts the interests of the Leave group by using labels such as Leave liars. In using this label, the DMR is attempting to draw attention to supposed falsehoods in the arguments of the Leave group, as is apparent in the proposition in
Example 2. These labels could reflect how Brexit discourse is challenged because by conceptualising the opposing side negatively, the editorials dismiss the entire opposing position. In the process of challenging the discourse, it may be that, from a CDA perspective, ideology is expressed to “promote the interests” of groups (Flowerdew & Richardson, 2018, p. 3; see Tables E1 & E2 in Appendix E for more propositions containing labels). Propositions by the Daily Mail and the Daily Mirror:
(1) “ …our grossly disproportionate handouts to the EU’s foreign aid programmes, and the debts owed to us by Brussels rapidly mount up. Indeed, to pluck a figure from the air, you could say they come to well over £50billion. Would the Bremoaners –and Britain’s negotiators – please bear this in mind, before they quote Mr Barnier’s fantasies as gospel?” (Daily Mail, December 21st , 2016)
(2) “People didn’t vote for prices to go up in the shops or the pound to crash, yet that is what we’re getting instead of the mythical £350million a week for the NHS dangled by the Leave liars.”
(Daily Mirror, October 28th , 2016)
Overall, the investigation into these labels demonstrates the emergence of what Lalić-Krstin and Silaški (2019) refer to as “Brexit-induced neologisms” in Brexit discourse (p. 225). LalićKrstin and Silaški (2019) and Lutzky and Kehoe (2019) also discover similar linguistic items through their investigation into Brexit discourse. They both list new word formations derived from the main term Brexit. From a linguistic perspective, Kelly (2016) suggests that the term Brexit, being a blend itself, invited new word formations through prefixes and suffixes. Although the attention is not on the grammatical rules of word formations, these neologisms are important because they perform functions that strengthen the editorial influence, such as involving humour to “mock”, “ridicule”, or “undermine” the opposition (Lalić-Krstin and Silaški, 2019, p. 230, see Tables E1-2 of Appendix E).
It was posited earlier that editorials might also challenge the political opinions of their readers through interpersonal metadiscourse markers. By employing these markers, the editorials reveal how the writer orients to both the content of the writing and the readers (Hyland, 1998, 2004a). Therefore, as discussed earlier, writers form a connection with their readers through intrinsically interactive writing, a sign of the processes that occur when writers take a stance. Considering this, the researcher demonstrates how stance is revealed with examples 1-10 of metadiscourse markers (for more examples, see Tables F1-4 in Appendix F & Tables G1-5 in Appendix G). As AntConc was used to reveal word frequencies for all the types of metadiscourse markers (except for relational markers), the examples below represent the most frequent markers in the editorials of DML and DMR.
Beginning with emphatics, must emerged as the most frequent in the two newspapers. As these markers display confidence and certainty in one’s assertions (Hyland, 1998, 2004a; Zarza, 2018), must serves to strengthen each newspaper’s arguments
on Brexit. However, according to Zarza (2018), the ability of editorials to influence thought decreases with opinion-driven propositions as opposed to fact-driven propositions. Thus, must is being used to validate opinions as knowledge. As example 1 shows, DML attempts to demonstrate their knowledge of the unfavourable position of Remain. Conversely, DMR, in example 2, attempts to shed light on the losses that Britain could face due to the Leave position.
Emphatics:
Daily Mail:
1) “For the increasingly bitter Remainers, these figures must be a huge concern, as they campaign to keep Britain inside the single market.” (December 2nd , 2016)
Daily Mirror:
2) “Whatever the Brexiteers say, we are not going to be able to have our cake and eat it. But we must be careful not to allow our cake to be thrown in the bin before we have even taken a bite.” (April 2nd , 2017)
Unlike emphatics, hedges display less certainty or confidence in one’s assertions (Hyland, 2004a). Similar to the case for emphatics, would emerged as the most frequent in both newspapers, as examples 3 and 4 demonstrate. Both examples attempt to make a statement about the outcome of the opposing vote in a non-committed way, which ultimately decreases accountability for the propositions of the newspapers if the reverse is discovered true (Zarza, 2018).
Hedges:
Daily Mail:
3) “For the first time in over 40 years the British government would be free to decide who should be allowed to cross our borders… ” (October 3rd , 2016)
Daily Mirror:
4) “There is no doubt that breaking the economic partnership with nations across the Channel would inevitably create tremors… ” (May 22nd , 2016)
One of the most frequent attitude markers for DML was embittered, whereas, for DMR, one of the most frequent was important. Essentially, these markers denote the “affective attitude” towards the proposition (Hyland, 1998, p. 444). For instance, example 5 references the ‘other’ negatively with the adjective embittered, as it refers to feelings of anger due to experiencing unfortunate situations (Cambridge Dictionary, n.d.-a). In addition, because the adjective important assigns value and necessity to propositions (Cambridge Dictionary, n.d.-b), example 6 attaches significance to the apparent dangers of Brexit in the hands of the then prime minister, Theresa May. Attitude Markers: Daily Mail:
5) “In another bad day for embittered Remain campaigners, more cheering signs emerged that our post-Brexit future may be far brighter… ” (August 19th , 2016)
Daily Mirror:
6) “We urgently need to take back control of Brexit when the future prosperity and security of our country is far too important a question to be left to an unelected Prime Minister… ” (October 28th, 2016)
The following metadiscourse markers are important as they demonstrate the interactive quality of editorials. That is, person markers include the readers in the arguments of the editorials. For instance, example 7 shows that the possessive determiner our was most frequent in DML, whereas example 8 shows that the firstperson plural pronoun we was most frequent in DMR. Using these markers, the writer assigns a role to others that makes them a part of the proposition (Breeze, 2015; Thompson & Thetela, 1995). Accordingly, the readers of the editorials may be unconsciously persuaded into siding with the arguments that challenge the ‘other’ and, by extension, siding with the Remain or Leave position.
Person Markers:
Daily Mail:
7) “Not for the first time in our history, Britain has lit a beacon to inspire millions across Europe who feel ignored, disdained and oppressed by ruling elites.” (June 30th , 2016)
Daily Mirror:
8) “Brexit deal cannot possibly be everything we hope for – that’s if we get a deal at all. We are not being remoaners, but realists.” (April 2nd , 2017)
Relational markers are another way the editorials channel the readers’ position on Brexit because the markers actively draw the attention of or incorporate readers in the text through linguistic devices such as questions, pronouns, and imperatives (Hyland, 1998; Le, 2004). Both examples 9 and 10 demonstrate this with second-person pronouns in the phrases you could say and you can hear. The presence of you is notable because this pronoun is typically associated with casual language. However, Breeze (2015) notes a shift to informal language in media discourse while
discussing a corpus of The Guardian's editorials. Although there are many reasons for this change (see Talbot, 2007), it generally indicates the persuasive function of making the readers a part of the arguments in editorials.
Relational Markers:
Daily Mail: 9) “you could say they come to well over £50 billion.” (December 21st , 2016)
Daily Mirror: 10)“You can hear exactly the same conversations… ” (February 1st , 2017)
Overall, the results reveal how the newspapers challenge the political narrative through their editorials. The polarisation strategy and the metadiscourse enable the editorials to refute the arguments or the position of ‘Them’, thereby conveying the newspapers’ ideological position. However, this conclusion is somewhat problematic because the language used may not necessarily
represent the true nature of their ideology despite the idea that opinions are affected by ideology. As van Dijk (1998) claims, opinions conveyed result from the attitudes of groups arranged by ideologies. Thus, the fundamental question is what occurs when ideology meets text because, as Hall (2006) argues, ideology and language are two separate constructs. Two ideologies may be expressed in the same language (e.g., the socialist notion of freedom differs from the liberal notion of freedom, p. 396). Furthermore, having revealed the language in the editorials, one might expect that this suggests something about the genre of newspaper editorials, contributing to the Genre Analysis field as it is interested in revealing the language commonly used in specific types of text (Biber, 2010; Jones, 2012). However, because the data comprises a small number of editorials from a specific period based on a specific topic, it cannot be confirmed whether the results represent editorials or are purely coincidental. As Jones (2012) states, making generalisations is more feasible when the data size increases. Therefore, the researcher calls on other researchers to expand on this study by analysing more newspaper editorials on
different socio-political topics.
Conclusion:
This study conducted a comparative investigation into the editorials of DMR and DML to reveal the language associated with Brexit. From a CDA perspective, this was important because editorials are powerful mechanisms for channelling public opinion. It was thought that the newspapers would exercise this by using polarisation strategies. Accordingly, the paper demonstrates the use of labels associated with the ‘other’ (e.g., Bremoaner). This is a noteworthy finding given that new word formations have emerged in media discourse on Brexit, displaying creative use of language to influence readers (Lalić-Krstin & Silaški, 2019). In addition, the paper also reveals how editorials connect the readers in their arguments using metadiscourse markers. In particular, the interactive markers (e.g., relational markers) highlight a shift towards informalisation in media discourse (Breeze, 2015). However, as posited earlier, it cannot be confirmed whether such results are generalisable; thus, more research is necessary.
References:
Anthony, L. (2022). AntConc (Version 4.0.5) [Computer Software]. Tokyo, Japan: Waseda University. Available from https://www.laurenceanthony.net/software
Bax, S., Nakatsuhara, F., & Waller, D. (2019). Researching L2 writers’ use of metadiscourse markers at intermediate and advanced levels. System, 83, 79–95.
https://doi.org/10.1016/j.system.2019.02.010
Bennett, S. (2019). Values as tools of legitimation in EU and UK Brexit discourses. In V. Koller, S. Kopf & M. Miglbauer (Eds.), Discourses of Brexit (pp. 17-31). Routledge.
Biber, D. (2010). What can a corpus tell us about registers and genres? In A. O’Keeffe & M. McCarthy (Eds.), The Routledge Handbook of Corpus Linguistics (pp. 241-254). Routledge.
Breeze, R. (2015). “Or so the government would have you believe”: Uses of “you” in Guardian editorials. Discourse, Context & Media, 10, 36–44.
https://doi.org/10.1016/j.dcm.2015.07.003
Cambridge Dictionary. (n.d.-a). Embittered. In Cambridge Dictionary.com. Retrieved January 5, 2023, from https://dictionary.cambridge.org/dictionary/english/embittered Cambridge Dictionary. (n.d.-b). Important. In Cambridge Dictionary.com. Retrieved January 5, 2023, from https://dictionary.cambridge.org/dictionary/english/important Cambridge Dictionary. (n.d.-c). Moaner. In Cambridge Dictionary.com. Retrieved January 5, 2023, from https://dictionary.cambridge.org/dictionary/english/moaner Cap, P. (2019). ‘Britain is full to bursting point!’: immigration themes in the Brexit discourse of the UK Independence Party. In V. Koller, S. Kopf & M. Miglbauer (Eds.), Discourses of Brexit (pp. 69-85). Routledge. Cook, G. (2005). The discourse of advertising. Taylor & Francis eLibrary.
Daily Mail. (2016, June 22). DAILY MAIL COMMENT: If you believe in Britain, vote Leave. Lies, greedy elites and a divided, dying Europe - why we could have a great future outside a broken EU.
https://www.dailymail.co.uk/debate/article-3653385/Liesgreedy-elites-divided-dying-Europe-Britain-great-futureoutside-broken-EU.html
Daily Mirror. (2016, June 22). Why the Mirror is backing Remain for the sake of our great nations.
https://www.mirror.co.uk/news/uk-news/mirror-backingremain-sake-great-8251613
Du Bois, J. W. (2007). The stance triangle. In R. Englebretson (Ed.), Stancetaking in discourse: Subjectivity, evaluation, interaction. (pp. 139-182). John Benjamins Pub.
Du Bois, J. W., & Kärkkäinen, E. (2012). Taking a stance on emotion: affect, sequence, and intersubjectivity in dialogic interaction. Text & Talk, 32(4), 433–451.
https://doi.org/10.1515/text-2012-0021
Flowerdew, J., & Richardson, J. E. (2018). Introduction. In J. Flowerdew & J. E. Richardson (Eds.), The Routledge Handbook of Critical Discourse Studies (pp. 1-10). Routledge.
Fowler, R. (1991). Language in the news: Discourse and ideology in the press. Routledge.
Garrett, P., & Bell, A. (1998). Media and discourse: A critical overview. In A. Bell & P. Garrett (Eds.), Approaches to media discourse (pp. 1-20). Blackwell Publishers.
Greenberg, J. (2000). Opinion discourse and canadian newspapers: The case of the Chinese “Boat People”. Canadian Journal of Communication, 25(4), 517–537.
https://doi.org/10.22230/cjc.2000v25n4a1178
Hall, S. (2006). The whites of their eyes. In A. Jaworski & N. Coupland (Eds.), The Discourse Reader (2nd ed., pp. 396-406). Routledge.
Hyland, K. (1998). Persuasion and context: The pragmatics of academic metadiscourse. Journal of Pragmatics, 30(4), 437–
455. https://doi.org/10.1016/S0378-2166(98)00009-5
Hyland, K. (2004a). Disciplinary interactions: metadiscourse in L2 postgraduate writing. Journal of Second Language Writing, 13(2), 133–151.
https://doi.org/10.1016/j.jslw.2004.02.001
Hyland, K. (2004b). Disciplinary discourses: Social interactions in academic writing. University of Michigan Press.
Jones, R. H. (2012). Discourse analysis: a resource book for students. Routledge.
Kahn, K. F., & Kenney, P. J. (2002). The slant of the news: How editorial endorsements influence campaign coverage and citizens’ view of candidates. American Political Science Review, 96(2), 381–394.
https://doi.org/10.1017/S0003055402000230
Kelly, J. (2016, June 29). Branger. Debression. Oexit. Zumxit. Why did Brexit trigger a Brexplosion of wordplay? Slate.
https://slate.com/human-interest/2016/06/why-has-brexitsparked-an-explosion-of-wordplay.html
Koller, V., Kopf, S., & Miglbauer, M. (2019). Introduction: context, history and previous research. In V. Koller, S. Kopf & M. Miglbauer (Eds.), Discourses of Brexit (pp. 1-13). Routledge.
Lalić-Krstin, G., & Silaški, N. (2019). ‘Don’t go Brexin’ my heart’: The ludic aspects of Brexit-induced neologisms. In V. Koller, S. Kopf & M. Miglbauer (Eds.), Discourses of Brexit (pp. 222236). Routledge.
Le, E. (2004). Active participation within written argumentation: metadiscourse and editorialist’s authority. Journal of Pragmatics, 36(4), 687–714. https://doi.org/10.1016/S03782166(03)00032-8
Lutzky, U., & Kehoe, A. (2019). ‘Friends don’t let friends go Brexiting without a mandate’: changing discourses of Brexit in The Guardian. In V. Koller, S. Kopf & M. Miglbauer (Eds.), Discourses of Brexit (pp. 104-120). Routledge.
Macmillan Dictionary. (2017). Bremoaner. In Macmillan Dictionary.com. Retrieved January 4, 2023, from
https://www.macmillandictionary.com/dictionary/british/brem oaner
Masroor, F., & Ahmad, U. K. (2017). Directives in English language newspaper editorials across cultures. Discourse, Context & Media, 20, 83–93.
https://doi.org/10.1016/j.dcm.2017.09.009
Molek-Kozakowska, K., & Chovanec, J. (2017). Media representations of “other” Europeans: Common themes and points of divergence. In J. Chovanec & K. MolekKozakowska (Eds.), Representing the Other in European media discourses (pp. 1-22). John Benjamins Publishing Company.
Moore, M., & Ramsay, G. (2017). UK media coverage of the 2016 EU Referendum campaign. King’s College London.
https://doi.org/10.18742/pub01-029
Partington, A., & Marchi, A. (2015). Using corpora in discourse analysis. In D. Biber & R. Reppen (Eds.), The Cambridge Handbook of English Corpus Linguistics (p. 216-234). Cambridge University Press.
Richardson, J. E. (2007). Analysing newspapers: an approach from critical discourse analysis. Palgrave Macmillan.
Rone, J. (2021). “Enemies of the people”? Diverging discourses on sovereignty in media coverage of Brexit. British Politics.
https://doi.org/10.1057/s41293-021-00157-9
Talbot, M. (2007). Media discourse: Representation and interaction. Edinburgh University Press. Weblingua Ltd. (n.d.). Text Inspector. Text Inspector.com.
https://textinspector.com/workflow
Thompson, G., & Thetela, P. (1995). The sound of one hand clapping: The management of interaction in written discourse. Text & Talk, 15(1), 103–128.
https://doi.org/10.1515/text.1.1995.15.1.103
van Dijk, T. A. (1998). Opinions and ideologies in the press. In A. Bell & P. Garrett (Eds.), Approaches to media discourse (pp. 21-63). Blackwell Publishers.
Wenzl, N. (2019). ‘This is about the kind of Britain we are’: national identities as constructed in parliamentary debates about EU membership. In V. Koller, S. Kopf & M. Miglbauer (Eds.), Discourses of Brexit (pp. 32-47). Routledge.
Westin, I., & Geisler, C. (2002). A multi-dimensional study of diachronic variation in British newspaper editorials. ICAME Journal, 26, 133-152.
Woollen, C. (2022). The space between leave and remain: archetypal positions of British parliamentarians on Brexit. British Politics, 17(1), 97–116.
https://doi.org/10.1057/s41293-021-00184-6
Zarza, S. (2018). Hedging and boosting the rhetorical structure of English newspaper editorials. UKH Journal of Social Sciences, 2(1), 41–51.
https://doi.org/10.25079/ukhjss.v2n1y2018.pp41-51
Obama makes case for Britain staying in the EU better than any of our politicians
road lies ahead as the Prime Minister talks tough on Brexit
fool
dismiss the role of the EU in keeping the peace for Britain
means broken unless the PM involves the public, unions, MPs and businesses in her
August 4th , 2016
The Bank of England cutting interest rates shows how quickly Brexit has affected us
https://www.mirror.co.uk/money/voicemirror-bank-england-cutting-8565001.amp
234
July 2nd, 2016
Brexit and the holy grail of 'democracy' has left the country in turmoil
https://www.mirror.co.uk/news/uk-news/brexitholy-grail-democracy-left-8337464
396
February 2nd , 2017
Brexit backlash in store for Theresa May when voters realise it will make little difference to immigration
https://www.mirror.co.uk/news/uk-news/brexitbacklash-store-theresa-voters-9747716
246
April 2nd, 2017
Brexit deal cannot possibly be everything we hope for – that’s if we get a deal at all
https://www.mirror.co.uk/news/politics/brexitdeal-cannot-possibly-everything-10142880
439
February 1st , 2017
MPs still in Brexit bind as MPs face remain backlash
https://www.mirror.co.uk/news/uk-news/voicemirror-mps-still-brexit-9741887
241 Total: 4,856
Appendix
https://textinspector.com/
https://www.dailymail.co.uk/debate/article-4011816/DAILY-MAILCOMMENT-Surely-means-t-stop-Brexit-now.html
Yellow: Emphatics (boosters)
Blue: Hedges
“Surely this means they can’t stop Brexit now
Last night's resounding 372 Commons majority calling on ministers to trigger Brexit before the end of March must surely put the matter beyond doubt.
Indeed, it would be perverse in the extreme if the Supreme Court were now to rule that the timing of withdrawal must go back to Parliament, giving die-hard Bremoaner MPs and unelected peers a chance to sabotage a policy backed by 17.4million voters.
As the court's president Lord Neuberger put it before last night's vote, with studied understatement: 'It would be a bit surprising if the Referendum Act and referendum had no effect in law.'
Acutely, he added that the average person would think it 'a bit odd' if his court ruled that an Act of Parliament was needed to trigger Brexit, after both Houses had, in his own words, 'ceded authority to the people'. Fingers crossed, his fellow judges may yet come to the same conclusion.
Indeed, the real mystery is how 89 MPs had the appalling arrogance to dismiss the public's verdict by voting against the Government last night.
True, with their pretensions to independence – and a Remain majority north of the border – it is perhaps understandable that 51 Scottish Nationalist MPs refused to respect UK voters' demand for Brexit.
But as for the rest, who sit for English and Welsh constituencies, how can they look the electorate in the eye after delivering such an insult to democracy?”

Appendix D: Corpus-Assisted Discourse Analysis in AntConc (Examples of the Daily Mirror Corpus)
Searching Strategies of Polarisation using the Key-Word-In-Context (KWIC) Tool in AntConc.
Searching Strategies of Polarisation using the File Tool in AntConc.
 Figure D1.
Figure D2.
Figure D1.
Figure D2.
Figure D3. Searching Metadisourse Markers using the Key-Word-In-Context (KWIC) Tool in AntConc


Searching Metadiscourse Markers using the File Tool in AntConc

Searching the Frequencies of Metadiscourse Markers using the Word Tool in AntConc.
 Figure D4.
Figure D5.
Figure D4.
Figure D5.
1 Bremoaners
“…our grossly disproportionate handouts to the EU’s foreign aid programmes, and the debts owed to us by Brussels rapidly mount up. Indeed, to pluck a figure from the air, you could say they come to well over £50billion. Would the Bremoaners – and Britain’s negotiators – please bear this in mind, before they quote Mr Barnier’s fantasies as gospel?”
2 Remain campaigners “In another bad day for embittered Remain campaigners more cheering signs emerged that our post-Brexit future may be far brighter than the doom-mongers would have us believe.”
3 Doom-mongers
4 Remain camp
“But don’t such cheering signs cast yet more doubt on the relentless doom-mongering of the Remain camp and its ‘expert’ hangers-on?”
5 Remain supporters
“This suggests that by continuing to fret and carp about the referendum result, Remain supporters are actively damaging their own, as well as Britain’s, financial prospects. They need to get a grip.”
6 Whingers
“Day after day, endless airtime is given to these whingers, who trot out unsubstantiated claims that Britain will fall into an economic abyss if we leave the single market.”
7 Europhiles
“…they suggested, most voters were too stupid, deluded or ‘hate-filled’ to know what they were doing – while only europhiles were clever enough to understand the issues.”
No. of Daily Mirror Example
Lexical Items in Reference to “Them” Propositions (through KWIC)
1
• Leave liars
“People didn’t vote for prices to go up in the shops or the pound to crash, yet that is what we’re getting instead of the mythical £350million a week for the NHS dangled by the Leave liars.”
2
3
• Brexiteers “Whatever the Brexiteers say, we are not going to be able to have our cake and eat it.”
• Leave camp
4
• The quitters
5
• Leavers
“The Leave camp is running out of time to make a coherent case.”
“The quitters are unlikely to gain credibility if they ask their major supporter, Russia’s new Tsar Vladimir Putin, for a public endorsement.”
“The Leavers who won the referendum didn’t vote to lose their jobs…”
Appendix F: Metadiscourse in the Daily Mail Editorials.
Table F1.
Interpersonal Metadiscourse Markers in the Daily Mail Editorials.
“For the increasingly bitter Remainers, these figures must be a huge concern, as they campaign to keep Britain inside the single market.”
“…while only europhiles were clever enough to understand the issues.”
“Indeed, the Brexit victory has inspired dozens of demands for referendums”
“

Of course there will be difficult times ahead, but we will weather them much more successfully if the country rolls up its sleeves and moves forward together.”
“They claim to be standing up for democracy but in fact they are flouting it.”
“Surely this means they can’t stop Brexit now.”
“But don’t such cheering signs cast yet more doubt on the relentless doom-mongering of the Remain camp...”
“In any objective view, it is immediately clear that if money is owing to either side after Brexit...”
“the UK has a far stronger claim to reimbursement than Brussels.”
“Remain supporters are actively damaging their own, as well as Britain’s, financial prospects.”
“For the first time in over 40 years the British government would be free to decide who should be allowed to cross our borders…”
“...more cheering signs emerged that our post-Brexit future may be far brighter than the doom-mongers have us believe.”
“Mrs May announced she would trigger Article 50 of the Lisbon Treaty, which begins the formal process of quitting the EU, before the end of March. Two years later – if not before –we could be out.”
“… with their pretensions to independence – and a Remain majority north of the border – it is perhaps understandable that 51 Scottish Nationalist MPs refused to respect UK voters' demand for Brexit.”
“If only they had offered David Cameron the slightest meaningful reform, the vote might have gone the other way.”
“In another bad day for embittered Remain campaigners, more cheering signs emerged that our post-Brexit future may be far brighter…”
“These arrogant anti-democrats – all members of the self-serving political elite – will try to slow up or torpedo every piece of Brexit legislation.”
“As it was, they suggested, most voters were too stupid, deluded or ‘hate-filled’ to know what they were doing – while only europhiles were clever enough to understand the issues.”
“Remain supporters – led by the Prime Minister –have tried to portray those who want to leave the EU as dishonest, deluded, or downright mad.”
“These contemptible wreckers are in total denial about the referendum result.”
“…also laying out an inspiring vision of Britain’s future after we become an independent sovereign country once more.”
“But don’t such cheering signs cast yet more doubt on the relentless doom-mongering of the Remain camp and its ‘expert’ hangers-on?”
“…die-hard Remainers are already quoting this sum as the received wisdom, as if it had any authority beyond the fevered imagination of Michel Barnier…”
“…isn't
excuse
British-based firms stand to gain handsomely from
“How pathetic, but how typical, that die-hard Remainers are already quoting this sum as the received wisdom…”
“…isn't it contemptible to exaggerate the risks and exploit the uncertainty…”
“…the countries that stay behind in the EU, chained to a backward system collapsing under its bureaucracy, which have more to fear from the future.”
“Chancellor George Osborne sneeringly described Brexit campaigners as a bunch of conspiracy theorists…”
“…Remain supporters are actively damaging their own, as well as Britain’s, financial prospects.”
“Their arrogant message, delivered with an astonishing lack of self-awareness, was that the referendum would only have counted if they, the Remainers, had won.”
“How sickening, but how typical, that this antidemocratic message was echoed at the weekend…”
“Forget, too, that the EU’s accounts are so chaotic and corrupt that its own Court of Auditors has found them ‘materially affected by error’ every year since 1994.”
“Not for the first time in our history, Britain has lit a beacon to inspire millions across Europe who feel ignored, disdained and oppressed by ruling elites.”
“It is emphatically not racist – while acknowledging the huge contribution that migrants have made to this country – to question whether we can cope with the scale of numbers coming in now.”
“Above all, she offers an inspiring vision of the sort of country we can become when unshackled from the sclerotic Brussels machine that has held us back for so long: a Britain that is freer, more outward-looking, more prosperous and stronger than ever before.”
“By contrast, here is Mr Hilton’s positive case for getting out. ‘I believe it is [about] taking back power from arrogant, unaccountable, hubristic elites and putting it where it belongs – in people’s hands.’”
Relational Markers 42
“you could say they come to well over £50billion.” 43
“The next thing you know…”
Metadisco
1 Must 18
“Whatever the Brexiteers say, we are not going to be able to have our cake and eat it. But we must be careful not to allow our cake to be thrown in the bin before we have even taken a bite.”
2 Only 9
“US President-elect Donald Trump’s declaration that Brexit will be successful is hollow, and only a fool could believe a billionaire American speculator would cut Britain a sweetheart deal.”
3 Need to 4
urse Markers No. Examples Freq. KWIC Boosters
“Treasury claims that Britain would be plunged into recession if we quit the EU are worrying calculations that need to be answered by the Leave camp.”
4 Moment ous 3
“And while the full economic impact of this momentous decision has yet to be felt, one thing is clear – we may have voted for a return of sovereignty but nobody voted to be poorer.”
5 Obvious 3
“We were told that would let us “take back control” but it’s obvious that no one is in control or knows how to get it.”
6 Finally 2
“…whoever takes over when David Cameron finally goes will push on blindly with Brexit without a clue what to do.”
7 In truth 1
“Leavers won the referendum by demanding we take back control of a Parliamentary sovereignty that in truth we never lost to Europe.”
8 Let alone 1
“Unelected as Prime Minister by Tory members let alone the nation in a general election, May clearly intends to substitute with spin what she lacks in political legitimacy.”
9 No doubt 1
“There is no doubt that breaking the economic partnership with nations across the Channel would inevitably create tremors which, in the short term at least, may pose a serious threat to jobs, wages, house prices….”
10 Inevitably 1
“…breaking the economic partnership with nations across the Channel would inevitably create tremors…”
11 Merely 1
“Citing role models for Britain in countries as far removed as Albania, Norway, Canada and Switzerland merely muddy the waters.”
Hedges
12 Would 21
“There is no doubt that breaking the economic partnership with nations across the Channel would inevitably create tremors…”
13 May 11
“…breaking the economic partnership with nations across the Channel would inevitably create tremors which, in the short term at least, may pose a serious threat to jobs, wages, house prices, investment, industrial output, financial services and trade.”
14 Could 9
“David Cameron will hit the campaign trail and will warn Brexit could lead to World War Three.”
15 Might 3
You might think Theresa May would resist behaving like a tinpot dictator.
1
“We urgently need to take back control of Brexit when the future prosperity and security of our country is far too important a question to be left to an unelected Prime Minister…”
“…quitting the single market would jeopardise jobs, businesses and risk another fall in the value of the once-mighty pound.”
“Departing the European single market, an institution even Margaret Thatcher considered crucial, disrupting vital trade with our nearest neighbours, is a huge risk.”
“The country voted to leave the EU but, as Tony Blair argues forcefully, it makes no sense to agree to a house swap without first seeing the house you’ll be living in.”
“Brexit means many things to many people yet what is indisputable is May’s cluelessness about what it ultimately means for British jobs, prosperity and security.”
“The Leavers who won the referendum didn’t vote to lose their jobs, reduce the standard of living, destroy public services, jeopardise security and risk Britain’s place in the world.”
1
“…may pose a serious threat to jobs, wages, house prices…”
“Obama may have gilded the lily by declaring Britain would be at the “back of the queue” for US trade deals should we quit Europe but the warning is cataclysmic for the Brexit brigade.”
“Respected world leaders all believe Britain would be mad to turn its back on the EU…”
“The real concern is the Bank’s actions are a temporary dam which may not be able to withstand more torrential forces if the Government cannot negotiate a successful EU withdrawal.”
“Brexit deal cannot possibly be everything we hope for –that’s if we get a deal at all. We are not being remoaners, but realists.”
“Barack Obama makes case for Britain staying in the EU better than any of our politicians could.Voice of the Mirror says it's well worth listening to others when deciding our future on June 23 after the US President's visit.”
“Almost half of us are bracing for an economic slump as we quit the EU – but Brexiteers still have no regrets.”
2 “The choice is ours but it is well worth listening to others.
“You can hear exactly the same conversations…”
“You’d think the senior figures who worked…” 34
“You might think Theresa May would…” 35
“Let’s be honest…” 36
“Let us hope Prime Minister May will be able…”
Introduction
Forensic linguistics is a field of linguistics that deals with the analysis of language in the context of law, either as evidence, which is “the attribution of authorship and the interpretation of meaning”, or as legal discourse (Olsson and Luchjenbroers, 2014, pp.1). Linguist Jan Svartvik is said to be a pioneering Forensic Linguist, after his publication of The Evans Statements: A Case for Forensic Linguistics (1968). In it he analysed a series of statements that were said to have been made to police officers by a man named Timothy Evans, following the death of his wife and child. Svartvik (1968) discovered that the grammatical styles of the statements were different from that of uncontested parts of the statements, making Timothy Evans not guilty (Coulthard et al., 2016).

Language evidence has over the years become an invaluable tool in the criminal justice system, for example in cases of false

confessions such as the Birmingham Six. In this case, six men were accused of bombing pubs in Birmingham which led to false confessions being beaten out of them by police (Coulthard et al., 2016). Forensic linguistics aided in proving their innocence. In this essay, I will critically evaluate the importance and role of linguistic evidence in three specific legal cases, focusing on the linguistic tools used to determine authorship and the difficulties associated with this process, in addition to the way that forensic linguists have addressed them.
Firstly, it is important to understand and define the different types of linguistic tools available for forensic linguists, and secondly to describe how they can be used in legal cases. The forensic linguist’s toolkit contains tools such as phonological, morphological, syntactical, lexical, pragmatic and discoursal analysis (Coulthard et al., 2016, pp.121), all of which can help forensic linguists to “measure the ‘rarity’ and therefore the evidential value of individual expressions, or how one can assess the reliability of verbal memory” (Coulthard et al., 2016, pp.6).
Coulthard et al. (2016) describe forensic linguistics as a fastgrowing subfield of linguistics, which has received attention in many legal cases.
The first case that will be discussed is the case of the Unabomber. Between 1979 and 1995, the Unabomber, later revealed to be a man named Ted Kaczynski, delivered and mailed explosives to academics and corporate executives involved in technology development (Solan and Tiersma, 2005). The explosive devices ultimately killed three people and injured several others. His identity was discovered after he published a 35,000-word manifesto entitled ‘Industrial Society and Its Future’, which Ted Kaczynski’s brother read about and believed it to be written by him. The case was conducted by FBI special agent, James Fitzgerald, who conducted a stylistic comparison of letters sent by the Unabomber to documents known to have been written by Ted Kaczynski (Solan and Tiersma, 2005). The tool of corpus analysis was used by Fitzgerald to discover that both the Unabomber and Kaczynski
commonly spelt words unconventionally, such as the use of the British spelling of ‘licence’ instead of the American spelling. Additionally, syntactic analysis was utilised to compare the similar grammatical filler expressions used in both documents, including “take the liberty of” and “at any rate” (Solan and Tiersma, 2005). The use of idioms in both documents were also analysed. Interestingly, Fitzgerald found the Unabomber document and a document written by Kaczynski to include the expression “eat one’s cake and have it” instead of the conventional idiom “have one’s cake and eat it” (Solan and Tiersma, 2005, pp.161). It is important to approach this peculiar phrasing with caution however, as this may just be a part of both the Unabomber and Kaczynski’s idiolects. Idiolects are “similarities in the language use of an individual” (Louwerse, 2004, pp.207). These similarities may be down to factors like changes in location and social setting in the individual’s lifetime (Grant, 2020).
Kaczynski believed the FBI’s stylistic comparison was flawed, so he called upon linguist Robin Lakoff, who submitted an affidavit to the FBI also claiming that the FBI’s comparison was flawed
(Solan and Tiersma, 2005). Lakoff argued that attributing authorship to Kaczynski was problematic for a multitude of reasons. Firstly, although some words that the Unabomber and Kaczynski used were similar, many of them are in fact common words that people use every day. Kaczynski, who worked as an academic, and the Unabomber both also used words that are common among academics (Solan and Tiersma, 2005). This means that anyone who works in academia could use this sort of language. Lakoff concluded that the overlap between the vocabulary and grammar used by the Unabomber and Kaczynski is common to that of the average person, denoting that attributing authorship to Kaczynski would be unfair (Solan and Tiersma, 2005).
In response to Lakoff’s input, the government called upon Donald Foster to provide a declaration. Foster declared that he believed the FBI had done a “remarkably careful job” in attributing authorship to Kaczynski, and that we should not dismiss the unmistakable similarities between the texts (Solan and Tiersma, 2005, pp.162). It is important to consider both sides of this argument to avoid wrongful convictions, but Foster addressed this problem by
ensuring the police consider both sides and interpret the linguistic evidence carefully. Furthermore, the police had sufficient nonlinguistic evidence to issue a search warrant and arrest Ted Kaczynski (Solan and Tiersma, 2005).
The second case discussed in this essay that exhibits the challenges that arise with attributing authorship is the case of Derek Bentley. In the 1950s, two teenaged boys, Derek Bentley, aged 19, and Chris Craig, aged 16, were caught climbing onto the roof of a warehouse, armed with a gun. Three unarmed police officers were called to the scene to arrest them. Bentley instantly surrendered, whereas Craig began shooting. Chris Craig ultimately injured one officer and killed a second (Coulthard et al., 2016). Due to Craig being underage at the time of the murder, he was sentenced to life imprisonment. Bentley, however, was sentenced to death, even though he himself did not murder the officer. Linguistic evidence was the main reason behind Derek Bentley’s prosecution and execution. During Bentley’s statement, he tells the
police, “I did not know he was going to use the gun”. The Lord Chief Justice of this case believed this utterance to be of great importance to this case because Bentley said, ‘the gun’ instead of ‘a gun’. The Lord Chief Justice and the jury believed that the way in which he worded this sentence meant that Bentley must have been aware that Chris Craig was in possession of a gun (Coulthard et al., 2016). However, this sentence is contradicted towards the end of Bentley’s statement, as he changes his original sentence to “I did not know Christ had one [gun] until he shot”, thus making Bentley an unreliable witness (Coulthard et al., 2016). One thing we know about Derek Bentley from this case is that he was epileptic, had the mental age of about 11, and could not read nor write (Tuft and Nakken, 2017). With hindsight, attributing authorship to Derek Bentley based solely on this statement quote is problematic, as it may not be a fair representation of what he intended to say and therefore mean.
This was not the only piece of linguistic evidence used to prosecute Bentley. In court, when the police officers were required to give their statements, they declared that Bentley had uttered the
words ‘Let him have it, Chris’, just before Chris Craig shot the police officers (Coulthard et al., 2016, pp.174). Single and dual authorship is a factor that can confound authorship attribution, specifically in this case. The three officers at the trial swore on oath that their statements were of unaided monologue dictation, but Bentley believes that the police had taken their questions and his replies to them, and reported them as monologue (Coulthard et al., 2016, pp.175). Malcolm Coulthard, the linguist of this case, agreed with Bentley that the police statements may not have been ‘verbatim record’. This is due to a section of the statement constituting a ‘meta-narrative’ which can be best explained because of “clarificatory questions about Bentley’s knowledge at points in the narrative” (Coulthard et al., 2016, pp.176). Derek Bentley’s guilty verdict was overturned in 1998, unfortunately after his death (Coulthard et al., 2016), giving us more of a reason to criticise the linguistic evidence used to prosecute him.
The Sandra Weddell caseThe final case discussed in this essay is the case of Sandra Weddell. In 2007, a police inspector named Garry Weddell sought
help from his neighbour to try and find his missing wife, Sandra Weddell. After a short time looking, Sandra was found dead in the garage of her and Garry’s home. She was found with a cable tie around her neck and pronounced dead by asphyxiation (Olsson, 2012). Garry Weddell discovered a printed suicide note next to her body, which was addressed to Garry himself. The police had two candidates for authorship of the note, Sandra Weddell and Garry Weddell. Bedfordshire Police called upon John Olsson, one of the world’s only full-time forensic linguists, to look at the note (Olsson, 2012).
Olsson used pragmatic analysis when analysing the note and discovered many interesting features that helped solve this case. On the alleged suicide note, Sandra Weddell had written her name in full (Sandra Jane Weddell) at the end of the page. Olsson (2012) believed this to be a peculiar feature because it is assumed that Garry would have known who Sandra was just by her first name. Olsson (2012, pp.117) brings up the factor of mode in this instance which refers to the medium of communication, whether this be spoken, written, or dictated (Stockwell, 2007, pp.7, as cited in
Olsson and Luchjenbroers, 2014). He further explains that the type of mode that language is written may differ the way a person uses language. In the case of Sandra’s suicide note, it is typed. Olsson (2012, pp.117) believes that mode was a factor of the authorship of the typed suicide note, as some of it was typed on a laptop, and some was typed on a desktop computer. As these two devices are different in terms of keyboard and mouse, a person may change the way that they write on either device (Olsson, 2012, pp.117). It was important to contemplate this potential factor before jumping to conclusions on the case.
Olsson (2012) also used corpus analysis to break down the note, after he noticed that the average sentence length of the note was just 12 words. When this was compared to previous letters written by Sandra, Olsson (2012) discovered that she wrote much longer sentences, with an instance of her writing over 130 words in one sentence in one of her letters. When this was compared to examples of letters written by Garry, Olsson (2012) discovered that the average sentence length of one of his letters was only 9 words. Olsson (2012, pp.119) concluded that this matter of sentence length
can be narrowed down to a factor that can contribute to variations in our writing style called linguistic fingerprint. Olsson (2012, pp.119) describes this as the idea that we all have a unique, identifiable way of using languages. However, the idea of a linguistic fingerprint in the case of Sandra Weddell must be thought of carefully, due to within author variation and inter-author variation. Within author variation refers to how an individual writer’s language use varies, and this includes factors such as personal circumstances and vocabulary (Olsson, 2012, pp.119). This includes how your vocabulary changes when writing an email to a friend (informal) versus writing an email to a work colleague (formal). Olsson (2012, pp.120) describes inter-author variation on the other hand, as how authors may vary from each other, whether this be similar or different social backgrounds or educations levels for example.
The texts written by both Garry and Sandra that were analysed contain variation, in that different types of texts were used. For example, business letters. However, one of Garry’s analysed texts was a personal email. The texts analysed that were written by
Sandra on the other hand, did not include any of her personal communications. Although this factor contributes to variation between the authors, it makes linguistic fingerprint a complicated factor in assessing her style, as suicide notes are considered a form of personal communications (Olsson, 2012, pp.121). Moreover, Olsson (2012, pp.120) scrutinizes the idea of linguistic fingerprint by illustrating the possibility of an author showing a lot of within author variation, but not a lot of inter-author variation across different authors. Seeking to find differences between these authors would be tough (Olsson, 2012). Interestingly, Olsson (2012) questions the use of convergence of style between the couple’s texts. This is when people, a married couple in this case, adopt each other’s language habits. Olsson (2012, pp.121) later debunked this as he has seen no evidence that married couples start to write like each other, especially in this case.
The challenges of linguistic fingerprint and mode were later backed up by additional evidence that the police had discovered, and Garry Weddell was arrested on suspicion of murdering Sandra Weddell. He was however released on bail. Not even a year later,
Garry was found to have murdered his mother-in-law, before committing suicide, thus finally concluding his guilt (Olsson, 2012).
Conclusion
To summarise, forensic linguistics is an important tool in law and the criminal justice system. As evidenced by the cases discussed above, linguistic evidence has been used to determine authorship, prove innocence, and aid in criminal convictions.
Linguistic tools like phonological, morphological, syntactical, lexical, pragmatic, and discoursal analysis can be used to assess the value of an individual’s speech both in cases of unknown authorship, like in the case of the Unabomber, and in cases of known authorship, like in the Derek Bentley case. However, authorship attribution can be a difficult process, and it is critical to approach the analysis with caution. Forensic linguistics is not a key to solving cases, but the evidence above has shown how it can help. The application of forensic linguistics in legal proceedings continues to grow, develop, and gain attention from around the world.
Reference List
Coulthard, M., Johnson, A., & Wright, D. (2016). An introduction to forensic linguistics: Language in evidence. Routledge.
Grant, T. (2020). Text messaging forensics: Txt 4n6: idiolect-free authorship analysis?. In The Routledge handbook of forensic linguistics (pp. 558-575). Routledge.
Leonard, R. A., Ford, J. E., & Christensen, T. K. (2017). Forensic linguistics: Applying the science of linguistics to issues of the law. Hofstra Law Review, 45(3), 11.
Louwerse, M. M. (2004). Semantic variation in idiolect and sociolect: Corpus linguistic evidence from literary texts. Computers and the Humanities, 38, 207-221.
Olsson, J. (2012). Wordcrime : Solving crime through forensic linguistics. Bloomsbury Publishing Plc.
Olsson, J., & Luchjenbroers, J. (2014). Forensic linguistics. Bloomsbury Publishing.
Solan, L., & Tiersma, P. M. (2005). Speaking of crime the language of criminal justice. University of Chicago Press.
https://doi.org/10.7208/9780226767871
Svartvik, J. (1968). The Evans Statements. University of Goteburg.
Tuft, M., & Nakken, K. O. (2017). The hanging of Derek Bentley, a 19-year-old boy with epilepsy. Epilepsy & Behavior, 76, 136-138.