
An Enhancement of Braille Character Perception Using Deep Learning and Artificial Intelligence Techniques
Ms. A.Varshini 1 , Dr.S. Gopinathan21 M.Phil Research Scholar, Department of Computer Science, University of Madras, Tamil Nadu, India. 2 Professor, Department of Computer Science, University of Madras, Tamil Nadu, India.

Abstract - India is the largest popular country in the world. Due to shortage of vitamins, by birth 1% of the children are born with blindness. Blind people start their career with Braille. Braille makes reading and writingpossibleforvisually impaired people. Braille-to-text translation serves as a bridge between the two worlds. The communicationprocesshasbeen simplified by advances in technology. This research article describes how to convert Braille to English using deep learning. In this work, 26 English Braille Images are used as a dataset after the segmentation process. The proposed method converts braille visuals to English text using convolutional neural network CNN models such as LeNet, VGG-16, DenseNet121, ResNet50, and Inceptionv3. The implemented system Inceptionv3 achieves a high level of prediction accuracy of 92%. Experiments show that the proposed Braille character recognition gives an accurate result.
Key Words: Braille, Deep Learning, Convolutional Neural Network, LeNet, VGG-16, DenseNet121, ResNet50, and Inceptionv3.
1. INTRODUCTION
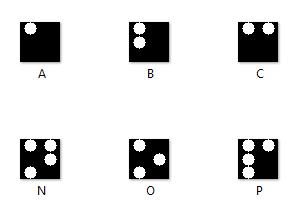
Over 2.2 billion people worldwide are blind or visually impaired, according to the World Health Organization (WHO)[1].Thepeoplehavingimpairmentsofvisionutilize Braille,asystemofpointeddotsthatmaybereadbyfinger contact,asitisdifficultforthemtoreadandwritetext[2].A Braillecellorblockismadeupofsixdotsthatareorganized intwocolumnsandthreerows.Eachdotwithinthecellcan be either raised or not raised, representing different combinationsofdotsthatcorrespondtospecificcharacters. Countingstartsatthetopandgoesdowntothebottom
marks, and even special symbols can be represented in Braille.
Understanding the patterns of raised dots and their correspondingcharactersisfundamentalinrecognizingand interpretingBrailletextaccurately.
Bycombiningdifferentcombinationsofraiseddotswithin thecell,allthelettersofthealphabet,numbers,punctuation
1.1 Challenges
In Braille images, it is challenging to preprocess the imagestoremoveallthenoisethatisintroduced.Afterall the braille cells have been recognized, they need to be translatedinto theappropriate Englishalphabet. Whena singlealphabetisrepresentedbyrecognizedbraillecells, thereisachancethattheymighthavesignificantvariations



Infigure5,therecognizedbraillecellsarelikelytocontain largevariationsrepresentingthesamealphabet.
max-pooling,andfullyconnectedlayersthatlearnhighlevel informationfromlowlevelrepresentations[4].
Inthisstudy,weconstructeda deep CNN model with two keylayers:featureextractionandclassification.Forfeature extraction, the proposed deep CNN networks selected are LeNet,VGG-16,DenseNet121,ResNet50,andInceptionv3.
Dataset:
The standard dataset "Braille Character Dataset" is downloadedtothelocaldirectory"C:BrailleDATASET"from the Kaggle website in order to be used for training and testing the CNN model. According to the English alphabet from"A"to"Z,"theBraillecharacterdatasetwasseparated into26groups.Eachcategoryhasitsownfolder.Themodel takes into account 1560 photos altogether, divided by 26 alphabetfoldersand3uniquefolders.So,eachBraillecell may be recognized in 60 different ways using our trained model. Fig. 6 displays the Sample dataset for category (Directory)'A', whichconsistsof60sets.

1.2
To improve the accuracy of Braille text recognition, it is essential to create a dataset of Braille characters and comparethecollecteddatatoidentifymatchingpatterns.By carefullyanalyzingthedatasetandcomparingittotheinput Brailletext,thatenhanceahigherlevelofprecisioncanbe achievedintherecognitionprocess.Thisapproachenables accurateinterpretationandtranslationofBraillecharacters intoreadabletext.
1.3. Proposed Model:
ThesuggesteddeepCNNmodeliscarefullypresented,and several approaches are addressed. Convolutional neural networks(CNNs)areanartificialneuralnetwork(ANN)type thatarefrequentlyusedforpatternrecognitionapplications. Deep CNN primarily consists of alternative, convolution,
1.4. Proposed model of Algorithm
Python-3wastheprogramminglanguageusedtocreatethe model,whiletheearliestversionofJupyternotebookutilized was6.4.11.AdditionallyutilizedareNumPy,glob,random, Matplotlib,TensorFlow,andKeras,amongothertoolsand libraries.BelowisthemethodfortheBrailleclassifiermodel.
1.SavetheBrailledatasettoalocaldirectoryusingKaggle.
2.CNNmodelarchitectureforimporttransferlearning
3.Imagepreparation.

4. Feature for training, testing and validation and classificationlayers.
5. Add Fully connected layers with softmax and relu activationfunction
6.Compileandfitthemodel
7.Assessthemodel.
Step 1: Create the training, validation, and testing directories in the first stage. Each directory now has 26 directories,eachrepresenting26classesand26alphabets. There are 60 identical photos in each directory. Figure 6 displaysthe60photosindirectory'A'thatarepartofclass 'A'.

Step-2: Equation 1 is used to import the five CNN architectures needed to categorize the multiclass picture. (input_shape="IMAGE_SIZE,""imagenet"weights, "include_top"False)

TheVGG-16modelcomprisesatotalof16convolutionaland fully connected layers, according to a summary of the model'slayers.isdepictedinfig7.
Step-3: Before being fed into the model, each picture is transformedtoanegativeimageusingthecv2package.
Figure 8 displays both the original image and a sample outputnegativeimage.
It is discovered that the original picture size is 28x28. 100x100 is the new image's new foundation size for our model.Thephotosareshowninafigure-8beforeandafter scaling.
Step-4: In step 4, the features from the training, test, and validationdatasetareextractedusingthepredict_generator ()functionandconvertedtoaNumPyarrayasindicatedin equation 2. Dense(len(folders), activation='softmax')(x) = prediction-(2)
Step 5: The final fully linked layer is given a convolution foundation at this point. Initialization of the sequential modelcomesfirst.Flattenlayer,Dense1layer,Dropoutlayer, Dense2layer,andanotherDropoutlayerareallfullylinked
layers that are inserted as the convolution foundation. In these layers, the ReLu activation function was used. The SoftMax activation Dense layer, which has 26 classes, is inserted as the final output layer. Figure 9 displays the summaryoftheConvolutionmodel.
Step6: Step6involvescompilingthemodelwith10epochs and 32 batch sizes. It is important to point out that the system'saccuracyincreaseswitheachtrainingdatasetrun.
2. Methodology:
Afterthetextedithasbeencompleted,thepaperisreadyfor thetemplate.DuplicatethetemplatefilebyusingtheSaveAs command,andusethenamingconventionprescribedbyyour conferenceforthenameofyourpaper.Inthisnewlycreated file,highlightall ofthecontentsandimportyourprepared textfile.Youarenowreadytostyleyourpaper.
2.1 Preprocessing
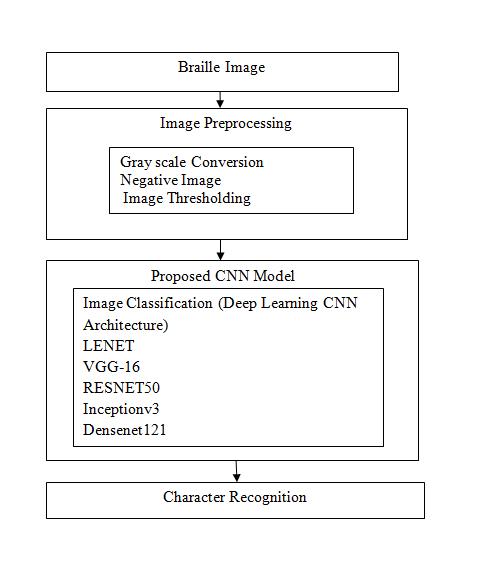
ThetwoprimarystepsofthisBraillecharacterrecognition system are described below. Using image preprocessing techniques,picturealignmentandenhancementarecarried out in the first stage. The suggested convolution neural networkisthenusedtorecognizecharactersinthesecond stage.TheBraillecharacter recognition flowdiagram.
2.1 Proposed Image Classification Method
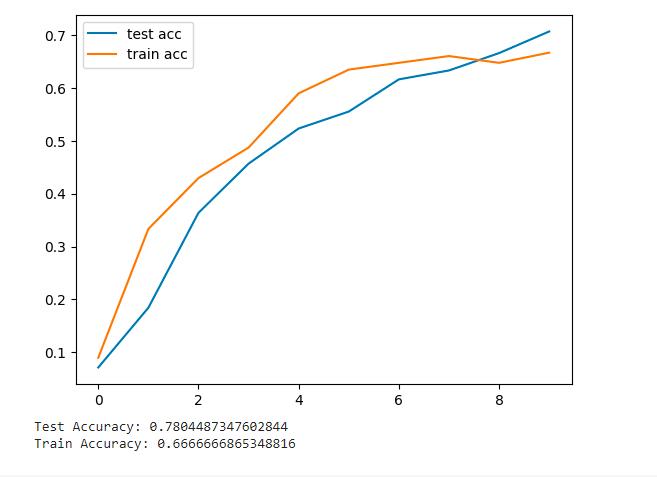
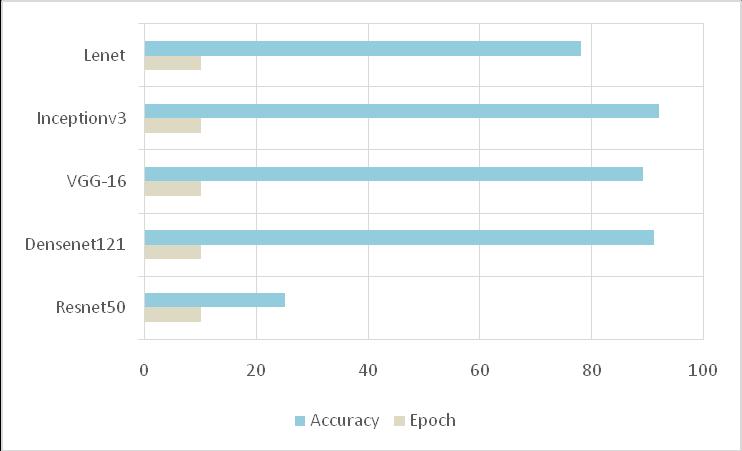
LENET : Oneofthefirstpre-trainedmodelswasLeNet-5[7] Recognizing the handwritten and machine printed characters. LeNet model can achieve a test accuracy of 78.0%.ShowninFigure13.

Classification Layers :
ConvolutionalLayers:ThefirstConv2Dlayerwith6filters andakernelsizeof(5,5)appliesconvolutionaloperationsto theinputimages,extractingvariousfeaturesthroughtheuse oflearnedfilters.
The first MaxPooling2D layer with a pool size of (2, 2) performsdown-sampling,reducingthespatialdimensionsof thefeaturemapsandretainingthemostprominentfeatures. ThesecondConv2Dlayerwith16filtersandakernelsizeof (5, 5) further extracts higher-level features from the previouslyobtainedfeaturemaps.
The second MaxPooling2D layer with a pool size of (2, 2) performs additional down-sampling, further reducing the spatial dimensions and capturing the most important features.
Fully Connected Layers:
FullyConnectedLayers:FlattenlayertoflattentheOutput. Denselayerwith120unitsandReLUactivation.An84-unit dense layer activated by ReLU. Dense layer withnum_ classunits(softmaxactivation).
VGG-16:VGGstandsforVisualGeometryGroup[6]. VGG-16 was used for creating the model and to extract featuresfromtheimages[10].VGG-16modelcanachievea testaccuracyof 89.9%inImageNet.ShowninFig14.
KeyfeaturesoftheVGG-16architecture: Input Layer: The input to the VGG-16 network is an RGB imageofsize224x224pixels.
VGG-16 Base Model:
The VGG-16 base model is loaded using the VGG16 class from Keras with pre-trained weights from the ImageNet dataset. The input_shape parameter specifies the input image size (224x224 pixels) and the number of color channels (3 for RGB). The include_top parameter is set to Falsetoexcludethefullyconnectedlayersatthetopofthe VGG-16architecture.
FreezingLayers:Thecodefreezestheweightsofalllayersin the VGG-16 model to prevent them from being updated duringtraining.Theforloopiteratesthroughalllayersinthe VGG-16modelandsetslayer.trainable=False.OutputLayer: ADenselayerwithasoftmaxactivationfunctionisaddedas theoutputlayer.
INCEPTIONv3: InceptionisalsomuchlowerthanVGGorits higher performing successors. These methods could be applied to optimize the Inception architecture as well, wideningtheefficiencygapagain[5].TheInceptionV3base modelisloadedwithpre-trainedweightsfromtheImageNet dataset.Inceptionmodulethatreducesthegrid-sizewhile expands the filter banks[13]. The base model consists of multiple layers, including convolutional layers, pooling layers, and inception modules. Each Inception module consists of parallel branches of convolutional layers of varyingfiltersizes(1x1,3x3,5x5)andamaxpoolinglayer. Toreducecomputationalcomplexity,InceptionV3employs factorizationtechniquessuchasusing1x1convolutionsto reducethenumberofinputchannelsbeforeapplyinglarger filters.Inceptionv3 model can achieve a test accuracy of 92.8%.showinFig15
This factorization helps in reducing the number of parametersandimprovescomputationalefficiency.
Thisallowsustousetheconvolutionallayersandinception modules as a feature extractor by taking the output from theselayersandfeedingitintocustomclassificationlayers.
DENSENET-121:
DenseNet121standsforDenselyConnectedConvolutional Network-121 [9]. DenseNet121 model can achieve a test accuracyof 91.1% showninFig16
DenseNet-121 promotes feature reuse by allowing information to flow directly from earlier layers to later layers. This reduces the vanishing gradient problem and
encouragesbettergradientflowduringtraining.MultipathDenseNetiscapableofmoreaccuratepredictionswithfewer parameters[12].
Gradient Propagation: The dense connections facilitate gradient propagation by providing shorter paths for gradients to flow through the network during backpropagation.
The gradients computed during backpropagation become extremelysmallastheypropagatefromthehigherlayersto thelowerlayersofthenetwork.Asaresult,theweightsin the lower layers receive minimal updates, which leads to slowornolearninginthoselayers.
TheDenseNet-121architectureconsists ofmultipledense blocks,transitionlayers,andafinalclassificationlayer.
Eachlayerwithinadenseblocktypicallyconsistsofabatch normalization layer, a ReLU activation, and a 3x3 convolutional layer. Layers of transition include batch normalization, 1x1 convolution, and average pooling. The DenseNet121 model with pre-trained ImageNet weights, excludingthetop(classification)layer.Themodelisstored inthevariableDenseNet.
The fully connected layers are defined as: x = Flatten() (DenseNet.Output).
The Flatten layer is used to flatten the output from the previouslayerintoa1-dimensionalvector.Thisflattening operationisnecessarytoconnectthefullyconnectedlayers.
RESNET50: Resnet stands for Residual Network-50 [8].ResNet-50isadeepnetworkarchitectureconsistingof 50layers.ResNeteasestheoptimizationbyprovidingfaster convergence at the early stage [11]. It includes multiple residual blocks with different numbers of filters in each block.TheclassificationlayerusedisaDenselayerwitha softmaxactivationfunction.thefinalclassificationbasedon the extracted features from the ResNet50 base model. Prediction=Dense(len(folders),activation='softmax')(x)
Thelen(folders)representsthenumberofclasses,andthe activation='softmax' specifies the softmax activation function.Thesoftmaxfunctioncalculatestheprobabilities for each class, allowing the model to output the class probabilitiesformulti-classclassification.
Theclasswiththehighestprobabilityisconsideredthefinal predicted class label for a given input image. ResNet50 modelcanachieveatestaccuracyof 25%
3. Experimental Results:



The dataset is downloaded from the Kaggle website and savedinthelocaldirectory.TheEnglishalphabetsfrom"A" to"Z"weresearchedforusing26foldersfromthecollection ofallalphabets.Eachfolderhasaseriesof60photosthatare variantsofthesamealphabet.1560imagestotal 26x60 weretakenintoconsiderationforthemodel.Thementioned model was ran through 10 epochs. The figures below indicatethemodel'soutputaccuracy


4. CONCLUSIONS
Thisstudyexaminesthebrailleidentificationaccuracyfor fiveCNNswithvariousdepthsandarchitectures.Theinput imagesarepreprocessedandsegmentedbeforethetrainand testphase.Thedatasethasincreasedtheaccuracyalsogets increased.TheproposedsystemdeliversthatDensenet121 andInceptionv3showthehighestaccuracyof 91.1% and 92.8%.
REFERENCES
[1] T.Kausar,S.Manzoor,A.Kausar,Y.Lu,M.WasifandM. A. Ashraf, "Deep Learning Strategy for Braille Character Recognition," in IEEE Access, vol. 9, pp. 169357-169371, 2021, doi: 10.1109/ACCESS.2021.3138240.
[2] A.Mousa,H.Hiary,R.AlomariandL.Alnemer,"Smart Braillesystemrecognizer",Int.J.Comput.Sci.Issues, vol.10,no.6,pp.52,2013.
[3] Murthy,VishwanathVenkatesh;Hanumanthappa,M.; RuizMendoza,JuanCarlos,“VGG16CNNbasedBraille CellclassifiermodelforTranslationofBrailletoText” SpecialEducation.2022,Vol.1Issue43,p4388-4396. 9p.
[4] A.Krizhevsky,I.Sutskever,andG.E.Hinton,‘‘ImageNet classifification with deep convolutional neural networks,’’ Commun. ACM, vol. 60, no. 6, pp. 84–90, May2017,doi:10.1145/3065386.
[5] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens and Z. Wojna, "Rethinking the Inception Architecture for Computer sVision," 2016 IEEE Conference on ComputerVisionandPatternRecognition(CVPR),Las Vegas, NV, USA, 2016, pp. 2818-2826, doi: 10.1109/CVPR.2016.308.
[6] K. Simonyan and A. Zisserman, ‘‘Very deep convolutional networks for large-scale image recognition,’’Tech.Rep.,2015.
[7] ChangjianLiandWeiqiYan,“BrailleRecognitionUsing Deep Learning”, ICCCV '21: Proceedings of the 4th International Conference on Control and Computer Vision August 2021
https://doi.org/10.1145/3484274.3484280
[8] K. He, X. Zhang, S. Ren and J. Sun, "Deep Residual Learning for Image Recognition," 2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR),LasVegas,NV,USA,2016,pp.770778,doi:10.1109/CVPR.2016.90.
[9] G. Huang, Z. Liu, L. Van Der Maaten and K. Q. Weinberger, "Densely Connected Convolutional Networks,"2017IEEEConferenceonComputerVision and Pattern Recognition (CVPR), Honolulu, HI, USA, 2017,pp.2261-2269,doi:10.1109/CVPR.2017.243.
[10] ShazzadulIslamandSabitIbnAliKhan,“BirdSpecies ClassificationfromanImageUsingVGG-16Network”, ICCCM '19: Proceedings of the 7th International Conference on Computer and Communications Management July 2019
https://doi.org/10.1145/3348445.3348480.
[11] K. He, X. Zhang, S. Ren and J. Sun, "Deep Residual Learning for Image Recognition," 2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR),LasVegas,NV,USA,2016,pp.770778,doi:10.1109/CVPR.2016.90.
[12] Hasan, N., Bao, Y., Shawon, A. et al. DenseNet Convolutional Neural Networks Application for PredictingCOVID-19UsingCTImage.SNCOMPUT.SCI. 2,389(2021).https://doi.org/10.1007/s42979-02100782-7.
[13] ChristianSzegedyGoogleIncandVincentVanhoucke, “RethinkingtheInceptionArchitectureforComputer Vision”, https://doi.org/10.48550/arXiv.1512.00567
BIOGRAPHIES
A.Varshini, is a M.Phil. Research scholar at the Department of ComputerScience,University of Madras. She received M.Sc., a degree from Bhaktavatsalam Memorial College for Women, Tamil Nadu, India. Her research area includes Digital Image Processing and Braille Character Perception.

Dr.S.GopinathanistheProfessor in the Department of Computer Science at the University of Madras.Hehasmorethan26years ofexperienceinteaching. Hehaspublishedmorethan70 articles in SCOPUS and SCI INDEXEDjournals.
