1 minute read
Literature and old Trials


Literature and our Old Trials
Most recent works in UDA for semantic segmentation, adopt an adversarial training strategy either at feature level or output level. Some works also include Style Transfer or Image Translation to obtain target-looking source images while keeping source annotation.
Advertisement
We have tried two experiments before settling to the current setup. PIX2PIX Image-to-Image Translation. PIX2PIX-HD Image-to-Image Translation.
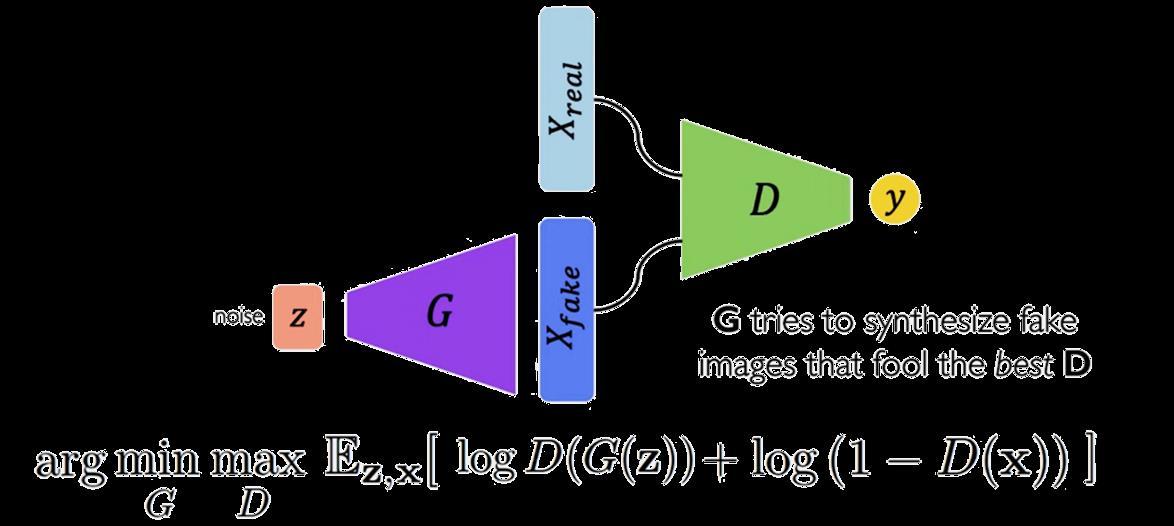
As shown in Figure 6.a, The pix2pix or image2image translation is based on GANS architecture which composed of the Generator (G) and discriminator (D). Simply, the generator generates fake images to fool the discriminator. But the discriminator try to discriminate the fake image by comparison with the real image to decide if the generated image is synthesized or real.
GAN Loss Function: [ Generator + Discriminator]
Fig6.a -
The total loss Function of generator and discriminator.
Conditional GAN:
Fig6.b

In conditional GAN is the same idea of the standard GAN except that the generator will generate the image based on a Condition.
The Generator and Discriminator both receive some additional conditioning input information. This could be the class of the current image or some other property.
The results of pix2pix was not that good to dig in, as we see in figure 7-a-2, so we tried also the pix2pix HD as the improvement of pix2pix, but unfortunately the results was not satisfied because of the colors are merged in together, because it's based on style transfer. And you can see the results in figure 7-b-2.
01- PIX2PIX Image-to-Image Translation:
02- P I X 2 P I X-H D:

Fig7-a-1 Fig7-a-2
Fig7-b-2 Fig7-b-1







