
1 minute read
Results


Predict the Images which have COARSE Segmentation in Cityscapes
The RGB image in fig 17-a-1 is one from the 20000 images from cityscapes dataset. The ground truth of the RGB image is coarsely segmented, so as our model predicted the fine annotated segmentation that's appear in the figure 17-a-2. We propose that to use it as ground truth instead of coarse segmentation GT
Advertisement



Coarse Segmentation
Fig17-a-1
Our Segmentation
Fig17-a-2
MTKT Outperforms the Baseline clearly in some examples such as
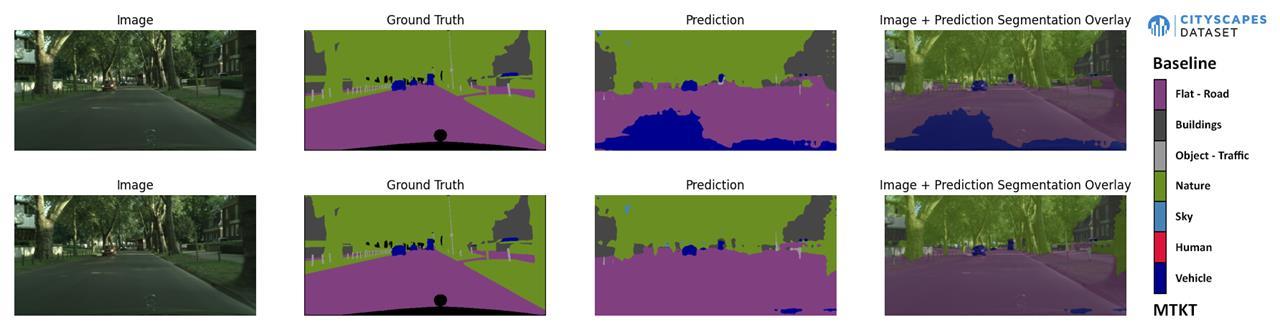
Fig17-b-1
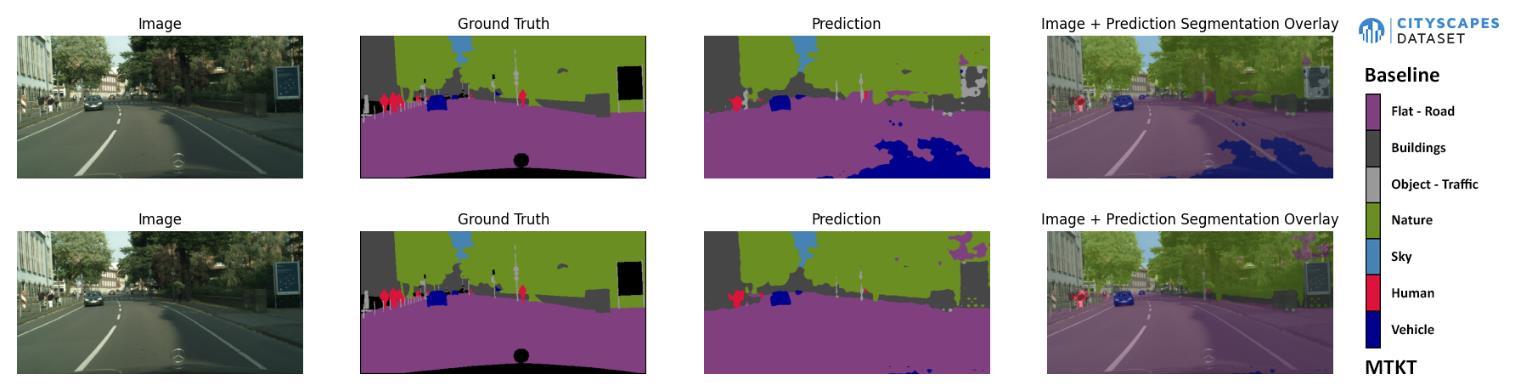
Fig17-b-2
Comparison between BASELINE vs MTKT on Cityscapes Validation Datasets
We can notice the difference between two models, the MTKT performs better than baseline
Fig18-a
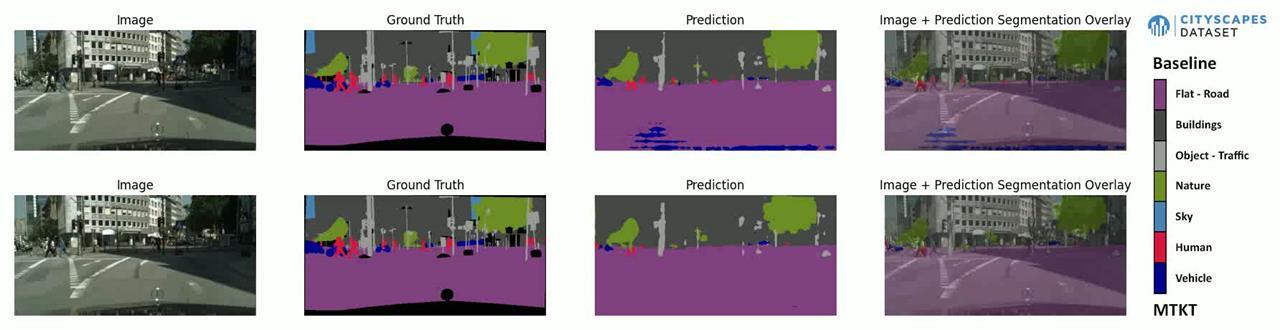
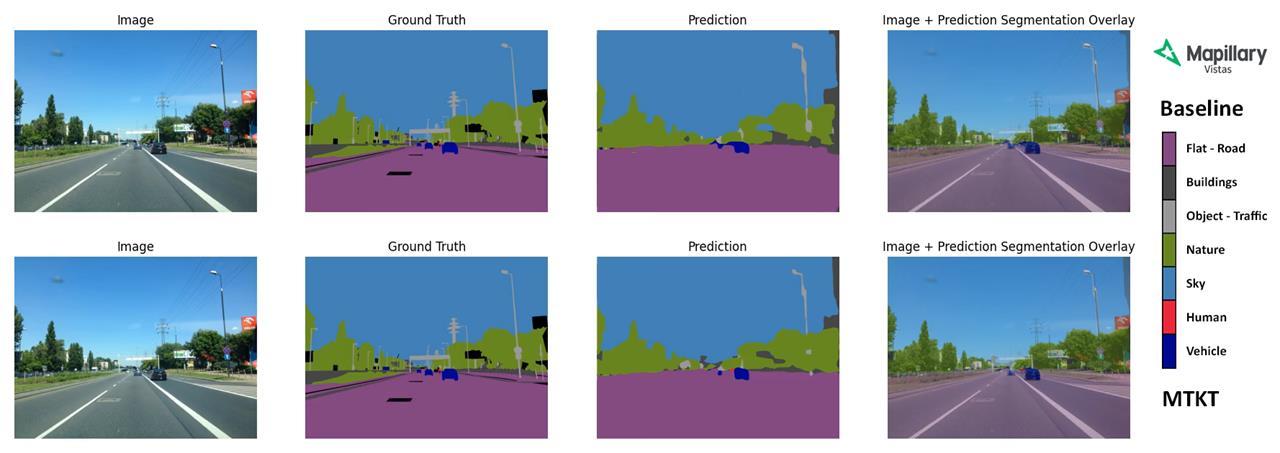
Our Segmentation of a Video example from Cityscapes

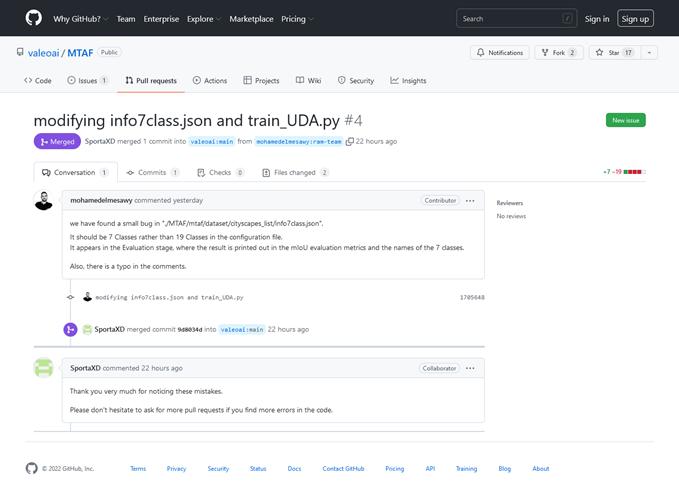
Our Contribution and Accepted Pull-Request on Valeo France Repo
There was a bug in the configuration file in the code of main value branch repo , and we pulled a request to merge on the main branch for Value France.
The Difference between our IoU, and their IoU







