3 minute read
Deep Reinforcement Learning – DQN in Carla


Reinforcement learning in our project
Deep Reinforcement Learning – DQN in Carla:
Advertisement
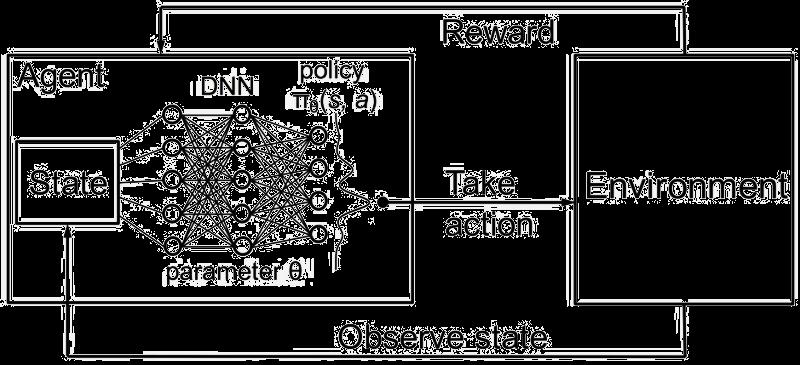
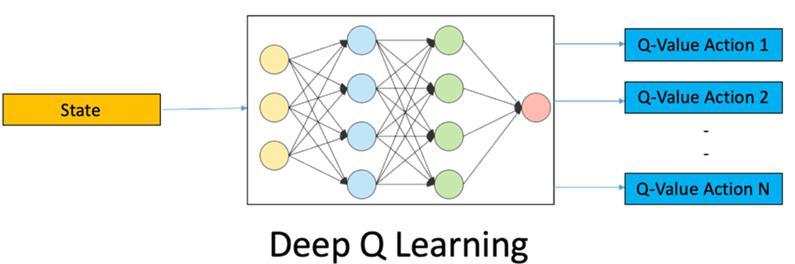
In deep Q-learning, we use a Neural Network to approximate the Q-value function, which is called a Deep Q Network [DQN].
This function maps a state [Input] to the Q-values of all the actions that can be taken from that state [Output].
DQN Algorithm:
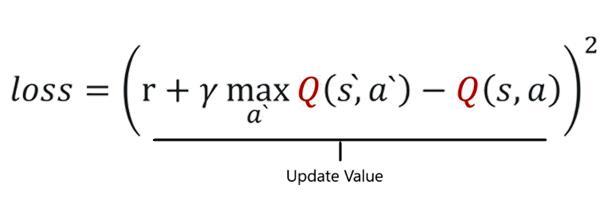
EQN 2
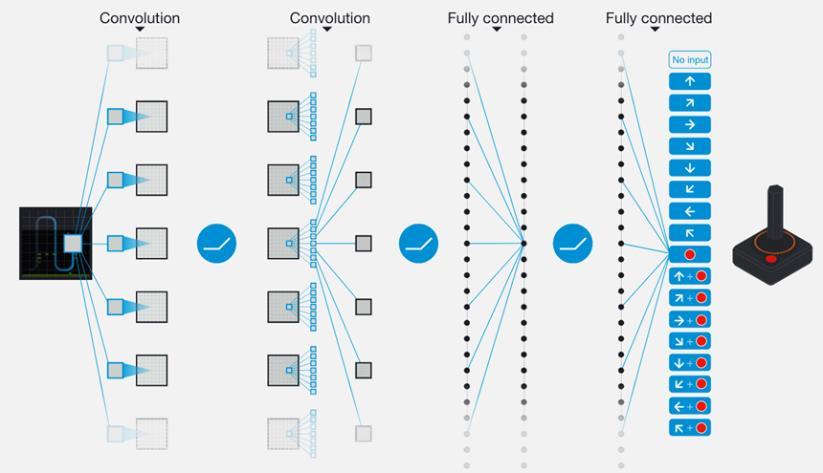

Fig23-b Fig22-a
DQN Algorithm and Architecture Components
EQN 3
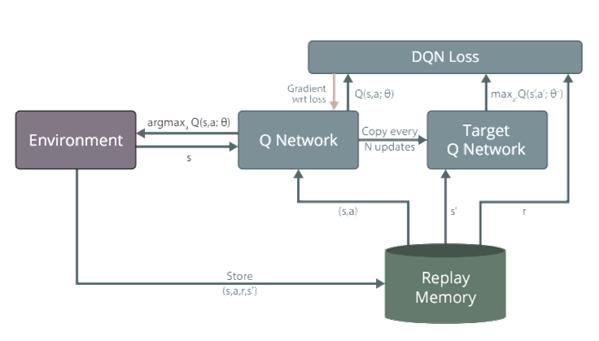
1. Feed the DQN Agent with the preprocessed segmented urban scene image (state s) and it returns the Q-values of all possible actions in the state [different values for throttle, steer]. 2. Select an Action using the Epsilon-Greedy Policy. a. With the probability epsilon, we select a random action a. b. With the probability 1-epsilon, we select an action that has a maximum Q-value, such as a = argmax(Q(s,a,w)). 3. Perform this Action in a state s and move to a new state s’ to receive a reward. a. This state s’ is the next image. b. We store this transition in our Replay Buffer as <s,a,s’>

Fig23-c
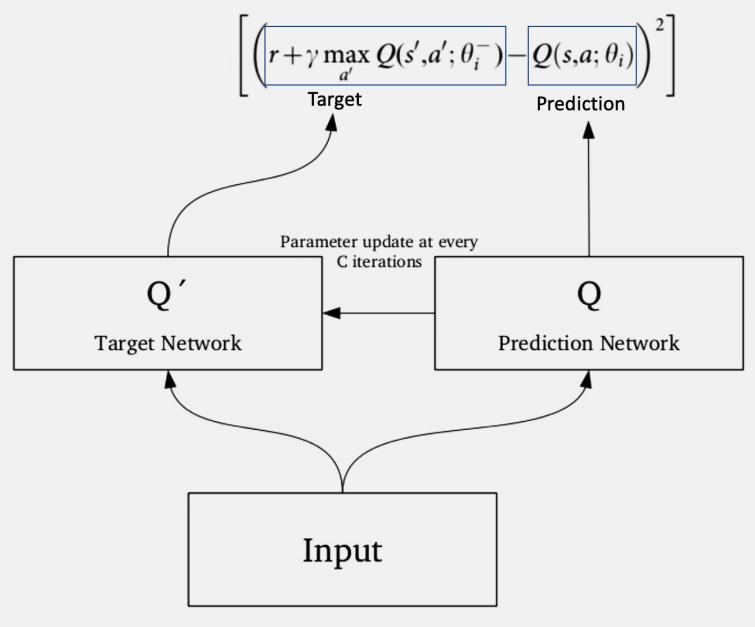
4. Next, sample some Random Batches of transitions from the Replay Buffer. 5. Calculate the Loss which is just the squared difference between target-Q and predicted-Q.
6. Perform Gradient Descent with respect to our actual network parameters [DQN Agent] in order to minimize this loss.
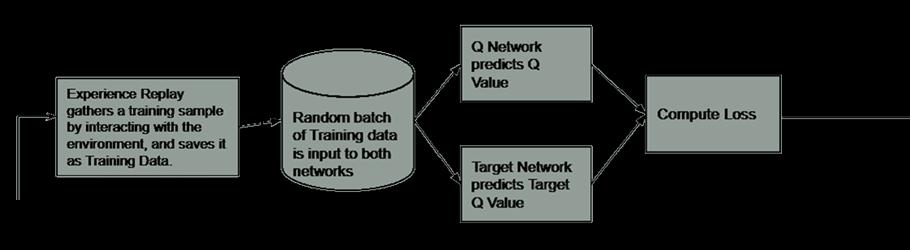
Fig24-a
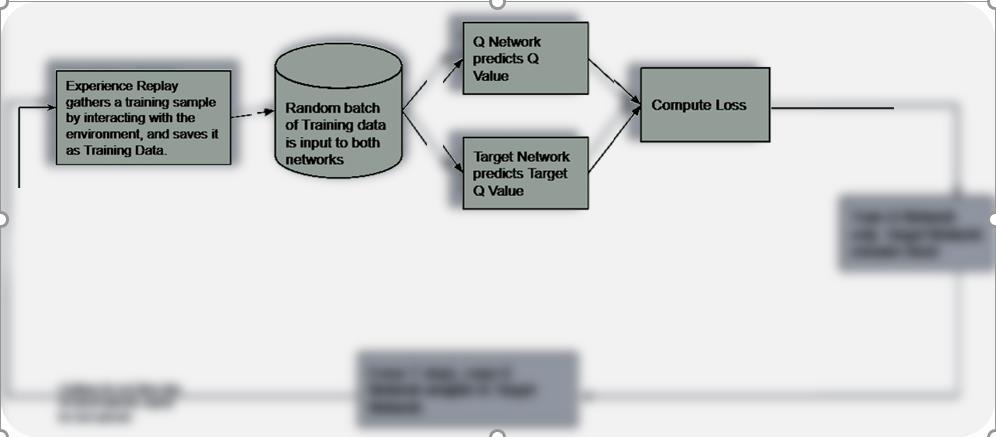
Fig24-b
7. After every C iteration, copy our actual network weights to the Target network weights.
8. Repeat these steps for M number of episodes.
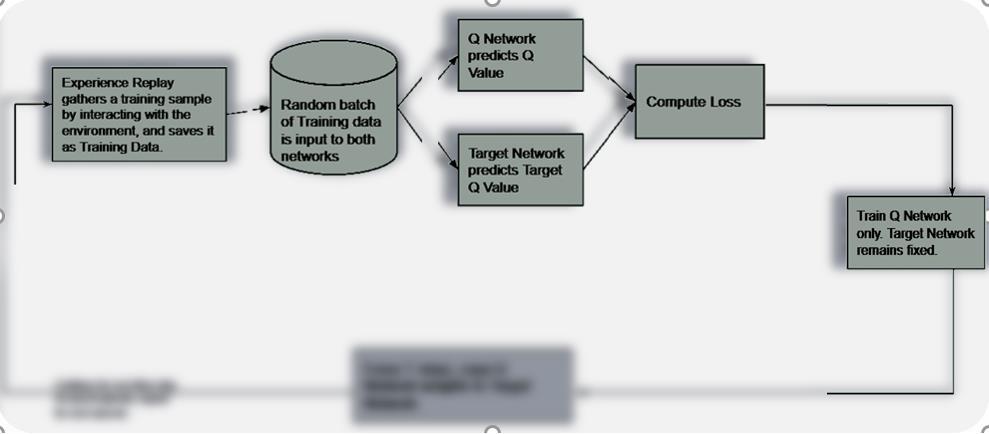
Fig25-a
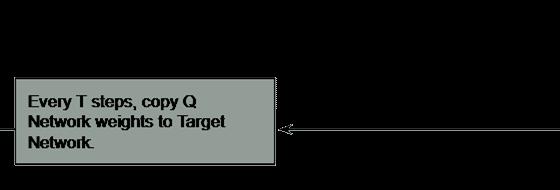


Fig25-b
DQN Architecture Components
#1 Target Network:
The Target network is identical to the Q network. The Target network takes the Next State from each data sample and predicts the best Q-value out of all actions that can be taken from that state which is the
‘Target Q Value’. The Target network is NOT-trained and remains fixed, so no Loss is computed. After every C iteration, the Target Network is getting updated by the Agent
Network weights.
Fig26
#2 Experience Replay:
Experience Replay interacts with the Environment to generate data to train the
Q-Network. It selects an ε-greedy action from the current state, executes it in the environment, and gets back a reward and the next state. Save Transitions ( St, At, Rt+1, St+1) into buffer and sample batch B. Use batch B to train the agent.
Fig27
#3 Epsilon Greedy Policy:
Deep Q-Network starts with arbitrary Q-value estimates and explores the environment using the ε-greedy policy. With the probability epsilon, we select a Random Action a. With the probability 1-epsilon, we select an action that has a maximum Q-value such as : a = argmax(Q(s,a,w))
It balances the Exploration/Exploitation.

Fig28
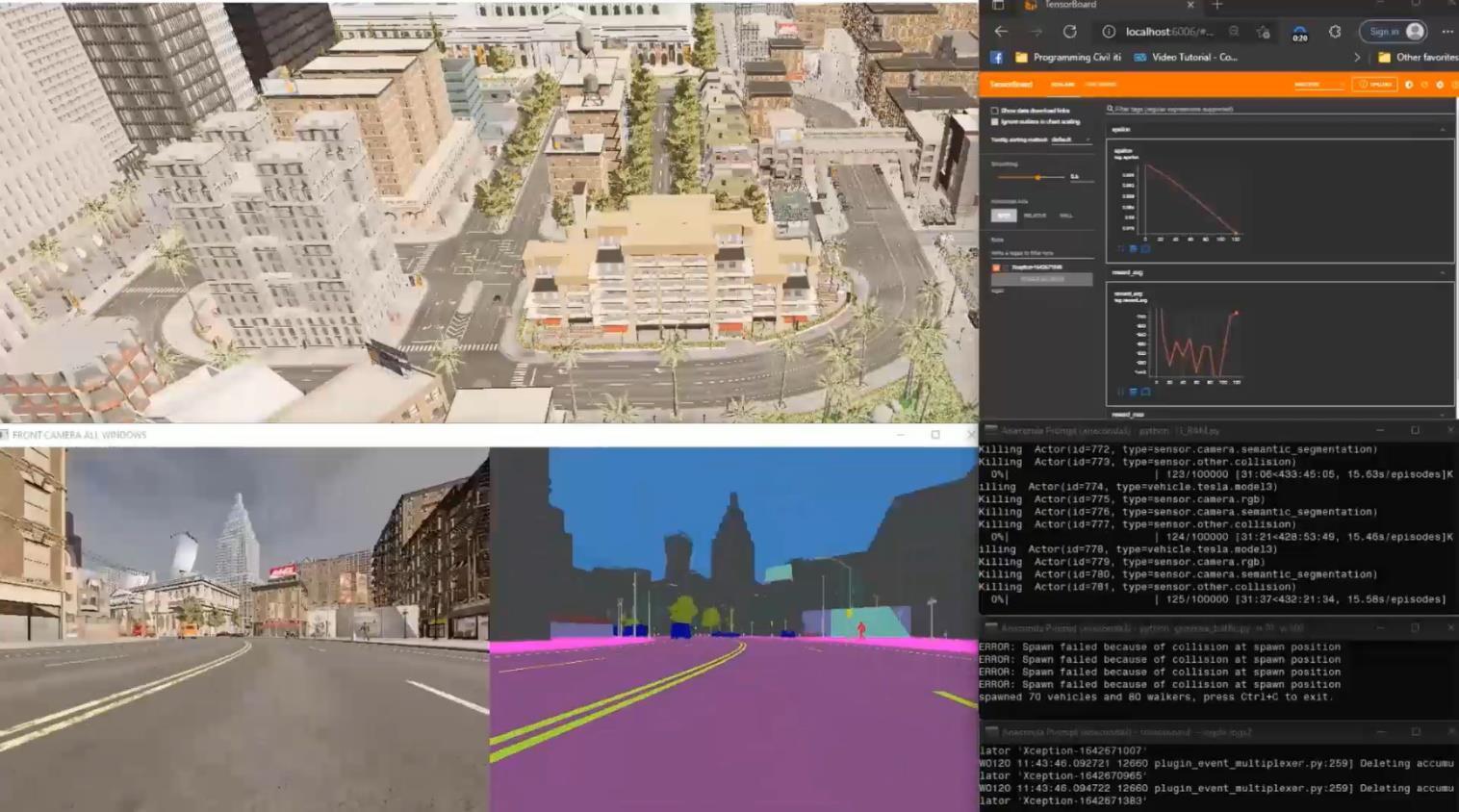
Our CARLA Simulator
- CARLA provides open digital assets (urban layouts, buildings, vehicles) that were created for this purpose and can be used freely. The simulation platform supports flexible specification of sensor suites, environmental conditions, full control of all static and dynamic actors, maps generation, and much more. - This project shows how to train a Self-Driving Car agent by segmenting the RGB Camera image streaming from an urban scene in the CARLA simulator to simulate the autonomous behavior of the car inside the game, utilizing the Reinforcement Learning technique Deep QNetwork [DQN].
DQN Agent inside CARLA Simulator:
Fig29-a