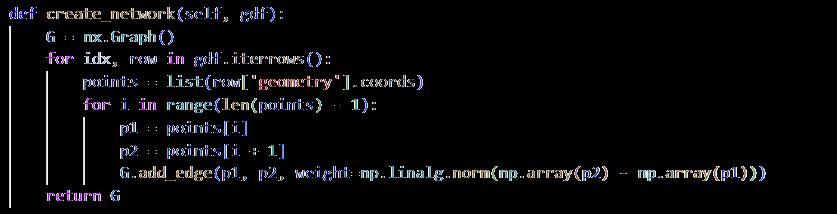Optimal Placement of Green Space in Urban Layouts Using Reinforcement Learning
Author: Labiba Tasnim
Supervisor: Prof Wassim Jabi & Dr Simon Lannon
A dissertation submitted to Cardiff University in partial fulfilment of the requirements for the degree of Master of Science
Computational Methods in Architecture
The Welsh School of Architecture
Cardiff University September 2024
Welsh School of Architecture
Session 2023-2024
ID NUMBER: C23051447
TITLE: Ms FULL FORENAMES: LABIBA LAST NAME: TASNIM
DECLARATION
This work has not previously been accepted in substance for any degree and is not concurrently submitted in candidature for any degree.
Signed: Labiba
STATEMENT 1
Date: 19.09.2024
This dissertation is being submitted in partial fulfilment of the requirements for the degree of MSc Computational Methods in Architecture.
Signed: Labiba
STATEMENT 2
Date: 19.09.2024
This dissertation is the result of my own independent work/investigation, except where otherwise stated. Other sources are acknowledged by footnotes giving explicit references. A Bibliography is appended.
Signed: Labiba
Date: 19.09.2024
STATEMENT 3 (TO BE COMPLETED WHERE THE SECOND COPY OF THE DISSERTATION IS SUBMITTED IN AN APPROVED ELECTRONIC FORMAT)
I confirm that the electronic copy is identical to the bound copy of the dissertation.
Signed: (candidate)
STATEMENT 4
Date:
I hereby give consent for my dissertation, if accepted, to be available for photocopying and for inter-library loan, and for the title and summary to be made available to outside organisations.
Signed: Labiba
STATEMENT 5 - BAR ON ACCESS APPROVED
Date: 19.09.2024
I hereby give consent for my dissertation, if accepted, to be available for photocopying and for inter-library loans after expiry of a bar on access approved by the Graduate Development Committee.
Signed: Labiba
Date: 19.09.2024
Abstract
This paper examines the advantages of integrating Reinforcement Learning (RL) and Space Syntax to optimize the process of placing green spaces in urban setting. Space syntax provides quantitative metrics like betweenness, centrality, and step depth, enabling the RL model to use these numeric values to which improve the model’s adaptability to various urban contexts. Additionally, the study delves into the use of Genetic Algorithms (GA) to automate the procedure of 3D modelling of any given urban block, optimizing certain parameters. The combination of these two methods, suggests the possibility of streamlining the urban design process, enablingfasterprocedural modelling and visualization compared to traditional manual methods.
The primary objective of this paper is to examine the potential of leveraging computational methods for improved accuracy, sustainability, scalability and time efficiency in urban design Integration of space syntax with reinforcement learning supports data-driven decision making that allows the user to explore multiple design options in a very short amount of time, while the genetic algorithm contributes to optimizing building configurations. However, due to limited computational resources and time constraints, the models lack input parameters what are also very important in urban design, resulting in some errors in accuracy.
Acknowledgements
I would like to express my deepest gratitude to my supervisors, Professor Wassim Jabi and Dr. Simon Lannon, for their invaluable guidance and wisdom, which shaped this dissertation in ways I could not have imagined. Your support has been more valuable than a perfectly placed green space in a bustling city. My best friend, thank you for your endless patience and belief in me, especially during the times I wanted to give up. Thanks, your constant inspiration and encouragement to push boundaries has meant the world to me. To my wonderful family, thank you for your unwavering love belief in me. And finally, to my brain for always being there (despite shaky evidence at times)!
Abbreviations and Symbols and Glossary
AC (Actor-Critic): An RL agent with separate models for choosing and evaluating actions.
Axial Map: Graph of paths used to analyse movement.
Betweenness Centrality: Measures a node’s importance in connecting paths.
CAD – Computer-Aided Design.
Centrality: Indicates a node's importance in a network.
Data-Driven Urban Planning: Using data to optimize city design.
Deep Q-Network (DQN): RL algorithm that uses deep learning for decision-making.
DXF – Drawing Exchange Format (used for CAD data files).
Epsilon-Greedy Strategy: Balances exploring and exploiting actions in RL.
Exploration vs. Exploitation: Trade-off between trying new or known actions in RL.
Fitness Function: Evaluates solution quality in genetic algorithms.
Floor Area Ratio (FAR): Ratio of building area to land area.
GA (Genetic Algorithm): Optimization method inspired by natural selection.
GNNs – Graph Neural Networks (for graph-structured data).
GIS – Geographical Information System: System for analysing spatial data.
LiDAR – Light Detection and Ranging: Laser-based remote sensing technology.
Markov Decision Process (MDP): RL framework defining states, actions, and rewards.
MDP – Markov Decision Process.
Multi-Objective Optimization: Balancing multiple goals simultaneously.
OBJ – Object File Format (used for 3D geometry files).
PG (Policy Gradient): An RL method where the agent learns a policy to maximize rewards.
PPO (Proximal Policy Optimization): An RL algorithm that ensures stable policy updates.
Procedural Modelling: Automatically generating 3D models with algorithms.
Prominence Score: Measures a building’s visibility or importance.
Replay Buffer: Stores past experiences in RL for learning.
RL (Reinforcement Learning): Machine learning by interacting with environments.
Solar Gain: Amount of solar energy a building absorbs.
Space Syntax: Analysis spatial configurations and their effects.
Step Depth: Distance between spaces in a network.
1 Introduction
Rapid Urbanization has brought up some profound challenges which are related to urban environment and the lack of incorporation of mandated ratio of urban green spaces (Kabisch et al. 2015). Several studies emphasizethe significance of greenspace as the green infrastructure, including parks, gardens, and urban forests, plays a dynamic role in minimizing the environmental consequences caused by urbanization while enhancing environmental sustainability and the quality of life for citizens (Tzoulas et al. 2007, Breuste et al. 2013). Nevertheless, the integration of optimal green space allocation into urban plans is frequently a challenge for conventional planning methods, resulting in designs that fall short in achieving a harmonious coexistence of built and natural elements (Pauleit et al. 2005).
Despite the immense importance of integrating spatial ontology into urban design during the planning stage, it is often overlooked. Space syntax can provide a quantitative analysis of the spatial relationship between different functions in an urban environment which enables ease of connectivity, accessibility and helps identify the ideal location for the placement of green spaces (Hillier 1996). Incorporating space syntax principles systematically into urban design and planning could result in more functional, sustainable, and equitable cities as it provides quantitative analysis.
Also, the traditional pen and paper approach to urban design is time intensive and relies on manual effort which results in prolonged decision making and potentially inadequate outcomes (Batty 2008). To overcome this, reinforcement learning (RL) can be used which allows autonomous agents to perform actions in an environment to change its state and learn through the actions with a reward-based system to generate optimized outputs which is basically learning the optimal behaviour to a defined state to obtain maximum reward (Synopsys n.d.).
According to Zheng et al. 2023, Reinforcement learning has the potential to enhance the urban zoning patterns as it can take decisions based on the interactions with the environment.
3D procedural modelling for urban planning can be more efficient by incorporating parcel subdivision, clustering, and creating diverse layouts to fulfil different functional objectives. The use of GIS-based procedural modelling tools to improve urban design and planning processes, while giving a systematic method to creating diverse and productive urban environments can help improve functionality (Zhang et al. 2022). 3D modelling using computational methods include faster model generation and increased accuracy than a human (Toolify.ai 2023).
Therefore, integration of space syntax principles into a reinforcement learning model can reinvent and automate the urban planning process with the aim of increased functionality and resilience in cities. This interdisciplinary methodology proposes diverse and environment friendly and aids in achieving more time efficient urban zoning layouts with optimal green space. Along with the green space allocation with reinforcement learning, using a genetic algorithm to visualize the urban block with optimum height considering the surroundings, can make the decision-making process easier and faster.
1.1 Context
In the 21st century, over 50% of the entire population of earth reside in cities (Debnath et al. 2014) and one of the most essential elements for healthy human life in cities is the environment of it. In the past few decades, a wide range of academic fields have focused on how the environment is changing in urban settings as metropolitan ranges are hotter than their surrounds, according to recent studies on the environment of metropolitan areas (Grimm et al. 2008). Urban green spaces (UGS) are fundamental for the mitigation of the impacts of rapid urbanization as these aid in physical and mental recovery of the residents, water and soil conservation, and reduces heat stress and pollution (Vancutsem et al. 2009, Haq 2011,
Shackleton et al. 2015). The effective allocation of urban green spaces is outlined in the Urban Greening Guidelines of the World Health Organization (WHO) in 2014 which includes guidelines for allocating appropriate green spaces per capita and the evaluation of it. To implement Green Infrastructure effectively in urban zoning planning the integration of green principles into city planning, secure funding and community support needs to be prioritized (Anguluri & Narayanan 2017).
Architects and planners can optimize and automate numerous steps of their project delivery process thanks to advances in computer science and their widespread influence across various fields (Gerber & Lin 2014). Researchers at Tsinghua University have developed a deep reinforcement learning (DRL) model for urban zoning planning that utilizes graphs to optimize spatial efficiency of an urban layout (Zheng et al. 2023). Various machine learning models like cellularautomatamodels,artificialneuralnetworks, anddecisiontreesarebeingusedtopredict land use of growing cities (Koutra & Ioakimidis 2023). In another research, a genetic algorithm-based approach was developed that can generate urban layouts with improved energy performance (Yi & Malkawi 2009). Thus, it is evident that there’s a significant shift in design towards data-driven and computational methods. Enhancement of the automation and optimization in urban design can be done effectively with procedural modelling using genetic algorithm, where the genetic algorithm can optimize the building placement, orientation, accessibility, and other building parameters (Vanegas et al. 2012). A study by Saldaña (2020) explores the adaptability of classical architectural principals into systematic city planning with interactive street grid testing and conjectural model representation. The studies emphasize the significance of procedural modelling in urban design for creating intricate, visually appealing, and functionally accurate virtual 3D city models, which creates new possibilities of using genetic algorithms for generating 3D models in less time.
1.1.1 Emerging Trends and Technologies in Urban Design
The 21st century is marked by unparalleled innovation. Urban design and architecture are transforming due the emerging trends of sustainability and cutting-edge technologies. To name a few, participatory planning and multi-agent reinforcement learning frameworks warrants diverse stakeholder inputs that ensure inclusivity (Kejiang Qian et al. 2023). Graph Neural Networks (GNNs) leverages advanced data analytics for applications like traffic prediction and energy management, enhancing city efficiency (Li et al. 2022). Smart mobility solutions, includingautonomousvehiclesandintelligenttransportationsystems,aimtoreducecongestion and emissions (Montes 2024). Conventional data collection methods using paperwork are slow and prone to errors and delays. More efficient techniques, like reinforcement learning, have gained popularity for reducing costs and uncertainties. This emphasizes the need for innovative approaches, including advanced technology, which accelerates the process and presents urban planners with diverse options.
In recent days, space syntax is used so that the new design proposals for urban environments haveabetterchancetofunctionaspertheintendedpurpose.Spacesyntaxprovidesquantifiable data that helps design practitioners and researchers to understand and validate observation on the built environment while bridging the gap between theory and practice. Space syntax has been applied to various urban areas for regeneration and completely new projects to improve functionality and sustainability (Nes & Yamu 2021). Research by Volchenkov & Blanchard, 2007 shows GNNs are excellent when it comes to training from graph-based data. This quality of this type of network makes it suitable for modelling complex urban networks as spatial interactions are crucial for it. The duality of space syntax enables comprehensive urban network analysis and GNNs can process large datasets which aids in finding patterns in urban dynamics (Volchenkov& Blanchard2007,Valipour et al. 2019) These studies showspotential that combining space syntax principles with machine learning can yield functional results.
Reinforcement learning (RL) is changing the dynamics of urban design by optimizing complex spatial layouts and enhancing planning efficiency. Studies from the past few decades show that RL can effectively generate and improve transportation networks, balancing multiple objectives simultaneously (Smith et al. 2023). This AI-driven approach allows for rapid scenario testing and data-driven decision-making, potentially leading to more sustainable and liveable urban environments (Jones and Lee 2024). However, challenges remain in model interpretability and integrating human expertise with AI-generated solutions (Brown 2022). Advancements in procedural modelling technology hold potential to transform architectural design methods and urban planning approaches. Leveraging computational methods like genetic algorithms, reinforcement learning, etc. can help optimize building parameters, placement, connectivity while streamlining the design process. To improve spatial representation and placement of 3D buildings within predefined spaces and optimize generation, analysis, and design in urban planning and architecture, this research proposal explores the integration of genetic algorithm into procedural modelling.
1.1.2 Research Gaps
Limited research on integration of space syntax principles with reinforcement learning despite the theoretical potential for time efficient and diverse outcomes, has been identified as the research gap for this study. Particularly in the areas of public green spaces, and latent activity behaviours, that can be addressed through space syntax. In addition to that the present tools for procedural modelling, like city engine and Arc GIS primarily focus on 3D visualization and lack capabilities for optimization and relies heavily on manual input for any changes and data. The aim of this research is to suggest ways to combine GA with procedural modelling to aid the automation process while providing optimal solutions for urban development and insights into how the city may evolve over time. Additionally, adaptability to different environmental needs and scalability will be addressed in this study
1.1.3 Research Aim & Objectives
The purpose of this project is to investigate the potential of integrating space syntax principles in a Reinforcement Learning (RL) framework to optimize the placement of green spaces within any given urban layouts. With this goal in mind, the project aims to achieve the following objectives:
• Identify quantifiable space syntax principles for placing public and green spaces
• Define the problem and desired outcomes focused on the ideal placement of green spaces
• Create a custom environment, selection of suitable agent for the task, define the reward function, state representation, and action space
• Train the RL agent using space syntax metrics to optimize the placement of urban green spaces.
• Test the model in different urban layouts
• Evaluate model performance based on each episode and results
• Useageneticalgorithmtorecommendtheoptimalbuildingheightsfornon-greenareas, enabling a rough visualization
• Assess thepotential ofthis tool tostreamline andsimplifythe process of urbanplanning
1.2
Dissertation Overview
This study aims to investigate the potential integration of space syntax and reinforcement learning (RL) within the field of urban design, with a particular focus on optimizing the
placement of green spaces. Specifically, the research explores how RL algorithms can be utilized to incorporate key space syntax metrics, such as centrality and depth, to identify optimal locations for green spaces in urban layouts. The primary goal is to determine whether reinforcement learning can be more time-efficient of this process compared to traditional methods of calculating and analysing these metrics for optimal site selection. Additionally, the research examines the adaptability of the proposed approach across different urban contexts, based on user-defined inputs regarding the desired number of green spaces and the layout of the urban area. Furthermore, this research uses a genetic algorithm to assign optimum heights of the buildings which gives the users a rough visual of the urban block.
1.2.1
Research Problem
Although previous research reveals minimal exploration into the integration of space syntax with machine learning for urban design, it suggests that this approach holds significant potential. If we represent a city as a graph, incorporating space syntax measures such as connectivity, integration, and adjacency to enhance the state representation of a reinforcement learning agent, we may achieve better outcomes than using a reinforcement learning model alone.
1.2.2
Methodology Overview
The methodology for this study is structured in three stages: understanding urban design principles, developing the algorithm, and validating the system's effectiveness. It begins with a comprehensive review of urban design, space syntax, and reinforcement learning (RL) to identify research gaps. The algorithm development involves defining the problem, collecting GIS data, creating realistic urban environments, representing states and actions, adopting sequential Markov decision processes, designing a reward function, and iterative evaluation. Additionally,thestudyincludesextrudingbuildingfootprintstooptimalheightsusingagenetic algorithm. This approach, inspired by natural selection processes, leverages parameters like solar gain, prominence score, and floor area ratio to generate and optimize 3D building models. Finally, the validation stage compares RL-generated urban zoning layouts to conventional methods to ensure practical viability and effectiveness.
1.2.3 Scope and Limitations
The project has potential to incorporate a wider range of parameters into the model, enhancing its ability to account for complex urban factors. Expanding the scope beyond green networks to include various types of land use could transform the tool into a more comprehensive urban planning solution. Developing a user-friendly interface, possibly by integrating with platforms like Viktor.ai, would make the tool more accessible to urban planners without coding expertise. The integration of energy simulation capabilities could offer a more holistic approach to urban planning and sustainability. Finally, improving the model's scalability to handle larger and more complex urban layouts would make it suitable for diverse urban planning scenarios, from small neighbourhoods to entire cities. These advancements aim to evolve the tool into a more robust, versatile, and user-friendly solution for optimizing various aspects of urban planning beyond just green space placement.
The current implementation of the algorithm has several constraints that limit its full potential in urban planning applications. It primarily focuses on suggesting optimal locations for green spaces based on user input, accepting only a limited set of space syntax metrics. This restricts its ability to handle more complex urban layouts. Additionally, it does not provide area calculations, consider land use, or take environmental factors into account, making it heavily
reliant on user input for decision-making. The transition from green space placement and 3D generation is not seamless as the RL gives out the output as .dxf file and due to limited resources, it takes too long to compute the output directly. This is why the user must input the files as .obj for the 3D generation as it requires lesser computational resources and is easier for the algorithm to use. The code's lack of robust error handling, particularly for face-related issues, can lead to premature termination of the process, potentially causing inefficiencies in analysis. A significant limitation is the absence of a user interface, which limits its accessibility to urban planners who may not have coding expertise. Furthermore, the model doesn't account for all factors affecting building heights in urban areas, which could impact the accuracy of results. Lastly, the current setup may not provide comprehensive visualization options, making it challenging for urban planners to easily interpret and utilize the outputs effectively.
1.2.4 Structure of the Dissertation
Chapter 1: Introduction


Chapter 2: Literature Review

Chapter 3: Methodology
Chapter 4: Results and Discussion

Chapter 5: Conclusions
Chapter 6: Recommendations
Chapter 7: References
Chapter 8: Appendix
Dissertation Structure (Author)
1.2.5 Significance of the Study
This research serves as an initial foundation for a time-efficient, data-driven model for urban design that combines Reinforcement Learning (RL), Space Syntax, and Genetic Algorithms (GA). The key contribution of this study is listed below:
Time efficiency: The use of computational tools significantly reduces the time required to explore multiple design options
Reduced error: Minimum human error and ensures that the design outputs are accurate, particularly in the optimization quantitative parameters.
Scalability: These methods are adaptable for smaller to larger scale scenarios.
Multidisciplinary Use: This tool, if further developed, can be adapted for various use starting with urban planning, traffic analysis, video games and virtual simulations.
2 Literature Review
Tostartwiththeprocess,keywords,relatedtothetopicwereidentifiedandwassearchedacross various academic databases. The results were screened based on factors like peer review, publication, citation count etc. so the information is reliable. Key information related to the research topic were extracted from the sources to find the research gap, have a better understanding of the subject and aid formulating the methodology.
2.1
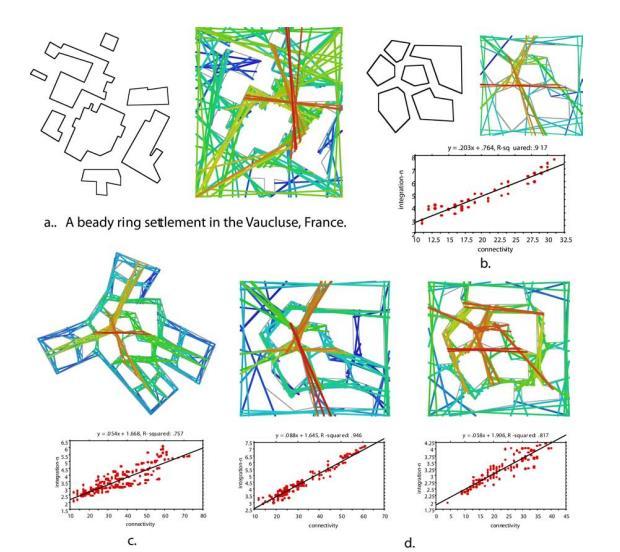
Space syntax, first conceived by Bill Hiller, Julienne Hanson et al. in the late 1970s to 1980s, is a set of theories and techniques that are used to analyse spatial configurations based on the relationships between spaces (Nes & Yamu 2021). It gives quantitative data by calculating the degree of spatial integration of spaces in relation to others in a given system as it is a set of analytical methods that is directed to recognize the relationship between the spatial configuration of the built environment, human behaviour and urban dynamics. It is used by practitioners and researchers in countless fields like architecture, urban design and planning, urban geography, road engineering etc. This method has been tested and applied worldwide to analyse the impacts of new design proposals (Nes & Yamu 2021).
To represent patterns of potential actions in a given environment, space syntax uses edges that are connected to one another, considering actions and spaces. These lines are more than just a representation of spaces, they also represent the people in the context as we can get data of their movement density, frequency etc. The use of coordinated color in space syntax models makes complex data understandable to not only scientists, but also designers, politicians, and people (Hillier 1996).

Space syntax gives a set of approaches for creating an abstract model of the layout of a city. The spaces being considered for analysis are usually characterized by their topology, which is the spatial relationships between them like connections and adjacencies. From previous research on space syntax, it is evident that space syntax models can also capture and analyze social and cognitive features like built environment, road networks etc. of a city (Bafna 2023)
2.1.1 Space Syntax in Urban Design
For instance, space syntax has been used for analysis in Trafalgar Square, London which shows the north section was the only part with pedestrian activity while revealing the underlying spatial structure was causing this uneven usage of the square as the users had to walk around the edges (Mohamed et al. 2023).
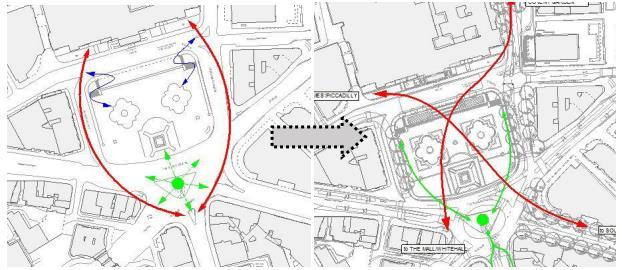
Figure 4 Performance of Trafalgar Square before and after development (Mohamed et al. 2023).
Another case is the analysis of Nottingham's Old Market Square, which unveiled the spatial issues and helped take informed decisions to increase functionality and liveliness of the urban space (Mohamed et al. 2023).
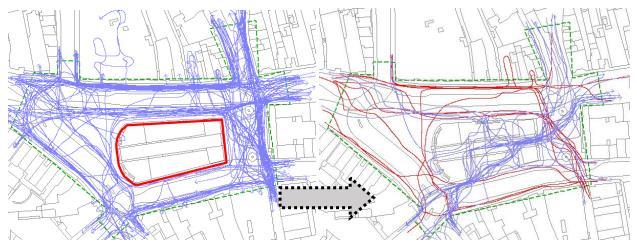
Figure 5 PerformanceofNottingham’sOldMarketSquarebeforeandafterdevelopment (Mohamed et al. 2023).
2.1.2
Metrics of Space Syntax
Centrality: In terms of space syntax, centrality is a configurational study with respect to space and the effect that configuration has on users’ interaction with urban spaces. Centrality is a measure of the accessibility of a space in a certain network. This influences social interactions of the residents, spatial functionality along with pedestrian flow (Mahmoud, et al. 2023, Leite et al. 2024).
Betweenness: Betweenness can measure a node’s control over the flow of communication which proves vital for network analysis (Kumar & Balakrishnan 2020). It’s also addressed as “choice” in space syntax as it defines how often a space falls on the shortest paths among a few spaces in the system (Feng et al. 2022, Dudzic-Gyurkovich 2023). This measure can revel hierarchy of movements of routes in different scales too (Crescenzi et al. 2020, DudzicGyurkovich 2023).
Step Depth: Step depth refers to the measure of topological distance from one space to another, which means the count of the number of segments or steps is required to navigate from one location to reach another location within the certain spatial configuration. This methos helps determine the permeability of an urban spaces, road networks and the connectivity (Nes 2021). Step depth can enhance navigability by optimizing circulation space in diverse setting of space (Brösamle, et al., 2007)
Control: Control in space syntax refers to the measurement of the extent to which a street segment lies on the most direct paths between other segments, influencing movement patterns within urban spaces. Control helps identify spaces that act as local hubs or have strategic importance in the spatial network (Xiao 2016).
2.2 Reinforcement Learning
Reinforcement learning (RL) is a type of machine learning (ML) that is uses Markov Decision Process (MDP) to learn sequential decision making in complex problems, where the agent's goal is to learn a policy that maximizes the expected sum of rewards over time. This is used in various fields i.e. robotics, gaming, spatial planning, and autonomous vehicles (Buffet et al. 2020).
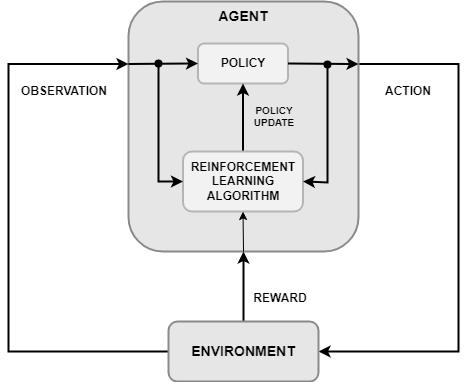
Basically, RL is inspired by the trial-and error-based learning process seen in human and animals. The RL agent can learn optimal policies autonomously with the knowledge based on the actions performed in a stochastic dynamical environment. These days, RL agents can surpass human performance in challenging and advanced tasks without any human interventions (Shakya et al. 2023).
2.2.1 Elements of Reinforcement Learning
Agents: Agents engage with their surroundings through actions, and their actions determine the rewards they obtain.
Environment:Theexternalsystemanagentengageswithincludingallthattheagentencounters during the process of learning and decision-making.
State: This refers to the agents' location inside the environment at a particular time step. The agent gets rewarded or punished as they make changes into the environment by performing actions.
Policy: A policy specifies the expected behaviour of the agent at a specific moment.
Reward: When an agent completes an action at a state or states in the environment, they are rewarded with a numerical value. The agent's activities determine whether the numerical value is positive or negative.
Value function: A value function describes what is beneficial over the long term. In general, a state's valueis the total reward that an agent might anticipate earning over time (Sutton& Barto 2015, Singh 2019).
2.2.2 Reinforcement Learning in Urban Planning
Reinforcement Learning (RL) for example, is showing a lot of promise in the sector of urban planninganddesign.ResearchatTsinghuaUniversityhasshownthatusingdeepreinforcement learning (DRL) with Graph Neural Networks (GNNs) can increase efficiency in the design process and generate improved urban zoning layouts in less time. According to the research, using DRLtogenerate spatial plansand GNNsto describe citytopologies resultintoinnovative and practical urban design solutions (Zheng et al. 2023)
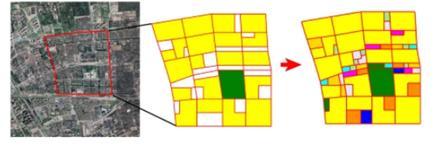
Figure 7
Use of reinforcement learning for renovating a community. The existing roads and functions are kept as is and the agent places different facilities and services in the vacant lands to maximize accessibility (Zheng et al. 2023).
A project from The Alan Institute demonstrates, simulating cities using AI agents involves employing agent-based modelling (ABM) incorporation to Reinforcement learning to create dynamic representations of urban environments. This approach allows for the modelling of individual entities, such as residents and vehicles, which interact in ways that reflect real-world behaviour (The Alan Turing Institute 2024) According to a conference proceeding, it is proposed that, a framework that integrates agent-based modelling with reinforcement learning (RL) to simulate and optimize urban design scenarios (Menges et al. 2024)
2.3 Genetic Algorithm
Genetic algorithm (GA) is a method inspired by natural selection, used to solve constrained and unconstrained problems. It includes iteratively improving a population of potential solutions using strategies such as selection, crossover, and mutation. And over time, the population "evolves" toward an optimal solution based on a fitness function (Mallawaarachchi 2017; MathWorks 2024). Potential solutions are represented as arrays of bits or other data structures in a GA. Each individual's fitness level is determined by comparing their performance to the problem's objective function (Kanade 2023).
2.3.1 Genetic Algorithm in Urban Design
Ariffin et al. (2017) combine the Interactive Genetic Algorithm (IGA) with other 3D model generation techniques to help enhance the production of intricate and aesthetically pleasing 3D models. Genetic algorithms are widely used in optimization because they efficiently explore a large rangeof options for optimal or nearly optimal solutions (Kabolizadeet al. 2012). As these algorithms are inspired by natural selection processes, they provide benefits such as optimizing continuousandindependentvariables. Theyarealsoeffectiveatlarge-scaleoptimizationissues and can handle complex topologies (Kabolizade et al. 2012). Barriga et al. (2014) propose a strategy for optimizing building placement in Real Time Strategy games, specifically to enable defending players to withstand base attacks effectively.
2.4 Synthesis Table
2.4.1 Space Syntax Literature
"Space is the Machine" -
"Introduction to Space Syntax in Urban Studies"
"Analytics for Urban Networks: Integrating Graph Neural Networks with Space Syntax"
Exploring the synergy between Graph Neural Networks (GNNs) and space syntax techniques to analyse urban road networks
Development of space syntax theory and analytical tools for architectural and urban design.
Space syntax provides a comprehensive framework for analysing the spatial properties of buildings and cities and has been widely applied in research and design.
Space syntax analysis
Combining GNNs, with space syntax measures
Space syntax offers a way of thinking about urban space from a spatial ontology, which is consistent with cognitive processes and can be integrated with other modelling methods.
Space syntax features improved performance in road classification tasks. The study developed a graph autoencoder model for undirected link prediction.
"Towards Robust and Scalable Space Syntax Analysis"
"Space Syntax as a Vital Tool to Enhance Urban Spaces"
Improving the robustness and scalability of space syntax analysis
"Construction and Optimization of Green Infrastructure Network Based on Space Syntax: A Case Study of Suining County, Jiangsu Province"
The challenge of developing and designing urban places that are conducive to pedestrian movement.
The need to construct and optimize green infrastructure networks in rural areas to improve ecological functions and create a green living environment.
2.4.2 Reinforcement Learning
Visibility graph analysis, agentbased simulation
Space syntax-based visibility graph analysis and agentbased simulation can be used to improve the robustness and scalability of space syntax analysis for large-scale urban environments.
Application of space syntax to make decisions about shared, vehicle, and pedestrian streets.
Space syntax analysis, landscape connectivity evaluation, and optimization algorithms.
Literature Problem Method
"Spatial planning of urban communities via deep reinforcement learning"
Spatial layout optimization, human-AI collaborative workflow Deep reinforcement learning (DRL) based approach.
Space syntax is an efficient tool for enhancing urban spaces, supporting the design of pedestrian-friendly environments.
The study proposes a framework for constructing and optimizing green infrastructure networks based on space syntax, which can improve the ecological functions of rural areas and create a green living environment.
Findings
With a collaborative workflow between humans and AI, the proposed DRL model can generate land and road layout with superior spatial efficiency, improving the productivity of human planners.
"Simulating Cities with AI Agents"
Urban simulation
Agent-based modelling, urban simulation techniques
"Unveiling the Potential of Machine Learning Applications in Urban Planning Challenges"
"Innovative Urban Design Simulation: Utilizing AgentBased Modelling through Reinforcement Learning"
Applying machine learning techniques to urban planning challenges
The need for efficient and adaptive urban design simulation tools to support decision-making.
Supervised learning, unsupervised learning, various ML algorithms
The study proposes an agent-based modelling framework that leverages reinforcement learning (RL) to simulate and optimize urban design scenarios.
AI agents used in urban simulation can yield insightful data for management and development of urban areas.
ML techniques can be applied to urban planning challenges such as polycentric analysis, flow analysis, and spatial simulations.
The RL-based agentbased model can effectively simulate complex urban dynamics, such as pedestrian movement and interactions, and optimize urban design parameters to achieve desired outcomes.
"A PerformanceBased Urban Block Generative Design Using Deep Reinforcement Learning and Computer Vision"
The challenge of designing urban blocks that optimize performance metrics, such as solar radiation and building configurations.
3 Methodology
Deep reinforcement learning (DRL) agent, cosimulation with MATLAB and Rhino/Grasshopper, and Ladybug for simulating direct sunlight hours and solar heat gains.
The study demonstrates the feasibility of using DRL to optimize urban block design by training an agent to generate designs that maximize solar radiation performance and minimize building configurations.
The entire methodology can be divided into three stages: first, understanding space syntax in urban planning, integration of space syntax with reinforcement learning and use of these methods for urban planning, and second, developing the reinforcement learning model and genetic algorithm and lastly comparing the output with real world to validate the use of the systemtoensureitseffectiveness.Buildinganalgorithmforurbandesignstartswithathorough review of the literature on urban design, space syntax, reinforcement learning (RL) and genetic
algorithm (GA). This requires analysing previous research on the integration of RL and Space Syntax and its application in urban planning and use of genetic algorithm in procedural 3D modelling for generating 3D urban layouts with optimum building heights based on set parameters. The study should also reveal any existing research gaps in this area and provide an understanding of how to develop it further.
Libraries like GeoPandas and Shapely are used for handling spatial data, while NetworkX is employed to create the spatial graph representing the urban road networks and other key urban infrastructure. Matplotlib and Seaborn were used for visualization and ezdxf to save the proposed urban design into .dxf files. Python library, Topologicpy and PyGAD was used for the genetic algorithm, due to their compatibility of these and the efficiency in management of time. Other libraries used in this research are PyTorch, Gymnasium, Numpy, Pandas etc.
The data (GeoData) for training and testing has been collected from Digimap, which is a reliable source as it provides mapping from Britain's mapping agency, Ordnance Survey.
System the code was tested on has the configuration listed below:
Processor Intel(R) Core(TM) i7-8750H CPU @ 2.20GHz 2.21 GHz
Installed RAM 16.0 GB (15.9 GB usable)
System type 64-bit operating system, x64-based processor

Methodology (Author)
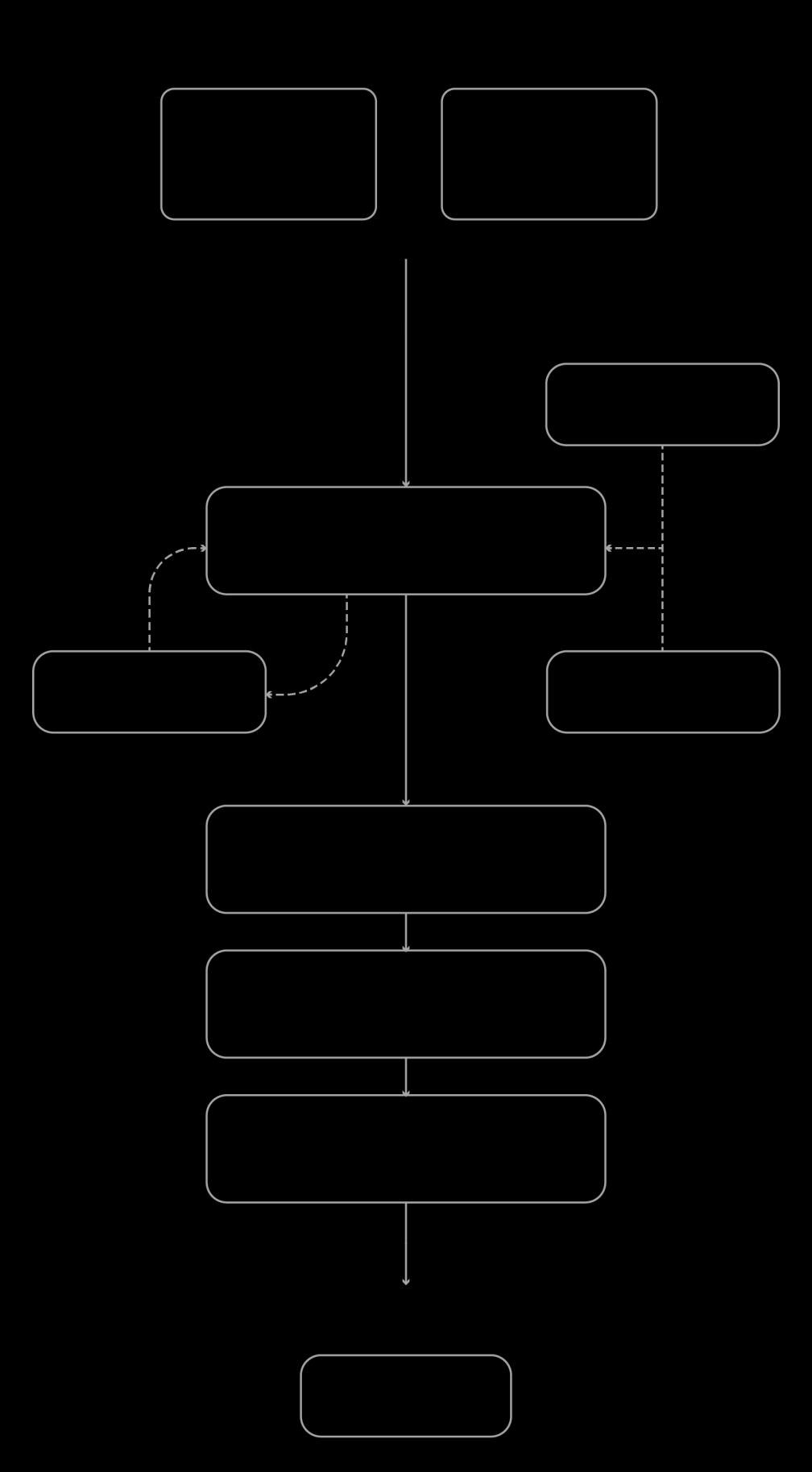
9 Diagram of the algorithm (Author)
3.1 Analysing Space Syntax and Procedural Modelling for Urban Design
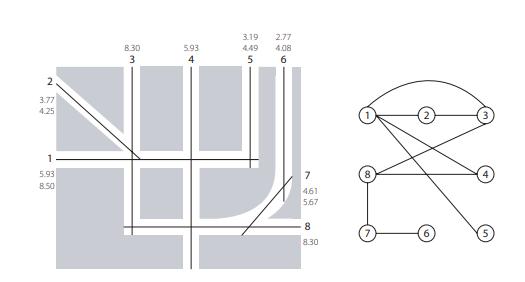
Space Syntax is a methodology for analysing spatial configuration which is gives quantitative outputs. It deals with the street networks and public spaces as an interconnected system of lines and nodes which allows it to create graphs to aid quantify the spatial relationships. This method reveals spatial hierarchy that allows designers to optimize various components of urban areas by measuring connections and integration between them (Karimi 2023) Space Syntax can predict likely pedestrian and vehicular movement patterns, helping to identify natural movement corridors and activity centres as well, by analysing the spatial configuration (Cheng 2022).
3.2 Developing The Reinforcement Learning Algorithm


Figure 10 Flow Diagram for the Algorithm (Author)

Figure 11 Basic diagram of the algorithm (Author)
3.2.1 Defining the Problem
The primary aim of this research is to optimize the placement of green spaces within urban layouts using reinforcement learning (RL), in order to achieve rapid and diverse design outcomes, allowing the user to compare between design solutions. The goal is to develop an algorithm the allows the reinforcement learning agent to autonomously take action within a custom environment to strategically identify best locations to place urban green spaces taking space syntax principles like centrality, control, step depth etc. into account.
3.2.2 Data Collection of Existing Cities
GIS (Geographical Information System) data of real cities was collected from a trusted source to provide the required spatial information to the simulation environment which has been used to train the reinforcement learning agent. The datasets are updated as of April 2024 and include detailed layout of urban areas, street networks, nodes and open spaces. These geodata enable
modelling a custom environment that is relevant for training a RL agent for urban planning applications.
3.2.3 Creating Custom Environment
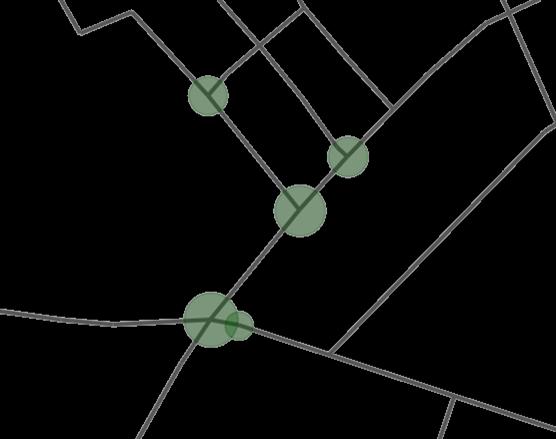
A custom environment has been built using GIS data and axial maps integrating space syntax analysis, which helps to capture the intended spatial arrangement for the agent to interact with. Axial maps are spatial layouts of an urban layout that depict the most direct paths of circulation through the urban area These axial maps are abstracted into a graph-based network, using the NetworkX library, in which nodes represent either junctions or other significant points within an urban context, and edges are those that correspond to the strongest paths and streets between important nodes (refer to appendix 9.1.1). The agent interacts with this through the selection of actions specified for placing green spaces across various locations within the urban network. The spatial structure of the environment is visualized using Matplotlib and then exported to .dxf files using ezdxf (refer to appendix 9.1.2).
3.2.4 Action & State Representation
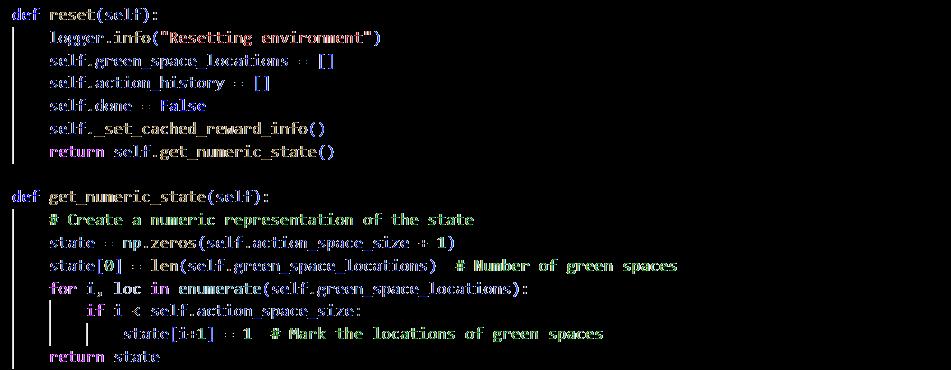
State representation is an estimate of the states that will be used in the reinforcement learning algorithm (Mei et al. 2023), which defines every potential action the agent can take. In this context, an action corresponds to selecting a location within the urban environment to place a green space. These locations are represented as nodes within a graph, with each node corresponding to a particular intersection or street segment. It includes the number and positionsofgreenspaces,trackingbothhowmanyhavebeenplacedandtheirspecificlocations within the urban layout. Furthermore, the state includes spatial syntax measures like centrality, betweenness, and control, that help the agent understand how each location affects accessibility, connectivity, and how that influence the urban network. This enables the agent to assess the effectiveness of potential placements. The state is represented numerically as an array, with the first element representing the total number of green spaces set and the following elements indicating their exact locations inside the action space, allowing the agent to effectively assess and change the environment (refer to appendix 9.2.1).
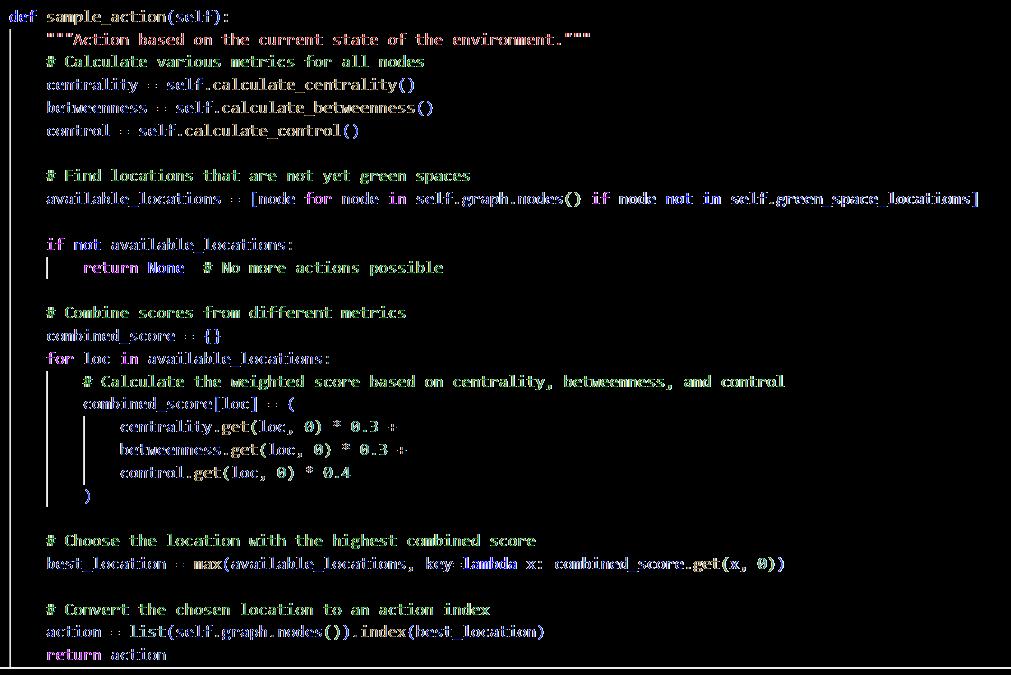
The agent performs actions based on the state representation. Actions are placement of green areas in specified locations within the graph. The various actions are represented as discrete nodes in the graph-based urban environment, with each node representing an intersection or streetsegment.Theactionspaceisconstrainedbythenumberofpotentialgreenspacelocations that have not yet been utilized. The agent computes different space syntax metrics (centrality, betweenness, and control) for all nodes and chooses the area with the best score as the next action for green space placement (refer to appendix 9.2.2).
3.2.5 Designing the Reward Function
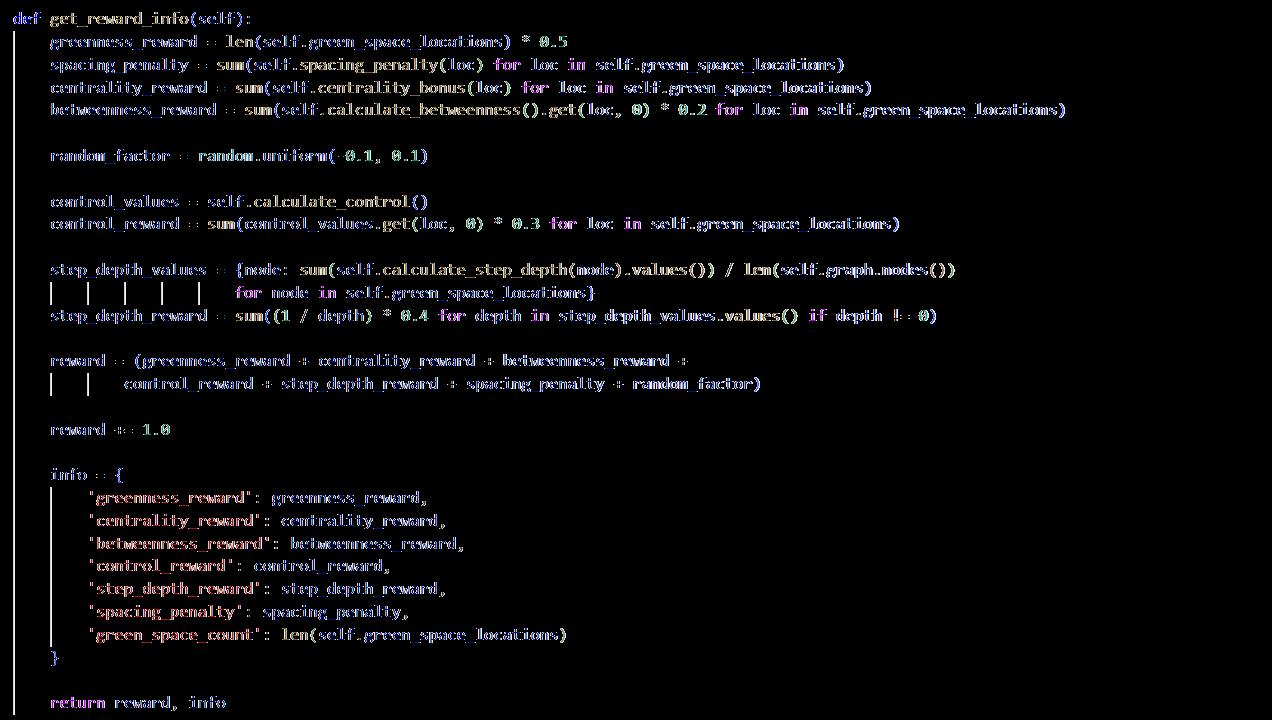
A reward function has been developed which rewards the RL agent for every right action and punishes for every wrong one with the objective of placing green spaces in strategic locations in the given environment. The reward function has been designed considering the space syntax parameters: centrality, betweenness, control and step depth along with a spacing penalty so the agent don’t cluster all the green spaces around the same node but also not excessively far from each other so it can be developed into a coherent green network (refer to appendix 9.3). The reward function drives the agent's behavior, ensuring that green areas are placed in suitable places. It includes various key factors that balance the trade-offs associated with green space placement in terms of spatial efficiency and strategic positioning. The reward function considers the following elements:
Greenness Reward: The reward increases proportionally with each additional addition of green space made by the agent, motivating the agent to complete the goal of allocating the desired number of green spaces green space.
Centrality Reward: The agent receives rewards for placing green spaces in locations with high closeness centrality. This ensures that green space is placed in accessible locations, increasing the overall layout's connection.
BetweennessReward: Positions withhigh betweenness importance(importantjunctionswithin the network) are rewarded because they directly connect crucial points in the urban plan where green space would have a more significant impact.
Control Reward: This reward is dependent on a node's influence on its nearby nodes, which is determined by the control values obtained using space syntax. To promote strategic placement, nodes with more influence over their surroundings receive a bigger payout.
Step Depth Reward: This metric considers the topological distance from one space to another in terms of the number of turns or direction changes required to analyse the relative accessibility and connectivity of spaces. Green landscapes in easily accessible locales receive a larger reward.
Spacing Penalty: A penalty for too little or too much spacing between green areas encourages regular spacing of green spaces within the layout.
Random Factor: The random factor has been added to the reward function to keep the agent from getting too deterministic and make it more suitable for diverse use.
All these rewards and punishments were calculated using PyTorch tensors to be compatible with the RL agent, which optimizes its actions via gradient-based learning.
3.2.6 Selection of The Type of Agent
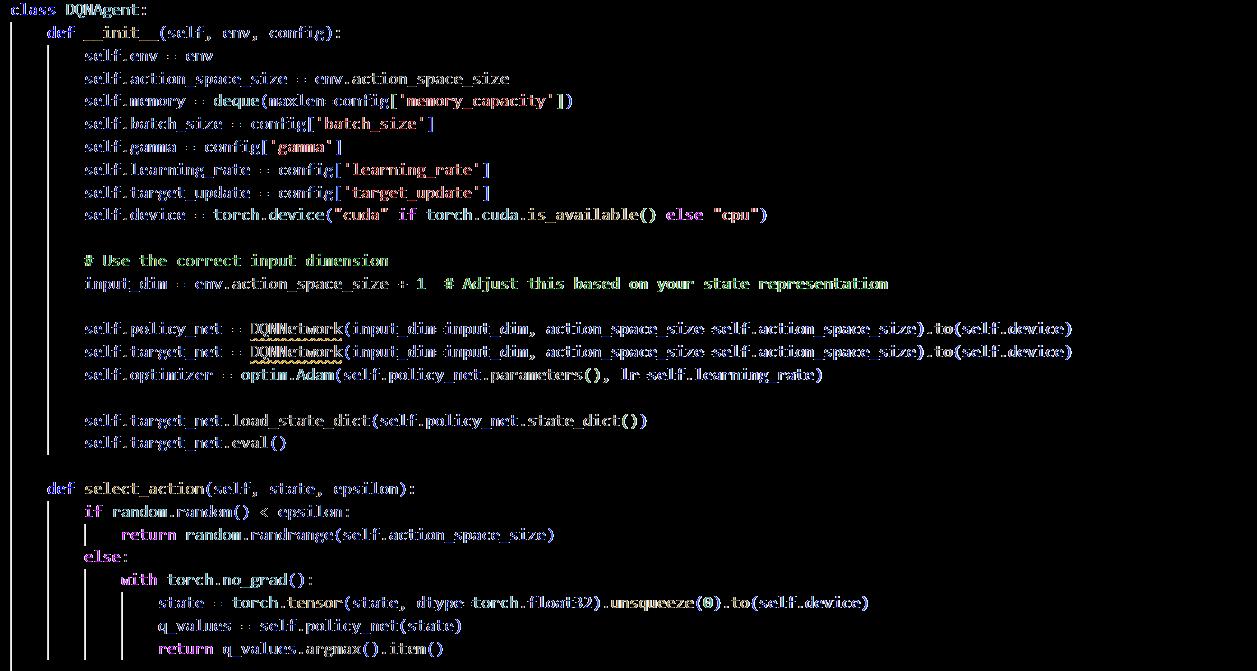
DQN (Deep Q-Network) agent was selected for this model as it’s more equipped to handle complex decision making, is compatible for handling high dimensional state spaces, and has a balanced exploration and exploitation which makes it suitable for urban design compared to PPO and AC, PG etc. (Di Napoli, et al. 2023)
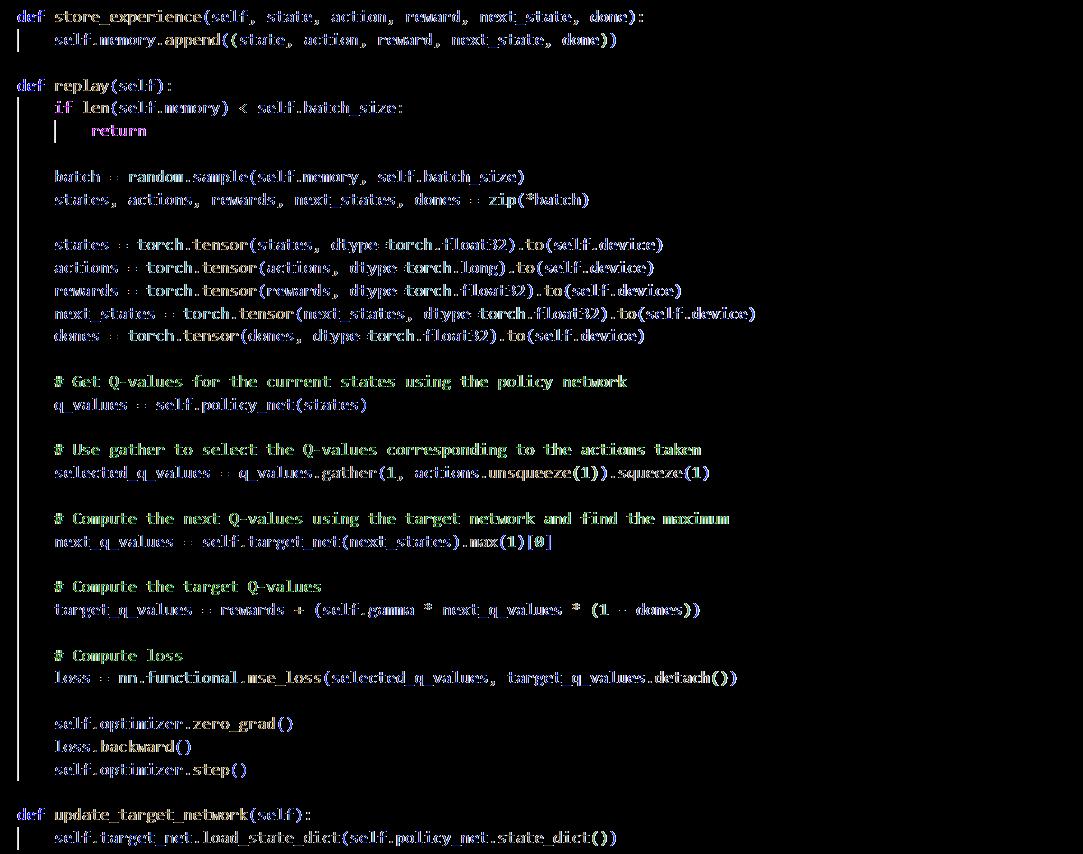
DQN's architecture is implemented in PyTorch, which includes two connected layers for feature extraction, followed by an output layer that corresponds to the actions in your action space. The DQN agent uses experience replay, which is a buffer that saves previous transitions of state and actions along with the corresponding rewards; and uses a target network, a separate network that estimates the stable Q-values during the training process and creates a table with the updated values to prevent oscillations (refer to appendix 9.4)
3.2.7
Training The Agent
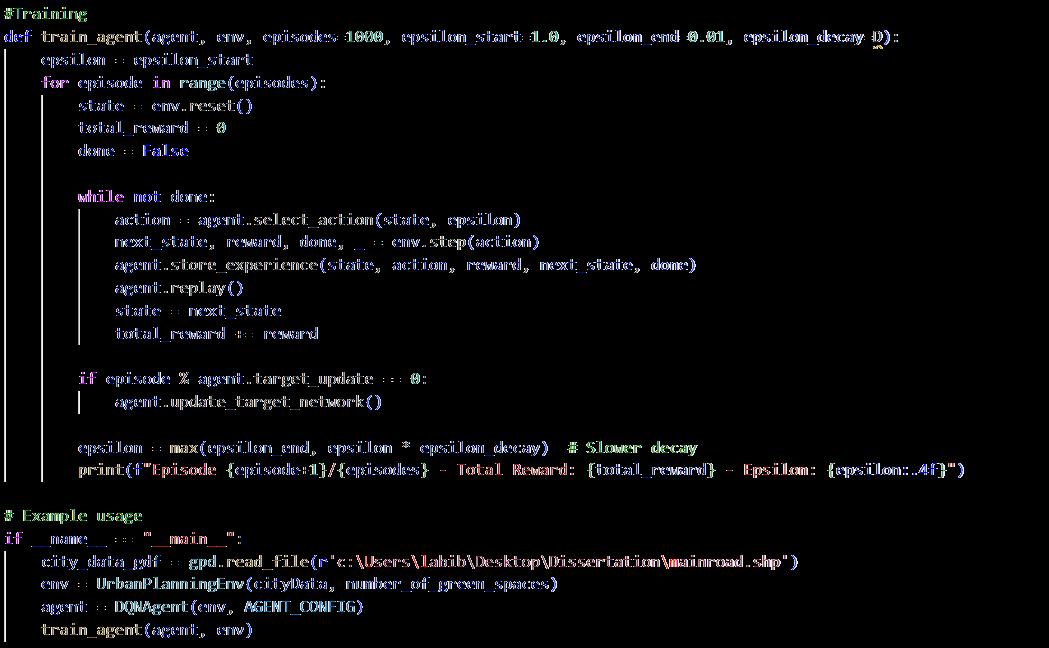
ThereinforcementlearningagentistrainedusingaDeepQ-Network.Theagentistrainedusing a Geodata file that provides information of urban areas including roads, intersections, open spaces etc. This method lets the agent to learn to operate within a realistic spatial network where nodes and edges represent key urban spaces and streets sequentially. Training the agent is done with a policy-based reward function with an epsilon greedy exploration strategy so there’s a balance between exploration and exploitation. As training progresses, epsilon decays, leading to more exploitation of learned strategies
Training requires storing the agent’s experiences which consist of state transitions, action and rewards in a replay buffer, using ‘deque’ to allow the agent to access small samples of experiences from previous training. The Q-Network is optimized using the Adam optimizer for its adaptive learning rates and computational efficiency.
The training is done over one thousand episodes. The environment is reset for each episode and the agent updates the Q-network as this helps to stabilize the learning process and provides a more stable set o Q-values for the Q-table. The performance is tracked by preserving the total rewards and epsilon values at the end of each episode, which allows the agent to maximize cumulative rewards over time (refer to appendix 9.5)
3.2.8 Testing
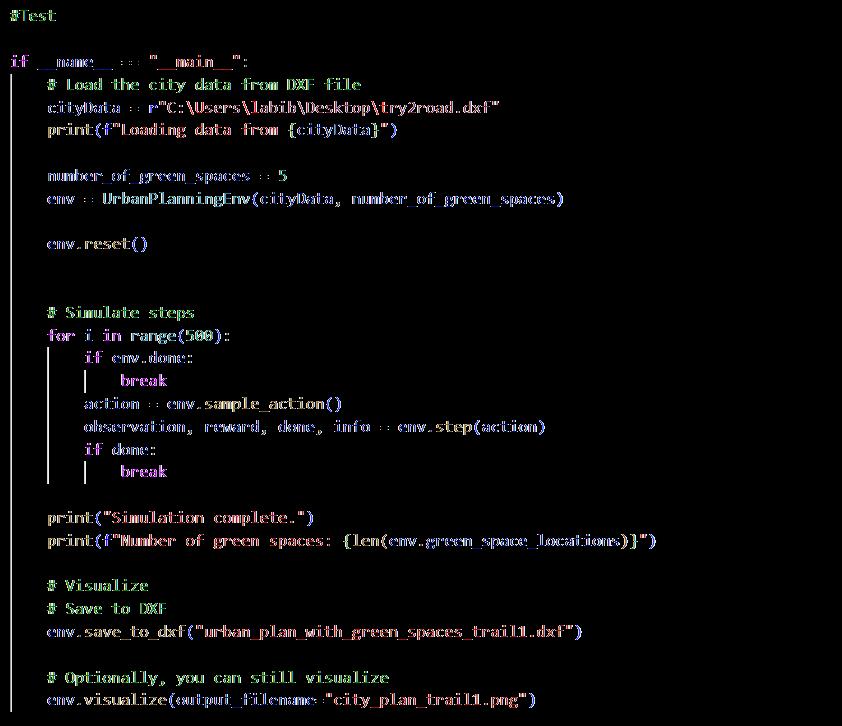
The testing was done using .dxf files that contain road network data so it’s easier for users with non-coding background to use, also .dxf files are easier to obtain and clean up than Geodata files. The number of green spaces can be changes in the input to suit any requirements. The agent interacts with the environment over 500 simulations to find the best locations and resets after each simulation. Finally, the output is visualized using Matplotlib and saved into a .dxf file (refer to appendix 9.6).
The RL model was tested on 2 urban blocks. The results have been included in results and discussion (refer to 4.1).
3.2.9 Evaluation
Evaluation in reinforcement learning (RL) is the process of assessing an agent's performance in completing tasks or navigating environments (Sutton & Barto 2014). It typically involves
measuring metrics such as cumulative reward, success rate, and average episodic reward (Francois-Lavet, et al. 2018). Theevaluation is comprisedof the environment,thetrained agent and the number of episodes. The agent’s performance is evaluated based on three parameters. The total accumulated reward for the entire episode, length of the episodes which is the number of steps taken by the agent in the episode, and the count of green spaces placed within the environment. All these parameters are avaraged to provide a summary of the agents performance. The mean of these parameters over all the episodes are visualized to evaluate the agent’s training and performance
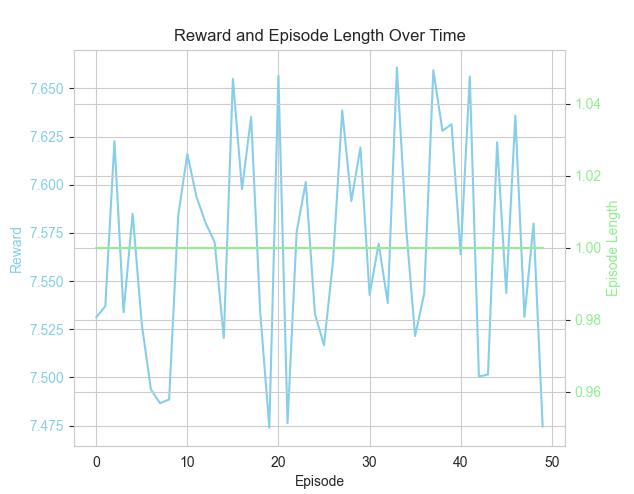
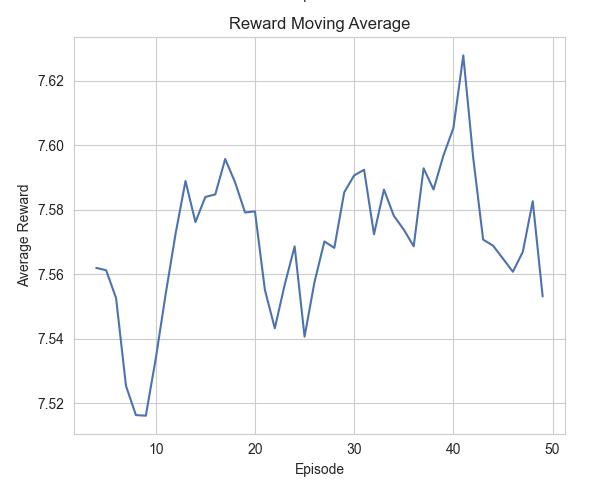
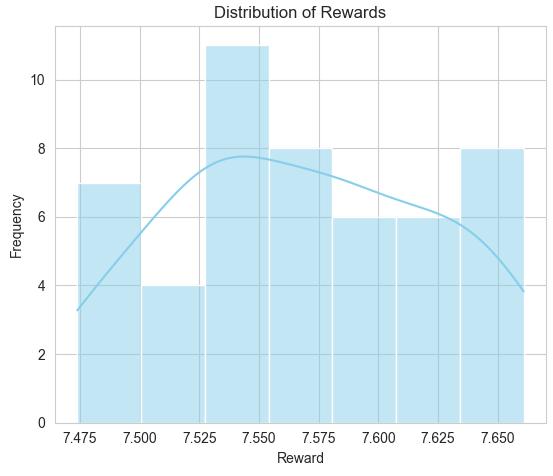
Figure 13 Evaluation of the agent after training (Author)
Reward and Episode Length Over Time chart shows the agent’s reward fluctuates around the average of 7.75. The Reward Moving Average graph shows minor oscillations in the average reward over time, with an upward trend. The Distribution of Rewards histogram shows that most rewards fall between 7.50 and 7.60, with some occasional high which means the agent’s performance is stable. The evaluation results suggest that the agent's performance is highly consistent and steady. The reward distribution reflects a stable and reliable performance across episodes. The slight upward trend in the reward moving average implies the agent may be improving its placement strategy over time.
3.3 Developing The Genetic Algorithm
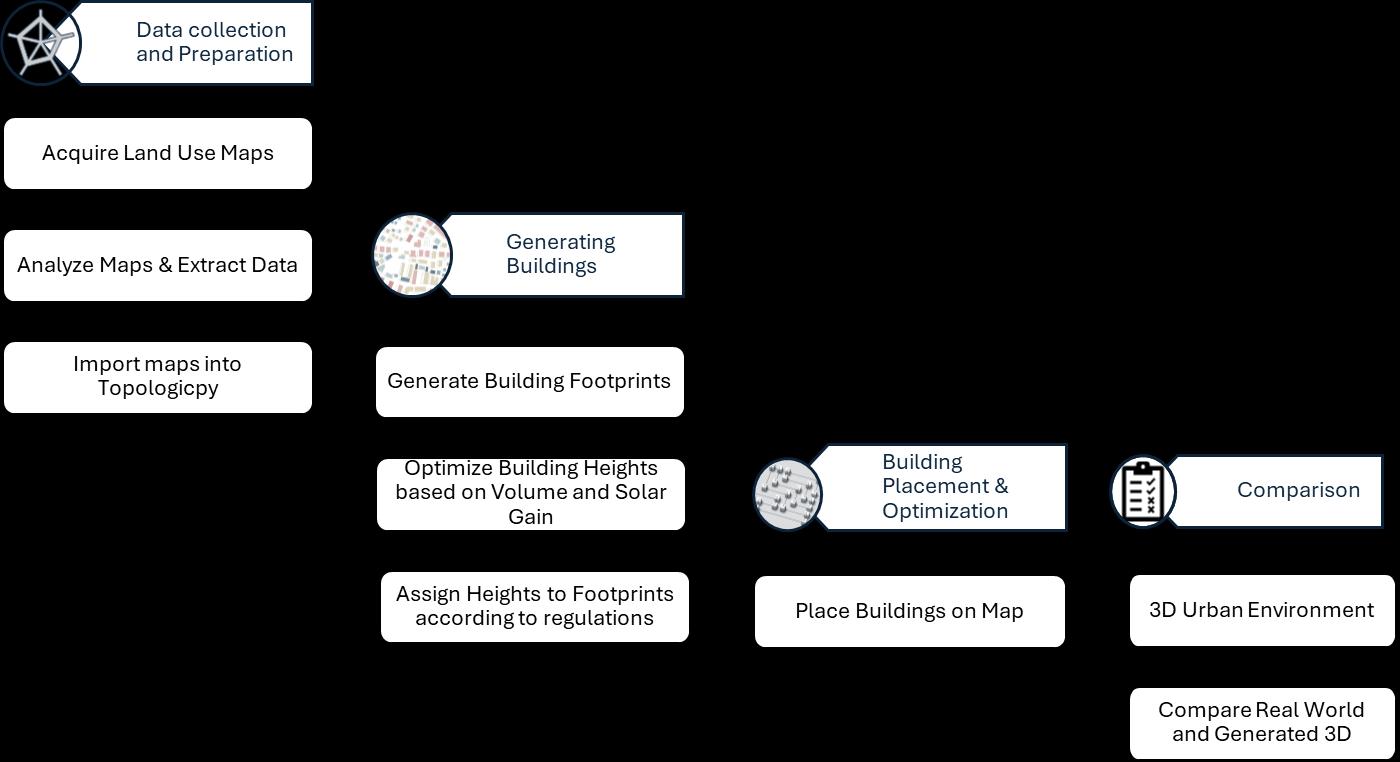
Figure 14 Workflow for automated procedural modelling for urban environment (Author)
3.3.1 Data Acquisition and Analysis
Initially a land use map of a certain block of the city was collected from an online database named Digimap. Attributes and parameters like land use types, building regulations and parcel dimensions were extracted from the data and further research into building codes of the area.
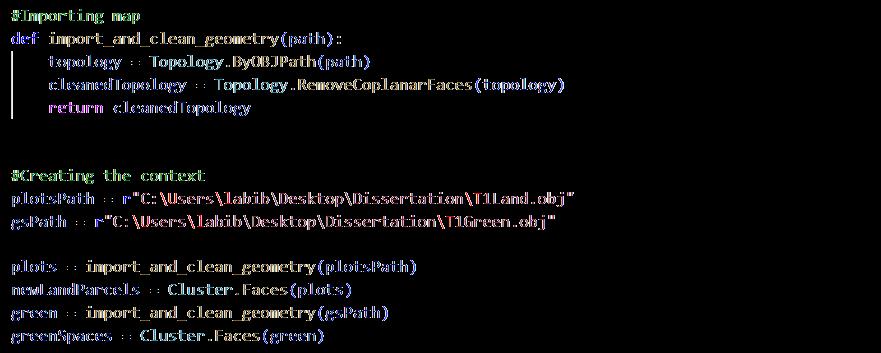
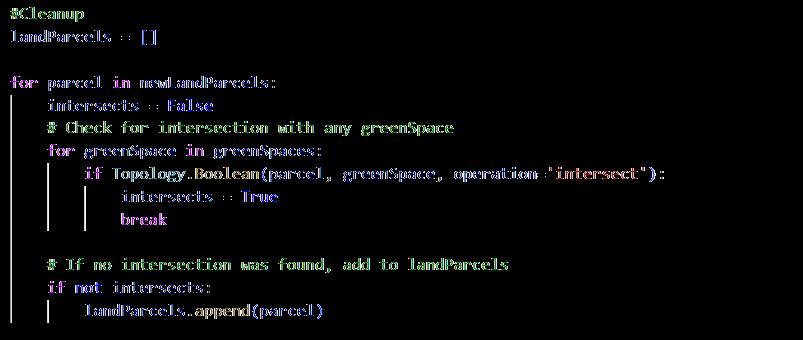
3.3.2 Preparing The Context [refer to appendix 9.7]
The map was cleaned up using Topologicpy where the coplanar faces of the land parcels were removed to prepare the context for the algorithm.
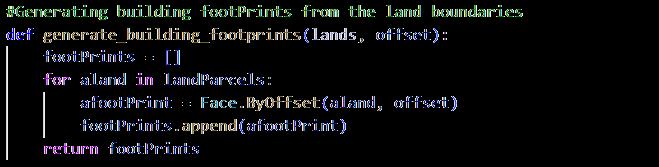
3.3.3 Algorithm Development for Building Footprints [refer to appendix 9.8]
Getting the initial building footprints are quite simple, it is based on the parcel dimension, shape, and the setback according to regulations of corresponding land use. The algorithm uses simply use TopologicPy to offset the edges of the land parcels inwards to generate the building footprint with maximum useable space.
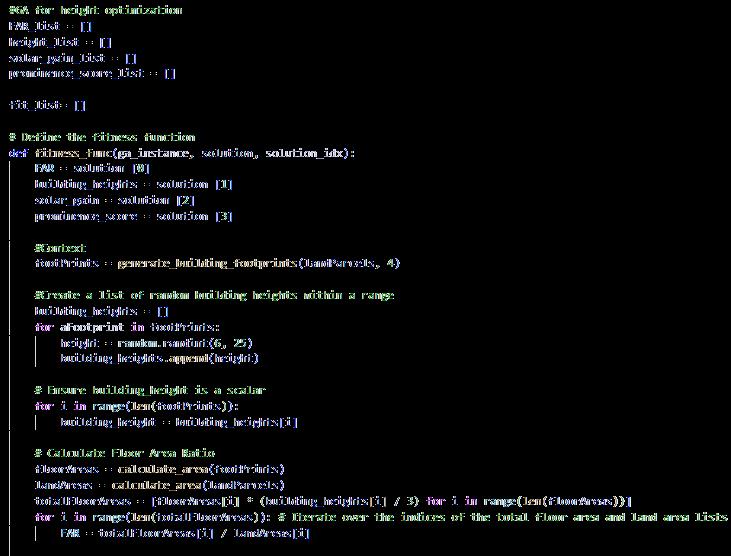
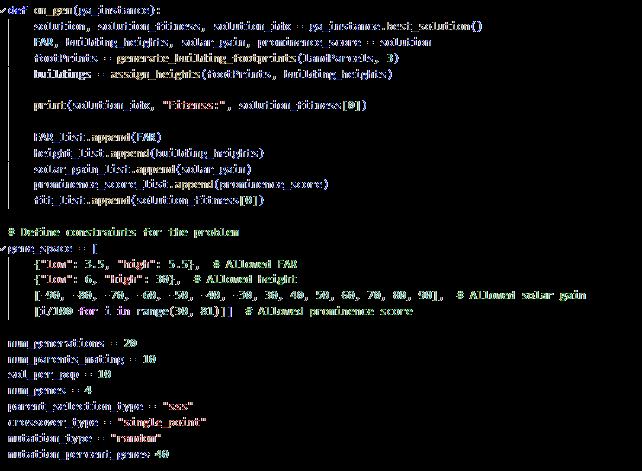
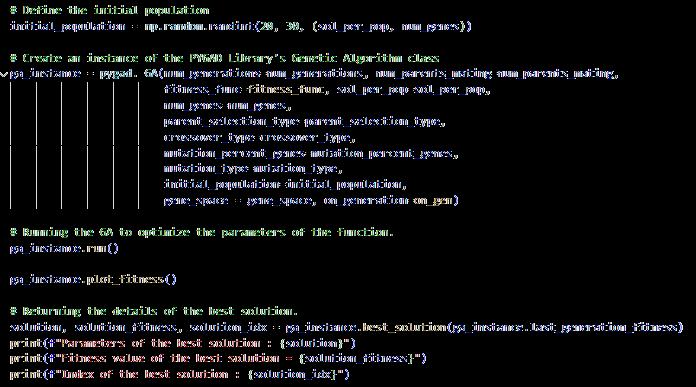
3.3.4 Optimization of Building Heights and Volumes [refer to appendix 9.9]
Application of GA to optimize the building height and volume according to floor are ratio (FAR) solar gain and prominence score of each building, as genetic algorithms are capable of mutating over many solutions to suggest an optimum or near optimum solution. The algorithm calculated solar gain for each building within the range of different heights, prominence score of each building so everything blends into the site in harmony and tries to maximize the FAR. Keeping all these into account a weighted fitness function was implemented to suggest optimum heights for each building in the site.
3.3.5 Assigning Heights to The Building Footprints [refer to appendix 9 10]
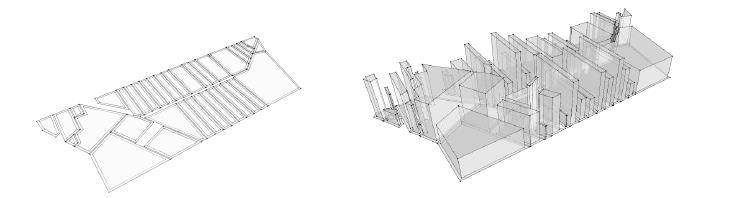
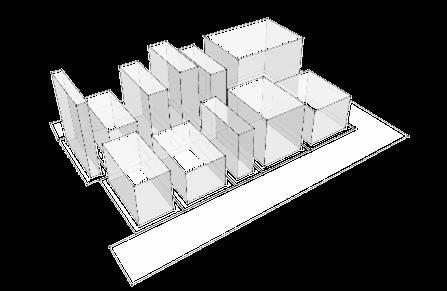
Figure 15 Demonstration of the process for automated city generation (Author)
Once the building height is optimized, the vertices were translated in the Z direction as per the matching height and the wires can be used to add faces, so the buildings have volume. To generate each building on the corresponding land, the land parcels were iterated through and given heights that belong to the same index.
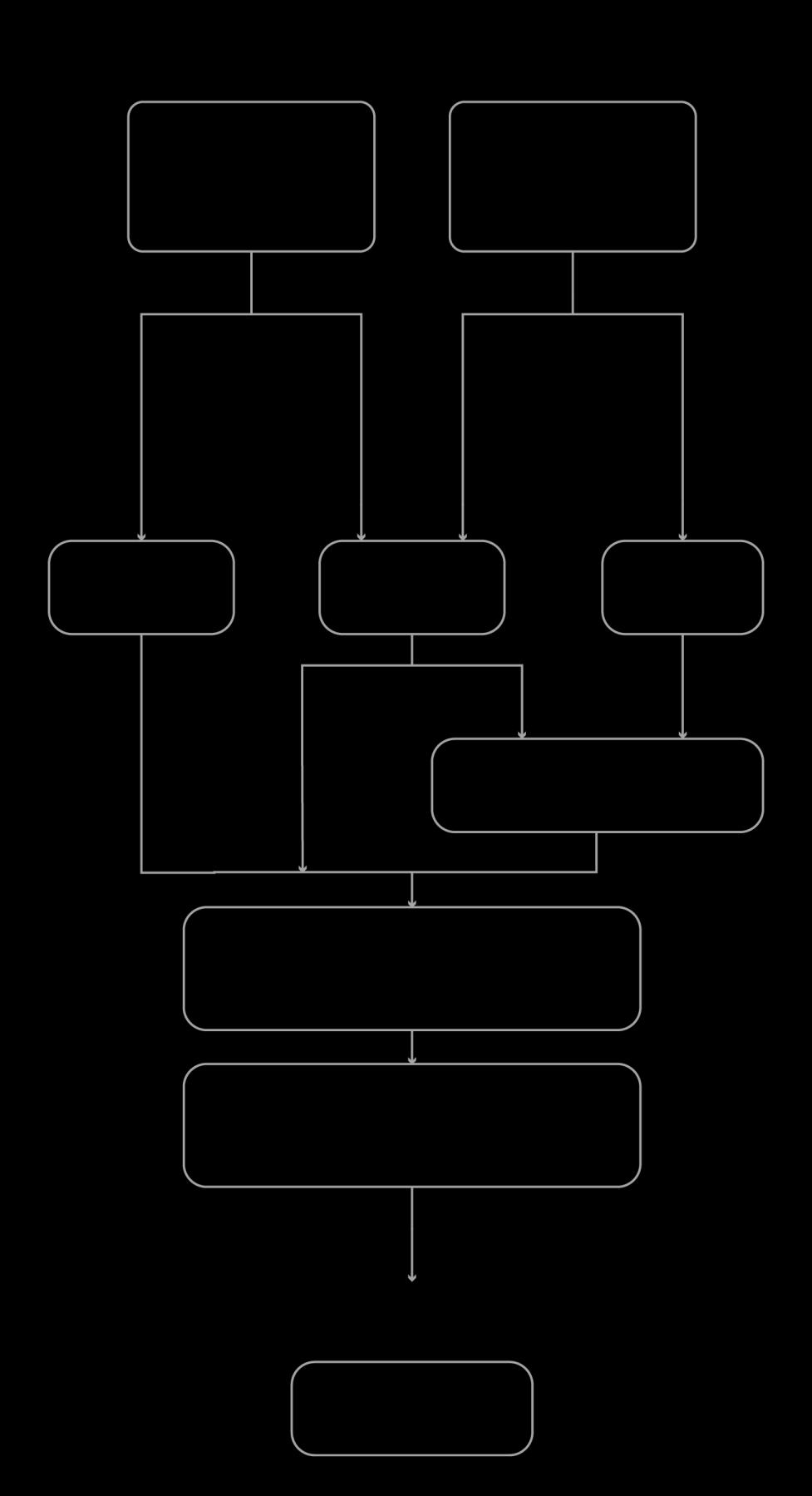
Figure 16 A representation of the Genetic Algorithm model (Author)
4 Results and Discussion
4.1 Results
4.1.1 Reinforcement Learning
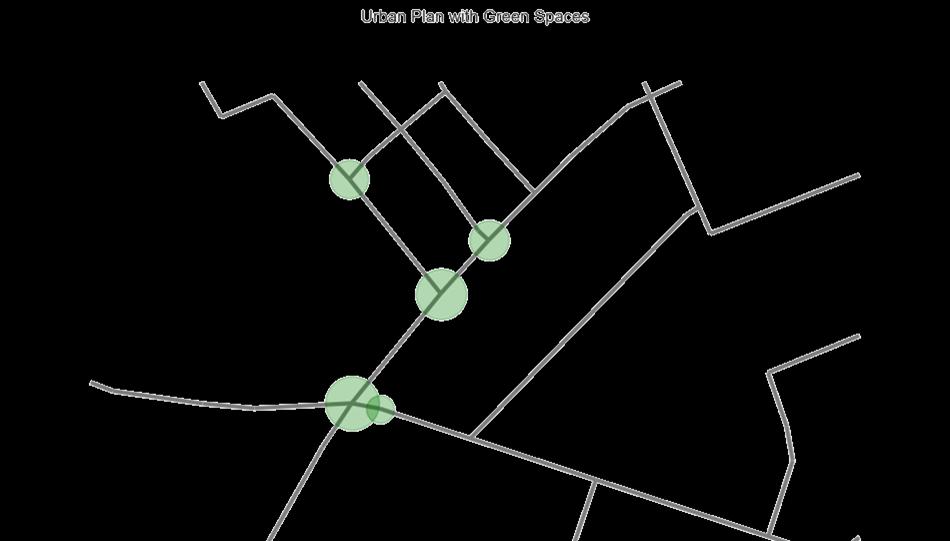
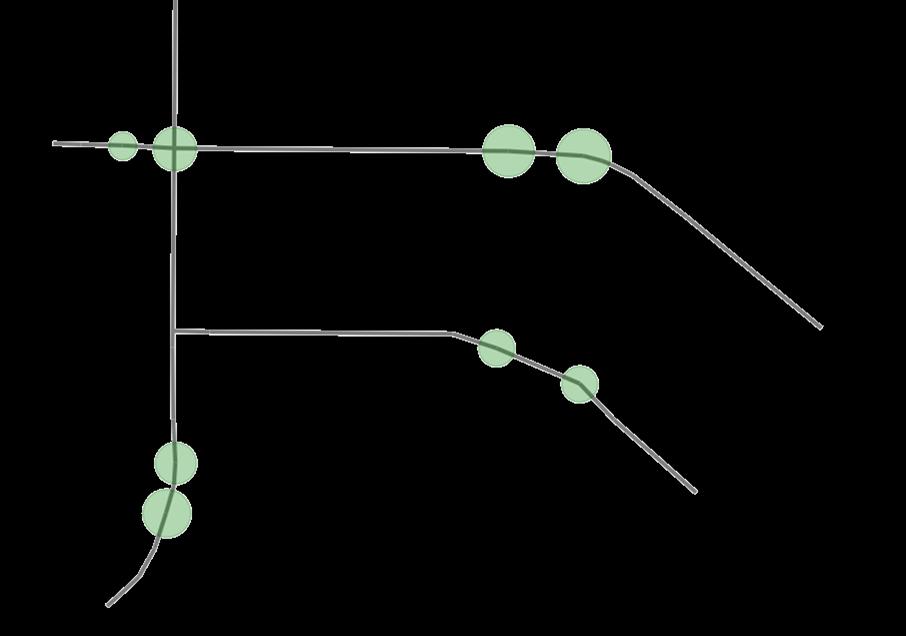
Figure 17 Results from reinforcement learning model (Author)
The reinforcement learning (RL) algorithm shows potential in optimizing green space placement across diverse urban layouts. The agent efficiently explores spatial metrics like centrality, step depth and decides on locations of green spaces
The results of this research are:
o Effectiveness in optimizing the placement of green space placement rapidly and adapting to a variety of urban environments.
o Ability to handle urban layouts of different scales.
o Potential for wider adoption in data-driven urban planning, supporting more informed and sustainable design decisions.
4.1.2 Genetic Algorithm
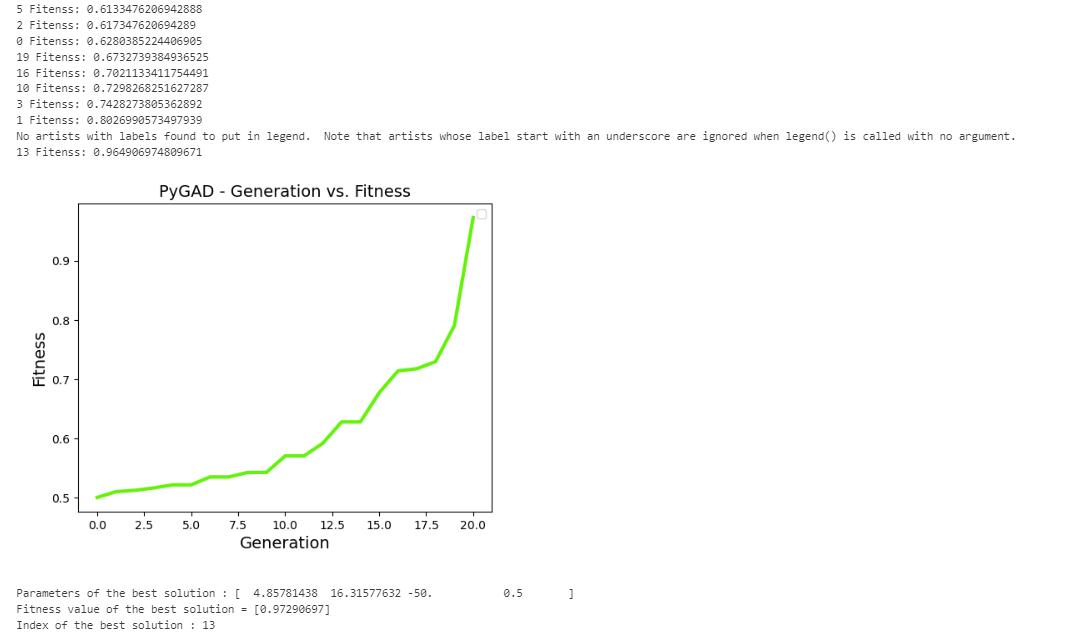

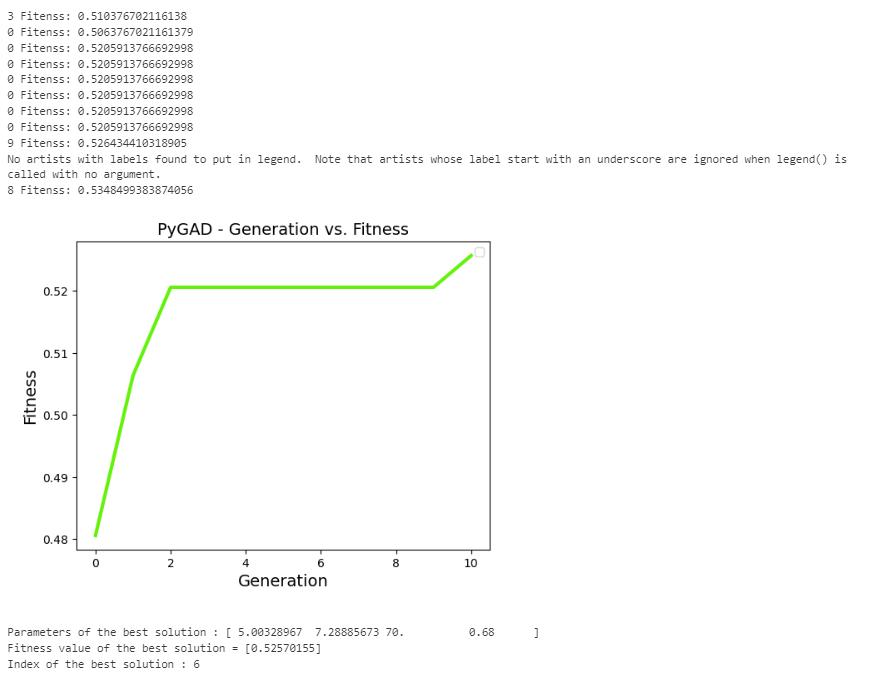
Figure 18
Results from Genetic Algorithm (Author)
The genetic algorithm shows potential in generating realistic and optimized 3D city models from any land use map across different urban contexts. The algorithm explores a few parameters and converges on realistic solutions tailored to different city blocks’ unique constraints and objectives. The result of using the genetic algorithm includes:
• Effectiveness in generating realistic and optimized 3D city models in very less time.
• Ability to handle diverse urban contexts and constraints.
• Improvements in optimization of quantitative metrics like solar gain, FAR.
4.2 Comparative Analysis of Results with Real-World Data
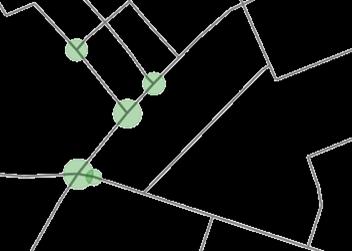
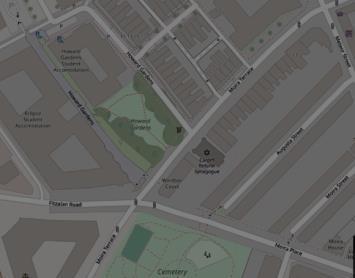
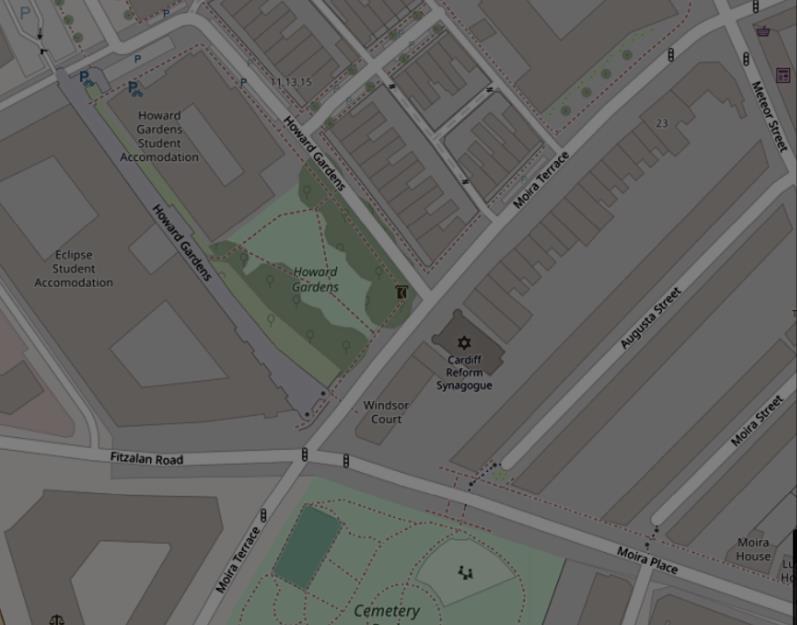
The output from the developed tool shows alignment with the real-world urban plans, though there’s some inaccuracies due to the constrains in the present algorithm. The reinforcement learning algorithm suggests green spaces that closely mirror the existing world. The images above are from an urban block situated in Adamsdown, Cardiff, UK. The top left image is the output from the RL algorithm and the bottom left image is the current map of that area. As shown in the image on the right, when it’s superimposed the suggestions of the RL algorithm closely match the green spaces that have been designed by professionals.


20
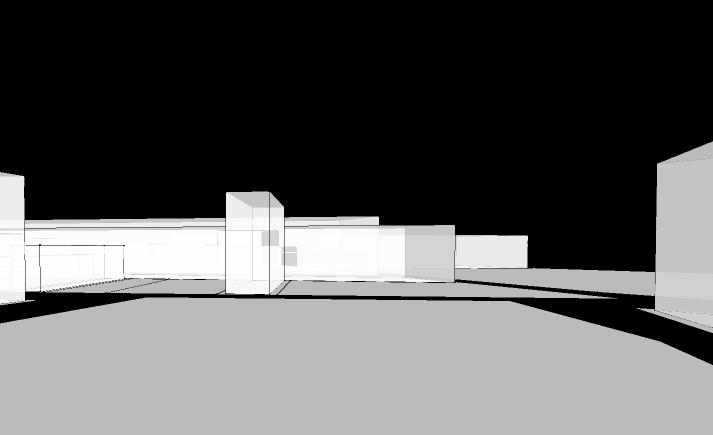
The GA produced a 3D city model that was optimized for parameters such as FAR, solar gain and prominence score, resulting in slight variations from the real-world site. In the real-world scenario, buildings in the target area tend to be highly uniform in height, whereas the GA introduced slight variations in building heights to maximize the optimization of quantitative metrics. These differences were anticipated given the parameters incorporated into the GA model.
4.3 Discussion
The aim of research was to analyse if integrating reinforcement learning model with space syntax principles can optimize the placement of green areas in an urban layout and if the use of GA with parameters like solar gain, floor area ratio and prominence score can be more time efficient for visualizing the city in 3D.
Based on the results, I reckon it’s safe to suggest that RL is a viable tool for urban planning when it’s combined with spatial analysis. These results demonstrate consistency with previous research on the applicationof machine learninginurbanplanning(Zheng etal. 2023) andusing GNN (Graph Neural Network) for spatial data analysis (Li et al. 2022) to enhance urban network analysis. However, the output was not fully accurate, as the input parameters were limited due to time constraints. The RL model primarily considered centrality and connectivity but did not account for more sophisticated factors like environmental conditions or land use constraints, which massively affect the public green spaces in an urban area. Setting up the neural network to match the input and output parameters, as well as readjusting the reward system to ensure that the outputs are suitable to train the agent. The successful combination of RL and space syntax provides an unconventional technique to enhance urban layouts, leading to more sustainable cities since it is purely data driven. The findings imply that these methods have the potential for substantially enhancing the urban planning processes.
According to the results discussed above, GA can generate a 3D model of a city within a very short amount of time. Taking certain parameters into account, it can suggest optimized heights for all the buildings in an urban block. Like previous studies (Di Napoli et al. 2023), the GA in this study effectively optimized city layouts based on multiple parameters. However, while other studies focused on aesthetic outcomes, this research prioritized quantitative metrics like solar gain and FAR, adding a functional dimension to the 3D models. The tool shows potential for scalability and adaptability in different context while providing the viewers with control over the parameters.
5 Conclusions
With the evolution of architecture and design, computational methods are getting increased attention and been a topic of discussion. As new technologies emerge with the advancement of science, the traditional ways of designing and thinking are also shifting.Urban design is getting more adapted towards sustainability and becoming data driven. Space syntax is one of the methods that is often used to understand how space influences human behavior by analyzing spatial configurations, such as pedestrian movement in cities. Artificial intelligence, Machine Learning, Genetic algorithm like many other computational methods is gaining popularity these days as these methods allow urban planners to handle large datasets, run simulations, and explore multiple design iterations with greater speed and accuracy than traditional approaches. This offers new possibilities for improving productivity, expanding design options, and reducing human error in the design process. This research explored the potential of combining space syntax principles with reinforcement learning as space syntax analyse cities as graphs and provides quantitative data as the output on the other hand, reinforcement learning uses neural networks for training, which is equipped for handling large amount of data. Meanwhile, genetic algorithms can simulate the process of natural selection by using a fitness function to determine the most efficient design solutions based on specific criteria. The qualities these methods have make them complementary and efficient. Space syntax enables the planner to analyze how urban spaces affect the users. Reinforcement learning can enhance the process of designing by testing hundreds of different layouts, adjusting variables like number of parks, road width, etc. to meet specific goals such as maximizing green space. Genetic algorithms can optimize the building heights for each plot, ensuring maximum sunlight, floor area ration and any other parameters. When combined with space syntax, reinforcement learning can analyze multiple design iterations rapidly. For example, urban planners can input a city's layout and specify parameters like the number of green spaces. The system then processes various iterations, providing the designer withoptimized solutions thatmeet the desired criteriain a fractionof the time itwould take using manual methods. The genetic algorithm uses a weighted fitness function to determine the heights of the building in each plot that is present in the urban area and figures out the building footprint and assigns the heights. this entire process generates a 3D urban area in less than half an hour. The advantages of using computational methods in urban design are substantial. As these tools can significantly reduce the time needed to develop and evaluate complex urban plans, what once might have taken weeks of manual work, now is achieved in a matter of hours or days with the ability to explore a wide range of design options enabling flexibility. However, there are also a few limitations for using these methods as it takes a lot of processing power, and the accuracy of this specific tool s still goof high as due to time constraints, all the parameters that affect urban design, like cultural and environmental aspects are not yet accounted for. Despite the limitations, it is definite that, as machine learning models become more refined and capable of integrating a wider range of variables, the potential for highly accurate, context-sensitive urban design increases.