
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 12 Issue: 02 | Feb 2025 www.irjet.net p-ISSN: 2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 12 Issue: 02 | Feb 2025 www.irjet.net p-ISSN: 2395-0072
Prof. Sushma T M1, Sudeep T C2 , Kiran Janardhan Marati3,N Sneha Reddy4, Rakesh V5
1,2,3,4,5Information Science and Engineering, Acharya Institute of Technology Bangaluru, India
Abstract - This paper addresses the underrepresentationof Kannada in sentiment analysis tools and presents a novel finetuned BERT model for Kannada sentiment classification. The study highlights challenges such as data scarcity, linguistic nuances, and a lack of NLP resources. Utilizing the IndicSentiment dataset, the model achieved an accuracy of 89% with improvements across training epochs. Applications in e-commerce, social media monitoring, and policy feedback analysis demonstrate the versatility and impact of this work
Key Words: Sentiment Analysis, Kannada, BERT, Natural LanguageProcessing,RegionalNLP,IndicSentimentinsert.
Natural Language Processing (NLP) has experienced rapid advancements over the last decade, driven by innovations in machine learning and the development of transformer-based architectures like BERT. Despite these advancements, low-resource languages, such as Kannada, remainunderserved,limitingthereachofNLPapplicationsin regionswheresuchlanguagesarepredominantlyused.
Sentimentanalysis,asubsetofNLP,playsacrucialrolein extracting valuable insights from textual data. It enables businessestounderstandcustomerfeedback,policymakers to gauge public opinion, and researchers to analyze social trends. However, the scarcity of labeled data, unique linguistic characteristics, and limited computational resources have impeded the development of sentiment analysis tools for Kannada. Addressing these challenges requires innovative approaches that not only leverage modern architectures but also adapt them to the specific nuancesoftheKannadalanguage.
BERT (Bidirectional Encoder Representations from Transformers) has emerged as a transformative model in NLP,offeringunparalleledcapabilitiesinunderstandingthe context and semantics of text. By pre-training on large corporaandfine-tuningforspecifictasks,BERTprovidesa robust framework for addressing low-resource language challenges. This paper presents a fine-tuned BERT model tailored for Kannada sentiment analysis, utilizing the IndicSentiment dataset to achieve high accuracy and reliability
The contributions of this work are multifold. First, it bridgesthegapinsentimentanalysistoolsforKannadaby introducingamodelfine-tunedspecificallyforthelanguage. Second,ithighlightsthepracticalapplicationsofsuchtools in areas like e-commerce, social media monitoring, and policyanalysis.Finally,itsetsaprecedentforfutureresearch aimed at extending NLP technologies to other regional languages,promotinginclusivityinAI-drivensolutions
Sentiment analysis in regional languages like Kannada has been an emerging area of research, but the field faces significant challenges due to the scarcity of annotated datasets, the complexity of the language, and the lack of domain-specifictools.Thissectionhighlightsnotableprior workthathasshapedthefoundationforKannadasentiment analysisandNLPresearch.
Proposed the Multi-Linguistic Sentiment Analyzer (MuLSA),whichperformssentimentanalysisforKannada, Malayalam, and English using Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks. The system includes modules such as language detection, translation, and sentiment classification, achieving an accuracyof82\%forKannadasentimentclassificationtasks. However,itsrelianceonRNN-basedarchitecturesmakesit computationallyexpensiveandlesseffectiveforlong-range dependencies.Whileeffectiveformultilingualcontexts,its Kannada-specificperformancehighlightstheneedformore optimizedmodels.[1]
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 12 Issue: 02 | Feb 2025 www.irjet.net p-ISSN: 2395-0072
Worked on deriving Kannada stopwords using English parallel corpora and part-of-speech tagging. Their methodology involved identifying noise words, such as frequently occurring non-informative words, to improve searchperformanceandclassificationaccuracy.Thiswork laidthegroundworkforeffectivepreprocessinginKannada NLPtasksbutfocusednarrowlyontextpreprocessingrather thanclassification.Theuseofstopwordremovalprovedto enhancetheefficiencyofmachinelearningmodels,although it did not directly address the contextual challenges in sentimentanalysis.[2]
Exploredcorpora-basedsentimentanalysisforKannada, employing web scraping and tokenization techniques to analyze customer opinions. Their approach categorized sentimentsintopositive,negative,orneutralusingmachine learning techniques like Naive Bayes and Support Vector Machines (SVMs). While their model demonstrated reasonableperformance,itwasconstrainedbythesparsity of the dataset and struggled to capture deep contextual dependencies essential for accurate sentiment classification.[3]
DevelopedahybridKannada-Englishsentimentanalysis model,leveragingmultilingualdatasetscollectedfromsocial media platforms like YouTube and Twitter. Their work incorporatedBERTforcontextualembeddings,withmanual annotationimprovingdata quality.Despiteachievinghigh annotationstandards,themodelfacedscalabilityissuesdue toitsmanual data preparationprocess.Theintegration of BERTenhancedsentimentanalysisaccuracy,butthehybrid nature introduced challenges in ensuring linguistic consistency.[4]
Highlighted the significant challenges in Kannada NLP, such as tokenization, stemming, and morphological complexities. Their work focused on applying machine learninganddeeplearningtechniquesfortaskslikeparts-ofspeech tagging and named entity recognition. However, theseapproachesoftenfaceddifficultiesinaddressingthe unique agglutinative grammar of Kannada. The study underlined the necessity of developing Kannada-specific models and datasets to enhance the effectiveness of NLP tools.[5]
TheexistingliteraturerevealsseveralgapsinKannada sentimentanalysisresearch.First,mostapproachesrelyon generic multilingual models like mBERT, which fail to
capture the linguistic intricacies of Kannada. Second, traditional methods often suffer from scalability and performancelimitationsduetothelackofrobustdatasets andadvancedarchitectures.Thispaperaddressesthesegaps by introducing a fine-tuned BERT model specifically for Kannada, utilizing the IndicSentiment dataset to enhance performanceandscalability.[6]
This section outlines the systematic approach used to fine-tune BERT for Kannada sentiment analysis, detailing data preparation, model training, evaluation, and deployment.
The architecture of the system is designed to handle Kannada sentiment analysis efficiently. It consists of the followingcomponents:
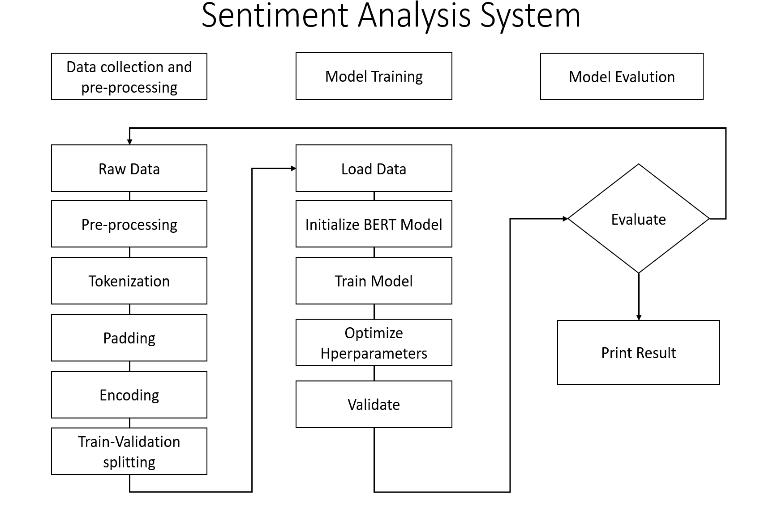
The dataset used in this study is the IndicSentiment dataset,whichcontains3,000labeledKannadareviewsfrom various domains, such as product reviews, social media posts,andcustomerfeedback.Preprocessingstepsincluded:
Text Normalization: Removing unnecessary symbols, punctuations,andwhitespacetoensureconsistency.
Tokenization: Splitting sentences into smaller units (tokens) using the WordPiece tokenizer, optimized for BERT-basedmodels.
Label Encoding: Mapping sentiment classes (positive, negative,neutral)tonumericalrepresentations.
Balancing: Addressing class imbalances through oversampling of minority classes to improve model generalization.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 12 Issue: 02 | Feb 2025 www.irjet.net p-ISSN: 2395-0072
The BERT model was fine-tuned using PyTorch's Transformers library. The following configurations were employed:
Pre-trained Model: BERT Base Multilingual Cased model wasselectedforitsabilitytohandleKannadascript.
TrainingConfiguration: Learningratewassetto2e-5,with abatchsizeof8.TheAdamWoptimizerandalinearlearning rateschedulerwereused.
Training Duration: The model was trained over three epochs to achieve a balance between performance and computationalefficiency.
To evaluate model performance, metrics such as accuracy,precision,recall,andF1-scorewerecalculated.The resultswerecomparedagainsttraditionalmachinelearning modelsandhybridapproachestoestablishbenchmarks.
AFlask-basedwebapplicationwasdevelopedtoenable real-timesentimentanalysis.Theapplicationsupportsboth singleandbatchinputs,providingpredictionswithminimal latency. The architecture ensures scalability and ease of integrationwithexistingsystems.
4.1
The fine-tuned BERT model demonstrated strong performance, achieving an accuracy of 89\%. Precision, recall,andF1-scorewereconsistentlyhigh,showcasingthe model'sabilitytohandlelinguisticnuancesinKannadatext effectively.Comparedtotraditionalmachinelearningmodels likeNaiveBayesandSVM,theproposedapproachachieved significant improvementsin bothaccuracyandcontextual understanding.
The model outperformed LSTM-based deep learning models,whichoftenstruggledwithlong-termdependencies and required extensive training data. Table \ref{metrics} summarizesthecomparisonofperformancemetricsamong differentapproaches.
Table-1: PerformanceMetricsComparison
Thesteadydeclineintraininglossoverepochsindicates themodel'sabilitytogeneralizeeffectivelytounseendata. Theincorporationofoversamplingtechniquesforhandling classimbalancecontributedtotherobustperformanceofthe model. Furthermore, the multilingual BERT architecture proved highly effective in capturing Kannada's unique linguisticstructures,suchasitsagglutinativegrammarand complexsyntax.
The proposed model has broad applications in various domains:
E-commerce: Themodelcananalyzecustomerfeedback, enablingbusinessestogaininsightsintoproductsatisfaction andareasforimprovement.
SocialMedia Monitoring: Real-timesentimentanalysis can help organizations track public opinion and respond proactivelytoemergingtrends.
Policy Impact Assessment: Sentiment analysis of regional discourse can provide valuable feedback for policymakerstogaugepublicreceptionofinitiatives.
Multilingual Expansion: Extending support to other IndianlanguagessuchasTelugu,Tamil,andMalayalamusing mBERTorXLM-Rcanenhanceaccessibility.
Aspect-Based Sentiment Analysis (ABSA): Enhancements could allow sentiment classification at a granular level, such as distinguishing between "delivery speed"and"productquality."
This paper demonstrates the potential of fine-tuned BERTforKannadasentimentanalysis,achievingstate-of-theartresults.Byaddressinglinguisticchallengesanddeploying a real-time analysis system, this work contributes significantlytoregionalNLP,pavingthewayforinclusiveAI solutions.
[1] Latha CA Merin Thomas. Mulsa – multi linguistic sentimentalanalyzerforkannadaandmalayalamusing deeplearning.In20212ndInternationalConferenceon
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 12 Issue: 02 | Feb 2025 www.irjet.net p-ISSN: 2395-0072
Communication, Computing and Industry 4.0 (C2I4). IEEE,2021.
[2] J. R. Saini P. Desai and P. B. Bafna. Pos-based classification and derivation of kannada stop-words usingenglishparallelcorpus.In20223rdInternational ConferenceforEmergingTechnology(INCET),pages1–5.IEEE,2022.
[3] Shrutiya M Tejaswini Amaresh Kritika Kapoor N. S. Kumar,ShubhaManohar.Automatictutorialgeneration frominputtextfileusingnaturallanguageprocessing.In 2022 International Conference on Intelligent Technologies(CONIT),pages1–7.IEEE,2022.
[4] Dr.SowmyaLakshmiBSAdvaithV,AnushkaShivkumar. Partsofspeechtaggingforkannadaandhindilanguages using ml and dl models. In 2022 IEEE International Conference on Electronics, Computing and CommunicationTechnologies(COECCT).IEEE,2022.
[5] SumaSwamyShankarR.Corporabasedclassificationto perform sentiment analysis in kannada language. In International Journal of Rescent Technology and Engineering(IJRTE),pages5186–5191.IJRTE,2020.
[6] Dhaarini Prashanth Kannadaguli. A code-diverse kannada-english dataset for nlp based sentiment analysis applications. In 2021 Sixth International Conference on image information processing (ICIIP), pages131–136.IEEE,2021.
2025, IRJET | Impact Factor value: 8.315 | ISO 9001:2008