Key
2 RELATED LITERATURE
:
Deep Neural Networks
Machine Learning,
1
AwiderangeofMachineLearningmodelshavebeenusedforpredictingthe short term/long termpriceofbitcoin.Themodels aremostlyeitherrelyingonsentimentanalysisorananalysisofhistoricalpricedataforfuturepriceprediction.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 09 Issue: 01 | Jan 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page415 Bitcoin Price Prediction using Sentiment and Historical Price Shorya Sharma1, Sarang Mehrotra2 1 2School of Electrical Sciences, Indian Institute of Technology Bhubaneswar, Bhubaneswar, Odisha, India *** Abstract
Cryptocurrency, Sentiment
[6]MatthewDixon1, DiegoKlabjan2andJinHoonBangusedDNN(basicallyMLP)toevaluatetheaccuracyofamodeltrainedonthedatacollectedfrom 43 CME listed commodity from March 1991 to September 2014 in 5 minute intervals and obtained around 40% accuracyin predictingwhetherthecommoditypricewouldincrease, beneutral,ordecreaseoverthenext time interval, which is slightly betterthanrandompredictions.[7]SeanMcNally,JasonRocheandSimonCatonmadeacomparisonofthetraditionalARIMA modelforpredictingtime seriesdataandmorerecentdeeplearningmodelLSTM,RNNtrainedusingBitcoinPriceIndexdata andconcludedthattheLSTMoutperformsARIMAandachieved52%classificationaccuracy. Theyevaluatedtheimpactofthe windowsizeofpricedataandconcludedthatthemosteffectivelengthwas100daysfortrainingLSTM.
[3]GiuliaSerafini,PingYianalyzedthesentimentfeaturesfromeconomicandcrowd sourceddataandusedARIMAXandRNN formakingpricepredictiontoachieveanaccuracywithameansquared errorlowerthan0.14%withbothmodels.[4]Rajuaand AliMohammadTarifusedacombination ofbitcoinhistoricalpricedataandtweetsforsentimentanalysis.Theyextractedthe polarity from the tweets and achieved a 197.515 RMSE with LSTM compared with 209.263 with ARIMA. [5] Ray Chen presentedaspecialstrategy toanalyzethesentimentintweetsforstockmarketmovementprediction. They pre generated a dictionaryofwordsandassociatethemwithlogprobabilitiesof happinessandsadnessassociatedwitheachwordtocompute anaveragesentimentforeachtweettomakestockmarketmovementpredictionandachievedaround60%accuracy.
[1] Siddhi Velankar proposed the necessity of pre processing the bitcoin price data through using different normalization techniquessuchaslognormalizationandBox Coxnormalizationbefore feedingthedataintothemodel.
Bitcoin is one of the first digital currencies that were first introduced around 2008.The decentralized currency gained huge popularity in the past decade and it is now trading around USD 18000 per coin. Speculations around its future upside potential have attracted a large number of individual and institutional investors despite the price volatility. Therefore, price prediction for bitcoin has become a relevant but challenging task. In this project, we will be utilizing sentiment analysis and historical price data to maximize the accuracy of price prediction of bitcoin. Words Bitcoin, Analysis, Historical Price,
INTRODUCTION
Bitcoinisatypeofdigitalcurrencythatcanbesentbetweenpeoplewithouttheneedforintermediate administration.Transactions madeusingbitcoincanbemoreefficientasitisnottiedtoanycountry.Despitethefactthatbitcoinisnotofficiallyrecognizedas atypeofsecurity,itstillsharesalotofsimilaritieswithothersecuritieslikestocks.Thismeansthatthetraditionaltechniques for trading stocksbasedonananalysisofhistoricalprice(MACD,EMA)canstillbeappliedtoit. Ontheother hand, bitcoin’s institutional holding percentage is only around 36% compared with the 80% US equity institution holding. This means that bitcoin’spricecouldbemoreeasilyimpactedbymarketsentimentandnewscoveragebecauseindividual investorsaremore unstable. This paper intends toexplore the potential of recent advancements in deep learning in improving the accuracy of making apricetrendmovementpredictionforbitcoin (upward/downward) from theprevious 50% achieved byxxx which is equivalenttorandomguessing.

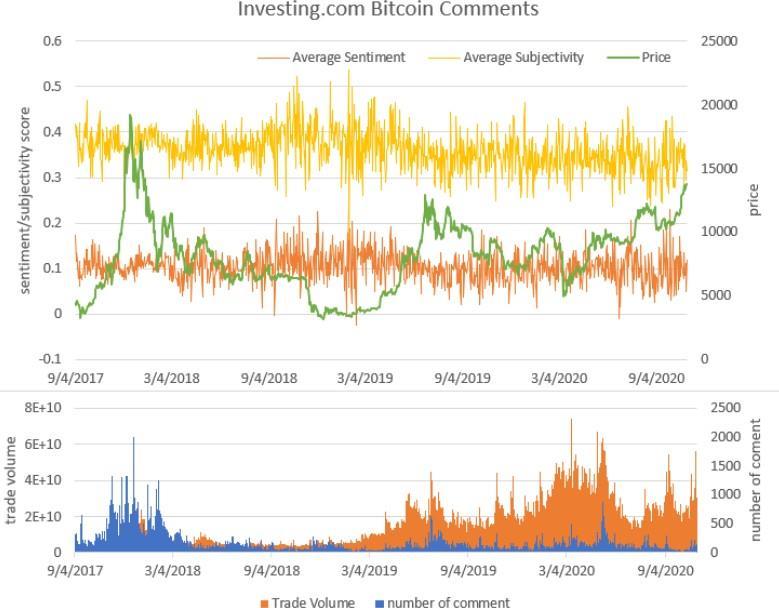
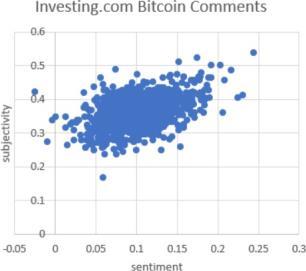
Figure1:(a)Commentvolumedistribution (b)Commentoverallsubjectivityandsentiment Data Processing
Intermsofsentiment,theaveragesentimentofthecommentscalculatedusingTextBlobwasnotvery volatileandtendedtostayina range. Part of the reason is that text sentiment related to securities tend to be more subtle than product reviews. An interesting findingisthat,thehigherthesubjectivityscore,the higher the sentiment score (figure 1b). It indicates that comments that express strongopiniontendtobethebullishones.Thispatternisshowninbothdatasets.
3.2
ThebitcoindailypricedataspansfromJan2012 Nov2020.Forthesentimentanalysispart,theinvestingforumdiscussions include comments from 2017 till 2020, containing a total of 201,104 comments. Therefore, only the relevant price data between2017 2020iskeptandisshuffledandsplitintotrain/validationby70%/30%proportions. Therawdatascrapedfromonlinesourcesisnoisyandcontainsalargenumberoftoxiccomments,whichisthereasonwhydata processingbecomesparticularlyimportantfortraining.Belowaresomerealexamplestakenfromthesources.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 09 Issue: 01 | Jan 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page416 3 3.1DatasetSource We scrapped several major websites and decided to use comments from investing.com, a popular financial website that has quotesformostofthetradedsecuritiesandtheirdedicateddiscussionpages,astheyhavehigherdesiredqualitiescomparedwith social mediabasedTwitterdatasetandforum basedRedditdatasetwhicharenoisier From2017 09 04to2020 11 01,thereareanaverage167commentsfromInvesting.comperday.The numberofcommentsisnot evenlydistributed.Themorevolatiletheprice,themorethecomments(figure1a).
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 09 Issue: 01 | Jan 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page417
Thepredictivepowerofthepriceindexwasinvestigatedusingstand alonemodelstoinvestigateandisolatetheauto regressive performanceofthepriceindexuponitself. Thedependentvariablebeingthe1 daydirectionalpricemovementintheBitcoin priceindexwhichiseither1inthecasethatthecloseprice1 dayinthefutureishigherthanorequaltothecurrentcloseprice or0whenitislower.
In keeping with the objective, two simple architectures were selected. The first was a bidirectional LSTM network with 2 layersof64neurons eachfollowedbya linearlayertonarrowthe128 dimensional outputtoa singleneuron anda sigmoid activationwhichcapturesthebinaryresponse.Thesecond,amulti layerperceptron(MLP)networkmodel,isasimple3 layer modelwith540,256and 128 dimensions in the layers respectively which then are combined into a single output layer and sigmoid activation. While several architectures which combined an LSTM model with prior convolutions were also experimentedwith,noneoftheseyieldedresultsbetterthanchance.Assuch,thesefinaltwomodelswerechosenforsimplicity asaninitialbaseline. Thehistoricaldatawassummarizedintodailysegmentsandforeachdaythefollowingfeatureswereextracted: firstly,thedaily closepriceandsecondlythehistoricalmovementindicatordata(indicating anupmovementordownmovementintheprice).In thecaseofbothvariables,theprior270trading days worth ofdata was used topredictthe following day’s movements. The
4 Methodology
Thepricemovementtrendpredictionisapproachedfromtwodifferentmethods. Sentiment based andhistoricalprice index based.
Figure2:Textualinputprocessingpipeline
4.1 Historical price index
Inordertoimprovetheoverallqualityofrawdata,apipelineisdesigned tocleanthetextualinput.Thepipelineaimstodeal withseveralcommonproblemsoftextualdatainNLPtasks.
Thepipelinecontainstwomajorparts.Thefirstpartisrelatedtotextualcleaning andit basically ensuresthatwhenthetext data is passed into the embedding layer, it has a consistent and clean format. Thegoalofthesecondpartistomaximizethe qualityofcomments byfilteringoutgibberishcomments that contain a large number of words that never showed up in the dictionaryofcommonEnglishwordsandshortcommentsthataretoxicandcontainminimalsentiment relatedinformation.

rationalebeingthatthistimeperiod would capture mediumtermseasonality which may occurina year e.g., annual bonuses whichpeoplereceiveorseasonalinvestmentflows. In this case, one fifth of the data was kept as a hold out validation set and the rest was used to train the models. The models were trained over 20 epochs optimizing for a BCE loss function (Binary cross entropy loss function) and using an Adamsearchoptimizationalgorithm.TheBCE lossfunctionisthemostappropriateinthisscenarioaswearepredictingbinary categoricalvariables.Themodelperformancewasmeasuredusingbycalculatinganaccuracypercentage.Thefollowing table summarizestheresultsofthemodelperformance:
Table3:BestperformanceoftwobaselinemodelsonHistoricalPriceModels
The improvements in the quality of the pretrained embeddings in the last few years have significantly boosted the accuracy of modelsrelatedtoNLPtaskssuchasmachinetranslation,sentimentanalysis,question answering.Earlier NLPmodelsthatare based on pretrained word level embeddings have been gradually replaced by novel sentence level embeddings. Word level embeddings such as Glove (left) are able to capture the semantic similarity between words, on the other hand, sentence embeddings such as UHS or Infersent’s major advantage is that it also captures syntactical information on top of word by word basedsemanticinformation.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 09 Issue: 01 | Jan 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page418
Figure3:(a)Gloveword embedding(b)USEsentence embedding
A simple visualization created for our raw data indicates how sentence level embedding couldpotentially recognize the importanceofeachwordandhelpimprovethemodeltraining
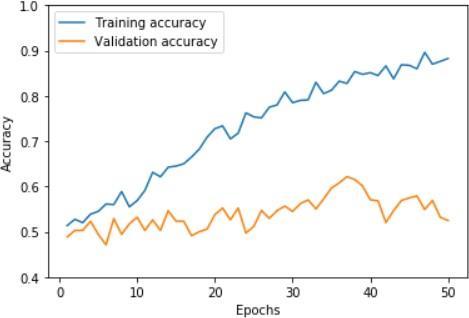
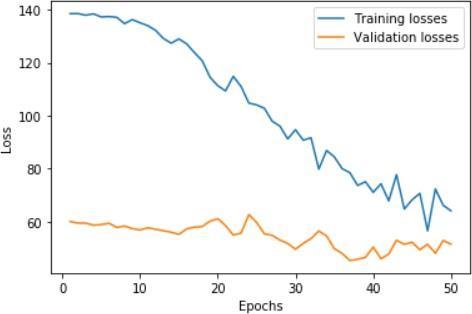
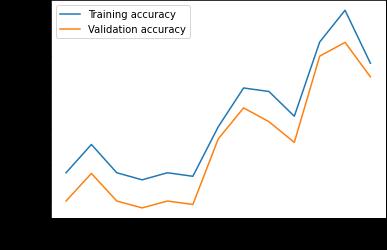
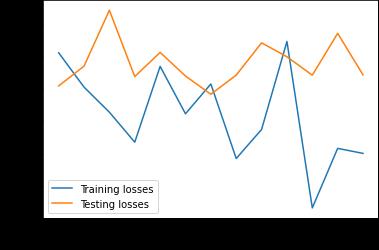
While the models may be only just better than chance, this is typical prediction performance for financial stocks and indices suchasBitcoin.ThebestperformingmodelofthetwoistheLSTM Modelwith54.8%overallaccuracy.Itisnotedthatthecost oferrorisasymmetricalforthiscontext.Incorrectlypredictingadownmovementresultsinamissedopportunityforatrader withalong onlystrategywhileincorrectlypredictinganupmovementwouldresultinportfoliolosses. 4.2 4.2.1SentimentInput/Embeddings

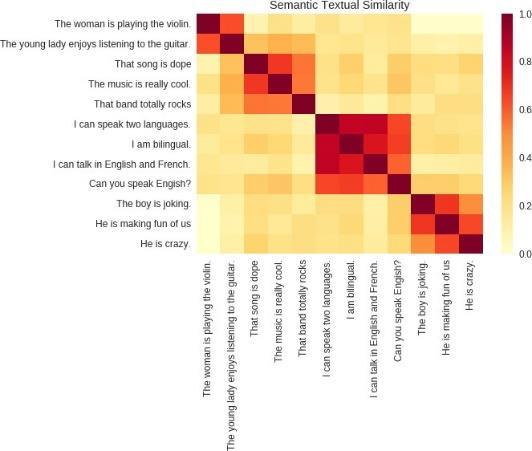
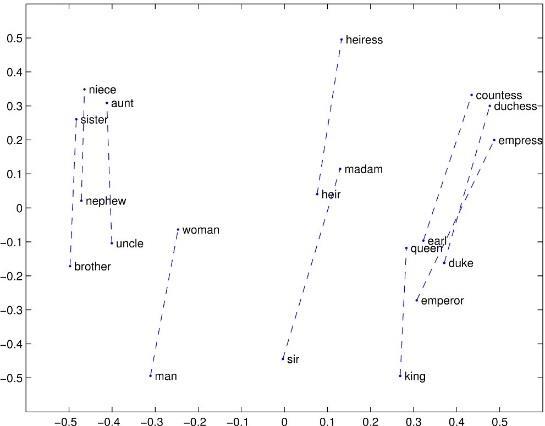
Figure4:Infersent basedsentenceembeddingvisualization
Figure5:Overallarchitecture
4.2.2 Architecture
Theoverallarchitecturecontainsthreemajorcomponents:thepreliminaryencoder,thesecondary encoderforawindowand the final decoder for prediction generation. The overall architecture is based on a CNN LSTM baseline except that we introducetheconceptofwindowsizeasanewhyper parameterthatcanbeexperimentedandtuned.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 09 Issue: 01 | Jan 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page419
In the first part, the preliminary encoder, we take the previously processed and filtered investing forumcommentsforeach dayandusethepre trainedinfersentmodeltogenerateahighdimensional(4096),sentiment/semantic based representation foreachcomment.Thereasonwhytheinfersentmodel is able to capture the semantic information of a sentence is because it is trained based on the original glove/fast text word embeddings using bidirectional LSTMs that learn the weights of individualwordsandthesyntacticstructureofasentence.Afteralltheembeddingsaregenerated, wetaketheaverageofthe batchofcommentstorepresenttheoverallsentimentforthatday.
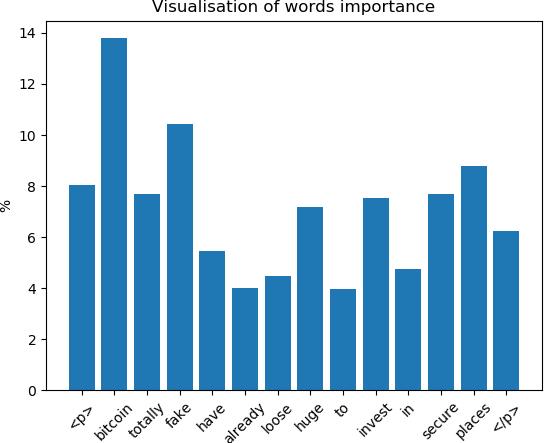
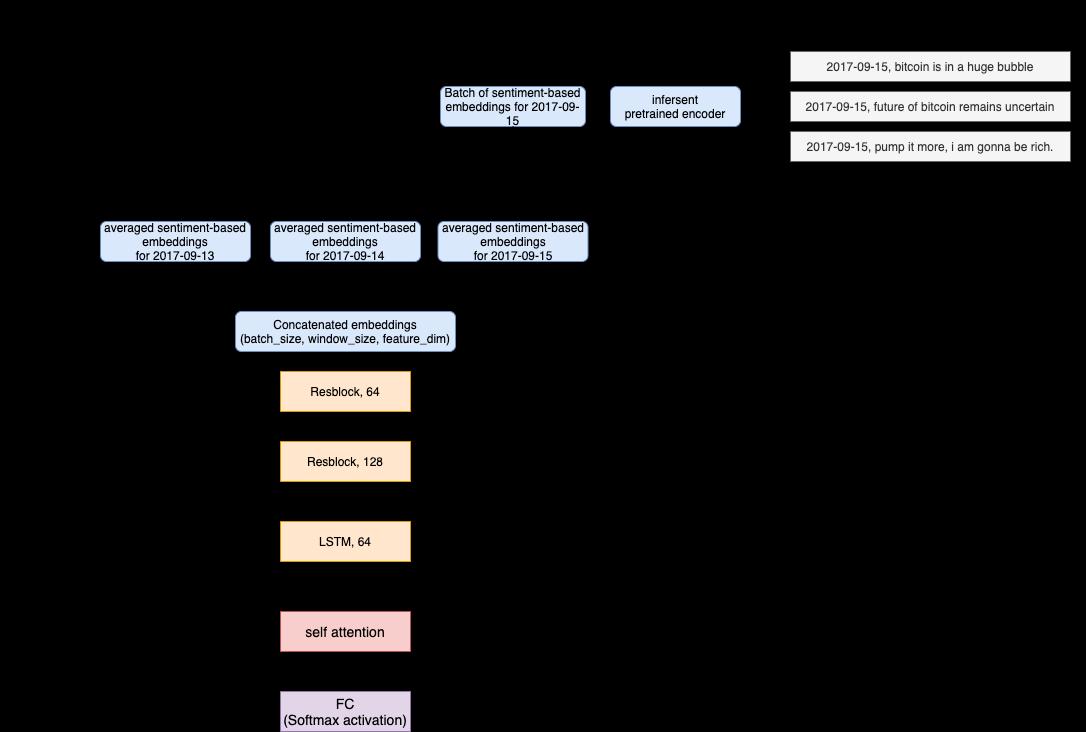
Figure6:Infersentmodel
Afterthepreliminaryencodingisgeneratedforourinputforeachday,thesecondpartofthe architecturefocusesonfeature extraction from the high dimensional input. Here the concept of window_size is introduced. When asked to generate a prediction for the closing price for a given day, we use all comments predating the given date within window_size. (It is a tunableparameter)The weight/significance for each day is not necessarily the same. Averaged comment for each day is vertically concatenated and passed into simple residual blocks with 64/128 output filters.The extracted features then goes into the LSTM layers as the last part of the encoding process.(Theimplementation oftheresblockfollowsthedesignin[13]DeepResidualLearningforImageRecognition)
Figure7:(a)Resblock(b)Self attention
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 09 Issue: 01 | Jan 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page420
Thedecoderpartofthenetworkisjustasimplefullyconnectedlayerwithsoftmaxactivationprecededbyaself attentionlayer. The self attention layer use the weight to learn a weighted versionoftheinput,whichisaconcatenationofthefeatureswithin thewindow.Thepurposeofusingtheattentiontolearnaweightingoftheinputisthatwehypothesizethattheimportanceof theoverallmarketsentimentisdifferentforeachday(withinthewindow)predatingthedatetobepredicted.Forexample,ifwe wanttopredictwhethertheclosingpricefor2017 09 15wouldincrease/decreasefrom2017 09 14,themorerecentdates’(2017 09 14,2017 09 15)marketsentimentshouldbeassignedahigherweightingassomenewscouldhavecomeup tohavemore significantimpactontheprice.Theformulasforobtainingtheweighted inputthroughattention weightsareasfollows.
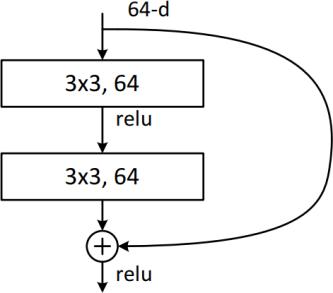
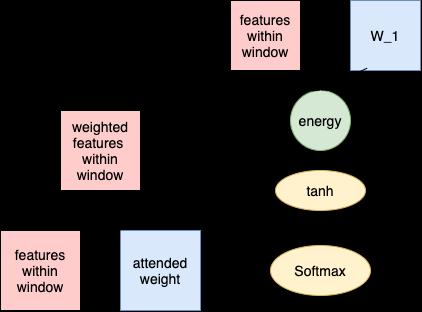
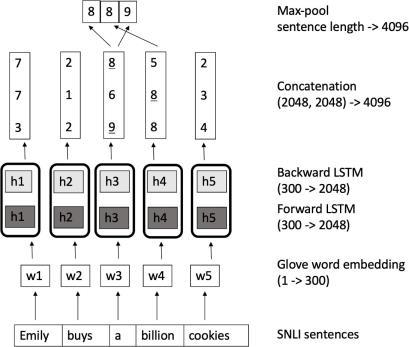

Figure8:Xentloss
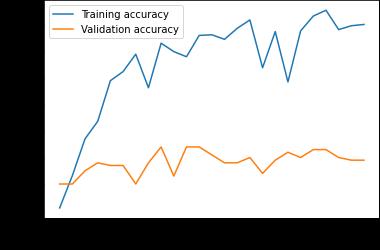
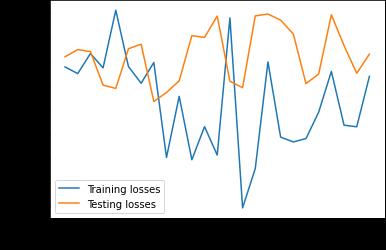
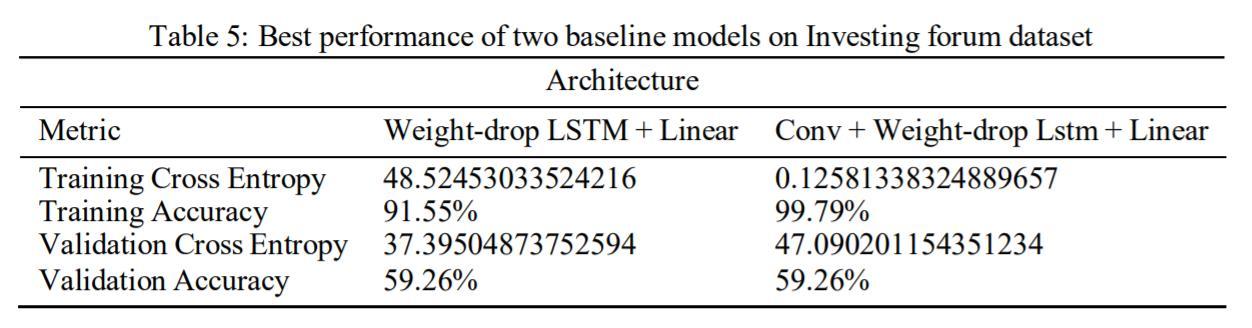
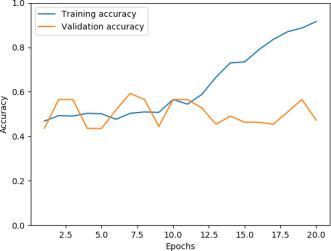
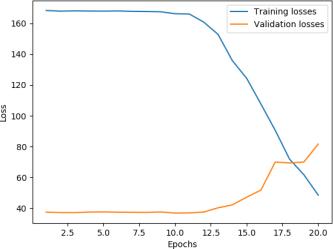
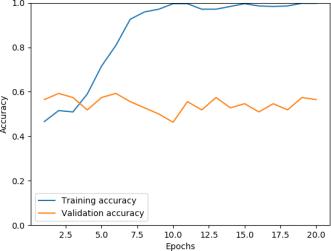
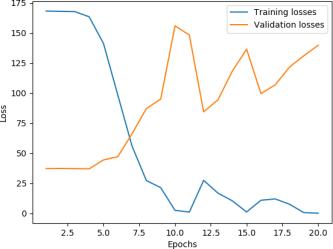
Overall, the CNN+weight dropped LSTM+Linear baseline has a more stable performance on validation above 50%. For both models, the training accuracy significantly increases while the validation performance actually gets worse with further training.Itseemsthatfeatureextractionmakesthemodel’strainingperformanceconvergefaster. Thejitteryupdatecouldbe caused by hyperparameters (learning rate too high, batch_size too small,or context too big) or the noise in dataset and embedding. Further experimentation with different embeddings, text processing technique, hyperparameter tuning and architecturaladjustmentscouldpotentiallyboostthevalidationaccuracyto65%.
Table4:Hypermetersforbaselinemodel
The model performance on validation plateaus around 5 10 epochs. Performance on validation seems jittery and over fitting becomesaseriousissueafter10epochswithouttheusageofaschedulertode creaselearningrateonplateauforvalidationloss.
Thetablebelowsummarizestheperformanceoftwobaselinemodelsaftertrainingfor20epochs usingadamsoptimizerand thehyperparametersthatweusedduringtraining.Theplotsareattachedintheappendix.
5 5.1ExperimentsSentimentbaseline model performance
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 09 Issue: 01 | Jan 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page421 4.2.3 Metric Our hypothesis is that market sentiment could potentially predate the movement of price of bitcoin.However, it is unlikely that we could precisely quantify the change in market sentiment and use that to calculate the percentage change in bitcoin Therefore,price. we transform the problem into aclassification problem by producing 0/1 target labels denoting whether the closing priceofthebitcoindecreaseorincreasesfromthepreviousday.Intheexperiment,weusethecross entropylossthatispopular forclassificationproblems.
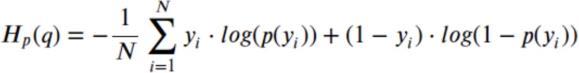

The training accuracy steadily increases but the validation accuracy fails to break through 65% and thus we experience overfittingissues eventhoughseveralregularizationtrickssuchaslockeddropout,embeddingdropout,weightdecay,decreasing themodelsize,wereapplied.
6.1ConclusionReflection
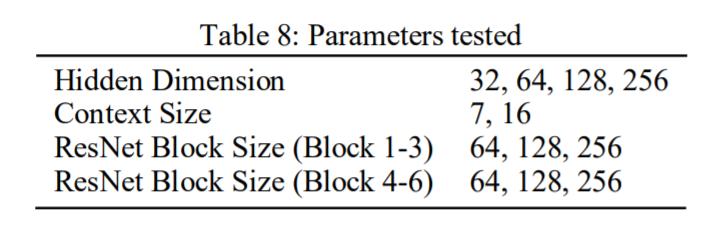
Weexperienceddifferentparametersandwereabletoachieveanaccuracyrateof62.17%with smallerhiddendimensionand biggercontextsizecomparingtobaselinemodel.Thedecreaseofhiddendimensionandtheincreaseofcontextsizestabilized themodelperformance.Performanceonvalidationseemslessjittery. Thevalidationplateausaround35 38epochsandstarts torise.Theaccuracyratehangsaround60%foracoupleepochsandstartstodrop.
Thetablebelowsummarizestheparameterstested.Basedonthetuningexperiencewithallcombination of below parameters, generally we found smaller hidden dimensions perform better and are more stable than bigger hidden dimensions. A median contextsizeisbetterthanthebaselinecontextsize4forthisdataset.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 09 Issue: 01 | Jan 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page422
Window size Wehaveobservedthatthewindow_sizeactuallyhaveahugeimpactontheperformanceofthe model.Forawindow_sizeof1, the training and validation performance is completely stagnant for the whole 50 epochs. On the other hand, slightly larger window_sizelike14whichconsidersthemarketsentiment within two weeks before making a prediction seems to be having steadyimprovementofperformanceastraininggoeson.
5.2 Sentiment final model performance
Overall, the architecture achieves slightly better performance than Ray Chen’s experiment on stockprice prediction using sentiments of tweets. However, performance of the model is still sub optimaleven when we add self attention and several regularizationtechniquesontopoftheregularLSTMthatistypicallyusedforsentimentanalysis.
6

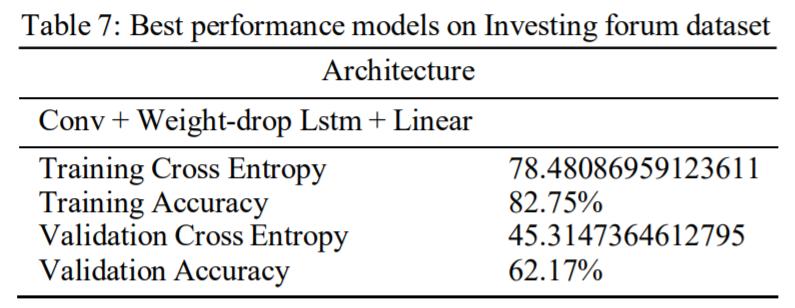
Toxic comment filtering
[2] Serafini,G.,Yi,P.,Zhang,Q.,Brambilla,M.,Wang,J.,Hu,Y.andLi,B.(2020).Sentiment DrivenPricePredictionoftheBitcoin basedonStatisticalandDeepLearningApproaches.IEEEXplore.
Thetaskishardbynatureasitischallengingfortwomajorreasons.
Self-attention
6.2
[5] Dixon, M.F., Klabjan, D. and Bang, J.H. (2016). Classification Based Financial Markets Prediction Using Deep Neural Networks.SSRNElectronicJournal.
[9] GmbH,finanzennet(n.d.). Asmanyas36%oflargeinvestorsowncryptoassets,andbitcoinisthemostpopu lar,Fidelitysays| CurrencyNews|FinancialandBusinessNews|MarketsInsider. markets.businessinsider.com.
[4] Chen, R.and Lazer, M.(n.d.).Sentiment Analysis ofTwitter Feeds forthePrediction ofStock MarketMovement.
The comments on the investing forum are between 2017 09 and 2020 11. Therefore, the training/validation dataset size is quite small. There are only hundreds of target labels and the commentsfor thosedays used for training, which could be the reasonwhythemodelishavingtroublegeneralizing.
2. Theactualrelationshipbetweenmarketsentimentandbitcoinpricecouldbeweak.
Data collection
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 09 Issue: 01 | Jan 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page423
Thequalityofthecommentsscrapedfromonlinesourcesisquiteunstable.Thelengthofthecommentscouldvaryfromafew characters to over 500 characters. The processing techniques significantly helped by filtering the comments based on its length and content by checking whetherthe comment contains meaningless words or emoji or digits which could interfere with training. However, the processing ignores the semantics of the comment. [15]The Semantically Enriched Machine Learning Approach to Filter YouTube Comments for Socially Augmented User Models presented a way of filtering the comments by computing a relevance score for each of the commentbased on a bag of words and setting a threshold for labellingthecomments.
1. Itishardtolearnthemarketsentimentoveragivenwindowoftimewithnoisydatescrapedbyourselveseventhoughthe forumispopular.
[6] McNally, S., Roche, J. and Caton, S. (2018). Predicting the Price of Bitcoin Using Machine Learning. 201826th Euromicro InternationalConferenceonParallel,DistributedandNetwork basedProcessing(PDP).
7 References
The self attention mechanism implementation is mainly based on [14]A Structured Self Attentive Sentence Embedding paper by Zhouhan Lin. We did notice a slight improvement in the performanceofthemodelontopofthebaselinebyassigningaweight formarketsentimentswithinthemodel,butas we failed to beat 65% validation performance, it is hard to conclude that it is effective. Future work
[3] Raju,SM Tarif,Ali.(2020).Real TimePredictionofBITCOINPriceusingMachineLearningTechniquesandPublicSentiment Analysis.
[7] Nakamoto,S.(2008).Bitcoin:APeer to PeerElectronicCashSystem.
[8] Pensions Investments.(2017).80%ofequitymarketcapheldbyinstitutions.
[10]T. Fischer and C. Krauss, “Networks for Financial Market Predictions,” FAU Discuss. Pap. Econ. No.11/2017, Friedrich
[1] Velankar,S.,Valecha,S.andMaji,S.(2018). Bitcoinpricepredictionusingmachinelearning. IEEEXplore.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 09 Issue: 01 | Jan 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page424 Alexander UniversitätErlangen Nürnberg,Inst.Econ.Erlangen,pp.1 34,2017. [11]Jacob Devlin, Ming Wei Chang, Kenton Lee, and Kristina Toutanova. (2018). BERT: Pre training of DeepBidirectional TransformersforLanguageUnderstanding [12]Merity,S.,Keskar,NitishShirishandSocher,R.(2017). RegularizingandOptimizingLSTMLanguageModels.arXiv.org. [13]Lin, Z., Feng, M., Nogueira, C., Santos, M., Yu, B., Xiang, B., Zhou, Y., Bengio and Watson, I. (n.d.). ASTRUCTURED SELF ATTENTIVESENTENCEEMBEDDING.[online]arXiv.org. [14]Ammari, A., Dimitrova, V., Despotakis, D. (2011). Semantically Enriched Machine Learning Approach toFilter YouTube CommentsforSociallyAugmentedUserModels. 8 Appendix Figure9:Weight DroppedLSTM+Linearaccuracy&loss Figure10:Conv+Weight DroppedLSTM+Linearaccuracy&loss Figure11:HistoricalpriceonlyLSTMmodelaccuracy&loss
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 09 Issue: 01 | Jan 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page425 Figure12:HistoricalpriceonlyMLPmodelaccuracy&loss Figure13:Finalmodelaccuracy&loss