
Several machine learning methods were used to create classifiersbeforeclassifyingthedatasamples.Thesemodels areexpectedtobeeitherasignalorabackground.Training data was used to determine the component models. An integratedmodelwascreatedtoboostperformance.
1.2 Overview
2. DATASET
High energyphysicistsemployavarietyofmachinelearning approachestooptimiseandanalysetheselectionzonethat generates these signal occurrences. Simulated signal and background events are used to train classifiers, which are given a weight to account for the difference between the event'spriorprobabilityandthesimulator'sprobability.
Key
The Higgs Boson is a fundamental particle that imparts mass to all matter in nature. The search for the Higgs boson is a major undertaking in particle physics. The Higgs Boson Classification Problem is proposed to be solved using machine learning (ML) approaches such as long short term memory (LSTM) and decision trees in this research (DT). The accuracy and AUC measures of those machine learning approaches are compared. We employ a huge dataset as the Higgs Boson, obtained from the public site UCI, and a Higgs dataset collected from the Kaggle site during the experimentation stage. Words: Dataset, Workflow of Machine Learning, Deployment.1.INTRODUCTION
The Higgs Boson's discovery is a big issue for the field of High Energy Physics. To overcome the challenge of signal separation from background events, machine learning algorithmsarepresented.Thesignalisthedecayofexotic particles,whichcreatesazoneinfeaturespacethatisnot explained by background processes. The background is madeupofdissolvingparticlesthathavebeenfoundinprior tests.Particle physicshasprogressedinseveral ways that are pertinent to the quest for the Higgs Boson. ATLAS detector researchers evaluated the Standard Model predictions as part of one of the key experiments at the EuropeanOrganizationforNuclearResearch's(CERN)Large HadronCollider(LHC).SixalgorithmswereusedintheHiggs BosonMachineLearningChallenge,whichwasheldin2014. Support Vector, Machine Affinity Propagation, Random Forest, Decision Tree, K Nearest Neighbors, K Means Clustering, Support Vector, Machine Affinity Propagation They used Higgs datasets to test the Deep Networks Classifier. Alves employed Stacking Machine Learning classifiersinamultivariatestatisticalanalysis(MVA)tofind HiggsBosonsattheLHC,outperformingBoostedDecision Drees and Deep Neural Network applications in particle physics. The following study suggests using machine learning (ML) approaches to address the Higgs Boson categorization problem: long short term memory (LSTM) anddecisiontree(DT).UsingtheHiggsdatasetUCIandthe HiggsdatasetKaggle,wecomparetheaccuracyofthoseML algorithms.
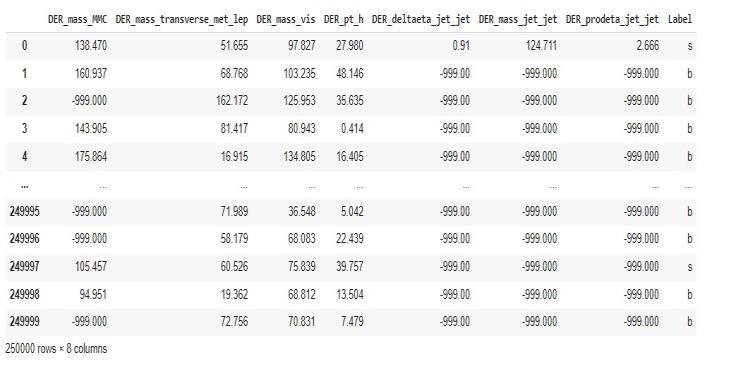
Inaneight dimensionalfeaturespace,thedatacomprisesof simulated signal and background events. Each event data pointisallocatedanIDandaweight,aspreviouslystated. The8attributeswereactualvaluesandcomprisedestimated particle mass, invariant mass of hadronic tau and lepton, vector sum of the transverse momentum of hadronic tau, centralityofazimuthalangle,pseudo rapidityoftheleptons, number of jets and their properties, and so on. A total of 250,000incidentswereincludedinthedata.Weightswere notincludedwiththetestresults.Eachtrainingdataevent waslabelledwithoneoftwolabels:"s"forsignaland"b"for background.
1.1 Working Principle
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056 Volume: 08 Issue: 12 | Dec 2021 www.irjet.net p ISSN: 2395 0072 © 2021, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page1548 Higgs Boson Discovery using Machine Learning Vinay Chaukate1 , Abhishek Yadav2 , Ravi Jogdand3, Jayesh Vanmare4, Prof. Ankur Ganorkar5 1Vinay Chaukate, Elec. and Telecomm. Engineering, Rajiv Gandhi Institute and Technology, Mumbai, India 2Abhishek Yadav, Elec. and Telecomm. Engineering, Rajiv Gandhi Institute and Technology, Mumbai, India 3Ravi Jogdand, Elec and Telecomm. Engineering, Rajiv Gandhi Institute and Technology, Mumbai, India 4Jayesh Vanmare, Elec. and Telecom. Engineering, Rajiv Gandhi Institute and Technology, Mumbai, India 5Prof. Ankur Ganorkar, Rajiv Gandhi Institute and Technology, Mumbai, India *** Abstract
Datapre processing,datapurification,featureidentification, and feature engineering will also be discussed, as well as howtheyaffectMachineLearningModelPerformance.We'll alsogothroughafewpre modelingproceduresthatcanhelp themodelrunfaster.Fordeployment,wecreatedawebapp. Python Libraries that would be need to achieve the task: 543.TensorFlow2.Pandas1.NumPyScikitLearn.Matplotlib

What is the machine learning Model?
Why do we need it?
Understanding the machine learning workflow candefinethemachinelearningworkflowin3stages. data Datapre processing Researchingthemodelthatwillbebestforthetype ofdata Trainingandtestingthemodel
Mostofthereal worlddataismessy,someofthesetypesof dataare:
We
3. Researching the model that will be best for the type of data Ourmaingoalistotrainthebestperformingmodelpossible, usingthepre processeddata.
1. Missing data: Missing data can be found when it is not continuously created or due to technical issues in the 2.application.
Supervised Learning
Noisy data:Thistypeofdataisalsocalledoutliners;this canoccurduetohumanerrors(humanmanuallygathering thedata)orsometechnicalproblemofthedeviceatthetime ofcollectionofdata.
The method for acquiring data depends on the sort of projectwewanttocreate.Forexample,ifwewanttocreate anMLprojectthatusesreal timedata,wecancreateanIoT systemthatusesdatafromvarioussensors.Thedatasetcan comefromavarietyofplaces,includingafile,adatabase,a sensor, and many other places, but it cannot be utilised immediatelyforanalysissincetheremaybealotofmissing data,extremelybigvalues,disorganisedtextdata,ornoisy data.Asaresult,DataPreparationiscompletedtoaddress this issue. We can also make use of various free data sets availableontheinternet.Themostpopularrepositoriesfor creating Machine Learning models are Kaggle and the UCI Machine Learning Repository Kaggle is one of the most popularwebsitesforpractisingmachinelearningalgorithms. Theyalsoholdeventsinwhichuserscancompeteandput theirmachinelearningskillstothetest.
What is data pre processing?
3. Inconsistent data:This type of data might be collected duetohumanerrors(mistakeswiththenameorvalues)or duplicationofdata.
Data pre processing, as we all know, is the process of converting raw data into clean data that can be utilised to train the model. To get decent outcomes from the applied model in machinelearning and deep learning projects,we surelyrequiredatapre processing.
In the classification and regression phase, we used a few approaches
Gathering
2. Data pre processing
InSupervisedlearning,anAIsystemissuppliedwithdata whichislabelled,whichmeansthateachdatataggedwith therightlabel.Thesupervisedlearningisclassifiedinto 2 morecategorieswhichare“Classification”and“Regression”.
A machinelearning model is nothing more than a pieceof codethathasbeentrainedwithdatabyanengineerordata scientist. So, if you feed the model garbage, you'll receive garbageback,i.e.,thetrainedmodelwillmakeerroneousor incorrectpredictions.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056 Volume: 08 Issue: 12 | Dec 2021 www.irjet.net p ISSN: 2395 0072 © 2021, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page1549 Dataset 3. WORKFLOW OF MACHINE LEARNING
Evaluation
1. Gathering Data
Data pre processing is the process of cleaning raw data, whichisdatathathasbeenobtainedintherealworldand convertedintoacleandataset.Inotherwords,anytimedata isreceivedfrommanysources,itiscollectedinarawformat, which makes analysis impossible. As a result, specific processesaretakentoconvertthedataintoasmaller,clean dataset,whichisreferredtoasdatapre processing.
Oneofthemostimportantstepsinmachinelearningisdata pre processing.Itisthemostcrucialstepinimprovingthe accuracyofmachinelearningmodels.Thereisan80/20rule inmachinelearning.Everydatascientistshoulddevote80% oftheirtimetodatapre processingand20%oftheirtimeto actualanalysis.
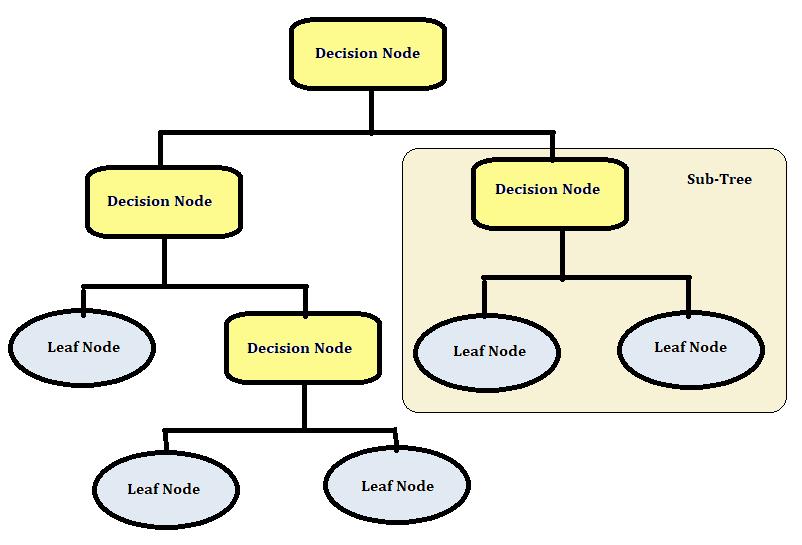
Adecisiontreeisatreestructurethatlookslikeaflowchart, withaninternalnoderepresentingafeature(orattribute),a branch representing a decision rule, and each leaf node representing the outcome. The root node is the topmost nodeina decision tree.Itlearnsto partition basedonthe valueofanattribute.Recursivepartitioningisamethodof partitioningthetreeinarecursivemanner.Thisflowchart likestructureassistsyouinmakingdecisions.It'saflowchart diagram style depiction that closely resembles human thinking. As a result, decision trees are simple to comprehendandinterpret. The decision tree is a non parametric or distribution free strategy that does not rely on probability distribution assumptions.Withgoodaccuracy,decisiontreescanhandle high dimensionaldata.
You use a 'training data set' to train the classifier, a 'validationset'tomodifytheparameters,anda'unseentest data set' to test the classifier's performance. It's worth noting that only the training and/or validation sets are availabletotheclassifierduringtraining.Thetestdataset mustnotbeused whenthe classifierisbeingtrained.The test set will only be available while the classifier is being
Wecanbeginthetrainingprocedureoncethedatahasbeen separatedintothethreesegmentsspecified.
Set of validations: Cross validation is a technique used in applied machine learning to estimate a machine learning model'sskillonunknowndata.Totunetheparametersofa classifier,acollectionofunseendataisusedfromthetraining
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056 Volume: 08 Issue: 12 | Dec 2021 www.irjet.net p ISSN: 2395 0072 © 2021, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page1550
Linear Regression
Atrainingsetisusedtodevelopamodelinadatacollection, whereasatest(orvalidation)setisusedtotestthemodel. The test (validation) set excludes data points from the trainingset.Ineachiteration,adatasetisusuallydividedinto atrainingset,avalidationset(somepeoplecallita'testset' instead),oratrainingset,avalidationset,andatestset. Anyofthemodelswechooseinstep3/point3areusedin the model. We canuse the same trained model to forecast
4. Training and testing the model on data
Asupervisedclassificationalgorithm,logisticregressionis. For a given collection of features (or inputs), X, the target variable (or output), y, can only take discrete values in a classificationissue.Logisticregression,contrarytopopular assumption, is a regression model. The model creates a regressionmodeltoforecastthelikelihoodthatagivendata entrybelongstothe"1"category.Logisticregressionmodels the data using the sigmoid function, just like linear regression assumes that the data follows a linear distribution.Whenadecisioncriterionisintroduced,logistic regressiontransformsintoaclassificationprocedure.Setting thethresholdvalueisacrucialpartofLogisticregression, anditisdeterminedbytheclassificationproblem.
Thetested.trainingsetisthecontentthatthecomputerusestolearn how to process information. The training component of machinelearningisdonethroughalgorithms.Asetofdata usedforlearning,orfittingtheclassifier'sparameters.
TheLSTMhasachainstructurethatconsistsoffourneural networksandseveralmemoryblocksknownascells.
Tobegintrainingamodel,wedivideitintothreesections: 'Trainingdata,"Validationdata,'and'Testingdata.'
Decision Tree Algorithm
Long Short Term Memory (LSTM): A recurrent neural network is a type of long short term memory.Theoutputofthepreviousstepisusedasinputin the current step in RNN. Hoch Reiter and Schmid Huber created LSTM. It addressed the issue of RNN long term dependency,in whichtheRNN isunable to predict words stored in long term memory but can make more accurate predictionsbasedoncurrentdata.RNNdoesnotprovidean efficientperformanceasthegaplengthrises.Bydefault,the LSTMcankeeptheinformationforalongtime.Itisusedfor time series data processing, prediction, and classification.
Adata.testsetisacollectionofpreviouslyunseendatausedsolely toevaluatetheperformanceofafullystatedclassifier.

Heroku allows you to launch, execute, and manage Ruby, Node.js, Java, Python, Clojure, Scala, Go, and PHP applications. An application is made up of source code writteninoneoftheselanguages,maybeaframework,anda dependencydescriptionthattellsabuildsystemwhichother dependencies are required to create and run the programmed.Thesourcecodeforyourproject,alongwith thedependencyfile,shouldofferenoughinformationforthe Herokuplatformtobuildandrunyourapp.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056 Volume: 08 Issue: 12 | Dec 2021 www.irjet.net p ISSN: 2395 0072 © 2021, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page1551 usingthetestingdata,i.e.theunseendata,oncethemodelhas been trained. After that, wecancreatea confusion matrix, which will tell us how successfully our model has been trained.Truepositives,TrueNegatives,FalsePositives,and False Negatives are the four parameters of a confusion matrix. To create a more accurate model, we desire to get more values in the True negativesand True positives. The numberofclasseshasnobearingonthesizeoftheConfusion matrix. True positives: These are instances where we predicted TRUEandouranticipatedoutputwasaccurate. True negatives:WepredictedFALSEandwerecorrectinour Falseprediction.positivesoccurwhenweexpectTRUEbuttheactual outcomeisFALSE. FalsenegativesoccurwhenweexpectFALSEwhiletheactual projectedoutputisTRUE. The confusion matrix can also be used to determine the model's Accuracycorrectness.=(TruePositives +True Negatives) / (Total numberofclasses) i.e.fortheaboveexample: Accuracy=(100+50)/165=0.9090(90.9%accuracy) 5. Evaluation Model evaluation is an important step in the creation of a model.Itaidsintheselectionofthebestmodeltorepresent ourdataandthepredictionofhowwellthechosenmodelwill perform in the future. We could tweak the model's hyper parameters to improve accuracy, as well as look at the confusionmatrixtoseeifwecanincreasethenumberoftrue positivesandtruenegatives. 4. DEPLOYMENT Wedesignedawebappfordeployment.Usingstreamlitand Heroku,wedeployedthetrainedmodel.Weusedstreamlitto create a frontend, which we then deployed to the Heroku server.WeusedMaunatodeployourGitHubrepositoryto Heroku;thedeploymentoptionwasManually.
5. CONCLUSIONS
Ithasbeenagreatopportunitytogainlotsofexperiencein real time projects, followed by the knowledge of how to actuallydesignandanalyzerealprojects.Forthatwewantto thankallthepeoplewhomadeitpossibleforstudentslike
ManydevelopersuseGittomanageandversionsource code because it is a powerful, distributed version management system. Git is the primary method for deployingapplicationsontheHerokuplatform. Whenyou createanapponHeroku,itcreatesanewGitremote,usually named Heroku, that is linked to your app's local Git repository.Deployment, then, is the process of moving your programmedfromyourlocalsystemtoHeroku,andHeroku offersnumerousoptionsfordoingso.
Future Scope Morehiggsdatawillbeavailableinthefuture.Wecaneasily determine whether they are signals or background using machine learning. Using several models, we can improve accuracy.Wecreateprogrammedthataresimpletousefor everybody.
N=165 NoPredicted NoPredicted NoActual: 50 10 YesActual: 5 100
ACKNOWLEDGEMENT
EvenintheHiggsfield,it'sdifficulttofindsignalsfromthe background.Toovercomethechallengeofsignalseparation frombackgroundevents,machinelearningalgorithms are presented. We used a machine learning model to detect Higgsbosonsignalsorbackgroundwithhighaccuracy,and becausethismachinelearningmodelisfast,itsavesusalot oftime.AsfarasHiggsbosonpracticaldiscovery,TheLSTM runswellwithaccuracyachieved79%.Itworksbetterthan DecisionTree(72%)andLinearRegression(67%).
Streamlit is a Python based app framework for deploying machine learning apps. It's a free and open source frameworkthat'ssimilartoR'sShinypackage.Herokuisa cloud basedplatform as a service(PaaS)thatfacilitatesthe deploymentandmanagementofappswritteninavarietyof programminglanguages. Herokuletsyoudeploy,runandmanageapplicationswritten inRuby,Node.js,Java,Python,Clojure,Scala,GoandPHP.
REFERENCES
[1] CeciliaTosciri,“MachineLearningApplicationsand Observation of Higgs Boson Decays into a Pair of BottomQuarkswiththeATLASDetector”,in2020. [2] Present by Mourad Azharia, Abdallah Abardab, Badia Ettakia, c, Jamal Zerouaouia, Mohamed Dakkon “Higgs Boson Discovery using Machine LearningMethodswithPyspark”,in2020 [3] PresentbyAntonApostolatosandLeonardBronner “Identifying the Higgs Boson with Convolutional NeuralNetworks”,in2017 [4] Present by S. Raza Ahmad “Higgs Boson Machine LearningChallenge”,in2014. [5] PresentbyDenniseSilverman“ImportanceofThe HiggsBosonDiscovery”,in2012 /importancehttps://sites.uci.edu/energyobserver/2012/11/25ofthehiggsbosondiscovery/ [6] PresentbyAlexanderRadovic,MikeWilliams,David Rousseau, Michael Kagan, Daniele Bonacorsi, AlexanderHimmel,AdamAurisano,KazuhiroTerao & Taritree wongjirad “Machine learning at the energyandintensityfrontiersofparticlephysics”,in 2018. [7] PresentbyJocelynPerez,RaviPonmalai,AlexSilver, Dacoda Strack, “Higgs Boson Machine Learning Challenge”,in2014. [8] Present by Vishal S. Ngairangbam, Akanksha Bhardwaj, Partha Konar, Aruna Kumar Nayak “InvisibleHiggssearchthroughvectorbosonfusion: adeeplearningapproach”,in2020. [9] PresentbyG.Rajasekaran“THESTANDARDMODEL ANDTHEHIGGSBOSON”,in2010. [10] 10]PresentbyP.Baldi,P.Sadowski&D.Whiteson, “Searching for exotic particles in high energy physicswithdeeplearning”,in2014
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056 Volume: 08 Issue: 12 | Dec 2021 www.irjet.net p ISSN: 2395 0072 © 2021, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page1552 us. Special thanks to the graduation Project Unit for the effortstheydidtoprovideuswithallusefulinformationand makingthepathclearforthestudentstoimplementallthe educationperiodsinreal timeprojectdesignandanalysis. Furthermore,wealltheprofessorsandvisitingindustryfor the interesting lectures they presented which had great benefitforall ofus.Wewouldliketoexpressourdeepest gratitudetoourgraduationprojectsupervisorProf.Ankur Ganorkarforhispatienceandguidancealongthesemester. In addition, we would like to express our sincere appreciationstoours.