
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056 Volume: 08 Issue: 12 | Dec 2021 www.irjet.net p ISSN: 2395 0072 © 2021, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page1348 A Case Study on Software Defect Prediction Rajesh Kumar1 , Harsh Sinha2 , Ankita Sharad3 , Rupali Sahu4 1,2,3,4M. Tech(IT), Dept. of IT, NIT Raipur, Chhattisgarh, India *** Abstract
Asthepresentprogrammingdevelopsquicklyinsizeand
2.LITERATURE SURVEY
The main aim of Software Defect Prediction (SDP) is to spot the defect prone in ASCII text file, therefore to scale back the trouble and time taken also the value incurred by it with guaranteeing the standardofsoftware. The machine learning algorithms is employed both code and non code metrics are trained to predict software defects Identification and elimination of defects in software is time and resource consuming activity. The upkeep of a defective software is burdensome. Software defect prediction (SDP) at an early stage of the Software Development Life Cycle (SDLC) leads to quality software andreduces its development cost. Because the size of software projects becomes larger, software defect prediction (SDP) will play a key role in allocating testing resources reasonably, reducing testing costs, and speeding up the event process. Words: Software Development Life Cycle(SDLC), SoftwareDefectprediction(SDP),MachineLearning,Kernel Fisher’s Discriminant (KFD), Stacked De Noising Auto Encoder(SDAE)
1.INTRODUCTION
Key
Thegeneticsetofrulesisusedtourgewormintroducing commits from a troublesome and quick of bug solving commits.Themaliciousprogram introducingcommitsare typicallyextractedeachfromaTrojan[2]horsechasedevice which includes Jira and sincerely with the assistance of sorting out commits that state that they're resolution one thing.Therecognizedbug[1]introducingcommitswillthen beusedtoaidempiricalcodeengineering[3]analysis,e.g., unwellness prediction or code quality today, with the massiveenlargementofcodeusage,thesizeand,ultimately, thecomplexnessofcodemodulesareapaceincreasing,and consequently testing prices are exploding. code defect prediction (SDP) models are projected to identify code modules, or categories are additional seemingly to be defective [4] throughout this example, if SDP will predict defectsbeforecatharticacodepackage,codeproducerswill apportionrestrictedresourcesforcodequalityassurance[4] supported this reason, among the past decades, SDP has been one of the foremost active analysis areas in code engineering.Mostcodedefectpredictionstudieshaveused machinelearningtechniques[5]toformapredictionmodel, the first step is to urge instances from code comes. every instance is commonly portrayed from a system, a code element(orpackage),a ASCIIcomputerfile,a class,anda operate(ormethod).forexample,inClanguageaoperate maywellbethought aboutasANinstanceorinJava,aclass is AN instance. therefore, on defect predictions, some numericalmetricsoughttobeextractedfrominstances. Todoso,therearesomecommonmetrics,whichcouldbe classified into 3 categories, they are “source code,” “network,” and “process.” ASCII computer file metrics are mostfrequentlyutilisedincodedefectprediction[6].This metricslivethecomplexnessofthesupplycodesandassume thatthedefectsadditionalseeminglyseeminsupplycodes, that are additional advanced. The foremost in style ASCII computer file metrics are Halstead [9] and McCabe’s Cyclomatic[8]metrics.Networkmetricsaresocialnetwork analysis metrics calculated on the dependency graph of a code.Methodmetricsreplicatethechangestocodesystems overtime.Thoughseveralmetrics(calledfeatures)maywell beextractedfromcodemodules,notallofthemarehelpful for defect prediction. In some datasets, for each module, quite eighty options are extracted. Among the machine learningfield,thesetypesofdatasetsarereferredtoashigh dimensional.High dimensionaldatasetsarewell knownfor reducing ability of a machine learning rule to predict the classlabel[7]. InSDPliterature,thereare2typesofstrategiestotake careofthehighspatialpropertyproblem:featurechoiceand have extraction. Feature choice selects solely those input dimensions that contain the relevant info concerning categorylabel.Featureextractioncouldalsobeaadditional generaltechniquethattriestodevelopaamendmentofthe inputhouseontothelow dimensionaltopologicalspacethat preserves most of the relevant info. Another drawback oftentimes encountered SDP is that a real SDP dataset consists solely one or two of defective elements and numerousnon defectiveones.Consequently,thedistribution ofcodedefectknowledgeisincrediblyskew,saidasclass imbalancedknowledgeinmachinelearning.throughoutthis example,modelstrainedonunbalancedcodedefectdatasets are typically biased toward the non defective category samples(majoritycategorytaggedbyzero)andignorethe defective category samples (minority category tagged by one).Theforemostcurrenttechniquetobeat.
advancementprogrammingprogrammingrevisingBonsignourissuesLamentably,particularlyanmultifacetednature,programmingauditsandtestingassumeurgentjobwithintheproductimprovementprocess,incatchingprogrammingsurrenders.programmingdeformitiesorprogrammingareoverthehighestexpensiveincost.Jonesandannouncedthattheexpenseoffindingandsurrendersisoneamongthemostexpensiveimprovementexercises.Theexpenseofdeformityincrementsoverthemerchandisestep.Duringthecodingstep,catchingand

4. Machine Learning based Software Defect Prediction Systems
featureextractionwaysreliesonpairwise cannotlinkconstraints(C)andmust linkconstraint(M).The Csetisthatthepairwiseinformationthatbelongtothesame categoryandMispairwiseinformationwithheterogeneous categorylabel.supportedthisinfolookatthisforresearch paper and the author, Xinag et al. deeply projected a alternative for replacement feature extraction technique supported Mahalanobis distance metric learning. Mahalanobis learning matrix is trained thus on maximise totaldistanceinC’spairwiseandminimizetotaldistancein M’spairwise. This technique does not sufer from multimodal and small sampleinformation.Featureextractionsupportednonlinear projection nonlinear feature extraction ways could be classifed into 2 categories: The frst ones ar the ways that extend and generalize linear projection to nonlinear projection mistreatment kernel trick, and second class includes the ways supported artifcial neural network and deep learning. The notable technique from frst class is Kernel Fisher’s Discriminant (KFD) which can be a well knownnonlinearextensiontoLDA.Theinstabilitydrawback isalotofsevereforKFDasaresultoftheatintervalsclass scatter matrix within the feature house is sometimes singular.nearlylike,KFDmerelyaddsaperturbationtothe within classscattermatrix.Ofcourse,it'sthesamestability drawbackasthatinasaresultofeigenvectorsarsensitiveto littleperturbation.Insecondclass,Wangetal.utiliseddeep belief networks to seek out out linguistics options mechanically.Atintervalstheoppositework,Vincentetal. used Stacked Denoising automobile Encoder (SDAE) to extractalotofsturdyoptions.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056 Volume: 08 Issue: 12 | Dec 2021 www.irjet.net p ISSN: 2395 0072 © 2021, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page1349 rectifying deserts costs $977 per imperfection. the value increments to $7,136 per deformity within the product testing stage. At that time within the support stage, the expense to catch and evacuate increments to $14,102. Programming imperfection forecast approaches are considerably more cost effective to acknowledge utilizeddiscoveriesforecastlikelihoodtestingprogrammingabandonswhencontrastedwithprogrammingandaudits.Lateexaminationsreportthattheofrecognitionofprogrammingimperfectionmodelscouldbetheabovelikelihoodofmanyofjustimmediatelyprogrammingastheauditsincurrentmoderntechniquesduringthisway,exact forecast of defect‐ prone programming assists with coordinating test exertion, to reduce costs, to enhance the merchandisetestingprocessbyconcentratingondeformity inclined modules, lastly to enhance the character of the merchandise ( T. Lobby, Beecham, Bowes, Gray, and utilizedexaminationThisimperfectionalongandNumerousproductexpectationCounsell,).that'stherationale,todayprogrammingdeformitymaybeanoteworthyresearchpointwithinthedesigningfield(Song,Jia,Shepperd,Ying,andLiu,).productdeformityforecastdatasets,techniquesstructuresaredistributeddivergentandsophisticated,theselinesanexhaustiveimageoftheflowconditionofexpectationinvestigatethatexistsisabsent.writingauditintendstoacknowledgeanddissectthepatterns,datasets,strategiesandstructuresinprogrammingimperfectionforecast.
3. Feature extraction approach SDPmetrics,thatoffernumericalfeaturetypically,arenot smart centrifuge of the defect and non defect categories. Throughout this case, feature choice ways are not economical,andit'srequiredtoextractappropriateoptions. Supervisedfeatureextractionapproachescouldbeclassified into 2 categories: linear and nonlinear. The vital ways of eachclassinconsecutive2subsectionsarreviewed.Feature extractionsupportedlinearprojectionapproachescouldbe divided into two: The frst ones ar the ways supported categorylabelinfoofworksamples.Thenotabletechnique throughout this class islinear discriminant analysis (LDA, additionallyreferredtoasFisher’sLinearDiscriminant)that isusedinseveralapplications.theaimofLDAistomaximise thebetween classscatterwhileatthesametimeminimizing thewithin classscatter.aheavydownsideofLDAisthatit cannotbeappliedtothewithin classscattermatrixonceit's singularbecauseofthelittlesamplesizedrawback.tobeat this drawback, Tian et al. used the pseudo inverse matrix instead of the inverse matrix for the within class scatter matrix. Hong and rule tried to feature a singular price perturbation to within class scatter matrix to create it Thenonsingular.secondquite
Fig- 1: Clusterofmachinelearning
Inthisstudy,thecomparativegeneralperformanceanalysis ofvariousmachinelearningtechniquesforsoftwaredefect prediction was investigated. Machine learning techniques haveproventobeusefulforsoftwaredefectprediction.the infoobtainedfromthesoftwarestorecontainstonsofdata withintheevaluationofthesoftwarequality.becauseofthis information,it'seasiertoseekoutsoftwaredefectsalongside machinelearningtechniques.Machinelearningtechniques fallundertwobroadcategoriestomatchtheirperformance: supervisedlearningandunsupervisedlearning
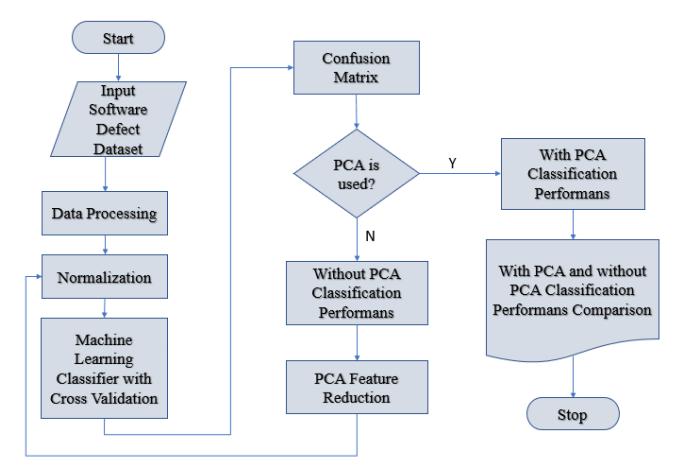
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056 Volume: 08 Issue: 12 | Dec 2021 www.irjet.net p ISSN: 2395 0072 © 2021, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page1350 Fig 2: WorkingStrategy 5. Following are a number of the fundamental kinds of defects within the software development: 1.ArithmeticDefects 2.LogicalDefects 3.SyntaxDefects 4.MultithreadingDefects 5.InterfaceDefects 6.PerformanceDefects Rayleigh distribution curve could even be a proposed modelingtechniquewonttoidentifypredictorvariablesand indicatestheamountofdefectsinvolvedindevelopingSDLC. Simplerectilinearregressionmodelandmultipleregression models are wont to predict the number of defects in software. simple regression attempts to draw a line that comesclosesttotheinfobyfindingtheslopeandintercept thatoutlinetheroadandminimizeregressionerrors.Iftwo or more explanatory variables have a linear relationship withthevariable,theregressionisunderstoodasamultiple regression 5.1 Arithmetic Defects: It includes the defects created by the developer in some arithmeticexpressionormistakenoticeresolutionofsuch arithmetic expression. this kind of defects is essentially created by the computer user due to access work or less data 5.2 Logical defects Theyaremistakesdoneconcerningtheimplementationof the code. once the computer user does not perceive the matterclearlyorthinksthroughouta wrong manner then such varieties of defects happen. additionally, whereas implementingthecodeifthecomputeruserdoesnotlook outofthecornercasesthenlogicaldefectshappen.
1
6.1vaticinationofCooperativefilteringgroundedrecommendationslicestylesforsoftwaredisfigurement.TheproposedmethodCFSR
5.4 Multithreading Defects: Multithreadingmeansthatrunningorcorporalpunishment themultipletasksatconstanttime.thusinmultithreading method there is risk of the complicated debugging. In multithreadingprocessesgenerallythereisconditionofthe stalemateandthusthestarvationiscreatedwhichcancause system'sfailure.
5.3 Syntax defects
Table 1 : External linearstatement levelmetrics introducedfortheSLDeep ID Metric Description Function Isthelinelocatedinafunction 2 FunctionRecursive Isthelinelocatedinarecursive function CounBlocks Thenumberofnestedblocksin whichthelineislocated 4 CounBlocksRecursive Thenumberofnestedrecursive blocksinwhichthelineislocated 6.
Itmeansthatmistakeatintervalstheexpressivestyleofthe code.Itadditionallyfocusesonthelittlemistakecreatedby developerwhereaswritingthecode.typicallythedevelopers dothesyntaxdefectsastheremightbesomelittlesymbols free.
Framework of CFSR
In the field of software disfigurement vaticination, the performanceofvaticinationmodelsisgenerallyhinderedby theimbalancednatureofthesoftwaredisfigurementdata, during which there are naturally morenon defective modulesthantheimperfectmodules.Fortunately,colorful slice styles are proposed within the environment of imbalance data literacy, among which some styles are employed to support the disfigurement vaticination performance.Still,it'sdiscouragingbutnotsurprisingthat nosingleslicesystemisplanttoperformslightlyoverflowall datasets, which is harmonious with the proved ‘‘ No Free Lunch’’theorem.Thus,it'svitalandnecessaryforoptingthe properslicestyleswhenerectingdisfigurementvaticination modelsforareliefdisfigurementdata.Still,totheonlyofour
3
The goal of this survey paper to understand what are common software related defects happens during programmingandthewaywewillreducethisdefectsusing differenttechniques.during thissurveypaperwealsosee manysortsofdefectsanddifferentapproachtounravelit.In future attempttoimproveoversamplingthroughsome algorithms.
we'll
7. A organized reappraisal of unsupervised learningmethodsforsoftwaredeformityprognosis
REFERENCES
[2] Majd, Amirabbas, et al. "SLDeep: Statement level softwaredefectpredictionusingdeep learningmodelon staticcodefeatures."ExpertSystemswithApplications 147(2020):113156.
knowledge,nopreviousstudiesareconcentratedonsimilar problem. Sampling Ranking Based Method As different slice styles may show distinct vaticination performance when handling a given imbalanced disfigurementdata,slicesystemrankingpointsatfurnishing anthoroughrankofthesedifferentslicestylesaccordingto their connection over the specified data, which could be measuredbysomecommonbracketevaluationcriteria,like F MeasureandAUC.Likewise,thevaticinationperformance ofslicestylesmaychangewithcolorfulbracketalgorithms.
Vaticinationorpredictionperformancemeasuresfordata bracket, the confusion matrix is that the abecedarian descriptor from which the bulk of performance pointers could also be deduced. Although immaculately all primary studieswouldreportharmoniousperformancepointers,in practice, a good range of pointers are used like delicacy, perfection,recall,theF measure,theG measurealsoforth. Accordingly,wereconstructtheconfusionmatrixwherever deficientthepossible.Unfortunately,thereremainabout33(823/2456)ofexperimentalresultsthatthiswasnotpossible,thankstoreporting.
[6] Malhotra, Ruchika, and Kishwar Khan. "A study on software defect prediction using feature extraction techniques." 2020 8th International Conference on Reliability, Infocom Technologies and Optimization (TrendsandFutureDirections)(ICRITO).IEEE,2020.
These are the survey based results that we came across whiledoingresearchsurveyanalysisforthispaper.
[5] Sun, Zhongbin, et al. "Collaborative filtering based recommendation of sampling methods for software defectprediction."AppliedSoftComputing90(2020): 106163.
Table 2: SurveyTable S.No. Model used Reference purposeAchieved 1. filteringCollaborativebased [3] yes 2. over sampling [2] partially 3. SLDeep [1] yes 4. learningunsupervised [10] yes 5. LearningMachine [5] yes 9. CONCLUSION
[4] Morasca,Sandro,andLuigiLavazza."Ontheassessment ofsoftwaredefectpredictionmodelsvia ROCcurves." Empirical Software Engineering 25.5 (2020): 3977 4019.
[7] Shao,Yuanxun,etal."Softwaredefectpredictionbased oncorrelationweightedclassassociationrulemining." Knowledge BasedSystems(2020):105742.
Inpresentstudy,wehaveemployedthefoldcross validation systemtorankslicestyleswithaspecificbracketalgorithm foragivensoftwaredisfigurementdata. Data similarity mining Intend to mine the word similarity between two different data while taking under consideration the idea that analogousdataaremorelikelytopartaketheanalogousslice styles.Miningthesimilarityofknowledgeisapivotalapart of the advice. There are two major way included in Data SimilarityMining,duringwhichtheprimarystepistoprize themeta featuresofknowledgeandthusthealternatestep aimstocalculatethesimilaritysupportedthemeta features.
Stoner groundedrecommendationrankedstylesdepository and similarity depository attained from the former two sections,weshallrecommendslicestylesforareliefdataby using the stoner grounded cooperative filtering recommendationalgorithm.
[3] Li, Ning, Martin Shepperd, and Yuchen Guo. "A systematicreviewofunsupervisedlearningtechniques for software defect prediction." Information and SoftwareTechnology(2020):106287.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056 Volume: 08 Issue: 12 | Dec 2021 www.irjet.net p ISSN: 2395 0072 © 2021, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page1351
8. Results
[1] Majd, Amirabbas, et al. "SLDeep: Statement level softwaredefectpredictionusingdeep learningmodelon staticcodefeatures."ExpertSystemswithApplications 147(2020):113156.
[8] Zheng,Shang,etal."SoftwareDefectPredictionBased on Fuzzy Weighted Extreme Learning Machine with
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056 Volume: 08 Issue: 12 | Dec 2021 www.irjet.net p ISSN: 2395 0072 © 2021, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page1352 RelativeDensityInformation."ScientificProgramming 2020(2020). [9] Qiao, Lei, et al. "Deep learning based software defect prediction."Neurocomputing385(2020):100 110. [10] Li, Ning, Martin Shepperd, and Yuchen Guo. "A systematicreviewofunsupervisedlearningtechniques for software defect prediction." Information and SoftwareTechnology(2020):106287. [11] Kumar, Rajesh, Jaykumar Lachure, and Rajesh Doriya. "UseofHybridECCtoenhanceSecurityandPrivacywith Data Deduplication." 2021 Second International Conference on Electronics and Sustainable CommunicationSystems(ICESC).IEEE,2021.