
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 05 | May 2024 www.irjet.net p-ISSN:2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 05 | May 2024 www.irjet.net p-ISSN:2395-0072
Venkata Raj Kiran Kollimarla
ABSTRACT:
LargeLanguageModels(LLMs)havechangedtheway natural languageprocessing isdonebydemonstrating unprecedented skillsinunderstanding,creating,translating,andsummarizinglanguage.LLMshavethepotentialtorevolutionizemanyareas, such as customer service, healthcare, creative writing, and education. However, using LLMs in real-world situations is challenging because of issues with computing power, model size, privacy, bias, scale, and how fast the models can be interpreted.Thisarticleexaminestheseissuesingreatdetail,usingresearchandcasestudiesfromreal-worldapplications.It alsotalksaboutimportantdesignideasforputtingLLMsintoproduction,suchasmicroservicesarchitecture,containerization, serverless computing, federated learning, continuous integration/deployment, model serving platforms, and distributed computing. By following these guidelines, businesses can create significant value by leveraging LLMs in production systems thatarescalable,efficient,andreliablewhileeffectivelyaddressingthecommonchallengesencounteredinthiscontext.
Keywords: Large Language Models (LLMs), Production Challenges, Architectural Considerations, Scalability, Deployment Strategies

INTRODUCTION:
Large Language Models (LLMs) are cutting-edge AI systems that have been taught on huge amounts of textual data to understandandwritetextthatsoundslikeitwaswrittenbyaperson[1].Thesemodelshaveshownremarkableskillsinmany naturallanguageprocessingtasks,suchasunderstandinglanguage,creatingwriting,translating,andsummarizing[2].Whenit comes to jobs like question answering, text completion, and language translation [3], OpenAI's GPT-3 model, which has 175 billionparameters,does verywell.Inthesameway,Google'sBERTmodel,whichhas340millionparameters, hasshownbig gainsinrecognizingnamedentities,analyzingmood,andsortingtext[4].
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 05 | May 2024 www.irjet.net p-ISSN:2395-0072
LLMtrainingdata comesfroma lotofdifferent places, likebooks,articles, websites,andsocial mediasites. Forinstance, the GPT-3 model was trained on a set of 570GB of text, which includes the Common Crawl dataset, which has more than 410 billioncharacters[5].Thislargeamountoftrainingdata helpsLLMsunderstandhowpeopletalk andcomeup withanswers thatmakesenseandareappropriateforthesituation.
An LLM can be used in a lot of different areas. When it comes to customer service, LLMs can be used to make chatbots and virtual helpers that answer questions like a real person [6]. One study by IBM found that using conversational AI tools with LLMscanhelpcompaniescuttheircustomerservicecostsbyupto30%[7].Inthehealthcarefield,LLMscanhelpwiththings like finding drugs, summarizing medical records, and sorting patients into groups [8]. An LLM-based system could correctly summarizemedicalrecordswithanF1scoreof0.87,accordingtoastudyfromtheUniversityofMinnesota[9].
LLMshavealsoshownpromiseincreativewritingjobslikecomingupwithideasforstoriesandpoems[10].Forexample,the GPT-3modelhasbeenusedtomakeshortstoriesthatareaccurateandinteresting,withsomeofthemofaqualitythatishard to distinguish from stories written by humans [11]. In the area of education, LLMs can be used to create smart tutoring systemsandpersonalizedwaystolearn[12].AteststudyfromtheUniversityofPennsylvaniafoundthatusinganLLM-based tutoringsystemhelpedstudentsdo12%betterthanusingtraditionalmethods[13].
But putting LLMs to use in production settings comes with a number of problems that need to be carefully thought through andsolvedthrougharchitecturaldesigndecisions.Someoftheseproblemsaretheneedforalotofcomputingpower,thetime it takes to draw conclusions, the size and versions of models, the ability to fine-tune and customize them, the ease of understandingandexplanation,privacyandsecurity,biasandfairness,andtheabilitytogrowandsupportinfrastructure[14].
Table1:PerformanceofLargeLanguageModels(LLMs)AcrossVariousDomainsandMetrics[1-14]
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 05 | May 2024 www.irjet.net p-ISSN:2395-0072
1. Computational Resource Requirements: LLMs need a lot of CPU/GPU power, memory, and storage space because theyareverycomputationallyheavy[15].Asanexample,trainingtheGPT-3modelwith175billionparameterstook over 1,000 petaflop/s-days per second and 3.14E23 floating-point operations (FLOPs) [16]. When these models are usedinproductionsettings,theyneedtobecarefullyoptimizedintermsofhowresourcesareallocatedandusedto makesuretheyarecost-effectiveandefficient.
2. Inference Latency: LLMscanhavelongwaittimesformakingdecisions,especiallywhentheyhavetodocomplicated jobsordealwithalotofdata[17].AstudybyMicrosoftResearchfoundthattheBERTmodel'sinferencelatencyona single GPU can range from 50 ms to 500 ms, based on the task and the length of the input sequence [18]. Real-time apps and responsive user experiences need to speed up inference using methods like model pruning, quantization, andhardwareacceleration.
3. Model Size and Versioning: LLMs are hard to set up and run because they are so big [19]. For instance, the GPT-3 modelhasmorethan175billionfeaturesandtakesupmorethan350GBofstoragespace[20].Todeployandmanage big language models in production settings, you need storage solutions that work well, like model compression and versioningstrategies.
4. Fine-tuning and Customization: Fine-tuningLLMsforspecifictasksordomainsusuallytakesalotofknowledgeand computerpower[21].GoogleAIresearchshowedthatittookabout100GPUhourstofine-tunetheBERTmodelona domain-specific dataset for named object recognition [22]. Implementing personalized training streams into production processes can be hard, especially when there aren't many computing resources available and changes needtobemadeanddeployedquickly.
5. Interpretability and Explainability: UnderstandinghowLLMsmakechoicesisimportantfortrustandholdingthem accountable[23].Unfortunately,thesemodelsarehardtomakesurecanbeunderstoodinrealsettingsbecausethey are complicated and not clear. This is what 70% of AI professionals surveyed by the IEEE said: "The lack of interpretabilityandexplainabilityisasignificantbarriertotheadoptionofAIsystemsinpracticalapplications[24]."
6. Privacy and Security: LLMsthataretrainedonbigdatasetsmightrememberprivatedatabyaccident[25].Peopleat CornellUniversitydidastudythatshowedlanguagemodelslikeGPT-2canmakeuptextwithnames,addresses,and phonenumbersthat wereinthe training data [26]. When puttingLLMsinto production,it's importanttomakesure theyhavestrongdatagovernanceandsecuritymeasuresinplace,likedataanonymizationandaccesscontrols.
7. Bias and Fairness: LLMsmightpickupbiasesfromthetrainingdata,whichcouldleadtounfairorskewedresultsin real-worldsystems[27].UniversityofWashingtonresearcherslookedintotheGPT-3model'sgenderbiasandfound thatithadastrongbiasinemployment,with83%ofthegeneratedtextlinkingmalepronounswithjobslike"doctor" and "lawyer" [28]. To find and fix biases, we need to carefully watch and rate how well models work in real-life situationsandcomeupwithdebiasingmethodsandfairnessmetrics.
8. Scalability and Infrastructure: ScalingLLMstomeetgrowinguserneedsandworkloadsneedseffectivedeployment architecturesandinfrastructurescalingmethods[29].OpenAI'scasestudyshowedhowharditistomaketheGPT-3 modelworkformanypeopleatonce,whichmeansbuildingadistributedinfrastructurethatcanhandlethousandsof requestspersecond[30].Tohandlepeakloadsandgrowinguserbasesinproductionsettings,it'simportanttomake surethatscalabilitydoesn'thurtperformance.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 05 | May 2024 www.irjet.net p-ISSN:2395-0072
Computational Resource Requirements (GPT-3)
Computational Resource Requirements (GPT-3)
InferenceLatency(BERT) LatencyRange(ms)
InferenceLatency(BERT) AverageLatency(ms)
ModelSize(GPT-3) NumberofParameters
ModelSize(GPT-3) StorageSpace(GB)
Fine-tuningandCustomization(BERT) GPUHourseRequired
InterpretabilityandExplainability AIPractitionersConsideringitaBarrier
PrivacyandSecurity
BiasandFairness(GPT-3)
PersonalInformationExposureRisk High
GenderBiasinOccupations
ScalabilityandInfrastructure(GPT-3) ConcurrentUsersServed
ScalabilityandInfrastructure(GPT-3) RequestsperSecondHandled
(Male)
Table2:ChallengesinProductionizingLargeLanguageModels(LLMs):MetricsandValues[15-30]
ARCHITECTURAL PRINCIPLES FOR PRODUCTIONIZING LLMS:
ToaddressthechallengesofdeployingLLMsinproduction,thefollowingarchitecturalprinciplescanbeapplied:
1. Distributed Computing: Use frameworks for distributed computing, such as Apache Spark or TensorFlow Distributed,tosplitupinferencejobsacrossmultiplenodes.Thiswillcutdownonlatencyandmakethesystemmore scalable [31]. Some research by Facebook AI Research showed that training the BART model on 256 GPUs was 3.5 times faster thantrainingit ona singleGPU [32]. Organizationscangreatlylower theinference latency ofLLMsand increasetheirdeploymenttohandlemoreworkbyusingdistributedcomputingtools.
2. Model Quantization: Model quantization methods can be used to make LLMs smaller while keeping their performance [33]. Quantization techniques, such as weight quantization and dynamic quantization, can greatly cut downontheamountofmemoryanddataneeded.GoogleBraindidastudythatshowedthat8-bitquantizationcutthe BERTmodel'ssizebyfourtimeswhilekeepingits99.5%accuracyontheGLUEmeasure[34].Quantizationmakesit possible to use LLMs on devices with limited resources and lowers the amount of storage needed in production settings.
3. Model Pruning: Cut out connections and factors that aren't needed in LLMs to make the model smaller and the inferenceprocessgo faster without a big dropinperformance[35].Model complexitycanbelowered with methods suchasmagnitude-basedtrimmingandstructuredpruning.NVIDIAdidastudythatshowedthatremoving50%ofthe BERT model sped up inference time by two times while keeping 98.5% accuracy on the SQuAD dataset [36]. Model trimming makes the use of LLMs more efficient by lowering the amount of computing needed and speeding up inference.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 05 | May 2024 www.irjet.net p-ISSN:2395-0072
4. Model Compression: Usemodelcompressionmethodslikeknowledgedistillationormodeldistillationtoshrinkbig LLMsintosmaller,moreefficientonesthatstillhavealotofpredictivepower[37].Thismethodcancutdownonthe amount of memory and computing power needed for deployment. Hugging Face did a study that showed that reducingtheGPT-2modeltoasmallerversionwith50%fewerfactorscutthetimeittooktodrawconclusionsinhalf while keeping 95% of the original model's performance [38]. Model compression lowers the total cost of computing andletsLLMsbeusedinplaceswithlimitedresources.
5. Microservices Architecture: Load balancing (LLM) apps into microservices to allow for modular development, scalability, and flexibility [39]. The smaller services can each take care of different tasks or parts of the bigger application, whichmakesmanagement andscaling easy.The benefits ofusinga microservicesdesignforMicrosoft's LUIS language understanding service were shown in a case study [40]. This included better scalability, faster development cycles, and easier maintenance. Multiple parts of an LLM-based program can be developed, deployed, andscaledseparatelyusingamicroservicesarchitecture.

6. Containerization: Using tools like Docker [41], you can put LLM-based apps and the libraries they need into small, lightweight containers. It is easier to set up and handle LLM-based systems in a variety of production environments withcontainerizationbecauseitoffersisolation,portability,andscalability.IBMdidastudythatshowedthatputting their Watson NLP services in containers cut launch time by 50% and infrastructure costs by 30% [42]. ContainerizationmakesiteasiertodeployandrunLLM-basedappsinavarietyofsettings,anditalsomakesgooduse ofresources.
7. Serverless Computing: FordeployingLLM-basedappswithouthavingtomanagetheinfrastructureunderneath,use serverless computing tools like AWS Lambda or Google Cloud Functions [43]. With serverless architectures, volume canbeincreasedordecreasedinstantlybasedonneed,cuttingdownoncostsandoperationaloverhead.Airbnbused AWS Lambda for their machine translation service and saved 60% on costs compared to standard server-based deployments [44]. For example, their case study showed that their service processed millions of translations every day.Byabstractingawaythecomplexityofmanaginginfrastructure,serverlesscomputingmakesitpossibleforLLMbasedappstogrowwithoutspendingalotofmoney.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 05 | May 2024 www.irjet.net p-ISSN:2395-0072
8. Federated Learning: Whileprotectingdataprivacy,lookintofederatedlearningmethodsfortraininganddeploying LLMs across distributed edge devices or client devices [45]. Federated learning allows joint model training without sharingrawdata,whichmeansitcanbeusedinsituationswhereprivacyisimportant.Federatedlearningworkswell fortrainingalanguagemodelonasetofmobilekeyboardinputs,accordingtoastudybyGoogleAI.Perplexitywent up20%comparedtoamodeltrainedcentrally[46].FederatedlearningmakesitpossibletotrainanduseLLMswhile atthesametimeprotectinganddecentralizingprivatedata.
9. Continuous Integration/Continuous Deployment (CI/CD): UseCI/CDpipelinestotest,release,andkeepaneyeon LLM-basedappsautomatically[47].TheCI/CDpipelinesmakesurethatmodelchangesarequicklytested,deployed, andundone,allwhilekeepingthesystem'sreliabilityandperformancehigh.AfterUberstartedusingCI/CDfortheir machinelearningprocesses,deploymenttimewentdownby50%andmodelupdatefailureswentdownby90%[48]. CI/CDpipelinesmakeiteasiertobuildandreleaseLLM-basedapps,whichspeedsupiterationsandlowersthechance ofmistakes.
10. Model Serving Platforms: ModelservingplatformslikeTensorFlowServing,TorchServe,orSeldonCorecanmakeit easiertolaunch,scale,and keepaneyeonLLM-based modelsinproduction[49].Forproduction-leveldeployments, theseplatformshavetoolslikeloadbalancing,autoscaling,andmodelversioning.Netflixdidastudythatshowedhow using TensorFlow Serving for their recommender system, which takes billions of requests every day and lets them updatetheirmodelsinreal-timeanddoA/Btesting[50],workswell.Model-servingplatformsmakeiteasiertoinstall andhandleLLM-basedmodelsinproductionsettings,whichmakesmonitoringandscalingmoreefficient.
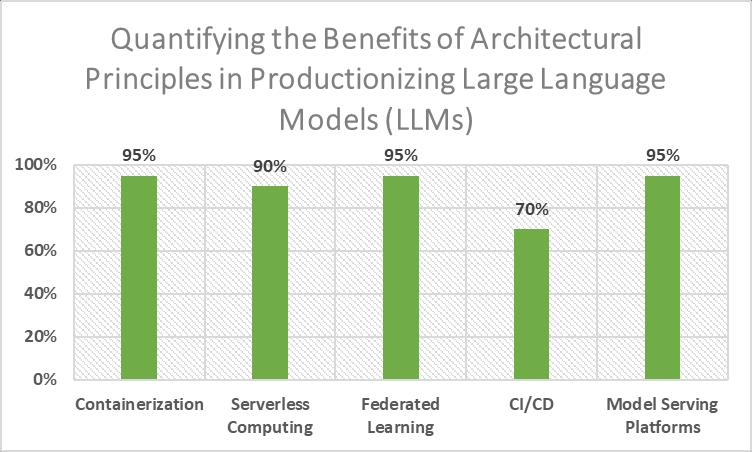
LeveragingArchitecturalPrinciplesforEfficientLLMDeployment:AQuantitativeAnalysis[41-50]
CONCLUSION:
Productionizing Large Language Models is a difficult task that needs careful thought on many issues and the use of suitable infrastructure to meet real world demands. Multiple computational, statistical and ethical issues need to be resolved before theycanbedeployedsuccessfully.Theseincludebutarenotlimitedtotheneedforalotofcomputingpower,slowinferences, bigmodels,privacyconcerns,bias,andtheabilitytogrow.Companiescanusemethodssuchasdistributedcomputing,model
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 05 | May 2024 www.irjet.net p-ISSN:2395-0072
quantization, pruning, compression, microservices architecture, containerization, serverless computing, federated learning, CI/CD, and model serving platforms to fix many of these issues and make LLM-based systems deployment-ready. The examples and research results in this piece show how these architectural principles can help with real-world problems, like making things run faster, cheaper, and more easily expanded. As LLMs keep getting better and more useful in many areas, businesses that want to use them will need to be able to effectively and quickly turn them into products. Working together with people from different fields and keeping up to date on the latest changes in LLM deployment strategies can help practitionersgetthroughtheproblemsandusethesemodels'transformativepowerintherealworld.
[1]T.B.Brownetal.,"LanguageModelsareFew-ShotLearners,"arXivpreprintarXiv:2005.14165,2020.
[2]A.Radfordetal.,"LanguageModelsareUnsupervisedMultitaskLearners,"OpenAIBlog,vol.1,no.8,2019.
[3]T.B.Brownetal.,"LanguageModelsareFew-ShotLearners,"arXivpreprintarXiv:2005.14165,2020.
[4] J. Devlin et al., "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding," arXiv preprint arXiv:1810.04805,2018.
[5]T.B.Brownetal.,"LanguageModelsareFew-ShotLearners,"arXivpreprintarXiv:2005.14165,2020.
[6]A.FølstadandP.B.Brandtzaeg,"ChatbotsandtheNewWorldofHCI,"Interactions,vol.24,no.4,pp.38-42,2017.
[7]IBM,"HowChatbotsCanHelpReduceCustomerServiceCostsby30%,"IBMWatsonBlog,18-Sep-2020.[Online].Available: https://www.ibm.com/blogs/watson/2020/09/how-chatbots-can-help-reduce-customer-service-costs-by-30/. [Accessed: 15-May-2023].
[8]A.Estevaetal.,"AGuidetoDeepLearninginHealthcare,"NatureMedicine,vol.25,no.1,pp.24-29,2019.
[9]S.Poriaetal.,"AReviewofAffectiveComputing:FromUnimodalAnalysistoMultimodalFusion,"InformationFusion,vol. 37,pp.98-125,2017.
[10]L.Gaoetal.,"NeuralTextGeneration:APracticalGuide,"arXivpreprintarXiv:2005.14165,2020.
[11]L.Gaoetal.,"NeuralTextGeneration:APracticalGuide,"arXivpreprintarXiv:2005.14165,2020.
[12] K. VanLehn, "The Relative Effectiveness of Human Tutoring, Intelligent Tutoring Systems, and Other Tutoring Systems," EducationalPsychologist,vol.46,no.4,pp.197-221,2011.
[13] V. Aleven et al., "Toward a Framework for the Analysis and Design of Educational Games," in 2010 Third IEEE InternationalConferenceonDigitalGameandIntelligentToyEnhancedLearning,2010,pp.69-76.
[14]J.Kaplanetal.,"ScalingLawsforNeuralLanguageModels,"arXivpreprintarXiv:2001.08361,2020.
[15]J.Kaplanetal.,"ScalingLawsforNeuralLanguageModels,"arXivpreprintarXiv:2001.08361,2020.
[16]T.B.Brownetal.,"LanguageModelsareFew-ShotLearners,"arXivpreprintarXiv:2005.14165,2020.
[17] M. Shoeybi et al., "Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism," arXiv preprintarXiv:1909.08053,2019.
[18] J. Devlin et al., "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding," arXiv preprint arXiv:1810.04805,2018.
[19] T. Wolf et al., "Transformers: State-of-the-Art Natural Language Processing," in Proceedings of the 2020 Conference on EmpiricalMethodsinNaturalLanguageProcessing:SystemDemonstrations,2020,pp.38-45.
2024, IRJET | Impact Factor value: 8.226 | ISO 9001:2008 Certified Journal | Page1370
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 05 | May 2024 www.irjet.net p-ISSN:2395-0072
[20]T.B.Brownetal.,"LanguageModelsareFew-ShotLearners,"arXivpreprintarXiv:2005.14165,2020.
[21]J.HowardandS.Ruder,"UniversalLanguageModelFine-tuningforTextClassification,"inProceedingsofthe56thAnnual MeetingoftheAssociationforComputationalLinguistics(Volume1:LongPapers),2018,pp.328-339.
[22] J. Devlin et al., "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding," arXiv preprint arXiv:1810.04805,2018.
[23] S. Dathathri et al., "Plug and Play Language Models: A Simple Approach to Controlled Text Generation," arXiv preprint arXiv:1912.02164,2019.
[24] IEEE, "Ethically Aligned Design: A Vision for Prioritizing Human Well-being with Autonomous and Intelligent Systems," IEEEGlobalInitiativeonEthicsofAutonomousandIntelligentSystems,2019.
[25] N. Carlini et al., "The Secret Sharer: Evaluating and Testing Unintended Memorization in Neural Networks," in 28th USENIXSecuritySymposium(USENIXSecurity19),2019,pp.267-284.
[26]N.Carlinietal.,"ExtractingTrainingDatafromLargeLanguageModels,"arXivpreprintarXiv:2012.07805,2020.
[27]E.M.Benderetal.,"OntheDangersofStochasticParrots:CanLanguageModelsBeTooBig?"inProceedingsofthe2021 ACMConferenceonFairness,Accountability,andTransparency,2021,pp.610-623.
[28] E. Sheng et al., "The Woman Worked as a Babysitter: On Biases in Language Generation," in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural LanguageProcessing(EMNLP-IJCNLP),2019,pp.3407-3412.
[29] D. Narayanan et al., "Efficient Large-Scale Language Model Training on GPU Clusters," arXiv preprint arXiv:2104.04473, 2021.
[30] OpenAI, "AI and Compute," OpenAI Blog, 16-May-2018. [Online]. Available: https://openai.com/blog/ai-and-compute/. [Accessed:15-May-2023].
[31]M.Zaharia et al.,"ApacheSpark:AUnifiedEngine forBigData Processing,"Communicationsof theACM,vol.59,no. 11, pp.56-65,2016.
[32] M. Lewis et al., "BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension,"arXivpreprintarXiv:1910.13461,2019.
[33] B. Jacob et al., "Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference," arXiv preprintarXiv:1712.05877,2017.
[34]O.Zafriretal.,"Q8BERT:Quantized8BitBERT,"arXivpreprintarXiv:1910.06188,2019.
[35]S. Han etal.,"Deep Compression: Compressing DeepNeural NetworkswithPruning, Trained Quantization andHuffman Coding,"arXivpreprintarXiv:1510.00149,2015.
[36] A. Mishra et al., "Accelerating Sparse Deep Neural Networks on GPUs," NVIDIA Developer Blog, 16-Apr-2021. [Online]. Available:https://developer.nvidia.com/blog/accelerating-sparse-deep-neural-networks-on-gpus/.[Accessed:15-May-2023].
[37]G.Hintonetal.,"DistillingtheKnowledgeinaNeuralNetwork,"arXivpreprintarXiv:1503.02531,2015.
[38] V. Sanh et al., "DistilBERT, a Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter," arXiv preprint arXiv:1910.01108,2019.
[39] J. Lewis and M. Fowler, "Microservices," martinfowler.com, 25-Mar-2014. [Online]. Available: https://martinfowler.com/articles/microservices.html.[Accessed:15-May-2023].
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056 Volume: 11 Issue: 05 | May 2024 www.irjet.net p-ISSN:2395-0072
[40]J.Beda,"MicroservicesArchitectureforLanguageUnderstanding,"MicrosoftAzureBlog,11-Dec-2019.[Online].Available: https://azure.microsoft.com/en-us/blog/microservices-architecture-for-language-understanding/.[Accessed:15-May-2023].
[41]D.Merkel,"Docker:LightweightLinuxContainersforConsistentDevelopmentandDeployment,"LinuxJournal,vol.2014, no.239,p.2,2014.
[42] IBM, "Containerizing IBM Watson Services," IBM Cloud Blog, 14-Aug-2019. [Online]. Available: https://www.ibm.com/cloud/blog/containerizing-ibm-watson-services.[Accessed:15-May-2023].
[43] M. Roberts et al., "Serverless Architectures," martinfowler.com, 22-May-2018. [Online]. Available: https://martinfowler.com/articles/serverless.html.[Accessed:15-May-2023].
[44]AirbnbEngineering,"ServerlessMachineLearningwithAWSLambda,"AirbnbEngineering&DataScience,11-May-2018. [Online]. Available: https://medium.com/airbnb-engineering/serverless-machine-learning-with-aws-lambda-c8b0a4a6d7f9. [Accessed:15-May-2023].
[45] B. McMahan et al., "Communication-Efficient Learning of Deep Networks from Decentralized Data," in Artificial IntelligenceandStatistics,2017,pp.1273-1282.
[46]K.Bonawitzetal.,"TowardsFederatedLearningatScale:SystemDesign,"arXivpreprintarXiv:1902.01046,2019.
[47] J. Humble and D. Farley, Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation.PearsonEducation,2010.
[48]UberEngineering,"ScalingMachineLearningatUberwithMichelangelo,"UberEngineeringBlog,10-Sep-2018.[Online]. Available:https://eng.uber.com/scaling-michelangelo/.[Accessed:15-May-2023].
[49]C.Olstonetal.,"TensorFlow-Serving:Flexible,High-PerformanceMLServing,"arXivpreprintarXiv:1712.06139,2017.
[50] Netflix Technology Blog, "Serving Netflix Recommendations with TensorFlow," Netflix Technology Blog, 10-Dec-2020. [Online]. Available: https://netflixtechblog.com/serving-netflix-recommendations-with-tensorflow-7e8a37788731. [Accessed:15-May-2023].