
Utilizing Machine Learning, Detect Chronic Kidney Disease and Suggest A Healthy Diet
Meghashree M B1 , Dr. Shreekumar T2 ,1Master in Technology Student, Dept. of Computer Science and Engineering, Mangalore Institute of Technology and Engineering, Moodbidri.
2Associate Professor, Dept. of Computer Science and Engineering, Mangalore Institute of Technology and Engineering, Moodbidri. ***

Abstract – TheUN'sthirdsustainabledevelopmentobjective, "Good health and well-being," emphasizes the rising importance of non-communicable diseases. One of them is to reduce byhalf,by2030,therateofnon-communicablediseaserelatedpremature death. Chronickidneydisease(CKD),oneof the leading causes of morbidity and death from noncommunicable diseases, may affect 10–15% of the world's population. In order to minimize the effects of patient health complications like hypertension, anemia (low blood count), minerals bone disorder, poor nutritional health, and neurologicalcomplicationswithpromptinterventionthrough appropriate medications, early and accurate detection of the stages of CKD is essential. Four prediction models are employed: Decision tree (DT),
K-NearestNeighbor(K-NN),RandomForest(RF),andSupport Vector Machine (SVM). Evaluation of difference & recursion characteristics elimination using was employed for feature selection. Using tenfold cross-validation, the models were evaluated. Results of the experiment demonstrating the superiorperformanceofRFutilizingrecursivereductionof features with cross-validation over SVM and DT.
Key Words: Chronic Kidney Disease (CKD), Machine Learning, Random Forest (RF), Support Vector Machine (SVM),DecisionTree(DT)
1. INTRODUCTION
Twobean-shapedorgans,namedkidney,aretwoimportant parts in human body. Filtering by the kidney eliminates wastefromtheblood.Proteincanleakintourineandwaste materials can stay in blood if this filtration mechanism is compromised.Eventually,thekidney'sfilteringcapacityis lost.ChronicKidneyDisease(CKD),alsoknownasChronic NephroDisease,isthetermusedtodescribekidneyfailure. Kidney failure affects the whole body. People generally experience this disease in accordance with their age, howeverasofrecentyears,childrenandyouthasyoungas5 yearsoldarealsoexperiencingCKDdisease.Therearesome symptoms which shows kidneys are beginning to fail like muscle cramps, nausea and vomiting, appetite losses, swelling in your feet and ankles, too much urine or not enoughurine,troublecatchingyourbreath,troublesleeping, fever and vomiting. Risk factors of CKD are diabetes,
smoking,lackofsleeping,hyper tension,improperdiet,etc. Amongthemdiabetesisthemoredangerousfactor.Atthe last stage, the patient must take dialysis or do kidney transplantation. Oneofthebestwaystoreducethisdeath rate is early treatment. Therefore, early prediction and propertreatmentscanpossiblystop,orslowtheprogression ofthischronicdiseaseAttheconclusionoftheprocedure, thepatientmusthavedialysisorapatienttransplant.Among the best way to reduce this death rate is early therapy. Therefore,quicktreatmentandappropriatediagnosismay beabletostoporslowthegrowthofthischroniccondition. Atleast2.4millioneachyeardeathsoccur.Eachyear,deaths occur, from kidney related disorders, in accordance with 2019 World Kidney Day study. CKD is currently the sixth fastest growing cause of death worldwide, and with an increasingincidence,itevolvingintodifficultpublichealth issue.Thecountryranks138thgloballyintermsofmortality rates with 0.77% of worldwide deaths. Due to its ageadjusted mortality rate of 8.46 per 100,000 people and growing mortality rate of 12.70 per 100,000 people, the nationisranked109in2018.
2. EXISTING SYSTEM
Topredictdiseases,Datasciencetechniqueusingmachine learning models are playing a vital role. By making some mathematicalapproaches,machinelearningmodelsextract patternsfromdataandlaterthesepatternsareusedforthe survivalofpatients.SupportVectorMachine(SVM),Nearest Neighbor(KNN),DecisionTree(DT),RandomForest(RF), etc. are some renowned machinelearning methods which weresuccessfullyimplementedtoexamineandclassifythe kidneydisease.Inrecenttimes,someresearchershavebeen working on CKD by applying different computational techniquesforthepredictionanddiagnosisofthisdisease.
3. PROPOSED SYSTEM
Several machine learning models are suggested in this section. Various machine learning techniques utilized samples of data for identifying the algorithms before creating the classifiers. In addition, we trained the model usingK-NearestNeighborClassifier,DecisionTreeClassifier, SVM,andRandomForest.Followingthat,wemaycompare and decide which of the following approaches can most
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume:
accurately forecast the possibility of CKD based on the outcomesofeachofthesemachinelearningmethods.
classification use it. This model consists of several decisiontreesandproducestheclassgoal,whichisthe target generated by each tree that received the most votes. In order to build the tree, Random Forest employsbothclumpingandrandomfeatureselection, resulting in a random forest of trees. The collective forecast is more precise than any single tree's. Followingtheconstructionoftheforest,testexamples are diffused through each tree, and the trees individuallyofferaclassificationprediction.
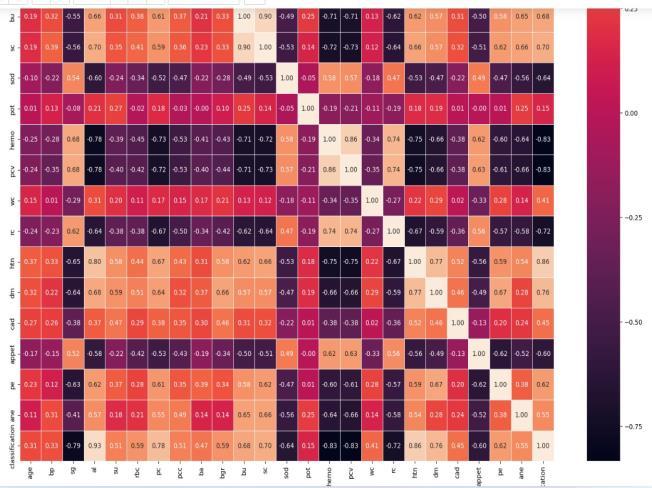
Datasetisexploredinthepythonenvironmentalongwitha datadictionaryofattributes.Wehaveseparatedourdataset into a training set and a testing set. It is crucial for any predictive modeling and is the process where you automatically or manually select those features which contribute most to your prediction variable or output in which you are interested in. The dataset consists of 24 featureswhichweredividedinto11numericalfeaturesand 13categoricalfeatures. Thediagnosticclasscontainstwo values namely ckd and not ckd. All features contained missingvaluesexceptforthediagnosticfeature.
4. IMPLEMENTATION AND RESULT
The algorithm listed below were used to complete the project
4.1 Decision Tree (DT): Regression and classification problems.ThegeneralobjectiveofusingDecisionTreeisto create a model that predicts classes or values of target variablesbygeneratingdecisionrulesderivedfromtraining data sets. Decision tree algorithm follows a tree structure withroots,branchesandleaves.Theattributesofdecision making are the internal nodes and class labels are representedasleafnodes.DecisionTreealgorithmiseasyto understandcomparedwithotherclassificationalgorithms.
4.2 KNN (K-nearest Neighbor): Thek-nearestneighbor’s algorithm (k-NN) is a non-parametric technique for classification and regression in pattern recognition. The k nearesttraininginstancesinthefeaturespacemakesupthe input in both scenarios. Whether k-NN is applied for regressionorclassificationdeterminestheresults.Theresult of k-NN classification is a class membership. An item is allocatedtotheclassthathasthemostsupportfromitsk closestneighbors(kisapositiveintegerthatisoftensmall) based on a majority vote of those neighbors. The item is simplyputintotheclassofitsonenearestneighborifk=1.

4.1 Random Forest (RF): An ensemble learning techniquecalledRandomForestismadeupofseveral groupings of decision trees. Both regression and
4.2. Support vector machine (SVM): Oneofthewellknown and practical supervised machine learning algorithmsforclassification,learning,andpredictionis thesupportvectormachine.Inordertocategorizeall inputinhigh-dimensionaldata,aseriesofhyperplanes are constructed. In the signifier space of the training data, a discrete hyper plane is constructed, and compoundsarecategorizedaccordingtothesideofthe hyper plane. The decision lines that divide the data points are known as hyper planes. The position and directionofthehyperplanearedeterminedbysupport vectors,whicharepointsofdatathatarenearertothe hyperplane.SVMshavemostlybeenpresentedtodeal withbinarycategorization,butduetothevastquantity of data available nowadays, several academics have soughttoadaptittomulticlassclassification.
Thefollowingscreenshotsaredepictedtheflowandworking processofproject
Mostofthefocusinpre-processingistoremoveanyoutliers orerroneousdata,aswellashandlinganymissingvalues. Missingdatacanbedealtwithintwoways.Thefirstmethod is to simply remove the entire row which contains the missing or erroneous value. While this easy to execute method,itisbettertouseonlyonlargedatasets.Usingthis method on small datasets can reduce the dataset size too much,especiallyiftherearealotofmissingvalues.Thiscan severely affect the accuracy of the result. Since ours is a relatively small dataset, we will not be using this method. Insteadwewouldbefillingourmissingvalueswithaverage ormodeofthecolumnbasedonthetypeofattribute.Ifthe attributeisnominalthanwewillusetheaverageandifitis non-nominalwewouldbeusingthemode.
Fig- 2: Stepdonedataforpre-processing
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 10 Issue: 07 | Jul 2023 www.irjet.net p-ISSN: 2395-0072
Accuracy
The capacity of the method of classification to properly forecasttheclassesofthedatasetisimpliedbytheterm accuracy.Itisameasurementofhowcloselyornearlythe real or theoretical value matches the expected value. Accuracyisoftendefinedastheratioofaccurateforecasts tototalinstances.Theaccuracyequationisshownbelow.
Accuracy = (���� + ����)/ (���� + ���� + ���� + ����)
5. CONCLUSIONS
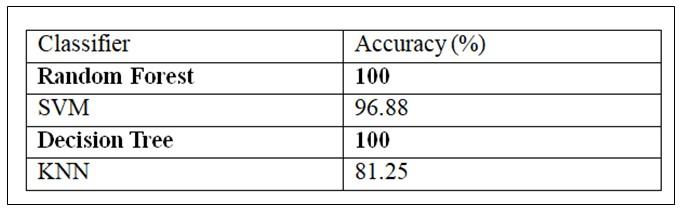
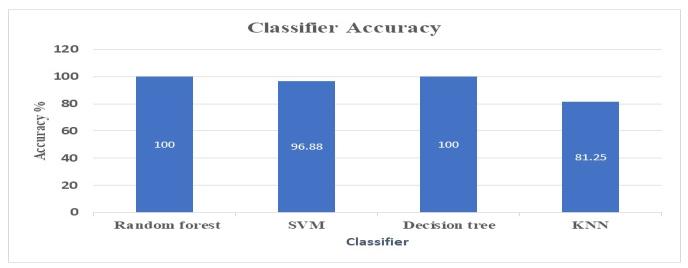
Thispaperelaboratestheproposedsystemconsistingof4 main modules, which are data pre-processing, feature extraction,definingzonesbasedonbloodpotassiumlevel, diet recommendation module. The dataset comprises 25 majorcharacteristics,andusinga statisticalapproachlike regression, extremely useful values for CKD identification are extracted. The decision tree algorithm, SVM, and KNN random forest algorithms have been demonstrated to be more effective at predicting chronic renal illnesses. Their relative levels of accuracy were determined to be 100%, 96.88%, 81.25%, and 100%. The sole basis for the diet guidancemoduleisthebloodpotassiumlevel.Overall,this technique can identify food recommendations that are helpfultobothpatientsandclinicians.


REFERENCES
[1] M.R.a.M.Dabhi,"Burdenofdisease–prevalenceand incidence,"ClinicalNephrology,vol.74,pp.9-12,/2010.
[2] T. F. T. N. W. C. Anusorn Charleonnan, "Predictive Analytics for Chronic Kidney Disease," in The 2016 ManagementandInnovationTechnologyInternational Conference(MITiCON-2016),2016.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 10 Issue: 07 | Jul 2023 www.irjet.net p-ISSN: 2395-0072
[3] M. Dr. S. Vijayarani, "data mining classification algorithmaforkidneydiseaseprediction,"International JournalonCybernetics&Informatics(IJCI),vol.4,no.4, p.13,August2015
[4] M.K.J.Ms.AsthaAmeta,"Data MiningTechniquesfor the Prediction of Kidney Diseases and Treatment: A Review," International Journal Of Engineering And ComputerScience,vol.4,no.2,p.20376,february2017
[5] D. N. S.Ramya, "Diagnosis of Chronic Kidney Disease Using Machine Learning Algorithms," International Journal of Innovative Research in Computer and CommunicationEngineering,vol.4,no.1,pp.812-813 january2016.
[6] Guneet Kaur, Ajay Sharma , Predict Chronic Kidney Disease Using Data Mining Algorithms in Hadoop , International Journal of Advanced Computational EngineeringandNetworking,ISSN:2320-2106,Volume5,Issue-6,Jun-2017
[7] Krupa Joel Chabathula, Jaidhar C.D, Ajay Kumara M.A Comparative Study of Principal Component Analysis Based Intrusion Detection Approach Using Machine Learning Algorithms , 2015 3rd International Conference on Signal Processing, Communication and Networking(ICSCN).
[8] Arif-Ul-Islam and S. H. Ripon, "Rule Induction and Prediction of Chronic Kidney Disease Using Boosting Classifiers, Ant-Miner and J48 Decision Tree," 2019 International Conference on Electrical, Computer and Communication Engineering (ECCE), Cox'sBazar, Bangladesh,2019,pp.1-6.
[9] S. Vijayarani, S. Dhayanand, "KIDNEY DISEASE PREDICTION USING SVM AND ANN ALGORITHMS", International Journal of Computing and Business Research(IJCBR),vol.6,no.2,2015.
[10] U.N.DulhareandM.Ayesha,"Extractionofactionrules forchronickidneydiseaseusingNaïvebayesclassifier," 2016IEEEInternationalConferenceonComputational IntelligenceandComputingResearch(ICCIC),Chennai, 2016,pp.1-5

[11] M.P.N.M.Wickramasinghe,D.M.PereraandK.A.D.C. P.Kahandawaarachchi,"Dietarypredictionforpatients with Chronic Kidney Disease (CKD) by considering blood potassium level using machine learning algorithms,"2017IEEELifeSciencesConference(LSC), Sydney,NSW,2017,pp.300-303.

[12] Deepti Sisodiaa , Dilip Singh Sisodia, Prediction of Diabetes using three classification algorithms, Computational International Conference on Data IntelligenceandScience(ICCIDS2018)
[13] Maryam Soltanpour Gharibdousti Kamran Azimi, SaraswathiHathikal,DaeHWon,PredictionofChronic Kidney Disease using Data mining techniques, 2017 IndustrialandSystemsEngineeringConference.
[14] V. Mohan, “Decision Trees: A comparison of various algorithms for building Decision Trees,” Available at: http://cs.jhu.edu/~vmohan3/document/ai_dt.pdf
[15] A.K.Pandey,P.Pandey,K.L.Jaiswal,A.K.Sen,”AHeart Disease Prediction Model using Decision Tree,” IOSR JournalofComputerEngineering(IOSR-JCE),Vol.12,pp 83-86,2013.
[16] L.A Stevens, A.S Levey, “Current status and future perspectives for CKD testing”. American Journal of KidneyDiseases,Vol.53,No.3,Supplement3,2009
BIOGRAPHIES
MEGHAREEMB
Masters in Technology Student, Dept. of Computer Science and Engineering,MITE
DR.SHREEKUMART
Associate Professor, Dept. of Computer Science and Engineering,MITE