
Volume:
Classification of Images Using CNN Model and its Variants
Narayan Dhamala1 , Krishna Prasad Acharya21Teaching Assistant, Department of Computer Science & Application, Mechi Multiple Campus, Jhapa, Nepal

2 Assistant Professor, Department of Computer Science & Application, Mechi Multiple Campus, Jhapa, Nepal ***
Abstract - Imageclassificationisamethodofassigninga labeltoanimageanditissuitabletousedeeplearningforthis task due to spatial nature of image which can leverage the massivelyparallelstructuretolearnvariousfeatures.Inthis research,aConvolutionNeuralNetworks(CNN)modelis presentedwiththreeconfigurations.Thefirstconfiguration issimpleandothertwoconfigurationsareimprovementof firstconfigurationbyusingtechniquestopreventoverfitting. ThetrainingandtestingisperformedonaCIFAR-10dataset whichconsistsof60000setsofimagesof10differentobjects. During comparison of variants of model using different performance matrices it is observed that the dropout regularization technique can significantly make the model moreaccurate.Italsoshowsthatlowerbatch sizecangive betterresultthanhigherbatchsize.
Key Words: Convolution Neural Network, Epos, Pooling, relu, softmax.
1.INTRODUCTION
Image classification is considered as an intelligent task of classifyingimagesintodifferentclassesofgivenobjectsbased on features. The classification problem can be binary or multipleclassifications.Examplesofbinaryclassificationare classifyingbetweencatordogimages,absenceorpresenceof cancer cells in the medical images etc. Similarly, multiple classificationsincludeclassifyingcatordogimages,different animals,digitrecognitionetc.Imageclassificationisusedin thefieldofcomputervisionforanalyzingvariousimagedata togetusefulinsight.Itcandifferentiatebetweenthegiven imagesbasedontinydetailswhichcouldbemissedevenby experthumansinthegivendomainItisoftenmisunderstood withobjectrecognition.Objectrecognitionisaboarderterm which is a combination of computer vision tasks including imageclassificationtodetectandrecognizedifferentobjects in the image. So, the main difference is that image classificationonlydealswithclassifyingimagesintodifferent typesorclasseswhileobjectrecognitioninvolvesdetectionof various objects in the image and recognizing them. Image classification involves training the machine learning model usinglargedatasetsofimages.Themodellearnsthepattern and features present in various classes of objects and can predicttheclassofobjectfrompreviouslyunseenimage.
1.1 Convolution Neural Network (CNN)

CNNisatypeofDeepNeuralNetworkswhichismainlyused forsolvingimagerecognitionrelatedproblems.Itavariantof
Multi-Layer Perceptron (MLP) also called fully connected neuralnetworks.Insuchnetworks,eachlayerinonelayeris connected to every neuron in next layer. CNNs can form complexpatternsfromsimpleroneswhichmakesthemmore effectiveinrecognitionofimageswithlotsoffeatures.Inthis CNNarchitecture,thethreedifferentlayersarepresentwhich are:convolutionlayer,poolinglayerandfullyconnectedlayer.
1.1.1 Convolutional layer
Itisfirstandmostsignificantlayer.Thislayerisresponsible forlearningfeaturesfromtheinputimage.Ittakesimageas inputandappliesakernel(filter)toanimageandproduces the output. This operationis calledconvolution. It helps to reduce shape of the image while retaining its features. Different filters can be stacked together to extract many features. In CNN, an image with a shape (no. of images) x (image height) x (image width) is passed through Convolution layer which in turn produces a feature map of shape(no.ofimages)x(featuremapheight)x(featuremap width)x(featuremapchannels).
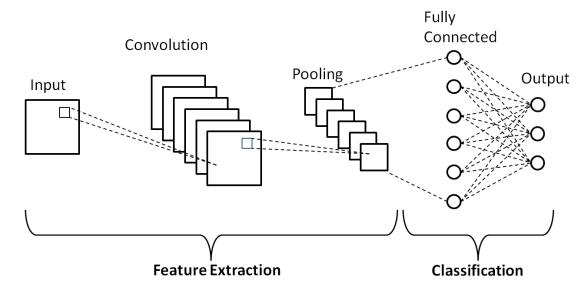
© 2023, IRJET | Impact Factor value: 8.226 | ISO 9001:2008 Certified Journal | Page1062
Figure1:BasicarchitectureofaCNN
Figure2:Convolutionoperation
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
p-ISSN:
10 Issue: 07 | Jul 2023 www.irjet.net
2395-0072
1.2.2 Pooling layer
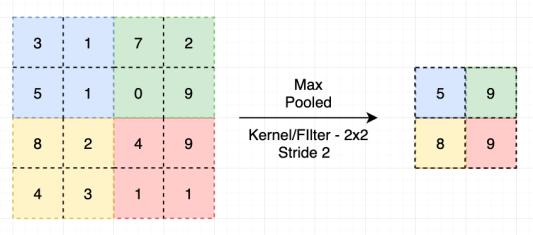
Itisrelatedtodownsamplingthefeaturemapsbysummarize -ngthepresenceoffeatures inpatchesofthefeaturemap. Thepoolingisusedtofurtherreducethesizeofthefeature map.Thesizeofpoolingfilterisalwaysintheformof2by2 matrixeswithastrideof2pixels.
Thetwomostlyusedpoolingmethodsare:maxpoolingand averagepooling.Inmaxpooling,the2by2filterisslidedover thefeaturemapandfindoutthemaximumvalueinthebox. Inanaveragepooling,thepoolingfilterofsize2by2isslided over the feature map and the average value in the box is chosen.
1.3 Problem statement
operation
1.2.3 ReLU layer
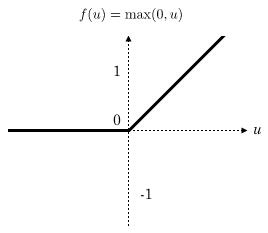
It is a rectified linear unit which removes negative values fromactivationmapbysettingthemtozero.Itincreasesnonlinear properties of the network. It applies the activation functionf(x)=max(0,x).Ithelpstoovercomethelimitations of other activation functions like sigmoid and tanh. Layers deep in large networks using these nonlinear activation functionsfailtoreceiveusefulgradientinformation.
Thedifferentmachinelearningalgorithmsusedindetection and recognition of objects are: Support Vector Machines (SVM),K-NearestNeighbor(KNN),NaïveBayes(NB),Binary DecisionTree(BDT)andDiscriminantAnalysis(DA).Mostof thesetraditionalmachinelearningalgorithmsarenotsuitable forproblemswhicharenon-linearinnature.Theycanoften provideinaccuratemodelandsufferfromhigherrorrate.So, for solving such problems a type of machine learning technique called deep learning is becoming more popular. Although neural networks were developed very early, they were not explored extensively due to lack of sufficient computing power. Due to advancements in computer hardware and rise of accelerated processing units such as GPUandTPUsuchneuralnetworksarebeingusedtoachieve greaterperformanceinvariousintelligenttasks.Similarly,it canbecombinedwithtraditionaltechniquestomakethem morepowerful.Itmassivelyparallelnetworksimilartothe biological network of neurons.Due tothespatial natureof images,theycanbemoreefficientlyprocessedusingneural networks.Itbecomesharderfortheneuralnetworkstofind underlyingpatternsoffeaturesbyanalyzingeachandevery pixel in the image. So, this simple way of using Neural Networks cannot perform well in the high-quality images havinglotsoffeatures.So,inordertosolvetheaboveproblem, amoreadvancedtypeofneuralnetworkscalledCNNcanbe used.
1.4 Objectives
Themainobjectivesofthisresearchareasfollows:
•ToimplementConvolution Neural Network model andit's variantsforimageclassification.
•Tocompareandanalyzethedifferentvariantsofthemodel using different performance metrics like: classification accuracyrate,errorrate,sensitivity,specificity,precision,F1 scoreandeffectofbatchsizeonthegivenimagedataset.
2. Literature Review
1.2.4 Fully Connected layer
Thislayertakestheoutputproducedfromconvolutionand pooling method to classify the input image into different classes (labels). The result from previous layer is flattened intoasinglevectorofvalues,eachrepresentingaprobability that a certain feature belongs to a label. For example, in handwritingrecognitionsystemthelabelscanbelettersfrom AtoZ.Iftheinputimageisofletter‘P’thentheprobabilities offeaturesrepresentingcircleandalineshouldbehigh.
In2021,RuchikaAroraet.al[1]proposedanoptimizedCNN forimageclassificationofTuberculosisimagesusingefficient tuning of hyper parameters based on hyper band search optimizationapproach.ThetuberculosisdiseasesinchestXray images are trained using NLM china dataset and also testedonthem.Theefficienthyperparametersarechosenby trialanderrormethodandaccordingtotheexperienceofthe designer. The experiment shows that usage of hyper parametersonagivendatasetusingCNNmethodachieves 91.42%accuracy.
TheAlexKrizhevskyetal.builtImageNet[2]CNNforILSVRC2012contestwherethetaskwastoclassify1.2millionhigh resolution images into 1000 different classes. The authors were able to achieve top-1 and top-5 error rates of 37.5% and17.0%onthetestdata.Itisconsideredtobebetterresult
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 10 Issue: 07 | Jul 2023 www.irjet.net p-ISSN: 2395-0072 © 2023, IRJET | Impact Factor value: 8.226 | ISO 9001:2008 Certified Journal | Page1063
Fig1-3:Max-pooling
Figure4:ReLUactivationfunction
than previous state-of-art. The CNN model consists of five convolutional layers some of which are followed by max poolinglayersandthreefullyconnectedlayers.Thismodel usesefficientGPUimplementationtomaketrainingfaster.It alsoutilizesdropoutregularizationtechniquetoreduceover fitting. This paper showed that a deep CNN is capable of achievingstateofartresultusingpurelysupervisedlearning.
The Md. Anwar Hossain et al. [3] proposed a CNN image classificationwhichwastrainedusingCIFAR-10dataset.The architecture of the CNN model consists of three blocks of ConvolutionandReLUlayer.ThefirstblockisfollowedbyMax pooling,secondisfollowedbyAveragepoolingandlastoneis followed by a fully connected layer. The author has implemented this model using MatConvNet. In the experiment,themaximumaccuracyof93.47%wasyielded with batch size 60, no. of epochs 300 and learning rate 0.0001.
ForImageNetchallenge2014,TheKarenSimonyanetal.[4] atVGGteamcameupwithmoreaccurateCNNarchitectures which not only achieve the state-of-the-art accuracy on ILSVRC classification and localization tasks, but are also applicabletootherimagerecognitiondatasets.Theauthors presentdifferentconfigurationofthenetworkwhichdiffers onlyindepthfromnetwork8convolutionallayerswith3FC layersto16convolutionallayerswith3FClayers.Themain highlight of this network is that it used very small filters throughoutthe network whichhelpstoachievesignificant improvement.

GoogLeNet[5] wasable to pushthe limit of theCNN depth with a 22 layers structure. It is found that the deeper and widerlayerhelpstoimproveaccuracy Themainhallmarkof this architecture is the improved utilization of computing resourcesinthenetwork.Theauthorswereabletoincrease the depth simultaneously keeping the computational requirement constant by improving the architecture. The paper discusses the idea of applying dimension reduction wherevercomputationalrequirementsincrease.Theauthors have presented a type of network configuration called inceptionnetwork whichconsistsofmodulesstackedupon eachother.Thus,thispapershowsthestrengthofinception architectureandprovidesevidencethatitcanachievesimilar resultasmorecomputationallyexpensivenetworks.
TheShivametal.[6]performsimageclassificationusingfive different architecture of image classification that are made basedonvaryingconvolutionlayer,fullyconnectedlayersand filter size. To perform the experiment the different hyper parameterslike:activationfunction,optimizer,learningrate, dropout rate and size of batch are considered. The result showsthatthechoiceofactivationfunction,dropoutrateand optimizerhasinfluenceontheaccuracyofthearchitecture. TheCNNModelgives99%ofaccuracyforMNISTdatasetbut lowerthanthatforFashion-MINSTdatasetthismaybedueto complexnatureofdataintheFashion-MINSTdataset.
3. Methodology
3.1 Data Collection
ThedatasetusedinthisresearchisCIFAR-10dataset.Itisone of the most widely used dataset for machine learning. It consistsof60,000imageswitha32x32colorimagesin10 classes,with6,000imagesperclass.Thetendifferentclasses inthe datasets are airplane, automobile, bird,cat, deer, dog, frog,horse,shipandtruck.Sincetheresolutionoftheimage islow,itcanbeusedtotestnewmachinelearningalgorithms quicklywithverylesscomputingpower
3.2 Tools used
Followingarethehardwareandsoftwaretoolsusedto implementthisresearch
3.2.1 Hardware requirements
CPU:Intelx64_86
RAM:4GB
HDD:1TB
3.2.2 Software requirements
OperatingSystem:Windows1064bit
DevelopedIn:Python3.7
LibrariesUsed:Keras,Scikit-Learn,Matplotlib,Seaborn
3.3 Data preprocessing
It is necessary to apply some preprocessing on the data beforeprovidingitintothenetwork.Thedatasetof60,000 imagesissplitinto40,000trainingset,10,000forvalidation
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 10 Issue: 07 | Jul 2023 www.irjet.net p-ISSN: 2395-0072 © 2023, IRJET | Impact Factor value: 8.226 | ISO 9001:2008 Certified Journal | Page1064
Figure5:SomeimagesonCIFAR-10dataset
during training and 10,000 for testing. The pixel data in x valuesisconvertedintofloatingpointvalueandnormalized into range 0-255. The output or y value consists of categoricaldatawhichareconvertedintonumericvalues.
3.4 Architecture of CNN model
Thefourthlayerisaconvolutionallayersimilartofirstlayer.It applies64filtersofsize3x3andproduceoutputfeaturemaps of size 64@15*15. It has stride, padding and activation functionsameasfirstlayer.
Thefifthlayerisaconvolutionlayersameassecondlayer.It producesfeaturemapsofsize64@13*13.Likesecondlayer,it doesn’thavepaddingaroundboundary.Ithasstride,padding andactivationfunctionsameassecondlayer.
The sixth layer is pooling layer same as third layer. It also applies max-pooling using 2x2 filter with stride=2. It producesoutputfeaturemapsofsize64@6*6.
Nextthreelayersaresimilarasfourth,fifthandsixthlayers respectively.Theseventhlayerwhichisconvolutionallayer producesfeaturemapsofsize64@6*6whichisfedintonext convolutional layer that outputs feature maps of 64@4*4. Next,theninthlayerwhichispoolinglayerproducesoutput ofsize64@2*2.
Figure6:ThearchitectureofCNNModel
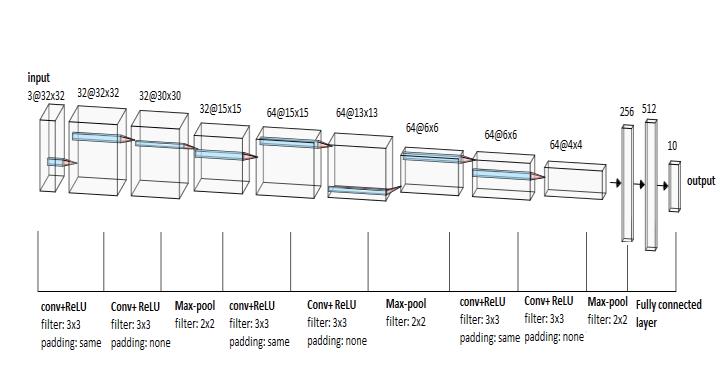
Thenetworkofthemodelisstructuredin3-blockVGGstyle having sequence of CONV-CONV-POOL-CONV-CONV-POOLCONV-CONV-POOL-FC-FC. Each block consists of two convolution layer (CONV) followed by a max pooling layer (POOL).Therearetwofullyconnectedlayers(FC)attheend ofthenetwork.
Thefirstlayerofthenetworkisaconvolutionallayerinwhich the input images are fed. Each image is of size n*n=32*32 withdepthof3foreachcolorchannels.Itusesf*f=3*3kernel forconvolutionoperation.ItusesReLU(RectifiedLinearUnit) activation function. The stride is 1 which means the filter windowismovedby1pixelatatime.sinceour32*32image is reduced to 30*30, zero padding around input layer is appliedsuchthatoutputimagesizeissameasinput.Inthis casepadding=1isapplied.Next,32filtersareappliedinthis layer. This layer produces feature maps of size 32@32*32 wherefirst32isno.offeaturemapsand32in32*32isgiven as:((n+2p-f)/s)+1.So,inthiscase,((32+2*1-3)/1)+1=32. Theno.offeaturemapsinnextlayerscanbecalculatedusing sameformula.
The second layer is also a convolutional layer which takes inputfrompreviouslayerandproducesfeaturemapsofsize 32@30x30. It also applies 32 filters of 3*3 size. It also has stride=1butitdoesn’tapplyanyzeropadding. The third layer is pooling layer which applies max-pooling using2*2filterwithstride=2.Itproducesoutputfeaturemaps of size 32@15*15. This layer doesn’t apply any activation function.
Thenextlayerisafullyconnectedlayerwhichconvertsthe 3Darrayintoa1Darrayofsize2*2*64=256.Itisalsocalled flattenedlayer.ItusesReLUactivationfunction.Finally,the lastlayerisalsoafullyconnectedlayerwhichhas10nodesfor representingeachclassinCIFAR-10dataset.Itusessoft-max activationfunction.
3.5 Variants of the model
3.5.1 Baseline model
This model is built using the architecture presented in previous section. It is a 3 block VGG style model which is modularandeasytoimplement.ItusesStochasticGradient Descent (SGD) for optimizing model with learning rate of 0.001.Thisvariantofthemodeldoesn’tuseanytechniques fortheimprovementofthemodel.Itistrainedusingbatch sizeof32and64andno.ofepochs100.Batchsizerefersthe totalnumberoftrainingexamplesusedbeforethemodelis updated.The numberof eposisdefinedasthe numbers of timesthealgorithmswillworkinthegiventrainingdatasets. Generallythehighernumberofeposischosenandcanlater reduce it to a number at which optimal performance is achieved.Highernumberofepochscanleadtoover-fitting
3.5.2 Improved model I
Thismodelusessamearchitectureasbaselinemodel butit applies a technique called dropout regularization. This techniquerandomlyremovescertainnodesfromthenetwork. Ithelpstopreventtheconditionofoverfittinginourmodel which causes the model to memorize or fit so closely to training data that it performs poorly on unseen or test dataset.Thismodelappliesdropoutrateof25%aftereach blockCONV-CONV-MAXand5%beforefinalfullyconnected layer.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 10 Issue: 07 | Jul 2023 www.irjet.net p-ISSN: 2395-0072 © 2023, IRJET | Impact Factor value: 8.226 | ISO 9001:2008 Certified Journal | Page1065
3.5.3 Improved model II
Thismodelfurtherimprovesthepreviousmodelbyapplying imageaugmentationtechniquewhichaugmentationhasbeen used which increases size of training data by adding more imagesobtainedbytransformingtrainingimages.Inthiscase theheightandwidthofimageisshiftedrandomlybetween110%.
3.6 Comparative Criteria
Thevariantsofthemodelwillbeanalyzedbasedonthe followingperformancemetrics.
3.6.1 Classification accuracy rate
Classificationaccuracy=
Where,TruePositives(TP)=actualpositiveswhichare predictedpositive
TrueNegatives(TN)=actualnegativeswhichare predictednegative
FalsePositives(FP)=actualpositiveswhicharepredicted negative
FalseNegatives(FN)=actualnegativeswhichare predictedpositive
3.6.2 Error rate
Errorrate=
3.6.3 True positive rate (TPR) or Sensitivity or Recall
TPR=
3.6.4True negative rate (TNR) or Specificity
TNR=
3.6.5 Positive Predictive Value (PPV) or Precision
PPVorPrecision=
3.6.6F1Score
Foranygeneralvalueβ:
F
=
Forβ=1:
F1Score=
4. Result, Analysis and Comparison
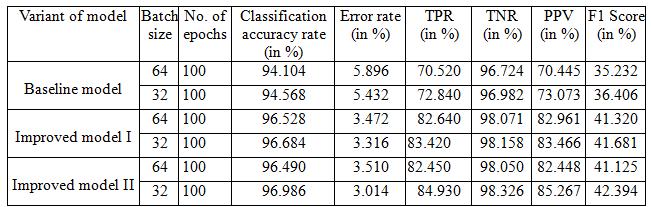
Inthissection,thevariantsoftheCNNmodelarecompared alongwithothertrainingparameterslikebatchsizeandno. of epochs. The comparison is done based on performance matrices: classification accuracy rate, error rate, TPR and TNR.TheTable4showsperformancemetricsofvariantsof themodelbasedonbatchsize32and64.Thevariantsofthe model were trainedandtestedupto100 epochs.For each configurationofmodel,theperformancemetriceshasbeen presented.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 10 Issue: 07 | Jul 2023 www.irjet.net p-ISSN: 2395-0072 © 2023, IRJET | Impact Factor value: 8.226 | ISO 9001:2008 Certified Journal | Page1066
β
Table-1:Performancemetricsofdifferentvariantsofmodel
rate
rate 92.5 93 93.5 94 94.5 95 95.5 96 96.5 97 97.5 Batchsize32 Batchsize64 classifcationaccuracyrate(inpercentage) Baselinemodel ImprovedmodelI ImprovedmodelII
4.1 Comparison result of classification accuracy
Figure7:Comparisongraphofclassificationaccuracy
Thegraphonfigure7showsthattheaccuracyrateishigher formodel withlower batch sizei.e. 32incomparisonwith higher batch size i.e. 64 for first two variant. In slightly decreasesonlastvariantforbatchsize64.Forbatchsize32, theratewasincreasedby2.116%frombaselinetoimproved model I. Similarly, it was further increased by 0.302% in improvedmodelII.Forbatchsize64,theratewasincreased by2.424%from baseline to improved model I. Similarly, it wasfurtherincreasedby0.038%inimprovedmodelII.

Basedongraphonaboveimage,theTPRincreasesfromfirst varianttofinalexceptwhenbatchsizeis64.Itincreasesby 10.58%frombaselinemodeltoimprovedmodelIandagain slightlyincreasesby1.51%inImprovedmodelIIwhenbatch sizeis 32.For batchsize 64, It increases by 12.12 % from baselinemodeltoimprovedmodelIbutslightlydecreasesby 0.19%inImprovedmodelII
Basedonfigure:8,itisclearthatthesecondvariantofthe modelsignificantlydecreasestheerrorrateanditdecreases furtherforbatchsize32butincreasesslightlyforbatchsize 64infinalvariant.
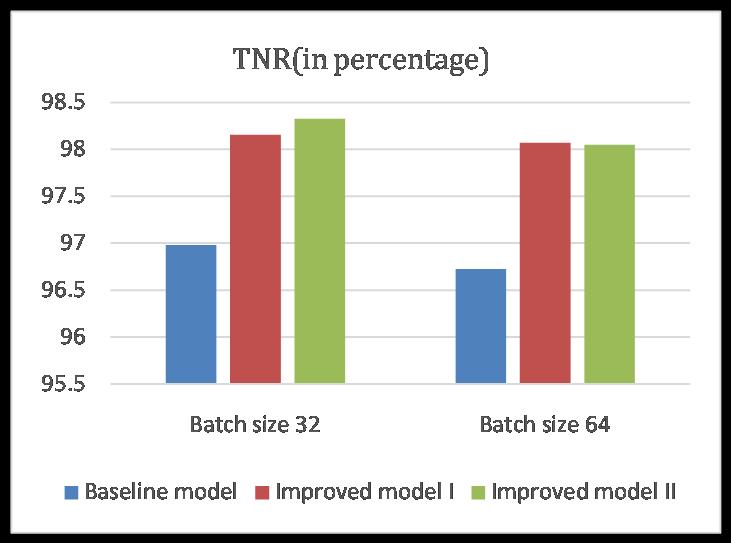
Thegraphonthefigure10showsthattheTNRincreasesin eachsuccessivevariant by 1.176% and0.168% whenthe batchsizeis32.Incaseofbatchsize64,itincreasesby1.347 %fromfirsttosecondvariantbutdecreasesby0.021%on thirdvariant.
4.5
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 10 Issue: 07 | Jul 2023 www.irjet.net p-ISSN: 2395-0072 © 2023, IRJET | Impact Factor value: 8.226 | ISO 9001:2008 Certified Journal | Page1067
4.2 Comparison result of error rate
Figure9:ComparisongraphofTPR
4.4 Comparison result of True Negative Rate
Figure10:ComparisongraphofTNR
Comparison result of Positive Predictive Value
0 1 2 3 4 5 6 7
size 32 Batch size 64
errorrate(inpercentage) Baseline model Improved model I Improved model II 0 10 20 30 40 50 60 70 80 90
size
Batch
percentage)
model Improved model I Improved model II
Figure11:ComparisongraphofPPV
Batch
classifcation
Batch
32
size 64 PPV(in
Baseline
Figure:8Comparisongraphofclassificationerrorrate
4.3 Comparison result of True Positive Rate
Thegraphonthefigure11showsthatthePPVincreasesin each successive variant by 10.393 % and further 1.801 % when the batch size is 32. In case of batch size 64, it increases by 12.516 % from first to second variant but decreasesby0.513%onthirdvariant
4.6 Comparison result of F1 score
resultsbyadjustingvariousparameters.Itcangiveusmore accurate results by using even more datasets and deeper network. It was also realized that high performance GPU computingisnecessarytotrainmodeltoachievesignificant results.Thismodelcanbefurtherextendedanddevelopedto solve other more complex tasks such as classification of medical images to detect diseases like cancer, cataract, pneumoniaetc.Besidethisitcanbedevelopedvariousother imageclassificationtasksinthefuture.
REFERENCES
[1] Ruchika Arora, Indu Saini and Neetu Sood, "Efficient Tuning of Hyper-parameters in Convolutional Neural Network for Classification of Tuberculosis Images," Proceedings of International Conference on Women Researchers in Electronics and Computing (WREC 2021) April22–24,2021,DOI:10.21467/proceedings.114.
[2] Krizhevsky, Alex, Sutskever, Ilya, and Hinton,Geoffrey. ImageNet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems25(NIPS’2012).2012.
Figure12:ComparisongraphofF1 Score
Basedonthefigure12,theF1scoreincreasesby5.275%in improvedmodelIandagainby4.287%onImprovedmodel II when the batch size is 32. In case of batch size 64, it increases by 6.088 % from first to second variant but decreasesby0.195%onthirdvariant.

5.Conclusion
Inthisresearch,aCNNmodelisbuiltwiththreevariationor configuration. It is tested by solving image classification problemusingCIFAR-10dataset.Thefirstvariantisbaseline modelandtwootherimprovedvariantsusetechniqueslike imageaugmentationanddropoutregularization.Theresult fromthisresearchshowsthatthedropouttechniquegreatly increasedtheperformanceofthemodelwhilethatofimage augmentationslightlyimprovedthemodel.Italsoshowsthat theperformancecanbedecreasedifsomeparameterisnot optimalassuchinimprovedmodelIIwhenbatchsizeis64. Thisresearchalsodemonstratesthatthedeeplearningcanbe appliedtosolvevisionrelatedtasks.Itcanbealsoconcluded that the parameters of the model should be tweaked and testedusinghitandtrialmethodtogetoptimalresultfrom the network and lower batchsize gives more classification accuracyascomparedtothatofhigherbatchsize.
6. Future Works
Itcanbefurtherdevelopedandextendedtoworkonother datasets.Thismodelcanbefurtherfine-tunedtogetbetter
[3]Hossain,Md.Anwar&Sajib,Md.(2019).Classificationof Image using Convolutional Neural Network (CNN). Global Journal of Computer Science and Technology. 19. 13-18. 10.34257/GJCSTDVOL19IS2PG13.
[4] Simonyan, Karen & Zisserman, Andrew. (2014). Very Deep Convolutional Networks for Large-Scale Image Recognition.arXiv1409.1556.
[5]C.Szegedyetal.,"Goingdeeperwithconvolutions,"2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, 2015, pp. 1-9, doi: 10.1109/CVPR.2015.7298594.
[6]Kadam,Shivam&Adamuthe,Amol&Patil,Ashwini.(2020). CNNModelforImageClassificationonMNISTandFashionMNISTDataset. Journal ofscientific research.64.374-384. 10.37398/JSR.2020.640251.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 10 Issue: 07 | Jul 2023 www.irjet.net p-ISSN: 2395-0072 © 2023, IRJET | Impact Factor value: 8.226 | ISO 9001:2008 Certified Journal | Page1068