6 minute read
References


Acero, A., Huang, X. and Hon, H. (2001) Spoken Language Processing: A Guide to Theory, Algorithm, and System Development. 1st edn. New Jersey: Prentice Hall.
Bachem, O., Lucic, M. and Krause, A. (2017) ‘Distributed and Provably Good Seedings for k-Means in Constant Rounds’. PMLR.
Advertisement
Baniya, B. K., Lee, J. and Li, Z.-N. (2014) ‘Audio feature reduction and analysis for automatic music genre classification’, in. IEEE (2014 IEEE International Conference on Systems, Man, and Cybernetics (SMC)). doi: 10.1109/SMC.2014.6973950.
Bishop, C. M. (2010) Pattern recognition and machine learning. 10th edn. New York: Springer.
Brent, W. (2010) Physical and Perceptual Aspects of Percussive Timbre. University of California.
Cabral, F. S., Fukai, H. and Tamura, S. (2019) ‘Feature Extraction Methods Proposed for Speech Recognition Are Effective on Road Condition Monitoring Using Smartphone Inertial Sensors’, 19(16). doi: 10.3390/s19163481.
Choi, K. et al. (2018) ‘A Comparison of Audio Signal Preprocessing Methods for Deep Neural Networks on Music Tagging’, in. EURASIP (2018 26th European Signal Processing Conference (EUSIPCO)). doi: 10.23919/EUSIPCO.2018.8553106.
Chung, Y.-A. et al. (2016) ‘Audio Word2Vec: Unsupervised Learning of Audio Segment Representations using Sequence-to-sequence Autoencoder’.
Du, X., Xu, H. and Zhu, F. (2021) ‘Understanding the Effect of Hyperparameter Optimization on Machine Learning Models for Structure Design Problems’, 135. doi: 10.1016/j.cad.2021.103013.
Dusan, S. and Deng, L. (1998) ‘Recovering Vocal Tract Shapes from MFCC Parameters’.
Evain, S. et al. (2021) ‘Human beatbox sound recognition using an automatic speech recognition toolkit’, 67, p. 102468. doi: 10.1016/j.bspc.2021.102468.
Everitt, B. et al. (2011) Cluster Analysis. Chichester: Wiley (Wiley series in probability and statistics).
Ghahramani, Z. (2004) Unsupervised Learning.
Gonzalez, R. (2012) Better Than MFCC Audio Classification Features. New York, NY: Springer (The Era of Interactive Media). doi: 10.1007/978-1-4614-3501-3_24.
Hastie, T., Tibshirani, R. and Friedman, J. H. (2009) The elements of statistical learning. 2nd edn. New York: Springer (Springer series in statistics).
Hazan, A. (2005) ‘Towards Automatic Transcription of Expressive Oral Percussive Performances’, in. ACM (IUI ’05), pp. 296–298. doi: 10.1145/1040830.1040904.
Jiang, N. and Liu, T. (2020) ‘An Improved Speech Segmentation and Clustering Algorithm Based on SOM and K-Means’, 2020. doi: 10.1155/2020/3608286.
Kapil, S. and Chawla, M. (2016) ‘Performance Evaluation of K-means Clustering Algorithm with Various Distance Metrics’, in. Piscataway: The Institute of Electrical and Electronics Engineers, Inc. (IEEE) (The Institute of Electrical and Electronics Engineers, Inc. (IEEE) Conference Proceedings).
Kaur, C. and Kumar, R. (2017) ‘Study and Analysis of Feature Based Automatic Music Genre Classification Using Gaussian Mixture Model’, in. Piscataway: The Institute of Electrical and Electronics Engineers, Inc. (IEEE) (The Institute of Electrical and Electronics Engineers, Inc. (IEEE) Conference Proceedings).
Knees, P. and Schedl, M. (2016) Music Similarity and Retrieval. Berlin, Heidelberg: Springer Berlin (The information retrieval series).
Lakatos, S. (2000) ‘A Common Perceptual Space for Harmonic and Percussive Timbres’, 62(7). doi: 10.3758/BF03212144.
Likas, A., Vlassis, N. and J. Verbeek, J. (2003) ‘The global k-means clustering algorithm’, 36(2). doi: 10.1016/S0031-3203(02)00060-2.
McDonald, S. and Tsang, C.P. (1997) ‘Percussive Sound Identification Using Spectral Centre Trajectories’, Proceedings of 1997 Postgraduate Research Conference.
McLachlan, G. J. and Rathnayake, S. (2014) ‘On the Number of Components in a Gaussian Mixture Model’, 4(5). doi: 10.1002/widm.1135.
Mehrabi, A. (2018) Vocal Imitation for Query by Vocalisation. Queen Mary University of London.
Mehrabi, A., Dixon, S. and Sandler, M. (2019) ‘Vocal Imitation of Percussion Sounds: On the Perceptual Similarity Between Imitations and Imitated Sounds’, 14(7). doi: 10.1371/journal.pone.0219955.
Micheyl, C. and Oxenham, A. J. (2010) ‘Pitch, harmonicity and concurrent sound segregation: Psychoacoustical and neurophysiological findings’, 266(1). doi: 10.1016/j.heares.2009.09.012.
Mitrović, D., Zeppelzauer, M. and Breiteneder, C. (2010) Features for Content-Based Audio Retrieval. Elsevier Science & Technology (Advances In Computers). doi: 10.1016/S00652458(10)78003-7.
Olukanmi, P. O., Nelwamondo, F. and Marwala, T. (2018) ‘k-Means-Lite: Real Time Clustering for Large Datasets’, in. IEEE (2018 5th International Conference on Soft Computing & Machine Intelligence (ISCMI)). doi: 10.1109/ISCMI.2018.8703210.
Picart, B., Brognaux, S. and Dupont, S. (2015) ‘Analysis and Automatic Recognition of Human Beatbox sounds: A Comparative Study’, in. IEEE (2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)), pp. 4255–4259. doi: 10.1109/ICASSP.2015.7178773.
Shutaywi, M. and Kachouie, N. N. (2021) ‘Silhouette Analysis for Performance Evaluation in Machine Learning with Applications to Clustering’, 23(6). doi: 10.3390/e23060759.
Sinha, A. and Soni, H. (2021) ‘Segmentation and Classification of Beatboxing Acoustic Voice Tract Variations in MRI through Image Processing Technique’. MDPI AG. doi: 10.20944/preprints202105.0127.v1.
Somashekara, M. T. and Manjunatha, D. (2014) ‘Performance Evaluation of Spectral Clustering Algorithm using Various Clustering Validity Indices’, 5(6).
Stowell, D. (2010) Making Music Through Real-time Voice Timbre Analysis: Machine Learning and Timbral Control. Queen Mary University of London.
Stowell, D. and Plumbley, M. D. (2008) ‘Characteristics of the beatboxing vocal style’.
Stowell, D. and Plumbley, M. D. (2010) ‘Delayed Decision-making in Real-time Beatbox Percussion Classification’, 39(3). doi: 10.1080/09298215.2010.512979.
Sunu, J. and Percus, A. G. (2018) ‘Dimensionality Reduction for Acoustic Vehicle Classification with Spectral Embedding’, in. IEEE (2018 IEEE 15th International Conference on Networking, Sensing and Control (ICNSC)), pp. 1–5. doi: 10.1109/ICNSC.2018.8361290.
Syakur, M. A. et al. (2018) ‘Integration K-Means Clustering Method and Elbow Method for Identification of The Best Customer Profile Cluster’, 336(1). doi: 10.1088/1757-899X/336/1/012017.
Tzanetakis, G. and Kapur, A. (2004) ‘Query-By-Beat-Boxing: Music Retrieval for The DJ’. Zenodo. doi: 10.5281/zenodo.1418032.
Umesh, S., Cohen, L. and Nelson, D. (2002) ‘Frequency Warping and the Mel Scale’, 9(3). doi: 10.1109/97.995829.
Vassilvitskii, S. and Arthur, D. (2007) ‘k-means++: The Advantages of Careful Seeding’, in. Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms. doi: 10.1145/1283383.1283494.
Velardo, V 2021, ‘Beyond the Code’, The Audio Programmer Virtual Meetup. Available from: https://www.youtube.com/watch?v=mlRXBzFwQEs [14 September 2021]
Winursito, A., Hidayat, R. and Bejo, A. (2018) ‘Improvement of MFCC feature extraction accuracy using PCA in Indonesian speech recognition’, in. IEEE (International Conference on Information and Communications Technology (ICOIACT)). doi: 10.1109/ICOIACT.2018.8350748.
Appendix
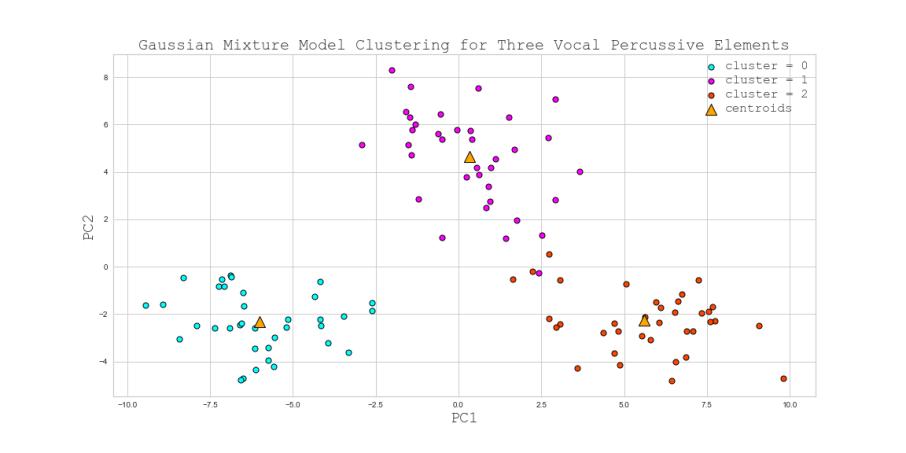
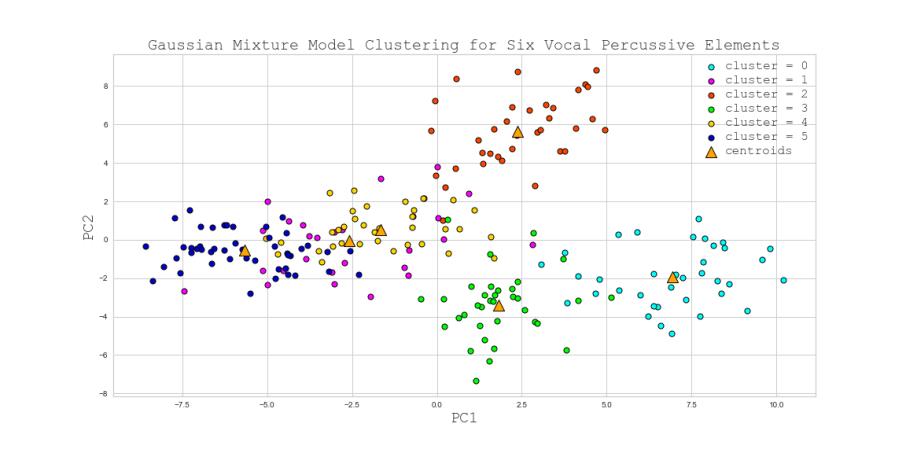
I. Baseline/Control








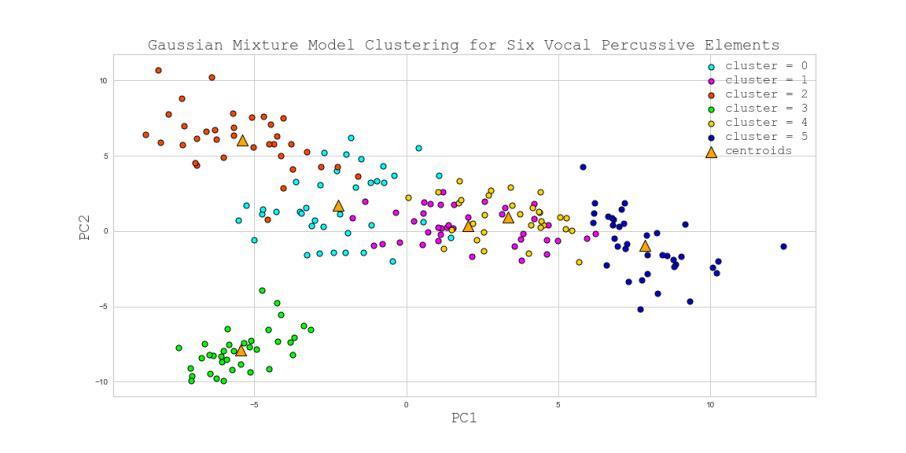
II. Low Latency






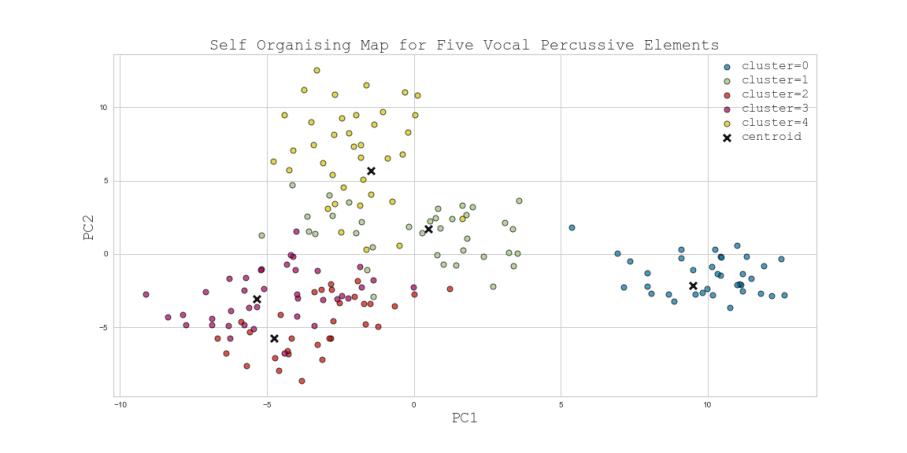
III. Ultra-Low Latency