
9 minute read
A deep dive into DRL


Gadi Briskman, Modcon Systems, UK, explains how to safely deploy Deep Reinforcement Learning (DRL) for process control, via integration with online analysers.
The drive towards sustainability, together with the volatile price of raw materials and the current competitive environment, present a growing challenge for the processing industry. Finding a narrow path, allowing the players in the industry to maintain profitability while complying with the tightening environmental regulations, requires the adoption of modern manufacturing techniques. Analytical equipment, allowing for the ongoing understanding of the process state, together with an optimising control solution that leverages this knowledge to find the most appropriate settings of the process in real time, plays a significant role in these techniques.
This article demonstrates how the use of Deep Reinforcement Learning (DRL) technology, coupled with the deployment of online analysers, offers an effective solution for a implementing an optimisation system.
The application of machine learning (ML) technologies has facilitated the achievement of high precision in process modelling, while allowing for low computational delay and lower maintenance overhead in comparison to legacy approaches. Precise modelling of the process is necessary for fully exploiting the optimisation potential that exists in its present state. The design of the real-time optimisation system, most suitable for leveraging the advantages of the process digital twins implemented using the tools of ML, should take into account the potential challenges inherent to this modelling paradigm – and avoid them.
As the essence of ML is learning the dependencies between the parameters of interest from the historical data of the process, one possible challenge is maintaining the quality of the prediction as the optimisation algorithm moves into evaluating the states of the process that are not present in historical data. While the predictive models allow for interpolation and extrapolation of the known states to the ones not present in the data used for the model training, the quality of the prediction will degrade as the distance from the known state increases. The existence of process states for which the training data allows for the derivation of no reliable prediction is the first challenge that the optimisation solution has to deal with.
The second challenge is the often highly non-linear nature of the real processes as it is reflected in the dependencies

between the process parameters of the digital twin. This non-linear nature of the dependencies between the process variables, especially when modelling the relationships between dozens of process variables trained on historical process data, may create local sub-optimal minima in the vicinity of a much better solution. Finding the true minima may be complicated when the optimisation problem is solved in real time, thus imposing calculation time constraints. Avoiding sub-optimal solutions becomes even more challenging with the shift from a single unit optimisation to optimising a chain of technological units.
The DRL technology as a basis for optimising control function implementation can serve as a viable alternative for calculating the optimal process setpoints in real time. Reinforcement Learning (RL) is a training approach in ML, inspired by how living organisms learn to interact with the world. RL learns the most suitable action for the present state of the environment by taking a sequence of actions, observing the reward, and adapting the next actions – in a way increasing the reward. DRL is an implementation of RL that uses a neural network to model the control law as it evolves during the training process. The DRL optimising controller produces the most effective action for the controlled object, while taking as a parameter the list of variables necessary to determine this action. In the context of process optimisation, the training involves adjusting the manipulated variables (MVs) and observing the rewards, mainly depending on the values of the controlled variables (CVs) of the process. The optimal policy should generate the optimal set of MVs for any technologically-relevant combination of disturbance variables (DVs).
While the DRL can be trained by directly interacting with the optimised process, this approach is hardly practical, as applying unvalidated actions to a real process can result in damage to the equipment and other unintended consequences. This is why it is more practical to train the DRL on the digital twin of the process, and deploy the controller to a live system only when it is already trained and validated on the digital twin. Training the DRL control policy in an offline simulation removes the long calculation time constraints involved in solving the process optimisation problem in real time.
Training the DRL in simulation involves evaluating a large number of control signal options for the present state of the process, and observing the corresponding reward that is collected by following the current version of the control law, which is generated by the DRL. The DRL is gradually tuned to generate process control parameters that maximise the reward. This approach, when compared to solving an optimisation problem to find the optimal process control parameters in real time, allows for the avoidance of sub-optimal minima. It makes DRL a more consistent and computationally-stable way to control non-linear processes than real-time optimisation approaches, such as non-linear Model Predictive Control (MPC).
While the digital twin emulates the real process, its predictions are reliable in the vicinity of historically-visited process states present in the data used for its training. In practice, the historical data of a life process is likely to contain a limited set of process states. These can be states convenient for the human operator. Alternatively, these are the states that the legacy Advanced Process Control (APC) system, guiding the process routinely, steers the process through. As the ML algorithm tries to predict the behaviour of the process significantly deviating from that known to it historical states, the prediction error will increase. If the set of process states that the DRL controller may guide the process through – as a result of implementing the control law it iteratively converges to – is not constrained, there is a danger of visiting states for which the digital twin prediction is not reliable.
Imposing constraints on the admissible states during DRL learning is a well-researched area in RL. Its origins are in the

Figure 1. Steps for safe DRL deployment.
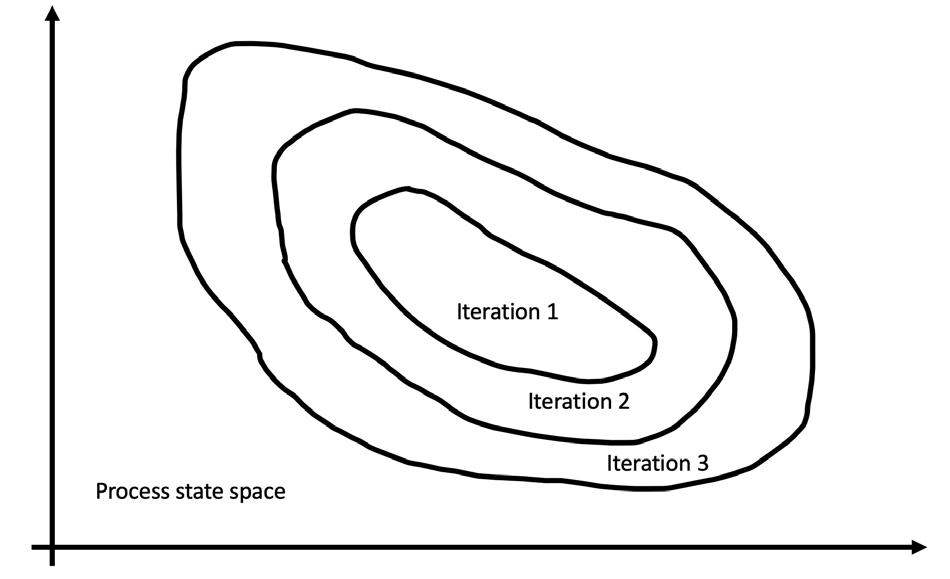
Figure 2. The gradual expansion of admissible process states.
Figure 3. Training the digital twin by online analysers.

area of robotics, where the objective was training a robot without causing it mechanical damage. The fruits of this research are applicable to using DRL in process control. In evaluating the reward accrued by following the DRL control law, the reward collected from the states that are remote from the historically-visited ones is penalised.
The successful and safe deployment of a DRL-based, real-time process optimisation solution will involve cyclically repeating the three steps, as depicted in Figure 1. In the first step, the current version of the DRL control law is applied to steer the live process. Under this updated control policy, over time the process will visit new states not visited under the previous versions of the controller, as shown in Figure 2. In the second step, online analysers are installed on the inbound and outbound flows of each of the units within the optimised technological chain to precisely capture the new aspects of the process dynamics. In the third step, the newly-captured historical process data is used to further update the digital twins of each of the optimised units.
As the DRL controller takes the state of the process as an input and produces the appropriate process control signal as an output, a decision needs to be made with regards to which elements of the process data should be incorporated into formulation of the state for each process. In process control, the control signals are the MVs that are periodically applied to the controlled unit. For example, when dealing with a technological unit that gradually responds to a change in MVs, a relevant number of the MVs produced by the DRL in a number of the previous iterations may need to be incorporated into the state vector.
This is analogous to considering a series of historic values of the MVs when calculating the next one in a traditional MPC multivariate control algorithm. The selection of the parameters constituting the DRL state will require the corresponding choice of the digital twin parameters. If the real process responds gradually to a change in MVs, the digital twin should allow an operator to take a series of historic values of the MV over a certain time horizon as a parameter, to allow for the training of the DRL in simulation.
Conclusion
Predictable behaviour and safety are the important factors in deciding on an APC solution. This article has shown that DRL technology allows for a scalable optimising control solution, without compromising the fidelity of the process modelling. For the processes modelled by the digital twins, based on ML/AI technology, safe deployment of DRL entails the gradual expansion of the range of permitted process states that the DRL controller can guide the process through. Online analysers are an important part of implementing this approach, as they capture the additional blocks of historical data used to update the digital twin with the process dynamics in the new states visited by the process, as depicted in Figure 3.



OPEN FOR REGISTRATION
Register today to take advantage of pre-conference discount by visiting: https://opportunitycrudes.com/registration22.php
Hydrocarbon Publishing Co. is inviting you to attend the 8th Opportunity Crudes Conference, which will be held in person (in Houston, Texas, US) and virtually (via Zoom) during October 24-26.
Please visit https://opportunitycrudes.com/ to learn more about this 2½-day meeting, which is centered on the theme:
Refining in Transition: from Vision to Execution amid Crude Disruptions
We have assembled over 20 excellent oil industry strategists and technology experts for our upcoming meeting to tackle the unprecedented challenges facing the crude market and the refining world that have been caused by Russia's invasion of Ukraine and the growing calls for decarbonization. As shown in the agenda (https://opportunitycrudes.com/?topics=conf&subtopics=agenda), the conference consists of five core sessions to look at changing crudes for sustainability.
1. Outlooks and insights of shifting global oil supply and demand in uncertain times amid the energy transition
2. Crude selection and trading: favoring low-carbon-intensity crudes
3. Crude management to improve feed quality and to aid in refinery decarbonization
4. Refiners' flexibility to process changing crudes and to meet product shortfalls
5. Refining process and catalyst innovations, biofuel production, and Internet of Things (IoT) technologies for
fuel transformations
Our meetings are known for providing a stimulating atmosphere for exchanging ideas, reconnecting, networking, and socializing with your colleagues over meals and receptions as well as productive discussions in townhall meetings.
This conference is coordinated with the Crude Oil Quality Association's (www.coqa-inc.org) Oct. 26-27 event which will focus on the challenges and opportunities in upstream and midstream businesses because of crudequality matters related to current shifts in global procurements and increasing exports of US oil abroad. So, come to join us at this special Opportunity Crudes-COQA summit!
Sponsored By: Media Partners:
Hosted By:
Hydrocarbon Publishing Company
Translating Knowledge into Profitability® Frazer, PA (US), 1-610-408-0117, info@hydrocarbonpublishing.com








