
Temporal Reasoning Graph for Activity Recognition
Sonali Chandole, Sajay Pingat
ABSTRACT: In this work, we expect to resolve the issue of human cooperation acknowledgment in recordings by investigating the long haul between related elements among various people. As of late, Long Short Term Memory (LSTM) has gotten a well known decision to display singular dynamic for single individual activity acknowledgment because of its capacitytocatch the transient movement data in a reach. In any case, most existing LSTM based techniques center just on catching the elements of human collaboration by basically consolidating all elements of people or demonstrating them in general. Such strategies disregard the between related elements of how human cooperation’s change after some time. To this end, we propose a novel various leveled Long Short Term Concurrent Memory (H LSTCM) to model the drawn out between related elements among a gathering of people for perceiving human connections. In particular, we first feed every individual's Static highlights into a Single Person LSTM to show the single individual dynamic. Consequently, at one time step, the yields of all Single Person LSTM units are taken care of into a novel Concurrent LSTM (Co LSTM) unit, which predominantly comprises of numerous sub memory units, another cell door, furthermore, another co memory cell. In the Co LSTM unit, each sub memory unit stores singular movement data, while this Co LSTM unit specifically coordinates and stores between related movement data between different communicating people from various sub memoryunitsbymeansofthecelldoorandco memorycell, individually. Broad investigations on a few public datasets approve the viability of the proposed H LSTCM by contrastingagainststandardandcuttingedge strategies.
KEYWORDS: Convolutional neural networks (CNNs), LSTM,Humanactivity
I. INTRODUCTION

1.1 Background
HUMAN communications (e.g. hand shaking, and talking) arerunofthemillhumanexercisesthathappenoutinthe open places and are pulling in significant consideration fromspecialists.Ahumancollaborationgenerallyincludes inanyeventtwoindividualelementsfromvariouspeople,
whoaresimultaneouslybetweenrelatedwithoneanother (e.g., a few people are talking together, a few people are handshaking with one another). Much of the time of human communication, the simultaneous interrelated elements between various people are unequivocally connecting (e.g., individual A kicks individual B, while individual B withdraws back). It has been shown that the simultaneous between related elements among various people, instead of single individual elements, can contribute discriminative data for perceiving human communications.
Having described the available data and the possible difficulties, we can now renew the questions to investigate in this project. First and foremost, we are interested in seeing if we can predict the criminal incidents, perhaps for a specific type of crime, for a small time frame and geographic region. Second, we are interested in learning which features have the most predictive power with respect to crime. Having an understanding of driving factors, cities can better work to mitigatetheriskfactorsforcrime.
In human associations, exercises have a hidden purpose. Thisreasoncanbetoachieveanobjective,ortorespondto some improvement. Both of these boundaries are governed by the climate of the people, which directs the logicalcomponentsinthescene.Sincethisenvironmentis shared by all people present in the scene, it is frequently the situation that the activities of people are interdependent and some coherency between these activities may exist. We call such exercises "aggregate". Instances of aggregate exercises are: Crossing the street, Talking,Waiting,Queuing,Walking,DancingandJogging.
1.2 Motivation
Inhumanassociations,exerciseshaveahidden purpose.Thisreasoncanbetoachievean objective,ortorespondtosomeimprovement.
Both of these boundaries are governed by the climate of the people, which directs the logical componentsinthescene.
Department of Computer Engineering, Smt. Kashibai Navale College of Engineering, Pune, India
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Activity recognition in videos has attracted increasing interest recently. An activity can be defined as a certain spatial and temporal pattern involving the movements of a single or multiple actors.
1.3 Objectives
To develop a system that recommends an appropriate human activity based to its users basedonthelengthyvideos.
Itfulfillsthehuman activity baseditsvideoof the user by taking various inputs and generating the menuaccordingly.
1]TocollectDatasetsofactivityvideos.
2]ImplementationofCNNalgorithm
3]ValidationofProposedAlgorithm
II. LITERATURE SURVEY:
The paper is written by. Kong, Y. Jia et al. [1] to comprehendhumantohumanmanagingprecisely,human collaboration acknowledgment (HIR) frameworks require strong component extraction and choice strategies dependent on vision sensors. In this paper, we have proposed WHITE STAG model to astutely follow human cooperation’s utilizing space time strategies just as shape based precise mathematical consecutive methodologies over full body outlines and skeleton joints, separately. After highlight extraction, include space is diminished by utilizing codebook age and direct discriminant investigation(LDA).Atlong last,partslidingperceptronis utilized to perceive various classes of human connections. The proposed WHITE STAG model is approved utilizing two openly accessible RGB datasets and one self clarified power intuitive dataset as oddity. For assessment, four examinationsareperformedutilizingforget aboutoneand cross approval testing plans. Our WHITE STAG model and bitslidingperceptronbeatthecurrentnotablemeasurable best in class strategies by accomplishing a weighted normal acknowledgment pace of 87.48% more than UT Interaction, 87.5% more than BIT Interaction and 85.7% over proposed IM IntensityInteractive7 datasets. The proposed framework ought to be pertinent to different sight and sound substance and security applications like reconnaissance frameworks, video based learning, clinical futurists,administrationrobots,andintelligentgaming
X. Chang, W. S. Zheng et al. [2] stated that present a framework for the recognition of collective human
Volume: 09 Issue: 04 | Apr 2022 www.irjet.net p ISSN:2395 0072 ISO 9001:2008
activities. A collective activity is defined or reinforced by the existence of coherent behavior of individuals in time and space. We call such coherent behavior ‘Crowd Context’. Examplesofcollectiveactivitiesare“queuingina line”or“talking”. Following[7],weproposeto recognize collectiveactivitiesusingthecrowdcontextandintroduce anewschemeforlearningitautomatically. Ourschemeis constructed upon a Random Forest structure which randomlysamplesvariablevolumespatiotemporalregions to pick the most discriminating at tributes for classification. Unlike previous approaches, our algorithm automatically finds the optimal configuration of spatiotemporal bins, over which to sample the evidence, by randomization. This enables a methodology for modelling crowd context. We employ a 3D Markov Random Field to regularize the classification and localize collective activities in the scene. We demonstrate the flexibility and scalability of the proposed framework in a number of experiments and show that our method outperforms state of the art action classification techniques.
Y.KongandY.Fuetal.[3]proposedthattheAuthorIndex contains the primary entry for each item, listed under the first author’s name. The primary entry includes the co authors’names,thetitleofthepaperorotheritem,andits location, specified by the publication abbreviation, year, month, and inclusive pagination. The Subject Index contains entries describing theitem underall appropriate subject headings, plus the first author’s name, the publication abbreviation, month, and year, and inclusive pages. Note that the item title is found only under the primaryentryintheAuthorIndex.
Y. Zhang, X. Liu et al. [4] stated that the local feature based approaches have become popular for activity recognition. A local feature captures the local movement and appearance of a local region in a video, and thus can be ambiguous; e.g., it cannot tell whether a movement is from a person’s hand or foot, when the camera is far away from the person. To better distinguish different types of activities, people have proposed using the combination of local features to encode the relationships of local movements. Due to the computation limit, previous work only creates a combination from neighboring features in space and/or time. In this paper, we propose an approach that efficiently identifies both local and long range motion interactions; taking the “push” activity as an example, our approach can capture the combination of the hand movement of one person and the foot response of another person, the local features of which are both spatially and temporally far away from each other. Our computational complexity is
in linear time to the number of local features in a video. The extensive experiments show that our approach is generically effective for recognizing a wide variety of activities and activities spanning a long term, compared toanumberofstate of the artmethods.
J. Donahue, L. Anne Hendricks et al. [5] proposed that the models based on deep convolutional networks have dominated recent image interpretation tasks; we investigate whether models which are also recurrent, or "temporally deep", are effective for tasks involving sequences, visual and otherwise. We develop a novel recurrent convolutional architecture suitable for large scale visual learning which is end to end trainable, and demonstrate the value of these models on benchmark video recognition tasks, image description and retrieval problems, and video narration challenges. In contrast to current models which assume a fixed spatio temporal receptivefieldorsimpletemporalaveragingforsequential processing, recurrent convolutional models are "doubly deep"' in that they can be compositional in spatial and temporal "layers". Such models may have advantages whentargetconceptsarecomplexand/ortrainingdataare limited.Learninglong termdependenciesispossiblewhen nonlinearities are incorporated into the network state updates.Long termRNNmodelsareappealinginthatthey directlycanmapvariable lengthinputs(e.g.,videoframes) tovariablelength outputs(e.g., natural languagetext)and can model complex temporal dynamics; yet they can be optimizedwithbackpropagation.Ourrecurrentlong term models are directly connected to modern visual convent models and can be jointly trained to simultaneously learn temporal dynamics and convolutional perceptual representations. Our results show such models have distinct advantages over state of the art models for recognition or generation which are separately defined and/oroptimized.
Q.Ke,M.Bennamoun,S.An,etal.[6]statedthatthehuman interaction prediction, i.e., the recognition of an ongoing interaction activity before it is completely executed, has a wide range of applications such as human robot interactionandthepreventionofdangerousevents.Dueto the large variations in appearance and the evolution of scenes, interaction prediction at an early stage is a challengingtask.Inthispaper,anovelstructuralfeatureis exploited as a complement together with the spatial and temporal information to improve the performance of interaction prediction. The proposed structural feature is captured by Long Short Term Memory (LSTM) networks, which process the global and local features associated to each frame and each optical flow image. A new ranking score fusion method is then introduced to combine the
spatial, temporal and structural models. Experimental results demonstrate that the proposed method outperforms state of the art methods for human interaction prediction on the BIT Interaction, the TV HumanInteractionandtheUT Interactiondatasets.
X.Shu,J.Tang,G. J.Qi,etal.[7]proposedthattherecently, Long Short Term Memory (LSTM) has become a popular choice to model individual dynamics for single person action recognition due to its ability of modeling the temporal information in various ranges of dynamic contexts. However, existing RNN models only focus on capturing the temporal dynamics of the person person interactionsbynaivelycombiningtheactivitydynamicsof individualsormodelingthemasawhole. Thisneglectsthe inter related dynamics of how person person interactions change over time. To this end, we propose a novel Concurrence Aware Long Short Term Sub Memories (Co LSTSM) to model the long term inter related dynamics between two interacting people on the bounding boxes covering people. Specifically, for each frame, two sub memoryunitsstoreindividualmotioninformation,whilea concurrent LSTM unit selectively integrates and stores inter related motion information between interacting people from these two sub memory units via a new co memory cell. Experimental results on the BIT and UT datasetsshowthesuperiorityofCo LSTSMcomparedwith thestate of the artmethods.
III. PROPOSED SYSTEM ARCHITECTURE: Methodology: Proposed Architecture
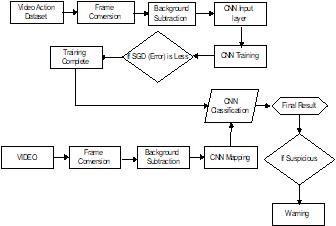
Humanactivityrecognitionhasbeenaveryactiveresearch topicinthepasttwodecadesforitsapplicationsinvarious fields such as health, remote monitoring, gaming, security and surveillance, and human computer interaction. Activity recognition can be defined as the ability to recognize/detect current activity on the basis of information received from different sensors. These sensors can be cameras, wearable sensors, or sensors attached to objects of the daily use or deployed in the environment. With the advancements in technology and thereductionindevicecosts,theloggingofdaily activities hasbecomeverypopularandpractical.Peoplearelogging their daily life activities, such as cooking, eating, sleeping, or watching TV. To capture these activities, different approacheshavebeenused.
In this work we present a neural network model which combines convolutional neural networks and backgroundSubtraction.Wefirstevaluatetheeffectofthe convolutional network used for understanding static frames on action recognition.Our method uses the technique known as CNN to automatically detect the actions an in order to maximize its activity recognition accuracy.
Proposed system steps mention below:
Backwardelimination.
Step5:Modeltesting
Applytestingdatasettopredictivemodel. Evaluate model comparing predicted value on exactvalue.
2. Algorithms
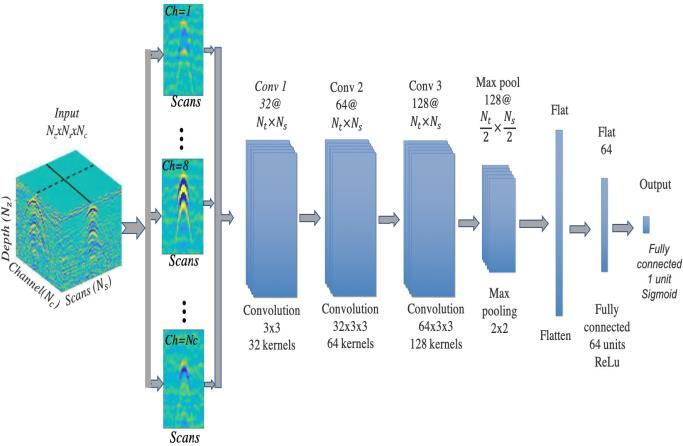
Convolutional Neural Networks (CNN)
Convolutional Neural Networks (which are additionally called CNN/ConvNets) are a kind of Artificial Neural Networksthatareknowntobetremendouslystronginthe fieldofdistinguishingproofjustaspictureorder.
Four main operations in the Convolutional Neural Networksareshownasfollows:
Fig. CNN Architecture
(i) Convolution
TheprincipleutilizationoftheConvolutionactivityifthere should be an occurrence of a CNN is to recognize fitting highlights from the picture which goes about as a contribution to the primary layer. Convolution keeps up the spatial interrelation of the pixels this is finished by fulfillmentofpicturehighlightsutilizingminisculesquares ofthepicture.Convolution equation.Everypictureisseen as a network of pixels, each having its own worth. Pixel is thelittlestunitinthispicturegrid.Allowustotakea 5by 5(5*5) framework whose qualities are just in twofold (for example 0 or 1), for better agreement. It is to be noticed that pictures are by and large RGB with upsides of the pixelsgoingfrom0 255i.e256pixels.
(ii) ReLU
ReLU follows up on a rudimentary level. All in all, it is an activitywhichisappliedperpixelandoverrideseveryone of the non positive upsides of every pixel in the componentmapbynothing.
(iii) Pooling or sub-sampling
Spatial Pooling which is likewise called subsampling or down sampling helps in lessening the elements of each element map yet even at the same time, holds the most importantdataoftheguide.Subsequenttopoolingisdone, inthelongrunour3D elementmapischangedovertoone dimensionalcomponentvector.
(iv) Fully Connected layer
Theyieldfromtheconvolutionandpoolingactivitiesgives noticeablehighlights whichareremovedfrom thepicture. These highlights are then used by Fully Connected layer for consigning the info picture into various classes predicatedonthepreparationdataset.
IV. CONCLUSION:
In this work, a wide range of strategies needs to investigate in machine Learning and artificial intelligence tailored for human behavior. In this report, we are proposed a new model based on CNN for human activity identification. First, extract the most important features and use a linear combination of these features to identify important feature vector. In this step, we choose a new feature extraction method based on the characteristics of news video using neural network. With this system we provideauser friendlyapplicationthat coversaspectslike nameofthatnewspaper.Usingthechallengingdatabasein which the newspapers are taken. At the front end, i.e. the UserInterface,theinputwillbethenewspaperbytheuser. We observe that the image representation from CNN significantly outperforms Traditional Method. This shows thata goodrepresentation ofstaticimages isessential for good video classification. From related works we can conclude that CNN is a good motion feature and captures temporalinformationthatenablesactionrecognition.
REFERENCES:
[1]Y.Kong,Y.Jia,andY.Fu,“Interactivephrases:Semantic descriptionsforhumaninteractionrecognition,”
[2] . S. Zheng, and J. Zhang, “Learning person person interactionincollectiveactivityrecognition,”
[3] Y. Kong, Y. Jia, and Y. Fu, “Learning human interaction byinteractivephrases,”
[4]Y.Zhang, X. Liu,M. Chang,W.Ge,andT. Chen, “Spatio temporalphrasesforactivityrecognition,”inECCV,2012.
[5] Donahue, L. Anne Hendricks, S. Guadarrama, M. Rohrbach,S.Venugopalan,K.Saenko,andT.Darrell,“Long term recurrent convolutional networks for visual recognitionanddescription,”
[6] B. Clarkson, A. Pentland, and K. Mase, “Recognizing user context via wearable sensors,” in Int’l Symp. on WearableComputers(ISWC2000),2000,pp.69 75.
[7] T. Maekawa, Y. Yanagisawa, Y. Kishino, K. Ishiguro, K. Kamei, Y. Sakurai, and T. Okadome, “Object based activity recognition with heterogeneous sensors on wrist,” in Pervasive2010,2010,pp.246 264.
[8] H. Pirsiavash and D. Ramanan, “Detecting activities of daily living in first person camera views,” in CVPR 2012, 2012,pp.2847 2854.
[9]M.Ma,H.Fan,andK.M.Kitani,“Goingdeeperintofirst person activity Recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016,pp.1894 1903.
[10]S.Singh,C.Arora,andC.Jawahar,“Firstpersonaction recognition using deep learned descriptors,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR),2016,pp.2620 2628.
[11] M. Vieira, D. R. Faria, and U. Nunes, “Real time application for monitoring human daily activity and risk situations in robot assisted living,” in Robot 2015: Second IberianRoboticsConference.Springer,2016,pp.449 461.