
Disease Prediction System using Machine Learning
Dhiraj Parikarma Gupta Kishin Fatnani1Undergraduate student, Thadomal Shahani Engineering College, Mumbai, India
2 Undergraduate student, Thadomal Shahani Engineering College, Mumbai, India
Abstract - With the change in lifestyle of people, chronic diseases have become very common. And as peoplearegetting exposed to internet and gadgets, a large amount of data associated with their health is generated each day. With the evolution of machine learning algorithm this data canbe used to monitor the health and wellbeing of people. With this research we aim at providing a complete solution to assist people in avoiding any future health complications. Proposed model uses machine learning algorithms to predict the possibility of diseases namely Diabetes, Heart disease, Kidney disease, Liver disease and Cancer. Proposed model alsohelp to find the nearest medical facilities and maintainhealthrecords of patients. We ran various algorithms on each dataset and determined that Random Forest was the most accurate for Diabetes, with a score of 77.21%. Logistic regression performed the best for heart disease, withanaccuracyscoreof 90.25%. Similarly, Random Forest gave a recall score of 97% for liver disease, and Decision Tree proved to be the best for cancer with 98.62%. Random Forest provided an accuracy score of 96.45% for kidney disease.
Key Words: Chronic disease, Machine learning, Decision Tree Classifier, KNN, SVM, Random Forest Classifier, Data Mining,JavaScript,Flaskframework,MySQL,EDA.
1.INTRODUCTION
The covid 19 lockdown proved to be a nightmare for each one of us. None of us could get out of their homes, travel, or do anything at all.Even in medical emergencies, patientswereunabletoreachhospitalsowingtoa lackof transportation.Eveniftheycould,theywouldhavetotakea mandatorycovidtest,whichtookupasignificantamountof time for the patients and consequently delayed the procedureforwhichtheywerethere.Weencounteredalot of people who had their test results in hand but couldn't meet with the doctors. This is when we discovered the necessity for intelligent software that might address this problem using MachineLearning and allowing patients to findoutiftheyhadanillnessornotevenatmidnight.
To address this issue, we proposed our disease predictionsystem,inwhichwetaketestdatafrompatients andapplymachinelearningalgorithmstotheminorderto assisttheminterprettheirresults.Thefactthatmostpeople have access to internet 24/7 largely contributed in our solution. Our model now offers analysis for five diseases: liver disease, heart disease, diabetes, kidney disease, and
cancer. Our system examines several algorithms like N Nearest Neighbours, Support Vector Machine, Logistic Regression, Random Forest Classifier and Naïve Bayes classifierforeachmodelandselectsthebestmodelforeach ailment, as well as providing the findings. Along with the patients,oursoftwarecouldalsoproveusefulforthedoctors toconfirmtheiropinionswiththepreviousdatasets.This wouldalsoaidinanearlydetectionofthediseaseandcould improve the chances for recovery tremendously for the patient.Ourproposedsoftwarewouldalsoassistingivinga freeoptiontothosewhoareunabletovisitadoctordueto financialconstraints.
2. LITERATURE REVIEW

Inthispaper,Mr.SanthanaKrishnan.J&Dr.Deetha.S[1] have used 2 main machine learning algorithms namely decision tree algorithm and Naive Bayes algorithm. Using these algorithms, they predicted if a person has any heart diseaseornot.Thismodeluses13medicalattributesasinput andthengivestheresult.Theyhavecomparedtheaccuracy rate of the 2 classifiers (decision tree and naive Bayes classifier)and haveconcluded that the Decision treehasa higheraccuracyratewhichisof91%andtheaccuracyrateof NaiveBayesalgois87%.Tocalculatethisaccuracyratethey hadconsidered70%ofthedatasetasthetrainingsetandthe remaining30%wastakenasatestdataset.
Here,theyarepredictingifapersonishavinganyliver disease. The algorithms that they have used are KNN (K Nearest Neighbour) and CNN (Convolutional Neural Network). Theaccuracy ratethat they havegot for CNN is 98.4%andthatforKNNis91%.[2]
Inthispaper[3]theyarepredictingifapersonhasany kidneydiseaseornot.Ifthepersonhasakidneydiseasethey wouldclassifythediseaseintostagesanddependingonwhat stagethepatientisatandlookingatthepatient'spotassium level,theywillprovideabalanceddietscheduleforhim/her.
In2016, Priyanka Sonar & Prof. K. JayaMalini [4] performed an examination to determine whether or not a personhaddiabetes.Theycompared11testattributesfrom the person's test report and used machine learning algorithmssuchasthedecisiontreeclassifier,SupportVector confusionSupportclassifierandLogisticRegression.Outofthesealgorithms,theVectorClassifierwasmoreaccurateto82%andmatrixwasusedtoevaluatethemodel.
In2017,DebadriDutta,DebpriyoPaul&Prof.Parthajeet Ghosh[5]performedtheexaminationtodeterminewhether or not a person had Cancer disease. They usedsupervised machine learning algorithms such as the Random Forest classifierandKNearestNeighboursclassifier.Outofthese algorithms,RandomForestClassifierwasmoreaccuratewith a Recall score of 89% and confusion matrix was used to evaluatethemodel.
KAshfaqAhmed,SultanAljahdali,NisarHundewale&K IshthaqAhmed[6]usedSupportVectorMachine(SVM)and random forest in their model to identify whether an individual has duke, breast or colon cancer. For them, the radialbasisfunctionprovedtobethebestwithSVMandin some cases, results were comparable with random forest gaveadependentdiseaseanusfolloweddiseasesupportDecisiontechnique.FatimaDilawarMulla&NaveenkumarJayakumar[7]usedtree,Bayesiannetwork,KNearestneighbourandvectormachinetoidentifyifapersonhasaheartornot.Intheirmodel,SVMhadthehighestaccuracybyKNN.ThehighestaccuracyofSVMwas84.33%.P.MokshaSriSai,G.Anuradha&VVNVPhanikumar[8]edKmean,KNNandSVMalgorithmstoidentifywhetherindividualhasdiabetesdiseaseornotandclassifiedtheintothecorrecttype.Theyclassifiednoninsulinandinsulindependentdiabetesandalsoprovidedbalanceddiet.Intheirmodel,thesupportvectormachinethebestaccuracyscoreof94%.
3. SYSTEM ARCHITECTURE
I. Algorithms used
a) K NearestNeighbours:
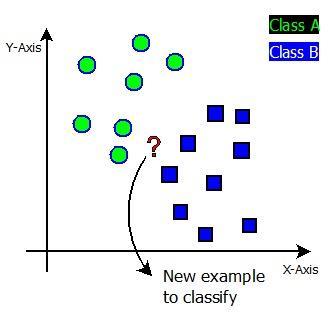
In K Nearest Neighbours(KNN), K is the number of nearest neighbours. Here the neighbours mean the output classificationclasses.IntheKNNalgorithm,thecore deciding factor is the number of neighbours. When the number of classesistwo,Kisusuallyanoddnumber,indicatingthatthe problemisabinaryclassificationproblem.Thealgorithmis knownasthenearestneighbouralgorithmwhenK=1.Weuse Hamming,Euclidean,Manhattan,andMinkowskidistanceto findthedistancebetweentwopoints.
ThestepsinvolvedinKNNare:
a.Calculatedistance
b.Findingtheclosestneighbouringpoint
c.Classifyingthedependentfeatureintoyesorno
Fig.1.K NearestNeighbour
b) LogisticRegression:

Forpredictingbinaryclasses,weusestatisticalmethods like logistic regression. The target variable or outcome is binary in nature which means that there are only two possible classes. It calculates the likelihood of an event occurring. It uses a sigmoid function, also called logistic function.ThesigmoidfunctiongeneratesanS shapedcurve which can be used to transform any real valued number between0and1.The ypredictedbecomes1whenthecurve reachespositiveinfinity,whileypredictedbecomes0when thecurvereachesnegativeinfinity.Wecanclassifytheresult as1orYESifthesigmoidfunctionoutputisgreaterthan0.5. Wecanclassifytheoutputofthesigmoidfunctionas0orNO if it is less than 0.5. Assuming that we are using Logistic Regression to determine whether or not a person has a diabetic illness,iftheoutputis0.75,wecanassumethata patient has a 75% risk of developing diabetes. The cost functionislimitedbetween0and1bythelogisticregression hypothesis.Asaresult,wecan'tjustrelyonlinearfunctions because they can have values more than 1 or less than 0, whichisn'tfeasibleaccordingtothelogisticregression.
LRhypothesisexpectation
Thesigmoidfunctioncomesintoplayatthispoint.The sigmoid function is used in machinelearning to transform anyrealnumberintoavaluebetween0and1.
Sigmoidfunctionformula
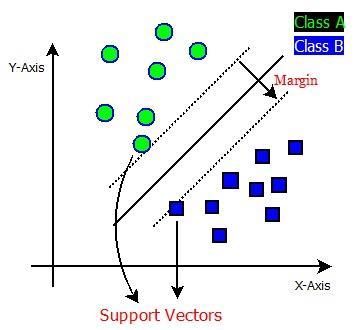
c) SupportVectorMachine:
AlthoughSVMsareclassifiedasclassificationtools,they can also be used to solve regression problems. Support vectors are the data points closest to the hyperplane. By
computing margins, these places will aid in defining the separationline.Thesepointsaremorerelevanttothedesign oftheMultipleclassifier.continuous and categorical variables can be handledwitheaseusingSVM.Todistinguishvariousclasses. In multidimensional space, SVM builds a hyperplane. The distancebetweenthetwolines ontheclasspointsthatare closesttoeachotherarecalledasMargins.Theperpendicular distanceiscalculatedusingthesupportvectors.
Entropy:Itmeasurestheimpurityinagivendataset.
Where,
n=totalnumberofsampleinthegivendatatset
P(yes)=probabilityof“yes”
P(no)=probabilityof“no”
Gini Index: Itmeasuresthepurityorimpurityoffeatures whilecreatingthedecisiontree.
Giniindexformula
e) RandomForestClassifier:
Fig.2.SupportVectorClassifier
d) DecisionTreeClassifier:
Adecisiontreeisaflowchart liketreestructurewithan internalnoderepresentingafeature(orattribute),abranch representingadecisionrule,andeachleafnoderepresenting the outcome. In a decision tree, the root node is the uppermostnode.Itlearnstopartitionbasedonanattribute's value.It partitionsthe tree recursively, which isknownas recursivepartitioning.Makingjudgmentsiseasierwiththis flowchart likeframework.It'sshownasaflowchartdiagram, which closely resembles how people think. As a result, decisiontreesareeasytounderstandanduse.
When we implement the decision tree algorithms, the biggesttaskisselectionofrootnode.So,tosolvethistaskwe haveatechniquecalledAttributeselectionmeasureorASM. TwopopulartechniquesforASMare:
a)InformationGain
b)GiniIndex
Information Gain: Itcalculatesthechangesinentropy afterthedatasethasbeensegmentedbyattribute.
It's technically a decision tree ensemble method based on a randomly divided dataset. A group of decision tree classifiers is referred to as the forest. An attribute selectionindicatorsuchasgainratio,informationgainorGini indexisusedtogenerateindividualdecisiontreesforeach attribute.Eachtreeisbuiltusingadifferentrandomsample. In a classification problem, each tree votes, and the top fewclassesarechosenasthefinalresult.Thefinaloutcomeof regressionistheaverageofalltreeoutputs.Itisbothsimpler and more powerful than previous non linear classification techniques.
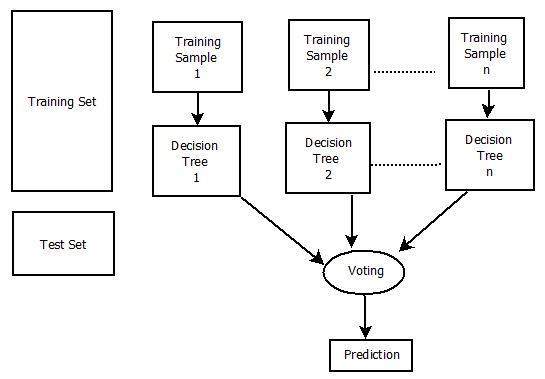
Fig.3.RandomForestClassifier
InformationGainFormula
Fig.4.ProposedModel
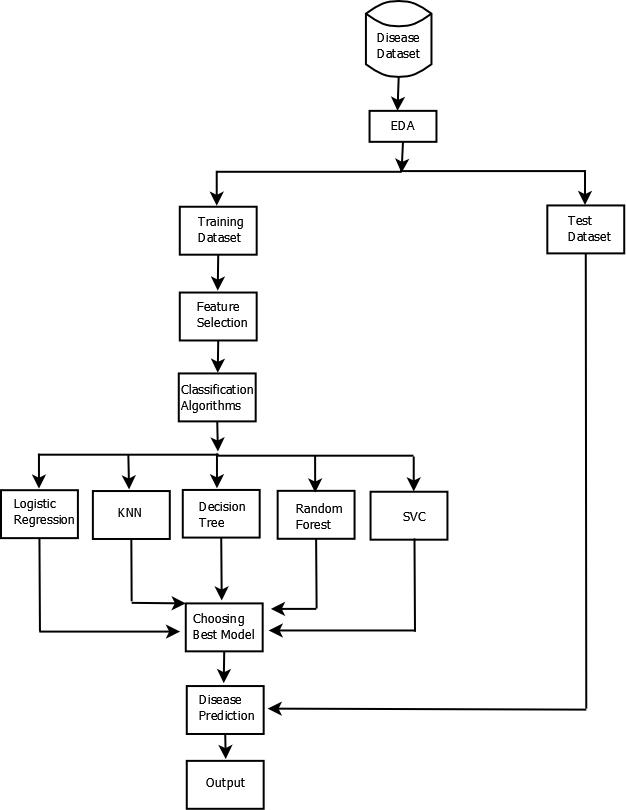
Forourproject,weexperimentedwithvariousalgorithms tobuildourpredictivemodel themostaccurate.Ourmain aim was to compare and figure out the most perfect predictivealgorithmforeachdiseaselikeDiabetesdisease, Cancer disease, Liver disease, Heart disease, and Kidney disease.ThefirstalgorithmthatweusedwasKNN.Next,we used Logistic Regression, followed by Support Vector Machines, Decision Tree Classifier, and Random Forest Classifier on every disease. The algorithms were implementedontheKaggleandUCIdatasets.Todeliveran accurateanddependableexperiencetoourconsumers,we havemadesurethatwecompareallalgorithmsandchoose thebestoneforeachconditioninourwebapp.
Weexperimentedwithfivedifferentalgorithmsonevery dataset. We have performed hyperparameter tuning and featurescalingoneverydatasetandoutofallthealgorithms, theonewiththehighestaccuracywaschosenbyusforthe prediction.Wepickledthebestmodelandthenwemadeour webappusingHTML,CSSandJavaScriptandintegratedthis pickled model with our web application using flask framework.Wemadetheuserinputformtotaketheinput fromtheuserbasedonhis/hertestreport.Foreachdisease, basedonthefeaturespresentinthatparticulardisease.We
createdAPIsforeachdiseasesothatwhentheusersubmits theform,wecanprocessthedataenteredbytheuserinthe backendusingthebest fitmodelforthatcondition.Thenwe showtheoutputonthescreenand thenforconfirmationwe alsoemailthetestresulttotheuseronhisregisteredemail address.Inour
proposedmodel,wehaveplannedtoincorporate variousfeatureslikerecommendingmedicineswhichcould givethepatientimmediaterelief.Theseincludesomebasic medicineslikeparacetamol,coughsyrup,etc.Alongwiththis, wealsoplantoincludesomehomeremedies.Wewouldalso recommend a suitable balanced diet which would aid in a fasterrecoveryofthepatient.Alistofdoctorsandlocation alongwithdirectionstothehospitalhasalsobeenaddedonto ourmodel.Inthenearfuture,wewouldalsobeabletocall thedoctorsorchatwiththemdirectlyonourapp.
4 RESULTS AND DISCUSSIONS
A) ExperimentalSetup
All of the experiments were run on a machine with an Intel core i7 processor,Windows 10(64 bit) with 16GB of RAM. For this project, we have usedHTML, CSSand JavaScriptforthefrontend.Forthebackend,wehaveused MySQL & flask framework.Along withthese, wehave also usedessentialtoolslikevscodeandjupyternotebook.
B) Comparisonresults&Analysis
WeDiabetescompared
fivedifferentalgorithmsnamelyGaussian Naïve Bayes, Logistic Regression, K Nearest Neighbour, SupportVectorClassifierandDecisionTreeforthediabetes disease.ForevaluationofthesemodelsweusedAccuracyand CV Scores. On comparing these scores for different algorithms,weconcludedthatKNNgavethehighestaccuracy of77.21%.WhileperformingtheEDA,therewerenonullor duplicatevaluesaswefetchedthepreprocesseddatasets[9] forthis
TheHeartdisease.heartdataset
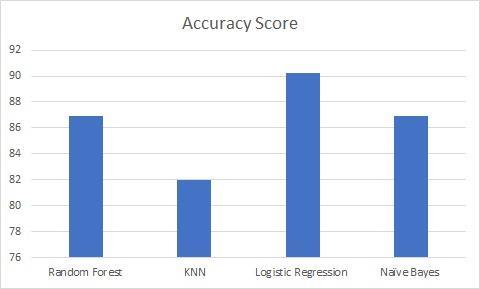
[10]thatwehaveusedcontained76 attributes but it did not seem meaningful to use all these featuressoweperformedanextratreeregressorclassifier functionandselectedthetop14featuresoutofitforafaster prediction.Oncomparingfouralgorithms,wefiguredthatthe LogisticRegressiongavethehighestaccuracyof90.25%.
SinceLiver
wesawariseinthecasesofliverdiseasesduetoan increase in consumption of alcohol, inhalation of harmful gasesandintakeofcontaminatedfood,wefounditnecessary forustoincludetheliverdiseasepredictionsystemonour software. The dataset that we used[11] for our prediction contained416recordsofliverpatientsand167recordsfor which the liver disease was not detected. We compared different algorithms using different evaluationcriteria like accuracyscore,precision,recallandf 1scoreandfoundthat RandomForestgavethebestpredictionforthisdiseasewith arecallscoreof97%.
InCancerthisdataset[12],
wehad32featuresand569patient records.Outofthese569records,357wereBenignand212 areMalignant.Weperformedexploratorydataanalysisand found that there were no null values in any record. While buildingthemodel,wealsoperformedExtratreeregression toexplorethemostimportantfeaturesfortheprediction.
ThisKidneydataset[13]
contains25featureslikeredbloodcell count,whitebloodcellcount,etc.Outofthe25featureswe onlychosethefirst7featuresasweobservedthattheother 18featureshadverylowimportance.Thisdatasethadalotof nullvalues.Wereplacedthenullvaluesbytakingthemodeof that feature. We performed OneHotEncoding on various features and encoded various categorical features with 0s and1s.Foranexample,weconvertedNotckdto0andckdto 1.Inthismodel,weobservedhatRandomforestperformed thebestwithanaccuracyscoreof96.45%.
REFERENCES
[1] Mr.Santhana Krishnan.J&Dr.Geetha.S,“Predictionof Heart disease usingmachinelearningalgorithms”
[2] Dhiraj Dahiwade, Prof. Gajanan Patle & Prof. Ektaa Meshram, “Designing Disease Prediction Model Using MachineLearningApproach”.
[3] AkashMaurya,RahulWable,RasikaShinde,SebinJohn, Rahul Jadhav & Dakshayani.R, “Chronic Kidney Disease Prediction and Recommendation of Suitable Diet plan by usingmachinelearning”.
[4] Mrs. Priyanka Sonar & Anjali K JayaMalini, “Diabetes PredictionUsingDifferentMachineLearningApproaches”.
[5] Mrs.DebadriDutta&DebpriyoPaul,“AnalysingFeature Importances for Diabetes Prediction using Machine Learning”.
[6] KAshfaqAhmed,SultanAljahdali,NisarHundewale&K Ishthaq Ahmed, “Cancer disease prediction with support vectormachineandrandomforestclassificationtechniques”.
[7] Fatima Dilawar Mulla & Naveenkumar Jayakumar, “A reviewofDataMining&MachineLearningapproachesfor identifying Risk Factor contributing to likelihood of cardiovasculardiseases”.
[8] P. Moksha Sri Sai, G. Anuradha, VVNV Phani kumar, “Survey on Type 2 Diabetes Prediction Using Machine Learning”.
[9] Diabetes dataset: https://www.kaggle.com/datasets/uciml/pima indians diabetes database
[10] Heart diseasehttps://www.kaggle.com/datasets/johnsmith88/heartdataset:dataset
[11] Liverdataset:https://www.kaggle.com/uciml/indian liver patient records
Fig.6.ExtraTreeClassifier
Decision Tree classifier outperformed all the other algorithms like SVC, KNN, LR and Random Forest with an accuracyof98.62percent.
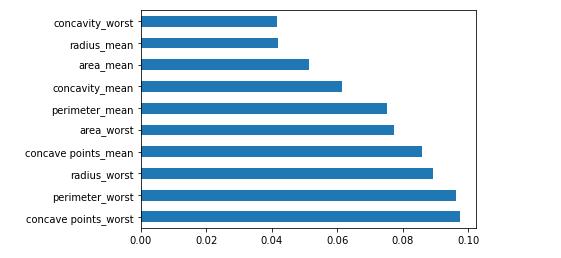
[12] Cancer dataset: https://www.kaggle.com/datasets/uciml/breast cancer wisconsin data
[13] Kidney https://www.kaggle.com/datasets/mansoordaku/ckdiseaseDataset:
Fig. HeartAccuracyScorecomparison