
1,2,3,4Student, Dept. of Computer Science and Engineering, Gokaraju Rangaraju Institute of Engineering and Technology, Hyderabad, Telangana, India
1. INTRODUCTION
Key Words: Fraud Detection, K Nearest Neighbors, Decision Tree, Random Forest, Extreme Gradient Boosting
p ISSN: 2395 0072 2022, IRJET Impact Factor value: 7.529 9001:2008
Venkat Dinesh Seetha1 , Srikanth Narabathoju2 , Gnaneshwar Bollam3 , Charan Pulipalupula4 , Y. Lakshmi Prasanna5
5Assistant professor, Dept. of Computer Science and Engineering, Gokaraju Rangaraju Institute of Engineering and Technology, Hyderabad, Telangana, India ***
Fraudulent Activities Detection in E-commerce Websites
©
eCommercefraudiswhenacriminalorfraudsterusesstolen paymentinformationtoconductonlinetransactionswithout theaccountowner'sknowledgeonaneCommerceplatform. Purchase fraud is another name for it. It may be accomplished through the use of a fraudulent identity, a stolencreditcard,forgedcardsandinformation,andfalse personalandcardinformation,amongothermethods.
Deeplearningisbeingutilisedtocreateafrauddetection modelthatworkssimilarlytoahumanneuralnetwork,with databeingcreatedinvariouslayersthataretiedtogetherfor theprocess,startingwiththeencoderatlayer1andending with the hinge decoder at layer 4. The Deep Learning approachiscomparedtootheralgorithmssuchastheHidden MarkovModelbytheresearcher(HMM)[2]
|
2. LITERATURE REVIEW
Volume: 09 Issue: 03 | Mar 2022 www.irjet.net
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056

The electronic buying and sale of goods via the Internet utilisingonlineservicesisknownase commerce.Electronic funds transfers, Mobile commerce, Internet marketing, supplychainmanagement,electronicdatainterchange(EDI), online transaction processing, automated data gathering systems, and inventory management systems are all examples of electronic commerce technologies Technologicalimprovementsinthesemiconductorindustry helpelectroniccommerce,whichisthedominantindustryof theelectronicssector.
Fraudoncreditcardsisatypeoffrauddetectionthathas evolved quickly. The fraud approach is discussed in many studies. The auto encoder and constrained Boltzmann machineisoneofthedeeplearningstudies[1].
Certified Journal | Page910
It goes without saying that the growth of the eCommerce industry, as well as the proliferation of payment methods like cards and online payment solutions, is linked to an increaseinfraud.
| ISO
Eventhoughotherservices,suchase mail,aresometimes utilised,e commercefrequentlyemploystheinternetforat least part of the transaction's life cycle. Purchases of productsorservicesareacommone commercetransaction. E commerceismadeupofthreetypes:onlineselling,online auctions, and electronic markets. Electronic commerce makese commercepossible.
Abstract In e commerce money is transferred through websites in the form of transaction. As the number of users in e commerce increases the numberoftransactionsmadebythe users also increases as well. The chances of the online transaction being fraud also increases. Through using machine learning, detection of fraud in e commerce can be developed. There are various number of machine learning algorithms such as Decision Trees, Random Forest. Analysis is done on these machine learning algorithms to find a suitable machine learning algorithm. The amount of money processed through transaction by users in e commerce can be large or small. The chances for the user engaging in fraudulent activities are very high. The fraudulent activities thatusercan engage are such as Use of stolen credit cards, money laundering, etc. Due to wide spread of e commerce in last years, there is a rapid increase in the online transactions by many numbers of users. There has also been a huge growth in the percentage of fraudulent transactions. Hence it necessary to develop and apply different techniques that can help in detecting fraud transactions.
According to the poll, eCommerce fraud has expanded rapidly in recent years, exceeding eCommerce sales by a factoroftwo.Thechargebackrateisincreasingatarateof morethan20%peryear.SinceFY17,thenumberofonline shoppingscamsreportedtotheNationalConsumerHelpline has nearly doubled, from 977 to 5,620 cases in FY20, bringing the total number of cases to 13,993. There are severalgroundsforfraudineCommercestores,tosaythe least. As everything gets digital and AI is employed, fraudsters are becoming more intelligent, creating new tactics,andbecomingmoresophisticatedwitheachpassing year.Withtoday'sadvancedtechnologies,stealingdataand purchasinginformationissimple.Theuseofinternetaliases makesidentifyingandapprehendingthecriminalharder.In comparison,acquiringevidenceandprosecutingcasesare subjecttolesstimeandresourceconstraints.Youmustusea high quality fraud detection and management system and includecreativeapproachesintoyourfirmtocombatfraud
4. A ball tree divides data recursively into nodes defined by a centroid C and radius r, with each node's point falling within the hyper sphere describedbyrandC.
Each excellent tree is integrated into one model via RandomForest.ArandomvalueofvectorisusedinRandom Forestwiththeequivalentdistributionsacrossalltrees,with amaximumdepthofeachdecisiontree.[7]
3.2.1 Ball Tree
International Research Journal of Engineering and Technology (IRJET)
Fig 1: SystemArchitecture
| ISO
Thestepsofthesystemarchitectureareasfollows:
p ISSN: 2395 0072 2022, IRJET Impact Factor value: 7.529 9001:2008
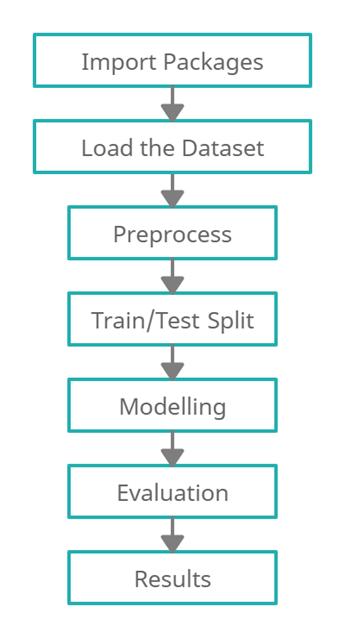
5. Buildthemodel,i.e.,trainit.
2. Classification is determined by a simple majority vote of each point's nearest neighbors: a query point is assigned to the data class with the most representatives among the point's nearest neighbors.
|
TheBallTreeAlgorithmcanbedescribedusingametrictree. Metric trees use the metric space in which the points are placedtoorganiseandarrangedatapoints.Pointsdon'thave tobefinite dimensionalorinvectorswhenusingmetrics.
6. Modelpredictionisusedtotestthemodel.
Machine learning was also used in the identification of credit card fraud [3] Decision Tree algorithms, Neural Networks,NaiveBayes,andRandomForestsareallexamples ofmachinelearningalgorithms.Becauseitissimpletouse, decisiontreesarecommonlyemployedinfrauddetection.A decisiontreeisahierarchicalortree structuredprediction model.Because
1. ImportofRequiredPackages.
3. 3.1METHODOLOGYProposedMethod
3. Thefeaturesinthedatasetshouldbenormalized.
3.2 K Nearest Neighbors
1. Neighbors based categorization is a sort of instance based learning, also known as non generalizinglearning,becauseitdoesn'ttrytobuild ageneralinternalmodel,insteadstoringinstances ofthetrainingdata.
©
Certified Journal | Page911
e ISSN: 2395 0056
Randomforestisalsousedincreditcardfrauddetection [6]
2. Takealookatthedataset.
Volume: 09 Issue: 03 | Mar 2022 www.irjet.net
7. Systemevaluation(accuracyscore,F1 score,etc.)
3. Aballtreeisadatastructurethatcanbeextremely efficient on highly organized data, even when the dimensionsareextremelylarge.
4. Train/TestSplitdividestheentiredatasetintotrain andtestdatasets.
Whenitcomestoidentifyingfraud,machinelearningisquite effective. A risk team is responsible for avoiding machine learningfraudonanywebsitewhereyouenteryourcredit card information. The influence of applying multiple techniquestoconductonlinetransactionfrauddetectionon the online shopping website, as well as the merchant and consumer,isdiscussedinthisstudy.Thetopaccuracyresults from the transaction dataset in e commerce will be comparedusingthismachinelearningapproach.
NaiveBayesisaclassificationbasedonstatistical andprobabilityapproaches,itisutilisedinfrauddetection credit cards. In real world situations, Naive Bayes is incrediblyquickandaccurate.Geneticalgorithmsareusedto decide the number of hidden layer topologies on neural networksforfrauddetectiononcreditcards[4]Thegenetic algorithmgeneratesthemostidealnumberofhiddenlayers withthegeneticalgorithm[5].
2. In random forest, each tree in the ensemble is constructed using a sample selected from the trainingsetwithreplacement.
1. Arandomforestismadeupofacollectionofbasic treepredictors.
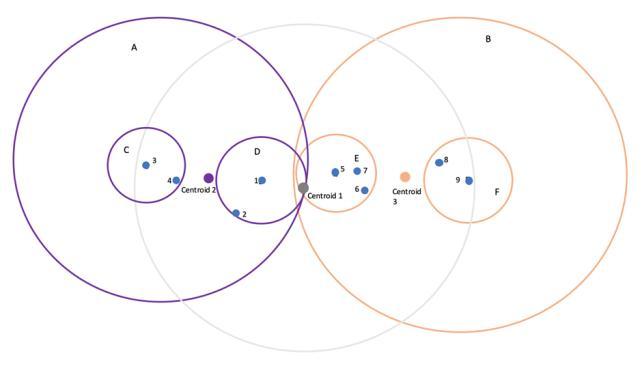
Ateachlevelofthetree,theoffspringarepickedtohavethe greatest possible spacing between them, often using the followingarchitecture.
Fig 2: BallTree
p ISSN: 2395 0072 2022, IRJET Impact Factor value: 7.529 9001:2008
e ISSN: 2395 0056
|
The centroid of the whole cloud of data points is first determined.Thecentreofthefirstclusterandchildnodeis chosenasthesitewiththegreatestdistancetothecentroid. Thesecondcluster'scentre ispickedasthe pointfurthest away from the previous cluster's centre. The node is then allocatedtoallotherdatapoints,andtheclusterisassigned totheclosestcentre,eithercluster1orcluster2.Eachpoint can only belong to one cluster. Although the sphere lines mightcross,thepointsmustbeunambiguouslyassignedto onecluster.Apointmustbeallocatedtooneclusterifitis exactly in the middle of both centres and has the same distancetobothsides.Unbalancedclustersarepossible.The BallTreeAlgorithmisbasedonthisfundamentalprinciple. Within each cluster, the procedure of separating the data points into two clusters/spheres is continued until a predetermined depth is attained. As a result, a layered clusterwithmoreandmorecirclesemerges.
3.3 Decision Tree
Balltreealgorithmgetsitsnamefromthecluster'ssphere shape.Anodeofthetreeisrepresentedbyeachcluster.Let's takeapeekatthealgorithminaction.
2. The goal is to construct a model using machine learningthatcanpredicttheresultwhichissimilar to the target variable value by learning basic decisionrulesfromdataproperties
4. Whenunusualbehavioursinatransactionfroman authoriseduserneedtobeclassified,decisiontree algorithmsareusedinfrauddetection.
| ISO
5. Thesealgorithmsuserestrictionsthataretaughton thedatasettocategorisefraudtransactions
©
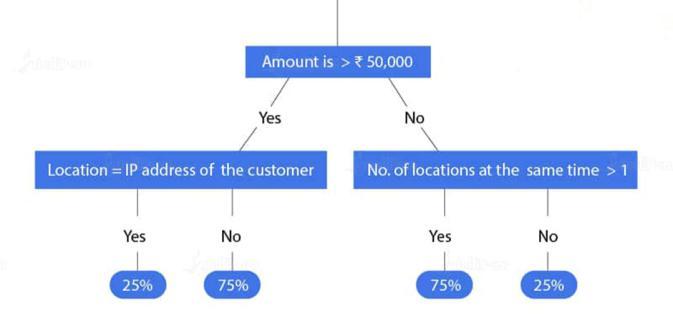
Considerascenarioinwhichauserperformstransactions. Based on the transaction, we'll create a decision tree to forecastthelikelihoodoffraud.
1. Decision trees are a non parametric supervised learningapproachforclassificationandregression.
3. With the help of decision tress, objects can be classifiedinbinary([ 1,1])andmulticlass([0, ,K 1])modes
First,we'llusethedecisiontreetoseeifthetransactionis higherthan$50,000.Iftheanswerisyes,wewillinvestigate thetransaction'slocation.Iftheanswerisno,we'lllookinto the transaction's frequency. The transaction will then be classifiedas'fraud'or'non fraud'basedontheprobabilities obtainedfortheseconditions.
Certified Journal | Page912
Thereisonlya25%chanceof"fraud"anda75%chanceof "non fraud"whentheamountisgreaterthan50,000andthe locationisequaltothecustomer'sIPaddress.Thereisa75 percentpossibilityoffraudanda25%chanceofnon fraudif theamountisgreaterthan50,000andthenumberofsitesis greaterthanone.InMachineLearning,adecisiontreecan helpinthecreationoffrauddetectionsystems.
3.4 Random Forest
Fig 3: DecisionTree
International Research Journal of Engineering and Technology (IRJET)
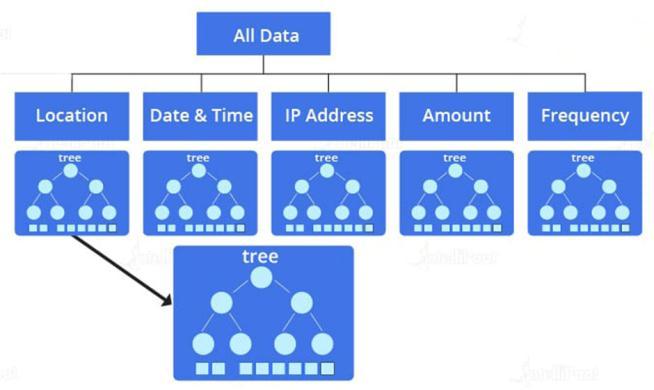
3. By fitting numerous decision tree classifiers to distinct sub samples of the dataset, a Random Forest uses averaging to increase projected accuracyandcontrolover fitting.Eachdecisiontree evaluatesadifferentsetofconditions.
Volume: 09 Issue: 03 | Mar 2022 www.irjet.net
4. Toimprovetheresults,RandomForestemploysa variety of decision trees. Different conditions are checkedbyeachdecisiontree.
5. device id: deviceidistheidentifierforthedevice. It'ssafetopresumethatit'saone of a kinddevice. Transactions having the same device ID, for example,indicatethatthesamephysicaldevicewas usedtomakethepurchase.
sub treesaremadeupofvariablesandthe criteria that must be met in order for the variables to be checkedforanapprovedtransaction.Allthesub treeswill indicate the probability for a transaction being 'fraud' or 'non fraud' once all the requirements have been checked. Themodelclassifiesthetransactionas'fraud'or'real'based onthecombinedresults.Thisishowarandomforestisused inMachineLearningforfrauddetectionalgorithms.
Extreme Gradient Boosting, or XGBoost for short, is a fast implementationofthestochasticgradientboostingmachine learning technique. The stochastic gradient boosting algorithm,alsoknownasgradientboostingmachinesortree boosting, is a powerful machine learning technique that excels at a variety of difficult machinelearning situations. Forawiderangeofregressionandclassificationpredictive modellingapplications,theXGBoostmethodisuseful.
3.6 DATASET
1. user id: Theuser'sidentifier.User specific
Fig 4: RandomForest
3. purchase time: the time when the item was purchasedbytheuser(GMTtime)
7. browser: The user's browser is referred to as "browser."
3.5 Extreme Gradient Boosting
e ISSN: 2395 0056
Volume: 09 Issue: 03 | Mar 2022 www.irjet.net
Certified Journal | Page913
trainingprocesstopaygreaterattentiontominorityclass misclassification in datasets with a skewed class Thisdistribution.isasupervised
5. They'retrainedonrandomdatasets,anddepending onthedecisiontrees'training,eachtreeshowsthe likelihood of a transaction being 'fraud' or 'non fraud.'Inthisway,themodelforecaststheoutcome.
Fraud Data: Dataconcerningeachuser'sinitialtransaction.
8. sex: male/female
6. user marketingchannel: advertisements,SEO,and direct marketing (i.e., came to the site by directly typingthesiteaddressonthebrowser).
2. signup time: the time the user signed up for an account(GMTtime)
11. class: we'retryingtofigureoutwhetherornotthe conductwasfraudulent(1)orgenuine(0).
Wheneverthemodelgetsatransactionrequest,itlooksfor information such the transaction's location, date, time, IP address, amount, and frequency. As an input, the whole dataset is delivered to the fraud detection algorithm. The fraud detection algorithm then chooses factors from the given dataset to aid in the splitting up of the dataset. The dataset is divided into multiple decision trees in the Asillustration.aresult,the
p ISSN: 2395 0072 2022, IRJET Impact Factor value: 7.529 9001:2008
The dataset was split into two files, each containing the followinginformation:
|
| ISO
9. age: ageoftheuser
10. Ip address: numericIpaddressoftheuser
©
IpAddress to Country: assignsacountrytoeachnumericIP address.Itshowsarangeforeachcountry.IfthenumericIp address fits inside the range, it is associated with the appropriatecountry.
It'safastimplementationofthestochasticgradientboosting algorithmwithavarietyofhyperparametersforfine grained control of the model training process. Although the technique performs well in general, even on unbalanced classificationdatasets,itdoesprovideawaytomodifythe
International Research Journal of Engineering and Technology (IRJET)
4. purchase value: thepriceoftheitemyoubought (USD)
1. lower bound Ip address: thenumericIpaddressof thatcountry'slowerbound.
learningapproachthatusesadecision tree based machine learning algorithm. It's an ensemble approachthataimsto build a strongclassifieroutof poor ones. When we have a large number of observations, we employthismethod.
Considerthefollowingscenario:atransactionismade.Now we'll look at how Machine Learning's random forest is employedinfrauddetectionmethods.
2. upper bound Ip address: thenumericIpaddress ofthatcountry'supperbound
p ISSN: 2395 0072 Factor value: 7.529 9001:2008
Fig 5: FraudandNon Fraudtransactions Fig 6: Gender Fig 7: MarketingChannel
Volume: 09 Issue: 03 | Mar 2022 www.irjet.net
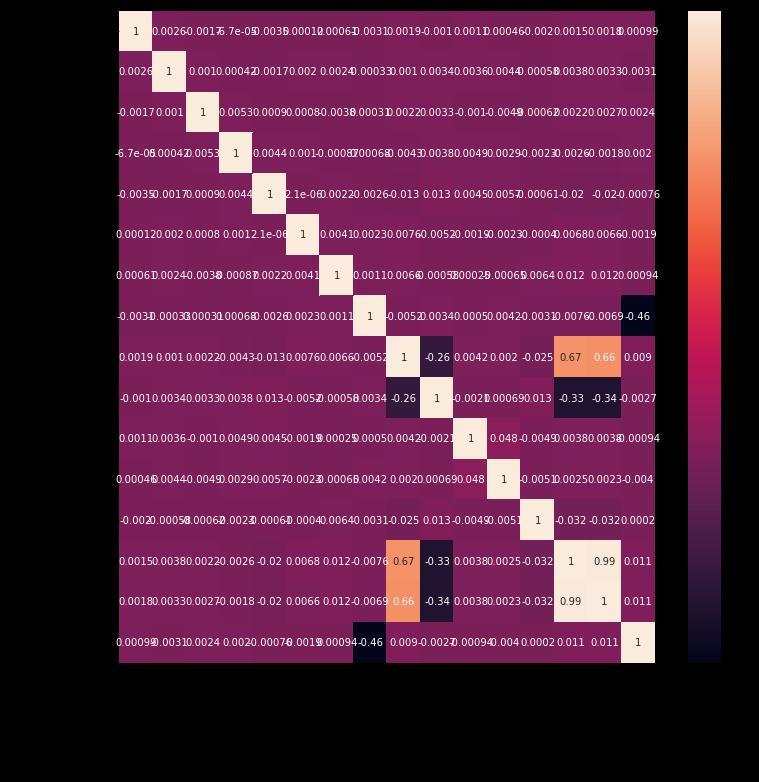
To comprehend the dataset, a correlation matrix is employed.Ifthereislittleornoassociationbetweenspecific attributes and the desired column, the correlation matrix willshowit.Itoffersanotionofhowfeaturesarerelatedto oneanotherandcanassistindeterminingwhichfeaturesare moreimportantforourforecast.
3. country: therelatedcountry'snumericIpaddress's numericIpaddress'snumericIpaddress'snumeric Ip address's numeric Ip address If a user's Ip addressfallswithinthetopandlowerbounds,sheis aresidentofthisnation.
Fig 9: Correlation
International Journal of Engineering and Technology (IRJET)
© 2022, IRJET | Impact
e ISSN: 2395 0056
Certified Journal | Page914
| ISO
Research
Understanding the dataset
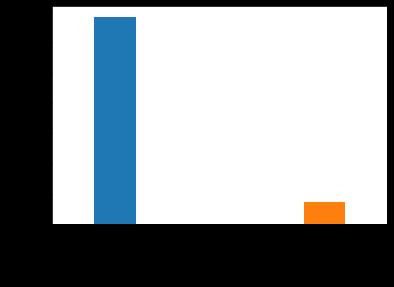
Fig 8: Browser
Thecorrelationbetweenthevariablesoneachaxisisshown ineachsquare.Correlationmightbeanywherebetween 1 and +1. Closer to 0 suggests that the two variables do not havealinearconnection.Thecloserthecorrelationistoone, the more positively associated they are; that is, when one rises,sodoestheother,andtheclosertoonetheyare,the strongertheassociation.Acorrelationaround 1issimilar, exceptinsteadofbothvariablesrising,onewilldropasthe other grows. Because the squares are connecting each variable to itself (thus it's a perfect correlation), the
Thedatasetusedinthispaperhasatotalof151,112records. The dataset classified as fraud is 14,151 records. The percentageoffrauddatais0.093percent.
diagonalsareall 1/white.Fortheremainder,thestronger the correlation between the two variables, the larger the numberandthelighterthecolour.
Model Accuracy
Accuracy is calculated by dividing the correctly predicted resultswiththetotalnumberofobservations Itreferstothe percentageoftestsamplesthatarecorrectlyclassified.This statisticassesseshowclosethemodel'spredictionistothe actualdata.
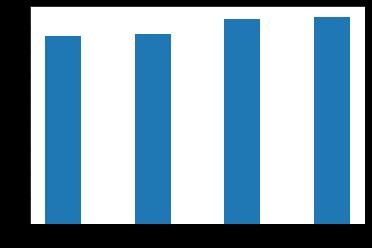
76% DecisionTrees 77% RandomForest 83% ExtremeGradientBoosting 84%
Thebelowfigureshowsthegraphicalrepresentationofthe accuracyofeachclassifieri.e.,KNN,DecisionTree,Random Forest,ExtremeGradientBoostingwhichclearlyshowsthat Extreme Gradient Boosting beats the Random Forest by a closemargin.ExtremeGradientBoostingisthebestclassifier forthefrauddetectioninecommerce.
Pre processingisadataminingapproachfortransforming rawdataintoaformatthatisbothusableandefficient.Pre processing is the process of extracting, transforming, normalising,andscalingnewfeaturesforuseinthemachine learningalgorithmprocess.Pre processingistheprocessof converting raw data into a usable format. We map the Ip addressesofthetransactionswiththeirrespectivecountries. We also find the difference in the signup time and the purchasetimetomakeapurchaseandconverteverythingin thedatasettonumericvalues.Savethepre processeddatain anew.csvfile.
Fig 10: Accuracy
5. CONCLUSION
4.1 Accuracy
4.2 ROC AUC Curve
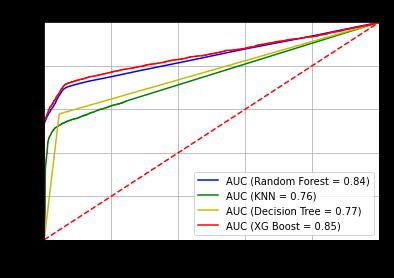
TheROC AUCCurveisaperformancestatisticforidentifying problems at different thresholds. The AUC stands for the degree of separation, and it’s a probability curve. It expressesthemodel’sabilitytodifferentiateacrossclasses. The AUC measures how effectively the model correctly predicts0sas0sand1sas1.WithTPRonthey axisandFPR onthex axis,TPRisplottedversusFPR.
3.7 PRE-PROCESSING
The accuracy of each classifier is found by using cross validationscore.ItisfoundthatExtremeGradientBoosting shows better accuracy than the other classifiers i.e., KNN, DecisionTreesandRandomForest
e ISSN: 2395 0056
KNN
Volume: 09 Issue: 03 | Mar 2022 www.irjet.net
| ISO 9001:2008 Certified Journal | Page915
Inthispaper,FraudulentActivitiesDetectioninE commerce Websites is studied using transaction dataset. We have trained the dataset on four different classifiers for fraud detection.Wefoundabestapproachamongthoseclassifiers for detecting fraud activities. We found that Extreme Gradient Boosting gives better results than KNN, Decision Tree and Random Forest. From that, we deduced that ExtremeGradientBoostingisbestsuitedforfrauddetection in ecommerce. This paper's main goal was to examine a range of machine learning techniques for detecting
4. EXPERIMENTAL RESULTS
International Research Journal of Engineering and Technology (IRJET)
Table -1: Accuracy
FPR=1TPR=TP/TP+FNPrecision=FP/TN+FP
Fig 11: Performanceofmodels
© 2022, IRJET | Impact
p ISSN: 2395 0072 Factor value: 7.529
[5] Bouktif,Salah,etal."Optimaldeeplearninglstmmodel forelectricloadforecastingusingfeatureselectionand geneticalgorithm:Comparisonwith machinelearning approaches."Energies11.7(2018):1636.
[2] Srivastava,Abhinav,etal."Creditcardfrauddetection using hidden Markov model." IEEE Transactions on dependableandsecurecomputing5.1(2008):37 48.
[7] Hong,Haoyuan,etal."Landslidesusceptibilitymapping using J48 Decision Tree with AdaBoost, Bagging and Rotation Forest ensembles in the Guangchang area (China)."Catena163(2018):399 413.
[1] Pumsirirat, Apapan, and Liu Yan. "Credit card fraud detection using deep learning based on auto encoder and restricted boltzmann machine." International Journalofadvancedcomputerscienceandapplications 9.1(2018):18 25.
© 2022, IRJET | Impact
p ISSN: 2395 0072 Factor value: 7.529
[3] Lakshmi,S.V.S.S.,andS.D.Kavilla."MachineLearning forCreditCardFraudDetectionSystem."International JournalofAppliedEngineeringResearch13.24(2018): 16819 16824.
fraudulenttransactions. Thecomparisonrevealedthatthe XGBoost algorithm delivers the best results, i.e., correctly detectswhethertransactionsarefraudulentornot.Accuracy andtheAUC roccurve,wereusedtodeterminethis.
International Research Journal of Engineering and Technology (IRJET)
[4] Aljarah, Ibrahim, Hossam Faris, and Seyedali Mirjalili. "Optimizing connection weights in neural networks using the whale optimization algorithm." Soft Computing22.1(2018):1 15.
| ISO 9001:2008 Certified Journal | Page916
REFERENCES
Volume: 09 Issue: 03 | Mar 2022 www.irjet.net
e ISSN: 2395 0056
[6] Xuan,Shiyang,GuanjunLiu,andZhenchuanLi."Refined weighted random forest and its application to credit card fraud detection." International Conference on ComputationalSocialNetworks.Springer,Cham,2018.