PROGNOSTICATION
© 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008
UTILIZING MACHINE LEARNING
1.INTRODUCTION
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056 Volume: 09 Issue: 02 | Feb 2022 www.irjet.net p ISSN: 2395 0072
Abstract Diabetes is a disease caused by an increase in glucose level in the human body. Diabetes should not be ignored Left untreated, diabetes can cause serious problems for a person such as: heart problems, kidney problems, high blood pressure, eye damage can also affect other parts of the human body. Diabetes can be controlled if it is predictedearly. In order to achieve this project goal we will make early diagnosis of Diabetes in the human body or patient with high accuracy by applying, Various Machine Learning Strategies. Machine learning strategies Provide a better predictive effect by creating models from data sets collected from patients. In this activity we will use the Learning Machine Planning and integrate databases to predict diabetes. Neighboring K Nearest (KNN), Logistic Regression (LR), Decision Tree (DT), Support Vector Machine (SVM), Gradient Boosting (GB) and Random Forest (RF). Accuracy is different for all models compared to other models. Project Work provides a more accurate or accurate model showing that the model is able to accurately predict diabetes. Our result shows that Random Forest has achieved higher accuracy compared to other machine learning strategies.
Certified Journal | Page118 DIABETES
Key Words: Diabetes, Machine, Learning, Prediction, Dataset,Ensemble
Diabetesisoneofthemostdangerousdiseasesintheworld. Diabetescausedbyobesityorhighbloodglucoselevels,and soon.Itaffectsthehormoneinsulin,whichleadstoaltered crab metabolism and improves blood sugar levels blood. Diabetes occurs when the body does not produce enough insulin.AccordingtotheWorldHealthOrganization(WHO), about422millionpeoplehavediabetes,mainlyfromlow incomeorlow incomecountries.Andthiscouldincreaseto$ 490billionby2030.Howeverthespreadofdiabetesisfound invariouscountriessuchasCanada,China,andIndiaetc.The population of India is now over 100 million so the actual number of diabetics in India is 40 million. Diabetes is the leading cause of death in the world. Early predictors of diseases such as diabetes can be controlled and save a person's life. To achieve this, this work assesses diabetes prognosis by taking into account a variety of diabetes related traits. For this purpose we use the Pima Indian DiabetesDataset,usingvariousmachineclassificationsand compilingDiabetesPredictionStrategies.MachineLearning Themethodusedtotraincomputersorequipmentexplicitly. Variety Machine Learning Strategies provide an effective Information Collection effect by creating a variety of classifications and integrating models from collected databases.Suchdatacanbehelpfulinpredictingdiabetes. Various machine learning strategies can predict, yet it is difficulttochoosethebestmethod.Soforthispurposewe usepopularclassificationsanddatabasestopredict.
2. LITERATURE REVIEW
K.VijiyaKumar et al.[1] The proposed Forest Forest AlgorithmforPredictionofDiabetescreatesasystemthat canpredictdiabetesinapatientwithhighaccuracyusingthe RandomForestalgorithminmachinelearningtechniques. The proposed model provides the best possible diabetes forecast results and the result showed that the predictive systemisabletopredictdiabeteseffectively,efficientlyand most importantly, instantly. Nonso Nnamoko et al. [5] presented to predict the onset of diabetes: an integrated targetedlearningmethodtheyusedtobreakdownintofive mostcommonlyusedcategoriesinensemblesandameta classifier used to compile their results. The results were presentedandcomparedwithsimilarstudiesthatusedthe same database within the textbooks. It is shown that by usingtheproposedmethod,predictingtheonsetofdiabetes can be done with high accuracy. Tejas N. Joshi et al. [4] introduces Diabetes Prediction Using Machine Learning Strategies aims to predict diabetes with three different machinelearningmodesinclude:SVM,retrieval,ANN.This projectproposesaneffectivewaytodiagnosediabetesearly.
DeerajShettyetal.[6]Proposedprognosisofdiabetesusing data mines includes the Intelligent Diabetes Disease PredictionSystemwhichanalyzesdiabetesusingadatabase ofdiabeticpatients.Inthisprogram,theyproposetheuseof algorithmssuchasBayesianandKNN(K NearestNeighbor) for use on a diabetic patient's website and analyzed by takingvariousdiabetictraitstopredictdiabetes.Muhammad Azeem Sarwar et al. [7] The proposed study of predicting diabetesusingmachinelearning algorithms inhealthcare using six different machine learning algorithms The effectiveness and accuracy of the algorithms used are discussed and compared. A comparison of the different machine learning techniques used in this study reveals which algorithm is most suitable for predicting diabetes. Diabetes Prediction is becoming an area of interest for researchers to train their diabetic patient through the appropriate section of the database. Based on previous research work, it has been noted that the classification processisnotsignificantlyimproved.Soasystemisneeded as a Diabetes Prediction is an important component of computers, handling issues identified based on previous research.
Suyog Nemade Student Dept. of Information Technology Engineering, Shah & Anchor Kutchhi Engineering College, Mumbai, India ***

5 Insulin 6
Dataset
2). Splitting of data Afterdatacleaning,thedataisusually trainedandtestedmodel.Whendataisspitoutthenwetrain thealgorithmonthetrainingdatasetagainkeeptestdata setaside.Thistrainingprocesswillproduceatrainingmodel based on concepts and algorithms and feature values in trainingdata.Basicallythepurposeofthepracticeistobring alltheelementsunderthesamescale.
Algorithm-
•Choosethetopflightthatseparatestheclassbest.
•Chooseaclasswithahigherlimit.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056 Volume: 09 Issue: 02 | Feb 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page119
• To get the best flight you must calculate the distance betweentheplanesandthedatacalledMargin.
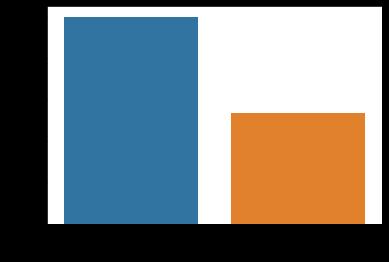
Distribution of Diabetic patient We did the diabetes modelingmodelbutthedatasetwasinconsistentasithad about500classeslabeled0meanyoudonothavediabetes and268labeled1meansgoodmeansyouhavediabetes.
1). Missing Values removal- Subtractallzeroconditions (0) as a value. Having a zero number is not possible. This event is therefore deleted. By removing unnecessary features/conditionswecreateafeaturesetandthisprocess is called small selection selection features, which reduces datadialingandhelpstoworkfaster.
The purpose of this paper is to investigate the model to predict diabetes with better accuracy. We experimented withdifferentcategoriesandcompiledalgorithmstopredict diabetes.Next,wewillbrieflydiscusstheparagraph.
1 Pregnancy 2 Glucose 3 BloodPressure 4
7
Figure 1: RatioofDiabeticandNonDiabeticPatient
A. Dataset Description data are collected at a UCI site calledthePimaIndianDiabetesDataset.Thedatabasehas manypatientcharacteristicsof768. Table 1: DatasetDescription Description No. Attributes Skinthickness BMI(BodyMassIndex) DiabetesPedigreeFunction 8 Age Attribute 9 is a class variation of each data point. This variabilityofclassindicatesaresultof0and1indiabetics indicatingwhetheritisgoodorbadfordiabetics.
Thefollowingstrategies
Margin =distancetopositivepoint + Distance to negative point 2) K Nearest Neighbor KNN is also an algorithm for machinelearninglearning.KNNhelpssolvebothplanning
3. PROPOSED METHODOLOGY
S
1) Support Vector Machine VectorSupportMachinealso knownassvmisasupervisedmachinelearningalgorithm. Svmisthemostpopularmethodofpartitioning.Svmcreates a hyperplane that divides the two classes. It can form a hyperplane or a set of hyperplane in an area of high magnitude. This hyper plane can be used for splitting or retreating.Svmseparatestheconditionsdirectlyclassesand can also classify non data based businesses. Separation is doneusing a hyperplanethatmakestheseparationtothe nearesttrainingareaofanyclass.
B. Data Preprocessing Dataprocessingisaveryimportant process.Inparticulardatarelatedtohealthcarecontainsa missing vale and other contaminants that may affect the performanceofthedata.Inordertoimprovethequalityand performance obtained after the excavation process, data analysisisperformed.UsingMachineLearningTechniques on Database Successfully This process is essential for achieving accurate and successful results forecast. In the Pima Indian diabetic data database we need to do a preliminaryanalysisintwosteps.
C. Apply Machine Learning Oncethedataisreadyweuse the Machine Learning Technique. We use a different one classificationandintegrationstrategies,predictingdiabetes. Methods used in the Pima Indians diabetes database. The maingoalistouseMachineLearningStrategiestoanalyze the effectivenessof these methodsand todetermine their accuracy, and to be able to identify the responsible / importantfactorthatplaysamajorroleinprediction.
•Ifthedistancebetweenclassesislowthenthechancesof missingapregnancyarehighandviceversa.Soweneedto
•Then,DeterminetherandomvalueofK.number.tonearby neighbors • Then with the help of these small distances and the Euclideandistancefindthecolumnforeachnth.
Volume: 09 Issue: 02 | Feb 2022 www.irjet.net p ISSN: 2395 0072
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
•Findthesameoutputvalues.Ifthevaluesarethesame,the patienthasdiabetes,otherwiseitisnot.
Themainpurposeoftheretrospectiveisapositivebalance thatisresponsiblefordefiningtherelationshipbetweenthe target and the volatility of the forecast. The reversal of objects is based on the line reversal of the line. The retrospectivemodelusesthesigmoidfunctiontopredictthe chancesofapositiveandnegativeclass.
Algorithm
•Thefirststepistoselectthe“R”elementsfromallthe“m” featureswhenR<<M.
•FindtheEuclideandistancewiththehelpofaformula
•Amongthe“R”features,theareausingthebestseparating point.
•Repeatatocuntil“l”isthenumberofnodesreached.
PandQi.e.P(p1,p2,….Pn)andQ(q1,q2,..qn)isdefinedby thefollowingnumbers:
Annotationisusedwhenwewanttoclassifyorclassifyother dataobjectsintocategories.Separatingdatainabinaryway only means 0 and 1 when referring to the condition of distinguishingagoodorbadpatientfromsugar.
4) Logistic Regression-Moving backwards is also an algorithm for dividing supervised learning. It is used to measuretheprobabilityofabinaryresponsebasedonone or more predictions. They can be continuous or separate.
SigmoidfunctionP=1/1+e (a+bx)HereP=probability,a andb=Modelparameter.
Ensembling Ensembling is a machine learning method Integration means using multiple learning algorithms togethertodoaspecifictask.Itoffersbetterpredictionsthan anyothermodelwhichiswhyitisused.Themaincauseof errorisbiasandnoisevariation,thecombinationmethods help to reduce or minimize these errors. There are two popularwaystocombine Wrap,Encourage,ada boosting, Gradientboosting,voting,ratingetc.HereInthisactivitywe haveusedBagging(randomforest)andGradientintegration techniquesforpredictingdiabetes.
• The maximum information gain is calculated for each attributeineachtreearea.
•Divideanodeintosubnodesusingthebestpartitions.
Algorithm
•Repeatstep2tocreateathinthreadusingafeaturethat canbeappliedtothesurface
•Buildatreewithnotesasaninputelement.
5) Random Forest Itisaformofintegratedlearningand is used for classification and retrospective activities. The accuracy it offers is on a grater and compared to other models.Thismethodcaneasilyhandlelargedatasets.The randomforestwasbuiltbyLeoBremen.Itisanintegrated learning approach. The Random Forest Improves the FunctionoftheDecisionTree byminimizingvariability.It worksbybuildingapileofdecisiontreesduringtrainingand issuing a phase which is a mode of division or division or directprediction(reversal)ofeachtree.
•Takeasetoftestdataforattributesandlines.
3) Decision Tree Thedecisiontreeisthebasicmethodof differentiation.Itisasupervisedlearningmethod.Decision tree used where response variability is category. Decision treehasatree basedmodelthatdescribestheclassification processbasedontheinputfactor.Variablesincludeinputof anytypesuchasgraph,text,obscure,continuousetc.Steps totheDecisionTree.
•TakeasampledatabaseofcolumnsandrowscalledPima IndianDiabetesdataset.
Algorithm-
• Select a feature to predict output from the input benefit featurewithadvancedinformation.
© 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page120 and retrospective problems. KNN is a way of predicting laziness.KNNthinksthesamethingsarenear.Manytimes thesamedatapointsareveryclose.KNNhelpsconsolidate newworkbasedonthesimilarityscale.TheKNNalgorithm records all records and classifies them according to their similarity.Tofindthedistancebetweenpointsusesatree likea building. To predicta newdata point,thealgorithm finds nearby data points in a training data set nearby neighbors.HereK=Thenumberofthenearestneighbors,is alwaysthepositivenumber.Neighborvalueisselectedfrom the class set. Intimacy is best described in terms of the Euclideanrange.TheEuclideandistancebetweentwopoints
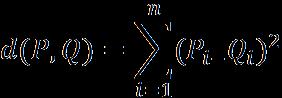
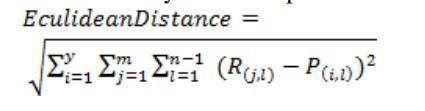
•ConsiderasampleoftargetvaluessuchasP
Step 1: Enter the required libraries, Enter the diabetic database. Step 2: Pre deletedatatodeletemissingdata.
•Measuretheerrorintargetvalues.
•P[x]=p[x]+alphaM[x]
Procedure of Proposed Methodology
Step 4: ChooseamachinelearningalgorithmnamelyKClose Neighbor,VectorSupportMachine,DecisionTree,Backbone, RandomForestandGradientdevelopmentalgorithm.
•Buildaforestbyrepeatingstepsfromatodtogetthe“a” numberoftimestobuildan“n”numberoftrees.
Step 8: Afteranalyzingbasedonthevariousstepscombine anexcellentalgorithm
Step 5: Create a differentiated model of machine learning algorithmbasedonthetrainingset.
providedby: Thefirststepistocarefullyconsidertheselectionanduseof the bases for each randomly generated decision tree to predict the outcome and maintain the expected outcome from time to time in the targeted area. Second, count the votesforeachpredictedtargetandfinally,acceptthehighly voted target as the result of a complete prediction from a randomforestformula.SomeoftheRandomForestoptions makeappropriatepredictionsastotheoutcomeofagiven application.
5. EXPERIMENTAL RESULTS In this process various steps were taken. The proposed methodusesdifferentmethodsofpartitioningandmerging
The Random Forest finds the best classification using the Gin CostIndexWork
Step 6: Test the Classifier model of machine learning algorithmbasedonthetestset.
Algorithm
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056 Volume: 09 Issue: 02 | Feb 2022 www.irjet.net p ISSN: 2395 0072
6) Gradient Boosting Gradient Boosting is a powerful integration method used for forecasting and is a split method.Itbringsthechurchreadertogetherinordermake strong student models for prediction. It uses the Decision Tree model. separates complex data sets and is a very efficientandpopularmethod.Inthegradientimprovement modeltheperformanceisimprovedbyrepetition.
4. MODEL BUILDING
© 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page121
•ReviewandadjustweightstoreduceM error.
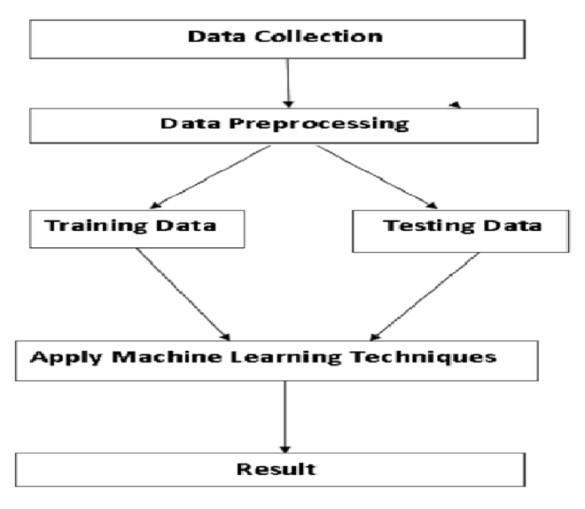
Figure 2: OverviewoftheProcess
This is the most important stage in the development of a diabetic prediction model. In this case we have used the machine learning algorithms discussed above to predict diabetes.
Step 7: Perform an Assessment Comparison of the psychologicalperformanceresultsobtainedbyeachstudent.
• Model students are analyzed and calculated for the loss functionF •RepeatthestepsuntilyouwishandthetargetresultisP.
Step 3: Perform an 80% split to split the database as a Trainingsetand20%createatestset.
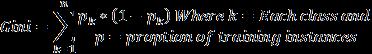
© 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page122
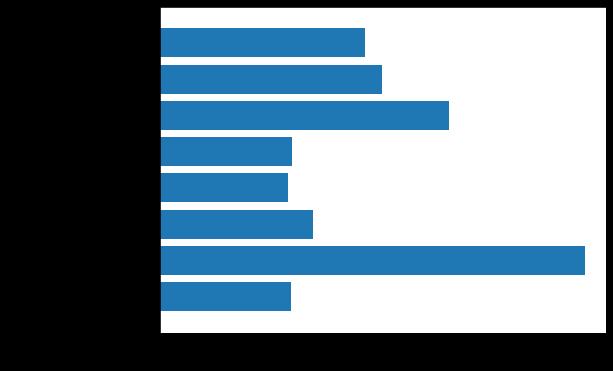
Figure 4: FeatureImportancePlotforRandomForest 6. CONCLUSION
[7] Nahla B.,Andrew et al,"Intelligiblesupportvector machines for diagnosis of diabetes mellitus. Information Technology in Biomedicine", IEEE Transactions. 14, (July. 2010), 1114 20. [8] A.K., Dewangan, and P., Agrawal, “Classification of Diabetes Mellitus Using Machine Learning Techniques,” International Journal of Engineering andAppliedSciences,vol.2,2015.
Here is a feature that has played an important role in predicting the introduction of a random forest algorithm. The total value of each factor that plays a major role in diabeteshasbeendetermined,wheretheX axisrepresents the value of each factor and feature and Y Axis feature names.
[4] TejasN.Joshi,Prof.Pramila M.Chawan,"Diabetes PredictionUsingMachineLearningTechniques".Int. Journal of Engineering Research and Application, Vol.8,Issue1,(Part II)January2018,pp. 09 13
7. REFERENCES
[5] Nonso Nnamoko, Abir Hussain, David England, ComputationLearning"PredictingDiabetesOnset:anEnsembleSupervisedApproach".IEEECongressonEvolutionary(CEC),2018.
[1] Debadri Dutta, Debpriyo Paul, Parthajeet Ghosh, "Analyzing Feature Importance’s for Diabetes PredictionusingMachineLearning".IEEE,pp942 928,2018.
[3] Md.FaisalFaruque,Asaduzzaman,IqbalH.Sarker, "Performance Analysis of Machine Learning Techniques to Predict Diabetes Mellitus". International Conference on Electrical, Computer and Communication Engineering (ECCE), 7 9 February,2019.
[2] K.VijiyaKumar, B.Lavanya, I.Nirmala, S.Sofia Caroline, "Random Forest Algorithm for the PredictionofDiabetes".ProceedingofInternational Conference on Systems Computation Automation andNetworking,2019.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056 Volume: 09 Issue: 02 | Feb 2022 www.irjet.net p ISSN: 2395 0072
The main objective of this project was to design and implement Diabetes Predictability using Mechanical Learning Methods and Performance Analysis of those methodsandsuccessfullyachieved.Theproposedmethod uses a variety of classification and integration learning methods where SVM, Knn, Random Forest, Decision Tree, Logistic Regression and Gradient Boosting divisions are used. And 77% stage accuracy was achieved. Test Results canbeastronomicalhealthcaretotakeearlypredictionsand makeearlydecisionstotreatdiabetesandsavelives.
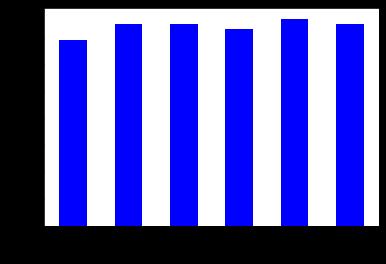
Figure3: AccuracyResultofMachinelearningmethods
[6] DeerajShetty,KishorRit,SohailShaikh,NikitaPatil, "Diabetes Disease Prediction Using Data Mining ".International Conference on Innovations in Information, Embedded and Communication Systems(ICIIECS),2017.
and is implemented using python. These methods are the mostcommonmechanicallearningmethodsusedtoobtain the best accuracy of data. In this work we see that the informal forest class benefits best compared to others. OverallwehaveusedthebestMachineLearningmethodsto predict and achieve the highest accuracy of performance. The diagram shows the effect of these Machine Learning methods.