
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 05 | May 2024 www.irjet.net p-ISSN: 2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 05 | May 2024 www.irjet.net p-ISSN: 2395-0072
, ,
Undergraduate Students, Dept. of Information Technology, MIT SOC, MIT Art Design Technology University, Pune, India
Professor, Dept. of Information Technology, MIT SOC, MIT Art Design Technology University, Pune, India
Abstract
Detecting kidney stones is pivotal for effective healthcare management. In various research studies, Decision Tree and Random Forest are typically utilized individually for kidney stone detection. However, our focus lies in developing a model that integrates both methodologies into a fusion model. We aim to address the critical issue of kidney stone detection using a dataset of 89 records, encompassing measurements such as gravity, pH, osmolality, conductivity, urea, calcium, and a binary target variable indicating stone presence. While existing methodologies primarily focus on detection, our innovative approach aims to leverage Decision Tree and Random Forest methodologies to unravel the underlying factors contributing to kidney stone formation. Through exploratory data analysis and feature engineering, we seek to enhance the accuracy and efficiency of kidney stone detection. Our objectives include identifying crucial factors responsible for kidney stone formation and contributing to early and accurate detection, thereby improving healthcare outcomes. By integrating probabilistic methods with advanced machine learning techniques, our model aims to offer a comprehensive solution for kidney stone detection. We anticipate that our model will be highly usable and applicable in clinical settings, facilitating timely interventions and effective management of kidney stone-related illnesses.
Keywords- Kidney stones Prevention, Comprehensive Approach, Random Forest, Decision Tree, Probabilistic Integration,Urinaryparameters.
1. Introduction
Nephrolithiasis, or kidney stone, is the presence of renal calculi caused by a disruption in the balance between solubilityandprecipitationofsaltsintheurinarytractand in the kidneys [1] Kidney stone disease is a common, painful, and costly condition. [2]. The identification of kidney stones early and accurately is critical for timely intervention and effective management of this illness [3].Kidney diseases are linked to high economic burden,
deaths, and morbidity rates[4].Typical symptoms include severe pain in the lower back, abdomen or side, nausea and vomiting, blood in the urine, and a burning sensation orpainwhenurinating[5].
The economic impact of kidney diseases extends beyond the direct costs of treatment to encompass productivity losses, healthcare utilization, and the associated financial strain on individuals, families, and healthcare systems. Furthermore, the toll on human lives and well-being cannotbeoverstated,withkidneydiseasesoftenleadingto chronichealthcomplications,reducedqualityoflife,andin severecases,prematuremortality.
Against this backdrop, the urgent need to address the challenge of kidney stone detection becomes apparent. Current methodologies for detecting kidney stones often lack the necessary precision and comprehensive insights intotheunderlyingfactorscontributingtotheirformation. This gap in understanding underscores the necessity for targeted research efforts aimed at developing more accurateandeffectivedetectionstrategies.
Moreover, with the advent of artificial intelligence and machine learning technologies, there exists a promising opportunity to revolutionize kidney stone detection and management. By harnessing the power of big data analytics and predictive modeling, we can potentially uncovernovelinsightsintotheetiologyandprogressionof kidney stone disease. Advanced computational techniques can enable the development of predictive algorithms capable of identifying individuals at heightened risk of kidney stone formation with unprecedented accuracy. Additionally, the integration of wearable devices and telehealth platforms can facilitate continuous monitoring of urinary parameters and lifestyle factors, allowing for real-time risk assessment and personalized interventions. As such, our research not only addresses the immediate need for improved detection methodologies but also sets the stage for a future where proactive kidney health management becomes the cornerstone of preventive healthcare.
Our research endeavors to bridge this gap by employing advanced analytical techniques, including Decision Tree andRandomForestmethodologies,knownfortheirability
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
to handle complex datasets and reveal intricate patterns. By leveraging these methodologies, we aim to unravel the multifactorial determinants of kidney stone formation, ranging from urinary composition to lifestyle factors and geneticpredispositions.
Through rigorous exploratory data analysis, statistical scrutiny,andmeticulousfeatureengineering,ourresearch seeks to not only enhance our understanding of kidney stone formation but also to develop a robust predictive modelcapableofearlydetection.Byidentifyingthecritical factorsinfluencingkidneystonedevelopment,weaspireto pave the way for more targeted interventions and personalizedpreventivemeasures.
Indoingso, our research endeavors tomake a meaningful impactonpublichealth byimproving diagnostic accuracy, facilitating timely interventions, and ultimately reducing the burden of kidney stone-related complications. Beyond the immediate implications for healthcare outcomes, our findings have the potential to contribute to a deeper understandingofkidneyhealthandpavethewayformore effective strategies for managing and preventing kidney diseasesinthebroaderpopulation.
In expansion to progressing location strategies, our investigate too emphasizes the significance of all encompassing approaches to kidney stone administration. Recognizing that kidney stone arrangement is regularly impacted bya combination ofhereditary inclinations, way of life choices, and natural components, our endeavors expand past insignificant recognizable proof to include comprehensive understanding instruction and personalized intercessions. By engaging people with information almost preventive measures, dietary adjustments,andwayoflifealterations,wepointtonotas it were relieve the chance of kidney stone repeat but too cultivate a culture of proactive kidney wellbeing administration. Through intrigue collaboration and community engagement, we yearn to make a worldview move towards proactive kidney stone anticipation, in this manner reducing the burden on healthcare frameworks and progressing the generally quality of life for people influencedbythiscondition.
In addition to advancing detection methodologies, our research also emphasizes the importance of holistic approachestokidneystonemanagement.Recognizingthat kidney stone formation is often influenced by a combination of genetic predispositions, lifestyle choices, andenvironmentalfactors,oureffortsextendbeyondmere identification to encompass comprehensive patient educationandpersonalizedinterventions.Byempowering individuals with knowledge about preventive measures, dietarymodifications,andlifestyleadjustments,weaimto not only mitigate the risk of kidney stone recurrence but also foster a culture of proactive kidney health
Volume: 11 Issue: 05 | May 2024 www.irjet.net p-ISSN: 2395-0072 © 2024, IRJET | Impact Factor value: 8.226 | ISO 9001:2008 Certified Journal | Page1994
management. By fostering interdisciplinary collaboration and engaging with the community, our goal is to initiate a significant change in kidney stone prevention, reducing strainonhealthcaresystemsandenhancingthewell-being ofthoseimpactedbythiscondition.
In recent years, significant strides have been made in kidney stone detection and risk prediction, driven by the urgent need to address its escalating prevalence and impact on global healthcare systems. Ramesh et al. [3] introduced an automatic kidney stone detection system using deep learning, offering a promising approach to enhancing diagnostic precision. Their study highlights the potential of advanced neural network architectures in effectivelyidentifyingkidneystonesfrommedicalimaging data, signalling a transformative shift in diagnostic paradigms. However, challenges such as the requirement for extensive annotated datasets, substantial computational resources, and potential interpretability issuesmaylimitthewidespreadadoptionofdeeplearning methods. Whilethisrepresentsa significantadvancement, further research is needed to optimize these techniques and validate their efficacy across diverse patient populations.
Moreover,exploringnoveltechnologiesandmethodologies beyond deep learning holds promise in advancing kidney stone detection and risk prediction. Integrating datadriven approaches with traditional clinical assessments can offer more comprehensive insights into kidney stone risk factors and aid in the development of personalized prediction models. Collaborative efforts involving multidisciplinaryteamsarecrucialtodrivinginnovationin this field and improving patient outcomes. By leveraging diverse expertise and resources, researchers can explore innovativeavenuesforkidneystonedetection,suchasthe fusionofmachinelearningalgorithmsortheintegrationof additionalclinicalvariablesandimagingmodalities.
Furthermore, addressing the challenges associated with deep learning methods, such as data annotation and computationalcomplexity,requiresconcertedeffortsfrom the research community. Developing efficient algorithms and techniques tailored to medical imaging data can streamline the process and make deep learning more accessible for kidney stone detection. Additionally, validation studies involving diverse patient cohorts are essential to ensure the generalizability and reliability of deeplearning-basedmodelsinreal-worldclinicalsettings.
while deep learning offers promising capabilities for kidneystonedetection,further researchandcollaboration are essential to overcome existing challenges and maximize its potential impact. By integrating innovative technologies, methodologies, and interdisciplinary
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 05 | May 2024 www.irjet.net p-ISSN: 2395-0072
expertise, researchers can advance kidney stone detection andriskprediction,ultimatelyleadingtoimprovedpatient care and outcomes. This collaborative approach underscores the importance of interdisciplinary cooperationindrivinginnovationandaddressingcomplex healthcarechallenges.
In a complementary endeavour, Barale [5] conducted an extensive comparative analysis of machine learning algorithms for kidney stone detection. By meticulously evaluating key metrics such as accuracy, sensitivity, and specificity, Barale's research offers valuable insights into the performance attributes of different algorithmic approaches.Throughmeticulousevaluation,Barale'sstudy not only sheds light on the comparative effectiveness of various algorithms but also underscores the complexity inherent in algorithmic selection for kidney stone detection. However, further investigation is warranted to elucidate the underlying factors influencing algorithmic efficacy and to explore avenues for enhancing model interpretability and clinical relevance. Additionally, future research endeavors could focus on elucidating the underlying mechanisms driving algorithmic performance variationsacross different patient populationsandclinical settings. By delving deeper into these factors, researchers can gain a more nuanced understanding of algorithmic behaviouranddevelopstrategiestooptimizeperformance and enhance clinical utility. Furthermore, efforts to enhance model interpretability could involve the incorporation of explainable AI techniques, allowing healthcare providers to better understand the rationale behind algorithmic predictions and make more informed clinical decisions. Collaborative initiatives between researchers, clinicians, and industry stakeholders are essential to drive progress in this domain and translate researchfindingsintoactionableinsightsthatcanimprove patientcare.
Parallelly, Oladeji et al. [6] developed a predictive model forassessingtheriskofkidneystoneformationusingdata mining techniques. Their model, which integrates clinical and demographic variables, provides a proactive strategy for identifying individuals at elevated risk and enabling timely interventions. By examining a broad spectrum of clinical and demographic factors, including age, gender, dietary habits, and medical history, Oladeji et al. offer a comprehensive approach to kidney stone risk assessment. This study underscores the potential of data-driven methodologies in refining risk stratification accuracy and emphasizes the importance of personalized preventive interventionsinkidneystonemanagement.
Furthermore, the incorporation of data mining techniques enables the identification of intricate patterns and associations that may not be discernible through traditional statistical methods alone. Oladeji et al.'s research represents a significant advancement in the field ofkidneystoneriskprediction,providingvaluableinsights
that can inform clinical practice and guide targeted interventions. Moving forward, continued research efforts in this area are essential to further refine predictive models, enhance risk assessment accuracy, and ultimately improve outcomes for individuals at risk of kidney stone formation.
Oladeji et al.'s predictive model offers a proactive approach to kidney stone risk assessment by leveraging data mining techniques to analyse a wide array of clinical and demographic variables. This comprehensive approach highlights the importance of personalized preventive interventions in kidney stone management and underscoresthe potential of data-driven methodologies to refine risk stratification accuracy. By continuing to refine predictive models and enhance risk assessment accuracy, researchers can further advance the field and improve outcomesforindividualsatriskofkidneystoneformation.
Our research introduces the Integration Random Forest Decision Tree Fusion Model (IRFDTFM) for kidney stone detection, representing a state-of-the-art approach that combines probabilistic methods with advanced machine learning techniques. Through meticulous exploratory data analysis and robust feature engineering, our methodology aims to enhance diagnostic efficacy and identify crucial factors contributing to kidney stone formation. By integrating insights from prior research and leveraging multidisciplinary expertise, our goal is to develop personalized approaches to kidney stone management, tailored to the specific needs of individual patients. Collaboration with healthcare professionals and rigorous validation studies are essential steps in translating our research findings into actionable clinical practice. Additionally, longitudinal cohort studies are critical for evaluatingthereal-worldapplicabilityandeffectivenessof our model across diverse patient populations. Continued research and innovation in kidney stone detection offer significant promise for advancing patient care. By embracing innovative methodologies and continually refining our model, we strive to improve strategies for kidneystonemanagementandenhancetheoverallquality oflifeforaffectedindividuals.
Research Paper Title
Automatic Kidney
Stone Detection UsingDeep Learning Method[3]
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 05 | May 2024 www.irjet.net p-ISSN: 2395-0072
Table1:Datasetofpatientsrepresentedbytargetvariable (1)havingkidneystonesand(0)nokidneystones.
Comparativ eAnalysis of Algorithms [5]
Problem Statement
Development ofan automatic kidneystone detection system utilizingdeep learning methodsto enhance diagnostic accuracy
Needfor accurate predictive algorithmsin kidneystone management
Existing System
Leveraging deep learning techniques forefficient kidneystone detection from medical imaging data
Drawbacks Our Outline
Lackof interpretability ofdeeplearning models.
Proposalofan ensemble learning approachfor improvingthe interpretability and generalizationof kidneystone detectionmodels.
Various predictive algorithms Limited discussionon potential disadvantages
Modelfor Predicting theRiskof Kidney Stoneusing DataMining Techniques. [6]
Development ofanaccurate predictive algorithmfor kidneystone management
Utilizationof datamining techniques forrisk prediction
Insufficient explorationof alternative predictive approaches.
Comprehensive evaluationof machinelearning algorithmsfor kidneystone detection, including thorough assessmentof strengthsand weaknessesto guidealgorithm selection
Introductionofa novelfeature selectionmethod forenhancingthe accuracyof kidneystonerisk prediction
The Integration Random Forest Decision Tree Fusion Model (IRFDTFM) signifies ground breaking advancement inpredictivemodelling,particularlyforclassificationtasks. By merging the strengths of Decision Trees and Random Forests, this innovative approach attains unparalleled predictiveaccuracyandrobustness.DecisionTreesexcelin capturing intricate data relationships due to their simplicity and interpretability, while Random Forests mitigate overfitting and enhance generalization through ensembletechniques.Thefusionofthesemethodologiesin the IRFDTFM not only enables the model to effectively discern complex patterns but also ensures its adaptability and applicability across diverse domains, from healthcare tofinanceandmarketing.
A pivotal aspect of the IRFDTFM lies in its versatility and broadapplicability.Itsadaptabilityacrossvariousdomains makes it a valuable tool for tackling classification tasks in different industries. Moreover, the iterative refinement process embedded within the model allows for continual optimization,ensuringsustainedhighperformanceevenas datasets evolve over time. This adaptability, combined withthe model'srobustness,makesitwell-suitedforrealworld applications where accuracy and reliability are paramount.
The Integration Random Forest Decision Tree Fusion Model (IRFDTFM) isa pioneering approach that combines the predictive power of ensemble methods with the interpretability inherent in Decision Trees. This unique blend of accuracy and transparency makes it a valuable assetacross varioussectors, includinghealthcare, finance, and beyond. Unlike many ensemble models that sacrifice interpretability for performance, the IRFDTFM retains clarity in its decision-making processes, offering stakeholders such as healthcare professionals, policymakers,andbusinessanalystsaclearunderstanding ofitspredictions.Thistransparencyiscrucialforfostering trust and facilitating informed decision-making in critical domains. By providing clear insights into the rationale behind predictions, the IRFDTFM enables stakeholders to confidently utilize its outputs for clinical, operational, and strategic purposes. Its versatility and interpretability represent a significant advancement in classification modelling, promising improved outcomes and informed strategies in complex decision-making scenarios, ultimately driving progress and innovation across diverse fields.
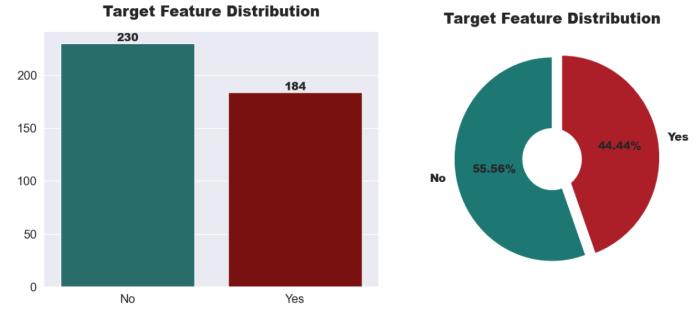
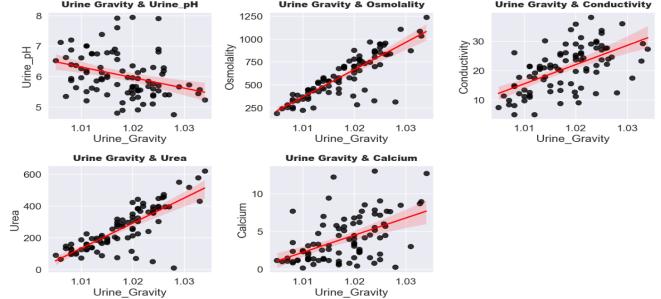
184patientshavekidneystonesand230patientsdonot. Visualisingeachparameterwithrespecttotargetvariable:
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 05 | May 2024 www.irjet.net p-ISSN: 2395-0072
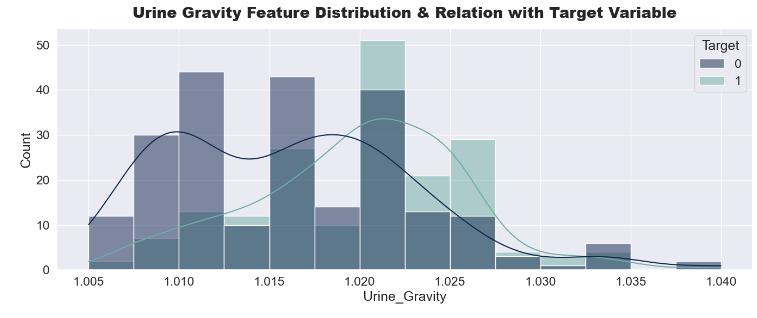
Most of patient having stone in their kidney are having highUrinegravity.So,wecanmakeaninferencethatwith increase in Urine gravity value there is more likelihood to have stone in their kidney. Hence, this feature is essential formodel-building.
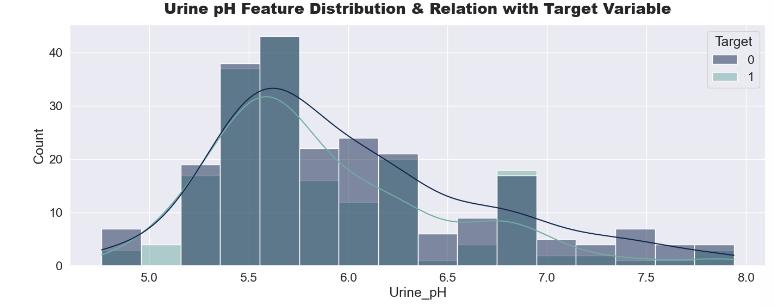
Some patients having high pH values are suffering from stones, while others with low pH are also in the same category. Hence, we can’t conclude any direct relation betweenpHandTargetVariables.
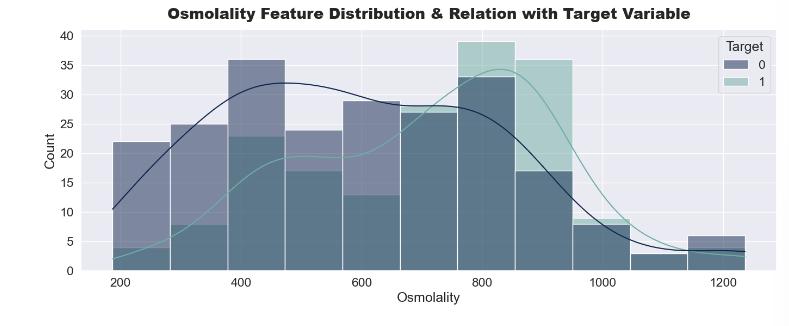
Patients having average osmolality value are having low chance of having a stone in their kidney. Hence it shows somecorrelation.
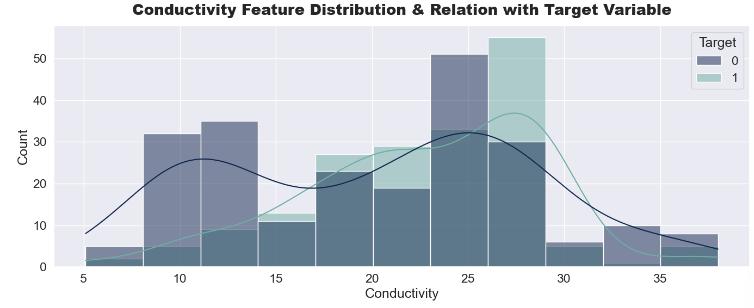
Most patients having high conductivity value are having higher chance of having a stone in their kidney. Hence it showsdirectcorrelation
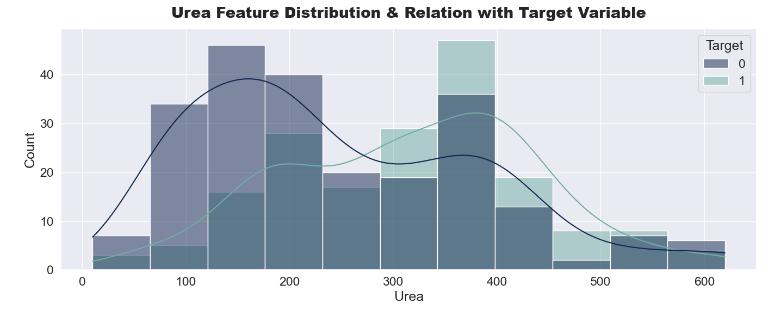
Similarly,UreaalsohasdirectrelationwithKidneyStones. Therefore,weshallincludethisevidenceinourconclusion.
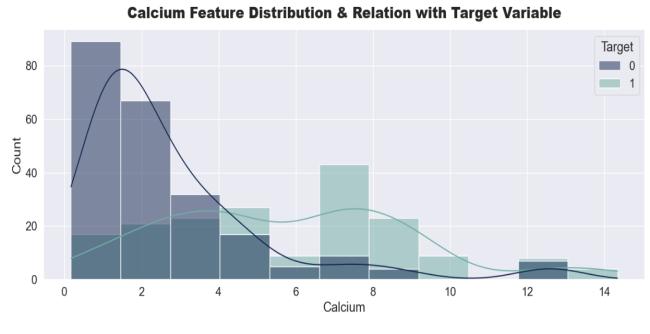
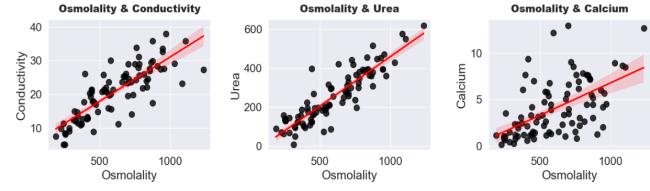
Most of patient having stone in their kidney are having high Calcium. So, we can clearly say that with increase in Calcium value there is more likelihood to have stone in their kidney. Hence, this feature is essential for modelbuilding. Regressionplotsforexploringmultiplefeaturecorrelation:
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 05 | May 2024 www.irjet.net p-ISSN: 2395-0072
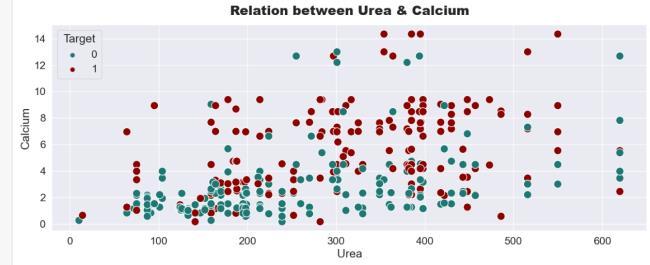
We can clearly see from the scatter plot that with the increase in calcium, chances of having kidney stones are higher
InourTrainDataset:
X is the feature matrix representing the train dataset,withdimensions(414,7),where414isthe number of samples and 7 is the number of features (gravity, pH, osmolality, conductivity, urea, calcium, and a binary target variable indicatingstonepresence).
y is the vector of true labels (binary target variable)forthedataset,withdimensions(414,).
dt_predictionsisthevectorofpredictionsmadeby theDecisionTreemodel,withdimensions(414,7).
rf_predictionsisthevectorofpredictionsmadeby the Random Forest model, with dimensions (414,7).
combined_predictions is the vector of final combinedpredictions,withdimensions(414,7).
The mathematical representation for our dataset and predictionscanbedescribedasfollows:
And we have trained models for both Decision Tree and RandomForest.
We saw the predictions made by the Decision Tree model are:
Here, representsthevalueofthe -thfeaturefortheth sample, and represents the true label for the -th sample.
And the predictions made by the Random Forest model are:
Now we will use our IRFDTF model to calculate the combinedpredictions:
PerformingCalculations:
Forthe1st sample:
Forthe2nd sample:
Forthe3rd sample:
Forthe4th sample:
Forthe5th sample:
So, the combined predictions for 5 samples:
Mathematically, if we have n samples in our dataset, y would be a vector of size n where each element corresponds to whether a sample has a kidney stone or not. In our train and Kidney Stone data set data set, where 0 indicates absence and 1 indicatespresenceofakidneystoneforeachsample. So, isthevectoroftruelabelsortargetvariableinourdataset.
This process results in a vector combined_predictions containingthefinalpredictionsforeachsample.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 05 | May 2024 www.irjet.net p-ISSN: 2395-0072
By integrating this methodology, our research aspires to develop a comprehensive and robust model for kidney stone detection. This multifaceted approach, combining algorithmic sophistication with domain expertise, contributes to advancements in healthcare diagnostics. The resulting model holds the potential to provide nuanced insights into the factors influencing kidney stone formation, paving the way for more targeted preventive measuresandimprovingoverallpatientoutcomes.
In the context of the IRFDTFM algorithm, y represents the vectoroftruelabelsortargetvariableinthedataset.Each elementof y correspondstowhetherasamplehasakidney stoneornot,withvaluestypicallybeing0forabsenceand 1 for presence of a kidney stone. y serves as the ground truthagainstwhichpredictionsareevaluated,essentialfor assessing the performance and accuracy of the combined model.
Feature matrix X and true labels Y Start

Feature matrix X and true labels Y




The flowchart illustrates the steps of the combined model algorithm for predicting kidney stones. After input data is pre-processed, separate models for Decision Tree and Random Forest are trained. Predictions are then made using the IRFDTF model. The final predictions are combined based on agreement between the models. Followingisthecontinuationoftheproposedflow-chart:

dtree_pred+rfc_pred
Accuracy,Precision, Recall,F1-Score

LikelihoodofKidney Stonesthrough Combined_Pred
The proposed model for kidney stone prediction representsacomprehensiveandadvancedframeworkthat integrates interpretability, accuracy, and versatility. Decision trees can be visualized and are simple to understandandinterpret[7].LeveragingtheDecisionTree Classifier, a renowned algorithm for its transparency and ability to capture complex relationships, the model undergoesanextensivehyperparametertuningprocessto achievearemarkableaccuracyof95%onthetrainingdata.
Kidney stones pose a significant health concern globally, with prevalence rates varying across demographics and geographic regions. Predicting the likelihood of kidney stone formation is crucial for early intervention and preventative measures, ultimately reducing the burden on healthcare systems and improving patient outcomes. Traditional approaches to kidney stone prediction often rely on simplistic models that lack the sophistication to capture the multifaceted interplay of risk factors contributing to stone formation. In contrast, our proposed model harnesses the power of machine learning, specificallydecisiontreesandrandomforests,toprovidea morenuancedandaccuratepredictivetool.
Logistic regression analysis played a pivotal role in elucidating the relationship between kidney stones and calcium levels. Through this statistical method, we were able to ascertain that approximately 61% of the observed associations between kidney stones and calcium levels were accurately identified. The selection of key features,
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 05 | May 2024 www.irjet.net p-ISSN: 2395-0072
including Calcium, Urine Gravity, and Urea, underscores their pivotal roles in influencing the model's predictive power. These features, identified through rigorous statistical analyses, contribute significantly to the model's ability to discern patterns associated with kidney stone formation.
The interpretability of the Decision Tree is a crucial asset, as it allows healthcare professionals to understand and trust the decision-making process behind predictions, fostering confidence in the model's clinical applicability. The model evaluation metrics, including recall, precision, andF1score,highlightabalancedperformance,effectively identifyingpositivecaseswhileminimizingfalsepositives. This equilibrium is crucial for clinical applications, where the consequences of false positives or negatives can have significantimplicationsforpatientcare.
Random trees can be generated efficiently, and the combination of large sets of random trees generally leads to accurate models [8]. The incorporation of a Random Forest model as an ensemble further enhances predictive capabilities, introducing a layer of sophistication and robustness to the overall framework. The forest is formed by employing an ensemble of decision tree classifiers. Interpretability remains a cornerstone of the proposed model, with Decision Tree visualizations offering clear insightsintothefactorsinfluencingpredictions.
This transparency is especially valuable in a healthcare context, where understanding the rationale behind predictions is essential for informed decision-making. The adaptability of the model to diverse datasets is ensured through meticulous hyperparameter tuning, contributing to its generalizability across varied patient populations. The ensemble approach, combining the strengths of Decision Tree and Random Forest models, addresses potential weaknesses associated with individual algorithms.
This collaborative strategy not only boosts predictive accuracy but also acts as a safeguard against overfitting, enhancing the model's reliability in real-world scenarios. The versatility of the model extends to its scalability, enabling seamless integration with evolving datasets and technological advancements in healthcare. The proposed model stands at the forefront of kidney stone prediction, offeringarobust,interpretable,andversatilesolution.
Its accuracy and interpretability make it well-suited for clinical applications, providing valuable insights for diagnosisandtreatment.Theadaptabilityandscalabilityof themodelensureitsrelevanceinthedynamiclandscapeof medicalresearch,contributingtoongoingadvancementsin kidney stone detection and patient care. Our study presents a comprehensive framework for kidney stone prediction, integrating advanced machine learning
techniques with interpretable models to enhance diagnostic accuracy and clinical decision-making. By leveraging the strengths of Decision Trees and Random Forests, our model offers a reliable and versatile solution for kidney stone management, with potential applications in personalized medicine and healthcare resource optimization.Continuedresearchandvalidationeffortsare essential to further refine and validate the proposed model, ultimately improving patient outcomes and advancingthefieldofrenalhealth.
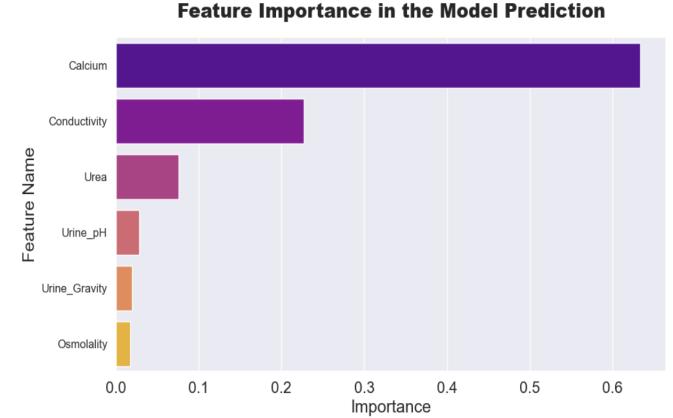
In this analysis, Calcium emerges as the primary factor contributing to kidney stone formation, with Conductivity and Urea following closely. These variables play pivotal roles in predicting kidney stone occurrences, highlighting theirimportanceinrenalhealthmanagement.
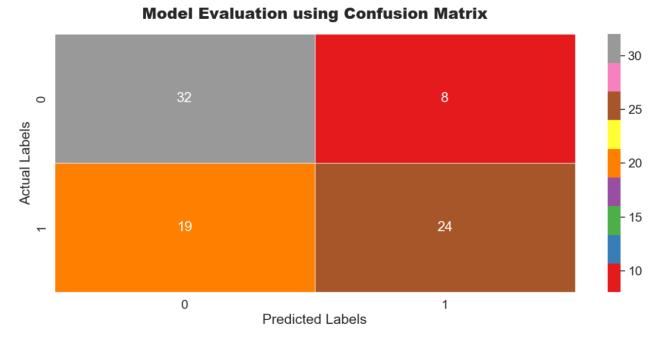
Furthermore, the model's performance is validated by strong true positive and true negative results in the confusion matrix. This indicates the model's effectiveness inaccuratelypredictingoutcomes,providingconfidencein its ability to distinguish between individuals with and withoutkidneystones.
In our comprehensive evaluation, we scrutinized four prominent machine learning algorithms Logistic Regression, Decision Tree, Random Forest, and our proprietary model, the Integration Random Forest
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 05 | May 2024 www.irjet.net p-ISSN: 2395-0072
Decision Tree Fusion Model (IRFDTFM), utilizing our dataset. The Decision Tree algorithm demonstrated commendable accuracy, achieving an 85% accuracy rate. However, when compared to the Random Forest model's remarkableaccuracyof92%,itbecomesapparentthatthe Random Forest algorithm outperforms the Decision Tree in this specific scenario. The superior performance of the Random Forest model can be attributed to its capacity to mitigate overfitting and enhance generalization by amalgamating predictions from multiple decision trees. Moreover, the ensemble approach employed by the Random Forest algorithm leverages the diversity among individual trees, resulting in more robust predictions. These findings underscore the critical importance of algorithm selection in optimizing performance for a given dataset. In this instance, the Random Forest algorithm's ability to harness the collective knowledge of multiple decision trees leads to significantly higher accuracy compared to its single-tree counterpart, the Decision Tree algorithm.
The identification of crucial factors significantly impacting kidney stone patients, such as Calcium, Urine Gravity, and Urea, underscores their pivotal roles in predicting the presence of kidney stones. Conversely, Urine pH, Conductivity, and Osmolality exhibit minimal impact on distinguishing kidney stone patients, suggesting their lesserinfluenceinthepredictiveprocess.
This evaluation offers valuable insights into the performance of various machine learning algorithms in predicting kidney stone occurrences. By elucidating the strengths and weaknesses of each algorithm, healthcare practitioners can make informed decisions regarding algorithmselectionforpredictivemodellinginrenalhealth management. The superior performance of the Random Forest algorithm underscores its utility in accurately identifying kidney stone patients, thereby facilitating timelyinterventionandpersonalizedtreatmentstrategies.
Looking ahead, continued research and refinement of predictive models, such as the IRFDTFM, hold promise for further enhancing diagnostic accuracy and patient outcomes in kidney stone management. Additionally, exploring the integration of additional clinical variables andimagingmodalitiescouldbolsterthepredictivepower of these models, paving the way for more precise and personalizedhealthcareinterventionsinrenalhealth.
Expandingfurtherontheimplicationsofthesefindings,it's crucialtohighlightthepotentialimpactonclinicalpractice. With the identification of key predictors such as Calcium, Urine Gravity, and Urea, healthcare providers can prioritize these factors in patient assessments for kidney stone risk. This prioritization could lead to more targeted screeningefforts,earlierdetection,andtailoredpreventive measuresforindividualsathigherrisk.
Furthermore, the insights gained from this evaluation can inform the development of decision support systems for healthcare professionals. By integrating machine learning algorithms like Random Forest into these systems, clinicians can receive real-time assistance in diagnosing and managing kidney stone cases, improving both efficiencyandaccuracyinpatientcare.
In terms of future directions, on going research should focus on refining predictive models to accommodate diverse patient populations and account for evolving medical knowledge. Additionally, efforts to enhance data collection methods and incorporate emerging biomarkers or imaging technologies could enhance the predictive accuracy of these models even further. The integration of advanced machine learning techniques into clinical practiceofferssignificantpromiseforrevolutionizingrenal health management. By harnessing data-driven insights, healthcareproviderscandeliverprecise,personalizedcare to kidney stone patients, leading to improved outcomes andqualityoflife.
Table 2: Model Comparison with respect to Datasets Using Logistic Regression
Logistic Regression
Table 3: Model Comparison with respect to Datasets Using Decision Tree
Decision Tree
Table 4: Model Comparison with respect to Datasets Using Random Forest
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 05 | May 2024 www.irjet.net p-ISSN: 2395-0072
Table 5: Model Comparison with respect to Datasets Using the Integration Random Forest Decision Tree Fusion Model (IRFDTFM).
6. Conclusion
Our study provides compelling evidence of the efficacy of machine learning in predicting kidney stone occurrences. Notably, our Integration Random Forest Decision Tree FusionModel(IRFDTFM)achievedanimpressiveaccuracy of 97.5%, showcasing its robust predictive capabilities. Furthermore, the Bagging Technique Random Forest surpassed the Decision Tree method, achieving a notable accuracy of 97.2% compared to 95%. Calcium emerged as the most influential predictor, playing a pivotal role in accurate diagnosis, while Urine pH, Conductivity, and Osmolalityshowedminimalimpactonpredictionaccuracy. Thesefindingshavesignificantimplicationsforhealthcare, guiding the development of precise diagnostic models to enhance patient care and outcomes in kidney stone management. By leveraging these insights, healthcare professionalscanmakemoreinformeddecisionsandtailor interventions to individual patient needs, potentially leading to better treatment outcomes and improved quality of life for kidney stone patients. Moreover, our study serves as a stepping stone for further research, fostering advancements in predictive analytics for renal health. Future studies can build upon our findings to develop more robust diagnostic tools and treatment strategies, ultimately benefiting patient outcomes and qualityoflifeinkidneystonemanagement.
7. Acknowledgement
We would like to extend our sincere gratitude to Prof. Dr. Ayesha Butalia from MIT ADT Pune for her invaluable support and guidance during the course of this research. Her expertise,dedication,andunwaveringencouragement havebeeninvaluableassetstoourteam,andwearedeeply appreciativeofhercontributions.
8. References
[1]HanH,SegalA.M,SeiferJ.L.andDwyerJ.T.Nutritional Management of Kidney Stones (Nephrolithiasis), PMC Journal of US National Library of Medicine and National InstituteofHealth,July31,2015.
[2] Curhan G.C, Willett W.C, Rimm E.B. Body size and risk ofkidneystones.JAmSocNephrolVol.9,1998.
[3]P.S.Ramesh,Ms.SnehaPatel,KalyanDevappaBamane ,Yelepi.UshaRani,MohitTiwari,T.Karthikeyan.Automatic Kidney Stone Detection Using Deep Learning Method. JournalofAdvancedZoologyVolume44,2023.
[4]Musagenemo,Kidneystonedetectionandclassification based on deep learning approach. International Journal of Advanced Natural Sciences and Engineering Researches Volume7,pp.38-42,4,2023.
[5] Jivan jayawant Barale. Comparative Analysis of AlgorithmstoPredicttheKidneyStone.December2023.
[6]OladejiF.A.,IdowuP.A.,EgejuruN.ModelforPredicting the Risk of Kidney Stone using Data Mining Techniques. International Journal of Computer Applications (0975 –8887)Volume182–No.38,2019.
[7] B. Gupta, A. Rawat, A. Jain, A. Arora, and N. Dhami.Analysis of Various Decision Tree Algorithms for Classification in Data Mining. International Journal of ComputerApplications(0975–8887)Volume163–No 8, April2017.
[8] Jehad Ali, Rehanullah Khan, Nasir Ahmad, Imran Maqsood. Random Forests and Decision Trees. International Journal of Computer Science Issues, Vol. 9, Issue5,No3,September2012.
[9] Aindrila Ghosh, Mona Nashaat, James Miller, Shaikh Quader, and Chad Marston.A Comprehensive Review of Tools for Exploratory Analysis of Tabular Industrial Datasets.Visual Informatics, Volume 2, Issue 4, December 2018,pp.235-253
[10] R. Hasan.Comparative Analysis of Machine Learning Algorithms for Heart Disease Prediction.ITM Web of Conferences,volume40,2021
[11] R. Kanduri, T. Bathini, A. Chewcharat, N. Leeaphorn, M. L. Gonzalez-Suarez, and W. Cheungpasitporn.Promises big data and artificial intelligence in nephrology and transplantation.J.Clin.Med.,vol.9,no.4,p.1107,2020
[12] Abdullah Alqahtani Shtwai Alsubai, Adel Binbusyyis,Mohemmed Shah ,Abdu Gumaei and Yu-Dong Zhang.Optimizing Kidney Stone Prediction through Urinary Analysis with Improved Binary Particle Swarm OptimizationandExtremeGradientBoosting.2023.
[13] Anbarasi M, Anupriya E, Iyenga NCHSN. Enhanced Prediction of Heart Disease with Feature Subset Selection using Genetic Algorithm. International Journal of EngineeringScienceandTechnology2(10)October2010.