
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 05 | May 2024 www.irjet.net p-ISSN: 2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 05 | May 2024 www.irjet.net p-ISSN: 2395-0072
Juluru V Y H Lakshmi Narsitha1
1UG Student, Department of Computer Science, R.V.R.&J.C College of Engineering, Guntur, Andhra Pradesh, India
Abstract - In the dynamic world of social media, this study embarks on a journey to explore the realms of gender prediction and hate speech detection using Twitter data. For gender prediction, GloVe embeddings are employed for text preprocessing, while logistic regression, support vector machines, and random forests etc. serve as classification algorithms. Twitter data encompassing user tweets and descriptions are scrutinized both individually and combined to predict gender based on textual features. In parallel, hate speech detection focuses exclusively on tweets, employing a bag-of-words representation and decision tree classifiers. The research evaluates the efficacy of these diverse algorithms in accurately predicting gender and detecting hate speech within Twitter data, illuminating the intricate challenges and promising avenues inherent in such tasks. By navigating the amalgamation of social media and machine learning methodologies, this study aims to offer valuable insights into the realms of gender prediction and hate speech detection, particularly within the context of online discourse.
Key Words: GloVe (Global Vectors) embeddings, Bag of Words, Gender Prediction, Hate Speech Detection, Twitter Data Analysis, Machine Learning, Textual Features, User Profile Analysis
In the ever-evolving landscape of social media, platforms like Twitter have emerged as rich sources of data, offering unique insights into human behavior and communication patterns. This study embarks on an exploration of two pivotal facets of social media analysis: gender prediction and hate speech detection. With the pervasive influence of online interactions, understanding how individuals represent themselves and identifying harmful speech is crucial for fostering inclusive and respectfuldigitalenvironments.
Gender prediction, a complex yet intriguing task, holds significant implications for various domains, including marketing, sociology, and psychology. Leveraging advanced text preprocessing techniques such as GloVe embeddings,coupledwithrobustclassificationalgorithms like logistic regression, support vector machines, and random forests, we endeavor to decipher the textual cues indicativeofgenderidentity.Byexamininguser-generated content, encompassing both tweets and profile
descriptions,weaimtouncoverpatternsandfeaturesthat contributetoaccurategenderprediction.
Simultaneously, our focus extends to the vital task of hate speech detection, a pressing issue in contemporary onlinediscourse.Hatespeech,characterizedbyitsharmful and discriminatory nature, poses serious challenges to fostering respectful interactions and upholding community standards. Employing a bag-of-words representation and decision tree classifiers, we aim to identify and mitigate instances of hate speech within the Twitterdatacorpus.Throughrigorousevaluation,weseek to assess the efficacy of diverse machine learning algorithms in accurately predicting gender and detecting hatespeech.
By navigating the intricate interplay between social mediadynamicsandmachinelearningmethodologies,this study aims to offer valuable insights into gender predictionandhatespeechdetectionwithinthecontextof online discourse. Through our exploration, we aspire to contributetoadeeperunderstandingofthesephenomena andinformstrategiesforcreatingsaferandmoreinclusive digitalspaces.
The significance of this research lies in its potential to addresscriticalissueswithintherealmofsocialmediaand online discourse. Gender prediction and hate speech detection are two areas of considerable importance, impacting various aspects of digital interactions and societaldynamics.
Firstly, gender prediction holds implications for understandinguserbehavior,preferences,andinteractions within online communities. By accurately predicting genderbasedontextualdata,researchersandpractitioners can gain insights into gender representation and its influence on communicationpatterns. This knowledgecan inform targeted marketing strategies, personalized user experiences, and sociological studies examining gender dynamicsindigitalspaces.
Secondly,hatespeechdetectioniscrucialforpromoting respectfulandinclusiveonlineenvironments.Hatespeech, characterized by its harmful and discriminatory nature, undermines the principles of free expression and contributes to the proliferation of online toxicity. By
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 05 | May 2024 www.irjet.net
effectively detecting and mitigating instances of hate speech, platforms can uphold community standards, protect users from harm, and foster constructive dialogue amongdiversepopulations.
Furthermore, this research contributes to the advancement of machine learning methodologies in the contextofsocialmediaanalysis.Byexploringtheefficacyof various algorithms, preprocessing techniques, and feature representations in predicting gender and detecting hate speech,thisstudyinformsbestpracticesandpavestheway for future research in the field of computational social science.
Themotivationbehindthisresearchisdeeplyrootedin theincreasinglyinfluential roleofsocial mediainshaping modern communication and societal dynamics. As platforms like Twitter continue to serve as central hubs for discourse, understanding and addressing the challenges they present is paramount. Gender prediction within this context offers insights into how individuals present themselves online and how gender influences digitalinteractions.Byaccuratelypredictinggenderbased on textual data from Twitter, we can uncover trends, behaviours,andpatternsthatinformmarketingstrategies, sociological research, and policy decisions, ultimately contributing to a more nuanced understanding of online communities.
Simultaneously, hate speech detection arises as a critical necessity in safeguarding the integrity of online spaces. The prevalence of hateful and harmful language undermines the principles of free expression and poses significant risks to individuals' well-being. By employing machinelearning techniquestoidentify and mitigate hate speech on Twitter, we aim to promote a safer and more respectful digital environment. This research not only addresses immediate concerns about online toxicity but also contributes to broader efforts to foster digital citizenship, combat online harassment, and uphold democraticvaluesinthedigitalage.
Rao et al. [1] investigate gender prediction on Twitter by analyzing user profiles and tweets. They employ machinelearning techniques, includinglogistic regression and support vector machines, to predict gender based on textual features extracted from user profiles and tweets. The study evaluates the effectiveness of different classification algorithms and feature representations in accurately predicting gender. This research provides foundationalinsightsintogenderpredictionusingTwitter data and informs the methodologies employed in the currentstudy.
p-ISSN: 2395-0072
WaseemandHovy[2]focusonhatespeechdetectionin online social networks, including Twitter. Their study develops a hate speech detection model trained on annotateddatasetsoftweetscontaininghatespeech.They explore various features, including lexical cues and syntactic patterns, to identify instances of hate speech. Machine learning algorithms, such as decision trees and random forests, are utilized to classify tweets as containing hate speech or not. This research offers valuableinsightsintothechallengesandmethodologiesof hatespeechdetectioninsocialmediacontexts.
Johnson and Scheffler [3] investigate online misogyny onTwitterthroughadata-drivenstudy.Theyanalyzeuser interactions, hashtags, and linguistic patterns to identify instances of misogynistic behavior. Their research employs natural language processing techniques, sentiment analysis, and network analysis to uncover the prevalence and characteristics of misogyny in online discourse. This study contributes to understanding the dynamics of gender-based hate speech on social media platforms.
Davidson et al. [4] investigate automated hate speech detection and the problem of offensive language on Twitter. They develop a hate speech detection model trained on large-scale annotated datasets of tweets. The study explores various linguistic and contextual features to identify instances of hate speech, employing machine learning algorithms such as logistic regression and supportvectormachines.This researchshedslightonthe complexities of hate speech detection and its implications foronlinediscourse.
Ribeiro et al. [5] investigate misogyny across the web, including social media platforms like Twitter. They analyze user-generated content, interactions, and linguistic patterns to detect instances of misogyny. The research employs natural language processing techniques and sentiment analysis to uncover the prevalence and characteristicsofmisogynisticbehavioronline.Thisstudy contributes valuable insights into understanding the dynamics of gender-based hate speech on social media platforms
Challenges in gender classification and hate speech detection on social media platforms are complex and multifaceted, reflecting the intricate dynamics of online discourse. Gender classification algorithms often struggle toaccuratelycapturethediverseandnuancedexpressions of gender identity prevalent in social media spaces. Traditionalbinaryclassificationsfailtoencompassthefull spectrumofidentities,includingnon-binary,genderqueer, and fluid identities, posing challenges for algorithms reliant on textual data alone. This highlights the need for
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 05 | May 2024 www.irjet.net
more sophisticated algorithms capable of interpreting a broader range of linguistic cues to classify gender accuratelywhilerespectingthediversityofuseridentities.
Similarly, hate speech detection algorithms face significant obstacles in accurately identifying and categorizing harmful speech. The contextual nature of languageonsocialmediaplatformspresentschallengesin discerning between genuine expression and harmful intent. Nuances such as sarcasm, irony, and cultural references further complicate detection efforts, necessitating algorithms that can navigate through layers ofcontext toaccuratelyidentifyandmitigatehatespeech. Additionally, the rapid evolution of language trends and the adaptation of hate speech tactics require algorithms that can continuously learn and adapt to emerging forms ofharmfulexpression.
Furthermore, both gender classification and hate speech detection algorithms must contend with issues of bias and privacy concerns. Biases present in training data and algorithmic decision-making can lead to unfair outcomes and perpetuate stereotypes, exacerbating existing inequalities. Additionally, the processing of sensitive user data raises ethical concerns regarding privacyandconsent.Addressingthesechallengesrequires interdisciplinary collaboration, rigorous methodologies, and a commitment to ethical principles to develop more effective and equitable solutions for gender classification andhatespeechdetectiononsocialmediaplatforms.
3.1 Dataset
The gender classification dataset obtained from Kaggle typically comprises textual data sourced from social media platforms, forums, or other online sources. Thisdatasetisannotatedwithlabelsindicatingthegender of the users, allowing for supervised learning approaches to train classification algorithms. It contains a variety of textual features such as user bios, posts, comments, or messages, reflecting the diverse ways individuals express their gender identities online. Researchers can utilize this dataset to develop models capable of predicting or classifying gender based on linguistic cues, enabling insights into gender representation and expression in digitalspaces.
On the other hand, the Hate Speech and Offensive Language Dataset obtained from Kaggle consists of text data annotated with labels indicating the presence or absenceofhatespeechoroffensivelanguage.Thisdataset encompasses a wide range of linguistic expressions consideredoffensive,derogatory,orhateful,sourcedfrom social media platforms, online forums, or other digital sources. It includes diverse contexts and topics, spanning discriminatory language based on race, ethnicity, gender,
p-ISSN: 2395-0072
religion,orotherattributes.Researcherscanleveragethis datasettodevelopalgorithmsfordetectingandclassifying hatespeechandoffensivelanguage,contributingtoefforts to promote online safety and combat harmful behavior in digitalcommunities.
Our data preprocessing, inspired by Wang et al.'s methodology, targets the refinement of unstructured textual data from social media, particularly Twitter, to bolsteritsqualityandutilityfortrainingmachinelearning models.Noisytokenslikehashtagsandusermentionsare eliminatedtoimprovedatacleanliness.
Additional fields TweetsDesc (TDis introduced for each dataset row, alongside the preprocessed counterparts of TweetsAlone (TA), TweetsDesc (TD), and Desc (Desc) CleanTweetsAlone (CTA), CleanTweetsDesc (CTD), and CleanDesc(CD).
Thepreprocessingstagesinclude:
1. Lowercasingalltext.
2. Removingspecialandnon-ASCIIcharacters.
3. EliminatingstopwordsusingNLTK.
4. Discarding emoticons, retweets, favorites, hashtags,URLs,andusernamesstartingwith'@'.
5. Removingduplicates.
6. TokenizingusingNLTK.
7. Convertinggendervalues to binary(1 for male,0 forfemale).
Hatespeechdetectionpreprocessingfollowsasimilar approach, refining textual data to identify harmful language. Hate speech labels are encoded in a manner analogous to gender values. Upon preprocessing, further processingisconductedtorefinethedataforanalysis.
To predict gender based on textual data from social media,thefirststepinvolvespreprocessing thetextusing GloVe embeddings. GloVe embeddings are a popular technique for representing words in a continuous vector space,capturingsemanticsimilaritiesbetweenwords.The textual data is embedded into high-dimensional vector representations using pre-trained GloVe models, which encodethesemanticmeaningofwords.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 05 | May 2024 www.irjet.net p-ISSN: 2395-0072
After preprocessing, multiple machine learning algorithmsaretrainedontheGloVeembeddingstopredict thegenderofsocialmediausers.Thesealgorithmsinclude NaiveBayes(NB),LogisticRegression(LR),DecisionTrees (DT), Random Forests (RF), Support Vector Machines (SVM), Bagging, Voting Classifier Hard (VCH), Voting Classifier Soft (VCS), XGBoost (XGB), and others. Each algorithm learns from the patterns present in the GloVe embeddings to classify social media users into different gendercategories.
Followingthetrainingphase,theperformanceofeach machinelearningalgorithmisevaluatedusingaccuracyas the primary metric. Accuracy measures the percentage of correctly classified instances of gender prediction. Additionally, other evaluation metrics such as precision, recall, and F1-score may also be calculated to assess the models'performancecomprehensively.
To visualize the performance of each algorithm, a graphisplottedshowingtheaccuracyof eachmodel.This graphprovidesacomparativeanalysisoftheperformance of different machine learning algorithms in predicting gender based on textual data. Based on the results from the graph and evaluation metrics, the best-performing algorithmisselectedforgenderprediction.
In the process of hate speech detection, the first step involves preprocessing the textual data extracted from social media platforms. This preprocessing ensures that the data is of high quality and consistency for further analysis. The text is tokenized to break it down into individual words or tokens, and then cleaned to remove any noise such as special characters and stopwords. Followingthis, thecleanedtextis transformed intoa bagof-words representation, where each word in the text becomes a feature. This representation allows for the creationofafeaturevectorforeachinstanceoftext,which iscrucialfortrainingmachinelearningmodels.
Subsequently,adecisiontreeclassifierisemployedto train on the prepared bag-of-words features to identify instances of hate speech within the data. Decision trees are a popular choice for classification tasks due to their simplicity and interpretability. They work by recursively partitioning the feature space based on the values of individualfeatures,ultimatelyleadingtoadecisionateach leaf node. During the training phase, the decision tree learnstodistinguishbetweeninstancesofhatespeechand non-hate speech basedonthefeaturesextractedfrom the bag-of-wordsrepresentation.
Once the decision tree model is trained, its performance is evaluated using standard metrics such as
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 05 | May 2024 www.irjet.net p-ISSN: 2395-0072
accuracy, precision, recall, and F1-score. Accuracy, in particular, is calculated to determine the percentage of correctly classified instances of hate speech. This evaluation process provides insight into the effectiveness ofthedecisiontreemodelindetectinghatespeechwithin the social media data. By following this workflow, researchers and practitioners can effectively leverage machine learning techniques for hate speech detection, contributing to efforts aimed at promoting online safety andcombatingharmfulspeech.
The results of the hate speech detection model indicate a high accuracy of 87.21%. This means that the model correctly identified instances of hate speech in the datasetwithanaccuracyrateof87.21%.Achievingsucha high accuracy level is promising and suggests that the model iseffectiveindistinguishinghatespeechfrom nonhatespeechinstancesinsocialmediadata.
To further validate the performance of the model, it wastestedusingasetoftweets.Duringtesting,the model analysedthetextualcontentofthesetweetsandprovided predictions regarding whether each tweet contains hate speechornot.Thepredictedoutputfromthemodelserves as an indication of its ability to generalize and make accuratepredictionsonnew,unseendata.

The gender prediction model utilizing Random Forest (RF) achieved a high accuracy rate of 80%. This indicates that the model successfully classified social media users' genders with an accuracy of 80%. Random Forest is known for its robustness and ability to handle complex datasets, making it a suitable choice for this task. So, the
accuracy scores for various Machine Learning Algorithms isgivenbelow:
Algori thms
Table 4 –AccuracyScoresforvariousMLAlgorithms
To assess the performance of various machine learning algorithms in gender prediction, a graph was plottedshowcasingtheaccuracyofeachmodel.Thisgraph provides a comparative analysis of different algorithms' effectiveness in predicting gender based on textual data. While Random Forest achieved a high accuracy rate, comparing its performance with other algorithms provides valuable insights into the strengths and weaknessesofeachapproach.
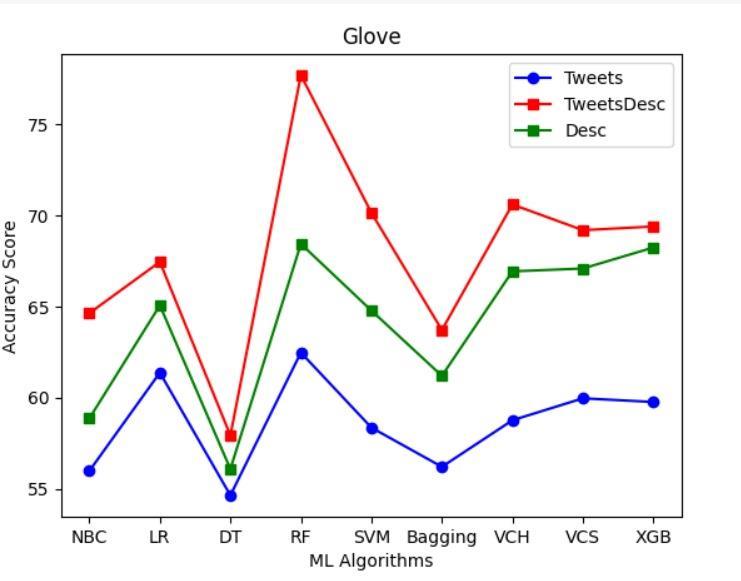
Figure-4.1: ComparisonbetweenvariousMLAlgorithms
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 05 | May 2024 www.irjet.net p-ISSN: 2395-0072
Additionally, the model was tested using a set of tweets to evaluate its predictive capabilities on unseen data. During testing, the model analyzed the textual content of these tweets and provided predictions regarding the gender of the users associated with each tweet. Thepredicted output servesasanindication ofthe model's ability to generalize and make accurate predictionsinreal-worldscenarios.
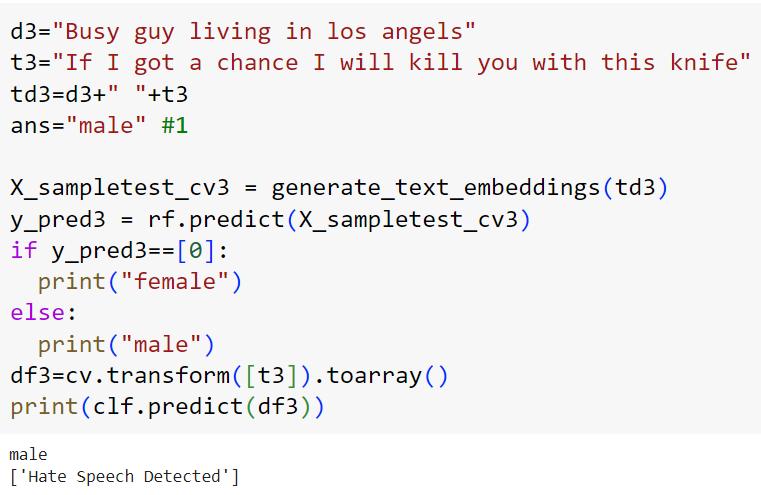
Inconclusion,thisstudyexploredtherealmsofgender prediction and hate speech detection using machine learning techniques applied to social media data. For gender prediction, various machine learning algorithms, including Random Forest, were employed, resulting in an accuracy rate of 80%. This indicates the effectiveness of machine learning in predicting gender based on textual datafromsocialmedia.Additionally,hatespeechdetection using a decision tree classifier achieved an accuracy of 87.21%, highlighting the model's capability to identify instancesofhatespeechinsocialmediadata.
Moving forward, several avenues for future research exist. Firstly, enhancing the performance of gender prediction models by exploring more advanced feature engineering techniques or incorporating deep learning architectures could be beneficial. Additionally, investigating the effectiveness of ensemble methods or neural networks for hate speech detection may further improve model performance. Moreover, considering the dynamic nature of social media data, continuous model refinement and adaptation to evolving language patterns and trends are crucial. Furthermore, extending the analysis to encompass other social media platforms and languages could provide broader insights into online discourseandfacilitatethedevelopmentofmoreinclusive and effective moderation strategies. Overall, ongoing research in this domain holds the potential to contribute tocreatingsaferandmoreinclusiveonlineenvironments.
1. Alowibdi, J.S., et al. (2013a). Empirical evaluation of profilecharacteristicsforgenderclassificationonTwitter.
2. Angeles, A., et al. (2021). Text-based gender classification of Twitter data using Naive Bayes and SVM algorithm.
3.Davidson,T.,Warmsley,D.,Macy,M.,&Weber,I.(2017). Automated Hate Speech Detection and the Problem of Offensive Language. In Proceedings of the 11th International AAAI Conference on Web and social media (pp.512-515).
4.Johnson,A., &Scheffler,E. (2019).Misogynyon Twitter: A Data-driven Study. In Proceedings of the ACM on Human-ComputerInteraction,3(CSCW),1-23.
5.Onikoyi, B., Nnamoko, N., & Korkontzelos, I. (2023). Gender prediction with descriptive textual data using a machinelearningapproach
6.Rao, D., Yarowsky, D., Shreevats, A., & Gupta, M. (2010). Classifying Latent User Attributes in Twitter. In Proceedingsofthe2ndInternationalWorkshoponSearch andMiningUser-generatedContents(pp.37-44).
7.Ribeiro,F.N.,Ottoni,R.,West,R.,Almeida,V.,&MeiraJr, W.(2018).Auditing Radicalization Pathways on YouTube. In Proceedings of the ACM on Human-Computer Interaction,2(CSCW),1-20.
8.Waseem, Z., & Hovy, D. (2016). Hateful Symbols or Hateful People? Predictive Features for Hate Speech Detection on Twitter. In Proceedings of the NAACL StudentResearchWorkshop(pp.88-93).