
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN: 2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN: 2395-0072
Mr. Chethan HK1, Ms. Anjali K2, Mr. Rajesh M3, Mr. Shivakumar M4, Ms. Vidya MG5
1 Assistant Professor, Dept. of Computer Science and Engineering, Maharaja Institute of Technology, Thandavapura
2,3,4,5Students, Dept of Computer Science and Engineering, Maharaja Institute of Technology, Thandavapura ***
Abstract - InsidethefieldofPCvision,vehicleandpedestrian discoveryisacomplicatedcyclethatrequirestheutilizationof refined calculations for the constant translation of visual information. The primary objective is to utilize softmax actuation capabilities to dole out class probabilities and expect to bound enclose requests to recognize and arrange vehicles and walkers unequivocally. Non-most extreme concealment and different methodologies that eliminate excess location ensure the enhancement of these gauges. Extraordinarily, these systems are more grounded and work better in various normal conditions because of the joining of multimodal data from sensors like lidar and cameras. These systems track down realistic application in autonomous vehiclesandsplendidcityestablishments,wheretheygoabout asbasicpartsforsettlingoneducatedchoices.Theyareready on colossal datasets and a significant part of the time coordinate move learning for capability.
Key Words: Computervision,Non-maximumsuppression, Softmaxactivation.
Various nations by and large dislike road traffic of late, including defilement, blockage, and setbacks. The World ProsperityAffiliationreportsthat1.35millionpeoplepassed onasaresultofvehiclecrashesin2016,withanormal20to 50 million setbacks. Reliably, wounds end up peopling. In addition,itwassaidthattheessentialdriverofpassingsfor youngsters and energetic adults is car crashes. These upsettingestimationsaregenerallytheoutcomeofhuman bumble and tactlessness, for instance, driving while intoxicated, depleted, speeding, and using a remote while workingavehicle.
The World Wellbeing Association (WHO) reports that, contrasted with other street clients, bikers and walkers endureroughly50%ofalltrafficfatalitiessincetheyneed defensive stuff like protective caps and garments. Being abilitytopredicttheexpectationofAwalkerwhoutilizations presentassessmentandacknowledgmenttechniqueswould expandeverybody'swellbeingoutandabout.Asindicatedby a 2013 WHO research, street mishaps are anticipated to climbfromtheircurrenteighth-placepositioningtothefifth spotamongtheprimarydriversofdeathby2030.Over25% of setbacks in street mishaps in 2013 were VRUs. Of the fatalitiesfromtrafficepisodesthatwereaccountedfor,42%
included walkers and 16% involved bikes, with 69% of these.
Examinationintotheformationofkeendrivingadvancesis beingfinishedwithanendgoaltodiminishdriversleepiness and increment driving security. Considering that human securityshouldconstantlystartthingsoutincannydriving, researchonhelpeddrivingframeworks(Promotions)andits capacity to build wellbeing is a famous point. For Advertisements in savvy vehicles, the impact evasion cautioning framework (CAWS) [3] is exceptionally significant.Monitoringone'senvironmentalelementsisone ofCAWS'sprincipalconcerns.Objectdiscoveryinnovationis utilized to distinguish, identify, and group the pictures of vehiclesandwalkerstakenviacarcameras.Bethatasitmay, thisinnovationexperiencesissuessincecomplexscenedata is available. AI based and profound learning-based approaches are the two essential strategies for distinguishingvehiclesandindividuals.Inthefirstplace,AI strategies.
InthefieldsofpictureID,significancelearning,andPCvision progressions, object acknowledgment is a urgent investigation locale. It fills in as the speculative beginning stageformoreproblematiccriticallevelPCvisionendeavors, forexample,expectinganarticle'sdirectinanimageafterit has been recognized. Vector machine or Crowd computations are the mainstays of standard disclosure strategies.Theirfundamentalmethodologyfortargetareais sliding Windows. This approach isn't fitting for colossal degreeapplicationsinviewofitsbroadplainmonotonyand horrid goodness. Significant learning-based target unmistakableevidencecomputationshavebeencoherently completed in a couple of spaces in the past two or three years.Thesignificantlearning-basedapproachisdepictedby its exceptional constant execution and high revelation accuracy.Inthismanner,asignificancelearning-basedtarget acknowledgmentestimation.
In recent years, deep learning-based object detection systems have shown impressive accuracy when using populardatasetssuchasMSCOCOandPascalVOC.However, thepoorobjectcontentineachimageofthesetwodatasets and the 640 px picture resolution limit the practical applicability of target detection. VisDrone and UAVDT are two instances of high-resolution remote sensing image collections[4],althoughbothdatasetsimageresolutions roughly2000pixels arenottypicalofreal-worldscenarios.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN: 2395-0072
Autonomous vehicle and pedestrian detection systems represent noteworthy advancements in computer vision, withfar-reachingimplicationsforautomation,effectiveness, andsecurityinseveralsectors.
Withahostofadvantagesrangingfromcollisionavoidance toimprovedvisibility,thesetechnologieshavethepotential tocompletelytransformurbanplanning,transportation,and surveillance.
Thetargetofawalkerandvehicleidentificationprojectisto execute a savvy framework that precisely recognizes and tracks people on foot and vehicles progressively. This innovationupgradessecuritybygivingidealadmonitionsof possiblecrashesandaddstotheimprovementofbrilliantcity framework.
Whilerecognizingvehiclesandpeopleusingsignificant learningcomputations,differenttangledissuescomeup.One of the fundamental troubles is the range of people and vehicles concerning shapes, sizes, tones, and headings. Further confounding the recognition cycle is the scale fluctuation where these things show up in photographs, requiringmodelsthatcanperceiveobjectsatvarioussizes. Besides, the cutoff points forced by ongoing handling requests call for calculations and designs that can rapidly break down pictures to go with ideal choices, which are fundamentalinapplicationslikeindependentdriving.One more trouble is the multifaceted design of foundations, whicharehabituallyloadedwiththingsliketrees,structures, or different vehicles and require exact partition between forefront items and foundation commotion. The issue is aggravated by incompleteimpediment,sincethings might becomedisguised.
Duetotheirviabilityindecipheringvisualinformation, convolutionalbrainorganizations(CNNs)arefundamental forprofoundlearning-basedrecognizableproofofvehicles andwalkers.CNNsaresuccessfulcomponentextractorsin this present circumstance, ready to separate complex examples and spatial ordered progressions from pictures. Learnable channels distinguish low-level highlights like edges and surfaces in the convolutional layers of CNNs, which are first answerable for handling approaching pictures. Resulting layers separate more unpredictable highlights likewheels,headlights,orhumanbodyshapes thatarerelevanttovehiclesandindividualsastheinfo travelsthroughtheorganization.CNNsworkwithexactitem restriction and characterization inside pictures when utilizedrelatedtoprotestidentificationstructureslikeJust goforitorSSD.CNNsarechangedbylimitchangesduring
gettingreadytoreducethedistinctionbetweentheexpected andground-truthobjectclarifications.
YouOnlyLookOncerendition7,orYOLOv7,isastate-of-theartobjectacknowledgmentmodelthatishabituallyutilized inprofoundlearningapplicationsforvehicleandpersonon foot recognizable proof. The objective of YOLOv7, a progressionoverpriorConsequencesbedamneddesigns,is toincrementongoingitemrecognitionsituations'precision and proficiency. For this model to work, the information pictureisseparatedintoalattice,andforeverymatrixcell's item, bouncing boxes, certainty scores, and class probabilitiesareatthesametimeanticipated.In YOLOv7, qualitiesareextricatedfromtheinformationpictureutilizing a succession of convolutional layers, and afterward object properties are anticipated utilizing distinguishing heads. Since YOLOv7 canperceive objectswithvarioussizesand perspective proportions, it is an amazing decision for recognizingvehiclesandwalkers.
ZhihulChen,XiaoyanChenandKeyingRenapproachedan improvednetworkforpedestrian-vehicledetectionbasedon YOLOv7,inthispaper,atremendousnumberofassessments have been made to additionally foster the disclosure accuracy of walkers, vehicles and labels in metropolitan networks.ThebettercomputationconsideringYOLOv7was used to lead a colossal number of preliminaries on the metropolitanbystandervehicledataset[1].
In the paper "Exploiting the Potential of Overlapping CroppingforReal-WorldPedestrianandVehicleDetection withGigapixel-LevelImages,"ChunleiWang,WenquanFeng, BinghaoLiu,XinyangLing,andYifanYangpresentedamidline reply for the issue of a gigantic number of managed concentrations in picture altering. When stood out from before assessments, their philosophy rarely required computations and could further develop area execution. Theirsuggestedmidlineapproach,inanycase,hasacouple of drawbacks, including higher computation and terrible appearance for enormous cut things. In this manner, they meantoincludemoreusefulandlightweightproceduresin theirapproachingaudittoextrafurtherdevelopthemodel's distinguishingprooflimits[2].
Ujwalla Gawandea, Kamal Hajarib and Yogesh Golharc approached to Real-Time Deep Learning Approach for Pedestrian Detection and Suspicious Activity Recognition his work offers a novel and solid profound learning technique along with a remarkable person on foot informationalindexcontainingunderstudywaysofbehaving liketakinglab gear, questioning amongunderstudies,and jeopardizingconditionsininstructivesettings.Itisthefirst of offering a predictable and solid ID explanation to pedestrians’kind.Yetagaingaveasimilarinvestigation of
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN: 2395-0072
resultsaccomplishedbythemostrecentprofoundlearning strategy for procedures of distinguishing dubious action, following people on foot, and identifying them on a new benchmarkdataset[3].
YujiaoLiuaandXuanGuoResearchonVehicleDetectionand Recognition Algorithm Based on Improved YOLOv5, This explorationstudiestheimprovedYOLOv5-basedcalculation forvehicleandwalkeridentificationandacknowledgment. Toexpandtheaccuracyandviabilityofdiscovery,upgrades aremadetothepost-handlingcalculation,neckorganization, and spine organization. With the refreshed technique, the testing results show prominent upgrades in common and vehicle acknowledgment undertakings, as well as quicker handlingtimeandhigherprecision[4].
KefuYi,KaiLuo,TuoChenandRongdongHudevelopedAn ImprovedYOLOXModelandDomainTransferStrategyfor Night time Pedestrian and Vehicle Detection. This paper constructed a YOLOX-based calculation for vehicle/pedestrianidentification.Moreover,apreparation procedure in view of information space move was recommended to additional increment the calculation's identification precision in low light. They utilized the recommended area move way to deal with train the upgradedYOLOX,andtheoutcomesweregreat[5].
There are different issues with the ongoing profound learning-based approach for identifying vehicles and walkers.Mostimportantly,itregularlyexperiencesdifficulty withtroublesomelightingandclimateconditions,asserious downpourorhaze,whichcouldlessentheaccuracyofarticle discovery. It's possible that the system won't manage occlusions situations in which cars or people are partially obscured from view well. Its processing demands may preventitfrombeingappliedinreal timeondeviceswith limitedresources.Systemperformancemaybeimpactedby real-timeprocessingrequirements,particularlyincontexts with limited resources. Diverse surroundings, such rural locations with dirt roads, odd road markings, or unique trafficcircumstances,mightbedifficultfordetectionsystems to adjust to. Adversarial attacks can damage machine learning-baseddetectionmodelsbyintroducingmaliciously generatedinputsthatleadtomisclassifications.
To improve road safety, a deep learning-based system for detecting vehicles and pedestrians is suggested. It utilizes object identification techniques. by putting sensors and camerasinkeyspots.Theclimateiscontinuallyandinasplit secondcheckedbytheframework.Itisfitforexactvehicle and passerby ID, following, mishap aversion, and observation. It can handle information at quick paces and with incredible precision, which further develops traffic signal and independent driving frameworks' effectiveness
andwellbeing.Withthepossibilitytoradicallybringdown mishap rates and further develop traffic stream, this innovationwilleventuallyassistwithmakingmoresecure andmorewisetransportationorganizations.Fashionerscan give a strong and useful vehicle and walker revelation system through mindfully organizing each piece of the proposed structure and contemplating the uncommon necessitiesoftheapplication.
Severalessentialpartsmakeupthesystemarchitecture fordeeplearning-basedcarandpedestrianidentification.To begin with, visual information is assembled, for the most partbymeansofcameras.Preprocessingisfinishedonthis information to work on its quality and normalize its configuration.Then,fromthepre-handledpicturesorvideo outlines, a Convolutional Neural Network (CNN) or other profound learning model is utilized to remove important data.
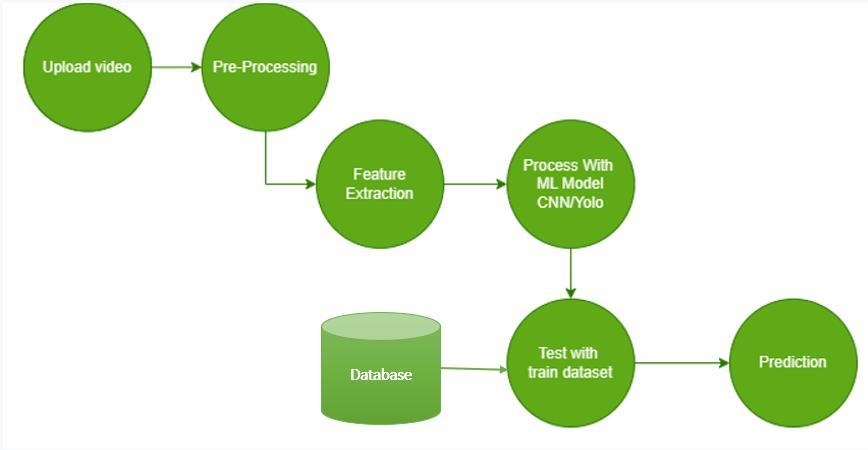
Thesequalitiesfindisolatingattributeslikeedges,surfaces, and designs that are major for perceiving vehicles and individuals by walking. Following part extraction, the significantlearningmodeldoesadditionalexaminationon thedatatoperceivethepresenceandareaofvehiclesand people.Thisplanmakesitpossibletodistinguish vehicles and walkers with precision and capability in different applications, for instance, surveillance systems and traffic light.
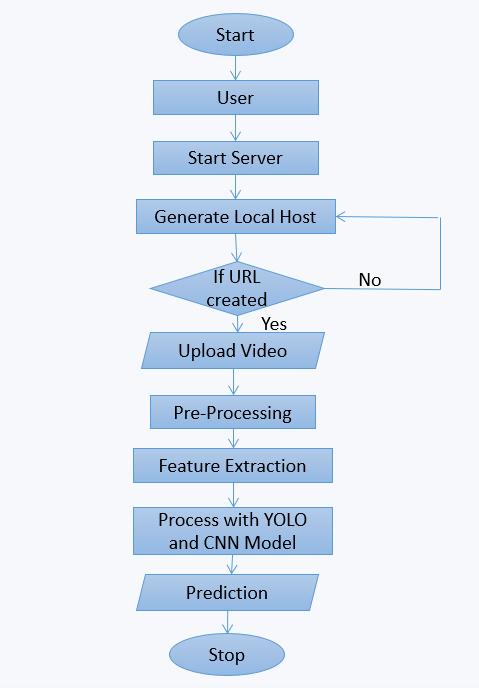
The means engaged with assessing a video document are displayedinthisflowchart.Tohavetheprogram,theclient shouldinitiallymakeanearbyhostandbeginaserver.The client transfers a video assuming that they are fruitful in making the URL that will have the application. After prehandlingthetransferredvideotosetitupforinvestigation, itselementsareseparatedtorecognizethemainsections. From that point onward, by using CNN and Just go for it displays to decipher the recovered information, the
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN: 2395-0072
frameworkcananticipatethetraitsorcontentofthevideo. Following the creation of figures, the method arrives at a resolution,shuttingtheexaminationofthevideo.
Kaggle Cityscapes dataset contains pictures from metropolitanconditions,clarifiedwithpixel-levelmarksfor differentarticlesincludingpeopleonfoot,vehicles,andthen some.It'sbroadlyutilizedforsemanticdivisionerrandsin PCvision,includingpersononfootandvehiclerecognition.

7. Implementation and Result
1.Input Video: Inthisstep,thesystemreceivesinputfroma videofeedfromintersection-mountedcameras.Thetraffic scenario, which includes pedestrians and vehicles passing throughtheintersection,iscapturedbythevideofeed.
2.Pre-Processing: Preparingtheinputvideodataforfurther processing and analysis is part of pre-processing. To improvethequalityofthevideodata,thisstepmayinclude taskslikeresizingthevideoframes,adjustingbrightnessand contrast,andremovingnoise.Pre-handlingguaranteesthat theinfoinformationisreasonableforexactrecognitionand characterizationofitems.
3.YOLO Algorithm Implementation to Track Objects and Draw Boxes:
The object detection algorithm YOLO (You Only Look Once) is capable of locating and identifying objects within video frames or images. The YOLO algorithm is used to identify vehicles and pedestrians in the pre-processed video frames in thisstep.
The YOLO algorithm analyzes each frame of the inputvideoandidentifiesregionsofinterestwhere objectsarelocated.Itthenpredictsboundingboxes aroundtheseobjectsandassignsclasslabels(e.g., vehicleorpedestrian)toeachdetectedobject.
Oncetheobjectsaredetectedandboundingboxes are generated, the YOLO algorithm draws boxes around the detected objects in the video frames, makingitvisuallyapparentwhichregionscontain vehiclesandpedestrians.
4.Process with CNN (Convolution Neural Network):
After the initial detection and bounding box generationusingtheYOLOalgorithm,thenextstep involves processing the detected objects using a ConvolutionalNeuralNetwork(CNN).
TheCNNistrainedtoperformobjectclassification, distinguishing between different types of objects such as vehicles and pedestrians. It takes the croppedregionsofinterest(ROI)fromthedetected bounding boxes as input and predicts the class labelsforeachobject.
TheCNNutilizesitslearnedfeaturesandpatternsto accurately classify objects based on their visual characteristics,suchasshape,texture,andcolor.
5.Pedestrian Classification and Vehicle Classification:
Inthisstep,theCNNperformsclassificationtasksto distinguish between pedestrians and vehicles withinthedetectedboundingboxes.
Forpedestrianclassification,theCNNanalyzesthe visual featuresoftheobjectswithinthebounding boxes and predicts whether they represent
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN: 2395-0072
pedestrians based on learned patterns of human bodyshapeandmovement.
Similarly, for vehicle classification, the CNN identifiesvisualcuesindicativeofvehicles,suchas wheels, headlights, and body structure, to accuratelyclassifyobjectsasvehicles.
Resultscanshiftinviewofvariableslikethesizeandnature ofthedataset,thepickedmodeldesign,andtheadequacyof preprocessing strategies. Most of the time, cutting-edge models can detect vehicles and pedestrians with high accuracy, and some can even perform in real time on hardwarethatisuptothetask.
Allinall,profoundlearning-basedvehicleandpersononfoot discoveryisauniqueadvantageinvariousfields,including independent driving, public security, and reconnaissance. Theexactnessandproficiencyofdiscoveryframeworkshave beenincrediblyworkedonbytheutilizationofperplexing profound learning models, like Convolutional Brain Organizations (CNNs), and refined object identification systems, like Consequences be damned. Indeed, even in convoluted visual scenes with evolving conditions, these frameworks can perceive vehicles and walkers with exactness continuously. All things considered, notwithstanding critical headways, issues like overseeing impediments,adjustingtodifferentsettings,handlinglimits continuously still exist. To beat these obstructions and improve the usefulness and versatility of vehicle and passerby recognition frameworks, it is important to continuous innovative work. Future advancements in profound learning procedures, along with the developing accessibilityofexplaineddatasetsandcomputationalassets, look good for the improvement of considerably further developedandtrustworthylocationframeworks,whichwill eventually work on the security and productivity of metropolitanconditionsandtransportationframeworks.
OursignificantappreciationgoesouttoDr.HKChethan,our projectcoordinator,forhissteadyhelpandenergeticwork in guaranteeing that this task is finished on time. We likewise praise our specialty head, Dr. Ranjit KN, for cultivating a climate that supports development and functional executionof our educational program. Towrap thingsup,wemightwanttothankourhead,Dr.YTKrishne Gowda, for continuously supporting our scholar and exploration attempts and for furnishing us with the incrediblechancetochipawayataventurenamed"Vehicle andPedestrianDetectionUsingDeepLearning."
[1] T. Zhang et al., "HOG-ShipCLSNet: A Novel Deep Learning Network with HOG Feature Fusion for SAR ShipClassification,"inIEEETransactionsonGeoscience and Remote Sensing, vol. 60, pp. 1-22, 2022, Art no. 5210322, doi:10.1109/TGRS.2021.3082759M. Young, The Technical Writer’s Handbook. Mill Valley, CA: UniversityScience,1989.
[2] A.AlbayrakandM.S.Özerdem,"GasCylinderDetection Using Deep Learning Based YOLOv5 Object Detection Method," 2022 7th International Conference on ComputerScienceandEngineering(UBMK),2022,pp. 434-437,doi:10.1109/UBMK55850.2022.9919478.
[3] Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland,6–12September2014;pp.740–755.
[4] Shrivastava,A.;Gupta,A.;Girshick,R.Trainingregionbasedobjectdetectorswithonlinehardexamplemining. In Proceedings of the IEEE Conference on Computer VisionandPatternRecognition,LasVegas,NV,USA,27–30June2016;pp.761–769.
[5] Wang,X.;Zhang,X.;Zhu,Y.;Guo,Y.;Yuan,X.;Xiang,L.; Wang, Z.; Ding, G.; Brady, D.; Dai, Q.; et al. Panda: A gigapixel-level human-centric video dataset. In ProceedingsoftheIEEE/CVFConferenceonComputer VisionandPatternRecognition,Seattle,WA,USA,13–19 June2020;pp.3268–3278
[6] WHO. Global Status Report on Road Safety 2018: Summary;TechnicalReport;WorldHealthOrganization: Geneva,Switzerland,2018
[7] Girshick,R.;Farhadi,A.;Divvala,S.;Redmon,J.Unified, Real-TimeObjectDetection YouOnlyLookOnce.pp. 779–788inProceedingsofthe2016IEEEConferenceon ComputerVisionandPatternRecognition(CVPR),held June27–30,2016,inLasVegas,NV,USA.