
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN: 2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN: 2395-0072
12345Graduate Student,6Assistant Professor, Department of Electronics and Communication Engineering, Sri Vasavi Engineering College, Tadepalligudem, West Godavari, Andhra Pradesh, India ***
Abstract -Multiplication serves as the center of many computer processes, hence the creation of efficient multiplication algorithms is a crucial area of research. The Karatsuba method is widely recognized for its ability tospeed multiplication by dividing big operands into smaller, simpler to handle sub problems. However, delivering high-speed performance while preserving area is still a difficulty in real applications. Thispaperproposesanovelapproachtoenhance both speed and area efficiency of Karatsuba multiplication through the integration of Sklansky adders. Sklansky adders are a type of parallel prefix adder, known for their inherent parallelism and compact layout, offer a promising solution to address the performance and resource utilization concerns associated with traditional multiplicationarchitectures. The proposed design leverages the recursive nature of Karatsuba multiplication to exploit parallelism at various stages of the algorithm. By incorporating Sklansky adders into critical sections ofthe Karatsubamultiplier,theproposedarchitecture achieves significant improvements in both speed and area efficiency compared to Vedic multiplier implementation. Furthermore, the design exhibits scalability across different operand sizes, making it suitable for a wide range of applications demanding high-performance multiplication capabilities.
Key Words: Karatsuba Multiplier, Sklansky Adder, Vedic multiplier.
IntherealmofVeryLarge-ScaleIntegration(VLSI)design, optimizingarithmeticoperationsforfloating-pointnumbers iscrucialforachievinghigh-performancecomputingsystems. Floating-point multiplication, a fundamental arithmetic operation in many computational tasks, demands efficient algorithms and hardware implementations to meet the increasingdemandsofmodernapplications.
Therealmoffloating-pointmultiplicationunderliesawide rangeofscientificcalculations,fromsimulatingcomplicated phenomena in nature to processing enormous datasets in machinelearning.However,thetypical,elementary-school approachofmultiplyingbigfloating-pointnumbersrapidly becomescomputationallycostly.Thisiswherethebrilliant Karatsubaalgorithmshines.
Traditional methods for floating-point multiplication often face challenges in terms of speed and area efficiency. One promisingapproachtoaddressthesechallengesisleveraging the Karatsuba algorithm, a fast multiplication technique known for its divide-and-conquer strategy, whichreduces massivenumbermultiplicationtosmaller,moremanageable subproblems.Itaccomplishesthisbyintelligentlybreaking downthetwofloating-pointvalues(AandB)intohighand low-orderbits.Thisdecompositionfacilitatesrecursivecalls to the Karatsuba algorithm on the smaller parts. The real magic,isitsabilitytoestimatethemiddleproduct(P2)-the productofAandB'smiddle-orderbits-usingjusthighand low-orderdata.Thisestimationreducestherequirementfor afullmultiplication,resultinginaconsiderablereductionin thenumberofmultiplicationstepsnecessary.
The benefits of the Karatsuba algorithm are numerous. Firstly,ithasatimecomplexityofaroundO(n^1.58),whichis significantlybetterthantheO(n^2)difficultyofthegradeschooltechnique,especiallyforlargenumbers.Thisleadsto considerably quicker computations, which is beneficial for applicationsthatrelyheavilyonfloating-pointcalculations. Second, its divide-and-conquer nature makes it ideal for hardwareimplementationinprocessorsandothercomputing devices.Thisenableseffectiveuseofhardwareresourcesfor floating-pointmultiplicationapplications.
This paper explores the design and implementation of floating-pointmultiplicationusingtheKaratsubamultiplierin VLSI.Webeginbyprovidingabriefoverviewoffloating-point representation and the challenges associated with its multiplication.Subsequently,wedelveintotheprinciplesof theKaratsubaalgorithmanditsadaptationforfloating-point arithmetic.
Haripriya A et al. present a special Vedic multiplier architecture that utilizes the fundamental components of digitalsignalprocessors,theRCAandCSLAarchitectures.The study encourages CSLA integration, emphasizing power, speed,andareaefficiencyinordertoincreasemultiplication. The Urdhva-Tiryakbhyam approach is used to divide the input operands into smaller blocks. The intermediate productsarethenobtained,andtheCSLAisusedtosumthe resultstoachievethefinalresult.Despiteproblemswitharea efficiencybroughtonbyCSLA'stwinRCAdesign,synthesis
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN: 2395-0072
experiments using Xilinx ISE 14.7 demonstrate a 12% reduction in latency and an increase in area of 3% when comparedtotheRCA-basedVedicmultiplier[1].
Sumit Vaidya et al. explore the computational burden of multiplicationoperationsinprocessors,aimingtoenhance performanceandminimizepowerconsumption.Leveraging insightsfromAncientIndianVedicMathematics,specifically the"UrdhvaTiryakbhyam"algorithm,theyseektoimprove multipliers speed and area efficiency. Additionally, they introduce the "Nikhilam Sutra" formula to expedite multiplication, thereby enhancing overall multiplier performance[2].
K.N. Vijeyakumar et al. introduce a novel approach to enhance the speed and area efficiency of Arithmetic Units (AUs)crucialforsignalandimageprocessingarchitectures. Byintegratingthe"verticalandcrosswisesutra"fromVedic mathematics,theresearchfocusesonimprovingmultipliers. Thismethodeffectivelyreducescriticaldelaybysimplifying PartialProduct(PP)generatingunits.Implementationresults demonstrate significant improvements, with a 19.2% decrease in the Area-latency Product (ADP) and a 13.7% reductioninlatency,particularlyutilizingtheTSMC180nm CMOS process with CADENCE Encounter Digital Implementation[3].
S.AlwynRajivetal.stresstheimportanceoffloating-point multipliers in DSP, delving into IEEE 754 standard representationsandadvocatingtheVedicmethodfor24-bit multiplication.Theyscrutinizeadderdesigns 9-bitto36-bit variants including Carry Look Ahead, Carry Save, Ripple Carry, and Kogge Stone types, aiming to enhance VLSI efficiency for DSP. The research seeks to optimize adder performance for DSP via Verilog HDL implementation and Xilinx ISE simulation, focusing on area and latency evaluations[4]
Ranjeeta Yadav et al. conduct a comparative analysis of various combinations of Finite Impulse Response (FIR) filters, multipliers, and adders sourced from literature. Emphasizing the significance of FIR filters in digital signal processingapplications,theyassessdifferenttypesofadders and multipliers, including Vedic Multipliers, Han Carlson, Dadda, Booth, Ripple Carry, and Carry Look Ahead. LeveraginginsightsfromVedicmathematics,theyevaluate keycriteriasuchasarea,latency,powerconsumption,and Look-UpTable(LUT)utilizationtodetermineeffectiveFIR Filter designs. Notably, the Vedic Multiplier emerges as a high-speed and low-power option among the compared multipliers[5]
S.Jayakumaretal.investigatesignalprocessingapplications, withafocusonthecrucialroleofFiniteImpulseResponse (FIR)filtersinenhancingsignalquality.Theyadvocateforthe adoptionoftheAnurupymultipliertoaddresscriticalpath challenges,leadingtoenhancedefficiencyandspeedinFIR filter designs, as demonstrated through comprehensive
simulationandsynthesisusingVHDL,ModelSim,andXilinx tools[6].
ArishSandR.K.Sharmaunderscorethepivotalroleofbinary multiplicationinfloating-pointmultiplierdesignsandhighpowercomputing,emphasizingitsimpactontime,area,and powerconsumption.Tooptimizeimplementationefficiency, theyproposeanoveltechniqueforunsignedbinarynumber multiplication,blendingtheUrdhva-Triyakbhyamalgorithm from Vedic Mathematics for lower bit operations with the Karatsubaalgorithmforhigherbitoperations.Implementing this approach in Verilog HDL, they develop an unsigned binarymultipliertailoredforSpartan-3EandVirtex-4FPGA devices[7].
Y. Srinivasa Rao et al. highlight the widespread use of floating-pointarithmetic,especiallyinscientificanddigital signal processing applications requiring double-precision arithmetic.Theyemphasizethecomplexityofmultiplication, proposing the Urdhva Tiryagbhyam method to optimize mantissa multiplication for improved speed and area efficiency.Implementationofthedouble-precisionfloating multiplier is done using Verilog HDL and Xilinx ISE tools, targetingVirtex-5FPGAplatforms[8]
Anand Mehta et al. focus on efficient floating-point multiplicationforresource-intensivedigitalsignalprocessing and media applications. They implement the Karatsuba algorithminVerilogHDL,adheringtotheIEEE754standard, toenhancepowerandtimeefficiency.Themultiplieremploys a three-stage pipelining mechanism with an 8 clock cycle delay, and mantissa bits are divided into three halves to utilize common multipliers in the FPGA Cyclone II device family[9]
Arish S et al. acknowledge the significant time and power consumption associated with efficient floating-point multiplication, particularly in high-power computing applications. They propose a unique method for implementing an unsigned binary multiplier for mantissa multiplication in IEEE 754 floating-point format by combining the Urdhva-Triyakbhyam and Karatsuba algorithmsfromVedicmathematics.
Theimplementation,conductedinVerilogHDL,targetsFPGA platformssuchasVirtex-4andSpartan-3E.Thestudyaimsto enhance the latency and power efficiency of floating-point multiplicationoperations,crucialforsignalprocessing,image processing,andothercomputingtasks[10]
Ravi Kishore Kodali et al. underscore the computational challenges posed by IEEE-754 standards, emphasizing the importance of floating-point arithmetic, particularly multiplication, in scientific and signal processing domains. They address the constraints imposed by large mantissa multiplications on space and performance. Through implementation on a standardized reconfigurable FPGA architecture, the study evaluates the performance of two
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN: 2395-0072
widelyusedmultiplicationalgorithms BoothandKaratsuba (Normal and Recursive). The recursive Karatsuba method emergesasthemostefficientsolution,offeringinsightsinto effective floating-point multiplication techniques through comparisons of resource consumption and execution speed[11]
RahulRathodetal.focusonthecomputationaldemandsof floating-point multiplication in signal processing and multimedia applications. Acknowledging its resourceintensivenature,thestudyevaluatescomplexfloating-point multiplication performance using Vedic, array, and CIFM multipliers.ThroughVerilogimplementationusingVIVADO DESIGNSUITE2018.3,theresearchaimstooptimizefloatingpoint multiplication for efficient signal processing and multimediacomputationsbycomparingspeedandresource consumption[12].
Vijeta Iyer et al. introduced a Vedic Mathematics-based method for efficient multiplication, particularly suited for binarystringsofone,withpotentialapplicationtodecimal values.Thisalgorithm'seffectivenessliesinitsadeptnessat processing decimal numbers within specific formats, enhancingcomputationalefficiencyandofferingversatilityin solvingarithmeticproblems[13].
N.MohanaPriya et.al The study presents a brand-new strategyforimprovingFIRdigitalfilters'effectivenessinDSP applications.Forhigh-speedandlow-powermultiplication,it suggestsasignedvedicmultiplierthatmakesuseofparallel operationsandtheUrdhvaTriyakbhyamsutra.Thesuggested methodexhibitsanotable52%reductioninpowerusageand a15%speedboostovertraditionalradix-4Boothmultipliers. Thecrucialdemandforincreasedperformanceandenergy economy in signal data processing is addressed by this breakthrough. It provides flexibility for a range of DSP applicationsbycombiningsignedandunsignedmultiplications. The importance of designing multiplier topologies for improved performance in digital signal processing is emphasizedinthestudy.Thisworkprovidesimportantnew understandings for improving FIR filter architectures forpracticaluses[14].
a. Vedic multiplier
TheVedicmultiplierisamathematicalmethodthatisbased onancientIndianmathematicalprinciplesfromtheVedas.It isanefficientandquicktechniqueusedformultiplyingtwo numbers.TheVedicmultiplierisespeciallybeneficialwhen dealingwithlargenumbersasitsimplifiesthemultiplication processbyreducingthenumberofstepsrequired.
The 64-bit Vedic multiplier technique can be utilized to multiply two 64-bit numbers. By leveraging the inherent propertiesoftheVedicmathematicssystem,the64-bitVedic multiplier performs the multiplication in a streamlined
manner.Itachievesthisbybreakingdownthemultiplication processintosmallerstepsandemployingvarioussutrasor formulasfromVedicmathematics.Consequently,the64-bit Vedic multiplier significantly decreases the number of computationsneeded.
The above Fig-1 illustrates the block diagram of a 64-bit Vedicmultiplier.Thisinnovativeandefficientmultiplieris designedtoperformhigh-speedmultiplicationoperationson 64-bitnumbers.Theblockdiagramshowcasesthevarious components and stages involved in the multiplication process. These components work together seamlessly to ensure accurate and fast multiplication results. The Vedic multiplier is known for its ability to perform complex multiplicationoperationswithreducedlatencyandpower consumption.Withitsadvancedarchitectureandoptimized design, the 64-bit Vedic multiplier is a valuable tool for applications that require high-performance multiplication capabilities.
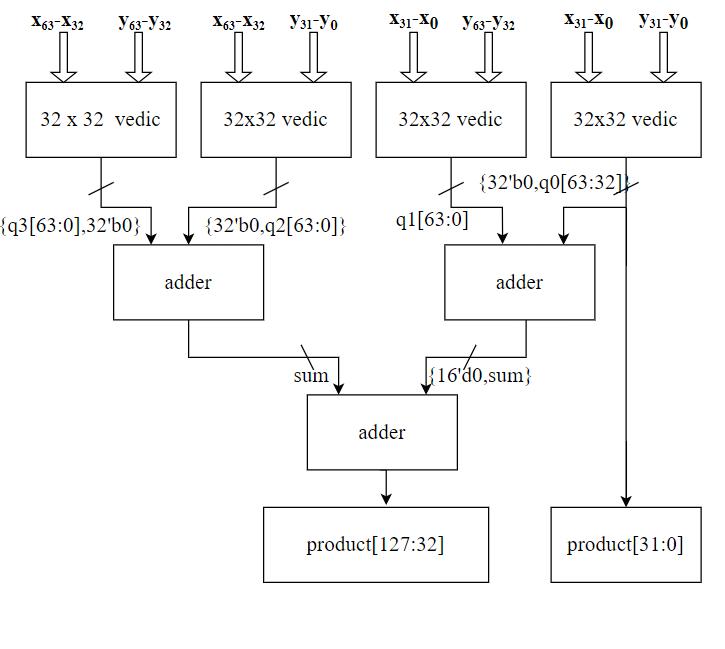
The use of a 64-bit Vedic multiplier can have practical applicationsinvariousfields,suchascomputerscienceand engineering. The use of a 64-bit Vedic multiplier can help improve the efficiency and speed of computations. Additionally, in signal processing and digital signal processingapplications,wherehigh-speedmultiplicationis required, the 64-bit Vedic multiplier can offer significant performancebenefits.
The Karatsuba multiplier is an algorithm used for multiplying large numbers efficiently. Specifically, it is designedtoperformmultiplicationonnumberswithalarge numberofdigits,suchas64-bitnumbers.Thealgorithmwas developedbyAnatoliiAlexeevitchKaratsubain1960andhas
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN: 2395-0072
since become widely used in computer science and cryptography.
ThemainadvantageoftheKaratsubamultiplierisitsability toreducethenumberofmultiplicationsrequiredtoperform themultiplicationoperation.Traditionally,themultiplication of two n-digit numbers would require n^2 individual multiplications.However,theKaratsubaalgorithmreduces this number to roughly n^(log3/log2), resulting in a significantimprovementinefficiency.
The key idea behind the Karatsuba algorithm is to break downtheoriginalmultiplicationproblemintosmallersubproblems that can be solved recursively. Instead of performingindividualmultiplicationsforeachdigitpair,the algorithmsplitsthenumbersintotwohalvesandperforms threeseparatemultiplications:oneforthehigh-orderdigits, oneforthelow-orderdigits,andoneforthecrossproduct.
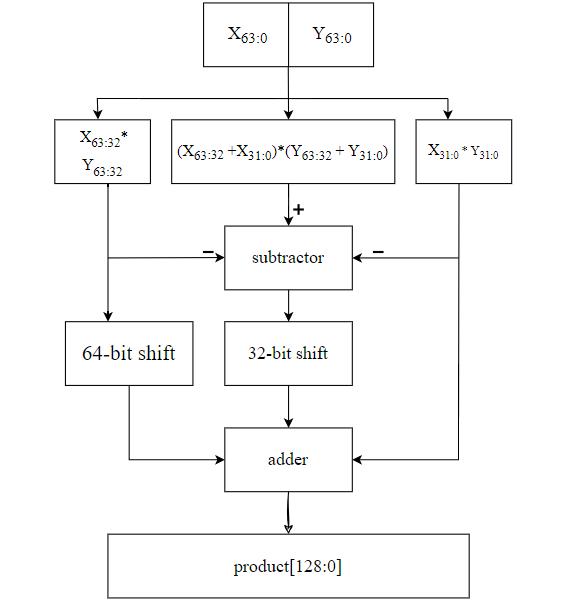
ThefigurelabeledasFig.2,representsa 64-bitKaratsuba multiplier.TheKaratsubaalgorithmisamethodusedforfast multiplication of large numbers. This particular implementation is designed to handle 64-bit numbers efficiently.Thefigureprovidesavisualrepresentationofthe circuitry and components involved in the Karatsuba multiplier. By utilizing this algorithm, multiplication operationscanbeperformedmorequicklyandefficiently, makingitanidealchoiceforapplicationsthatinvolvelarge numbersandrequirehigh-performancecomputing.
P1=Xh*Yh
=Xl*Yl
=(Xh+Xl)*(Yh+Yl)
product
Multiplicationoftwo64-bitnumberscanperformby(1),(2), (3)and(4)asshowninabove.
4 Double precision floating Point Multiplication
Double precision floating-point in the IEEE 754 standard referstotheformatforrepresentingfloating-pointnumbers using64bits.Thisformatiscommonlyusedforrepresenting real numbers in computer systems. The following three fields are present in format of double precision floating point:Signbit(1bit):Itspecifiesthesignofthenumber.0 meanspositiveand1meansnegative.
Exponent(11bits):Thisfieldrepresentstheexponentofthe number in a biased form. Bias is added to the actual exponenttoallowbothpositiveandnegativeexponentsto berepresented.Fordoubleprecision,thebiasis1023,soan exponent of 0 in this fields represents -1023, and an exponentof2047represents+1024.Mantissa(52bits):This fieldstoresthesignificantdigitsofthenumberinbinary.The leadingbitisalways1(exceptfordenormalizednumbers), andtheremainingbitsrepresentthemantissapart.TheFig3 Showsthefieldformatofdoubleprecisionfloatingpoint
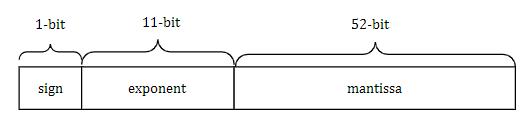
Fig- 3: FormatofDoubleprecisionfloatingpointnumber inIEEE754standardrepresentation
Multiplication of two double precision floating-point numbersinvolvesthefollowingsteps:
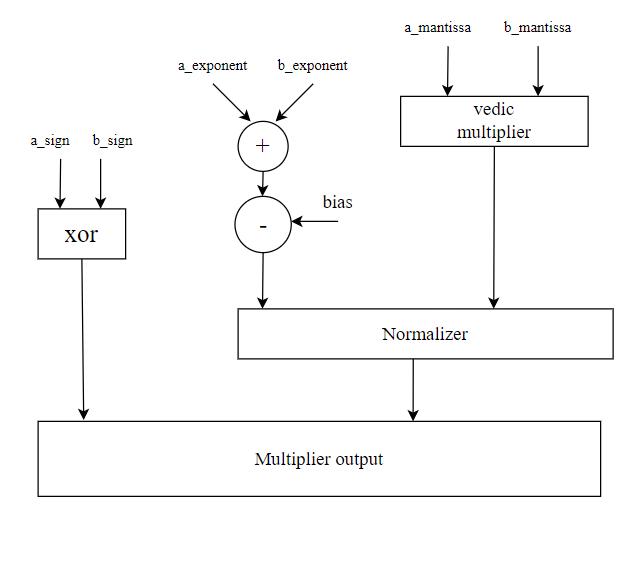
Sign Bit Multiplication: Multiply the sign bits of the two numbers to determine the sign of the result, simply performingtheex-oroftwosignbits.
ExponentAddition:Addtheexponentsofthetwonumbers together.Sincetheexponentsarebiased(by1023indouble precision),subtract1023fromthesumtogettheunbiased result.
Significand Multiplication: Multiply the significands of the twonumberstogether.Thisisamultiplicationoftwo53-bit numbers(includingtheimpliedleading1bit).
Normalization: Normalize the result of the significand multiplication by shifting the result and adjusting the exponent accordingly. Normalization involves shifting the binarypointtotherightuntilthereisonlyonenon-zerodigit to the left of the binary point. Adjust the exponent accordinglytocompensatefortheshifts.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN: 2395-0072
Rounding:Roundtheresultaccordingtotheroundingmode specifiedintheIEEE754standard.Theresultmayneedto beroundedup,down,ortothenearestrepresentablevalue.
Overflow and Underflow: Check for overflow (result too largetoberepresented)orunderflow(resulttoosmalltobe represented).Ifanoverfloworunderflowoccurs,adjustthe resultandexponentaccordingly.
a. Double precision Vedic multiplier
A floating-point Vedic multiplier is a hardware implementation that performs multiplication on floatingpointnumbersusingtheVedicmathematicstechnique.This technique,derivedfromancientIndianmathematics,offersa fastandefficientwayofperformingcomplexcalculations.In thecontextofa64-bitfloating-pointmultiplier,thismeans that the hardware is designed to handle numbers with a precisionof64bits,includingboththeintegerandfractional parts. This type of multiplier is commonly used in applicationsthatrequirehighprecisionandaccuracy,suchas scientificsimulations,financialmodeling,anddataanalysis. ByleveragingtheVedicmathematicsprinciples,thefloatingpointVedicmultipliercandeliverfasterandmoreaccurate resultscomparedtotraditionalmultiplicationalgorithms.
b.
In a traditional floating-point multiplicationalgorithm, the twofloating-pointnumbersaremultipliedusingthestandard multiplication rules. This involves multiplying the significands (mantissas) of the numbers and adding their exponents.However,thisapproachcanbecomputationally expensive,especiallyforlargerfloating-pointnumbers.
Thefloating-pointKaratsubamultiplieraddressesthisissue by breaking down the multiplication process into smaller sub-problems. It recursively divides the original floatingpoint numbers into smaller parts and performs multiplicationsontheseparts.Theseintermediateresultsare then combined to obtain the final product as shown in Figure5
ThekeyideabehindtheKaratsubamultiplieristoexploitthe properties of polynomial multiplication. Floating-point numbers can be represented as polynomials, where the coefficientscorrespondtothebitsofthesignificandandthe exponentsrepresentthepowersof2.Byusingpolynomial multiplication techniques, the Karatsuba algorithm can efficiently compute the product of two floating-point numbers.
One of the main advantages of using the floating-point Karatsuba multiplier is its ability to reduce the number of multiplication operations required. This is achieved by breaking down the original problem into smaller subproblemsandreusingintermediateresults.Asaresult,the overallefficiencyofthemultiplicationprocessisimproved.
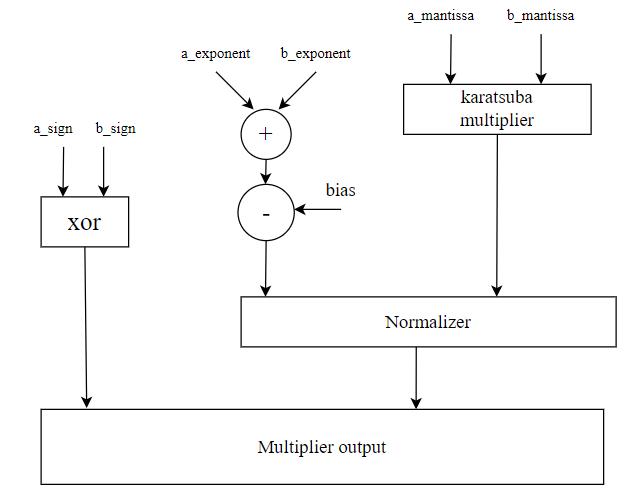
:Doubleprecisionfloatingpointmultipliermultiplier usingkaratsubamultiplier
6. Results
The designed and existing multiplier is synthesized in cadencegenussynthesizertoolandthesimulationsresults areobtainedfromthevivadotool.
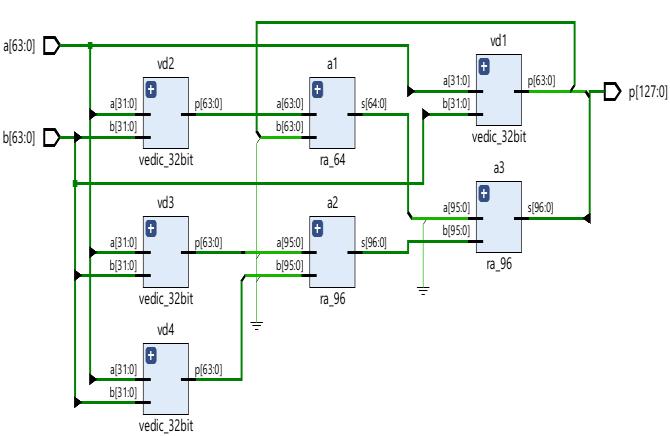
The schematic and simulation results of 64-bit Vedic multiplierareshowninFig-6andFig-7simultaneously
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN: 2395-0072
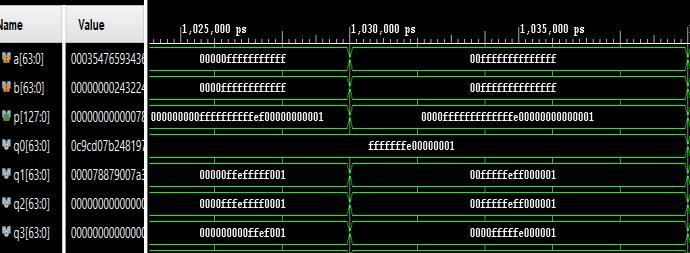
-7 Simulationresultsof64-bitvedicmultiplier
Theschematicandsimulationresultof64-bitmultiplieris showninFig-8andFig-9respectively.
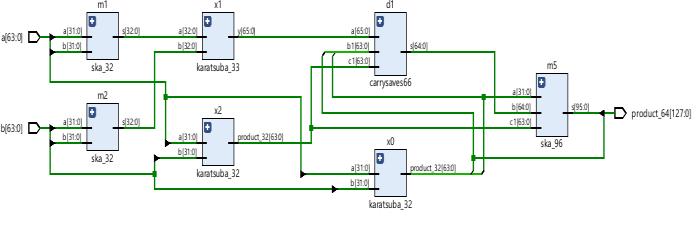
Fig-8: Schematicresultsof64-bitkaratsubamultiplier

-9: Simulationresultsof64-bitkaratsubamultiplier
Thetable-1presentstheperformanceparametersof64bit multiplication.
Table-1: Performanceparametersof64-bitmultipliers
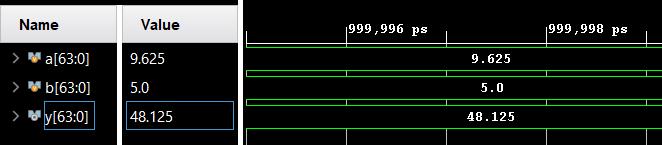
The schematic and simulation results of double precision floating multiplier using Vedic multiplier are shown in Fig-10andFig-11respectively
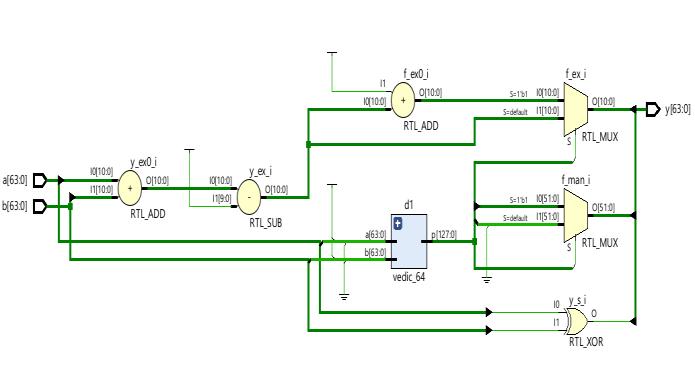
Fig -10: SchematicofDoubleprecisionfloatingpoint
MultiplierusingVedicmultiplier
SimulationofDoubleprecisionfloatingpoint multiplierusingVedicmultiplier
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN: 2395-0072
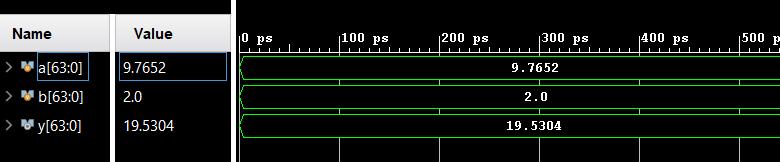
Fig-12: SimulationofDoubleprecisionfloatingpoint multiplicationusingkaratsubamultiplier
The schematic and simulation results of double precision floating point multiplier using karatsuba multiplier are showninFig-12andFig-13respectively.
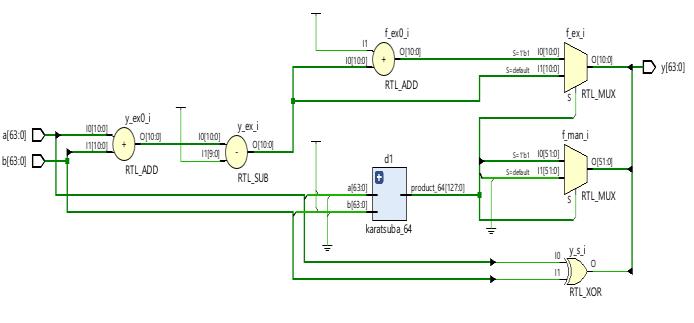
Fig13:SchematicofDoubleprecisionfloatingpoint multiplicationusingkaratsubamultiplier
Thetable-2givestheperformanceparametersof floatingpointmultiplication(FPM)
Table-2:Performanceparametersoffloating-point multiplier
Multiplier Area(um^2) Delay(ps) Power(mw)
FPMusing vedic 98281 30747 8
FPMusing karatsuba 91869 30165 18
The proposed karatsuba multiplier rather than other multipliershasadvantagetoreducetheareaanddelay.The areaiscalculatedintermsofmicrometers^2(um^2).Areais reducedin floatingpoint karatsubamultipliercomparedto floating point vedic multiplier and also reduced delay in floatingpointkaratsubamultipliercomparedtofloatingpoint Vedicmultiplier. Finallytheareaanddelayarereducedfor karatsubamultiplierthanthe vedicmultiplier.
This workcarriedoutbyResearchandDevelopmentcenter, department of ECE, Sri Vasavi Engineering College(A), Tadepalligudem,WestGodavari,AndhraPradeshandIndia.
[1] Haripriya A, “Design and Analysis of 16-bit Vedic Multiplier using RCA and CSLA”, 2023 International Conference on Signal Processing, Computation, Electronics, Power and Telecommunication (IConSCEPT)
[2] R. Sridevi, “Design of a High Speed Multiplier (Ancient VedicMathematicsApproach)InternationalJournalof EngineeringResearch(ISSN:2319-6890)VolumeNo.2, IssueNo.3,pp:183-186
[3] K.N.Vijeyakumar,“VlsiImplementationOfHighSpeed AreaEfficientArithmeticUnitUsingVedicMathematics”, IctactJournalOnMicroelectronics,April2016,Volume: 02,Issue:01
[4] S.AlwynRajiv,“ComparativeStudyonPerformanceof variousAddersusedinVedicMultiplier”,©2019JETIR May2019,Volume6,Issue5
[5] R.Yadav,"ReviewonFIRFiltersUsingDifferentAdders and Multipliers Based on Vedic Mathematics,"2021 InternationalConferenceonSimulation,Automation& SmartManufacturing(SASM),Mathura,India,2021,pp. 1-5
[6] Jayakumar,“High-PerformanceFIRFilterImplementation UsingAnurupyeVedicMultiplier”,CircuitsandSystems, 7, 3723-3733 Circuits and Systems,Vol.7 No.11, September2016
[7] Arish S,“Anefficientbinarymultiplierdesign forhigh speed applications using Karatsuba algorithm and UrdhvaTiryagbhyam algorithm”, Proceedings of 2015 GlobalConferenceon Communication Technologies (GCCT2015)
[8] Y.SrinivasaRao,M.Kamaraju,”AnFPGAImplementation of High Speed and Area Efficient Double-Precision
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN: 2395-0072
Floating Point Multiplier Using Urdhva Tiryagbhyam Technique”, 2015 Conference on Power, Control, Communication and Computational Technologies for SustainableGrowth(PCCCTSG)December11-12,2015, Kurnool,AndhraPradesh,India
[9] Anand Mehta,” Implementation of Single Precision Floating Point Multiplier using Karatsuba Algorithm”, 978-1-4673-6126-2/13/$31.00©2013IEEE
[10] ArishS,”Anefficientfloatingpointmultiplierdesignfor highspeedapplicationsusingKaratsubaalgorithmand Urdhva-Tiryagbhyam algorithm”, 978-1-4799-67612/15/$31.00©2015IEEE
[11] RaviKishoreKodali,”FPGAImplementationofIEEE-754 FloatingPointKaratsubaMultiplier”,978-1-4799-41902/14/$31.00©2014IEEE
[12] R. Rathod, P. Ramesh, P. S. Zele and A. K. Y, "Implementation of 32-Bit Complex Floating-Point MultiplierUsingVedicMultiplier,ArrayMultiplierand Combined integer and floating point Multiplier (CIFM),"2020 IEEE International Conference for Innovation in Technology (INOCON), Bangluru, India, 2020,pp.1-5,
[13] Vijeta Iyer, “Generalised Algorithm for Multiplying Binary Numbers Via Vedic Mathematics”, 021 InternationalConferenceonAdvancementsinElectrical, Electronics, Communication, Computing and Automation(ICAECA)
[14] N.MohanaPriya,” High performance fr flter based onvedicmathematics”,IntJSystAssurEngManag(June 2023)14(3):829–835
BIOGRAPHIES


Mr. Sai Rama Rao T Final Year B.TechstudentintheElectronics & Communication Engineering Department,SriVasavi EngineeringCollege, Tadepalligudem,WestGodavari, AndhraPradesh,India.
Ms. Tulasi Ratnam K FinalYear
B.TechstudentintheElectronics & Communication Engineering Department,SriVasavi EngineeringCollege Tadepalligudem,WestGodavari, AndhraPradesh,India.




Ms Navya Sri L FinalYear
B.TechstudentintheElectronics & Communication Engineering DepartmentSriVasavi EngineeringCollege Tadepalligudem,WestGodavari, AndhraPradesh,India.
Ms. Bhagya Sree E Final Year
B.TechstudentintheElectronics & Communication Engineering Department,SriVasavi EngineeringCollege Tadepalligudem,WestGodavari, AndhraPradesh,India.
Ms. Nalini Devi G Final Year
B.TechstudentintheElectronics & Communication Engineering Department,SriVasavi EngineeringCollege Tadepalligudem,WestGodavari, AndhraPradesh,India.
Mr. Nagaraju P Completed his M. Tech in 2013 from JNTUK, Hyderabad. He has totally 11 Years of teaching experience. Presently he is working as Assistant Professor in theDepartment,SriVasavi EngineeringCollege, Tadepalligudem,WestGodavari, Andhra Pradesh, India. His interested Research area is Microwaveandmmwavefilters.