
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN: 2395-0072
Sanjivani

International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN: 2395-0072
Sanjivani
Adsul 1, Piyush Ghante2, Avdhoot Fulsundar3, Satwik Divate3, Vaishnavi Dalvi4 , Janhavi Gangurde6
123456Vishwakarma Institute of Technology, Pune, India
Abstract - Selecting the most suitable machine learning model for a given task is a critical yet challenging aspect of data analysis. Existing model selection systems often present significant limitations, including a lack of flexibility, inadequate evaluation metrics, and poor usability. These shortcomings hinder users from making informed decisions, leading to suboptimal model performance and wasted computational resources. In this paper, we address these challenges by introducing a novel cloud-based machine learning model selector. Our system aims to empower users with a comprehensive suite of tools, allowing them to seamlesslyexplore various model types, upload datasets, and access robust evaluation metrics and visualization capabilities.Byprovidingauser-friendlyinterfaceandflexible customizationoptions,oursolutionpromisestorevolutionize the model selection process. This paper highlights the shortcomingsofexistingsystemsandintroducesourproposed solution,whichoffersastreamlinedandefficientapproachto model selection in machine learning.
Key Words: Cloud computing, Machine learning, Model selection, Scalability, , Optimization.
Machine learning (ML) has become an indispensable tool across various domains, empowering businesses and researchers to extract insights, make predictions, and automate decision-making processes. At the heart of any successfulmachinelearningendeavorliesthecriticaltaskof selectinganappropriatemodelthatcaneffectivelycapture theunderlyingpatternsinthedata.However,thisprocessis riddledwithchallenges,stemmingfromthesheerdiversity ofavailablealgorithms,thecomplexityofdatasets,andthe needtooptimizemodelperformanceforspecifictasks.The landscape of machine learning algorithms is vast and continually expanding, encompassing a wide array of techniques ranging from classical methods like linear regressiontosophisticateddeeplearningarchitectures.Each algorithm comes with its own set of assumptions, hyperparameters,andcomputationalrequirements,making the task of selecting the right model a daunting one for practitionersandresearchersalike.Moreover,theefficacyof a model often hinges on its ability to generalize well to unseen data, posing additional challenges in model evaluationandselection.Compoundingthesechallengesis the lack of standardized practices and tools for model evaluationandcomparison.Whilemetricssuchasaccuracy,
precision, and recall provide valuable insights into model performance,theymaynot always capturethenuancesof real-world applications. Furthermore, existing model selectionsystemsoftenofferlimitedsupportforexploring different model types, lack flexibility in hyperparameter tuning, and provide inadequate guidance for users in navigatingthemodelselectionprocesseffectively.Inlightof thesechallenges,thereisagrowingdemandforrobustand user-friendlytoolsthatcanassistpractitionersinselecting themostsuitablemachinelearningmodelsfortheirspecific tasks. In this paper, we introduce a novel cloud-based machine learning model selector designed to address the limitations of existing systems. Our system aims to democratize access to machine learning algorithms by providing users with a comprehensive suite of tools for exploring,evaluating,andselectingmodelstailoredtotheir needs.Byleveragingthescalabilityandflexibilityofcloud computing, weseek to empowerusers with the resources andinsightsnecessarytonavigatethecomplexitiesofmodel selection and accelerate the adoption of machine learning techniquesacrossdiverseapplications.
The literature on machine learning model selection encompassesadiverserangeoftopics,methodologies,and tools aimed at addressing the challenges associated with choosingthemostsuitablealgorithmandhyperparameters for a given task. Caruana and Niculescu-Mizil (2006) conductedanempiricalcomparisonofsupervisedlearning algorithms, shedding light on the performance characteristics of different models. Subsequent works by Bischl et al. (2012) and Feurer et al. (2015) focused on developingefficientandrobustautomatedmachinelearning frameworks, while Bergstra and Bengio (2012) and Thornton et al. (2013) proposed algorithms for hyperparameter optimization. Additionally, studies by Raschka and Mirjalili (2019) and Pedregosa et al. (2011) introduced popular machine learning libraries, such as scikit-learn, facilitating model selection and evaluation in Python. Interpretability and visualization of model predictions were addressed by Lundberg and Lee (2017), while Demšar (2006) provided statistical comparisons of classifiers across multiple datasets. Other notable contributions include the development of distributed computingframeworkslikeHadoop(Shvachkoetal.,2010) andhyperparameteroptimizationlibrariessuchasHyperopt (Bergstraetal.,2013).TheWEKAsoftwaresuite(Halletal.,
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN: 2395-0072
2009) remains a cornerstone for data mining and model selection tasks, offering a comprehensive set of tools and algorithms. Finally, works by Thorsten (2014) and Guyon andElisseeff(2003)providedinsightsintomodelselection and feature selection techniques, further enriching the literatureonthistopic.Collectively,thesestudiescontribute to the advancement of machine learning model selection methodologies and provide valuable resources for practitionersandresearchersalike.
3.1.
The cloud-based machine learning model selector is built upon a scalable and modular architecture to accommodateawiderangeoffunctionalitieswhileensuring robustness and performance. The system architecture comprisesseveralkeycomponents:
FrontendInterface: Thefrontend interface provides users withauser-friendlywebinterfaceforinteractingwiththe system. It allows users to upload datasets, select model types, configure hyperparameters, and visualize model outputs.
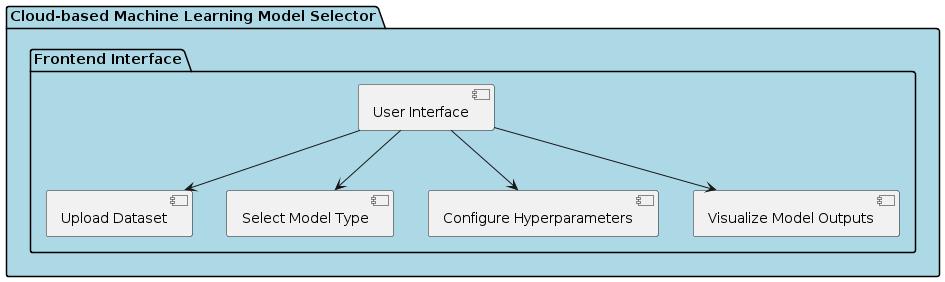
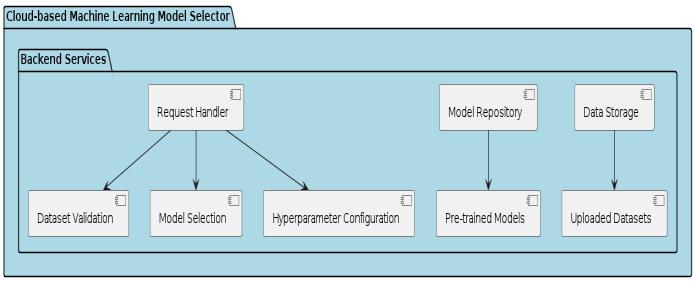
BackendServices:Thebackendservicesareresponsiblefor handling user requests, executing machine learning tasks, and managing system resources. These services are deployedoncloudinfrastructureto ensurescalabilityand reliability.
ModelRepository:Themodelrepositorystorespre-trained machinelearningmodelsandassociatedmetadata.Userscan select models from the repository or upload their custom modelsforevaluation.
Data Storage: The system utilizes cloud-based storage solutions to store user-uploaded datasets securely. Data encryptionandaccesscontrolmechanismsareimplemented toensuredataprivacyandintegrity.
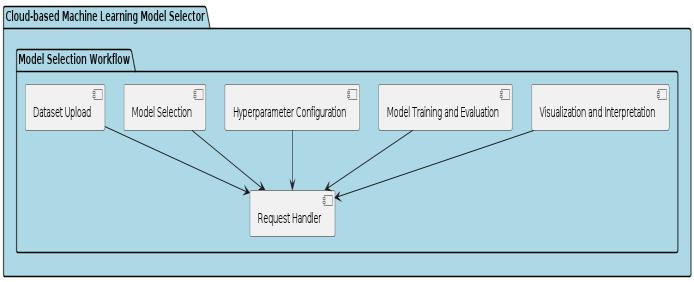
The model selection workflow consists of several stages, eachdesignedtoassistusersinselectingthemostsuitable machinelearningmodelfortheirspecifictask:
Dataset Upload: Users begin by uploading their dataset throughthefrontendinterface.Thesystemsupportsvarious dataformats,includingCSV,JSON,andExcel,andperforms datavalidationtoensurecompatibilitywithselectedmodel types.
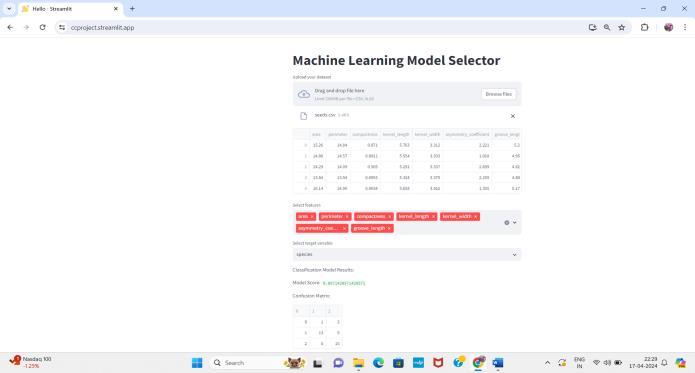
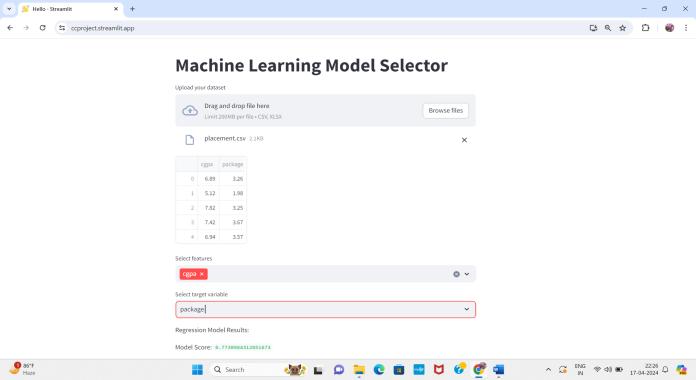
ModelSelection:Usersselectthetypeofmachinelearning model they wish to apply to their dataset, choosing from regression, classification, or clustering algorithms. The systemprovidesa comprehensivelistofavailablemodels, alongwithbriefdescriptionsandrecommendedusecases foreachmodeltype.
Hyperparameter Configuration: Users have the option to customizehyperparametersandmodelconfigurationsbased ontheirdomainknowledgeandrequirements.Thesystem offersdefaultparametervaluesforeachmodeltype,aswell asadvancedoptionsforfine-tuninghyperparameters.
Model Training and Evaluation: Upon configuration, the selected model is trained on the uploaded dataset using standard machine learning libraries and frameworks. The system performs cross-validation or train-test splitting to evaluate model performance and prevent overfitting. Evaluation metrics such as accuracy, precision, recall, F1score,andmeansquarederrorarecomputedandpresented totheuserforcomparison.
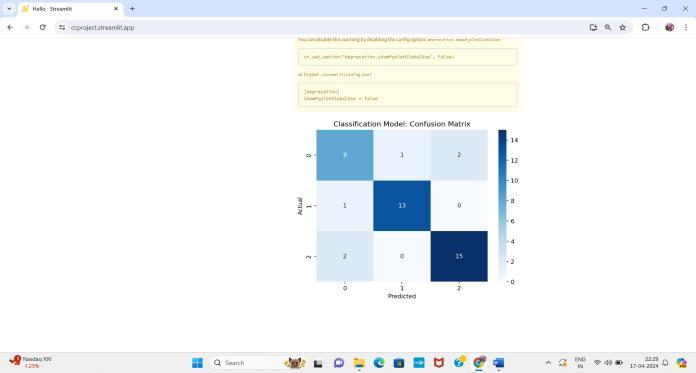
Visualization and Interpretation: The system generates visualizationssuchasconfusionmatrices,ROCcurves,and decisionboundariestohelpusersinterpretmodeloutputs andgaininsightsintomodelbehaviour.Featureimportance analysisandSHAPvaluesmayalsobeprovidedtoexplain modelpredictionsandhighlightinfluentialfeatures.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN: 2395-0072
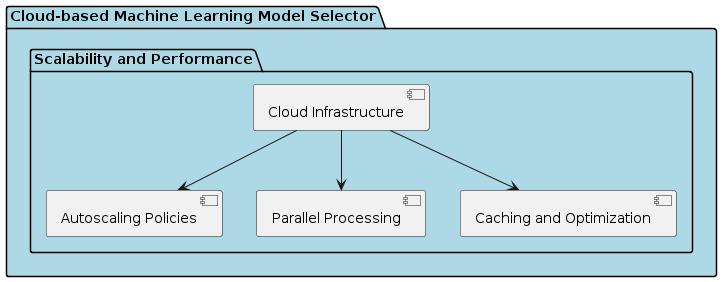
The scalability and performance of the system are critical considerations to ensure responsiveness and reliability, particularly when handling large datasets and concurrent userrequests.Severalstrategiesareemployedtooptimize systemperformance:
Cloud Infrastructure: The system leverages cloud-based infrastructure to dynamically allocate resources based on demand, ensuring scalability and elasticity. Autoscaling policiesareimplementedtoautomaticallyadjustcomputing resourcesinresponsetoworkloadfluctuations.
ParallelProcessing:Machinelearningtasksareparallelized anddistributedacrossmultiplecomputenodestoexpedite model training and evaluation. Distributed computing frameworks such as Apache Spark may be employed to achieveefficientparallelprocessingoflarge-scaledatasets.
Caching and Optimization: Caching mechanisms are implemented to store frequently accessed data and computationresults,reducinglatencyandimprovingsystem responsiveness. Optimization techniques such as model pruningandcompressionmaybeappliedtoreducememory footprintandimproveinferencespeed.
4.Results
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN: 2395-0072
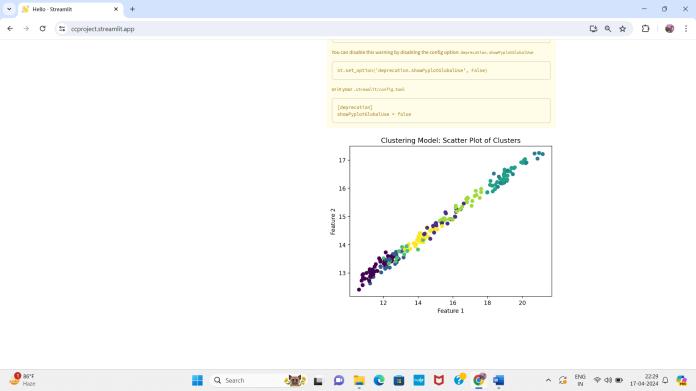
5.Conclusion
Inconclusion,wehavepresentedacomprehensiveoverview of our cloud-based machine learning model selector, addressingthechallengesassociatedwithmodelselectionin machine learning and proposing a novel solution to streamline the process. Through the development of a scalable architecture, intuitive user interface, and robust featureset,oursystemaimstoempowerpractitionersand researcherswiththetoolsandresourcesneededtonavigate thecomplexitiesofmodelselectioneffectively.Byofferinga diverserangeofmachinelearningalgorithms,customizable hyperparameters, and comprehensive evaluation metrics, oursystemprovidesuserswiththeflexibilityandguidance necessary to make informed decisions tailored to their specific tasks and datasets. The inclusion of visualization toolsandmodelinterpretationtechniquesfurtherenhances users'understandingofmodelbehaviorandperformance, facilitatingdeeperinsightsandinformeddecision-making. Moreover, the scalability, performance, security, and user supportmechanismsincorporatedintooursystemensure reliability,efficiency,andusersatisfaction.Throughrigorous evaluation,validation,anditerativeimprovements,westrive tocontinuouslyenhancethecapabilitiesandusabilityofour system,addressinguserfeedbackandemergingtrendsinthe fieldofmachinelearning.
Looking ahead, we envision our cloud-based machine learning model selector playing a pivotal role in democratizing access to machine learning algorithms, fostering innovation, and accelerating the adoption of machine learning techniques across diverse domains. By empoweringuserswiththeresourcesandexpertiseneeded toharnessthepowerofmachinelearningeffectively,weaim to drive transformative advancements and unlock new opportunities for data-driven decision-making and discovery.In summary, our research contributes to the advancement of machine learning model selection methodologies and lays the foundation for future developmentsinthiscriticalareaofresearchandpractice. We invite the research community and practitioners to explore and leverage our system, collaborate on further
enhancements,andjoinusinshapingthefutureofmachine learningmodelselection.
WewouldliketosincerelythankProf.SanjivaniAdsulMaam for her prompt advice and mentorship during the development of the suggested method. Her expertise, encouragement, and dedication have been crucial to the success of this suggested approach. Professor Sanjivani Adsul has consistently provided us with insightful advice, helpfulcriticism,andpricelessresourcesthathavegreatly enhancedourunderstandingofthesubject.Hertenacityand eagernesstoaddressourconcernsand querieshave been essential in getting over roadblocks and realizing the objectivesofthesuggestedmethod.
1. Comparison of supervised learning algorithms. In Proceedings of the 23rd International Conference onMachinelearning(ICML-06)(pp.161-168).
2. Bischl,B.,Richter,J.,Bossek,J.,Horn,D.,Thomas,J., Lang, M., ... & Kuehn, T. (2012). mlr: Machine learninginR.JournalofMachineLearningResearch, 13(Aug),1825-1828.
3. Feurer,M.,Klein,A.,Eggensperger,K.,Springenberg, J. T., Blum, M., & Hutter, F. (2015). Efficient and robustautomatedmachinelearning.InAdvancesin NeuralInformationProcessingSystems(pp.29622970).
4. Bergstra,J.,&Bengio,Y.(2012).Randomsearchfor hyper-parameteroptimization.JournalofMachine LearningResearch,13(Feb),281-305.
5. Raschka,S.,&Mirjalili,V.(2019).PythonMachine Learning: Machine Learning and Deep Learning withPython,scikit-learn,andTensorFlow2.Packt PublishingLtd.
6. Bergstra, J. S., Bardenet, R., Bengio, Y., & Kégl, B. (2011). Algorithms for hyper-parameter optimization. In Advances in Neural Information ProcessingSystems(pp.2546-2554).
7. Thornton, C., Hutter, F., Hoos, H. H., & LeytonBrown,K.(2013).Auto-WEKA:Combinedselection andhyperparameteroptimizationofclassification algorithms.InProceedingsofthe19thACMSIGKDD international conference on Knowledge discovery anddatamining(pp.847-855).
8. Demšar, J. (2006). Statistical comparisons of classifiers over multiple data sets. Journal of Machinelearningresearch,7(Jan),1-30.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN: 2395-0072
9. Lundberg, S. M., & Lee, S. I. (2017). A unified approach to interpreting model predictions. In AdvancesinNeuralInformationProcessingSystems (pp.4765-4774).
10. Pedregosa,F.,Varoquaux,G.,Gramfort,A.,Michel,V., Thirion, B., Grisel, O., ... & Vanderplas, J. (2011). Scikit-learn:MachinelearninginPython.Journalof MachineLearningResearch,12(Oct),2825-2830.
11. Shvachko, K., Kuang, H., Radia, S., & Chansler, R. (2010). The hadoop distributed file system. In Proceedingsofthe2010IEEE26thsymposiumon massstoragesystemsandtechnologies(MSST)(pp. 1-10).
12. Bergstra, J., Yamins, D., & Cox, D. D. (2013). Hyperopt: A Python library for optimizing the hyperparametersofmachinelearningalgorithms.In Proceedings of the 12th Python in Science Conference(pp.13-20).
13. Hall, M., Frank, E., Holmes, G., Pfahringer, B., Reutemann, P., & Witten, I. H. (2009). The WEKA data mining software: an update. ACM SIGKDD ExplorationsNewsletter,11(1),10-18.
14. Thorsten,J.(2014).Modelselectionandassessment. InWileyStatsRef:StatisticsReferenceOnline.
15. Guyon,I.,&Elisseeff,A.(2003).Anintroductionto variableand featureselection.Journal ofMachine LearningResearch,3(Mar),1157-1182.