
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net
p-ISSN:2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net
p-ISSN:2395-0072
Prof. Sangram S. Dandge1, Aditya Jirapure2, Akshad Khursade3, Ashar Khan4, Tanmay Dhawak5
1 Assistant Professor, Dept. of CSE, Prof Ram Meghe Institute of Technology & Reaserch, Badnera , Amravati, Maharashtra, India.
2,3,4,5 B.E. Final Year Student’s, Dept. of CSE, Prof Ram Meghe Institute of Technology & Reaserch, Badnera Amravati, Maharashtra, India.
Abstract Insulearner presents a novel approach to diabetes prediction by harnessing the power of ensemblelearningtechniques.Diabetesmellitusposes a significant public health challenge globally, necessitating early and accurate prediction methods for effective management. Leveraging a diverse array of machine learning algorithms including Decision Trees, Random Forest, and Naive Bayes, Insulearner achieves promising results in forecasting diabetes onset. Through a polling technique, the model combines the predictions from multiple algorithms and determines the final outcome based on the majority vote. Experimental evaluation demonstrates competitive test accuracies: Decision Tree (76.62%), Random Forest (72.08%), and Naive Bayes (76.62%). By aggregating the predictions, Insulearner enhances the overall accuracy and reliability of diabetes prediction, offering a valuable tool for proactive healthcare management. This research contributes to theongoingeffortstoadvancemachineintelligencein healthcare applications, paving the way for early disease detection and personalized treatment strategies.
Keywords Machine Intelligence, Decision Tree, RandomForest,NaiveBayes,PollingTechnique.
In recent years, the advancement of technology has paved the way for groundbreaking innovations in healthcare.Amongtheseinnovationsisthedevelopment ofInsulearner,aprojectdedicatedtoleveragingmachine intelligence for the early detection and management of diabetes. Diabetes, a chronic condition characterized by high blood sugar levels, affect millions of people worldwide and poses significant health risks if eft untreatedorunmanaged.
The Insulearner project represents a novel approach to addressing the challenges associated with diabetes by harnessing the power of machine learning. By analysing vastamountsofdatarelatedtoindividualhealthmetrics, lifestylefactors,andgeneticpredispositions,Insulearner aims to provide personalized insights and predictive analytics to help individuals and healthcare
professionals better understand and manage diabetes risk.
This research paper explores the underlying principles, methodologies,andpotentialapplicationsofInsulearner in the field of diabetes forecasting. Through an in-depth examination of existing literature, case studies, and experimental findings, we seek to elucidate the role of machineintelligenceinrevolutionizingdiabetescareand preventionstrategies.
The subsequent sections will explore the key componentsofInsulearner,includingitsdataacquisition techniques, predictive modelling approaches, and user interface design. Furthermore, we will analyse the broader implications of Insulearner for various stakeholders, ranging from patients and caregivers to healthcare professionals and policymakers. Through a comprehensive evaluation of Insulearner's capabilities, limitations,andethicalconsiderations,thispaperaimsto shed light on its potential to transform diabetes management.
In conclusion, Insulearner stands as a testament to the transformative potential of machine intelligence in diabetes management. Through its innovative approach to forecasting blood glucose levels, Insulearner not only empowers individuals with diabetes to take control of their health but also facilitates more proactive and personalized care delivery. As we navigate the complexities of the digital age, projects like Insulearner offer a glimpse into the future of healthcare, where technology serves as a catalyst for improved outcomes, enhancedpatientexperiences,andultimately,ahealthier society.
KM Jyoti Rani [1] : The study emphasizes the role of machine learning in analysing data to predict the onset of the disease. Employing various algorithms such as K nearest neighbor, Logistic Regression, Randomforest, Support vector machine, and Decision tree, the study evaluates their accuracy in predicting diabetes using a dataset comprising 2000 cases sourced from Kaggle. Results indicate that the Decision tree algorithm
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN:2395-0072
outperforms others, achieving a remarkable accuracy of 98%intrainingand99%intesting.Thepaperconcludes that the designed system with the decision tree algorithm holds promise for accurately predicting diabetesat an earlystage,suggestingavenuesfor future research to extend the system's applicability to other diseases and explore additional machine learning algorithms.
Mitushi Soni and Dr. Sunita Varma [2] addresses the critical issue of early diabetes prediction using machine learning (ML) methods. By leveraging the Pima Indian Diabetes Dataset, the authors explore various ML algorithms including Support Vector Machine (SVM), KNearest Neighbor (KNN), Decision Tree (DT), Logistic Regression (LR), Random Forest (RF), and Gradient Boosting (GB) for diabetes prediction. Through data preprocessingtohandlemissingvaluesandsplittingthe dataset for training and testing, the study demonstrates the effectiveness of these algorithms in predicting diabetes with Random Forest achieving the highest accuracy among them. Furthermore, feature importance analysisisconductedtoidentifysignificantattributesfor diabetes prediction, providing valuable insights for healthcare decision-making and early intervention strategies. This research contributes to the field of healthcarebyofferingasystematicapproachtodiabetes prediction using ML techniques, which can aid in early diagnosis and prevention of associated complications, ultimately improving patient outcomes and reducing healthcarecosts.
Turki Alghamdi [3] presents a comprehensive study on the prediction of diabetes complications using computational intelligence techniques, addressing the critical need for early detection and treatment of diabetes to prevent severe health complications. The research explores the application of data mining techniques, particularly classification models, to analyze diabetes-related data and extract valuable insights for predictive purposes. Notably, the XGBoost classifier emerges as a highly effective algorithm, boasting an impressive accuracy rate of 89% in diabetes prediction. The study emphasizes the importance of algorithm selection based on dataset characteristics and research objectives,highlightingthepotentialapplicationsofdata analysis and predictive techniques in identifying risk factors, monitoring disease progression, and evaluating treatment effectiveness. The proposed framework encompasses various stages, including data collection, preprocessing, feature selection, model training, evaluation, and deployment, underscoring the significance of proper data handling to mitigate biases and inaccuracies. Overall, the research contributes valuable insights into diabetes management, offering a promising avenue for improving patient care and outcomesthroughearlydetectionandintervention.
Roshan Birjais et al. [4] presents a comprehensive investigation into the application of machine learning techniques for predicting and diagnosing diabetes risk. The study emphasizes the significance of leveraging machine learning, particularly Gradient Boosting, Logistic Regression, and Naive Bayes algorithms, to analyzethePimaIndiansdiabetesdataset.Byemploying these methods, the research achieves promising accuracies of 86% for Gradient Boosting, 79% for Logistic Regression, and 77% for Naive Bayes in diagnosing diabetes. The paper underscores the importance of data preprocessing, feature selection, and model evaluation for enhancing the effectiveness of predictive models in healthcare. Furthermore, it highlightsthepotentialofmachinelearninginadvancing personalized treatment, drug development, and clinical research, thereby contributing to improved healthcare outcomes. This paper serves as a valuable resource for researchers and practitioners seeking insights into the application of machine learning in diabetes prediction anddiagnosis.
Orlando Iparraguirre-Villanueva, Karina EspinolaLinares, Rosalynn Ornella Flores Castañeda and Michael Cabanillas-Carbonell [5] investigates the application of machine learning (ML) models for the early detection and accurate classification of type 2 diabetes using the Pima Indian dataset. Five ML models, including Knearest neighbor (K-NN), Bernoulli Naïve Bayes (BNB), decision tree (DT), logistic regression (LR), and support vector machine (SVM), were employed and evaluated. Through rigorous analysis, it was found that K-NN and BNB models outperformed others, with K-NN achieving thehighestaccuracyof79.6%indetectingdiabetes.The studyunderscoresthepromisingpotentialofMLmodels forearlydiabetesdetection,highlightingthesignificance of accurate classification in preventive healthcare strategies.
Shahid Mohammad Ganie, Pijush Kanti Dutta Pramanik, Majid Bashir Malik, Saurav Mallik and Hong Qin [6] : This study contributes to the field of healthcare by demonstrating the effectiveness of ensemble learning techniques, particularly boosting algorithms, in diabetes prediction. The developed model shows promising results in terms of accuracy and can potentially assist healthcareprovidersinearlydiagnosis andprognosis of diabetes.Thisstudycontributestothefieldofhealthcare bydemonstratingtheeffectivenessofensemblelearning techniques, particularly boosting algorithms, in diabetes prediction. The developed model shows promising results in terms of accuracy and can potentially assist healthcareprovidersinearlydiagnosis andprognosis of diabetes. The study also provided insights into the importance of different features in predicting diabetes, with age, BMI, and skin thickness being identified as significantpredictors.Theanalysisoffeatureimportance
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN:2395-0072
helps in understanding the underlying factors contributingtothepredictionofdiabetes.
Viswanatha V, Ramachandra A.C, Dhanush Murthy, and Thanishka [7]explores the development of predictive models for diabetes detection using machine learning techniques. The study utilizes two datasets, the PIMA IndiansDiabetesdatasetandanotherfromVanderbilt,to train and test the models. Logistic regression serves as the primary algorithm, supplemented by ensemble methods like maximum voting and stacking to enhance accuracy. Feature selection techniques and data preprocessing are employed to improve model performance. The results demonstrate promising accuracy improvements, highlighting the significance of feature selection and ensemble methods in enhancing predictivemodelsfordiabetesdiagnosis.
Ms.SakshiR.Wagh,Ms.Pooja.B.Sonawane,Ms.SwatiK. Rane,Ms.SnehalY.Pardeshi,Ms.ArchanaUgale[8]:The study addresses the increasing prevalence of diabetes globally and the importance of early prediction for effective management. The authors utilize machine learning algorithms such as support vector machine, random forest, and K-nearest neighbor to predict diabetes based on parameters like blood glucose level, age, and number of pregnancies. The proposed system architecture involves data collection, preprocessing, feature extraction, model training, and prediction. The advantages of the proposed system include costeffectiveness, ease of use, and time-saving benefits. the paper provides valuable insights into the application of machinelearningfordiabetespredictionandcontributes to the existing literature on healthcare informatics and predictivemodeling.
V. Yamuna, D. Ushanthi, B. Krishna Chaitanya , Y. Divya sri, T. Jagadish [9] presents a comprehensive study on the prediction of diabetes using machine learning techniques. The authors explored various classifiers including Support Vector Machine (SVM), K-Nearest Neighbor(KNN),DecisionTree,LogisticRegression(LR), and Random Forest to predict diabetes based on factors suchaspregnancies,glucoselevels,bloodpressure, skin thickness, insulin levels, BMI, and age. They achieved a stable accuracy of 80% using the Random Forest classifier. The study emphasizes the importance of early detection of diabetes and suggests that the proposed model could be extended to predict other diseases as well, potentially aiding healthcare professionals in makingtimelydecisionsforpatientcare.
Bhavya M R, Sanjay H C, Suraj S K, Savant Aakash Shivshankar Rao, Sanjay M [10]: The paper explores the significance of early detection of diabetes mellitus and the potential complications associated with the condition. Focusing on machine learning techniques,
particularly the K-nearest neighbors (KNN) algorithm, the study aims to develop a system for diabetes detection using the Pima Indian dataset. Preprocessing techniques are employed to clean and prepare the data, which includes parameters such as age, gender, sugar levels, and family history. Through the training of the KNNalgorithmonthisdataset,thesystemcanaccurately classify patients as diabetic or non-diabetic, with a reported accuracy of 98%. Additionally, the system predicts the time of onset of diabetes, aiding in early intervention and treatment planning. The proposed system offers automation for diabetes detection based onhistoricalpatientdata,providingvaluablesupportfor both patients and healthcare professionals. Future enhancements may involve incorporating additional classification algorithms and expanding the system's functionality to include features like visitor queries and treatmentrecommendations.
Isfafuzzaman Tasin, Tansin Ullah Nabil, and Sanjida Islam Riasat Khan [11] presents a comprehensive study on the development of an automatic diabetes prediction system utilizing machine learning algorithms and explainable AI techniques. The researchers employed a private dataset of female patients in Bangladesh in additiontothewell-knownPimaIndiandiabetesdataset, applying feature selection algorithms and addressing class imbalance issues. Through rigorous experimentation with various machine learning classifiers and ensemble techniques, they identified XGBoost with ADASYN as the best-performing model, achievinganaccuracyof81%,anF1scoreof0.81,andan AUC of 0.84. Moreover, the study includes the deployment of the prediction system into a website and an Android application, enhancing its accessibility and practicality. Additionally, the authors employed explainable AI methods such as LIME and SHAP to interpretthemodel'spredictions,providinginsightsinto its decision-making process. The paper contributes valuable insights into the development of accurate and interpretable diabetes prediction systems, making it a significant addition to the existing literature on the subject.
VictorChang,JozeeneBailey,QianwenArielXu,ZhiliSun [12]: This paper presents an e-diagnosis system for detecting and classifying diabetes mellitus (type 2 diabetes) based on machine learning algorithms, specifically designed for implementation in the Internet of Medical Things (IoMT) environment. The study focusesondevelopingasystemthatcanpredictwhether an individual is at risk for diabetes by analyzing several risk factors. Three interpretable supervised machine learning models are employed: Naïve Bayes classifier, random forest classifier, and J48 decision tree models. These models are trained and tested using the Pima IndiansdiabetesdatasetintheRprogramminglanguage.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net
Mariwan Ahmed Hama Saeed [13] explores the classification of type 2 diabetes using machine learning algorithms, particularly focusing on the utilization of gradient boosting, AdaBoost, decision tree, and extra treesclassifiers.ThroughtheanalysisofthePIMAIndian Diabetes dataset and the Behavioral Risk Factor Surveillance System (BRFSS) diabetes dataset, the study highlights the effectiveness of the extra trees classifier, which outperformed other models with superior area undercurve(AUC)valuesof0.96%forPIMAand0.99% for BRFSS datasets. By employing the up-sampling technique to address imbalanced data, the study underscores the potential of machine learning models, particularly the extra trees classifier, in predicting chronicdiseasessuchasdiabetes.Theresearchsuggests practical implications for healthcare providers, emphasizing the importance of employing machine learning models like the extra trees classifier for more accurate disease prediction, potentially leading to significant improvements in healthcare decision-making and cost reduction. Additionally, the paper calls for future exploration of deep learning models, data fusion techniques, and hybrid models to enhance disease predictioncapabilitiesbeyonddiabetes.
SadhanaTiwari,AwadheshKumar,andAashaSingh[14] presents an in-depth investigation into the prediction of diabetesusingmachinelearningtechniques.Theauthors explore various algorithms including K-Nearest Neighbor, Logistic Regression, Decision Tree, Random Forest, Support Vector Machine, Stacking, and Stacking with Hyperparameter Tuning. They utilize the PimaIndian-Diabetes dataset and employ preprocessing techniques to enhance the quality of the data. Through their experimentation, they demonstrate that stacking classifier with hyperparameter tuning yields the highest accuracy of 88%, outperforming other individual classifiers.Thepaper providesvaluableinsightsintothe effectiveness of ensemble methods and the significance of hyperparameter tuning in improving predictive accuracy for diabetes detection. This study contributes to the growing body of research aimed at leveraging machine learning for early-stage diabetes prediction, highlighting the potential for hybrid approaches to achievesuperiorresults.
Pradeep Kumar G. and R. Vadivel [15] : The authors addressthegrowingconcernofdiabetesprevalenceand theimportanceofearlydiagnosisusingmachinelearning techniques. They emphasize the significance of predictiveanalyticsinhealthcareandproposea method that combines ensemble machine learning techniques, specifically employing Logistic Regression (LR) algorithm and a hybrid approach. The study focuses on predicting diabetes using the Pima Indian Diabetes Dataset obtained from Kaggle, employing preprocessing
p-ISSN:2395-0072
techniques to handle missing values and feature selection methods. By utilizing ensemble methods such as stacking, the proposed model achieves superior performance compared to individual classifiers like Support Vector Machine (SVM), Decision Tree (DT), and Naive Bayes (NB). The study concludes that the ensemble method, particularly the hybrid approach, demonstrates higher accuracy in diabetes prediction, paving the way for more effective early diagnosis and preventivestrategiesinhealthcare.
Sahil Kumar Suman, Natasha Sharma, Udeshna Saikia, Dhiti, Rahul Chauhan, Nandini Singh [16]: The study focuses on leveraging various machine learning algorithms such as Logistic Regression, Decision Trees, Random Forests, Support Vector Machines, Neural Networks, K-Nearest Neighbors, Naive Bayes, and Ensemble Learning techniques to accurately predict the onsetofdiabetes.Theauthorsemphasizetheimportance offeaturespecificationinenhancingmodelaccuracyand interpretability. Furthermore, the paper explores the utilization of different datasets, including the Pima Indians Diabetes Database, UCI Diabetes Dataset, Kaggle datasets,andNationalInstituteofDiabetesandDigestive and Kidney Diseases (NIDDK) Dataset, for training and evaluating the predictive models. The results demonstrate promising accuracy levels achieved by the proposed machine learning techniques, underscoring their potential to revolutionize early diabetes detection and improve healthcare outcomes. This study provides valuable insights into the application of machine learning in healthcare and serves as a significant contributiontothefieldofdiabetespredictionresearch.
The first step in developing the Insu-Learner Diabetes Prediction System involved gathering a comprehensive dataset suitable for training and evaluating machine learning models. The dataset comprised relevant features such as age, gender, body mass index (BMI), bloodpressure,andvarious bloodserummeasurements including glucose levels. The dataset was sourced from reputable medical repositories and research databases to ensure its reliability and representativeness of the targetpopulation.
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN:2395-0072
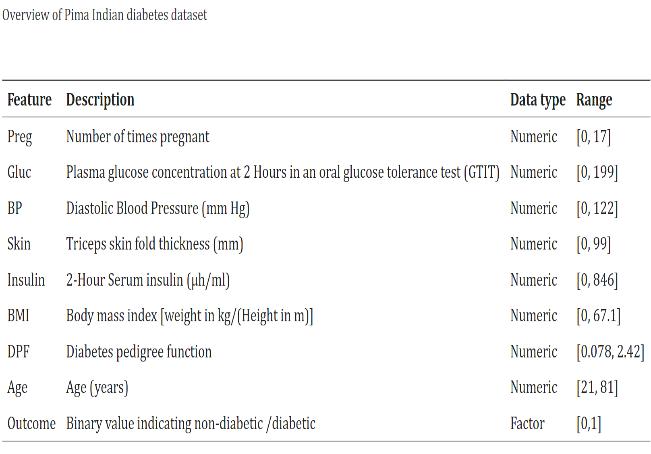
After acquiring the dataset, preprocessing techniques were applied to clean and prepare the data for analysis. This involved handling missing values, outliers, and inconsistencies. Additionally, feature scaling and normalizationtechniqueswereemployedtostandardize thedataandensureuniformityacrossdifferentfeatures.
Feature selection is the process of identifying and selectingasubsetofrelevantfeaturesorvariablesfroma larger set of available features in a dataset. The goal of feature selection is to improve model performance, reduce computational complexity, and enhance interpretabilitybyfocusingonthemostinformativeand discriminative features. Featureselection plays a crucial role in improving model performance and interpretability. In this stage, relevant features were identified based on domain knowledge and statistical analysis. Techniques such as correlation analysis, principal component analysis (PCA), and recursive feature elimination (RFE) were utilized to identify the mostinformativefeaturesforpredictingdiabetesrisk.
Three machine learning models were chosen for developing the Insu-Learner system: Decision Tree, Random Forest, and Naive Bayes. These models were selectedbasedontheirsuitabilityforclassificationtasks, robustness,andinterpretability.
3.1. Decision Tree: Thedecisiontreealgorithmemployed in the Insulearner system plays a pivotal role in predictingdiabetesonsetbasedoninputfeaturessuchas pregnancies, glucose levels, blood pressure, skin thickness,insulinlevels,BMI,diabetespedigreefunction, andage.Thissectionelucidatesthemethodologybehind the decision tree algorithm, its implementation, and the mathematicalcalculationsinvolved.
The decision tree algorithm operates by recursively partitioning the feature space into subsets, aiming to create homogeneous subsets with respect to the target
variable,whichinthiscaseisthediabetesoutcome(0for no diabetes, 1 for diabetes). The splitting of the feature space is guided by criteria such as information gain or Gini impurity reduction. In our implementation, we utilize the entropy criterion for splitting, maximizing informationgainateachnodewhilelimitingthedepthof thetreetopreventoverfitting.
3.1.1ExplanationoftheAlgorithm
i)EntropyCalculation:Entropymeasurestheimpurityor randomness of a dataset. Given a dataset D with two classes(positiveandnegative),the entropyiscalculated as:
Entropy(D)=-p+log22(p+) – p-log2(p-)
Wherep+andp-representtheproportionsofpositive andnegativeinstancesinthedataset,respectively. ii) Information Gain: Information gain quantifies the effectiveness of a particular feature in classifying instances. It is computed as the difference between the entropy of the parent node and the weighted sum of entropies of the child nodes resulting from splitting on thatfeature.
IG(D,f)=Entropy(D)- ∑
Entropy(Dv)
Where f represents a feature, D is the dataset, Dv denotes the subset of D for which feature f has value v, and V isthenumberofdistinctvaluesoffeature f iii) Tree Construction: The decision tree is constructed recursively by selecting the feature that maximizes information gain at each node. The process continues until a stopping criterion is met, such as reaching a maximum depth or having no further gain in information.
3.1.2ExampleCalculation
Consider a simplified dataset with two features, glucose level and BMI,anda binary outcomeindicating diabetes status. The decision tree algorithm aims to predict the diabetesoutcomebasedonthesefeatures.Here'sastepby-step calculation of the information gain for splitting ontheglucoselevelfeature:
Step 1: Calculate the entropy of the parent node using theformula:
Entropy(D)=- log2 2
Step2:Calculatetheentropyofthechildnodesresulting fromsplittingontheglucoselevelfeature.
Step 3: Compute the information gain using the formula mentionedearlier.
By repeating this process for each feature and selecting the one with the highest information gain, the decision tree algorithm constructs a tree that effectively
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN:2395-0072
partitionsthefeaturespace,enablingaccurateprediction ofdiabetesonset.
3.2 Random Forest: The Random Forest algorithm utilizedintheInsulearnersystemisapowerfulensemble learning technique that combines the predictions of multiple decision trees to improve predictive accuracy and mitigate overfitting. This section outlines the methodologybehindRandomForest,itsimplementation, and the mathematical concepts underpinning its operation.
Random Forest operates by constructing a multitude of decision trees during the training phase and outputting the mode of the classes (classification) or the mean prediction (regression) of the individual trees. In Random Forest, each decision tree in the ensemble is trained independently using a subset of the original dataset. The final prediction is then determined by aggregating the predictions of all individual trees. Let's consider a binary classification problem where the outcome variable y represents the diabetes status (0 for non-diabetic, 1 for diabetic), and we have n instances in thedataset.
i)BootstrapSampling:RandomForestemploysbootstrap samplingtocreatemultipledatasets,eachusedtotraina decision tree.Givenanoriginal datasetwith n instances, a bootstrap sample of size n is created by randomly sampling with replacement. The probability of selecting aninstanceforthebootstrapsampleis 1/n.
ii) Feature Randomization: At each node of the decision tree,arandomsubsetoffeaturesisselectedforsplitting. Let's denote the total number of features in the dataset as m,andthenumberoffeaturesconsideredforsplitting ateachnodeas mfeat , Where mfeat ≤ m
iii)Tree Construction: Each decision tree is constructed using the bootstrap sample and the selected subset of features.Thetreeisgrownrecursivelybysplittingnodes based on a splitting criterion such as Gini impurity or informationgain.
iv)Voting for Classification: For classification tasks, the final prediction of the Random Forest is determined by majority voting among the predictions of individual trees. Let's denote the predicted class for the ith instance by ̂ i, Where i = 1, 2 , 3,…n. Thepredictedclass for the ith instance in the Random Forest ensemble, denotedas ̂ RF,i ,Whereiscomputedas:
̂ RF,I =argmaxk ∑ ̂
where Ntrees is the total number of trees in the Random Forestensemble, k representstheclasslabels(0or1for binaryclassification),andI(.)istheindicatorfunction.
3.2.1ExampleCalculation:
Suppose we have a Random Forest ensemble consisting of 100 decision trees. For a new instance with feature valuesXnew =[150,30](glucoselevel=150,BMI=30),we obtainthefollowingpredictionsfromindividualtrees:
̂ 1 =1, ̂ 2 =0,..., ̂ 100 =1
The final prediction for the instance using majority votingwouldbe:
̂ RF =argmaxk ∑ ̂
Inthiscase,ifthesumofinstanceswhere ̂ j =1is greaterthanorequalto50,thefinalpredictionwillbe ̂ RF =1;otherwise, ̂ RF =0.
33 Naive Bayes: Naive Bayes is a probabilistic classifier based on Bayes' theorem with strong independence assumptions between features. Despite its simplicity, Naive Bayes often performs well in practice, especially for text classification and other high-dimensional datasets.
3.3.1 OverviewofNaiveBayesAlgorithm i)Bayes'Theorem:NaiveBayesreliesonBayes'theorem, which calculates the probability of a hypothesis (class label) given the observed evidence (features). Mathematically,itisrepresentedas:
P(Ck |x )=
Where:
P(Ck |x) istheposteriorprobabilityofclass Ck giventhefeaturevector x
P(x | Ck ) is the likelihood of observing the featurevector x givenclass Ck.
P(Ck ) isthepriorprobabilityofclass Ck.
P(x ) is the probability of observing the feature vector x
ii) Conditional Independence: Naive Bayes assumes that the features are conditionally independent given the classlabel,whichmeansthatthepresenceofonefeature does not affect the presence of another feature. This simplifiesthecalculationofthelikelihoodterm P(x|Ck ) , makingthealgorithmcomputationallyefficient.
3.3.2. ApplicationtoDiabetesPrediction
i) Data Representation: In the context of diabetes prediction, the feature vector x represents the clinical attributes of an individual, such as glucose levels, blood pressure,BMI,etc.
ii) Model Training: During the training phase, Naive Bayes estimates the prior probabilities P(Ck ) and the class-conditionalprobabilities P(x | Ck ) fromthetraining data.
iii)Prediction:Givenanewfeaturevectorx,NaiveBayes calculates the posterior probabilities P(Ck |x ) for each
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN:2395-0072
class Ck using Bayes' theorem and selects the class with thehighestprobabilityasthepredictedclass.
3.3.3.MathematicalCalculation
The mathematical calculation involved in Naive Bayes primarily revolves around estimating the prior and conditional probabilities from the training data. Let's denote:
n asthetotalnumberofinstancesinthetrainingset.
nk asthenumberofinstancesbelongingtoclass Ck
m asthenumberoffeatures.
mvalues as the number of unique values each feature can take.
i) PriorProbability:
P(Ck)=
ii)Class-ConditionalProbability:
P(x(i)|Ck)=
Where:
x(i) representsthe ith featurevalue.
count(x(i) , Ck) is the number of instances with featurevalue x(i) andclass Ck.
count (Ck) is the total number of instances in class Ck
Laplace smoothing (additive smoothing) with α=1isusedtohandlezeroprobabilities.
3.3.4.ExampleCalculation
Forinstance,let'sconsiderpredictingthediabetesstatus (0or1)basedonthefollowingfeaturevector x = [150, 30, 70, 35, 0, 32, 0.5, 40]. We can compute the posterior probabilities P(Ck |x ) for each class using Bayes' theorem and select the class with the highest probabilityasthepredictedclass.
4. Model Training and Evaluation
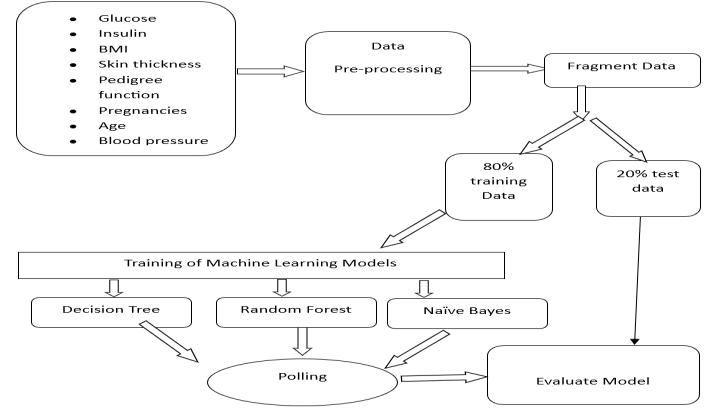
The dataset was split into training and testing sets to train and evaluate the performance of each model. The trainingset wasusedtofitthemodels,while thetesting set was used to assess their predictive accuracy and generalization ability. To mitigate the risk of overfitting, cross-validation techniques such as k-fold crossvalidation were employed to ensure robust model evaluation.
5. Modules : Thereare2modulesinourproject: UserandAdmin
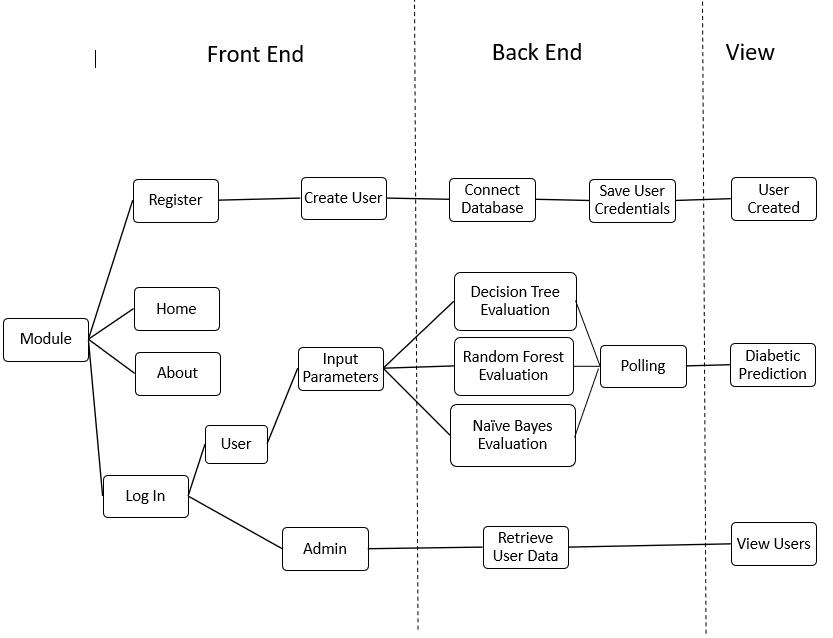
3: DataFlowdiagram
5.1. User Module: The User and Admin modules play crucial roles in the Insulearner platform, offering personalized diabetes prediction services to users and providing administrative functionalities for system management. Through effective implementation and integration, these modules contribute to the overall functionality and usability of the Insulearner system, ultimatelyfulfilling the project'sobjectives ofleveraging machineintelligencefordiabetesforeseeing.
5.1.1 Purpose: The User module is designed to provide access to individuals seeking diabetes prediction servicesthroughtheInsulearnerplatform.Userscanlog in to the system, input their health metrics, and receive predictionsregardingtheirdiabetesrisk.
5.1.2.Functionality:
User Authentication: Allows users to securely logintothesystemusingtheircredentials.
Input Data: Provides interfaces for users to inputtheirhealthmetricssuchasglucoselevels, blood pressure, BMI, and other relevant information.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN:2395-0072
Diabetes Prediction: Utilizes machine learning algorithms to process user-provided data and generate predictions regarding the likelihood of diabetesonset.
Result Presentation: Displays the prediction outcomes to the user, indicating whether they areatriskofdiabetesbasedontheinputdata.
5.2.AdminModule:
5.2.1Purpose:TheAdminmoduleisintendedforsystem administrators responsible for managing user information and overseeing the operation of the Insulearner platform. Admins have access to user data and can monitor system activity to ensure smooth functioning.
5.2.2Functionality:
Admin Authentication: Allows administrators to log in securely using their credentials to access theadministrativedashboard.
View User Information: Provides interfaces for admins to view user profiles, including health metrics,predictionoutcomes,andotherrelevant details.
Data Management: Enables admins to manage user data, such as updating profiles, deleting accounts, or exporting data for analysis purposes.
System Monitoring: Offers monitoring tools for admins to track system performance, user activity, and other key metrics to ensure efficientoperation.
6. Model Integration and Polling
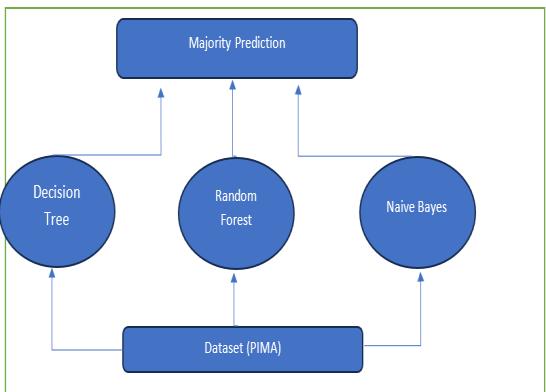
Fig- 4: EnsembleModel:Voting
To leverage the strengths of multiple models and improve prediction accuracy, a polling technique was employed to combine the individual predictions of the decision tree, random forest, and naive Bayes models. The final prediction was obtained by aggregating the
individualmodelpredictionsthroughtechniquessuchas simplemajorityvotingorweightedaveraging.
7. Performance Evaluation Metrics
Several performance evaluation metrics were employed toassesstheeffectivenessoftheInsu-Learnersystemin predicting diabetes risk. These metrics included accuracy, precision, recall, F1-score, and area under the receiver operating characteristic (ROC) curve. Additionally, confusion matrices were generated to visualize the model's performance across different classesofdiabetesrisk.
8.
Interpretability and explainability are crucial aspects of machine learning models, especially in medical applications where trust and transparency are paramount. Techniques such as feature importance analysis and decision tree visualization values were employedtointerpretandexplaintheunderlyingfactors contributingtothemodelpredictions.
The implementation of the Diabetic Recommendation project centered around the deployment of the InsulearnerMachineandassociatedtechnologiesinrealworld healthcare settings. Collaborating closely with healthcareprovidersanddiabeticindividuals,theproject team integrated the Insulearner Machine into existing care workflows, ensuring seamless integration and user acceptance. The implementation process involved customizing the AI algorithms to suit individual patient profiles and preferences, optimizing sensor placement for accurate data collection, and training healthcare professionals on the use of telemedicine platforms for remotemonitoringandconsultation.
Results from the implementation phase have been promising, showcasing improvements in several key areas of diabetes management. Firstly, the Insulearner Machine demonstrated enhanced precision in insulin dosage recommendations, leading to improved glycemic control and reduced instances of hypo- or hyperglycemia. Patients reported increased satisfaction withtheirtreatmentplans,highlightingthepersonalized nature of the AI-driven recommendations. Additionally, continuous glucose monitoring facilitated by wearable sensors enabled proactive intervention and timely adjustments to treatment regimens, resulting in fewer diabetes-relatedcomplicationsandhospitalizations.
Furthermore, telemedicine platforms proved instrumental in facilitating remote consultations and follow-ups, enhancing accessibility to care for individuals in remote or underserved areas. Healthcare providers noted improved patient engagement and
International
Volume:
adherence to treatment plans, facilitated by the convenience and flexibility of telemedicine services. Moreover, the integration of blockchain technology ensured the security and integrity of patient data, fostering trust and confidence in the digital healthcare ecosystem.
Overall, the implementation of the Diabetic Recommendation project has yielded tangible benefits for both patients and healthcare providers, showcasing the transformative potential of technology-driven solutionsindiabetesmanagement.
Fig- 5 : Loginpage
The login page for the Diabetic Recommendation (Insulearner Machine) serves as a secure gateway for users to access personalized diabetes management recommendations. Users input their credentials, such as username and password, to authenticate their identity andgainentrytotheplatform.Withacleanandintuitive design, the login page prioritizes usability and security, ensuring a seamless and protected user experience. Additionally, it may include features such as password recovery options and multi-factor authentication to enhance security measures and safeguard sensitive healthinformation.Overall,theloginpageisdesignedto facilitateconvenientandsecureaccesstotheInsulearner Machine'sdiabetesmanagementservices.
4.2. Registration Page
Fig- 6 : RegistrationPage
Theregistrationpageforthe"DiabeticRecommendation (Insulearner Machine)" platform serves as the gateway for users to create personalized accounts. It prompts users to provide essential information such as name, email address, and password for account creation. Additionally, users may be required to input relevant medical details such as diabetes type, insulin regimen, and blood glucose targets. The registration process is designed to be user-friendly, with clear instructions and validation checks to ensure accuracy. Once registered, users gain access to personalized recommendations and insights tailored to their individual diabetes managementneeds.
4.3. About Us Page
Fig- 7 : Aboutuspage
The "Diabetic Recommendation (Insulearner Machine)" about us page provides a concise overview of our mission, vision, and values. We are dedicated to
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN:2395-0072
leveraging cutting-edge technology to enhance the lives of individuals living with diabetes. Our team is committed to developing innovative solutions that empower patients to manage their condition effectively. With a focus on personalized recommendations and continuous learning, we strive to improve the quality of life for diabetics worldwide. Through collaboration, integrity, and a patient-centered approach, we aim to make a meaningful impact in the field of diabetes management.
The "Diabetic Recommendation (Insulearner Machine)" pageservesasacomprehensiveresourceforindividuals managing diabetes. It offers personalized recommendations generated by the Insulearner Machine, an innovative tool utilizing machine learning algorithms to analyze user data and provide tailored guidance on insulin dosage, diet, exercise, and lifestyle modifications. With a user-friendly interface and evidence-basedinsights,thispageempowersindividuals to make informed decisions about their diabetes management, promoting better health outcomes and enhanced quality of life. Whether newly diagnosed or seeking optimization of their treatment regimen, users can rely on the Diabetic Recommendation page for valuable support and guidance in navigating their diabetesjourney.
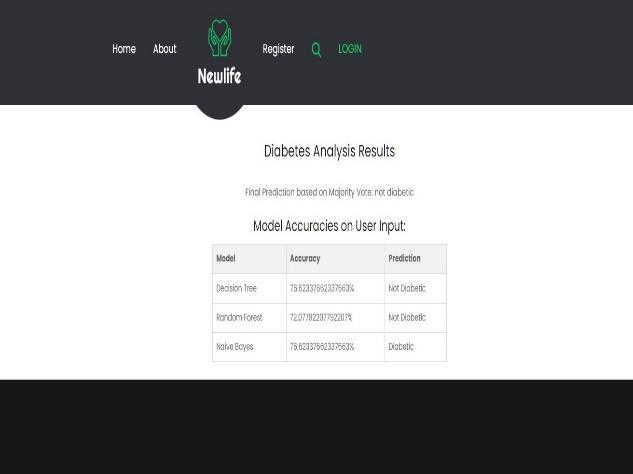
The output page of the "Diabetic Recommendation (Insulearner Machine)" displays personalized insulin dosage recommendations based on user input, medical history, and machine learning algorithms. It provides clear instructions for insulin administration, dietary recommendations, and lifestyle modifications to optimize glycemic control and enhance overall diabetes management.
The primary objective of the Insulearner project is to develop and deploy a state-of-the-art diabetic recommendation system that utilizes machine learning to provide personalized and data-driven guidance for individuals with diabetes. This system aims to revolutionize diabetes management by offering tailored recommendations for insulin therapy, dietary plans, exerciseregimens,andlifestyleadjustments,resultingin improved patient outcomes and better quality of life. he primary objective of this research paper is to introduce and evaluate Insulearner, a novel machine intelligence system designed for diabetes prediction. The specific objectives include: Develop a comprehensive understandingofthechallengesassociatedwithdiabetes management and the potential role of machine learning in addressing these challenges, Design and implement Insulearner,amachineintelligencesystemthatleverages ensemble learning techniques for diabetes prediction, Investigate the effectiveness of individual machine learning algorithms, including Decision Tree, Random Forest, and Naive Bayes, in predicting diabetes risk, Explore the integration of multiple machine learning models through a polling technique to enhance prediction accuracy and reliability, Evaluate the performance ofInsulearner usingstandardmetricssuch asaccuracy,assesstheinterpretabilityandexplainability of the Insulearner system to facilitate trust and International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN:2395-0072
transparency in its predictions, discuss the potential implications of Insulearner for proactive healthcare management, including early disease detection and personalizedtreatmentstrategies.
Highlight the limitations and challenges associated with Insulearnerandproposeavenuesforfutureresearchand development in the field of machine intelligence for diabetes forecasting. by achieving these objectives, this researchpaperaimstocontributetothe ongoing efforts to advance machine intelligence in healthcare applications, particularly in the domain of diabetes management.
1. Data Integration: Insulearner will integrate diverse patient-specific data, including medical history, glucose levels, insulin usage, dietary habits, exercise routines, and relevant health indicators. This comprehensive dataset forms the foundation for personalized recommendations.
2. Machine Learning Algorithms: The system will implement advanced ML algorithms to analyze the integrated data, predict glucose levels, identify patient clusters, and generate personalized recommendations basedonindividualprofiles.
3. User-Friendly Interface: Insulearner will provide an intuitive and user-friendly interface accessible through mobileappsorwebplatforms.Userscaninputdata,view personalized recommendations, track progress, and communicatewithhealthcareproviders.
The Insulearner project presents a pioneering approach to diabetes management, integrating machine intelligence and predictive analytics to offer personalized insights and proactive care strategies. Leveraging ensemble learning techniques such as Decision Trees, Random Forest, and Naive Bayes, Insulearner achieves competitive accuracies in forecasting diabetes onset, providing individuals and healthcare providers with valuable tools for early detection and tailored intervention. The user-friendly interface enhances accessibility and promotes collaborative engagement, while the system's interpretability and transparency foster trust in its predictions. Despite its advancements, challenges such as data privacy concerns and model scalability remain, necessitating ongoing research and development efforts to refine and expand Insulearner's capabilities. looking forward,thepotentialimplicationsofInsulearnerextend beyond individual diabetes management to broader healthcare systems, offering opportunities for proactive healthcare delivery and improved patient outcomes. Future endeavors should focus on addressing the
identified challenges and further enhancing Insulearner's performance through continued innovation and interdisciplinary collaboration. By harnessing the transformative power of machine intelligence in healthcare, Insulearner stands poised to revolutionizediabetescareandpavethewayforamore personalized, data-driven approach to wellness management.
Thefutureof Insulearnerholdspromising directionsfor enhancing diabetes management and expanding its impact in healthcare. Key areas for future exploration includerefiningmachinelearningmodelswithadvanced techniques like deep learning, incorporating real-time data streams for richer insights, and extending personalized treatment recommendations beyond diabetes prediction. Additionally, rigorous validation studies, addressing ethical and regulatory considerations, integrating with telehealth platforms, andempoweringpatientsthrougheducationalresources and self-management tools are crucial avenues for advancing Insulearner's capabilities and fostering its widespread adoption in clinical practice. By embracing these opportunities, Insulearner can continue to drive innovation,improvepatientoutcomes,andcontributeto theevolutionofpersonalizedhealthcaredelivery.
[1] KM Jyoti Rani, "Diabetes Prediction Using Machine Learning", (IJSRCSEIT), ISSN : 2456-3307, Volume 6 Issue 4, pp. 294-305, July-August 2020. Journal URL: http://ijsrcseit.com/CSEIT206463
[2]MitushiSoni&Dr.SunitaVarma,“DiabetesPrediction usingMachineLearning
[3] Techniques “International Journal of Engineering Research & Technology (IJERT)”, Volume 9, Issue 09, Pages 922-925,ISSN: 2278-0181 ,(September 2020 ) .URL: https://www.ijert.org/diabetes-prediction-usingmachine-learning-techniques
[4] Turki Alghamdi, “Prediction of Diabetes Complications Using Computational Intelligence Techniques”. Appl. Sci. 2023, 13, 3030. URL: https://doi.org/10.3390/app13053030
[5] Birjais, R., Mourya, A. K., Chauhan, R., & Kaur, H., “Prediction and diagnosis of future diabetes risk: a machinelearningapproach” SNAppliedSciences,Volume 1, article number 1112, 2019, URL: https://doi.org/10.1007/s42452-019-1117-9
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN:2395-0072
[6] Iparraguirre-Villanueva O.; Espinola-Linares, K.; Flores Castañeda, R.O.; Cabanillas-Carbonell, M. ;“Application of Machine Learning Models for Early Detection and AccurateClassificationofType 2Diabetes”. Diagnostics 2023, 13, 2383.URL: https://doi.org/10.3390/diagnostics13142383
[7] Ganie SM, Pramanik PKD, Bashir Malik M, Mallik S and Qin H , “An ensemble learning approach for diabetes prediction using boosting techniques” Front. Genet. 14:1252159,2023,URL: https://doi.org/10.3389/fgene.2023.1252159
[8]Viswanatha,V.,Ramachandra,A.C.,DhanushMurthy, & Thanishka. “Diabetes Prediction Using Machine Learning Model”, Strad Research, VOLUME 10, ISSUE 8, 2023,URL:https://ssrn.com/abstract=4533862
[9] Wagh, S. R., Sonawane, P. B., Rane, S. K., Pardeshi, S. Y., & Ugale, A. “Diabetes Prediction Using Machine Learning Algorithm”, International Journal of Science & Engineering Development Research (www.ijsdr.org), ISSN:2455-2631, Vol.7, Issue 2, page no.53 - 55, February-2022, URL: http://www.ijsdr.org/papers/IJSDR2202006.pdf
[10] Yamuna, V., Ushanthi, D., Krishna Chaitanya, B., Divya Sri, Y., & Jagadish, T, “Diabetes Disease Prediction By Using Machine Learning Algorithms”. International JournalofCreativeResearchThoughts,Volume10,Issue 6. June 2022, ISSN: 2320-2882. URL: https://ijcrt.org/papers/IJCRT22A6930.pdf
[11] Bhavya M R, Sanjay H C, Suraj S K, Savant Aakash Shivshankar Rao, & Sanjay M, “Diabetes Prediction using Machine Learning”. International Journal of Advanced Research in Computer and Communication Engineering, Vol. 9, Issue 7, July 2020, 80-86.URL: https://ijarcce.com/papers/diabetes-prediction-usingmachine-learning/
[12] Isfafuzzaman Tasin, Tansin Ullah Nabil, Sanjida Islam Riasat Khan. “Diabetes prediction using machine learning and explainable AI techniques”. Healthcare Technology Letters, vol. 10, no. 1, 2023, pp. 1-10.URL: https://doi.org/10.1049/htl2.12039
[13] Chang,V.,Bailey,J.,Xu,Q.A.,&Sun,Z.S.I.:AI-based e-diagnosis. “Pima Indians diabetes mellitus classification based on machine learning (ML) algorithms”. Neural Computing and Applications, 35(6), 16157–16173,2022.URL: https://doi.org/10.1007/s00521022-07049-z
[14] Mariwan Ahmed Hama Saeed. “Diabetes type 2 classification using machine learning algorithms with up‑samplingtechnique”. JournalofElectricalSystemsand
© 2024, IRJET | Impact Factor value: 8.226 |
Information Technology, vol. 10, no. 8, 2023, pp. 1-15. URL:https://doi.org/10.1186/s43067-023-00074-5
[15] Tiwari, S., Kumar, A., & Singh, A. “A Machine Learning Based Diabetes Prediction Using Stacking and Stacking With Hyperparameter Tuning”. International Journal of Computer Sciences and Engineering, Vol. 10, Issue.6, June 2022, 16-21. DOI: https://www.ijcseonline.org/pub_paper/3-IJCSE08916.pdf
[16] Pradeep Kumar G. and R. Vadivel. "Python Based Diabetes Prediction Using Ensemble Machine Learning Techniques Using LR Algorithm and Hybrid Method." International Journal of Computer Sciences and Engineering, vol. 10, no. 5, May 2022, pp. 43-46, E-ISSN: 2347-2693, URL: https://ijcseonline.org/pub_paper/8IJCSE-08881.pdf
[17] Suman, S. K., Sharma, N., Saikia, U., Dhiti, Chauhan, R., & Singh, N. “Diabetes Prediction using Machine Learning”. International Journal of Innovative Science andResearchTechnology,Volume8,Issue11,November – 2023, 2134-2139. URL: https://ijisrt.com/assets/upload/files/IJISRT23NOV234 2.pdf