
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN: 2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN: 2395-0072
Trupti Sutar1 , Mrunali Hirave2 , Samruddhi Sasavade3 , Karan Barale4, Tanaya Patil5 , Prof. S. A. Babar6
1,2,3,4,5Students of department of Computer Science & Engineering. 6Professor of department of Computer Science & Engineering. Sanjeevan Engineering & Technology Institute, Panhala-416201
Abstract - More individuals than ever before are creating and sharing knowledge thanks to the growth of social networks, but many of these things are unrelated to reality. The proliferation of social media and communication capabilities has led to a rapid expansion of the false news phenomena. A rapidly developing field of study that is attractingalotofinterestisfakenews detection.Duetoalack of resources, including processing and analysis methods as well as datasets, it does confront certain difficulties. As a result, fake news is spreading swiftly for a variety of commercial and political objectives. Finding reliable news sources has become more difficult with the rise of online newspapers. This work compiles news stories in Hindi from a variety of news sources. There is a thorough discussion of the preprocessing, feature extraction, classification, and prediction procedures. Fake news is identified using a variety of machine learning methods, including logistic regression, NaïveBayes.Fakenewsisbecomingmoreandmoreprevalent on social media and other platforms, and this is a serious worry since it has the potential to have devastating effects on society and the country. Its detection is already the subject of extensive research. Using tools like Python's scikit-learn and Natural Language Processing (NLP) for textual analysis, this paper analyses existing research on fake news detection and selects the best traditional machine learning models to develop a model of a product with supervised machine learningalgorithmthatcanclassifyfake newsastrueorfalse.
Key Words: Naïve Bayes Classifier, Decision Tree Classifier, Gradient Boosting Classifier, Logistic Regression, Sklearn, Pandas, Matplotlib
Misleadinginformationthatcanbeverifiedcanbefoundin fake news. This perpetuates false information about a country'sstatisticsorinflatesthepriceofparticularservices, which can cause unrest in some nations, as it did in the Arabic Spring. Certain organisations, such as the House of Commons and the Crosscheck project, are attempting to addressmatterssuchasauthoraccountabilityconfirmation. Butbecausetheyrelyonhumanmanualidentification,which isnotreliableorpracticalgiventhatmillionsofarticlesare published or withdrawn every minute around the world, theirreachisseverelyconstrained.Thisstudypresentsan approachtodevelopamodelthatusessupervisedmachine
learningalgorithmsonanannotated(labelled)datasetthat is manually classified and guaranteed to determine if an article is legitimate or fraudulent based on its words, phrases,sources,andtitles.Then,basedontheresultsofthe confusion matrix,featureselectiontechniquesareused to experimentandpickthebestfitfeaturesinordertogetthe highest precision. We suggest employing various categorizationalgorithmstobuildthemodel.Theproduct willbeamodelthatcanbeutilisedandintegratedwithany systemforfutureusage,onethatcanidentifyandcategorise phoneyarticles.Themodelwilltesttheunseendataandplot thefindings.Socialnetworkshaveplayedapartintherecent explosion of information. Social networks are now the primary means of communication for people on a global scale.Butit'sfrequentlyimpossibletotellifnewssharedon socialmediaplatformsisaccurate.Useofsocialnetworksis therefore not without its drawbacks. It will therefore be advantageous if the information obtained from social networksisaccurate.Ontheotherhand,ifthisnewsisfalse, it will have numerous negative effects, and the amount of harm caused by false information spreading rapidly is unimaginable.Thedisseminationofmisleadingcontentora complete misrepresentation of real newsstoriesmight be facilitatedbythecreativeinformationincludedinfakenews. Furthermore,theriseinpopularityofthesekindsofstories canbeattributedprimarilytosocialmedia.Informationthat is intentionally intended to mislead readers is considered false. Particularly for financial or political gain, false informationisspread.Thanksinlargeparttosocialmedia, thefalsenewsepidemichasspreadsignificantlythroughout thelasttenyears.Thereareseveralwaystodisseminatethis falseinformation.Somearemadejusttogetmorepeopleto clickonyourwebsiteandvisitit.Othershaveanimpacton publicperceptionoffinancialmarketsandpoliticalpolicies. For instance, by harming an organization's or company's online reputation. Social media fake health news is dangerous for everyone's health. did. People often find it challengingtolocatetrustworthysourcesandtrustworthy information when they need it. Disinformation overload causesworry,fear,insecurity,andbigotrytospreadmore widelythaninpastepidemics.
Creating a Reliable System for Identifying Fake News. Developareliableandprecisetechniqueforidentifyingfake
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net
news in order to slow down the dissemination of false information on the internet. The public's trust and the welfare of society are seriously threatened by the proliferation of fake news in digital media. There is an immediate need for a trustworthy fake news detection systemduetothequickspreadofincorrectinformationvia internet platforms. Current platforms are frequently imprecise,unabletokeepupwiththeconstantlychanging strategiesused by disseminatorsof falseinformation,and sometimes inflexible in a variety of linguistic and cultural situations. The goal of this research is to create a cuttingedgesystemfordetectingfakenewswhileaddressingthese issues.
A fake news detection system's goals are as follows:
1. Boost Accuracy: Reducefalsepositivesandnegativesby fine-tuning the fake news detection algorithm.
2. Multilingual Adaptability: Gaintheabilitytorecognise false information in a variety of languages while taking linguistic and cultural quirks into account.
3. Real-time Analysis: As information circulates through online channels, put in place a system that can quickly identify and flag possible fake news.
4 User -Centric Design: Provideanintuitiveuserinterface thatpromotesinteractionandletspeopleoffercommentson information that has been identified.
5. Continuous Learning: Putinplaceasystemthatisableto adjustandlearnonaconstantbasis,keepingupwithnew strategiesemployedbydisseminatorsoffalseinformation.
6. Cooperationwith Fact-CheckingGroups: Formalliances withfact-checkinggroupstodouble-checkdataandimprove the detection system's dependability. Together,thesegoalsseektodevelopastrongandefficient system for identifying fake news that tackles important issues with disinformation detection and guarantees accuracy,openness,andflexibility.
2.1 Fake news detection:Asurveyofgraphneuralnetwork methods: They review publications that use graph neural networks to detect bogus news in this section. They classifiedGNN-basedfalsenewsdetectiontechniquesinto fourcategories:conventionalGNN-based,GCN-based,AGNNbased, and GAE-based, based on GNN taxonomies (see to Section 2.3.2). Numerous social networks have arisen, producingenormousamountsofdata.Effectivetechniques for gathering, differentiating, and screening actual news from bogus are becoming more and more crucial, particularlyinlightoftheCOVID-19epidemic.
2.2 Fake news detectionon Hindinewsdataset: Detecting false news has drawn the attention of many scholars worldwideinrecentyears.Thissectionfocusesoncurrent methods for identifying or predicting false information.
p-ISSN: 2395-0072
Characteristicextractionisakeycomponentofmanyofthe popularfalseinformationdetectionalgorithms.Thevarious classifiers incorporated into these solutions have been appropriatelylabelled.
2.3 A smart System for Fake News Detection Using Machine Learning: The primary goal is to identify false news,whichisawell-knowntextclassificationissuewithan obvious solution. A model that can distinguish between "real"and"fake"newsmustbedeveloped.
2.4 A Review Paper on Fake News Detection: Withsocial media and mobile technologies becoming more and more popular,informationiseasilyaccessible.Intermsofnews distribution,socialmediaandmobileappshavesupplanted conventionalmedia.Withtheriseintheuseofsocialmedia platforms such as Facebook, Twitter, and others, news spreads rapidly among a huge number of users who have verylittletimetodedicatetoonethingatatime.Thetwo methods used to examine the veracity of the content are machinelearningandknowledge-basedapproaches.
2.5 Fake News Detection Using Machine Learning Approaches: Thispaper'sresearchfocusesonidentifying bogusnewsthroughtwolevelsofreview:characterisation anddisclosure.Thefundamentalideasandpreceptsoffake newsareemphasisedonsocialmediaduringthefirstphase. This procedure will lead to feature extraction and vectorization;wesuggesttokenizingandextractingfeatures fromtextdatausingthePythonscikit-learnmodule.
3.1 Data Collection: assembleavariedcollectionofphoney andlegitimatenewsstoriesinarangeofsubjectsandmedia types(text,photos,videos).Providelabelledexampleswith each article's authenticity indicated. Machine learning modelsaretrainedandtestedusingthisdatasetasthebasis. Severalpackagesareusedinthisproject,andpandasisused to load and read the data collection. Through the use of pandas, we are able to read the CSV file and display the datasetinitscorrectformaswellasitsshape.Thedatawill beusedfortrainingandtesting;supervisedlearningentails labellingthedata.
3.2 Data Preprocessing:
3.2.1. Cleaning:Text,IteliminatesHTMLtags,extraneous characters, and symbols from the text. Clear Explanation: Organising the text to make it easier to read.
3.2.2. Tokenization: Dividesthetextintodiscretewords,calledtokens.reducing sentences to a list of terms that may be examined.
3.2.3. Lowercasing:
Thisfeature makesall wordssmallersothatcomparisons are consistent. Regardless of case, all words are treated equally.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net
3.2.4.Stopword Removal: Removesoverusedandunhelpful terms. Eliminating terms that don't add much to the explanation,suchas"the"or"and".
3.2.5. Stemming or lemmatization:
Words are reduced to their root or base form Reducing words to their most basic form to facilitate analysis.
3.2.6. Numerical Data Handling: Function:Handlestext's numericaldatainasuitablemanner. Ensuringthatnumbers are handled appropriately and don't lead to confusion.
3.2.7. Quality Control: Functions:Evaluatesandmodifies preprocessing procedures on a regular basis in light of continuing analysis. Plain Interpretation: Verifying and refining the text preparation process used by the system before analysis. Together, these characteristics and technologies enable the collection of trustworthy news sourcesandguaranteethetext'scleaningandorganisationin preparationforpreciseanalysisbythefalsenewsdetection system.
3.3 Model Selection:
Dependingonthenatureoftheproblem,selecttheproper machine learning approaches and algorithms. Frequently employedalgo CompriseSVMs,orsupportvectormachines NeuralnetworkswithRandomForestRandomForestNaive BayesTransformermodels(BERT,GPT)
3.4.Validation and Training:
Split the dataset into test, validation, and training sets. ModelTraining:Utilisingthetrainingdata,trainthechosen models. Hyperparametertuning:Usemethodssuchasgrid search and cross-validation to optimise the model's parameters in order to improve performance. Validation and Evaluation: To fine-tune the model, evaluate its performanceonthevalidationsetusingmeasuressuchas accuracy,precision,recall,andF1-score.
3.5.Model Assessment and Testing:
Determine the accuracy and generalizability of the topperformingmodelbyassessingitonanuntestedtestdataset.
3.6. Deployment and Implementation:
Usetheverifiedmodeltohandlefreshnewsarticlesinbatch orreal-time. Usethemodeltocreateasystemorapplication that can distinguish between phoney and authentic news stories.
4.1. Python:
Pythonisanobject-oriented,high-level,interpretedscripting language. The design of Python emphasises readability. It hasfewer syntactical structures than otherlanguagesand typicallyemploysEnglishkeywordsinsteadofpunctuation different tongues. Python is Interpreted: The interpreter processesPythonatruntime.Itisnotnecessaryforyouto assemble your programme before running it. This is
p-ISSN: 2395-0072
comparabletoPHPandPerl.PythonisInteractive:Youcan writeprogrammesbyjustinteractingwiththeinterpreter while seated at a Python prompt. It is an object-oriented programminglanguagethatfacilitatestheencapsulationof codewithinobjects.ItisaBeginner'sLanguage:Pythonisan excellentlanguagefornovice programmers,asitfacilitates thecreationofadiversearrayofprogrammes,rangingfrom basictextmanipulationtowebbrowsersandgaming.
4.1.2.sklearn
A machine learning package for the Python programming language,scikit-learn(formerlyknownasscikits.learnand also called sklearn) is available as free software.[3] With support-vectormachines,randomforests,gradientboosting, k-means,DBSCAN,andotherclassification,regression,and clusteringtechniques,itiscompatiblewiththeNumPyand SciPy scientific and numerical libraries for Python. ScikitlearnisaprojectfinanciallysupportedbyNumFOCUS.Most ofscikit-learn'scodeiswritteninPython,anditmakesheavy useofNumPyforarrayandhigh-performancelinearalgebra operations. To further enhance performance, a few fundamental algorithms are written in python. A python wrapper around LIBSVM is used to create support vector machines;asimilarwrapperaroundLIBLINEARisusedfor logistic regression and linear support vector machines. It might not be possible to use Python to enhance these methods in such circumstances. Numerous other Python libraries, including SciPy, Pandas data frames, NumPy for arrayvectorization,Matplotlibandplotlyforgraphing,and manymore,interactwellwithscikit-learn
4.1.3.Numpy
APythonpackagecalledNumPyisusedtoworkwitharrays. It also includes functions for working with matrices, the Fourier transform, and linear algebra. In the year 2005, TravisOliphantfoundedNumPy.Youarefreetouseitasitis anopensourceproject.NumericalPythonisreferredtoas NumPy. Lists can be used in place of arrays in Python, although processing them takes a while. Up to 50 times fasterarrayobjectsthanconventionalPythonlistsarewhat NumPyseekstodeliver.TheNumPyarrayobjectisknownas nd-array,anditcomeswitha numberofhelpful functions thatmakeusingitabreeze.Indataresearch,whenresources and performance are critical, arrays are employed extensively.
APythonpackagecalledSeabornisusedtocreatestatistical visualisations. It strongly integrates with pandas data structures and is built upon the matplotlib framework. Seabornfacilitatesdataexplorationandcomprehension.Its charting functions work with data frames and arrays that hold entire datasets, and they internally carry out the statistical aggregation and semantic mapping required to
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN: 2395-0072
createvisuallyappealinggraphs.Youmayconcentrateonthe meaningofthevariousplotpartsratherthanthespecificsof how to design them thanks to its declarative, datasetorientedAPI.
AcompletePythonvisualisationtoolkitforstatic,animated, and interactive graphics is called Matplotlib. Matplotlib enables both difficult and easy tasks. Make plots fit for publication.Createdynamicfigureswiththeabilitytopan, zoom,andupdate. Customisethelayoutandvisualdesign. Export data to numerous file formats. Integrated with GraphicalUserInterfacesandPythonLab. Utiliseadiverse rangeofthird-partypackagesconstructedusingMatplotlib.
Pandasisa well-known Pythonpackagethatisfrequently usedforanalysisanddatamanipulation.Inordertomake workingwithorganisedortabulardataquick,simple,and expressive, it offers high-level data structures and operations.DataFrame:Thefundamentaldatastructurein Pandas is a two-dimensional labelled data structure with columnsthatmayincludevarioussortsofdata.Considerit similartoaSQLtableorspreadsheet.Becauseoftheirgreat versatility, Data Frames can handle heterogeneous data types as well as time-series data. Data Manipulation: A wide range of functions, such as filtering, selecting, sorting, grouping, merging, reshaping, andaggregatingdata,areavailableinPandas.Itissimplclean andpreparedataforanalysisusingtheseprocesses,which can be carried out effectively on both Data Frames and Series.
Totrainthemodel,wemustfirstgathertwodatasets:one authenticandonefake.Thesedatasetsarethenuploadedto theprojectandtrainedusingmachinelearningalgorithms such as logistic regression, random forest, naive bayes regression,andclassification.Oncethedataistrained,itis testedusingonlinenewssources,andthemoduleprovides ananswerindicatingwhetherthenewsisauthenticorfake.
Theprocessofchoosingasubsetofpertinentfeaturestobe used in the creation of a model is known as feature extraction.Thedevelopmentofanaccuratepredictivemodel is aided by feature extraction techniques. They aid in the selection of traits that provide increased accuracy. An algorithmwillconvertinputdataintoareducedillustration setoffeatures,alsoknownasfeaturevectors,whentheinput data is too big to handle and is intended to be redundant. employing this smaller representation in place of the full-
sizeinputtochangetheinputdatainordertoaccomplish the intended task. Before using any machine learning algorithms on the changed data in feature space, feature extractionisdoneontherawdata.
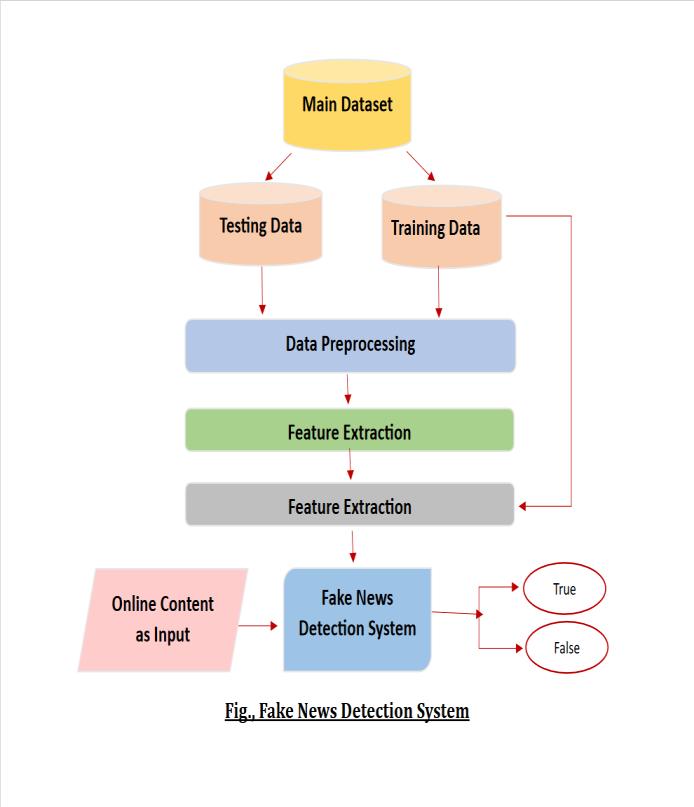
AsForthisproject,I'mimplementingthearchitectureusing the Scikit-Learn Machine learning library. Included in the third distribution, Anaconda, is an open-source Python machine learning package called Scikit Learn. All that is neededistoimportthepackages,andassoonasyouwrite thecommand,itcanbecompiled.Wecanreceivetheerrorat the same moment if the command fails to execute. I have trainedfourmodelsusingdistinctalgorithms:NaïveBayes, SupportVectorMachine,KNearestNeighbours,andLogistic Regression. These are widely used techniques for solving document categorization problems. We may assess the models'performanceonthetestsetoncetheclassifiershave beentrained.Usingthetrainedmodels,wecanforecastthe wordcountofeachmessageinthetestsetbyextractingits vector.
Withinthedisciplineofartificialintelligence(AI),machine learning(ML)isthestudyofcreatingmodelsandalgorithms that allow computers to learn from data and make predictions or judgements without explicit programming. Machine learning seeks to create systems. that, when exposed to further data, will automatically enhance their performance over time. Applications for machinelearningcanbefoundinmanydifferentfields,such asfinance,healthcare,naturallanguageprocessing,picture and audio recognition, and many more. The amount and quality of data available for training, the selection of algorithms,andtheproperparametertuningallplayamajor roleinmachinelearningperformance.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN: 2395-0072
Aneffectiveandquickapproachforpredictivemodelling,it is one of the supervised learning algorithms based on the probabilistic classificationtechnique. Ihaveemployedthe MultinomialNaiveBayesClassifierforthisassignment.
1.Bayes' Theorem: The foundation of Naive Bayes is the Bayes theorem, which determines the likelihood of a hypothesis (class label) in light of the available data (features).
P(labelclass−features)=Pfeatures−classP(features)
P(features−classlabel)⋅P(classlabel)=P(features)P(features∣ classlabel)⋅P(classlabel)
2. Assumption of Independence: The"naive"assumption ofNaiveBayesisthatcharacteristics,giventheclasslabel, areconditionallyindependent.Thisindicatesthatafeature's presence or absence has no bearing on the existence or absenceofanyotherfeature.
3. Training: Thealgorithmdeterminesthelikelihoodofeach feature given the class (P (features ∣class label)P(features ∣classlabel))andthepriorprobabilityofeachclass(P(class label)P(classlabel))duringthetraining
4.Prediction: given the observed data, Naive Bayes computes the posterior probability of each class to make predictionsforanewinstance.Itthenchoosestheclasswith thehighestprobabilityasthepredictedclass.SVMSupport VectorMachines(SVM)canbeusedtoidentifyfalsenewsby takingadvantageoflinguisticcharacteristicsthataretaken outofnewsarticles.Thegoalistousethepatternsandtraits foundinthetexttotrainanSVMclassifiertodifferentiate betweenrealandfakenews. phase.
SupportVectorMachines,orSVMs,areaclassofsupervised learning techniques used in regression and classification. Usingasubsetoftrainingpointsinthesupportvector,itis memory economical and effective in high dimensional spaces.
Regression using Logistic Regression Instead of using regression, use a linear model for categorization. The response variable's predicted values are derived from a combinationofthepredictors'values. Withfeaturestaken fromtextdata,LogisticRegressioncanbeusedtodetectfake news. A statistical technique called logistic regression is applied to binary classification problems in which the responseisabinaryvariable(0/1,True/False,Yes/No).In spite of its name, Instead of using regression for classification, logistic regression is employed. It simulates
the likelihood that a specific instance falls into a specific category.
Althoughdecisiontreesareasupervisedlearningtechnique, theyareprimarilyemployedtosolveclassificationproblems. However, they can also be used to solve regression problems. This classifier is tree-structured, with internal nodes standing in for dataset attributes, branches for decisionrules,andleafnodesforeachoutcome.TheDecision NodeandtheLeafNodearethetwonodesthatmakeupa decision tree. While leaf nodes represent the result of decisions and do not have any more branches, decision nodes are used to make any kind of decision and have numerous branches. The characteristics of the provided datasetareusedtoinformthedecisionsorthetest. Itis a graphical tool that shows all of the options for solving a problemormakingadecisiongivencertainparameters.
A well-liked boosting technique in machine learning for regressionandclassificationproblemsisgradientboosting. Onetypeofensemblelearningtechniqueiscalled"boosting," inwhichthemodel istrainedsuccessively,with eachnew modelattemptingtoimproveupontheonebeforeit.Itturns a number of ineffective learners into effective ones. AdaBoostGradientBoostingisoneofthetwomostwidely usedboostingalgorithms.Withgradientdescent,eachnew modelistrainedtominimisethelossfunction,suchasmean squared error or cross-entropy of the preceding model. Gradientboostingisapotentboostingprocedurethatturns several weak learners into strong learners. The approach calculatesthegradientofthelossfunctioninrelationtothe currentensemble'spredictionsforeachiteration,andthen trainsanewweakmodeltominimisethisgradient.Next,the newmodel'spredictionsareincludedintheensemble,and theprocedureiscontinueduntilastoppingrequirementis satisfied.
Theabilitytoeffectivelyidentifyandcategorisenewsstories orothermaterialaseitherrealorfraudulentisthedesired resultoffakenewsdetection.Minimisingfalsepositives whichmisclassifyrealnewsasfake andfalsenegatives which misclassify phoney news as real is the goal of effectivefakenewsdetectionsystems.reachingahighrecall andprecisionlevel.Thefollowingaresomeimportantgoals andresultsfortheidentifyingthefakenews:
1. Accuracy: Newspiecesshouldbecorrectlyclassifiedby the system, with a high degree of general accuracy in differentiatingbetweenauthenticandfraudulentnews.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN: 2395-0072
2. Precision: Outofallarticleslabelledasfake,precisionis the percentage of accurately recognised fake news. A low rate of false positives is shown by a high precision, which means that when the system labels news as bogus, it is probablyaccurate.
3.Recall (Sensitivity): Outofalltherealfakearticles,recall isthepercentageofaccuratelyrecognisedfakenews.Alow proportion of false negatives is indicated by a high recall, which suggests that the system successfully detects the majorityoffakenews
.4.Efficiency: Inordertokeepupwiththedynamicnatureof news transmission, the detection procedure needs to be effective, producing results in real-time or almost in realtime.
5. User-Friendly Interface: A user-friendly interface is essentialforanyfalsenewsdetectionsystemthatismeantto beusedbythegeneralpublic.Itshouldmakeitsimplefor users to comprehend and analyse the findings. Reaching these goals would help develop more dependable instruments to stop fake news and mis information from spreading across different internet platforms and media channels.
In conclusion, the most effective way to identify false information is to combine cutting-edge technology with human judgement. Algorithms are capable of identifying patterns, but humans also contribute context and critical thought.Thisprojectdependsoncontinuousimprovement and collaboration between technology and human judgement.Essentially,theabilityofcutting-edgetechnology and human intelligence to work together is critical to combating fake news efficiently. Although algorithms are quiteproficientatidentifyingpatterns,humanjudgementis essential for comprehending context. This cooperative method, whichcombineshumanjudgement with machine learning,guaranteesathoroughandnuancedassessmentof thedata.Stayingaheadofemergingdisinformationtactics requirescriticalthinkingabilitiesandconstantalgorithmic refining. In the end, detecting fake news effectively necessitates a continuous collaboration between technological advancements and human knowledge, resultinginastrongerdefenceagainstthedisseminationof misinformationinthedigitalera.
[1] Sudhanshu Kumar, Thoudam Doren Singh “Fake newsdetectiononHindinewsdataset”2022.
[2]ZKhanam,BNAlwasel,HSirafiandMRashid“FakeNews DetectionUsingMachineLearningApproaches”:ZKhanam etal2021IOPConf.Ser.:Mater.Sci.Eng.1099012040.
[3]HuyenTrangPhan,NgocThanhNguyen,DosamHwang “Fake news detection: A survey of graph neural network methods”24March2023.
[4] Mayur Bhogade, Bhushan Deore, Abhishek Sharma, OmkarSonawane,Prof.Manisha Singh“AREVIEW PAPER ONFAKENEWSDETECTION”May2021.
[5] Anjali Jain, Harsh Khatter, AvinashShakya “A SMART SYSTEM FOR FAKE NEWS DETECTION USING MACHINE LEARNING"20october2020.
[6]M.Granik and V.Mesyura,“Fakenews detection using naive Bayes classifier,” 2017 IEEE 1st Ukr. Conf. Electr. Comput.Eng.UKRCON2017-Proc.,pp.900–903,2017.
[7]S.Chandra,P.Mishra,H.Yannakoudakis,M.Nimishakavi, M. Saeidi, E. Shutova, Graph-based modeling of online communitiesforfakenewsdetection,2020,arXivpreprint arXiv:2008.06274.
[8] Shu, K., Sliva, A., Wang, S., Tang, J., & Liu, H.(n.d.)."fake newsdetectiononsocialmedia: AdataMiningPerspective.