No part of this publication may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying, recording, or any information storage and retrieval system, without permission in writing from the publisher. Details on how to seek permission, further information about the Publisher’s permissions policies and our arrangements with organizations such as the Copyright Clearance Center and the Copyright Licensing Agency, can be found at our website: www.elsevier.com/permissions.
This book and the individual contributions contained in it are protected under copyright by the Publisher (other than as may be noted herein).
Notices
Knowledge and best practice in this field are constantly changing. As new research and experience broaden our understanding, changes in research methods, professional practices, or medical treatment may become necessary.
Practitioners and researchers must always rely on their own experience and knowledge in evaluating and using any information, methods, compounds, or experiments described herein. In using such information or methods they should be mindful of their own safety and the safety of others, including parties for whom they have a professional responsibility.
To the fullest extent of the law, neither the Publisher nor the authors, contributors, or editors, assume any liability for any injury and/or damage to persons or property as a matter of products liability, negligence or otherwise, or from any use or operation of any methods, products, instructions, or ideas contained in the material herein.
Library of Congress Cataloging-in-Publication Data
A catalog record for this book is available from the Library of Congress
British Library Cataloguing-in-Publication Data
A catalogue record for this book is available from the British Library
ISBN: 978-0-12-817086-1
For information on all Elsevier publications visit our website at https://www.elsevier.com/books-and-journals
Publisher: Stacy Masucci
Acquisition Editor: Tari K. Broderick
Editorial Project Manager: Anna Dubnow
Production Project Manager: Maria Bernard
Cover Designer: Matthew Limbert
Typeset by SPi Global, India
3. Diseases of the blood
3.1
4. Endocrine,
4.1
diseases
expression and degradation in epithelial cells in cystic
(class I-II
Failure of the ion channel function of CFTR in cystic fibrosis airway epithelium (class III-IV mutations)
5. Diseases of the nervous system
5.1
Amyloid-beta
5.2
5.3
6. Diseases of the eye
stress, all-trans-retinal, and lipofuscin toxicity in age-related macular
7. Diseases of the ear
7.1
of mechanoelectrical transduction and potassium cycling in the
8. Diseases of the circulatory system
9. Diseases of the respiratory system
10. Diseases of the digestive system
11. Diseases of the skin and subcutaneous tissue
12. Diseases of the musculoskeletal system
TGFB signaling provokes endochondral ossification with osteophyte formation in OA
13. Diseases of the genitourinary system
13.1
Contributors
Anastasia P. Nesterova, PhD, formulated the idea of this book and led its creation, discussion about the format, writing of chapters, reconstruction of pathways, and more as deemed necessary. Dr. Nesterova is a senior scientist in the Life Science Research and Development department at Elsevier with a focus on mammalian genetics and human diseases since 2015. Her current scientific interests include signaling pathways and biomedical data repositories, genetics and proteomics analysis, and drug research. Anastasia P. Nesterova received her PhD degree in genetics from the Vavilov Institute of General Genetics, Russian Academy of Science in 2010.
Sergey Sozin, Vladimir Sobolev, Maria Zharkova, and Eugene S. Klimov all equally contributed to writing chapters about diseases and to the reconstruction of disease models.
Sergey Sozin, MD, Novel Software Systems employee, has been serving as a scientist at the Life Science Research and Development department at Elsevier with a focus on the reconstruction of disease signaling pathways since 2015. His interests include internal medicine, hematology, cancer biology, oncogenomics, and clinical trials. Dr. Sozin contributed greatly to the content of this book and ensured the quality of the descriptive aspects of the pathogenesis of the various included diseases. Sergey Sozin received his MD degree from the Pavlov State Medical University in Saint Petersburg in 2004.
Dr. Eugene A. Klimov is the head of the group of Medical and Veterinary Genetics in the Faculty of Biology at Lomonosov Moscow State University and the deputy director of the Center of Experimental Embryology and Reproductive Biotechnology, Russian Academy of Science. He is also the lecturer in several courses and the advisor for the analysis of biological information at Elsevier. Dr. Klimov’s expertise is in structural and functional genomics, molecular biology, and viral and neurological diseases.
Eugene A. Klimov received his PhD degree in genetics in 2002 and obtained the degree of full doctor of biology in genetics in 2010 from the Vavilov Institute of General Genetics, Russian Academy of Science.
Maria Zharkova, PhD Novel Software Systems employee, works as a scientist at the Life Science Research and Development department at
Elsevier with primary research interests in signaling pathways and biochemistry. Her competence was important in describing the molecular interactions of proteins, pharmacology, and endocrine and metabolic diseases. Dr. Zharkova’s expertise and attentiveness to details was indispensable for making the text in the book accurate and relevant. She received her degree from the Pirogov Russian National Research Medical University in 2010.
Vladimir Sobolev, PhD, is a senior scientist at the Mechnikov Research Institute of Vaccines and Sera and at the Center for Theoretical Problems of Physicochemical Pharmacology, Russian Academy of Science. Dr. Sobolev is also an advisor at Elsevier with specializations in signaling pathways and cell biology. Dr. Sobolev was responsible for ensuring the accuracy of pathways of cell communication and differentiation, cytokine cascades, and inflammation. His knowledge and laboratory experience in immunology and dermatology were indispensable for this book. Vladimir Sobolev received his degree from the Russian State Agrarian University, RSAU-MTAA in 2004.
Natalia Ivanikova, PhD, Novel Software Systems employee, works as a senior scientist at the Content and Innovation group at Elsevier's Operations division with a focus on the automated construction of biological knowledge bases using natural language processing technologies. She was responsible for the glossary and contributed to the production of this book’s introductory chapters. Dr. Ivanikova received her degree from Bowling Green State University in 2006.
Many thanks to Maria Shkrob, PhD, and Anton Yuryev, PhD, for their broad advice and for participating in constructive discussions. Maria and Anton work on the front line of biomedicine and pharmacological research in Elsevier Life Science Services and have diverse skills and experience. Maria and Anton are experts in natural language processing and term taxonomies. Dr. Anton Yuryev is the leading specialist in the area of personalized medicine and the pathway analysis of biomedical experiments.
Special thanks to Paul Golovatenko-Abramov, Andrey Kalinin, Philipp Anokhin, Chris Cheadle, Stephen Sharp, and the rest of the team of Pathway Studio for their advices and technical support.
Foreword: The future of medical discovery
Gary R. Skuse
Biological Sciences, Rochester Institute of Technology, Rochester, NY, United States
For centuries, scientists and clinicians have published their findings in the traditional professional literature. Many of us, as scientists, clinicians, or as students of science or medicine, have read that the literature voraciously trying to understand the complexities of biological systems. Perhaps the most challenging systems are those of humans because, for a variety of good reasons, we cannot perform laboratory-based studies on humans. Instead, we turn to model organisms or the results of clinical observations.
Our lack of understanding arises from both the challenges of ingesting the sizeable corpus of literature and the natural and inescapable variations observed in biological systems. This book coalesces a wealth of scientific and medical literature into an organized body that is rich with illustrations and explanations. As an atlas of selected human disorders, the facts regarding involved entities and their relationships depicted herein are the products of computer-based analyses of published literature. Those analyses exploit the tools of natural language processing applied to existing literature along with the expertise of a group of scientists with extensive and complementary experience. The resulting disease pathways were created by those scientists based on the entities and relationships revealed through their computer-based analyses.
This work is remarkable in several regards. It is the product of the collaboration between an amazing technology and human curation. Currently, there are a variety of software tools that enable us to explore, mine, and reduce an otherwise unapproachably large and complex body of literature to identify relationships among molecular entities such as genes and proteins, cells of similar and disparate types, tissues and organ systems, and, in some cases, environmental factors and deduce their roles
in human disease. That alone is a feat that was impossible only a few years ago. In this work the authors provide information about a number of human diseases by walking us through the fruits of their analyses of several infectious diseases and many human physiological systems. In that regard, this book is an outstanding example of contemporary computational systems biology.
Another unique aspect of this work is the team of scientists who brought their collective expertise to bear on the challenge of understanding and assembling the results of those computerized analyses. Nature is inescapably interdisciplinary and interdisciplinary teams that are necessary to truly understand it. Consequently, this book is the result of collaborative efforts among natural and medical scientists.
Finally, this book embodies and foretells the future of medical discovery. The vast and rapidly growing body of scientific and medical literature can only be understood by using computerized tools joined with the expertise of scientists and clinicians. Computers can identify entities and relationships involved with disease, but humans must apply their knowledge to verify those results. This collaboration between computers and humans is likely the only way that medical discovery can proceed at a rate that will ensure the deep understanding of disease, at the molecular level, that will be required for the development of effective diagnostic and therapeutic techniques.
Preface
The size and volume of our knowledge are replenished very quickly in the modern era of biology. Every week, new facts are published, new genomes are sequenced, and new proteins are discovered. Unlike any time before now, a detailed understanding of the behavior of biomolecules, changes in gene expression, the regulation of hormone synthesis, or enzymatic reactions are available for the diagnosis and pharmacological manipulation of diseases.
This book is designed to fill a void in the literature of illustrated reviews of the well-documented and understood mechanisms of human disease at the cellular and molecular levels. The core of the book is based on the Elsevier Disease Pathway Collection (signaling pathways of 250 diseases), which was compiled by the team of authors throughout 2012–18 (http:// www.pathwaystudio.com).
Pathways and networks are becoming indispensable tools in many areas of molecular biology, pharmacology, and medicine. Our knowledge about protein-protein interactions accumulated in the form of pathway models allows us to interpret the results of molecular screenings and identify targets for drug design. A unique aspect of this book is the images of disease pathways, which are a registered trademark of Elsevier, and this is the first time they are being published outside of Elsevier’s commercial software. A link to the repository where the described pathway models can be freely browsed or downloaded is also provided.
The most difficult part of assembling this book was deciding which diseases to include. There are so many diseases that were covered by the team of authors and so few available pages to fill. We have included 42 the most common widespread diseases in the human population and other well-studied ones that can together illustrate the interactions between molecular causes and disease symptoms.
We have not covered oncological diseases because we believe that the oncology domain must be described separately as an intensively studied and important part of human disease. We also have not included syndromes (with rare exception) or mental disorders in this book, but we hope we can publish them in the future.
Objectives
This atlas has a dual intent: to provide readers with detailed information about the basic concepts of disease signaling pathways on a high scientific level while simultaneously keeping the presentation simple and clearly understandable for a general biologist.
To meet these objectives, we shaped disease descriptions as an atlas, a richly illustrated book with a short narrative. We listed definitions and all terms that facilitate understanding disease mechanisms before the description of molecular signaling pathways for each disease. At the same time, we attempted to motivate readers to find more information about each disease by providing specialized web links and references.
The authors are not responsible for any conclusions or consequences arising from the use of the information presented in this book such as drug names and another disease treatment–related information. Any drugs or products mentioned in this publication should be used in accordance with the prescribing information prepared by relevant specialists or the drug’s respective manufacturers.
Assembly
This book is divided into three parts:
The first part gives introductory information about pathways as described in the guide and legend. Chapter 1 in the first part provides an introduction to cell biology, molecular signaling biochemistry, and a systems biology approach to the study disease mechanisms.
The second part (Chapters 2–13) focuses on an overview of the molecular mechanisms underlying 42 diseases and covers 12 areas of human disease. Diseases are grouped into 12 areas following the International Statistical Classification of Diseases and Related Health Problems, https://icd.who.int. Each disease description includes a summary, a short glossary, and images of disease signaling pathways along with a descriptive narration. The mechanisms of molecular signaling are discussed briefly but thoroughly.
Chapter 14, located in the third part, discusses the application of signaling pathways and networks in the analysis of big data for personalized and precision medicine. The third part also includes a glossary and the links to other resources.
Intended audience
The book is intended for general biologists, bioinformaticists, medical workers, and students. Readers who require information about the cellular and molecular mechanisms of human diseases may also find it useful.
Guide and legend
Elsevier pathway collection
Images with disease pathways were generated with Elsevier’s Pathway Studio software (http://www.pathwaystudio.com). Pathway Studio provides a combination of three foundations: a graph database with biological interactions extracted from millions of scientific articles using natural language processing technology (NLP) technology, a flexible visualization tool for building models of pathways, and an analytical tool for performing bioinformatics analyses of experimental results.
The Elsevier Pathway Collection, 2018 contains 2411 pathways and groups that cover 290 diseases, 6351 proteins, 2165 compounds, and 47,865 relations in total. These are manually reconstructed models in which all molecular interactions (“relations”) are curated and ensured by verifying relevant sentences from their source articles.
The Elsevier Pathway Collection, 2018 includes several series of pathways including biological processes, cell processes, biomarkers, receptor signaling, canonical signal transduction pathways, cell lineage, diseases, toxicity pathways, and cancer hallmarks. Unique molecular models are present in the collection such as pathways illustrating the human physiological processes of lactation and memory formation or eating behavior. For public access to selected data, please visit Ask Pathway Studio, https://mammalcedfx.pathwaystudio.com/app/search
Elsevier pathway studio database
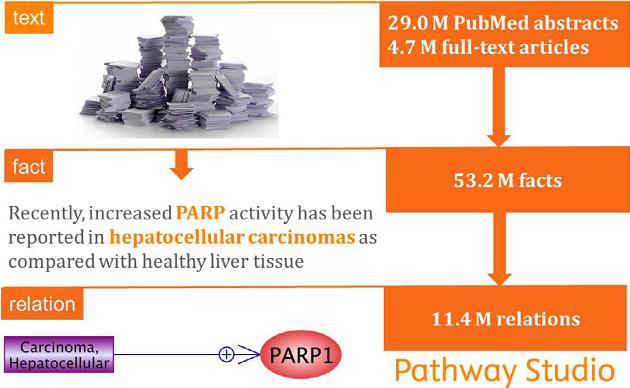
The Elsevier Pathway Studio database (PSD or ResNet) is the core of the system. Proteins or genes and their interactions with other biologically relevant entities are central concepts in the PSD. PSD-2018 contains 93 thousand objects and more than 11 million relationships with more than 50 million supporting facts including records from the published papers (Fig. 1). Importantly, PSD contains mammal-centered information. It covers published facts on a rat, mouse, and human molecular biology. A plant database is also available (Elsevier, 2018; Yuryev et al., 2009).
The semiautomated text-mining tool (MedScan), which uses natural language processing technology (NLP) is the basic tool for assembling the PSD. Text processing involves two critical phases: identifying concepts
Text-mining technique is a central component of the Pathway Studio.
(entities) and identifying relationships among them. The accurate and effective identification of concepts is guided by a manually created ontology of terms (names and synonyms of proteins, diseases, etc.). Moreover, MedScan identifies subject-verb-object triplets in scientific texts (e.g., insulin regulates glucose uptake) as indicators of meaningful relationships between terms (Daraselia et al., 2007; Novichkova et al., 2003). Manually written by specialists, strict linguistic rules determine the sentence structure and the type of relationship, which will be extracted. Overall, the MedScan text-mining technology has a 98% accuracy rate for concept annotation and an 88% accuracy rate for relationship extraction. Both are essentially similar to the rates achieved by expert high-quality manual annotation. MedScan can process and annotate 100,000 articles per hour allowing Pathway Studio to get updates of extracted facts and relationships weekly (Elsevier R&D Solutions, 2018).
Since PSD keeps interactions extracted from articles as object-relation type-object triplets, the union of all relationships can be visualized as one giant network or map or “knowledge graph,” and the individual pathway models are the parts of this map.
Individual disease pathway data files are written in a special Pathway Studio format (RNEF) and represent the model of interactions between molecules and concepts. RNEF files keep shaped images of members or interactions as clickable links to their descriptions and annotations. In Pathway Studio, it is possible to select a member and open the descriptive page with a list of member synonyms, ontological relations, and links to external molecular databases. If an arrow is selected, it is possible to read the supporting sentences with scientific evidence (references) directly from the publications where the relationship was described. Each disease pathway from the book can be viewed as an interactive model here: http://www.smartbio.ai/nbs/ pathways or http://www.transgene.ru/disease-pathways/.
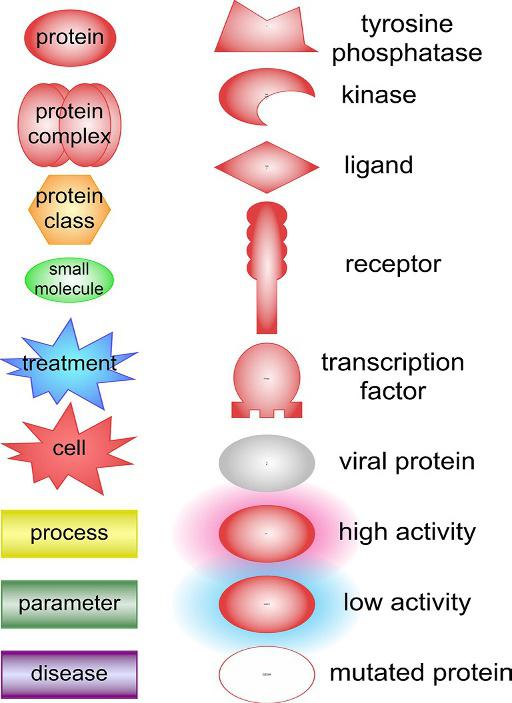
As a graphical representation, a disease pathway uses different shapes to distinguish compounds and proteins. Cell types, diseases, and processes
FIG. 1
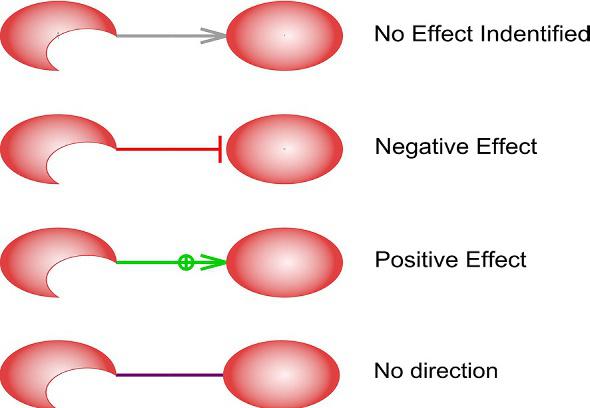
also have their specific shapes (Fig. 2). An arrow indicates the relationship between objects. Arrowheads graphically indicate the direction of the interaction and whether its effect is promotive (positive) or suppressive (negative) (Fig. 3). Types of interactions are marked by the color and style of arrows. For example, a gray dotted line without a head indicates an association
FIG. 2 Shapes of different concepts used in Pathway Studio and in the book.
FIG. 3 Graphical representation of relationships between concepts used in Pathway Studio and in the book.
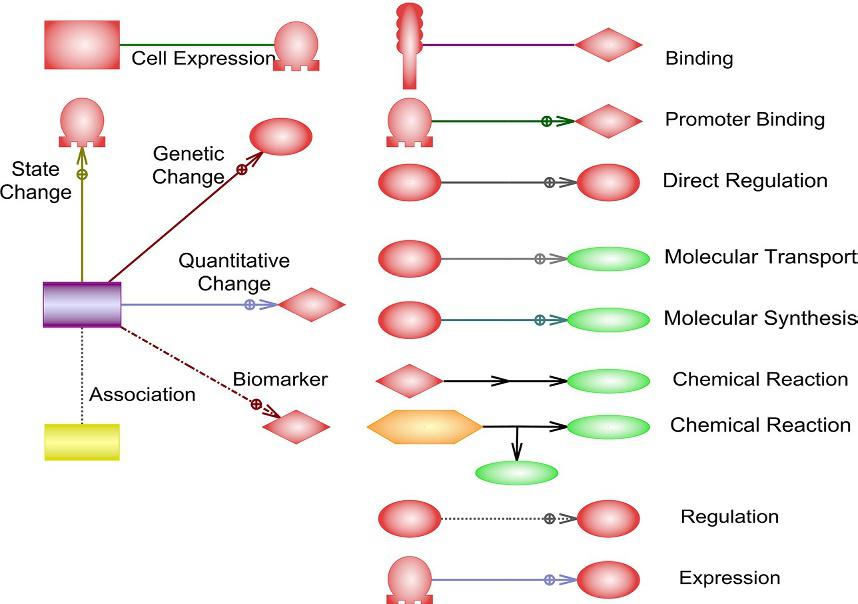
FIG. 4 Types of relationships between concepts used in Pathway Studio and in the book. Physical connections (top); interactions between molecules (right); associative connections between a disease and other concept (left).
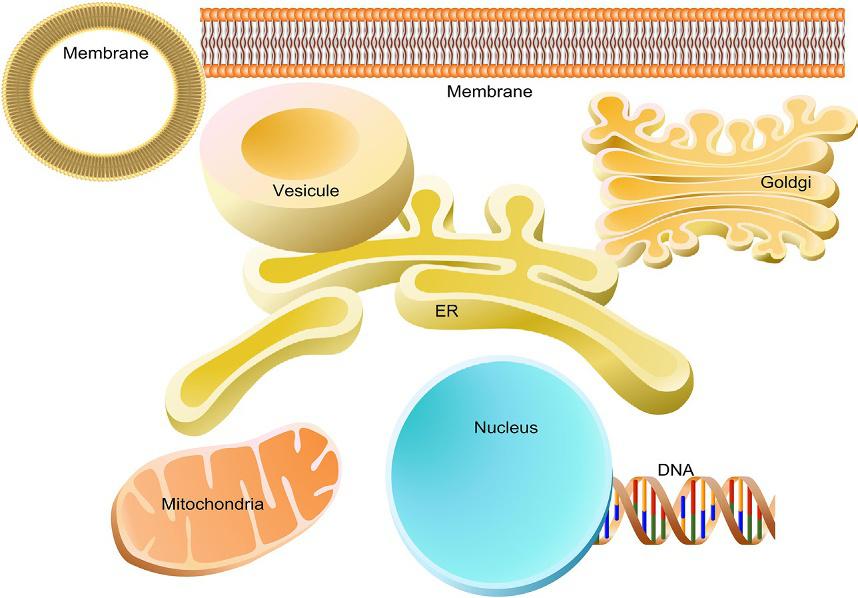
between two concepts or processes rather than a relationship between physical objects (Fig. 4). Although the direction and effect are the most vital pieces of information for the graphical representation of pathways, having different types of relationships is also very important for bioinformatic analyses where the pathway is used as a data file (read more in Chapter 13). Finally, stylized images illustrate intercellular components and organelles (Fig. 5).
Elsevier Pathway Studio software and the ResNet database (PSD) support and keep data about molecular interactions for at least nine types of members such as proteins, cells, or diseases and 14 types of relationships between them.
Gene and gene products
On disease pathways and in the ResNet database, genes and gene products, including proteins, RNAs, and their isoforms, are combined in one concept type defined by the identification number of the gene in the NCBI Gene database (National Center for Biotechnology Information's, www. ncbi.nlm.nih.gov/gene). The NCBI Gene database is the gold standard for gene-centered resources (Brown et al., 2015). Therefore, different protein shapes used in the images of the disease pathway (Fig. 2) may refer to a gene, a, mRNA, or a protein. There are 30,494 individual human gene concepts that have relations in the PSD-2018.
Images of cellular organelles and components used in Pathway Studio and in the book.
Protein complexes
Several proteins can be grouped and represented as a single object in the database termed the container-type object. Protein complex is the first type of container object which specifies proteins that form a complex via physical interactions. For protein families or functional classes, protein class (functional class) is the second type of container object which groups proteins according to their classification in the molecular function gene ontology (GO) project (Ashburner et al., 2000; Gene Ontology Consortium, 2017). GO keeps biological terms organized in a hierarchical structure with protein and gene names associated with those terms. The Enzyme Commission (EC) database, BRENDA, UniProt, and other knowledge bases well known for containing protein families are also used as sources for the Pathway Studio protein class. There are 4513 protein classes and 973 protein complexes in the PSD-2018.
Compounds, peptides, and small molecules
The mixed group of chemicals and metabolites is represented as a single object type small molecule. Members of this type are typically described and have a unique number in either the CAS or PubChem databases (https://www.cas.org, https://pubchem.ncbi.nlm.nih.gov). The small