AcceleratorsforConvolutionalNeural Networks
ArslanMunir
KansasStateUniversity
USA
JoonhoKong
KyungpookNationalUniversity
SouthKorea
MahmoodAzharQureshi
KansasStateUniversity
USA
Copyright©2024byTheInstituteofElectricalandElectronicsEngineers,Inc. Allrightsreserved.
PublishedbyJohnWiley&Sons,Inc.,Hoboken,NewJersey. PublishedsimultaneouslyinCanada.
Nopartofthispublicationmaybereproduced,storedinaretrievalsystem,ortransmittedinany formorbyanymeans,electronic,mechanical,photocopying,recording,scanning,orotherwise, exceptaspermittedunderSection107or108ofthe1976UnitedStatesCopyrightAct,without eitherthepriorwrittenpermissionofthePublisher,orauthorizationthroughpaymentofthe appropriateper-copyfeetotheCopyrightClearanceCenter,Inc.,222RosewoodDrive,Danvers, MA01923,(978)750-8400,fax(978)750-4470,oronthewebatwww.copyright.com.Requeststo thePublisherforpermissionshouldbeaddressedtothePermissionsDepartment,JohnWiley& Sons,Inc.,111RiverStreet,Hoboken,NJ07030,(201)748-6011,fax(201)748-6008,oronlineat http://www.wiley.com/go/permission.
Trademarks:WileyandtheWileylogoaretrademarksorregisteredtrademarksofJohnWiley& Sons,Inc.and/oritsaffiliatesintheUnitedStatesandothercountriesandmaynotbeused withoutwrittenpermission.Allothertrademarksarethepropertyoftheirrespectiveowners. JohnWiley&Sons,Inc.isnotassociatedwithanyproductorvendormentionedinthisbook.
LimitofLiability/DisclaimerofWarranty:Whilethepublisherandauthorhaveusedtheirbest effortsinpreparingthisbook,theymakenorepresentationsorwarrantieswithrespecttothe accuracyorcompletenessofthecontentsofthisbookandspecificallydisclaimanyimplied warrantiesofmerchantabilityorfitnessforaparticularpurpose.Nowarrantymaybecreatedor extendedbysalesrepresentativesorwrittensalesmaterials.Theadviceandstrategiescontained hereinmaynotbesuitableforyoursituation.Youshouldconsultwithaprofessionalwhere appropriate.Further,readersshouldbeawarethatwebsiteslistedinthisworkmayhave changedordisappearedbetweenwhenthisworkwaswrittenandwhenitisread.Neitherthe publishernorauthorsshallbeliableforanylossofprofitoranyothercommercialdamages, includingbutnotlimitedtospecial,incidental,consequential,orotherdamages.
Forgeneralinformationonourotherproductsandservicesorfortechnicalsupport,please contactourCustomerCareDepartmentwithintheUnitedStatesat(800)762-2974,outsidethe UnitedStatesat(317)572-3993orfax(317)572-4002.
Wileyalsopublishesitsbooksinavarietyofelectronicformats.Somecontentthatappearsin printmaynotbeavailableinelectronicformats.FormoreinformationaboutWileyproducts, visitourwebsiteatwww.wiley.com.
LibraryofCongressCataloging-in-PublicationDataAppliedfor: HardbackISBN:9781394171880
CoverDesign:Wiley
CoverImage:©Gorodenkoff/Shutterstock;MichaelTraitov/Shutterstock
Setin9.5/12.5ptSTIXTwoTextbyStraive,Chennai,India
ArslanMunirdedicatesthisbooktohiswifeNedaandhisparentsfortheir continuoussupport.
JoonhoKongdedicatesthisbooktohiswifeJiyeon,childrenEunseoandEunyu, andhisparentsfortheircontinuoussupport.
MahmoodAzharQureshidedicatesthisbooktohisparents,siblings,andhiswife Kiran,allofwhomprovidedcontinuoussupportthroughouthisacademicand professionalcareer.
Contents
AbouttheAuthors xiii
Preface xv
PartIOverview 1
1Introduction 3
1.1HistoryandApplications 5
1.2PitfallsofHigh-AccuracyDNNs/CNNs 6
1.2.1ComputeandEnergyBottleneck 6
1.2.2SparsityConsiderations 9
1.3ChapterSummary 11
2OverviewofConvolutionalNeuralNetworks 13
2.1DeepNeuralNetworkArchitecture 13
2.2ConvolutionalNeuralNetworkArchitecture 15
2.2.1DataPreparation 17
2.2.2BuildingBlocksofCNNs 17
2.2.2.1ConvolutionalLayers 17
2.2.2.2PoolingLayers 19
2.2.2.3FullyConnectedLayers 20
2.2.3ParametersofCNNs 21
2.2.4HyperparametersofCNNs 21
2.2.4.1HyperparametersRelatedtoNetworkStructure 22
2.2.4.2HyperparametersRelatedtoTraining 23
2.2.4.3HyperparameterTuning 25
2.3PopularCNNModels 26
2.3.1AlexNet 26
2.3.2VGGNet 26
2.3.3GoogleNet 27
2.3.4SqueezeNet 27
2.3.5BinaryNeuralNetworks 29
2.3.6EfficientNet 29
2.4PopularCNNDatasets 30
2.4.1MNISTDataset 30
2.4.2CIFAR 30
2.4.3ImageNet 31
2.5CNNProcessingHardware 31
2.5.1TemporalArchitectures 32
2.5.2SpatialArchitectures 34
2.5.3Near-MemoryProcessing 36
2.6ChapterSummary 37
PartIICompressiveCodingforCNNs 39
3ContemporaryAdvancesinCompressiveCoding forCNNs 41
3.1BackgroundofCompressiveCoding 41
3.2CompressiveCodingforCNNs 43
3.3LossyCompressionforCNNs 43
3.4LosslessCompressionforCNNs 44
3.5RecentAdvancementsinCompressiveCodingforCNNs 48
3.6ChapterSummary 50
4LosslessInputFeatureMapCompression 51
4.1Two-StepInputFeatureMapCompressionTechnique 52
4.2Evaluation 55
4.3ChapterSummary 57
5ArithmeticCodingandDecodingfor5-BitCNNWeights 59
5.1ArchitectureandDesignOverview 60
5.2AlgorithmOverview 63
5.2.1WeightEncodingAlgorithm 64
5.3WeightDecodingAlgorithm 67
5.4EncodingandDecodingExamples 69
5.4.1DecodingHardware 72
5.5EvaluationMethodology 74
5.6EvaluationResults 75
5.6.1CompressionRatioandMemoryEnergyConsumption 75
5.6.2LatencyOverhead 78
5.6.3Latencyvs.ResourceUsageTrade-Off 81
5.6.4System-LevelEnergyEstimation 83
5.7ChapterSummary 84
PartIIIDenseCNNAccelerators 85
6ContemporaryDenseCNNAccelerators 87
6.1BackgroundonDenseCNNAccelerators 87
6.2RepresentationoftheCNNWeightsandFeatureMapsin DenseFormat 87
6.3PopularArchitecturesforDenseCNNAccelerators 89
6.4RecentAdvancementsinDenseCNNAccelerators 92
6.5ChapterSummary 93
7iMAC:Image-to-ColumnandGeneralMatrix Multiplication-BasedDenseCNNAccelerator 95
7.1BackgroundandMotivation 95
7.2Architecture 97
7.3Implementation 99
7.4ChapterSummary 100
8NeuroMAX:ADenseCNNAccelerator 101
8.1RelatedWork 102
8.2LogMapping 103
8.3HardwareArchitecture 105
8.3.1Top-Level 105
8.3.2PEMatrix 106
8.4DataFlowandProcessing 108
8.4.13 × 3Convolution 109
8.4.21 × 1Convolution 111
8.4.3Higher-OrderConvolutions 116
8.5ImplementationandResults 118
8.6ChapterSummary 124
PartIVSparseCNNAccelerators 125
9ContemporarySparseCNNAccelerators 127
9.1BackgroundofSparsityinCNNModels 127
x Contents
9.2BackgroundofSparseCNNAccelerators 128
9.3RecentAdvancementsinSparseCNNAccelerators 131
9.4ChapterSummary 133
10CNNAcceleratorforInSituDecompressionandConvolution ofSparseInputFeatureMaps 135
10.1Overview 135
10.2HardwareDesignOverview 135
10.3DesignOptimizationTechniquesUtilizedintheHardware Accelerator 140
10.4FPGAImplementation 141
10.5EvaluationResults 143
10.5.1PerformanceandEnergy 144
10.5.2ComparisonwithState-of-the-ArtHardwareAccelerator Implementations 146
10.6ChapterSummary 149
11Sparse-PE:ASparseCNNAccelerator 151
11.1RelatedWork 155
11.2Sparse-PE 156
11.2.1SparseBinaryMask 158
11.2.2Selection 159
11.2.3Computation 164
11.2.4Accumulation 170
11.2.5OutputEncoding 172
11.3ImplementationandResults 174
11.3.1Cycle-AccurateSimulator 175
11.3.1.1PerformancewithVaryingSparsity 177
11.3.1.2ComparisonAgainstPastApproaches 179
11.3.2RTLImplementation 181
11.4ChapterSummary 184
12Phantom:AHigh-PerformanceComputationalCorefor SparseCNNs 185
12.1RelatedWork 189
12.2Phantom 190
12.2.1SparseMaskRepresentation 191
12.2.2CoreArchitecture 192
12.2.3LookaheadMasking 192
12.2.4Top-DownSelector 193
12.2.4.1In-OrderSelection 194
12.2.4.2Out-of-OrderSelection 195
12.2.5ThreadMapper 196
12.2.6ComputeEngine 197
12.2.7OutputBuffer 199
12.2.8OutputEncoding 201
12.3Phantom-2D 201
12.3.1 R × C ComputeMatrix 202
12.3.2LoadBalancing 203
12.3.3Regular/DepthwiseConvolution 204
12.3.3.1IntercoreBalancing 204
12.3.4PointwiseConvolution 204
12.3.5FCLayers 207
12.3.6IntracoreBalancing 207
12.4ExperimentsandResults 209
12.4.1EvaluationMethodology 209
12.4.1.1Cycle-AccurateSimulator 209
12.4.1.2SimulatedModels 211
12.4.2Results 211
12.4.2.1TDSVariantsComparison 211
12.4.2.2ImpactofLoadBalancing 212
12.4.2.3SensitivitytoSparsityand Lf 213
12.4.2.4ComparisonAgainstPastApproaches 215
12.4.2.5RTLSynthesisResults 217
12.5ChapterSummary 218
PartVHW/SWCo-DesignandCo-SchedulingforCNN Acceleration 221
13State-of-the-ArtinHW/SWCo-DesignandCo-Scheduling forCNNAcceleration 223
13.1HW/SWCo-Design 223
13.1.1CaseStudy:CognitiveIoT 225
13.1.2RecentAdvancementsinHW/SWCo-Design 227
13.2HW/SWCo-Scheduling 228
13.2.1RecentAdvancementsinHW/SWCo-Scheduling 229
13.3ChapterSummary 230
14Hardware/SoftwareCo-DesignforCNNAcceleration 231
14.1BackgroundofiMACAccelerator 231
14.2SoftwarePartitionforiMACAccelerator 232
14.2.1ChannelPartitionandInput/WeightAllocationtoHardware Accelerator 232
14.2.2ExploitingParallelismWithinConvolutionLayerOperations 234
14.3ExperimentalEvaluations 235
14.4ChapterSummary 237
15CPU-AcceleratorCo-SchedulingforCNNAcceleration 239
15.1BackgroundandPreliminaries 240
15.1.1ConvolutionalNeuralNetworks 240
15.1.2BaselineSystemArchitecture 241
15.2CNNAccelerationwithCPU-AcceleratorCo-Scheduling 242
15.2.1Overview 242
15.2.2LinearRegression-BasedLatencyModel 243
15.2.2.1AcceleratorLatencyModel 243
15.2.2.2CPULatencyModel 246
15.2.3ChannelDistribution 246
15.2.4PrototypeImplementation 247
15.3ExperimentalResults 251
15.3.1LatencyModelAccuracy 251
15.3.2Performance 253
15.3.3Energy 254
15.3.4CaseStudy:TinyDarknetCNNInferences 255 15.4ChapterSummary 257
16Conclusions 259
References 265 Index 285
AbouttheAuthors
ArslanMunir iscurrentlyanAssociateProfessor intheDepartmentofComputerScienceatKansas StateUniversity.Hewasapostdoctoralresearch associateintheElectricalandComputerEngineering(ECE)DepartmentatRiceUniversity,Houston,Texas,USA,fromMay2012toJune2014.He receivedhisMAScinECEfromtheUniversityof BritishColumbia(UBC),Vancouver,Canada,in 2007andhisPhDinECEfromtheUniversityof Florida(UF),Gainesville,Florida,USA,in2012. From2007to2008,heworkedasasoftwaredevelopmentengineeratMentorGraphicsCorporationin theEmbeddedSystemsDivision.

Munir’scurrentresearchinterestsincludeembeddedandcyberphysicalsystems,artificialintelligence,deeplearninghardware,computervision,secureand trustworthysystems,parallelcomputing,andreconfigurablecomputing.Munir receivedmanyacademicawardsincludingthedoctoralfellowshipfromNatural SciencesandEngineeringResearchCouncil(NSERC)ofCanada.Heearnedgold medalsforbestperformanceinelectricalengineering,andgoldmedals,andacademicrollofhonorforsecuringrankoneinpre-engineeringprovincialexaminations(outofapproximately300,000candidates).HeisaseniormemberofIEEE.

JoonhoKong iscurrentlyanAssociateProfessorwiththeSchoolofElectronicsEngineering, KyungpookNationalUniversity.HereceivedtheBS degreeincomputerscienceandtheMSandPhD degreesincomputerscienceandengineeringfrom KoreaUniversity,in2007,2009,and2011,respectively.Heworkedaspostdoctoralresearchassociate withtheDepartmentofElectricalandComputer Engineering,RiceUniversity,from2012to2014. BeforejoiningKyungpookNationalUniversity,he alsoworkedasaSeniorEngineeratSamsungElectronics,from2014to2015.Hisresearchinterests includecomputerarchitecture,heterogeneouscomputing,embeddedsystems, hardware/softwareco-design,AI/MLaccelerators,andhardwaresecurity.Heis amemberofIEEE.

MahmoodAzharQureshi iscurrentlyaSenior DesignEngineeratIntelCorporation.Hereceived hisPhDinComputerSciencefromKansasState University,Manhattan,Kansas,in2021wherehe alsoworkedasaresearchassistantfrom2018to 2021.HereceivedhisMSinelectricalengineering fromtheUniversityofEngineeringandTechnology (UET),Taxila,Pakistan,in2018andBEinelectrical engineeringfromNationalUniversityofSciences andTechnology(NUST),Pakistan,in2013.From 2014to2018,heworkedasaSeniorRTLDesign EngineeratCenterforAdvancedResearchin Engineering(CARE)Pvt.Ltd,Islamabad,Pakistan.Duringthesummerof2020, heinternedatMathWorks,USA,wherehewasactivelyinvolvedinaddingnew featuresinMatlabwhichisatoolusedgloballyinindustryaswellasacademia. Duringfall2020,heinternedatTesla,workingonthefailureanalysisofthe infotainmenthardwarefortheTeslaModel3andModelYglobalfeet.
Preface
Convolutionalneuralnetworks(CNNs)havegainedtremendoussignificance inthedomainofartificialintelligence(AI)becauseoftheiruseinavarietyof applicationsrelatedtovisualimageryanalysis.Therehasbeenadrasticincrease intheaccuracyofCNNsinrecentyears,whichhashelpedCNNsmakeitsway inreal-worldapplications.Thisincreaseinaccuracy,however,translatesintoa sizablemodelandhighcomputationalrequirements,whichmakethedeployment oftheseCNNsinresource-limitedcomputingplatformsachallengingendeavor. Thus,embeddingCNNinferenceintovariousreal-worldapplicationsrequiresthe designofhigh-performance,area,andenergy-efficientacceleratorarchitectures. ThisbooktargetsthedesignofacceleratorsforCNNs.
Thisbookisorganizedintofiveparts:overview,compressivecodingforCNNs, denseCNNaccelerators,sparseCNNaccelerators,andHW/SWco-designand co-schedulingforCNNacceleration.Thefirstpartofthebookprovidesan overviewofCNNsalongwiththecompositionofdifferentcontemporaryCNN models.Thebookthendiscussessomeofthearchitecturalandalgorithmic techniquesforefficientprocessingofCNNmodels.Thesecondpartofthebook discussescompressivecodingforCNNstocompressCNNweightsandfeature maps.ThispartofthebookthendiscussesHuffmancodingforlosslesscompressionofCNNweightsandfeaturemaps.Thebookthenelucidatesatwo-step losslessinputfeaturemapscompressionmethodfollowedbydiscussionofan arithmeticcodinganddecoding-basedlosslessweightscompressionmethod.The thirdpartofthebookfocusesonthedesignofdenseCNNaccelerators.Thebook providesadiscussiononcontemporarydenseCNNaccelerators.Thebookthen presentsaniMACdenseCNNaccelerator,whichcombinesimage-to-columnand generalmatrixmultiplicationhardwareaccelerationfollowedbythediscussion ofanotherdenseCNNacceleratorthatutilizeslog-basedprocessingelementsand 2Ddataflowtomaximizedatareuseandhardwareutilization.Thefourthpart ofthebooktargetssparseCNNaccelerator.Thebookdiscussescontemporary sparseCNNsthatconsidersparsityinweightsandactivationmaps(i.e.,many
weightsandactivationsinCNNsarezeroandresultinineffectualcomputations) todeliverhigheffectivethroughput.ThebookthenpresentsasparseCNN acceleratorthatperformsinsitudecompressionandconvolutionofsparseinput featuremaps.Afterwards,thebookdiscussesasparseCNNaccelerator,which hasthecapabilitytoactivelyskipahugenumberofineffectivecomputations(i.e., computationsinvolvingzeroweightsand/oractivations),whileonlyfavoring effectivecomputations(nonzeroweightsandnonzeroactivations)todrastically improvethehardwareutilization.ThebookthenpresentsanothersparseCNN acceleratorthatusessparsebinarymaskrepresentationtoactivelylookahead intosparsecomputations,anddynamicallyscheduleitscomputationalthreads tomaximizethethreadutilizationandthroughput.Thefifthpartofthebook targetshardware/softwareco-designandco-schedulingforCNNacceleration. Thebookdiscusseshardware/softwareco-designandco-schedulingthatcan leadtobetteroptimizationandutilizationoftheavailablehardwareresources forCNNacceleration.Thebooksummarizesrecentworksonhardware/software co-designandscheduling.Thebookthenpresentsatechniquethatutilizes software,algorithm,andhardwareco-designtoreducetheresponsetimeof CNNinferences.Afterwards,thebookdiscussesaCPU-acceleratorco-scheduling technique,whichco-utilizestheCPUandCNNacceleratorstoexpeditetheCNN inference.Thebookalsoprovidesdirectionsforfutureresearchanddevelopment forCNNaccelerators.
ThisisthefirstbookonthesubjectofacceleratorsforCNNsthatintroduces readerstoadvancesandstate-of-the-artresearchindesignofCNNaccelerators. Thisbookcanserveasagoodreferenceforstudents,researchers,andpractitionersworkingintheareaofhardwaredesign,computerarchitecture,andAI acceleration.
January24,2023
Manhattan,KS,USA
PartI Overview
Introduction
Deepneuralnetworks(DNNs)haveenabledthedeploymentofartificialintelligence(AI)inmanymodernapplicationsincludingautonomousdriving[1], imagerecognition[2],andspeechprocessing[3].Inmanyapplications,DNNs haveachievedclosetohuman-levelaccuracyand,insome,theyhaveexceeded humanaccuracy[4].ThishighaccuracycomesfromaDNN’suniqueabilityto automaticallyextracthigh-levelfeaturesfromahugequantityoftrainingdata usingstatisticallearningandimprovementovertime.Thislearningovertime providesaDNNwithaneffectiverepresentationoftheinputspace.Thisisquite differentfromtheearlierapproacheswherespecificfeatureswerehand-crafted bydomainexpertsandweresubsequentlyusedforfeatureextraction.
Convolutionalneuralnetworks(CNNs)areatypeofDNNs,whicharemost commonlyusedforcomputervisiontasks.AmongdifferenttypesofDNNs, suchasmultilayerperceptrons(MLP),recurrentneuralnetworks(RNNs),long short-termmemory(LSTM)networks,radialbasisfunctionnetworks(RBFNs), generativeadversarialnetworks(GANs),restrictedBoltzmannmachines(RBMs), deepbeliefnetworks(DBNs),andautoencoders,CNNsarethemostlycommonly used.InventionofCNNshasrevolutionizedthefieldofcomputervisionand hasenabledmanyapplicationsofcomputervisiontogomainstream.CNNs haveapplicationsinimageandvideorecognition,recommendersystems,image classification,imagesegmentation,medicalimageanalysis,objectdetection, activityrecognition,naturallanguageprocessing,brain–computerinterfaces,and financialtime-seriesprediction.
DNN/CNNprocessingisusuallycarriedoutintwostages,trainingandinference,withbothofthemhavingtheirowncomputationalneeds.Trainingisthe processwhereaDNNmodelistrainedusingalargeapplication-specificdata set.Thetrainingtimeisdependentonthemodelsizeandthetargetaccuracy requirements.Forhighaccuracyapplicationslikeautonomousdriving,traininga DNNcantakeweeksandisusuallyperformedonacloud.Inference,ontheother
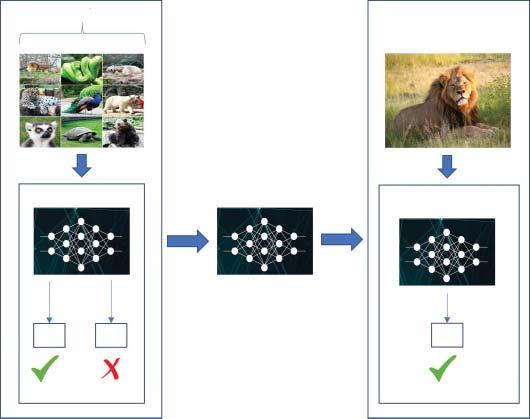
Trainingdataset
Devicesensorcapturing real-worlddata
Edgedeviceprocessing system
TrainedDNNmodel deployedonthe edgedevice
Cloud-hostedtrainingEdgedeviceinference
Figure1.1 DNN/CNNprocessingmethodology.Source:(b)Daughter#3Cecil/WikimediaCommons/CCBY-SA2.0.
hand,canbeperformedeitheronthecloudortheedgedevice(mobiledevice, Internetofthings(IoT),autonomousvehicle,etc.).Nowadays,inmanyapplications,itisadvantageoustoperformtheinferenceprocessontheedgedevices,as showninFigure1.1.Forexample,incellphones,itisdesirabletoperformimage andvideoprocessingonthedeviceitselfratherthansendingthedataoverto thecloudforprocessing.Thismethodologyreducesthecommunicationcostand thelatencyinvolvedwiththedatatransmissionandreception.Italsoeliminates theriskoflosingimportantdevicefeaturesshouldtherebeanetworkdisruption orlossofconnectivity.Anothermotivationfordoinginferenceonthedeviceisthe ever-increasingsecurityriskinvolvedwithsendingpersonalizeddata,including imagesandvideos,overtothecloudserversforprocessing.Autonomousdriving systemswhichrequirevisualdataneedtodeploysolutionstoperforminference locallytoavoidlatencyandsecurityissues,bothofwhichcanresultinacatastrophe,shouldanundesirableeventoccurs.PerformingDNN/CNNinference ontheedgepresentsitsownsetofchallenges.Thisstemsfromthefactthatthe embeddedplatformsrunningontheedgedeviceshavestringentcostlimitations whichlimittheircomputecapabilities.Runningcomputeandmemory-intensive DNN/CNNinferenceinthesedevicesinanefficientmannerbecomesamatterof primeimportance.
LionLion Dog
1.1HistoryandApplications
Neuralnetshavebeenaroundsincethe1940s;however,thefirstpracticallyapplicableneuralnetwork,referredtoastheLeNet[5],wasproposedin1989.Thisneuralnetworkwasdesignedtosolvetheproblemofdigitrecognitioninhand-written numericdigits.Itpavedthewayforthedevelopmentofneuralnetworksresponsibleforvariousapplicationsrelatedtodigitrecognition,suchasanautomated tellermachine(ATM),opticalcharacterrecognition(OCR),automaticnumber platerecognition,andtrafficsignsrecognition.Theslowgrowthandalittletono adoptionofneuralnetworksintheearlydaysismainlyduetothemassivecomputationalrequirementsinvolvedwiththeirprocessingwhichlimitedtheirstudy totheoreticalconcepts.
Overthepastdecade,therehasbeenanexponentialgrowthintheresearchon DNNswithmanynewhighaccuracyneuralnetworksbeingdeployedforvarious applications.Thishasonlybeenpossiblebecauseoftwofactors.Thefirstfactoris theadvancementsintheprocessingpowerofsemiconductordevicesandtechnologicalbreakthroughsincomputerarchitecture.Nowadays,computershavesignificantlyhighercomputingcapability.Thisenablestheprocessingofaneural networkwithinareasonabletimeframe,somethingthatwasnotachievablein theearlydays.Thesecondfactoristheavailabilityofalargeamountoftraining datasets.Asneuralnetworkslearnovertime,providinghugeamountsoftraining dataenablesbetteraccuracy.Forexample,Meta(parentcompanyofFacebook) receivesclosetoabillionuserimagesperday,whereasYouTubehas300hoursof videouploadedeveryminute[6].Thisenablestheserviceproviderstotraintheir neuralnetworksfortargetedadvertisingcampaignsbringinginbillionsofdollars ofadvertisingrevenue.Apartfromtheiruseinsocialmediaplatforms,DNNsare impactingmanyotherdomainsandaremakingahugeimpact.Someoftheseareas include:
● SpeechProcessing:Speechprocessingalgorithmshaveimprovedsignificantly inthepastfewyears.Nowadays,manyapplicationshavebeendevelopedthat useDNNstoperformreal-timespeechrecognitionwithunprecedentedlevels ofaccuracy[3,7–9].ManytechnologycompaniesarealsousingDNNstoperformlanguagetranslationusedinawidevarietyofapplications.Google,for example,usesGoogle’sneuralmachinetranslationsystem(GNMT)[10]which usesLSTM-basedseq2seqmodelfortheirlanguagetranslationapplications.
● AutonomousDriving:Autonomousdrivinghasbeenoneofthebiggesttechnologicalbreakthroughsintheautoindustrysincetheinventionoftheinternal combustionengine.Itisnotacoincidencethattheself-drivingboomcameatthe sametimewhenhighaccuracyCNNsbecameincreasinglypopular.Companies
likeTesla[11]andWaymo[12]areusingvarioustypesofself-drivingtechnologyincludingvisualfeedsandLidarfortheirself-drivingsolutions.Onething whichiscommoninallthesesolutionsistheuseofCNNsforvisualperception oftheroadconditionswhichisthemainback-endtechnologyusedinadvanced driverassistancesystems(ADAS).
● MedicalAI:AnothercrucialareawhereDNNs/CNNshavebecomeincreasinglyusefulismedicine.Nowadays,doctorscanuseAI-assistedmedical imagerytoperformvarioussurgeries.AIsystemsuseDNNsingenomicsto gatherinsightsaboutgeneticdisorderslikeautism[13,14].DNNs/CNNsare alsousefulinthedetectionofvarioustypesofcancerslikeskinandbraincancer [15,16].
● Security:TheadventofAIhaschallengedmanytraditionalsecurityapproaches thatwerepreviouslydeemedsufficient.Therolloutof5Gtechnologyhascaused amassivesurgeofIoT-baseddeploymentswhichtraditionalsecurityapproaches arenotabletokeepupwith.Physicalunclonabilityapproaches[17–21]were introducedtoprotectthismassivedeploymentofIoTsagainstsecurityattacks withminimumcostoverheads.Theseapproaches,however,werealsounsuccessfulinpreventingAI-assistedattacksusingDNNs[22,23].Researchershave nowbeenforcedtoupgradethesecuritythreatmodelstoincorporateAI-based attacks[24,25].BecauseofamassiveincreaseinAI-assistedcyber-attackson cloudanddatacenters,companieshaverealizedthatthebestwayofdefeating offensiveAIattacksisbyincorporatingAI-basedcounterattacks[26,27].
Overall,theuseofDNNs,inparticularCNNs,invariousapplicationshasseen exponentialgrowthoverthepastdecade,andthistrendhasbeenontheriseforthe pastmanyyears.ThemassiveincreaseinCNNdeploymentsontheedgedevices requiresthedevelopmentofefficientprocessingarchitecturestokeepupwiththe computationalrequirementsforsuccessfulCNNinference.
1.2PitfallsofHigh-AccuracyDNNs/CNNs
Thissectiondiscussessomeofthepitfallsofhigh-accuracyDNN/CNNmodelsfocusingoncomputeandenergybottlenecks,andtheeffectofsparsityof high-accuracymodelsonthroughputandhardwareutilization.
1.2.1ComputeandEnergyBottleneck
CNNsarecomposedofmultipleconvolutionlayers(CONV)whichhelpinextractinglow-,mid-,andhigh-levelinputfeaturesforbetteraccuracy.AlthoughCNNs areprimarilyusedinapplicationsrelatedtoimageandvideoprocessing,theyare
Table1.1 PopularCNNmodels. CNNmodelLayers
AlexNet[30]863.384.662M666M
VGG-16[31]1674.391.9138M15.3B
GoogleNet[35]2268.9886.8M1.5B
MobileNet[35]2870.989.94.2M569M
ResNet-50[32]5075.392.225.5M3.9B
alsousedinspeechprocessing[3,7],gameplay[28],androbotics[29]applications.WewillfurtherdiscussthebasicsofCNNsinChapter2.Inthissection, weexploresomeofthebottleneckswhenitcomestoimplementing high-accuracy CNNinferenceenginesinembeddedmobiledevices.
ThedevelopmentofhighaccuracyCNNmodels[30–34]inrecentyearshas strengthenedthenotionofemployingDNNsinvariousAIapplications.TheclassificationaccuracyofCNNsfortheImageNetchallenge[2]hasimprovedconsiderablyfrom63.3%in2012(AlexNet[30])toastaggering87.3%(EfficientNetV2 [4]in2021).Thishighjumpinaccuracycomeswithhighcomputeandenergy costsforCNNinference.Table1.1showssomeofthemostcommonlyusedCNN models.ThemodelsaretrainedusingtheImageNetdataset[2],andthetop-1and top-5classificationaccuracyisalsogiven.Wenotethattop-1accuracyistheconventionalaccuracy,whichmeansthatthemodelanswer(i.e.,theonepredicted bythemodelwiththehighestprobability)mustbeexactlytheexpectedanswer. Top-5accuracymeansthatanyofthefivehighestprobabilityanswerspredicted bythemodelmustmatchtheexpectedanswer.ItcanbeseenfromTable1.1that theadditionofmorelayersresultsinbetteraccuracy.Thisaddition,however,also correspondstoagreaternumberofmodelparameters,requiringmorememory andstorage.Italsoresultsinhighermultiply-accumulate(MAC)operations,causinganincreaseincomputationalcomplexityandresourcerequirements,whichin turn,affectstheperformanceoftheedgedevices.
Eventhoughsomeeffortshavebeenmadetoreducethesizeofthehighaccuracy models,theystillrequiremassiveamountsofcomputationsoveraseriesofnetworklayerstoperformaparticularinferencetask(classification,segmentation, etc.).Thesetremendousnumberofcomputations(typicallyintensofmillions) presentahugechallengeforthe neuralnetworkaccelerators (NNAs)running theCNNinference.NNAsarespecializedhardwareblocksinsideacomputersystem(e.g.,mobiledevicesandcloudservers)thatspeedupthecomputationsof theCNNinferenceprocesstomaintainthereal-timerequirementsofthesystem
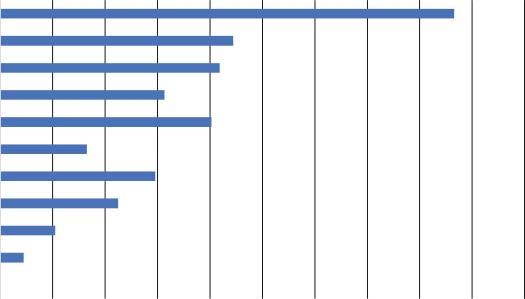
32bDRAMRead
32bSRAMRead
32bFPMultiply
16bFPMultiply
32bINTMultiply
8bINTMultiply
32bFPAdd
16bFPAdd
32bINTAdd
16bINTAdd
Figure1.2 Energycost(relativeto8bitAddoperation)shownonalog10scalefora 45nmprocesstechnology.Source:Adaptedfrom[6,36]. andimprovesystemthroughput.Apartfromthemassivecomputationalrequirements,theadditionofmorelayersforhigheraccuracydrasticallyincreasesthe CNNmodelsize.ThispreventstheCNNmodelfrombeingstoredinthelimited on-chipstaticrandomaccessmemory(SRAM)oftheedgedevice,and,therefore, requiresoff-chipdynamicrandomaccessmemory(DRAM)whichpresentsahigh DRAMaccessenergycost.
Toputthisinperspective,theenergycostperfetchfor32bitcoefficientsinan off-chiplow-powerdoubledatarate2(LPDDR2)DRAMisabout640pJ,which isabout6400× theenergycostofa32bitintegerADDoperation[36].Thebigger themodelis,themorememoryreferencingisperformedtoaccessthemodeldata whichinturnexpendsmoreenergy.Figure1.2showstheenergycostofvarious computeandmemoryoperationsrelativetoan8bitintegeradd(8bitINTAdd) operation.ItcanbeseenthattheDRAMReadoperationdominatestheenergy graphwiththe32bitDRAMReadconsuminggreaterthan4ordersofmagnitude higherenergythanthe8bitINTAdd.Asaconsequence,theenergycostfromjust theDRAMaccesseswouldbewellbeyondthelimitationsofanembeddedmobile devicewithlimitedbatterylife.Therefore,inadditiontoacceleratingthecompute operations,theNNAalsoneedstominimizetheoff-chipmemorytransactionsfor decreasingtheoverallenergyconsumption.
Manyalgorithm-leveltechniqueshavebeendevelopedtominimizethecomputationalrequirementsofaCNNwithoutincurringalossinaccuracy.Sincethe maincomputebottleneckinCNNinferenceistheCONVoperation, Mobilenets [33,34]weredevelopedtoreducethetotalnumberofCONVoperations.These CNNsdrasticallyreducethetotalnumberofparametersandMACoperationsby
breakingdownthestandard2Dconvolutionintodepthwiseseparableandpointwiseconvolutions.Thedepthwiseseparableandpointwiseconvolutionsresultin 8× to9× reductionintotalcomputationscomparedtoregularCONVoperations, withaslightdecreaseinaccuracy.Theyalsoeliminatevaryingfiltersizes,and instead,use3 × 3and1 × 1filtersforperformingconvolutionoperations.This makesthemidealforembeddedmobiledevicesbecauseoftheirrelativelylow memoryfootprintandlowertotalMACoperations.
Awidelyusedapproachfordecreasingthememorybottleneckisthereductionintheprecisionofbothweightsandactivationsusingvariousquantization strategies[37–39].Thisagaindoesnotresultinasignificantlossinaccuracyand reducesthemodelsizebyaconsiderableamount.Hardwareimplementationslike Envision[40],UNPU[41],andStripes[42]showhowreducedbitprecision,and quantization,translatesintobettersavingsinenergy.
1.2.2SparsityConsiderations
Nonlinearactivationfunctions[6],inadditiontodeeplayers,isoneofthekeycharacteristicsthatimprovetheaccuracyofaCNNmodel.Typically,nonlinearityis addedbyincorporatingactivationfunctions,themostcommonbeingtherectified linearunit(ReLU)[6].TheReLUconvertsallnegativevaluesinafeaturemapto zeros.Sincetheoutputofonelayeristheinputtothenextlayer,manyofthecomputations,withinalayer,involvemultiplicationwithzeros.Thesefeaturemaps containingzerosarereferredtoas one-sided sparsefeaturemaps.Themultiplicationsresultingfromthisone-sidedsparsitywastecomputecyclesanddecreasethe effective throughputandhardwareutilization,thus,reducingtheperformanceof theaccelerator.Italsoresultsinhighenergycostsasthetransferofzerosto/from off-chipmemoryiswastedmemoryaccess.Inordertoreducethecomputational andmemoryaccessvolume,previousworks[43–45]haveexploitedthisone-sided sparsityanddisplayedsomeperformanceimprovements.Toexacerbatetheissue ofwastedcomputecyclesandmemoryaccesses, two-sided sparsityisintroduced inCNNsoftenbypruningtechniqueswhen,inadditiontothefeaturemaps,the weightdataalsoconsistsofzeros.DesigningaCNNacceleratorthatcanovercome thewastedcomputecyclesandmemoryaccessesissuesofone-sidedandtwo-sided sparsitiesisquitechallenging.
Inrecentyears,manypruningtechniqueshavebeendevelopedforthecompressionofDNNmodels[46–49].Hanetal.[46]iterativelyprunedtheconnectionsbasedonparameterthresholdandperformedretrainingtoretainaccuracy. Thistypeofpruningisreferredtoasunstructuredpruning.Itarbitrarilyremoves weightconnectionsinaDNN/CNNbutdoeslittletoimproveaccelerationontemporalarchitectureslikecentralprocessingunits(CPUs)andgraphicsprocessing units(GPUs)whichrelyonacceleratingmatrixmultiplications.Anotherform
ofpruning,referredtoasstructuredpruning[50,51],reducesthesizeofweight matricesandmaintainsafullmatrix.ThismakesitpossibletosimplifytheNNA designsincethesparsitypatternsarepredictable,therefore,enablingbetterhardwaresupportforoperationscheduling.
Bothunstructuredandstructuredpruningstrategies,asdescribedabove,result in two-sided sparsity,(i.e.,sparsityinbothweightsandactivations)whichlead toapproximately9× modelreductionforAlexNetand13× reductionforVGG-16. Thepurningstrategiesalsoresultin4–9× effective computereduction(depending onthemodel).Thesegainsseemverypromising;however,designinganacceleratorarchitecturetoleveragethemisquitechallengingbecauseofthefollowing reasons:
● DataAccessInconsistency:Computationgatingisoneofthemostcommon waysbywhichsparsityisgenerallyexploited.Wheneverazerointheactivation ortheweightdataisread,nooperationisperformed.Thisresultsinenergy savingsbuthasnoimpactonthethroughputbecauseofthewastageofcompute cycle.Complexreadlogicneedstobeimplementedtodiscardthezeros,and instead,performeffectivecomputationsonnonzerodata.Someprevious works[52,53]usesparsecompressionformatslikecompressedsparsecolumn (CSC)orcompressedsparserow(CSR)torepresentsparsedata.Theseformats havevariablelengthsandmake lookingahead difficultifboththeweight andtheactivationsparsityarebeingconsidered.Otherthanthat,developing thecomplexcontrolandreadlogictoprocesstheseformatscanbequite challenging.
● LowUtilizationoftheProcessingElement(PE)Array:Convolution operationsforCNNinferenceareusuallyperformedusinganarrayof two-dimensionalPEsinaCNNaccelerator.Differentdataflows(inputstationary,outputstationary,weightstationary,etc.)havebeenproposedthat efficientlymaptheweightdataandtheactivationdataontothePEarrayto maximizethethroughput[6,54].Sparsityintroducesinconsistencyinthe schedulingofdatatherebyreducinghardwareutilization.ThesubsetofPEs providedwithmoresparsedatahaveidletimeswhilethoseprovidedwithless sparse(ordenser)dataarefullyactive.Thisboundsthethroughputofthe acceleratortothemostactivePEs,andtherefore,leadstotheunderutilization ofthePEarray.
Consideringtheabovementionedissues,manyacceleratorshavebeenproposed inthepastthatattempttostrikeabalancebetweenhardwareresourcecomplexityandperformanceimprovements.TheCNNacceleratorsthatexploitsparsityin CNNmodelsarecoveredindetailinPartIVofthisbook.
1.3ChapterSummary
ThischapterdiscussedthehistoryandapplicationsofDNNs,focusingonCNNs. Thechapteralsohighlightedthecomputeandenergybottlenecksaswellasthe effectofsparsityinhigh-accuracyCNNmodelsonthethroughputandhardware utilizationofedgedevices.