with HEIDI HURST

ISSUE 2 EDF: BUSINESS CASE STUDY
DATA SCIENCE CITY FRANCESCO GADALETA: DATA PLATFORMS
WE TALK SAT ELLITE IMAGING
AMSTERDAM:
CONTRIBUTORS
Heidi Hurst
Francesco Gadaleta
Ryan Kearns
Philipp Diesinger
Nicole Janeway Bills
Mikkel Dengsøe
Damien Deighan
Anna Litticks
Rebecca Vickery
George Bunn
Katherine Gregory
EDITOR
Anthony Bunn
anthony.bunn@datasciencetalent.co.uk +44 (0)7507 261 877
DESIGN Imtiaz Deighan
PRINTED BY Rowtype Stoke-on-Trent, UK +44 (0)1782 538600 sales@rowtype.co.uk
NEXT ISSUE
9th May 2023
The Data Scientist is published quarterly by Data Science Talent Ltd, Whitebridge Estate, Whitebridge Lane, Stone, Staffordshire, ST15 8LQ, UK. Access a digital copy of the magazine at datatasciencetalent.co.uk/media.

DISCLAIMER
The views and content expressed in The Data Scientist reflect the opinions of the author(s) and do not necessarily reflect the views of the magazine or its staff. All published material is done so in good faith.
All rights reserved, product, logo, brands, and any other trademarks featured within The Data Scientist magazine are the property of their respective trademark holders. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form by means of mechanical, electronic, photocopying, recording, or otherwise without prior written permission. Data Science Talent Ltd cannot guarantee and accepts no liability for any loss or damage of any kind caused by this magazine for the accuracy of claims made by the advertisers.
02 | THE DATA SCIENTIST PRODUCTION

DETECTING FINANCIALLY VULNERABLE CUSTOMERS AT SCALE With Rebecca Vickery , Data Science Lead at EDF 05 START-UP We speak with Ryan Kearns on what motivates his interest in the world of Data Science 11 A GUIDE TO SATELLITE IMAGING We look at the field of satellite imaging and speak to an expert in this area, Heidi Hurst 14 DS RECRUITMENT: THE IMPACT OF CHAT GPT3 Damien Deighan writes about the possible impact of the new chatbot on the Data Science recruitment sector 19 HOW SCALING DATA SCIENCE PILOTS IS A KEY COMPONENT OF INDUSTRIALISING DATA Philipp Diesinger demonstrates how industrialising data is critical for insight-driven organisations 24 TEN BOOKS Nicole Janeway Bills reviews ten books that you need to read in 2023 29 DATA SCIENCE CITY Our second city focus features Amsterdam , economic hub of the Netherlands 34 THE DIFFICULT LIFE OF THE DATA LEAD Mikkel Dengsøe examines why balancing the management of a team with demanding stakeholders and still being hands-on is no easy task 37 EVOLUTION OF DATA PLATFORMS With Francesco Gadaleta , the Founder and Chief Engineer of Amethix Technologies and the Host of the Data Science At Home podcast 40 ANNA LITTICKS Our spoof Data Scientist. Or is she? 43 COVER STORY We talk Satellite Imaging with HEIDI HURST THE DATA SCIENTIST | 03 INSIDE ISSUE #2
HELLO, AND WELCOME TO ISSUE 2 OF THE DATA SCIENTIST
Issue 1 has been hitting the inboxes and mailboxes of hundreds of leading Data Science professionals since last November, and we’re absolutely delighted with the feedback and comments we’ve received off the back of our inaugural issue.
As we stated in our first editorial, our mission was very simple: We wanted to produce a serious Data Science magazine that serious Data Scientists wanted to read and be featured within. That’s certainly been the case so far, and it has been great to speak to so many of you since we launched.
We promised that issue 2 would be bigger and better. Well, we can certainly say that what you are looking at right now is bigger (and hopefully will increase even further in future issues). As for better - well, that’s for you to decide, but we feel that the quality of contributors in this issue really does speak for itself.
Inside issue 2, you will find an in-depth interview with Heidi Hurst that focuses on satellite imaging; a business case study on the great work that EDF are undertaking; and we feature Amsterdam as our second Data Science focus city. Plus, there’s a raft of articles from key figures within the Data Science and AI sectors, too.
The Data Scientist is a broad and welcoming church. Please contact the editor with your feedback, thoughts, and ideas - and even better - to find out how you, your team, or your organisation can feature in future issues. And on that subject, please be assured that we do not charge any fee for featuring in these pages. We simply want as much outstanding Data Science-related content within the magazine as possible.
We would also be delighted to send out digital or print copies to any of your colleagues and influencers that you feel would enjoy reading this magazine.
We know that we are preaching to the converted when we say how vitally important Data Science is in the modern world and how important it will be in the future. We wanted The Data Scientist to reflect this importance - issue 1 showed that to be the case, and we are really excited for this and future issues.
We hope that you enjoy this issue - and once again, please don’t hesitate to contact us to find out how you can become a part of The Data Scientist
The Data Scientist Editorial Team
EDITORIAL 04 | THE DATA SCIENTIST
DETECTING FINANCIALLY VULNERABLE CUSTOMERS AT SCALE
BY REBECCA VICKERY, DATA SCIENCE LEAD AT EDF

In the UK, a typical household has seen their energy bills rise considerably over the last year despite government interventions such as the energy price guarantee. This disproportionately impacts those already in financially vulnerable positions and in response the energy sector is increasing the support that is offered to customers and ensuring that the maximum number of eligible households* are reached with this support.
EDF had already increased the support that they could offer to customers throughout 2022. This included a doubling of the finan cial assistance for struggling customers to £10m, partnerships with charities such as Income Max to help customers access financial support entitlements and offering £20m of funding for home insulation. However, EDF were keen to ensure that this support could be offered to the customers who needed it most.

THE DATA SCIENTIST | 05
INDUSTRY CASE STUDY
To help solve this challenge the data science team at EDF partnered with business stakeholders and used unsupervised machine learning and data from smart prepayment meters to proactively identify financially vulnerable customers. The development of this model and the need to rapidly scale the time to production for its use additionally led to a whole new Machine Learning Model Operationalisation Management (MLOps) solution for EDF. In this article, I will provide a detailed look at how this algorithm was developed and how this project shaped a new path to production for the data science team.
THE APPROACH
The data science team at EDF takes an agile approach to tackling business problems with data science. At the core of this is the principle of working closely with the business end users and domain experts from the first day of the project. The final data science solution is shaped not only by the Data Scientists but also by the business stakeholders ensuring an actionable product is delivered.
Data science solutions are also developed iteratively with the team, aiming to produce a lean but usable solution and to deploy to production quickly so that the end users can trial the output and generate a feedback loop for future improvements.
Using this approach, the development of a financial vulnerability detection algorithm started with a series of workshops with business users and Data Scientists. The outcome of these workshops was a target set of features that intuitively were likely to be indicative of financial vulnerability and an initial solution in the form of a simple clustering model to identify the targeted customer segments.
THE DATA
There are several methods available for customers to pay for the energy that they use. One method is known as Pay as You Go (PAYG). Customers utilising this payment method have meters where they pay in advance for the energy that they use, also commonly referred to as a top-up. The data available from PAYG smart meters are likely to contain markers of financial vulnerability such as periods of time with no credit, also known as self-disconnection, or erratic top-up patterns. For this reason, the features from the PAYG smart meter data were selected for the first iteration of the model.


An additional important data point the team also had available is the Priority Services Register (PSR) flag. The PSR is an industry-wide service where eligible customers can register so that they can access additional support from energy providers. The PSR flag records information about a wide range of vulnerabilities including
financial vulnerability. As the PSR flag relies on proactive registration, it is an imperfect indicator and therefore not accurate enough to act as a ground truth for a supervised learning solution. It would, however, later prove invaluable to validate the final model as I will cover in more detail later.
THE MODEL
As an accurate ground truth label was unavailable for identifying financially vulnerable customer groups an unsupervised learning approach was taken in the form of clustering.
Clustering algorithms use methods to identify similarities between data points and to generate clusters of similar observations. The goal is to generate distinct clusters where the differences between observations within the clusters are minimised whilst the distinction between different clusters is maximised. A clustering algorithm was applied to the PAYG smart meter features to determine if there was a meaningful segmentation of customers.
The team experimented with several clustering algorithms on different feature sets. The results of these experiments led to the selection of a K-means model trained on just five features. As previously mentioned, the bias for the team at this stage of the project is to deliver a simple working solution for end-user testing and feedback. K-means being a simple, interpretable algorithm fit this remit.
INDUSTRY CASE STUDY 06 | THE DATA SCIENTIST
HOW DO YOU VALIDATE UNSUPERVISED MODELS?
The performance of unsupervised machine learning tasks, where ground truth labels are unavailable, is not as easy to measure as for supervised problems where we can count errors and calculate standard metrics such as precision and recall. Where no ground truth is available, evaluation metrics which assess whether observations that belong to the same cluster are more similar compared to observations in other clusters are used. Silhouette score is an example of this method. However, these do not help us to understand if a target segment has been identified correctly as is the case with the problem of detecting financially vulnerable customers.
The data science team at EDF tackled this problem in two ways.

The first involved performing validation using the PSR Flag. Although not a perfect ground truth label the assumption could be made that a financially vulnerable cluster of customers would contain a higher concentration of observations containing this flag.
Analysing the three clusters the data science team observed a noticeable difference in the prevalence of the PSR flag. This initial piece of analysis provided a strong indicator that at least two unique clusters had been identified. These were provisionally labelled as financially vulnerable and financially secure.
THE DATA SCIENTIST | 07
PSR FLAG PROPORTION 0 2 4 6 8 1 10.80.60.40.2020.1% 7.9% 15.6% 14.6% Financially vulnerable Financially secure Undetermined Population Proportion False True
To give further validation that customers were being correctly identified the data science team performed further customer-level analysis and worked with the business experts. One important piece of analysis was looking at the top-up behaviour of individual customers over a period of time and plotting this against the number of selfdisconnections.
The images below show two examples of customers. On the left is one from the financially vulnerable segment. Here we can observe an erratic pattern of topup behaviour and several self-disconnections suggesting financial vulnerability. The chart on the right shows a customer from the segment that was labelled as financially secure. In this case, top-up behaviour is very regular and stable, and no self-disconnections are present.
TOP-UP BEHAVIOUR FOR TWO EXAMPLE CUSTOMERS
08 | THE DATA SCIENTIST INDUSTRY CASE STUDY
50 40 30 20 10 0 Top Up Amount ( £ ) Disconnections Sept 24 2021 Oct 10 Nov 21 Oct 24 Dec 5 Dec 19 Jan 2 2022 Nov 7 40 35 30 25 20 15 10 5 0 Top Up Amount ( £ ) Sept 24 2021 Oct 10 Nov 21 Oct 24 Dec 5 Dec 19 Jan 2 2022 Nov 7 Disconnections Mobile
Myaccount
App Top Up
Top Up PayPoint Top Up
DEPLOYING TO PRODUCTION
Once an initial solution to the business problem had been developed the next step was to deploy this model into production so that it could be used in initial trials to proactively reach greater numbers of customers with support.
The existing route to production for data science models was slow and cumbersome. As is still common with many MLOps platforms the workflow was fragmented. It consisted of numerous tools and a large amount of infrastructure all being managed and built in-house.
The data platform team had recently completed a migration of the company-wide data lake into Snowflake, a cloud computing based platform for large-scale data storage, processing and analytics. The existing workflow required data to be moved from Snowflake into Amazon S3 buckets where the team could make use of Apache Spark running on Amazon EMR clusters to prepare data for machine learning.
This fragmentation of workflow, the reliance on external teams and the management of several different tools and a large amount of infrastructure, meant that the path to production was slow and did not provide autonomy for the data science team to deploy their own models.
The need to operationalise the financial vulnerability detection algorithm at speed prompted a complete rethink of the data science platforms for EDF and the team spent time assessing numerous third-party tools and looking for a solution. After several planning sessions, a cross-functional product team was formed consisting of DevOps engineers, Data Engineers, Data Scientists and MLOps engineers and the team began a proof of concept for a new MLOps platform.
CONSIDERATIONS FOR THE PLATFORM
Development of the platform took an agile approach with the new product team aiming to develop a minimum viable product (MVP) within three months. The MVP platform had several requirements necessary to meet the needs of deploying machine learning models and data transformations.
Data pipelines - The data science team at EDF often work with exceptionally large datasets. For example, the team commonly use smart meter data consisting of billions of rows of half-hourly meter readings. It was therefore essential for data scientists to have access to a tool for big data transformation. Additionally, the security of data was paramount so minimising the need to move data for processing was key.
Development of new models - As well as being able to deploy existing models to production the data science team also needed to develop new data science models. Hosted Jupyter Notebooks with large-scale
compute behind them, alongside secure access to the Snowflake data lake, was crucial for this work.
Deployment - At the time, the data science team models only required batch deployment. So, the MVP platform only needed to support the pre-computation of inferences on a regular basis rather than deploying the models as endpoints.
These requirements, plus the existing technology used within EDF led to the selection of two primary tools to use for the core part of the data science platform.
SNOWPARK PYTHON
Snowpark Python is a Python API used for querying and processing data stored in the Snowflake data cloud. The API has a syntax like PySpark and enables efficient processing of substantial amounts of data using highly optimised Snowflake compute with the data science language of choice, Python. As the data required by the data science team was now stored in Snowflake and as the data science team were previously using PySpark to process data, Snowpark was an ideal choice to move to.
When the new data science platform was initially being developed Snowpark Python was still in private preview as it was a relatively new Snowflake product. The feedback the team were able to provide from the initial migration of existing PySpark data pipelines provided confidence to Snowflake to release this new tool into public preview. Making it available to all Snowflake customers.
The team now no longer needed to move the data out of Snowflake and into S3 storage to access EMR clusters. Instead, the Snowpark code could be executed within Snowflake where the data was already stored. Additionally, as the Snowflake infrastructure is a fully managed service it resulted in far less maintenance overhead for the team.
AMAZON SAGEMAKER
Snowpark enabled more efficient data access and processing, but the team also needed to develop machine learning pipelines for models. As EDF was already using a large amount of Amazon Web Services (AWS) Cloud infrastructure, Amazon Sagemaker was selected for the machine learning components of the platform.
Sagemaker consists of a fully managed set of tools for developing and deploying machine learning models in the cloud. The EDF data science team primarily made use of two core functionalities. Sagemaker Studio provided hosted Jupyter Notebooks with flexible computing behind them which the team leveraged for the initial exploratory development of models.
Sagemaker Jobs were used to run production workloads for machine learning pipelines. These jobs consist of
THE DATA SCIENTIST | 09 INDUSTRY CASE STUDY
INDUSTRY CASE STUDY
Python scripts and each job handles a different stage of the machine learning workflow. A processing job, alongside a custom Sagemaker image, enabled the team to execute Snowpark code within Snowflake for the preprocessing parts of the pipeline via the Sagemaker API. A separate training job handles the model training. A batch inference job then generates predictions and writes these back to the Snowflake database.
THE DATA SCIENCE PLATFORM
A key component of the data science platform was the ability to be able to securely promote new models to production whilst maintaining the reliability of outputs for models already in operation.
To achieve this the product team created four segregated environments each containing a Snowflake database with access to the Snowpark Python API and


an AWS account with access to Amazon Sagemaker.

The first environment is called Discovery. This is intended to be a place where the development of new data science products occurs. This environment is centred around Sagemaker Studio Jupyter notebooks for rapid prototyping of new models and data transformations.
Once a product is ready for production the code begins to be promoted into the next set of environments. The first of these is known as Production Development and is where the production quality machine learning and data pipelines are built. A further Pre-Production environment is used to test that these new pipelines integrate well with the existing code already in operation. Assuming all is well the code is promoted to the final production environment where Airflow is used to orchestrate and schedule the regular running of batch inferences or data transformations.
DATA SCIENCE PLATFORM
DISCOVER
The development of the financial vulnerability detection algorithm in combination with this new platform has enabled EDF to proactively identify financially vulnerable customers which means that as an organisation EDF can provide additional support to safeguard them.
The data science team is now using the first MVP version of this new MLOps platform to deploy, not only the financial vulnerability detection algorithm, but also many data science products. The team is now focused
on developing the platform further by adding additional capabilities for model monitoring, experiment tracking and a model registry.
These additional features will allow the team to scale the number of models running in production which will also mean a greater ability to use data science to improve the experience for all EDF customers.
* www.ofgem.gov.uk/sites/default/files/docs/2019/09/vulnerable_ consumers_in_the_energy_market_2019_final.pdf
10 | THE DATA SCIENTIST
CDL CDL Clones Production Pre-prod Test Pre-prod Dev Discovery CDL PRODUCTION DATA SCIENCE Transform Data Snowpark Python Python Libraries Transform Data Snowpark Python Python Libraries
Jupyter Notebooks MLOPs PRE-PRODUCTION Machine Learning Deployment Jupyter Notebooks MLOPs PRODUCTION Machine Learning Deployment Jupyter Notebooks MLOPs PRODUCTION DEV Machine Learning Deployment Jupyter Notebooks MLOPs Machine Learning Deployment
Orchestration and Scheduling OPERATE
IN EACH ISSUE OF THE DATA SCIENTIST , WE SPEAK TO THE PEOPLE THAT MATTER IN OUR INDUSTRY AND FIND OUT JUST HOW THEY GOT STARTED IN DATA SCIENCE OR IN A PARTICULAR PART OF THE SECTOR.
START-UP
WE SPEAK TO RYAN KEARNS FROM MONTE CARLO, ONE OF THE WORLD’S LEADING DATA RELIABILITY COMPANIES AND ASK HIM WHAT MOTIVATES HIS INTEREST IN THE WORLD OF DATA
SCIENCE…
Ryan is a founding Data Scientist at Monte Carlo, where he develops machine learning algorithms for the company’s data observability platform. Together with co-founder Barr Moss, he instructed the first-ever course on data observability. Ryan is also currently studying computer science and philosophy at Stanford University.

THE DATA SCIENTIST | 11
START-UP
Towards the end of summer 2020, I was a junior at Stanford University during the beginning of the pandemic. I was in school doing research at Stanford in Natural Language Processing when everything started going online. I found that the environment wasn’t really suited to the remote context, so I wanted a break from school while things settled down.
I actually reached out to my mentors at GGV Capital, which is a venture capital firm. I had worked with them previously as an intern doing some analysis work, and I emailed to ask if they knew of anything in the space related to data in AI - the types of things that I had been researching and was familiar with.

They were aware of a company that was doing some really interesting things and was still not overly big. Luckily for me, they were happy to take on someone without a bachelor’s degree at the time, and so I took my chance to jump in and get involved while I waited for school to come back online.
I really expected to be in this game for three to six months to help complete the intern project and then be on my way. But,
they put me in touch with Monte Carlo, and told me this company had got really strong validation and their thesis is correct, however, they hadn’t built out too much product yet.
The company was in the process of hiring and scaling that team and so I got involved in September 2020. I was the third data scientist, with the other team members coming from Israel. Once we drilled down what my role would be, I took the initiative to build out the distribution part of the platform.
For me, that took the form of metric-based anomaly detection. So, I got to work at a great company andfast-forward a few years - I’m still here. I have become really invested in the team, and I think that the thesis is great. I’ve really had a fantastic time being able to build something pretty cool here.
12 | THE DATA SCIENTIST
START-UP
I took the initiative to build out the distribution part of the platform. For me, that took the form of metric based anomaly detection.
The fundamental problem in language is that everything is incredibly ambiguous.
PHILIPP KOEHN

We have to be very specific on what type of causality we want to look at because this is something where there are very, very strong opinions.
MAURIZIO PORFIRI


Big data studies have found that fake news will travel faster and further than real news.
 DR EILEEN CULLOTY DR STEPHANE LATHUILLIER
DR EILEEN CULLOTY DR STEPHANE LATHUILLIER
Don’t just read about data science.
BY Dr Philipp Diesinger and Damien Deighan

datascienceconversations.com
to some of the industry’s leading trailblazers and explore the latest data science and AI innovations in the Data Science Conversations podcast.
cutting-edge research from the best academic minds to expand your knowledge and enhance your career. SCAN ME
PRESENTED
Listen
Featuring
“
PHILIPP KOEHN How Neural Networks Have Transformed Machine Translation
MAURIZIO PORFIRI How to Leverage Data for Exponential Growth
DR EILEEN CULLOTY DR STEPHANE LATHUILLIER Deep Fakes - Technological Advancements and Impact on Society
A GUIDE TO SATELLITE IMAGING

INTERVIEW 14 | THE DATA SCIENTIST
Heidi has previously consulted with government clients in emergency management, defence, and intelligence in Washington DC. She has also worked in the consulting industry, and is currently a Machine Learning Engineer at Pachama; a start-up using technology to tackle climate change.
Heidi, what motivated you to work in the field of satellite imaging?
My background is in mathematics. I was always passionate about the intersection of mathematics and geography and looking at how we can bring mathematical methods to bear on geographic questions. That naturally led to an interest in satellite imagery. If we have access to no constructed maps or no survey maps; but real time (or near real time) information about the surface of the planet… I realised that I could use a lot of the same mathematical tools that I had learned and apply them to satellite imagery to extract these geographic impacts. So, my interest was always in applying mathematics to these mathematical-related questions.
What’s most interesting to you about the field of satellite imaging?
The surface of the earth is always changing. The location of cars is always changing. The buildings that people are putting up and taking down are always changing. What excites me most about this field is having the opportunity to have an unprecedented view. It’s almost as if you’re an astronaut at the international space station looking at the surface of the earth to understand how things are changing - and then to trace those changes all the way down to the level of impact at the individual level, at the societal level, and to really understand how these systems are connected.
Can you explain what the differences are between satellite image data to the data that we use in our daily lives?
So often, when people think about computer vision or processing imagery, they see examples of models that can detect the difference between a cat and a dog. And what we’re doing with satellite imaging is in some ways similar, but in some ways very different because the imagery itself is very different.
The type of imagery that comes from your phone has three channels, RGB: red, green, and blue. Some satellite imagery has those channels as well, but may have additional channels, too. I’d say there are three differences between regular imagery and satellite imagery. One is the resolution. The second is the band, so the wavelengths are captured by the sensors - and the third is the spatial information or metadata that comes with this.
In satellite imagery, the resolution is limited by the sensor that you’re working with. With common resolutions, if you have something that’s very high resolution, each pixel might correspond to 20 centimetres on the ground, whereas with something that’s very low resolution like the Landsat satellites, it might correspond to 15 centimetres, but the resolution has physical meaning in the real world. The second is the spectral band.
Take traditional imagery... if you just take a picture with your phone, it will have three bands - red, green,
IN THE NEXT TWO ISSUES, WE LOOK AT THE RAPIDLY DEVELOPING FIELD OF SATELLITE IMAGING AND SPEAK TO AN EXPERT IN THIS AREA, HEIDI HURST.
INTERVIEW THE DATA SCIENTIST | 15
and blue. With satellite imaging, some satellites have additional bands. So, they’ll have near infrared bands or pan (panchromatic) bands that provide additional information that can be used to detect things that humans can’t see, which again, from a data processing perspective, is a far more interesting question. We don’t just want to train algorithms to see humans.
And then, on the last point about the differences is the spatial information and the metadata. When you take the information - such as taking an image from a satellite - it will contain information about where on earth that is, and the altitude, the angle, the time of day. All of which provides additional metadata that can be used to build advanced models about what’s happening within that image.
in this space, and that’s not to mention the traditional imagery sources from aircraft or imagery sources from drones.
What limitations and challenges are there with Satellite Imaging data? How do you overcome these?
There’s certainly no scarcity of challenges in this domain. I will point out one issue that you mentioned, and that I’ve mentioned previously: the weather.
So, you can imagine there are a lot of objects of interest, particularly around object detection in the national security domain. A lot of these objects of interest aren’t found in perfectly sunny places with nice weather, and in particular, trying to find objects in snowy conditions, in winter conditions and in low light conditions present very serious challenges. Both from an object detection standpoint, but also from an imagery sourcing standpoint, if you have outdated imagery, it’s going to be very difficult to find things.
How is the data acquired, and which types of data are you actually using for your analysis?
There are a variety of different satellites out there that have different resolutions. And in addition, there are a number of other platforms besides just satellites. So, with regards to satellites, there are commercially available sources - the likes of planet labs, digital globethose are commercially available sources. There are also government sources that are publicly available.
For example, with Landsat data, this is very coarse resolution data. That’s great for land cover and vegetation and disease. And then there’s also government sources that are not publicly available, and in addition to the satellite imagery sources, there are other sources from lower altitude platforms. In particular, one area of interest right now in terms of research and development is something called HAPS, which is High Altitude Platform systems. These are systems that operate at the altitude of a weather balloon, so lower than a satellite but higher than a plane.
There are also systems that can persist in the atmosphere for a significant amount of time on the order of hours, days, and weeks, but not years. A satellite’s advantage is that they can be beneath some of the clouds and you can receive different types of imagery. Imagine if you have a similar sensor on a weather balloon, then on a satellite. You’re going to get higher resolution data, and you’re also going to be able to avoid some of the atmospheric influence from clouds and other things. There’s a variety of sensors available
Another challenge that we face - and I think this is a challenge that’s quite common to a lot of people working across data science as a discipline - is data labelling.
If we’re building a training algorithm or we’re building it as a detection algorithm, we need a training data set that contains appropriately labelled instances of w hatever it is we’re trying to detect. Now, in some cases, for example, we have commercial applications that count the number of cars in a parking lot. It’s not difficult to obtain and label a significant Corpus of information to allow these algorithms to be successful. For instance, with rare classes of aircraft in the winter, it’s very difficult to attain the base data that’s needed to train up these models.
What developments are happening in your field that you are most excited about?
I think it’s a really exciting time. If we think back to the very genesis of satellite imaging, when the government first started with satellite imagery, the development has been wild. Back then they were using film cameras, it was all classified and the film was designed to disintegrate on impact with water. And so the satellites would drop film cameras, and then military aircraft would be responsible for retrieving those before they hit the water and disintegrated. We’ve gone from those incredibly low-resolution images that had to be poured over by classifying analysts, to cube sets that are the size of a loaf of bread that can be rapidly iterated on. And so the transformation that we’ve seen just on the technology side, even just on the sensor side, has been dramatic.
16 | THE DATA SCIENTIST
PHILIPPINTERVIEWKOEHN
[Some satellites] have near infrared bands or pan (panchromatic) bands that provide additional information that can be used to detect things that humans can’t see, which again, from a data processing perspective, is a far more interesting question.
There are a number of satellite imagery companies out there with really bold ambitions of imaging, working hardware side or the software side of the house.
There has also been significant advancements in convolutional neural networks. It’s a very fast-moving field in terms of new network designs and new network architectures that are coming out. One advance in the field that I’m very excited about is synthetic imagery and synthetic data. As I mentioned before, if we’re trying to detect a particular class of something - say something that only has existence in synthetics fill - generating that seemingly plausible network, then you can train the network. There are a lot of challenges that come with that.
Computers are very good at finding out how other computers made something. This ultimately doesn’t always map exactly to real world data, but I think synthetic imagery for EO (earth observation satellites), and also for SAR (synthetic aperture radar), is going to prove a very interesting field. In particular, for rare classes, difficult weather conditions, and all of these areas that we mentioned before where there are challenges in getting high quality label training data.
Creating satellite image data that covers the entire planet can now be taken in about 20 minutes and hopefully soon in real time - do you think this is realistic?
I think that’s something that folks have been excited
about for a long time. We’ll see how long it takes. We’ve certainly moved a lot in the last five years, but I do remember five years ago, people saying it’s right around the corner. To be honest, some satellite constellation might have been during the COVID pandemic, in terms of some of the launches and the ability to get hardware ready. We’re seeing some launches for both satellites and half platforms being impacted by COVID, which was unexpected.
I think it may happen. I certainly welcome it as a data source, but I wouldn’t hang my hat on it happening anytime in the next two years.
What are some of the more current applications in industry for satellite imaging?

One area of economic interest or commercial interest that I think is quite interesting is estimating global oil reserves. This is something that my previous company has a patent for and developed an algorithm to estimate the volume of oil in floating roof storage tanks.
These tanks are large cylinders where the roof of the tank moves up and down, depending on how much oil is present in the tank. If you have an understanding of the sun, this is where shadows can be an asset instead of a detriment. If you have an understanding of the angle it
INTERVIEW
We’ve gone from those incredibly low-resolution images that had to be poured over by classifying analysts, to cube sets that are the size of a loaf of bread that can be rapidly iterated on.
was taken at, the time and the sort of metadata that’s available from the satellite, you can estimate the volume of oil, scale that up to the number of known oil fields that you can get imagery for, and you can start to get a really good estimate of how much oil is out there. This allows you to anticipate some of the market changes in the price of oil and the availability of oil, which is a really interesting and difficult space to work in. There’s a lot of different applications for agricultural predictions. Of course, some of them are economics. Some of them are from a planning perspective. But, another interesting application of agricultural prediction is national security. So, when you think about what is a root cause that can exacerbate conflict; a lack of access to resources - and in particular famine - is a circumstance that can really worsen conflict. The ability to monitor the state of agriculture on a global scale and anticipate months in advance, or even years in advance, when you might be experiencing acute famine can help understand the sort of geopolitical tensions this could lead to.
Is there a commercial use case for satellite imaging data in assessing supply chain risk in advance?

My inclination with that is if you can combine it with
other types of information, then it could prove really useful. So, for example, you know the areas of interest for different manufacturing plants, or, you know where the semiconductors tend to be staged before they’re shipped, and you can detect activity in those areas of interest, that’s one way that this could be used to determine potential supply chain issues in advance.
Another method is if you can combine satellite imaging data with other information. There was a really exciting piece of work where we were tracing palm oil supply chains using geolocation voluntarily provided as well as satellite imagery. So, combining those sources can definitely give you an estimate if you understand how goods are flowing specifically, and where goods are flowing, because often providers don’t necessarily know the exact source of their upstream products. If you can use data to trace back to where exactly you are getting your palm oil or your raw materials from, then you might be able to detect concerns (e.g. decreased economic output or decreased availability of resources). From that you can then anticipate that this might be an issue in one month or two months.
In our next issue we talk to Heidi about how satellite imaging is helping to tackle Climate Change.
PHILIPP KOEHN
INTERVIEW
SHOULD YOU REASSESS YOUR CANDIDATE ASSESSMENT PROCESS IN THE WAKE OF CHAT GPT3?
DAMIEN DEIGHAN , CEO OF DATA SCIENCE TALENT, WRITES ABOUT THE POSSIBLE IMPACT OF THE NEW CHATBOT ON THE DATA SCIENCE RECRUITMENT SECTOR.

The last three months have seen a rapid shift in the employment market. Most of the large tech players have laid off 5% or more of their global workforce, which was unthinkable in the summer of 2022. While the medium to long-term problem of severe skills shortages in Data Science and engineering will continue, for now, the recruiting pendulum has shifted (albeit temporarily) in favour of the hiring company. As more Data Scientists enter the market looking for jobs, you will inevitably see an increase in applications. The heavy lifting in the recruitment process has now shifted from attraction to assessment.
The heavy lifting in the recruitment process has now shifted from attraction to assessment.
Given the current macroeconomic volatility, and the expectation to do more with less, it’s even more important that you avoid making hiring mistakes.
THE DATA SCIENTIST | 19
DS RECRUITMENT
WHAT GPT 3 AND OTHER AI TOOLS MEAN FOR HIRING DATA SCIENTISTS/ENGINEERS NOW AND IN THE FUTURE

Just like in every other sector, AI will change recruitment significantly in the next five years. But what does this mean for you if you are hiring and assessing candidates right now?
Setting aside the early hype, it’s far too early to say exactly what Chat GPT3 means for hiring. However, we can be fairly certain about the future direction of travel and also what the immediate effect could be on candidate assessments. Take-home tests, which are standard in most hiring processes for Data Scientists and Engineers could become problematic very quickly.
The education sector runs more tests than probably any other sector, so it might give us some clues about where we are going. Kevin Bryan, a University of Toronto Associate professor, posted on Twitter recently: “You can no longer give take-home exams. I think chat.openai. com may actually spell the end of writing assignments”.
Schools in the USA have already reacted by banning
the use of Chat GPT3. Educators are so worried that in many areas, they have stopped giving out takehome essays and tests that were previously completed on home computers and are insisting that essays are completed in school with a pen and paper.
The problem with assessing candidates using takehome coding tests is that Chat GPT3 can already write basic-intermediate levels of code in several languages. It’s also reasonably competent at generating explanations of how the code works. The technology is prone to error and the code needs to be checked by a human, but it’s probably still good enough to score 6070% in basic coding tests at the more junior end of the spectrum.
Chat GPT4 is just around the corner which means that at some point in the very near future (if not already), many take-home tests are likely to be unreliable when predicting job performance in relation to coding. This is especially true if the tests are the more basic type of coding challenges, or they are generic in nature.
DS RECRUITMENT
WHAT CAN YOU DO NOW TO IMPROVE YOUR ASSESSMENT PROCESS?
Back to basics - now is the time to improve interview skills

Most hiring managers in Data Science have never done any formal interview training. One of the most important principles of successful interviewing is making sure the same set of questions are asked in every candidate interview for the same job. If you don’t ask identical questions, how do you compare candidates fairly? As a minimum, there should be a scorecard for each of the main competencies for the job and the question used to assess this should be well thought out. The best resource we have found for this process is the Mark Horstman book, “ The Effective Hiring Manager ”. It will require some work to apply it to Data Science, but it’s worth it.
1 3 2
Check if your technical assessment is up to scratch and relevant to the job you are hiring for
Have you considered if your take-home test could be compromised by an AI tool such as ChatGPT3? Perhaps it’s time to consider replacing your current test with an onsite (if possible), half-day work trial for two or three final stage candidates. This entails sitting the candidate in your team for a day (or half day) and getting them to work with someone you trust on a real-life task or project to see how they perform. With this approach, you can assess technical ability in real-time over the course of a day, without having to worry about whether or not your take-home test results are reliable. And from a culture perspective, you can see how candidates interact with the rest of your team.
Understand Data Science DNA of the person you are interviewing
We define the Data Science DNA of an individual as the key skills, mindset and inclination towards specific types of Data Science or engineering tasks. Some important questions to consider in determining this are - what type of Data Science work does the person like doing and what are they good at? More specifically, what type of Data Scientist or Data Engineer profile are they? How well does this fit the job you are recruiting for and the type of work the role requires?
For example, a Data Scientist with a strong statistics education background will differ significantly to a Data Scientist with more of a machine learning pedigree - even if both list ML and statistics as their main skills.
The Statistics Data Scientist is typically a modeling expert who pays deep attention to the distributional properties of the data sample and applies highly advanced mathematical models. They look at the dataset from the data generating process perspective and work with models that are equations-based.
The Machine Learning Data Scientist is typically an expert at using feature engineering to implement machine learning models that can achieve high levels of prediction accuracy. The main goal of the Machine Learner is to deliver fast and efficient results based on the existing ML frameworks, rather than set up equations-based models from scratch. The mathematical detail is not usually of critical importance to the Machine Learner, and neither is causality. High learning/ prediction accuracy matters most, even if the model is non-interpretable and based on artificially engineered features.
If you can identify these types of differences in the hiring process, then you can predict how the candidate will attempt to create a Data Science solution for a business problem. This will tell you what mindset they apply to the problem and then how they will execute a solution. The results will indicate whether or not they will be successful and a right fit for the role.
In the next issue, I will do a deep-dive into the eight fundamental roles that exist in a corporate Data Science team and define them very clearly.
WHAT DOES THE FUTURE HOLD?
For at least the next three-six months, the heavy lifting in recruitment will be getting the assessment part right. Attracting a reasonable quantity of applicants won’t necessarily be the biggest issue in 2023 - but now is the time to improve your assessment process so that you
make the most of your hiring.
There are AI tools specific to every stage of the recruitment process that already exist in the marketplace, and combined with tools such as Chat GPT3, they are set to present both hiring managers and job seekers with both opportunities and challenges.
THE DATA SCIENTIST | 21 DS RECRUITMENT
You have a vision for your Data Science team

We have a way to get you there
* We are so sure that we can find you a suitable candidate, that if you recruit a Data Scientist (Permanent Hire) that is unsuitable or leaves within 12 months, then we’ll replace them for free.

Our proprietary DST Profiler
®
The DST Profiler is a model describing eight well-defined and interconnected profiles in a corporate Data Science and Engineering team. It is also a candidate assessment platform that measures a candidate’s inclination and competence in 12 fundamental Data Science skills mapped onto 8 profiles.
®
The output of the assessment is a detailed 9-page report with visuals precisely describing the “Data Science DNA” of a candidate - giving you a very clear picture of exactly what type of work the individual will succeed in and where their real strengths are.
Improve your hiring. Improve your team. Improve your results. Find your next hire today at datasciencetalent.co.uk

With our pre-assessed candidates, we’ll help you achieve your vision
system will help you recruit better Faster. More cost-effectively.
Architect Wrangler Statistician Researcher MachineLearner
PROFILER DST ®
Visualiser Analyst
Hacker
HOW SCALING DATA SCIENCE PILOTS IS A KEY COMPONENT OF INDUSTRIALISING DATA

INDUSTRIALISING DATA IS A CRITICAL CAPABILITY FOR INSIGHT-DRIVEN ORGANISATIONS
BY PHILIPP M. DIESINGER
Data industrialisation describes the process of leveraging insights from data for informed decision-making by relevant stakeholders, in a systematic and organised way and at an enterprise level. It often leads to the creation of significant business value, such as increased competitiveness.
Through agile collaboration, small teams can rapidly develop promising Data Science pilots. However, scaling such minimal viable products (MVPs) to enterprise level is a complex process with many challenges along the way. But, with the right approach and collaboration model, these challenges can be overcome - resulting in industrialised solutions that lead to significant business value.
24 | THE DATA SCIENTIST
DATA INDUSTRIALISATION
, DATA AND A.I. ENTHUSIAST; CURRENTLY PARTNER AT BCG X
It has never been easier for organisations to leverage their data by developing tailored software solutions. Backend, frontend and data analytics frameworks are readily available, integrated data platforms have advanced and matured significantly and cloud environments provide readily-available capabilities for analytics, software development and deployment. Developing tailored solutions to meet organisationspecific challenges can lead to competitive advantages and internal efficiencies.
While typically developed in small teams, Data Science solutions can be scaled up for large amounts of users. In contrast to other activities that provide business value, scaling Data Science solutions relies mostly on technology and not on manual labour, which represents a significant advantage. The ability to develop and scale Data Science solutions for relevant stakeholders across an organisation has become a critical capability for every medium to large-scale enterprise.
The process can be broken down into two major steps:
STEP 1 The development and field-testing of a Data Science pilot or MVP.
STEP 2 The industrialisation and scaling of successful MVPs to relevant users across an organisation.
Either of these steps can be achieved with the help of third parties, however, the initial creation of critical IP (Step 1), often takes place in-house.
While the industrialisation of a Data Science pilot depends on the situation (based on factors such as relevant data, user-types, available technology, business goals, etc), the process itself shows recurring patterns and phases across use-cases, organisations, and even industries - as illustrated in the chart (p17 & 18).
BEFORE INDUSTRIALISATION: START OF INDUSTRIALISATION
After a Data Science pilot has been developed and tested, the organisation can then decide whether to scale-up, industrialise and roll out the solution to relevant stakeholders. This decision typically depends on a number of relevant factors such as the expected business impact in light of the pilot’s field-test results, budgetary and capacity constraints, the degree of complexity added to IT systems and the required level of change management. Ideally, these topics have already been considered during the pilot development. In any case, a tested MVP allows a more accurate assessment which can then lead to an informed decision for - or against - industrialisation.
THE DATA SCIENTIST | 25
DATA INDUSTRIALISATION
It has never been easier for organisations to leverage their data by developing tailored software solutions.
Minimum Viable MVP
DATA SCIENCE MVP
INDUSTRIALISATION PROCESS
MPV DEVELOPMENT MVP INDUSTRIALISATION PROCESS
CONCLUSION OF PREPARATION
ALIGNMENT
2-4 WEEKS*
SETUP M1
Planning of minimal viable product (MVP)
● STAGE 1 : Project evaluation and definition of initial scope
● STAGE 2 : Project planning, capacity panning, resource allocation, data provisioning, sandboxed MVP infrastructure setup
● STAGE 3c:
• Model development / execution
• Early stage engagement with relevant business and technology stakeholders
● STAGE 3b: Initial UI / Frontend development
● STAGE 4: Evaluate pilot in field-test under real-world conditions (up to 3 months) with well-defined outcome metrics and measurement plan
● STAGE 5: Impact analysis of field-test
Milestone
Go / No-Go decision for scale up and industrialisation of pilot
MVP DEVELOPMENT PILOT INDUSTRIALISATION GO/NO-GO
Identification of relevant stakeholders from:
● Partnering business departments & change management capabilities
● Data Science team
● Data governance
● Data compliance
● Data owners
● IT department, platform, technology, architecture
● Legal and compliance, regulation and ethics
Alignment with technology stakeholders
● Alignment with internal IT, external providers, third party vendors, etc.
● Discussion of technologies, platforms, and tools previously used in pilot development and required adjustments for scale-up
● Discussion of used data, required ETL processes and interfaces
● Decisions on physical location, infrastructure, and platform/tool license requirements
● Decisions on integration with data governance and QA frameworks; discussion of cybersecurity considerations, compliance and integration with data QA
● Decision on production developer team (IT, external support, third party vendors, etc.)
Collaboration setup
● Nomination of global capability and process owners
● Nomination of product owner (PO)
● Nomination of IT / business / data science point of contact for communication & coordination
● Data protection, compliance and data privacy assessment by data compliance and data protection officers
● Initial timeline and roadmap including capacity planning for relevant stakeholders; definition of project milestones (anchors)
● Alignment with data governance, security and QA functions
● Definition of scope and timeframe
Milestone M1
● Establish initial roadmap for industrialisation
● Conclude preparation phase
● Kick-off setup phase
Project setup
● Nomination of IT project owner
● Nomination of technical expert from Data Science team
● Alignment on data sources, data flow, platforms/tools and technologies for operationalised solution
● Project leadership and project management style
● Finalisation and setup of project team; roles & responsibilities
Project setup
● Finalise scope, define concrete deliverables and deadlines
● Create schedule and roadmap including MVP-specific milestones
● Identify potential issues/risks, perform risk management planning
● Data architecture and flow plan, including data protection and privacy planning
● Alignment with relevant data compliance officers
● Solution architecture plan
● Alignment with relevant functions for integration with, data/IT security, data governance and QA frameworks
● Approvals from IT function, developer team and Business
● Profiling of user-base, concept for user authorisation and user management
● Identification of run-mode technical support team
Capacity planning
● Analysis of resource and budget availability and requirements
● Decision of resource and budget commitment from business and IT
● Approval of roadmap and decision on final product delivery deadline
● Definition of scope and timeframe
Planning of change management
● Identify right level of required change management
● Identification of relevant user profiles and user types
● Develop initial approach and roadmap for change management
Milestone M2
● Conclude technology alignment
● Establish and align execution roadmap & capacity management
● Kick-off execution phase
!
3-6 WEEKS*
*
time scales assuming industrialisation of enterprise data science solution of average scope and complexity
12 WEEKS + FIELD-TEST*
A structured approach for business operationalisation of data science MVPs
EXECUTION
KICK-OFF
EXECUTION
4-12 WEEKS
Kick-off workshop for execution phase
Data loading & data provisioning
● Alignment with data owners
● Implementation of automated data ingestion
● Data quality and integrity assurance
● Execution/extension of data third party agreements (TPAs) and data sharing agreements
● Data protection, compliance, GDPR/ privacy assurance and ethics
● Establish/update data models
Infrastructure & platform integration (depending on project need):
● Platform setup, on-premise or cloud
● Servers or services for hosting front-end, back-end and database
● ETL processes
● Platform for offline calculations, e.g. onpremise HPC system or on-demand cloud services
● Interfaces and connection components
● Automation and execution scheduling services
● License procurement
● Cybersecurity components
● Data governance and MDM
● User authorisation and user management
Software development
● Front-end and back-end development including UI, UX, user interviews and initial user testing
● Web service development
● Database development
● Data science model integration with application backend
● Implementation of offline model calculations
● Software testing
● Integration of data and model QC gates
Change management
● Workshops with business users and other relevant stakeholders
● Preparation of solution roll-out
● Preparation of tech support
● Update roles and responsibilities
● Hiring lacking capabilities
● Nomination of solution ambassadors
Rigorous testing
● Develop, define and compile testing procedures and define acceptance criteria
● Integrity testing for input and output data
● Iterative testing by relevant technology and business functions
● Automated testing protocols and solution monitoring
Business & technology integration
● Development of technical training materials
● Development of QC processes
● Change management and trainings with relevant business stakeholders
● User testing
● Rollout to user base and other relevant stakeholders
● User-support, establishing user-base feedback channels and processes
● Enablement plan - launch events, weekly newsletters, pulse check events, technical office hours, FAQ updates, etc.
● Go-live of trouble-shooting protocols
● Onboarding of technical support team
Milestone M3
● Conclusion of MVP industrialisation
● Handover workshops with relevant stakeholders
● Release into run-mode
RUN-MODE
Run-mode & maintenance
● Activation of technical support team
● SLA agreement on ongoing maintenance with technical support team
● Agreement on and setup of future product revision process and timeline, e.g. potential analytical engine update process
● Management of user base
SOLUTION RELEASE M3 M2
PHASE ONE - ALIGNMENT
Once the MVP has been approved, the industrialisation process can start. Typically, first steps include expanding the team of relevant collaborators by identifying stakeholders who need to be involved, plus an initial alignment with technology owners as well as the setup of a healthy collaboration model.
Early in the process, it’s important to discuss and agree on a shared vision. This should include agreeing on transparent success metrics and measurement frameworks for the desired business value the solution is expected to deliver to the organisation.
Industrialising an MVP is a highly collaborative effort which requires a significant degree of alignment between stakeholders with varying responsibilities across different parts of the organisation. Stakeholders typically include: the business departments benefiting directly from the solution (by consuming the datadriven insights), the Data Science teams involved in the development of the initial pilot, the IT departments required for integrating the solution into the techstack, the departments responsible for running and maintaining the solution. Other stakeholders may include data governance, master data management, legal, compliance, cyber-security experts, GDPR officers, ethics experts and important external thirdparties.
It can be challenging to align such a varied group of collaborators. A well-defined industrialisation scope, as well as clearly defined responsibilities, milestones and timelines can help significantly.
PHASE TWO - SETUP
Once the industrialisation process has been aligned, a more formal project setup can then be established. Nominating the right stakeholders into project leadership roles with short communication channels can be very beneficial (and it’s important to not leave out crucial stakeholders in the process). Often, challenges arise from miscommunication or missing alignment between different departments, as well as a lack of transparency or poor expectation management. Strong and early alignment can prevent such potential problems from becoming serious issues later in the process. Choosing and setting up the right collaboration model and collaboration framework can be equally important. The goal of establishing the right setup for an industrialisation process is to meet all the requirements needed for a successful execution phase. This typically includes finalising the scope, agreeing on clear deliverables and timelines, establishing collaboration roadmaps, creating awareness of potential risks, agreeing on platform and technology topics as well as establishing transparency on user types and user profiles.
Once the requirements become clear and transparent, it can be a good time to perform capacity planning of the involved stakeholders. It is important to have realistic timeframes and a roadmap that retains some degree of flexibility for unforeseen events and challenges.
An industrialised solution can only benefit the organisation if it is accepted and used by the target group of end users. Therefore, discussing the degree of change management as well as concrete steps to make the solution convenient to use can be of significant value.
PHASE THREE - EXECUTION
Once alignment has been reached and the industrialisation process set up, the main phase of the industrialisation process can start: the execution phase. At this point, ideally all stakeholders have a clear understanding and transparency on deliverables and timelines; plus they know who their partners are and how to align and communicate with them. As the industrialisation process is a highly collaborative effort that requires many different skill sets, it is important to keep timelines and roadmaps realistic and to communicate issues and delays early and transparently.
Industrialising data requires technical expertise across multiple areas. Adding a new component to a technology stack or platform increases its complexity often exponentially because connections to existing components need to be established. For instance, where a new node is added to an existing complex IT network. Therefore, it can be beneficial to consider re-using existing capabilities as much as possible. Especially, new APIs or ETL processes can increase complexity and cost substantially. Utilising datacentric setups can be key for making sure a solution experiences a long lifespan.
The industrialisation of a new Data Science solution can also present a great opportunity to deal with already problematic legacy systems, as a measure of hygiene for the entire tech-stack. During industrialisation, technical topics are often the dominating challenge, but it is important to keep the user base in mind as well. For instance, an end usercentric development model for components like the UI can significantly lower the bar of the required change management later. Including and empowering users, providing them with a degree of agency and a feeling of co-creation can be very beneficial.
AFTER INDUSTRIALISATION: RUN-MODE
Once the solution has been industrialised it can be released into run-mode. This entirely new phase of the life cycle comes with its own challenges, such as monitoring and maintaining new technology as well as managing the needs of end users.
28 | THE DATA SCIENTIST DATA INDUSTRIALISATION
TEN BOOKS TO EXPAND YOUR WORLDVIEW AS A DATA PROFESSIONAL










 By NICOLE JANEWAY BILLS
By NICOLE JANEWAY BILLS
THE DATA SCIENTIST | 29
TEN BOOKS
FACTFULNESS
AUTHORS
Hans Rosling, Anna Rosling Rönnlund, and Ola Rosling
TIME TO READ
5 hrs 52 mins (352 pages)
This book discusses how the majority of people in wealthy countries hold a skewed and outdated worldview. In general, people tend to think things are worse than they really are. This widely-held opinion seems to be the result of a lack of knowledge, a poor understanding of statistics, and the 24-hour news cycle.
Factfulness drills down into each of these issues in order to empower readers with a more fact-based worldview. The authors categorise the top ten biases in how we evaluate the state of the world. They offer education on how to recognise and prevent these misconceptions. Moreover, they highlight how good news is routinely underreported and how this contributes to an inaccurate understanding of other people.

The book criticises the notion that the world can be bifurcated into “developed” and “developing.” In fact, today nearly all countries could be considered “developed”
relative to their technological status when this categorisation was initially proposed.
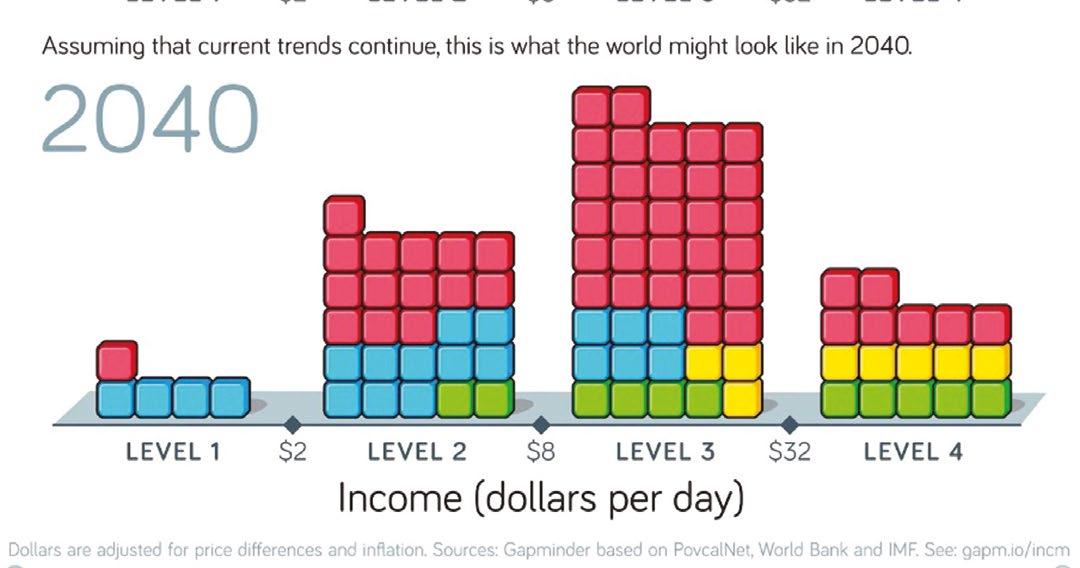
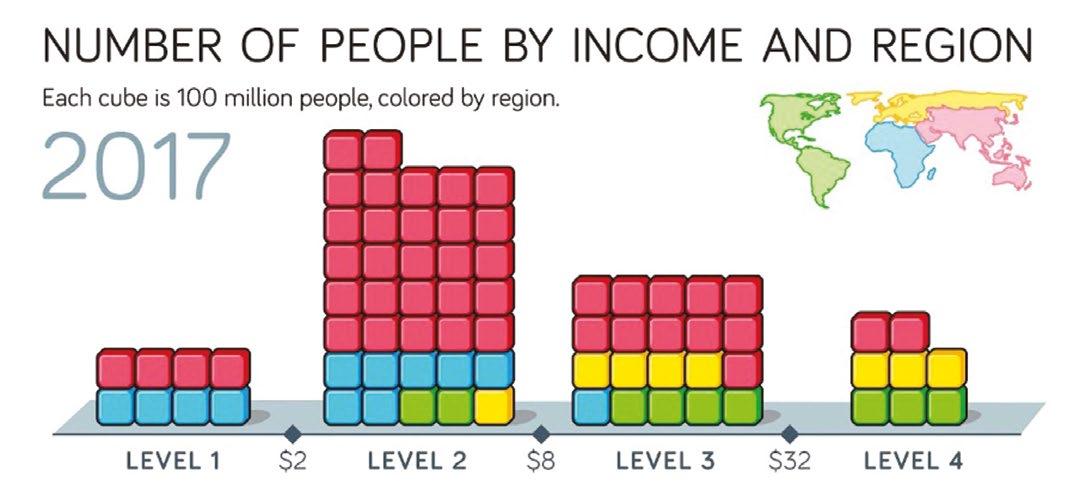
The authors put forward an updated model based on income per person adjusted for price differences:
• Level 1: less than $2 a day
Level 2: $2–$8 a day
• Level 3: $8–$32 a day
Level 4: $32+ a day
As you would expect based on your understanding of the normal distribution, the majority of the countries fall within Level 2 or Level 3 with a select few in Level 1 and Level 4. Thinking about global incomes in this way, as falling along a distribution curve rather than representing a gap between countries with extreme poverty and the so-called “developed world” helps combat this outdated perspective and the catastrophising 24-hour news media.
This charming book highlights how data can be used to shape an optimistic worldview.
30 | THE DATA SCIENTIST
TEN BOOKS
IN THIS ARTICLE, WE EXAMINE TEN BOOKS THAT WILL HELP YOU THINK ABOUT DATA IN DIFFERENT WAYS. I BELIEVE IT IS SO IMPORTANT FOR ALL OF US WHO WORK IN THIS FIELD TO BE ABLE TO FLEXIBLY EVALUATE DATA ACROSS DISTINCT MODALITIES AND USE IT TO CREATE A ROBUST AND COHERENT NARRATIVE.
THEREFORE, THIS LIST OF BOOKS SPANS TOPICS RANGING FROM GEOPOLITICS TO SOCIAL SCIENCE, FROM TECHNO-FUTURISM TO BEHAVIOURAL PSYCHOLOGY, AND FROM DATA VISUALISATION TO ARTIFICIAL INTELLIGENCE.
1
BEING WRONG: ADVENTURES IN THE MARGIN OF ERROR

AUTHORS
Kathryn Schulz
TIME TO READ 6 hrs 56 mins (405 pages)
...it does feel like something to be wrong. It feels like being right.
This statement serves as the thesis for Being Wrong . With engaging prose, Schulz elucidates all kinds of behavioural mistakes and perceptual errors. The book chronicles the journey of being wrong, denying it, realising it, feeling humiliated, and eventually finding humour in the mistake.
Schulz guides the reader through a history of error, from Socrates to Greenspan, and delves playfully into the psychology of mistakes, which
plague us all whether we like it or not. She argues that being wrong is an inescapable aspect of human existence.
This book, similar to Factfulness , will help you shape your worldview to become more positive, compassionate, and realistic. Given that it’s impossible to be right all the time, this one is definitely worth a read. An entertaining book that offers insight into how statistics and decision making apply to the real world.
INVISIBLE WOMEN
3 4
AUTHORS
Caroline Criado Perez
TIME TO READ
4 hrs 32 mins (432 pages)
This eye-opener raises awareness about the general paucity of data on women. This deficiency impacts many fields, ranging from medicine to social sciences. This book will make you more aware of the data quality issues that stem from this lack of gender parity in data availability.

By exploring the ramifications of treating male as default, Criado Perez exposes the flaws in a world created by men for men. She provides many unnerving examples of cases when the needs of women were completely ignored by product designers and also cases when the needs of women were inadequately
addressed by simply abstracting the gender and treating women like “smaller men.”
The author investigates the root cause of gender inequality through research into the lives of women around the world in various settings such as the workplace, the doctor’s office, and at home. In short, this book offers a groundbreaking summary of data quality issues impacting data about 50%+ of the world’s individuals.
If you’re seeking reliable data, this book offers an education in the issues around so-called gender neutrality and the troubling lack of representation of women.
THE INFINITE RETINA
AUTHORS
Irena Cronin and Robert Scoble
TIME TO READ
6 hrs 42 mins (404 pages)
The Infinite Retina explores how virtual and augmented reality technology could shape the future. This insightful book weaves a thorough picture of the present and future of spatial computing. It offers an introduction to the visionaries, subject matter experts, and up-andcoming businesses that are driving this technological revolution.

The authors provide a thorough treatment of the issues of privacy, security, identity, ownership, and ethics. The frequency at which society will interact with VR and AR technology in the near future will generate ever increasing amounts of data. Therefore, it’s beneficial for data practitioners to have at least a cursory understanding of the implications of spatial computing described in the book.
Overall, this is an excellent and authoritative account of a relatively new technology that should be read by anyone seeking to understand societal implications of changes to the digital landscape.
The Infinite Retina is an overview of the technological foundations that will enable the design of future immersive experiences through virtual and augmented reality.
THE DATA SCIENTIST | 31
TEN BOOKS
2
BEAUTIFUL EVIDENCE
AUTHORS
Edward Tufte
TIME TO READ
3 hrs 33 mins (213 pages)
Tufte is the OG, and this book is a beautiful and precise treatise on crafting analytical visualisations. This book is truly a joy to read. It is essential for rounding out a data practitioner’s understanding of analytics and presentation. Your Tableau dashboards and your coffee table will benefit.
Beautiful Evidence is about how seeing turns into showing, how data and evidence turn into explanation. The book identifies effective methods for showcasing just about every kind of information. Tufte suggests several new tools such as sparklines. The book concludes with two chapters that leave the world of two-dimensional representations and venture into three-dimensional considerations such as space and time.

Tufte offers the reader guidance on how to produce and how to consume presentations. He aims to enhance the viewer’s analytical toolkit for assessing the credibility of evidence presentations.
This is a foundational work on data visualisation that’s comprehensive and visually appealing.
ANALYTICS OF LIFE
AUTHORS
Mert Damlapinar
TIME TO READ
6 hrs 20 mins (348 pages)
Anyone looking for a broad overview of data should pick up this book - a short treatise on data analytics, machine learning, and artificial intelligence. Damlapinar describes the current technological situation and presents the opinions of several experts in order to inform the reader of possibilities on the horizon.

The author has outlined the effects of advancements in datarelated capabilities across various
industries. This aspect of the book provides a solid primer for how data can be used to improve organisational performance.
Furthermore, Damlapinar makes a case for analysing flaws in our way of thinking before we embark on the project of developing artificial general intelligence.
This is an interesting take on present and near future data capabilities.
STORYTELLING WITH DATA
AUTHORS
Cole Nussbaumer Knaflic
TIME TO READ
4 hrs 48 mins (288 pages)
This book is a great teacher of the art and science of getting your point across, whether verbally or visually, using data. Nussbaumer Knaflic draws upon the groundbreaking work of pioneers like Edward Tufte and brings in her own experience working with datadriven organisations as a consultant and executive in order to guide readers on the best practices of data communication.
Nussbaumer Knaflic provides instructions and examples of how to utilise data to create a captivating narrative. She advises on how to choose the correct data visualisation technique for a given audience and
circumstance.
Readers will learn how to think like a designer, eliminate the clutter clouding valuable information, direct the audience’s attention to the most important aspect of the data story, and leverage the power of storytelling to achieve emotional resonance.
This is an easy-to-read manual on the principles of data visualisation and successful data communication based in real world expertise. Readers may also be interested in Nussbaumer Knaflic’s newest book, Storytelling with You , which is more about presentation skills and comes out in September.

32 | THE DATA SCIENTIST TEN BOOKS
5 6
7
SUPERINTELLIGENCE

AUTHORS
Nick Bostrom
TIME TO READ
6 hrs 30 mins (390 pages)
A concise, convincing analysis of the potential hazards around artificial general intelligence (AGI). This book sets out the incredibly challenging task of ensuring that superintelligent AI systems are robust, safe, and beneficial to humanity. Bostrom outlines the strategies that must be undertaken prior to the development of AGI in order to minimise existential risk.
This classic work is a great read for those of us who interact with data, especially machine learning models. It is particularly relevant in light of recent advancements (e.g., GPT-3, Gato, DALL-E) that seem to be rapidly pushing us closer to this groundbreaking development.
This book outlines the risks associated with the development of artificial general intelligence.

DATA-DRIVEN LEADERS ALWAYS WIN
AUTHORS
Jay Zaidi
TIME TO READ
3 hrs 32 mins (212 pages)
Zaidi has done an excellent job highlighting the importance of data for effective decision making. He highlights the fact that many leaders take data for granted and only call upon it when crucial decisions must be made. These leaders may feel more comfortable governing based on intuition. They may not know what questions to ask to deepen their situational awareness using measurement and evaluation.
Zaidi aims to transform the management discipline by providing instruction on how to become a data-driven leader. He outlines an approach to using data to keep a pulse on the health of the organisation. Data quality improvement forms the basis of further strategies for executive data strategy. The book also discusses ways to prevent common
data management difficulties and how to empower owners to enrich data using interoperability and enhanced metadata.
Zaidi has labelled the Fourth Industrial Revolution the “Age of Data.” This book connects the dots across various data management fields, and their practical applications, using real life experience that the author gained while leading enterprise-wide data management programs in the financial services industry. The book helps develop core skills for leaders to win in the “Age of Data.”
The book is created with busy executives in mind. If you’re seeking a straightforward approach to ensure the success of your organisation based on better data management, this book is for you.
CODE
AUTHORS
Irena Cronin and Robert Scoble
TIME TO READ
6 hrs 42 mins (404 pages)
Petzold demonstrates the inventive ways we play with words and create new strategies to converse with one another. Code offers a lens on how the technological advancements of the last 200 years have been fueled by human inventiveness and the need to communicate.

The book gets off to a really good start discussing Morse Code to lay the fundamentals of what constitutes a code. It moves on to describing binary code in an engaging manner - not easy to do. The book is a cleverly illustrated and eminently comprehensible narrative. Along the way, the reader gains insight into objects of modern technological ubiquity. Whether you’re an experienced programmer or just want to learn more about how computers work, this is an excellent starting point.
This book bridges computer science fundamentals with the science of everyday things to offer a delightful reading experience that will deepen your appreciation for working with data.
THE DATA SCIENTIST | 33 TEN BOOKS
8 9 10
AMSTERDAM DATA SCIENCE CITY #2
Amsterdam is a stunning city full of beautiful, gabled buildings flanking picturesque canals. Indeed, this network of canals splits the inner city into 90 ‘islands’, with over 1,280 bridges connecting them. The city also boasts a wide range of world-class museums, and has a bustling cafe culture that is the envy of many.
Yet, whilst Amsterdam is a city of immense beauty and personality, it is bursting with technology and innovation too and is a major European Data Science hotspot.

34 | THE DATA SCIENTIST
AMSTERDAM
Amsterdam
AMSTERDAM
Overview of Amsterdam
Considered by many to be one of Europe’s most livable cities, Amsterdam is the economic hub of the Netherlands, and whilst the seat of the country’s government is actually in The Hague, Amsterdam is the nominal capital city and many refer to it and think of it as the capital. It is a magnet not only for tourists but also for companies and organisations who are looking to set up their headquarters and European offices.
Whilst its core is filled with historic canals, flowerladen bridges, and narrow, cobblestone lanes, Amsterdam is a modern, creative, enterprising city where you won’t be surprised to find cutting-edge tech start-ups standing next to an art gallery or pop-up restaurant. It has a laid back, yet energetic feel. ‘Gezellig’ (cosy and convivial), yet hip. Amsterdam is a fascinating city of contrasts. Where a golden past meets an innovative, technological future.
Amsterdam is the city that gave us the Python programming language; a city that came to prominence at the turn of the century as a tech city, and has since has been described as one of the most AI-ready cities in the world. It boasts a 175 acre Science Park, and is a superb location for start-ups to major European HQ’s. That’s why so many leading companies have a large presence within Amsterdam - including Philips, ING Group, Canon, Heineken, ABN Amro Bank, Tesla, Netflix, Cisco, Randstad, and Adyen.
The city joins the likes of London, Berlin, Paris, Frankfurt, and Dublin as one of the key Data Science Science centres in Europe. It’s also a focal location for European Data Science conferences as we’ll discover later in this article.
Location, Geography and Population
Amsterdam is a bustling port city that has a population of around 850,000, with an urban area population of around 2.5 million. It is located in the west of the Netherlands, in the province of Noord-Holland and connected to the North Sea. Parts of it, including the international airport Schiphol, are several metres below sea levelwith some land reclaimed from the sea. Its proximity to the UK and several EU countries plus its history, culture, and work/life balance make it one of the most popular destinations in Europe, welcoming more than 4.5 million tourists every year, and a great city to work in.
Transport
Schiphol Airport is the main international airport of the Netherlands and is located around 19 kilometres southwest of Amsterdam. Trains connect it directly to Amsterdam’s main railway station (Centraal Station) which is located right in the heart of the old city. Public transport in Amsterdam is an efficient and effective way to get around and into the city; from the iconic blue-
7 things about Amsterdam you may not know
1. There are around 1.2 million bicycles in the city, but only around 850,000 inhabitants. Indeed, there are four times more bicycles than cars in the city.
2. The city’s Rijksmuseum is the only museum in the world to feature an internal bike path.
3. Amsterdam has more canals than Venice and more bridges than Paris.
4. With over 90 museums, Amsterdam has the highest museum density in the world.
5. If you unfortunately pass away in Amsterdam but don’t have any family, friends or acquaintances there, then a poet will write a poem and recite it at your funeral.
6. You may wonder why so many houses are very narrow. That’s because in the 17th century, locals were taxed on the width of their property along the canal.
7. There are 2500 boathouses in the city and the city boasts the only floating market in the world.
and-white trams via an extensive bus system to a 39 station metro system. Transport by water is also popular, whilst a common sight in this beautiful city is seeing bicycles at every turn.
Education
Amsterdam contains two main universities and several applied universities, with a number of Bachelor and Master’s degrees in the likes of Data Science, Analytics, and Artificial Intelligence. These universities include the University of Amsterdam (Universiteit van Amsterdam, UvA), and the Vrije Universiteit Amsterdam (VU). The city also has other specialist institutions, including CWI, the national research centre for Mathematics and Computer Science.
There are also a number of schools for foreign nationals in Amsterdam, including the Amsterdam International Community School, British School of Amsterdam, Albert Einstein International School Amsterdam, Lycée Vincent van Gogh La HayeAmsterdam primary campus (French school), the International School of Amsterdam, and the Japanese School of Amsterdam.
THE DATA SCIENTIST | 35
ADS: A thriving Data Science community in Amsterdam
Whilst Amsterdam is a major city, it’s relatively small and compact compared to other major international cities. This makes it a perfect location for a dynamic Data Science community - and Amsterdam Data Science (ADS) is just that.

ADS was founded in 2014 and is a network of academic and commercial partners. It has established a strong Data Science and AI ecosystem based on many internationally renowned researchers in diverse Data Science & AI related fields. The network exists to facilitate the growth and international standing of the ecosystem.
This academia, industry and society bridge provides a platform for collaboration and engagement and is responsible for over a dozen (free) meet-ups a year. These gatherings boast leading Data Scientists and AI researchers and practitioners who discuss topics such as health, fintech, citizen welfare and the real-
world applications of their research. ADS brings together speakers from academia and commerce to showcase their expertise and world-class research in Data Science and AI, while promoting Amsterdam as a leading European hub in Data Science, AI research and education.
amsterdamdatascience.nl
CONFERENCES / AMSTERDAM / 2023
A sure sign that Amsterdam is one of Europe’s leading Data Science cities can be seen from the city holding a number of major tech conferences this year. Here are just three in 2023 to go to...
MAY 17-19th
World Data Summit
A three-day conference that aims at helping you to understand how data analytics can, and will, help to transform your business. Featuring market overviews, a range of workshops and practical case studies, and tackling key issues such as Data Governance in an Agile Environment, Privacy, Ethics and Data in a Global Context, and Applications of ML in Improving Customer Experience, this summit sees a host of key figures from the world of data including the likes of VP’s, Managers, Directors, and Analysts.
SEPTEMBER 26-27th
AI and Big Data Expo Europe
This two-day technology conference is expected to pull in more than 5000 visitors and showcases cutting-edge technologies from over 250 speakers who will be sharing both their experiences and industry knowledge.
This event really does cater for the ambitious enterprise technology professional or company, indeed anyone who is looking to explore the latest innovations, implementations and strategies to drive them forward, with the conference featuring a range of expert keynotes, interactive panel discussions and solutionbased case studies.
WIth well over 200 speakers,
AI & Big Data Expo Europe is held at the RAI and merges key industries for two days of top-tier content and discussion across 5 co-located events that cover: Blockchain, IoT, 5G, Cyber Security & Cloud, AI and Big Data.
OCTOBER 11th-12th
Amsterdam World AI Summitt Held every October in Amsterdam, the great and the good from the world of AI converge on the Dutch city: Enterprise, Big Tech, Startups, Investors... this conference tackles the big AI issues and helps to set the global AI agenda.
It’s two days full of great sector-leading speakers, debate, innovation, masterclass sessions, boardroom-style chats, workshops - and there’s even a DJ present, too!
36 | THE DATA SCIENTIST AMSTERDAM
THE DIFFICULT LIFE OF THE DATA LEAD

Working in data has never been harder. The data stack is becoming more complex and expectations are higher than ever before.
However, one data role has it harder than most: the Data Lead.
People in middle data management roles often go by the name of Data Lead or Data Manager. It’s the only role where you have to balance managing a team with working in a leadership group and still doing hands-on work. No easy combination.
Head of Data Data Lead IC IC IC Data Lead IC IC IC Data Lead IC IC IC
HIGHLY RESPECTED AND EXPERIENCED DATA LEADER MIKKEL DENGSØE EXAMINES WHY BALANCING THE MANAGEMENT OF A TEAM WITH DEMANDING STAKEHOLDERS AND STILL BEING HANDS-ON IS NO EASY TASK.
The difficult layer in-between
THE DATA SCIENTIST | 37 LEADERSHIP
A typical data team structure
If you’re an IC (individual contributor), your job is challenging but your focus is clear. You succeed by delivering high-quality analysis and data products, and work with stakeholders to make sure your work has impact. If you’re a Head of Data, you work on a strategic level and if you’re lucky you

have a seat at the top management table. Your role is difficult but your focus is also clear; build a great team around you and make sure the data team is working on the right priorities, and is set up to succeed in the future.
But if you’re a Data Lead you’ve got to do all of these at once.
As a Data Lead you have to manage your direct team. This includes dealing with performance management issues, making sure top performers are challenged and hiring the right people.
You also have to manage stakeholders who often have competing



priorities, and keep track of what goes on in each area where someone from your direct team is involved.
And you need to stay hands-on and be able to jump in to code, build a dashboard or deliver an analysis that sets the bar for what good looks like. This is a lot to balance.
38 | THE DATA SCIENTIST
LEADERSHIP
33% Stakeholders • Hiring • Compensation Perf. management Motivation • Coaching Alignment • Prioritisation • Goal setting • OKRs Strategy 33% Team management 33% IC Work • Dashboards SQL queries • dbt • Code reviews • Deep dives Data Lead 70% IC Work 30% Stakeholders 33% IC Work 33% Stakeholders 10% IC Work 50% Stakeholders 40% Team management 33% Team managemen t IC Head of Data Typical time spent doing different types of work Balancing it all as Data Lead
All of this combined makes the role of middle data management unique and as a data industry we haven’t figured out how to deal with this yet.
As the data IC career progression path is starting to become a viable alternative to the people management ladder, I’m starting to see more Data Leads being drawn to this. They’re still ambitious and want to progress in their careers but also want to get back to having time to focus on their craft and doing deep work.
If you look at engineering teams, many Engineering Managers have left behind most of their IC-related work. In fact, seeing an Engineering Manager push code to the production code base is uncommon in many organisations.
Companies still need Data Managers, so not everyone can move to the IC ladder. Some have suggested that Data Leads should operate more like Engineering Managers, but I’m not so sure that’s what they want. In my experience, being hands-on is the part of the job they often enjoy the most.
A likely root cause of the issue
As data teams get larger, the need for middle-level Data Managers will only increase; so figuring out the best operating model is key. One solution is to stop expecting these individuals to do everything at once.
If the top priority is to grow the team, stakeholders shouldn’t expect the Data Lead to be as hands-on until the team has been hired.
If there’s a performance management issue and someone on the team requires a lot of attention, the hiring team should take on more of the initial candidate calls.

My take on the most common root cause for the strain on Data Managers, is that it’s most often to do
with stakeholders. They are not deliberately being difficult (I hope) and often have good intentions to push for their own business goals. But many stakeholders don’t know how to work with data people. In highgrowth companies you often have stakeholders coming from all kinds of backgrounds. People coming from traditional companies in particular may expect the data team to operate more as a service function where the goal is to respond to ad-hoc data requests. This is a topic that I’ve seen consistently create a lot of friction.
It’s also not uncommon to see stakeholders fight for data “resources2” to be allocated to their projects, leaving the Data Lead in the difficult position of not being able to make anyone happy.
What can be done to improve this?
One problem is that many organisations don’t have a senior data person who has a seat at the top management table and can speak for data. This is unlike what you see in engineering, where it would be uncommon to not have at least one senior technical person present.
Another solution is to educate stakeholders. I’ve always found it much easier to work with senior stakeholders who have a background in data. They appreciate how difficult some work can be and know when to cut corners. It may be wishful thinking that all senior leaders have a data background but data teams who don’t work as service functions are still a relatively new thing. Hopefully more stakeholders will get accustomed to how to work with data people.
I’m still waiting for someone to write The Ultimate Manual for Stakeholders on How to Work with Data People .
LEADERSHIP
EVOLUTION OF DATA PLATFORMS
By FRANCESCO GADALETA
The work of the Data Scientist has changed in recent years. While it has improved for some, it’s probably degraded and become even more frustrating for others. For example, several of the tasks that Data Scientists performed a decade or so ago are no longer needed because there are better tools, better strategies, better platforms - and definitely better architectures.
Think about Oracle, the likes of PostgreSQL, MS SQL Server, and many others. Over the past couple of decades, these platforms have been the most important systems in the organisations of pretty much any sector, regardless of the size and data types. With an increased demand for more analytical tasks alongside the needs of key decision-makers in companies and organisations, engineers are using different types of architectures and platforms just to fulfill such new requirements. We can list these architectures from the data warehouse to the data lake, data fabric, the lake house and the data mesh. Chronologically, the data warehouse from the sixties and seventies has evolved to become the data mesh and the data lakehouse later. The lakehouse is one of the most recent architectures and evolutions of architectures in data.

40 | THE DATA SCIENTIST DATA PLATFORMS
Such a new concept overcomes some of the most evident limitations of databases, both structured and unstructured. Ignoring the fact that we have keyvalue stores, and one can, to a certain extent, manage unstructured data, the idea of the database is based on transactions; to have some sort of consistency, and to also have a schema in the data. This means that once you have an ingestion layer that takes data from a data source into the database, the Engineer has to know in advance what that data looks like. For some organisations, this is still a valid concept. The fact that data architectures evolve doesn’t necessarily mean that one has to migrate to the most novel approach overnight.
There are many organisations where their business (and the type of data they manage) hasn’t changed in a decade or more. The main reason why data lakes have been introduced is to overcome some of the technical limitations of old-school databases. For example, the fact that databases and data marks can’t deal nor process semi-structured data.
The concept of the data lake has its own benefits and limitations like any other data architecture. Probably a key benefit would be the fact that it is based on object storage technology, which is usually low cost.
Historically, proprietary data warehouses have been quite expensive pieces of technology where most of the costs have been due to maintenance performed by expensive consultants provided by the supplier. When it comes to proprietary data and proprietary data formats, there is yet another threat to keep an eye on, which is data lock-in.
Of course, all that glitters is not gold. Data lakes come with some challenges. For example, no support for transactional applications, meaning low reliability and potentially poor data quality.
When you incentivise someone to put their data into one place as a low-cost object storage, there is no schema enforcement, and no concept of transactionso no consistency at all (or what it is usually referred to as eventual consistency in distributed computing). Essentially, this means much lower reliability with respect to the old-school database. What happens to data is that as time goes on, quality starts degrading. That might become one of the most difficult challenges one is called to deal with. One of the best evolutions from the data lake that overcomes such limitations and definitely improves data quality is the data mesh.
The data mesh is, in my opinion, one of the most elegant solutions to evolve from the data warehouse to the data lake - and then to something even better than that. The concepts behind the data mesh are not necessarily new per se. Under the requirements of the data mesh there is a domain expert who is responsible for a particular business unit and the data related to it.
This new role, in a sort of decentralised fashion, owns the data, just like for a data product. There is no longer a centralised way of storing raw transactional data. There is, however, a way of decentralising the ownership of the data.
There is access control and global governance. There is decentralised ownership. There is the concept of the domain data product. I do believe that many organisations will migrate to the data mesh in the near future. I’m not only a big fan of the concept, but also it seems to be the most natural solution to the problems of today and tomorrow. However, there is no standard or product that implements a data mesh. Data mesh is a concept, not a product. While there will be several implementations of the data mesh, there’s currently not a single product that one can purchase anywhere. There are principles that demonstrate best practices of how to put a data mesh together for a business and leverage the particular use case.
Another architecture trying to solve similar problems is the data fabric. The data fabric is characterised by centralised data, it is metadata-driven and it has a technology-centric approach. There are three essential concepts that data fabric is usually built upon, including compliance, governance, and privacy. Looking at the architecture of the data fabric there are consumers on one side, and the entire data life cycle management just below. Below that, one can find the components that implement metadata management and data catalogues, ETL, data visualisation, etc. At the lowest layer sits the actual infrastructure that stores raw data.
Despite the constant evolution of platforms and architectures, there’s no need to adopt them overnight. It goes without saying, there’s no winner, and there’s no loser. There’s just the best approach and the best architecture that suits a particular business .
My take-home message is to pay much more attention to the organisational needs, the analytical workloads, the variety of the data and the data analytics maturity of the entire organisation, rather than committing to the latest technology.
datascienceathome.com
DATA PLATFORMS
FRANCESCO GADALETA is the Founder and Chief Engineer of Amethix Technologies and Host of the Data Science At Home podcast.
THE DATA SCIENTIST | 41
NEXT ISSUE
In Issue 3 of The Data Scientist you’ll find...
Arnon Houri-Yafin on using AI to drive the eradication of malaria


Our next Data Science City feature: London

Francesco Gadaleta feature on LLM’s and how to get the best from Chat GPT3
PART 2 of our Satellite Imaging conversation with Heidi Hurst talks about how Satellite Imaging is contributing to the fight against climate change

...and a wealth of articles from the world of Data Science and AI
ISSUE 3 OUT ON 9TH MAY 2023
SUBSCRIBERS
JOIN our ever-growing list of subscribers to get your free digital copies of The Data Scientist before anyone else.
GO TO datasciencetalent.co.uk/media or scan this QR code and fill in the subscription details. We’ll be in touch very soon.

BE A PART OF THE
DATA SCIENTIST MAGAZINE
We h ave a growing group of leading Data Scientists and organisations writing for us, and we are always looking for even more outstanding content for future issues.
For an informal discussion about writing for us (no fee or charge involved with featuring in the magazine) please contact our editor: Anthony Bunn
anthony.bunn@datasciencetalent.co.uk | 44 (0)7507 261 877
ANNA LITTICKS
ANNA LITTICKS: #2
AUTOMISATION MEANS CHANGE AND “CHANGE IS BAD”
Hi. Anna Litticks here. Welcome to the next story in my series of ‘Things I wish I knew before my career in Data Science.’ Today we’re looking at…

Automisation means change and “change is bad”
Every business owner or C-suite executive really believes they want answers to their problems. In my experience, they rarely actually do.
You see, change is normally perceived to be negative. It’s scary and means upheaval.
Sometimes, asking the C-suite to change is like asking your partner where they fancy dinner tonight. They respond whimsically with “ I actually fancy a bit of a change. ” You think they mean a different restaurant. They actually mean a divorce; emigrating to a shack in Bali to give boat tours.
You see, upper management typically wants easily-applicable outcomes and catchphrases that fit the narrative they currently have in their minds. They’ll pick up on terms like Bayesian Modelling or Machine Learning like these are shiny new iPhones they simply must have for business success.
They title emails ‘ Big Data ’ and attach a WeTransfer link for a 943Mb Excel file. They’ll talk about AI and BI and “ how well do you know Python then? ”
Only then comes the look of despair when you present your findings at the end of the first month of your project, and you require at least another three months of analysis before you can even begin to work on a model.
They’ll speak over you in meetings. They’ll assume that you being slightly introvert is a sign you don’t know what you’re talking about. Or worse, that the work you’ve done up to now isn’t worth completing because the results haven’t come out as quickly as they need them.
Occasionally, however, you will find people who are receptive to your suggestions. People who are pleased with your analysis. People who don’t react like you’ve just crashed your car into their dining room during Christmas dinner.
And on these occasions, the whole process is worth it. Real difference, pride and change await you here.
Just good luck finding them.
Until next time, take care out there.
Anna Litticks
“
THE DATA SCIENTIST | 43
Hire
the top 5% of pre-assessed Data Science/Engineering contractors in 48 hours
Quickly recruit an expert who will hit the ground running to push your project forward
Don’t let your project fall behind any further. You can access the top 5% of pre-assessed contractors across the entire candidate pool - thanks to our exclusive DST Profiler® skills assessment tool.
You can find your ideal candidate in 48 hours* - GUARANTEED
We recruit contractors to cover:
Skills or domain knowledge gaps
Fixed-term projects and transformation programmes
Maternity/paternity leave cover
Sickness leave cover
Unexpected leavers/resignations
Tell us what you need at datasciencetalent.co.uk


10K contractor guarantee: in the first two weeks - if we provide you a contractor who is not
fit,
replace them immediately and won’t charge
anything for the work
done.
*Our
a
we will
you
we’ve
Researcher
PROFILER DST ®
Visualiser Analyst Architect Wrangler Statistician
MachineLearner Hacker
