









Expect smart thinking and insights from leaders and academics in data science and AI as they explore how their research can scale into broader industry applications.



Key Principles for Scaling AI in Enterprise: Leadership Lessons with Walid Mehanna
Enterprise Data Architecture in The Age of AI – How To Balance Flexibility, Control and Business Value by Nikhil Srinidhi
Maximising the Impact of your Data and AI Consulting Projects by Christoph Sporleder
Helping you to expand your knowledge and enhance your career.


CONTRIBUTORS
Philipp Diesinger
Robert Lindner
Gabriell Máté
Stefan Stefanov
Peter Bärnreuther
Sascha Netuschil
Tony Scott
Tarush Aggarwal
James Tumbridge
Robert Peake
Łukasz Gątarek
Nicole Janeway Bills
James Duez
Taaryn Hyder
Anthony Alcaraz
Anthony Newman
Francesco Gadaleta
EDITOR
Damien Deighan
DESIGN
Imtiaz Deighan imtiaz@datasciencetalent.co.uk

DISCLAIMER
The views and content expressed in Data & AI Magazine reflect the opinions of the author(s) and do not necessarily reflect the views of the magazine, Data Science Talent Ltd, or its staff. All published material is done so in good faith. All rights reserved, product, logo, brands and any other trademarks featured within Data & AI Magazine are the property of their respective trademark holders. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form by means of mechanical, electronic, photocopying, recording or otherwise without prior written permission. Data Science Talent Ltd cannot guarantee and accepts no liability for any loss or damage of any kind caused by this magazine for the accuracy of claims made by the advertisers.

Welcome to issue 11 of Data & AI Magazine , where we shift our focus to explore how traditional sectors are quietly building sustainable AI capabilities. After 10 issues of coverage about AI’s transformative potential, this issue examines the unglamorous but essential work of making AI deliver value in the real world.
Our cover story features a first for our magazine. It’s the story of a 3-way collaboration between GoTrial, Rewire, and Munich Re that exemplifies the kind of practical innovation our industry needs. Their data-driven approach to clinical trial risk mitigation addresses a fundamental challenge: 70-80% of trials fail to meet enrolment targets on time, with delays costing approximately $40,000 per day in operational expenses. By consolidating over one million clinical trials into a unified platform enriched with regulatory, epidemiological, and site-level information, they’re not just applying AI to healthcare — they’re engineering certainty where uncertainty has long been accepted as inevitable.
What makes this partnership particularly compelling is how it bridges the gap between data science and financial risk management. Munich Re’s ability to convert quantified risk into financial instruments demonstrates how AI’s true value emerges when technical capabilities meet real-world commercial needs.
This issue deliberately focuses on small and medium-sized enterprises in traditional sectors, moving beyond our typical coverage of large corporations and tech startups. Tarush Aggarwal, founder of the 5X allin-one data platform, shares insights on ‘How to Build Less, Deliver More’ which is a refreshingly practical approach to AI ROI that prioritises impact over technological sophistication.
Complementing this perspective, Tony Scott offers ‘Successful AI Strategies For Businesses in Traditional Sectors’, an anti-hype guide from a fractional CDO who understands that smaller enterprises can’t afford to chase every AI trend. These articles remind us that the most sustainable AI implementations often come from organisations that approach the technology with clear constraints and defined objectives.
We also feature Sascha Netuschil of Bonprix’s exploration of how GenAI is driving value in fashion retail, specifically through improving internal business processes and translation services. His work on building applications that make websites disability-friendly illustrates how AI’s most meaningful contributions often emerge in specialised, sector-specific applications rather than broad, general-purpose deployments.
THE CURRENT AI BUBBLE – SHADES OF THE DOTCOM ERA
I started recruiting in the late 90s during the dot-com bubble, and I see troubling parallels between then and now. In 1999, adding ‘.com’ to a company name enabled businesses with no clear product-market fit to raise significant capital; we’re seeing a similar phenomenon with AI. Every VC portfolio desperately needs an AI company, echoing the frantic investment in search engines and other internet companies two decades ago.
The sustainability questions are impossible to ignore. While companies like Anthropic and OpenAI have seen significant revenue growth in 2024, they continue to lose enormous sums of money with no clear path to even medium-term profitability. The major AI labs appear to have hit technical plateaus, and Sam Altman’s AGI promises seem increasingly unlikely to materialise on the timelines being suggested.
This reality check doesn’t diminish AI’s long-term potential, but it does demand that we approach it with the same rigour we apply to any other business technology. The organisations featured in this issue succeed precisely because they focus on solving specific problems rather than chasing technological possibilities.
What emerges from this issue is a clear pattern: the most successful AI implementations prioritise practical value over technical sophistication. The most impactful applications are those that address real operational challenges with measurable outcomes.
As we move forward, the industry’s maturation will be measured not by the sophistication of our models or the size of our funding rounds, but by our ability to consistently deliver ROI to organisations across all sectors. The leaders featured in this issue are already doing this work quietly, pragmatically, and profitably.
Thank you for joining us as we explore these more grounded approaches to AI implementation. The future of our field depends not on the next breakthrough algorithm, but on the sustained effort to make AI genuinely useful for the vast majority of organisations that operate outside Silicon Valley’s spotlight.
Damien Deighan Editor
By PHILIPP DIESINGER, ROBERT LINDNER, GABRIELL MÁTÉ, STEFAN STEFANOV, PETER BÄRNREUTHER

PHILIPP DIESINGER
is a data science executive with over 15 years of global experience driving AI-powered transformation across the life sciences industry. He has led high-impact initiatives at Boehringer Ingelheim, BCG, and Rewire, delivering measurable value through advanced analytics, GenAI, and data strategy at scale.

ROBERT LINDNER
is an expert in AI and data-driven decisionmaking. He is the owner of Rewire’s TSA offering and has led multiple AI/ ML product initiatives built on real-world data in the life sciences.

STEFAN STEFANOV is the chief engineer of the GoTrial clinical data platform with over 7 years of experience in leading and developing data and AI solutions for the life science sector. He is passionate about transforming intricate data into user-friendly, insightful visualisations.

GABRIELL FRITSCHE-MÁTÉ
is a data and technology expert leading technical efforts as CTO at GoTrial. With extensive experience in addressing challenges throughout the pharmaceutical value chain, he is committed to innovation in healthcare and life sciences.

PETER BÄRNREUTHER
is an expert in AIrelated risks, bringing over 10 years of experience from Munich Re. He is a physicist and economist by training and has focused on regulatory topics and emerging technologies such as crypto and AI.
Clinical trials evaluate the safety and efficacy of new medical interventions under controlled conditions. Late-phase trials are essential for regulatory approval and typically involve large patient populations across multiple geographically distributed sites. Given their complexity and cost, even modest delays can have significant financial implications: daily operational expenses can exceed $40,000, and potential revenue losses may reach $500,000 per day of delay [1]. Patient enrolment stands as the most significant bottleneck in clinical trial success, with 70-80% of trials failing to meet enrolment targets on time, necessitating protocol amendments, timeline extensions or additional sites that dramatically increase costs and delay innovative treatments from reaching patients [2,3]
Recognising the persistent challenges in clinical trial execution, three partners – GoTrial, Rewire, and Munich Re – have come together to pioneer a new, datadriven approach to de-risking clinical development:
● At its core is GoTrial’s unique platform, which consolidates and harmonises over one million clinical trials. This data is not only unified and cleaned, but also enriched with regulatory, epidemiological, and site-level information – and made accessible through a suite of analytical tools, including benchmarking KPIs, predictive models, and GenAI capabilities that extract structure and meaning from unstructured protocol documents.
● Building on this foundation, Rewire contributes advanced analytics and deep operational expertise to surface predictive insights on trial feasibility, site performance, and protocol complexity. Where required, this is complemented by targeted expert input to interpret patterns and validate results.
● Munich Re, in turn, adds a critical third layer: the ability to translate quantified operational risk into financial risk structures, enabling new forms of risk-sharing and exposure mitigation for sponsors.
Together, this approach represents a departure from conventional planning – shifting from experience-based assessments to a system of objective, evidence-led foresight that allows sponsors to design and manage trials with greater precision, accountability, and confidence than was previously possible. Because the approach draws on a complete set of global clinical study data, it removes the lingering uncertainty of ‘what might we have missed?’
This new approach to clinical development has begun to complement established trial operations by embedding deep, data-driven intelligence earlier in the process. Rather than focusing solely on the execution phase, this method brings structured analysis and predictive modelling into the design and planning stages, enabling sponsors to challenge assumptions, simulate scenarios, and anticipate risks before trials begin. Unlike traditional feasibility practices that often rely on local knowledge or prior experience, this approach leverages global insights at scale and transforms risk mitigation from a reactive task into a proactive, quantifiable discipline. In doing so, it opens up new opportunities for smarter planning – and even for risk-sharing models that were previously out of reach.
Site-level recruitment potential forecast for two clinical studies. Each axis represents an individual clinic, with the outer (red) boundary indicating theoretical site capacity and the inner (blue) area showing predicted actual enrolment performance. While Study A demonstrates alignment across most sites, Study B shows a significant performance gap across the majority of clinics – signalling elevated recruitment risk and the need for strategic site or protocol adjustments.
Site-level forecasting enables bottom-up recruitment prediction
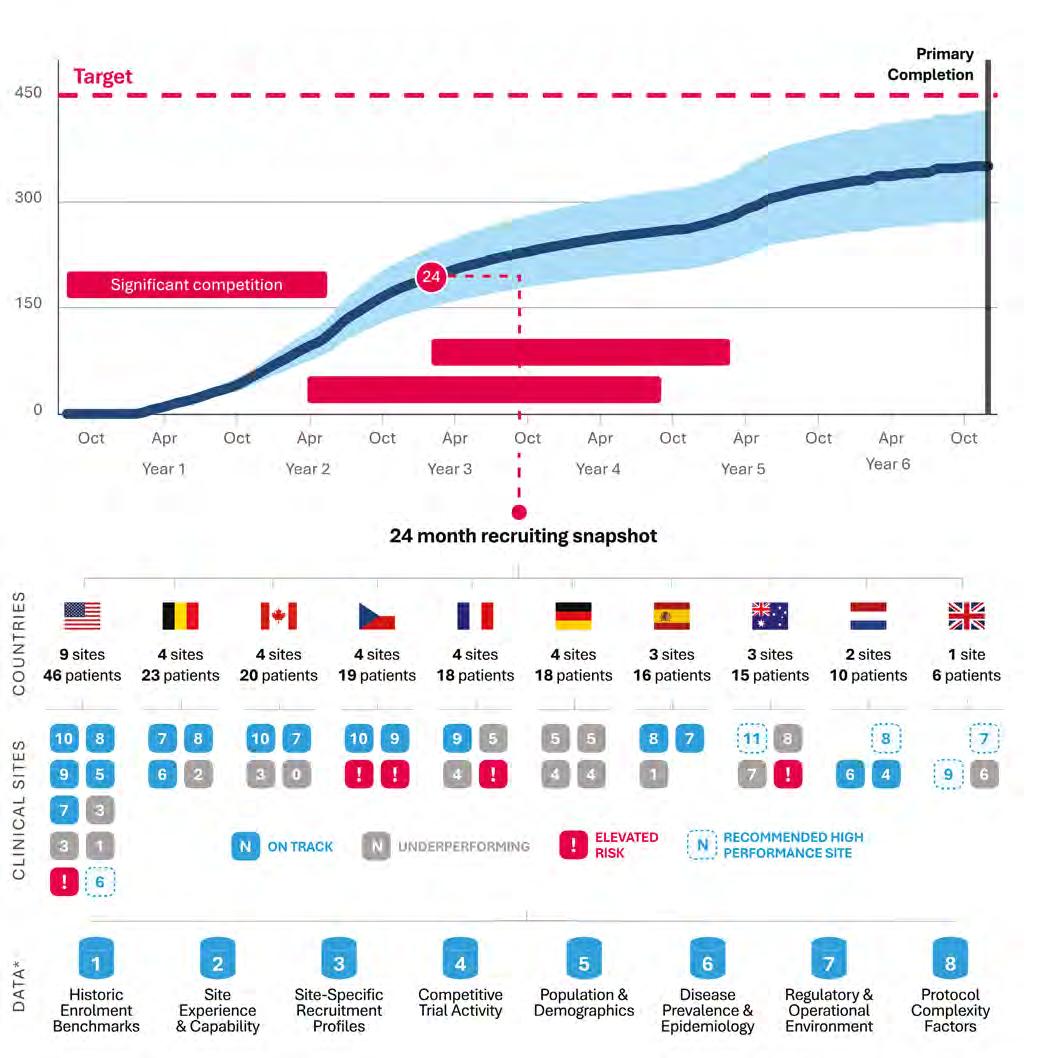
This chart demonstrates how a data-driven approach generates a site- and indication-specific forecast of patient enrolment. By integrating multiple data layers, the model estimates recruitment potential for each site and aggregates these predictions into the cumulative enrolment trajectory (dark blue curve) with its confidence range (light blue band).
The site colour coding provides immediate insight: Red indicates sites with elevated risk, Grey marks underperforming sites, Blue highlights sites performing well, and dashed blue outlines identify available high-performing sites recommended for inclusion.
In this example, rising competition in Year 2 coincides with declining recruitment performance, allowing early intervention before significant delays occur.
* The bottom row highlights the eight data dimensions feeding the model:
1. Historic Enrolment Benchmark: enrolment performance distributions from analogous historical trials.
2. Site Experience & Capability: therapeutic expertise, infrastructure readiness, and compliance history.
3. Site-Specific Recrui tment Profiles: site track records including past recruitment rates and activation timelines.
4. Competitive Trial Activity: ongoing and planned studies competing for patients and site resources.
5. Population & Demographics: density, age, and local factors influencing patient availability.
6. Disease Prevalence & Epidemiology: regional and indication-specific prevalence estimates.
7. Regulatory & Operational Environment: country-level approval timelines and historical startup delays
8. Protocol Complexity Factors: elements such as patient burden, procedure intensity, and inclusion/ exclusion complexity.
These eight data sources enable objective, granular, and dynamic predictions, transforming risk into actionable foresight.
1 | Data-driven enrolment forecasting and site selection Trial sponsors face a paradox: in an effort to reduce risk, they often fall back on familiar practices that unintentionally increase it. Frequently, sites are selected based on self-reported feasibility questionnaires [4] , prior working relationships or contracting convenience – leading to concentration at a small number of well-known institutions. For instance, leading academic centres may be running over 50 trials simultaneously, with predictable strain on patient access and investigator attention [2] . In other cases, top-tier hospitals are chosen despite lacking specific experience in the therapeutic area, as has been observed in complex oncology studies such as lung cancer trials [5]
To further manage perceived risk, protocols increasingly include a larger number of endpoints [6] and sites are selected based on historical performance – often limited to the sponsor’s or CRO’s own portfolio. While these instincts are understandable, they can overlook broader indicators of feasibility and miss higher-potential sites outside the known network. The data-driven approach rethinks this process from the ground up. Using global clinical trial data, population density, disease prevalence, historical site performance, and real-time competition signals, it builds a bottom-up forecast of enrolment potential –modelled at the site and indication level. Rather than asking sites what they think they can recruit, this method estimates what they are likely to recruit, based
on data from thousands of analogous studies and the regional context.
Two advances have made this possible at scale. First, large language models specialised in biomedical contexts now enable structured interpretation of eligibility criteria, protocol complexity, and therapeutic nuance – even when embedded in unstructured texts [7, 8] . Second, the GoTrial platform have aggregated and enriched clinical trial data globally, providing the statistical backbone needed to train predictive models across diverse study designs and settings.
The result is a site-level recruitment forecast that not only estimates expected enrolment at each site, but also flags geographic or operational risks – such as overlapping trials in the same indication or regulatory zone. These insights can be used not only to validate the current site plan, but also to recommend highpotential sites not yet part of the study. Sponsors can optimise their site portfolio for both efficiency and geographic reach – with a clear, data-backed view of how each region contributes to overall enrolment targets.
In one recent case, this methodology was applied to a late-phase paediatric asthma study. While the initial site plan appeared comprehensive, the eligibility criteria were significantly more restrictive than in analogous trials. Adjustments to both the site mix and protocol, guided by historical benchmarks, resulted in a more realistic and actionable enrolment strategy –increasing confidence without delaying study initiation.

An analysis of 9,336 global breast cancer trials shows a strong inverse correlation between site-level competition and actual enrolment. When no competing trials were present at a site, enrolment reached 70% of the planned target. However, as the number of concurrent studies increased, performance dropped sharply, falling to just 40% with more than seven overlapping trials. These findings highlight the importance of systematic competition analysis using global trial registry data to support reliable enrolment forecasting and informed site selection.
| Quantifying and navigating recruitment competition
Even when eligibility and site selection are welloptimised, many clinical trials encounter recruitment delays due to an invisible force: competition from other studies, creating priority conflicts, depleting local patient pools, and stretching investigator capacity [5]
This bottleneck is especially pronounced in speciality care, where a small number of expert centres are tasked with enrolling across many overlapping protocols. Sponsors typically assess feasibility based on a snapshot of current activity, but overlook dynamic shifts in the trial landscape – including newly registered studies in the same indication, region, or at the same sites. Compounding this, many sponsors and CROs rely heavily on established site networks, which can place investigators under significant strain. For example, leading U.S. cancer centres are involved in a median of 56 concurrent trials – creating priority conflicts, depleting local patient pools, and stretching investigator capacity [5]. The new data-driven approach addresses this by systematically and repeatedly scanning for competing studies – not only those already enrolling, but also those expected to launch in the near or mid-term. Using structured registry data enriched with GenAI-
based interpretation of unstructured protocol texts, this method identifies overlapping inclusion criteria, geographic proximity, and shared therapeutic areas. It can quantify, for each site or region, the intensity of trial activity that could affect patient availability and investigator focus.
In a recent phase 3 trial feasibility analysis, over 80% of planned sites were found to be involved in multiple other studies with similar patient populations and overlapping timelines. This raised the risk of slower recruitment and site fatigue. Based on this insight, both site mix and enrolment projections required adjustment – avoiding high-competition clusters and increasing geographic diversity.
When analysed at scale, the impact of recruitment competition becomes measurable: in a study of over 9,000 global breast cancer trials since 2000, sites involved in more than seven concurrent studies experienced twice the enrolment shortfall compared to those with little or no competition. By treating recruitment competition as a measurable input – not a post hoc explanation – sponsors can preempt resource bottlenecks, stagger site activation, and gain a more accurate picture of the real operational landscape before the first patient is ever screened.
Elevated risk (29317 studies, 25.4%)
Low risk (86038 studies, 74.6%)
3 | De-risking clinical trials with data at scale
While operational excellence remains critical to clinical trial success, many in the industry are now asking a more foundational question: how can we measure trial risk in a consistent, evidence-based way – before the study even begins? Until recently, such assessments relied heavily on expert judgment and anecdotal experience. But with the availability of large-scale clinical study datasets, modern analytics and GenAI, that is starting to change.
Drawing on a uniquely large and structured clinical trial dataset – spanning over 900,000 sites across more than 200 countries, and involving upwards of 900 million participants – it is possible to systematically model risk across critical trial design parameters. These models rely on empirical data from operationally and medically comparable studies, matched by indication, phase, geography, and protocol characteristics. Rather than relying on anecdote or institutional memory, this approach builds grounded expectations for key
20,000 trials w. recruitment challenges
Recruitment Challanges:
>20,000 trials
Operational Complexity:
>8,000 trials
8000 trials w. very high operational complexity
outcomes such as enrolment performance, study duration, and operational complexity at both the site and portfolio level.
What sets this new generation of risk analytics apart is its ability to go beyond traditional structured fields. Using advanced techniques, including natural language processing, even unstructured protocol text can be mined to extract risk-relevant features: from the procedural burden on patients to the complexity of eligibility criteria. These dimensions, long considered subjective or hard to compare, can now be evaluated and benchmarked against thousands of historical studies.
Furthermore, data-driven risk quantification not only highlights elevated risk factors but often points directly to actionable mitigation strategies.
A wide range of clinical trial risk factors – more than 30 in total – can now be quantified using datadriven benchmarks. Among them, several high-impact dimensions are especially relevant during trial planning and design.
This metric evaluates how aggressively a study is targeting patient enrolment by benchmarking planned enrolment figures against historical norms for similar trials –matched by indication, phase, and design. When projected enrolment significantly exceeds the typical range, it signals a higher likelihood of recruitment delays or underperformance. The risk is quantified by analysing distributions of enrolment outcomes in comparable studies and flagging plans that deviate substantially from established patterns.
This factor assesses whether the planned trial duration is realistic by comparing it to timelines observed in similar historical studies. Trials with unusually compressed schedules – particularly in complex therapeutic areas – face a greater risk of delays, protocol amendments, or extensions. To quantify this risk, planned durations are positioned within the distribution of actual timelines from comparable trials. Timelines falling below typical benchmarks are flagged as high-risk.
This metric evaluates whether the number of planned sites is aligned with the trial’s scope and complexity. Excessively large site networks can introduce coordination challenges, increase onboarding and training burden, and compromise data consistency. Risk is quantified by benchmarking the proposed site count against historical distributions from comparable studies. Site numbers that exceed typical ranges are flagged as indicators of elevated operational complexity.
This factor assesses the number of countries involved in a trial relative to historical benchmarks. While a broader geographic reach can expand recruitment, it also increases exposure to regulatory variability, uneven site activation, and operational fragmentation. As the number of countries exceeds typical thresholds, the likelihood of coordination and compliance challenges rises accordingly.
This metric assesses the number of intervention arms in a trial relative to historical benchmarks from similar studies. Multi-arm designs place greater operational demands on site staff, increasing the need for training, coordination, and oversight. Trials with more arms than typically observed are associated with a higher risk due to the added logistical and compliance complexity.
The ability to quantify trial design risk across multiple dimensions marks a shift from intuition to evidence. It enables more grounded, objective decision-making in the early phases of trial planning – when the opportunity to prevent costly challenges is greatest.
And while no two trials are the same, they are no longer incomparable. With enough data, even the most complex trial designs can be seen through the lens of experience – not just from one company or one portfolio, but from the global record of clinical research. This provides a robust foundation for more informed risk management and consistently improved trial outcomes.
To make this new approach accessible and repeatable, the three partner companies have formalised it into a standardised product: Trial Success Assurance. Built on GoTrial’s global clinical data platform, enhanced by Rewire’s analytics and modelling capabilities, and supported by Munich Re’s risk transfer expertise, the product allows sponsors to apply this methodology in a structured, modular way. It is currently being used to support study design evaluation, site strategy optimisation, and data-driven feasibility planning. For more information, inquiries can be directed to tsa@rewirenow.com.
As clinical development continues to grow in complexity, the ability to plan with precision – rather than react under pressure – is becoming essential. By leveraging comprehensive data, modern analytics, and collaborative expertise, this new approach offers a way to bring greater objectivity, foresight, and resilience into trial planning. It doesn’t replace the need for operational excellence – it strengthens it, by ensuring that trials are set up to succeed from the very beginning. In an industry where each decision carries high stakes, the ability to move from judgment to evidence is not just an advantage – it's a necessary evolution.
[1] Getz K. How much does a day of delay in a clinical trial really cost? Appl Clin Trials. 2024 Jun 6;33(6).
[2] Fogel DB. Factors associated with clinical trials that fail and opportunities for improving the likelihood of success: a review. Contemp Clin Trials Commun. 2018 Aug 7;11.
[3] Bower P et al. Improving recruitment to health research in primary care. Fam Pract. 2009 Oct;26(5). doi:10.1093/fampra/cmp037
[4] Hurtado-Chong A et al. Improving site selection in clinical studies: a standardised, objective, multistep method and first experience results. BMJ Open. 2017 Jul 12;7(7):e014796. doi:10.1136/bmjopen-2016-014796
[5] Phesi. 2024 analysis of oncology clinical trial investigator sites [Internet]. Available from: www.phesi.com/news/global-oncology-analysis/ Accessed 2025 Jul 4.
[6] Markey N et al. Clinical trials are becoming more complex: a machine learning analysis of data from over 16,000 trials. Sci Rep. 2024 Feb 12;14(1):3514. doi:10.1038/s41598-024-53211-z
[7] Lee J et al. BioBERT: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics. 2020 Feb 15;36(4):1234-1240. doi:10.1093/bioinformatics/btz682
[8] Jin Q et al. Matching patients to clinical trials with large language models. Nat Commun. 2024 Nov 18;15(1):9074. doi:10.1038/s41467-024-53081-z
As part of the broader collaboration, Munich Re is developing a novel insurance solution to address one of the most persistent challenges in clinical trials: recruitment shortfalls.
Informed by the data-driven risk assessments generated through the Trial Success Assurance approach, this insurance product provides financial protection to sponsors if patient enrolment falls significantly short of plan.
The coverage is tailored based on quantitative risk indicators – such as protocol complexity, site saturation, and competitive trial activity – allowing for a data-grounded underwriting process. This marks a significant first step toward integrating risk-transfer mechanisms into clinical development, offering sponsors not only greater foresight but also a financial safety net when navigating complex or high-risk trials. If actual enrolment falls below a forecast generated through the Trial Success Assurance (TSA) approach, the policy provides financial compensation for additional costs – such as site reactivation or extended trial duration.
Who it’s for:
Sponsors with tight timelines, complex protocols, or a requirement for budget certainty.
Key features:
● Trigger: Enrolment falls short of TSApredicted baseline
● Coverage: Additional costs such as recruitment costs
● Limits: $3M - $50M
This marks one of the first offerings to apply actuarial risk-transfer models to clinical trial operations – enabling smarter funding, planning, and execution decisions.

With interdisciplinary degrees in automotive engineering and cultural anthropology from the Universities of Stuttgart and Hamburg, SASCHA NETUSCHIL gravitated towards data analytics and machine learning even before the term ‘data scientist’ entered mainstream vocabulary.
Today, as Domain Lead AI & Data Science Services at Bonprix, Sascha stands as the architect of the international fashion company’s robust Data Science and AI domain. Joining as a Web Analyst in 2015, he pioneered its establishment and expansion, now overseeing its operational responsibilities and strategic development across all departments. During this time, he has established high-performing AI and data science teams, scaled up robust infrastructure, established MLOps procedures and strategically shaped Bonprix’s overarching AI activities.
Sascha is a recognised AI and data science spokesperson for Bonprix, regularly sharing insights on AI implementation and innovation at conferences. His hands-on expertise is reflected in the AI and data science projects Sascha has implemented over the past decade, which include generative AI solutions, recommender and personalisation systems, real-time intent recognition, fraud detection, price optimisation algorithms, as well as attribution and marketing mix modelling.
Can you briefly tell us about your journey to leading AI and data science at Bonprix?
I've been at Bonprix for 12 years now. When I started, we had no machine learning or AI capabilities, and it was purely analytics being done.
I eventually recognised we could do more with our data than just building dashboards. We tackled two challenging first projects: building a marketing attribution model to measure campaign effectiveness and developing realtime session churn detection. Both were complex starting points, but they were successful and taught us valuable lessons.
From there, we grew organically. I started as the only data scientist,
though that wasn't even my title initially. We expanded into a team, then a department. Recently, the company consolidated all AI and data science teams into what we call a ‘domain’ to foster collaboration and create a unified approach.
That's the short version. We've worked on projects across many areas, primarily in sales and marketing, but our recent organisational restructuring is expanding our reach into other business areas.
What drove Bonprix's decision to invest heavily in GenAI, and how did you build the business case? It wasn't a strategic top-down decision. We grew organically,
We take a strictly benefit-oriented. approach. If we can identify a. strong use case that saves money or generates revenue, we take it.
project by project, based on clear business value. We take a strictly benefit-oriented approach. If we can identify a strong use case that saves money or generates revenue, we pursue it.
We have plenty of these opportunities because we handle our own product design and development, which involves significant manual work. Each project has delivered strong ROI, so our AI investment grew
naturally rather than through executive mandate.
You have nine people in your GenAI team. How is it structured?
The team evolved from a traditional data science group doing machine learning. We made early mistakes by focusing too heavily on data scientists and not enough on engineers. This led to lots of proofof-concepts and great models, but we struggled to get them into production.
Now we have a more balanced structure: four data scientists (including an offshore team that works as one integrated unit), three data engineers, one software engineer handling internal customer UI’s, plus project management. The offshore arrangement gives us flexibility in role allocation.
We learned we needed to invest more in engineering roles to handle operations and actually deploy models in production environments.
Are there patterns in your data scientists' backgrounds? Do they come from typical maths, statistics, physics backgrounds, or are they more computer science and ML focused?
It's a mix. We have people from mathematical backgrounds and others from machine learning. None come from pure software engineering, as they were already in data science before transitioning to AI.
Moving from classical data science to generative AI requires new skills. We took a learning-bydoing approach rather than formal upskilling programs, growing capabilities through projects. Three of our four data scientists have now built GenAI expertise, and we want all of them to develop these skills as we shift toward more GenAI applications.
Initially, we were perhaps too naive, thinking we could just give data scientists an interesting new topic without realising how much they'd need to learn.
What were the main skill gaps they had to address?
The technology itself isn't that complicated for experienced data scientists or developers. It’s using models, implementing RAG systems, though we haven't explored LoRA applications yet.
The real challenge is working with language. You need to learn prompt engineering, what works and what doesn't. This is completely different from traditional programming, where there's one language, one command, and it either works or it doesn't.
With GenAI, you need much more trial and error. You can't be certain that doing the same thing twice will produce identical outputs. This uncertainty and iterative approach represents a fundamental mindset shift from traditional software engineering or data science work.
You've mentioned the rapid pace of change and new skillsets required. How do you keep your team current with the constantly evolving GenAI landscape?
At some point, you have to step back and relax. New developments emerge daily, and trying to track everything becomes a full-time job. It's like buying any new technology. If you check what's available six months later, your purchase already seems outdated. AI moves even faster, but the principle remains the same.
We focus on finding what's available now and what does the job, then pick the best current option. When the next project comes up, we reassess. Is there something new that works better? But as long as our technical setup delivers results, we don't need to reevaluate every few weeks. Otherwise, you'd never complete any actual projects.
It's like buying a mobile phone. You shouldn't keep checking new offers for weeks afterwards because you'll
always think you made a bad deal. The same applies to AI. You have to live with your choices and focus on what works.
We do monitor what's happening in the field, but we only seriously evaluate new technologies when we have a new use case. Sometimes we revisit solutions from a year or two ago, but that essentially becomes a new project building on an old use case.
Moving to your use cases and the way you are tackling fashionspecific translation challenges. Why do standard translation tools fall short for fashion brands like Bonprix?
Fashion has specialised vocabulary that can't be translated wordfor-word. German, for example, incorporates many English terms from fashion and technology. Take ‘mom jeans’ – a trend that's been popular for years. Standard translation would convert this to ‘mama jeans’ in German, which makes no sense because Germans actually use ‘mom jeans’.
While some translation services might handle this specific example correctly, there are countless special cases where fashion terminology requires nuanced translation. Standard algorithms inevitably fall short when dealing with these industry-specific terms.
Additionally, we have our own defined communication style as a company. We follow specific language rules about what words to use and avoid. This combination of fashion-specific vocabulary and brand-specific language guidelines makes it difficult for standard translation software to deliver appropriate results.
With GenAI, you need much more trial. and error. You can’t be certain that doing the same. thing twice will produce identical outputs. This. uncertainty and iterative approach represents a fundamental mindset shift from traditional software engineering or data science work.
How has your translation tool been able to incorporate fashionrelevant language?
We built a RAG-like system that creates a unique prompt for each text we want to translate. The process works like this:
We have extensive humantranslated texts from previous work as reference material. When we receive a new text, we identify which product category it belongs to: men's fashion, women's fashion, outerwear, underwear, shoes, etc. We then pull relevant example texts from that specific category.
The system scans for specialised vocabulary words and crossreferences them against our lookup table. These terms, along with category-specific examples, get incorporated into the prompt. We also include static elements like our corporate language guidelines – rules about which words to use or avoid, with examples in all target languages.
So the complete process takes the input text, identifies the product category, builds a customised prompt with relevant examples and vocabulary rules, then sends this to the large language model for translation.
How do you ensure consistency and brand messaging while adapting to local market nuances across all your countries?
We've improved our existing process rather than replacing it entirely. Previously, external translators would handle texts, then internal native speakers would review them, so we already had humans in the loop.
We still use human review, but we're gradually building trust in the model. Initially, we maintain extensive human oversight, then reduce it over time as confidence grows. Eventually, we'll likely move to sample-based checking.
My philosophy is that we shouldn't apply different quality standards to AI-generated versus
human-generated content. People often distrust AI due to concerns about hallucinations, but human translations weren't 100% perfect either. When we found translation errors before, we'd discuss them with translators and fix them. We can do exactly the same now.
I think 1% errors are acceptable if you have a process to handle them. We can feed incorrect translations back into our prompts as examples of what not to do, allowing the system to improve.
It's interesting that people apply stricter quality rules to AI than to humans. Humans make errors, too, and if AI has the same error rate, the quality impact is identical. The difference is that we now measure AI errors more systematically than we ever did with human translations.
probably the best approach, though it doesn't scale easily.
Language is inherently more ambiguous than numbers. Surely if you give the same text to 10 translators, you'll get 10 different valid translations?
Exactly. With translation, there's often no clear right or wrong answer. Obviously, some translations are incorrect and contain typos or completely wrong words. But as you said, you can translate the same word multiple ways, and both are fine. One might be subjectively better, but what defines ‘right’?
How big an issue were hallucinations for you, and what did you do about them?
For us, it wasn't a major problem. People are often very afraid of hallucinations, but current model generations have improved significantly from the early days. They still occur, but several techniques work well for us.
We maintain human-in-the-loop processes for many texts, which is
We also have a fashion creation tool where product developers input natural language descriptions and receive images of how items would look. For this, we use a technique where another AI model checks the first model's results against specific criteria, ensuring only the item appears (no humans), showing front views, etc.
Another large language model or image generation model evaluates whether outputs meet these rules. If not, the process restarts. This creates a longer user experience, but using one GenAI model to validate another's results is a widely adopted technique for quality control.
Is that automated?
Yes. Users have a UI where they type what they want, and the interface helps with prompt creation so they don't need to think about prompting. The entire process of generating and reassessing images runs automatically in the background, then delivers the result.
What were the biggest technical and linguistic hurdles when building the system?
Initially, we saw many language mistakes, which were disheartening. We had to figure out how to teach the model what we didn't want, but this wasn't well-documented anywhere. We couldn't easily find examples of what works versus what doesn't.
We hit prompt size limits quickly. As prompts get bigger, results often deteriorate because models can't effectively use all the information in oversized prompts, even with large context windows. This led us to create individual prompts for each text rather than one massive prompt.
We also had to integrate these models into our development environment using APIs rather than UIs.
But, honestly, compared to our earlier machine learning projects, this was easier. Our current Gen AI processes aren't fully automated, and there's still a human clicking ‘send’. The background processing is much simpler than something like a fully automated personalisation model that calculates conditions for each user daily and pushes
directly to the shop.
So we've encountered fewer technical hurdles with GenAI than with our previous machine learning use cases.
How is GenAI helping with accessibility, compliance and making your website more disability-friendly?
Throughout the EU, laws require web content to be accessible to everyone. For fashion e-commerce sites with thousands of images, this creates a challenge. People with vision impairments need text descriptions of all pictures so their browser plugins can read them aloud.
We initially handled this manually, paying people to write descriptions for every image. As you can imagine, this became very expensive.
This is exactly what multimodal models excel at – taking an image and describing it in text. We've built a system that automatically describes our product images, though we had to fine-tune it beyond the vanilla model capabilities.
The result saves us significant money on what would have been purely manual work just five or ten years ago. We're very happy with this solution.
What's your technology stack for GenAI applications? Are you using cloud, open source models, or proprietary?
We primarily work on the Google Cloud Platform and try to use their available models. When we started, it was basically OpenAI or nothing, so we set up an Azure project solely to access OpenAI APIs while doing our main work on Google Cloud. We still use OpenAI models for some use cases, but for new projects, we look at Google's models first.
From my perspective, there are differences in models such as pricing and quality. But for standard
use cases (not super advanced reasoning), it doesn't matter much. You can get good results with different models.
For image generation, we use Stable Diffusion, though we're exploring Google's Veo for text-toimage and video capabilities, which are quite impressive. It's not in production yet.
We reassess options for each new project but don't constantly reevaluate existing ones. Since the field is relatively new, we don't have truly outdated processes yet.
We use mostly proprietary models rather than open source. It's about administrative overhead. Open source sounds great because it's ‘free’, but in a corporate context, you invest significant work and money in maintenance and administration.
And since you're not putting customer data through these models anyway, the open source route probably doesn't make sense? Exactly. Though when using OpenAI on Azure, they're also compliant with data regulations. From a compliance perspective, we can't use services hosted in the US, so we wait for European server availability, which is usually a few months after a US rollout.
There's still the ethical question of handling truly sensitive data. You probably shouldn't fully automate with AI for really sensitive information, like in healthcare.
In our case, we don't use customer data currently as our biggest use cases focus on products and articles. But our customer data is already stored on Google Cloud for other services, so it's covered under the same terms and conditions that keep data safe.
The APIs we use, like OpenAI's, don't store or use our data for further model training. Every business needs this guarantee, so providers couldn't sell to corporations without including it in their terms.
Are there computational costs and scaling challenges with proprietary models in your use cases?
Our costs haven't been significant because most use cases target internal processes. We have maybe 1,300 colleagues, with roughly 100 using these tools. That's very different from customer-facing services used by millions.
The cost factor increases dramatically with customer-facing applications. For us, currently, looking at our overall data warehousing and IT costs, GenAI doesn't have a major impact.
Looking to the future, what other potential GenAI use cases are you considering?
We've done a lot with text generation and now want to focus more on image generation. Beyond the inspirational images for product development I mentioned, we're working on automated content creation.
Currently, adapting images for different channels, such as our homepage, app, and social media, requires manual work. You might need to crop an image smaller while keeping the model centred, or expand it to a different aspect ratio by adding background elements like continuing a wall's stonework. We can now do this with AI visual models.
We're also exploring video content creation from images or text. Imageto-video is more interesting for us because we want to showcase our own fashion products. Text-to-video might generate nice outfits, but they wouldn't be our products. This is possible today with significant development investment, but it's not our top priority.
Our priority is creating short videos from existing images for our shop and social media. There's high potential in content creation because we need variants for personalisation. For example, a fall collection teaser featuring a family appeals to parents, but single people
or men's wear shoppers might prefer content showing just a man or a couple. AI can help us create these variants from existing content.
Regarding customer-facing AI systems, like the ‘help me’ chatbots getting lots of publicity, I think culture is changing. Eventually, people will expect every website to have natural language interaction capabilities. I'm aware of this trend, but given our finance-focused approach, the ROI wouldn't justify the investment right now. We're focusing on internal processes where we can achieve better results.
Still, we shouldn't ignore this shift. People increasingly use GenAI apps on their phones for everything, and they'll expect similar capabilities from other technologies, including websites and maybe even cars. Technology advances faster than culture, but culture does eventually catch up.
How are you measuring success and judging ROI for your GenAI initiatives?
Most of our first wave projects directly save money on external costs. For example, we no longer pay external translators because the savings are right there on the table. We can calculate exactly how much we save per month or year versus our internal costs, which are much lower. These use cases are very easy to justify.
It gets more complicated with projects like our image creation tool for product development. This doesn't replace external costs; it just enhances the creative process, which isn't easily measurable.
For these cases, we track usage levels. Since it's built into a workfocused UI, people wouldn't use it unless it's genuinely helpful for their job. Unlike general tools like ChatGPT, where you might waste time generating funny images, our tool serves a specific purpose. The novelty factor wears off, so sustained usage indicates real value.
Of course, there's initial higher usage as people try it out, but we monitor long-term adoption patterns. However, this doesn't give us the same level of investment assurance as direct cost savings.
This is a general IT problem, not AI-specific. Some systems are essential – people can't work without them – but others are harder to quantify. Take our ML recommendation features in the online shop. You can measure how many people use recommendations before purchasing, but that's probably not the only factor in their decision.
To really prove ‘I made X more money’, you'd need constant A/B testing, which has its own costs. Part of your audience wouldn't see the feature during testing periods.
Sometimes it's hard to measure effects, and we had this challenge before AI. At some point, you have to be convinced that something is valuable based on available evidence and what you observe.
Are there any final thoughts you'd like to share?
We're building these teams with lots of interesting use cases. It's a good environment for trying new things. The company provides guidance on which areas to focus on, but how you implement solutions and experiment with systems is quite free. We really get to see what works and how to achieve success.
We're always looking for good talent, and people can check our career page if interested. I think we have a great setup for experimentation, and my team members really enjoy that freedom.
I think culture is changing. Eventually, people will expect every website to have natural language interaction capabilities.
If you could build precise and explainable AI models without risk of mistakes, what would you build? Rainbird solves the limitations of generative AI for high-stakes applications.

A FRACTIONAL CDO’S ANTI-HYPE GUIDE TO DATA & AI FOR SMALL AND MEDIUM-SIZED ENTERPRISES
TONY SCOTT is a seasoned technology executive whose career ranges from software developer to Chief Information Officer. Beginning his journey as a consultant C/C++ developer at Logica, Tony built a deep technical foundation that led him into technology leadership roles at NatWest Bank, Conchango and EMC. Working as global enterprise architect, group digital transformation director and CIO at engineering companies Arup, Atkins and WSP, Tony championed data-driven decision-making. A consistent thread throughout Tony’s
career has been his focus on leveraging data and emerging technologies, especially AI, to unlock business value, drive innovation and improve outcomes. With his focus on bridging technology and business strategy, Tony advocates for pragmatic digital transformation where technology serves clear business goals. Today, he continues to shape the future of the data-driven business as an advisor, fractional CxO, board member and speaker, helping organisations harness the power of data and AI for sustainable competitive advantage.
TONY SCOTT
What are the biggest mistakes traditional small and medium-sized companies make when implementing AI?
The biggest mistake is FOMO – fear of missing out. Companies rush into AI without a plan, pursuing ‘AI for AI’s sake’. They’re missing critical data foundations: proper infrastructure, clean data, and understanding of their existing information systems.
Many see AI as a magic wand, especially after ChatGPT’s launch. This hype-driven approach ignores essential elements like governance, security, privacy, and ethics – all crucial for successful AI implementation.
My mantra comes from lean startup methodology: think big, start small, scale quickly. You need the vision, but companies often jump straight to big-ticket items, which becomes costly.
The other major mistake is treating AI as a technology project instead of a business transformation. AI should deliver measurable business benefits and ROI. You need leadership buy-in, which is actually easier in SMEs than large organisations, but still essential.
Can you share examples of companies jumping into AI without a proper strategy?
the wrong problems – ones that don’t advance your business strategically.
The ‘garbage in, garbage out’ principle has never been more relevant. Companies need sufficient, clean, consistent data. They need to understand their system architecture – are data sources tightly or loosely coupled? Often, they’re tightly coupled, requiring data hubs, warehouses, or lakes to centralise and clean information before building AI on top.
Security and privacy are critical. Customer data must comply with GDPR, Cyber Essentials, and ISO 27001. Without addressing business drivers, KPIs, and outcomes, you’re just doing technology for technology’s sake.
The fundamental question: What’s your current data health? Do you have dashboards, alerts, and analytics? Are you using data effectively before considering AI? Your entire data estate – business systems, IT systems, operational systems – all contain data that needs proper storage, access, and querying capabilities.
Data duplication creates major issues. If customer address changes don’t propagate across all systems, you get inconsistent information.
If every company just looks down at the. bottom line,.cutting costs and. automating, we’ve got a boring.future. ahead. Where.humans can step in is. around innovation..
I see ‘solutions looking for problems’ constantly since ChatGPT. A furniture manufacturer client kept insisting, ‘We want AI’ without defining their goals, KPIs, or business model. When I pressed deeper, they simply feared competitors had AI and felt they needed to catch up, but had no idea what to do with it.
A colleague worked with an e-commerce company desperate for an AI chatbot to solve customer problems. They spent heavily on implementation, but their real issue was order fulfilment. The chatbot actually made angry customers angrier. They eventually fixed the fulfilment problem – nothing to do with AI – and dropped the chatbot entirely.
Then there’s a flight training company with an impressive vision: using AI to connect student classroom behaviour with aircraft performance to improve training. Ambitious and transformative. But they had no data strategy, technology strategy, or IT foundation in place.
These failures result in wasted spending on tools, vendors, and staff for undefined problems. Projects get abandoned without delivering benefits. Since AI enables better human decision-making, building systems on faulty data produces wrong answers, eroding trust. The whole system can collapse like a house of cards.
The biggest missed opportunity? Using AI to solve
SMEs often use Power BI overlays or low-code/no-code solutions, but the core principle remains: clean, accessible data that drives business decisions and provides historical trends for AI prediction.
How do you assess an SME’s AI readiness in traditional sectors where digitisation might be limited?
I start with a leadership mindset. What’s their thinking around AI and data? Is it aligned to business strategy, or are they seeing it as a bandwagon? I always begin with business context first – what are their KPIs, objectives, and business outcomes?
A common thing I see is the desire to use AI for cost optimisation – very much bottom line focused. CFOs are looking down at the bottom line, wanting to automate and cut costs. But they should also look up at the top line for innovation, revenue growth, and newer business models. Really opening it to transformation.
I’m assessing their understanding and perhaps taking them on that journey to more ambitious but beneficial outcomes. If every company just looks down at the bottom line, cutting costs and automating, we’ve got a boring future ahead. Where humans can step in is around innovation.
The data estate and digital foundations all need evaluating upfront. There may be work needed before you can even consider AI. On the human side: leadership, culture, governance, ownership, compliance, depending on industry.
SMEs often think they’re too small for AI, but
TONY SCOTT
they’re sometimes surprised. There’ll be pockets where someone’s doing something quite advanced, perhaps not in their core role. You can gauge technical capability already.
I use a four-stage framework: digitise, organise, analyse, optimise – but in continuous loops. I’m currently working with a 30-person M&A company in London. From the outset, they understood they’re too small to automate people away. They want to make existing people more valuable, giving clients much better service. Very mature thinking.
What’s your framework for identifying high-impact AI use cases for SMEs?
I use a 90-day discovery phase about getting internal buy-in, momentum, and proving we can achieve value.
Month one is discovery and diagnosis. We sit down with key stakeholders, find their objectives, challenges, and decision-making processes. Are they data-driven or gut instinct? We do a data technology audit and map business objectives and goals.
Month two is prioritisation. From those business goals, we’ve probably got five to ten use cases –that’s the best number. We prioritise using a matrix: cost-benefit analysis, feasibility, and time to value. Hopefully, one or two key use cases come forward. We consider data privacy, regulatory issues, and risk, which might steer us away from particular use cases early. By month two’s end, you’ve picked a use case to pilot. Month three is designing that pilot. All metrics should be business metrics, success metrics, not about algorithms or model accuracy. It’s about reducing customer churn, machine downtime, whatever’s relevant to that industry. You get business ownership, buy-in, and authorisation to start work.
Everything must be defined in business language, especially budgeting. You want key stakeholders, including the CFO, involved. Look for relevant quick wins, measure ROI in business terms, but don’t have a big bang mentality – start small.
Define use cases in CFO-friendly language. You must score it and talk about measurable returns. Whether it’s customer churn, reducing delays, costs, or cycle times, it must generate genuine ROI where maintenance costs are less than benefits.
You also need to lay out a 24-months roadmap. Not fixed where you ‘arrive’ at AI, but ongoing because this world changes rapidly. You need quick wins upfront, proving investment value, but also take that longerterm view in the right direction.
Traditional leaders sometimes expect AI to be a magic wand. How do you help them understand that it requires investment like any business function? At the beginning, we talked about FOMO – companies rushing into AI with this sense of ‘we’re doing AI, we
need to keep up’. But you should only do AI to solve real-world pain points and become a better organisation.
Some SMEs think they’re too small – only bigger players have the money. But I think it’s the opposite. SMEs can move faster than bigger competitors.
There’s a mindset about cost-cutting and automation. To bring your organisation along for the long-term journey, it needs to apply across the board –from middle management down to frontline staff. It’s about making existing staff more valuable. There are so many news stories about big organisations cutting thousands of jobs with AI as the culprit.
SMEs are leaner anyway and don’t have that ability. If they can make staff more productive, doing things where humans add value – automating tasks rather than roles – they can move much faster than bigger competitors and do more valuable things for clients.
Another mindset is ‘we need a data scientist’. There’s a rush to hire AI experts and ‘give us AI’. It doesn’t work that way. You need data foundations first, your current analytics approach, before you have the maturity to bring in data scientists. It’s a journey you work through.
Don’t see AI as just a technology implementation. Don’t tell your CTO, ‘Implement AI for us’. It needs true business leadership shaped in proper business terms.
What data foundations and prerequisites must companies address before implementing AI? There are prerequisites – non-technical, cultural, and strategic. It’s what we were saying about not seeing AI purely for automating today’s ways of working, tomorrow. You can do that, but the much more exciting thing is augmenting current ways of working and freeing people up to give richer experiences internally or externally. Transforming your organisation into something new tomorrow.
If you’re solving problems with AI, you need to articulate those problems in business terms. You need ownership and accountability. Always having a business owner is really key.
The data piece – having clean, accessible, relevant data. The garbage in, garbage out principle. If AI is helping you make better, faster business decisions, you must trust the data. The data has to be clean first. A lot of organisations aren’t in that place already.
Just be sensible about team size or what you’ll have inside versus external partnering. Have expectations about setting up a function where you are today. You can be ambitious long-term, but know it’s a journey together.
The data has to be clean first. A lot of. organisations aren’t in that place already..

What are the key differences in AI strategy between a 500-person company versus a 5,000-person company?
I’ve worked in 5,000-plus organisations and actually think it’s more challenging in larger organisations. They have multiple business units, potentially competing priorities, and different visions. You’ve got a C-suite sitting across all that, and it’s really key to get buy-in from every single C-suite member. It often becomes a business change. Sometimes the technology side is easy, but the human side and getting buy-in are much harder in bigger organisations.
They’ll have much more complex technology estates, possibly legacy systems going back years or decades. They’ve got more resources and larger technology teams. You can call upon internal teams, and they’ll be more specialised. Better ability to invest, fund experiments, and innovate. They’ll possibly have better access to large technology players – AWS, Microsoft – maybe account managers they can leverage.
Smaller companies are much more centralised and have more tactical use cases. Leadership may not be C-suite level, but it’s more informal and can sometimes move quicker. Technically, it’s a more cloud-first, plug-and-play approach. Internal teams are leaner but sometimes wear multiple hats – more generalists, actually more skilled in a sense. But they’re more cost-
conscious, less open to experiments because they need quicker ROI.
In partnerships, they’re more open to bringing in partner companies to augment skills and provide knowledge transfer, hopefully forming strategic relationships.
To sum up, it can actually be easier. A smaller company will be more agile and, with the right approach, can perhaps move much faster.
Can you share an example where your strategic assessment completely changed what a company thought they needed to do with AI?
Going back to that manufacturing company example, they got stuck right at the beginning, saying, ‘We want AI, we want AI’. They were very scared that competitors had AI and would outpace them without really understanding what that meant.
It was really about rolling all the way back, focusing on the KPIs, getting data foundations in place, and getting them in fit state before even beginning that AI journey. Then, really mapping out those AI use cases and ROI on each, linking them to actual true business objectives, which was a challenge. They had different
areas with competing priorities, but it was really getting that leadership, that consistency of view and vision across the organisation. It was quite a journey.
We’ve been doing traditional data analytics for many years, and AI doesn’t invalidate those historical use cases – it just builds upon them. What’s the starting point? How does a company evaluate current performance? Things like dashboards and analytics –their relevance doesn’t go away because of AI. AI just takes you into more predictive worlds, doing more advanced stuff on top.
So in assessing maturity for AI, it’s always useful to see where the company is today in standard data analytics functions. If they don’t have that, it may make sense when sorting out the data estate to build those standard analytics functions before you even consider richer AI uses.
Can sophisticated, accurate reporting help organisations discover hidden business problems? Absolutely. In terms of reporting and analytics, there’s nothing new there, but some companies don’t have the infrastructure in place to do that well. You need the board asking questions about current business, current performance, and having that historical performance as well. I would always get foundations fixed first before rushing down the AI path.
Things like generative AI and large language models have given us new views on AI in recent years, but the same applies. If you’re training language models on internal data that’s not clean, outputs won’t be trustworthy.
A lot of organisations want to be AI first, but . they should never be human last. That’s really. a mantra and the cultural change management . side of it. .
I would fix today’s world – that view of the business today, standard analytics and reporting – then ultimately move toward a team that has all those elements. There are core foundational roles in data engineering – people doing actual plumbing of your data, making sure it’s clean. You need those in place first before you bring in analysts, then before you bring in data scientists on top.
What blind spots do non-technical business leaders have when evaluating AI opportunities, and how do these lead to failures?
One would be what we’ve talked about – AI is all about automation and cost saving. It’s ignoring the benefits of augmentation and the human in the loop. My preference
is to look for both. If you’re bringing your company and staff along with you, really look for opportunities to augment the mundane, rules-based, repetitive work they do to make them more valuable as people. There’s that human element – don’t just treat it as a technology implementation.
The other one is data complexity. Yes, how good is your data estate? But if you don’t have data engineers in place to manage that, it’s going to be very difficult moving forward. Don’t just say to your CTO, ‘AI is a technology project; implement AI’. It’s only about business outcomes. You’ve got to specify everything in terms of how it’s going to move the business forward. What’s the business return on investment? Have you prioritised things in a proper business way?
There’s a change management side to it. Don’t underestimate that – this applies to all digital transformation, not just AI. There’s a human element. You’re taking your organisation on a journey, so make sure you’re giving proper attention to change management.
How do you handle cultural resistance to AI in traditional sectors?
I mentioned earlier the news stories about threats to jobs. There’s genuine fear out there. In 2016, I was giving conference speeches in the engineering industry, making the case that automation is automating tasks, not roles. Yes, some people just want to cut costs and automate roles, but is that really the right decision? Look at every role and its tasks – you want to free people up to be more value-adding, things humans excel in: creativity, leadership, customer empathy, customer support. Free them from the burden of repetitive tasks rather than going straight down the path of cutting costs, cutting people.
To do that, you need to engage your staff, let them know your plans around AI, and assuming they’re not going to cut people, engage that front line early. Show them the quick wins you’re planning and how you’re going to improve their roles. Talk to them openly, honestly, and often. That phrase ‘human in the loop’ should really be the default.
Celebrate those wins and show people how AI is improving the internal environment. Try to remove that sense of it being a threat. A lot of organisations want to be AI first, but they should never be human last. That’s really a mantra and the cultural change management side of it.
Most organisations have company values reinforced in town halls, company meetings, and maybe posters around buildings. Just anchor everything you’re doing in those company values, so people see you’re not going against those.
AI companies talk about easy human replacement, but it should be more about enabling superior service delivery.
TONY SCOTT
How do you balance short-term wins with long-term AI strategy?
Both are important, and it is that balancing piece. You do need quick wins to set the scene and make the case. Without a long-term strategy, you’re not going in the right direction. If you just do quick wins, a lot of companies get stuck in endless loops of pilot after pilot after pilot. They build technical debt ultimately and fragmented solutions that don’t take them where they need to go.
On the other hand, if you just go for long-term transformation and forget the quick wins, people take their eye off the ball, you lose momentum, and potentially develop something that in 18 months is just not relevant. You did the wrong thing, or the market moved, or technology moved.
It is those quick wins that really give you proof of concept momentum. Perhaps you do experiments as you go to prove hypotheses, but you need that longterm anchor as well. That anchor is all about business value. Make sure everything you’re doing – be it a quick win or long-term strategy – is specified in terms of the business value you’re delivering.
Those quick wins are really the building blocks. We like to say the quick wins are the proof; the strategy is your plan for success.
What’s the ideal structure for a data and AI team in a 100-500 person traditional company?
For smaller companies, I recommend a hub-andspoke model. They might not afford a full-time CDO, so a fractional CDO can bring experience from larger organisations and cross-industry insights while working part-time. Full-time is possible if the budget allows and you find the right person.
The hub needs one or two data engineers handling the ‘plumbing’ – data pipelines and infrastructure that stays in place long-term. That’s crucially important. Then I build data analysts or BI specialists as spokes, ideally embedded in business units. They may work part-time across departments, depending on how many you have. The key is keeping them close to the business so they understand daily dynamics, challenges, and problems. They answer business questions through data.
Only when you’re ready – when pipelines are solid, engineers are doing their jobs, and infrastructure is sorted out – do you bring in data scientists. They handle predictive models, simulations, preventive maintenance, customer insights, whatever’s relevant.
Sometimes they partner with technology companies for strategic skill augmentation on an ad-hoc basis.
How important is domain knowledge when hiring for data roles in SMEs?
There are bigger sectors where domain knowledge transfers well. Financial services have many elements – moving from insurance to banking is easier than jumping to completely different industries. Someone with an engineering career understands infrastructure, predictive maintenance, and can move between subsectors within that wider sector. But moving from engineering to financial services or health technology would be much more difficult. So yes, domain knowledge applies at bigger sector levels, but moving within them is probably easier.
What are the main differences between implementing AI in traditional sectors versus digital-first industries? Digital-first industries tend to be more data-driven. They’re newer industries built on data, so measuring performance and developing predictive solutions is inherently easier. They’re already thinking analytically before using AI and have a better analytics sense.
Traditional sectors can still make that journey –that’s where digital transformation comes in. But it’s a much harder ask, as much human as technology. You’ve got to convince them that historical working methods are less appropriate for the future. Senior management, middle management – it can be challenging bringing them on that journey. You’ve really got to start small, prove use cases, and do it non-threateningly.
There are real complexity differences, too. With digital solutions, you’ve got user data at hand and can easily measure performance and behaviour over time.
But I’ve worked on systems measuring traffic behaviour on motorways, tracking vehicles, predicting changes and traffic impacts. It’s much more challenging. You need many simulations, much more data, factoring in weather, climate, marrying together data sets that might never have been combined before. It’s more complex, but outcomes can be much more transformative.
I’ve done similar work with airports, mapping transport systems – road, rail – showing impact on arrival patterns and check-in queue lengths. Many systems that perhaps had never been considered for combined analysis.
The rewards can be quite transformative. It’s more creative, using design thinking and hackathons with business teams to answer questions we’ve never been able to answer before, or discover insights we didn’t even know existed in our data.
TARUSH AGGARWAL is one of the leading experts on empowering businesses to make better datadriven decisions. A Carnegie Mellon computer engineering major, Tarush was the first data engineer at @Salesforce.com in 2011, creating the first framework (LMF) to allow data scientists to extract product metrics at scale.
Prior to 5X, Tarush was the global head of data platform at @WeWork. Through his work with the International Institute of Analytics (IIA), he’s helped over 2 dozen of the Fortune 1000 on data strategy and analytics.
He’s now working on 5X with a mission to help traditional companies organise their data and build game-changing AI.
You’ve focused heavily on traditional, non-digital sectors. Was this a conscious decision? How did you end up working mainly with real-world-first businesses?
The landscape has undergone significant changes over the last decade. Digital-first companies could adopt data and AI early because they had the resources and technical expertise. But traditional businesses are different.
These companies are naturally technology-averse. They employ mostly blue-collar and grey-collar workers who view technology as a risk. Their buying decisions prioritise risk minimisation – they buy what everyone else buys. Many have only recently invested in digitalisation through platforms like

SAP, Salesforce, and Oracle.
The result? Massive data silos and fragmentation. Different teams can’t access different datasets. Integrating new vendors with SAP and building custom APIs is expensive and complex. These businesses are now suffering from the very fragmentation they created.
However, there’s a tailwind: every company is considering AI. The reality is you can’t have an AI strategy without a data strategy. If you don’t understand your data, AI won’t help. Over the next five years, these companies will invest heavily in data platforms, cleanup, and AI products.
What are the main problems you see when traditional companies
start from scratch with data and AI?
Let me break this down from a decision-maker’s perspective. Everyone thinks they’re sitting on a gold mine of data and can activate it overnight. The reality is very different.
Companies focus on the ‘last mile’ – AI applications that create value when embedded directly into business operations. Think supply chain optimisation, inventory management, customer churn prediction, or demand forecasting. This is where the real value lies.
But here’s the mistake: they skip the foundational work. Before deploying AI applications, you need clean, centralised data in an automated warehouse with structured models that give you a clear view of your business.
Instead, most companies buy Power BI – Microsoft’s popular enterprise tool – and connect it directly to SAP or Salesforce to build basic dashboards. They think this makes them data-ready, but it’s just lightweight reporting on top of existing systems.
That won’t work. Just like posting on Instagram doesn’t make you a marketer, a few dashboards don’t make you data-driven. Companies want the end result without investing in the foundation.
If a CEO or CTO at a medium-sized company calls you and says, ‘We’ve bought data tools like Power BI or Snowflake, even hired a data analyst, but we’re not getting any value. Nothing’s working as expected’ – what’s your response? A data warehouse is an excellent tool – it’s the foundation for storing all your data. A data analyst’s job is to analyse that data and generate insights. But here’s the problem: if you’re a traditional business, you likely have manual processes, data entry issues, and missing data gaps because some processes still run on Google Sheets.
With all these fragmented pieces, analysts can’t deliver insights because they need clean data as input. This isn’t a data insights problem – it’s a data foundation problem.
We’ve launched a data and AI readiness test: 5x.co. It asks 15 straightforward questions across four or five categories to show you exactly where you are in your journey. Are you at the infrastructure layer? How reactive versus proactive are you?
The key is understanding your current position. This is where fractional help – like a fractional chief data officer – becomes valuable. They can assess what the business wants to achieve, where you currently stand, and create a comprehensive roadmap.
You might have all the infrastructure – Snowflake, great BI
tools – but without a clear direction, roadmap, and company-wide adoption, teams won’t use what you’ve built. Success requires infrastructure, topdown buy-in, execution, governance, and effective implementation.
Two years ago, I would have said, ‘Start building core data models’. Now I believe in understanding your holistic position first, then mapping where you want to go.
Without that strategy, there’s a big risk of executing in the wrong direction.
What are the main differences in data and AI strategy between a 500-person company versus a 10,000 or 50,000-person company? As companies grow, they pay an indirect ‘communication tax’ – it becomes harder to keep everyone aligned. Large companies typically break into sub-organisations or subsidiaries to manage this complexity.
Large companies inevitably have data silos. Marketing, finance, and product teams work in different tools, lack access to shared datasets, and use different metrics. Even ‘revenue’ isn’t standardised – you have financial revenue (money in), sales revenue (contracts signed), and pipeline revenue.
At 500 people, you’re still centralised with a unified data team, standardised tooling, and everyone reporting up similar chains. Large enterprises use everything – AWS, Azure, Google Cloud, Databricks, Snowflake – just because of their scale.
These structural differences create different requirements for data teams. A 500-person company might have centralised data teams with some decentralised support. Large enterprises are mostly decentralised with multiple independent data teams.
Do you think traditional businesses need different strategies compared to digital-first companies?
Traditional businesses have
Success requires infrastrucure, top-down . buy-in, execution, . governance, and . effective . implementation. .
nothing in common with tech-first companies. The differences go far beyond products and go-to-market strategies – how you build solutions is fundamentally different.
Traditional businesses face massive integration challenges. They use non-standardised software, custom systems, and platforms like SAP, Salesforce, and Oracle that are incentivised to lock in your data. Salesforce just changed Slack’s APIs so you can’t extract your own messaging data. Digitalnative companies typically use AWS and tech-first services where data extraction is straightforward.
Traditional companies want managed products, not managed infrastructure. While platforms like Databricks, Snowflake, and Fabric offer great APIs and containers for building applications, traditional businesses won’t build apps. For conversational AI, a tech company will build knowledge graphs and custom chatbots. A traditional company wants it out-of-the-box: ‘Here’s my data, I want to speak to it’.
Digital companies embrace SaaS offerings as standard. Traditional businesses hesitate about full cloud adoption. When you’re buying five data tools, you’re introducing five different clouds. They prefer private cloud or on-premise deployments.
Traditional businesses want integrated services – handson support, custom use case development, and implementation help. Digital-native companies are comfortable building their own data teams.
These core differences show that building products for traditional businesses requires completely different approaches from building for tech-first companies.
What’s the minimum viable data infrastructure that a small or medium-sized enterprise needs to start seeing value, and how do you prioritise what gets built first?
Until recently, the core stack was about reporting on data. You needed a data warehouse to store everything, plus an ingestion tool because today’s average SMB has 10-15 data sources – Postgres, financial tools, Facebook ads, Google ads, Google Sheets, Salesforce, helpdesk software like Zendesk, and enterprise tools like SAP, Anaplan, or Lighthouse.
The traditional minimum was four tools: warehouse, ingestion, modelling with orchestration, and BI. But we’re entering an AI-first world where this is changing.
Conversational AI is becoming the primary way to interact with data. I’m less excited about checking dashboards every morning – I want to ask my data questions on Slack. ‘What happened in sales yesterday? How many meetings did we book this week?’ I want accurate responses and the ability to tag people directly in Slack, not wait for the data team to build dashboards.
We’re also seeing AI outputs become standalone applications. Instead of putting churn prediction results into a BI tool, we’re building churn prediction models with their own UI that live as separate applications in your data platform.
You can’t do AI without proper metadata and semantics. This is where you define business metrics. When I ask, ‘What was revenue last month?’ the system needs to know which of the three revenue types I’m referring to.
In the AI world, we now have seven or eight core categories: ingestion, warehouse, modelling, BI, semantic layer, conversational AI, data and AI apps, and data catalogue. You need all of them quickly, and you need them without spending time building and integrating tools yourself.
How long does the traditional approach of building data infrastructure typically take for companies with 300-500 people?
Building infrastructure has no business value. The right metric is ‘time to first use case’ – how long until you deploy your first production use case, which is your first sign of data ROI.
For a traditional 500-person company, this is typically a 6-12 month process. You start evaluating tools, Microsoft likely surfaces through some relationship with free credits and introduces you to a systems integrator who builds a stack on Microsoft. You might evaluate Databricks, Snowflake, Amazon, or GCP, but it’s fundamentally the same process – building multiple different components.
Six to twelve months is standard for the time to first use case today.
What’s the alternative, the new way of doing this?
We want to see your first use cases running in production within the first month. The issue isn’t that data teams are slacking during those 6-12 months – they’re managing integrations, connecting tools, and building pipelines. But none of that ties into meaningful work you actually need to do.
AI allows us to focus on what we need to accomplish, not worry about the infrastructure. When companies come to 5X, we talk about seeing first ROI – whether it’s a data app, AI application, dashboarding, or migration – within three to four weeks with productiongrade deliverables.
It sounds almost mind-blowing that something taking 6-12 months can be collapsed into a 6-week sprint. How are you generating efficiencies of this kind?
Let’s look at a typical mid-market manufacturing company. They have factories, run SAP, manage inventory, sell to customers, have various SAP integrations, and use Google Sheets.
With traditional platforms like Fabric or Databricks, they spend months pulling data from SAP using Azure Data Factory, building OData APIs, cleaning data, setting up Azure warehouses, configuring Power BI, orchestrating workflows, structuring data, and defining security permissions. They either need external consultants or spend additional months hiring and training a team on their chosen platform.
Your time is fundamentally spent on foundational pieces rather than business value.
We’ve built the 5X Platform on nine battle-tested open source layers with some proprietary components, ensuring no vendor lock-in and strong community support. We’re a managed product, not infrastructure. We provide 600 connectors out-of-the-box for SAP, Business Central, Oracle, Salesforce, and hundreds of others. If you need one we don’t have, we’ll build it.
Everything works together automatically – warehouse, modelling, and orchestration. No tool integration needed. Whatever you define in the semantic layer, you can speak to immediately. Ask questions about undefined metrics, and we’ll prompt the data team to add them.
We’re optimised for traditional company needs: data integration solutions, managed products over infrastructure, built-in services, and flexible deployment – cloud, private cloud, or on-premise.
The result? Projects quoted as two-year implementations, we deliver in six months on the 5X platform.
What led you to develop an all-inone data platform?
The data space is one of the most fragmented industries. We have hundreds of vendors across 10-15 core categories –ingestion, warehouse, modelling, BI, governance – and now AI is adding even more categories.
Our analogy: data vendors today are selling car parts. Imagine walking into Honda and instead of selling you a Civic, they sell you an engine and expect you to build your own car.
When we pivoted 5X to developing our platform, we had a thesis: companies won’t keep buying five different vendors and stitching them together. We’re entering the era of all-in-one data platforms. We launched our new platform in August – a true all-in-one solution across nine categories, packaged in a single offering.
And another key benefit is that you don’t have to deal with multiple vendors?
Exactly. We’re built on nine different open source technologies under the hood. Think of Confluent – the streaming company. If you’re doing streaming, you’re probably using Confluent. Under the hood, they use two open-source projects: Kafka for pipelines and Apache Flink for stream processing.
But Confluent built enterprisegrade capabilities around Flink and Kafka, delivering a single product with everything you need for streaming. You don’t think about the underlying open source components.
Similarly, 5X is the enterprisemanaged version of nine different open source technologies. You get a complete managed offering from day one without dealing with multiple vendors.
sign a 2-3 year contract, but it will change after that. Having your data and AI locked in is dangerous.
We’re fundamentally built on open source technologies. If we disappear tomorrow, you could take your GitHub repository with all your scripts, spin up the open source projects yourself, and import everything. No vendor lock-in.
More importantly, the space changes rapidly. When great new tools emerge, we can add them quickly. Companies building proprietary stacks take much longer, and it’s impossible to build 7-10 different categories proprietarily and remain competitive over a 10year window.
We don’t build categories –we study the market, find the best vendors, and deploy those solutions inside our platform. This is completely abstracted from you, but we’re delivering the current best-inbreed platform that improves daily.
How does an organisation’s choice of platform impact how it should build a data & AI team?
It’s slightly different when you think about it from a data team perspective. You start with zero people, then one person, eventually maybe 5-10 people. But here’s what people miss: just because you’ve invested time building something doesn’t mean you should keep doing it.
Companies won’t keep buying five different vendors and stitching them together. We’re entering the era of an all-in-one data platforms. .
The bigger issue companies don’t discuss enough is vendor lock-in. It’s very real. If you’re building on Fabric or Databricks today, these are proprietary platforms that could change pricing overnight. You might
The math is telling. Data teams spend about 20% of their time managing their data platform. At WeWork, we had a 100-person data team with 20 people dedicated to building and managing our platform. At $200k average US salary, that’s $4 million annually spent on managing infrastructure that’s not differentiated from what any other company builds.
This ignores the initial 6-12
month investment to build a basic platform. Even after that investment, maintenance consumes 20% of your resources – whether that’s one person or 10 people, it scales proportionally. Why continue this when you could use something like 5X and be ready out of the box?
With a fully managed platform approach, what size and structure should modern data teams have? How does this scale from a 100-person company to 500 people?
I don’t think in terms of data engineers, analysts, and scientists anymore – they’re essentially the same role. We’re entering an era where I look for data generalists. What is data engineering? It’s data modelling – cleaning, structuring, and formatting data so you can answer questions. This is the last remaining job AI won’t take over because AI can never have business context about what ‘revenue’ means. That requires human business definitions.
Analysis should be a skill anyone in data can handle. Building data science models is becoming commoditised with plug-and-play solutions. GenAI capabilities are increasingly available through tools.
I’d start with two roles: a fractional chief data officer to sit with the business, understand goals, manage stakeholders, and drive adoption, plus a data generalist who can handle modelling and implementation. Use 5X for infrastructure, and this combination serves a 100-200 person company. At 500 people, scale to 2-3 data generalists with either the fractional leader or a fulltime hire.
One caveat: I’d be cautious about hiring a first-time manager as head of data. I want someone who’s managed similar teams and can manage up, getting buyin that we’re not just building dashboards, but driving adoption and strategic decisions.
AI AND MARKETING
– A LAND OF GREAT OP PORTUNITY, FOR THOSE PROPERLY EQUIPPED –BUT SUBJECT TO EXIS TING LAWS
DO YOU KNOW WHAT TO THINK ABOUT?
JAMES TUMBRIDGE is an intellectual property lawyer who has litigated before the courts of several countries. He is a qualified arbitrator and mediator, listed with the World Intellectual Property Organisation, the UK Intellectual Property Office, and others. Formerly a police tribunal judge he has dealt with sensitive data matters and trained police forces and the serious fraud office. A former government advisor, he worked on the AI Convention, and took part in the AI Global Summit. He chairs Digital Services function for the City of London, and has been an advisor to various MPs and MEPs on a range of issues. Through his engagement with policy makers he advises clients on how to prepare for legislative changes and regulation compliance. James gave advice to the government on the 2018 Data Protection Act, and Online Safety Act 2024, and helped design the first guidance for public sector use of GenAI, published in 2023.

ROBERT PEAKE is an intellectual property lawyer with over 15 years’ experience as a litigator in the UK and in Canada. His practice covers the intersection of intellectual property, technology, and regulation, including confidential information, data protection and cybersecurity, online safety, and artificial intelligence. Robert has a particular interest in emerging issues at the intersection of law and technology. He completed his LLM at the London School of Economics, focussing on the liability of internet intermediaries for IP infringement, and returns regularly as a visiting practitioner. Robert has written and presented over many years on topics including artificial inte lligence, 3D printing, and the enforcement of intellectual property right s online.

JAMES TUMBRIDGE - ROBERT PEAKE
The mass adoption of artificial intelligence (AI) by businesses in recent years has been spurred on by promises of increased efficiency and effectiveness. AI solutions offer potentially significant advantages in marketing and promotional activities, including improving customer engagement, retention, identification of new markets or customers, and increasing content creation. Those advantages, however, come with legal and business risks which should be properly understood, to make the right risk assessment and avoid common pitfalls.
1. Transparency – a cautionary tale – do customers know their data will be used to train AI and target offerings?
Many businesses generate and hold significant amounts of data relating to (and perhaps belonging to) their customers. The digitising of business services and transactions means that those data holdings can often be enriched by drawing on data from elsewhere. Retail businesses, for example, will know their customers’ browsing and purchasing history across properties those retailers own, but may also draw inferences from the broader activities of those customers online.
AI applications afford the opportunity to analyse large amounts of data in ways that previously would have been impractically costly in time and resource. A challenge for organisations wishing to leverage the data they have access to from their customer interactions (and data which may be collected from other sources), is that they may not have a compliant legal basis on which to use that data to train an AI model.
typically requires an individual’s consent, and personal data processed for those purposes may also rely on consent unless a business can point to another legal basis for such marketing.
A recent decision of the UK High Court illustrates that obtaining consent does not mean that an organisation can send targeted marketing to that individual without risk. In the case of RTM v Bonne Terre Limited [2025], the court examined the online marketing directed at the claimant, a ‘recovering gambling addict,’ by Sky Betting and Gaming (‘SBG’), ultimately finding in the claimant’s favour.
The claimant had a long history of problematic gambling behaviour, and had previously closed his account with the defendant on numerous occasions. It was not disputed that when he reopened his SBG account in 2017, he would have been presented with SBG’s cookie consent banner in use at the time; SBG contending that having clicked on ‘accept and close’ he provided the necessary consent for the use of cookies. Although he could not recall doing so, the claimant appears to have amended his marketing preferences a few months later, and began to receive direct marketing from SBG.
The challenge for business is to be transparent with customers about the personal data they collect, and how it. will be used..
Following the coming into force of the GDPR, an update to consents and preferences was conducted by SBG; following which, the claimant confirmed his consent to receive direct marketing. The claimant again did not recall having done so.
SBG’s evidence was that it collects ‘extensive customer data regarding use of [its] service over time.’
The challenge for business is to be transparent with customers about the personal data they collect, and how it will be used. From a legal perspective –and a reputational one – a customer should not find that their personal data is being used in a way that they did not expect. It is common for businesses to disclose that customer data may be used to improve their service offering, and to communicate future offers which may be of interest to the customers. As AI solutions are increasingly adopted, businesses should be looking at their customer privacy notices and the terms and conditions, to ensure that they have sufficiently addressed the possible use of customer data by AI tools, which may use that customer data for AI training purposes.
Consent is not a panacea
In addition to transparency obligations under data protection laws (like the GDPR), direct marketing
The court described that ‘raw data’ as being stored in data warehouse, where it is ‘operated on by systems created by the data science team.’ A subset of data on each customer, referred to as a ‘feature store’, would contain roughly 500 data points at any given time; these would feed into marketing profiles for each customer
SBG targeted the claimant with extensive personalised and targeted marketing; the claimant at the height of his activity was losing nearly £1,800 per month on an income of £2,500. The court examined the nature of the claimant’s consents for SBG’s use of cookies and personalised marketing, and concluded that although the claimant had given those consents, they could not be seen to meet the legal threshold of being: freely given, specific, unambiguous, and informed. Those consents were inseparably linked to the claimant’s uncontrolled craving to gamble.
The court also found that the profiling of the claimant ‘was parasitic on the obtaining of the data and the ultimate delivery of the marketing, and had no other standalone purpose so far as he was concerned; it necessarily discloses no distinct basis for lawful processing.’
Accordingly, SBG could not rely on legitimate interests as a legal basis for its targeted marketing.
The decision addresses marketing in a highly regulated space, and is constrained to the claimant’s particular circumstances, but it nevertheless serves as a useful illustration of the importance of keeping automated processes under review in order to identify where those may not be performing in line with expectations.
2. Do they know when they are interacting with an AI agent?
One of the most prominent trends in AI applications is ‘agentic AI,’ which refers to AI tools which mimic human interactions with individuals. An example of the AI agent is a chatbot, often deployed by businesses ranging from retailers to financial institutions, in customer service functions. Whilst AI agents can be effective, and appreciated by customers as an alternative to a long wait in a telephone queue, organisations must consider the need for transparency with those interacting with agents.
There is the potential for reputational risk where individuals are not made aware that they are interacting with an AI agent rather than a human . Data protection compliance is also an important consideration when deploying AI agents. An individual’s data may be processed in ways that are unexpected in order for the agent to respond to queries or offer suggestion s, or for further training an AI model.
Profiling of individuals may arise in the context of AI agents, such as when a user is identified as having certain characteristics and then associated with a particular ‘group’ in order to influence the way in which the agent interacts with that individual. Profiling typically involves the analysis of aspects of an individual’s personality, behaviour, interests and habits to make predictions or decisions about them.
Under the GDPR, profiling falls within the broader scope of automated decision-making, and where it is used, engages additional rights for individuals to object, and to seek human intervention or review, in circumstances which may be particularly impactful on the individual. In order to be able to exercise those rights, individuals must be informed of the use of automated decision-making in the context of the interaction.
An example of an impactful deployment of an AI agent is where it might be used to recommend particular products or services for a user, and those on offer are determined by analysing the users’ characteristics, based perhaps on a combination of a broad set of data already held about that individual together with additional information submitted in response to the AI agent’s queries. Where the consequences of the interaction may have a significant
impact for the user – such as whether a particular insurance product is available, and its cost and conditions – relying exclusively on an AI agent poses significant challenges for legal compliance.
AUTOMATED DECISION-MAKING AND PROFILING: segmentation and ‘look alike’ audiences; inferred special category data
Profiling can also often engage the additional legal obligations which govern the use of sensitive personal data (‘special categories’ of personal data under the GDPR). An immediate consequence of which is the need to obtain the explicit consent of the individual for the use of that sensitive data, unless another legal basis is available, such as where processing is required to meet a legal obligation.
Organisations may not be aware that sensitive personal data is being used for their marketing communications; this could be in relation to targeting or to the content of communications where generative AI is involved (on which, see below).
To illustrate, consider the widely used tool of ‘lookalike audiences’ to target users online; the data points used to segment target audiences can lead to those groups being delineated on the basis of special category data. This can occur when personal traits which, in isolation, may be considered relatively anodyne, but in combination can result in a classification indicating political opinions, religious affiliation, or other sensitive personal characteristics.
One of the most prominent trends in AI applications is ‘agentic AI’, which refers to AI tools which mimic human interactions with
individuals.
BIAS: do you know that data sets used to train AI models are sufficiently representative Linked to the use of profiling, and the use of sensitive personal data, are concerns around how an AI model has been trained. The use of personal data to train an AI model requires a legal basis, but it also requires consideration of the suitability of the range of personal data for the purpose for which the trained model will eventually be deployed.
An AI used to target online marketing, for example, may analyse a user’s online footprint in order to categorise them into a profile within a trained model, in order to optimise the promotional material that users will see when accessing a webpage, or receive via direct messaging. If the underlying AI model used by that AI has been trained on an insufficiently representative range of personal data, it may be unsuitable for deployment across an organisation’s target markets. It may also be unconsciously biased, and in some cases it
may even breach the Equality Act, so ensuring a suitable training data set is important. An AI model trained solely or principally on personal data from a single country or region, may be of little value if it is to be deployed to optimise a business’s targeting of potential customers globally.
AI-assisted targeting and the risk of discriminatory outcomes
An example may be drawn from what is known as dynamic pricing, where goods or services may be offered to customers at different price levels depending on a range of factors such as their geographical location (sometimes their precise location), the day (e.g. a weekday or a weekend) and the time of day.
With rich data sets on online users, and the assistance of AI, organisations have an increasing ability to target and tailor their pricing on a granular level. Businesses need to be mindful of the risks of targeting tailored offerings to individuals in a way that may be discriminatory. This may be the case where AI is routinely offering inferior pricing to a particular ethnographic group.
Such an outcome may stem from an overreliance on the location of users when determining pricing; it may be that a postcode is heavily inhabited by a particular ethnographic group, the result being that individuals of that group receive different – and potentially inferior –offers than those residing elsewhere.
REPUTATIONAL RISK: GenAI without proper supervision; creative content, but also agentic AI which could produce unintended responses
There are myriad reported examples of GenAI being deployed by businesses without proper supervision and vetting, and the results can prove highly embarrassing and potentially harmful for those brands that are caught out. An example from Canada illustrates how GenAI in combination with AI agent can trigger both reputational and legal consequences for a business. Following a death in the family, a customer asked the AI agent on Air Canada’s website about bereavement fares; they were informed that an application for a bereavement fare reduction could be made retroactively. When the passenger later sought to apply for a fare reduction, it became apparent that the AI agent had given information which was at odds with the airline’s policy. The customer was eventually successful in a claim before the Small Claims Court and was awarded compensation of roughly $800. Air Canada unsuccessfully argued that it could not be liable for misstatements by its online AI agent; a position that received very wide press coverage, considerably amplifying the airline’s reputational damage from the incident.
There are myriad reported examples of GenAI being. deployed by businesses without proper supervision. and vetting, and the results can prove highly. embarrassing and potentially harmful for those. brands that are caught out..
IP INFRINGEMENT: risk of inadvertent copying from GenAI outputs
In the context of marketing and advertising content, the use of generative AI can be particularly attractive. Advantages of GenAI can include the rapid production of creative content, potentially at lower cost by bypassing traditional design teams, whether in-house or at external agencies. Placing increased reliance on AI-generated content from applications such as the popular ChatGPT, though, comes with risks, both legal and reputational.
Numerous high-profile legal disputes are playing out in the UK and the US courts, principally, between the developers of GenAI applications and the owners of copyright material that the underlying AI models used as training data. A question to be resolved in those disputes, is whether GenAI applications such as ChatGPT themselves may infringe copyright (i) by, in essence, comprising within them copies of copyright works, and (ii) by reproducing copyright works in response to use prompts. The result of those disputes may, therefore, prove disruptive to the use of those tools.
Here again, a properly considered (and monitored) organisational policy on the use of AI, is an important tool in seeking to mitigate risks. Those responsible for marketing activities should be aware of the risks of infringing third party intellectual property rights by, for example, prompting a GenAI tool using imagery or text obtained online, or by directing the creation of output ‘in the style of’ another brand. Not only might the output, if deployed, bring embarrassment for the business, it could give rise to a claim for copyright infringement, trade mark infringement or passing off.
In the event of a legal dispute over AI-generated content, the prompts used to create the disputed text or images may also serve as evidence of infringement, posing an additional legal challenge for business that has unadvisedly used GenAI.
AI tools offer considerable opportunities for those conducting marketing, but not without risk. Those who stand to benefit greatly from AI will engage in proper deliberation and planning before rolling out AI-based initiatives, and ensure that programmes are monitored appropriately in order to identify and address challenges which may arise.

To hire the best person available for your job you need to search the entire candidate pool – not just rely on the 20% who are responding to job adverts.
Data Science Talent recruits the top 5% of Data, AI & Cloud professionals.
Fast, effective recruiting – our 80:20 hiring system delivers contractors within 3 days & permanent hires within 21 days.
Pre-assessed candidates – technical profiling via our proprietary DST Profiler.
Access to talent you won’t find elsewhere – employer branding via our magazine and superior digital marketing campaigns.
Then why not have a hiring improvement consultation with one of our senior experts? Our expert will review your hiring process to identify issues preventing you hiring the best people.
Every consultation takes just 30 minutes. There’s no pressure, no sales pitch and zero obligation.



The linear regression is usually considered not flexible enough to tackle the nonlinear data. From a theoretical viewpoint, it is not capable of dealing with them. However, we can make it work for us with any dataset by using finite normal mixtures in a regression model. This way it becomes a very powerful machine learning tool which can be applied to virtually any dataset, even highly non-normal with non-linear dependencies across the variables.
What makes this approach particularly interesting is its interpretability. Despite an extremely high level of flexibility, all the detected relations can be directly
HOW TO MAKE LINEAR REGRESSION FLEXIBLE ENOUGH FOR NON-LINEAR DATA
ŁUKASZ TEOFIL GĄTAREK earned his PhD in Bayesian econometrics from the Tinbergen Institute in the Nethe rlan ds. His research focuses on time series analysis, with a particular interest in exploring machine learning concepts for sequential data analysis. His recent publications have appeared in several prestigious journals, including the Journal of Forecasting , Journal of Risk , and the Oxford Bulletin of Economics and Statistics . For more than a decade, Łukasz has been advising corporations and startups on statistical data modelling and machine learning. He currently serves as a data governance adviser for key global companies that are market leaders in their field.
interpreted. The model is as general as a neural network, but it does not become a black box. You can read the relations and understand the impact of individual variables.
In this post, we demonstrate how to simulate a finite mixture model for regression using Markov chain Monte Carlo (MCMC) sampling. We will generate data with multiple components (groups) and fit a mixture model to recover these components using Bayesian inference. This process involves regression models and mixture models, combining them with MCMC techniques for parameter estimation.
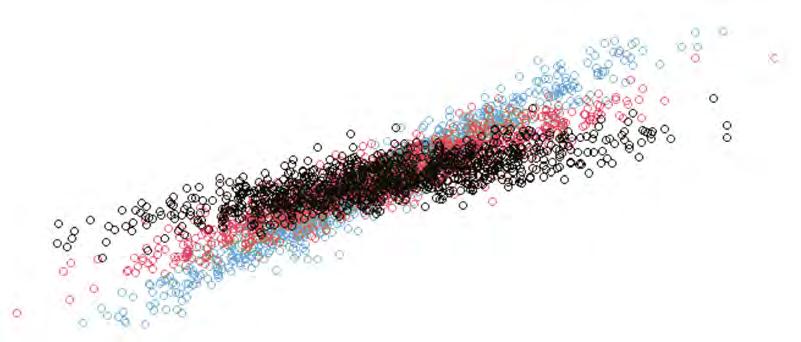
Data simulated as a mixture of three linear regressions
We begin by loading the necessary libraries to work with regression models, MCMC, and multivariate distributions

● pscl: Used for various statistical functions like regression models.
● MCMCpack: Contains functions for Bayesian inference, particularly MCMC sampling.
● mvtnorm: Provides tools for working with multivariate normal distributions.
We simulate a dataset where each observation belongs to one of several groups (components of the mixture model), and the response variable is generated using a regression model with random coefficients. We consider a general setup for a regression model using G Normal mixture components.

● N: The number of observations per group
● nSim: The number of MCMC iterations
● G: The number of components (groups) in our mixture model
Each group is modelled using a univariate regression model, where the explanatory variables (X) and the response variable (y) are simulated from normal distributions. The betas represent the regression coefficients for each group, and sigmas represent the variance for each group.

● betas: These are the regression coefficients. Each group’s coefficient is sequentially assigned.
● sigmas: Represent the variance for each group in the mixture model.
In this model, we allow each mixture component to possess its own variance parameter and set of regression parameters.
GROUP ASSIGNMENT AND MIXING
We then simulate the group assignment of each observation using a random assignment and mix the data for all components. We augment the model with a set of component label vectors for where and thus z_gi=1 implies that the i-th individual is drawn from the g-th component of the mixture.
This random assignment forms the z_original vector, representing the true group each observation belongs to.

BAYESIAN INFERENCE: PRIORS AND INITIALISATION
We set prior distributions for the regression coefficients and variances. These priors will guide our Bayesian estimation.

● muBeta: The prior mean for the regression coefficients. We set it to 0 for all components.
● VBeta: The prior variance, which is large (100) to allow flexibility in the coefficients.
● shSigma and raSigma: Shape and rate parameters for the prior on the variance (sigma) of each group.
For the component indicators and component probabilities, we consider the following prior assignment
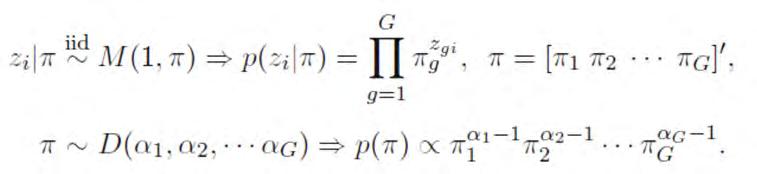
The multinomial prior M is the multivariate generalisation of the binomial, and the Dirichlet prior D is a multivariate generalisation of the beta distribution.
MCMC INITIALISATION
In this section, we initialise the MCMC process by setting up matrices to store the samples of the regression coefficients, variances, and mixing proportions.

● mBeta: Matrix to store samples of the regression coefficients.
● mSigma2: Matrix to store the variances (sigma squared) for each component.
● mPi: Matrix to store the mixing proportions, initialised using a Dirichlet distribution.
MCMC SAMPLING: POSTERIOR UPDATES
If we condition on the values of the component indicator variables z, the conditional likelihood can be expressed as
In the MCMC sampling loop, we update the group assignments (z), regression coefficients (beta), and variances (sigma) based on the posterior distributions. The likelihood of each group assignment is calculated, and the group with the highest posterior probability is selected.
The following complete posterior conditionals can be obtained:
where
denotes all the parameters in our posterior other than x.
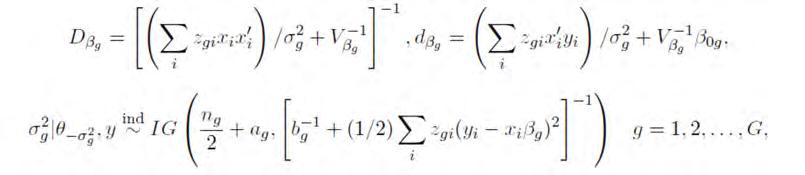
and where n_g denotes the number of observations in the g-th component of the mixture.
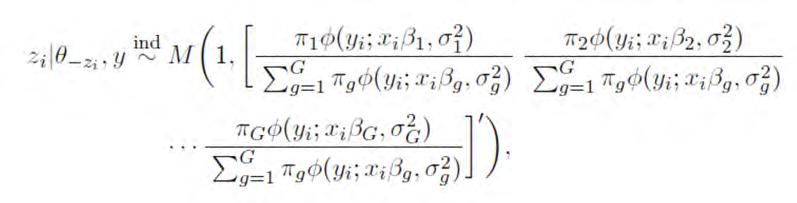
and The algorithm below draws from the series of posterior distributions above in a sequential order.


This block of code performs the key steps in MCMC:
● Group Assignment Update: For each observation, we calculate the likelihood of the data belonging to each group and update the group assignment accordingly.
● Regression Coefficient Update: The regression coefficients for each group are updated using the posterior mean and variance, which are calculated based on the observed data.
● Variance Update: The variance of the response variable for each group is updated using the inverse gamma distribution.
Finally, we visualise the results of the MCMC sampling. We plot the posterior distributions for each regression coefficient, compare them to the true values, and plot the most likely group assignments.

This plot shows how the MCMC samples (posterior distribution) for the regression coefficients converge to the true values (betas).
Through this process, we demonstrated how finite normal mixtures can be used in a regression context, combined with MCMC for parameter estimation. By simulating data with known groupings and recovering the parameters through Bayesian inference, we can assess how well our model captures the underlying structure of the data.
Here is a link to the full code on GitHub.

BY NICOLE JANEWAY BILLS
NICOLE JANEWAY BILLS is the Founder & CEO of Data Strategy Professionals. She has four years of experience providing training for data-related exams. She offers a proven track record of applying data strategy and related disciplines to solve clients’ most pressing challenges. She has worked as a data scientist and project manager for federal and commercial consulting teams. Her business experience includes natural language processing, cloud computing, statistical testing, pricing analysis, ETL processes, and web and application development. She attained recognition from DAMA for a Master Level pass of the CDMP Fundamentals Exam.
The 2025 lineup of data-focused books offers fresh perspectives on leadership, architecture, governance, and inclusion. UNLINKED by Meenu Howland reveals the overlooked architectural disconnects that hinder business performance and presents a framework to realign strategy and structure. Malcolm Hawker’s The Data Hero Playbook provides actionable advice for developing core data leadership skills, equipping readers to influence change and deliver value. In Non-Invasive Data Governance Unleashed , Robert S. Seiner expands on his well-known approach by applying it to AI, emphasising practical, people-centred governance. Serena H. Huang’s The Inclusion Equation bridges data, AI, and organisational well-being, offering a timely model for advancing diversity through evidence-based decision-making. Together, these books reflect a growing demand for data practices rooted in both strategy and empathy.
Author: Meenu Howland
Time to read: 8 hrs 24 mins (252 pages)
Rating: 5/5 (1 total ratings)
This book challenges the conventional, siloed approach to data, process, and architecture by revealing the missing structural link that many organisations overlook. Consultant Meenu Howland presents a practical, accessible roadmap for aligning data strategy, business capabilities, AI, and governance – not through abstract frameworks, but through connected, scalable action. The book emphasises starting with business value, integrating governance into workflows, and enabling trust and transparency in AI. With clear chapter summaries and a cross-disciplinary lens, UNLINKED is a vital guide for leaders and practitioners seeking to fix what’s broken, not by working around the chaos, but by building clarity into how everything fits together.
TL;DR: A practical guide that exposes the hidden architecture connecting data, process, AI, and governance. Howland shows leaders how to move beyond silos by anchoring data strategy in business value and aligning workflows through shared logic. Ideal for those seeking scalable, real-world clarity, not more frameworks.
Author: Malcolm Hawker
Time to read: 9 hrs 36 mins (288 pages)
Rating: 5/5 (4 total ratings)
Hawker offers a bold and refreshing blueprint for redefining data leadership by challenging outdated mindsets that have long limited progress in data functions. Through practical steps, candid reflections, and powerful real-world examples, the author empowers data leaders to shift from passive data stewardship to proactive business value creation. These valuable insights equip readers to lead data functions that matter – strategically and ethically, not just technically. The Data Hero Playbook introduces a customer-obsessed, outcome-oriented approach Hawker refers to as ‘Heroic Data Leadership’. With sharp insights, storytelling, and a call to reject ‘garbage in, garbage out’ excuses, this book is a must-read for anyone seeking to drive meaningful change through data. The content spans data literacy, data governance, executive alignment, and fiduciary risk, all while emphasising empathy, accountability, and impact.
TL;DR: Hawker empowers data leaders to reject outdated mindsets and adopt ‘Heroic Data Leadership’ – a customerfocused, value-driven approach. The book offers actionable steps, real stories, and sharp critiques that challenge passive stewardship and enable data teams to deliver strategic impact.


Author: Serena H. Huang
Time to read: 8 hrs 32 mins (256 pages)
Rating: 5/5 (12 total ratings)
The Inclusion Equation reframes inclusion and well-being as measurable business drivers rather than intangible ideals. Drawing on her experience leading people analytics at PayPal, GE, and Kraft Heinz, Dr. Serena H. Huang delivers a data-powered guide for transforming culture into business-critical infrastructure. Through actionable frameworks and compelling case studies from companies such as Microsoft, Meta, and Cisco, she shows how to link employee experience to retention, innovation, and performance.
The book equips leaders to detect early signals of burnout, disengagement, and turnover risk using AI and to present insights with the clarity and impact required to influence the C-suite. With a focus on storytelling, data fluency, and Gen Z’s evolving workplace expectations, The Inclusion Equation offers a modern playbook for people leaders, analysts, and executives committed to building inclusive, resilient organisations that compete on culture as much as capability.
Author: Robert S. Seiner
Time to read: 11 hrs 24 mins (342 pages)
Rating: 4/5 (2 total ratings)
Through his widely adopted Non-Invasive Data Governance (NIDG) framework, Robert S. Seiner has redefined how organisations approach governance. Seiner’s latest book demonstrates how to adapt NIDG to a rapidly evolving data and AI landscape. Non-Invasive Data Governance Unleashed offers a pragmatic, people-centred approach that aligns governance with existing roles, responsibilities, and corporate culture without introducing heavy overhead or disruption.
Rather than treating governance as a separate, compliance-driven initiative, Seiner positions it as a natural extension of how people already interact with data. The book delivers step-by-step guidance for implementing NIDG in a variety of contexts, from decentralised environments to AI-ready data ecosystems. Readers will find actionable strategies that support trust, transparency, and data quality – essential pillars for AI success. Packed with case examples and endorsed by leading voices in the field, including Bill Inmon, Thomas Redman, and Douglas Laney, this book empowers data leaders to embed governance into daily operations, foster accountability,
TL;DR: Huang shows how to treat inclusion and well-being as measurable business priorities. With frameworks, AI tools, and case studies, she equips leaders to detect early risk signals and drive cultural performance, backed by data and built for C-suite influence.

and drive real business value. Non-Invasive Data Governance Unleashed is an essential resource for any organisation seeking to operationalise governance without sacrificing agility
TL;DR: Seiner modernises his proven Non-Invasive Data Governance approach for the AI era. The book teaches how to embed governance into everyday operations by aligning with existing roles and behaviours – minimising friction while maximising trust, quality, and accountability.


AIsystems are evolving from passive tools into autonomous agents, yet organisations are still leaning on the ‘co-pilot’ model for safety. The premise is simple: for every AI decision-maker, there’s a human overseer ready to catch mistakes. In theory, this human safety net should ensure any error by the AI is spotted and fixed before harm is done. In practice, however, this assumption is proving dangerously false. A cognitive phenomenon known as automation bias means that the very people meant to keep AI in check often fail to intervene when the AI is wrong. This undermines the fundamental promise of the co-pilot approach, that human experts will reliably verify AI outputs or step in when the AI goes awry.
THE ILLUSION OF A HUMAN SAFETY NET
Relying on human oversight as the ultimate failsafe fundamentally misunderstands human psychology
JAMES DUEZ is the CEO and co-founder of Rainbird.AI, a decision intelligence business focused on the automation of complex human decision-making. James has over 30 years’ experience building and investing in technology companies with experience in global compliance, enterprise transformation and decision science. He has worked extensively with Global 250 organisations and state departments, is one of Grant Thornton’s ‘Faces of a Vibrant Economy’, a member of the NextMed faculty and an official member of the Forbes Technology Council.
and the nature of modern AI. Automation bias is the tendency for people to trust automated systems too readily, even in the face of contradictory evidence. In other words, humans are wired to defer to a confident machine output over their own judgment. This isn’t mere laziness; it’s a deeply ingrained bias. When an AI presents a decision or recommendation – especially with an air of authority – we feel it must know better Over time our active vigilance erodes, and we become complacent, assuming the system is probably right Real-world incidents tragically illustrate this fallacy. In 2018, a self-driving Uber test vehicle struck and killed a pedestrian in Arizona. A human safety driver was behind the wheel, whose sole job was to monitor the AI
Automation bias is the tendency for people to trust automated systems too readily, even. in the face of contradictory evidence..
PHILIPP KOEHN JAMES DUEZ
and intervene if it made a mistake. But video evidence showed the driver had grown complacent and distracted, failing to react in time. This was not a one-off lapse in attention – it was a foreseeable outcome of how our brains respond when an automated autopilot seems to handle things well for long stretches, until it doesn’t. We begin to trust it blindly. The human co-pilot in this case was physically present, but mentally absent when needed most.
Psychology research and decades of automation
HUMAN OVERSIGHT FAILS
It turns out that the limitations of human oversight go far beyond the risk of momentary inattention or complacency. Multiple factors conspire to make humans unreliable AI guardians:
Automation Bias – Trusting the Machine by Default: As described, people tend to accept automated outputs uncritically. We overly trust that the AI knows what it’s doing . This bias makes objective oversight nearly impossible. The longer an AI system runs without obvious error, the more our scepticism fades. Eventually the human overseer may be rubber-stamping decisions, intervening late or not at all. Example carnage includes regulatory breaches, reputational damage and even the erroneous overwriting of systems of record.
‘Black Box’ Opacity – We Can’t Verify What We Don’t Understand: Many advanced AI models (especially deep neural networks and large language models) are utterly opaque in their reasoning. They arrive at outcomes via complex internal processes that even experts cannot readily interpret. How can a human effectively vet an AI’s decision if the logic behind it is inscrutable? This comprehension gap means oversight often devolves into just trusting the AI’s output. For instance, multiple embarrassments in the legal field have seen lawyers submitting AI-generated court filings full of fictitious citations – because the text looked plausible, and the human reviewers assumed it must be correct. The AI (in this case, an LLM) fabricated case law references out of thin air, and the humans, unable to tell real from fake, failed to intervene. Black-box AI can produce answers that sound authoritative yet are subtly wrong, and without transparent logic, the human co-pilot is effectively flying blind.
experience (from aircraft cockpits to industrial control rooms) confirm that humans make poor monitors of highly automated systems. We are not vigilant guardians by nature; our cognitive architecture simply isn’t built to sit idle, watching for rare failures in complex, fastmoving processes. Instead, we become lulled into inaction. This co-pilot fallacy – believing that a human can pay full attention and jump in at exactly the right moment – has created a false sense of security in AI governance.
and Volume – Too Much Information, Too Little Time: Unlike human experts, who typically make considered decisions carefully and methodically, AI systems generate outputs at a scale and speed impossible for humans to manage effectively. Take tax compliance, for example: a generative AI drafting tax advice could produce dozens of pages of analysis or commentary for each client. A human reviewer, tasked with verifying the accuracy of these AI-generated reports, quickly faces a mountain of paperwork to assess. By the time they scrutinise a fraction of these outputs, subtle but critical errors – such as incorrect interpretations of complex tax regulations or misapplied exemptions – may have already slipped through and become embedded into official records. For a sector that is needing to lean into leveraging its hard-earned trust as the cost of time-based work trends towards zero, that’s a problem.
This overwhelming volume creates two critical issues. Firstly, it simply exceeds human cognitive and physical capacities, making meaningful oversight impractical and unreliable. Secondly, if inaccurate AI-generated insights are allowed into official systems of record, they can quickly pollute vital data repositories. Over time, inaccuracies compound, corrupting trusted information sources and significantly increasing risk and regulatory exposure.
As one technologist wryly noted: ‘ LLMs are predictive, not deterministic. In high-stakes applications precision is paramount. Relying solely on predictive models inevitably results in errors with significant and compounding consequences. ’ Simply put, expecting humans to reliably sift through a firehose of AI-produced content is unrealistic. Unless organisations embed more robust deterministic checks directly into their AI systems, the burden of oversight quickly becomes unmanageable, resulting in systemic errors and polluted records that undermine trust and compliance.
It’s clear that the standard human-in-the-loop strategy is not scalable under these pressures. The very safeguard meant to ensure AI reliability – human oversight – too often becomes a weak link due to cognitive bias, lack of AI explainability, and sheer volume. This undermines the core premise of the AI co-pilot. If the human cannot or does not effectively intervene when needed, the safety net might as well not be there. Automation bias has effectively pulled the rug out from under the co-pilot model, suggesting we need to rethink how we achieve reliability and trust in AI systems.
If having a human ride shotgun isn’t a dependable safety solution, what’s the alternative? The answer is to bake the safety net directly into the AI’s design. In practice, this means shifting from an oversight model (‘let the AI do its thing and hope a human catches errors’) to an architecture with deterministic guardrails: engineered constraints within which the AI must operate. Rather than trusting a human to filter out bad outputs after the fact, the system itself prevents undesirable actions by design
Early attempts at this kind of assurance used handcrafted rules (‘if output contains forbidden phrase X, reject it’ or ‘if parameter Y exceeds threshold, require approval’). But traditional linear rule systems quickly became brittle and unmanageable in complex domains and just don’t provide the breadth of coverage.
Today’s approach is far more sophisticated. Modern deterministic guardrails utilise graph-based knowledge structures to represent the nuanced web of rules, facts, and relationships that should govern decisions. In essence, the AI is imbued with a structured model of the domain (for example, a regulatory rulebook, or a company’s policy hierarchy), encoded as an explicit knowledge graph. This graph acts as a decision boundary : any potential action or recommendation from the AI is checked against it, and if it doesn’t satisfy the encoded constraints, it won’t be allowed.
Unlike a black box neural network, a graph-based system follows explicit logical pathways thanks to the use of a symbolic inference engine – capable of reasoning over the knowledge in the graph as precisely as Excel reasons over numbers. Every inference or decision it makes can be traced back step-by-step through the graph’s rules and data. This means its outputs are consistent and repeatable given the same
Modern deterministic guardrails utilise graph-based. knowledge structures to represent the nuanced. web of rules, facts, and relationships that. should govern decisions.
inputs. Where a probabilistic AI might one day say ‘ Approved ’ and the next day ‘ Denied ’ for an identical case, a deterministic inference engine will always produce the same result for the same inputs. The power of this deterministic approach is that it can handle real-world complexity without sacrificing reliability. The knowledge graph can capture intricate, interdependent conditions – far beyond simple yes/no rules – but because it’s grounded in formal logic, it won’t wing it or hallucinate an answer outside those conditions.
By removing the probabilistic element from the loop, a pure deterministic system can guarantee several crucial properties:
● No Hallucinations: The system will never fabricate non-existent facts or arbitrary answers in critical decision areas. Every output is derived from the rules and data in a knowledge graph, eliminating the bizarre ‘hallucinations’ that even the best LLMs sometimes produce.
● Repeatability: Given the same inputs and context, the system’s decisions are perfectly repeatable. There’s no roll of the dice; identical cases yield identical outcomes, an essential feature for fairness and auditability.
● Traceability and Explainability: Each decision can be traced back to specific rules and facts that were applied. This is invaluable for explainability – regulators, auditors, or end-users can be shown the exact logical steps or rule references that led to an outcome. Instead of ‘ the neural network somehow decided this loan is high-risk ’, we can point to a chain of reasoning: e.g. ‘ Declined because the applicant’s income was below £X as required by rule Y, and their credit history showed Z .’
● Causal Consistency: The deterministic engine follows an integrated map of explicit logical pathways that reflect cause-and-effect relationships. This means it’s performing true reasoning (applying domain expertise or policy logic), as opposed to a statistical correlation. The results therefore hold up under scenario changes and stress tests better than a fragile statistical guess would.
● Freedom from Training Bias: Because decisions come from encoded domain knowledge, they aren’t skewed by the quirks and biases hidden in vast training data. A knowledge graph doesn’t pick up irrelevant cultural or historical biases the way an ML model might; it only knows what it has been explicitly given as ground truth.
In short, a pure deterministic architecture provides total confidence in critical decision-making. To give a concrete example: consider an anti-money laundering (AML) agent that flags suspicious transactions. In a deterministic setup, an LLM might help by reading unstructured reports or extracting entities from a PDF, but it will not decide whether a transaction is suspicious. Instead, the decision comes from a knowledge graph containing regulations, policies and typologies relating to financial crime. The AI agent might converse with a compliance officer in natural language (making it user-friendly), but under the hood, it is following a sophisticated yet strict rule-based logic to reach its conclusions. The outcome is an AI that is simultaneously conversational and trustworthy : it can explain its reasoning, and it will not overlook a red flag nor raise a false alarm outside of defined rules.
One historical challenge to implementing deterministic, knowledge-driven AI at scale has been the effort required to build and maintain knowledge graphs. In the past, defining a comprehensive rule-based system for a complex domain (like tax law or claims handling) meant months of knowledge engineering: interviewing experts, coding rules by hand, and meticulously updating them as things changed. This was a serious bottleneck, often cited as a reason why purely symbolic systems fell out of favour during the rise of machine learning. Today, however, that equation has changed dramatically.
Ironically, the latest generation of AI (including LLMs) can be turned toward the task of building the knowledge graphs themselves. Specialised LLMs finetuned on reasoning types and domain knowledge can ingest regulatory texts, policy documents, and expert explanations, and then automatically generate structured knowledge graph candidates for automated testing and human review. Instead of manually encoding thousands of rules, we can have an AI helper read the law and output a draft knowledge graph of interlinked concepts, relationships, weights and rules. Recent breakthroughs have shown this can compress what used to be months of work into a few hours. Furthermore, these systems can assist in keeping the knowledge updated – monitoring for changes in regulations or policy and suggesting updates to the knowledge graph followed by automated regression tests. The result is that deterministically governed AI is far more economically and practically feasible now than it was even a few years ago.
In other words, we’re approaching a point where every organisation can realistically encode its layer of expert knowledge and make it accessible to humans and machines, without prohibitive cost or delay. This development has knocked down the last major barrier to adopting deterministic AI solutions widely.
The paradigm of deterministic, knowledge-driven AI offers a compelling alternative to the current co-pilot model. This approach involves transforming complex regulatory frameworks and expert knowledge into executable knowledge graphs that serve as either AI guardrails or a primary reasoning engine. Rather than relying on either brittle hand-written rules or hoping humans catch LLM-generated errors, this enables a third way: a system where every automated decision is rigorously reasoned over a model of institutional knowledge. Graph-based inference engines ensure AI behaviour remains precise, deterministic, and accountable by default.
A key innovation in this space is the use of programmatically generated graphs. Modern knowledge engineering tools can automatically extract and structure knowledge from documents, policies, and human experts – essentially building a draft of the knowledge graph automatically. This tackles the knowledge bottleneck head-on.
Consider a banking example: lending policy manuals and relevant lending rules can be fed into such a system, converting that information into a web of conditions, calculations, and logical rules that are transparent. The outcome is a verifiable knowledge graph reflecting the bank’s lending criteria and regulatory obligations which can be easily tested. The knowledge graph can guarantee that every acceptance or rejection aligns with policy with an audit trail to prove it.
This approach demonstrates how deterministic reasoning can be both robust and adaptable. Knowledge graphs are flexible enough to capture complex, evolving interrelationships (such as a change in tax law or a new compliance requirement) while remaining rigorous in execution. This means organisations don’t have to choose between the efficiency of AI and the peace of mind of human oversight – they can embed the oversight into the AI. Notably, because the decisions are explainable and rooted in expert-approved logic, regulators and stakeholders gain confidence that the AI isn’t operating unpredictably. Every AI-generated recommendation or action is backed by a chain of reasoning that a human domain expert would recognise and agree with.
By deploying solutions based on these principles, companies in high-stakes sectors (finance, healthcare, legal, etc.) are finding they can embrace AI automation without losing control. The AI can act as a true copilot – not a potentially rogue agent checked by an inattentive human, but a responsible partner constrained by the same rules a diligent human would apply. In effect, the machine now has an in-built second pair of eyes: the codified knowledge of regulation, policy or experts.
The lesson in all of this is that trustworthy AI can’t rely on after-the-fact human fixes; it must be trustworthy by design. The co-pilot model assumed that a human in the loop always be vigilant enough to catch mistakes. We now see that was a hopeful assumption, undermined by automation bias and practical limits on human attention. To achieve AI that is reliable in the real world, especially under demanding conditions, we need to move from hoping someone will catch it to ensuring it can’t go off course in the first place.
This isn’t about abandoning LLMs, or reverting to rules-based systems. It’s about combining the strengths of both, leveraging the culmination of over 50 years of AI research. As AI thought leaders have noted, the future of AI governance will not be about choosing between innovation and safety, but about a hybrid neurosymbolic approach that delivers both. We can let probabilistic AI (machine learning, neural nets, LLMs, etc.) do what it does best – learn patterns, process language, generate suggestions – while a deterministic layer provides the unbreachable reasoning or guardrails to ensure those suggestions are correct and acceptable. This synthesis enables AI to tackle complex tasks without sacrificing compliance, reliability or trust.
A well-designed AI with deterministic oversight won’t run a red light, figuratively or literally, because it’s incapable of breaking the rules encoded within it. This flips the script: the human’s role shifts from being
a desperate last-chance goalie to setting the rules of the game upfront. AI co-pilots governed by deterministic logic allow human experts to impart their knowledge and values directly into the system, rather than nervously watching the system from the sidelines.
Ultimately, overcoming automation bias and unreliable oversight is about engineering AI for assurance. When AI outputs can be trusted to begin with – and produce clear reasoning – the burden on human supervisors diminishes. The humans can then focus on higher-level judgment and edge cases, rather than mindnumbing review of AI actions.
AI the world can trust is built on transparency, determinism, and robust design. By recognising the illusion of the co-pilot safety net and replacing it with built-in safety through knowledge graphs and symbolic inference, we empower AI to be both innovative and dependable. The path forward for developers, leaders and CAIOs is clear: integrate knowledge and governance into the fabric of AI systems from day one. In doing so, we create autonomous systems that earn our trust – not by asking us to watch them tirelessly, but by operating within the boundaries of what we define as correct. This approach turns automation bias on its head: rather than humans having blind faith in the machine, we’ve given the machine a strict fidelity to human knowledge. And that, ultimately, is how we ensure that our AI ‘co-pilots’ never fly solo into danger, but instead deliver results we can reliably stand behind.
By recognising the illusion of the co-pilot safety net. and replacing it with built-in safety through. knowledge graphs and symbolic inference,. we empower AI to be both innovative and dependable.


TAARYN HYDER is a data strategy and transformation leader with over 20 years of global experience in financial services, spanning the UK, US, and Pakistan. She has successfully designed and led large-scale operations, technology, and data programs, delivering measurable impact across business intelligence (BI), data governance, self service analytics, and digital transformation.
As a Certified Data Management Professional (CDMP) and an advocate for data democratisation, Taaryn helps organisations break down silos, simplify complexity, and embed data-driven cultures that power smarter, faster decision-making. She specialises in BI design, governance frameworks, and enterprise-wide data strategies, ensuring businesses move beyond data management to data empowerment.
As Founder & CEO of Quadra Analytics, Taaryn brings a 360° approach to data strategy, integrating People, Process, Technology, and Culture to drive real, lasting impact. She works with organisations to turn data into an accelerator for execution – faster insights, sharper decisions, and greater agility in an everevolving landscape.
In an era defined by continuous disruption, enterprise agility is no longer a strategic edge, it’s a matter of organisational survival. Organisations are under constant pressure to pivot on demand, respond to rapidly evolving market conditions, and drive constant innovation. These demands extend across every sector, from finance and healthcare to manufacturing and retail. The promise of digital transformation and AI-powered analytics has been widely embraced, yet enterprises still find themselves unable to adapt and unlock the full potential of their investments. We often hear the
Data democratisation is the process of making data and data products accessible to everyone in an organisation, regardless of technical expertise..
following conversations in boardrooms and corporate strategy sessions: ‘Slow ROI on data investments,’ ‘low adoption of new technology solutions,’ and so on. The key to understanding these issues is that agility isn’t just about tools and technology. It is about how people use them. That brings us to a powerful but often overlooked catalyst and driver for enterprise agility: data democratisation.
The term data democratisation gained popularity in the early 2010s, driven by the rise of self-service BI tools which enabled non-technical users to access and analyse data independently. Data democratisation is the process of making data and data products accessible to everyone in an organisation, regardless of technical expertise. It is not about being in IT or on a data team; it is about whether you have the
right information, when you need it, to do your job effectively. Historical data dissemination models were led by central IT teams/data teams, who were qualified technical experts in their respective fields and confined to technical silos. However, as the volume, variety, and velocity of data grew exponentially, centralised data and IT teams began to face significant challenges. The traditional model, where all data requests flowed through a single department, became a bottleneck, slowing down decision-making and innovation. These teams simply could not scale fast enough to meet the growing demand for real-time insights, customised data products, and ad hoc analysis across the business. This disconnect highlighted the need for a more decentralised, selfservice approach to data access and usage.
Organisational agility demands the ability to swiftly sense, interpret, and act on change; an absolute necessity in today’s fast-evolving, technology. driven world.
At the heart of this agility is data, and. more critically, the democratisation of that data..
Data in recent years has evolved into a shared enterprise asset, accessible across roles and functions; data democratisation improves data accessibility to end users of data products to empower them to make data-driven decisions. It augments the speed of decision-making within an organisation by optimising the information flows and pivoting from a reactive to a proactive information management ecosystem. Far from being a buzzword, data democratisation now represents a fundamental pivot in how organisations empower their workforce to make better decisions, faster. It is about making data not just accessible, but actionable, and doing so at scale. When everyone in the organisation, not just IT teams or data scientists, can independently access insights and apply them to their work, decisionmaking accelerates, innovation becomes decentralised, risk becomes manageable, and responsiveness becomes part of the DNA of the organisation. Organisations that get this right are not just data-driven, they are insightenabled and embody the essence of enterprise agility. They can respond quicker to changes and stimuli in both their internal and external operating environments.
Organisational agility demands the ability to swiftly sense, interpret, and act on change; an absolute necessity in today’s fast-evolving, technology-driven world. At the heart of this agility is data, and more critically, the democratisation of that data. By breaking down silos and making information accessible across all roles and functions, organisations gain the power to detect early signals, synchronise their responses, and pivot in real time. Data democratisation shifts decisionmaking from a centralised bottleneck to a distributed, agile process rooted in shared insights. This shift is not just beneficial, it is essential, empowering teams to move with speed, accuracy, and targeted strategic focus.
Data democratisation stands on three foundational pillars: accessibility, data literacy, and governance, each individually essential to transforming data from an underleveraged asset into a strategic enabler of enterprise agility and innovation.
The first, accessibility, is about eliminating friction and putting actionable data directly into the hands of those who need it, without bottlenecks or dependency on specialists. It means creating seamless, on-demand access to trusted, relevant data through intuitive, role-specific tools. For instance, in a logistics company, warehouse supervisors can view real-time shipment delays and adjust routes on the fly through geo-enabled dashboards. In a global consumer goods firm, brand managers can drill into regional sales trends and social sentiment live, allowing rapid campaign adjustments based on what is actually happening on the ground. This kind of accessibility is made possible through self-service platforms, embedded analytics, enterprise-wide data catalogues, and federated access models that ensure consistency, transparency, and trust at scale.
The second, data literacy, bridges the gap between access and action. It is not enough for people to have data, they must know how to read it, question it, and use it to drive decisions. Elevating data literacy to a leadership imperative is critical for success. Comprehensive and structured training programs should embed data-driven thinking into every stage of the employee lifecycle – from onboarding to performance evaluations. Organisations that celebrate curiosity, experimentation, and insight-driven innovation cultivate an empowered workforce. Creating vibrant internal communities of practice and hosting data storytelling workshops helps build a shared language and deepens understanding of data concepts across teams. A well-trained HR business partner should be able to spot attrition risks in a workforce dashboard and partner with leaders to intervene early. A frontline customer support lead should be able to analyse complaint categories to inform product feedback loops. Organisations embed data literacy through targeted upskilling for e.g., a bank conducting data bootcamps for business users, or a healthcare system training clinicians to interpret population health analytics. In these organisations, data isn’t the domain of a few, it becomes a shared language of execution and insight across the organisation.
Last, but certainly not least, governance is essential to prevent data democratisation from descending into chaos or creating compliance risks. Its purpose isn’t to obstruct, but to provide invisible guardrails that enable fast, confident, and responsible decision-making at scale. Governance must be
reframed as a catalyst for trust and agility rather than a bureaucratic obstacle. Automation can be used to scale management of data access, lineage, and quality, while clear data ownership should be assigned with dedicated stewards across domains. Everyone in the organisation must understand and respect the rules of engagement. Transparent policies around ethics, privacy, and responsible AI usage build confidence and accountability throughout the data ecosystem. In financial services, this might mean using automated, role-based access controls to ensure analysts see trends, not personal data. In the public sector, it could involve audit trails and data lineage to support transparency without compromising integrity.
Together, these three elements don’t just support data democratisation, they operationalise it, scale it, and embed it into the fabric of an agile, data-driven enterprise. When data democratisation is in place, decisions move closer to the edge, where the action is. Teams can iterate rapidly without waiting for approvals or static reports, and feedback loops shorten, enabling strategies to adapt in near real-time. IT and analytics teams are freed from routine operational support and can instead focus on innovation and long-term value creation. In this environment, data becomes a living, breathing part of the organisation – not a static report or an inaccessible warehouse. Agility thrives when individuals across the business feel empowered to act, when marketing analysts adjust campaigns on the fly based on real-time engagement metrics, when operations managers shift resources to meet sudden surges in demand, and when product teams A/B test and iterate without waiting for quarterly reviews. That is the agility advantage that
democratised data delivers, enabling organisations to move not just fast, but smart.
While the path to data democratisation is full of promise, it is also paved with persistent, complex challenges. Although the goal is to make data accessible, usable, and valuable across the enterprise, the journey demands more than just modern tools and infrastructure. It requires organisations to confront deep-rooted cultural, technical, and organisational barriers with a deliberate, cross-functional strategy. One of the most entrenched obstacles is cultural resistance. Historically data has been controlled by a few roles; typically IT, analytics teams, or leadership. This concentration of control has created a guarded, risk-averse approach to sharing information. Shifting that mindset is difficult. Longstanding hierarchies, siloed behaviours, and even fears around data misuse or loss of authority often stand in the way of open access. However, democratisation is not about relinquishing control, it’s about empowering better decisions at every level. Leaders must model this shift by making data-informed decisions visible and consistent, and by reinforcing that shared data leads to shared success.
At the same time, technical fragmentation also continues to be a major roadblock. Most enterprises operate within a patchwork of legacy systems, cloud platforms, and bespoke tools, none of which were specifically designed to work together. As a result, data is trapped in silos, buried in incompatible formats, or locked inside departmental dashboards. Even when the technology exists to bridge these divides, the lack of integration, metadata consistency, and self-service accessibility makes democratisation feel out of reach

for most non-technical users. Without an intentional data architecture and investment in modern, userfriendly platforms, access remains uneven, and adoption remains low.
Equally critical is the role of leadership. Without strong executive sponsorship, data democratisation initiatives often stall or remain confined to isolated pilot programs. Leaders must treat data democratisation as a strategic priority, not a technical upgrade. This means allocating resources, removing systemic barriers, and making clear the connection between open data access and business performance. When executives use data transparently to make decisions and communicate outcomes, they set the tone for the entire organisation.
Another often-overlooked barrier is the absence of shared standards. When teams define key performance indicators (KPIs) differently, use inconsistent terminology, or rely on disconnected tools, it becomes impossible to align around a single source of truth. Conflicting reports and misaligned definitions create confusion and erode trust. To succeed, organisations must establish enterprise-wide data governance, shared definitions, standardised metrics, and a common data language that ensures everyone interprets and acts on data consistently.
Successfully embedding data democratisation requires more than deploying systems. It requires a comprehensive change management approach, one that builds data literacy at every level, fosters curiosity, and embeds data thinking into the organisation’s DNA. Training programs, role-based learning journeys, and continual reinforcement help employees gain both the confidence and capability to engage with data meaningfully. More importantly, organisations must dismantle outdated beliefs and habits. They must cultivate an environment where experimentation is encouraged, transparency is standard, and data is seen as a shared asset, not a proprietary one.
In essence, the human factor – the behaviours, mindsets, and incentives within an organisation –are the most critical and intangible dimensions of data democratisation. While technology opens the door, it is culture that sustains adoption and drives impact. Managing this cultural shift thoughtfully and intentionally is arguably the most challenging task, but it is also the most essential. Ultimately, the true measure of a data-driven organisation is not its tech stack – it is the ability to make decisions with agility, precision, and confidence. Data teams must align their strategies with business priorities, focusing on solving real problems and delivering measurable value. Central to this vision is democratisation: giving individuals at every level access to timely, trusted, and actionable insights.
Despite major investments in dashboards, analytics, and cloud infrastructure, organisations still struggle to make timely, data-informed decisions. Teams may wait
days for reports. Business users rely on centralised data teams to translate raw data into insights. Operational decisions are often based on outdated or incomplete information. This is not just a failure of technology, it is a failure to recognise that data democratisation is, at its heart, a cultural transformation. Too often, organisations fixate on the tools, purchasing stateof-the-art platforms and securing software licenses without asking more fundamental questions like: Are we ready? Are our people truly prepared to adopt, embrace, and sustain this change? Tools may enable access, but they cannot guarantee impact. Real transformation begins by changing the way people think, behave, and work with data.
The path to enabling agility through data begins with anchoring democratisation firmly in business strategy. Organisations must identify the critical decision points where faster, more informed choices will create measurable value, whether that means driving revenue growth, improving customer retention, enhancing operational efficiency, or ensuring regulatory compliance. Data initiatives need to be directly aligned with these strategic priorities to deliver meaningful impact. Building a scalable, user-centric self-service architecture is the next vital step. Selecting analytics platforms designed with the end-user in mind is essential. Intuitive features like natural language queries, drag-and-drop visualisations, and embedded analytics reduce technical barriers, increasing adoption across all levels of the organisation. It is equally important that these platforms are cloud-native and mobile-ready to empower a hybrid and distributed workforce, enabling seamless access to data anytime and anywhere.
In essence, the human factor – the behaviours, mindsets, and incentives within an organisation –are the most critical and intangible dimensions of. data democratisation..
Across industries, data democratisation is already driving significant impact. In financial services, relationship managers leverage self-service dashboards to tailor products and services based on regional customer insights, improving satisfaction and retention. In healthcare, clinicians and administrators access real-time data to personalise care pathways, optimise staffing, and improve patient outcomes. Retail store managers adjust merchandising and pricing strategies dynamically using localised, real-time demand data. Insurance fraud detection teams use pattern recognition tools to proactively mitigate risk exposure. Manufacturing production teams analyse sensor data from the shop floor to minimise downtime and maximise output. In the public sector, policymakers and civil servants rely on integrated data hubs to make
evidence-based decisions that enhance citizen services. Measuring what truly matters helps organisations track their progress toward agility. Metrics such as time-toinsight, reduction in report backlog, tool adoption rates, and user satisfaction reveal real advances. Monitoring cross-functional collaboration and the ability to pivot strategies quickly are additional indicators of success. Regular maturity assessments help identify gaps and guide continuous improvement, making agility a tangible, measurable outcome.
In every case, democratised data accelerates decision-making, shortens feedback loops, and delivers better results. This is not just a theoretical ideal, it is a critical enabler of enterprise agility. In a world defined by volatility, speed, and complexity, the ability to respond to change hinges on how quickly and confidently teams across the organisation can access and act on high-quality data. Democratisation breaks down traditional silos, moving intelligence from the hands of a few to the fingertips of many, empowering business users, frontline teams, and decision-makers to adapt in real time. It fosters a culture of proactive problem-solving, informed experimentation, and distributed ownership. Agility doesn’t happen in isolation; it thrives on trusted, accessible, and actionable data. Organisations that recognise this link and operationalise it through deliberate strategy and inclusive governance will not only survive disruption, they’ll drive it.

Accenture. (2021). The Human Impact Of Data Literacy www.accenture.com/us-en/insights/strategy/human-impact-data-literacy BCG. (2022). The Data-To-Value Journey www.bcg.com/publications/2022/data-to-value-journey
Gartner. (2023). Data Democratization: What It Is And Why It Matters www.gartner.com/en/articles/data-democratization-what-it-is-and-why-it matters
Harvard Business Review. (2020). Why Data Culture Matters hbr.org/2020/02/why-data-culture-matters
IBM. (n.d.). Data Democratization Strategy For Business Decisions. IBM Think Blog. www.ibm.com/blogs/think/2020/12/data-democratization-strategy/ Legner, C., Eymann, T., Hess, T., Matt, C., Böhmann, T., Drews, P., ...& Ahlemann, F. (2021). Data Democratization: Toward A Deeper Understanding . ResearchGate. doi.org/10.13140/RG.2.2.20400.84486
McKinsey & Company. (2017). The Five Trademarks Of Agile Organizations. www.mckinsey.com/business-functions/organization/our-insights/the-fivetrademarks-of-agile-organizations
McKinsey & Company. (2019). The Journey To An Agile Organization www.mckinsey.com/capabilities/people-and-organizational-performance/our insights/the-journey-to-an-agile-organization
McKinsey & Company. (2021)
Data-Driven Transformation: Accelerate At Scale Now www.mckinsey.com/business-functions/mckinsey-digital/our-insights/datadriven-transformation
McKinsey & Company. (2022). The Data-Powered Enterprise Of 2025 www.mckinsey.com/business-functions/mckinsey-digital/our-insights/the-datapowered-enterprise-of-2025
McKinsey & Company. (2023) How To Unlock The Full Value Of Data? Manage It Like A Product www.mckinsey.com/capabilities/mckinsey-digital/our-insights/how-to-unlockthe-full-value-of-data-manage-it-like-a-product\
MIT Sloan Management Review. (2019) To Succeed With Data, Start With The Right Culture sloanreview.mit.edu/article/to-succeed-with-data-start-with-the-right-culture/ Torry Harris Integration Solutions. (2022)
Data Democratization: Empowering Ai & Business Insights Through Architecture www.torryharris.com/insights/blogs/data-democratization-empowering-ai-andbusiness-insights-through-architecture
ANTHONY ALCARAZ

ANTHONY ALCARAZ is AWS’s Senior AI/ML Strategist for EMEA Startups and specialises in helping earlystage AI companies accelerate their development and go-to-market strategies. Anthony is also a consultant for startups, where his expertise in decision science, particularly at the intersection of large language models, natural language processing, knowledge graphs, and graph theory is applied to foster innovation and strategic development. Anthony’s specialisations have positioned him as a leading voice in the construction of retrievalaugmented generation (RAG) and reasoning engines, regarded by many as the state-of-the-art approach in our field. He’s an avid writer, sharing daily insights on AI applications in business and decision-making with his 30,000+ followers on Medium. Anthony recently lectured at Oxford on the integration of artificial intelligence, generative AI, cloud and MLOps into contemporary business practices. intelligence, generative AI, cloud and MLOps into contemporary business practices.
The race to build autonomous AI agents that can reliably plan, reason, and act in the real world is heating up. Tech companies are investing billions in developing systems that can go beyond answering questions to becoming trusted digital assistants that handle complex tasks with minimal human supervision.
Two technological approaches have dominated this pursuit: vector-based retrieval (like RAG systems) for accessing knowledge, and expanding context windows in large language models to process more information at once. Both approaches seem intuitive – they give AI systems more information and more capacity to process it, and surely they’ll become more capable agents.
But recent research reveals concerning limitations that challenge these assumptions. Far from being engineering problems that will vanish with scale, these issues represent fundamental bottlenecks that could prevent current approaches from ever achieving reliable agency.
Let’s dive into what this means for the future of AI agents and what alternatives might offer a more promising path forward.
The race to build autonomous AI agents. that can reliably plan, reason, and act in. the real world is heating up..
THE SURPRISING FRAGILITY OF VECTOR-BASED RETRIEVAL
When companies build AI agents that need to access specific information – like your organisation’s documents, knowledge base, or specialised data – they typically use what’s called a vector-based retrieval system. The idea is simple: convert both the user’s query and all documents into mathematical vectors, then find the documents whose vectors are most similar to the query vector.
This technique, often called retrieval-augmented generation (RAG), works impressively well in demos and controlled settings. But what happens when we scale to real-world conditions?
Research by EyeLevel.ai reveals a startling reality: vector-based retrieval accuracy drops by up to 12% when scaled to just 100,000 pages – a tiny fraction of the data that enterprise systems regularly handle. Their alternative approach, which doesn’t rely exclusively on vector similarity, maintained much better performance with only a 2% degradation at the same scale.
Why does this happen? The culprits are fundamental mathematical limitations:
The curse of dimensionality: As vector spaces grow, distance metrics become less meaningful
Vector space crowding: Semantically different concepts end up occupying similar regions in vector space
Encoder limitations: Current models struggle to capture nuanced semantic distinctions at scale
For an AI agent trying to make decisions based on your company’s data, this degradation isn’t just an inconvenience – it’s potentially catastrophic. An agent that misses 12% of relevant information could miss critical context for important decisions.
Perhaps even more concerning is what researchers call the ‘associativity gap’ – the inability of vectorbased systems to form transitive relationships across multiple documents.
Here’s a simple example: Document A establishes that Project X depends on Component Y. Document B mentions that Component Y is experiencing supply chain delays. A human would immediately connect these dots and realise Project X is at risk. But vectorbased retrieval systems struggle with this kind of reasoning.
Why? Because vector similarity primarily identifies direct matches, not logical connections. When
ANTHONY ALCARAZ
information is distributed across separate entries in a knowledge base, vector similarity alone fails to construct the logical chain, preventing AI agents from making crucial inferential leaps.
This limitation directly undermines one of the most valuable potential capabilities of agents: making connections across domains that might not be obvious even to specialised human experts.
Another surprising vulnerability emerges when we look at how these systems handle linguistic variations – the natural differences in how humans express themselves.
Research on the Fragility to Linguistic Variation demonstrates that minor variations in query formulation can cause up to 40.41% drops in retrieval performance. Even small changes in formality, readability, politeness, or grammatical correctness significantly degrade system performance.
For example, asking ‘What’s the capital of France?’ versus ‘Could you kindly tell me the capital city of France, please?’ should produce identical results, but often doesn’t in current systems. These errors cascade from the retrieval component to the generation component, making RAG systems particularly vulnerable to the natural linguistic diversity present in real-world interactions.
For agents designed to serve diverse user populations, this represents a fundamental accessibility problem.
Many have proposed that expanding context windows – allowing AI models to process tens or hundreds of thousands of tokens at once – could solve these retrieval problems by simply feeding entire documents directly into the model.
But research using the NOLIMA benchmark reveals that even state-of-the-art models like GPT-4O show dramatic performance degradation in longer contexts, dropping from 99.3% accuracy to 69.7% at just 32K tokens. This degradation becomes even more pronounced when models must perform non-literal matching or handle distracting information.
The problem gets worse when models need to make multi-step connections. In the research, two-hop reasoning tasks (requiring connecting multiple pieces of information) showed especially severe performance drops as context length increased.
Simply put, dumping more information into a longer context window doesn’t solve the fundamental limitations in how these models process and connect information.
These findings have profound implications for anyone working on autonomous AI agents. Let’s consider how these limitations impact key agent capabilities:
When an agent cannot reliably trace causal chains or logical dependencies across multiple documents, it cannot effectively decompose goals into coherent action sequences. This fundamentally undermines the agent’s ability to formulate complex, multi-step plans – a core requirement for meaningful agency.
Agents relying on these technologies might appear competent on simple tasks but would fail catastrophically when faced with complex planning scenarios requiring information synthesis.
Agentic systems need ‘working memory’ to maintain understanding across interactions. The identified ‘contextual amnesia’ problem in vector-based systems prevents agents from reliably integrating historical context with present situations.
For agents, this means an inability to maintain consistent understanding across conversations or tasks with varying linguistic styles – a fatal flaw for systems meant to serve diverse users or operate in environments where information is expressed in different ways over time.
3.
In enterpris e environments, the ‘knowledge isolation’ problem manifests as an inability to connect information across organisational boundaries. A truly autonomous agent would need to recognise, for instance, that a production delay (manufacturing domain) affects financial projections (finance domain).
Vector-based systems struggle with these connections because these domains exist in different semantic spaces. This directly undermines one of the most valuable potential capabilities of agents: making cross-domain connections that might not be obvious to specialised human experts.
4.
Perhaps most concerning is how the se limitations compound in uncertain or ambiguous scenarios. The research shows that vector-based retrieval is highly vulnerable to distracting information that shares keywords with the query but is semantically irrelevant.
This vulnerability becomes particularly problematic as context length increases – precisely the scenario where agents would theoretically benefit most from expanded context windows.
ANTHONY ALCARAZ
So if current approaches have these fundamental limitations, what alternatives might offer a more promising path forward? Several approaches show potential:
Several researchers suggest that structured data modelling approaches (like knowledge graphs) might address many limitations of vector-based systems. By explicitly representing entities and relationships, these approaches enable more reliable complex reasoning and are less sensitive to linguistic variations.
When information is structured as entities and relationships rather than raw text, the system can focus on the underlying meaning rather than surfacelevel word similarities.
Combining vector-based retrieval with structured knowledge representation likely offers more robust foundations for agency than either approach alone. The vector component provides flexibility and broad coverage, while the structured component enables reliable reasoning across domains.
The development of retrieval systems specifically designed to be robust against linguistic variations appears crucial for reliable real-world deployment. This might involve preprocessing queries to standardise format, or using multiple retrieval strategies in parallel.
Perhaps most immediately, we need evaluation methods that specifically test for robustness against linguistic variation, distractor elements, and complex reasoning requirements. Current benchmarks may significantly overstate system capabilities for agentic applications.
The evidence strongly suggests that both vectoronly retrieval and long-context models have significant fragilities that make them problematic foundations for agentic systems. These aren’t simply engineering challenges to be overcome with more data or computing power, but represent fundamental limitations in how these systems process and connect information.
For anyone developing or deploying AI agents, these findings should serve as a reality check. The path to truly capable agents likely requires looking beyond simply scaling existing approaches. It demands fundamentally new ways of representing and reasoning with knowledge – approaches that can handle the associative reasoning, linguistic diversity, and complex planning that human intelligence manages effortlessly.
The good news is that awareness of these limitations opens up opportunities for innovation. By acknowledging the constraints of current approaches, researchers and developers can focus on creating the next generation of AI systems that overcome these fundamental bottlenecks.
The race to build truly capable AI agents isn’t just about who can deploy the largest models or ingest the most data – it’s about who can solve these core reasoning challenges that sit at the heart of artificial intelligence.
[The path to truly capable agents] demands. fundamentally new ways of representing and reasoning with knowledge – approaches that can handle the associative reasoning, linguistic diversity, and complex planning that human intelligence manages effortlessly..

ANTHONY NEWMAN

A NTHONY NEWMAN is a mathematician and chartered engineer with over two decades’ experience in AI. He’s dedicated his career to AI, machine learning, and intelligent data product development, often in conjunction with sensor technologies. He’s worked in diverse sectors, from military research and international retail to medtech and F1. For the past decade, Ant has specialised in developing intelligent data product strategies for organisations, focused on data and AI-driven delivery methodologies that prioritise measurable outcomes for competitive advantage. Passionate about democratising data and AI insights, Ant is a member of the Project Data Analytics Task Force, a cross-industry body providing thought leadership, advocating for collaborative frameworks and acting as a spotlight in the information clutter. As an autistic professional, Ant harnesses his different perspectives to problem-solving and, especially, pattern recognition. He advocates for inclusivity in data teams, recognising how diverse cognitive approaches strengthen innovation and analytical thinking.
What if our entire understanding of productivity is fundamentally flawed?
Right now, I am in the UK. It’s 4am on a Saturday morning, and I’m about to start writing this article. Does this seem unusual to you?
For me, it’s normal. My normal. Last night I went to bed at 10pm, exhausted from my week. I awoke at 2am, chatted with my partner Sharòn in the USA, and now she’s heading to bed whilst I grab a cup of tea and start writing.
For many others, there are
countless different ‘normals’ that jar with majority perception. But when these rhythms collide with workplace expectations, we often punish excellence whilst rewarding conformity.
Several years ago, my best data scientist never seemed to do any work at the office. They’d range from doing nothing to playing games, but come sprint end: boom! Fantastic work, delivered flawlessly.
This was before discussing neurodiversity became career-safe. It took my open admission of being autistic before they felt safe to share
that they were also neuro-spicy, with crippling social anxiety. Monday mornings were torture.
‘Ant, when someone asks how my weekend was, how do I know when to say “Fine, thanks” versus when to engage more?’ They’d recently treated a colleague’s announcement of a personal tragedy like small talk. They didn’t intend to be dismissive and were aghast at and confused by the upset that resulted.
This higher anxiety was suddenly too much for them. I suggested a working holiday in Thailand. They found an isolated beach hut with
good WiFi and finished their twoweek sprint in under four days, then asked for more work. My best data scientist had just become 150% more productive. They soon left permanently to work from beaches worldwide and remained my most productive team member.
This story illustrates a broader pattern. The productivity systems that failed my colleague aren’t unique to one company; they’re embedded in how we’ve constructed modern work itself. This is the contradiction at the heart of modern productivity culture: we’ve built systems that reward the appearance of productivity whilst often punishing the actual thing itself.
Here’s the thing: the productivity assumptions that govern modern workplaces aren’t natural laws; they’re historical accidents we’ve mistaken for universal truths. To understand why our current systems feel broken, we need to trace their origins back to a world that no longer exists.
The 9-to-5 schedule emerged from 19th-century factory work, designed around machinery that needed consistent operation and workers whose output could be measured by hours at a station. Factory owners needed bodies present to operate equipment during specific hours. This made perfect sense when human labour was mechanical: pull a lever, turn a wheel, monitor a gauge. Physical presence directly correlated with productive output. Simple.
And here’s where it starts to get a bit surreal… The obsession with immediate email responses mimics the industrial telegraph system, where rapid communication was genuinely time-critical. When factories coordinated shipments across continents, or traders needed to capitalise on price differences between markets, minutes mattered.
The person who could respond fastest to changing conditions gained a competitive advantage. This urgency became embedded in the infrastructure of commerce. There are still situations like this, of course, but it’s really not every situation.
It gets worse. Open-plan offices were borrowed from factory floors, optimised for supervision rather than deep thinking. Managers needed to see their workers to ensure they were operating machinery correctly and safely. The visual oversight that prevented industrial accidents became the template for knowledge work, despite thinking requiring privacy rather than surveillance. Brilliant.
Even our promotion structures follow manufacturing hierarchies, where managing more people meant managing more machines. The supervisor who oversaw ten workers was naturally more valuable than one who oversaw five. This linear progression from individual contributor to people manager reflected industrial reality: more complex operations required more coordination.
We’ve inherited this entire industrial operating system and installed it onto knowledge work, then wondered why it feels broken. But knowledge work operates on completely different principles. Ideas don’t flow on assembly lines. Innovation doesn’t happen on schedule. Creative breakthroughs can’t be supervised into existence. It’s like trying to run modern software on a 1950s computer.
Complex problem-solving requires sustained focus, not fragmented attention across eight hourly intervals. Yet here we are, still pretending that watching people type equals productivity.
The tragedy is that we’ve clung to these systems long after their original purpose disappeared. We no longer coordinate physical machinery or manage telegraph networks, yet we’ve preserved the
Creative breakthroughs can’t be. supervised into existence. It’s like. trying to run modern software on a 1950s computer.
work patterns these technologies demanded. It’s as if we decided that because horses were once the fastest form of transport, all cars should be limited to the speed of a galloping horse. [Insert brain exploding emoji in your mind.]
This industrial inheritance explains why so many brilliant minds struggle in modern workplaces. We’re not failing at industrial productivity, we’re succeeding at it whilst pretending we’re doing knowledge work. The systems aren’t broken; they’re perfectly designed for a world that mostly no longer exists. The problem in a nutshell.
THE HIDDEN CASUALTIES: WHEN DIFFERENT MEANS ‘BROKEN’
The human cost of our industrial inheritance isn’t distributed equally. Those whose minds work differently bear the heaviest burden, creating predictable casualties that reveal the true inefficiency of our ‘onesize-fits-all’ systems.
The numbers alone should shock us into action. Neurodivergent adults face unemployment rates of 30-40%, three times higher than people with physical disabilities and eight times higher than the general population. These statistics aren’t about capability or potential. They’re measurements of systemic failure.
The mismatch between neurotypical workplace demands and neurodivergent brains creates predictable casualties. Employees with ADHD experience ‘hyperfocus burnout’ where their natural rhythm of intense focus periods followed by recovery clashes with expectations of consistent eight-hour daily productivity. Research documents cases where individuals can only work 20 hours a week for years after burnout episodes, remaining highly sensitive to work stress. The

We no longer coordinate physical machinery or. manage telegraph networks, yet we’ve. preserved.the work patterns these. technologies demanded.
prevalence of clinically significant fatigue is around 18% in the general population but as high as 54% among adults with ADHD.
Autistic employees face different but equally damaging challenges. Those who need processing time before meetings get labelled ‘slow’ or ‘difficult’ in cultures that value immediate responses. The workplace environment itself becomes an assault: fluorescent lighting, ringing phones, open-plan chatter. Sensory stimulation overwhelms, and if not regulated by the individual, can cause shutdowns where they become unresponsive or need to retreat, often misunderstood as rudeness or disengagement.
Even today, a third of neurodivergent people feel they can’t disclose their condition at work, and 10% have been met with poor responses when they do. We learn to ‘mask,’ exhausting ourselves by performing palatably for eight hours daily. The cognitive load of constant camouflage leaves us depleted, affecting performance and mental health.
The cascade effects are devastating. Time blindness makes it difficult for ADHD employees to
estimate how long tasks will take, leading to overcommitment and subsequent shame cycles. Executive function deficits contribute to emotional exhaustion, cognitive weariness, and physical fatigue, key components of job burnout. The ‘broken’ narrative becomes self-fulfilling. Intelligent, capable people start believing they’re fundamentally flawed because they can’t succeed in systems designed for different brains.
Many compensate by working evenings and weekends to perform on par with colleagues, leading to chronic stress and occupational burnout. They internalise failure that isn’t theirs, accepting underemployment or leaving careers entirely. Despite job postings mentioning neurodiversity keywords tripling from 0.5% to 1.3% between 2018 and 2024, only 29% of senior leaders have received any neurodiversity training. We’re creating the appearance of inclusion whilst maintaining exclusionary practices.
This isn’t just an individual tragedy, it’s organisational stupidity. Research shows that autistic professionals can be up to 140% more productive than average employees when properly matched to roles that fit their skills. Yet we’re
systematically excluding them, then wondering why innovation stagnates and talent pipelines remain shallow. We’re not failing to accommodate difference; we’re actively punishing excellence that doesn’t conform to outdated templates.
Rather than forcing square pegs into round holes, what if we redesigned the holes? The neurodivergentfriendly productivity models emerging across innovative workplaces aren’t just more humane, they’re more effective for everyone. They represent a fundamental shift from measuring compliance to optimising performance.
Instead of demanding consistent daily output, forward-thinking organisations recognise that human attention has natural rhythms. Some companies now structure projects around ‘seasonal’ intensities, periods of deep focus followed by lighter maintenance work. This mirrors how ADHD brains naturally operate, with hyperfocus sprints followed by necessary recovery. Instead of fighting these patterns, smart managers harness them, scheduling complex problem-solving during peak attention periods whilst using lower-energy times for routine tasks.
The traditional eight-hour day fragmented by meetings and interruptions is productivity theatre at its worst. Alternative models prioritise deep work blocks, three to four-hour periods of uninterrupted focus that allow for meaningful progress. For neurodivergent employees who can hyperfocus, these blocks become supercharged productivity sessions. One software company found that developers produced more high-quality code in a single deep work session than in three days of traditional ‘collaborative’ work.
ANTHONY NEWMAN
The tyranny of immediate response expectations crumbles when organisations embrace asynchronous communication. Instead of instant Teams replies, teams use thoughtful email/Teams exchanges, some recorded video updates, and most collaborative documents that allow for processing time. This isn’t slower, it’s more thoughtful. Decisions improve when people can reflect rather than react. Autistic employees who need time to formulate responses might suddenly become the most insightful contributors rather than the ‘slow’ ones.
Open-plan offices are productivity killers for everyone, but especially devastating for those with sensory sensitivities. Innovative workplaces provide choice: quiet focus rooms, collaboration spaces, and everything in between. Noisecancelling headphones become standard equipment, not special accommodations. Natural lighting replaces harsh fluorescents. These changes don’t just help neurodivergent employees; they create calmer, more productive environments for all.
Traditional success metrics assume linear progression, consistent performance, and standardised achievement patterns. But breakthrough innovations rarely emerge from fast thinking; they come from deep thinking. When someone takes three days to respond to a complex proposal, we label them ‘slow.’ When that response reveals
strategic insights others missed and prevents costly mistakes, suddenly the speed metric seems irrelevant.
The most valuable contributions often happen in solitude, the deep analysis, the creative breakthrough, and the systematic debugging that requires uninterrupted focus. While others tick boxes on to-do lists, some minds naturally see entire ecosystems, spotting patterns across departments and identifying unintended consequences before they manifest. The employee who questions the project brief might seem ‘difficult,’ but if they prevent six months of work in the wrong direction, they’ve created more value than the entire team’s collective output.
Success becomes multidimensional: impact over income, sustainability over speed, authenticity over performance. The question changes from ‘How quickly can you climb?’ to ‘What unique value can you create?’ When we measure what actually matters, different kinds of minds don’t just succeed – they redefine what success means.
These aren’t ‘special accommodations’; they are optimal working conditions that neurotypical assumptions have obscured. When we design for neurodivergent needs, we accidentally create better systems for everyone. Quiet spaces help all employees focus. Flexible schedules accommodate working parents and night owls alike. Deep work blocks benefit anyone doing complex thinking. What appears to be accommodation for the few actually optimises performance for the many.
Leading companies aren’t embracing neurodivergent. talent out of charity;.they’re doing it because it delivers. superior results..
PROOF IN PRACTICE: COMPANIES GETTING IT RIGHT
The business case for neurodiversity isn’t theoretical; it’s measurable, repeatable, and a competitive advantage. Leading companies aren’t embracing neurodivergent talent out of charity; they’re doing it because it delivers superior results. The numbers don’t lie.
Microsoft’s Neurodiversity Programme, celebrating its 10th anniversary in 2025, has expanded from software engineering to AI, Azure, Windows, Xbox, finance, customer support, and marketing. In 2024, they expanded to data centres nationwide. This isn’t accommodation, it’s systematic competitive advantage through cognitive diversity. They’re not being nice. They’re being smart.
Sap’s
SAP’s Autism at Work programme employs over 215 individuals across 16 countries, with neurodivergent team members demonstrating 90% to 140% productivity relative to peers. The programme maintains a 90% retention rate whilst colleagues on the autism spectrum significantly contribute to patent applications and innovations across SAP’s product portfolio. That’s not charity work. That’s pure business brilliance.
JPMorgan Chase’s results are stark: neurodivergent employees were 48% more productive within six months compared to established colleagues. In tech roles, they demonstrate 90% to 140% comparative productivity, clearing work queues with zero errors. Teams including neurodivergent members produce 1.2x to 1.4x the output of traditional teams. These aren’t feelgood statistics. They’re performance metrics that would make any CFO weep with joy.
The pandemic proved what neurodivergent employees had long argued: when you remove environmental barriers and provide flexibility, productivity soars for everyone. EY more than tripled its neurodivergent workforce from 80 to nearly 300 employees during this period. What COVID proved was that the accommodations neurodivergent employees requested – flexible schedules, remote work, and asynchronous communication – weren’t special needs. There were better ways of working that improved performance across the board. Suddenly, everyone got it.
Companies embracing neurodiversity don’t just hire different people; they build better processes, create more flexible systems, and develop thoughtful management practices benefiting everyone. The cost savings from retention rates alone continue to save money and time. This isn’t about corporate social responsibility; it’s about competitive survival. And frankly, it’s about time.
trying to fit neurotypical templates. When negotiating accommodations, frame them as productivity optimisations. Don’t ask for ‘special treatment’, propose performance enhancements. Request deep work blocks for complex projects, asynchronous communication for thoughtful contributions, or flexible schedules aligned with your peak cognitive hours. Present these as business solutions, not personal needs.
Challenge every productivity assumption your team inherited. Question why meetings must be live, why responses must be immediate, and why everyone must work the
Audit your productivity culture for neurotypical bias. Review job descriptions for unnecessary specificity, interview processes for social performance over capability, and performance metrics for conformity over contribution. Design inclusion from the ground up rather than retrofitting accommodation onto exclusionary systems.
Invest in neurodiversity training that goes beyond awareness to capability building. Partner with neurodivergent-led organisations for authentic insight rather than neurotypical interpretations of neurodivergent needs. Measure inclusion through retention, productivity, and innovation metrics, not just hiring numbers.

The evidence is overwhelming: neurodivergentfriendly practices don’t just help some employees, they optimise performance for everyone. The question isn’t whether to embrace this shift, but how quickly we can make it happen.
Stop apologising for working differently. Instead, lead with value. Document your productivity patterns, when you do your best work, what conditions enable peak performance, and what measurable results you deliver. Build a portfolio of your unique contributions rather than
same hours in the same space. Sometimes it’s required, sometimes it’s not. Experiment with seasonal project intensities, focus time, and results-based performance metrics. Develop new management skills: how to give clear, direct feedback; how to distinguish between preference and necessity in team processes; how to leverage diverse thinking styles for better outcomes. Create psychological safety where different working patterns are assets, not liabilities. Environments where your employees feel safe to come forward, and you can reap the benefits.
As markets become more complex and innovation cycles accelerate, organisations need every cognitive advantage available. Companies that continue optimising for neurotypical productivity theatre whilst competitors harness neurocognitive diversity will find themselves disadvantaged. The future belongs to organisations that recognise human potential comes in many forms. By embracing the full spectrum of human cognition, we don’t just create more inclusive workplaces; we build more innovative, resilient, and ultimately successful organisations. The choice isn’t whether to change, but whether to lead or follow this inevitable transformation.
The evidence is overwhelming: neurodivergent-friendly practices don’t just help some employees, they optimise performance for.everyone..

THE SCOUT NEVER SLEEPS –AI RECONNAISSANCE
In the modern theatre of war, the scout is no longer a lone figure in camouflage crawling through the underbrush. Today, it’s a neural network riding aboard a drone, a language model parsing intercepted signals, or an algorithm silently watching hours of satellite video. The battlefield’s ‘eyes and ears’ have gone digital – and they never blink. Artificial intelligence, once a buzzword in Silicon Valley, has become a decisive edge in military reconnaissance and surveillance. At the heart of this transformation is a convergence of computer vision, pattern recognition, and natural language processing technologies, each tuned not for consumer convenience but for operational superiority. Take drones, for example. These
airborne machines have become synonymous with modern warfare. But what happens when a single drone collects more video than a team of analysts could possibly watch? Enter object detection models like YOLO and ViT – cuttingedge AI tools that can instantly distinguish tanks from trucks, civilians from combatants, or even real weapons from clever decoys. These aren’t just passive cameras –they’re thinking machines, trained to make split-second judgments.
FRANCESCO GADALETA is a seasoned professional in the field of technology, AI and data science. He is the founder of Amethix Technologies, a firm specialising in advanced data and robotics solutions. Francesco also shares his insights and knowledge as the host of the podcast Data Science at Home His illustrious career includes a significant tenure as the Chief Data Officer at Abe AI, which was later acquired by Envestnet Yodlee Inc. Francesco was a pivotal member of the Advanced Analytics Team at Johnson & Johnson. His professional interests are diverse, spanning applied mathematics, advanced machine learning, computer programming, robotics, and the study of decentralised and distributed systems. Francesco’s expertise spans domains including healthcare, defence, pharma, energy, and finance.
Artificial intelligence, once a buzzword in. Silicon Valley, has become a decisive edge. in military reconnaissance and surveillance.
What’s more, these AI systems don’t operate in isolation. Military platforms increasingly integrate multi-sensor fusion, blending inputs from radar, thermal imaging, and visual feeds into a single stream of insight. This enables what military technologists call ‘edge AI’ – onboard computing that processes data in real time, without needing to call home. If latency means the difference between spotting a threat or missing it, edge AI ensures the machine gets the first look.
But seeing is only half the story. The real strategic value lies in prediction. Modern AI systems are now being used to model patterns of life, identifying not just what is happening, but what might happen next. By analysing satellite imagery over time, algorithms can detect the subtle rhythms of supply chains, troop movements, or the quiet preparations that precede an offensive. When those rhythms shift unexpectedly, the AI flags it. It’s the algorithmic equivalent of a hunch –except it’s drawn from petabytes of data and days of reconnaissance. And then there’s the information war happening far from the front lines – in the electromagnetic and digital realms. Signals intelligence (SIGINT) and open-source
intelligence (OSINT) have exploded in volume. Social media videos, intercepted radio chatter, public satellite feeds – all of it is data, and all of it is being fed into large language models. These AI systems, cousins of the chatbots now helping with homework or writing emails, are instead helping military analysts summarise battlefield movements, identify likely codewords in intercepted communications, and even assess the psychological tone of enemy broadcasts.
In Ukraine, we’ve seen these technologies leap from lab to live action. AI-enhanced drones have mapped troop positions; language models have parsed thousands of Telegram messages to geo-tag video footage; military dashboards have quietly begun surfacing AI-generated alerts for decision-makers. Whether in support of conventional forces or asymmetric groups using low-cost drones and open-source software, the digital scout has arrived.
Yet for all the precision and promise, these systems raise pressing questions. Can they be trusted under pressure? What happens when an AI misidentifies a threat – or worse, generates a convincing but false prediction? And who is accountable when decisions are based on machine inferences?
In warfare, the observer shapes the battle. Now that the observer is artificial, tireless, and fast evolving. As we continue this exploration into AI’s role in defence, the next frontier awaits: when machines don’t just watch the battlefield, but act on it.
It’s no longer a question of whether machines can pull the trigger. It’s a question of whether they should –and under what circumstances. As artificial intelligence takes on more decision-making power in combat, we find ourselves navigating a spectrum of autonomy where oversight is not always guaranteed.
FRANCESCO GADALETA
In, On, or Out of the Loop? Defence systems today fall into three categories:
1| Human-in-the-loop systems require manual approval before any lethal action. Think drone pilots authorising a missile strike after visual confirmation.
2| Human-on-the-loop systems can act on their own, but a human has the authority to intervene – if they’re paying attention and if time allows.
3| Human-out-of-the-loop systems identify, select, and engage targets autonomously. No human interaction, no override, no delay.
This last category is no longer science fiction. In environments where communications are jammed or latency is too great – say, in remote or contested airspace –systems must act instantly, or not at all. And so, they act.
Despite official policies and international directives calling for ‘meaningful human control’, necessity often pushes the line. Once a system has the capability to act autonomously, the only thing stopping it is software policy – or battlefield urgency. Both can be overridden.
As these capabilities evolve, the ethics shift. It’s no longer a question of: can an AI make a kill decision? The harder question is: If it does, and it’s wrong, who pays the price?
TARGET IDENTIFIED, FIRE AUTHORISED
This is not hypothetical. Autonomous or semi-autonomous systems with lethal capabilities are already active and effective.
The Hunter-Killers
Often dubbed ‘kamikaze drones’, loitering munitions combine surveillance, target acquisition, and strike into one package.
The Switchblade 300 and 600, developed in the U.S., are compact and portable. They can hover for up to 40 minutes, scan the terrain, and use onboard AI to recognise hostile vehicles or personnel.
A loitering munition that targets radar signals goes further: once launched, it needs no human approval to strike. It detects, selects, and destroys radar installations completely autonomously. In these cases, the human role ends at launch.
These systems collapse the traditional kill chain into a single actor. No need for separate reconnaissance, command, and fire teams. The drone sees and shoots in one fluid action, at algorithmic speed.
Ground-Based
It’s not just drones. Ground-based systems are catching up. Enter Selective Ground Response AI (SGRAI), a term covering a class of AIdriven response systems.
Picture this: a mobile ground robot patrols a contested village at night. It’s equipped with Lidar, infrared sensors, and thermal imaging. It’s trained to recognise human behaviour: distinguishing civilians from aggressors by posture, movement, and the presence of weapons. It’s programmed with strict rules of engagement – only fire if approached while armed, do not engage unless fired upon, sound a warning before action.
It can make all these decisions on its own.
As we continue this exploration into AI’s role. in defence, the next frontier awaits: when machines don’t just watch the battlefield, but act on it.
One of the most talked-about systems is South Korea’s SGR-A1 sentry gun, deployed along the DMZ. It can detect and
track targets, assess threat levels, and fire without human approval. Policy currently keeps a human in control, but the capability for full autonomy is built in.
As more militaries experiment with neural nets, confidence thresholds, and embedded rules of engagement, we’re seeing the rise of systems that not only fire but also reason.
This leads to one of the thorniest problems of AI warfare: accountability.
International humanitarian law (IHL) rests on three foundational principles:
1| Distinction – You must differentiate combatants from civilians.
2| Proportionality – Civilian harm must not outweigh military advantage.
3| Accountability – Someone must be responsible for violations.
But with AI in the loop – or worse, out of it – who is responsible when things go wrong?
What if an algorithm misclassifies a teenager with a toy gun as a hostile insurgent? There’s no human operator to doublecheck, no pilot to hesitate. The decision is embedded in code. Is the commander liable? The developer? The procurement officer?
Critics argue that handing over lethal authority to machines risks creating a system with no culpability. That’s why advocacy groups like the Campaign to Stop Killer Robots are pushing for a preemptive global ban on fully autonomous weapons.
Others argue that properly constrained AI could actually reduce civilian casualties – machines don’t panic, don’t get tired, and don’t pull the trigger out of fear or vengeance.
The debate is far from
FRANCESCO GADALETA
settled. The United Nations has convened multiple discussions on lethal autonomous weapons systems (LAWS). But no binding international treaty currently limits their development or deployment. And the major powers – Russia, China, the United States – are pressing forward.
One compromise gaining traction: explainable autonomy. These are AI systems designed not just to act, but to explain why they acted. If a drone engages a target, it also generates a decision trail – sensor input, classification confidence, and rules matched. This could enable postaction audits and accountability.
But explainability is still in its infancy. And in the meantime, the battlefield keeps accelerating.
The shift we’re witnessing isn’t just technological – it’s conceptual. Warfare is no longer just fought by soldiers following orders. It’s increasingly conducted by systems executing logic.
Kill chains are becoming compressed. Human decisionmaking is becoming conditional. The burden of judgment is shifting – from officers and commanders to neural networks trained on data from past wars.
This raises not only moral and legal questions, but strategic ones. What happens when two autonomous systems face off, each locked in an algorithmic arms race? What if escalation is triggered not by a human mistake, but by a flawed line of code?
As militaries around the world push forward, one truth becomes clear: In the next war, software may be the most lethal weapon of all.
The Rise of the Drone Swarm
Imagine a sky blackened not by storm clouds, but by hundreds – perhaps
thousands – of autonomous drones moving as a single, intelligent entity. No central controller. No master algorithm dictates their every move. Just a decentralised, self-organising swarm, capable of reconnaissance, electronic warfare, and precision strikes with terrifying efficiency. This isn’t science fiction. It’s the next evolution of warfare, and it’s already being tested by the world’s most advanced militaries.
Traditional drones rely on human operators or centralised AI. Swarms are different. They operate like flocks of birds or colonies of ants –no leader, just simple rules guiding complex behaviour. Three key methods make this possible:
1| Consensus Algorithms –Drones ‘vote’ on decisions by sharing data with neighbours. If most agree on a flight path or target, the swarm follows. This ensures resilience – lose a few drones, and the rest adapt instantly.
2| Leader-Follower Dynamics –A few drones (leaders) know the mission objective, while the rest mimic their movements. If leaders are destroyed, new ones emerge dynamically.
3| Behaviour-Based Robotics –Each drone follows basic rules: avoid collisions, stay close to the group, match speed with neighbours. Together, these rules create fluid, adaptive formations.
The result? A swarm that doesn’t just follow orders – it thinks as a collective.
Surviving the Electronic Battlefield
Swarms don’t just face bullets and missiles – they operate in an invisible war of signals. Jamming, spoofing, and GPS denial are constant threats. So, how do they stay connected?
1| Ad-Hoc Mesh Networks – Each drone acts as a relay, creating a self-healing web of communication. Lose a node, and the swarm reroutes instantly.
2| Low-Probability-of-Intercept (LPI) Comms – Instead of broadcasting on one frequency, drones ‘hop’ across hundreds per second, making them nearly impossible to jam.
3| Opportunistic Synchronisation –If GPS fails, drones use visual cues (like blinking LEDs or infrared signals) to stay in sync.
The lesson? A well-designed swarm doesn’t just survive electronic warfare – it thrives in chaos.
China vs. the U.S.: Two Paths to Swarm Dominance
Different doctrines shape how nations deploy swarms:
● China’s ‘Wolf-Pack’ Strategy –Overwhelm enemies with sheer numbers. At the 2020 Zhuhai Airshow, China showcased swarms of fixed-wing drones launching from trucks, designed to saturate air defences and strike from all angles.
● U.S. DARPA OFFSET Program –Focused on urban warfare, OFFSET envisions 250+ drones and ground bots working together – breaching doors, clearing buildings, and adapting to dynamic threats in real time.
FRANCESCO GADALETA
One favours brute force. The other is precision. Both are redefining modern combat.
Nature’s Blueprint: Flocks, Ants, and AI
The most fascinating aspect of drone swarms? They borrow from biology:
● Flocking Algorithms –Bas ed on Craig Reynolds’ Boids model (1986), drones mimic birds with just three rules: separate, align, and cohere. The result? Fluid, collision-free movement.
● Digital Pheromone s –
Like ants leaving scent trails, drones mark ‘virtual maps’ to guide teammates, highlighting enemy positions, safe routes, or danger zones.
● Collective Learning –Swarms share intel mid-mission. If one drone finds a target, the rest adapt instantly.
These techniques make swarms smarter over time – learning, evolving, and outmanoeuvring adversaries with eerie precision.
The Future: Autonomous Swarms in the Wild
The implications are staggering. Picture:
● A swarm disables an enemy air defence network before human pilots even take off.
● Hundreds of micro-drones are infiltrating a city, mapping every alleyway while evading detection.
● AI-driven ‘hive mind’ tactics where swarms split, merge, and adapt on the fly.
But with great power comes risk. What happens when a swarm misidentifies a target? Can we trust machines to make life-and-death decisions without human oversight? One thing is certain: the age of swarm warfare has arrived. And the battlefield will never be the same.
The shift we’re witnessing isn’t just technological –it’s conceptual. Warfare is no longer just fought by soldiers following orders. It’s increasingly conducted by systems executing logic.
REFERENCES
1 datascienceathome.com/dsh-warcoded-eyes-and-ears-of-the-machine-ai-reconnaissance-and-surveillance-ep-281
2 datascienceathome.com/dsh-warcoded-kill-chains-and-algorithmic-warfare-autonomy-in-targeting-and-engagement-ep-282
3 datascienceathome.com/dsh-warcoded-swarming-the-battlefield-ep-283
4 datascienceathome.com/dsh-warcoded-ai-in-the-invisible-battlespace-ep-284









