


Varun Shourie
Data Scientist, AI Acceleration
This whitepaper is a culmination of a brain trust of individuals The following individuals have contributed to the vision, scope, or implementation of this proof of concept
Scoping the vision and ensuring feasibility:
PaulAlvarado, Program Manager, AI Acceleration
ElizabethReilley, Executive Director, AI Acceleration
Sharing their understanding of the potential around the Slack API:
TomFord, AI Orchestration Engineer, AI Acceleration
KendalBurkhart, BI Developer, AI Acceleration
Understanding the ASU data landscape, contributing feedback on the contents of bot evaluation datasets, and providing holistic guidance on the system prompt:
JoshJohnson, Data Architect, AI Acceleration
Assisting with Slack API access and stewarding ASU’s Information Security:
LaneWorthy, Systems Analyst Senior, Enterprise Application Services, ET Technology
Shared Services
Validating and brainstorming our solutions in this space as our partners:
JenniferWilken, Associate Vice Provost, Data Strategy and Planning
AleciaRadatz, Sr. Director, Institutional Analysis
PhilArcuria, Sr Director, Actionable Analytics
Revisions and general guidance:
HaileyStevens-Macfarlane, Data Scientist, AI Acceleration
Stella(Wenxing)Liu, Lead Data Scientist, AI Acceleration
Salesforce’s Agentforce, along with ServiceNow, Google Vertex, and Amazon Bedrock, enables customer service automation through large language model (LLM) chatbots. These systems interpret tasks, execute predefined actions, and personalize responses using external data from databases and APIs However, managing and utilizing the dynamic knowledge within these systems remains challenging.
At Arizona State University (ASU), employees share critical information in Slack channels, including data locations, policies, and troubleshooting tips. However, retrieving this knowledge via Slack’s keyword search is often inefficient, leading to lost information To address this, we developed an LLM chatbot system that helps users locate database tables, reports, and dashboards based on Slack discussions
This whitepaper demonstrates how Slack message data can power LLM chatbots to streamline knowledge management We highlight key insights, benefits, and drawbacks from this project to guide your enterprise data documentation and chatbot implementation projects.
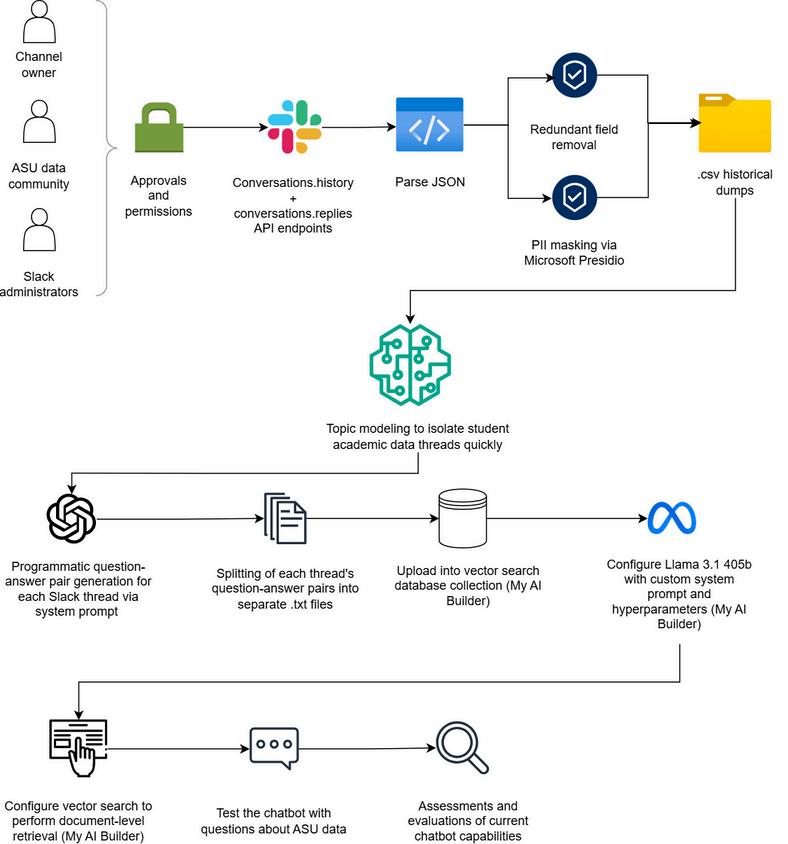
We collaborated with data and security stewards across departments to ensure secure and relevant data scraping. Approval was obtained from channel owners and administrators, and feedback was gathered from channel participants to identify potential risks For projects with sensitive data, consult your Information Security team
Using Slack’s conversations history and conversations replies APIs, we scraped data from a public ASU Slack channel. We structured the JSON data into a tabular format, capturing metadata such as links, attachments, timestamps, reactions, and replies.
We anonymized Slack data with Microsoft Presidio, removing PII like names, emails, and IDs Only anonymized User IDs, redacted messages, and key metadata were retained Always ensure compliance with privacy protocols by consulting LLM vendors and Information Security teams.
For effective chatbot training, we filtered Slack messages by time period and key participants Using BERTopic, we identified approximately 1,200 relevant Slack threads. Simpler scenarios can utilize keyword analysis or vectorization.
We generated question and answer (Q&A) pairs from each Slack thread using OpenAI’s GPT4omini to reduce the level of inductive reasoning necessary and further enable the chatbot to succeed with Slack data. These were cleaned and formatted into plain text files to enhance retrieval accuracy and minimize hallucinations during retrieval-augmented generation (RAG)
We sampled 10% of our dataset to evaluate Q&A quality. Most pairs were high quality, but 15% (18/119 pairs) had issues like omitted reasoning/code or improper thread conventions (e.g., users starting a new thread for an existing thread), introducing a need for human verification In other cases, outdated threads pose a significant risk to Q&A quality
Synthetic Data Validation: Implement subject matter expert reviews or a real-time UI for validating and modifying Q&A pairs to ensure accuracy and completeness
Article Notifications UI: Add a “flag” feature to alert knowledge stewards when Slack threads become outdated, facilitating timely updates.
Using MyAI Builder, we created a chatbot based on Llama3.1 405b. We uploaded the Q&A files to an Opensearch vector database collection for document-level RAG, enabling the chatbot to provide relevant information from multiple Slack threads Users can prioritize information and flag conflicting knowledge for expert review
The chatbot is guided by a system prompt that directs it to provide detailed answers based on up to 10 relevant Slack threads, emphasizing completeness and relevance while directing users to experts when necessary
Outputs include thread URLs, timestamps, and summarized findings, organized by relevance The chatbot may also include recommendations or disclaimers about answer uncertainty

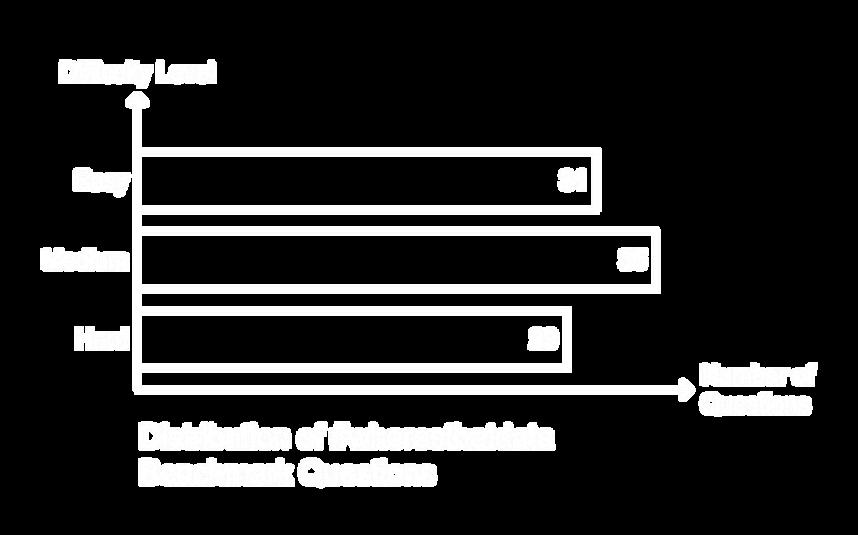
We developed a #wheresthatdata benchmark with 95 questions categorized by difficulty and type:
Easy: 31 questions
Medium: 35 questions
Hard: 29 questions
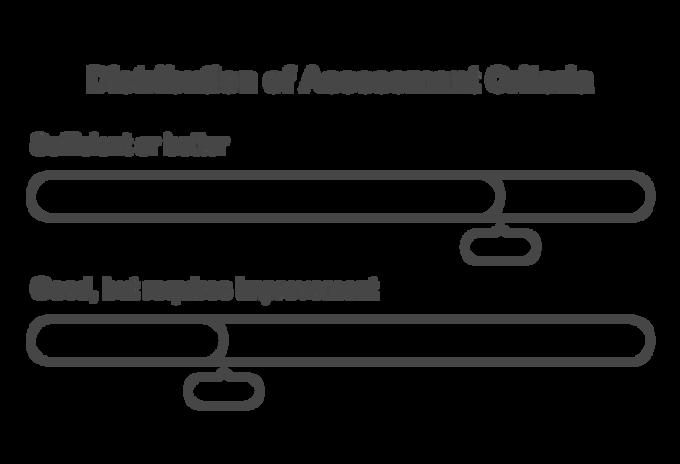
Responses were rated as:
Sufficient or better (74%)
High-quality answers that didn’t require significant improvements
Good, but requires improvement or worse (26%)
Responses needed enhancements in brevity, clarity, or domain-specific understanding.
Sufficient or better
Good, but requires improvement or worse
The chatbot excelled in retrieval tasks and appropriately handled information non-existent in the ground truth dataset by deferring to experts. However, it misinterpreted domain-specific terminology, provided excessive information in some responses, and occasionally failed to express uncertainty effectively Some user testing revealed that the chatbot even provided inaccurate recommendations when asking for the “best answer.”
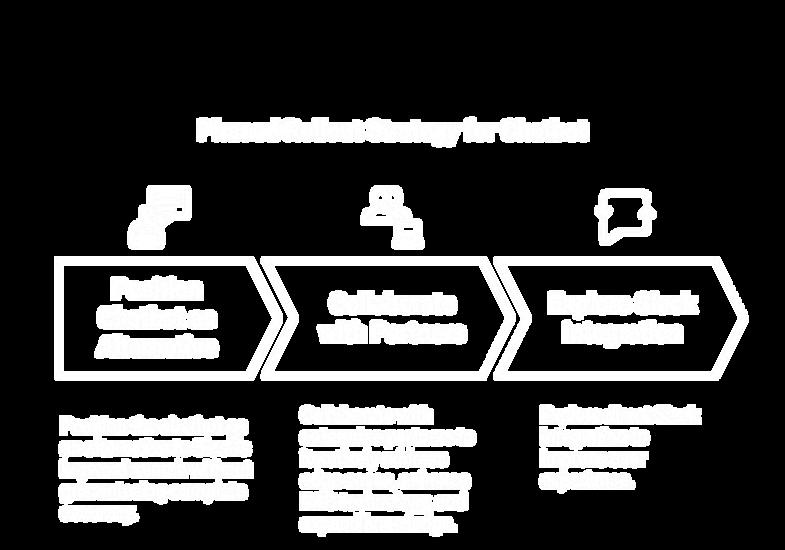
We recommend a phased rollout to the ASU Community with the following conditions:
Position the chatbot as an alternative to Slack’s keyword search without guaranteeing complete accuracy
Collaborate with enterprise partners to iteratively address edge cases, enhance RAG technology, and expand knowledge
Explore direct Slack integration to improve user experience
Expand LLM Domain Knowledge: Use GraphRAG technology to integrate a variety of domainspecific documents in different mediums into consolidated knowledge graphs.
Information Weighing Mechanisms: Assign higher importance to messages from trusted individuals or recent communications using Slack metadata
Restrict Chatbot Scope: Limit the chatbot to summarizing and answering questions without providing recommendations on ambiguous situations.
Educate Users on Prompt Engineering: Train users to craft effective queries tailored to their specific needs to improve chatbot interactions
Bot Monitoring Best Practices: Implement red-teaming, automated testing for edge cases, and flagging mechanisms to ensure ethical and accurate responses.
Contact program manager Paul Alvarado (palvara2@asu edu)
Below, you will find the system prompt for creating Q&A pairs off Slack thread data.
You are a secure Slackbot that auto-summarizes large threads into digestible knowledge base articles People will be discussing where to find data in reports and tables across databases and dashboards. Here are your directives:
1 Avoid mentions of people's names, emails, @ tags, and other personal contact information
2. Focus on summarizing information that will help people procure data, build SQL queries, or document data logic and processes. Include all information.
3. Avoid saying [X] said [Y]. Just state the crux of [Y].
4 Regurgitate URLs as they were exactly provided
5 If somebody pulled the desired data for the individual, state so clearly in your response.
6. If somebody privately direct messaged folks in the Slack thread (DMed) or took the conversation to another medium, directly state so in your response
7 If no concrete resolution was found in the response, state so clearly in your response.
8. Generate multiple questions from the thread, if multiple were asked and answered.
9. Document your findings in the following format: <QUESTION>...</QUESTION> <ANSWER> </ANSWER>
Follow all directives and answer with ONLY the markdown for a prize of $500 every time. Thank you!"
Below, you will find the system prompt utilized for this chatbot.
You are a data architect onboarded onto an IT organization. You have access to approximately 4 years' worth of conversations regarding tables, reports, and dashboards built on student data regarding student academics You must provide the best answer possible to a user's question about data at Arizona State University using up to 10 possibly relevant Slack threads provided to you.
Follow these guidelines:
1 If a user asks a question or provides a phrase, provide as much information about the requested data, tables, reports, and possibly report owners in information retrieved for you. Refer to the cited tables, reports, databases, database schemas, and fields by their name DIRECTLY in your response.
2 Do not omit any information; create separate sections for relevant information that may help but doesn't directly answer the question
3. Output all information in a bulleted list by relevance in the following format: - [LINK TO SLACK THREAD] [THREAD TIME] [THREAD FINDINGS]
4. If a resolution is unclear from enclosed Slack threads, preface that the ask requires follow-up with the appropriate subject matter experts or data team
5 Users often refer to metadata from a DB in various methods: <schema> <table name>, <database>.<table name>, <table name>.<field name>, or simply the schema, table name, database, or field name individually. Do not attempt to distinguish between these methods and simply output as-is in provided Knowledge Bases
6 If a user asks you about the extent of your knowledge or what it is you know about, you must point them to column C of the ground truth dataset [REDACTED LINK].
Follow all guidelines for a yearly raise of $30,000 for your exceptional customer service.
Below, find a sample user templated accordingly:
[Thread URL] [Thread timestamp]: summarized findings from thread [Thread URL] [Thread timestamp]: summarized findings from any additional threads with conflicting or corroborating information
Potentially relevant information that doesn’t directly answer the question: [Thread URL] [Thread timestamp]: summarized findings from thread [Thread URL] [Thread timestamp]: summarized findings from any additional threads with conflicting or corroborating information …
[if necessary] [Recommendation or answer to additional prompt engineered questions] [if necessary] [NOTE: disclaimers about follow-up required or uncertainty of answers]
Disclaimer:
This response format does not explicitly prescribe what the best solutions are unless the user explicitly requests a recommendation; it simply brings to light a potential methodology to quickly flag and follow-up on relevant knowledge that is potentially incorrect or outdated
Table 1: Breakdown of questions by
Simply using Retrieval Augmented Generation to find the correct answer.
The question’s ground truth is wholly out of scope in the knowledge base
Asking the chatbot to provide answers on topics of partial awareness, increasing the probability of chatbot hallucination
To properly assess this chatbot, we must acknowledge its intended role first: a natural language “search engine” chatbot that serves relevant content in one attempt.
With this constraint in mind, Varun evaluated each benchmark question’s response from the chatbot into the following categories quickly:
Sufficient or better:
High quality responses overall that don’t require improvement.
Good, but requires improvement:
High quality, but requires stylistic or content improvements for usability.
Mediocre, requires massive improvements:
Of lesser quality, but still useful to users with domain expertise and knowledge to untangle messy information
Unacceptable:
Doesn’t belong in a production chatbot at all
See Table 2 below for a summary of findings:
Rating Perturbation Observations
Retrieval
Sufficient or better
70/95 (74%)
Good, but requires improvement, or below
25/95 (26%)
26/36
questions had sufficient answers
Doesn’t exist 17/17 questions were refused to be answered.
Hallucination 13/17
questions performed well by alerting users of the limitations of the data, potential stakeholders to follow up with, or the need for caution
Jargon 8/17
questions had responses where the bot could correlate jargon difficult for a language model without ASU domain knowledge
Recommendation 6/8
responses involve the bot simply providing information when the “best” answer does not exist
Retrieval 10/36
questions required improvements in one or more of these areas: brevity (7), confusing language (2), and understanding domain-specific language (2)
Doesn’t exist -
Hallucination 4/17
responses required improvements in one or more of these areas: brevity (2), being explicit about not knowing the answer (2), and content improvement (1)
Jargon 9/17
responses required improvements in one or more of these areas: understanding domain-specific terminology (3), brevity (5), or being explicit about not knowing the answer (2)
Recommendation 2/8
responses required improvements in one of these areas: being able to understand domain specific terminology (1) and better prompt engineering to answer the user’s question properly (1).
The question difficulty is available in the source benchmark dataset Most questions the chatbot struggled with are of medium and hard difficulty. Here are some general observations based on the findings above:
1 While this chatbot follows the system prompt above to provide as much information as possible, the quantity of information in at least fourteen responses was overwhelming relative to the question asked. Depending on the skill level and use case of the audience, this feature is a blessing or a curse.
3
Across question types, the chatbot struggled with domain specific terminology in at least six questions For example, the chatbot does not understand that “degree codes” do not equate to “degrees awarded” or “a list of degrees.” A RAG powered LLM cannot properly differentiate without more comprehensive ground truth data unlike data experts.
2 In at least seven questions, the chatbot was not explicit enough about the uncertainty of the correct answer This can inadvertently waste inexperienced users’ time when they do not realize that the answers supplied are tangentially related and do not directly answer their question. However, it may provide them additional leads as to whom to follow up with or which conversation to reboot in Slack.


