
Stope & Pit Mine Planning

Stope & Pit Mine Planning
Geólogo
1. INTRODUCCIÓN
Se audita la importación de datos para la confección de pit shell geológico - estructural afectado por la intrusión de una red de vetas angostas en yacimiento tipo pórfido cuprífero. Modelamiento de tipo implícito usado como línea de base para la planificación corto plazo.
2. OBJETIVOS GENERALES
Brindar de información oportuna, calibrada y validada para las áreas de estimación (envolventes), geomecánica (optimización y diseño), tronadura (fragmentación a planta) y planificación corto plazo (polígonos)
3. OBJETIVOS ESPECÍFICOS
Crear plantas de actualización mensual de los desarrollos y bancos mapeados para las siguientes variables categóricas: litología, alteración, fracturamiento, estructuras, ore zone, techo del sulfuro (TDS), intensidad de sílice (crs), grade shell e índice de resistencia geológica (GSI).
4. MÉTODO DE TRABAJO
Se emplea una base de datos de sondajes con ensayos multi-elementos, agrupamiento de códigos litológicos considerando solo intervalos con recuperación de testigo y registro numérico de la temporalidad de unidades geológicas desde la más reciente a más antigua.
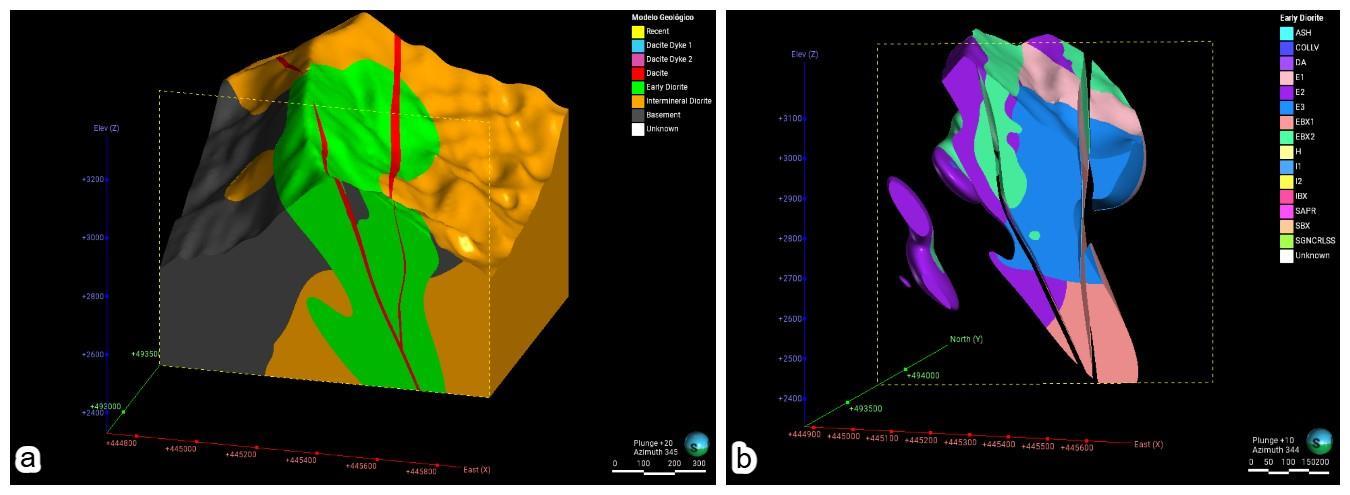
RBF. a) modelo geológico. b) agrupamiento de códigos en dominio diorita temprana.
La base de datos debe ser depurada eliminando inconsistencias para su validación, ya que el modelo depende de la calidad de los datos. Posteriormente, se realiza un análisis exploratorio (E.D.A.) para conocer la distribución de los leyes de cobre y oro, permitiendo seleccionar los valores numéricos (capping) y aplicarles los parámetros adecuados, según métodos de estimación
Un modelo numérico estima valores de una región importados desde la carpeta “puntos” o intervalos de sondajes agrupados para generar centroides. Es necesario aplicar un trend que defina dirección e intensidad mineral para delimitar isosuperficies con ajuste volumétrico.
Su construcción es un proceso iterativo, esto implica:
1) definición (topografía y límites).
2) refinar estructura interna (establecer trend y corrección de valores de puntos para ajuste de isosuperficies).
Por otra parte, la elección del interpolador dependerá del propósito del dominio:
1) interpolador RBF (función de base radial) para modelar dominios de isoleyes e identificación de target de exploración, donde se conoce muy bien el control mineralógico con gran densidad de sondajes.
2) Usar valores de contacto en sondajes convertidos a formato “categoría”.
3) RBF indicador. Genera isosuperficies cuyos valores no se ajustan a contactos en sondeos, por ejemplo:
a) mineralización diseminada que cruza varios contactos.
b) incertidumbre en agrupamiento de códigos.
c) asignar mena o ganga en venas que incorporan fragmentos de roca hospedante.
d) registro geológico deficiente.
6. ANÁLISIS ESTADÍSTICO DE DATOS
Para visualizar los valores de leyes se usa un mapa de colores discretos, basado en cuartiles e intervalos uniformes (Figura 5.1. a y b). Para correlacionar variables categóricas y cuantitativas se usan gráficos de fondo de pozo, valiéndose de la transformación log normal con el fin de observar claramente contenidos trazas (Figura 5.1. c).
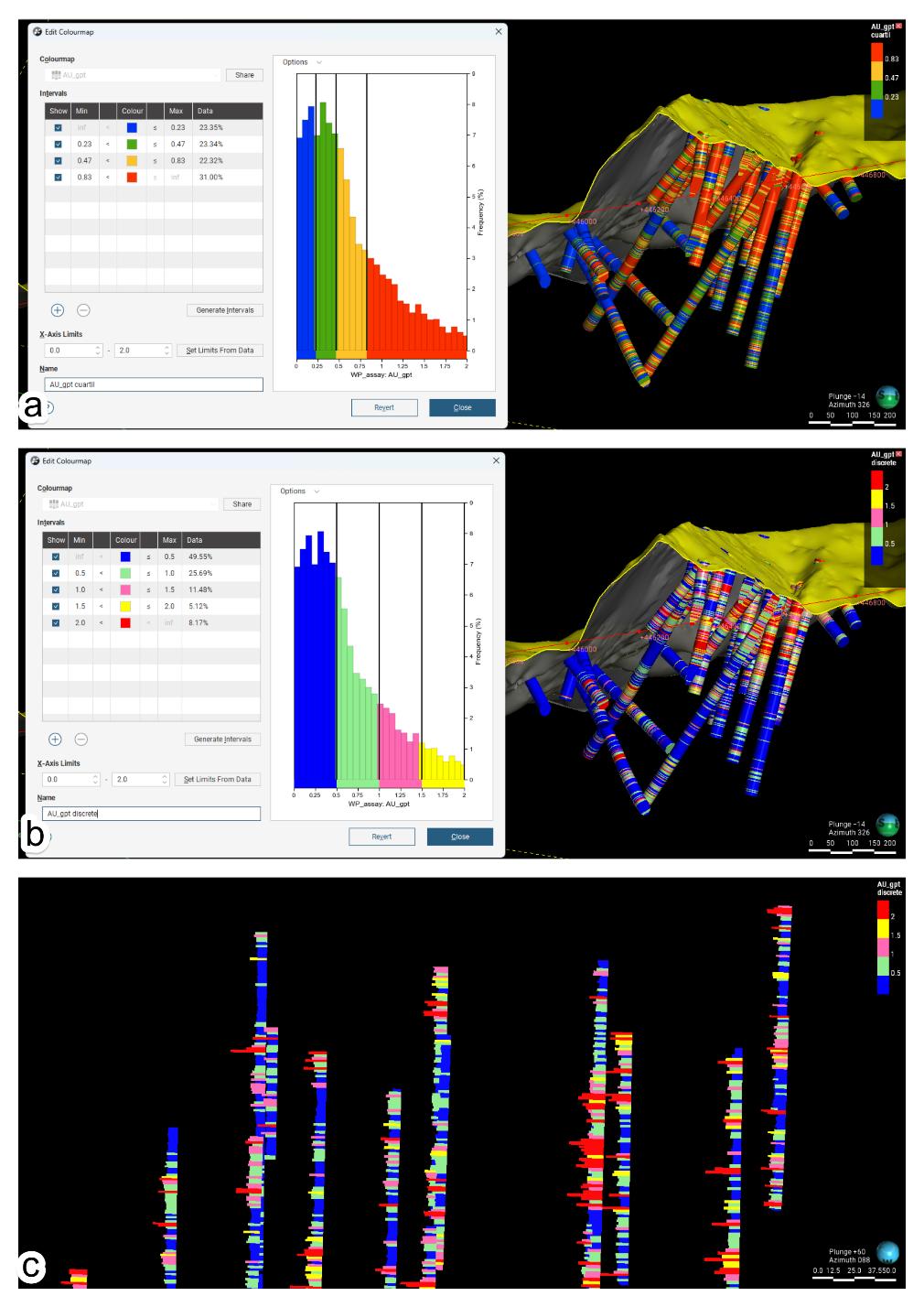
Figura 5.1. a) y b) evaluación estadística para discretización de leyenda. c) gráficos downhole
Se usan gráficas uni y bivariadas para E.D.A, con el fin de detectar outliers o clustered a partir de una tabla combinada Por ejemplo, analizar duplicados de terreno con las muestras originales (scatter plot, QQ plot) o comparar datos de ensayos de diversos laboratorios (box plot). Las estadísticas obtenidas se calculan por elemento.
La necesidad de controlar la cola definiendo un capping (top cut) se integran tipos de histogramas haciendo validación cruzada con box plot, QQ plot y variograma:
a) histograma normal o lineal para obtener un rango preliminar entre el cuerpo principal y la cola asociada a valores outliers.
b) histograma logarítmico para comprimir valores altos, revelar continuidad o quiebres y estabilidad de la cola.
c) histograma acumulativo para cuantificar cuántos datos se verán afectados.
El histograma lineal indica que posee una forma asimétrica positiva o sesgada a la derecha, caracterizada por una distribución no normal o lognormal común en leyes minerales donde un pequeño número de valores grandes empuja la media hacia arriba formando una cola larga hacia la derecha Su orden de menor a mayor es (moda, mediana y media). Esto sugiere que el fenómeno se forma por procesos multiplicativos asociados a eventos hidrotermales. La mediana o cuartil Q2 representa el valor típico
El ancho de intervalos se determinó mediante la regla de Freedman–Diaconis, asegurando una representación robusta de la distribución.

Tabla 1. Ecuación de Freedman - Diaconis para la determinación óptima del ancho de intervalo
Al usar un histograma lineal el ancho del bin es de 0.073 unidades, relativamente estrecho, pero coherente con un “n” grande de 8519 datos, mientras que el rango total de la variable Au_gpt, es el valor (mín – máx), obteniendo 597 barras, sin embargo, la mejor práctica es recalcular el número de bins en escala logarítmica resultando 72 intervalos con un ancho de 0.059 unidades.
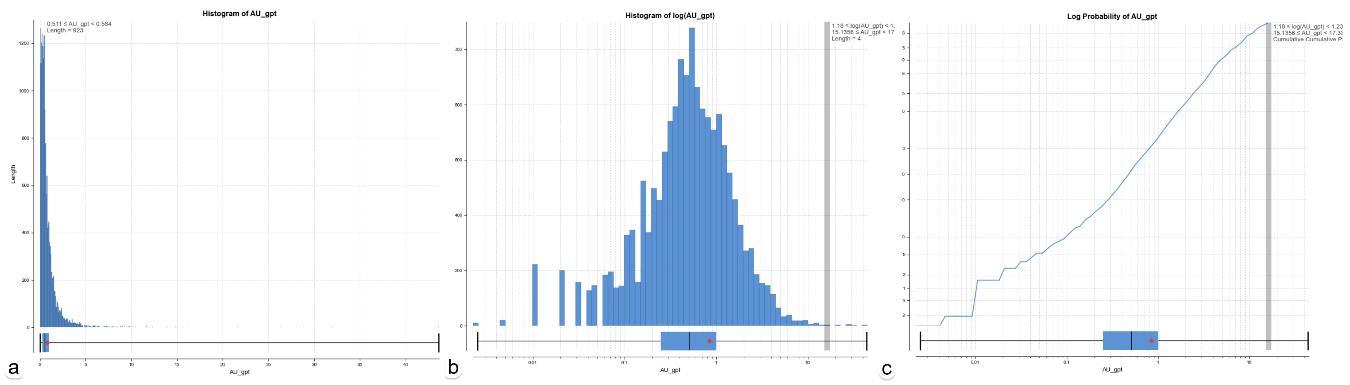
Figura 5.2. a) histograma lineal. b) histograma logarítmico. c) probabilidad acumulada logarítmica.
La mediana o Q2, corresponde a una ley de Au ~ 0.5 gpt, con un valor superior de la media representada por el punto rojo (figura 5.2.a). El histograma logarítmico muestra un quiebre de la cola con ley de Au 17 gpt (figura 5.2.b). Por último, el diagrama de probabilidad porcentual acumulada en escala logarítmica confirma un capping a los 17 gpt comprendiendo un 99% de los datos, identificado gracias a la formación de un sill de la función (figura 5.2.c).
También se puede examinar estadísticas para un dominio específico “Diorita inter-mineral” (figura 5.3 ).
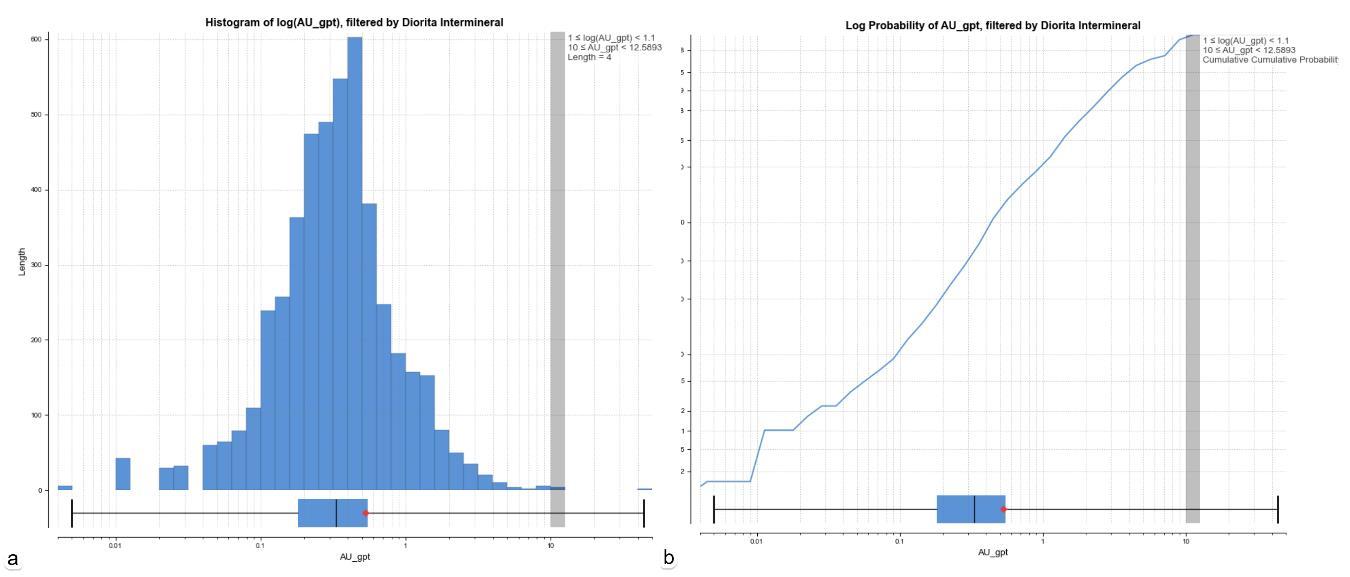
Figura 5.3 a) histograma logarítmico. b) probabilidad acumulada logarítmica.
En un análisis estadístico multivariable los elementos en escala logarítmica Au_gpt y Cu_gpt son seleccionados según dominios o un filtro de éste en un diagrama de dispersión o scatter plot (figura 5.4.)
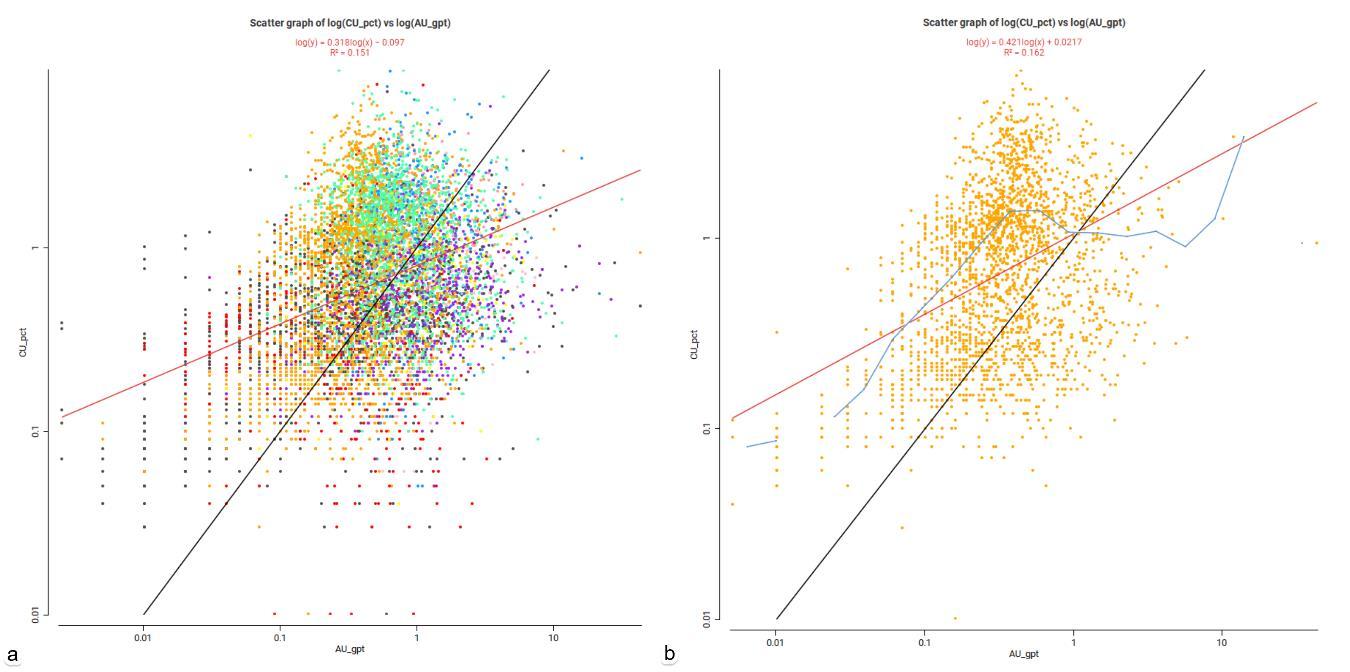
Figura 5.4. a) scatter plot multivariable. b) scatter plot en dominio “Diorita inter-mineral”
La recta de regresión ponderada en rojo se ajusta según soporte, es decir, por longitud de intervalo en sondajes, de esa manera se evita que muchos tramos cortos dominen el ajuste y sesguen la pendiente o bien, por volumen del bloque en un modelo de bloques hace que la recta refleje la relación por tonelaje Su uso se recomienda para modelos y reconciliación cuyo resultado busca representatividad y no un coeficiente de correlación (r) alto, en cambio, una recta de regresión no ponderada es útil para un QAQC simple por ser más sensible a outliers. La ecuación representa la mejor relación lineal promedio entre dos variables, es decir, como cambia en función de la otra considerando todos los datos disponibles, cuya línea o función minimiza el error total, por ejemplo, entre los valores estimados y observados (ley estimada “Y” versus ley de sondaje “X”), permite evaluar la coherencia del modelo, es decir, si posee sobrestimación o subestimación.
En la (figura 5.4. b) la recta de regresión muestra una pendiente positiva indicando una relación directa y un sesgo global según una pendiente débil a moderada de 0.421 distinta de 1, indicando un suavizado significativo ya que los valores altos de “X” no se reflejan en “Y”, existiendo pérdida de contraste y subestimación sistemática de valores. El coeficiente de determinación (R2) mide qué tan bien la recta explica la variabilidad Su valor R2 = r2 o coeficiente de correlación = (0.402)2 = 0.162 indica una fuerza de relación lineal muy débil, con presencia de una nube de puntos muy dispersa, por lo que solo explica un 16.2 % de la variabilidad.
El intercepto o valor esperado de “Y” cuando “X” = 0 basado en (log10) = 0.0217 es ligeramente positivo y muy pequeño indicando un sesgo aditivo despreciable La causa en los valores de tales métricas se genera por un efecto sin ponderación.
La baja correlación observada entre las leyes estimadas y los valores de sondaje se explica principalmente por diferencias de soporte, el efecto de capping y el suavizado inherente al kriging Al aplicar una regresión ponderada por longitud o volumen, la relación resulta más representativa del soporte físico de los datos, evidenciando que la baja correlación puntual es un comportamiento esperado y no un indicador de mala calidad del modelo.
La curva en expectación condicional en azul representa la media esperada de “Y” para cada valor, intervalo o bin de “X”, permitiendo identificar sesgos dependientes del rango y evidenciar el suavizado inherente al proceso de estimación en los tramos de muestreo en sondajes.
Por otra parte, el uso de box plot permite comparar diferentes dominios, sin embargo, la selección de la extensión de los bigotes en mínimo / máximo comprende el rango total de los datos, donde solo el límite exterior tres veces el rango intercuartil (RIC) e interior 1,5 veces el (RIC) son el modo para la identificación de outliers (figura 5.5).
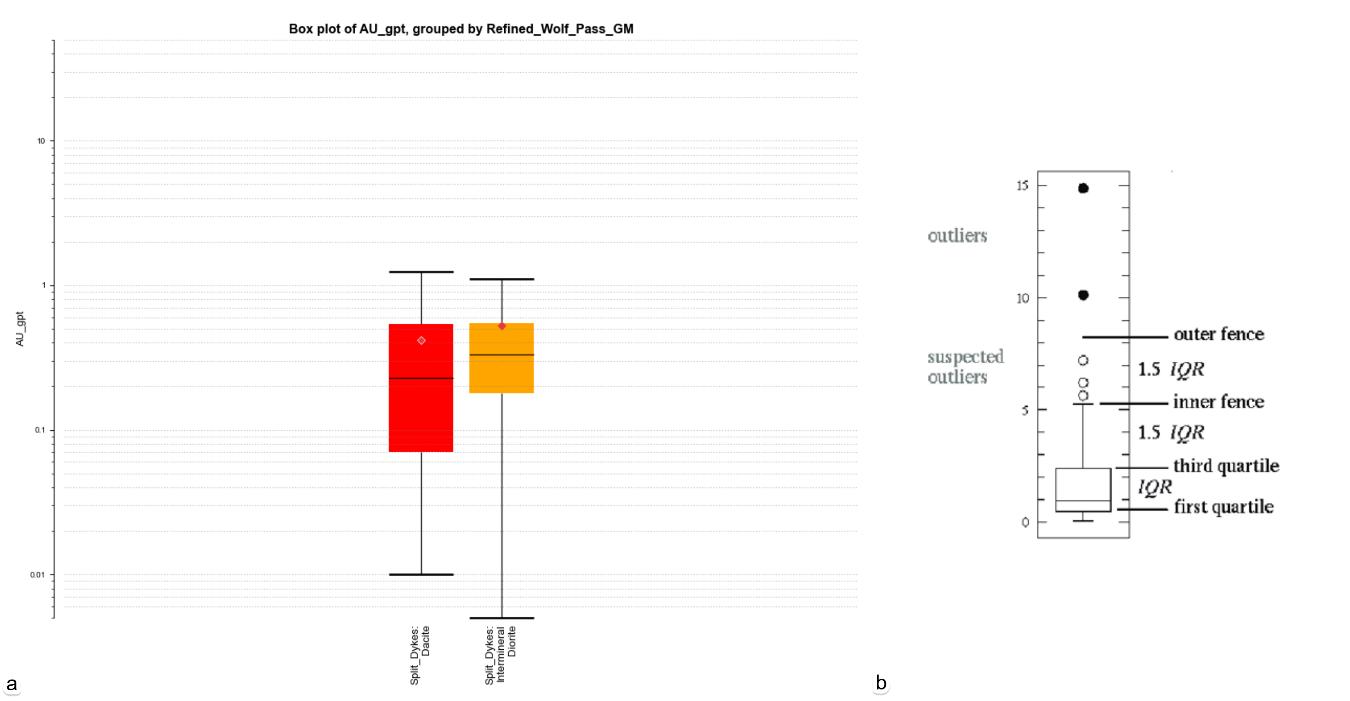
Figura 5.5. a) box splot con inner fence whiskers. b) modo de configuración de outliers
Los gráficos QQ o cuantil-cuantil, sirven para identificar si los datos siguen una distribución específica. En la (figura 5.6.) la línea de cuartil en azul informa sobre la distribución de los datos en comparación con la distribución teórica o ajuste ideal a la recta X = Y. Los datos no son normales ya que poseen una distribución asimétrica con colas desbalanceadas a la izquierda corta, centro bien calibrado y derecha pesada.
Los valores centrales se ajustan bastante bien a la línea de referencia, esto indica que los cuantiles medios son comparables entre ambos conjuntos o con la distribución teórica Según la escala logarítmica los valores bajos hacia el lado izquierdo están por sobre la línea de referencia indicando que lo observado es mayor a lo esperado generando una cola izquierda más comprimida con asimetría negativa, su desviación es sistemática y no aleatoria mientras que los valores altos hacia el lado derecho se desvían sobre la línea de referencia separándose progresivamente asociado a extremos altos (outliers), genera mayor variabilidad.
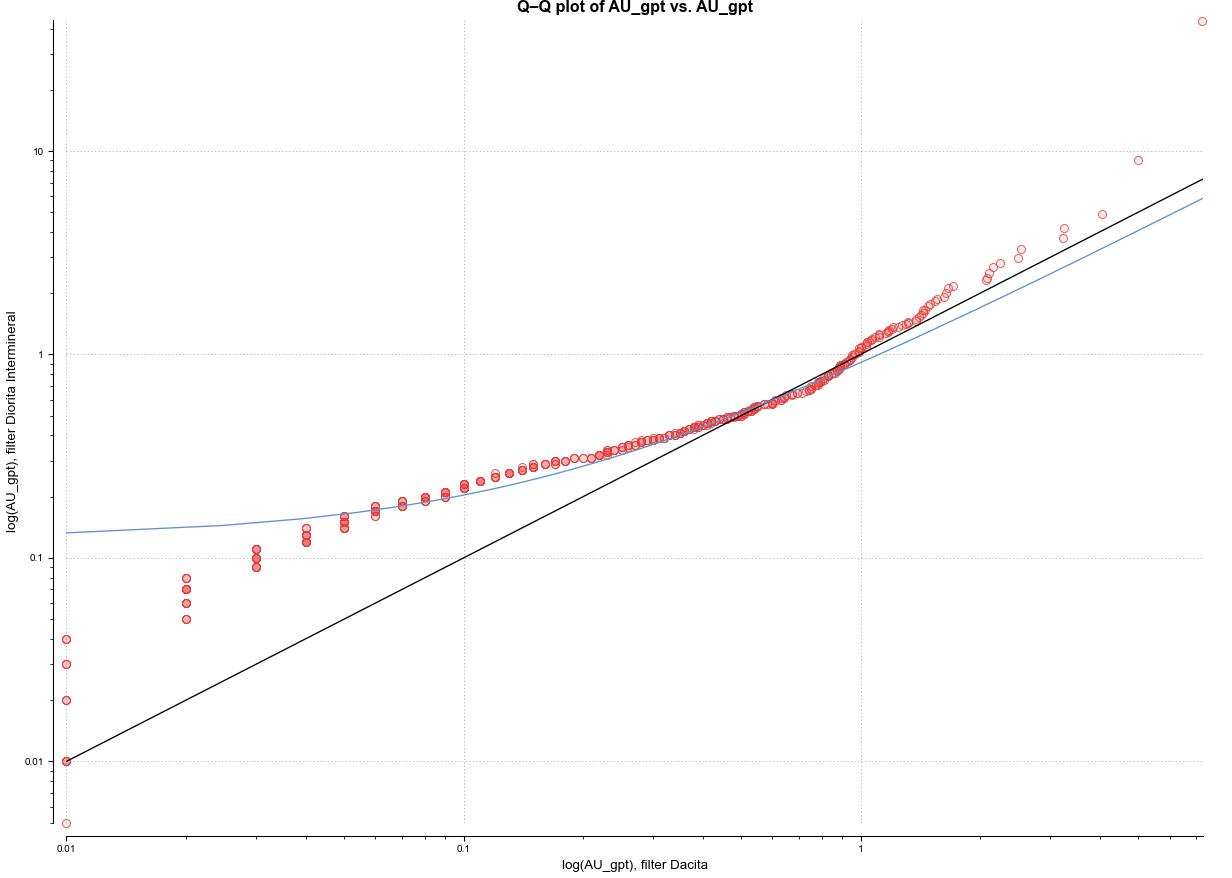
Figura 5.6 QQ plot para leyes de Au entre dos dominios geológicos.
También se obtiene la tabla de estadígrafos agrupada por elementos geoquímicos ponderados por longitud y ordenados de mayor a menor según la mediana.
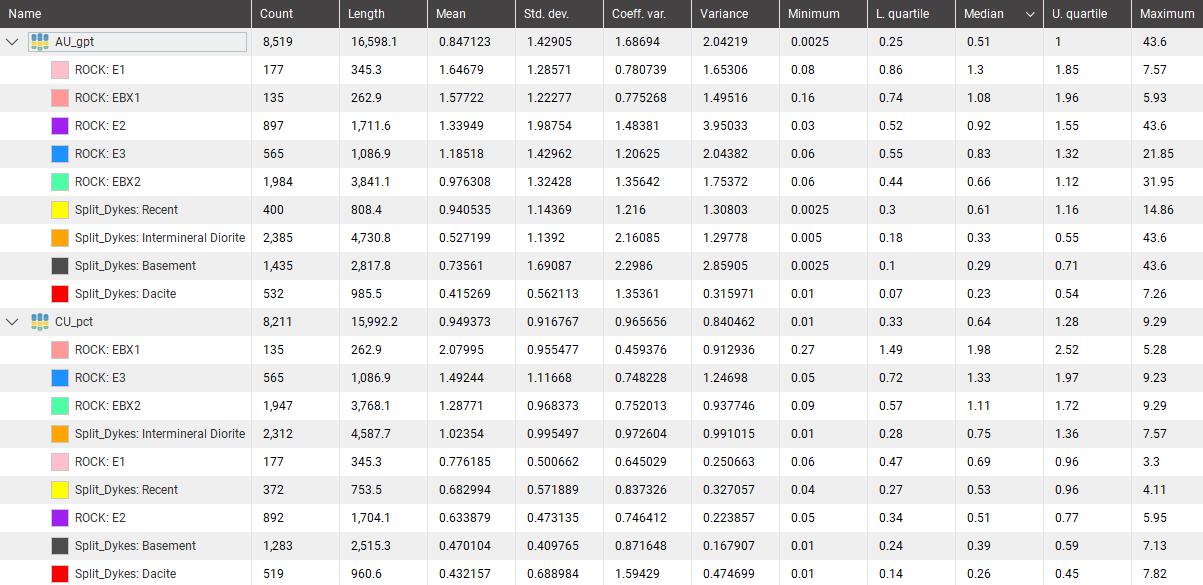
Tabla 1. Tabla de estadísticas principales agrupada por elementos.
7. CREACIÓN DE COMPÓSITOS
Se normaliza por longitud los intervalos de sondaje identificados con mineralización para la creación de modelos numéricos y estadísticas representativas. Se analizan las longitudes de intervalo:
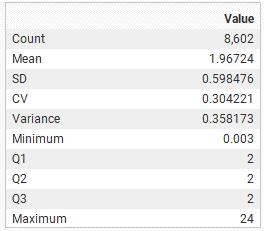
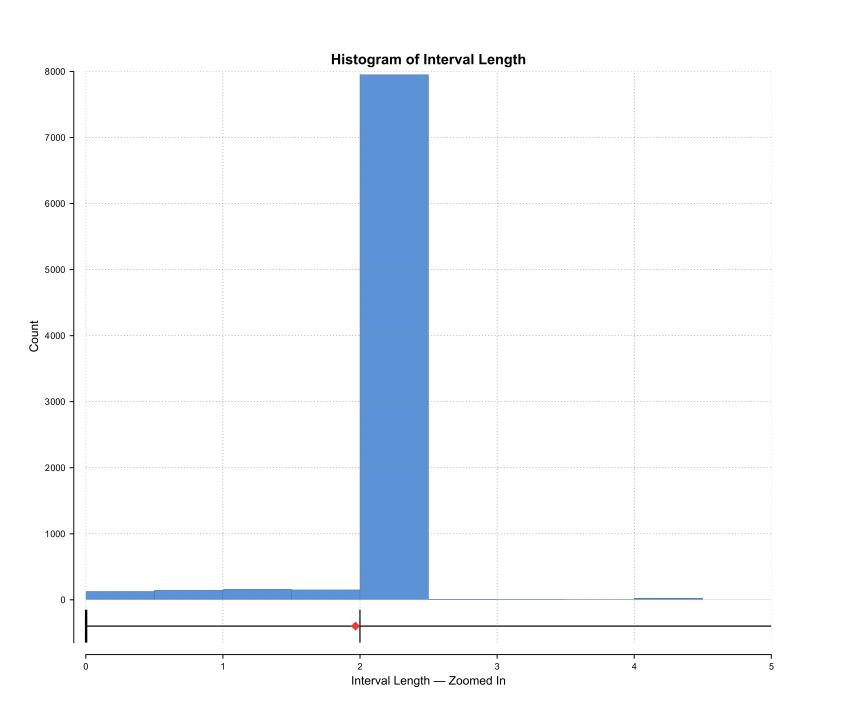
Figura 5.7. Histograma longitud de intervalo.
Preliminarmente se usa el valor de la mediana o cuartil (Q2) para una composición por longitud mínima, dado que la mayoría de las muestras poseen una longitud de intervalo cada 2 m. Como el fin del modelo numérico es estimar dentro de un dominio, se debe compositar por litología. Nuevamente, la longitud de la composición variará en función de varios factores, como el tipo de yacimiento (vetiforme, mantiforme o masivo), el método de extracción (vetas angostas, room and pillar, bancos) y la longitud de la muestra (espesor del cuerpo mineral o diseño mina).
En general, las minas subterráneas de alta ley requieren una longitud de composición menor debido a una varianza mayor dada la presencia de leyes anómalas a corta distancia, contrario a un yacimiento a cielo abierto con mena masiva diseminada. La división del intervalo muestral original de 2 metros genera una reducción artificial de la varianza al duplicar datos, lo que induce un suavizado no representativo de la variabilidad real de las leyes. Como resultado se cambia la longitud de composición a un múltiplo de 2, no elegimos 4 por el tiempo de procesamiento, sino 6 metros razonable con la geometría del cuerpo mineral. Se define una cobertura mínima de un 50% para la longitud residual adicionada al intervalo compuesto anterior con el fin de evitar sesgos.
Se ejecuta un modelo numérico de primera pasada con el fin de evaluar el comportamiento general de las isosuperficies, identificar inconsistencias geométricas y validar la coherencia espacial de los datos antes de la construcción del modelo definitivo, usando los valores numéricos de Au_gpt de la tabla compuesta, con una resolución de 20 (idealmente igual a la longitud compuesta de 6 m) debido a que representa un compromiso adecuado entre definición geométrica, estabilidad numérica y eficiencia computacional, coherente con la densidad y el soporte de los datos disponibles, también se aplica un filtro de superficie al modelo numérico con el fin de restringir las estimaciones al dominio geométricamente válido, eliminando extrapolaciones fuera de los límites definidos por las superficies de control (figura 5.8. a)
Posteriormente, se refina el modelo global y para la unidad mineral (figura 5.8. b y c). Se ajustan los valores ISO en Q2, Q3, 1 (resolución de 12), 1.25 y 1.5 (resolución de 6). Respecto a la edición del interpolador RBF (función de base radial). El interpolador lineal no es adecuado para valores con un rango finito de influencia ponderado por la distancia, no así uno esferoidal. El rango base del interpolador esferoidal define la distancia característica de influencia de los datos, controlando la escala de suavizado y la continuidad espacial del modelo coherente con la escala del fenómeno, ya sea, espaciamiento de sondajes o continuidad del cuerpo mineral.
Como regla general, el rango base debe establecerse entre 2 y 2.5 veces la distancia entre perforaciones. Considerando una distancia media entre sondajes de 100 m el rango base debería definirse entre 200 y 250. El umbral total o sill controla el límite superior de la función interpoladora, donde deja de existir correlación entre los valores y se ajusta elevando la varianza a la potencia de 10, (0.881)10 ~ 1
El nugget representa la variabilidad no explicada a escala nula, asociada a error de muestreo y heterogeneidad micro-escala. Un nugget elevado indica menor continuidad espacial y mayor incertidumbre local. Su valor varía según el tipo de yacimiento, en este caso, un pórfido aurífero un nugget del 10 al 20% del umbral total equivale a un valor de 0.15 de 1. La deriva o drift controla la forma en que el interpolador decae a partir de los datos. Dado que el modelo interpolante no está limitado a ningún dominio (geológico, estructural, meteorización, etc.), una deriva sensata sería ninguna.
El valor alfa determina la pendiente con la que el interpolador asciende hacia el umbral total. Al observar la función interpoladora mientras se modifica el alfa, se observa que un alfa alto otorga mayor influencia a los puntos a distancias intermedias que a los valores bajos de alfa. Los valores posibles de Alfa son 9, 7, 5 y 3.
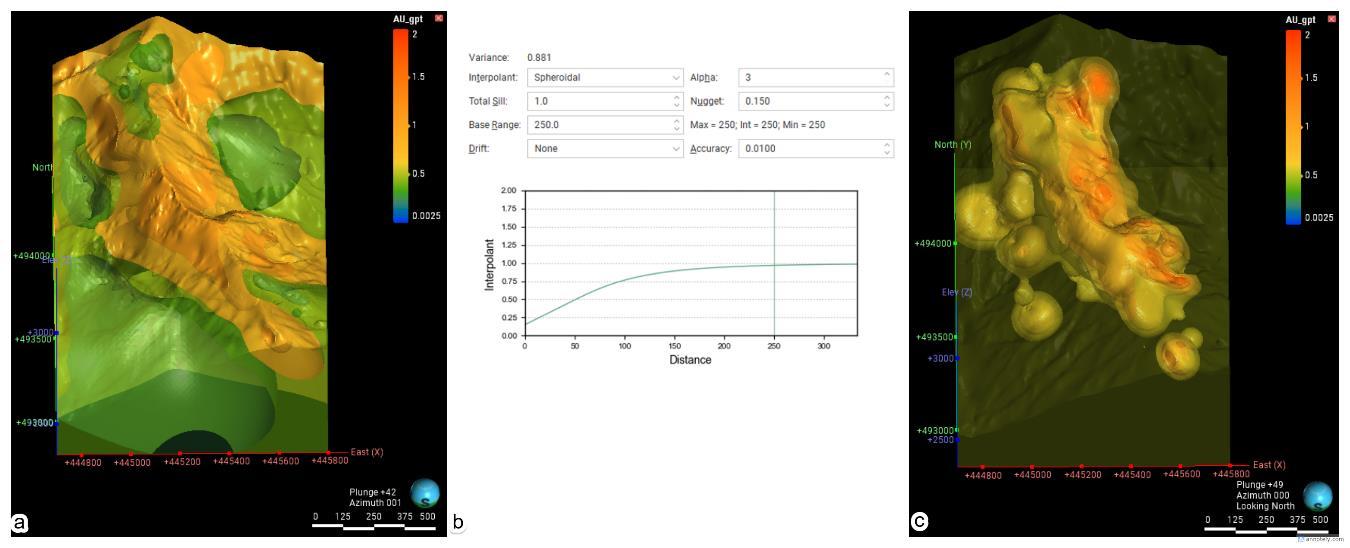
Figura 5.8 a) modelo numérico de primera pasada. b) parámetros de ajustes para interpolador esferoidal. c) refinamiento del modelo global
Luego se debe limitar la extensión del modelo numérico a un dominio geológicamente razonable (litológico, estructural, alteración, etc.) y editando nuevamente los parámetros de interpolación debido a una disminución de su varianza (figura 5.8 a).
Finalmente, se necesita añadir tendencias o trend para dar a la mineralización una forma más definida. Se crea una tendencia estructural usando una cantidad de mallas necesarias, aplicando diferentes intensidades y rangos de cada una, representativas de la dirección para depósitos minerales en diversas fases genéticas asociadas a múltiples zonas de alta ley. Se puede observar que cerca de las mallas la tendencia es más fuerte y a medida que nos alejamos de ellas, su fuerza disminuye, siendo directamente proporcional al tamaño del elipsoide (figura 5.8 b y c).
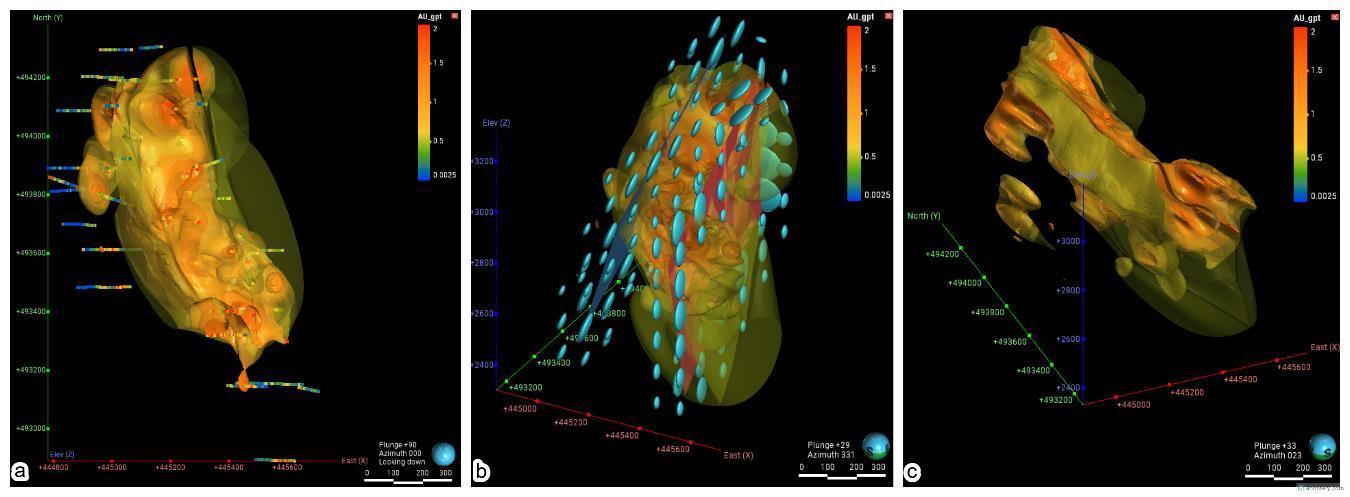
Figura 5.8. a) modelo numérico limitado al dominio. b) trend de elipsoides definidos por mallas. c) modelo numérico con trend estructural.
El sondaje WP052 termina con alta ley y es necesario mitigar posibles anomalías de leyes con uso de polilíneas de contorno para añadir una limitación manual sobre a una sección geológica.
Importar y validación visual en la escena para comprobar si hay errores, advertencias o manejo de valores inválidos en las tablas .csv. Casos típicos son la inconsistencia de collares con la topografía
Poseo la alternativa de corregir solo las filas con error exportando en archivo.csv, luego se recarga y actualiza dinámicamente el objeto en la escena. Los cambios realizados en la pestaña fix error solo alteran los datos importados en el proyecto leapfrog en creación. Lo recomendable es realizar correcciones externas a las tablas de origen, con respaldo en carpetas según fechas de actualización si quiero generar un proyecto distinto o exportar a otro software
Leapfrog no utiliza unidades, por tanto, asegurar que los datos tengan unidades y un sistema de coordenadas mina consistentes antes de importarlos.
Importar tablas con la información precisa, ya que las columnas importadas no se pueden eliminar, pero siempre se puede importar columnas o recargar datos más tarde.
Cargar tabla de densidad para creación de su modelo, o bien, añadir una columna adicional completando los valores con “Write to Selected Rows” para generar cálculos.