

Big Data
dataverwerking in 6 BeWe
Mr Bellinkx
4-sep-24
schooljaar 2024-25
1 Big Data
Big data is een term die gebruikt wordt om te verwijzen naar de enorme hoeveelheid en verscheidenheid van gegevens die in de digitale wereld worden geproduceerd, verzameld en geanalyseerd. Big data kan afkomstig zijn uit verschillende bronnen, zoals sociale media, websites, sensoren, camera's, smartphones, enz. Big data kan waardevolle inzichten opleveren voor verschillende doeleinden, zoals marketing, wetenschap, gezondheid, onderwijs, enz.
De term Big Data is ontstaan in 1990 maar is vooral sinds 2012 bekend aan het worden doordat meer internet gebruikers informatie delen en uitwisselen met verschillende platformen. Ook beginnen advertentie bedrijven en marketing bedrijven sterk in te zetten op het verzamelen van gegevens van gebruikers om zo het gedrag van gebruikers beter te voorspellen. Sinds 2018 wordt “Big Data” benoemd als de hoeveelheid data die niet meer met één enkele processorthread kan berekend worden maar waarbij parallel computing bij nodig is. Hierdoor moeten we vaak ook afstappen van het relationele datamodel gemaakt door Codd. Je zal namelijk redundante gegevens kunnen opslaan zonder prestatievermindering. Een relatie vertraagt echter wel de prestaties. Normalisatie is nog steeds belangrijk, maar redundantie is m.a.w. geen probleem meer.
Ter ‘opwarming’ een inschatting van de hoeveelheid data op een jaar geproduceerd!
1 zettabyte = ……… Gigabyte
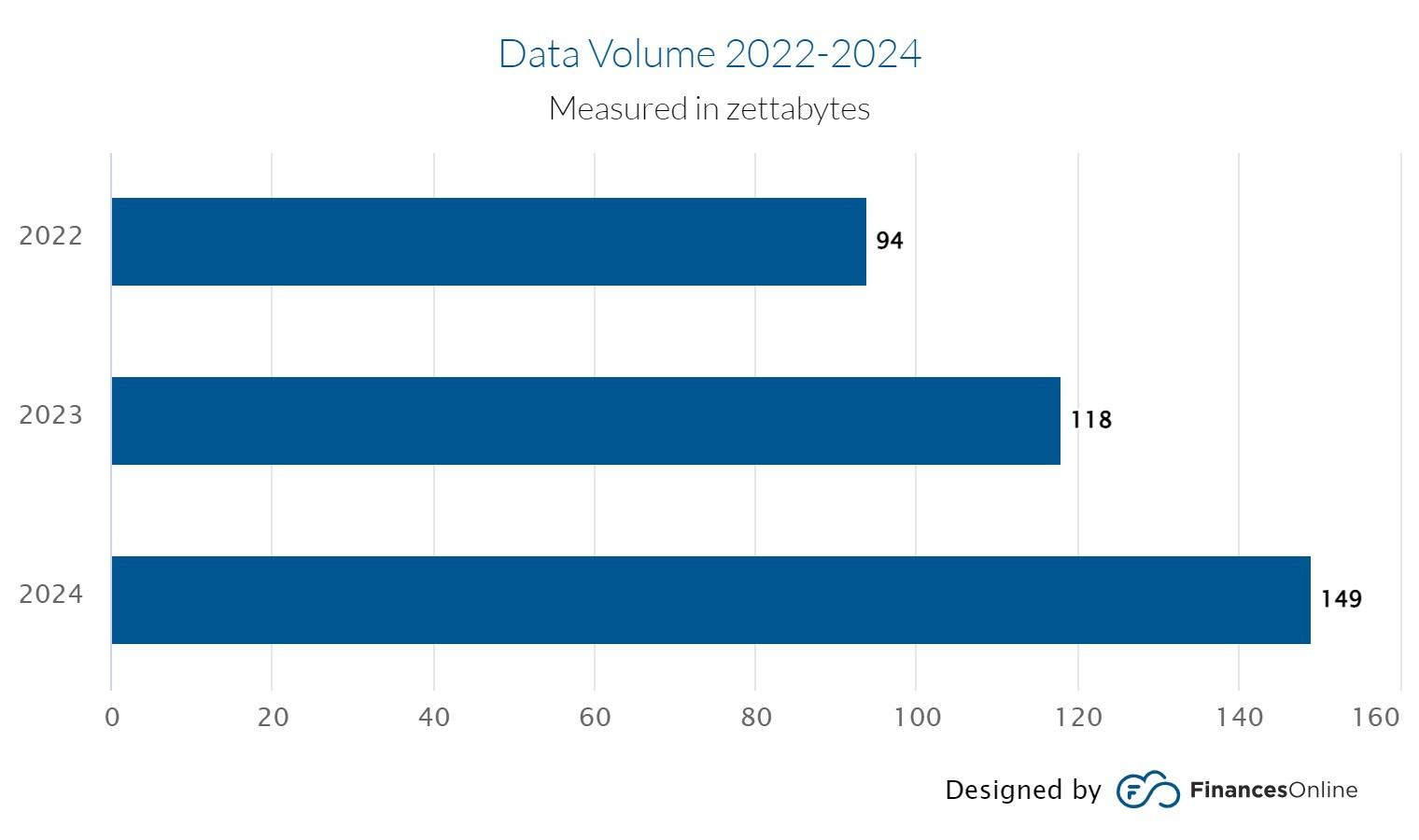
1.1 De 5 V’s van Big Data
1.1.1
Volume
De laatste jaren merken we een exponentiele groei in de nodige opslagcapaciteit van servers. Zettabytes aan hardeschijfruimte zijn de dag van vandaag een noodzaak aan het worden!
Wanneer men meer en meer data ter beschikking heeft (en deze data ook voortdurend aangroeit) moet men speciale technieken hanteren om deze data op een efficiënte en overzichtelijke manier te analyseren. Want traditionele databasemanagementsystemen zijn niet geschikt om big data op te slaan en te verwerken.
Op deze manier is de term ‘Big Data’ ontstaan.
1.1.2
Velocity
Verwijst naar de snelheid waarmee big data wordt gegenereerd en geanalyseerd. Big data kan in real-time of bijna real-time binnenkomen en opgevraagd worden. Dit vereist snelle en efficiënte verwerking van de gegevens om tijdige en relevante inzichten te leveren. Bijvoorbeeld, in het geval van fraudepreventie of noodsituaties is het belangrijk om snel actie te ondernemen op basis van de analyse van big data.
Het spreekt voor zich dat data van sensoren in een zelfrijdende auto in realtime zullen moeten verwerkt worden. Data van sensoren die de luchtkwaliteit in een stad meten, zullen wellicht pas dagelijks worden geanalyseerd.
1.1.3 Variety
Verwijst naar de diversiteit van de soorten en bronnen van de gegevens die big data vormen. Big data kan gestructureerd, ongestructureerd of semigestructureerd zijn. Gestructureerde gegevens hebben een vaste vorm en structuur, zoals cijfers, tabellen of formulieren. Ongestructureerde gegevens hebben geen vaste vorm of structuur, zoals tekst, afbeeldingen, video's of audio. Semigestructureerd gegevens hebben een gedeeltelijke vorm of structuur, zoals e-mails, XML of JSON. Big data kan ook afkomstig zijn uit verschillende bronnen, zoals sociale media, websites, sensoren, camera's, smartphones, enz. Dit betekent dat big data verschillende formaten, kwaliteiten en betekenissen kan hebben.
Daarom zijn er nieuwe technologieën ontwikkeld, zoals Power BI, die big data kunnen integreren, transformeren en visualiseren.
1.1.4 Veracity
Verwijst naar de betrouwbaarheid, nauwkeurigheid en consistentie van de gegevens die big data vormen. Big data kan onvolledig, onjuist, dubbelzinnig of verouderd zijn. Dit kan de kwaliteit en de
waarde van de analyse van big data beïnvloeden. Daarom zijn er nieuwe technologieën ontwikkeld, zoals AI, die big data kunnen valideren, verifiëren en corrigeren.
1.1.5 Value
verwijst naar het potentieel en het belang van de gegevens die big data vormen. Big data kan nuttige en relevante informatie bevatten voor verschillende doeleinden, zoals marketing, wetenschap, gezondheid, onderwijs, enz. Big data kan helpen om betere beslissingen te nemen, problemen op te lossen, trends te ontdekken, voorspellingen te maken, enz. Daarom zijn er nieuwe technologieën ontwikkeld, zoals AI, die big data kunnen analyseren, interpreteren en presenteren.
Big data is dus een belangrijk fenomeen in de hedendaagse wereld, dat veel mogelijkheden en uitdagingen biedt voor verschillende domeinen en sectoren. Door gebruik te maken van de juiste technologieën en methoden, kunnen we big data omzetten in waardevolle kennis en actie.
Recentere aanpakken spreken echter reeds over 8 V’s waarbij ook Visualisatie (kan je het nuttig voorstellen), Viscosity (blijft het plakken? Heeft het impact?) en Virality (Brengt het een verhaal dat presenteerbaar is) worden toegevoegd. Deze zijn echter niet de standaard.
2 Dataverwerking in Excel
Om de principes van analyse en presentatie van Big Data beter te kunnen inschatten, starten we deze cursus met wat Dataverwerking in Excel. We bekijken wat we kunnen aanvangen met draaitabellen.
Met een draaitabel kunnen we de gegevens uit een tabel samenvatten, ordenen en analyseren. Op die manier proberen we meer inzicht te verkrijgen in onze gegevens.
2.1 Een draaitabel maken
Open de werkmap Producten.xlsx en bestudeer de gegevens in het werkblad.
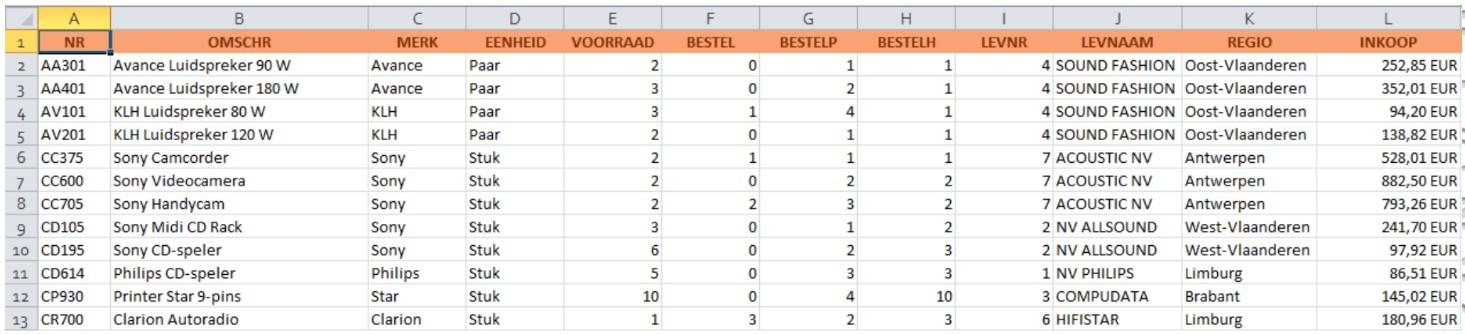
Je krijgt een lijst met producten. Deze lijst bevat onder meer de huidige voorraad en de inkoop- en verkoopprijs. We willen graag een duidelijk overzicht krijgen van de voorraadwaarde per merk. Hiervoor herschikken we de gegevens en maken we een draaitabel. Dit doen we als volgt: ( video )
1) Selecteer een cel in de tabel;
2) Ga naar het tabblad “Invoegen”;
3) Kies vervolgens voor “Draaitabel”;
4) Klik nogmaals op “Draaitabel” (en niet op “Draaigrafiek”).
Rechts bovenaan in de draaitabel vinden we een lijst met alle velden uit onze tabel.
Rechts onderaan hebben we vier gebieden: "Rapportfilter", "Kolomlabels", "Rijlabels" en "-waarden".
Door velden te selecteren in de veldlijst, plaatst Excel deze automatisch in een van de gebieden.
2.2 Een draaitabel aanpassen
2.2.1 De lay-out van een draaitabel wijzigen
Pas een draaitabelstijl toe op de draaitabel. Kies als rapportindeling Overzichtsweergave
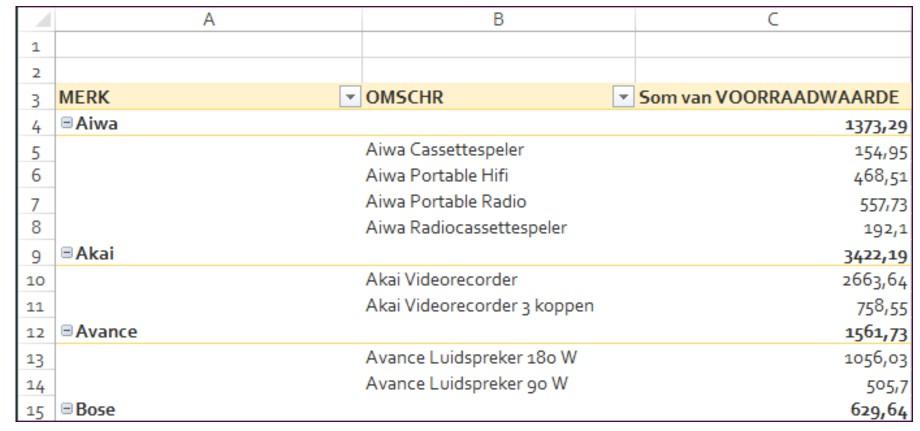
2.2.2 Veldinstellingen aanpassen
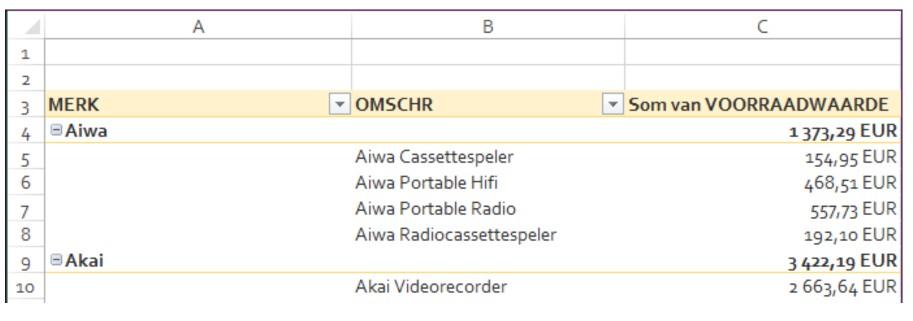
Tracht dit resultaat te bekomen!
Big Data
2.2.3 Gegevens filteren door een paginaveld toe te voegen
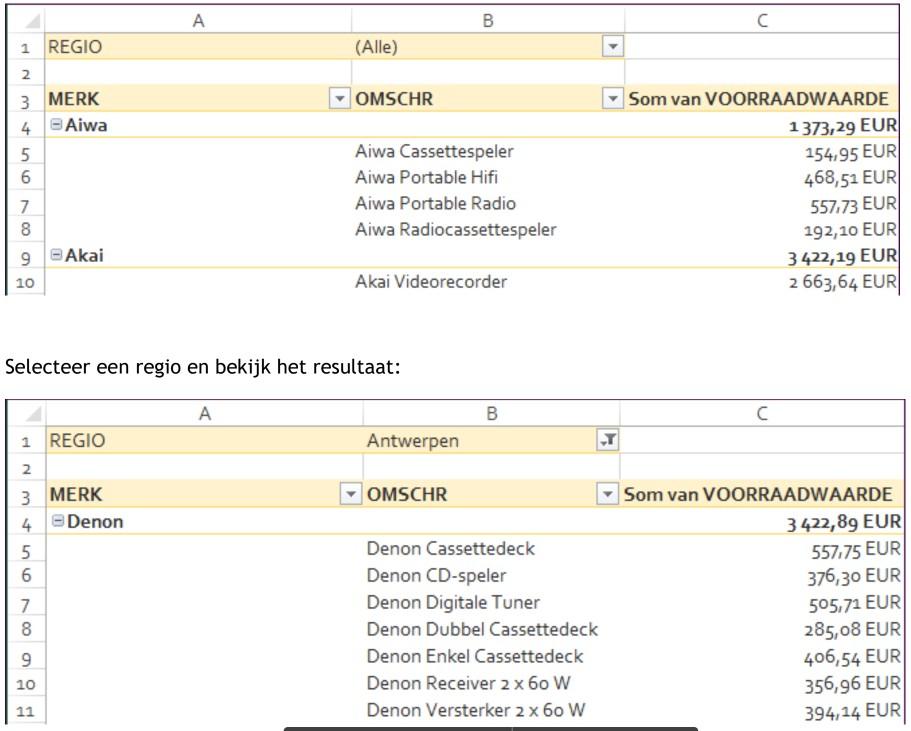
Voeg de regio als Rapportfilter toe zodat je de gegevens per regio kunt filteren.
Sleep het veld Regio uit de lijst met draaitabelvelden naar de Rapportfilter
2.3 Filteren met behulp van een slicer
Om de gegevens ook te kunnen selecteren per leverancier, voeg je een slicer toe.
Klik hiervoor op het tabblad Draaitabel analyseren in de groep Filter op Slicer invoegen.
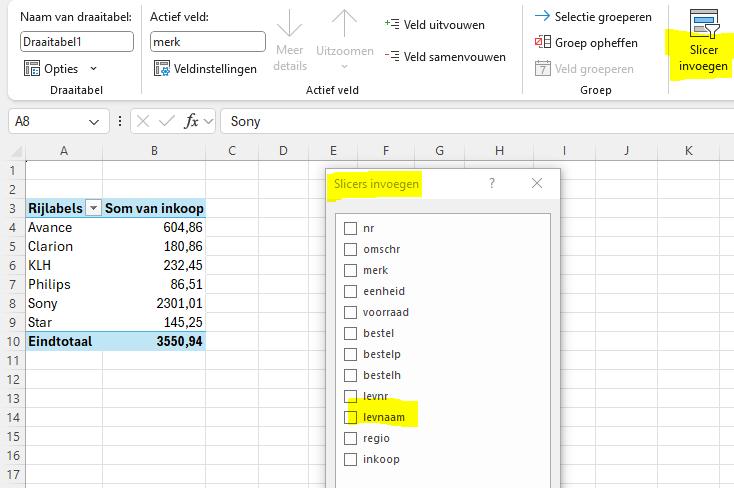
Speel een beetje met deze optie.
2.4 Oefening met de straatlampen van Kontich ( gegevens 2016 )
Maak een draaitabel die een overzicht geeft van de aanwezige straatlampen per straat
Maak een draaitabel waarbij de lampen kunt selecteren naargelang wattage