3 minute read
The snowball effect of integrity data compilation


comparisons help us understand the depth sizing error (bias and precision) of each of the ILI tool runs. The flawto-flaw (or more) depth comparisons allow us to estimate flaw growth rates. These two ‘inferred’ data sets allow us to calculate probabilistic flaw growth rates for both corrosion and cracks. This can provide either more or less confidence in our data, but will certainly provide a more defendable rationale for our decisions.
Impact of expanding data capture At OneBridge, we also recognise the enormous value of some ‘keystone’ data sets. Although this is under the early stages of consideration and analysis at OneBridge, we recognise that these data sets can be used in multiple ways and, in some cases, can provide significant value to different aspects of pipeline integrity. One example of this is soils data, which can provide substantial benefit to corrosion, cracking, and deformation analyses. The soils’ electrical conductivity and drainage can indicate a pipeline’s susceptibility to external corrosion. It is important in designing and optimising cathodic protection systems. Soil types with specific salt contents are known to influence stress corrosion cracking susceptibility. Soils’ mechanical properties affect their constraint against land movement and susceptibility to global bending strains. In the case of soils, it is not just the properties in the immediate area of a given corrosion flaw or bending strain that is important, but the patterns of soils properties between pipeline and rectifier or along the length of a pipeline in a geotechnically unstable area. Alignment of the soil properties with multiple data sets becomes increasingly important to integrity analyses, and this is where CIM relies on its core strength of data alignment.
Another keystone data set of interest is pressure cycling data. Pressure cycling data is typically used to construct pressure cycle histograms that are used for fatigue crack growth analyses. This helps analysts understand how defects are growing during operation, and when they might become a serious threat to the pipeline. The primary concern is usually long seam cracks, but we can also consider the role of pressure cycling in the growth of girth weld cracks or circumferential SCC. Here we need to rely on our keystone soils data to understand if the pipeline constrained or unconstrained and susceptible to local deformation. In the case of circumferential SCC, the soils conductivity and salt content become important. We can also review our pressure cycling data to determine our internal corrosion susceptibility, as it helps us understand if and when sediment might accumulate in the pipeline. The more we study different aspects of integrity management, the more we recognise the importance of data compilation and appreciate CIM’s ability to align various data sets effortlessly.
Data management does not come without its challenges. “Operators are often challenged by imperfect or incomplete historical data sets, and tasked with maintaining the integrity of assets that might have been put into service many decades ago before digital records were even a possibility,” says OneBridge CTO Jordan Dubuc, responsible for the development team that builds the CIM platform. “Cognitive Integrity Management aims to help operators make the most of the data they already have, aligning linear and spatial data sets while accommodating inconsistencies or uncertainty, identifying areas where we might find gaps or discrepancies and ultimately delivering greater confidence in integrity decision-making.”
Data avalanche transforms? I learned many years ago to line up every data set against every other data set I had. Most of the time you find no correlations, but sometimes you find some real surprises that help you understand the challenge of the day. If two data sets have no known reason to be correlated, but they are, then what are we missing in our understanding of the problem? If two data sets should be correlated but aren’t, where does the problem lie? Each comparison helps us learn a little bit more. At OneBridge, we’re always looking for new and better ways to analyse our users’ data. Much of this relies on data alignment and a willingness to try unusual combinations. We never know what might work until we try it. And the more data we can compile and align, the more we understand our pipeline condition, the better our integrity decisions become. So, let’s all think about the data avalanche we’re facing and how the industry can work together to build snowballs. As Alexander Pope wrote, “a little learning is a dangerous thing… but, more advanced, behold with strange surprise new distant scenes of endless science rise!”
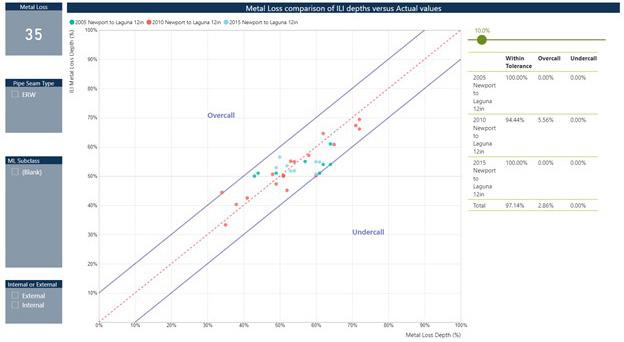
Figure 2. ILI flaw depth versus NDE flaw depth measurements across multiple data sets.










