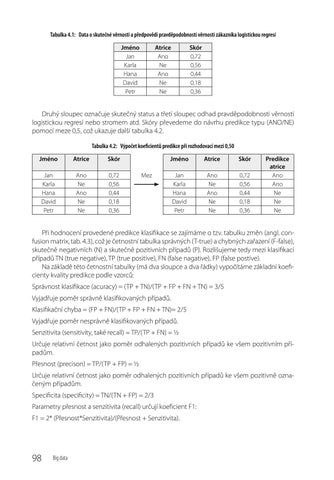
Tabulka 4.1: Data o skutečné věrnosti a předpovědi pravděpodobnosti věrnosti zákazníka logistickou regresí Jméno Jan Karla Hana David Petr
Atrice Ano Ne Ano Ne Ne
Skór 0,72 0,56 0,44 0,18 0,36
Druhý sloupec označuje skutečný status a třetí sloupec odhad pravděpodobnosti věrnosti logistickou regresí nebo stromem atd. Skóry převedeme do návrhu predikce typu (ANO/NE) pomocí meze 0,5, což ukazuje další tabulka 4.2. Tabulka 4.2: Výpočet koeficientů predikce při rozhodovací mezi 0,50 Jméno
Atrice
Skór
Jan Karla Hana David Petr
Ano Ne Ano Ne Ne
0,72 0,56 0,44 0,18 0,36
Jméno
Atrice
Skór
Jan Karla Hana David Petr
Ano Ne Ano Ne Ne
0,72 0,56 0,44 0,18 0,36
Mez
Predikce atrice Ano Ano Ne Ne Ne
Při hodnocení provedené predikce klasifikace se zajímáme o tzv. tabulku změn (angl. confusion matrix, tab. 4.3), což je četnostní tabulka správných (T‑true) a chybných zařazení (F‑false), skutečně negativních (N) a skutečně pozitivních případů (P). Rozlišujeme tedy mezi klasifikací případů TN (true negative), TP (true positive), FN (false nagative), FP (false postive). Na základě této četnostní tabulky (má dva sloupce a dva řádky) vypočítáme základní koeficienty kvality predikce podle vzorců: Správnost klasifikace (acuracy) = (TP + TN)/(TP + FP + FN + TN) = 3/5 Vyjadřuje poměr správně klasifikovaných případů. Klasifikační chyba = (FP + FN)/(TP + FP + FN + TN)= 2/5 Vyjadřuje poměr nesprávně klasifikovaných případů. Senzitivita (sensitivity, také recall) = TP/(TP + FN) = ½ Určuje relativní četnost jako poměr odhalených pozitivních případů ke všem pozitivním případům. Přesnost (precison) = TP/(TP + FP) = ½ Určuje relativní četnost jako poměr odhalených pozitivních případů ke všem pozitivně označeným případům. Specificita (specificity) = TN/(TN + FP) = 2/3 Parametry přesnost a senzitivita (recall) určují koeficient F1: F1 = 2* (Přesnost*Senzitivita)/(Přesnost + Senzitivita).
98
Big data
Ukázka elektronické knihy, UID: KOS505074