International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056

Volume: 09 Issue: 12 | Dec 2022 www.irjet.net p-ISSN: 2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 12 | Dec 2022 www.irjet.net p-ISSN: 2395-0072
Hitanshu Parekh1, Akshat Shah2, Grinal Tuscano3
1Student, Dept. of Information Technology, St. Francis Institute of Technology, Mumbai, Maharashtra, India
2Student, Dept. of Computer Engineering, Thadomal Shahani Engineering College, Mumbai, Maharashtra, India
3 Professor, Dept. of Information Technology, St. Francis Institute of Technology, Mumbai, Maharashtra, India ***
Abstract - According to the World Health Organization (WHO), there are approximately284millionpeople worldwide who have limited vision,andapproximately39millionwhoare completely blind [10]. Visually impaired people confront multiple challenges in their daily lives, particularly when navigating from one place to another on their own. They frequently rely on others to meet their daily needs. The proposed system is intended to help the visually impaired by identifying and classifying common everyday objects in realtime. This system provides voice feedback for improved comprehension and navigation. In addition, we have depth estimation, which calculates the safe distance between the object and the person, allowing them to be more self-sufficient and less reliant on others. We were able to create this model using TensorFlow and pre-trained models. The recommended strategy is dependable, affordable, realistic, and feasible.
Key Words: Object Detection, SSD Mobilenet, TensorFlow Object Detection API, COCO Dataset, Depth Estimation, Voice Alerts, Visually Impaired People, Machine Learning.
Withtherecentrapidgrowthofinformationtechnology(IT), a great deal of research has been conducted to solve everydaydifficulties,andasaresult,manyconveniencesfor peoplehavebeensupplied.Nonetheless,therearestillmany inconveniencesforthevisuallyimpaired.
The most significant inconveniences that a blind person faces on a daily basis include finding information about objects and having difficulties with indoor mobility. Currently, the majority of vision-impaired people in India relyonasticktoidentifypotentialobstaclesintheirpath. Previousresearchincludedobjectanalysisusingultrasonic sensors.However,itisdifficulttotellexactlywhereanobject islocatedusingtheseapproaches,especiallyinthepresence ofobstacles.
As a result, our contribution to solving this problem statementistocreateablindassistancesystemcapableof object detection and real-time speech conversion so that theymayhearitasandwhentheyneedit,aswellasdepth estimation for safe navigation. The SSD algorithm was combinedwithmachinelearningusingtheTensorFlowAPI packagestoproducethissystem.Thisisencapsulatedina
single system, an app, for a simple and better user experience.
Balakrishnanetal.[1]describedanimageprocessingsystem forthevisuallyimpairedthatuseswearablestereocameras and stereo headphones. These devices are attached to helmets.Thestereocamerascapturethesceneinfrontofthe visually impaired. The images are then analyzed, and significant features are retrieved to assist navigation by describingthescene.Thedistanceparametersarecaptured usingstereocameras.Thesystemisbothcomplexandcostineffectiveduetotheusageofstereocameras.
Mahmudetal.[2]describedamethodthatusesacaneand includes an ultrasonic sensor mounted to the cane and a camshaft position sensor (CMP) compass sensor (511), which gives information about various impediments and potholes.Thereareahandfulofdrawbackstothisstrategy. Becausethesolutionreliesonacaneasitsprincipalanswer, only impediments up to knee height can be recognized. Furthermore,anyironiteminthesurroundingareamight impact the CMP compass sensor. This strategy assists the blindintheoutdoorworldbuthaslimitationsintheindoor environment.Thesolutionjustdetectstheobstructionand doesnotattempttorecognizeit,whichmightbeasignificant disadvantage.
Jiangetal.[3]describedareal-timevisualrecognitionsystem with results converted to 3D audio that is a multi-module system.Aportablecameradevice,suchasaGoPro,captures video,andthecollectedstreamisprocessedonaserverfor real-time image identification using an existing object detection module. This system has a processing delay, makingitdifficulttouseinreal-time.
Jifeng Dai et al.[4] describe a fully convolutional network that is region-based. R-FCNN is used to recognize objects preciselyandefficiently.Asaresult,thisworkcansimplyuse ResNetsasfullyconvolutionalimageclassifierbackbonesto recognizetheobject.Thisarticlepresentsastraightforward yet effective RFCNN framework for object detection. This approachprovidesthesameaccuracyasthefasterR-FCNN approach. As a result, adopting the state-of-the-art image classificationframeworkwasfacilitated.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 12 | Dec 2022 www.irjet.net p-ISSN: 2395-0072
Choi D. et al.[5] describe current methods for detection models and also provide standard datasets. This paper discussed different detectors, such as one-stage and twostage detectors, which assisted in the analysis of various objectdetectionmethodsandgatheredsometraditionalas well asnewapplications.It alsomentionedvarious object detectionbranches.
A.A.DiazToroetal.[6]describedthemethodsfordeveloping a vision-based wearable device that will assist visually impaired people in navigating a new indoor environment. The suggested system assists the user in "purposeful navigation."Thesystemdetectsobstacles,walkingareas,and otheritemssuchascomputers,doors,staircases,chairs,and soon.
D.P.Khairnar et al.[7] suggested a system that integrates smart gloves with a smartphone app. The smart glove identifiesandavoidsobstacleswhilealsoenablingvisually impairedpeopletounderstandtheirenvironment.Various objectsandobstaclesinthesurroundingareaarerecognized usingsmartphone-basedobstacleandobjectdetection.
V.Kuntaetal.[8]presentedasystemthatusestheInternetof Things (IoT) to connect the environment and the blind. Among other things, sensors are used to detect obstacles, damp floors, and staircases. The described prototype is a simple and low-cost smart blind stick. It is outfitted with severalIoTmodulesandsensors.
Rajeshvaree Ravindra Karmarkar[9] proposes a deep learning-baseditemrecognitionsystemfortheblind.Voice assistancecanalsohelpvisuallyimpairedpeopledetermine thelocationofobjects.Thedeeplearningmodelforobject recognition employs the “You Only Look Once” (YOLO) approach.Toassisttheblindinlearninginformationabout items, a voice announcement is synthesized using text-tospeech (TTS). As a result, it utilizes an efficient objectdetection technology that assists the visually impaired in findingthingsinsideaparticularenvironment.
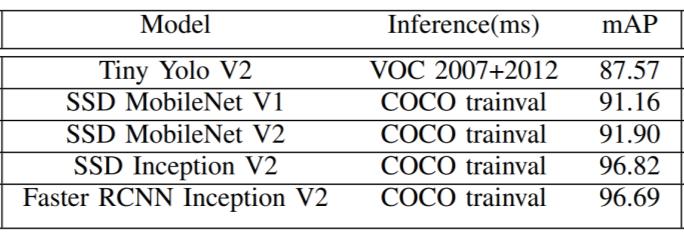
Table I compares multiple TenserFlow mobile object detection models in terms of inference time and performance. The models' mAP performance varies substantially,withthemorecomplexFasterRCNNInception modelachievingnear-optimalperformancebuttakingmuch longertoinferthanthelesscomplexTinyYolomodel.
Existingsolutionsincludelimitationssuchaslimitedscope andfunctionality,inefficiencyincost,systemsthatarenot portable,multiplesensorneeds,andtheinabilitytomanage visually impaired persons in both indoor and outdoor situations in real time. We have made sincere efforts to combine all of the excellent aspects of the preceding solutions in order to create a full, portable, cost-effective systemcapableofefficientlysolvingreal-worldchallenges.
[8]
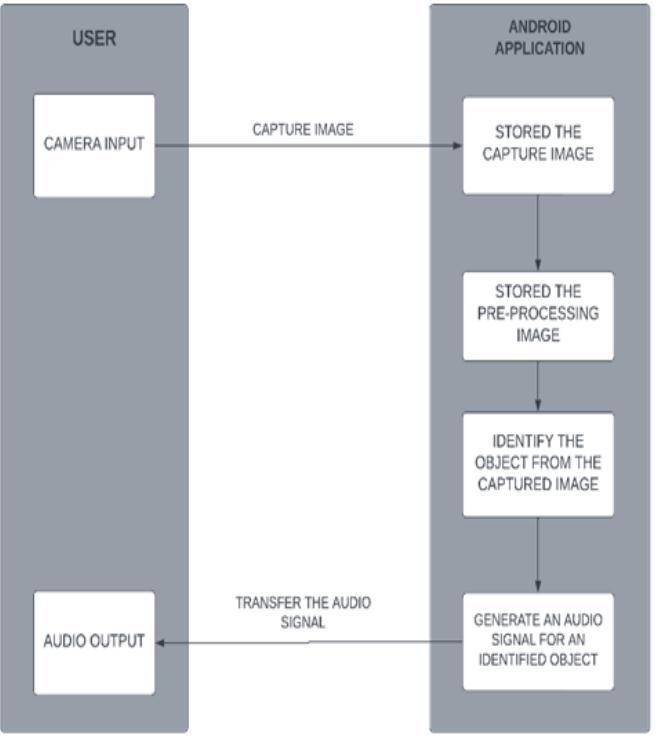
Theproposeddesignofoursystem(Fig.1)isbasedonthe detection of objects in the environment of a visually impaired individual. The suggested object detection technologyneedsanumberofphases,fromframeextraction to output recognition. To detect objects in each frame, a comparisonbetweenthequeryframeanddatabaseobjects isperformed.Wepresentareal-timeobjectrecognitionand positioning system. An audio file containing information abouteachidentifiedobjectisactivated.Asaresult,object detectionandidentificationareaddressedconcurrently.
Theusermustinitiallyactivatetheprogrambeforeusinga cameratocapturereal-time,liveimagestofeedintoamodel. Nowthattheimagehasbeencaptured,themodelmuststore itandevaluateittodeterminehowfaritisfromthesubject. The output parameter of this information is then transformedintoanaudiosignal.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 12 | Dec 2022 www.irjet.net p-ISSN: 2395-0072
Forfeatureextraction,thissystemusesaResidualNetwork (ResNet)architecture,asortofartificialneuralnetworkthat allows the model to skip layers without affecting performance.[11]
Thissystemmainlycomprisesof
1. Thesystemisconfiguredinsuchamannerthatan Androidapplicationcapturesreal-timeframesand sends them to a networked server, where all calculationsareperformed.
2. The server will use a pre-trained SSD detection modelthathasbeentrainedusingCOCOdatasets.It willthentestanddetecttheoutputclassusingan accuracymetric.
3. Followingtestingwithvoicemodules,theobject's class will be translated into default voice notes, which will then be sent to the blind victims for assistance.
4. Along with object detection, we have an alert systemthatwillcalculatetheapproximatedistance oftheobject.Iftheblindpersonisclosetotheframe orfarawayinasaferlocation,itwillproducevoicebasedoutputsinadditiontodistanceunits.
TheCommonObjectsinContext(COCO)datasetisoneofthe most widely used open-source object identification databases for training deep learning algorithms. This database contains hundreds of thousands of images along withmillionsofpre-labeledobjectsfortraining[12].
We used TensorFlow APIs to put it into action. The advantageofusingAPIsisthattheyprovideuswithaccessto a variety of standard actions. The TensorFlow object detection API is essentially a framework for developing a deep learning network that handles the object detection problem. There are trained models in their framework, whichtheytermthe"ModelZoo."Thispackagecontainsthe Open Images Dataset, the KITTI dataset, and the COCO dataset.COCOdatasetsareourprimaryinteresthere.
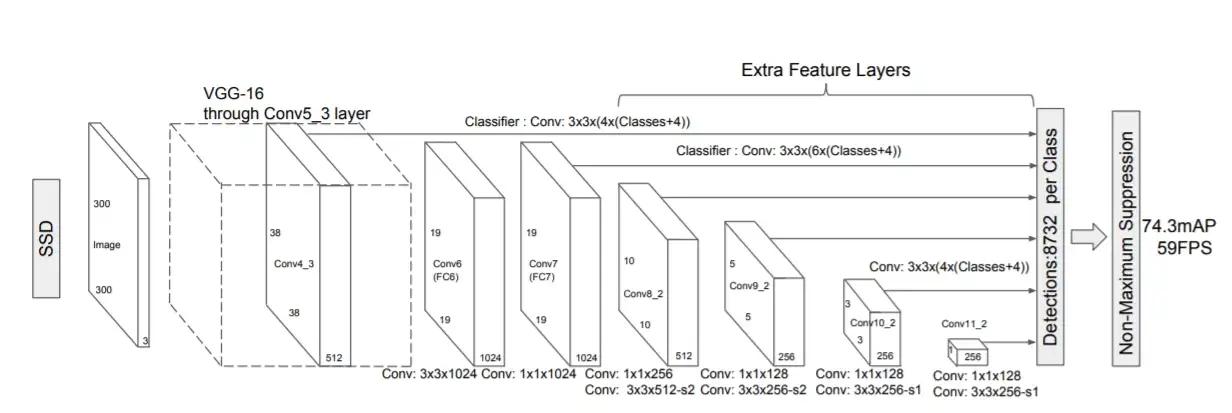
Manypre-trainedmodelsnowemployTensorflow.Thereare severalmodels foraddressingthistask.WeareusingSSD MobileNetdetectioninthisprojectsincethemajorityofthe systemperformswell,butyoucanalsouseMASKRCNNfor moreaccuracyorSSDdetectionforfasteraccuracy.Solet's takeacloserlookattheSSDalgorithm.
Fig -2:SSDModelArchitecture[13]
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 12 | Dec 2022 www.irjet.net p-ISSN: 2395-0072
SSDismadeupoftwoparts:anSSDheadandabackbone model.
The backbone model is essentially a trained image classificationnetworkthatisusedtoextractfeatures.Similar toResNet,thisisfrequentlyanetworktrainedonImageNet that has had the last fully connected classification layer removed.
TheSSDheadisjustoneormoreconvolutionallayersadded to this backbone, and the outputs are interpreted as the bounding boxes and classifications of objects in the final layeractivations'spatialposition.Asaresult,wehaveadeep neuralnetworkthatcanextractsemanticmeaningfroman inputimagewhilekeepingitsspatialstructure,althoughata lesserresolution.
Thebackboneproduces2567x7featuremapsinResNet34 foraninputimage.SSDsplitsthepictureintogridcells,with eachgridcellischargeofidentifyingobjectsinthatportion oftheimage.Detectingobjectsinvolvespredictingtheclass andlocationofanobjectinsideagivenregion.
In SSD, each grid cell can have many anchor/prior boxes associated with it. Within a grid cell, these pre-defined anchorboxesareindividuallyresponsibleforsizeandform. Duringtraining,SSDemploysthematchingphasetoensure that the anchor box matches the bounding boxes of each groundtruthobjectinsideanimage.Theanchorboxwiththe mostoverlapwiththeitemisresponsibleforpredictingthe object's class and location. After the network has been trained, this property is used to train it and predict the detectedobjectsandtheirlocations.Inpractice,eachanchor boxisassignedanaspectratioandazoomlevel.Weallknow thatnotallobjectsaresquareinform.Somearesomewhat shorter, slightly longer, and slightly broader. To cater for this, the SSD architecture provides for pre-defined aspect ratiosoftheanchorboxes.Thedifferentaspectratiosmaybe configuredusingtheratiosparameteroftheanchorboxes associatedwitheachgridcellateachzoomorscalelevel.
Theanchorboxesdonothavetobethesamesizeasthegrid cells.Theusermaybelookingforbothsmallerandbigger things within a grid cell. The zooms option is used to determinehowmuchtheanchorboxesshouldbescaledup ordowninrelationtoeachgridcell.
The MobileNet model, as its name implies, is intended for usageinmobileapplicationsandisTensorFlow'sfirstmobile computer vision model [14]. This model is built on the MobileNetmodel'sideaofdepthwiseseparableconvolutions andformsfactorizedconvolutions.Thesearefunctionsthat
convert basic conventional convolutions into depthwise convolutions.Pointwiseconvolutionsareanothernamefor these 1 x 1 convolutions. These depthwise convolutions enableMobileNetstofunctionbyapplyingageneric,single filter-based concept to each of the input channels. These pointwiseconvolutionscombinetheoutputsofdepthwise convolutions with a 1 x 1 convolution. Like a typical convolution,bothfilterscombinetheinputsintoanewsetof outputs in a single step. The depth-wise identifiable convolutionsdividethisintotwolayers:oneforfilteringand another for combining. This factorization process has the effectofsignificantlyreducingcomputationandmodelsize.
The depth estimation or extraction feature refers to the techniquesandalgorithmsusedtoproducearepresentation ofascene'sspatialstructure.Toputitanotherway,itisused tocomputethedistancebetweentwoobjects.Ourprototype is used to assist the blind, and it seeks to alert the blind about impending obstacles. To do so, we must first determine the distance between the obstacle and the individualinanyreal-timecircumstance.Afterdetectingthe object,a rectangular boxisformedaround it.If theobject occupiesthemajorityoftheframe,theestimateddistanceof theobjectfromthespecificindividualiscalculated,subject tosomeconstraints.
Followingthedetectionofanobject,itiscriticaltonotifythe individual of the existence of that thing on his/her path. PYTTSX3isessentialforthevoicecreationmodule.Pyttsx3 isaPythonconversionmodulethatconvertstexttovoice.To obtain a reference to a pyttsx. Engine instance, a factory functioncalledaspyttsx.init()isinvokedbyanapplication. Pyttsx3isasimpletoolforconvertingtexttovoice.
Thewaythisalgorithmoperatesisthateverytimeanobject is detected, an approximation of its distance is generated. Textsarethendisplayedonthescreenusingthecv2library's cv2.putText() function. We use Python-tesseract for characterrecognitiontofindhiddentextinapicture.OCR recognizestextcontentonimagesandencodesitinaformat that a computer can understand. This text detection is accomplishedbyimagescanningandanalyzing.Thus,text containedinimagesisidentifiedand"read"usingPythontesseract.
Asoutput,audiocommandsarecreated.Whentheobjectis tooclose,itdisplaysthemessage"Warning:Theobject(class ofobject)isveryclosetoyou.""Watchout!"Otherwise,ifthe itemisatasaferdistance,a voiceisgeneratedthatstates, "Theobjectisatasaferdistance."Thisisachievedthrough theuseoflibrariessuchaspytorch,pyttsx3,pytesseract,and engine.io.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 12 | Dec 2022 www.irjet.net p-ISSN: 2395-0072
Pytorch'sprimaryfunctionisasamachinelearninglibrary. Pytorchismostlyusedintheaudiodomain.Pytorchassists inloadingthevoicefileinmp3format.Italsocontrolsthe audiodimension rate.As a result,it isusedtomanipulate sound qualities such as frequency, wavelength, and waveform.
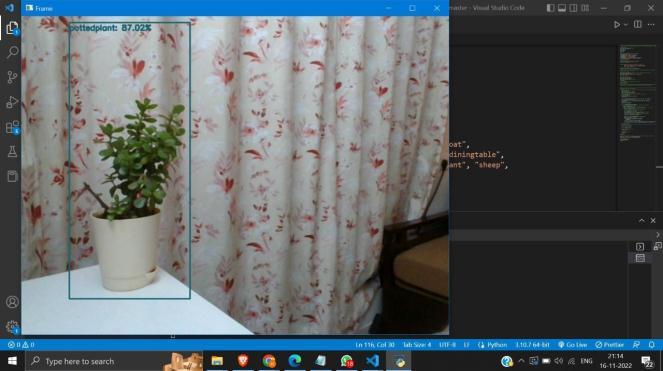
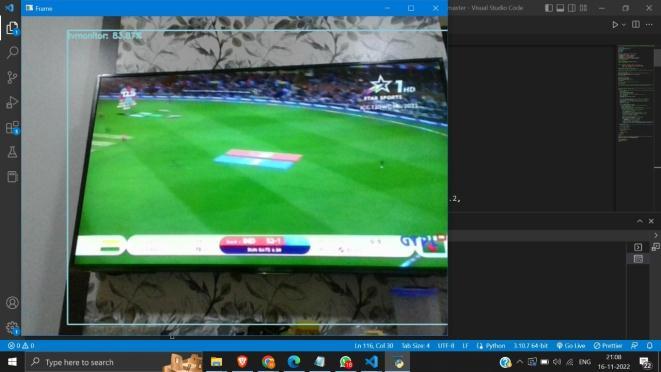
The suggested system successfully detects and labels 90 objects while also demonstrating its accuracy. When the person with the camera approaches the object, the model estimatesthedistancebetweentheobjectandthecamera andprovidesvoicefeedback.Thedatasetwastestedonan SSDMobilenetV1model.Themodelshowedlesslatencyand wasfasteratdetectingobjects.
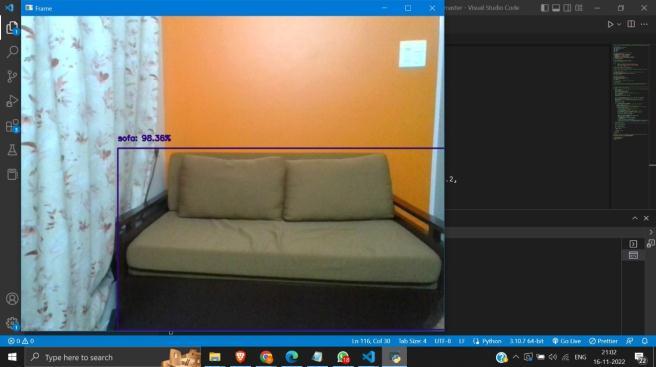
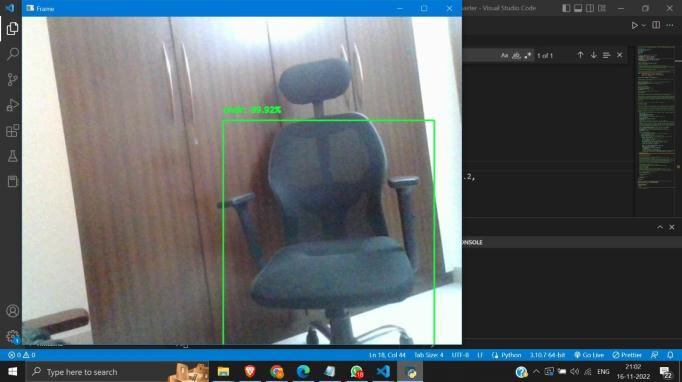
We can improve the system's accuracy. Furthermore, the current system is based on the Android operating system andmaybemodifiedtoworkwithanyconvenientdevice.
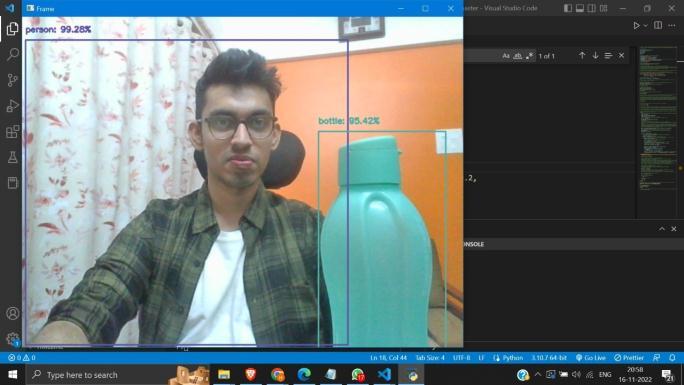
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 12 | Dec 2022 www.irjet.net p-ISSN: 2395-0072
Futureapplicationsofthetechnologymightincludelanguage translation, currency checking, reading literary works, a chatbotthatallowstheuser tocommunicateand interact, smart shopping, email reading, real-time location sharing, signboardidentification,suchasthe"Washroom"sign,etc.
I would like to express my deep gratitude to Ms. Grinal Tuscano,AssociateProfessorattheSt.Francis Instituteof Technology and my research supervisor, for their patient guidance,enthusiasticencouragement,andusefulcritiques ofthisresearchwork.
[1] Balakrishnan, G. & Sainarayanan, G.. (2008). Stereo Image Processing Procedure for Vision Rehabilitation.. AppliedArtificialIntelligence.
[2] N.Mahmud,R.K.Saha,R.B.Zafar,M.B.H.BhuianandS. S.Sarwar,"Vibrationandvoiceoperatednavigationsystem forvisuallyimpairedperson,"2014InternationalConference onInformatics,Electronics&Vision(ICIEV),2014,pp.1-5.
[3] Jiang,Rui&Lin,Qian& Qu,Shuhui.(2016).LetBlind People See: Real-Time Visual Recognition with Results Convertedto3DAudio.
[4] JifengDai,YiLi,KaimingHeandJianSun,“R-FCN:Object DetectionviaRegionbasedFullyCon-volutionalNetworks.” Conf.NeuralInform.Process.Syst.,Barcelona,Spain,Dec.4-6, 2016,pp.379-387
[5] Choi D., and Kim M. ’, “Trends on Object Detection Techniques Based on Deep Learning,” Electronics and TelecommunicationsTrends,Vol.33,No.4,pp.23-32,Aug. 2018.
[6] A.A.DiazToro,S.E.CampañaBastidasandE.F.Caicedo Bravo, "Methodology to Build a Wearable System for AssistingBlindPeopleinPurposefulNavigation,"20203rd International Conference on Information and Computer Technologies(ICICT),2020,pp.205-212.
[7] D. P. Khairnar, R. B. Karad, A. Kapse, G. Kale and P. Jadhav,"PARTHA:AVisuallyImpairedAssistanceSystem," 2020 3rd International Conference on Communication System,ComputingandITApplications(CSCITA),2020,pp. 32-37.
[8]V.Kunta,C.TunikiandU.Sairam,"Multi-FunctionalBlind StickforVisuallyImpairedPeople,"20205thInternational Conference on Communication and Electronics Systems (ICCES),2020,pp.895-899.
[9] Rajeshvaree Ravindra Karmarkar, “Object Detection System for the Blind with Voice Guidance”, International Journal of Engineering Applied Sciences and Technology(IJEAST),2021,pp.67-70.
[10] https://www.indiatoday.in/education-today/gkcurrent-affairs/story/world-sight-day-2017-facts-andfigures-1063009-2017-10-12
[11] https://builtin.com/artificial-intelligence/resnetarchitecture
[12] https://deepai.org/machine-learning-glossary-andterms/CoCo%20Dataset
[13] https://iq.opengenus.org/ssd-model-architecture/
[14] https://medium.com/analytics-vidhya/imageclassification-with-mobilenet-cc6fbb2cd470
[15] https://medium.com/analytics-vidhya/imageclassification-with-mobilenet-cc6fbb2cd470
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified