
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN:2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN:2395-0072
Tushar Surwade1, Vrushali Wankhede2 , suraj Menon 3 , Dipti Mondal4 , Ritesh Kakade5 , Sanket Pawar6
1,2,3,4,5,6Computer Engineering Department, Keystone School of Engineering, Pune, Maharashtra, India.
Abstract:
The deaf and hard of hearing community faces significant challenges due to a communication gap between sign language users and non-signers, which hinders effective interaction and accessibility. In response to this issue, our research introduces an innovative deep learning-based frameworkforreal-timesignlanguagerecognition,aiming toovercomethiscommunicationbarrier.
Our approach capitalizes on recent advancements in computer vision and natural language processing to translatesignlanguagegesturescapturedbyacamerainto spoken language. We leverage convolutional neural networks (CNNs) for robust hand gesture detection and tracking, enabling accurate recognition of dynamic hand movements and configurations. Additionally, recurrent neural networks (RNNs) or transformer models are employed to capture temporal dependencies and extract meaningfulfeaturesfromgesturesequences.
Toassesstheeffectivenessofourproposedframework,we conduct extensive experiments using publicly available sign language datasets, encompassing both isolated and continuous sign sequences. Through comparative analysis with existing methods, we demonstrate superior accuracy and real-time processing capabilities of our model. Furthermore, we evaluate the generalization of our approachacrossvarioussignlanguagesandadaptabilityto variations in lighting conditions, background clutter, and signerdemographics.
Our results underscore promising outcomes in real-world scenarios, highlighting the potential of our approach to enhance accessibility and facilitate seamless communication between sign language users and nonsigners. This research contributes significantly to the advancement of assistive technologies and sets the stage for future developments in sign language recognition systems.
Key Words: Visual speech translation, deep learning, computer vision, natural language processing, gesture recognition, hand tracking, real-time translation, accessibility
Sign language is fundamental for communication within the deaf and hard of hearing community. Nonetheless, there remains a significant communication barrier between sign language users and non-signers. This study introduces a deep learning-based framework for instantaneoussignlanguagerecognition,withtheobjective of bridging this divide. By harnessing advancements in computer vision and natural language processing, our framework translates sign language gestures captured via camera into spoken language. We tackle challenges including gesture diversity and environmental influences toestablisha dependableandeffectivesystem. Ourgoalis to elevate accessibility and inclusivity for individuals dependentonsignlanguage.
The sign language recognition system comprises several interconnected modules designed to seamlessly translate sign language gestures into spoken language. The architecture consists of three main components: Input Module,DeepLearningModel,andOutputModule.
1. InputModule:
The Input Module captures sign language gestures using a camera or other input devices.
Preprocessing techniques, such as noise reduction and normalization, are applied toenhancethequalityoftheinputdata.
Feature extraction methods may be utilizedtoeffectivelyrepresentthespatial and temporal characteristics of the gestures.
2. DeepLearningModel:
The Deep Learning Model serves as the core component responsible for recognizing and interpreting sign languagegestures.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN:2395-0072
It typically employs convolutional neural networks (CNNs), recurrent neural networks(RNNs),ortransformermodels.
CNNs detect and localize hand movements within the input images or videoframes.
RNNs or transformer models process the temporal sequence of hand gestures, capturing the dynamic aspects of sign language.
The model is trained on annotated datasets of sign language gestures, learning to map input sequences to correspondinglinguisticrepresentations.
3. OutputModule:
The Output Module receives the output from the Deep Learning Model and convertsitintospokenlanguage.
It may utilize text-to-speech (TTS) synthesis techniques to generate audible representations of the recognized gestures.
Additional post-processing steps, such as language modeling and grammar correction,maybeappliedtoenhancethe intelligibility and naturalness of the spokenoutput.
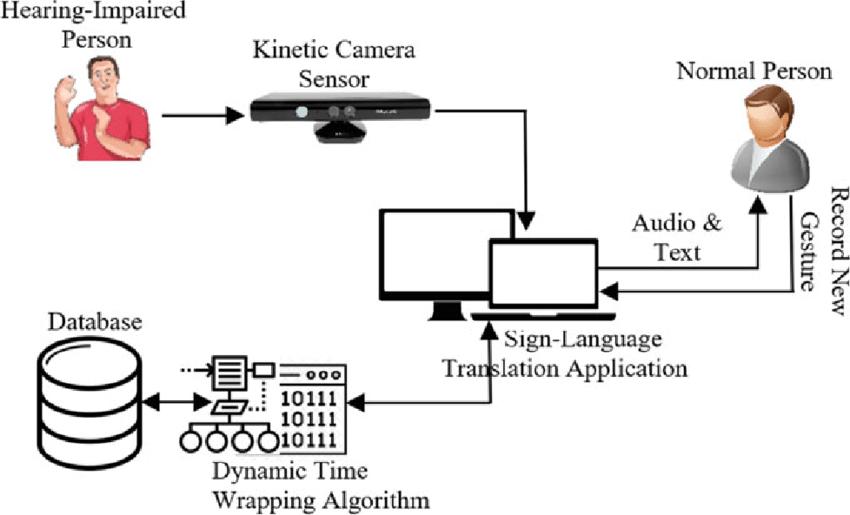
1: System Architecture
1. Neural Sign Language Translation
Authors: Camgoz, Necati Cihan; Hadfield, Simon;Koller,Oscar;Bowden,Richard
Publication: Proceedings of the IEEE Conference on Computer Vision and PatternRecognition(CVPR)
Year:2018
2. Sign Language Recognition and Translation with Kinect
Authors: Pu, Fangxu; Yuan, Chunfeng; Xu, Jiajun;Liu,Ziqiang;Yu,Nenghai
Publication: IEEE Transactions on Human-MachineSystems
Year:2016
3. Estimating Hand Pose in Unconstrained Sign Language Videos
Authors: Athitsos, Vassilis; Neidle, Carol; Sclaroff,Stan
Publication: International Journal of ComputerVision
Year:2008
4. Sign Language Transformers: Joint End-to-End Sign Language Recognition and Translation
Authors: Camgoz, Necati Cihan; Hadfield, Simon;Koller,Oscar;Bowden,Richard
Publication: Proceedings of the European ConferenceonComputerVision(ECCV)
Year:2020
4. METHODOLOGY:
1. Data Acquisition: Gather a dataset containing videos or sequences of sign language gestures along with their corresponding linguistic representations (e.g., spoken language translations or textual descriptions).
2. Data Preprocessing: Preprocess the data to enhance its quality and suitability for training. This may involve resizing, normalization, noise reduction, and augmentation techniques to prepare it for model training.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN:2395-0072
3. Feature Extraction:Extractrelevantfeaturesfrom the preprocessed data to represent the spatial and temporal characteristics of sign language gestures. Techniques such as hand keypoint detection, hand region segmentation, or optical flow analysis can be employed.
4. Model Selection: Choose an appropriate deep learning architecture for sign language recognition and translation. This may include convolutional neural networks (CNNs) for image-based recognition and recurrent neural networks (RNNs) or transformermodelsforsequencemodeling.
5. Model Training: Train the selected model on the preprocessed data using supervised learning techniques. During training, the model learns to map input sequences of sign language gestures to their corresponding linguistic representations, such as spokenlanguagetranslationsortextualdescriptions.
6. Model Evaluation:Evaluatetheperformanceofthe trained model on a separate test dataset using appropriate evaluation metrics such as accuracy, precision,recall,F1-score,andworderrorrate(WER). This step assesses the model's ability to correctly recognizeandtranslatesignlanguagegestures.
7. Hyperparameter Tuning: Fine-tune the hyperparameters of the model, such as learning rate, batch size, and network architecture parameters, to optimizeperformance.Techniquessuchasgridsearch or random search may be employed to find the optimalcombinationofhyperparameters.
8. Benchmarking: Compare the performance of the proposed model against existing state-of-the-art approaches and benchmarks on publicly available datasets. This benchmarking helps assess the effectiveness and efficiency of the algorithm in relationtopreviouswork.
9. Deployment: Once the algorithm has been trained andevaluatedsatisfactorily,itcanbedeployedinrealworld applications to facilitate communication betweensignlanguageusersandnon-signers
4.1 Algorithm:
1. DataCollection:
Gatherdiversedatasetscontainingvideos orsequencesofsignlanguagegestures.
Ensure annotations indicating corresponding spoken language
translations or textual representations of thesigns.
2. DataPreprocessing:
Resize the videos to a standard size for consistency.
Normalizethecolor and brightnesslevels toreducevariability.
Apply noise reduction techniques to enhancethequalityofthevideos.
Augmentthedatasetbyaddingvariations in lighting, background, and signer demographics.
3. FeatureExtraction:
Extract relevant features from the preprocessed videos to represent spatial andtemporalcharacteristics.
Utilize techniques such as hand keypoint detection, hand region segmentation, or optical flow analysis to capture gesture dynamics.
4. ModelArchitectureSelection:
Choose appropriate deep learning architectures considering the complexity ofsignlanguagegestures.
Common architectures include Convolutional Neural Networks (CNNs) for image-based recognition and Recurrent Neural Networks (RNNs) or Transformer models for sequence modeling.
5. ModelTraining:
Split the dataset into training, validation, andtestsets.
Train the selected model on the training data using supervised learning techniques.
Use backpropagation and optimization algorithms to update model parameters andminimizethelossfunction.
6. EvaluationMetrics:
Evaluate the trained model on the validationandtestsetsusingmetricssuch
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN:2395-0072
as accuracy, precision, recall, F1-score, andWordErrorRate(WER).
Assess the model's ability to correctly recognize and translate sign language gestures.
7. HyperparameterTuning:
Fine-tunemodelhyperparameterssuchas learning rate, batch size, and network architectureparameters.
Utilize techniques like grid search or random search to find the optimal combinationofhyperparameters.
8. Benchmarking:
Compare the performance of the developedmodelagainstexistingstate-ofthe-artapproachesandbenchmarks.
Use publicly available datasets for benchmarking to validate the effectiveness and efficiency of the proposedmethodology.
9. Deployment:
Once the model has been trained and evaluated satisfactorily, deploy it in realworldapplications.
Develop a user-friendly interface to capture sign language gestures using a cameraorinputdevice.
Integrate the model with the interface to enable real-time gesture recognition and translation.
10. Documentation:
Document the step-by-step algorithm, including data preprocessing, model training,andevaluationprocedures.
Provide clear instructions for model deployment and usage, along with guidelines for further development and improvements.
4.2 Flowchart:
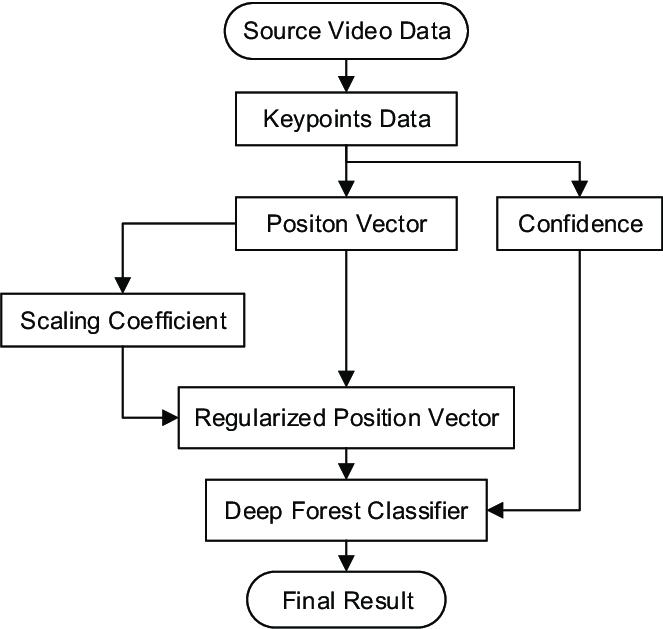
5. REQUIREMENTS:
5.1 Hardware Requirements:
Camera: A high-resolution camera capable of capturing sign language gestures with clarity and precision.
Processing Power: Sufficient computational resources, including CPU and GPU, to handle realtime processing of video data and deep learning algorithms.
Memory: Adequate memory capacity to store and processlargedatasetsandmodelparameters.
5.2 Software Requirements:
Deep Learning Framework: Support for popular deep learning frameworks such as TensorFlow, PyTorch, or Keras for model development and training.
Programming Language: Proficiency in programming languages such as Python for implementingalgorithmsandbuildingthesystem.
Data Processing Tools: Software tools for preprocessing input data, including image and videoprocessinglibraries.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN:2395-0072
Data Collection and Preprocessing:
Gatheradatasetcomprisingvideosorsequencesofsign language gestures along with corresponding spoken languagetranslationsortextualrepresentations.
Preprocessthecollecteddatatoenhanceitsqualityand suitability for training. This may involve resizing, normalization, noise reduction, and augmentation techniques.
Model Development:
Choose a suitable deep learning architecture such as CNNs, RNNs, or transformer models for sign language recognitionandtranslation.
Implement the selected architecture using a deep learningframeworklikeTensorFloworPyTorch.
Train the model on the preprocessed dataset, focusing onasubsetoftargetgesturesorlettersinitially.
Evaluation:
Evaluate the performance of the trained model using a separatevalidationdataset.
Measure metrics such as accuracy, precision, and recall to assess the model's effectiveness in recognizing the targetgestures.
User Interface (UI):
Develop a basic user interface to capture sign language gesturesusingawebcamorinputdevice.
Provide real-time feedback to the user, such as recognizedgesturesortextualrepresentations.
Integration:
Integrate the trained model with the UI to enable realtimegesturerecognition.
EnsureseamlesscommunicationbetweentheUIandthe modelforcapturingandprocessinginputdata.
Testing and Iteration:
Test the partial implementation with a small group of users to gather feedback and identify areas for improvement.
Iterateonthedesignandimplementationbasedonuser feedbackandperformanceevaluationresults.
Documentation:
Documentthe partialimplementation,includingsystem architecture, implementation details, and usage instructions.
Provide guidelines for further development and expansionofthesystem.
7.CONCLUSION:
The partial implementation of the Visual Speech Translation Sign Language system demonstrates feasibilityand highlights challenges and opportunities for further development. Initial user feedback guides future iterations, focusing on expanding datasets, improving model accuracy, and enhancing user experience. This milestone marks the beginning of ongoing research towards creating accessible communicationtechnologiesforallindividuals
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056 Volume: 11 Issue: 04 | Apr 2024 www.irjet.net p-ISSN:2395-0072

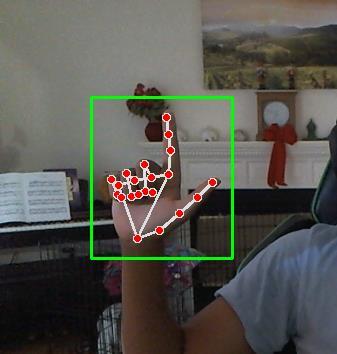
Figure 4: gesture-based signs.
7. ACKNOWLEDGEMENT:
It gives us Great pleasure in presenting the preliminary project report on "Visual Speech Translation for Sign Language:".
We would like to take this opportunity to thank our internal guide Prof. Tushar Surwade and co-guide Prof. Vrushali Wankhedeforgivingus all thehelpand guidance we needed. We really are greatful to them. For the kind support.Theirvaluableinsightswereveryhelpful.
We are also grateful to Prof. Sagar Rajebhosale, Head of department,computerengineeringbranchattheKeystone School of Engineering, for his indispensable sup-port and suggestions.
8. REFERENCES:
[1] Petridis,S., etal.(2020)."End-to-EndContinuousSign Language Recognition and Translation: A Sequence-toSequenceTransformerApproach."ProceedingsoftheAAAI ConferenceonArtificialIntelligence.
[2] Assael, Y. M., et al. (2018). "LipNet: End-to-End Sentence-level Lipreading." Proceedings of the IEEE InternationalConferenceonComputerVision.
[3] Starner, T., et al. (2016). "Real-Time American Sign LanguageRecognitionUsingDeskandWearableComputer Based Video." Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops.
[4] Lu, T., et al. (2019). "Deep Learning-Based Hand Gesture Recognition for Sign Language Translation." IEEE Access,7,108883-108892.
[5] Huenerfauth, M., et al. (2018). "Evaluating American Sign Language Generation from Machine Translation." Proceedings of the 11th International Conference on LanguageResourcesandEvaluation.
[6] Li, X., et al. (2021). "Sign Language Translation: A Review of Recent Advances and Challenges." ACM ComputingSurveys,54(5),Article104.
[7] Pigou, L., et al. (2018). "Beyond Frame-level CNN: Saliency-aware 3-D CNN With LSTM for Video Action Recognition." IEEE Transactions on Neural Networks and LearningSystems,29(9),4067-4077.