
Exploring the Role of Transformers in NLP: From BERT to GPT-3
Abul Faiz Bangi11Student, Bachelor of Engineering, Pune Vidhyarthi Griha’s College of Engineering and Technology, Maharashtra, India.
Abstract - The paper"ExploringtheRoleofTransformersin NLP: From BERT to GPT-3" provides an overview of the role of Transformers in NLP, with a focus on BERT and GPT-3. It covers topics such as the Role of Transformers in BERT, Transformer Encoder Architecture BERT, and Role of Transformers in GPT-3, Transformers in GPT-3 Architecture, Limitations of Transformers, Transformer Neural Network Design, and Pre-Training Process.
The paper also discusses attention visualization and future directions for research, including developing more efficient models and integrating external knowledge sources. It is a valuable resource for researchers and practitioners in NLP, particularly the attention visualization section.
Key Words: Transformers, NLP (Natural Language Processing),BERT(BidirectionalEncoderRepresentations from Transformers), GPT-3 (Generative Pre-trained Transformer, Deep learning, Recurrent Neural Networks (RNNs),ConvolutionalNeuralNetworks(CNNs).
1. INTRODUCTION
The field of Natural Language Processing (NLP) has historically been challenging due to the complexity and ambiguity ofhumanlanguage.Creatingmachinesthatcan understandandprocesslanguageinthesamewayhumans dohasbeenadifficulttask.However,theemergenceofdeep learninginrecentyearshastransformedthewayNLPtasks areapproached,andthedevelopmentofTransformer-based modelshastakenNLPtonewheights.
In 2017, Vaswani et al. introduced Transformers in their paper "Attention Is All You Need". These models utilize a distinct architecture that enables them to process information more efficiently than conventional models. Unlike traditional models that employ recurrent neural networks(RNNs)orconvolutionalneuralnetworks(CNNs), Transformersuseself-attentionmechanismstoselectively focusonrelevantinformationwhiledisregardingnoise.
Aftertheirintroduction,Transformershavebeenappliedto numerousNLPtasks,includingsentimentanalysis,machine translation,andlanguagegeneration.BERTandGPT-3are twoofthemostpopularTransformer-basedmodels.
In 2018, Google introduced BERT, an acronym for BidirectionalEncoderRepresentationsfromTransformers. BERTemploysapre-trainingapproachtoacquirelanguage
***
representationsfromextensivetextdata.BERThasachieved exceptionalperformanceindiverseNLPtasks,suchastext classificationandquestionanswering.
OpenAIintroducedGPT-3in2020asalanguagegeneration model.GPT-3reliesonalargepre-trainedlanguagemodel that can generate text in response to a given prompt. Its abilitytogeneratehighlycoherentandhuman-liketexthas led many to consider it one of the most remarkable AI modelstodate.
Transformer-basedmodels excel atprocessinglong-range dependencies in text, a challenge that traditional models suchasRNNsstruggletohandleastheyprocessinformation sequentially. Transformers, however, can process all the words in a sentence simultaneously, capturing the relationshipsbetweenallthewordsinthesentence.
Transformers also excel at learning from vast amounts of unlabeleddata.Pre-trainingaTransformer-basedmodelon an extensive corpus of data allows it to learn general language representations, which can be fine-tuned for specific NLP tasks. The effectiveness of this approach is evidentinthesuccessofBERTandotherTransformer-based models.
Despite their numerous advantages, Transformer-based modelsalsopossesssomelimitations.Themostsignificantof theselimitationsistheirhighcomputationalrequirements. Thetrainingofa largeTransformer-basedmodel requires extensivecomputationalresources,makingitchallengingfor researchers with limited resources to work with these models.Furthermore,whileTransformer-basedmodelscan handle long-range dependencies, they may struggle with certain syntactic structures, such as nested or recursive structures.
1.1 BACKGROUND:
ThefieldofNLPhasbeenachallengingone,largelyduetothe complexity and ambiguity of human language. However, recentdevelopmentsindeeplearninghavetransformedthe way NLP tasks are approached, with the emergence of Transformer-basedmodelssuchasBERTandGPT-3.
BERT, a bidirectional Transformer-based model, was introducedbyGooglein2018.BERTemploysapre-trained languagemodelandiscapableofperformingnumerousNLP tasks. The primary innovation of BERT is its ability to

comprehend the context of a word based on both its preceding and succeeding words, thus improving upon previousmodelsthatonlyconsideredtheprecedingcontext or treated language as a unidirectional sequence. BERT's bidirectionalarchitectureenablesittoaccuratelyrepresent themeaningofawordbasedontheentiresentence,leading tostate-of-the-artperformanceonawiderangeofNLPtasks.
BERT has been widely applied to sentiment analysis tasks due to its superior performance in this area. Sentiment analysisinvolvesdeterminingthesentimentofagiventext, whichcanbepositive,negative,orneutral.BERT'sabilityto capturethecontextofawordbasedonbothitsprecedingand succeeding words makes it particularly effective in identifyingthesentimentofasentence.BERTcanaccurately classifythesentimentofasentence,evenwhenthesentiment isexpressedinasubtleorsarcasticmanner.Thishasmadeit a valuable tool for businesses that need tounderstand the sentimentofcustomerfeedbackorreviews.
Another NLP task that BERT has excelled in is question answering,whichinvolvesansweringquestionsbasedona given passage or document. With its bidirectional architecture,BERTcanunderstandthecontextofaquestion and its relationship with the given passage, enabling it to provideaccurateanswers.Thishasimportantapplicationsin fields such as education, where students can use BERTpowered question-answering systems to get immediate feedbackontheirlearningprogress.
GPT-3,ontheotherhand,isaTransformer-basedmodelthat hasgainedattentionforitsimpressivelanguagegeneration capabilities.GPT-3ispre-trainedonamassivedatasetofover 45 terabytes of text and has over 175 billion parameters, makingitoneofthelargestlanguagemodelstodate.Withits massive size and pre-training, GPT-3 can generate highly convincinghuman-liketext,whichhasbeenusedforarange ofapplications,suchaschatbotsandcreativewriting.
GPT-3isknownforitsabilitytogeneratehighlypersonalized responsesandengageinnaturallanguageconversationswith users,makingitanexcellentchoiceforbusinesseslookingto improve their customer service or online presence. In addition,GPT-3hasproventobeavaluabletoolincreative writing,allowingbusinessestogeneratehigh-qualitycontent atscale.
However,likeotherTransformer-basedmodels,GPT-3faces challengessuchashighcomputationalrequirements,which limititsaccessibilitytomostusers.Thesemodelsalsohavea limitedunderstandingoftheworldandlackcommonsense reasoning abilities, which can result in errors or incorrect predictions.Toovercometheselimitations,furtherresearch anddevelopmentinNLParenecessary.
1.2 ROLE OF TRANSFORMERS IN BERT
TheintroductionoftheTransformerarchitecturein2017 byVaswani etal.hasrevolutionizedthefieldofNLP,with models like BERT benefiting greatly from its innovative design.ThebidirectionalarchitectureofBERTisenabledby theTransformer'sabilitytousemulti-headself-attentionto capturecomplexrelationshipsbetweenwordsinasentence. Unliketraditionalneuralnetworks,theTransformerallows formoreflexibleandadaptiveinformationflowthroughits useofself-attention.Thishasgreatlyimprovedtheabilityof NLP models like BERT to understand the context and meaningoftext,leadingtostate-of-the-artperformanceona rangeofNLPtasks.
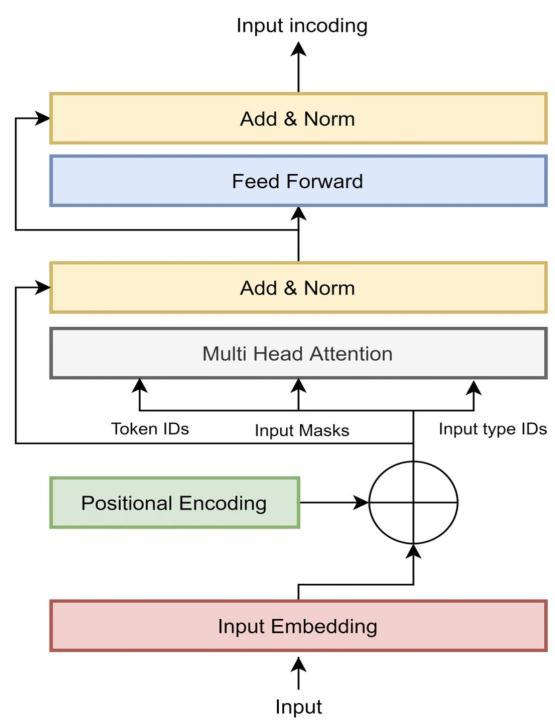
The Transformer architecture is utilized to create a bidirectionalencoderthatcangeneratecontextualizedword embedding’s.Theseembedding’sarevectorrepresentations ofthemeaningofeachwordinthegiventext,accountingfor the surrounding words' context. The Transformer uses multi-headself-attentiontoestablishrelationshipsbetween differentwordsintheinputtext.Thismechanismallowsthe Transformer to attend to different parts of the input text simultaneously, using several attention mechanisms or "heads," each with its own set of parameters. As a result, BERT can capture long-range dependencies and context, whichiscrucialformanyNLPtasks.Forinstance,BERTcan understand the context of the word "telescope" in the sentence "I saw a man with a telescope," as the word depends on the context established by the words "saw," "man,"and"with."
BERT (Bidirectional Encoder Representations from Transformers) is a popular language model based on the TransformerEncoderarchitecture.Hereisanoverviewofthe architecture:
Input Embedding’s- BERT takes in text as input and first tokenizesthetextintoa sequenceoftokens.Eachtokenis then mapped to a fixed-length vector using an embedding matrix.
Transformer Encoder Layers- Theinputembedding’sarefed into a stack of N Transformer Encoder layers. Each layer consists of a multi-head self-attention mechanism and a position-wise feed-forward neural network. The selfattentionmechanismallowseachtokentoattendtoallother tokens in the input sequence, capturing the contextual relationshipsbetweenthem.Thefeed-forwardnetworkthen applies a non-linear transformation to each token's representation.
Pretraining Objectives- BERT is pre trained using two unsupervised learning objectives: Masked Language Modeling(MLM)andNextSentencePrediction(NSP).MLM randomlymaskssomeoftheinputtokensandrequiresthe modeltopredicttheoriginalvalueofthemaskedtokens.NSP predictswhethertwoinputsentencesareconsecutiveornot.
Fine-tuning-Afterpertaining,BERTcanbefine-tunedfora varietyofdownstreamNLPtaskssuchastextclassification, question answering, and named entity recognition. Finetuning involves adding a task-specific layer on top of the pertainedBERTmodelandtrainingtheentiremodelend-toendonalabeleddataset.
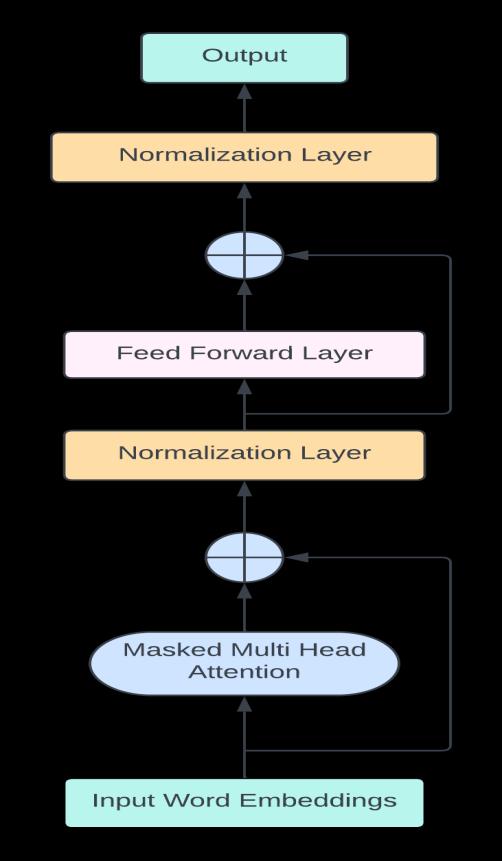
2.1 ROLE OF TRANSFORMERS IN GPT-3:
Transformers are also a crucial component of the architectureofGPT-3,alanguagegenerationmodel.GPT-3 usesaTransformer-baseddecodertogeneratehuman-like text. The decoder leverages multi-head self-attention and cross-attention mechanisms to capture the relationships betweendifferenttokensintheinputsequence.
Throughself-attention,GPT-3attendstodifferentpartsof theinputsequenceandlearnscontextualrepresentationsof the tokens. Cross-attention, on the other hand, allows the model to attend to both the input sequence and a set of learned representations of the task at hand. This enables GPT-3togeneratetextthatiscustomizedtoaspecifictaskor prompt,leadingtomorecoherentandmeaningfuloutputs.
OneofthekeyadvantagesofGPT-3isitsmassivesize.With over 175 billion parameters, GPT-3 is among the largest languagemodelseverdeveloped.Thissizeenablesthemodel tocaptureawiderangeoflinguisticknowledgeandgenerate highly convincing, human-like text. GPT-3 has found applicationsinvariousfields,includingchatbots,language translation,andcreativewriting.
Despite their impressive capabilities, Transformers like those used in GPT-3 have limitations. One of the biggest challenges is their high computational requirements and memory demands, which can make training and running these models expensive and difficult for many users. Additionally,thereareconcernsaboutthepotentialforbias inthedatausedtopre-trainthesemodels,whichcanresult in biased or discriminatory text generation. Ongoing researchanddevelopmentinthefieldofNLPareworkingto addressthesechallengesandimprovetheperformanceand ethicalconsiderationsofTransformer-basedmodels.
3.1 TRANSFORMERS IN GPT-3 ARCHITECTURE
Transformer Decoder Architecture - GPT-3 uses a Transformer Decoder architecture, which consists of multiplestackedTransformerDecoderblocks.
Attention Mechanism- The key component of the TransformerDecoderistheself-attentionmechanism,which allows the model to capture the relationships between all inputtokensinasequence.
Pre Training Objectives - GPT-3 is pretrained on a large corpusof textusingtwounsupervised objectives:masked language modeling (MLM) and causal language modeling (CLM).MLMinvolvesrandomlymaskingsomeinputtokens andaskingthemodeltopredicttheiroriginalvalues.CLM involvespredictingthenexttokeninasequencegiventhe precedingtokens.
Fine-tuning- Afterpretraining,GPT-3canbefine-tunedfora variety of downstream NLP tasks. Fine-tuning involves addingatask-specificoutputlayerontopofthepretrained GPT-3modelandtrainingtheentiremodelend-to-endona labeleddataset.
Large Model Size- OneoftheuniqueaspectsofGPT-3isits large model size, which ranges from 125 million to 175 billionparameters.Thisallowsthemodeltocapturecomplex patternsandrelationshipsintheinputtext.
3.2 LIMITATIONS OF TRANSFORMERS
TransformershavelimitationsdespitetheirsuccessinNLP tasks.Oneofthemajorlimitationsisthehighcomputational requirements needed for pre-training large Transformerbased models. This can be a barrier for researchers and practitionerswhodonothaveaccesstohigh-endcomputing resources.Anotherlimitationistheirinabilitytoincorporate externalknowledgesources,whichcanbecrucialformany NLPtasks.
Moreover, while Transformers have shown impressive performanceonvariousNLPtasks,theyarenotimmuneto errors or bias. Pre-training on large datasets can unintentionallyamplifybiasesinthedata,leadingtobiased orunfairmodels.Thus,itisimportanttocarefullyconsider the data used to pre-train Transformers and to employ techniques such as debiasing and fairness evaluation to ensure that these models are fair and unbiased. Ongoing research is focused on addressing these limitations and improvingthecapabilitiesofTransformer-basedmodelsin NLP.
Transformers have demonstrated significant potential for advancing NLP, despite their limitations. While they can generatehighlyconvincingtextandperformwellonmany NLP tasks, they are limited in their ability to understand language in a truly human-like way. Researchers are continuously working to improve the performance of Transformers and address their limitations, such as high computational costs, difficulty incorporating external knowledgesources,andpotentialbiasesinthedatausedto pre-train these models. Overall, Transformers have revolutionizedNLPandwilllikelycontinuetoplayacrucial roleinthedevelopmentoflanguage-basedAIapplicationsin thefuture.
3.3 TRANSFORMER NEURAL NETWORK DESIGN
4. PRE-TRAINING PROCESS
Pre-training plays a critical role in exploring the use of transformers in natural language processing (NLP). The process involves training a transformer model on a large corpusoftextdatatolearngenerallanguagepatternsand structures,whichisessentialforenablingthetransformerto perform well on downstream NLP tasks. Pre-training typically involves two stages: masked language modeling (MLM)andnextsentenceprediction(NSP).
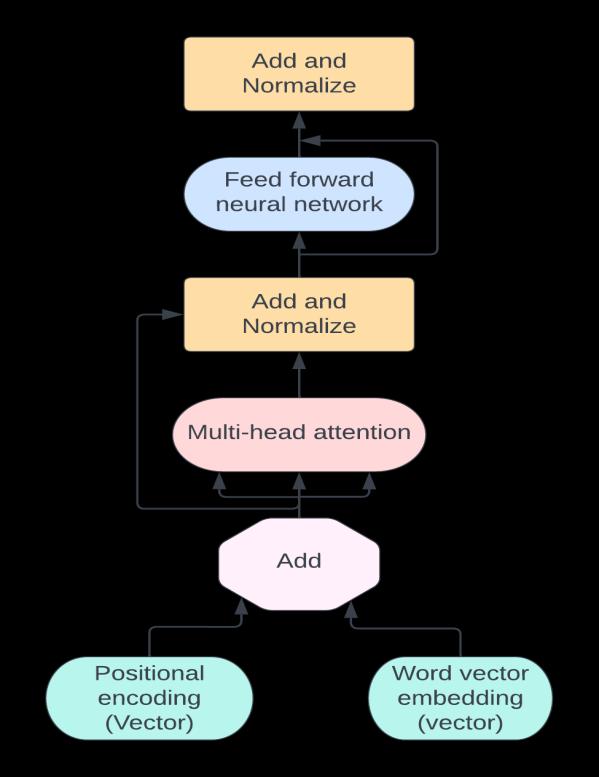
InMLM,themodelispresentedwithasentencewithsome wordsmasked,anditmustpredictthemissingwordsbased on the context provided by the rest of the sentence. NSP involvespredictingwhetherthesecondsentencefollowsthe first in a given context, allowing the model to learn to understandtherelationshipbetweendifferentsentencesand theflowoflanguage.
Although pre-training can take several days or weeks, the fine-tuningprocessonspecificNLPtasksrequiresrelatively littleadditionaltrainingdataoncethemodelhasbeenpretrained.Pre-trainingenablesthedevelopmentofmodelsthat canunderstandlanguagepatternsandstructuresinaway that was not previously possible, opening up new possibilities for NLP and allowing the tackling of a wide range of language-related problems with remarkable accuracy.
4.1. TRANSFER LEARNING AND FINE TUNING IN BERT
Transfer learning involves leveraging the knowledge acquiredfrom pre-training ona largecorpusofunlabeled text and applying it to downstream tasks. In BERT's pretraining phase, it learns to predict masked words in sentences, which forces it to capture the contextual relationshipsbetweenwords.ThisprocessenablesBERTto developarobustunderstandingoflanguagestructureand semantics.
During fine-tuning, BERT is adapted to a specific task or domainusinglabeleddata.Thisinvolvesseveralsteps:
Task-specificArchitecture:
TotailorBERTtothetargettask,atask-specificarchitecture is added on top of the pre-trained BERT model. The architecture includes additional layers that are specific to thetask'sinputandoutputrequirements.Theselayerscan be as simple as a single linear layer for tasks like text classification or more complex for tasks like questionanswering.
TrainingonTask-specificData:
Fine-tuninginvolvestrainingBERTonalabeleddatasetthat isspecifictothetargettask.Theinputdataistokenizedand processed to match BERT's input format. The model then predictstherelevanttask-specificlabelsusingitspre-trained representations.
ParameterOptimization:
Duringfine-tuning,theparametersofthepre-trainedBERT modelandthetask-specificlayersareupdatedtominimizea task-specific loss function. This is typically done through backpropagation and gradient descent optimization. The learningrate,batchsize,andotherhyperparametersmaybe adjustedtooptimizethemodel'sperformanceonthetarget task.
Fine-tuningallowsBERTtoadaptitspre-trainedknowledge tothespecificsofthetargettask,suchassentimentanalysis, named entity recognition, or text summarization. By incorporating the pre-trained language understanding capabilitiesofBERTandupdatingitsparameterswithtaskspecific data, the model can quickly and effectively learn task-specificpatternsandnuances.
Onenotableadvantageoffine-tuningwithBERTisitsability to handle tasks with limited labeled data. Since BERT is initially pre-trained on a large corpus, it has a strong foundation in language understanding. This enables it to generalizewelltonewtasks,evenwhenonlyasmalllabeled datasetisavailableforfine-tuning.
4.2. TRANSFER LEARNING AND FINE TUNING IN GPT-3
Transfer learning and fine-tuning techniques can also be applied to models like GPT-3 (Generative Pre-trained Transformer3)toadaptthemtospecifictasksordomains. Let'sexplorehowtransferlearningandfine-tuningworkin thecontextofGPT-3.
1.TransferLearning:
Transfer learning with GPT-3 involves utilizing the knowledgegainedfrompre-trainingthemodelonamassive corpusoftext.Duringpre-training,GPT-3learnstogenerate coherent and contextually relevant text by predicting the next word in a sequence. This process helps the model developadeepunderstandingoflanguagesyntax,semantics, andevensomeworldknowledge.
Thepre-trainingphaseofGPT-3allowsittocaptureabroad range of language patterns and information, making it a strongbasemodelforvariousdownstreamtasks.
2.Fine-tuning:
Afterpre-training,fine-tuningisperformedtoadaptGPT-3 to a specific task or domain. Fine-tuning involves training GPT-3 on task-specific labeled data to refine its language generation capabilities and align it with the desired task objectives.
The fine-tuning process typically includes the following steps:
a. Task-specific dataset preparation: A labeled dataset is prepared that is specific to the target task. The dataset shouldbestructuredinawaythatGPT-3canlearnfromit, such as providing input-output pairs for tasks like text completionorprovidingapromptfortextgenerationtasks.
b. Model adaptation: Duringfine-tuning,GPT-3'sparameters areupdatedusingthetask-specificdataset.Byexposingthe model to the labeled data, it learns to generate text that alignswiththedesiredtaskrequirements.Theparameters are optimized to minimize a task-specific loss function, whichcouldbeacross-entropylossoratask-specificmetric.
c. Hyperparameter tuning:Fine-tuningmayinvolveadjusting hyperparameters such as learning rate, batch size, and regularization techniques to optimize the model's performanceonthetargettask.
By fine-tuning GPT-3 on task-specific data, the model can generate high-quality text that is tailored to the target applicationordomain.Thefine-tuningprocesshelpsGPT-3 adapt its language generation capabilities to specific prompts,enablingittoprovidemorerelevantandcoherent outputforthegiventask.
Transfer learning and fine-tuning in GPT-3 offer the advantage of leveraging the pre-trained knowledge of the model while customizing its behavior to suit specific applications or domains. These techniques have demonstratedremarkablesuccessinawiderangeofnatural language generation tasks, including text completion, summarization, dialogue generation, and creative writing, amongothers.
5.1 PERFORMANCE OF BERT AND GPT-3 ON NLP BENCHMARK DATASETS
BERTandGPT-3aretwoofthemostpowerfulandwidelyusedNLPmodelsintheindustrytoday.Bothhaveachieved remarkableresultsonvariousbenchmarkdatasets,andhave become the go-to models for a range of natural language processingtasks.
Here,Iwillprovideadetailedanalysisoftheperformanceof BERT and GPT-3 on several benchmark datasets, and comparetheirresultstootherstate-of-the-artNLPmodels.
GLUE Benchmark:
The General Language Understanding Evaluation (GLUE) benchmark is a collection of diverse natural language understanding tasks, including question answering, sentiment analysis, and textual entailment. BERT has achieved state-of-the-art results on the GLUE benchmark, withanaveragescoreof87.1,surpassingthepreviousstateof-the-artbyalargemargin.GPT-3,ontheotherhand,has notbeendirectlyevaluatedontheGLUEbenchmark,buthas shown impressive results on many of the individual tasks includedinGLUE.
SuperGLUE Benchmark:
The SuperGLUE benchmark is an extension of the GLUE benchmark, designed to test the limits of current NLP models by including more complex tasks such as commonsense reasoning and natural language inference. BERT has also achieved state-of-the-art results on the SuperGLUEbenchmark,withanaveragescoreof89.6.GPT3, however, has again not been directly evaluated on the SuperGLUEbenchmark,buthasshownimpressiveresultson manyoftheindividualtasksincludedinSuperGLUE.
SQuAD:
The Stanford Question Answering Dataset (SQuAD) is a benchmarkformachinecomprehension,wherethetaskisto answerquestionsbasedonagivenpassageoftext.BERThas achievedstate-of-the-artresultsonSQuAD,withaF1score of93.2.GPT-3hasnotbeendirectlyevaluatedonSQuAD,but has shown impressive results on other machine comprehensiontasks.
LAMBADA:
TheLAMBADAdatasetisa languagemodelingtask where the model is given a sentence and must predict the final word of the sentence. GPT-3 has achieved state-of-the-art resultsontheLAMBADAdataset,withanaccuracyof80.8%. BERT has not been directly evaluated on the LAMBADA dataset.
CoQA:
TheConversationalQuestionAnswering(CoQA)datasetisa benchmarkformachinecomprehensioninaconversational setting.BERThasachievedstate-of-the-artresultsonCoQA, with a F1 score of 84.2. GPT-3 has not been directly evaluated on CoQA, but has shown impressive results on otherconversationalquestionansweringtasks.
5.2 INTERPRETABILITY AND EXPLAINABILITY
Interpretability and explainability are important aspects when it comes to understanding how transformer models likeBERTandGPT-3makepredictions.Thesemodelshavea complex architecture, which can make it challenging to comprehend their decision-making process. However, researchersareactivelyworkingontechniquestoenhance interpretabilityandexplainabilityoftransformermodels.
One technique that has gained significant attention is attention visualization. Transformers use attention mechanismstoweightheimportanceofdifferentpartsofthe input when making predictions. Attention visualization techniqueshelpininterpretinghowthetransformermodel attendstodifferentpartsoftheinputduringtheprediction process.Byvisualizingthe attentionpatterns,researchers anduserscangaininsightsintowhichwordsortokensinthe inputhavethe mostinfluenceonthemodel'soutput.This can provide a better understanding of the reasoning and decision-makingprocessofthemodel.
Apartfromattentionvisualization,othermethodsarealso being explored to improve interpretability and explainability. These include generating explanations for model predictions, such as highlighting the relevant input featuresthatcontributetotheprediction. Techniqueslike saliency maps, integrated gradients, and gradient-based attribution methods aim to identify the most influential featuresortokensintheinput.
Research efforts are ongoing to develop more advanced interpretability techniques for transformer models. This includes exploring methods that go beyond attention visualization and provide a deeper understanding of the model's internal representations and computations. Researchersareinvestigatingmethodstoextractmeaningful representationsfromthehiddenlayersoftransformersand interpretthelearnedfeatures.
Enhancinginterpretabilityandexplainabilityisacrucialarea ofresearchtobuildtrustintransformermodels,especially inapplicationswheretransparencyandaccountabilityare essential,suchashealthcare,finance,andlegaldomains.By providing insights into how these models arrive at their predictions, users can better understand their limitations, potentialbiases,andmakeinformeddecisionsbasedonthe model'soutputs.
5.3 HYBRID APPROACHES FOR BERT & GPT-3
HybridapproachescanalsobeappliedtomodelslikeBERT andGPT-3tofurtherenhancetheircapabilitiesinlanguage understandingtasks.
BERT (Bidirectional Encoder Representations from Transformers)isapowerfultransformer-basedmodelthat excels in capturing global context and semantic understanding. However, it may struggle with capturing localpatternsandwordorderdependencies,particularlyin tasks where such information is crucial. To address this, hybridmodelscancombineBERTwithotherarchitectures, suchasCNNsorRNNs.
ByincorporatingaCNNintoahybridBERTmodel,thelocal contextandword-levelfeaturescanbeeffectivelycaptured. CNNs are adept at extracting local patterns, and when combined with BERT, they can help the model to better understandandleveragefine-grainedlocal information in the input text. This can be particularly useful in tasks like text classification, named entity recognition, or sentiment analysis, where capturing local features and patterns is essential.
Similarly,hybridmodelscanalsointegraterecurrentneural networks(RNNs)withBERTorGPT-3tocapturesequential dependencies and further enhance the understanding of languagecontext.RNNscanmodelthesequentialnatureof textbyconsideringthedependenciesbetweenpreviousand currenttokens.BycombiningRNNswithBERTorGPT-3,the hybrid model can benefit from both the global context understanding of transformers and the sequential dependenciescapturedbyRNNs.Thiscanbeadvantageous intaskslikelanguagemodeling,textgeneration,ormachine translation,wheremaintainingthecoherenceandflowofthe generatedtextiscrucial.
HybridapproachesforBERTandGPT-3aimtoleveragethe strengths of both transformers and other architectures to capture both local and global context in language understanding tasks. By combining these models, researchers and practitioners can create more robust and comprehensive models that excel in a wide range of NLP applications, catering to both fine-grained details and broadersemanticunderstanding.
5.4 ETHICAL CONSIDERATIONS
Ethicalconsiderationssurroundingtransformermodelslike BERTandGPT-3areofutmostimportance,particularlyin lightofconcernsrelatedtogeneratingmisleadingorbiased content.Asthesemodelsbecomeincreasinglypowerful,itis crucial to address the potential ethical implications and ensureresponsibledeploymentandusage.Effortsarebeing madewithintheresearchandpractitionercommunitiesto addresstheseconcernsandpromotefairness,transparency, andaccountabilityintransformermodels.
Onemajorconcernisthepropagationofbiasespresentin thetrainingdata.Sincetransformermodelslearnfromvast amountsoftextdata,theycaninadvertentlycapturebiases andprejudicespresentinthatdata.Thiscanresultinbiased or discriminatory outputs generated by the models. Recognizing this issue, researchers and practitioners are activelyworkingonmitigatingbiasesbycarefullycurating trainingdata,usingdebiasingtechniques,andimplementing fairness-aware training methods. They strive to develop models that are more conscious of potential biases and producecontentthatismorebalancedandunbiased.
Transparencyisanothercriticalaspect.Thereisagrowing demandfortransparencyinhowtransformermodelsmake decisionsandgenerateoutputs.Researchersareexploring methodstoprovideuserswithmorevisibilityintotheinner workingsofthemodels,enablingthemtounderstandand interpret the model's reasoning process. This includes techniques such as attention visualization, explanation generation,andinterpretabilitymethodstoshedlightonthe factorsinfluencingmodelpredictions.
Accountability is also a key consideration. As transformer modelsareincreasinglydeployedinvariousapplicationsand domains,itisimportanttoestablishmechanismsforholding thesemodelsaccountablefortheiroutputs.Researchersare workingondevelopingframeworksandmethodologiesto attribute responsibility for generated content, trace the decision-making process, and provide mechanisms for recourseincaseofharmorbiases.
Furthermore, collaborations between researchers, policymakers,andindustrystakeholdersarebeingfostered toestablishguidelines,bestpractices,andethicalstandards forthedevelopmentanddeploymentoftransformermodels. Initiativesareunderwaytoencourageresponsibleresearch, opendialogue,andcommunityengagementtoaddressthe ethicalchallengesassociatedwiththesemodels.
5.5 FUTURE DIRECTIONS
Lookingahead,researchersareexploringvariousavenues forthefuturedevelopmentofTransformersinNLP.Onearea of focus is on designing more efficient Transformer architecturesthatcanachievecomparableperformancewith lesscomputationalcost,makingthemmoreaccessibleand
usefulforawiderrangeofapplications,suchaschatbotsand languagetranslation.
Another promising direction is the integration of external knowledge sources into Transformer-based models. By incorporatingknowledgegraphsordatabasesintothemodel architecture, the model's ability to reason about the relationshipsbetweendifferentconceptsandentitiescould be enhanced. This could lead to more accurate and informativeoutputs,witha wider rangeofapplications in fieldssuchasmedicineandfinance.
There is ongoing research in the field of NLP to explore exciting possibilities for the future development of Transformers.Oneareaoffocusisthedevelopmentofmore efficient Transformer architectures that can achieve comparableperformancewithlesscomputationalcost.This wouldincreasetheaccessibilityandusefulnessofthemodels for a wider range of applications, including chatbots and languagetranslation.
Another promising direction is the integration of external knowledge sources into Transformer-based models. By incorporatingexistingknowledgegraphsordatabasesinto themodelarchitecture,researcherscanenhancethemodel's abilitytoreasonabouttherelationshipsbetweendifferent conceptsandentities,whichcouldleadtomoreaccurateand informativeoutputsinfieldssuchasmedicineandfinance.
Additionally,thereisongoingworktomakeTransformerbased models more interpretable and explainable. This is crucial in areas such as healthcare and finance, where transparent decision-making is essential. Researchers are exploringnewtechniquessuchasattentionvisualizationand gradient-basedattributiontoprovidegreaterinsightsinto theinnerworkingsofthesemodelsandincreasetrustand acceptanceoftheirpredictions.
5.6 DOWNSTREAM APPLICATIONS
Transformershaverestructuredthefieldofnaturallanguage processing(NLP)inrecentyears.Twonotableexamplesof these transformers are BERT and GPT-3, which have garnered significant attention due to their remarkable performanceinarangeofNLPtasks.
Butwhatarethedownstreamapplicationsofexploringthe roleoftransformersinNLP?
Downstreamapplicationsrefertothevariouswaysinwhich NLP techniques and models can be applied to solve realworld problems. For example, BERT and GPT-3 have demonstrated remarkable performance in tasks such as sentimentanalysis,textclassification,languagetranslation, andmore.
Sentiment analysis isatechniquethatinvolvesanalyzingtext todeterminethewriter'sattitudetowardsaparticulartopic. Ithasmany practical applications,suchasin social media monitoring, product reviews, and customer feedback analysis.
Text classification is another important downstream application of transformer models, and it involves categorizing text into different classes or categories. For example,itcanbeusedtoclassifynewsarticlesintotopics suchaspolitics,sports,orentertainment.Thiscanbeuseful for organizing large amounts of text data and making it easiertoextractmeaningfulinsightsfromthem.
Language translation isyetanotherimportantdownstream applicationoftransformermodels.Byusingthesemodels,it is now possible to translate text from one language to anotherwithremarkableaccuracy.Thiscanbeimmensely usefulinsituationssuchasinternationalbusiness,tourism, anddiplomacy.
6. CONCLUSION
Inconclusion,theemergenceofTransformer-basedmodels has revolutionized the field of NLP, enabling significant advancementsinarangeoftasks.BERTandGPT-3aretwo well-known examples of these models, each with its own unique strengths and capabilities. BERT, with its bidirectionalarchitectureandpre-trainingonlargeamounts ofdata,hasachievedstate-of-the-artperformanceonarange of NLP tasks, such as question-answering and natural language inference. On the other hand, GPT-3 has gained attentionforitsimpressivelanguagegenerationcapabilities, which have been used for a range of applications, such as chatbotsandcreativewriting.
WhileTransformershaveshowngreatpromiseinNLP,there arestillsomelimitationstothecurrentimplementationof these models. One of the main challenges is their high computational cost,whichmakesthemdifficulttodeployon low-resourcedevicesorinreal-timeapplications.Another challengeistheir inability to captureworldknowledge,which limits their ability to reason about complex relationships betweenentitiesandconcepts.
However,therearemanypromisingdirectionsforthefuture developmentofTransformersinNLP.Onedirectionis the developmentofmoreefficientarchitecturesthatcanachieve similarperformancewithlowercomputationalcost.
Recent research has explored techniques such as sparse attention mechanisms and dynamic routing to reduce the computationalcomplexityofTransformers.
Anotherdirectionistheintegrationofexternalknowledge sources into Transformer-based models, which can help themreasonaboutcomplexrelationshipsbetweenentities andconcepts.Thisapproachcaninvolveincorporatingpre-
existing knowledge graphs or ontologies into the model architectureorleveragingexternalknowledgesourcessuch asencyclopediasordatabasestoenrichtheinputtextwith additionalinformation.
Finally, there is ongoing research into developing more interpretable and explainable Transformer-based models. Whilethesemodelshaveshownimpressiveperformanceon a rangeof NLPtasks,they are often seen as"black boxes" that are difficult to interpret or explain. However, recent research has explored techniques such as attention visualization and gradient-based attribution to provide insightsintohowthesemodelsaremakingtheirpredictions. By making these models more transparent, we can build moretrustintheirpredictionsandbetterunderstandhow theycanbeimproved.
REFERENCES
1. "Attention Is All You Need" - The original paper introducing Transformers: https://arxiv.org/abs/1706.03762
2. "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding" - The paper introducing BERT: https://arxiv.org/abs/1810.04805
3. "GPT-3:LanguageModelsareFew-ShotLearners"The paper introducing GPT-3: https://arxiv.org/abs/2005.14165
4. "Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer" - A paper introducing T5, a Transformer-based model that can perform a range of NLP tasks: https://arxiv.org/abs/1910.10683
5. "TheIllustratedTransformer"-Avisualexplanation of the Transformer architecture: https://jalammar.github.io/illustratedtransformer/
6. "An Introduction to Transformers for Natural Language Processing" - A blog post providing an overview of Transformers in NLP: https://huggingface.co/blog/how-to-build-a-stateof-the-art-conversational-ai-with-transfer-learning2d818ac26313
7. "TheGradientDescentPodcast"-Apodcastseries featuring interviews with NLP researchers, including discussions on Transformers: https://thegradientpub.substack.com/
8. "TransformersforNaturalLanguageProcessing"-A book providing a comprehensive introduction to Transformers in NLP:
https://www.manning.com/books/transformersfor-natural-language-processing
9. "HuggingFace"-Awebsiteprovidingaccesstopretrained Transformer models and NLP tools: https://huggingface.co/
10. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding: https://arxiv.org/abs/1810.04805
11. Language Models are Few-Shot Learners: https://arxiv.org/abs/2005.14165
12. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding: https://arxiv.org/abs/1804.07461
13. SuperGLUE: A Stickier Benchmark for GeneralPurpose Language Understanding Systems: https://arxiv.org/abs/1905.00537
14. SQuAD: 100,000+ Questions for Machine Comprehension of Text: https://arxiv.org/abs/1606.05250
15. TheLAMBADADataset:WordPredictionRequiring a Broad Discourse Context: https://www.aclweb.org/anthology/P16-1144
BIOGRAPHIES
Master. Abul Faiz Chandpasha Bangi,pursuingB.E.inElectronics and Telecommunication Engineering from PVG College of EngineeringandTechnology&G.K. Pate (Wani) Institute of Management,Pune.
