
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 12 Issue: 10 | Oct 2025 www.irjet.net p-ISSN:2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 12 Issue: 10 | Oct 2025 www.irjet.net p-ISSN:2395-0072
Veeransh Shah1, Moksh Shah2, Purab Tamboli3, Prof. Pramila M Chawan4
11B. Tech Student, Dept of Computer Engineering, and IT, VJTI College, Mumbai, Maharashtra, India
21B. Tech Student, Dept of Computer Engineering, and IT, VJTI College, Mumbai, Maharashtra, India
31B. Tech Student, Dept of Computer Engineering, and IT, VJTI College, Mumbai, Maharashtra, India
4 Associate Professor, Dept of Computer Engineering and IT, VJTI College, Mumbai, Maharashtra, India
Abstract – The project presents an automated system for translating American Sign Language (ASL) into English in real-time. The system is designed to bridge the communication gap for the deaf community in various social and professional settings. Leveraging advancements indeeplearning,thisworkutilizestheMS-ASLdatasetanda pre-trained I3D model to achieve accurate sign language recognition. The methodology involves a comprehensive data pre-processing pipeline including video trimming, cropping,andframeconversion.TheI3D modelisfine-tuned using transfer learning to adapt to the specifics of ASL recognition.Thisprojectlaysthegroundworkforapractical and scalable solution to facilitate seamless communication forthedeafandhardofhearing.
This research specifically focuses on word-level sign recognition, establishing a foundational vocabulary that can be accurately translated. The core challenge addressed is the model's ability to discern subtle spatio-temporal variations between different signs, a task for which the I3D architecture is exceptionally well-suited. By successfully implementing this system, we demonstrate the viability of using pre-trained action recognition models as a powerful starting point for the more nuanced domain of sign language. The ultimate vision is a low-latency, highly accurate translation tool that can be integrated into everyday communication platforms, empowering users with greater independence and fostering more inclusive interactions.
Key Words: Deep Learning, I3D Model, MS-ASL Dataset, TransferLearning
1.INTRODUCTION
Communication is a fundamental aspect of human interaction. However, for the deaf community, communicationwiththehearingworldcanbeasignificant challenge. This project aims to address this issue by developinganautomatedsystemthattranslatesAmerican Sign Language (ASL) into english text in real-time. By leveraging recent advancements in deep learning and computervision,weaimtocreateapracticalsolutionthat can be used in various scenarios, such as doctor’s appointments, educational settings, and conferences. Our work builds upon existing research and utilizes the large-
scale MS-ASL dataset to train a robust and accurate translationmodel.
The complexity of sign language extends beyond simple hand gestures; it is a complete visual language incorporating facial expressions, body posture, and the speed and rhythm of movements to convey meaning and grammatical structure. Traditional interpretation methods, while invaluable, are not always accessible or practicalforspontaneousdailyinteractions.Anautomated system offers the promise of immediate, on-demand translation, reducing reliance on human interpreters and empowering individuals with autonomy. This work seeks to harness the power of deep neural networks to learn these intricate visual patterns directly from video data, creating a system that not only recognizes gestures but alsounderstandsthetemporaldynamicsthatdefinethem, pavingthewayformorenaturalandfluidcommunication.
2.1.1 3D Convolutional Neural Networks (3D CNNs): These model extend the concept of 2D CNNs to the time domain, making them ideal for video analysis. 3D CNNs use 3D filters to convolve over both spatial and temporal dimensions of video data, allowing them to learn features thatrepresentboththeappearanceofhandshapesandthe motionofgestures.
Unlike hybrid approaches that use a 2D CNN to extract features from each frame and then feed them into a separate temporal model like an RNN, 3D CNNs perform spatio-temporal feature learning in a unified, hierarchical manner. The 3D convolutional kernels slide across a cube of video frames, enabling the network to directly learn motionprimitives,suchasthearc ofahandmovement or the change in a handshape over time, within its early layers. This integrated approach often leads to more robust representations of dynamic gestures compared to methods that decouple spatial and temporal feature extraction.
2.1.2 Recurrent Neural Network (RNNs) with LSTMs: These models are designed to process sequential data. In sign language recognition, LSTMs can be combined with
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 12 Issue: 10 | Oct 2025 www.irjet.net p-ISSN:2395-0072
CNNstofirstextractspatial featuresfromeachframeand then model the temporal relationships between them to recognizeacompletesign.
The key innovation of Long Short-Term Memory (LSTM) units is their gating mechanism comprising the input, forget,andoutputgates whichmeticulouslycontrolsthe flow of information through the network. The forget gate determines which information from the previous state should be discarded, while the input gate decides what new information to store. This allows LSTMs to mitigate the vanishing gradient problem, enabling them to effectively learn long-range dependencies in a video sequence. For sign language, this is critical for distinguishingbetweensignsthatmaysharesimilarinitial movementsbutdivergesignificantlytowardstheend.
2.1.3 Transformers: They are originally developed for natural language processing, Transformer models use an attentionmechanismtoweigh theimportanceofdifferent frames in a video sequence. This allows them to capture long-range dependencies and complex grammatical structures in sign language, making them suitable for continuoussignlanguagerecognition.
The self-attention mechanism is the cornerstone of the Transformerarchitecture.Itenablesthemodeltoevaluate theentirevideosequenceatonce,calculatingan"attention score" for every frame in relation to every other frame. Consequently, the model can dynamically focus on the mostsalient partsofa sign,regardlessoftheir position in the sequence. For instance, it can learn that the final handshape and the initial location of a sign are the most critical components for its meaning, effectively bypassing the sequential processing bottleneck of RNNs and capturingamoreholisticunderstandingofthegesture.
The reviewed papers confirm that deep learning architectures are the most effective for sign language recognition.Specifically,theworkofCarreria& Zisserman on the I3D model established a powerful baseline for action recognition, which has been successfully adapted for sign language. This is further supported by Cui et al., whoachieved95.7%accuracyusing3DCNNsandLietal., who reported an exceptional 99.8% accuracy for wordlevel ASL recognition. These results strongly validate the choice of a 3D CNN for this project, as its ability to learn spatio-temporal features directly from video is ideal for recognizingisolatedsignswithhighprecision
Acleardirectionforfutureworkisalsohighlightedbythe literature.TheresearchbyCamgozetal.,onsignlanguage transformers and by Koller et al. On weakly supervised learning with transformers demonstrates the superiority of these models for continuous sign language recognition, where context and grammar are crucial. While our
proposed3DCNN isoptimal forthecurrentgoal ofwordlevel translation, these findings suggest that integrating a Transformer-based architecture would be the next logical step to expand the system’s capabilities to full sentence translation.
Synthesizing these findings reveals a clear technological trajectory in the field. The high accuracy achieved by modelslike3DCNNsonword-leveldatasetsconfirmsthat thechallengeofrecognizing isolatedsignsislargelybeing solved.Theresearchfrontierhasnowshiftedtowardsthe more complex problem of continuous, sentence-level translation,whichmirrorsnaturalhumancommunication. The success of Transformers in this area underscores the importance of modeling linguistic context and grammar, which isolated sign recognizers inherently ignore. Therefore, our proposed system serves as a critical and robust component a word recognizer that could in the futurefeeditspredictionsintoahigher-levelTransformer model designed to interpret and translate full signed sentences.
Author Technique Used Accuracy
Carreira.J, Zisserman.A
Two-StreamInflated 3DConvNet(I3D)
State-of-the-arton Kineticsdataset
Koller.O,etal WeaklySupervised Learningwith Transformers Highaccuracyon RWTH-PHOENIXWeather2014T
Cui.R,etal 3DCNNswithhand andandpose estimation
95.7%onalargescaleChineseSign Languagedataset
Camgoz.N.c SignLanguage Transformers State-of-the-art resultoncontinuous signlanguage recognition
Li.D Word-levelDeepsign LanguageRecognition
99.8%onawordlevelASLdataset
Rastgoo.R ASurveyofvisionbasedSLRmethods Comprehensive reviewofdeep learningmodels
4.1 Problem Statement
“ToTranslateAmericanSignLanguage(ASL)gesturesinto textinreal-timeusingdeeplearningtechniques.”
4.2 Problem Elaboration
For the deaf and hard to hear community, communicationwithnon-signersposesaseriousproblem, as it can result in social isolation and limited access to
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 12 Issue: 10 | Oct 2025 www.irjet.net p-ISSN:2395-0072
information. Traditional methods of interpretation are frequently unavailable and have trouble capturing the nuances of a live conversation, which leads to communication breakdowns.The volume ofvisual data in signlanguagevideonecessitatestheuseofmoreadvanced algorithms to translate gestures accurately. Sign language totexttranslationcanbeautomatedanddata-drivenwith deep learning; nevertheless choosing the best model can be difficult. In order to determine which deep learning modelperformsbest,thisstudywillfocusontheefficiency of a 3D CNN model in translating ASL gestures. Assisting the deaf and hard-of-hearing community in communicatingmoreeffectivelyistheaim.
4.3 Proposed Method:
3D CNN Model for Sign Language to Text translation The 3D CNN model leverages the strengths of deep learning to improve the accuracy and robustness of sign language translation. In this approach, the model is trained on a sign language video dataset after it has been preprocessed for cleaning and normalization. The model learnstorecognizesignsbasedontheinputvideoframes, reflecting itsuniquelearningapproach.Thecomplexity of the model helps capture various patterns in the data, which is crucial for nuanced sign language gestures that maynotbeeasilyunderstoodbyasimplermodel.
Aftergeneratingpredictions,themodel’sperformancewill beevaluatedbasedonmetricssuchasaccuracy,precision, and recall. This evaluation will provide insights into performance of the model. This method harnesses the powerofdeeplearning,ultimatelyenhancingtheabilityto translatesignlanguageeffectively.
Theimplementationwillfollowastructuredmethodology. First, the MS-ASL dataset will undergo rigorous preprocessing where videos are normalized to a consistent frame rate and resolution. We will apply data augmentation techniques, such as random horizontal flipping, scaling, and slight rotations, to create a more diversetrainingsetandpreventoverfitting.Forthemodel architecture, we will use a pre-trained I3D model, initialized with weights from the Kinetics dataset, and replaceitsfinalclassificationlayerwithanewonetailored toourASLvocabulary.Themodelwillbefine-tunedusing the Adam optimizer and a categorical cross-entropy loss function. The learning rate will be managed with a scheduler to ensure stable convergence. This transfer learning approach is expected to significantly reduce training time and leverage the powerful, generalized motion features learned from the large-scale action recognitiondataset.
For a rigorous evaluation of the model's performance, we will conduct a detailed analysis beyond simple accuracy. We will generate a confusion matrix to gain qualitative insights into the model's predictions. This matrix will
allow us to identify specific misclassifications, revealing whichsignsarecommonlyconfusedwithoneanotherdue to similar handshapes or motion trajectories. Furthermore, we will calculate the Precision, Recall, and F1-Score for each sign class. This per-class analysis is crucial,asoverallaccuracycanbemisleadingifthedataset is imbalanced. A high recall for a particular sign will indicate that the model is effective at identifying all instances of that sign, while high precision will show that it does not frequently mislabel other signs as that sign. This comprehensive evaluation framework will not only providearobustmeasureofthesystem'seffectivenessbut also highlight specific weaknesses to guide future iterationsandmodelimprovements.
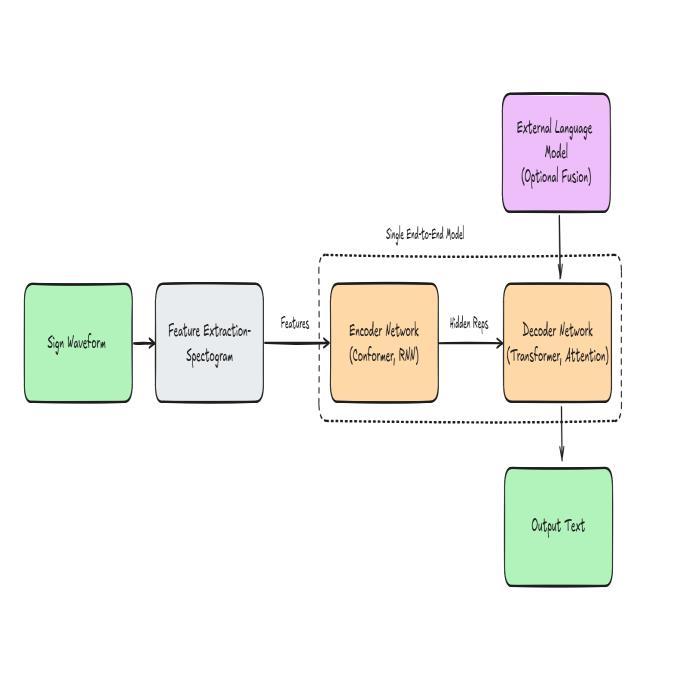
In this paper, we explored various deep learning models for sign language translation and found that 3D CNNs generally yield high accuracy due to their ability to learn bothspatialandtemporalfeatureseffectively.Buildingon thisinsight,weproposedamorecomplexmodelthatuses transfer learning from a model pre-trained on a large video dataset. By fine-tuning this model on our sign langauge dataset, this layered approach can further enhance translation accuracy and robustness making it a highly reliable tool for real time sign language to text translation.
[1] Carreria.J, & Zisserman.A, (2017). Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. Proceedings of the IEEE conference on computer vision andpatternrecognition.
[2] Koller.O, Zargaran.S, & Ney.H, (2019). Weakly supervised learning for sign language recognition with dense trajectory-based features.Proceedings of the IEEE Internationalconferenceoncomputervisionworkshops.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 12 Issue: 10 | Oct 2025 www.irjet.net p-ISSN:2395-0072
[3] Li.D, et al.(2020). Word-level Deep Sign Language Recognition. 2020 25th International conference on patternrecognition.
[4] Rastgoo.r,Kiani,K,&Escalera.S(2021).SignLanguage Recognition: A Deep Survey. Expert Systems with Applications.