Poseidon-Bot: A Streamlined Document
Parsing RAG Model
Kendree Chen Quinten Jin
Efrain Morales
Senior Thesis | 2025


Kendree Chen, Quinten Jin, Efrain Morales
March 2025
The state of arti,icial intelligence (AI) is ever changing, advancing every day in the amount and ef,iciency of tasks AI can complete. In the modern age, AI computing power has been doubling every 3.4 months and AIenhanced technologies have become more widely available, being easy to access in many apps or search engines. Today, AI is present in intelligent applications, neuronal networks, AI platforms as a service, and AI cloud services. The recent in,lux of AI-enhanced technologies is due to affordability and ease of integration into existing websites and applications. AI is able to serve as a security feature in analyzing faces, detecting antivirus threats, and being effective in management systems, typically for warehouses [1].
Every investment in AI has increased its effectiveness and leads to improvements that could greatly impact the everyday lives of everyone. For example, AI has improved so much in the last few years that in StarCraft II, a real-time strategy game, an AI developed by DeepMind has achieved grandmaster status and has outperformed 99.8 percent of players on StarCraft II [1]. Open-source AI and machine learning projects also further enable developers to integrate machine learning, deep learning, image recognition, and voice recognition into their work. Machine Learning is the capability of AI to imitate intelligent human thinking and behavior, while deep learning is an AI that uses arti,icial neural networks to teach computers how to process data. Alongside tech companies like Google and Apple, investments in AI are advancing applications in all different ,ields. The investment has not only helped research labs implementing AI to assist in the research of cancer cells [2] but also companies like Gaia using AI to help manage forests [3]. In addition, AI in ,ields like smart logistics, language translation, ,inancial trading, and education are also ,lourishing. With breakthroughs in the ability to smell and touch, AI can now interpret odors and process tactile feedback [4]. AI systems are beginning to mirror biological systems in unprecedented ways [5].
Despite these signi,icant advances in deep learning algorithms and extensive data repositories, contemporary AI systems continue to face limitations in processing and contextual understanding. AI models can be subject to hallucinations, content that seems plausible but is in reality a summary of varying learned patterns, resulting in content that is factually untrue or fantastical. Pre-trained neural large language models (LLMs) are trained on a dataset that becomes a working parametric “memory” for the model. While models are able to learn a signi,icant amount of knowledge through this method, and can subsequently recall information in responses without access to an external information source, the lack of ,lexibility and transparency of the parametric memory can contribute to hallucinations.
Retrieval augmented generation (RAG) is a hybridized AI technique that combines parametric memory with a retrieval-based fact source that serves as a non-parametric memory. Information in the non-parametric memory can be easily accessed and updated. An example of a non-parametric memory data source, utilized in a 2020 study by Lewis et al, was the online Wikipedia encyclopedia, in a vectorized and indexed format [6]. RAG work,lows have been found capable of reducing model size and generation costs in addition to minimizing hallucinations and increasing accuracy of generated responses [7].
Here we discuss Poseidon-Bot, which serves as an example of the ongoing development of RAG as AI technology evolves and continues to enable more coherent and contextually aware responses. Poseidon-Bot was developed with the goal of increasing user oversight and control over the non-parametric memory of a RAG model. While a typical RAG model utilizes large vector-formatted data sources for its non-parametric memory, it ethically relies heavily on the public accessibility of that data, which limits the scope of the memory of the model [8]. In Poseidon-Bot, speci,ic fact sources are uploaded by the user into the working non-parametric memory, providing the model with retrievable data in a more secure format. The increased user oversight and privacy of data used in the non-parametric memory of Poseidon-Bot’s modi,ied RAG model is intended to enhance its potential for usage in processing sensitive or non publicly accessible information. The narrowed scope of data used in the non-parametric memory of Poseidon-Bot allows for the simpli,ication of the retrieval process of the RAG work,low, utilizing a vectorized and similarity searchable database of user-uploaded information instead of requiring a generated question to search a large online data source. We examine the performance of Poseidon-Bot in comparison to a standard LLM to assess the response quality, accuracy, and ef,iciency of its modi,ied RAG approach.
The RAG work,low centers around the searching of a data source for relevant information each time a user posts a query; this information is then turned into an input to the model that informs its response. The correctness of the LLM response in turn relies on the power and accuracy of the search algorithm used to ,ind relevant information. RAG methods allow for quicker adaptation to new data, eliminating the need to retrain the model with every information change. External data commonly is retrieved from web-based sources including databases and web pages.
The Poseidon-Bot project aims to take advantage of the training modularity of the RAG method by allowing user-uploaded documents to be used as data sources for informing LLM responses. Although many search algorithms used in RAG are limited by the need for extensive web access and the time consumption of processing large amounts of data, this project’s user-driven approach to data allows for a faster work,low. Collected data is processed and stored in a vector database, which is then used for retrieval.
Typical RAG work,lows utilize an LLM twice: once to generate a standalone question used when querying the vector store for relevant data, and again when the data-augmented query is fed into the LLM to generate a response (Figure 1).
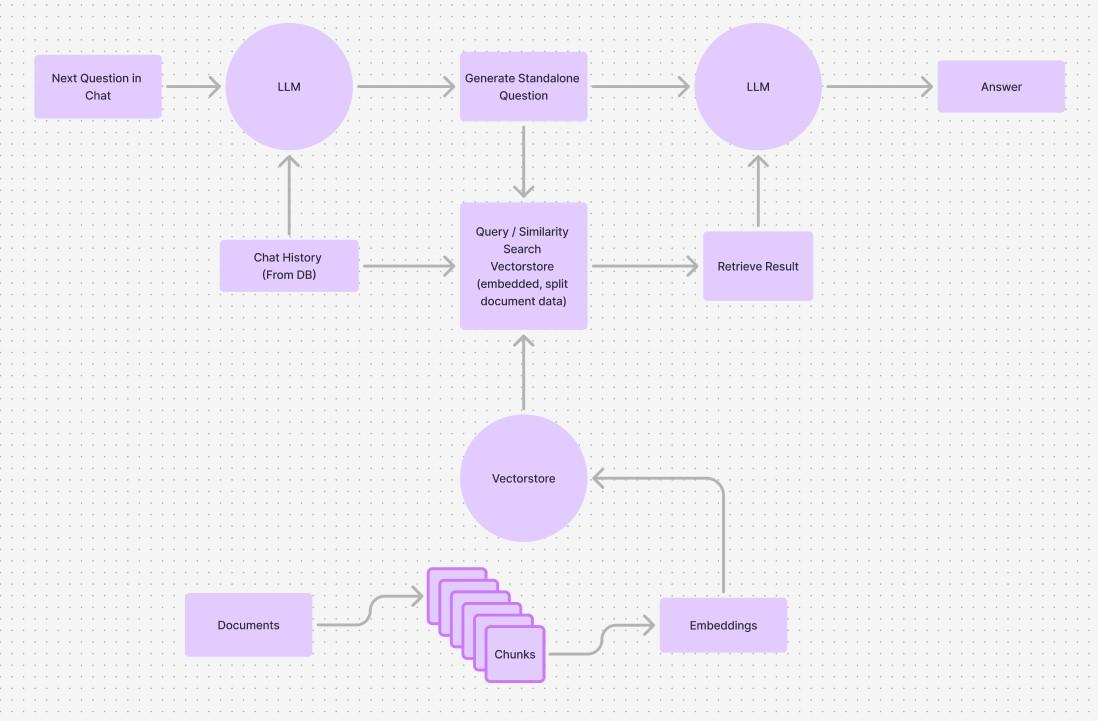
Figure 1: Standard RAG Work.low with inclusion of standalone question
With the reduction of data loaded into the model’s non-parameterized memory, we tested a simpli,ied work,low that utilized a vector store with integration of ChromaDB [9], an AI-native open-source vector database capable of complex similarity searches, to eliminate the need for the standalone question.
Poseidon-Bot accepts user queries from a frontend interface created in Flutter [10]. Users can upload documents for the LLM to search, send queries to the model, and add and delete messages and chats. PoseidonBot uses the Llama 3.1 LLM [11]. Backend request processing uses FastAPI [12], a high-performance web
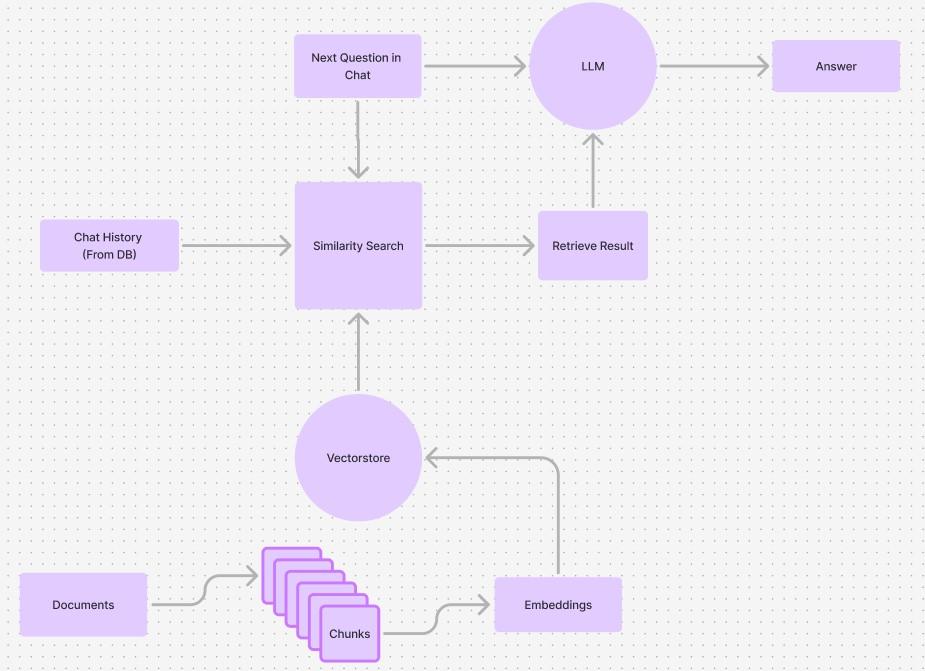
Figure 2: Poseidon-Bot RAG Work.low utilizing ChromaDB
framework for creating Application Programming Interfaces (APIs) in Python, which enables seamless communication between the frontend and backend. The backend data vector store relies on ChromaDB, which stores chunked data that is searched using a similarity basis with each new backend query. This allowed for the elimination of the standalone question when querying documents from the vector store (Figure 2). Vector store data is sent with the user query to the LLM, and the response is returned to the frontend. Backend chat and message history are supported by a PostgreSQL [13] database and fetched when rendering the frontend.
The performance of the RAG model was evaluated using a series of tests and compared against a nonRAG Llama 3.1 chatbot, the same model without a RAG work,low. Tests evaluated two functions of an LLM model: summarizing text and answering conversational questions. Poseidon-Bot performances on both the Summary Test (ST) and Question Response Test (QRT) were compared against the Llama 3.1 model. Ten responses were generated for each model in each test, and responses were evaluated and graded on a Likert [14] scale by a group of human readers on a set of outlined metrics.
The Summary Test (ST) examined the ability of a model to synthesize information in a document without excluding necessary details or including excessive unimportant information. The RAG model received the document uploaded to its data vectorstore, while the non-RAG model was provided with the document alongside the user query. The summary test was scored along four metrics: coherence, consistency, ,luency, and relevance (Figure 3).
Coherence, as a metric, represents the collective quality of generated sentences, abiding by the DUC guideline of structure wherein the summary should be organized to contain relevant information that builds to a coherent body of information [15]. Consistency represents the accuracy of the information in a model summary to the original document. Incorrect information is penalized. A consistent summary only contains facts or details from the original source document. Fluency is a measure of the quality, grammatical
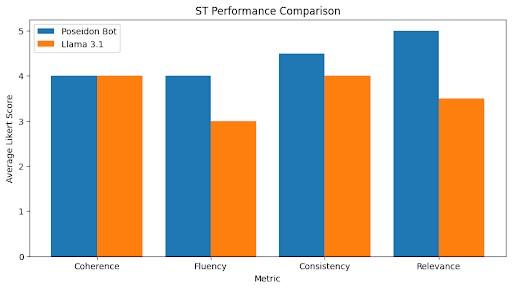
Figure 3: Comparison of average ratings of Poseidon-Bot and Llama 3.1 responses in the Summary Test. correctness, and naturality of individual sentences in the answer as graded by a ,luent human speaker. Relevance measures the presence of important information in the response. Out of facts presented in the source document, the model response must contain pertinent information and omit extraneous facts [16].
In the Summary Test, the Poseidon-Bot responses averaged higher consistency and relevance, producing a more correct summary of a popular story than a standard model and drawing directly from the provided document (Figure 3). Fluency and relevance showed a signi,icant increase in the Poseidon-Bot response of >1 rating point. Consistency ratings increased slightly by 0.5 rating points from the standard response to the Poseidon-Bot response. Coherence was scored as approximately equivalent between the standard response and the Poseidon-Bot response.
In a test to summarize the opening chapter of Arthur Conan Doyle’s A Study in Scarlet, the Poseidon-Bot response included speci,ic details from the ,irst chapter of the novel:
As they travel through London streets in a carriage, Stamford discusses his impressions of Holmes, describing him as “scienti,ic” to the point of cold-bloodedness. He shares a humorous anecdote about Holmes’ approach to scienti,ic inquiry, which makes Watson laugh.
Figure 4: Sampled Poseidon-Bot response from an ST prompt to summarize the opening chapter of Arthur Conan Doyle’s A Study in Scarlet.
The Llama response, in comparison, included a factually inaccurate summary of the opening chapter of the novel, while providing a less speci,ic description of the alleged events of the ,irst chapter:
Watson is walking through the streets of London, lost in thought, as he recalls his experiences during the Afghan War. He re,lects on his time as a medical doctor and his close relationships with his fellow soldiers.
Figure 5: Sampled Llama 3.1 response from an ST prompt to summarize the opening chapter of Arthur Conan Doyle’s A Study in Scarlet.
This suggests that responses from Poseidon-Bot in the Summary Test demonstrated higher detail, accuracy, and presence of relevant information in the generated summaries. Meanwhile, grammatical correctness remained consistent between the responses. The increase in ,luency ratings in the Poseidon-Bot response when compared to the Llama response may be due to the increased vagueness of the Llama response, with a pattern of ending sentences with “...” characters, which may have decreased perceptions of ,luency.
The Question Response Test (QRT) examined the ability of the model to answer and explain the answers to simple boolean or multiple-choice questions with factual accuracy. This test compared RAG and nonRAG models as well, with the RAG model being provided relevant information via data upload. Question responses were scored along four metrics: coherence, groundedness, ,luency, and relevance (Figure 6).
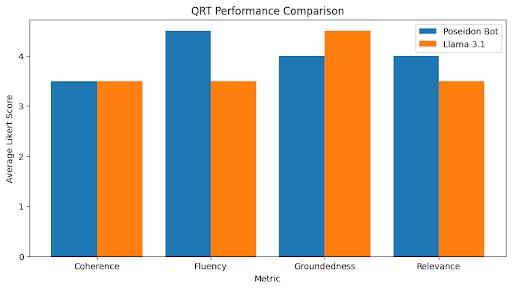
Figure 6: Comparison of average ratings of Poseidon-Bot and Llama 3.1 responses in the Question Response Test.
Groundedness represents the logical reasoning and demonstrated understanding of conversational context in model responses. Responses should logically build from conversation history and informational context. Groundedness was used as a metric for the QRT, replacing the consistency metric that was used in the ST, due to the conversational nature of the QRT when compared to the focus of the ST on accurately synthesizing and conveying data.
The Question Response Test was conducted with both Poseidon-Bot and a standard Llama model. The Poseidon-Bot responses averaged higher scores on ,luency, relevance, and similarity. Coherence remained approximately constant. Groundedness was scored as slightly lower in Poseidon-Bot’s response, dropping by 0.5, showing a slightly lower awareness of conversational context.
When prompted to answer the question “Are oranges part of the melon family?” both models produced responses with detail beyond answering the initial question.
No, oranges are not part of the melon family. Oranges are actually a type of fruit that comes from a tree in the family Rutaceae, also known as the citrus family. Melons, on the other hand, belong to the family Cucurbitaceae. In fact, relatives of the orange, such as mandarins and pomelos, are all part of the same Rutaceae family.
Figure 7: Sampled Poseidon-Bot response to a QRT prompt asking if oranges are part of the melon family.
While the Llama 3.1 response contained signi,icant additional detail about the melon and citrus families and examples of members of these families, the Poseidon-Bot response contained slightly less detail, and did not list examples of members of the Cucurbitaceae family. While the Llama 3.1 response showed a higher conversational groundedness in its response awareness of the informative nature of the exchange, it presented more irrelevant information in its answer to the prompt, contributing to a lower relevance score. Conversationally, the Llama response also responded with a tone that did not line up with the mood of the exchange, which is likely why it scored lower on ,luency. In short, Poseidon-Bot showed improvement in succinct and factually relevant responses, while potentially showing a decline in conversational groundedness and context awareness.
No, oranges are not part of the melon family. They actually belong to a different plant family altogether. Oranges are members of the Rutaceae family, also known as the citrus family.
This family includes other popular fruits like lemons, limes, grapefruits, and tangerines. Melons, on the other hand, belong to the Cucurbitaceae family, which is a separate plant family that also includes cucumbers, squash, and gourds. So while both oranges and melons are delicious and popular fruits, they come from different families!
Figure 8: Sampled Llama 3.1 response to a QRT prompt asking if oranges are part of the melon family.
Poseidon-Bot has shown progress in enhancing the accuracy of data summarization and retrieval when parsing specialized and domain-speci,ic documents. However, this advancement appears to have introduced tradeoffs, with observed declines in the groundedness (factual consistency) and coherence (logical ,low) of its responses. To address these challenges, future testing could explore alternative approaches, such as activation steering or other model calibration techniques, to better balance precision in data extraction with the maintenance of contextually relevant, well-structured outputs. This iterative evaluation aims to re,ine the system’s performance while mitigating unintended regressions in response quality.
Arti,icial intelligence (AI) is at a fascinating crossroads, where the boundaries between science ,iction and reality are beginning to blur. Technology has evolved from machines struggling to interpret an image to generating videos and movies. This is an era where machines might begin to experience the world in ways that mimic biological systems.
However, signi,icant challenges remain. When humans process an image, they perceive more than just pixels; they see the world captured in that image geography, events, and time. This is “special intelligence,” referring to how AI can model the 3D world with reasoning about objects, space, and time. However, current AI remains constrained to understanding only the present moment.
The social implications of these developments are profound and multifaceted. Take autonomous vehicles as an example: while they promise to reduce global traf,ic fatalities by up to 85%, resistance and disengagement hinder progress. This paradox illustrates that the capability of technology alone does not guarantee acceptance from the public. Progress, like a child’s development, requires patience, re,inement, and managed expectations [17].
Despite this, optimism persists. The successful creation of a Japanese meal using non-invasively collected brain signals by a team led by Feifei Li demonstrates AI’s potential to enhance human capabilities and assist those in need. Future advancements in technological applications will require overcoming current limitations in 3D understanding and temporal processing. The future of AI is not just about computational power; it is about developing systems that can truly comprehend and interact with a four-dimensional world [18].
As of real-life implementations of RAG, many companies are using it to boost system performances. For instance, a recent combination of RAG and knowledge graphs has been introduced to enhance questionanswering in customer service. During the question-answering phase, it parses consumer queries and retrieves related sub-graphs to generate accurate answers. Empirical assessments have shown that this method outperforms baselines by 77.6% in Mean Reciprocal Rank (MRR) and by 0.32 in BLEU scores. Notably, this AI usage in LinkedIn’s customer service team has reduced the median per-issue resolution time by 28.6% [19].
RAG also offers a solution for AI-generated misinformation and hallucinations. A system leveraging RAG has been devised to improve the quality of structured outputs, signi,icantly reducing hallucinations. This implementation enhances the generalization of large language models in out-of-domain settings. Additionally, it demonstrates that using a relatively
small well-trained retriever encoder can reduce the size of the LLM, making deployments of LLM-based systems less resource-intensive [20].
In this ever-changing era, both caution and optimism are necessary. The convergence of computational breakthroughs and transformative possibilities while being remindful that meaningful progress demands methodical development and integration into human society.
[1] M. Hanes, The current state of ai, h"ps://marsner.com/blog/the-currentstate-of-ai/, Accessed: Mar. 3, 2025, 2023.
[2] S. P. Ethier, Using functional genomics and arti5icial intelligence to reverse engineer human cancer cells, 2023.
[3] G. AI, Gaia ai, h"ps://www.gaia-ai.eco/, Accessed: Mar. 3, 2025, 2023.
[4] O. AI, Osmo ai, h"ps://www.techradar.com/touch-sensing-tech, Accessed: Mar. 3, 2025, 2023.
[5] U. D. of State, Arti5icial intelligence (ai), h"ps://www.state.gov/ar:ficialintelligence/, Accessed: Mar. 3, 2025.
[6] P. Lewis, E. Perez, A. Piktus, et al., “Retrieval-augmented generation for knowledge-intensive nlp tasks,” in Proc. 34th Int. Conf. Neural Inf. Process. Syst. (NIPS ’20), Art. 793, Red Hook, NY, USA: Curran Associates Inc., 2020, pp. 9459–9474.
[7] P. Zhao, H. Zhang, Q. Yu, et al., “Retrieval-augmented generation for aigenerated content: A survey,” ArXiv, vol. abs/2402.19473, 2024.
[8] K. D. Martin and J. Zimmermann, “Arti,icial intelligence and its implications for data privacy,” Curr. Opin. Psychol., vol. 58, p. 101829, 2024. doi: 10.1016/j.copsyc.2024.101829
[9] Chroma, Chroma: A fast, open-source, vector database, h"ps://www.trychroma.com/, Accessed: Mar. 3, 2025, 2023.
[10] Flutter, Flutter: Build natively compiled applications for mobile, web, and desktop from a single codebase, h"ps://flu"er.dev/, Accessed: Mar. 3, 2025, 2023.
[11] Meta, Llama 3.1: Open-weight large language model, h"ps://ai.meta.com/, Accessed: Mar. 3, 2025, 2023.
[12] S. Ram´ırez, Fastapi: A modern, fast (high-performance) web framework for building apis with python, h"ps://fastapi.:angolo.com/, Accessed: Mar. 3, 2025, 2023.
[13] P. G. D. Group, Postgresql: The world’s most advanced open source database, h"ps://www.postgresql. org/, Accessed: Mar. 3, 2025, 2023.
[14] R. Likert, “A technique for the measurement of attitudes,” Archives of Psychology, vol. 140, no. 1, pp. 1–55, 1932.
[15] H. T. Dang, “Overview of duc 2005,” in Proc. Document Understanding Conf., vol. 2005, 2005, pp. 1–
[16] A. R. F. et al., “Summeval: Re-evaluating summarization evaluation,” Trans. Assoc. Comput. Linguistics, vol. 9, pp. 391–409, 2021. doi: 10.1162/ta-cl-a0037
[17] Raj, Asian american pioneer medal symposium and ceremony, 2024.
[18] Feifei, Asian american pioneer medal symposium and ceremony, 2024.
[19] J. Huang, W. Zhang, and X. Chen, “Knowledge graph-based retrievalaugmented generation for customer service improvement,” arXiv preprint, vol. arXiv:2404.17723, 2023.
[20] U. Khandelwal, P. Lewis, and O. Levy, “Reducing hallucinations in language models with retrievalaugmented generation,” arXiv preprint, vol. arXiv:2404.08189, 2023.
My experience working at BU’s Software and Application Innovation Lab (SAIL) was unique, as it was the ,irst time I had been immersed in a structured 10–5 work environment and collaborating with others. Even though I had previously held internships, this one felt signi,icantly different. Everyday, I would arrive at the school by 10 a.m. and dive deeply into coding projects until 5 p.m.
On our ,irst day when we were doing our initial setup, we faced many technical issues,such as software installations, because we lacked administrative access to our assigned computers. Consequently, we spent the entirety of our ,irst day attempting various inef,icient methods to bypass administrative restrictions. On our second day, all these efforts became unnecessary when admin rights were provided to all of us.
When I began, my knowledge of web development while collaborating with others was minimal. When we started working on our ,irst project, which involved rendering a combination of CSS ,iles and Tailwind CSS, my unfamiliarity with Tailwind caused me to initially continue to write completely separate CSS ,iles as functions and then call these within my main program. However, midway through the process, I learned that our team exclusively used TailwindCSS, and the CSS ,iles were old ,iles that they had abandoned. As a result, I completely restructured my approach and rapidly learned how to Tailwind CSS and integrate it with React. Although this was initially challenging, it drastically accelerated my understanding of front-end development and ultimately made me a more ef,icient and adaptive programmer.
Additionally, when I entered this internship, my primary experience was with C++ and Python. Transitioning to JavaScript and TypeScript was initially uncomfortable, as these languages have distinctly different syntaxes and operational logics. At ,irst, concepts such as asynchronous operations, callbacks, and dynamic typing seemed abstract. Over time, however, I began to see the connections and patterns between these languages and my familiar languages, which allowed me to adjust and eventually thrive in this new coding environment.
Despite these challenges, the positive experiences of this internship signi,icantly outweighed the dif,iculties. Greg Frasco was dedicated to helping us debug endless backend code and skillfully manage our projects. Asad Malik played an important role in onboarding us to the CYCM project and graciously encouraged us to present our work in meetings. He has
always been kind to all of us, signi,icantly boosting our con,idence and communication skills. I am also grateful for Dr. William Tomlinson and Jeff Simeon, who organized the logistics of the entire internship and ensured that we had everything necessary to succeed.
Everyone working at SAIL was extremely kind, approachable, and consistently willing to help whenever we faced dif,iculties. They also provided valuable guidance. They would frequently suggest what might be helpful for us to explore or technologies to learn when we were uncertain about what to do next. Their mentorship helped us beyond technological questions; they taught us communication skills for work and allowed us to learn in a supportive environment that encouraged curiosity in these topics.
Beyond my coding and teamwork challenges, this internship allowed me to explore new technological concepts. My work on Poseidon-Bot introduced me to retrieval-augmented generation (RAG). It has also provided me with hands-on experience with backend materials like FastAPI, PostgreSQL, and Chroma vector stores which I never had a chance to do. Learning to manage document conversions, data chunking, and implementing sophisticated AI models such as Llama 3.1 offered insights into contemporary AI development.
Another rewarding part of this experience was collaboratively writing a research paper with two other teammates. I was responsible for writing the conclusion, which initially presented challenges because I had limited access to the data and the analysis in the intermediate sections. However, this also became an enjoyable experience because it allowed me to incorporate broader insights from my external knowledge. For example, I included the experiences gained from attending an AI conference at Stanford University over the summer and conversations with leading experts in arti,icial intelligence. Conducting additional research and integrating these broader perspectives into our paper was a wonderful experience.
Ultimately, this internship taught me far more than programming languages or development tools; it expanded my knowledge of communication, adaptability, and professional resilience. Moving forward, these lessons will guide me toward the right approach to both challenges and opportunities, professionally and personally.
While working at BU’s Software and Application Innovation Lab, I was excited to begin building Poseidon-Bot as it became my ,irst experience with coding an application from beginning to end. I had helped code other websites during that internship, but this was different in how we were given the vision and were told to make it. Throughout the entire process, I was
learning how to code better and even learning a little bit of different languages as I was doing so.
We split up the work between the three of us with me working on the frontend code like the UI of the application. Poseidon-Bot allowed me to use what I had learned earlier in that internship and put it to some use in making it, although we did run into technical issues. Two people were working on the frontend separately, which meant that each of our different branches of the frontend had different assets and different ways of integrating them. This led to a more pressing problem in which integrating each other’s functions prevented us from accessing the LLM in the main application leaving me with a working frontend and no working backend.
Other than that, the process of the project was a mostly enjoyable and fruitful experience. The project had some key successes, such as the collaborative aspect of it. We worked well enough together, as we were able to divide tasks and work on our individual areas, which kept the progress steady. My work on the frontend allowed me to experiment with different things about the UI and re,ine my skills in web development in general.
However, a key area for improvement was our communication and version control practices. We should have merged our branches more frequently in our work to avoid discrepancies. Poseidon-Bot holds the potential to be part of a larger ecosystem for AI-based tools. If we ,ix the integration issues, it could serve as a template for other similar applications. The project could be expanded by adding more features, improving its scalability, and enhancing its user experience.
Building Poseidon-Bot was an incredibly valuable learning experience. It showed me the importance of teamwork, clear communication, and adaptability when working on complex projects. My biggest takeaway was that while challenges are inevitable, they are also opportunities for growth. Re,lecting on the project, I feel more con,ident in my coding abilities and more prepared to take on future development projects. Additionally, I’ve gained a deeper understanding of the signi,icance of planning and structuring code ef,iciently, as well as balancing speed with quality in a collaborative environment. I also gained a deeper appreciation for the testing and debugging process, realizing how crucial it is to ensure that every part of the application functions seamlessly before moving forward. The lessons learned from Poseidon-Bot will undoubtedly shape how I approach future projects, especially when working in teams with differing skill sets. Kendree Chen
My internship this year with BU’s Software Application and Innovation Lab (SAIL) was a very rewarding and valuable experience for me. In addition to getting practice with professional software development and learning
about retrieval augmented generation (RAG) and LLM applications, I learned a lot about the aspects of teamwork and project management that go into application development. This was my ,irst exposure to many aspects of software engineering and research collaboration, and throughout the process, I developed both technical and interpersonal abilities that have already helped me make strides towards a future in tech.
I had a great time practicing and re,ining my knowledge of web development. Prior to this internship, I had some experience in Cascading Style Sheets (CSS) and CSS frameworks like Tailwind, but limited experience in building complete web applications. When I did full-stack development in the past, I almost always stuck to the same style of JavaScript backend, and usually used React or Svelte for frontend development. But at SAIL, I got to branch out and challenge myself to try new things. I gained signi,icant con,idence using Tailwind by designing the frontend of the CYCM website. On the Poseidon-Bot AI project, I wrote my ,irst Python backend, using Pydantic, which was a new structure for me, and I learned to use Flutter to develop the frontend. Using Flutter was very different from the HTML and CSS I was more familiar with, and I had a great time learning about its crossplatform development and state management. The experience I picked up at SAIL has boosted me to be able to take on a part-time job this year as a web developer at KTBYTE Computer Science Academy, where I have been responsible for coding the website frontend in React and Tailwind as well as developing elements of the backend.
A major focus of our internship was arti,icial intelligence, particularly retrieval-augmented generation (RAG). Prior to this, I had limited experience with AI applications, and there was a largely self-taught component to developing the Poseidon-Bot project. It was fun to tackle the challenge of building out a RAG structure, which none of us had experience with, and we combined research with practical work as we tested and iterated on our code. This was a great way to gain a deeper understanding of how AI and RAG based AI models work.
Another major learning experience of this internship was getting better at coding with a group. Unlike individual web development projects where I had full control over the codebase, working in a team required us to practice effective and orderly version control, coordinate with each other to distribute tasks, and ensure that our code was readable and understandable. We relied heavily on Git, where I got better at practicing good habits such as writing clear commit messages, resolving merge con,licts, and reviewing code before merges. As the most experienced in web development, I was able to take on a bit of a code admin role when it came to giving feedback on pull requests and ensuring that merged code was consistent. Collaboration also meant dividing tasks ef,iciently and minimizing overlap or con,licting
work. At times, it was dif,icult, and when building Poseidon-Bot, we nearly ended up with two different versions of the frontend. This experience was de,initely a learning curve, but we got better and better at communicating and directing progress throughout the internship.
Beyond just coding, the experience of writing a senior thesis with a group offered a lot of learning opportunities. Unlike other coursework, where individual assignments have clear guidelines and deadlines, the thesis required us to establish our own structure, divide responsibilities, and hold each other accountable. What the structure of the paper should be like was hard to ,igure out at ,irst, since we did not have much experience with computer science or application development papers. We ended up settling on a fairly standard academic article structure, and divided up responsibility among sections of the paper. We also had to establish our own expectations for what those sections needed to include, and we found ourselves ,iguring things out as we went. I ended up running additional tests to add to the paper when we realized we needed metrics for our paper. Other challenges included ensuring that language used in the paper was consistently clear and formal, and organizing research and sources for the introduction and conclusion sections of the paper. Since we were three partners, it was sometimes dif,icult to ensure everyone stayed responsible for meeting important deadlines and making necessary progress. Weekly check-ins and working meetings helped a lot with this, as did reviewing each other’s sections of the paper. Nonetheless, I had a great time writing the paper, and I learned a lot more about academic writing in computer science ,ields. (And I learned a lot about LaTeX!)
Overall, working on my group senior thesis with SAIL was a challenging but incredibly rewarding experience. I gained from it a stronger foundation in web development, improved teamwork and collaboration skills, a deeper understanding of AI and RAG, and valuable experience in academic writing. I would offer four pieces of advice to anyone else interested in a SAIL internship and senior thesis:
1. Come prepared, and prepared to learn. The projects you work on at SAIL will be largely self-directed,so I would say that prior experience with web development or code is important. Without a strong existing foundation in web development, students should be prepared to selfteach a lot (which can be dif,icult and frustrating), or to learn from their fellow interns if they are more experienced already.
2. Communicate and set clear expectations. The group senior thesis relies on responsibility from eachof the members of the group, so it is a great idea to establish clear communication channels early on so
that each member of the group always knows what they are responsible for doing. Group partners missing deadlines or responsibilities due to communication breakdowns can contribute to additional stress and dif,iculty, so it is important to ensure early on that this will not happen.
3. Do not be afraid to ask questions. Although the internship is selfdirected, the SAIL supervisors arealways there to help answer questions if you have them. Asking questions is one of the best ways to learn.
4. Have fun! It is great to be part of a group like SAIL. The of,ice is sleek, the view is gorgeous, andthere is so much to learn and contribute to. Good luck!