
6 minute read
Data Lake vs Data Lakehouse vs Data Warehouse


Figure 10
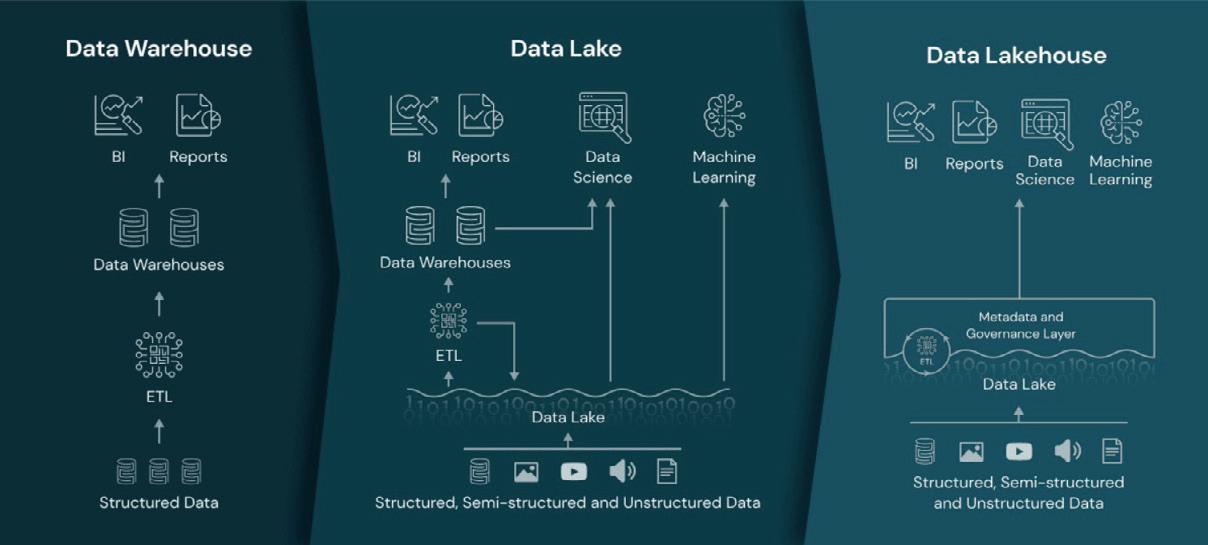
It’s a specification using which data governance can be implemented. But before looking at Data Lakehouse, we need to understand a few traditional architectures. The traditional one is a relationship Database where you can store and work on structured data. However, it does not have data ready for analytics applications or reporting applications. To solve that issue, the Data Warehouse concept was devised which still stores structured data, but it also supports analytics and reporting solutions with data that can be consumed by them readily. But still there is a problem which is that it can only store structured data, not unstructured data. Unstructured data is when systems generate different types of data and formats all of which have knowledge in them. We cannot just rely on structured data alone. To store structured and unstructured data the Data Lake concept was devised which is a storage system where you can dump all your structured and unstructured data which is then immediately available for data science models and analytics solutions for consumption. The problem with a Data Lake is that, as with a Data Swamp, you can dump all the data in it but there are no tools to manage it.
Considering all of this, a new concept was devised incorporating the best of Data Lake and Data Warehouse. It was named the Data Lakehouse architecture.
Data Lakehouse: Simplicity, Flexibility, and Low Cost
advantage is that a governance layer has been introduced in the Data Lakehouse. It is not present in either a Data Warehouse or a Data Lake. With the Data Lakehouse, you can plug in a governance layer, and, in an automated manner, you can manage your data. Another advantage offered by Data Lakehouse is that it provides scalable metadata handling. For every data in a Data Lakehouse, there will be scalable metadata layers which provide more insights on the data. Any processes that work on such data, such as artificial intelligence or data science models, can work on it and provide meaningful insights. The Data Lakehouse approach is designed to be faster than Data Lake.
Delta Lake is one of the implementations of Data Lakehouse architecture which we would like to highlight.
Implementation of a Data Lakehouse Architecture
Source htt:ps://www.databricks.com/glossary/data-lakehouse
Time travel, Fast DML operations
If you’ve worked on a traditional database system, you know that it can provide ACID properties, consistency and more. Similar properties are offered by Data Lake houses. It also helps the streaming and batching of real time data. Systems and algorithms can consistently work on such data. Another important
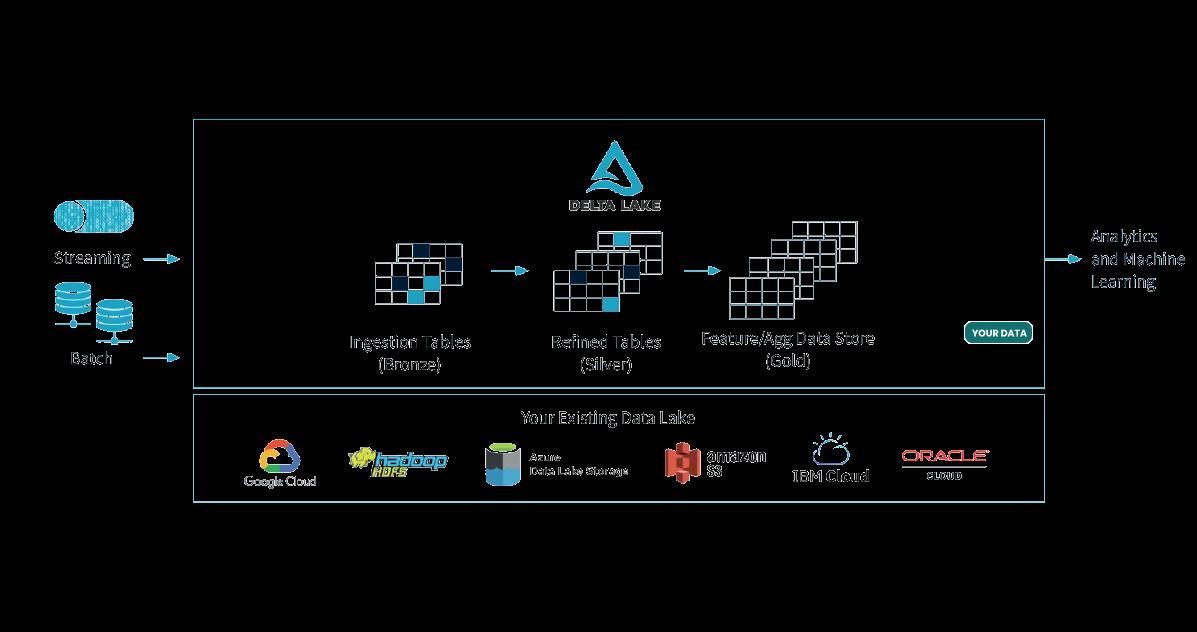
Figure 12


Source: https://delta.io/
Figure 12 shows all the existing Data Lake systems at the bottom. On the layer above that, Delta Lake has been applied. The data that is streamed into Delta Lake comes out in a well-structured format which various analytics and machine learning applications can use. What you can see in the middle is how the Deta Lake manages data in three tables; bronze, silver and gold. So, whenever data is
“… all your privately identifiable data should be anonymized. One of the approaches called homomorphic encryption can be used for this purpose. It is a concept where algorithms can work on encrypted data without decrypting it…” streamed into the system it goes into the bronze table as raw data with nothing having been done to it. Then transformation and cleanup logics are applied to remove unwanted data, fill out the missing values, etc. and that is when we get the silver table. To understand gold table, let’s consider an example where you have multiple customers and are creating multiple silver tables from each customer’s data. Now, all that is aggregated, and a structure is created that’s called a knowledge structure. The knowledge structure doesn’t know what each customer has put in, it has just gained the knowledge using all customer data tables. Now, we have clean, fulfilled knowledge data ready for consumption and assisting in data governance with good quality data.
The governance layer is provided by some of the tools which can be plugged in to the Delta Lake to achieve a governance layer. A few examples are shown in Figure 13. One of the tools is Unity Catalog provided by Databricks which we would like to highlight. It provides a central console where you can look at your data lineage, see what processes are happening, plus on your data. It also provides granular level control where you can provide access control at each layer. Governance policies you want to use can be applied on the data using data governance tools. It also assists in reducing Data swamps as we have more insights on data using governance.
Data Governance w ith Data Lakehouse
Tools: Unity Catalog
Dataedo
Alation Data Catalog
Talend Data Fabric etc
• Centrally manage and govern all data assets.
• Manage fine-grained access controls with ease.
• Unified and secure data search experience.
• Enhanced query performance at any scale.
• Automated and real-time data lineage.

• Secure data sharing across organizations.
Source: https://delta.io/
Having covered all this, the most important part is data privacy. We won’t go very deep into data privacy but here are a few ideas on how data privacy can be achieved (figure 14).
Data Privacy
Regional Data segregation. Anonymization for ensitive information. Homomorphic ryption on data by models. Differential privacy algorithms.
One thing is that, even though there may or may not be any regional data residency laws, you should always try to segregate your customer’s data regionally. It improves performance due to proximity to customer location and also gives confidence to the customer that their data is not shared with other customers. This is one of the simplest ways of achieving data privacy.
Another point is that all your privately identifiable data should be anonymized. One of the approaches called homomorphic encryption can be used for this purpose. It is a concept where algorithms can work on encrypted data without decrypting it which ensures that the algorithms do not know about the personally identifiable data they are working on. This gives confidence to the customer that their data is private.
Another approach growing in popularity is Differential Privacy where noise is purposely added to the data. What this achieves is that, even though we’ve put noise, Differential Privacy algorithms ensure that we’re getting the same output as with no noise. It’s like traditional radio systems where, if you tune to a dial a bit and you’ll still be able to interpret the output but with some additional noise. That’s differential privacy. Data privacy is very relevant to aviation data too. The Differential Privacy approach can achieve a good level of data privacy. We also need to discuss data exchange ecosystems. Aviation is one of those industries where despite technological advancements when it comes to flying, a lot of the maintenance and records keeping processes are still very manual and laborious. Despite efforts by ATA, AWG and IATA to come up with strategies to digitize these processes, we’ve seen various levels of adoption from simple CMS tools all the way to Tier-1 predictive tools like Skywise, Aviatar and GE Predix. Making sense out of unstructured data to help make maintenance and commercial decisions is where AI tools can play a great role in easing the burden of labor heavy functions.
ATA Spec standards (Spec2500, Spec2400 etc.,) are some of the standards which are available to standardize aircraft data. All the data of a particular aircraft can be presented in relevant ATA Spec formats which can be easily consumed by multiple systems. This is one of the ways you can achieve data consistency across an organization. Having covered the importance of aviation tuned language models, security first data driven platforms, it is down to the sector to make data management arrangements that leverage the most and most useful value out of their data in the most secure ways possible.
Sriram Haran
With a strong international trading background, Sriram Haran founded KeepFlying® with aviation professionals. Sriram holds a diploma in Manufacturing Engineering from Nanyang, Singapore and a Bachelors in Computer Science from the UK. He has been an entrepreneur from the age of 21. As Chairman and MD of CBMM Supply Services and Solutions Pte Ltd, Singapore, he has continued to evolve the Group’s portfolio of brands for highly specialized verticals.
Varun Prakash Anbumani
Varun Prakash is a Senior Solution Architect with KeepFlying®. He has Masters in Theoretical Computer Science with 12 years of experience in Enterprise software development majorly in Construction and Engineering domain. He has spent a considerable amount of his career working on Cloud Architecture and Cyber Security, compliance initiatives such as FedRAMP and ISO Certifications. In his present role at KeepFlying®, Varun Prakash is applying his software development and architecting expertise to launch pioneering cloud-based Data Science products in the aviation
Vamsi Krishna
Vamsi Krishna is a Data scientist at KeepFlying®. He has Masters in Computational Engineering and Networking with two Years of experience in building explainable and reliable AI models majorly in the aviation domain. His area of research includes Explainable AI, Dynamical Systems and Data-Driven Modelling. His interests apart from Data Science are in Quantum Computing, Productivity systems, Music Production and Chess.
Keep Flying
KeepFlying® focuses on the application of explainable AI to help Engine Asset Owners, Lessors and MROs visualize the commercial impact of their decisions before taking them, using underlying Airworthiness and Maintenance data. The Digital FinTwin® platform processes Engine Assets, MRO shop floor historic and dynamic airworthiness, maintenance and operational data to accurately forecast maintenance costs and value economics, cashflows, revenue potential.









