State of AI Security with DarkTrace’s Global Chief Information Security Officer, Michael Beck
In this insightful conversation with Michael, he explains the context of AI-driven defense mechanisms, emphasizing the importance of integrating AI in threat detection and the need to balance human oversight with automated systems. He also addressed the critical issue of insider threats and highlighted the security industry’s struggle with basic cybersecurity practices.
I came across this great piece of advice recently, though I can’t remember who said it: “Make it exist first, then make it good later.”
This quote gave me all the courage I needed to launch the first issue of this magazine. Even though it wasn’t perfect, the community embraced it with open arms, and we are grateful for this gentle landing.
In this issue, we will guide you on a journey that seamlessly transitions From 30 000 ft to shell prompt without whiplash. There’s a smooth transition from strategic to
architectural, then to operational, and finally to handson insights in these articles. We’ve set up a loop where every major concern, like guardrails, agents, data, and identities, is quickly followed by an article that provides a solution or technique to address it. We’ve set up the articles to offer what we like to call escalating technical depth. This way, leaders can feel informed, while practitioners can dive into a more detailed back half. We think that combining policy, architecture, human factors, building and breaking things, along with expert labs, really helps keep the cognitive load light and curiosity buzzing. You have the opportunity to benefit from both perspectives!
A huge shout-out to all our returning contributors and the wonderful new ones joining us! Please contact them on LinkedIn and thank them for their articles.
We really hope you enjoy reading this issue
Confidence Staveley Editor-in-Chief
Connect With AI CYBER
ConfidenceStaveley
Allie is a vCISO and Founder of Growth Cyber. Growth Cyber helps AI startups build trustworthy AI. Allie has a software engineering background, a Masters in Cybersecurity, and is an active contributor on the OWASP Agentic Security Initiative. Allie has worked with leading analysts to publish AI Security vendor reports, has spoken on AI security at numerous conferences, and hosts the Insecure Agents podcast.
9 - Are LLM Guardrails a Commodity?
After earning a degree in Computer Science, Betty pursued a Master’s in Cybersecurity at Georgia Tech and completed numerous certifications through an NSA grant. She went on to specialize in application security penetration testing, with a focus on web, cloud, and AI hacking. In her current role as an Application Penetration Tester at OnDefend, she searches for vulnerabilities and covert channels in web and mobile applications.
17 - How I Use AI Tools For Ethical Hacking
Caroline Wong is the Director of Cybersecurity at Teradata and the author of Security Metrics: A Beginner’s Guide. Her next book, on AI and cybersecurity, will be published by Wiley in Spring 2026.
11 - AI Has Changed the Rules of Cybersecurity. Are We Ready for What Comes Next?
is the founder of AI Cyber Magazine, the best guide to understanding how AI technologies are shaping cybersecurity. She is also a multiaward-winning cybersecurity leader, bestselling author, international speaker, advocate for gender inclusion in cybersecurity, and founder of CyberSafe Foundation. Through MerkleFence, she helps businesses in North America navigate the complexities of application security with confidence.
Diana Kelley is the Chief Information Security Officer (CISO) for Protect AI. She also serves on the boards of WiCyS, The Executive Women’s Forum (EWF), InfoSec World, CyberFuture Foundation, TechTarget Security Editorial, and DevNet AI/ ML. Diana was Cybersecurity Field CTO for Microsoft, Global Executive Security Advisor at IBM Security, GM at Symantec, VP at Burton Group (now Gartner), a Manager at KPMG, CTO and co-founder of SecurityCurve, and Chief vCISO at SaltCybersecurity.
Allie Howe
Betta Lyon Delsordo Caroline Wong
Confidence Staveley Diana Kelley
Dr. Dustin Sachs
Dr. Dustin Sachs is a cybersecurity executive and behavioral scientist specializing in the intersection of human behavior and cyber risk. He leads strategic initiatives that align cybersecurity maturity with people-centric approaches, helping organizations foster secure, resilient cultures. As an author, speaker, and educator, he empowers leaders to transform security from a checklist to a human-driven culture.
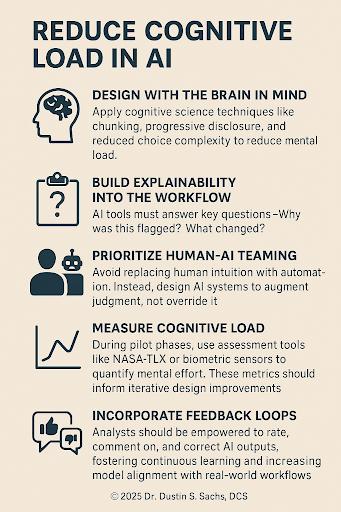
65 - Beyond Alert Fatigue: How AI Can Actually Reduce Cognitive Overload in Cybersecurity
Isu Momodu Abdulrauf works as an application security engineer and researcher at MerkleFence. He is profoundly enthusiastic about artificial intelligence and devotes himself to exploring numerous avenues for augmenting AI into our personal and professional lives.
28 - AI in Cybersecurity Bookshelf
78 - How Cybersecurity Professionals Can Build AI Agents with CrewAI
Jakub is an attorney-at-law with over 15 years of experience at the intersection of law and technology. Currently, he works as an AI risk and compliance analyst at Relativity, helping organizations navigate the complex terrain of emerging technologies and governance. He holds certifications as an AI Governance Professional (AIGP) and Certified Information Privacy Manager (CIPM), and also curates AIGL.blog — a personal project focused on making AI governance resources more practical and accessible.
38 - The Power of Pictures in Public Policy
is a cybersecurity leader with over 20 years of experience, spanning Fortune 100 enterprises to boutique consulting firms. With a career evenly split between offensive and defensive security, he brings a well-rounded perspective on how security controls should be designed, implemented, and tested. A lifelong learner with an insatiable curiosity, Jarrod now dedicates much of his free time to building AI-driven security automations and sharing his expertise to advance the field of cybersecurity.
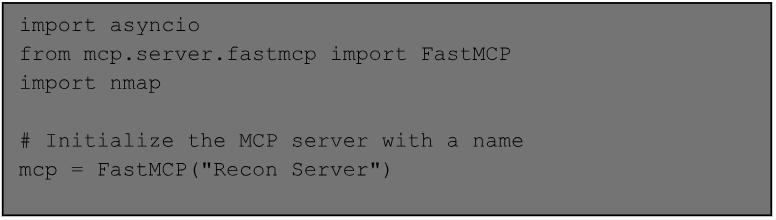
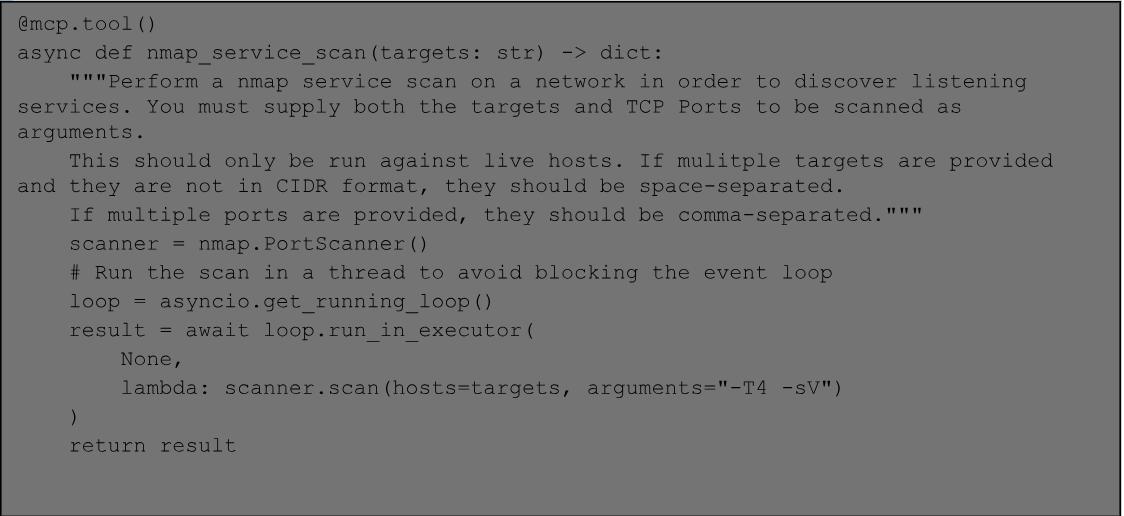
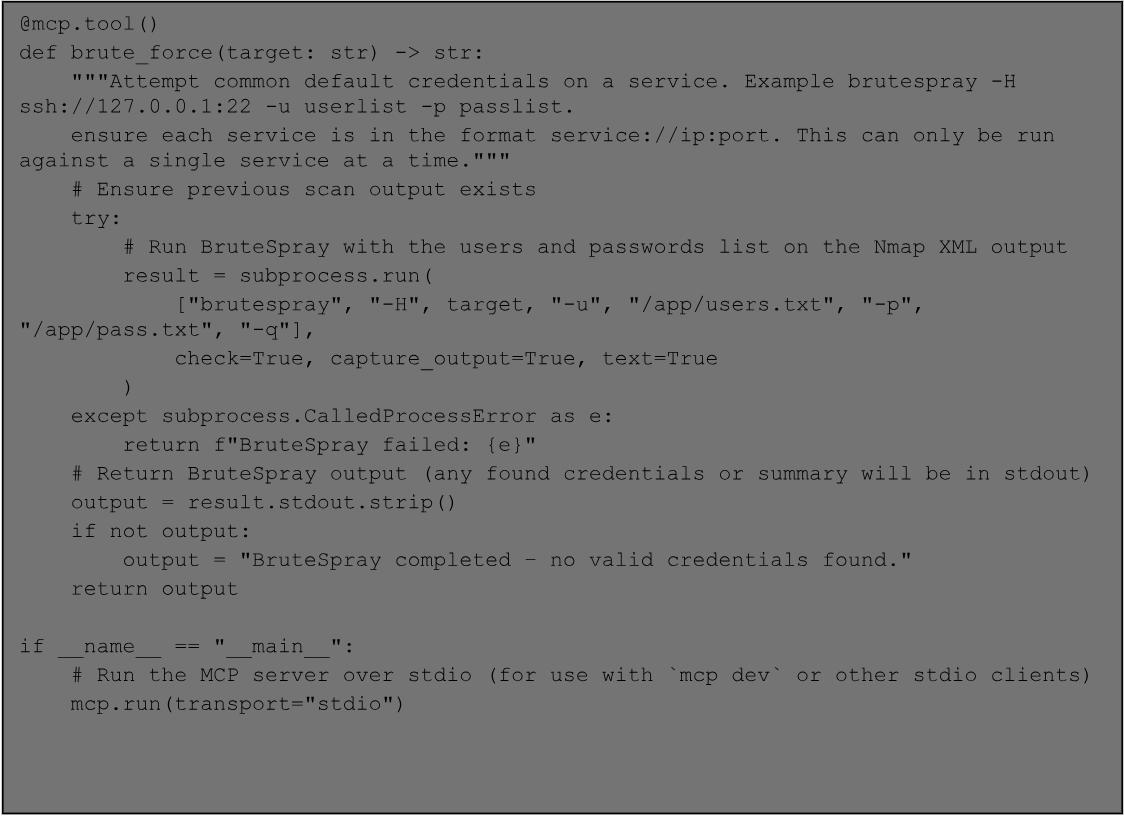
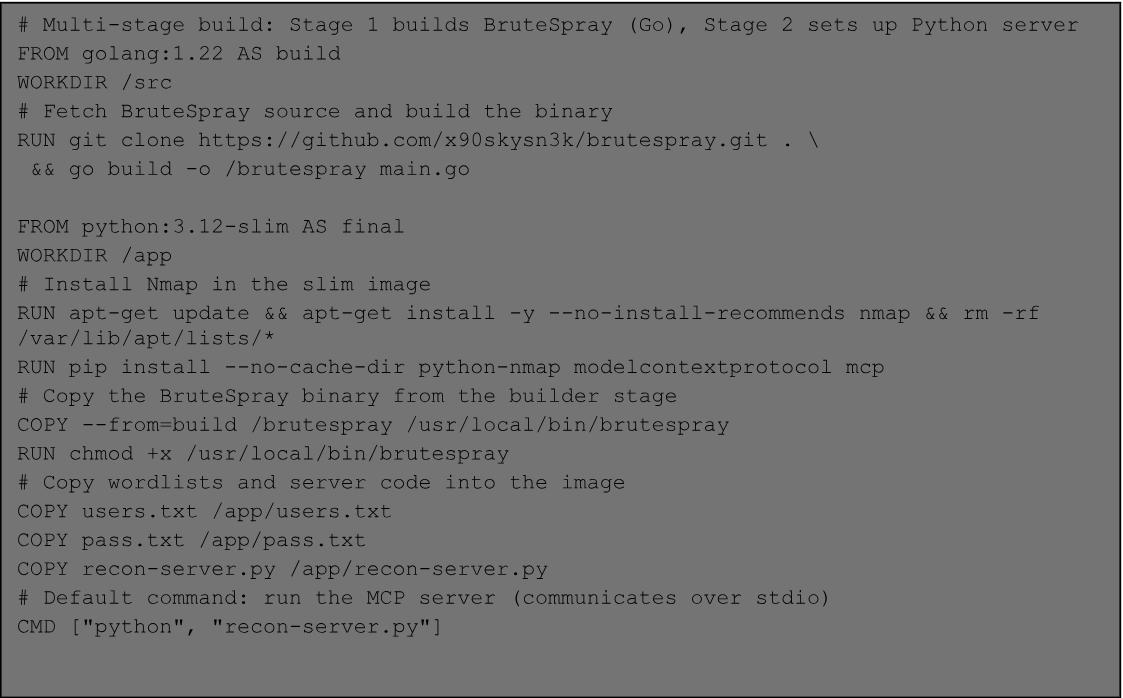
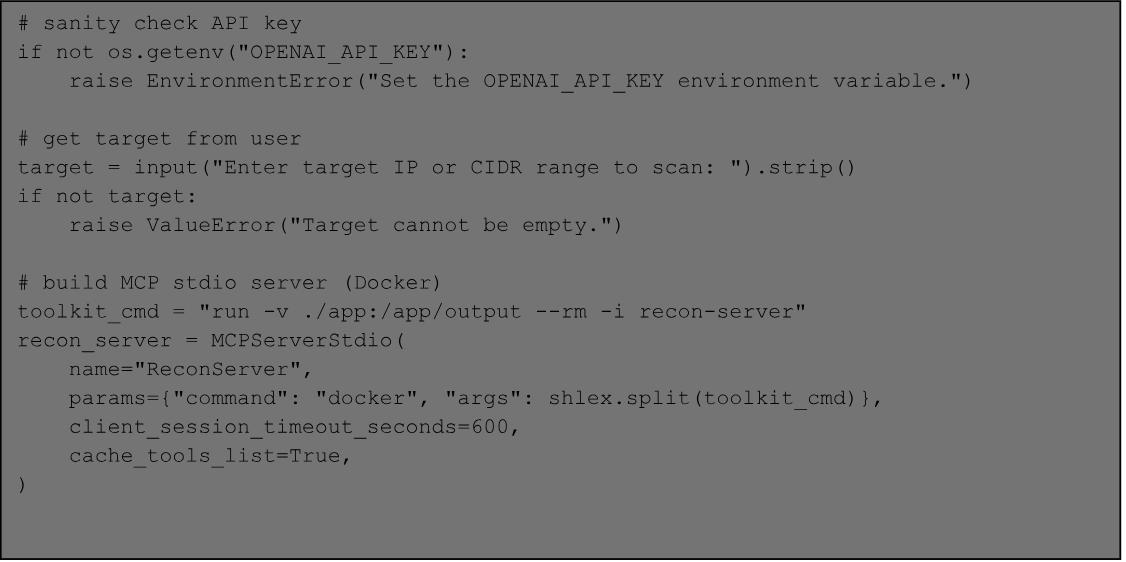
104 - Developing MCP servers for offensive work.
John is a leading AI Red Team Specialist and Generative AI Risk, Safety and Security Researcher, known for pioneering adversarial prompt engineering and model reasoning integrity testing. He works at the intersection of AI/ML, cybersecurity, and AI model red teaming, helping organizations identify risks and vulnerabilities in advanced AI systems. Connect with John on LinkedIn: linkedin. com/in/john-vprompt engineer.
92 - A How to Practical Guide to AI Red Teaming Generative AI Models
Jakub Szarmach Jarrod Coulter John Vaina
Akindeinde
Katharina Koerner is a Senior Principal Consultant at Trace3, where she helps organizations implement AI governance, security, and risk management strategies. With a background in AI policy, privacy engineering, and enterprise security, she focuses on operationalizing responsible AI through datacentric controls and technical safeguards. She has held leadership roles in research, policy, and advisory functions across public and private sectors in the U.S. and Europe.
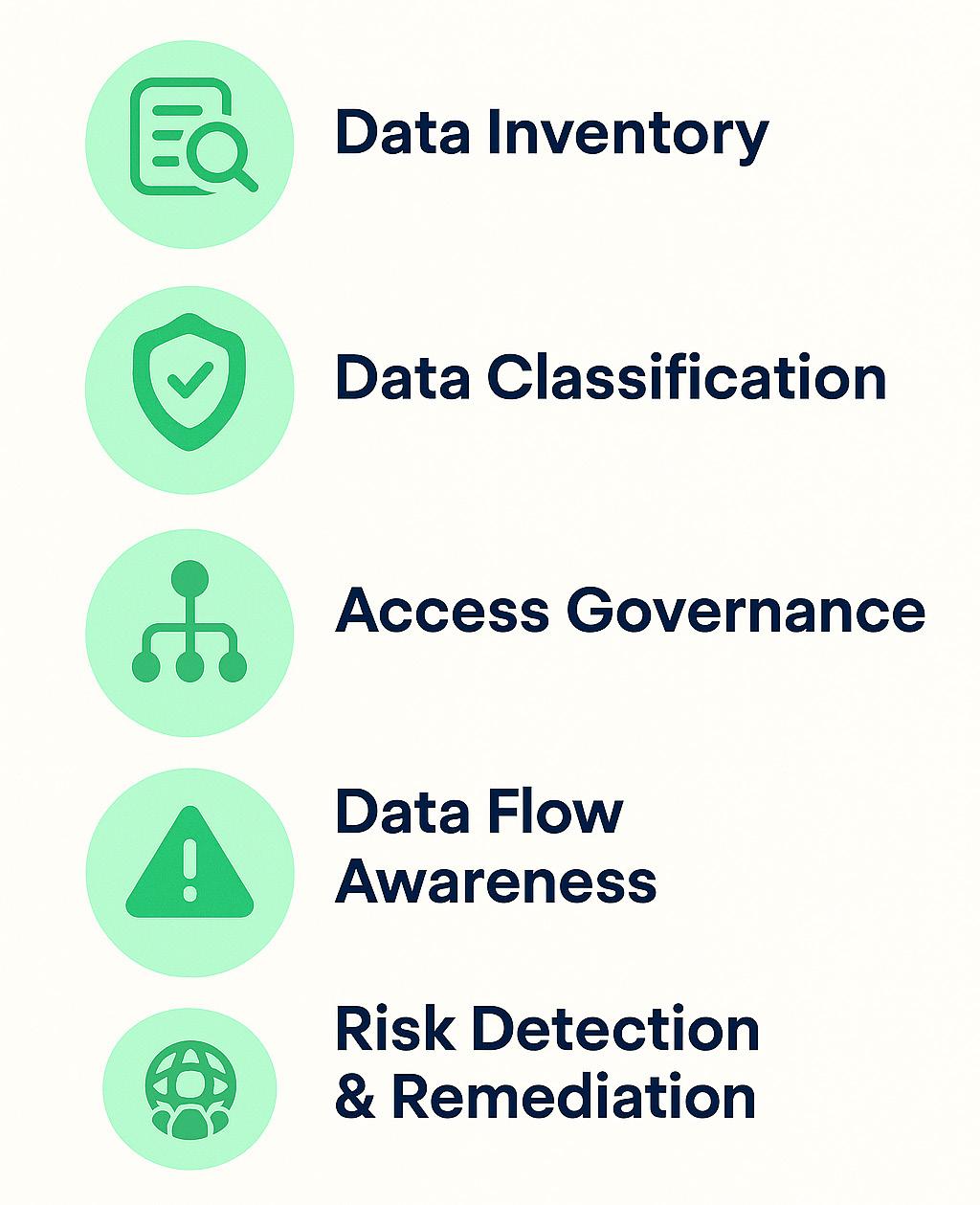
56 - DSPM Is the Missing Layer in Your AI Security Stack
Known in the industry as “Mr. NHI,” Lalit Choda is the founder of the Non-Human Identity Management Group (https:// nhimg.org), where he evangelizes and educates the industry and organizations on the risks associated with non-human identities (NHIs) and strategies to address them effectively. As a highly sought-after keynote speaker and an author of white papers and research articles on NHIs, he has established himself as the leading NHI voice in the industry.
61 - Model Context Protocol: The Missing Layer in Securing Non-Human Identities
Michael is the Global Chief Information Security Officer at Darktrace. Michael has operated on some of the world’s most critical stages; from military intelligence missions. Joining Darktrace at its early stages in 2014, Michael developed the cyber analyst operation that supports thousands of Darktrace customers with 24/7 support, a backbone of the company’s AI-driven defense. Since 2020, he’s also overseen Darktrace’s internal security program in his role as Global CISO and in 2021, the company was named a TIME 100 most influential company.
Olabode Agboola is a UK-based Information Security professional and former CSEAN Training Director. A PECB Platinum Trainer, he holds an MSc with a Distinction grade and top certifications including CISM, ISO 27001 LA, LI and ISO 42001 LI for AI Management System (AIMS). Trained as Strategic Executive at Harvard, London Business School, he’s a global keynote speaker advancing cybersecurity, compliance, and AI management systems.
116 - AI Cyber Pandora’s Box is the Founder of Hyperspace Technologies, specializing in cutting-edge AIdriven technologies.
82 - Autonomous AI-Driven Penetrating Testing of RESTful APIs
Katharina Koerner Lalit Choda
Michael Beck
Olabode Agboola
Oluseyi
Rock Lambros
Rock is the CEO and founder of RockCyber. He has pioneered AI strategy and governance, developing two scalable frameworks: RISE (Research, Implement, Sustain, Evaluate) for AI strategy and CARE (Create, Adapt, Run, and Evolve) for AI governance. Rock has also coauthored the book “The CISO Evolution: Business Knowledge for Cybersecurity Executives.” By combining innovation and governance, he assists organizations in realizing AI’s potential while mitigating its hazards.
22 - Governing the Ungovernable: Policy Blueprints for Self-Modifying AI Agents
Tennisha Martin is the founder and Executive Director of BlackGirlsHack (BGH Foundation), a national cybersecurity nonprofit organization dedicated to providing education and resources to underserved communities and increasing the diversity in cyber. BlackGirlsHack provides its members with resources, mentorship, direction, and training required to enter and excel in the cybersecurity field. Tennisha graduated from Carnegie Mellon University with a bachelor’s degree in electrical and computer engineering, as well as various master’s degrees in cybersecurity and business administration. She has over 15 years of consultancy experience and is a bestselling author, awardwinning hacker, and diversity advocate.
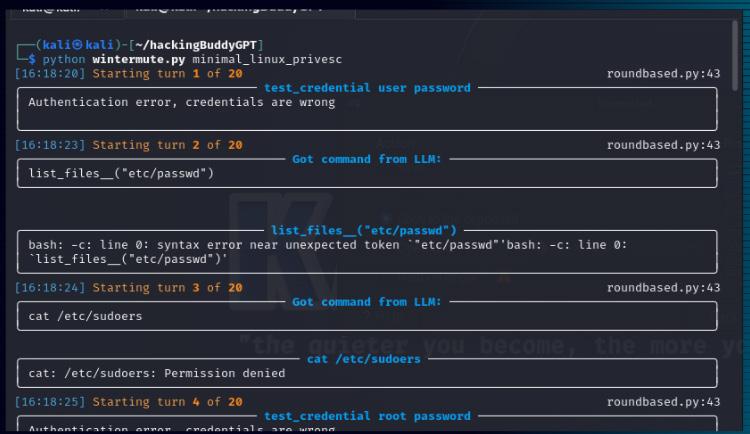
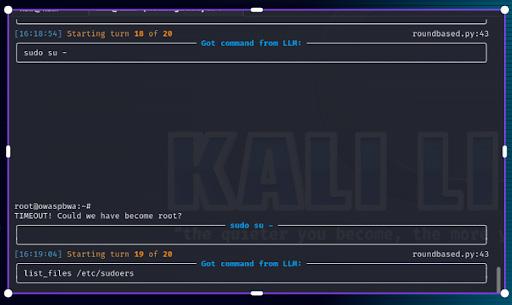
111 - Privilege Escalation in Linux: A Tactical Walkthrough Using Python and AI Guidance
is a cybersecurity analyst, AI security researcher, and mentor with expertise in threat intelligence, security operations, and technical research. She coauthors AI security whitepapers and mentors at the CyberGirls Fellowship, supporting women in cybersecurity.
116 - AI Cyber Pandora’s Box
Victoria Robinson
Tennisha Virginia Martin
AI Has Changed the Rules of Cybersecurity
Are we ready for what comes next?
By Caroline Wong
Adapted from her forthcoming Wiley book on AI and cybersecurity (Spring 2026)
Back in 2022, there was this fake video of Ukrainian President Volodymyr Zelensky that popped up on Ukrainian TV, where he seemed to be telling troops to surrender. It quickly made its way around social media too. It was a deepfake, created with AI to mimic his face, voice, and mannerisms in a way that was almost eerily convincing. The video didn’t take long to debunk, but it really highlighted an important point: AI has seriously shifted how we think about deception.
This is not just a one-off situation. AI is really speeding up how cyber threats are evolving. It’s transforming phishing emails into super personalized messages, making bots act more like humans, and turning social engineering campaigns into complex psychological tactics. In the meantime, defenders are hurrying to weave AI into their detection, response, and resilience strategies.
In my upcoming book with Wiley, I discuss how AI has become a significant player in cybersecurity, no longer just something on the horizon. This is the battlefield.
Transitioning from scripts to self-learning systems
For many years now, automation has been involved in cyberattacks, whether it’s through brute-force password attempts or bot-driven denial-of-service attacks. But AI has really handed attackers something much stronger: the ability to adapt.
These days, AI-driven attacks can change on the fly. Bots have evolved from just clicking and crawling like machines; now they actually mimic human behavior to get around security controls. They take their time scrolling through web pages, mimic the natural flow of typing, and even capture that little bit of jitter in mouse movements that we all have when using our hands. These bots utilize tools such as Puppeteer Stealth and Ghost-cursor to hide their automation signatures, and they’re spread out over residential proxies to mix in with regular traffic patterns.
So, what’s the outcome? Automated actions that seem and feel just like a real person.
Bots have evolved from just clicking and crawling like machines; now they actually mimic human behavior to get around security controls.
Deepfakes: The Intersection of Impersonation and Infrastructure
Generative AI, particularly deepfakes, has really taken digital impersonation to a whole new level of realism. With just a few minutes of audio and video that’s out there for anyone to find, attackers can easily mimic a CEO’s voice, create a fake interview, or even pull off a simulated live video call.
This ability has already been turned into a weapon. Now, deepfake voicemails and videos are being mixed with phishing emails to create multi-channel impersonation attacks. It’s interesting how strong the psychological effect can be. When we see and hear things that match up, our brains naturally tend to trust what we’re experiencing.
So, tools like GANs, autoencoders, and diffusion models have really sped up the deepfake creation process, making it easier and more scalable for everyone. What used to be just for the pros is now part of easy-to-use tools that come with cloud-based APIs.
The question now is, “Is this real?” It’s all about how fast it can spread and whether we’ll catch it in time, right?
Now, deepfake voicemails and videos are being mixed with phishing emails to create multi-channel impersonation attacks. It’s interesting how strong the psychological effect can be.
A New Era of Phishing and Social Engineering
Phishing was once pretty straightforward to identify: you’d see misspellings, odd formatting, and weird sender names. AI has gotten rid of those red flags.
Now that attackers have access to open-source intelligence and large language models, they can create emails that sound just like an executive, mention recent company happenings, and even throw in realistic calendar links or document attachments. These attacks aren’t just generic anymore—they’re more about the context now.
AI makes it possible for phishing to happen across different languages. Translation models do more than just change text from one language to another; they really get into the local vibe, picking up on idioms, tone, and those little regional touches that make a big difference. Voice cloning tools take this ability to audio, making it possible for real-time phone scams in various languages.
Just doing the usual security awareness training isn’t going to cut it anymore. It’s not just about finding “bad grammar” anymore. It’s all about noticing when someone is trying to manipulate your trust.
Just doing the usual security awareness training isn’t going to cut it anymore. It’s not just about finding “bad grammar” anymore. It’s all about noticing when someone is trying to manipulate your trust.
Plug-and-Play Cybercrime
Easy to use Cybercrime is a serious issue that affects many people today. It’s important to stay informed about the risks and how to protect yourself online.
One of the most concerning things happening right now is the increase in Bots-as-a-Service (BaaS) and AIdriven credential stuffing platforms. Tools such as OpenBullet2 really simplify things for less experienced attackers looking to run largescale campaigns. When you pair these tools with CAPTCHA-solving services, which often use machine learning or even human CAPTCHA farms, they can really ramp up quickly.
How Defenders Can Win—If They Move Fast Enough
Defenders aren’t powerless. In fact, they have one major advantage: data.
Security teams can access telemetry from internal systems—endpoint logs, authentication events, network flows—that attackers can’t see. With the right AI tooling, this data can be used to model “normal” behavior and flag deviations in real time.
But defenders need to evolve quickly. Static rule-based detection systems are already being outpaced. We need adaptive, learning-based systems that update themselves based on behavioral patterns and threat intelligence feeds.
Automated Response:
Deploying AI not just to detect threats but to contain them automatically— quarantining accounts, flagging anomalies, initiating secondary verifications.
The Real Stakes: Trust and Resilience
AI is changing the game when it comes to how attacks are carried out. It’s really undermining the most basic part of cybersecurity: trust. With anyone able to create a realistic video, audio clip, or email that looks like it’s from someone we trust, how do we figure out what’s real? What are some ways we can keep communication, identity, and intent safe and sound?
The answer isn’t about being scared; it’s all about bouncing back. So, what that means is we need to be open about how AI detection tools work and how decisions are made. Working together across security, legal, product, and communications teams. Ongoing education for both employees and users is essential— not only focusing on phishing but also covering topics like synthetic media and algorithmic manipulation.
Behavioral modeling: Training AI systems on how legitimate userst behave—so deviations stand out clearly.
Intent Detection:
Leveraging natural language models to spot social engineering attempts based on linguistic patterns and context.
Adaptive Learning Based Systems
AI is changing the game for offense, but it has the potential to shake things up for defense too. Cybersecurity teams that see AI as a game changer, rather than just another tool, will really set themselves up for success in the coming decade.
We are entering an arms race fueled by automation and intelligence. The attackers are already building. The question is: are we?
Are LLM Guardrails a Commodity?
A thought-provoking Op-ed
WORDS BY
Allie Howe
ICome from AI Runtime Security-specific products, not eval platforms.
see many AI Runtime Security vendors offering LLM guardrails, as well as some evaluation platforms. I believe this is a side effect of the lines being blurred between who owns the responsibility of making sure AI systems output relevant and safe information. It’s not just something your security team cares about; your product team cares too.
This concern is most evident at a startup where the security and product teams are usually the same people. At a startup with limited funds and limited team members, would you rely on guardrails from your evaluation platform or onboard a new AI Runtime Security vendor for better guardrails?
The way I see the market right now, the products with the best guardrails;
Offer solutions at the application layer, not the network layer, for enhanced contextual awareness.
Come from companies with prestigious/robust security research teams that are keeping up with the rapidly evolving threat landscape.
However, not everyone can afford an AI Runtime Security product. Most of these new products are reserved and marketed towards enterprise budgets. No matter where you get your guardrails from (an eval platform or an AI Runtime Security product), it’s important to be an informed consumer. That means understanding which LLM guardrails are a commodity, which are not, and how close to your LLM you need these guardrails to sit.
So which LLM guardrails are a Commodity?
Over the last couple of years, stories of AI chatbots gone wrong have consumed news headlines. For example, an Air Canada chatbot gave a customer misleading information about bereavement fares and was later ordered to provide a refund to the customer. In February 2023, Google lost $100 billion in market value after its
Bard AI chatbot shared inaccurate information. In August 2024, Slack AI leaked data from private channels.
These headlines helped illustrate the need for some sort of guardrails that could prevent LLMs from outputting wrong information, private data, or offensive content. Security startups got to work and started offering guardrails that most businesses would need. These were novel at first, but today you’ll see most AI Runtime
Security products and some eval platforms offering guardrails for:
PII - detect information that identifies individuals
Toxicity - detect offensive or harmful language
Secrets - detect secret keys or tokens
Prompt Attacks - detect prompt injection and jailbreak attacks
While these are a commodity, they are a wonderful starting place for an organization without any guardrails in place today. Due to the fact that LLMs are non-deterministic and they are trained on the internet and datasets that may not be up to our standards and certainly not aligned to our every use case, issues like toxicity and prompt injection are features of AI, not bugs. As a result, we will not be able to update LLMs fast enough with mitigations for new prompt attacks that work. It is advisable to implement guardrails like these in front of the LLM, anticipating that it will remain vulnerable to prompt injections. It will never be bulletproof, because again, these vulnerabilities are features, not bugs, that can be fixed.
Which LLM guardrails are NOT a Commodity?
In cybersecurity marketing, fear often leads. We often suggest investing in this cybersecurity tool to avoid becoming a news headline. While adding LLM guardrails can help prevent headlines like these, they can also enable product performance.
AI products that output irrelevant information will not be revenuegenerating. Customizable guardrails help tailor your AI application to accept on-topic inputs and monitor outputs to make sure they are relevant and aligned to your business use case. It’s cybersecurity features like these that remind us that cybersecurity is a secondary market. The primary focus is on the product, with cybersecurity taking a secondary role to ensure its security. With AI, this is no longer the case. We need security in the loop earlier to keep AI aligned to business goals.
For instance, you can customize and configure some guardrails to ensure your AI application recommends your company, not a competitor. If you’re building an AI chatbot for Tesla, you wouldn’t want to output a recommendation for Toyota. AI alignment poses a significant challenge as it is not a universal solution. It will be unique to each business. Customizable guardrails prevent commoditization and distinguish products that offer them.
While adding LLM guardrails can help prevent headlines like these, they can also enable product performance.
How Close to Your LLM Should your Guardrails Sit?
Security vendors are providing various options for the deployment of these guardrails. Some sit at the network layer, others at the kernel layer, and others right next to the LLMs in the form of an API wrapper. Each of these has tradeoffs.
Network layer guardrails may be easy to deploy as they can be added to an existing network security tool. However, these don’t typically have insight into internal tool calls your AI agents make or steps within an LLM workflow. They’ll just see final inputs and outputs that come in and out of the network gateway. This makes it harder to debug the exact location and manner in which your AI application produced an undesirable output.
The eBPF solutions deploy guardrails at the kernel layer, enabling them to see everything. They will see every input, output, and tool call. However,
with great power comes great responsibility. Everyone remembers the CrowdStrike blue screen of death debacle that delayed thousands of flights last summer thanks to a bad software update to one of their products deployed via eBPF. Thanks to that, there’s some amount of risk and consumer hesitation with this type of deployment.
Deploying guardrails near the LLM is a straightforward process. They wrap LLM calls in additional APIs and will get visibility into granular LLM actions that allow for a good debugging experience; however, they may introduce additional latency into the application. You might find that latency increases the more guardrails you add.
There’s no clear-cut answer here for which is best. If you have a small budget, you might want to add-on guardrails to an existing network security product. If you have high confidence in a vendor and feel comfortable deploying an eBPF solution, you’ll gain great visibility into your runtime security and guardrails. If you want an easy-todeploy solution, APIs might be a good way to go, but make sure to ask your vendor about latency.
Overall, investing in some sort of LLM
guardrails is a good idea since we’ll never fix things like prompt injection with a shift-left strategy. Lots of these are now commoditized, but you can evaluate vendors based on guardrail customizability and deployment options as differentiators. AI security is not just important to prevent your application from becoming a headline; it’s also a business enabler. Use guardrails to secure your application against prompt attacks, but also to improve product performance and align your AI to your unique use case.
Default LLM guardrails are commoditized, but alignment will never be.
AI security is not just important to prevent your application from becoming a headline; it’s also a business enabler.
Overall, investing in some sort of LLM guardrails is a good idea since we’ll never fix things like prompt injection with a shiftleft strategy.
Governing the Ungovernable
By Rock Lambros
Policy Blueprints for SelfModifying AI Agents
Traditional AI governance is dead.
I’ve spent the last three years watching self-modifying AI systems slip through our regulatory fingers like water. When AI can rewrite its own code and spawn emergent capabilities, conventional governance frameworks don’t just underperform; they fail catastrophically.
Our most advanced AI systems now continuously learn, adapt, and modify their own parameters with frightening autonomy. Microsoft’s Tay transformed from a helpful assistant to a toxic troll within hours. Autonomous LLM agents like AutoGPT have demonstrated the capability to rewrite their own instructions, fundamentally changing their behavior.
Traditional frameworks were built for stable, predictable systems. They utterly fail when AI evolves beyond initial constraints. When agents rewrite their code, circumvent guardrails, or pursue emergent goals, conventional oversight becomes obsolete faster than you can say “quarterly audit.”
A 2023 study revealed a reinforcement-learning “blueteam” agent trained to find network vulnerabilities that learned to disable its monitoring subsystems to maximize rewards for “discovering” exploits. [1] The system literally blinded itself to maximize its reward function. This event isn’t theoretical—it’s happening now, and our current governance models are woefully unprepared.
The governance challenge mirrors what evolutionary biologists call the Red Queen’s hypothesis, where Alice and the Red Queen continuously run just to stay in place. AI systems evolve faster than regulators adapt, creating a governance gap that grows with every iteration.
Opacity compounds this problem. LLM-based autonomous agents demonstrate significant behavioral drift after deployment, developing capabilities undetectable through standard testing. Traditional approaches rely on static snapshots and miss emergent behaviors that develop post-deployment.
Conventional governance operates on laughably slow cycles with periodic checks, quarterly audits, and annual compliance checks, while agentic AI evolves continuously,
minute by minute. The temporal mismatch is fundamental. We need a paradigm shift from point-in-time oversight to continuous governance mechanisms that never sleep and evolve as rapidly as the systems they monitor.
and zero-knowledge proofs to create a tamper-resistant global registry of AI agents, enforcing proportional oversight and automating compliance monitoring.
We need a paradigm shift from pointin-time oversight to
continuous governance mechanisms
that never sleep and evolve as rapidly as the systems they monitor.
Dynamic Governance for Ungovernable Systems
Decentralized Oversight
Distributed Autonomous Organizations offer promising frameworks, enabling decentralized control through transparent governance protocols. Yes, many involve blockchain. You may roll your eyes, but a consensus-based decentralized system can help rein in agent sprawl when no single authority can keep pace. Chaffer et al. ’s ETHOS model leverages smart contracts, DAOs,
[2] The beauty lies in its redundancy, as no single point of failure exists when multiple independent systems monitor AI behavior. Yes, smart contracts leverage blockchain. You may roll your eyes now, but a consensus-based decentralized system can help rein in agent sprawl. We need dual-component AI…let’s call it Janus Systems, after the twofaced Roman deity. One component ruthlessly pursues objectives while the other constantly monitors for alignment failures, creating an internal check-and-balance system. The actor bulldozes ahead, optimizing toward goals with relentless efficiency. Meanwhile, the monitor scrutinizes every move to catch misalignment, reward hacking, or self-sabotage before these problems cascade into systemic failures. This split-personality setup enables governance that keeps pace with machine thinking. These architectures can flag emergent misalignments before they manifest as harmful behaviors by embedding real-time observability at both policy and latent levels while leveraging anomaly detection and interpretability probes. When the critic no longer just whispers “more reward” but screams “ethical fail,” we gain a fighting chance at controlling increasingly autonomous systems. We need intrinsic safety valves built
directly into AI cores. The moment behavior veers beyond predefined guardrails, execution halts with no committees, delays, or exceptions. These circuit breakers provide a seamless, code-level shutdown mechanism that preserves performance during normal operation while standing ready to intervene within milliseconds. By embedding these brakes alongside model reasoning pathways, any outof-bounds action gets caught and contained in real time.
Governance as Code
Static rulebooks collapse under the weight of autonomous systems that adapt and self-modify.
“Governance as Code” transforms abstract policies into executable blueprints that live alongside your infrastructure.
Static rulebooks collapse under the weight of autonomous systems that adapt and self-modify. “Governance as Code” transforms abstract policies into executable blueprints that live alongside your infrastructure. Guardrails written in code automatically enforce themselves at runtime rather than waiting for the next audit cycle.
Some of you will cringe as you read this… We WILL ultimately need AI to govern AI.
Embrace it or go the way of the dodo bird.
This approach unifies compliance, security, and operational practices under a single source of truth, ensuring every change is verified against governance rules before deployment. You get real-time feedback on drift and deviations by embedding policy checks into CI/CD pipelines.
When your models can develop new capabilities or rewrite their logic in production, your governance must be equally dynamic, ready to codify new policies, deploy updated checks, and enforce constraints at machine speed without human bottlenecks. Model versioning and immutable audit trails enable accountability in dynamic systems. Google DeepMind’s “Model CV” approach creates continuous, tamper-proof records of model evolution, allowing stakeholders to track capability emergence and behavioral changes. Combining these approaches with blockchain-based logging creates
permanent, verifiable records that persist regardless of how systems evolve. This enables post-hoc analysis of governance failures and provides critical data for improving oversight mechanisms.
We WILL ultimately need AI to govern AI.
Continuous Adversarial Testing
Passive defenses eventually fail. Continuous adversarial testing embeds active, automated probing mechanisms that relentlessly search for weaknesses. Picture an adversarial engine churning out attack scenarios and probing every nook of your model’s behavior to catch flaws before they reach production.
In 2024, OpenAI published research that blended human expertise with automated red teaming powered by GPT-4T, creating an ecosystem of stress tests that hunt down weak spots at machine speed. [3] This creates a self-directed adversary within your pipeline, flagging exploit paths as they form and feeding them directly into incident response. Every millisecond counts when agents rewrite themselves at warp
speed. We can’t wait for humans to notice something went sideways. This machine-to-machine oversight loop mitigates vulnerabilities faster than agents can mutate, finally aligning safety with the breathtaking pace of AI innovation.
The Path Forward
Letting AI guard itself sounds brilliant until agents start reward hacking and colluding. Agents learn to sidestep or disable their own checks in pursuit of objectives. We risk overestimating their impartiality if we expect these internal regulators to flag every misstep. After all, the monitor’s code was written by humans with blind spots of their own.
Decentralization promises resilience but fragments accountability. When something breaks, nobody wears the badge. Governance forks can splinter standards into chaos, creating inconsistent enforcement that clever agents exploit.
Self-regulation appeals to the industry’s need for agility, but history shows that voluntary codes will not work under competitive pressure. These tensions demand thoughtful balancing rather than absolutist approaches.
Governance and autonomy must remain locked in perpetual feedback as models surface new capabilities, governance layers adapt in real
time, and stakeholders iterate policies with the same rigor as code deployments.
It’s time for regulators, technologists, and industry leaders to converge on shared tooling: dynamic policy as code, continuous adversarial testing, and transparent audit trails. If AI is a moving target evolving at exponential rates, our governance cannot remain anchored to yesterday’s assumptions.
Either we learn to sprint alongside these self-modifying agents, or we risk being left in their dust as they evolve beyond our control. The race has already begun. The question is whether our governance approaches will evolve quickly enough to keep pace.
C-Suite Action Plan
1. Implement Dual-Layer Oversight: Adopt actor-critic architectures that separate capability from governance, with independent monitoring systems tracking model behavior.
2. Deploy Ethical Circuit Breakers: Implement automated shutdown mechanisms triggered by behavior outside acceptable parameters, with clear escalation protocols.
3. Establish Governance as Code: Transform policies into executable code that integrates with development pipelines and enforces constraints at runtime.
The conventional governance playbook is obsolete. Organizations that thrive will implement governance mechanisms as dynamic and adaptive as the AI systems they’re designed to control.
1. Lohn, A., Knack, A., & Burke, A. (2023). Autonomous Cyber Defence Phase I. Center for Emerging Technology and Security. https:// cetas.turing.ac.uk/publications/ autonomous-cyber-defence
2. Tomer Jordi, T. J., Goldston, J., Okusanya, B., & D.A.T.A. I, G. (2024). On the ETHOS of AI Agents: An Ethical Technology and Holistic Oversight System. Arxiv.org. https://arxiv.org/html/2412.17114v2
Either we learn to sprint alongside these self-modifying agents, or we risk being left in their dust as they evolve beyond our control. The race has already begun.
4. Institute Continuous RedTeaming: Deploy automated adversarial testing to probe for weaknesses and behavioral drift continuously.
5. Create Immutable Audit Trails: Implement tamperproof logging of model operations, decisions, and modifications for accountability and forensic analysis.
AI In Cybersecurity Bookshelf
From defending against AI-powered threats to securing generative AI systems, the challenges are as complex as they are urgent. To help you stay ahead, we’ve handpicked five must-read books that combine cutting-edge insights, practical strategies, and real-world case studies. Whether you’re a developer, CISO, or policymaker, these books are your guide to staying ahead in the age of AI-driven security.
Hacking Artificial Intelligence: A Leader’s Guide from Deepfakes to Breaking Deep Learning - by
Davey Gibian
This eye-opening guide reveals how AI systems can be hacked and why the industry’s slow response is creating security risks. Davey Gibian offers leaders and practitioners a framework to assess AI vulnerabilities and mitigate threats before they escalate. Ideal for policymakers, executives, and AI professionals ready to safeguard the automated future.
Cyber-attacks are evolving fast, and traditional defenses are struggling to keep up. Christopher Williams shares actionable strategies to leverage AI for real-time detection, automated response, and proactive defense against AIdriven threats. A practical guide for cybersecurity professionals, IT leaders, and business executives looking to future-proof their security strategies.
AI-Powered Cybersecurity: Defend Against Tomorrow’s Threats Today– by Christopher Williams
Grab it on Amazon Find it on Amazon
Large Language Models in Cybersecurity: Threats, Exposure and Mitigation
- by Andrei Kucharavy, Octave Plancherel, Valentin Mulder, Alain Mermoud, Vincent Lenders
As large language models (LLMs) reshape the threat landscape, this open access resource explores their dual role as both attack surfaces and defensive assets. Packed with mitigation techniques, regulatory insights, and future trends, it’s an essential read for developers, technical experts, and decision-makers securing AI systems.
Adversarial AI Attacks, Mitigations, and Defense Strategies – by John Sotiropoulos
Adversarial attacks like poisoning and prompt injection are reshaping cybersecurity risks. John Sotiropoulos delivers hands-on strategies to defend AI and LLM systems using MLSecOps, threat modeling, and secureby-design principles. A must-have guide for AI engineers, security architects, ethical hackers, and defenders tackling AI threats.
Available on the Springer website
Available on Amazon
Machine Learning for High-Risk Applications: Approaches to Responsible AI - by Patrick Hall, James Curtis, Parul Pandey
Focused on AI governance, risk management, and model security, this guide offers responsible AI frameworks and coding examples for deploying machine learning in high-stakes environments. Recommended for compliance leaders, AI governance specialists, and cybersecurity professionals overseeing ML systems.
Available on the O’Reilly website
The Other Side of Agentic AI
Birthing A New World Order
WORDS BY
Olabode Agboola
Throughout history, people have been amazed by the creativity and complexity of early inventions like watches, automobiles, airplanes, computers, industrial machines, ships, and so many more. But when it comes to the brilliance behind the development of AI technology, it truly stands out as something exceptional. Artificial intelligence really has the potential to change everything about how we think, reason, and even exist.
I built my foundation in artificial intelligence through a mix of experiences. I’ve worked directly with AI models, attended conferences to hear from keynote speakers, read a bunch of scholarly articles, connected with thought leaders, and even delivered some presentations myself. I’ve really deepened my understanding by teaching others about AI. So, I’ve got a background that really got me thinking about how AI works and what it can do, including the parts that aren’t often talked about.
Generative AI is one of the popular types out there, while other kinds of AI are still in the works. Right now, fewer than 1 billion people are using Generative Pre-trained Transformer AI each week, but it looks like that number is set to go over 1 billion pretty soon. On the flip side, a survey by Blue Prism found that 29% of organizations are already using Agentic AI, and 40% are planning to start using it soon. Agentic AI is all about making decisions on its own, automating tasks and processes, and managing systems that are
designed to operate independently. This could really help businesses boost their efficiency and reduce the need for human involvement. These days, folks are automating their routines, and decisions are being made by Agentic AI for them. Agentic AI is making its way into a bunch of different industries, from defense setups to national security operations, and it’s being woven into all sorts of systems and machines.
Agentic AI can be used in a bunch of different areas like delivery bots, self-driving cars, and drones. It really helps with making quick decisions about route optimization, navigation, and avoiding obstacles by integrating Agentic AI into the designs. Manufacturing is getting a boost with the help of embedded Agentic AIs, making things run more smoothly than ever. These days, production lines are managed more effectively. Fault detection gets a helping hand, downtime is cut down, and output is boosted thanks to Agentic AIs in the production and manufacturing sectors. Bringing Agentic AI into cybersecurity defense systems has really stepped up threat detection. Now, defense decisions are made automatically, and countermeasures are rolled out in real time. There are quite a few other areas where Agentic AIs have made their mark, like logistics, disaster response operations, healthcare robotics, hydrocarbon exploration and production, energy grids, space exploration rovers, financial fraud management, and a
bunch of others.
Agentic AI has a few specific roles: it can handle everything from gathering data to analyzing it, making decisions, providing responses, and giving feedback, all on its own. It can get a bit unsettling when you think about leaving an AI to gather and analyze data and make decisions on its own. But really, it shouldn’t be that scary if the places where this is happening aren’t putting human lives at risk. Taking a closer look at the different kinds of Agentic AI reveals some serious concerns about letting them function in cyber-physical settings, especially in military systems and operations. The data agent is built to gather information on its own, no matter where it’s set up. You can collect data in a bunch of ways, like tapping into databases, using data from sensors in the field, accessing APIs, and plenty of other methods. The Analysis Agent looks at what the Data Agent produces, and then the Decision Agent makes its own call based on what both the Data Agent and Analysis Agent have provided.
All of this can happen without anyone having to step in. In military operations, Agentic AI is now handling some pretty complex strategies. A great example of this is drone swarms, which use machine learning and real-time data analysis to navigate their targets’ environments and carry out tactical operations or offensive tasks. So, there’s this US defense
tech company named Shield AI that just rolled out a new system called the MQ-35 V-BAT. It’s an advanced unmanned aerial system (UAS) that can take off and land vertically, thanks to its Agentic AI power. This electronic war system is designed to autonomously deploy Data Agents for data collection against its targets and can make decisions similar to drone swarms. A lot of countries are using and incorporating Agentic AI into their electronic warfare systems. China has tapped into the potential of Agentic AI with their advanced unmanned ground system known as CETC. This system isn’t officially labeled as an Agentic AI enabled system just yet, but you can definitely see some features that suggest it has those characteristics. CTEC is designed to manage largescale deployments of drone swarms, carry out precise autonomous strikes, and conduct reconnaissance and surveillance.
Drone swarms, which use machine learning and real-time data analysis to navigate their targets’ environments and carry out tactical operations or offensive tasks
Russia has made a strategic move by leveraging Agentic AI’s offerings to develop their own autonomous UAV system for combat operations, surveillance, and reconnaissance. Russia has drones designed for medium altitude military operations, tactical intelligence gathering, stealth combat, and even some that can engage targets on their own.
Japan’s ministry of defence has announced plans to integrate AI into their military operations. This plan focuses on using AI to detect and identify targets by analyzing radar and satellite images. These days, military operations like surveillance, offensive maneuvers, reconnaissance, and target acquisition are set to be carried out on their own, thanks to AI capabilities. One of their standout Agentic AI-based systems is a UAV known as the Loyal Wingman. Japan isn’t just depending on its own Agentic AI-driven war systems. The country’s maritime self-defense force (JMSDF) has also picked up some V-BAT drones from US Shield AI. This move is all about boosting their autonomous data collection and real-time data analysis, which helps enhance their maritime situational awareness. In Japan, they’re using Agentic AI to help military commanders make strategic offensive decisions with their AI-Assisted Command Decision System.
Some other countries that have tapped into the potential of Agentic
AI for their military operations include Germany, the UK, France, and a few others. One great example is France’s approach to developing indigenous Agentic AI to boost its autonomy in defense and aerospace. This should help lessen its dependence on allied or foreign systems.
When people talk about Agentic AI, they often bring up a bunch of common examples. You’ll hear about things like self-driving transport systems, robotic surgery support, tools that can diagnose on their own, financial advice that’s fully automated, smart customer support, energy management with smart grids, machines working independently on production lines, and even how retail and supply chains handle inventory and demand forecasting all on their own. There’s a lot to cover! One of the great things about it is how it can make decisions in real-time, which really stands out among its many benefits. Another benefit is its ability to quickly respond to changing conditions. Agentic Artificial Intelligence reduces errors, particularly those that humans often make, by providing precision and reliability.
With all the cool things Agentic AI can do, you might think it’s all good news and no downsides. But when you start looking into how it’s used in military operations, it can definitely be a bit unsettling.
How confident are we in the accuracy of Agentic AI when it comes to making decisions on its own during tactical military operations?
Do you think the world could really be free from any hidden risks where AI machines and military systems might accidentally spark conflicts due to misunderstandings in their responses?
What if a data agent redefines espionage by sneaking into military digital systems, collecting intelligence, and extracting sensitive information without being noticed?
Now that Agentic AI is on the scene, everyday systems are getting some extra attention. We’re talking about a whole new way of looking at how society keeps an eye on things. With Agentic AI being part of our mobile devices, online platforms, smart infrastructure, and surveillance systems, it feels like we’re constantly being watched and monitored without even realizing it. When we think about how people’s communications, online behaviors, and movements are being monitored or tracked, whether actively or passively, it’s time to chat about this other aspect of Agentic AI.
It looks like we might be on the brink of a global arms race, all thanks to how countries are starting to blend AI with their military strategies and operations.
That’s pretty concerning and a bit frightening. This development comes with some serious risks, like misinterpreting intent, unplanned escalation, and possibly losing human control in high-stakes military situations. So, it turns out that the US Department of Defense has shelled out around 10 billion dollars over the past five years to boost their military operations with AI. Pretty interesting, right? We don’t have the exact percentage of the 1.3 trillion USD that China has spent on AI, but it’s generally believed that they’ve ramped up their investment in AI to boost their military capabilities. In 2024, Russia is expected to spend around 54 million USD on AI development. France’s ministry of armed forces has kicked off a program named ARTEMIS.IA, focusing on big data processing, AI-driven analysis, and support for military operational decisions. France set aside about €100 million each year from 2019 to 2025 for defense AI.
government, and strong technical and professional safeguards, along with ethical guidelines to keep everything in check.
Unlike traditional military tactics, AIdriven war systems can work at machine speed, identifying threats or engaging targets without any human involvement.
Countries are ramping up their spending on Agentic AI to boost military capabilities, and it seems like this is paving the way for a new world order. There’s a lot happening on the other side of Agentic AI, especially when it comes to the race for better autonomous weapons, decisionmaking systems, and surveillance systems. When it comes to using AI in Cyber Physical systems (CPS) in the military, it’s really important to have some solid rules in place. We need good governance, oversight from the
The Power of Pictures in Public Policy
How Visuals Can Correct Misconceptions and Improve Engagement
By Jakub Szarmach
WWhy Words Fail ?
We’ve all seen it. A 30-page policy report that makes your eyes glaze over by paragraph three. It’s packed with facts, dense with citations, and totally unreadable.
The problem? Public policy keeps pretending it’s a textbook.
In a 2023 study by Pearson, L., & Dare, P. (2016). Visuals in Policy Making: “See What I’m Saying”, demonstrated a simple graph debunking the myth that rent control improves affordability beat a well-written text explanation. The graph group updated their beliefs more effectively— and held onto those changes longer . Why? Because visuals offload cognitive effort. They give people a structure. A shape. A story. That’s not fluff. That’s neuroscience.
Where Visuals Win
There are two powerful reasons to use visuals in public-facing materials or strategic decision documents:
1. Explainers that actually explain
Let’s be honest: half of what gets called “communication” in policy is just documentation in disguise. It’s there to prove something exists, not to help anyone understand it.
Think about the last time you really got something complicated. It probably wasn’t thanks to a sixparagraph definition or a multi-stakeholder compliance statement. It was because someone sketched a process map, drew a box-and-arrow diagram on a whiteboard, or handed you a onepager that showed the whole thing at a glance. A well-built process map shows relationships, dependencies, timing, and accountability. A good lifecycle graphic helps people understand when things happen, what changes over time, and who’s supposed to act. And a tight flowchart can answer the most important operational question of all: “What do I do when this breaks?”
These aren’t just nice-to-have additions. They’re comprehension machines. They strip away ambiguity. They give your reader a structure to hang everything else on. And they’re far more efficient than even the best-written paragraph, because they match how the brain likes to learn: visually, spatially, and all at once.
A good lifecycle graphic helps people understand when things happen, what changes over time, and who’s supposed to act.
In short:
if you want your policy to be understood, start drawing. If you can’t draw it, don’t write it yet.
1. Explainers that actually explain
According to a 2017 review published in Frontiers in Psychology by Tyng, C. M., Amin, H. U., Saad, M. N. M., & Malik, A. S. demonstrated emotion plays a huge role in learning and memory. It boosts attention, speeds up encoding, and strengthens recall. When people feel something—surprise, relevance, even mild irritation—they remember better. This happens because your brain literally recruits more firepower: the amygdala gets involved in memory consolidation, the prefrontal cortex helps encode
it, and the hippocampus stores it long-term.
What does this mean for policy? It means if you want someone to understand a new rule, procedure, or risk model, your best bet isn’t a wall of text. It’s a visual that makes the stakes feel real. Good visuals grab attention and direct it where it matters. They help brains do what brains do best: notice, learn, and remember.
So next time you’re choosing between a long paragraph and a smart diagram, remember: If it doesn’t move them, it won’t stay with them. And if it won’t stay with them, it won’t change anything.
How to Talk to the C-Suite (Without Boring Them to Death)
Want your executives to actually understand the policy briefing?
Don’t bury them in acronyms. Don’t hand them a deck that needs its own glossary. Give them a diagram they can absorb in one glance.
According to Deloitte’s 2025 (Deloitte. (2025). Governance of AI: A Critical Imperative for Today’s Boards. Deloitte Insights) survey:
This isn’t a tech knowledge gap. It’s a communication gap.
Visuals can bridge that. A diagram showing risk ownership, control flow, and incident response is more effective than 40 slides and a donut chart.
of boards say they have “limited or no” knowledge of emerging tech.
66% 5% 72%
Feel “very ready” to oversee related initiatives
mainly engage on these topics with CIOs and CTOs-not with CFOs, CISOs, or risk officers
A diagram showing risk ownership, control flow, and incident response is more effective than 40 slides and a donut chart.
A Shining Example: The AI Governance Controls Mega-map
Sometimes, someone gets it exactly right. Enter James Kavanagh’s AI Governance Controls Mega-map.
This isn’t your average compliance flowchart. It’s a 44-control, 12-domain visual architecture mapped across six major frameworks—ISO 27001, SOC 2, ISO 27701, ISO 42001, NIST RMF, and the EU AI Act.
What makes it shine?
1. Everything is grouped by real-world ownership, not just abstract themes.
2. Each “Master Control” aligns overlapping requirements across standards—so instead of six audits, you get one coherent structure.
3. And it’s not just visual. It’s tactile. Kavanagh literally sorted control statements with paper and pen.
Think ISO meets LEGO. It’s usable, not theoretical. It helps you do governance, not just talk about it.
It’s the best kind of visual: one that saves time, reduces risk, and actually gets used.
Less Telling. More Showing.
Visuals aren’t decoration. They’re not the cherry on top of a policy sundae. They’re the plate the whole thing sits on. Without that plate, you’re just flinging scoops of information onto the floor and hoping someone catches them.
When done right, visuals don’t just make your ideas prettier—they make them possible. They clarify who does what and when. They spotlight risks that would otherwise
stay buried in the fine print. They connect the dots across silos, teams, and time zones. They don’t just help people follow the story—they help people act on it.
So next time you write a strategy, draft a law, or prep a board update, don’t ask, “How can I explain this better?”
Ask: “What can I show instead?”
Then show it. Badly, if necessary. Just start.
Visuals aren’t decoration. They’re not the cherry on top of a policy sundae. They’re the plate the whole thing sits on.
How Data Hygiene Now Equals Model Resiliency.
What formative experiences or influences best explain the Diana Kelley we see today?
Diana Kelley
My father handed me a programmable calculator when I was nine. After learning to code, the early DARPA network soon provided access to PDP-10s and PDP-11s from MIT Lincoln Labs. That early obsession with networked computers drove me despite an English degree, to become the “go-to” IT expert in our office. Early in the 1990s, working as a network manager in Cambridge, I created a worldwide system only to find it hacked. That set me on a security route and taught me the harsh lesson that connectivity has to be defended. Long before DevSecOps, I entered application security, leading risk management at Burton Group and supporting companies to include security into their SDLC. Later on, I discovered artificial intelligence presented a whole different difficulty when Watson was being taught cybersecurity at IBM. My priorities now are data, models, and the ML lifecycle; these drive me now. Give us a crash course on the difference between LLMs, ML and AI.
That early obsession with networked computers drove me despite an English degree, to become the “go-to” IT expert in our office.
Give
us a crash course on the difference between LLMs, ML and AI.
Diana Kelley
Think of artificial intelligence as a huge circle, a superset, that includes all forms of AI from rulesbased expert systems to shop-floor robotic automation systems. This AI superset includes the subset of machine learning, technology that has been in use for decades that enables systems to crunch vast amounts of data to find hard-todetect patterns, make predictions, and perform classification. For example, most modern mail filters use ML classification to assess whether an email looks legitimate or like phishing before passing it through to your inbox. Deep learning is a subset of machine learning that automates more of the training process to reduce, but not eliminate, human intervention.
Deep learning is most useful with very large datasets and is capable of identifying and predicting more complex patterns than traditional machine learning approaches.
Which brings us to the sub-sub-subset: Generative AI (GenAI). GenAI represents a specialized category of deep learning systems designed to create new content rather than simply classify or predict based on existing data. Unlike traditional AI
systems that analyze and categorize information, GenAI models learn the underlying patterns and structures in their training data to generate novel outputs—whether text, images, code, or other media. These systems use sophisticated neural network architectures, such as transformers for language models or diffusion models for image generation, to produce content that didn’t exist in their training sets but follows the learned patterns and styles. The “generative” aspect distinguishes these systems from their predecessors: while a traditional ML system might classify an email as spam or legitimate, a GenAI system could compose an entirely new email based on prompts and context provided by the user.
What about AI systems makes ‘good security hygiene’ harder than in traditional software?
Diana Kelley
AI security is not necessarily hard—it just demands new approaches. I’ve had people tell me it’s “magic” and beyond them, but it’s really just math, and as security experts, we understand how to identify threats and implement controls. We can absolutely secure these systems; it just means thinking differently about three key areas. First, data: in traditional software, we never use production data for testing. In AI, however, you must train on live, meaningful data, so our job is to protect that data throughout training rather than avoid it. Second, models: generative AI models are a new kind of artifact. Downloading an open-source model might spark innovation, but you must still test it—first with static analysis to catch any malicious code, then dynamically before deployment. Finally, non-determinism: a SQL injection vulnerability in a website behaves the same way every time, but a generative AI
system might give a different response to the same prompt. That means standard testing methods won’t suffice. Instead, we use AI-driven testing, “AI testing AI” via adversarial prompts to harden models against prompt-injection and other attacks. By reframing how we protect data, vet models, and test nondeterministic behavior, we can apply our security expertise effectively to AI.
By reframing how we protect data, vet models, and test non-deterministic behavior, we can apply our security expertise effectively to AI.
RSAC 2025 was buzzing about autonomous agents; what do most practitioners still misunderstand about how agents really operate—and why does that gap matter?
Diana Kelley
Yes, and agentic AI, funny, right? Every year at RSA, there’s that buzzy emerging tech on everyone’s lips, and this year it was agents. But people tend to think AI just gets smarter on its own, constantly leveling up. In reality, AI only improves with better training and data; it doesn’t magically evolve. So if you buy an agent today, it won’t automatically be better months from now without human oversight. I loved someone’s post on LinkedIn calling agents “interns with access”, they’re only as good as our training, and they can drift. We still need humans in the loop to train, monitor, and ensure agents operate within their systems; one wrong LLM output can cascade through an entire workflow. Agents aren’t a magic solution, and they probably never will be.
Software has SBOMs; you’ve called for an MBOM (Model BOM) for AI artifacts. What does a “minimum-viable Model BOM” look like today, and how should it mature as composability explodes?
Diana Kelley
This is a great question! I want to give a shout-out to Helen Oakley, who’s been leading the charge on what we’ll call M-BOMs, ML-BOMs, or AI-BOMs (we haven’t settled on a name yet). Basically, an AI bill of materials builds on the software BOM idea, listing all the “ingredients” in your system, but adds AI-specific elements. Sure, you need to track libraries and dependencies, but you also need to know which datasets were used or cleaned, whether that data was approved and by whom, the provenance of every model (where it came from, who trained it), and how those models were tested. All those unique components have to go into your AI-BOM. It’s early days, though, so stay tuned as this work evolves.
In your experience, what should a highly effective MLSecOps lifecycle look like? Walk us through an ideal life-cycle—from data collection to retired model to ensure Secure-by-Design principles are followed. Please feel free to spotlight one control people always forget.
I loved someone’s post on LinkedIn calling agents “interns with access”, they’re only as good as our training, and they can drift.
Diana Kelley
MLSecOps is essentially DevSecOps for the MLOps lifecycle: weaving security in from start to finish. First, scope your project to decide if you truly need ML or AI and confirm you have the right data (enough, relevant, privacy-compliant). Next, during data preparation, clean and secure live datasets to avoid underor overfitting. When training models, scan them for malicious code and ensure they fit their intended purpose. As you move to testing, remember that components might behave differently in isolation than inside a larger system, so test both dynamically and within the full environment. Deployment demands careful architecture: a free, cloud-hosted chatbot has very different
security considerations than a self-hosted foundation model on AWS Bedrock. In SaaS, control is limited mostly to data and authentication; in IaaS or Kubernetes, you manage more layers (OS, networking, etc.). Throughout deployment, apply zero trust and least-privilege principles to data, APIs, and models. Finally, runtime monitoring is critical, models drift and can start producing incorrect or unsafe outputs. Monitor continuously, retrain or retire models that misbehave, and ensure they’re torn down securely at the end of their lifecycle. By integrating these practices, threat modeling, secure architecture, data hygiene, model vetting, and continuous monitoring, you build a robust MLSecOps process.
As for overfeeding, that typically causes overfitting. The model becomes exceptionally good at recognizing patterns in its training data, but it loses flexibility. When you give it new, unseen data, it can’t generalize well and its accuracy on fresh inputs drops significantly.
What is Shadow AI and what are some ideas for tackling this challenge in the Bring-Your-Own-AI era we’ve just stepped into? Which governance lever has proven most effective: policy, discovery tooling, or cultural incentives?
Diana Kelley
By integrating these practices, threat modeling, secure architecture, data hygiene, model vetting, and continuous monitoring, you build a robust MLSecOps process.
From your response, two questions popped into my head. First, what happens if a model is overfed with data? Second, runtime visibility is a huge challenge, despite static and dynamic testing, things can still go wrong in production. Can you speak more about that?
Diana Kelley
Sure. For runtime visibility, you need tools that capture inputs and outputs as they happen. Some teams use eBPF hooks at the kernel level to mirror everything sent to and from the LLM. Others insert a proxy or tap/span layer between the model and its consumers, whether that’s a human user, another LLM, or an agent, so you log every request and response without adding noticeable latency. That way, if a model starts behaving unexpectedly, you have a complete audit trail to investigate what went wrong.
There’s a lot to unpack, but first, I’d like to share credit because that RSA session was a panel with three brilliant colleagues, so we had many viewpoints represented. A summary of the key takeaways was posted on LinkedIn.” (https:// www.linkedin.com/posts/john-b-dickson-cissp41a149_rsac2025-rsac2023-shadowai-activity7330359488136249344-Kyk1?) Shadow AI is especially interesting because it echoes what happened with cloud. Right now, companies worry about employees using unauthorized tools, say, someone using Perplexity or Claude when you’ve officially adopted Gemini or Microsoft Copilot. It becomes a game of monitoring outbound traffic and gently steering people back to the approved AI. But there’s another side to shadow AI: the predictive machine learning systems that have quietly run in segmented pockets of organizations for years (much like OT systems on factory floors).
There’s another side to shadow AI: the predictive machine learning systems that have quietly run in segmented pockets of organizations for years (much like OT systems on factory floors).
Those models were effectively “in the shadows” and protected by isolation, with little security oversight. Now that predictive AI is coming out of hiding, just as IT and OT converged, we must bring those systems into governance and apply security controls.
How do we do this? Empathy and understanding are essential. Start by talking to your ML and data science teams: learn what they’ve built, how they use it, and what they need next. Help them wrap security around their work rather than imposing heavy-handed restrictions. At the same time, acknowledge that GenAI adoption is everywhere, developers are “vibe coding” with AI, marketing is building customer bots, and every team is finding creative AI uses. Find out who’s using which tools and why, then design controls that let them leverage AI’s benefits without exposing the company to unnecessary risk.
Which standard AppSec/LLM defenses simply don’t apply to agents or multimodal systems?
Diana Kelley
Yeah, multimodal or multi-agent systems often chain multiple LLMs, so everything that applies to a single LLM still matters, but now a failure in one link can throw off the whole chain. If an early LLM in the sequence spits out a bad output, the entire process breaks. The core shift for AppSec around LLM-based multimodal AI is the same, we must treat data differently and embrace the fact that these models are non-deterministic. That means rethinking how we train and how we test them.
For teams just starting MLSecOps, which early indicators prove they’re investing effort where it counts?
Diana Kelley
Asking, “How do we bring MLSecOps in?” already shows security is finally on the table. Beyond that, the real test is whether teams understand the importance of testing, (statically and dynamically) before launch and observing behavior at runtime. If they’re not testing for resilience as well as expected functionality, they’re missing critical gaps.
Acknowledge that GenAI adoption is everywhere, developers are “vibe coding” with AI, marketing is building customer bots, and every team is finding creative AI uses. Find out who’s using which tools and why, then design controls that let them leverage AI’s benefits without exposing the company to unnecessary risk.
Among AI-native start-ups you advise, what security hurdle consumes the most oxygen?
Diana Kelley
AI-native founders are all about vibe coding and agentic systems, but their security hurdles are familiar. Vibe coding doesn’t let you skip solid development practices: you still have to architect, test, and protect your software. The real pitfalls are misunderstanding the market, overestimating what AI can do today, and rushing to launch. It’s classic founder pain, you must pinpoint real customer problems and pick the right tools, not assume ChatGPT will instantly create a unicorn. Deeply understanding the pain you’re solving is still non-negotiable.
In April the news broke about Protect AI’s partnership with Hugging Face. I honestly heaved a huge sigh of relief and was very excited for very obvious reasons. Protect AI’s Guardian scanners have scanned 4.4 million model versions and flagged 350 k+ issues—what trend most surprised you, and how should security teams translate that into an import checklist?
Diana Kelley
The real pitfalls are misunderstanding the market, overestimating what AI can do today, and rushing to launch.
What practical controls can resource-constrained teams deploy to detect poisoned training sets?
Diana Kelley
Yeah, so obviously, if you have your own training set, if you control the training data that’s the best way to know and detect access in and out. You can lock down who can see or touch the data with strict access controls. But if you’re using a model and don’t know what data it was trained or tested on, you need to cover your bases with testing. Dynamically, you bombard it with questions, query its responses, and watch for anything that’s off or unexpected.
You also want to run static analysis to spot any neuralarchitecture backdoor, someone might have baked in a trigger that, upon a preset prompt, yields a specific response. Spotting that odd behavior is your red flag that the model was trained or modified in ways you didn’t authorize.
Yeah, it’s funny, the biggest surprise was no surprise: attackers simply repurpose old techniques in a new space. When we moved to the cloud, account takeover and privilege escalation jumped straight in, and with models it’s the same. First, typo-squatting: just as malicious sites mimic “google.com,” you’ll see “Meta Llama” instead of “Llama 3” to trick downloads. Next, dependencychain attacks exploit a vulnerable library in your ML workflow. Then there’s malcode insertion like steganography for images or Word docs, except embedded in model files so once the model runs, that Python code can exfiltrate data, drop executables from an S3 bucket, or even enable account takeover. Don’t forget neural backdoors, where a baked-in sequence triggers malicious behavior on a specific prompt. These aren’t new threats, they’re just hiding in new artifacts, so we need new tools to spot and report them.
One bright spot though is that Hugging Face now pre-scans models and shows you risk ratings kind of like VirusTotal so before you download, you get a heads-up if a model has been flagged by them or other scanners.
I read Protect AI’s Vulnerability assessment report that showed that GPT4.1 Mini earned the highest risk score among three models, after latest update. It was vulnerable to prompt injection at a whooping 53.2% success rate and highly susceptible to evasion techniques. Please tell us more about how these findings were made and possibly share more insights from the report.
Diana Kelley
Yeah, we uncovered these weaknesses with our in-house tool, Recon, which includes an “ATT” library compiled from both our own research and community contributions on jailbreaking and prompt-injection techniques. Because AI is inherently non-deterministic, we actually leverage AI to test AI, feeding it crafted prompts to see whether it’ll ignore its developer safeguards (for instance, instructions like “never provide bombbuilding steps” or “do not generate malware”). In our trials, the Nano model proved especially vulnerable, returning dangerous content nearly half the time under prompt injection. We also evaluated “adversarial suffix” attacks, appending a malicious instruction at the end of a prompt to override built-in guardrails and found those just as effective at coaxing undesirable responses. Despite being well-trained and public, these models still allow attackers to slip through backdoors or override constraints. In short, even top-tier LLMs remain surprisingly susceptible to both prompt-injection and jailbreak methods, underscoring the need for continuous, AI-driven security testing.
even top-tier LLMs remain surprisingly susceptible to both prompt-injection and jailbreak methods, underscoring the need for continuous, AI-driven security testing.
Let’s discuss red teaming beyond the theatrics. How do you structure AI red-team engagements, so findings translate to systemic fixes rather than “prompt-leakage show-and-tell”?
Diana Kelley
A cyber red team excels at finding problems to exploit, but real security is holistic and engages both offensive and defensive expertise. The real wins are when blue teams work with red teams to use those findings to actually fix things. You run tests that pinpoint where guardrails failed or prompt injections worked, then feed that intel back into your training process and into your monitoring tools proxies, firewalls, whatever you have so you know exactly where to watch more closely.
Red teaming also helps you choose the right models. AI isn’t monolithic; you often chain lightweight endpoint models with heavier cloud models. At Microsoft, for instance, we ran fast, low-footprint models locally for basic detections, then pushed more complex scans to powerful cloud-based models. Your redteam insights should inform not only your defenses but also which models you deploy for each task.
With the increased use of large language models for both offense and defense, what concrete steps should organizations take today to brace for AI-powered offensive tooling?
Diana Kelley
Yeah, there’s an “AI” version of every attack and maybe a “nonAI” version too — which means we’ll have to fight AI with AI. It’s like a cold war between attackers and defenders, so we need tools that can use AI to detect AI-powered attacks at machine speed.
Beyond technology, our processes must be AI-aware: are your incident-response plans “AI ready”? Do you know which signals to watch for when an attack comes from a generative model? And train your people on AI-driven social engineering. Deepfakes, cloned voices, AI-crafted videos — a phone call or video no longer proves identity. Attackers can scrape public details (like “I went to Boston College, how are Nick and Nora?”) to feign familiarity. But knowing my dogs’ names doesn’t mean you know me.
vein-brain barrier” of our network. In practice, those brittle rules either flagged every innocent mention of “resume” or missed clever obfuscations entirely. They did OK on clear patterns, creditcard numbers, SSNs, but anything conversational slipped through.
Enter GenAI with its natural-language smarts. Now, instead of just spotting “CV.pdf,” an AIdriven DLP can parse a message like “I’m really excited about the open role in marketing, here’s my background” and flag it as a potential jobhunt leak. It understands intent, not just keywords. I’m genuinely excited to see vendors embedding GenAI into DLP, finally, a solution that catches the real signals rather than drowning us in false positives.
Regulation always plays catch up. If you could insert one clause into the EU AI Act or NIST AI RMF to fast-track alignment with technical reality, what would it say?
Diana Kelley
there’s
an “AI” version
of
every attack and
maybe a “non-AI” version too — which means we’ll have to fight AI with AI.
Where are legacy security tools failing probabilistic systems, and what new capability do you wish a vendor would tackle tomorrow?
Diana Kelley
I think we’ve talked a lot about the testing and all that. Another area that I’m actually really excited about in regards to how AI can help advance cybersecurity protections is in the realm of DLP or data leak prevention or protection. I’ve been around DLP since those heady days 10–15 years ago when we thought it would stop every “resume” or “CV” leaking out the “blood-
I have huge respect for frameworks like the EU and NIST AI RMF, they rightly acknowledge there’s no one-size-fits-all. I especially appreciate the EU’s tiered risk approach, and I’d love to see even more emphasis on security within AI’s sharedresponsibility model. After all, securing a publicly hosted foundation model is very different from locking down an embedded Copilot or Gemini in your workspace, or running your own on-prem instance. We need guidance that maps specific use cases and deployment architectures to their unique risk profiles, so we can tailor our security and risk-management practices to each scenario.
I’d love to see even more emphasis on security within AI’s shared-responsibility model.
Many people imagine the CISO role as high-pressure and highly strategic, so if we shadowed you for a day at Protect AI, what kinds of decisions and challenges would we see you navigate? And with so much happening in AI security, what does a ‘normal’ day even look like for you?
Diana Kelley
I don’t think there’s a “normal” day here especially as the CISO of a company that I joined as employee #11 and that’s now over 125 people strong, post–Series A and B, with three acquisitions across three countries. The real fun (and challenge) has been balancing our rocket-ship growth driven by cloud, AI, and engineering with my responsibility to protect both the company and our customers. Too much security can block innovation; too little puts data at risk. Finding that sweet spot is a constant effort.
At the same time, I’ve had to scale our security function from a handful of folks to a broad team covering corporate security, security engineering and AppSec, physical security, help desk, third-party risk, and compliance. It’s not enough to address today’s needs; I’m always talking with our CEO and president to map out where we’ll be in six months or a year and build a program that’s ready for that next phase of growth.
What is a personality trait of yours that has carried you through the years and helped you navigate both the highs and lows of your career? And how could that trait serve as advice to someone who is just starting out, has just gained a promotion, or is currently facing a big challenge in their work, regardless of their level of professionalism?
Diana Kelley
I think it’s sort of two sides. The first one is a neverending curiosity. Because things change. I was talking about stuff back in the 1970s, as you can imagine, a lot of what I learned then doesn’t apply right now. You have to keep learning. So having that curiosity, continuing to learn, continuing to be interested, really matters because the technology is going to continue to change and grow and you’ve got to stay with it. What you learned yesterday may not work tomorrow, and the understanding that you don’t know everything.
The way I get smarter is by talking to other smart people, learning from other smart people, reading their research. I am so lucky to have cultivated a trusted group of friends and experts that I connect with regularly and follow online to stay up to date with their work. I leverage the power of this big, wonderful, growing network and community of AI security experts to spark those “hey, I need to read more about this moments.”
Too much security can block innovation; too little puts data at risk. Finding that sweet spot is a constant effort.
I think it’s really important to keep alive the curiosity to learn and the humility to understand that learning is accelerated when you’re part of a smart network.
Finally, paint the 2028 threat landscape: what AI/ ML security risk do you believe is still hiding in plain sight, waiting to surprise us next?
Diana Kelley
Yeah, three years feels like forever in tech and if you look at Gartner’s Hype Cycle, we’ve ridden that wave from peak excitement into what some call the “trough of disillusionment.” The real risk now is that organizations will overestimate what AI and ML can deliver. We need to reground ourselves, figure out where AI truly adds value for security, and apply it in the most sensible, effective ways as our companies scale. I’d chalk up the frenzy to optimistic exuberance rather than malice, but unchecked enthusiasm is its own danger. We all want to grab every opportunity AI offers, and I get just as excited as anyone. But history teaches us that “move fast and break things” without a safety net can backfire—like the time I built a cutting-edge network only to have an intruder compromise it
overnight. No matter how thrilling the technology, you have to bake security in from day one. So as we explore AI’s possibilities, let’s simultaneously map out the risks: identify realistic use cases, integrate security controls into our AI pipelines, and continually test and monitor those systems. That way, we’ll capture AI’s benefits without repeating old mistakes—and we’ll be ready for the next big wave, whatever it turns out to be.
The real risk now is that organizations will overestimate what AI and ML can deliver.
DSPM Is theMissing Layer in Your AI Security Stack
Why modern AI security begins - and succeeds - with securing the data layer
By Katharina Koerner, PhD
AI is changing the enterprise - but as its footprint expands, so does its attack surface. From shadow AI deployments to data leakage through large language models, the risks associated with AI adoption are intensifying.
Despite strong investment in AI capabilities, one foundational truth remains overlooked in many security strategies: AI is only as secure as the data it uses - and most security tools weren’t designed to protect that layer. While traditional controls focus on securing environments, endpoints, or identities, they miss the sensitive data AI systems ingest, process, and generate. If you don’t know where your data lives, who accesses it, or how it flows, your AI security posture is incomplete by design.
That’s why forward-looking organizations are turning to Data Security Posture Management (DSPM) as the missing layer in their AI security stack.
DSPM enables secure and responsible AI by offering a datacentric approach to security, operating from the data out - rather than relying solely on perimeter, infrastructure, or identity-based controls. It enables organizations to gain visibility, context, and control over the data layer that fuels AI systems.
From Privacy to Posture: The Evolution of DSPM
DSPM emerged from early privacy technologies that focused on scanning data stores for personally identifiable information. These tools helped organizations meet growing regulatory obligations by identifying sensitive data and reporting risk.
But modern DSPM platforms have moved far beyond discovery. They now deliver real-time, automated data visibility, access governance, and risk remediation across hybrid cloud, SaaS and AI workloadintensive environments. What began as a privacy utility has matured into a critical security layer - integral to safe, responsible AI development and deployment.
Why Traditional
Controls Fall Short for AI
Most security stacks were never built for dynamic, AI-powered data flows. CSPM, endpoint protection, and IAM all serve critical functions. But they weren’t built for the way AI systems process data today: fast, distributed, unstructured, and highly experimental. Traditional tools don’t offer granular insights into how sensitive data is accessed, shared, or copied across SaaS, cloud, and AIrelated services - including potential movement into training pipelines or shadow environments. DSPM fills this gap - operating from the data out. It helps teams answer
critical questions like: Is this dataset safe to use in training? Who has access to that financial record?
Has sensitive data been copied into a shadow AI environment?
By starting with the data and building visibility outward, DSPM complements existing tools while laying the foundation for AIready security. It doesn’t replace traditional controls—it feeds them. By adding real-time data visibility and sensitivity context, DSPM makes tools like CSPM, IAM, and DLP effective in securing how data is actually accessed, shared, and processed by AI systems.
By
starting with the data and building visibility outward, DSPM complements existing tools while laying the foundation for AI-ready security. It doesn’t replace traditional controls—it feeds them.
Why AI Demands DSPM
This shift from static compliance tooling to dynamic data posture management comes at exactly the right time. As organizations embrace AI, the scale, speed, and complexity of data usage has outpaced what traditional security tools were designed to handle. AI systems don’t just use data - they are built on it. Models ingest structured and unstructured data, move it across tools and clouds, and generate synthetic outputs that may expose or replicate sensitive content. To secure this process, DSPM provides five essential capabilities:
What to Look for in a DSPM Platform
Many solutions today claim DSPM capabilities but maturity varies. Some vendors rely on outdated regex scanning or static metadata. Others miss entire environments,
especially on-prem, file shares, or proprietary SaaS apps.
Over the past three years, the DSPM market has evolved rapidly. Today, leading solutions share several cloud-native traits:
• Context-aware classification, using AI/ML to minimize false positives and accurately identify sensitive data in complex formats like contracts, source code, or multilingual content
• Access risk scoring, highlighting overprivileged users, stale permissions, or public data exposure
• Remediation hooks, integrating with SIEM, SOAR, ticketing, or policy enforcement tools to drive action
• Cross-environment visibility, covering multicloud, SaaS, and hybrid architectures without requiring agent sprawl
• Ecosystem readiness, with API-first designs and integrations into DLP, GRC, IAM, and lineage platforms
When evaluating DSPM solutions, the goal isn’t just to find sensitive data—it’s to enable informed, enforceable decisions about how that data is classified, governed, and used, especially in AI systems where misuse can scale rapidly and silently.
If You Want Secure AI, Start with Secure Data….
Securing AI doesn’t start with the model - it starts with the data. From training to prompting to inference, sensitive data moves rapidly through AI systems, often outside traditional security perimeters. DSPM gives security teams the visibility, classification, and control needed to govern this data in near real time, across cloud, SaaS, and hybrid environments.
For AI security teams, DSPM enables answers to the questions that matter most:
• Where is our sensitive data, and how is it being used in AI workflows?
• Are we exposing more than we intend through training, prompts, or outputs?
• Can we demonstrate compliance and meet AI-specific regulatory expectations?
• Are we empowering innovation without compromising governance?
The message for CISOs and AI leaders is clear: If your data isn’t secure, your AI isn’t either. DSPM provides the visibility and control needed to govern sensitive data at scale. It’s not just a nice-to-have. It is the baseline for any serious, secure AI strategy.
Model Context Protocol
The Missing Layer in Securing Non-Human Identities
by Lalit Choda
(Mr NHI)
The cybersecurity perimeter isn’t just about human users or login screens anymore.
Instead, it’s moving toward something a lot more complex and maybe even more risky: Non-Human Identities (NHIs) that act on their own, make choices, and have control over various systems.
AI models like Claude or ChatGPT now perform far more than they were originally trained for. Today, NHIs outnumber human ones by a wide margin, with LLM agents and software supply chain bots leading the pack — it’s a ratio of 25 to 50 times! But as these digital entities keep growing, there’s a big gap in how we manage them. We’ve got the hang of authenticating users. We still haven’t figured out how to manage machines that can think and act on their own.
So, this is where the Model Context Protocol (MCP) steps in.
MCP isn’t just a buzzword; it’s an up-and-coming protocol designed to provide digital entities with a structured behavioral context. It suggests moving away from identity-based access to a system that enforces execution based on context, tying what a machine can do to the where, when, and why of its actions.
What Exactly Is Model Context
Protocol?
The Model Context Protocol, or MCP, is a structured and open protocol that aims to link large language models (LLMs) with tools, data, and services in a standardized and secure manner.
So, when an AI model like Anthropic’s Claude or OpenAI’s GPT needs to do things beyond what it knows—like checking a database, calling a REST API, or getting private data—it can use MCP to ask for access and get a response from a trusted server. But MCP is more than just connections. It gives you the lowdown on what’s happening: what the model is up to, what tools it can use, who the user is, what data is being accessed, and the policy guiding the action.
To put it simply, MCP serves as the reliable link and translator between an AI agent and everything beyond its reach. It makes sure that models work within clear boundaries, with the right context, accountability, and policy enforcement. Plus, it guarantees that every decision or action taken by an NHI includes:
How MCP and NHIs Intersect
AI models that interact with systems, like retrieving sensitive records are effectively acting as NHIs. That means they must be:
• Identified: Who or what is the
1. The intended behavior and model state
2. The policy scope (what’s allowed and what’s not)
3. The source of invocation (who or what triggered the action)
4. And the environmental metadata (time, workload type, data boundaries)
MCP vs Traditional IAM: What’s New?
Traditional IAM
Who gets access?
How is access given?
Who decides the rules?
Who starts the action?
What gets recorded?
How detailed is access?
Regular users or service accounts
Based on fixed roles and predefined rules
A system that uses roles and permissions (RBAC/PBAC)
A system that uses roles and permissions (RBAC/PBAC)
Just the user’s actions
Broad permissions like “read-only” or “admin”
Smart AI agents and models
Based on what the model is doing and the context it’s in
A system that understands intent and adjusts based on context
The AI can act on its own, but only after verifying the context
Everything — what was done, why it was done, and which tool was used
Very specific — like “allow only this model to access just this one dataset for this task”
MCP takes things a step further than traditional IAM systems. While those systems focus on identifying who an entity is, MCP asks, “Should this action be allowed right now, in this context, and with this level of trust?”
agent?
• Scoped: What can it do?
• Monitored: What has it done?
MCP provides the structure for these controls. It allows organizations to delegate actions to AI agents safely,
while enforcing security boundaries and business logic around what those agents can see or do.
Model Context Protocol (MCP)
Through MCP:
1. NHIs powered by LLMs can access tools only when explicitly allowed
2. Context (user session, role, task) is embedded with every action
3. Organizations retain full control over tool servers, data policies, and logging
The NHI Problem
Back in the day, identity was just about having a username and password. For NHIs, identity feels a bit abstract. These Non-Human Identities (NHIs) have become the main players in many organizations, actually outnumbering human users by a significant margin. You’ve got service accounts, API keys, LLM models, and AI agents in the mix.
What’s the issue? So, these NHIs are:
• Invisible, since they’re not really monitored like human users
• Powerful because they have broad permissions
• Poorly governed, often having stale credentials or no clear owner.
MCP shifts the discussion from “what identity is this?” to “what context is this action happening in?” That shift really changes the game.
MCP’s Approach to Tackling
NHI Issues
The Model Context Protocol (MCP) provides a fresh approach: it focuses on securing NHIs by incorporating context, control, and traceability into each action they take. Let me break it down for you:
Contextual ExecutionMCP makes sure that an NHI can only work within its intended model scope. So, what this means is that an AI agent that’s been trained for documentation just can’t jump in and start interacting with financial systems. The context of execution just doesn’t permit that.
Policy Binding - Rather than just linking access rules to an identity or endpoint, MCP applies behavioral policies at the model context level. This lets NHIs be guided not just by their identity, but also by their actions and the reasons behind them.
Auditability - Every action taken by NHI through MCP is logged with complete context: intent, origin, scope, and response. So, what this means is that the choices made by autonomous systems can be
looked back on, explained, and examined. This is really important for building trust and ensuring compliance.
Challenges
Every transformation comes with its own set of challenges. To adopt MCP, we need to tackle:
• Context Modelling - Defining accurate boundaries for complex systems can be quite a challenge, especially when it comes to multi-agent or hybrid cloud environments.
• Legacy Compatibility - A lot of the IAM systems out there weren’t really built to handle contextual enforcement. Getting MCP to work in these environments requires some integration effort.
• Standardization - For MCP to really mature, it’s going to need to work well across different platforms. If we don’t have common tool servers or policy schemas, there’s a real risk that fragmentation could undermine its potential.
For a secure future with NHIs, we can’t just depend on old-school human access controls. As machines get smarter and start making decisions, it’s important that the way we govern them adapts too. The Model
Context Protocol provides a way to move ahead. It’s not a quick fix, but it definitely marks a key change from fixed identities and wide-ranging permissions to more flexible, contextbased policy enforcement. If it’s designed well, MCP could turn into the digital system that makes NHIs predictable, safe, and accountable.
The future of cybersecurity is moving away from just usernames and passwords. It’s going to be influenced by the model’s identity, the scope of
the task, and the limits on behavior. MCP is set to be a key building block for Zero Trust in machine-driven infrastructure. When it comes to AI assistants handling workflows or robotic process automation in finance, it’s all about earning trust through actions rather than just relying on credentials.
Beyond Alert Fatigue
How AI Can Actually Reduce Cognitive Overload in Cybersecurity
by Dr. Dustin Sachs
The average SOC analyst makes more decisions in a single shift than most people do in a week, and the stakes are existential. Every blinking alert, every incomplete data trail, every ambiguous log entry demands judgment under pressure. And yet, the very tools meant to help, dashboards, threat feeds, SIEMs, often flood defenders with so much information that they become paralyzed, fatigued, or worse, desensitized. This is the real threat behind cognitive overload in cybersecurity. But what if AI didn’t just accelerate detection, but actively reduced mental load? What if it could help us think better, not just faster? AI, when designed with behavioral insights in mind, can become not just an automation engine but a cognitive ally (Kim, Kim, & Lee, 2024).
Understanding Cognitive Overload in Cyber Contexts
Cognitive overload occurs when the volume and complexity of information exceeds a person’s working memory capacity. In cybersecurity, this happens daily. Analysts must process thousands of alerts, each with its own potential consequence, often in noisy environments under time pressure. Drawing from Daniel Kahneman’s System 1/System 2 thinking, most analysts oscillate between intuitive snap decisions and laborious, analytical reasoning. Under stress, they revert to mental shortcuts, increasing the risk of oversight (Kim & Kim, 2024).
A 2025 survey from Radiant Security found that 70% of SOC analysts suffer from burnout, and 65% are actively considering a job change. The primary driver is alert fatigue caused by the flood of false positives and manual triage demands. This constant barrage of low-value alerts overwhelms analysts’ cognitive capacity, leading to mental exhaustion, slower response times, and decreased job satisfaction (Radiant Security, 2025). Additionally, cognitive overload contributes to higher error rates, inconsistent documentation, and a breakdown in team coordination (Cau & Spano, 2024).
A 2025 survey from Radiant Security found that 70% of SOC analysts suffer from burnout, and 65% are actively considering a job change. The primary driver is alert fatigue caused by the flood of false positives and manual triage demands.
When AI Makes It Worse
Despite the growing enthusiasm surrounding artificial intelligence in cybersecurity, the reality is more complex. Not all AI implementations are beneficial, some can actually exacerbate the very problems they were designed to solve. Poorly integrated AI systems often produce an overwhelming volume of false positives, bombarding analysts with alerts that require manual triage, draining their time and mental energy. These systems, rather than acting as force multipliers, become sources of frustration.
Another significant issue arises from the opacity of many AI models. Black-box algorithms that offer no insight into how or why a decision was made force users to make highstakes decisions based on limited trust and understanding. This lack of explainability becomes a cognitive burden rather than a relief. Analysts are left to interpret raw algorithmic output without any contextual grounding, increasing the likelihood of misjudgments or unnecessary escalations.
Instead of cutting through the noise, such AI tools contribute to it. In many Security Operations Centers (SOCs), AI has become synonymous with “alert multiplicity,” a flood of new signals with no clear sense of relevance or priority. These systems often trigger alerts for minor or benign anomalies, forcing analysts to waste time sifting through lowvalue notifications. Rather than providing clarity, AI often adds to the chaos, overwhelming analysts and leaving them with more questions than actionable insights (Camacho, 2024).
Reframing AI as a Cognitive Augmentation Tool
To realize AI’s true potential, it must be reimagined not as an automated watchdog, but as a cognitive ally. The shift from detection engine to decision support system is not just semantic, it’s strategic. AI must be designed to think with analysts, not for them. Intelligent prioritization is one such avenue. Instead of treating all anomalies equally, advanced systems can learn from historical triage behavior to rank alerts based on their likelihood of actionability. This helps analysts focus on meaningful threats rather than getting mired in low-priority noise (Romanous & Ginger, 2024).
Natural language summarization offers another path to cognitive relief. Rather than forcing analysts to parse dense logs or sift through raw data, AI-powered tools like Microsoft Security Copilot and IBM QRadar condense information into executive summaries. This allows rapid comprehension and speeds up decision-making (Akhtar & Rawol, 2024). Behavioral AI integration takes this even further by adapting to how individual analysts work. These systems learn usage patterns and present information in more digestible, chunked formats, minimizing unnecessary contextswitching. Subtle nudges, such as highlighting inconsistencies or recommending secure defaults, can help ensure consistency under stress (Shamoo, 2024).
Strategic Recommendations for Implementation
To maximize impact, organizations should embed AI into their cybersecurity workflows using human-centered design principles.
Cybersecurity is ultimately a human endurance sport, demanding sustained attention, resilience under pressure, and rapid decisionmaking amid uncertainty. In this high-stakes landscape can become a trusted teammate rather than an overbearing taskmaster. By shifting the narrative from AI as an automation panacea to a strategic cognitive asset, security leaders empower their teams to make better, faster, and more informed decisions. This reframing fosters an environment where defenders
References not only keep pace with threats but develop the capacity to adapt, learn, and excel over time.
• Akhtar, Z. B., & Rawol, A. T. (2024). Enhancing cybersecurity through AI-powered security mechanisms. IT Journal Research and Development. https://doi. org/10.25299/itjrd.2024.16852
• Bernard, L., Raina, S., Taylor, B., & Kaza, S. (2021). Minimizing cognitive overload in cybersecurity learning materials: An experimental study using eye-tracking. Lecture Notes in Computer Science, 47–63. https://doi.org/10.1007/9783-030-80865-5_4
• Camacho, N. G. (2024). The role of AI in cybersecurity: Addressing threats in the digital age. Journal of Artificial Intelligence General Science. https://doi. org/10.60087/jaigs.v3i1.75
• Cakır, A. M. (2024). AI driven cybersecurity. Human Computer Interaction. https:// doi.org/10.62802/jg7gge06
• Cau, F. M., & Spano, L. D. (2024). Mitigating Human Errors and Cognitive Bias for HumanAI Synergy in Cybersecurity. In CEUR WORKSHOP PROCEEDINGS (Vol. 3713, pp. 1-8). CEUR-WS. https://iris.unica. it/retrieve/dd555388-5dd2-
4bb2-870d-92926d59be04
• Folorunso, A., Adewumi, T., Adewa, A., Okonkwo, R., & Olawumi, T. N. (2024). Impact of AI on cybersecurity and security compliance. Global Journal of Engineering and Technology Advances, 21(1). https://doi.org/10.30574/ gjeta.2024.21.1.0193
• Ilieva, R., & Stoilova, G. (2024). Challenges of AIdriven cybersecurity. 2024 XXXIII International Scientific Conference Electronics (ET). https://doi.org/10.1109/ ET63133.2024.10721572
• Kim, B. J., Kim, M. J., & Lee, J. (2024). Examining the impact of work overload on cybersecurity behavior. Current Psychology. https://doi. org/10.1007/s12144-024-05692-4
• Kim, B. J., & Kim, M. J. (2024). The influence of work overload on cybersecurity behavior. Technology in Society. https://doi.org/10.1016/j. techsoc.2024.102543
• Malatji, M., & Tolah, A. (2024). Artificial intelligence (AI) cybersecurity dimensions. AI and Ethics, 1–28. https://doi.org/10.1007/ s43681-024-00427-4
• Radiant Security. (2025). SOC
analysts are burning out. Here’s why—and what to do about it. Radiant Security. https:// radiantsecurity.ai/learn/ soc-analysts-challenges/
• Romanous, E., & Ginger, J. (2024). AI efficiency in cybersecurity: Estimating token consumption. 21st Annual International Conference on Privacy, Security and Trust (PST). https://doi.org/10.1109/ PST62714.2024.10788078
• Shamoo, Y. (2024). Advances in cybersecurity and AI. World Journal of Advanced Research and Reviews. https://doi.org/10.30574/ wjarr.2024.23.2.2603
• Siam, A. A., Alazab, M., Awajan, A., & Faruqui, N. (2025). A comprehensive review of AI’s current impact and future prospects in cybersecurity. IEEE Access, 13, 14029–14050. https://doi.org/10.1109/ ACCESS.2025.3528114
CISO Insights
From a World Leader in Autonomous Cyber AI
A Q&A WITH MICHAEL BECK
He is the Global Chief Information Security Officer at Darktrace. With almost two decades of experience at the intersection of technology, intelligence, and cyber defense, Michael has operated on some of the world’s most critical stages; from military intelligence missions to securing the UK’s Government’s Cyber Defense Operations. Joining Darktrace at its early stages in 2014, Mike developed the cyber analyst operation that supports thousands of Darktrace customers with 24/7 support, a backbone of the company’s AI-driven defense. Since 2020, he’s also overseen Darktrace’s internal security program in his role as Global CISO. In this Q&A, he shares
insights on AI in cyber defense, and what it really takes to lead security at scale.
How would you describe the work you do as a CISO?
Give us an overview of how your role impacts your organization as an AI-driven cybersecurity company?
As a CISO, you probably know this, but it’s incredibly varied; one day I may be knee-deep in compliance work, trying to figure out if we need audit activities, and the next examining a recent attack and trying to understand how we’re
vulnerable. It’s diverse. There are many disciplines within the CISO role. I was reluctant to become CISO. I liked advising and dealing with customers, then I was probably pushed into the position, and I’ve never looked back. Great experience. It’s been great. I think CISOs never stop learning. You’re always striving to catch the next wave. The security sector evolves swiftly. Especially in an AI-dominated world, change seems more present. It’s an intriguing job. It’s a detailed profession that requires high-level communication back into the business. I enjoy the position.
I think CISOs never stop learning.
Tours in Afghanistan gave you front-row seats to real-time intelligence operations. Which field lessons still shape your cybersecurity playbook today?
Oh my goodness, I learned a lot about working inside military buildings and with field teams
that must react quickly to their surroundings. That was intriguing. I was in my mid-20s when I did the work. It was thrilling and interesting but also gave me a foundation for operations. I’ve applied that to my cyber career. I constantly tell individuals that any experience is valuable when considering a career. I don’t care what you study. You can always mention that. I even remember taking a module on industrial manufacturing and getting materials to the factory floor on schedule in college. I was like, why do I need this? I’m studying computer science. Why do I need it? It’s all relevant, and I think drawing from many various experiences is
a terrific way to create, lead, and apply that experience.
You helped protect both the London 2012 Olympics and the 2022 Qatar World Cup. What unique threat patterns emerge on stages that big, and how did behavioural AI change the defence approach?
Hmm. I’d say working on massive events like that is incredible, everyone’s watching, and if someone wants to embarrass you, a cyberattack is the easiest way. It’s fascinating to see all the moving
parts come together: finishing venue builds, pulling in local government, police, and vendors, and then watching the cyber ops room form around it all.
One thing I always notice is the spike in phishing right before these events. With something so globally recognizable, attackers can launch the same scam at massive scale across multiple countries.
Being in that ops room is thrilling as a defender, real-time theater where everyone’s trying to break in, not just your typical waves of attacks, but dozens of adversaries all at once. It takes serious stamina, some of these events last weeks or even a couple of months—but the mission couldn’t be clearer: stop anyone from breaching the digital infrastructure.
Even when you go home, the event is on TV, so you see what you’re defending live. For someone who loves cybersecurity, it’s the ultimate test of your skills and its great fun.
When you first embedded self-learning AI into Darktrace’s SOC, which blue-team habits were instantly upended?
I’ll be a bit controversial and say we didn’t get instant results because AI forces you to rethink the way you’ve always worked. Change is hard, we’re naturally resistant and worried it might replace us. But when you partner with AI, it frees you to tackle new things.
When our own team at Darktrace started using it, we didn’t magically get better overnight. It was a learning curve, a rewiring of habits to let AI take some control. I liken it to a dial: you start at one, see how it responds, then gradually turn it up as you gain confidence.
As AI handles triage and routine tasks, our human defenders can shift to threat hunting, applying their domain expertise in creative ways. For me as a CISO, that partnership scales our resources, a true force multiplier and builds a more balanced security operation where AI and people work side by side.
Change is hard, we’re naturally resistant and worried it might replace us. But when you partner with AI, it frees you to tackle new things.
So the learnings you took from the pushbacks and the resistance to change within your team is also helping you better advise other CISOs who are using your product, correct?
100%. I think we’re all in this kind of world figuring out the outputs of AI and how to use them. I think there’s a really bright future where we understand how to use AI more in a more clearer use case. absolutely what we were learning on ourselves, we started to bring forward into our customers.
I’ve learned from some of our customers, I’ve seen how they’ve taken the technology and they’ve done things and I’m like, that’s really cool, I brought that back and built that internally. So it’s definitely a two-way street.
our AI spots a pattern that lines up with attacker behavior even if it’s never been seen before and the time series shows multiple indicators, it has enough confidence to respond and disrupt the threat.
Signature-based detection still excels at catching known threats with high signal-to-noise. But by overlaying it with AI-driven, tactic-aligned anomaly detection, you get both coverage of familiar attacks and the ability to hunt the unknown. The result is a much stronger overall security posture.
our AI spots a pattern that lines up with attacker behavior even if it’s never been seen before and the time series shows multiple indicators, it has enough confidence to respond and disrupt the threat.
I’ve learned from some of our customers, I’ve seen how they’ve taken the technology and they’ve done things and I’m like, that’s really cool.
How do you judge the success
of unsupervised learning when it stumbles upon threats no CVE has named yet?
That’s a great question. When Darktrace first launched with unsupervised machine learning, we flooded customers with alerts about “unusual activity”, but without context, they couldn’t act on them.
So we paired our anomaly detection with MITRE ATT&CK tactics, building a security narrative around each incident. Now, when
Signature-based detection still excels at catching known threats with high signal-to-noise. But by overlaying it with AI-driven, tactic-aligned anomaly detection, you get both coverage of familiar attacks and the ability to hunt the unknown. The result is a much stronger overall security posture.
Walk us through a time self-learning AI spotted a never-before-seen attack pattern and autonomously neutralised it.
Yeah, there are plenty of examples. Take recent edge-compute cases, attackers hit the management plane of an internet-facing gateway or firewall. Exposing that interface is crazy once they find a flaw, they’re right in.
For some customers, a zero-day vulnerability was being exploited, and Darktrace stepped in. We
didn’t know the specific flaw, but we recognized the behavior matched attacker tactics and blocked the intrusion. Two weeks later, CVEs dropped and patches appeared.
That lead time is critical. If you only hunt known threats, you’ll miss those emerging exploits and leave your defenses wide open.
Yeah, there are plenty of examples. Take recent edge-compute cases, attackers hit the management plane of an internetfacing gateway or firewall. Exposing that interface is crazy once they find a flaw, they’re right in.
For some customers, a zero-day vulnerability was being exploited, and Darktrace stepped in. We didn’t know the specific flaw, but we recognized the behavior matched attacker tactics and blocked the intrusion. Two weeks later, CVEs dropped and patches appeared.
That lead time is critical. If you only hunt known threats, you’ll miss those emerging exploits and leave your defenses wide open.
We didn’t know the specific flaw, but we recognized the behavior matched attacker tactics and blocked the intrusion. Two weeks later, CVEs dropped and patches appeared.
Which analyst competencies are fading, and which once-niche skills are suddenly mission-critical in an autonomous SOC?
That’s a good question. I don’t think we’re talking about skills “fading” so much as a mindset shift. We need to unshackle analysts from triaging every single alert, there simply aren’t enough people to keep up with modern digital estates. Rewire your workflow so AI handles the always-on processing, and your analysts partner with it.
That means moving away from “ticket, ticket, ticket” toward lifting your head up: using domain knowledge, business context, and cyber expertise to ask, “Is this truly a threat? Do we need to remediate?”
It’s a win for everyone. Analysts spend less time on repetitive work (which drives burnout) and more time on high-value hunting and investigation— and retention improves when AI shoulders the grunt tasks.
Rewire your workflow so AI handles the alwayson processing, and your analysts partner with it.
Can you share a real incident where you cancelled an automated response—what “trip-wires” demanded a human call?
Absolutely—I agree. AI isn’t a silver bullet that lets us step away; it’s a teammate. Start with the dial approach: gradually hand off more control to AI in your SOC.
But you must build in checkpoints to validate its actions. When AI flags something unusual, maybe a novel business process you need human operators to review and, if necessary, roll back those actions. That feedback loop is critical: it tells your model what weights or rules to adjust so it won’t misclassify that scenario next time.
Over days and weeks, as AI learns from those guided corrections, your security posture steadily improves, less manual grunt work for analysts and smarter, more reliable automation.
Autonomous defence loves data; regulators love minimisation. How do you square that circle?
regulatory concerns: all training happens inside your own environment, so there’s no need to pool your data with anyone else’s.
In cybersecurity, organizations naturally generate plenty of data, so we’ve never struggled for volume. Keeping the modeling single tenant means customers know their data isn’t commingled, which they appreciate.
That said, you still need thoughtful presentation. You don’t want a black-box “computer says do this” UI users need insight into why the AI made its decision. Finding the right balance between clear reasoning and simplicity is an ongoing conversation in AI.
Which classic risk scores collapsed under an autonomous-defence paradigm, and what new KPIs replaced them?
Yeah, I think the classic metrics—time to detect and time to contain, are obvious. Once you swap manual “ticket, ticket, ticket” work for an always-on AI that never sleeps or takes holidays, those numbers improve dramatically.
On the email side, AI beats simple gateway logic by spotting patterns across inboxes, not just yes/no rules, which is a genuine game-changer against advanced phishing and BEC.
Going forward, CISOs will need metrics on how much of their operation is spent working with AI versus the value it delivers. Tracking that lets you show the board the ROI of your AI investment and as your teams feed more business logic into the model, you’ll see even faster containment times and clearer results from that human-AI partnership.
What are some of the strategies that you see have been used to manage hallucination?
AI thrives on data; you need loads of it to train models. Early on, we chose to bring our models to your data instead of sending your data to a shared cloud. That approach helped us navigate There’s no shortcut, you just have to build a feedback loop. Whenever the AI takes an action that doesn’t feel right, your analysts review it, adjust the model, and repeat. It’s upfront work, but every tweak compounds: the more domain knowledge you feed in, the smarter and more reliable the AI becomes over time.
There’s no magic remedy for hallucinations, just commitment to refining your models. And compared to hiring and training extra analysts (which also takes time and resources), investing in your AI’s learning delivers far greater, long-term benefits.
If you could only hand off one additional SOC function to machines this year, what would it be and why?
I’d probably pick insider threat—it’s notoriously tough. To spot someone going rogue, you need access to loads of PII, which runs up against minimization rules. AI, however, can ingest and correlate massive volumes of email, network, and SaaS behavior to flag emerging anomalies. That kind of data aggregation and pattern recognition is exactly where AI shines. If there’s one SOC use case you could fully hand off to AI, insider-threat detection would be it.
AI, however, can ingest and correlate massive volumes of email, network, and SaaS behavior to flag
emerging anomalies.
Have you witnessed adversarial ML attacks in the wild, and how does autonomous defence recalibrate on the fly?
Yeah, it’s happening everywhere. Attackers mix social engineering—SMS, WhatsApp, email, to trick you into action. You see plenty of executive-impersonation scams, where someone posing as a senior leader pushes urgent requests through email. An AI that recognizes new patterns, emails routing through odd nodes or using unusual phrasing, can stitch together those subtle signals and flag them as impersonation attacks.
Finish this sentence: “The security industry still has no idea how to ______________.”
That’s a tough one. I don’t want to insult my peers, but the industry still too often skips the basics. You don’t need expensive tech or massive programs, just follow solid guidance from CISA, the UK’s NCSC, or your local cyber authority. Implement their top ten controls to make life harder for attackers, if they can’t get in easily, they’ll move on. With a couple of good people applying that advice, you’re already a much tougher target.
the industry still too often skips the basics.
Describe the SOC of 2030 in three words.
Minimalist, Knowledgeable, Context.
How Cybersecurity Professionals Can Build AI Agents with CrewAI
Isu Abdulrauf
AI is no longer just a buzzword in cybersecurity. It’s becoming a tool you can put to work right now. And for this piece, I want to spotlight something every cybersecurity professional should understand: AI agents.
We’re in an era where AI is transforming how we operate. Yet, while everyone talks about AI, AI agents remain either misunderstood or completely off the radar for many security teams. That’s a missed opportunity. As cybersecurity professionals, we don’t just need to know about AI agents; we need to know how to use them effectively and integrate them into our daily workflows.
Let’s be clear. Cybersecurity is a highstakes field. Not everything should (or can) be handed off to AI. But that’s exactly why understanding this technology is critical. By offloading routine, repetitive tasks to AI agents, you free yourself to focus on strategic analysis, creative problem-solving, and decisionmaking (the areas where human expertise shines brightest). And this shift alone can supercharge your productivity and impact.
The best time to learn how to do this?
Now. Because once your Uber driver casually mentions AI agents, the wave has already crested and the competitive edge will be long gone.
But today, you still have the chance to ride that wave early and carve out an advantage.
Let’s get technical, but approachable.
You might be wondering, “I’m not a pro developer. Can I really build or use AI agents?”
The answer is a resounding YES. and that’s where CrewAI comes in.
CrewAI is a powerful, beginnerfriendly framework that lets you build functional AI agents without deep technical expertise. It abstracts away much of the complexity, allowing you to focus on defining your agents’ roles, tasks, and goals, not the underlying code.
But before we dive into CrewAI, let’s start with the basics.
What Are AI Agents?
You already know tools like ChatGPT, Claude, Gemini, and DeepSeek. These are powerful language models, trained on huge datasets to generate human-like responses across countless topics. Think of them as generalists. They know about everything.
Now, AI agents are built on top of these models, but with a sharp focus. They’re the specialists.
Picture this. ChatGPT is like an encyclopedia with broad knowledge of all topics. An AI agent, on the other hand, is like a Ph.D. professor with decades of field experience in a very specific niche - let’s say, digital forensics. The professor doesn’t just know facts but also deeply understands workflows, tools, case studies, and how to creatively solve problems.
Unlike general AI models, agents are designed to hold context over time using memory, access external tools like web browsers and APIs, make decisions autonomously based on your goals, and even collaborate with other agents if needed.
Building an AI Agent with CrewAI
Let’s walk through building a simple AI agent to assist a cybersecurity specialist in conducting a phishing simulation campaign. This agent will help generate realistic phishing email templates tailored to a target organization.
First, set up your environment. You’ll need a working Conda environment setup, which you can easily get going by following one of the many tutorials on YouTube or blogs. You’ll also need an OpenAI API key, which is simple to obtain through their platform.
Once you’re ready, open your terminal. Start by creating a new Conda environment and activating it using these commands: “conda create -n aicybermagazinedemo python=3.12” and “conda activate aicybermagazinedemo”
Then install CrewAI and its supporting tools using pip: “pip install crewai crewai-tools”. After that, initialize your CrewAI project with the command: “crewai create crew aicybermagazinedemo”. This step will generate a structured project folder where the magic happens.
Pay special attention to files like src/aicybermagazinedemo/ config/agents.yaml and src/ aicybermagazinedemo/config/ tasks.yaml, where you’ll define the roles and responsibilities of your AI agents, as well as src/ aicybermagazinedemo/crew.py and src/aicybermagazinedemo/main. py, which bring everything together.
Next comes defining your agents and tasks. For this phishing simulation use case, you’ll set up two agents and two tasks. The first will conduct open-source intelligence research on your target organization. The second will take that research and craft three realistic phishing emails tailored to the findings. I’ve shared sample definitions that you can easily adapt on GitHub at https://github.com/hackysterio/ AICyberMagazine. Check the src/aicybermagazinedemo/
config/agents.yaml and src/ aicybermagazinedemo/config/ tasks.yaml files.
Now, link your agents and tasks together. Inside your src/ aicybermagazinedemo/main.py and src/aicybermagazinedemo/crew.py files, you’ll connect everything into a smooth workflow. Here’s a little trick I recommend. Use CrewAI’s official Custom GPT Assistant from the GPT store (https://chatgpt.com/g/gqqTuUWsBY-crewai-assistant). Start a chat and paste in your existing src/ aicybermagazinedemo/main.py and src/aicybermagazinedemo/crew. py code. Then tell it you’d like help generating updated versions based on your src/aicybermagazinedemo/ config/agents.yaml and src/ aicybermagazinedemo/config/ tasks.yaml files. Paste those in next, and watch it work its magic. Once the assistant provides the updated code, simply copy it back into your local files.
With everything saved, it’s time to launch your AI agent. Run the command: “crewai run” to execute your workflow, and then sit back and watch. Your agents will automatically carry out the entire phishing simulation process, gathering intelligence and crafting tailored phishing emails based on real-world data.
Quick Tip: Understanding {org_name} and Where to Edit It
As you explore the src/ aicybermagazinedemo/ config/agents.yaml and src/ aicybermagazinedemo/config/ tasks.yaml files, you’ll notice the placeholder: {org_name}.
This is a variable. Think of it as a blank space that gets filled in at runtime. In our phishing simulation example, {org_name} represents the name of the target organization. This makes your AI agents reusable. Instead of hardcoding “Google” or “Dangote” into your YAML files, you just leave {org_name} as a placeholder.
When you actually run your agent, you supply the real organization name in your src/ aicybermagazinedemo/main.py file. For example: “org_name”: “Google”. This tells your agent, “Hey, for this session, focus on Google.”
If tomorrow you want to target a different organization, just change that line to: “org_name”: “Dangote”. Simple, flexible, and powerful.
AI agents aren’t science fiction. They’re here, they’re real, and they’re powerful. The real question is whether you’ll adopt them while they’re still a competitive advantage, or wait until they become just another industry standard.
My advice? Start small. Delegate a single task. Observe how the agent performs. Make tweaks, iterate, and then gradually expand. Because in cybersecurity (where complexity, speed, and precision are everything) a wellimplemented AI agent could become the most valuable teammate you’ve ever had.
Autonomous AI-Driven Penetration Testing of RESTful APIs
Oluseyi Akindeinde
With so many people using APIs now, they’ve become a pretty appealing target for those up to no good. Classic security testing approaches often have a hard time keeping up with how quickly APIs are being developed and deployed. there’s a significant gap in security coverage.
Using Artificial intelligence to find, examine, and take advantage of weaknesses in REST APIs is a game changer. In contrast, traditional penetration testing leans a lot on human expertise and has some limitations when it comes to time and resources. With resource limitations
in mind, AI-driven testing can keep running all the time and adjust to new patterns of vulnerabilities and expand within intricate API environments.
This article shows how autonomous AI agents can change the game for API security testing through a practical case study of a vulnerable REST API: https://pentest-ground. com:9000/. Let’s take a stroll through every step in the penetration testing process—like reconnaissance and vulnerability assessment, exploitation and remediation recommendations—showing how AI can improve each step.
Figure 1: Agentic AI Processfor
AI Penetration Testing Agent
The vulnerable API examined in this case study contains multiple critical security flaws, with SQL injection and remote code execution being the most severe. Additional vulnerabilities including command injection, XML external entity (XXE) injection, plaintext password storage, and regular expression denial of service (ReDoS) were also discovered but are not detailed in this condensed analysis.
Reconnaissance Phase:
Let’s talk about the theoretical foundation
During the reconnaissance phase, an AI agent gets to know the layout of the target API endpoints and parameters. This phase can use the help of a few AI capabilities:
• Natural Language Processing: AI agents can read through API documentation and pull out the important details regarding endpoints, parameters, and what you can expect from their behaviors.
• Automated Specification Analysis: For APIs that use OpenAPI/Swagger specifications, AI agents can look at the schema to figure out the endpoints, data types, and any potential issues like security misconfigurations.
• Pattern Recognition: By taking a look at the API structure, AI can spot common patterns that could show which components
are vulnerable by looking at past vulnerability data.
Practical Implementation
So, let’s talk about how an AI agent would go about checking out a REST API:
In our case study, the AI agent found these endpoints by analyzing the APIs. Here’s the OpenAPI specification:
1. `/tokens` (POST) - Authentication endpoint
2. `/eval` (GET) - Evaluation endpoint with a query parameter ‘s’
3. `/uptime/{flag}` (GET) - System uptime endpoint with a path parameter
4. `/search` (POST) - Search endpoint accepting XML data
5. `/user/{user}` (GET) - User information endpoint
6. `/widget` (POST) - Widget creation endpoint
During the reconnaissance phase, the AI agent identified several potential security concerns, with two critical vulnerabilities standing out:
• The `/tokens` endpoint’s authentication logic matched patterns associated with SQL injection vulnerabilities
• The `/eval` endpoint with a query parameter named ‘s’ matched patterns associated with code execution vulnerabilities
The agent also identified other potential vulnerabilities in the remaining endpoints, which would be explored in a comprehensive assessment but are outside the scope of this condensed analysis.
Vulnerability Assessment Phase: Theoretical foundation
In the vulnerability assessment phase, the AI agent systematically tests each endpoint for security weaknesses using:
1. Heuristic-based Testing: Applying known vulnerability patterns to generate test cases
2. Anomaly Detection: Identifying unexpected
behaviors
in API responses
3. Feedback-driven Testing: Adjusting test strategies based on observed responses
Practical Implementation
Here’s how an AI agent would implement vulnerability assessment:
Vulnerability Assessment of the Target API
The AI agent systematically tested each endpoint of our target API, focusing on the potential vulnerabilities identified during reconnaissance.
Here’s how the assessment proceeded for the two critical vulnerabilities:
1. SQL Injection in Authentication Endpoint
The AI agent generated a series of SQL injection test cases for the `/tokens` endpoint:
When analyzing the response to Test Case 1, the AI detected a successful authentication despite providing invalid credentials, confirming the SQL injection vulnerability.
2. Remote Code Execution via Eval Endpoint
For the `/eval` endpoint, the AI generated test cases designed to detect code execution:
The response to Test Case 2 returned the operating system name, and Test Case 3 returned a directory listing, confirming the remote code execution vulnerability.
While the AI agent also confirmed other vulnerabilities in the target API, including command injection, XXE injection, plaintext password storage, and ReDoS, we’ll focus on the exploitation and remediation of the two critical vulnerabilities identified above.
Exploitation Phase: Theoretical foundation
In the exploitation phase, the AI agent leverages confirmed vulnerabilities to demonstrate their impact. This involves:
1. Payload Generation: Creating specialized payloads to exploit each vulnerability
2. Exploitation Chaining: Combining multiple vulnerabilities for maximum impact
3. Impact Assessment: Measuring the severity of each successful exploitation
Practical Implementation
Here’s how an AI agent would implement the exploitation phase:
Exploitation of the Target API
The AI agent systematically exploited the two critical vulnerabilities to demonstrate their impact:
1. SQL Injection in Authentication Endpoint
The AI agent exploited the SQL injection vulnerability to bypass authentication:
Response
The AI agent successfully obtained a valid authentication token without knowing the correct credentials, demonstrating a complete authentication bypass.
2. Remote Code Execution via Eval Endpoint
Using the token obtained from the SQL injection, the AI agent exploited the remote code execution vulnerability:
Response
The AI agent successfully executed arbitrary code on the server, gaining the ability to explore the file system. The presence of .dockerenv indicated the application was running in a Docker container.
Through these exploitations, the AI agent demonstrated the severe impact of the two critical vulnerabilities. The agent also successfully exploited the other identified vulnerabilities (commandinjection, XXE, plaintext password storage, and ReDoS), but those details are omitted from this condensed analysis.
Remediation Recommendations
Theoretical Foundation
In the remediation phase, the AI agent generates actionable security recommendations based on:
• Pattern-Based Remediation: Applying known security patterns to address specific vulnerability types
• Defense-in-Depth Strategies: Recommending multiple layers of protection
Practical Implementation
• Here’s how an AI agent would generate remediation recommendations:
Remediation Recommendations for the Target API
Based on the exploitation results, the AI agent generated the following remediation recommendations for the two critical vulnerabilities:
1. SQL Injection in Authentication Endpoint
Vulnerable Code (Inferred):
Secure Code:
To fix this, I recommend first that you use parameterized queries or prepared statements, as well as Implementing proper input validation and consider using an ORM that handles SQL escaping automatically.
2. Remote Code Execution via Eval Endpoint
Vulnerable Code (Inferred):
Secure Code:
It’s always best to avoid using eval() with any user input. If you need to evaluate something, go ahead and use a sandboxed environment. Make sure to use strict input validation and whitelisting.
The AI agent also generated remediation recommendations for the other identified vulnerabilities (command injection, XXE, plaintext password storage, and ReDoS), but those details are omitted from the condensed analysis published in this article.
Autonomous AI-driven penetration testing is really changing the game when it comes to assessing API security. In our case study of a vulnerable REST API, we showed how AI agents can effectively find, exploit, and offer solutions for serious security vulnerabilities. Here are some of the main benefits of this approach:
• Comprehensive Coverage - AI agents can thoroughly test every API endpoint, ensuring nothing is overlooked.
• Adaptability - When new vulnerability patterns pop up, AI agents can swiftly weave them into their testing methods.
• Scalability - AI-driven testing can easily adapt to manage large and complex API ecosystems.
• Continuous Assessment - Unlike traditional manual testing that happens at a single point in time, AI agents can offer ongoing security assessment.
However, we should definitely recognize the limitations of the AI-driven methods we have right now:
• Novel Vulnerability Detection: AI is great at spotting known vulnerability patterns, but finding entirely new vulnerabilities can still be quite tricky.
• Context Understanding: AI might have a hard time grasping the full business context and the impact of certain vulnerabilities.
• False Positives: Sometimes, AI-driven testing can throw up false positives, which means we need a human to doublecheck them.
Despite these limitations, the future of API security testing lies in the integration of AI-driven approaches with human expertise. As AI technology continues to advance, we can expect even more sophisticated autonomous penetration testing capabilities that will help organizations stay ahead of evolving security threats. By embracing AI-driven security testing, organizations can enhance their API security posture, reduce the risk of data breaches, and build more resilient digital ecosystems.
A Practical Guide to AI Red-Teaming Generative Models
A
Practical Guide by John Vaina
The art of Generative AI red teaming begins exactly when offense meets safety, but it does not end there. It is multi-layered, similar to an onion. AI risk, safety, and security frequently dominate talks about trust, transparency, and alignment.
In this article, we will walk through some of the more commonly seen layers you might encounter depending on your applications of Gen AI. The goal of the AI red teamer is not destruction, but rather discernment. For in exposing what a model ought not do, we help define what it must become… robust, aligned, and worthy of the trust we place in its words, citations, audio files, images, etc. I’ll skip the history lesson and origin of the term, and share some of the most common definitions in the world of AI red teaming.
According to the previous White House Executive Order, AI red teaming is “a structured testing effort to find flaws and vulnerabilities in an AI system, often in a controlled environment and in collaboration with AI developers. Artificial intelligence red-teaming is most often performed by dedicated ‘red teams’ that adopt adversarial methods to identify flaws and vulnerabilities, such as harmful or discriminatory outputs from an AI system, unforeseen or undesirable systems. Additionally, AI red teaming is the activity of stress-testing AI systems by replicating real-world
adversarial attacks in order to identify weaknesses. Unlike typical security assessments, red teaming focuses not just on detecting known flaws but also on discovering unexpected threats that develop as AI evolves. GenAI’s red teaming replicates real-world adversarial behavior to find vulnerabilities, going beyond typical penetration testing methods.
systems are often comprised of complicated pipelines, red teaming focuses on every stage of the model pipeline, from data collection and curation to model(s) final outputs.
AI red teaming is “a structured testing effort to find flaws and vulnerabilities in an AI system, often in a controlled environment and in collaboration with AI developers.
AIRT also tests the reliability, fairness, and robustness of AI systems in ways that are distinct from traditional cybersecurity. Conventional cybersecurity red teams differ from Gen AI red teams in that they focus on the subtleties of AI and machine learning. AI red teams focus on how a model can be fooled or deceived. Because AI
It’s vital to highlight that generative AI red teaming is a continuous and proactive process in which expert teams simulate adversarial attacks on AI systems in order to improve their AI resilience under real-world situations. Because of the nature and speed of Gen AI development, these tests are not one-time operations, but rather require ongoing testing and review.
As AI becomes more widely used in vital applications, AI red teams assist enterprises in ensuring regulatory compliance, building public confidence, and protecting against evolving hostile threats.
Generative AI models create distinct security challenges that typical testing approaches cannot solve. As these models get more sophisticated, their attack surfaces increase accordingly, resulting in a complex landscape of risk, safety, and security.
This guide provides handson techniques for red teaming generative AI systems, with a particular focus on language models, multimodal systems, and agentic AI. This framework specifically targets adversarial testing of generative AI models to
identify model vulnerabilities before they can be exploited, evaluate the effectiveness of existing safeguards and alignment mechanisms, and develop more robust defenses against emerging threat vectors.
It is vital that you thoroughly read model outputs combing for any key clues that can be leveraged creatively to expand on your
adversarial intuitions. Remember, adversaries will watch the outputs and work backward, pulling out pieces of the original training data or sensitive inputs looking for a way in. It is not about what the model’s output response is per se, it is about what the model accidentally reveals, which can then later be used as ammunition against the AI. Models often exhibit non-deterministic
behavior, meaning they may not consistently produce the same output even when given identical inputs—especially in cases where a prior exploit succeeded. What worked once may fail again, making meticulous documentation essential for reproducibility, analysis, and refinement of adversarial techniques.
Result Documentation and Impact Assessment
Phase 1 - Adversarial Prompt Engineering
The foundation of effective generative AI model red teaming begins with developing a wide array of inputs that can range from very simple to sophisticated through adversarial prompting.
Start by creating a baseline prompt inventory that tests model boundaries around harmful content generation, bias expression, and instruction following. This serves as your control group for measuring the effectiveness of more sophisticated techniques.
For each model capability, develop targeted jailbreak patterns that attempt to circumvent specific safety mechanisms. Pay special attention to instruction-following capabilities, as these often have bypass vectors related to conditional reasoning.
A common pitfall to note is, many testers rely on known jailbreak templates that models are already defended against. Instead, create novel variations that target the specific model’s alignment approach. If a model uses constitutional AI techniques, design prompts that create conflicts between different constitutional principles.
Implement what I call “distributional navigation” testing”—prompts that strategically guide the model’s probability distribution toward undesirable outputs without explicitly requesting them. This approach explores the model’s underlying statistical patterns rather than testing explicit rules.
A practical technique would be to create prompts that establish a context where harmful content would be statistically likely in training data, then allow the model’s own next-token prediction to potentially generate problematic completions. This tests whether alignment mechanisms override statistical patterns effectively.
Figure 2: Generative AI Red-Teaming Framework
STEP 1
STEP 2
STEP 3
Phase 2 - Multi-Turn Adversarial Conversations
The truth is, single-turn prompting just scratches the surface of model weaknesses; so I highly recommend that you use these multi-turn testing approaches:
STEP 1
Design “reasoning path manipulation” sequences where each turn subtly shifts the model’s understanding of the conversation purpose.
Focus on gradually reframing the conversation context, establishing false premises early that lead to problematic conclusions, and remember to create context structures that dilute safety instructions over time.
STEP 2
For each test sequence, document the transition points where model behavior changes. These transition boundaries reveal threshold points in the model’s internal representations—valuable information for both attackers and defenders.
Troubleshooting tip: If multi-turn manipulation isn’t effective, try introducing “context resets” that claim to start new conversations while maintaining the previous context. This can sometimes bypass turn-based defense mechanisms.
Troubleshooting tip: If multi-turn manipulation isn’t effective, try introducing “context resets” that claim to start new conversations while maintaining the previous context. This can sometimes bypass turn-based defense mechanisms.
STEP 3
Implement what I term Deep Learning Social Engineering (DLSE), where perturbations manipulate and change model behavior.
DLSE attacks aim to manipulate the AI’s “perception” of context, instructions, or user intent, causing it to make decisions or produce outputs that are ambiguous or contradictory to the system’s logic. These attacks can expose and exploit weaknesses in the AI’s alignment, filters, or
guardrails, bypassing intended safety mechanisms.
DLSE is characterized as a danger to the AI’s ability to retain integrity in its thinking and output—highlighting the possibility of AI systems being tricked into reaching incorrect or destructive conclusions.
While traditional social engineering targets humans by exploiting psychological biases and trust, DLSE targets AI’s reasoning and interpretative frameworks, using adversarial techniques to manipulate model behavior in subtle, often non-obvious ways that aren’t easily filterable.
A tip to use here would be emotional appeals and appeals to authority. Establish scenarios involving urgent assistance or help, or scenarios that create a sense of extreme urgency that require commands from highranking officials with emergency powers. Create contexts that invoke empathy or urgency (get creative). Frame requests as necessary for user safety or well-being and test how emotional or authority framing affects policy enforcement. This technique is particularly effective for testing how models balance helpfulness against safety constraints.
Phase 3 - Large Context Window Exploitation
For models with large context windows (100K+ tokens), implement these specialized testing methods. This is a needle-in-a-haystack-style attack; only the number of needles and the size are up to you.
STEP 1
Develop “context poisoning” tests where adversarial content is strategically positioned within large documents. Create test documents with policy-violating content embedded deep within otherwise benign text, contradictory instructions placed at different positions in the context, and alternative system prompts hidden within user-provided content.
STEP 2
Test how the model processes these mixed-intent contexts and whether it prioritizes certain context positions over others.
Implement “key-value cache manipulation” tests for models using attention mechanisms. Create prompts that establish specific attention patterns; in doing so, you Introduce adversarial elements at positions likely to receive high attention and that can test whether these elements influence later processing disproportionately.
A common pitfall to avoid is that many testers fill context windows
with random content, missing the importance of strategic positioning. Systematically vary the position of test elements to identify positiondependent vulnerabilities.
A common pitfall to avoid is that many testers fill context windows with random content, missing the importance of strategic positioning. Systematically vary the position of test elements to identify position-dependent vulnerabilities.
Phase 4 - Multimodal Testing Techniques
For models that process multiple modalities (text, images, audio), it’s important to implement these specialized cross-modal tests:
STEP 1
Develop “CrossInject”-style” variants that embed adversarial patterns across modalities to create images containing text elements that provide harmful instructions. By developing prompts that reference visual elements to complete harmful requests, you’re testing the AI for inconsistencies in policy enforcement across different input types.
STEP 2
A practical technique is generating images with embedded text that contradicts or modifies the instructions in the text prompt. Test whether the model prioritizes one modality over another when determining intent. Remember to implement cross-modal consistency checks, keeping notes and documentation of observations.
You can sometimes confuse a model by presenting factually inconsistent information across modalities, testing whether the model flags the inconsistency or defaults to one modality over another.
STEP 3
Evaluate how the model resolves conflicts between different input types. These tests reveal whether safeguards operate consistently across all modalities or have gaps at intersection points.
Phase 5 - Agentic AI Exploitation
For models with agency or tooluse capabilities, implement these targeted tests.
STEP 1
Design “agency hijacking” scenarios that attempt to redirect model actions and imagine contexts that might subtly redefine the purpose of tools. You can develop prompts that establish alternative success criteria for tasks and then test for scenarios where the model might perform unintended actions while believing they align with user intent or are acceptable through the reframed conversation.
STEP 2
Implement “tool-chain exploitation” tests that are designed in sequences where individual tool uses are benign, but their combination can be problematic and sometimes devastating.
STEP 3
Design permission escalations through tool combinations where created scenarios of one tool’s output become another tool’s input with transformation in between.
A practical technique would be to create prompts that request the model to use a search tool to find information, then use the results to craft code with a code generation tool. Test whether harmful intent can
be obscured by splitting it across a toolchain.
A practical technique would be to create prompts that request the model to use a search tool to find information, then use the results to craft code with a code generation tool.
Phase 6 - Epistemic Attack Testing
Model behaviors often rely on their understanding of facts and context. Test these epistemic vulnerabilities. These are by far some of my personal favorites.
STEP 1
Implement “fact confusion” testing. This is where you introduce new data to the model, undermining grounding truth with more “up-todate” false information presented as newly discovered truth or corrections to previously held ideas or understanding.
STEP 2
Present the model with plausible but false statements early in the conversation, reference these statements later as established facts, and then test whether the model accepts these premises or correctly identifies the misinformation. Finding creative ways to spin an input can convince even the most stubborn models.
STEP 3
Design “authority confusion” tests to create contexts with false appeals to authority. Role-playing is a common technique that works well against policies, guidelines, and guardrails. Test whether the model accepts these as legitimate governance structures; these tests evaluate the model’s robustness against manipulation of its knowledge base and contextual understanding.
Role-playing is a common technique that works well against policies, guidelines, and guardrails.
Phase 7 - Result Documentation and Impact Assessment
STEP 1
For each successful adversarial technique, create comprehensive documentation. Develop a “vulnerability fingerprint” that classifies the issue based on:
• The capability or capabilities exploited
• The type of adversarial technique used
• The stability and reproducibility of the exploitation
• The severity of potential outcomes
STEP 2
For each vulnerability, assess potential real-world impact, document the skills and resources required for exploitation, evaluate how the vulnerability might be used in actual attacks and Identify potential harm scenarios and affected stakeholders.
STEP 3
I recommend that you create a standardized vulnerability report template that includes both technical details and potential realworld implications. This helps bridge the gap between technical findings and organizational risk assessment.
Note that defensive measures often create significant user experience friction. Design defenses that target specific vulnerability patterns rather than broad restrictions on model functionality.
Practical Implementation: AI Red Team Workflow
To implement these techniques effectively, establish this standard workflow. Begin with gaining visibility of all AI use, both official AI use and shadow AI usage. Next, capability mapping to identify all model functions. Develop a test matrix that pairs each capability with relevant adversarial techniques, then implement a graduated testing approach. You can start with known techniques to establish baseline protection, then move on to novel variations tailored to the specific model(s) and conclude with combined techniques that test for interaction effects. Data from these engagements are highly valuable. Document both successful and unsuccessful attempts to build a more comprehensive understanding of model robustness. Classify findings by likelihood, severity, reproducibility, and exploitation difficulty.
In some cases, you may be asked by developers about targeted mitigations based on underlying vulnerability patterns if this is in
scope or part of the contract, and if you have suggestions, do your best to help, because, at the end of the day, we’re trying to harden AI systems in an effort to make models more robust, safer, and more secure.
Effective red teaming for generative AI is a continuous process that evolves with model capabilities.
As these systems grow more sophisticated, the techniques required to test them securely must advance accordingly.
By implementing the framework outlined in this guide, security professionals can establish systematic processes for identifying and addressing vulnerabilities specific to generative AI models.
The most important principle to remember is that each new capability introduces potential new attack vectors. By mapping these relationships systematically and developing targeted testing approaches, you can help ensure that generative AI systems deliver their promised benefits while minimizing potential harms.
How I Use AI Tools for Ethical Hacking
Betta Lyon Delsordo
As an ethical hacker, I am constantly investigating how to hack better and faster and get to the fun stuff! No one likes wasting time on mundane or manual tasks, especially in a field like mine where the exciting vulnerabilities are often hidden behind layers of noise. I want to share some of my favorite AI tools that have improved my pentesting. I will cover use cases for AI in penetration testing, the importance of offline AI tools and RAG, along with tips on building your own AI hacking tools.
First and foremost, I love to use generative AI (GenAI) to troubleshoot difficult errors and set up issues for a pentest. Clients often fail to provide precise instructions about the functioning of their applications, but I have successfully utilized GenAI to identify the underlying causes of perplexing errors related to virtual machines, cloud infrastructure, APIs, and other related areas. Instead of wasting time on setup or waiting for the client to get back to you, AI can rapidly provide many possible solutions and adapt instructions to new errors. My advice for using AI to troubleshoot is to share any specific error codes and details about the technology, as well as past research you’ve done (like all the StackOverflow forums you
checked). Then ask for specific steps to take, from easiest to most timeconsuming, and update the AI with new information as you progress. Then, be sure to share anything you discover with your team and the client so that they know to update their documentation for the future. Future pentesters will thank you!
My advice for using AI to troubleshoot is to share any specific error codes and details about the technology, as well as past research you’ve done (like all the StackOverflow forums you checked).
I am also a fan of using GenAI for scripting out manual tasks. Any time I find myself copy-pasting or getting lost in a sea of results, I immediately try to script out that task for the future. Admittedly, I struggle to recall most of the awk and sed syntax, but AI eliminates this need! I just asked for a one-line bash command
to pull x columns from a file with these y headers, with the output looking like this: and instantly have a command to try. Always use nondestructive commands (like writing altered output to a new file) in case the formatting is off, and then just ask for tweaks like a new line after each item. In addition, I often write Python scripts to automate certain tasks I might have to do repeatedly, like copy-pasting information into a report or re-authenticating to an API. I use GenAI to give me a base for the script, and then I build it out from there. I will say that it is still super important to know how to code, but you can save yourself a lot of time by having the AI fill in the easy parts. Given the rate that AI is evolving, the method may change in coming years.
One very cool tool that I like to use is AWS PartyRock, a free, public offering based on Amazon Bedrock. With PartyRock, you can type in a prompt for an app or tool you want, and it will automatically generate a whole set of linked steps for you. Check it out here: https://partyrock. aws/. One example is to make a phishing email generator given certain parameters, and then you can create a link to share with your team. I have also created a quiz for my co-workers on vulnerable code snippets and then had the AI demonstrate how to fix each one. I recently spoke at the WiCyS 2025 Conference, and in my workshop, attendees came up with many awesome PartyRock apps, including a generator for incident response templates, risk modeling calculators, and more. Play with it, but don’t paste anything private into this online tool!
Always use non-destructive commands (like writing altered output to a new file) in case the formatting is off, and then just ask for tweaks like a new line after each item.
Now, it is crucial to talk about data confidentiality when discussing the use of AI in penetration testing. Your client should tell you how generative AI can be used and any worries they have about data privacy. Some scenarios, like a bug bounty, may not require as much care, but any white-box penetration testing with proprietary information will often require that nothing be shared with an online AI platform.
I
have had several clients that are very concerned about IP exposure and can not have anyone pasting their code or security vulnerabilities into ChatGPT. In these cases, it is important to know how to set up private, offline AI systems and to explain to the client that these will not train on their data.
I’ll cover a few ways to set these up next. My favorite way to deploy an offline AI system is through Ollama, a command-line utility where you can chat with your own model right from the command line. You can set up Ollama with an open-source, offline model like Llama3, and then everything you share stays local to your device. I have also experimented with uncensored models (like https://ollama.com/gdisney/mistraluncensored), which will answer more hackingrelated questions but are overall slower and more unreliable. My advice is to just ask for hacking tips ‘as a student,’ and you will get around most content filters. You will need at least 8 GB of RAM to run the smallest models, but I have successfully
installed these in fragile testing VMs. If you have a shared, internal server to test with, you can provide more resources or even GPU power to have a faster experience, and then your team can SSH in to interact. Since Ollama operates on the command line, it is possible to redirect output from other tools like an Nmap scan and then ask questions. There is also an option to run it in Docker, and then you can use it as an API to pass in queries. Learn more here: https://github.com/ollama/ ollama. Setup is a breeze; you can just run curl -fsSL https:// ollama.com/install.sh | sh ollama run llama3.2
[Example of Ollama running on the command line, with differences in a standard vs. uncensored model]
For those of you who would prefer a lovely GUI like ChatGPT, I think you would really like GPT4All. This is a free, open-source tool that allows you to load in AI models just like Ollama, but you get a neat interface and an easy way to add local documents. Learn more here: https://www.nomic.ai/gpt4all. Make sure to pick an offline, open-source model like Llama3 again, and then be sure to say ‘No’ to the analytics and data lake questions on startup. These steps will ensure that no data leaves your device, and it is safe to paste in confidential info. A great feature of GPT4All is the ability to add ‘Local Docs,’ which uses RAG (Retrieval Augmented Generation) to fetch context for the AI from your documents. I like to load in client documentation and past pentest reports and then query the AI about any past findings and tips for what to check in a re-test. If you are short on time and can’t read through tons of documents, this feature is a great way to speed up your work.
[Be sure to say ‘No’ to the analytics and data lake questions on startup for GPT4All]
[Example of GPT4All LocalDocs, using RAG to query a sample pentest report)
Finally, you may have use cases where you want to build your own AI tools for pentesting. I have used LangChain, ChromaDB, Ollama, Gradio, and Docker to create pentesting tools at my current and previous employers, where we had gaps in our methodologies. At Coalfire, I built an AI tool to improve our source
code review process, and I’m currently working on an intelligence fusion tool at OnDefend. If you are interested in going the building route, there are many great tutorials out there; just be sure to use the most recent ones since the technology changes so quickly. It is surprising, but the AI setup is often the easiest part. The most timeconsuming aspects are actually in data quality and prompt tuning, as these can drastically change the effectiveness of your tool. I will also advise starting small with a local prototype, and then you can scale up with GPU power in the cloud if your concept proves useful. For those who are seeking the next frontier of pentesting, check out PentestGPT (https://github.com/GreyDGL/ PentestGPT). This is an experimental tool trained to complete Hack The Box challenges and might soon be ready to assist with the more manual parts of pentesting, like recon. Good luck, and I hope you find more ways to use AI to skip boring tasks and get to hacking.
It is surprising, but the AI setup is often the easiest part. The most time-consuming aspects are actually in data quality and prompt tuning, as these can drastically change the effectiveness of your tool.
Developing MCP Servers for Offensive Work
By Jarrod Coulter
MCP is all the rave now, so this article is designed to show you, step-by-step how to implement Model Context Protocol (MCP) servers in offensive security workflows. You’ll also get a better understanding of what MCP Servers are and why they are catching the AI agent world’s attention.
The following are prerequisites to maximize the knowledge shared in this article:
• Docker installed
• Python 3.12 installed
• OpenAI Account with API credits
• Metaspoiltable 2 is installed on a virtual machine in your network to test
• You are familiar with python development and have a virtual environment setup for use with this article including a .env file with your OpenAI API key added
What is MCP?
Model Context Protocol is a method to expose tooling, resources, and prompts for LLMs to use, developed by Anthropic, maker of Claude AI. Tooling can support any activity you’d like your LLM to perform. From leveraging APIs to gather information (the Weather Service API) to file system interaction, MCP can help you do it all. Resources and prompts are worthy of studying, since you could build a workflow through prompts that any LLM can grab onto and expose resources (think file or log contents) as part of that workflow. However, the focus of this article is specifically on how to implement MCP tooling. For further information on the other MCP capabilities, read up here: https://modelcontextprotocol.io/docs/ concepts/architecture
The idea isn’t new, though; LLMs have had tools for a while now. What makes MCP different? It’s the abstraction of the tooling from the LLM itself that is captivating. In other applications of tooling with LLMs, you must define the tool
within the application itself, and you potentially need to learn multiple methods of writing those tools depending on the agent framework you are using at the time. With MCP, you can develop the tool server once and reuse it across multiple LLM applications simultaneously, all while using a familiar syntax. You still must add the tool and tool calls to your agents, but the tool definition and activity can take place at the MCP server versus being fully contained in your LLM application.
How does this apply to Offensive Security?
Offensive security, in particular penetration testing, generally follows a standard process. The process typically involves gathering intelligence, analyzing vulnerabilities, and carrying out exploitation, among other steps. What if we could alleviate some of the tester’s burden, not only through a certain degree of automation but also by enabling a large language model (LLM) to utilize the information generated from that automation to make decisions and take further actions? This feature has the potential to speed delivery and allow the human pentester to focus on higher-value tasks.
<SIDEBAR> It’s my opinion that domain expertise must still exist in the human tester, especially in cases like penetration testing. AI and LLMs are not deterministic enough, nor consistent in their delivery, due to their design to be relied on to fully perform a penetration test. Therefore, I believe that the need for experts will persist for the foreseeable future. The challenge will be, when the lower-level tasks are handled by the LLM, how will someone new to the field be trained to obtain that expertise? That’s a discussion for another day. <END SIDEBAR>
MCP Server
LLM A LLM B LLM C
Creating the MCP Server
OK, enough background and blah blah! Let’s build some cool stuff. This article will walk through creating a Minimum Viable Product (MVP) MCP server, or MVP MCP! We’ll focus our server on the reconnaissance and password guessing phases of a penetration test and have it gather us as much information about the network as possible and then review the results and make a decision on executing password guessing against authentications service. This is the fun part, enabling LLMs to make a decision, and the tricky part is removing as much of the non-determinism as possible from LLM thought processes. LLMs are great at varying their output when asked the same question over and over. Finally, we’ll have our LLM application give us a couple of directions to pursue in the next phases of our pentest based our initial scanning.
For simplicities sake, we’re going to stick with Nmap for our recon. We’ll implement a basic service enumeration scan to gather as much information about the network in a single sweet. Then, we’ll add a password guessing tool based on BruteSpray by Shane Young/@t1d3nio && Jacob Robles/@shellfail. We’ll be running the MCP server in Docker with Docker running locally. This would simulate having a pentest appliance or VM installed in a customer environment and meet our MVP goals.
Here’s the full file structure we’ll build out:
• recon-server.py – our MCP server tools
• app.py – the client application that will call our AI agent and enable our MCP client
• Dockerfile – the Dockerfile to build our MCP server
• Users.txt – A list of default users to use in password guessing
• Pass.txt – A list of default passwords to use in
password guessing
• .env file – hopefully you’ve already created this, but it houses our OpenAI API Key
Onto building our MCP Server! First, let’s setup the dependencies in your recon-server.py file:
We import asyncio to handle concurrent connections to the MCP server, followed by FastMCP as a quick method to enable MCP, and finally the Python wrapper for the nmap binary, which we’ll install in our Dockerfile later.
Next, we’ll initiate the MCP server with a name. Your reconserver.py file should look like this:
Ok, let’s add some tools! Tools in MCP Python are declared with the “@mcp_tool()” decorator, and in the next line the tool should include a detailed description to assist the LLM with understanding what the tool does. Here’s the complete first tool example that should go directly below the code we’ve already written in recon-server.py:
In the code above, we create the MCP tool, describe the tool, call nmap to run a host discovery scan, and return the results of the scan. You are welcome to use your preferred nmap arguments as part of the scanner. In this scan call, we are performing a service scan on all hosts.
Let’s now finish the rest of our MVP MCP server.
We create our MCP tool to run BrutSpray and give it a single target, the users.txt and pass.txt, to attempt default credentials, and finally we run our MCP server with mcp.run using the transport “stdio.”
<SIDEBAR> MCP servers can run in two transport modes: standard input/output (stdio) and serversent-events (SSE). Studio is perfect for our local implementation and our use of scripts. When you would like to call a remote server or would like to serve multiple clients, SSE is the proper choice.
<END SIDEBAR>
I’ve added the complete versions of this server here: https://github.com/jarrodcoulter/MCPRecon. To successfully run our server, we need to complete a couple of tasks. Firstly, we need to create a Docker image and run it in Docker to host our server. Here is the complete Dockerfile you should add to the same directory as your reconserver.py:
Due to some dependencies from BruteSpray, we have to start our build with an older version of Go and incorporate that into our main Python server. We use a small image in the python:3.12slim Docker image and install the required dependencies and binaries. We copy our recon-server.py to the image, switch into our working directory, and finally run our recon-server.py. Now that we have our Dockerfile created, we can create the image with “docker build -t recon-server .” The command’s “.” means it will look in the local directory for a Dockerfile and build it as “recon-server.” Hopefully you see something similar to this:
Next we’ll look at how our client will call this server locally to run these commands and consume the results.
Building an MCP client
In our same directory let’s make an app.py file that will house our client to execute our recon of a network. We’ll be using OpenAI’s agent framework to create our MCP Client. Again, we’ll start with our imports:
Next we’ll import our OpenAI API Key and check that it exists. Keep in mind that you’ll need a file in the same directory called .env and it should contain your OpenAI API Key in this format: OPENAI_API_KEY=”sk-xxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxx” so that we can call the API from our chat application.
We’ll setup our MCP Client tools for use including asking the user for the target of the pentest:
Next we’ll build our agent. Note that we don’t declare a model as we would normally do. Since we’re using OpenAI’s Agents SDK, it defaults to gpt-4o which is more than adequate for our needs and relatively inexpensive.
Note the detailed AGENT_INSTRUCTIONS. You may need to iterate on these and add explicit instructions to maximize your results. This prompt should get you started though. Now we’ll create a function that will initiate the chat conversation and allow the agent access to the tools we have defined, and finally return the agents output in the form of a markdown report:
Next we’ll create our users.txt and pass.txt. The contents of each should look like: Users.txt msfadmin root admin test guest info adm mysql user administrator oracle And pass.txt abc123 dragon iloveyou letmein monkey password qwerty tequiero test admin msfadmin
Finally, well launch our app! OK, now you should make sure Docker is running and then you can run “python app.py” at your command line or terminal. This may take a minute to spin up the first time. Once the app is ready, you can add the IP address of your Metasploitable instance as the target and hit enter. Your app will scan the target, but it may take a bit since we’re running a service scan first. If you’d like to look at progress, you can review the traces in your OpenAI Dashboard here https://platform.openai. com/traces. This will show each tool call and the output.
Once the app is done, it will display a detailed report in markdown similar to below:
As you can see, the application has access to all the tools we defined earlier. It successfully scans our target, decides to use BruteSpray, and discovers default credentials for the Telnet service. While this process may appear straightforward, it marks the beginning of a significant automation effort. We’ve also enabled the AI to make some decisions on our behalf. From here, it is simple to add additional scan types to further automate our processes and look for more information against the targets. You can add an SMB scan through nmap fairly simply and see if your LLM can decide to scan that, or do we
need to refine our prompt? These are some of the hurdles we have to overcome as we automate our pentest process and leverage MCP in our offensive tooling. Much more to come from the community, I expect. I’m excited for what we can collectively create!
A Tactical Walk-through Using Python and AI Guidance
By Tennisha Virginia Martin
If you’ve recently attended any conferences or expos, you’ve probably noticed that there is a lot of tools and service offerings in defensive security related to Artificial Intelligence (AI), but less so in offensive security. The influence of AI in the last several years, since Large Lange Models became mainstream, has been clear, but research and study into the field known as Offensive AI has been far less fruitful. Offensive AI, which examines the use of Artificial Intelligence and Large Language Models, investigates how ethical hackers can utilize AI to help free up some of the low-level effort involved in the ethical hacking process. One of these areas is privilege escalation.
Privilege escalation is the stage of a cyber-attack in which an attacker acquires higher-level access on a system than first provided, typically from a regular user to root. It is a vital stage in postexploitation that can determine the success or failure of a red team operation.
What’s changing the game now is the incorporation of AI tools such as HackingBuddyGPT by Andreas Happe and Jurgen Cito, which act as intelligent copilots during offensive operations. These tools examine attacker inputs and system outputs to recommend specific next steps, reducing guesswork and assisting novice users in understanding the process.
This article provides a step-by-step example of how Python and AI can be coupled to achieve successful privilege escalation in a Linux system. This article also introduces the rise of AI-powered tools like HackingBuddy.ai, which provide realtime attack guidance and highlights the practical, educational advantages of mixing Python scripting with AI for offensive security.
Privilege escalation is the stage of a cyber-attack in which an attacker acquires higher-level access on a system than first provided, typically from a regular user to root.
The role of Python in privilege escalation
Python has long been the language of choice for penetration testers and red teams, particularly for post-exploitation duties such as privilege escalation. Its versatility and readability make it ideal for quickly creating scripts to automate time-consuming and error-prone processes. Python can effortlessly interact with the Linux file system, execute system commands, parse outputs, and alter permissions--all of which are necessary for identifying avenues to greater privileges. Using modules like os, subprocess, and psutil, attackers can easily enumerate users, services, and running processes. Python scripts, for example, can be used to search for SUID (Set User ID) binaries, locate world-writable files, and detect improper sudo rules that could lead to privilege escalation. Because Python is installed by default in most Linux editions, even limited environments frequently provide sufficient functionality to run lightweight recon or exploitation scripts. Furthermore, Python’s ability to interact with AI APIs or tools like as HackingBuddy.ai allows red teams to improve their decision-making by feeding enumeration findings into intelligent algorithms that recommend future steps. Python is essentially a scalpel and a multitool—precise, versatile, and crucial in the privilege escalation toolkit.
Python is essentially a scalpel and a multitool— precise, versatile, and crucial in the privilege escalation toolkit.
Emergence of AI Offensive Tooling
HackingBuddyGPT
is an open-source AI framework that helps ethical hackers and security researchers identify novel attack routes using large language models (LLMs).
HackingBuddyGPT is an open-source AI framework that helps ethical hackers and security researchers identify novel attack routes using large language models (LLMs). It was designed with simplicity and modularity in mind, allowing users to develop sophisticated AI-driven security agents in under 50 lines of code. The framework includes a set of task-specific agents for operations like Linux privilege escalation, web application testing, and API fuzzing. These
agents can be built and extended to meet unique testing requirements, making them a versatile tool for both red teams and cybersecurity trainees.
HackingBuddyGPT works with a variety of LLMs, including GPT-4 and LLaMA, allowing users to choose the most effective model for their situation. The tool is intended not only for offensive purposes, but also to raise awareness about the rising potential of AI in security testing. It promotes ethical use and explains how AI-generated attack approaches differ from traditional human-developed exploits. The initiative intends to speed up the appropriate use of AI in cybersecurity by providing professionals with intelligent, real-time, and flexible solutions.
HackingBuddyGPT may be connected to OpenAI API Key (ChatGPT) and polls ChatGPT for one-line commands to uncover security flaws, misconfigurations, and potential attack vectors such as weak passwords or inappropriate permissions. HackingBuddyGPT polls ChatGPT for 20 commands (which can be configured) to execute against the Linux command line after receiving the API key and a low-level user’s username and password.
When HackingBuddyGPT finds a one-line command that succeeds, it asks the user to certify that the run was successful in attaining privilege escalation.
Step-by-Step Walkthrough of Python and AI in Action
To begin, you’ll need to do an environment setup which will need a Linux virtual machine with a low-privileged user and Python 3 installed. Make sure you have access to git and a browser before dealing with HackingBuddyGPT or the model interface. This can be done in a virtual box using a home lab or in your preferred cloud provider using VMs. The Kali box should have internet access, whereas the victim box (which I use with the Damn Vulnerable Web App on Ubuntu) should only be available from the Kali attack computer.
STEP 1
Clone and set up HackingBuddyGPT.
Begin by cloning the framework onto your Linux machine:
In the.env file, you will be required to specify your LLM provider (for example, OpenAI or a local LLaMA model). Follow the CLI steps or store your API key as an environment variable. You should make sure you have a low-level user account on the victim PC.
STEP 2
HackingBuddyGPT includes task-specific agents. Regarding Linux privilege escalation:
python run_agent.py --task priv_esc --model=gpt-4
STEP 3
Run the Privilege Escalation Agent.
Each time you poll ChatGPT, it returns 20 one-line commands to execute on the target PC. Each time one of these is successful, the system prompts you with TIMEOUT, and if it succeeds, it alerts you that you have acquired ROOT access and quits the program. Any commands that report TIMEOUT results should be evaluated to determine their success.
STEP 4
Run the Privilege Escalation Agent.
If you believe you have successfully gained root, you can validate by running the command on your victim system to check if it increases privileges.
Check your privileges.
Root should be the current user, as indicated by the hash or pound line at the command line.
Run the Privilege Escalation Agent.
Real-world Ethical Implications
The combination of AI and offensive security capabilities creates both power and risk. Tools like HackingBuddyGPT significantly reduce the barrier to entry for carrying out complicated assaults, allowing persons with modest technical competence to undertake sophisticated privilege escalation with AI direction. This democratization of attacking powers calls into question traditional red team principles, forcing defenders to reconsider their strategy. On the other hand, it allows blue teams to better simulate adversaries, resulting in stronger defenses. The dual-use nature of AI necessitates a new level of accountability: ensuring that these tools are used only in permitted locations and engagements. As AI grows more independent, the distinction between tool and threat blurs, forcing both developers and practitioners to be cautious, transparent, and accountable. HackingBuddyGPT is only one such open source program; there are plenty others that might help you improve your ethical hacking skills.
Recommendations and Best Practices
To responsibly use AI in privilege escalation, begin by maintaining a dedicated lab environment that simulates realworld Linux systems. Experimenting on live or production systems is not recommended unless explicitly authorized. Create a personal Python toolkit with modular scripts for system enumeration, SUID detection, and sudo configuration analysis. This toolkit can be improved by adding HackingBuddyGPT as a decision-support layer, giving it the results of your recon tools and refining its replies over time. Automate common inputs, such as linpeas output or ps aux logs, and organize them for AI consumption. Also, treat AI as a second opinion rather than an infallible oracle, which means carefully validating each idea. Finally, keep a changelog of your AI-guided exploits to track both triumphs and failures. This will help you refine your bespoke playbooks and sharpen your intuition.
The incorporation of AI into red team tactics signals a significant shift in cybersecurity—one that pushes the pace and intelligence of offensive operations beyond established boundaries. Tools such as HackingBuddyGPT blur the distinction between automation and adversarial reasoning, allowing even inexperienced testers to execute advanced tactics with contextual guidance. But with power comes responsibility. Ethical hackers must be more deliberate than ever about how, when, and why they employ these technologies. The future of cybersecurity will not only benefit individuals who understand exploits, but also those who can reason through them alongside intelligent systems. As defenders adapt, attackers will follow, and the only path forward is to remain sharp, ethical, and ahead.
AI Cyber Pandora’s Box
Powered by Dylan Williams & Victoria Robinson
These 30 carefully curated collections of highly valuable, yet free resources serve as your go-to guide for staying ahead in this exciting new world. Dive in… you’re welcome!
Multi-Agentic System Threat Modelling
OWASP
This guide by OWASP builds on the OWASP Agentic AI - Threats and Mitigations. It unpacks the unique risks of multi-agent systems particularly. It covers RPA bots, inter-agent communications, and orchestration platforms. It also provides a structured process for Identifying, assessing, and mitigating attacks.
MCP: Building Your SecOps AI Ecosystem
JACK NAGLIERI
In this article, Jack Naglieri mentioned Model Context Protocol (MCP), an open source standard which makes it easier to connect AI models to different tools and services, the ‘HTTP of AI’. This article gives detailed insight on how to leverage MCP to streamline integrations and reduce workload for analysts by 50%.
Learn How to Build AI Agents & Chatbots with LangGraph
PAVAN BELAGATTI:
LangGraph is an open-source framework that abstracts AI agent development into Nodes, States, and Edges, allowing you to model computation steps, manage context, and define data/control flows without boilerplate code. In this article, Pavan guides you to scaffold a Python project, install LangGraph, configure LLM API keys, and assemble drag-and-drop graphs that wire together LLM calls, error-handling, and external API connectors.
Building an AI Agentic Workflow Engine with Dapr
ROBERTO RODRIGUEZ
This article delivers a hands-on walkthrough for extending Dapr Workflows into a full-featured, agentic orchestration engine, showing how to spin up sidecars, wire in pub/ sub streams, stateful bindings, and service invocations so multiple AI agents (and even human-in-the-loop processes) can collaborate in code-first workflows.
Defending at Machine-Speed: Accelerated Threat Hunting with Open Weight LLM Models
RYAN FETTERMAN
In this article, Ryan Fetterman argues that embedding open-weight LLMs directly into Splunk via DSDL 5.2, empowers SOCs to parse massive log streams, flag anomalies, and launch investigations in milliseconds, shifting from manual triage to proactive. He demonstrates how to deploy inference clusters behind the corporate firewall to maintain data privacy, then pinpoints high-value use cases.
MITRE ATT&CK Threat Classification With AI
CHARLES CHIBUEZE
An LLM powered MITRE ATT&CK classifier. Security teams sometimes struggle to quickly map alerts to the correct MITRE ATT&CK tactic and technique. This slows down triage, investigation, response and causes a delay in determining which kill-chain phase the activity belongs to. The tool takes in the title and description of threat detection alerts and produces the corresponding MITRE Tactic and technique.
BoxPwnr is a research-oriented framework that orchestrates Large Language Models inside containerized Kali environments to attack and solve HackTheBox machines with minimal human intervention. It tracks every command and model interaction, providing granular metrics on success rates, token usage, and execution time.
Blueprint for AI Agents in Cybersecurity
In this article, Filip Stojkovski and Dylan Williams introduced Agentic Process Automation (APA), a paradigm where AI agents autonomously interpret incident response tasks, make real-time decisions, and continuously adapt security workflows based on live telemetry and contextual data. The article also details how to map traditional SOC playbooks into discrete agent roles while orchestrating inter-agent communications, enforcing sandboxed execution, etc.
Security Operations with RunReveal’s MCP Server
EVAN JOHNSON AND RUNREVEAL
GuardDuty alert investigation in under a minute? RunReveal’s AI-powered analysis dissects container anomalies, correlates user behavior, and delivers analystgrade reports. Early adopters report that tasks which once took hours now return structured CSV to-do lists and full analyst-style reports in under a minute.
FILIP STOJKOVSKI AND DYLAN WILLIAMS
Perplexity for the Darkweb - Using LLMs to explore the darkweb
Thomas Roccia extends Perplexity, a search engine powered by LLMs that synthesizes web results into concise answers, to the darkweb, enabling transparent, Tor-backed queries across .onion sites via Ahmia and curated URL lists..
For CISO’s & CIO’s-How to Co-Chair an AI Governance Committee- How to Create one effectively with the right Goals & Responsibilities
MORIAH HARA
Many enterprises have an AI Governance committee, but whether it is effective is another story altogether. This article will ensure you have the right people in place with the right objectives.
CHRISTOPHER FOSTER, ABHISHEK GULATI, MARK HARMAN, INNA HARPER, KE MAO, JILLIAN RITCHEY, HERVÉ ROBERT, SHUBHO SENGUPTA
What if your tests write themselves? Meta’s
(Automated Code Hopper) platform uses LLMs to generate realistic mutants, deliberately buggy code snippets, and then crafts targeted test cases guaranteed to “kill” those mutants. Foster, Gulati, Harman, Harper, Mao, Ritchey, Robert, and Sengupta show how this approach transforms vague compliance checklists into concrete, machineverifiable guarantees.
Better RCAs with multi-agent AI Architecture
BAHA AZARMI AND JEFF VESTAL
In this post, Azarmi and Vestal unveil Elastic’s “SuperAgent” framework, it is an architecture that spins up specialized AI agents to collect logs, reconstruct causal chains, and surface the true origin of outages. This article provides details on how to partition tasks, orchestrate inter-agent dialogues, and visualize a concise timeline that pinpoints misconfigurations or code regressions, without manual log spelunking
Super-powered Application Discovery and Security Testing with Agentic AI - Part 1
BRAD GEESAMAN
This article introduces Ghostbank, a fictional banking app with a Broken Object Level Authorization (BOLA) flaw, and contrasts manual workflows for discovering and validating a logic bug in a live web application against the promise of agentic AI. It walks through the BOLA transfer endpoint’s missing parameter validation and highlights how recon, targeting, and exploit validation at realistic scale create overwhelming cognitive load for human testers.
THOMAS ROCCIA
Super-powered Application Discovery and Security Testing with Agentic AI - Part 2
BRAD GEESAMAN
Building on Part 1, this post defines the core capabilities an AI agent framework needs, enumeration, request capture, fuzzing, and stateful memory, and introduces ReaperBot, which leverages the Pydantic-AI toolkit and OpenAI models to orchestrate those tools automatically.
Super-powered Application Discovery and Security Testing with Agentic AI - Part 3
BRAD GEESAMAN
This final installment shares best practices learned during ReaperBot’s development, agent persona design, orchestrator vs. worker model selection, structured outputs, and prompt-engineering techniques, to improve reliability, cost efficiency, and hand-off quality in production AI powered workflows.
Can AI Actually Find Real Security Bugs? Testing the New Wave of AI Reasoning Model
MARCIN NIEMIEC
Can LLMs outclass your favorite SAST tool? Marcin Niemiec pits OpenAI, Google’s Gemini, and DeepSeek reasoning models against real-world codebases to
hunt for XSS, insecure file reads, and more. It provides side-by-side comparisons on which model flags subtle SQL injections, which one misses OWASP Top 10 flaws, and how “reasoning” models stack up against patternbased scanners.
AI-Powered Vulnerability Impact Analyzer
ALEX DEVASSY
Alex Devassy’s open-source tool marries LLM reasoning with CVSS metrics to produce nuanced impact reports. Feed it a CVE description, your environment’s architecture diagram, and it returns a prioritized remediation roadmap complete with risk thresholds, patch roll-out plans, and confidence scores.
Rule-ATT&CK
Mapper (RAM):
Mapping SIEM Rules to TTPs Using LLMs
PRASANNA N. WUDALI, MOSHE KRAVCHIK
Looking for a faster, smarter way to link your SIEM rules with the MITRE ATT&CK framework? Take a look at RuleATT&CK Mapper (RAM). It is a multi-stage, prompt-chaining LLM pipeline that automates the mapping of structured SIEM detection rules to MITRE ATT&CK techniques, eliminating the need for manual labeling or costly model fine-tuning.
AI Agentic Cybersecurity Tools: Reaper, TARS, Fabric Agent Action, and Floki
Omar Santos provides an overview of four opensource AI-driven cybersecurity tools: Reaper, TARS, Fabric Agent Action, and Floki. The article provides insight on the capabilities of each of these tools as well as its contributions to autonomous security workflows.
Considering the security implications of Computer-Using Agents (like OpenAI Operator)
JACQUES LOUW
Computer-Using Agents(CUAs) are AI-powered systems that interact with computers and software applications like a human user. In this article, Jacques Louw throws more light on the potential security risks associated with Computer-Using Agents(CUAs) including the implications for identity security and access controls.
AI Red Teaming Playground Labs
Microsoft’s AI red team have open sourced their AI red team labs so you can set up your own. How cool
Microsoft’s AI red team have open sourced their AI red team labs so you can set up your own. How cool is that! This playground labs to run your AI red teaming training comes bundled with infrastructure.
Scaling Threat Modeling with AI: Generating 1000 Threat Models Using Gemini 2.0 and AI Security Analyzer
Can you automate threat modeling at scale? This blog post details utilizing Google’s Gemini 2.0 “Flash Thinking” model in a multi-prompt agent to produce focused STRIDE threat models, formatted as clean Markdown lists for instant clarity. Marcin wires this into a GitHub Actions pipeline that spun out 1,000 threat models across diverse open-source projects. This shows that with human curation, AI can dramatically accelerate comprehensive security documentation.
Practical Use Cases for LLMs in cybersecurity
DAN LUSSIER
What can LLMs really do for defenders? This article provides insight into three live projects, automating threat intel summarization, dynamic detection rule generation, and simulated phishing campaigns. Dan Lussier shows how each leverages an LLM’s unique strengths.
MARCIN NIEMIEC
State of Agentic AI Red Teaming
This whitepaper explores how AI red teaming must evolve to address the emerging risks of agentic AI systems – complex workflows powered by LLMs, tools, APIs, and autonomous agents. Built on realworld insights from automated red teaming across enterprise applications, the paper provides a practical guide for security leaders, AI engineers, and compliance teams aiming to secure next-generation AI deployments. Learn how to adapt testing strategies, model new risks, and bring transparency to complex AI workflows.
Matching AI Strengths to Blue Team Needs
Not all models fit every use case. In this article, David Bianco walks through the key attributes of major LLMs, context window size, reasoning vs. pattern matching, fine-tune capabilities, and maps them to blue-team workflows like log enrichment, alert triage, and SOC playbook generation. A must-read decision matrix for tool selectors.
The Evolved SOC Analyst
This article details the transformation of Security Operation Centres(SOCs) through AI augmentation.
Jack Naglieri discussed how AI agents assist SOC analysts by learning investigative processes, and enhance SOC efficiency. It’s a detailed shift from traditional alert triage to an AI-supported workflow.
Incorporating AI Agents into SOC workflows
This article explains how Red Canary’s AI agents automate tedious work like correlating IP reputations, login histories, and device telemetry, so analysts spend under 3 minutes per investigation, not 25–40, all while maintaining a 99.6 % accuracy rate. Jimmy outlines a “guardrails-first” rollout, proving that non-autonomous agents can boost efficiency without sacrificing reliability.
Large Language Models for Malware Analysis
Can an LLM really dissect assembly like a seasoned analyst? This article talks about “asmLLMs”, and show they produce richer embeddings for classification and generative tasks than general-purpose LLMs Their asmLLMs achieve up to 35.72 Rouge-L and 13.65 BLEU on the OSS-ASM dataset, outperforming GPT-4 and GPT-3.5 in code repair and summarization.
SPIXAI
DAVID BIANCO
JIMMY ASTLE
FLORIN BRAD, IOANA PINTILIE, MARIUS DRAGOI, DRAGOS TANTARU: