FIGURE 4.0 | Photo 51, showing the x-ray diffraction pattern that was used to determine the structure of DNA.

CHAPTER 4

FIGURE 4.0 | Photo 51, showing the x-ray diffraction pattern that was used to determine the structure of DNA.
CHAPTER 4
Here are a few essential terms used in genetics. By the end of this chapter, you should be able to apply these concepts and understand how they relate to each other.
Alleles
Amino Acid
Cell
Central Dogma of Molecular Biology
Chromosome
DNA
Genes
Genetic Code
Genome
messenger RNA (mRNA)
Mutations
Nucleic Acids
Nitrogenous Bases (bases)
Nucleotides
Proteins
RNA
Transcription
Translation
The field of genetics studies the inherited traits, genes, and genetic variations that create the diversity of life. Over the past 200 years, many scientists have contributed to the understanding of the basis of genetics. Core discoveries include the identification of proteins, DNA, and RNA. Then came the demonstrations showing that DNA and RNA are responsible for passing traits between generations, and proteins are responsible for the physical expression of genetically-encoded traits. In the present day, genome sequencing has transformed our understanding of the varying lifeforms on earth.
The genome is like an instructional manual for life. An organism’s genome is written in a universal genetic code, which can be documented in one of the two types of nucleic acids: DNA or RNA. A genome is a long string of nucleic acids, called nucleotides, and DNA and RNA each have four distinct forms of nucleotides that can encode information, much like a 4-letter alphabet. The genome is organized into genes, which can be thought of as the different chapters of the instruction manual. Each gene dictates how a different protein is to be constructed. The genome has many other elements that contribute to its organization and utility.
The chemical and structural qualities of nucleic acids underlie how traits are encoded and passed on between the generations. The basic building blocks of nucleic acids are nucleotides. These are made of three main components: a sugar, a phosphate group, and a nitrogenous base. The sugar and phosphate make up the backbone of nucleic acids. DNA and RNA each have four different types of bases, and these determine each nucleotide’s identity, allowing sequences to encode information along the genome. Bases also form bonds in a very specific way, allowing for DNA’s double-stranded nature, also known as the double helix, which holds the key to inheritance.
Our genome’s primary role is to copy its own genetic information to pass on and direct the production of proteins. DNA copies itself through a process called replication; this replication is the basis of inheritance. DNA can also make disposable copies of itself called mRNA through transcription. These mRNA copies then undergo translation, through which they direct the synthesis of proteins. Protein synthesis involves the process of protein
production. The structure of a protein and the amount in which it is produced influence the functions it can carry out.
Mutations can affect protein structure and function and can help trace the history of specific individuals and species. Mutations are changes in the genome and can occur through replication errors. Mutations can affect the organism’s protein synthesis and, therefore, traits. These differences can become important for pathogens when they impact characteristics like transmissibility or drug resistance. Some mutations can have no effect, but these can still be useful to identify and study specific strains of pathogens.
A pathogen’s genome underlies its biology. In outbreak science, information about a pathogen’s genome or its mutations can help design and develop responsive initiatives, including diagnostic tests, vaccines, therapeutics, and other surveillance countermeasures. Therefore, understanding the basis of genetics and inheritance and detecting how pathogens change over time is central to outbreak science.


By the end of this chapter, you will have a basic understanding of the principles of genetics and their application in outbreak science. You will learn about the central dogma of molecular biology and the different processes involved in transmitting genetic information to the next generation, as well as producing the physical traits instructed by the genome. Finally, you will learn about the application of genomic analysis in the development of diagnostics, therapeutics, vaccines, and surveillance tools.
It’s the year 1951, and you’ve just returned to your home country of England after a 4-year stint in France. At the State Chemical Laboratory in Paris, you’ve honed your skills in X-ray crystallography, a technique that is used to determine the structure of molecules too small for even the most robust microscope to see. Visualization using X-ray crystallography begins by shining x-rays at the molecule of interest and noting how the x-rays bounce off (diffract). With training, scientists can infer information about the molecule’s structure from the resulting patterns and angles.
Although you’ve faced your share of adversity in this field as a Jewish woman in a maledominated field, you soon gain a position at King’s College, working with biophysicist Maurice Wilkin, where you work to determine the structure of the DNA molecule. Since 1944, when DNA was discovered to be the medium by which genetic information is passed from generation to generation, the race to discover its structure has accelerated. You know there are other scientists working
towards this goal, but your talent and training in X-ray crystallography may help you uncover what this elusive molecule looks like and, by extension, how it can hold so much information. Unfortunately, you and Wilkin quickly clash, and your opposing personalities cause you to work in near-solitude for most of your time at King’s College with the support of just one graduate student, Raymond Gosling.
One afternoon, as you work with Raymond, you capture your clearest image. You title it
“All living things need their instruction manual (even nonliving things like viruses) and that is all they need, carried in one very small suitcase.”
—L.L. Larison Cudmore, American cell biologist
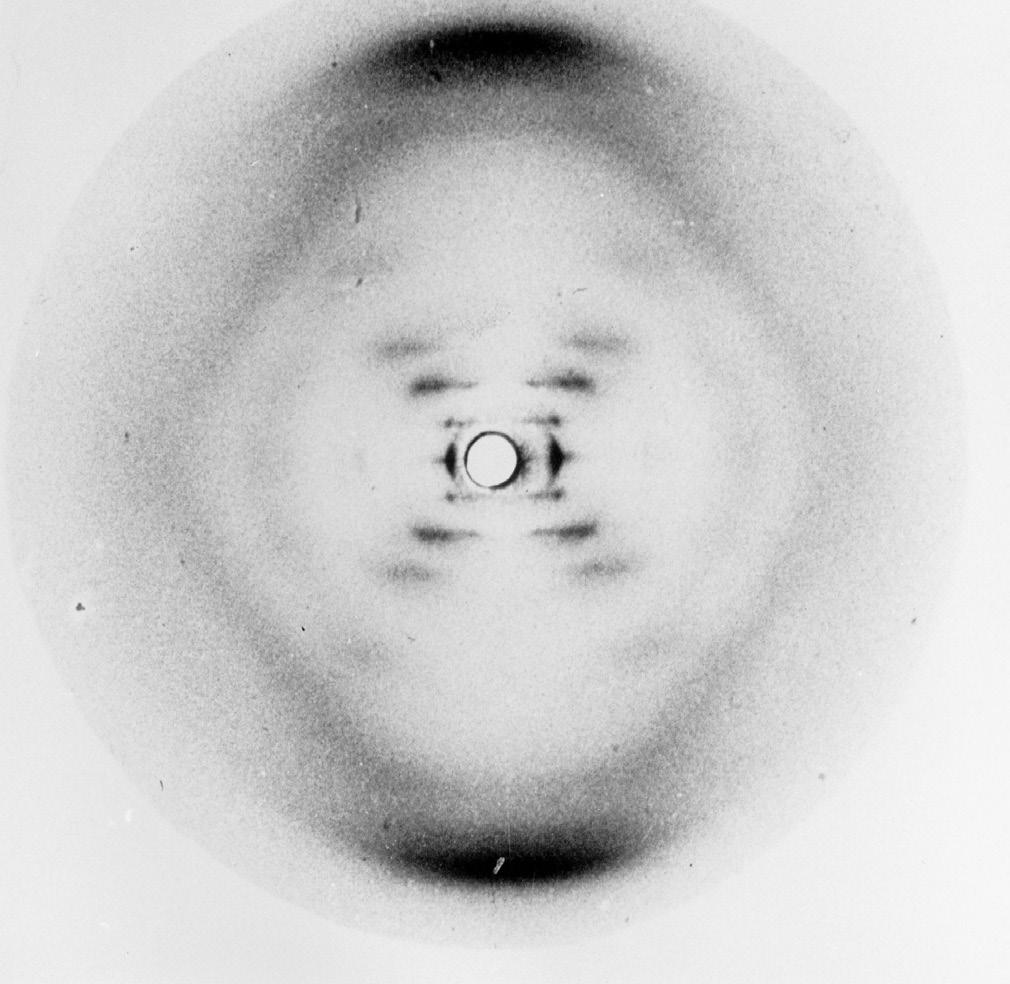
4.1 | Photo 51 of DNA. This x-ray crystallography photograph taken by Rosalind Franklin and Raymon Gosling shows the structure of what we now know to be the DNA double-helix. Known as Photo 51, it was the first-ever photograph of DNA.
“Photograph 51” – your 51st attempt at such an image – and realize that it has provided critical information for DNA structure (Figure 4.1). You use the diffraction pattern to confirm that the molecule appears in the now-famous double helix structure of DNA. As you detail in your notes, “an infinite variety of nucleotide sequences would be possible to explain the biological specificity of DNA,” you’re eager to show the world how structure and function finally intersect.
While drafting what you already sense will be a landmark research paper within your field, you visit the lab of fellow DNA researchers James Watson and Francis Crick. There, you hear startling news: you’ve been ‘scooped’. Watson and Crick have discovered the structure of DNA as well, complete with a physical model with far more details than you’ve currently collected, and they’re set to publish their findings ahead of you. Their work is quickly acknowledged and praised within the scientific community, while your landmark contributions go largely unrecognized.
Sadly, just 4 years later, you die of cancer at the age of 37 – perhaps partially as a result of the X-ray radiation central to your work. You never learn that Watson and Crick were secretly shown your pre-publication photo by Maurice Wilkin, providing them key information for their double helix model. Watson, Crick, and Wilkins went on to receive the Nobel Prize for “their discovery of the molecular structure of DNA” in 1962. Eventually, but far too late, the scientific community credits your work as a central clue to their discovery.
By providing crucial evidence to the structure of DNA, you’ve shed light on its function, as the structure dictates how it is passed between generations and can encode such a vast amount of information. Your work is fundamental to an entire field of study known as genetics. You’re Rosalind Franklin (Figure 4.2), a British chemist, and you’ve significantly contributed to the discovery of one of the most heavily-sought secrets to life.

4.2 | Rosalind Franklin with a microscope in 1955. Rosalind Franklin was historically undercredited for her discovery of the DNA structure, which allowed for a breakthrough in genetics.
For thousands of years, we have understood that traits, which are genetically encoded characteristics, such as eye color or height, are passed between generations; children often look like their parents, and plants and animals can be bred to show specific traits. But the molecular basis for these phenomena was only uncovered in the past 200 years, guided by the work of many different scientists who investigated both the rules for how traits are inherited and the material that contains information on traits. The scientists, whom we will soon introduce, developed the field of genetics, which is the study of the inherited traits, genes, and genetic variations that define organisms. The word “genetics” comes from the Greek genetikos, derived from the word genesis, meaning “origin”; true to its name, this field generated many revolutionary concepts that continue to shape our scientific studies to this day.
The field of genetics’ key discoveries began in 1838 with chemists Gerardus Johannes Mulder and Jöns Jacob Berzelius, who are credited with the formal discovery of proteins, the main functional molecules of the cell. After analyzing several biological substances and identifying common chemical structures between them, these scientists recognized the fundamental importance of these biological molecules and named them after the Greek word prōteios, meaning “holding first place.”
In 1869, Johann Friedrich Miescher made another landmark finding while running extensive experiments on white blood cells. After treating the cells with several different chemical solutions, he extracted a “white substance” that he called
nuclein from the nucleus, the compartment of the cell that encapsulates the genetic information of the cell. Based on its protected location within the cell, as well as its presence in all the biological samples he studied, Miescher suspected that nuclein held crucial information regarding the control of the cell. In 1881, Albrecht Kossel determined several key details about its chemical composition and formally defined it as nucleic acid, a specific class of biological molecules. The two fundamental forms are now known as deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). He understood that they contained nitrogen bases, discovering them as adenine, cytosine, guanine, thymine, and uracil.
Around the same time, the Augustinian friar Gregor Mendel was quietly unraveling the principles of inheritance, which would ultimately hold the key to understanding the function of genetic material. Often lauded as the “father of genetics,” Mendel extensively researched how certain properties were seemingly passed from parent to offspring. He cultivated a large collection of pea plants over many generations and examined how observable traits, like plant color and height, were transmitted from one generation to the next. The different versions of these observable traits, such as tall pea plants and short pea plants, are known as phenotypes
By collecting data from over 28,000 plants, Mendel began to understand the logic of how different phenotypes were determined. He posited that genetic variants or encoded “versions” of traits, called alleles, can be passed down over generations and give rise to these different phenotypes. In studying organisms that have two parents, Mendel also determined how the two alleles from each parent can together create a genotype, the alleles an




FIGURE 4.3 | Mendel studied different physical characteristics in pea plants and discovered that genes come in different versions or alleles. In the mid-1800s Mendel performed experiments with pea plants. At the time, it was believed that observable characteristics were the result of blending parental characteristics. The blending model predicted that when crossing a tall plant with a short plant the next generations of plants would all result in medium plants. Surprisingly, Mendel observed that the crossing of a tall plant with a short plant resulted in only tall plants. Later he understood that there are different genetic variants for one observable characteristic.
individual carries for a particular gene. Mendel also observed that alleles for different traits were transmitted “independently,” meaning that the pea’s height did not seem to affect its color (Figure 4.3). This left Mendel to question the physical basis of a genotype; what exactly was allowing these plants to “possess” and eventually pass down their traits?
Researchers were still unsure how exactly DNA was passed from parent generation to offspring. As you may remember from the introduction, Rosalind Franklin, with other credited players Maurice Wilkins, James Watson, and Francis Crick, established the now-famous double-helix
model of DNA in 1953. The model defined the DNA structure giving incredible insight into the molecule’s many functions (Figure 4.4). We will study the structure of DNA in detail in section 4.3.
As Watson and Crick noted in the final line of their widely-read paper, “it has not escaped our notice that the specific pairing we have postulated immediately suggests a possible copying mechanism for the genetic material.” In 1956, Arthur Kornberg and his team analyzed this mechanism and discovered the enzyme known as DNA polymerase, which is responsible for copying DNA for future generations of cells. These core discoveries continue to inform much of the research and advancement in the fields of genetics and genomics today.
As scientists continued to investigate the biological underpinnings for traits and inheritance, they learned that in order to fully

4.4 | James Watson and Francis Crick with their
(left) and Crick (right) and Wilkins (not in photograph) received the Nobel Prize in Physiology or Medicine in 1962 for their contribution to the discovery of the DNA structure. Rosalind Franklin had by then passed away and was therefore ineligible for the award.
comprehend the link between DNA, RNA, and proteins and eventually understand their relationship, it wasn’t enough just to isolate DNA and RNA from an organism’s cells. They needed to know the exact sequence of DNA and RNA molecules to understand better how they encode specific proteins and how different sequences lead to different phenotypes. In the following years, technologies arose that made these goals a reality.
One of the field’s landmark discoveries was the development of sequencing, the laboratory technique used for reading specific genetic sequences or complete genomes. Initially developed by Frederick Sanger and his team in 1977, the process has since grown to allow



scientists to determine the exact composition and ordering of virtually any DNA or RNA molecule of interest. A few years later, in 1983, a process known as Polymerase Chain Reaction (PCR) was created, which revolutionized what scientists could do with just a few DNA molecules. As we’ll further discuss in Chapter 7: Diagnostic Tests, PCR allows researchers to make multiple copies of DNA in the lab, paving the way for the identification of pathogens, analysis of genetic sequences, and other applications.
Technological breakthroughs and tremendous efforts by scientists since then led to the rise of genome sequencing, the process of determining the entire DNA or RNA sequence of an organism’s genome. These techniques have revealed the complete genome sequences of many organisms of increasing complexity (Figure 4.5). From Sanger’s first completed genome












FIGURE 4.5 | Timeline of completed genome sequences. Beginning with the phage phi X174 in 1977, genomic sequencing gave incredible insight into the composition of many organisms. Notice the increased organismal complexity and genome size over time.
sequence in 1977, taken from the extremely small phi X174 virus, to many common pathogens such as Haemophilus influenzae, E. coli, and the influenza viruses, this data began to advance our understanding of infectious agents and inform response initiatives all over the world.
These techniques were further refined until they could handle increasingly vast genomes. Efforts to sequence the human genome culminated in 2003 with the completion of the Human Genome Project (HGP). Today, we have the unprecedented ability to use genetics to learn more about the differences between species, and even the differences between individuals within the same species.
Within the field of infectious disease, genetics has further enabled researchers to identify,

track, and predict the movement of pathogens in ways that were practically unthinkable just a generation ago. With new tools such as genetic engineering, which can be used to recognize and alter specific DNA sequences, modern scientists continue to find new and exciting ways to use genomic technologies to develop outbreak response strategies.
Throughout this textbook, we’ll dive much deeper into many ways that genome sequencing and genetic analysis have revolutionized outbreak science. In the rest of this chapter, we will share an overview of genetic inheritance, the central dogma of molecular biology, and other fundamentals of genetics that will help you understand the field’s applications to outbreak science.
1. What are traits?
2. Describe three historical discoveries in the field of genetics that are major breakthroughs.
3. What is sequencing and what kind of applications does it have?
The field of genetics is both immense and intricate, and scientists continue to learn more about genes, their composition, and their function each day. To wrap our heads around this enormous topic, it might help to first consider an analogy, comparing genetics to an instruction manual. These concepts can be confusing at first sight, but we’ll revisit them throughout the chapter with their relevant applications to help you develop a firm grasp on the subject.
Just like an instruction manual is central to helping you put together a complex object or system, an individual’s genetic information is vital to building something as complex and multifaceted as a complete organism. As an example, we’ll use the analogy of a whole home’s worth of furniture and appliances that you bought from GeneKEA.
Let’s start by talking about how the genome or the cellular instruction manual is organized.
The genome is all of an organism’s genetic information and can be thought of as a complete instruction manual that contains all the information you will need to assemble every single element in your new house. Genomes are made up of nucleic acids, encoding the different sets of instructions to build an organism or virus.
Most genomes are packed in one or more chromosomes. These are discrete strings of genetic information that are akin to different volumes in the instruction manual. Viruses’ genomes are similarly made up of one or more segments
A gene is a defined genetic sequence found in the genome that encodes a functional
product, mainly a protein, and can be thought of as a chapter with a set of steps given in the instruction manual, dividing the instructions to tell you how to build each desk, chair, lamp, etc.
Now that we understand the organization let’s see how you would use the information it contains.
Nucleotides are the building blocks of DNA and RNA and are made up of three chemical components. One of these components is a nitrogenous base, which we’ll refer to as a base from now on. Bases each take one of four different forms, and the specific type of base within a nucleotide confers its identity. Bases are like letters in the alphabet that are used to spell all of the information you need to read out of the instruction manual. Just as the English alphabet consists of 26 letters, DNA and RNA each use 4 different letters – aka different bases – that spell out simple words that instruct the cell on what to build and how to build it.
A codon is a three-base long unit of a gene that codes for a specific amino acid and can be thought of as the three-letter names of the components of furniture, such as the “l-e-g” of a table.
Amino acids are highly specialized molecules within the cell, functioning as the basic units of any “object” our cells need to build. We could compare these to the components or the the physical pieces that you will use to build your given piece of furniture, like the actual leg of the dining room table or the nuts, bolts, and any other unique pieces used to build it. Finally, proteins are the cellular functional elements that perform actions and make up our traits, and they are made up of amino acids. Proteins can build the structures of cells, like their cell membrane, or can
perform functions, like breaking down the food you eat. These can be thought of as the completed dining table, dishwasher, or other furniture and appliances you successfully assembled, each with its own specific purpose to fulfill in your house.
For most organisms, the genome is housed in the nucleus, a membrane-bound organelle, where the DNA is tightly packed. You can compare this to the master copy of the instruction manual that you keep in a locked safe in your house. And let’s say you aim to decorate other houses in the exact same way; then you’d need to make and transport copies to each new home.
Replication is the duplication of genetic material and can be thought of as producing a new bound copy of the complete instructional manual exactly how it’s written, with the same organization, i.e., separating the instructions by chromosome (volume) and gene (chapter). Replication makes more bound copies of the instruction manual that will be placed in locked safes within new homes.
Transcription is also the duplication of genetic material, but only small sections at a time; these special copies are known as messenger RNA (mRNA), which is a relatively less-stable molecule compared to the original DNA. Transcription can be thought of as reading aloud the relevant sections of the instruction manual to your friend who is working on assembling specific pieces of furniture: the information from the instruction manual stays the same but is transmitted in a way that makes the assembly process easier.
A promoter is an element at the beginning of a gene that tells the transcription
machinery where to start. It can be thought of as a bookmark on the page where you would need to start reading to your friend, for example, at the beginning of the section that pertains to the office.
Translation is the process of reading the organism’s genetic material from the mRNA copy and assembling the required amino acids into the proteins that fulfill the cell’s needs. It is also one of the final steps of what we refer to as protein synthesis. In short, it is the process of assembling the furniture and appliances, collecting all the pieces the manual has told you that you’ll need, and putting them together.
All of these concepts fit together to support many of life’s most important and universal processes. Let’s break down how these ideas relate to each other to carry out essential tasks.
Let’s first take a quick look at one of the more compact instruction manuals, the Ebola virus’s genome. According to our GeneKEA analogy, we might say that the Ebola virus’s instruction manual is made up of a single volume, with seven chapters and just 19,000 characters –meaning that it has a single segment, seven genes, and 19,000 bases. The seven genes are labeled “NP,” “VP35,” “VP40,” “GP/SGP,” “VP30,” “VP24,” and “L,” and code for Ebola’s essential proteins (Figure 4.6). For example, the GP (glycoprotein) is a receptor on the virus’s surface that binds human cells, allowing it to enter and infect them. You may have noticed the regions between genes in the figure below that do not code for proteins; these are intuitively referred to as non-coding regions. These non-coding regions contain promoters and other elements involved in regulating protein production, as well as other important functions that scientists are still investigating.





















FIGURE 4.6 | Ebola virus and its genome. The genome of the Ebola Virus contains seven different genes, all on one segment with a length of 19,000 bases. It is a single-stranded RNA genome wrapped around viral proteins.
1. How do proteins relate to the genome, our “instruction manual”?
2. Based on what you learned in the instructional manual analogy, how many letters are there in the genetic alphabet (DNA/RNA)?
Millions of species, ranging from animals and plants to microscopic creatures, experience life here on Earth. These life forms share many similarities, including the cells that make them up. The cell is the most basic structural and functional unit of life. While certain organisms are made up of just one cell, like bacteria, others, like animals, plants, and even some pathogens, are multicellular, composed of millions, even trillions, of cells that can orchestrate highly specialized functions. Viruses are special exceptions to this. As we will talk about more in Chapter 5: Biology of Infectious Agents, viruses are often not even considered “living” by many since they require a host’s machinery to survive and are not made up of cells. However, they do have a basic unit, which is called a virion, and just like cells, viruses also contain a genome.
Earth’s many species are incredibly diverse, with extraordinary capabilities and unique biological advantages. For instance, hippopotami have the unique skill of secreting their own sunscreen (that also doubles as an antibiotic) to protect themselves from the sun’s rays. Wood frogs freeze up to 60% of their own bodies to survive Alaskan winters. Bacteria like Thermus thermophilus can not only survive but thrive at temperatures reaching 149°F, a climate that would spell certain death for organisms like us.
But what enables this grand diversity, and how can different organisms accomplish so many different functions? As discussed earlier, the answer to this question lies in their “instruction manuals”: their genomes, which contain the genes that allow living creatures to be so different while conserving their abilities to carry out the
tasks necessary for life. Since genomes are so fundamental to life, it is important we understand how they work in greater detail.
An organism’s genome is written in a universal genetic code, documented in the form of the two nucleic acids, DNA or RNA. These basic building blocks of nucleic acids are known as nucleotides which are chemical compounds with three main components: a sugar, a phosphate group, and a nitrogenous base (Figure 4.7).
The sugar and phosphate group together make up the backbone of a DNA or RNA molecule, allowing nucleotides to string together in a long genome. DNA has a deoxyribose sugar while RNA has a ribose sugar: DNA’s ribose group is missing an oxygen atom; hence ‘deoxy’ means without oxygen. The phosphate group is made up of a small, negatively-charged group of atoms that makes the molecule acidic, giving nucleic acids their name.
Bases are the one part of the nucleic acids that vary from nucleotide to nucleotide, giving each nucleotide position in the genome its specific identity and thus holding the key to decoding the genome. As described before, there are four bases in the alphabet of each DNA and RNA, and thus 4 letters of the alphabet of the genome. For DNA, the bases are adenine (A), cytosine (C), guanine (G), and thymine (T) (Figure 4.7). For RNA, they are A, C, G, and uracil (U) instead of T. Due to their importance, we often refer to individual nucleotides simply as ‘bases’ in reference to the specific nitrogenous base it possesses. We measure nucleotide sequences by base, with a 1000-nucleotide sequence being a kilobase (kb) long, a million-nucleotide sequence a megabase (Mb), and a billion being a gigabase (Gb).
DNA is a polymer made up of units called nucleotides. The nucleotides are made of three di erent components: a sugar group, a phosphate group, and a base. There are four di erent bases: adenine, thymine, guanine and cytosine.



FIGURE 4.7 | The sugar-phosphate ‘backbone’ and the bases make up the chemical structure of DNA. Nucleotides are the basic units of DNA. They are made of three main components: a sugar, a phosphate group, and a base. The sugar group and the phosphate group bind together and make the ‘backbone’ of the molecule of DNA. Adenine, Thymine, Guanine, and Cytosine are the bases found on the molecule of DNA. These bases pair together, forming hydrogen bonds holding the two DNA strands that result in the double helix.
Just like our alphabet allows us to create many different words, different combinations of the 4 bases can create an enormous variety of sequences. These can lead to an amazing assortment of proteins and other elements each with their own distinct cellular functions. Let’s pause and consider just how vast this diversity of nucleotide sequences truly is.
Imagine that you have a sequence that has five nucleotide positions along its length. Since you only have four bases to choose from at each position, you may expect there to only be a few
possible combinations for this short sequence. However, the combinations actually increase exponentially with each additional nucleotide position. If you have n positions, you would have 4 n possible combinations. In this case, that would create 45 = 1024 different possibilities for just this short sequence.
Even for creatures with extraordinarily small genomes, the possible combinations of nucleotides that make them up are incomprehensibly large. Take for example, one of the first genomes ever sequenced: phi X174, a
virus with an extremely small genome at 5,000 bases, or 5 kb. With 4 bases to choose from at each position, the number of possible sequences is 45000, which is a value over 3,000 digits long. Larger microbes and organisms have much bigger genomes, millions or even billions of nucleotides long. The human genome is 3 Gb or 3 billion bases, so you can appreciate the nearly-infinite possible genomes we can create (Figure 4.5).
At this point, you might be wondering how nucleic acids communicate the crucial information they hold. By looking closely at its structure and chemical properties, we can understand how it works and why these are important. Let’s then take a closer look at the chemical structure of DNA.
DNA is a double-stranded molecule, which means that two pairs of complementary strands pair with each other to form that iconic “double










FIGURE 4.9 | Molecular differences between DNA and RNA. DNA uses four bases C, G, A, and T, and is generally double-stranded, with bases on two different strands forming hydrogen bonds to create a double helix. RNA uses C, G, A, and U (as opposed to DNA’s T base). RNA is predominantly singlestranded and has a ribose sugar backbone rather than a deoxyribose sugar backbone.
helix” structure (Figure 4.8). As we noted, sugars and phosphate groups simply make up the backbone. The nitrogenous base not only gives the nucleotide position its unique identity; it also connects with another base on another strand to hold the two strands together. This is via hydrogen bonds, a type of chemical bond that can be easily broken, each base pairs with another on the opposite strand. Because of their specific chemical structures, bases always pair in an established way: A always pairs with T, and C always pairs with G (and vice versa). We call this complementary base pairing (Figure 4.8). Like rungs on a ladder, complementary base pairing holds the two strands of DNA together to create a stable double-stranded DNA molecule.
FIGURE 4.8 | Key features and partial chemical structure of DNA. A) shows the double helix form of DNA with complementary base pairs. B) shows the underlying chemical structure of paired DNA bases linked by hydrogen bonds (dotted lines).
There are a few essential differences between the structure and function of DNA and RNA. At the structural level, the molecule of RNA is also made up of sugars, phosphate groups, and nitrogenous bases. However, RNA is typically single-stranded rather than double-stranded, and where DNA uses deoxyribose sugars, RNA uses normal ribose sugars (Figure 4.9).
The structural differences make RNA an inherently less stable molecule than DNA, more prone to damage and degradation in the cell. Also, although RNA still uses 4 bases to produce a 4-letter alphabet, it uses uracil (U) rather than DNA’s thymine when matching with adenine, leading to strategic advantages in energy consumption and durability outside of a cell’s nucleus. These nuances are especially relevant in the context of infectious diseases, since as we briefly noted earlier, some viruses use RNA to form their genomes instead of DNA. Despite their differences, however, both DNA and RNA are capable of using their four nucleotides to encode vast amounts of genetic information. It is important to note that RNA is not just a slightly different form of DNA; it has several additional, varied, and important roles in biological processes, some of which we will describe later in this chapter.

In order to understand how genetic material is read and transmitted between generations, we need to understand where genetic information is located, and how it is stored. Living organisms on Earth can be classified as either prokaryotic or eukaryotic, based on their cellular composition (Figure 4.10). Prokaryotic and eukaryotic organisms store cellular material differently and have a few key functional differences as a result.
Prokaryotic cells and their genomes tend to be relatively small and less complex than eukaryotic ones. All prokaryotes are single-celled. Prokaryotes are a group of species that encompass bacteria and cyanobacteria. Genomes are not compartmentalized within the cell, but instead localized within a non-enclosed region of the cell called the nucleoid. The genome is organized into one or more circular or linear chromosomes.

FIGURE 4.10 | Prokaryotic and eukaryotic cells organize their genetic information in different ways. Prokaryotes tend to have smaller genomes that are organized into one or a few circular or linear chromosomes. Prokaryotic genomes can be found in a region of the cell called the nucleoid, which is not a tightly enclosed structure. Eukaryotic cells, on the other hand, typically have to pack away much larger genomes and thereby require much more internal organization. Eukaryotic genomes are condensed into multiple chromosomes and are contained within an enclosed nucleus.
Eukaryotic cells, in contrast, are highly compartmentalized, and as mentioned earlier, they store their genetic material in their cell’s nucleus. Eukaryotes can be single-celled or multi-celled – humans, for example, have over 30 trillion cells. Because eukaryotes have such large genomes, their genomes are often split up into a larger number of highly coiled linear chromosomes, in order to comfortably fit within a cell’s nucleus.
As we noted, viruses are neither prokaryotes or eukaryotes and are not even considered living organisms. Viruses are very diverse in their structures, but they all share some key features: a genome, a capsid, which is a protein shell where viruses store their genomes, and an envelope, a lipid membrane surrounding the capsid (Figure 4.11). However, all viral genomes are small, sometimes consisting of only a few genes. Viral genomes can be made of either DNA or RNA. They can also be single, or doublestranded and linear, circular or segmented, and you can think of these segments as the viral version of the chromosomes found in cellular organisms. Some of the single-stranded viruses pack their genomes in multiple segments. If you are curious, you can go and explore different human viruses in the ViralZone platform.


FIGURE 4.11 | Viral genomes are stored in the virus capsid. Capsids are protein shells housing the viral genomes. They come in different shapes for different viruses. In this illustration of cytomegalovirus, or CMV, you can see an icosahedral capsid surrounded by the envelope of the virus.

Scan this QR code or click on this link to visit the ViralZone, a database of different viruses that infect humans.
1. What are the three components of nucleotides?
2. What are the main differences between RNA and DNA?
3. Where do prokaryotic cells, eukaryotic cells, and viruses store their genomes?
We can understand the primary functions of DNA, the cell’s primary genetic storage molecule, in relation to a few key principles. First, it must have mechanisms to efficiently and accurately copy its own genetic information to pass to the next generation. Second, it must direct the production of proteins, the cell’s main functional elements.
So, how does the cell make two new identical copies of DNA from one double-stranded molecule of DNA? This all occurs through a process called replication. DNA replicates when cells undergo cell division to make new cells or when individuals produce new offspring; for example, this happens when one bacterium divides and results in two bacteria, each containing a copy of the original genome. DNA replication is the foundation of heredity, and in this section we’ll explore how it’s done.
We can easily visualize how DNA is replicated by taking a look at the molecule itself. The interwoven strands bound by complementary base pairing allow for a streamlined, elegant replication process: the two strands of the double helix separate, and each of these matching strands serves as a template for a new strand of DNA. Let’s look at this process more closely.
DNA replication, like most biological processes, makes use of several enzymes Enzymes are specialized proteins that can catalyze, or accelerate, reactions. The first enzyme utilized in this process is DNA helicase , which unwinds the double helix,
breaking the bonds between complementary strands in the process. The second enzyme, DNA polymerase, binds to the newly free strand and begins synthesizing a new, complementary strand of DNA by adding new nucleotides one-by-one. This process is determined by the rules of complementary base pairing described earlier in the chapter, matching A to T (or U, for RNA) and G to C.
To better understand the chemistry of complementary base pairing and strand orientation, look at the DNA double-stranded sample sequence below. Since A always binds to T, and G always binds to C, you could completely predict the sequence of the second strand by examining the first, and vice versa. Therefore, DNA will always carry an “extra” copy of its information using its two strands, facilitating an efficient way to copy itself.
A
Once DNA polymerase has constructed a full complementary strand, the enzyme will proofread the new strands to make sure that there are no mismatches and that every base is properly paired to its complement. If any mistakes are detected in the new DNA sequence, the enzyme can reverse direction to fix them. Once proofread, DNA ligase, the last enzyme in the process, seals the template strands to their respective new strands, generating two separate double-stranded DNA molecules (Figure 4.12). Since each new molecule conserves a strand of the original molecule and one strand is newly synthesized, this process is called semiconservative replication
Replication
FIGURE 4.12 | Semiconservative replication. As DNA replicates, each strand from the original DNA molecule serves as a template for another strand. This replication process somewhat ‘conserves’ both original DNA strands while pairing them up with new copies every time they are replicated.
Even with the ability to reverse direction to correct itself, the process of proofreading remains imperfect, and the incorrect base (or bases) can be incorporated into the new strand of genetic material. We will discuss more about the errors that make their way into the final product of replication in Section 2.5: Mutations.
Viruses with an RNA genome also use this same replication process. However,
for single-stranded RNA viruses, the strandseparating helicase enzyme isn’t needed. While some viruses do carry the codes for their own special RNA polymerases, viruses always depend on the host’s cellular machinery to complete this replication process.
Proteins direct critical functions of life on Earth, but how exactly are they made? It was originally believed to follow a repeated, predictable process, known as the central dogma of molecular biology. This dogma describes the flow of genetic information from its storage to its expression as proteins. The dogma states that DNA is transcribed into RNA and RNA is translated into protein (Figure 4.13).
We now know the actual process of protein synthesis can be a bit more complex, and not quite as unidirectional as the dogma implies. However, it remains an effective summary of the process of protein synthesis, and is an excellent introduction to the overarching concept of the flow of genetic information.
1. What is achieved by the process of replication?
2. What does semiconservative replication refer to?
3. Generate the complementary DNA sequence for the following strand of DNA:
ATCTAGCCATGGA


FIGURE 4.13 | Central dogma of molecular biology. T he classic view of this dogma states that the genetic information of a cell flows into one direction: DNA is transcribed into RNA, an d RNA is translated into protein.
Before proteins can be generated, specific sections of DNA (genes) are transcribed into mRNA through the process of transcription. Transcription is a closely regulated process, ensuring that a few select proteins are expressed (produced) at each time and in each particular cell, rather than constantly producing and degrading all the proteins encoded by the genome. There is an entire field dedicated to understanding gene expression, the process by which a gene is turned on in a cell to make RNA and proteins, but for now, we’ll focus on the basics.
As you might remember from our instruction manual analogy, mRNA is a form of RNA that carries a copy of the genome’s information for the production of proteins. In this way, it acts as a “messenger.” RNA is less stable than DNA and is thus regularly degraded, often once translation has concluded. But while it “lives,” the genetic information contained within mRNA is utilized to create proteins via a process called translation.
But first, how does the cell know when and where in the genome to begin transcription to make a specific protein? The genome has bookmarks in the form of promoters. Promoter sequences are located just before the start of each gene’s protein-coding region, providing the
cellular machinery involved in transcription with crucial details regarding both when to make the protein and how much of the protein to produce (Figure 4.14).
Promoters are the most widely understood example of a regulatory element, a sequence that helps regulate the expression of genes. Another regulatory element is known as an enhancer, which helps the cell create its desired number of copies of a particular gene. Promoters are recognized and bound by specialized

FIGURE 4.14 | Transcription machinery. The promoter for a given gene is crucial for transcription. The promoter indicates to the cellular machinery that the gene is about to start. The RNA polymerase and specialized proteins called transcription factors bind to the promoter to initiate transcription. Transcription factors can also bind other regulatory elements such as enhancers to further regulate the process.
proteins called transcription factors. The presence or absence of transcription factors can determine whether the nucleotide sequence can be transcribed at all. In other words, they regulate transcription by turning genes ‘on and off.’ This mechanism ensures that proteins are selectively expressed at specific times and places in a cell.
To initiate the transcription of a gene, an enzyme called RNA polymerase binds to the promoter of the gene of interest telling the enzyme where to start. RNA polymerases are enzymes that produce RNA. In transcription, when RNA polymerase binds to the promoter for a given gene, the DNA is prompted to unwind slightly, leaving just enough space for RNA polymerase to slide along the strand and “read” the bases to create mRNA (Figure 4.15).
As RNA polymerase travels down the sequence, it generates a strand of mRNA nucleotides complementary to those in the DNA sequence. The rules for complementary base pairing are the same as those discussed in the case of double-stranded DNA, but with one key difference; when an A is encountered on the template strand, a U is added to the RNA sequence to complement it since RNA uses uracil instead of thymine. RNA polymerase generates a transcript of the entire gene sequence in this manner and stops adding nucleotides when it encounters a
terminator, a specific sequence of nucleotides on the template DNA strand that prompts the polymerase to detach.
You may notice that many of the enzymes and steps involved in transcription sound familiar –does transcription remind you of DNA replication? In both processes, new strands of nucleotides are being generated that are complementary to a template strand, and in both cases, polymerases are responsible for building new growing chains. However, transcription and DNA replication have a few important differences. Aside from the different specific enzymes that are employed at each step, the most obvious difference is the resulting product: DNA replication produces DNA, while transcription produces mRNA. The goals of these processes are also fundamentally different; while DNA replication aims to construct a complete copy of all of an organism’s genetic information, transcription aims only to generate mRNA copies of a specific gene which then are translated to make proteins.
RNA viruses follow a similar pattern of transcription, but with some notable differences. For example, certain RNA viruses have functional mRNAs as part of their genomes. This means that as soon as they enter the host cell these mRNAs can be translated into proteins. One of the most important proteins that viruses produce like this is RNA-dependent RNA polymerase, the RNA viral enzyme used to replicate their genomes. This fascinating property allows these viruses to use the host cell ribosomes to produce their own proteins.
RNA viruses, known as retroviruses, are an exception to the central dogma of molecular biology. Retroviruses deviate from the central dogma in that they “revert” transcription. Using an enzyme called reverse transcriptase, they
convert their RNA genome to DNA – a move in the opposite direction of the dogma’s flow. These retroviruses then convert the DNA template they’ve made back to mRNA in order to finally build the protein products, using the host cell’s protein synthesis machinery. The human immunodeficiency virus (HIV) is an example of a retrovirus that you might already be familiar with; HIV, as well as all other retroviruses, pose such a unique threat to human health because of their reverse transcription abilities, allowing easier integration into the human host’s DNA genome.
Translation is the process by which cells synthesize proteins from mRNA. This process is executed by the cell’s many ribosomes. Ribosomes are protein-making organelles composed of ribosomal proteins and another type of RNA called ribosomal RNA (rRNA). Eukaryotic and prokaryotic cells have their own ribosomes, but viruses do not – another reason why viruses need to find a host cell in order to reproduce. In both viruses and cellular organisms, translation starts when the mRNA attaches to the ribosome via a special tag added after transcription.
When mRNA enters a ribosome it begins the process of translating the nucleotide sequence to the language of amino acids. Every three bases of a nucleotide sequence, known as codons, directly correspond to one of twenty amino acids that will be assembled into a final chain, allowing for cellular machinery to decipher the genetic code into a peptide, or short chain of amino acids that will later become a working protein. The codon chart in Figure 4.16 shows all the different codons and the amino acids (using their threeletter abbreviations) to which they correspond. As you can see, each codon can only encode for one amino acid, but an amino acid can be encoded by multiple codons. “The codon to
amino acid chart has been considered a “Rosetta Stone” of molecular biology, as it unlocked the understanding of how genetic information is translated into proteins.”
Now how do we get from mRNA sequence to the peptide chain? When mRNA enters a ribosome, a set of 3 bases in sequence, AUG, known as the “start” codon commands the ribosome to begin translation, starting the creation of a peptide chain with the amino acid methionine. As the ribosome reads codons, transfer RNA (tRNA), another form of RNA, carries the corresponding amino acid to the ribosome and adds it to the growing peptide. As a peptide gets longer, it is referred to as a polypeptide. For example, if the ribosome detected CCA, one of the codons encoding for the amino acid proline, a tRNA molecule would deliver proline to the ribosome and add it to the growing polypeptide. Translation continues along the length of the mRNA until one of three ‘stop’ codons (UAA, UAG, or UGA) is reached. This prompts the ribosome to detach from both the mRNA and the new polypeptide.
To illustrate how this all works, let’s imagine an mRNA sequence looks like this:
AUG - AUA - CGG - AAC - UGA
As we read the sequence, each of these codons correspond to a specific amino acid, start codon, or stop codon. Therefore, as the ribosome ‘reads’ each of these codons a polypeptide chain is made. The peptide chain for this specific mRNA sequence would then look like this:
Met - Ile - Arg - Asn - Stop

Scan this QR code or click on this link to practice genetics: transcribing DNA and translating RNA into protein.
FIGURE 4.16 | Genetic code. Codons are made up of three nucleotides, and each corresponds to a specific amino acid, a start codon (Met) or a stop codon (UAA, UAG or UGA). This table gives the corresponding codon and amino acid pairs, organized by first, then second, then third nucleotide of the codon. Notice that there is redundancy, in that most amino acids have more than one codon that codes for them. There are also codons that start or stop the translation.
Once the polypeptide has been fully synthesized, it detaches from the ribosome and folds into its final form. Since amino acids have distinct chemical properties – with certain amino acids being more positively charged or negatively charged than others, or being especially prone to either like or avoid water, as well as having inherently different structures and sizes – these properties promote the formation of chemical bonds between different parts of a polypeptide or in between polypeptides, guiding what is known as protein folding. The sequence and proximity of amino acids within a connected polypeptide chain
governs how it folds into a single, specific physical conformation. The many different chemical interactions together determine the three-dimensional (3D) structure of the protein. Some polypeptides can execute functions alone; others team up to form fully functional proteins. Once the polypeptide chain has folded and these interactions are finished, the protein product is finally complete.
The set of 20 amino acids can be arranged in a virtually infinite number of combinations, creating a vast array of potential proteins with distinct chemical properties, shapes, and sizes. On a molecular scale, the specific orientations and arrangements of amino acids within a given
protein impact its properties and interactions with not only the rest of the polypeptide chain, but also all of the other molecules it encounters. In this way, structure determines function—a guiding principle of molecular biology.
Let’s take a look at the spike protein of SARSCoV-2 to understand how a protein’s structure informs its function. The spike protein is a type of unique structure that mediates the entry of a virus into host cells. We can think of the spike protein as SARS-CoV-2’s key that can unlock the host cell. The host cell’s ‘lock’ is a specific receptor protein called ACE2, and it recognizes proteins of specific shapes to grant those molecules entry into the cell. Just like we’ve discussed, these protein structures are entirely dependent on their gene sequences and the subsequent amino acid chains they produce. As you can see in Figure 4.17, the spike protein’s shape is perfectly suited to unlock the ACE2 protein. Based on the spike protein’s gene sequence, it is able to take on the exact shape needed to function as a working key, binding to ACE2 and infiltrating the cell.


FIGURE 4.17 | SARS-Cov-2 structure. The SARSCoV-2 virus has a number of specialized proteins that determine its structure. Key proteins such as the spike proteins, the envelope proteins, the membrane proteins and the nucleocapsid protein are labeled in this image, The spike protein of SARS-CoV-2 serves as a ‘key’ to unlock the host cell and infect it. Specifically, the spike protein binds to the ACE2 receptor found on the cell membrane of the host cell to mediate the entry of the virus into the host cell.
1. What does the central dogma of molecular biology state?
2. What is transcription?
3. In order for translation to begin, what must occur first?
4. True/False: Translating a piece of mRNA which contains over 300 nucleotides will produce a polypeptide chain of 300 amino acids.
5. When studying protein function, we say that “structure determines function.” How is this guiding principle observed with the SARS-CoV-2 spike protein?
You can now begin to see the full picture of how genetic material is able to fulfill its essential tasks: the direction of DNA and RNA replication and the direction of protein synthesis. These processes, which employ DNA and RNA replication, transcription, and translation to accomplish their goals, are extremely precise and accurate. For example, DNA replication is a relatively error-free process; on average, a DNA polymerase makes a random mistake once every 100,000 nucleotides, and 99% of these mistakes are repaired during the proofreading stage. Based on these statistics, we only expect 1 mistake in every 10 million nucleotides. In pathogens, this number can be much higher, with HIV’s machinery, for example, incorporating an error every 200-400 bases. This higher rate of random error plays a large role in pathogen mutation over time.
These infrequent, random errors that persist after replication and proofreading can introduce errors in the genetic code, known as mutations. (Figure 4.18). These can be passed between generations, contributing to the genetic diversity within entire populations. These mutations can alter the structure and function of proteins, and they can often affect an organism’s fitness. They can also often have no impact on an organism or its offspring, acting as so-called neutral mutations
The three common types of mutations that occur within the genome are insertions, deletions, and substitutions. Insertion mutations occur when one or more nucleotides are added to a gene sequence where they do not belong.


4.18 | Mutations in the genetic code. Mutations have the potential to change the structure of the protein that is produced, or even stop translation entirely. This could lead to drastic phenotypic changes to the organism making for example a pathogen more transmissible.
Deletion mutations, the opposite scenario of insertions, occur when one or more nucleotides are removed from a gene sequence.
Insertions and deletions can have extended consequences. For example, let’s say that there is a deletion of one base (Figure 4.19). Since codons are made up of groups of three bases, this can affect codon groupings, and cause codons to be read incorrectly. This kind of mutation is called a frameshift mutation because it shifts all of the amino acids generated downstream of the insertion out of frame.
This has the potential to create an entirely new protein product for the remainder of the reading frame, or perhaps even prematurely terminate synthesis of the protein altogether! In the case that the indel encompasses exactly three nucleotides, or a multiple of three, the sequence will remain in frame; this protein product will still be different from the original, but will have discrete additions/eliminations, rather than a change to the entire sequence.
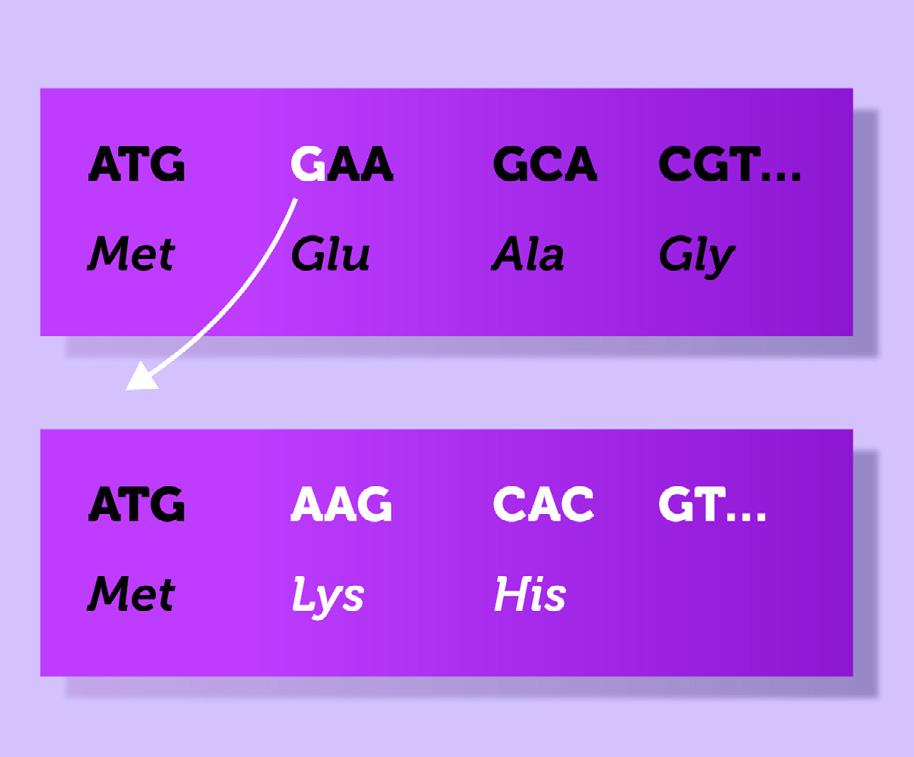
FIGURE 4.19 | Deletion mutation causing a frameshift. Deleting one base pair shifts the rest of the bases in the codon, resulting in entirely different proteins being produced downstream of the mutation. Here a Glycine was deleted causing a frameshift in the genetic sequence changing the amino acid from Glutamine (Glu) to Lysine (Lys).
Substitution mutations usually impact a single base at a time, swapping out one individual nucleotide with another. These are the most common form of mutation in most genomes. When substitution mutations occur in a gene, they can have one of three effects. Synonymous mutations create a change in the codon but do not modify the amino acid for which they code. They are often also referred to as silent mutations as they are believed to have no effect on the final protein product. Nonsynonymous mutations (also referred to as missense mutations) change the codon to one that codes for a different amino acid than originally specified by the genome. These can have a significant impact on the resulting protein, specifically its shape and function, if the new amino acid is substantially different from the original one. D614G, discussed further below, is an example of a nonsynonymous mutation, as it causes a glycine (G) to be added to the polypeptide instead of an aspartic acid (D). Lastly, nonsense mutations change the codon to a stop codon, prematurely terminating translation.
There are other kinds of mutations that alter the structure and location of various genes. For example, certain structural mutations can swap the orientation of a stretch of DNA within a chromosome. Others can even remove or add a chromosome, having massive impacts on the individual’s resulting phenotype.
To illustrate the impact of mutations, let’s consider one in SARS-CoV-2. A mutation called D614G the spike protein emerged in early 2020 and became the dominant form of SARS-CoV-2. This single substitution, located at the 614th position of the amino acid chain, caused one amino acid to be switched from an aspartic acid (Asp or D) to glycine (Gly or G). Scientists soon realized that the structural change within the polypeptide caused by D614G had actually
altered the lock-and-key interaction between the spike protein and the host’s receptor ACE2. Unfortunately for us, this change allowed SARS-CoV-2 to become even more efficient at entering host cells, increasing the virus’s ability to infect human cells and contributing to the
increased spread of COVID-19 and the rise in prevalence of the D614G variant. This example illustrates both the power of protein structure in directing biological functions and the functional impact of mutations, both big and small.
1. List the three major types of mutations that occur within the genome
2. Identify which type of mutation occurred in the genome based on each of the following transcribed mRNA segments when compared to the bolded reference sequence. Refer to the codon chart in Figure 4.16:
GAU UUG CUG UUU GAC GUU AGC UGC UGU UCG
a. GAU UUG CUG UUU GAC GUA GCU GCU GUU CG
b. GAU UUG CUG UUU GAC GUU AGC UGC UGU UUC
c. GAU UUG CUG UUU GAC GUU AGC UGC UGA UCG
3. How has the D614G nonsynonymous mutation identified in a SARS-CoV-2 variant promoted the spread of the virus in the human population?
The genetic differences from individual to individual not only make organisms within a species look and function differently from each other, but also give them their own distinguishable genomes. Just as your genome is unique to you, with the ability to identify you out from a pool of countless others, each individual pathogen has a completely unique genome. A pathogen’s genome drives its biology, interaction with its hosts, transmission, and virulence, affecting its ability to spread and cause disease. The information we obtain from these genomes is key in the design of diagnostics, vaccines, therapies, and surveillance tools to tackle target pathogens.
More specifically, scientists can use genetic analysis methods to figure out if a person is infected with a pathogen and which pathogen species is responsible for their illness. This work is central to the field of diagnostics, and as you will learn in Chapter 7: Diagnostic Tests, many of our tests for pathogens target the genome sequence of the pathogen directly or detect the proteins of the pathogens, which are themselves defined by the underlying genomic sequence. In Chapter 8: Therapeutics, we will see how many of our infectious disease treatments target specific pathogen proteins or boost our immune response to specific pathogen proteins. And in Chapter 9: Vaccines and Immunizations, we will see how the vaccines and therapies we use to treat or
prevent infection are designed with the pathogen genome sequences in mind. But for now, it’s important to understand that many of our actions against pathogens are made possible by our understanding of their genomes and the genetic variation that exists between species.
In our outbreak surveillance efforts, we can use a higher-resolution look at genetic variation to trace how specific strains of pathogens spread through the population. Pathogens tend to accumulate mutations at a relatively regular rate as they reproduce and spread. Mutations, therefore, serve as a log of infection: we can track which mutations arose when, where, and in whom.
Understanding how and why particular mutations persist through generations is crucial in outbreak science. Genetic variation facilitates adaptation and evolution. The more variation that exists within a population, the more options there are for natural selection – a process by which populations adapt to environmental pressures as the best-equipped individuals survive to pass on their genes. This is most clearly evident among pathogens, whose evolution we can track due to their quick reproduction rates. Some mutations can even allow pathogens to evade therapeutics. Indeed, antimicrobial resistance is a growing threat that occurs when a mutation makes a pathogen immune to previously successful drugs. Vaccines, too, can wane in efficacy as pathogen evolution occurs.
1. What can we learn from studying a pathogen’s genome?
2. Why are pathogen genome mutations a focus of attention in outbreak response?
1. Traits are genetically encoded observable characteristics, such as eye color or height. These are passed between generations or inherited.
2. Answers may vary but may include some of these: The discovery of proteins, the isolation of DNA, the elucidation of DNA as the molecule carrying and passing the genetically encoded characteristics between generations, the discovery of the molecular structure of DNA, the reading and elucidation of genetic sequences and genomes.
3. Sequencing is a laboratory technique that allows for the reading of genetic sequences and complete genomes. By discovering the genes of a particular pathogen in a patient’s blood has allowed scientists to identify the infectious disease and identify changes in its genome. We can also use this information to devise specific vaccines and therapies against them. We can also use pathogen sequences to understand how disease spreads during the course of an outbreak.
1. Our instruction manual and the genetic code that makes it up are used to create numerous discrete functional units that together constitute all of the parts of an organism, the most well-understood of which are proteins. Proteins are small molecules whose structure equips them to execute specific functions.
2. Four: Adenine (A), Cytosine (C), Guanine (G) and Thymine (T) for DNA; and A, C, T and Uracil (U) for RNA.
1. A phosphate group, a sugar group, and a base.
2. The main differences between RNA and DNA are that RNA is typically singlestranded rather than double-stranded, and RNA has a backbone composed of ribose sugars instead of deoxyribose sugars. These structural differences make RNA an inherently less stable molecule than DNA.
3. Prokaryotic cells store their genome in an unenclosed region called the nucleoid, since they don’t have a nucleus. Eukaryotic cells store their genome in the nucleus. Viruses store their genomes in their capsid.
1. Two strands of DNA are created from one original strand.
2. Semiconservative replication refers to the process of replication in which an original strand serves as a template to make another complementary strand. Each new copy of DNA contains an original strand and a new strand.
3. TAGATCGGTACCT
1. The central dogma of molecular biology is the guiding principle of the flow of genetic information. DNA is converted into RNA through ‘transcription,’ and RNA is translated into protein during ‘translation.’ Transcription is the process by which cells copy a section of DNA into RNA.
2. The mRNA must first make its way to a ribosome. The instructions to make a particular protein must be converted into a form that is readable by cellular machinery.
3. False: a codon is composed of three amino acids.
1. Insertions, deletions, and substitutions
2.
a. There was a deletion event of Uracil (U), causing a frameshift mutation in the sequence Mutation to GUA from GUU is still Valine (Val), all other amino acids have changed
b. The last codon changed from UCG to UUC, which mutated from Serine (Ser) to Phenylalanine (Phe), which is a non-synonymous or missense mutation.
c. The second to last codon UGU mutated to become UGA, which mutated from Cysteine (Cys) to a stop codon, causing a nonsense mutation.
3. The mutation altered the lock-and-key interaction between the SARS-CoV-2 spike protein and the host’s receptor ACE2. Unfortunately for us, this change allowed SARS-CoV-2 to become even more efficient at entering host cells, increasing the virus’s ability to infect human cells.
1. Answer may vary for here as complete set of options: We can learn about the biology of the pathogen and how this can drive its interaction with its host. We can get information about its transmission and virulence. We can learn about the proteins making it up to find potential targets to design diagnostics tools, vaccines, and therapies.
2. Mutations can affect the biology of a pathogen in a way that it may become resistant to therapeutics, make vaccines less effective and induce a new outbreak. Therefore monitoring how pathogens evolve is a focus of attention for outbreak response.
Alleles: Alternative forms of a gene that result in different observed traits.
Amino Acid: The building blocks of proteins. There are 20 different amino acids.
Capsid: A protein shell that houses the genome in viruses.
Cell: The fundamental unit of life; all living things are composed of cells.
Central Dogma of Molecular Biology: The guiding principle of the flow of genetic information. DNA is converted into RNA through a process called “transcription,” and RNA encodes the sequence of amino acids via a process called “translation.”
Chromosome: A bundle of DNA used to organize genetic material.
Codon: Combinations of three nucleotides that code for a specific amino acid.
Deletion Mutations: Mutation that occurs when one or more nucleotides are removed from a gene sequence.
Deoxyribonucleic Acid (DNA): Genetic material that forms the genome of all cellular organisms and some viruses; double-stranded and composed of deoxyribose sugars in a sugar-phosphate backbone and nitrogenous bases; more chemically stable than RNA.
DNA Helicase: Enzyme that unwinds DNA’s double helix structure, breaking the bonds between complementary strands; first enzyme used in DNA replication.
DNA Ligase: Enzyme that facilitates the joining of DNA strands together during DNA replication and DNA repair.
DNA Polymerase: Enzyme used to copy the genome during the process of DNA replication.
Double Helix: Model of the structure of DNA, composing a sugar-phosphate backbone and nitrogenous bases.
Envelope: A lipid membrane surrounding the capsid of a virus.
Enzymes: Specialized proteins that catalyze or accelerate biological reactions.
Eukaryotic: Organisms with membraneenclosed structures within their cells (including a nucleus).
Gene: The basic unit of heredity and a sequence of nucleotides in DNA that encodes the synthesis of a gene product, either RNA or protein.
Genetics: The study of the inheritance of genetic material and traits.
Genome Sequencing: Process of determining the entire DNA or RNA sequence of an organism’s genome.
Genotype: The alleles an individual carries in a particular gene.
Insertion Mutations: A type of mutation in which one or more nucleotides are added to the genome.
Messenger RNA (mRNA): A form of ribonucleic acid (RNA) used to convey instructions for cellular machinery to make a specific protein.
Mutations: Incorrectly-paired nucleotides that persist after proofreading and replication; can have effects on biological function and can be passed to offspring; the basis for genetic change.
Natural Selection: The process that results in the adaptation of an organism to its environment as a result of the selection of randomly occurring changes in the genotype.
Neutral Mutation: Change in DNA sequence that does not affect an organism’s ability to reproduce or survive, and therefore is neither beneficial nor detrimental.
Nitrogenous Base: Informally referred to as a “base,” one of the three main components of a nucleotide. Bases include adenine (A), thymine (T), cytosine (C), and guanine (G) for DNA, and uracil (U) replaces T in RNA.
Nonsense Mutation: Mutation that changes the codon to a stop codon, prematurely terminating translation.
Nonsynonymous Mutation: Change the codon to one that codes for a different amino acid than originally specified by the genome, also referred to as missense mutations.
Nucleic Acid: Biomolecules that serve as the primary information-carrying molecules in cells. The two types are DNA and RNA.
Nucleotides: The chemical compounds making up DNA and RNA. They are composed of three main parts: a deoxyribose sugar in DNA or ribose sugar in RNA, a phosphate group and a nitrogenous base.
Nucleus: A membrane-bound compartment of the cell containing genetic material.
Peptide: Short chain of amino acids.
Phenotype: Different versions of observable traits of an organism.
Polypeptide: Molecule composed of many amino acids; folds into a protein.
Prokaryote: Organism without membraneenclosed structures in its cell; tends to be smaller and less complex than eukaryotes. Prokaryotic genomes are localized in a region of the cell called the nucleoid.
Promoter: An element at the beginning of a gene that tells the transcription machinery where to start “reading” the sequence.
Proteins: Biological molecules encoded by the genome that are key in biological processes and whose structure equips them to execute specific functions; cellular functional elements that perform actions and make up our traits.
Protein Synthesis: Cellular process by which new proteins are made.
Replication: Biological process by which a cell produces two identical copies of DNA from one original DNA molecule.
Regulatory Element: A region in the genome that regulates the transcription of genes by serving as a binding site for transcription factors.
Retrovirus: A type of RNA virus that replicates by reverse-transcribing its RNA genome into DNA and integrating it into the host cell’s genome.
Reverse Transcriptase: Enzyme used by RNA viruses to generate complementary DNA from an RNA template during reverse transcription.
Ribonucleic Acid (RNA): Type of nucleic acid key to the central dogma of molecular biology and many other biological processes; mostly single stranded and is composed of ribose sugars. Utilizes the nucleotides adenine (A), guanine (G), cytosine (C), and uracil (U). It is less stable than DNA and plays a fundamental role in protein synthesis.
Ribosomes: Protein-making structures composed of ribosomal RNA (rRNA) found in cells.
RNA Polymerase: Enzyme that synthesizes RNA molecules from a template of DNA through the process of transcription. This enzyme transcribes DNA into precursors of messenger RNA (mRNA) and most small nuclear RNA (snRNA) and microRNA.
Semiconservative Replication: When DNA replicates, each new copy of DNA contains an original strand and a new strand.
Sequencing: Laboratory technique used for reading specific genetic sequences or complete genomes.
Spike Protein of SARS-CoV-2: A viral surface protein that facilitates viral entry into host cells by binding to the human angiotensinconverting enzyme 2 (ACE2) receptor.
Substitution Mutation: Mutation that changes one nucleotide base to another. Usually only a single nucleotide base is changed at a time.
Synonymous Mutation: Mutation that creates a change in the codon, but does not modify the amino acid for which they code.
Traits: Genetically encoded characteristics, such as eye color or height, which are passed down through generations.
Transcription: Process by which instructions to make a particular protein must be converted into a form that is readable by cellular machinery; the conversion of DNA to RNA. In eukaryotic cells, transcription takes place in the nucleus.
Transcription Factor: A protein that binds to specific DNA sequences, regulating the expression of target genes by controlling the rate of transcription.
Translation: Process by which ribosomes synthesize proteins after transcription. Translation occurs in the cytoplasm or endoplasmic reticulum of the cell.
Transfer RNA (tRNA): An RNA molecule that carries the corresponding amino acid to the ribosome and adds it to the growing amino acid chain (polypeptide).
Virion: The fundamental unit of viruses, also known as a viral particle.