8 minute read
Reinforcement Learning from Human Feedback (RLHF)

leewayhertz.com
As AI technology advances, the race to create AI innovations, especially in the field of generative AI, has intensified, resulting in promises as well as concerns.
Advertisement
While these technologies hold the potential for transformative outcomes, there are also associated risks. The development of Reinforcement Learning from Human Feedback (RLHF) represents a significant breakthrough in ensuring that AI models align with human values, delivering helpful, honest and harmless responses. Given the concerns about the speed and scope of the deployment of generative AI, it is now more important than ever to incorporate an ongoing, efficient human feedback loop.
Reinforcement learning from human feedback is a machine-learning approach that leverages a combination of human feedback and reinforcement learning to train AI models. Reinforcement learning involves training an AI model to learn through trial and error, where the model is rewarded for making correct decisions and penalized for making incorrect ones.
However, reinforcement learning has its own limitations. For instance, defining a reward function that captures all aspects of human preferences and values may be challenging, making it difficult to ensure that the model aligns with human values. RLHF addresses this challenge by integrating human feedback into the training process, making aligning the model with human values more effective. By providing feedback on the model’s output, humans can help the model learn faster and more accurately, reducing the risk of harmful errors. For instance, when humans provide feedback on the model’s output, they can identify cases where the model provides inappropriate, biased, or toxic responses and provide corrective feedback to help the model learn.
Furthermore, RLHF can help overcome the issue of sample inefficiency in reinforcement learning. Sample inefficiency is a problem where reinforcement learning requires many iterations to learn a task, making it time-consuming and expensive. However, with the integration of human feedback, the model can learn more efficiently, reducing the number of iterations needed to learn a task.
This article delves deep into the concepts and working mechanisms of reinforcement learning and reinforcement learning from human feedback and discusses how RHLF is useful in large language models.
The foundation: Key components of reinforcement learning
What is reinforcement learning?
How does reinforcement learning work?
What is Reinforcement Learning from Human Feedback (RLHF)?
How does RLHF work?
How is RLHF used in large language models like ChatGPT?
The foundation: Key components of reinforcement learning
Before we go deeper into reinforcement learning or RLHF concepts, we should know the associated terminology.
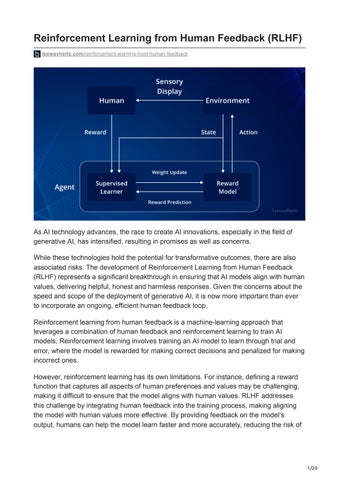
Agent
In reinforcement learning, an agent is an entity that interacts with an environment to learn a behavior that maximizes a reward signal. The agent is the decision-maker and learner in the reinforcement learning process. The agent’s goal is to learn a policy that maps states to actions to maximize the cumulative reward over time. The agent interacts with the environment by taking actions based on its current state and the environment responds by transitioning to a new state and providing the agent with a reward signal. The agent uses this reward signal to update its policy and improve its decision-making abilities. The agent’s decision-making process is guided by a reinforcement signal, which indicates the quality of the agent’s actions in the current state. The agent learns from this signal to improve its policy over time, using techniques such as Q-learning or policy gradient methods.
The agent’s learning process involves exploring different actions and observing their outcomes in the environment. By iteratively adjusting its policy based on the observed outcomes, the agent improves its decision-making abilities and learns to make better choices in different states of the environment. The agent can be implemented in various forms, ranging from a simple lookup table to a complex neural network. The choice of agent architecture depends on the environment’s complexity and the learning problem’s nature.
To explain it in simpler terms, reinforcement learning is like teaching a robot how to do something by rewarding it for good behavior. The robot is called the agent and it learns by trying different things and seeing which actions give it the best rewards. It makes decisions based on what it learns, aiming to get as many rewards as possible over time. The agent interacts with the environment and learns by exploring and observing what happens when it takes different actions. It keeps adjusting its behavior based on its rewards until it gets good at doing the task. The agent can be made using different techniques, depending on the task’s difficulty
Action space
In reinforcement learning, the action space refers to the set of all possible actions that an agent can take in response to the observations it receives from the environment.
The action space can be discrete or continuous, depending on the nature of the task at hand. In a discrete action space, an agent can only choose from a finite set of predetermined actions, such as moving left, right, up, or down. On the other hand, in a continuous action space, an agent has access to an infinite set of possible actions, such as continuously kicking a ball to reach a goal post.
The choice of the action space is an essential aspect of reinforcement learning since it determines the actions that an agent can take in response to its observations. The agent’s policy determines the optimal action in a given situation, essentially mapping states to actions. Therefore, selecting an appropriate action space is crucial for ensuring that the agent’s policy can learn and converge to an optimal solution.
Model
In reinforcement learning, a model refers to an agent’s internal representation of the environment or world it interacts with. It can be used to predict the next state of the environment given the current state and action or to simulate a sequence of possible future states and rewards. The agent can use a model to plan and choose the best actions based on the predicted outcomes. However, not all reinforcement learning agents require a model and can learn directly from interacting with the environment without any prior knowledge or assumptions. In such cases, the agent’s view only maps state-action pairs to probability distributions over the next states and rewards without explicitly modeling the environment.
Policy
In reinforcement learning, a policy is a function that maps the current observation or state of the environment to a probability distribution over possible actions that an agent can take. The policy is a set of rules or a “strategy” that guides the agent’s decision-making process. To simplify, the policy is like a recipe that tells the robot exactly what to do, or it can be like a game where the robot makes decisions based on chance. The idea is to find the best policy to help the robot get the most rewards possible.
The goal of a reinforcement learning policy is to maximize the cumulative reward that an agent receives over the course of its interaction with the environment. The policy provides the agent with a way to select actions that will maximize the expected reward, given the current state of the environment. The policy can be deterministic, meaning that it maps each state to a specific action with probability 1, or stochastic, meaning that it maps each state to a probability distribution over actions. The choice of a deterministic or stochastic policy depends on the nature of the task at hand and the level of exploration required.
Generally, reinforcement learning aims to find the optimal policy that maximizes the expected cumulative reward. The optimal policy is the one that guides the agent to select the best actions to take in each state, resulting in the highest possible reward over time.
Reward function
In reinforcement learning, a reward function is a function that maps a state and an action to a numerical value representing the “reward” that an agent receives for taking that action in that state. The reward function is a critical component of the reinforcement learning framework since it defines the objective of the agent’s decision-making process. It measures the goodness of a particular action in a particular state. The agent aims to learn a policy that maximizes the expected cumulative reward over time, starting from the initial state. The reward function plays a critical role in guiding the agent’s policy towards actions that maximize the expected cumulative reward.
The total reward is usually computed by adding up the rewards obtained by the agent over a sequence of time steps. The objective is to maximize the total reward, often computed as the sum of discounted rewards over time. The discount factor is used to weigh future rewards less than immediate rewards, reflecting the fact that the agent is uncertain about future rewards. It is often designed based on the specific task or problem the agent tries to solve. It can be a simple function that assigns a positive or negative value to each state-action pair, or it can be a more complex function that considers additional factors, such as the cost of taking action or the time required to complete a task.
Environment
In reinforcement learning, the environment refers to the world in which an agent operates and learns. The environment is usually modeled as a system with states, actions and rewards.
The environment is the context in which the agent takes action and receives feedback in the form of rewards. The agent interacts with the environment by taking actions based on its current state and the environment responds by transitioning to a new state and providing the agent with a reward signal. The environment can be physical, such as a robot navigating a room, or virtual, such as a simulated game environment. It can also be discrete or continuous, depending on the nature of the learning problem. The environment’s state is a representation of the current situation or configuration, which captures all relevant information that the agent needs to make decisions. The action taken by the agent affects the state of the environment, which in turn generates a reward signal for the agent.
The reward signal indicates the quality of the agent’s action in the current state, guiding the agent’s learning process. The agent learns from the reward signal to improve its decision-making abilities and maximize the cumulative reward over time. The environment can be fully observable or partially observable. In the former, the agent has access to the complete state of the environment, while in the latter, the agent only has access to a subset of the environment’s state, making the learning problem more challenging.
Value function
In reinforcement learning, the value function is like a math formula that helps the robot figure out how much reward it can expect to get in the future if it starts at a certain point and follows a certain set of rules (policy). The value of a point is like a reward the robot can expect if it starts at that point and follows the rules. This value considers both the immediate reward and the rewards the robot expects to get in the future.
The discount factor is like a way of thinking about how much the robot values future rewards compared to immediate ones. A high discount factor means the robot cares a lot about future rewards, while a low one means it focuses mostly on getting rewards immediately. Different ways to figure out the value function exist, like using maths or trial and error. The best value function is the one that helps the robot get the most reward starting from a certain point and following the best set of rules. The value function helps the robot determine which rules are the best to follow
States and observation space
In reinforcement learning, the state represents the complete description of the environment or world that the agent operates in. The state space refers to the collection of all possible states that an agent can interact with. On the other hand, the observation space refers to the subset of the state space that an agent can perceive or have access to.
If the agent can observe the complete state of the world, the environment is considered to be fully observed. However, in many cases, agents may not have access to the complete state of the environment and can only perceive a subset of it. This results in the environment being classified as partially observed.
The observation space is critical for an agent’s decision-making process since it provides information to the agent about the state of the world. Hence, an agent’s ability to perceive and interpret the observation space plays a significant role in its ability to learn and make