5 minute read
Ácidos nucleicos


Los ácidos nucleicos son las biomoléculas portadoras de la información genética. Son biopolímeros, de elevado peso molecular, formados por otras subunidades estructurales o monómeros, denominados nucleótidos. Desde el punto de vista químico, los ácidos nucleicos son macromoléculas formadas por polímeros lineales de nucleótidos, unidos por enlaces éster de fosfato, sin periodicidad aparente. Los ácidos nucleicos están formados por largas cadenas de nucleótidos, enlazados entre sí por el grupo fosfato. El grado de polimerización puede llegar a ser altísimo, siendo las moléculas más grandes que se conocen, con moléculas constituidas por centenares de millones de nucleótidos en una sola estructura covalente. De la misma manera que las proteínas son polímeros lineales aperiódicos de aminoácidos, los ácidos nucleicos lo son de nucleótidos. La aperiodicidad de la secuencia de nucleótidos implica la existencia de información. De hecho, sabemos que los ácidos nucleicos constituyen el depósito de información de todas las secuencias de aminoácidos de todas las proteínas de la célula.
Bases púricas y pirimidinas
Advertisement
Las Bases Nitrogenadas son las que contienen la información genética. En el caso del ADN las bases son dos Purinas y dos Pirimidinas. Las purinas son A (Adenina) y G (Guanina). Las pirimidinas son T (Timina) y C (Citosina). En el caso del ARN también son cuatro bases, dos purinas y dos pirimidinas. Las purinas son A y G y las pirimidinas son C y U (Uracilo).
Bases púricas
Están basadas en el anillo Purínico. Puede observarse que se trata de un sistema plano de nueve átomos, cinco carbonos y cuatro nitrógenos. En la siguiente se puede apreciar cómo se forma adenina y guanina a partir de una purina. El anillo purínico puede considerarse como la fusión de un anillo pirimidínico con uno imidazólico (fig.13)
Tomado de: https://n9.cl/v2sct (fig.13)
El nombre sistemático de la adenina es 6-amino purina y el de guanina es 2amino 6-oxo purina.
Bases pirimidínicas
Están basadas en el anillo pirimidínico. Es un sistema plano de seis átomos, cuatro carbonos y dos nitrógenos. En esta imagen puede observarse como derivan citosina, timina y uracilo de uirimidina. Las distintas bases pirimidínicas se obtienen por sustitución de este anillo con grupos oxo (=O), grupos amino (-NH2) o grupos metilo (-CH3) (fig.14)
El nombre sistemático de la timina es 2,4 dioxo5-metil pirimidina, el de la citosina es 2-oxo 4-amino pirimidina y el del uracilo 2,4 dioxo pirimidina.
Tomado de: https://n9.cl/v2sct (fig.14)
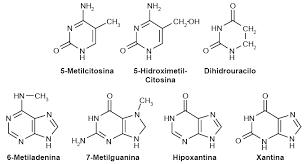
Bases modificadas
Además de las purinas y pirimidinas de las que hemos hablado anteriormente, es frecuente encontrar bases modificadas.
Entre las más abundantes encontramos:
• La 5-metilcitosina, la 5-hidroximetilcitosina y la 6-Metiladenina que se han relacionado con la regulación de la expresión del DNA. • L a 7-metilguanina y el dihidrouracilo que forman parte de la estructura de los RNA. • Hipoxantina y Xantina como intermediarios metabólicos y productos de reacción del DNA con sustancias mutagénicas (fig.15)
El ADN
Ácido Desoxirribonucleico (ADN), material genético de todos los organismos celulares y casi todos los virus. Es el tipo de molécula más compleja que se conoce. Su secuencia de nucleótidos contiene la información necesaria para poder controlar el metabolismo un ser vivo. El ADN lleva la información necesaria para dirigir la síntesis de proteínas y la replicación. En casi todos los organismos celulares el ADN está organizado en forma de cromosomas, situados en el núcleo de la célula.
Está formado por la unión de muchos desoxirribonucleótidos. La mayoría de las moléculas de ADN poseen dos cadenas antiparalelas (una 5´-3´ y la otra 3´-5´)
Tomado de: https://n9.cl/v2sct (fig.15)
unidas entre sí mediante las bases nitrogenadas, por medio de puentes de hidrógeno (fig.16)
Código Genético
El código genético es el conjunto de reglas que define cómo se traduce una secuencia de nucleótidos en el ARN a una secuencia de aminoácidos en una proteína. Este código es común en todos los seres vivos (aunque hay pequeñas variaciones), lo cual demuestra que ha tenido un origen único y es universal, al menos en el contexto de nuestro planeta. El código define la relación entre cada secuencia de tres nucleótidos, llamada codón, y cada aminoácido. La secuencia del material genético se compone de cuatro bases nitrogenadas distintas, que tienen una representación mediante letras en el código genético: adenina (A), timina (T), guanina (G) y citosina (C) en el ADN y adenina (A), uracilo (U), guanina (G) y citosina (C) en el ARN. Debido a esto, el número de codones posibles es 64, de los cuales 61 codifican aminoácidos (siendo además uno de ellos el codón de inicio, AUG) y los tres restantes son sitios de parada (UAA, llamado ocre; UAG, llamado ámbar; UGA, llamado ópalo). La secuencia de codones determina la secuencia de
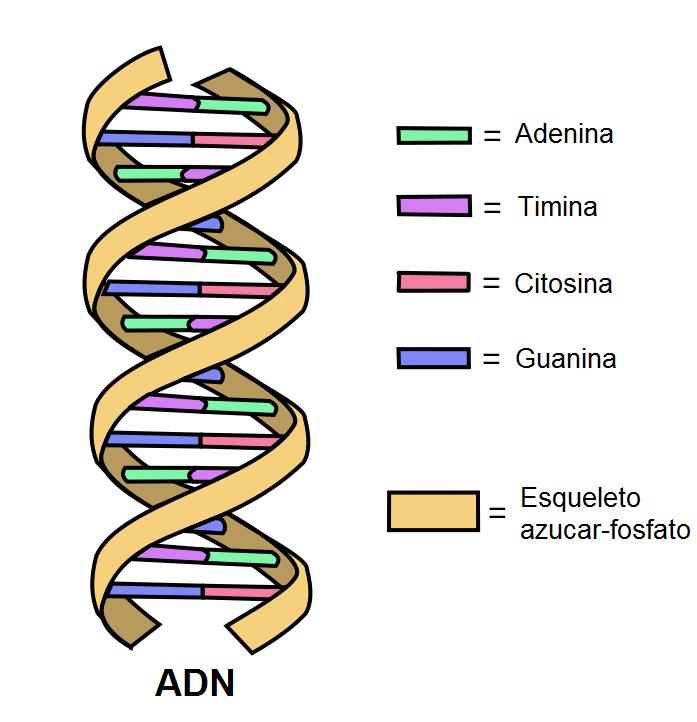
Tomado de: https://n9.cl/jx02 (fig.16)
aminoácidos en una proteína en concreto, que tendrá una estructura y una función específicas (fig.17)
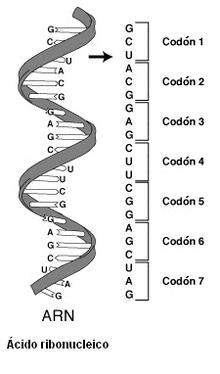
Tomado de: https://n9.cl/cu9dk (fig.17)
Codón
Las células decodifican el ARNm al leer sus nucleótidos en grupos de tres, conocidos como codones. A continuación, algunas características de los codones:
• La mayoría de los codones especifican un aminoácido • Tres codones de "terminación" marcan el fin de una proteína • Un codon de "inicio", AUG, marca el comienzo de una proteína y además codifica para el aminoácido metionina. Los codones en un ARNm se leen durante la traducción; se comienza con un codón de inicio, y se sigue hasta llegar a un codón de terminación. Los codones de ARNm se leen de 5' a 3' y especifican el orden de los animoácidos en una proteína de N-terminal (metionina) hasta C-terminal (fig.18)
Tomado de: https://n9.cl/yloov (fig.18)
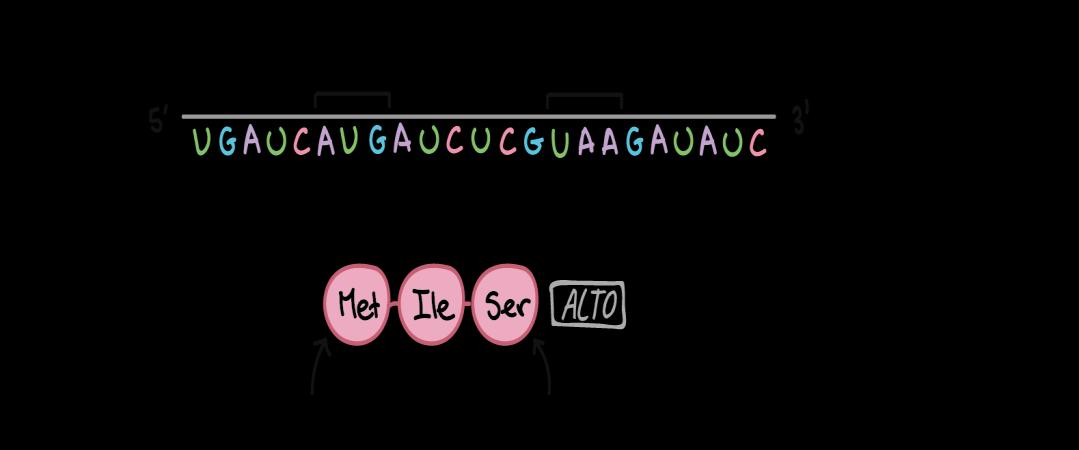
Tabla del código genético
El conjunto completo de relaciones entre los codones y los aminoácidos (o señales de terminación) se conoce como el código genético. A continuación, en la tabla será resumido el código genético (fig.19)
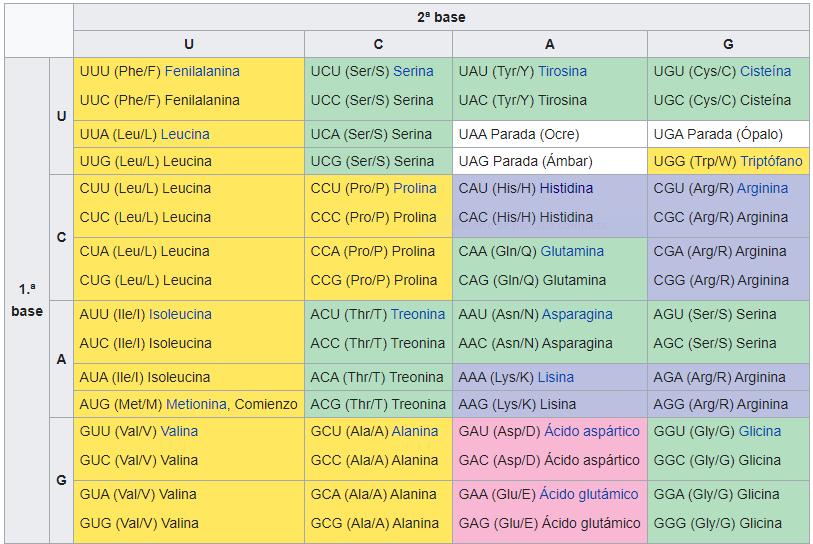
Tomado de: https://n9.cl/xjdye (fig.19)
En la tabla se puede observar cómo muchos aminoácidos están representados por más de un codón. Como ejemplo, hay seis formas distintas de "escribir" leucina en el lenguaje del ARNm. Una característica importante del código genético es que es universal. Es decir, con pequeñas excepciones, prácticamente todas las especies (desde las bacterias hasta las mismas personas) usan el código genético que se muestra arriba para la síntesis de protéinas.
Marco de lectura
El marco de lectura determina cómo se divide la secuencia de ARNm en codones durante la traducción.
El ARNm a continuación puede codificar tres proteínas totalmente diferentes, según el marco de lectura con el que se lea (fig.20)
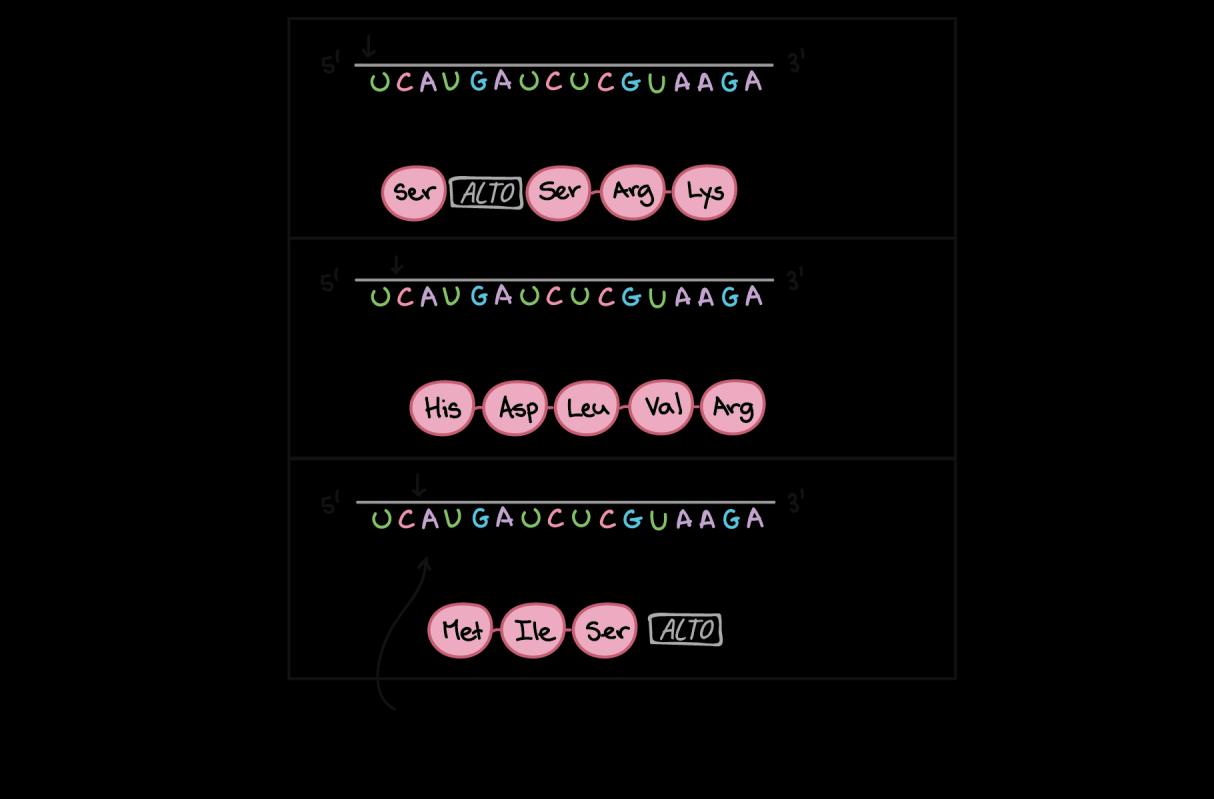
Tomado de: https://n9.cl/xjdye (fig.20)






